Merge pull request #61 from PaddlePaddle/develop
pgl v1.1
Showing
{kind=link}
{kind=link}
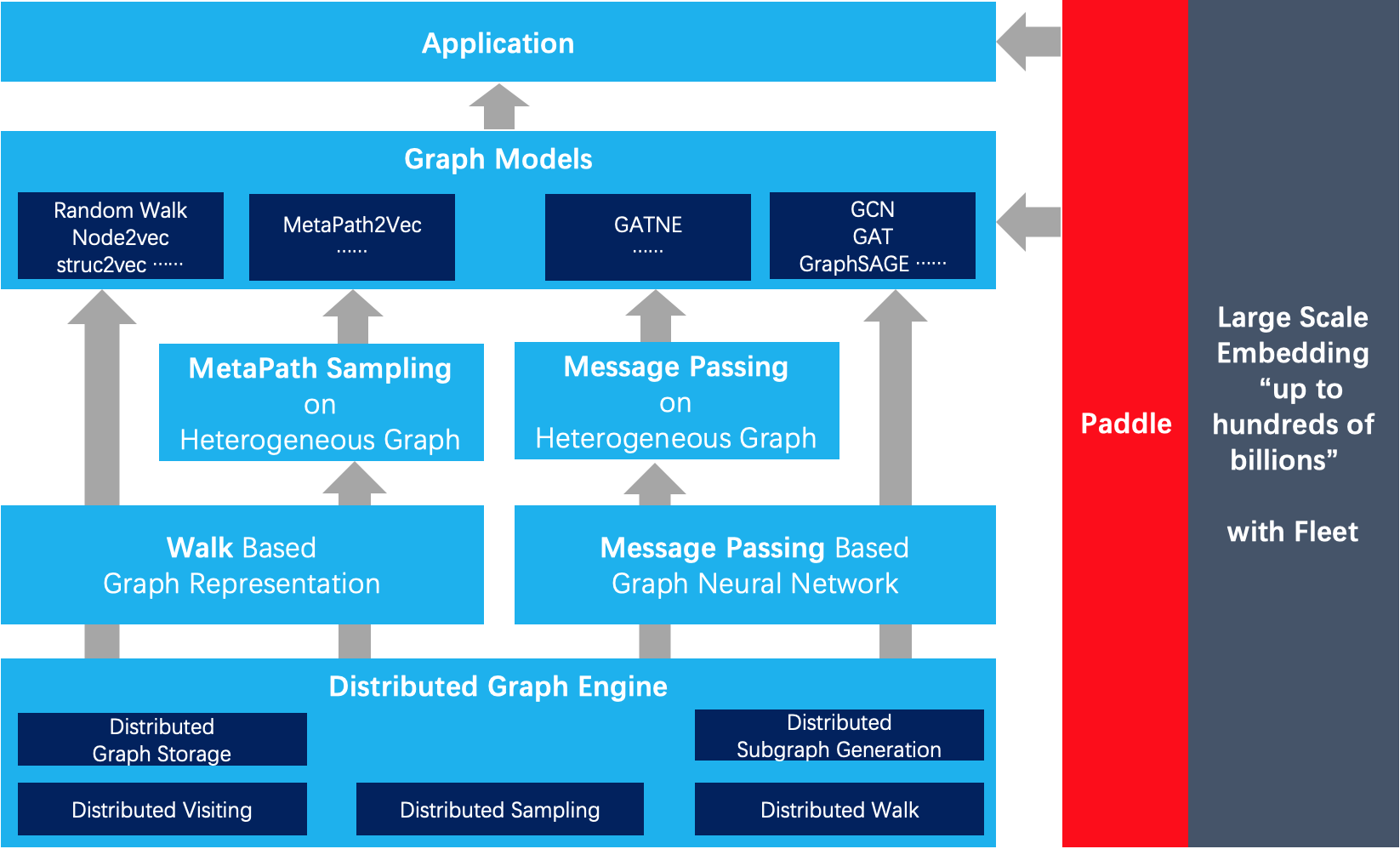
| W: | H:

| W: | H:
{kind=link}
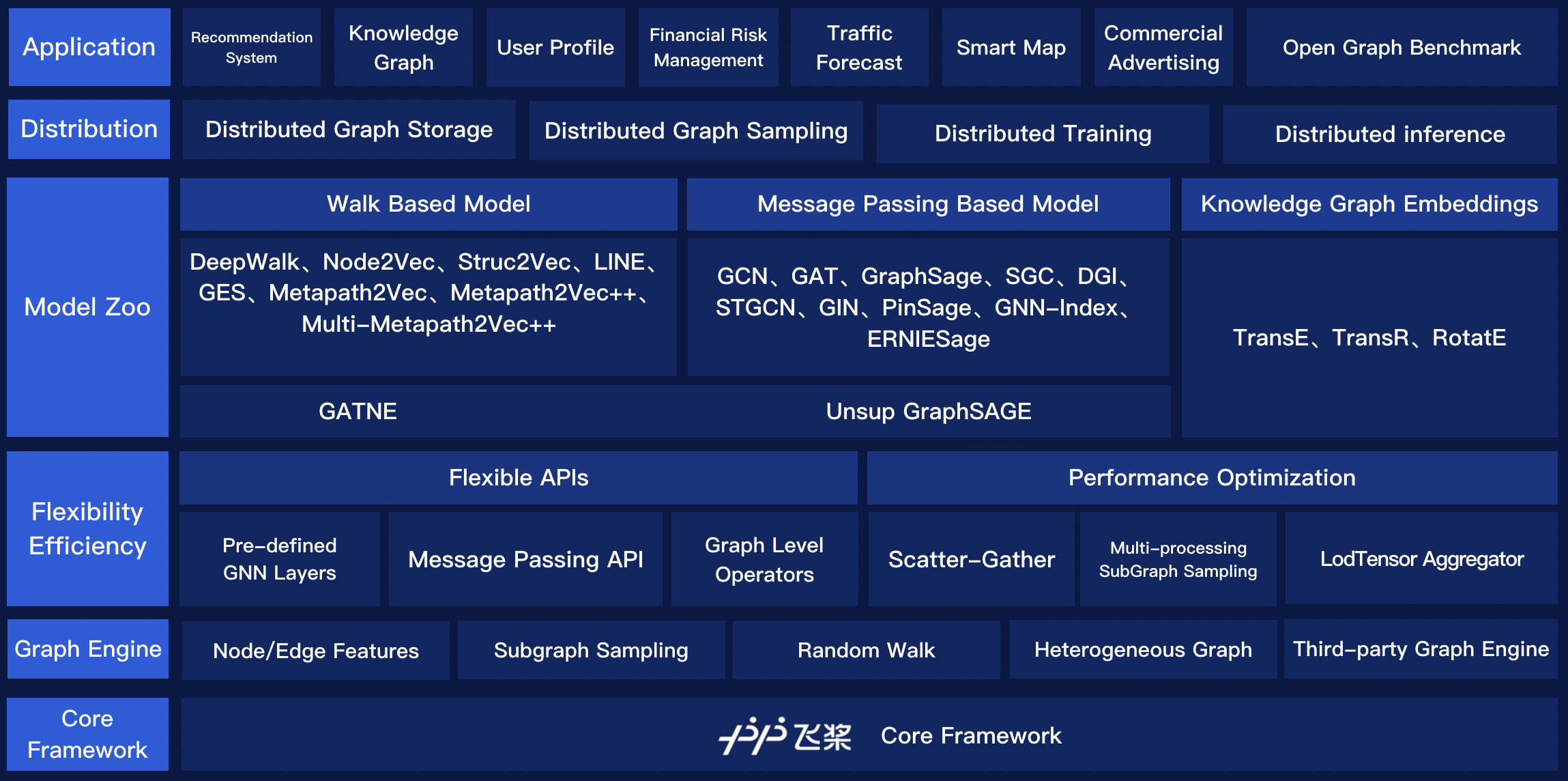
869.3 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
examples/erniesage/README.en.md
0 → 100644
examples/erniesage/README.md
0 → 100644
{kind=link}
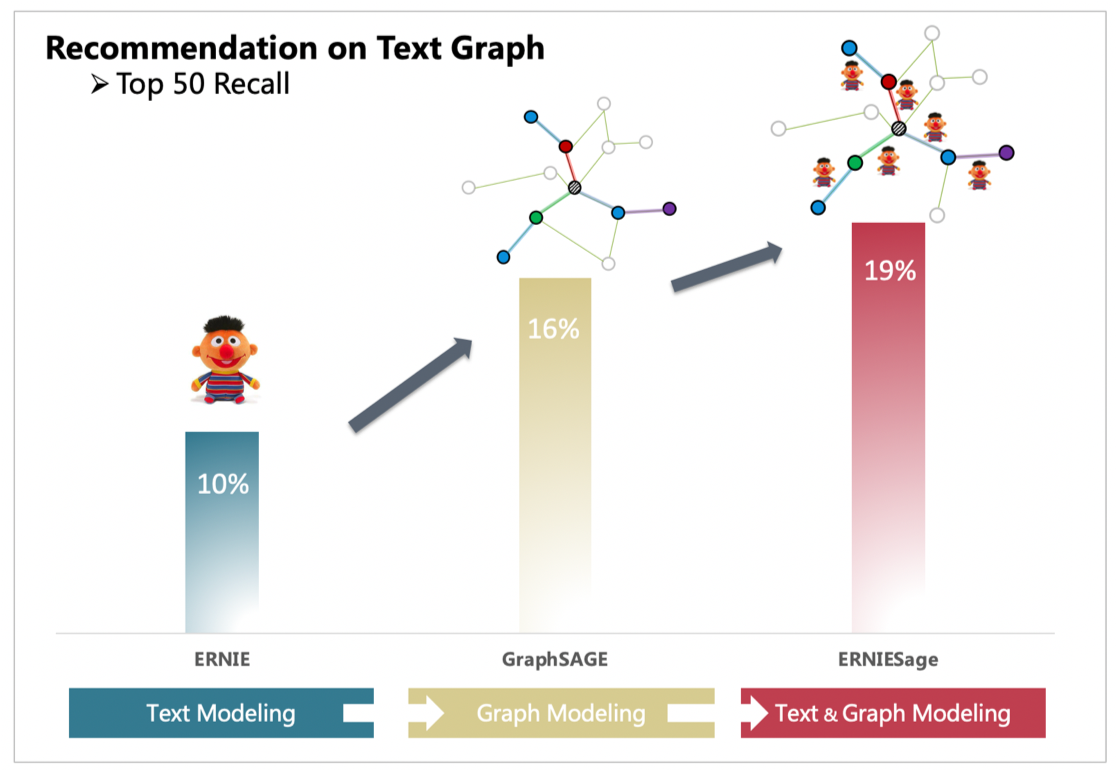
635.2 KB
{kind=link}
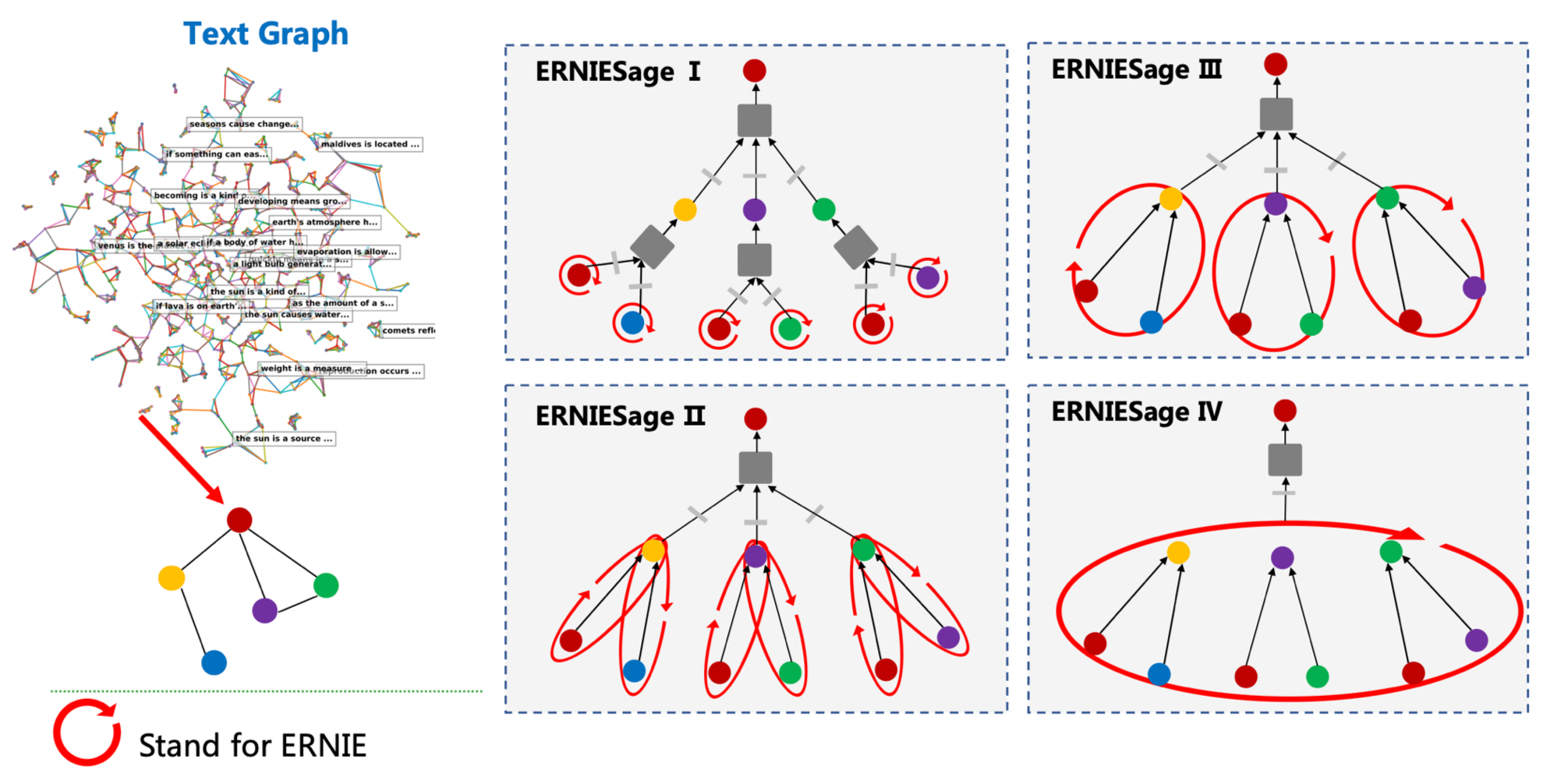
1.8 MB
{kind=link}
390.8 KB
{kind=link}
258.5 KB
examples/erniesage/infer.py
0 → 100644
examples/erniesage/job.sh
0 → 100644
examples/erniesage/learner.py
0 → 100644
examples/erniesage/local_run.sh
0 → 100644
examples/erniesage/models/base.py
0 → 100644
examples/erniesage/train.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。