diff --git a/README.md b/README.md
index 655ac0c278a0ae767fc82f77f9f48b705530618f..128cb90f8651f2e7616500fef8073906421c0fec 100644
--- a/README.md
+++ b/README.md
@@ -36,7 +36,7 @@ One of the most important benefits of graph neural networks compared to other mo
 -As shown in the left of the following figure, to adapt general user-defined message aggregate functions, DGL uses the degree bucketing method to combine nodes with the same degree into a batch and then apply an aggregate function  on each batch serially. For our PGL UDF aggregate function, we organize the message as a [LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html) in [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) taking the message as variable length sequences. And we **utilize the features of LodTensor in Paddle to obtain fast parallel aggregation**.
+As shown in the left of the following figure, to adapt general user-defined message aggregate functions, DGL uses the degree bucketing method to combine nodes with the same degree into a batch and then apply an aggregate function  on each batch serially. For our PGL UDF aggregate function, we organize the message as a [LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html) in [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) taking the message as variable length sequences. And we **utilize the features of LodTensor in Paddle to obtain fast parallel aggregation**.
-As shown in the left of the following figure, to adapt general user-defined message aggregate functions, DGL uses the degree bucketing method to combine nodes with the same degree into a batch and then apply an aggregate function  on each batch serially. For our PGL UDF aggregate function, we organize the message as a [LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html) in [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) taking the message as variable length sequences. And we **utilize the features of LodTensor in Paddle to obtain fast parallel aggregation**.
+As shown in the left of the following figure, to adapt general user-defined message aggregate functions, DGL uses the degree bucketing method to combine nodes with the same degree into a batch and then apply an aggregate function  on each batch serially. For our PGL UDF aggregate function, we organize the message as a [LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html) in [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) taking the message as variable length sequences. And we **utilize the features of LodTensor in Paddle to obtain fast parallel aggregation**.
 diff --git a/README.zh.md b/README.zh.md
index 8c2d7be4a988a99f8ea34c3ed1d43c8ed3bb321b..c41fdd485f8beda8569e7d70f3dc19670ed13673 100644
--- a/README.zh.md
+++ b/README.zh.md
@@ -29,11 +29,11 @@ Paddle Graph Learning (PGL)是一个基于[PaddlePaddle](https://github.com/Padd
# 特色:高效性——支持Scatter-Gather及LodTensor消息传递
-对比于一般的模型,图神经网络模型最大的优势在于它利用了节点与节点之间连接的信息。但是,如何通过代码来实现建模这些节点连接十分的麻烦。PGL采用与[DGL](https://github.com/dmlc/dgl)相似的**消息传递范式**用于作为构建图神经网络的接口。用于只需要简单的编写```send```还有```recv```函数就能够轻松的实现一个简单的GCN网络。如下图所示,首先,send函数被定义在节点之间的边上,用户自定义send函数会把消息从源点发送到目标节点。然后,recv函数负责将这些消息用汇聚函数  汇聚起来。
+对比于一般的模型,图神经网络模型最大的优势在于它利用了节点与节点之间连接的信息。但是,如何通过代码来实现建模这些节点连接十分的麻烦。PGL采用与[DGL](https://github.com/dmlc/dgl)相似的**消息传递范式**用于作为构建图神经网络的接口。用于只需要简单的编写```send```还有```recv```函数就能够轻松的实现一个简单的GCN网络。如下图所示,首先,send函数被定义在节点之间的边上,用户自定义send函数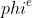会把消息从源点发送到目标节点。然后,recv函数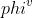负责将这些消息用汇聚函数  汇聚起来。
-如下面左图所示,为了去适配用户定义的汇聚函数,DGL使用了Degree Bucketing来将相同度的节点组合在一个块,然后将汇聚函数作用在每个块之上。而对于PGL的用户定义汇聚函数,我们则将消息以PaddlePaddle的[LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html)的形式处理,将若干消息看作一组变长的序列,然后利用**LodTensor在PaddlePaddle的特性进行快速平行的消息聚合**。
+如下面左图所示,为了去适配用户定义的汇聚函数,DGL使用了Degree Bucketing来将相同度的节点组合在一个块,然后将汇聚函数作用在每个块之上。而对于PGL的用户定义汇聚函数,我们则将消息以PaddlePaddle的[LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html)的形式处理,将若干消息看作一组变长的序列,然后利用**LodTensor在PaddlePaddle的特性进行快速平行的消息聚合**。
diff --git a/examples/distribute_graphsage/README.md b/examples/distribute_graphsage/README.md
index 0ce196f6417b676f8d1853f14c012bd86d5972ef..fcfe50a9bfecf258a7781b0ff158d3860cc85bc2 100644
--- a/examples/distribute_graphsage/README.md
+++ b/examples/distribute_graphsage/README.md
@@ -6,54 +6,32 @@ information (e.g., text attributes) to efficiently generate node embeddings for
For purpose of high scalability, we use redis as distribute graph storage solution and training graphsage against redis server.
### Datasets(Quickstart)
-The reddit dataset should be downloaded from [reddit_adj.npz](https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt) and [reddit.npz](https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2Jthe). The details for Reddit Dataset can be found [here](https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf).
+The reddit dataset should be downloaded from [reddit_adj.npz](https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt) and [reddit.npz](https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J). The details for Reddit Dataset can be found [here](https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf).
-Alternatively, reddit dataset has been preprocessed and packed into docker image, which can be instantly pulled using following commands.
+- reddit.npz: https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J
+- reddit_adj.npz: https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt
-```sh
-docker pull githubutilities/reddit_redis_demo:v0.1
-```
+Download `reddit.npz` and `reddit_adj.npz` into `data` directory for further preprocessing.
### Dependencies
-```txt
-- paddlepaddle>=1.6
-- pgl
-- scipy
-- redis==2.10.6
-- redis-py-cluster==1.3.6
+```sh
+pip install -r requirements.txt
```
### How to run
-#### 1. Start reddit data service
+#### 1. Preprocessing and start reddit data service
```sh
-docker run \
- --net=host \
- -d --rm \
- --name reddit_demo \
- -it githubutilities/reddit_redis_demo:v0.1 \
- /bin/bash -c "/bin/bash ./before_hook.sh && /bin/bash"
-docker logs -f `docker ps -aqf "name=reddit_demo"`
+pushd ./redis_setup
+ /bin/bash ./before_hook.sh
+popd
```
#### 2. training GraphSAGE model
```sh
-python train.py --use_cuda --epoch 10 --graphsage_type graphsage_mean --sample_workers 10
+sh ./cloud_run.sh
```
-#### Hyperparameters
-
-- epoch: Number of epochs default (10)
-- use_cuda: Use gpu if assign use_cuda.
-- graphsage_type: We support 4 aggregator types including "graphsage_mean", "graphsage_maxpool", "graphsage_meanpool" and "graphsage_lstm".
-- sample_workers: The number of workers for multiprocessing subgraph sample.
-- lr: Learning rate.
-- batch_size: Batch size.
-- samples_1: The max neighbors for the first hop neighbor sampling. (default: 25)
-- samples_2: The max neighbors for the second hop neighbor sampling. (default: 10)
-- hidden_size: The hidden size of the GraphSAGE models.
-
-
diff --git a/examples/distribute_graphsage/cloud_run.sh b/examples/distribute_graphsage/cloud_run.sh
new file mode 100755
index 0000000000000000000000000000000000000000..c5b5e45fe8990396da9e68cc68f7ebd5217dcbe7
--- /dev/null
+++ b/examples/distribute_graphsage/cloud_run.sh
@@ -0,0 +1,25 @@
+#!/bin/bash
+set -x
+mode=${1}
+
+source ./utils.sh
+unset http_proxy https_proxy
+
+source ./local_config
+if [ ! -d ${log_dir} ]; then
+ mkdir ${log_dir}
+fi
+
+for((i=0;i<${PADDLE_PSERVERS_NUM};i++))
+do
+ echo "start ps server: ${i}"
+ echo $log_dir
+ TRAINING_ROLE="PSERVER" PADDLE_TRAINER_ID=${i} sh job.sh &> $log_dir/pserver.$i.log &
+done
+sleep 10s
+for((j=0;j<${PADDLE_TRAINERS_NUM};j++))
+do
+ echo "start ps work: ${j}"
+ TRAINING_ROLE="TRAINER" PADDLE_TRAINER_ID=${j} sh job.sh &> $log_dir/worker.$j.log &
+done
+tail -f $log_dir/worker.0.log
diff --git a/examples/distribute_graphsage/cluster_train.py b/examples/distribute_graphsage/cluster_train.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ff2695bd5e09963bd497fadc8b5452cfe833288
--- /dev/null
+++ b/examples/distribute_graphsage/cluster_train.py
@@ -0,0 +1,191 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import time
+import os
+import math
+import numpy as np
+
+import paddle.fluid as F
+import paddle.fluid.layers as L
+from paddle.fluid.incubate.fleet.parameter_server.distribute_transpiler import fleet
+from paddle.fluid.transpiler.distribute_transpiler import DistributeTranspilerConfig
+import paddle.fluid.incubate.fleet.base.role_maker as role_maker
+from pgl.utils.logger import log
+
+from model import GraphsageModel
+from utils import load_config
+import reader
+
+
+def init_role():
+ # reset the place according to role of parameter server
+ training_role = os.getenv("TRAINING_ROLE", "TRAINER")
+ paddle_role = role_maker.Role.WORKER
+ place = F.CPUPlace()
+ if training_role == "PSERVER":
+ paddle_role = role_maker.Role.SERVER
+
+ # set the fleet runtime environment according to configure
+ ports = os.getenv("PADDLE_PORT", "6174").split(",")
+ pserver_ips = os.getenv("PADDLE_PSERVERS").split(",") # ip,ip...
+ eplist = []
+ if len(ports) > 1:
+ # local debug mode, multi port
+ for port in ports:
+ eplist.append(':'.join([pserver_ips[0], port]))
+ else:
+ # distributed mode, multi ip
+ for ip in pserver_ips:
+ eplist.append(':'.join([ip, ports[0]]))
+
+ pserver_endpoints = eplist # ip:port,ip:port...
+ worker_num = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ role = role_maker.UserDefinedRoleMaker(
+ current_id=trainer_id,
+ role=paddle_role,
+ worker_num=worker_num,
+ server_endpoints=pserver_endpoints)
+ fleet.init(role)
+
+
+def optimization(base_lr, loss, optimizer='adam'):
+ if optimizer == 'sgd':
+ optimizer = F.optimizer.SGD(base_lr)
+ elif optimizer == 'adam':
+ optimizer = F.optimizer.Adam(base_lr, lazy_mode=True)
+ else:
+ raise ValueError
+
+ log.info('learning rate:%f' % (base_lr))
+ #create the DistributeTranspiler configure
+ config = DistributeTranspilerConfig()
+ config.sync_mode = False
+ #config.runtime_split_send_recv = False
+
+ config.slice_var_up = False
+ #create the distributed optimizer
+ optimizer = fleet.distributed_optimizer(optimizer, config)
+ optimizer.minimize(loss)
+
+
+def build_complied_prog(train_program, model_loss):
+ num_threads = int(os.getenv("CPU_NUM", 10))
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", 0))
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = num_threads
+ #exec_strategy.use_experimental_executor = True
+ build_strategy = F.BuildStrategy()
+ build_strategy.enable_inplace = True
+ #build_strategy.memory_optimize = True
+ build_strategy.memory_optimize = False
+ build_strategy.remove_unnecessary_lock = False
+ if num_threads > 1:
+ build_strategy.reduce_strategy = F.BuildStrategy.ReduceStrategy.Reduce
+
+ compiled_prog = F.compiler.CompiledProgram(
+ train_program).with_data_parallel(loss_name=model_loss.name)
+ return compiled_prog
+
+
+def fake_py_reader(data_iter, num):
+ def fake_iter():
+ queue = []
+ for idx, data in enumerate(data_iter()):
+ queue.append(data)
+ if len(queue) == num:
+ yield queue
+ queue = []
+ if len(queue) > 0:
+ while len(queue) < num:
+ queue.append(queue[-1])
+ yield queue
+ return fake_iter
+
+def train_prog(exe, program, model, pyreader, args):
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ start = time.time()
+ batch = 0
+ total_loss = 0.
+ total_acc = 0.
+ total_sample = 0
+ for epoch_idx in range(args.num_epoch):
+ for step, batch_feed_dict in enumerate(pyreader()):
+ try:
+ cpu_time = time.time()
+ batch += 1
+ batch_loss, batch_acc = exe.run(
+ program,
+ feed=batch_feed_dict,
+ fetch_list=[model.loss, model.acc])
+
+ end = time.time()
+ if batch % args.log_per_step == 0:
+ log.info(
+ "Batch %s Loss %s Acc %s \t Speed(per batch) %.5lf/%.5lf sec"
+ % (batch, np.mean(batch_loss), np.mean(batch_acc), (end - start) /batch, (end - cpu_time)))
+
+ if step % args.steps_per_save == 0:
+ save_path = args.save_path
+ if trainer_id == 0:
+ model_path = os.path.join(save_path, "%s" % step)
+ fleet.save_persistables(exe, model_path)
+ except Exception as e:
+ log.info("Pyreader train error")
+ log.exception(e)
+
+def main(args):
+ log.info("start")
+
+ worker_num = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
+ num_devices = int(os.getenv("CPU_NUM", 10))
+
+ model = GraphsageModel(args)
+ loss = model.forward()
+ train_iter = reader.get_iter(args, model.graph_wrapper, 'train')
+ pyreader = fake_py_reader(train_iter, num_devices)
+
+ # init fleet
+ init_role()
+
+ optimization(args.lr, loss, args.optimizer)
+
+ # init and run server or worker
+ if fleet.is_server():
+ fleet.init_server(args.warm_start_from_dir)
+ fleet.run_server()
+
+ if fleet.is_worker():
+ log.info("start init worker done")
+ fleet.init_worker()
+ #just the worker, load the sample
+ log.info("init worker done")
+
+ exe = F.Executor(F.CPUPlace())
+ exe.run(fleet.startup_program)
+ log.info("Startup done")
+
+ compiled_prog = build_complied_prog(fleet.main_program, loss)
+ train_prog(exe, compiled_prog, model, pyreader, args)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='metapath2vec')
+ parser.add_argument("-c", "--config", type=str, default="./config.yaml")
+ args = parser.parse_args()
+ config = load_config(args.config)
+ log.info(config)
+ main(config)
+
diff --git a/examples/distribute_graphsage/config.yaml b/examples/distribute_graphsage/config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..915ef184c32db9ff6322ee9edc0cd57e1372b1f9
--- /dev/null
+++ b/examples/distribute_graphsage/config.yaml
@@ -0,0 +1,19 @@
+# model config
+hidden_size: 128
+num_class: 41
+samples: [25, 10]
+graphsage_type: "graphsage_mean"
+
+# trainging config
+num_epoch: 10
+batch_size: 128
+num_sample_workers: 10
+optimizer: "adam"
+lr: 0.01
+warm_start_from_dir: null
+steps_per_save: 1000
+log_per_step: 1
+save_path: "./checkpoints"
+log_dir: "./logs"
+CPU_NUM: 1
+
diff --git a/examples/distribute_graphsage/job.sh b/examples/distribute_graphsage/job.sh
new file mode 100644
index 0000000000000000000000000000000000000000..8b9ee4d1b5d981d9c4dfa920cffbb31723030dcc
--- /dev/null
+++ b/examples/distribute_graphsage/job.sh
@@ -0,0 +1,14 @@
+#!/bin/bash
+
+set -x
+source ./utils.sh
+
+export CPU_NUM=$CPU_NUM
+export FLAGS_rpc_deadline=3000000
+
+export FLAGS_communicator_send_queue_size=1
+export FLAGS_communicator_min_send_grad_num_before_recv=0
+export FLAGS_communicator_max_merge_var_num=1
+export FLAGS_communicator_merge_sparse_grad=0
+
+python -u cluster_train.py -c config.yaml
diff --git a/examples/distribute_graphsage/local_config b/examples/distribute_graphsage/local_config
new file mode 100644
index 0000000000000000000000000000000000000000..0e8ca14c66f40cfdc7beea1a0f0cd2f61b8a51ee
--- /dev/null
+++ b/examples/distribute_graphsage/local_config
@@ -0,0 +1,6 @@
+#!/bin/bash
+export PADDLE_TRAINERS_NUM=2
+export PADDLE_PSERVERS_NUM=2
+export PADDLE_PORT=6184,6185
+export PADDLE_PSERVERS="127.0.0.1"
+
diff --git a/examples/distribute_graphsage/model.py b/examples/distribute_graphsage/model.py
index 145a979e86951dc4b5a2522154a0dc0373eea065..7f5eb990fc9bad4f6475bb538b62266b6b5e7f41 100644
--- a/examples/distribute_graphsage/model.py
+++ b/examples/distribute_graphsage/model.py
@@ -11,10 +11,22 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+"""
+ graphsage model.
+"""
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+import math
+
+import pgl
+import numpy as np
import paddle
+import paddle.fluid.layers as L
+import paddle.fluid as F
import paddle.fluid as fluid
-
def copy_send(src_feat, dst_feat, edge_feat):
return src_feat["h"]
@@ -128,3 +140,87 @@ def graphsage_lstm(gw, feature, hidden_size, act, name):
output = fluid.layers.concat([self_feature, neigh_feature], axis=1)
output = fluid.layers.l2_normalize(output, axis=1)
return output
+
+
+def build_graph_model(graph_wrapper, num_class, k_hop, graphsage_type,
+ hidden_size):
+ node_index = fluid.layers.data(
+ "node_index", shape=[None], dtype="int64", append_batch_size=False)
+
+ node_label = fluid.layers.data(
+ "node_label", shape=[None, 1], dtype="int64", append_batch_size=False)
+
+ #feature = fluid.layers.gather(feature, graph_wrapper.node_feat['feats'])
+ feature = graph_wrapper.node_feat['feats']
+ feature.stop_gradient = True
+
+ for i in range(k_hop):
+ if graphsage_type == 'graphsage_mean':
+ feature = graphsage_mean(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_mean_%s" % i)
+ elif graphsage_type == 'graphsage_meanpool':
+ feature = graphsage_meanpool(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_meanpool_%s" % i)
+ elif graphsage_type == 'graphsage_maxpool':
+ feature = graphsage_maxpool(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_maxpool_%s" % i)
+ elif graphsage_type == 'graphsage_lstm':
+ feature = graphsage_lstm(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_maxpool_%s" % i)
+ else:
+ raise ValueError("graphsage type %s is not"
+ " implemented" % graphsage_type)
+
+ feature = fluid.layers.gather(feature, node_index)
+ logits = fluid.layers.fc(feature,
+ num_class,
+ act=None,
+ name='classification_layer')
+ proba = fluid.layers.softmax(logits)
+
+ loss = fluid.layers.softmax_with_cross_entropy(
+ logits=logits, label=node_label)
+ loss = fluid.layers.mean(loss)
+ acc = fluid.layers.accuracy(input=proba, label=node_label, k=1)
+ return loss, acc
+
+
+class GraphsageModel(object):
+ def __init__(self, args):
+ self.args = args
+
+ def forward(self):
+ args = self.args
+
+ graph_wrapper = pgl.graph_wrapper.GraphWrapper(
+ "sub_graph", node_feat=[('feats', [None, 602], np.dtype('float32'))])
+ loss, acc = build_graph_model(
+ graph_wrapper,
+ num_class=args.num_class,
+ hidden_size=args.hidden_size,
+ graphsage_type=args.graphsage_type,
+ k_hop=len(args.samples))
+
+ loss.persistable = True
+
+ self.graph_wrapper = graph_wrapper
+ self.loss = loss
+ self.acc = acc
+ return loss
+
diff --git a/examples/distribute_graphsage/reader.py b/examples/distribute_graphsage/reader.py
index 6617b6b86fe08facee1915edcd459a8c706c4191..88556d39a9d6c30e1b7c4e5e087e994de937566e 100644
--- a/examples/distribute_graphsage/reader.py
+++ b/examples/distribute_graphsage/reader.py
@@ -11,6 +11,8 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import os
+import sys
import numpy as np
import pickle as pkl
import paddle
@@ -147,3 +149,48 @@ def multiprocess_graph_reader(
return reader()
+
+def load_data():
+ """
+ data from https://github.com/matenure/FastGCN/issues/8
+ reddit.npz: https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J
+ reddit_index_label is preprocess from reddit.npz without feats key.
+ """
+ data_dir = os.path.dirname(os.path.abspath(__file__))
+ data = np.load(os.path.join(data_dir, "data/reddit_index_label.npz"))
+
+ num_class = 41
+
+ train_label = data['y_train']
+ val_label = data['y_val']
+ test_label = data['y_test']
+
+ train_index = data['train_index']
+ val_index = data['val_index']
+ test_index = data['test_index']
+
+ return {
+ "train_index": train_index,
+ "train_label": train_label,
+ "val_label": val_label,
+ "val_index": val_index,
+ "test_index": test_index,
+ "test_label": test_label,
+ "num_class": 41
+ }
+
+def get_iter(args, graph_wrapper, mode):
+ data = load_data()
+ train_iter = multiprocess_graph_reader(
+ graph_wrapper,
+ samples=args.samples,
+ num_workers=args.num_sample_workers,
+ batch_size=args.batch_size,
+ node_index=data['train_index'],
+ node_label=data["train_label"])
+ return train_iter
+
+if __name__ == '__main__':
+ for e in train_iter():
+ print(e)
+
diff --git a/examples/distribute_graphsage/redis_setup/before_hook.sh b/examples/distribute_graphsage/redis_setup/before_hook.sh
new file mode 100644
index 0000000000000000000000000000000000000000..1b5c101a2e77b7823b3d23a85a709e843812464c
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/before_hook.sh
@@ -0,0 +1,31 @@
+#!/bin/bash
+set -x
+
+srcdir=./src
+
+# Data preprocessing
+python ./src/preprocess.py
+
+# Download and compile redis
+export PATH=$PWD/redis-5.0.5/src:$PATH
+if [ ! -f ./redis.tar.gz ]; then
+ curl https://codeload.github.com/antirez/redis/tar.gz/5.0.5 -o ./redis.tar.gz
+fi
+tar -xzf ./redis.tar.gz
+cd ./redis-5.0.5/
+make
+cd -
+
+# Install python deps
+python -m pip install -U pip
+pip install -r ./src/requirements.txt -U
+
+# Run redis server
+sh ./src/run_server.sh
+
+# Dumping data into redis
+source ./redis_graph.cfg
+sh ./src/dump_data.sh $edge_path $server_list $num_nodes $node_feat_path
+
+exit 0
+
diff --git a/examples/distribute_graphsage/redis_setup/redis_graph.cfg b/examples/distribute_graphsage/redis_setup/redis_graph.cfg
new file mode 100644
index 0000000000000000000000000000000000000000..382ca1749082ecbec98f2666186d81c0534547b6
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/redis_graph.cfg
@@ -0,0 +1,6 @@
+# dump config
+edge_path=../data/edge.txt
+node_feat_path=../data/feats.npz
+num_nodes=232965
+server_list=./server.list
+
diff --git a/examples/distribute_graphsage/redis_setup/src/build_graph.py b/examples/distribute_graphsage/redis_setup/src/build_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..9fb1c6563bf24991bfd3dfa9bca78f513c9d21e5
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/build_graph.py
@@ -0,0 +1,275 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import json
+import logging
+from collections import defaultdict
+import tqdm
+import redis
+from redis._compat import b, unicode, bytes, long, basestring
+from rediscluster.nodemanager import NodeManager
+from rediscluster.crc import crc16
+import argparse
+import time
+import pickle
+import numpy as np
+import scipy.sparse as sp
+
+log = logging.getLogger(__name__)
+root = logging.getLogger()
+root.setLevel(logging.DEBUG)
+
+handler = logging.StreamHandler(sys.stdout)
+handler.setLevel(logging.DEBUG)
+formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
+handler.setFormatter(formatter)
+root.addHandler(handler)
+
+
+def encode(value):
+ """
+ Return a bytestring representation of the value.
+ This method is copied from Redis' connection.py:Connection.encode
+ """
+ if isinstance(value, bytes):
+ return value
+ elif isinstance(value, (int, long)):
+ value = b(str(value))
+ elif isinstance(value, float):
+ value = b(repr(value))
+ elif not isinstance(value, basestring):
+ value = unicode(value)
+ if isinstance(value, unicode):
+ value = value.encode('utf-8')
+ return value
+
+
+def crc16_hash(data):
+ return crc16(encode(data))
+
+
+def get_redis(startup_host, startup_port):
+ startup_nodes = [{"host": startup_host, "port": startup_port}, ]
+ nodemanager = NodeManager(startup_nodes=startup_nodes)
+ nodemanager.initialize()
+ rs = {}
+ for node, config in nodemanager.nodes.items():
+ rs[node] = redis.Redis(
+ host=config["host"], port=config["port"], decode_responses=False)
+ return rs, nodemanager
+
+
+def load_data(edge_path):
+ src, dst = [], []
+ with open(edge_path, "r") as f:
+ for i in tqdm.tqdm(f):
+ s, d, _ = i.split()
+ s = int(s)
+ d = int(d)
+ src.append(s)
+ dst.append(d)
+ dst.append(s)
+ src.append(d)
+ src = np.array(src, dtype="int64")
+ dst = np.array(dst, dtype="int64")
+ return src, dst
+
+
+def build_edge_index(edge_path, num_nodes, startup_host, startup_port,
+ num_bucket):
+ #src, dst = load_data(edge_path)
+ rs, nodemanager = get_redis(startup_host, startup_port)
+
+ dst_mp, edge_mp = defaultdict(list), defaultdict(list)
+ with open(edge_path) as f:
+ for l in tqdm.tqdm(f):
+ a, b, idx = l.rstrip().split('\t')
+ a, b, idx = int(a), int(b), int(idx)
+ dst_mp[a].append(b)
+ edge_mp[a].append(idx)
+ part_dst_dicts = {}
+ for i in tqdm.tqdm(range(num_nodes)):
+ #if len(edge_index.v[i]) == 0:
+ # continue
+ #v = edge_index.v[i].astype("int64").reshape([-1, 1])
+ #e = edge_index.eid[i].astype("int64").reshape([-1, 1])
+ if i not in dst_mp:
+ continue
+ v = np.array(dst_mp[i]).astype('int64').reshape([-1, 1])
+ e = np.array(edge_mp[i]).astype('int64').reshape([-1, 1])
+ o = np.hstack([v, e])
+ key = "d:%s" % i
+ part = crc16_hash(key) % num_bucket
+ if part not in part_dst_dicts:
+ part_dst_dicts[part] = {}
+ dst_dicts = part_dst_dicts[part]
+ dst_dicts["d:%s" % i] = o.tobytes()
+ if len(dst_dicts) > 10000:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, dst_dicts)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_dst_dicts[part] = {}
+
+ for part, dst_dicts in part_dst_dicts.items():
+ if len(dst_dicts) > 0:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, dst_dicts)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_dst_dicts[part] = {}
+ log.info("dst_dict Done")
+
+
+def build_edge_id(edge_path, num_nodes, startup_host, startup_port,
+ num_bucket):
+ src, dst = load_data(edge_path)
+ rs, nodemanager = get_redis(startup_host, startup_port)
+ part_edge_dict = {}
+ for i in tqdm.tqdm(range(len(src))):
+ key = "e:%s" % i
+ part = crc16_hash(key) % num_bucket
+ if part not in part_edge_dict:
+ part_edge_dict[part] = {}
+ edge_dict = part_edge_dict[part]
+ edge_dict["e:%s" % i] = int(src[i]) * num_nodes + int(dst[i])
+ if len(edge_dict) > 10000:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, edge_dict)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+
+ part_edge_dict[part] = {}
+
+ for part, edge_dict in part_edge_dict.items():
+ if len(edge_dict) > 0:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, edge_dict)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_edge_dict[part] = {}
+
+
+def build_infos(edge_path, num_nodes, startup_host, startup_port, num_bucket):
+ src, dst = load_data(edge_path)
+ rs, nodemanager = get_redis(startup_host, startup_port)
+ slot = nodemanager.keyslot("num_nodes")
+ node = nodemanager.slots[slot][0]['name']
+ res = rs[node].set("num_nodes", num_nodes)
+
+ slot = nodemanager.keyslot("num_edges")
+ node = nodemanager.slots[slot][0]['name']
+ rs[node].set("num_edges", len(src))
+
+ slot = nodemanager.keyslot("nf:infos")
+ node = nodemanager.slots[slot][0]['name']
+ rs[node].set("nf:infos", json.dumps([['feats', [-1, 602], 'float32'], ]))
+
+ slot = nodemanager.keyslot("ef:infos")
+ node = nodemanager.slots[slot][0]['name']
+ rs[node].set("ef:infos", json.dumps([]))
+
+
+def build_node_feat(node_feat_path, num_nodes, startup_host, startup_port, num_bucket):
+ assert node_feat_path != "", "node_feat_path empty!"
+ feat_dict = np.load(node_feat_path)
+ for k in feat_dict.keys():
+ feat = feat_dict[k]
+ assert feat.shape[0] == num_nodes, "num_nodes invalid"
+
+ rs, nodemanager = get_redis(startup_host, startup_port)
+ part_feat_dict = {}
+ for k in feat_dict.keys():
+ feat = feat_dict[k]
+ for i in tqdm.tqdm(range(num_nodes)):
+ key = "nf:%s:%i" % (k, i)
+ value = feat[i].tobytes()
+ part = crc16_hash(key) % num_bucket
+ if part not in part_feat_dict:
+ part_feat_dict[part] = {}
+ part_feat = part_feat_dict[part]
+ part_feat[key] = value
+ if len(part_feat) > 100:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, part_feat)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+
+ part_feat_dict[part] = {}
+
+ for part, part_feat in part_feat_dict.items():
+ if len(part_feat) > 0:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, part_feat)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_feat_dict[part] = {}
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='gen_redis_conf')
+ parser.add_argument('--startup_port', type=int, required=True)
+ parser.add_argument('--startup_host', type=str, required=True)
+ parser.add_argument('--edge_path', type=str, default="")
+ parser.add_argument('--node_feat_path', type=str, default="")
+ parser.add_argument('--num_nodes', type=int, default=0)
+ parser.add_argument('--num_bucket', type=int, default=64)
+ parser.add_argument(
+ '--mode',
+ type=str,
+ required=True,
+ help="choose one of the following modes (clear, edge_index, edge_id, graph_attr)"
+ )
+ args = parser.parse_args()
+ log.info("Mode: {}".format(args.mode))
+ if args.mode == 'edge_index':
+ build_edge_index(args.edge_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ elif args.mode == 'edge_id':
+ build_edge_id(args.edge_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ elif args.mode == 'graph_attr':
+ build_infos(args.edge_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ elif args.mode == 'node_feat':
+ build_node_feat(args.node_feat_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ else:
+ raise ValueError("%s mode not found" % args.mode)
+
diff --git a/examples/distribute_graphsage/redis_setup/src/dump_data.sh b/examples/distribute_graphsage/redis_setup/src/dump_data.sh
new file mode 100644
index 0000000000000000000000000000000000000000..052064b5ac5ae61d0270691726d299796fe2393a
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/dump_data.sh
@@ -0,0 +1,63 @@
+filter(){
+ lines=`cat $1`
+ rm $1
+ for line in $lines; do
+ remote_host=`echo $line | cut -d":" -f1`
+ remote_port=`echo $line | cut -d":" -f2`
+ nc -z $remote_host $remote_port
+ if [[ $? == 0 ]]; then
+ echo $line >> $1
+ fi
+ done
+}
+
+dump_data(){
+ filter $server_list
+
+ python ./src/start_cluster.py --server_list $server_list --replicas 0
+
+ address=`head -n 1 $server_list`
+
+ ip=`echo $address | cut -d":" -f1`
+ port=`echo $address | cut -d":" -f2`
+
+ python ./src/build_graph.py --startup_host $ip \
+ --startup_port $port \
+ --mode node_feat \
+ --node_feat_path $feat_fn \
+ --num_nodes $num_nodes
+
+ # build edge index
+ python ./src/build_graph.py --startup_host $ip \
+ --startup_port $port \
+ --mode edge_index \
+ --edge_path $edge_path \
+ --num_nodes $num_nodes
+
+ # build edge id
+ #python ./src/build_graph.py --startup_host $ip \
+ # --startup_port $port \
+ # --mode edge_id \
+ # --edge_path $edge_path \
+ # --num_nodes $num_nodes
+
+ # build graph attr
+ python ./src/build_graph.py --startup_host $ip \
+ --startup_port $port \
+ --mode graph_attr \
+ --edge_path $edge_path \
+ --num_nodes $num_nodes
+
+}
+
+if [ $# -ne 4 ]; then
+ echo 'sh edge_path server_list num_nodes feat_fn'
+ exit
+fi
+num_nodes=$3
+server_list=$2
+edge_path=$1
+feat_fn=$4
+
+dump_data
+
diff --git a/examples/distribute_graphsage/redis_setup/src/gen_redis_conf.py b/examples/distribute_graphsage/redis_setup/src/gen_redis_conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ded1f3d79d0d2d64071d6936d38e4514c28b453
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/gen_redis_conf.py
@@ -0,0 +1,72 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import socket
+import argparse
+import os
+temp = """port %s
+bind %s
+daemonize yes
+pidfile /var/run/redis_%s.pid
+cluster-enabled yes
+cluster-config-file nodes.conf
+cluster-node-timeout 50000
+logfile "redis.log"
+appendonly yes"""
+
+
+def gen_config(ports):
+ if len(ports) == 0:
+ raise ValueError("No ports")
+ ip = socket.gethostbyname(socket.gethostname())
+ print("Generate redis conf")
+ for port in ports:
+ try:
+ os.mkdir("%s" % port)
+ except:
+ print("port %s directory already exists" % port)
+ pass
+ with open("%s/redis.conf" % port, 'w') as f:
+ f.write(temp % (port, ip, port))
+
+ print("Generate Start Server Scripts")
+ with open("start_server.sh", "w") as f:
+ f.write("set -x\n")
+ for ind, port in enumerate(ports):
+ f.write("# %s %s start\n" % (ip, port))
+ if ind > 0:
+ f.write("cd ..\n")
+ f.write("cd %s\n" % port)
+ f.write("redis-server redis.conf\n")
+ f.write("\n")
+
+ print("Generate Stop Server Scripts")
+ with open("stop_server.sh", "w") as f:
+ f.write("set -x\n")
+ for ind, port in enumerate(ports):
+ f.write("# %s %s shutdown\n" % (ip, port))
+ f.write("redis-cli -h %s -p %s shutdown\n" % (ip, port))
+ f.write("\n")
+
+ with open("server.list", "w") as f:
+ for ind, port in enumerate(ports):
+ f.write("%s:%s\n" % (ip, port))
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='gen_redis_conf')
+ parser.add_argument('--ports', nargs='+', type=int, default=[])
+ args = parser.parse_args()
+ gen_config(args.ports)
diff --git a/examples/distribute_graphsage/redis_setup/src/preprocess.py b/examples/distribute_graphsage/redis_setup/src/preprocess.py
new file mode 100644
index 0000000000000000000000000000000000000000..42c641ccbf9bf8b623b8e3be159c37d2dffd9ebd
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/preprocess.py
@@ -0,0 +1,35 @@
+import os
+import sys
+
+import numpy as np
+import scipy.sparse as sp
+
+def _load_config(fn):
+ ret = {}
+ with open(fn) as f:
+ for l in f:
+ if l.strip() == '' or l.startswith('#'):
+ continue
+ k, v = l.strip().split('=')
+ ret[k] = v
+ return ret
+
+def _prepro(config):
+ data = np.load("../data/reddit.npz")
+ adj = sp.load_npz("../data/reddit_adj.npz")
+ adj = adj.tocoo()
+ src = adj.row
+ dst = adj.col
+
+ with open(config['edge_path'], 'w') as f:
+ for idx, e in enumerate(zip(src, dst)):
+ s, d = e
+ l = "{}\t{}\t{}\n".format(s, d, idx)
+ f.write(l)
+ feats = data['feats'].astype(np.float32)
+ np.savez(config['node_feat_path'], feats=feats)
+
+if __name__ == '__main__':
+ config = _load_config('./redis_graph.cfg')
+ _prepro(config)
+
diff --git a/examples/distribute_graphsage/redis_setup/src/requirements.txt b/examples/distribute_graphsage/redis_setup/src/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..2f955a8c35414405c0ef4bebd459d96d7934ab62
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/requirements.txt
@@ -0,0 +1,6 @@
+numpy
+scipy
+tqdm
+redis==2.10.6
+redis-py-cluster==1.3.6
+
diff --git a/examples/distribute_graphsage/redis_setup/src/run_server.sh b/examples/distribute_graphsage/redis_setup/src/run_server.sh
new file mode 100644
index 0000000000000000000000000000000000000000..e1268ad60df82c283d0e8d7cfc1e9ca6f7126b6f
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/run_server.sh
@@ -0,0 +1,14 @@
+start_server(){
+ ports=""
+ for i in {7430..7439}; do
+ nc -z localhost $i
+ if [[ $? != 0 ]]; then
+ ports="$ports $i"
+ fi
+ done
+ python ./src/gen_redis_conf.py --ports $ports
+ bash ./start_server.sh #启动服务器
+}
+
+start_server
+
diff --git a/examples/distribute_graphsage/redis_setup/src/start_cluster.py b/examples/distribute_graphsage/redis_setup/src/start_cluster.py
new file mode 100644
index 0000000000000000000000000000000000000000..570765d3696a4eafa924efe8c9ba1787eff574d0
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/start_cluster.py
@@ -0,0 +1,37 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import argparse
+
+
+def build_clusters(server_list, replicas):
+ servers = []
+ with open(server_list) as f:
+ for line in f:
+ servers.append(line.strip())
+ cmd = "echo yes | redis-cli --cluster create"
+ for server in servers:
+ cmd += ' %s ' % server
+ cmd += '--cluster-replicas %s' % replicas
+ print(cmd)
+ os.system(cmd)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description='start_cluster')
+ parser.add_argument('--server_list', type=str, required=True)
+ parser.add_argument('--replicas', type=int, default=0)
+ args = parser.parse_args()
+ build_clusters(args.server_list, args.replicas)
diff --git a/examples/distribute_graphsage/redis_setup/test/test.sh b/examples/distribute_graphsage/redis_setup/test/test.sh
new file mode 100644
index 0000000000000000000000000000000000000000..ec8695b9c75c921bc03bf56a3c381bbd279b1532
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/test/test.sh
@@ -0,0 +1,7 @@
+#!/bin/bash
+
+source ./redis_graph.cfg
+
+url=`head -n1 $server_list`
+shuf $edge_path | head -n 1000 | python ./test/test_redis_graph.py $url
+
diff --git a/examples/distribute_graphsage/redis_setup/test/test_redis_graph.py b/examples/distribute_graphsage/redis_setup/test/test_redis_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..f4a3a2541bbd96210e8f9eaef5bf38a07cbd9e60
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/test/test_redis_graph.py
@@ -0,0 +1,40 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+########################################################################
+#
+# Copyright (c) 2019 Baidu.com, Inc. All Rights Reserved
+#
+# File: test_redis_graph.py
+# Author: suweiyue(suweiyue@baidu.com)
+# Date: 2019/08/19 16:28:18
+#
+########################################################################
+"""
+ Comment.
+"""
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import sys
+
+import numpy as np
+import tqdm
+from pgl.redis_graph import RedisGraph
+
+if __name__ == '__main__':
+ host, port = sys.argv[1].split(':')
+ port = int(port)
+ redis_configs = [{"host": host, "port": port}, ]
+ graph = RedisGraph("reddit-graph", redis_configs, num_parts=64)
+ #nodes = np.arange(0, 100)
+ #for i in range(0, 100):
+ for l in tqdm.tqdm(sys.stdin):
+ l_sp = l.rstrip().split('\t')
+ if len(l_sp) != 2:
+ continue
+ i, j = int(l_sp[0]), int(l_sp[1])
+ nodes = graph.sample_predecessor(np.array([i]), 10000)
+ assert j in nodes
+
diff --git a/examples/distribute_graphsage/requirements.txt b/examples/distribute_graphsage/requirements.txt
index 7bda67a20635218a8786cfb872cfd2da5b2ddbe1..e0d28f3b6ce2ab2cea5d9674b871cc8d3e7ac932 100644
--- a/examples/distribute_graphsage/requirements.txt
+++ b/examples/distribute_graphsage/requirements.txt
@@ -1,3 +1,7 @@
+pgl==1.1.0
+pyyaml
+paddlepaddle==1.6.1
+
scipy
redis==2.10.6
redis-py-cluster==1.3.6
diff --git a/examples/distribute_graphsage/train.py b/examples/distribute_graphsage/train.py
deleted file mode 100644
index 4faafdd504415efd954f09d6d54dc7b38e6287c5..0000000000000000000000000000000000000000
--- a/examples/distribute_graphsage/train.py
+++ /dev/null
@@ -1,263 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import os
-import argparse
-import time
-
-import numpy as np
-import scipy.sparse as sp
-from sklearn.preprocessing import StandardScaler
-
-import pgl
-from pgl.utils.logger import log
-from pgl.utils import paddle_helper
-import paddle
-import paddle.fluid as fluid
-import reader
-from model import graphsage_mean, graphsage_meanpool,\
- graphsage_maxpool, graphsage_lstm
-
-
-def load_data():
- """
- data from https://github.com/matenure/FastGCN/issues/8
- reddit.npz: https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J
- reddit_index_label is preprocess from reddit.npz without feats key.
- """
- data_dir = os.path.dirname(os.path.abspath(__file__))
- data = np.load(os.path.join(data_dir, "data/reddit_index_label.npz"))
-
- num_class = 41
-
- train_label = data['y_train']
- val_label = data['y_val']
- test_label = data['y_test']
-
- train_index = data['train_index']
- val_index = data['val_index']
- test_index = data['test_index']
-
- return {
- "train_index": train_index,
- "train_label": train_label,
- "val_label": val_label,
- "val_index": val_index,
- "test_index": test_index,
- "test_label": test_label,
- "num_class": 41
- }
-
-
-def build_graph_model(graph_wrapper, num_class, k_hop, graphsage_type,
- hidden_size):
- node_index = fluid.layers.data(
- "node_index", shape=[None], dtype="int64", append_batch_size=False)
-
- node_label = fluid.layers.data(
- "node_label", shape=[None, 1], dtype="int64", append_batch_size=False)
-
- #feature = fluid.layers.gather(feature, graph_wrapper.node_feat['feats'])
- feature = graph_wrapper.node_feat['feats']
- feature.stop_gradient = True
-
- for i in range(k_hop):
- if graphsage_type == 'graphsage_mean':
- feature = graphsage_mean(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_mean_%s" % i)
- elif graphsage_type == 'graphsage_meanpool':
- feature = graphsage_meanpool(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_meanpool_%s" % i)
- elif graphsage_type == 'graphsage_maxpool':
- feature = graphsage_maxpool(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_maxpool_%s" % i)
- elif graphsage_type == 'graphsage_lstm':
- feature = graphsage_lstm(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_maxpool_%s" % i)
- else:
- raise ValueError("graphsage type %s is not"
- " implemented" % graphsage_type)
-
- feature = fluid.layers.gather(feature, node_index)
- logits = fluid.layers.fc(feature,
- num_class,
- act=None,
- name='classification_layer')
- proba = fluid.layers.softmax(logits)
-
- loss = fluid.layers.softmax_with_cross_entropy(
- logits=logits, label=node_label)
- loss = fluid.layers.mean(loss)
- acc = fluid.layers.accuracy(input=proba, label=node_label, k=1)
- return loss, acc
-
-
-def run_epoch(batch_iter,
- exe,
- program,
- prefix,
- model_loss,
- model_acc,
- epoch,
- log_per_step=100):
- batch = 0
- total_loss = 0.
- total_acc = 0.
- total_sample = 0
- start = time.time()
- for batch_feed_dict in batch_iter():
- batch += 1
- batch_loss, batch_acc = exe.run(program,
- fetch_list=[model_loss, model_acc],
- feed=batch_feed_dict)
-
- if batch % log_per_step == 0:
- log.info("Batch %s %s-Loss %s %s-Acc %s" %
- (batch, prefix, batch_loss, prefix, batch_acc))
-
- num_samples = len(batch_feed_dict["node_index"])
- total_loss += batch_loss * num_samples
- total_acc += batch_acc * num_samples
- total_sample += num_samples
- end = time.time()
-
- log.info("%s Epoch %s Loss %.5lf Acc %.5lf Speed(per batch) %.5lf sec" %
- (prefix, epoch, total_loss / total_sample,
- total_acc / total_sample, (end - start) / batch))
-
-
-def main(args):
- data = load_data()
- log.info("preprocess finish")
- log.info("Train Examples: %s" % len(data["train_index"]))
- log.info("Val Examples: %s" % len(data["val_index"]))
- log.info("Test Examples: %s" % len(data["test_index"]))
-
- place = fluid.CUDAPlace(0) if args.use_cuda else fluid.CPUPlace()
- train_program = fluid.Program()
- startup_program = fluid.Program()
- samples = []
- if args.samples_1 > 0:
- samples.append(args.samples_1)
- if args.samples_2 > 0:
- samples.append(args.samples_2)
-
- with fluid.program_guard(train_program, startup_program):
- graph_wrapper = pgl.graph_wrapper.GraphWrapper(
- "sub_graph", node_feat=[('feats', [None, 602], np.dtype('float32'))])
- model_loss, model_acc = build_graph_model(
- graph_wrapper,
- num_class=data["num_class"],
- hidden_size=args.hidden_size,
- graphsage_type=args.graphsage_type,
- k_hop=len(samples))
-
- test_program = train_program.clone(for_test=True)
-
- with fluid.program_guard(train_program, startup_program):
- adam = fluid.optimizer.Adam(learning_rate=args.lr)
- adam.minimize(model_loss)
-
- exe = fluid.Executor(place)
- exe.run(startup_program)
-
- train_iter = reader.multiprocess_graph_reader(
- graph_wrapper,
- samples=samples,
- num_workers=args.sample_workers,
- batch_size=args.batch_size,
- node_index=data['train_index'],
- node_label=data["train_label"])
-
- val_iter = reader.multiprocess_graph_reader(
- graph_wrapper,
- samples=samples,
- num_workers=args.sample_workers,
- batch_size=args.batch_size,
- node_index=data['val_index'],
- node_label=data["val_label"])
-
- test_iter = reader.multiprocess_graph_reader(
- graph_wrapper,
- samples=samples,
- num_workers=args.sample_workers,
- batch_size=args.batch_size,
- node_index=data['test_index'],
- node_label=data["test_label"])
-
- for epoch in range(args.epoch):
- run_epoch(
- train_iter,
- program=train_program,
- exe=exe,
- prefix="train",
- model_loss=model_loss,
- model_acc=model_acc,
- log_per_step=1,
- epoch=epoch)
-
- run_epoch(
- val_iter,
- program=test_program,
- exe=exe,
- prefix="val",
- model_loss=model_loss,
- model_acc=model_acc,
- log_per_step=10000,
- epoch=epoch)
-
- run_epoch(
- test_iter,
- program=test_program,
- prefix="test",
- exe=exe,
- model_loss=model_loss,
- model_acc=model_acc,
- log_per_step=10000,
- epoch=epoch)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(description='graphsage')
- parser.add_argument("--use_cuda", action='store_true', help="use_cuda")
- parser.add_argument(
- "--normalize", action='store_true', help="normalize features")
- parser.add_argument(
- "--symmetry", action='store_true', help="undirect graph")
- parser.add_argument("--graphsage_type", type=str, default="graphsage_mean")
- parser.add_argument("--sample_workers", type=int, default=10)
- parser.add_argument("--epoch", type=int, default=10)
- parser.add_argument("--hidden_size", type=int, default=128)
- parser.add_argument("--batch_size", type=int, default=128)
- parser.add_argument("--lr", type=float, default=0.01)
- parser.add_argument("--samples_1", type=int, default=25)
- parser.add_argument("--samples_2", type=int, default=10)
- args = parser.parse_args()
- log.info(args)
- main(args)
diff --git a/examples/distribute_graphsage/utils.py b/examples/distribute_graphsage/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5810f7fdd7a99b034505feaddf51a962ca34ac1
--- /dev/null
+++ b/examples/distribute_graphsage/utils.py
@@ -0,0 +1,55 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Implementation of some helper functions"""
+
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import os
+import time
+import yaml
+import numpy as np
+
+from pgl.utils.logger import log
+
+
+class AttrDict(dict):
+ """Attr dict
+ """
+
+ def __init__(self, d):
+ self.dict = d
+
+ def __getattr__(self, attr):
+ value = self.dict[attr]
+ if isinstance(value, dict):
+ return AttrDict(value)
+ else:
+ return value
+
+ def __str__(self):
+ return str(self.dict)
+
+
+def load_config(config_file):
+ """Load config file"""
+ with open(config_file) as f:
+ if hasattr(yaml, 'FullLoader'):
+ config = yaml.load(f, Loader=yaml.FullLoader)
+ else:
+ config = yaml.load(f)
+
+ return AttrDict(config)
diff --git a/examples/distribute_graphsage/utils.sh b/examples/distribute_graphsage/utils.sh
new file mode 100644
index 0000000000000000000000000000000000000000..6f6daa846d600e0bcecd4ce64e04946dba0fdd51
--- /dev/null
+++ b/examples/distribute_graphsage/utils.sh
@@ -0,0 +1,20 @@
+
+# parse yaml file
+function parse_yaml {
+ local prefix=$2
+ local s='[[:space:]]*' w='[a-zA-Z0-9_]*' fs=$(echo @|tr @ '\034')
+ sed -ne "s|^\($s\):|\1|" \
+ -e "s|^\($s\)\($w\)$s:$s[\"']\(.*\)[\"']$s\$|\1$fs\2$fs\3|p" \
+ -e "s|^\($s\)\($w\)$s:$s\(.*\)$s\$|\1$fs\2$fs\3|p" $1 |
+ awk -F$fs '{
+ indent = length($1)/2;
+ vname[indent] = $2;
+ for (i in vname) {if (i > indent) {delete vname[i]}}
+ if (length($3) > 0) {
+ vn=""; for (i=0; i
diff --git a/README.zh.md b/README.zh.md
index 8c2d7be4a988a99f8ea34c3ed1d43c8ed3bb321b..c41fdd485f8beda8569e7d70f3dc19670ed13673 100644
--- a/README.zh.md
+++ b/README.zh.md
@@ -29,11 +29,11 @@ Paddle Graph Learning (PGL)是一个基于[PaddlePaddle](https://github.com/Padd
# 特色:高效性——支持Scatter-Gather及LodTensor消息传递
-对比于一般的模型,图神经网络模型最大的优势在于它利用了节点与节点之间连接的信息。但是,如何通过代码来实现建模这些节点连接十分的麻烦。PGL采用与[DGL](https://github.com/dmlc/dgl)相似的**消息传递范式**用于作为构建图神经网络的接口。用于只需要简单的编写```send```还有```recv```函数就能够轻松的实现一个简单的GCN网络。如下图所示,首先,send函数被定义在节点之间的边上,用户自定义send函数会把消息从源点发送到目标节点。然后,recv函数负责将这些消息用汇聚函数  汇聚起来。
+对比于一般的模型,图神经网络模型最大的优势在于它利用了节点与节点之间连接的信息。但是,如何通过代码来实现建模这些节点连接十分的麻烦。PGL采用与[DGL](https://github.com/dmlc/dgl)相似的**消息传递范式**用于作为构建图神经网络的接口。用于只需要简单的编写```send```还有```recv```函数就能够轻松的实现一个简单的GCN网络。如下图所示,首先,send函数被定义在节点之间的边上,用户自定义send函数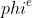会把消息从源点发送到目标节点。然后,recv函数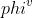负责将这些消息用汇聚函数  汇聚起来。
-如下面左图所示,为了去适配用户定义的汇聚函数,DGL使用了Degree Bucketing来将相同度的节点组合在一个块,然后将汇聚函数作用在每个块之上。而对于PGL的用户定义汇聚函数,我们则将消息以PaddlePaddle的[LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html)的形式处理,将若干消息看作一组变长的序列,然后利用**LodTensor在PaddlePaddle的特性进行快速平行的消息聚合**。
+如下面左图所示,为了去适配用户定义的汇聚函数,DGL使用了Degree Bucketing来将相同度的节点组合在一个块,然后将汇聚函数作用在每个块之上。而对于PGL的用户定义汇聚函数,我们则将消息以PaddlePaddle的[LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html)的形式处理,将若干消息看作一组变长的序列,然后利用**LodTensor在PaddlePaddle的特性进行快速平行的消息聚合**。
diff --git a/examples/distribute_graphsage/README.md b/examples/distribute_graphsage/README.md
index 0ce196f6417b676f8d1853f14c012bd86d5972ef..fcfe50a9bfecf258a7781b0ff158d3860cc85bc2 100644
--- a/examples/distribute_graphsage/README.md
+++ b/examples/distribute_graphsage/README.md
@@ -6,54 +6,32 @@ information (e.g., text attributes) to efficiently generate node embeddings for
For purpose of high scalability, we use redis as distribute graph storage solution and training graphsage against redis server.
### Datasets(Quickstart)
-The reddit dataset should be downloaded from [reddit_adj.npz](https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt) and [reddit.npz](https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2Jthe). The details for Reddit Dataset can be found [here](https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf).
+The reddit dataset should be downloaded from [reddit_adj.npz](https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt) and [reddit.npz](https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J). The details for Reddit Dataset can be found [here](https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf).
-Alternatively, reddit dataset has been preprocessed and packed into docker image, which can be instantly pulled using following commands.
+- reddit.npz: https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J
+- reddit_adj.npz: https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt
-```sh
-docker pull githubutilities/reddit_redis_demo:v0.1
-```
+Download `reddit.npz` and `reddit_adj.npz` into `data` directory for further preprocessing.
### Dependencies
-```txt
-- paddlepaddle>=1.6
-- pgl
-- scipy
-- redis==2.10.6
-- redis-py-cluster==1.3.6
+```sh
+pip install -r requirements.txt
```
### How to run
-#### 1. Start reddit data service
+#### 1. Preprocessing and start reddit data service
```sh
-docker run \
- --net=host \
- -d --rm \
- --name reddit_demo \
- -it githubutilities/reddit_redis_demo:v0.1 \
- /bin/bash -c "/bin/bash ./before_hook.sh && /bin/bash"
-docker logs -f `docker ps -aqf "name=reddit_demo"`
+pushd ./redis_setup
+ /bin/bash ./before_hook.sh
+popd
```
#### 2. training GraphSAGE model
```sh
-python train.py --use_cuda --epoch 10 --graphsage_type graphsage_mean --sample_workers 10
+sh ./cloud_run.sh
```
-#### Hyperparameters
-
-- epoch: Number of epochs default (10)
-- use_cuda: Use gpu if assign use_cuda.
-- graphsage_type: We support 4 aggregator types including "graphsage_mean", "graphsage_maxpool", "graphsage_meanpool" and "graphsage_lstm".
-- sample_workers: The number of workers for multiprocessing subgraph sample.
-- lr: Learning rate.
-- batch_size: Batch size.
-- samples_1: The max neighbors for the first hop neighbor sampling. (default: 25)
-- samples_2: The max neighbors for the second hop neighbor sampling. (default: 10)
-- hidden_size: The hidden size of the GraphSAGE models.
-
-
diff --git a/examples/distribute_graphsage/cloud_run.sh b/examples/distribute_graphsage/cloud_run.sh
new file mode 100755
index 0000000000000000000000000000000000000000..c5b5e45fe8990396da9e68cc68f7ebd5217dcbe7
--- /dev/null
+++ b/examples/distribute_graphsage/cloud_run.sh
@@ -0,0 +1,25 @@
+#!/bin/bash
+set -x
+mode=${1}
+
+source ./utils.sh
+unset http_proxy https_proxy
+
+source ./local_config
+if [ ! -d ${log_dir} ]; then
+ mkdir ${log_dir}
+fi
+
+for((i=0;i<${PADDLE_PSERVERS_NUM};i++))
+do
+ echo "start ps server: ${i}"
+ echo $log_dir
+ TRAINING_ROLE="PSERVER" PADDLE_TRAINER_ID=${i} sh job.sh &> $log_dir/pserver.$i.log &
+done
+sleep 10s
+for((j=0;j<${PADDLE_TRAINERS_NUM};j++))
+do
+ echo "start ps work: ${j}"
+ TRAINING_ROLE="TRAINER" PADDLE_TRAINER_ID=${j} sh job.sh &> $log_dir/worker.$j.log &
+done
+tail -f $log_dir/worker.0.log
diff --git a/examples/distribute_graphsage/cluster_train.py b/examples/distribute_graphsage/cluster_train.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ff2695bd5e09963bd497fadc8b5452cfe833288
--- /dev/null
+++ b/examples/distribute_graphsage/cluster_train.py
@@ -0,0 +1,191 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import time
+import os
+import math
+import numpy as np
+
+import paddle.fluid as F
+import paddle.fluid.layers as L
+from paddle.fluid.incubate.fleet.parameter_server.distribute_transpiler import fleet
+from paddle.fluid.transpiler.distribute_transpiler import DistributeTranspilerConfig
+import paddle.fluid.incubate.fleet.base.role_maker as role_maker
+from pgl.utils.logger import log
+
+from model import GraphsageModel
+from utils import load_config
+import reader
+
+
+def init_role():
+ # reset the place according to role of parameter server
+ training_role = os.getenv("TRAINING_ROLE", "TRAINER")
+ paddle_role = role_maker.Role.WORKER
+ place = F.CPUPlace()
+ if training_role == "PSERVER":
+ paddle_role = role_maker.Role.SERVER
+
+ # set the fleet runtime environment according to configure
+ ports = os.getenv("PADDLE_PORT", "6174").split(",")
+ pserver_ips = os.getenv("PADDLE_PSERVERS").split(",") # ip,ip...
+ eplist = []
+ if len(ports) > 1:
+ # local debug mode, multi port
+ for port in ports:
+ eplist.append(':'.join([pserver_ips[0], port]))
+ else:
+ # distributed mode, multi ip
+ for ip in pserver_ips:
+ eplist.append(':'.join([ip, ports[0]]))
+
+ pserver_endpoints = eplist # ip:port,ip:port...
+ worker_num = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ role = role_maker.UserDefinedRoleMaker(
+ current_id=trainer_id,
+ role=paddle_role,
+ worker_num=worker_num,
+ server_endpoints=pserver_endpoints)
+ fleet.init(role)
+
+
+def optimization(base_lr, loss, optimizer='adam'):
+ if optimizer == 'sgd':
+ optimizer = F.optimizer.SGD(base_lr)
+ elif optimizer == 'adam':
+ optimizer = F.optimizer.Adam(base_lr, lazy_mode=True)
+ else:
+ raise ValueError
+
+ log.info('learning rate:%f' % (base_lr))
+ #create the DistributeTranspiler configure
+ config = DistributeTranspilerConfig()
+ config.sync_mode = False
+ #config.runtime_split_send_recv = False
+
+ config.slice_var_up = False
+ #create the distributed optimizer
+ optimizer = fleet.distributed_optimizer(optimizer, config)
+ optimizer.minimize(loss)
+
+
+def build_complied_prog(train_program, model_loss):
+ num_threads = int(os.getenv("CPU_NUM", 10))
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", 0))
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = num_threads
+ #exec_strategy.use_experimental_executor = True
+ build_strategy = F.BuildStrategy()
+ build_strategy.enable_inplace = True
+ #build_strategy.memory_optimize = True
+ build_strategy.memory_optimize = False
+ build_strategy.remove_unnecessary_lock = False
+ if num_threads > 1:
+ build_strategy.reduce_strategy = F.BuildStrategy.ReduceStrategy.Reduce
+
+ compiled_prog = F.compiler.CompiledProgram(
+ train_program).with_data_parallel(loss_name=model_loss.name)
+ return compiled_prog
+
+
+def fake_py_reader(data_iter, num):
+ def fake_iter():
+ queue = []
+ for idx, data in enumerate(data_iter()):
+ queue.append(data)
+ if len(queue) == num:
+ yield queue
+ queue = []
+ if len(queue) > 0:
+ while len(queue) < num:
+ queue.append(queue[-1])
+ yield queue
+ return fake_iter
+
+def train_prog(exe, program, model, pyreader, args):
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ start = time.time()
+ batch = 0
+ total_loss = 0.
+ total_acc = 0.
+ total_sample = 0
+ for epoch_idx in range(args.num_epoch):
+ for step, batch_feed_dict in enumerate(pyreader()):
+ try:
+ cpu_time = time.time()
+ batch += 1
+ batch_loss, batch_acc = exe.run(
+ program,
+ feed=batch_feed_dict,
+ fetch_list=[model.loss, model.acc])
+
+ end = time.time()
+ if batch % args.log_per_step == 0:
+ log.info(
+ "Batch %s Loss %s Acc %s \t Speed(per batch) %.5lf/%.5lf sec"
+ % (batch, np.mean(batch_loss), np.mean(batch_acc), (end - start) /batch, (end - cpu_time)))
+
+ if step % args.steps_per_save == 0:
+ save_path = args.save_path
+ if trainer_id == 0:
+ model_path = os.path.join(save_path, "%s" % step)
+ fleet.save_persistables(exe, model_path)
+ except Exception as e:
+ log.info("Pyreader train error")
+ log.exception(e)
+
+def main(args):
+ log.info("start")
+
+ worker_num = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
+ num_devices = int(os.getenv("CPU_NUM", 10))
+
+ model = GraphsageModel(args)
+ loss = model.forward()
+ train_iter = reader.get_iter(args, model.graph_wrapper, 'train')
+ pyreader = fake_py_reader(train_iter, num_devices)
+
+ # init fleet
+ init_role()
+
+ optimization(args.lr, loss, args.optimizer)
+
+ # init and run server or worker
+ if fleet.is_server():
+ fleet.init_server(args.warm_start_from_dir)
+ fleet.run_server()
+
+ if fleet.is_worker():
+ log.info("start init worker done")
+ fleet.init_worker()
+ #just the worker, load the sample
+ log.info("init worker done")
+
+ exe = F.Executor(F.CPUPlace())
+ exe.run(fleet.startup_program)
+ log.info("Startup done")
+
+ compiled_prog = build_complied_prog(fleet.main_program, loss)
+ train_prog(exe, compiled_prog, model, pyreader, args)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='metapath2vec')
+ parser.add_argument("-c", "--config", type=str, default="./config.yaml")
+ args = parser.parse_args()
+ config = load_config(args.config)
+ log.info(config)
+ main(config)
+
diff --git a/examples/distribute_graphsage/config.yaml b/examples/distribute_graphsage/config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..915ef184c32db9ff6322ee9edc0cd57e1372b1f9
--- /dev/null
+++ b/examples/distribute_graphsage/config.yaml
@@ -0,0 +1,19 @@
+# model config
+hidden_size: 128
+num_class: 41
+samples: [25, 10]
+graphsage_type: "graphsage_mean"
+
+# trainging config
+num_epoch: 10
+batch_size: 128
+num_sample_workers: 10
+optimizer: "adam"
+lr: 0.01
+warm_start_from_dir: null
+steps_per_save: 1000
+log_per_step: 1
+save_path: "./checkpoints"
+log_dir: "./logs"
+CPU_NUM: 1
+
diff --git a/examples/distribute_graphsage/job.sh b/examples/distribute_graphsage/job.sh
new file mode 100644
index 0000000000000000000000000000000000000000..8b9ee4d1b5d981d9c4dfa920cffbb31723030dcc
--- /dev/null
+++ b/examples/distribute_graphsage/job.sh
@@ -0,0 +1,14 @@
+#!/bin/bash
+
+set -x
+source ./utils.sh
+
+export CPU_NUM=$CPU_NUM
+export FLAGS_rpc_deadline=3000000
+
+export FLAGS_communicator_send_queue_size=1
+export FLAGS_communicator_min_send_grad_num_before_recv=0
+export FLAGS_communicator_max_merge_var_num=1
+export FLAGS_communicator_merge_sparse_grad=0
+
+python -u cluster_train.py -c config.yaml
diff --git a/examples/distribute_graphsage/local_config b/examples/distribute_graphsage/local_config
new file mode 100644
index 0000000000000000000000000000000000000000..0e8ca14c66f40cfdc7beea1a0f0cd2f61b8a51ee
--- /dev/null
+++ b/examples/distribute_graphsage/local_config
@@ -0,0 +1,6 @@
+#!/bin/bash
+export PADDLE_TRAINERS_NUM=2
+export PADDLE_PSERVERS_NUM=2
+export PADDLE_PORT=6184,6185
+export PADDLE_PSERVERS="127.0.0.1"
+
diff --git a/examples/distribute_graphsage/model.py b/examples/distribute_graphsage/model.py
index 145a979e86951dc4b5a2522154a0dc0373eea065..7f5eb990fc9bad4f6475bb538b62266b6b5e7f41 100644
--- a/examples/distribute_graphsage/model.py
+++ b/examples/distribute_graphsage/model.py
@@ -11,10 +11,22 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+"""
+ graphsage model.
+"""
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+import math
+
+import pgl
+import numpy as np
import paddle
+import paddle.fluid.layers as L
+import paddle.fluid as F
import paddle.fluid as fluid
-
def copy_send(src_feat, dst_feat, edge_feat):
return src_feat["h"]
@@ -128,3 +140,87 @@ def graphsage_lstm(gw, feature, hidden_size, act, name):
output = fluid.layers.concat([self_feature, neigh_feature], axis=1)
output = fluid.layers.l2_normalize(output, axis=1)
return output
+
+
+def build_graph_model(graph_wrapper, num_class, k_hop, graphsage_type,
+ hidden_size):
+ node_index = fluid.layers.data(
+ "node_index", shape=[None], dtype="int64", append_batch_size=False)
+
+ node_label = fluid.layers.data(
+ "node_label", shape=[None, 1], dtype="int64", append_batch_size=False)
+
+ #feature = fluid.layers.gather(feature, graph_wrapper.node_feat['feats'])
+ feature = graph_wrapper.node_feat['feats']
+ feature.stop_gradient = True
+
+ for i in range(k_hop):
+ if graphsage_type == 'graphsage_mean':
+ feature = graphsage_mean(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_mean_%s" % i)
+ elif graphsage_type == 'graphsage_meanpool':
+ feature = graphsage_meanpool(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_meanpool_%s" % i)
+ elif graphsage_type == 'graphsage_maxpool':
+ feature = graphsage_maxpool(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_maxpool_%s" % i)
+ elif graphsage_type == 'graphsage_lstm':
+ feature = graphsage_lstm(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_maxpool_%s" % i)
+ else:
+ raise ValueError("graphsage type %s is not"
+ " implemented" % graphsage_type)
+
+ feature = fluid.layers.gather(feature, node_index)
+ logits = fluid.layers.fc(feature,
+ num_class,
+ act=None,
+ name='classification_layer')
+ proba = fluid.layers.softmax(logits)
+
+ loss = fluid.layers.softmax_with_cross_entropy(
+ logits=logits, label=node_label)
+ loss = fluid.layers.mean(loss)
+ acc = fluid.layers.accuracy(input=proba, label=node_label, k=1)
+ return loss, acc
+
+
+class GraphsageModel(object):
+ def __init__(self, args):
+ self.args = args
+
+ def forward(self):
+ args = self.args
+
+ graph_wrapper = pgl.graph_wrapper.GraphWrapper(
+ "sub_graph", node_feat=[('feats', [None, 602], np.dtype('float32'))])
+ loss, acc = build_graph_model(
+ graph_wrapper,
+ num_class=args.num_class,
+ hidden_size=args.hidden_size,
+ graphsage_type=args.graphsage_type,
+ k_hop=len(args.samples))
+
+ loss.persistable = True
+
+ self.graph_wrapper = graph_wrapper
+ self.loss = loss
+ self.acc = acc
+ return loss
+
diff --git a/examples/distribute_graphsage/reader.py b/examples/distribute_graphsage/reader.py
index 6617b6b86fe08facee1915edcd459a8c706c4191..88556d39a9d6c30e1b7c4e5e087e994de937566e 100644
--- a/examples/distribute_graphsage/reader.py
+++ b/examples/distribute_graphsage/reader.py
@@ -11,6 +11,8 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import os
+import sys
import numpy as np
import pickle as pkl
import paddle
@@ -147,3 +149,48 @@ def multiprocess_graph_reader(
return reader()
+
+def load_data():
+ """
+ data from https://github.com/matenure/FastGCN/issues/8
+ reddit.npz: https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J
+ reddit_index_label is preprocess from reddit.npz without feats key.
+ """
+ data_dir = os.path.dirname(os.path.abspath(__file__))
+ data = np.load(os.path.join(data_dir, "data/reddit_index_label.npz"))
+
+ num_class = 41
+
+ train_label = data['y_train']
+ val_label = data['y_val']
+ test_label = data['y_test']
+
+ train_index = data['train_index']
+ val_index = data['val_index']
+ test_index = data['test_index']
+
+ return {
+ "train_index": train_index,
+ "train_label": train_label,
+ "val_label": val_label,
+ "val_index": val_index,
+ "test_index": test_index,
+ "test_label": test_label,
+ "num_class": 41
+ }
+
+def get_iter(args, graph_wrapper, mode):
+ data = load_data()
+ train_iter = multiprocess_graph_reader(
+ graph_wrapper,
+ samples=args.samples,
+ num_workers=args.num_sample_workers,
+ batch_size=args.batch_size,
+ node_index=data['train_index'],
+ node_label=data["train_label"])
+ return train_iter
+
+if __name__ == '__main__':
+ for e in train_iter():
+ print(e)
+
diff --git a/examples/distribute_graphsage/redis_setup/before_hook.sh b/examples/distribute_graphsage/redis_setup/before_hook.sh
new file mode 100644
index 0000000000000000000000000000000000000000..1b5c101a2e77b7823b3d23a85a709e843812464c
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/before_hook.sh
@@ -0,0 +1,31 @@
+#!/bin/bash
+set -x
+
+srcdir=./src
+
+# Data preprocessing
+python ./src/preprocess.py
+
+# Download and compile redis
+export PATH=$PWD/redis-5.0.5/src:$PATH
+if [ ! -f ./redis.tar.gz ]; then
+ curl https://codeload.github.com/antirez/redis/tar.gz/5.0.5 -o ./redis.tar.gz
+fi
+tar -xzf ./redis.tar.gz
+cd ./redis-5.0.5/
+make
+cd -
+
+# Install python deps
+python -m pip install -U pip
+pip install -r ./src/requirements.txt -U
+
+# Run redis server
+sh ./src/run_server.sh
+
+# Dumping data into redis
+source ./redis_graph.cfg
+sh ./src/dump_data.sh $edge_path $server_list $num_nodes $node_feat_path
+
+exit 0
+
diff --git a/examples/distribute_graphsage/redis_setup/redis_graph.cfg b/examples/distribute_graphsage/redis_setup/redis_graph.cfg
new file mode 100644
index 0000000000000000000000000000000000000000..382ca1749082ecbec98f2666186d81c0534547b6
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/redis_graph.cfg
@@ -0,0 +1,6 @@
+# dump config
+edge_path=../data/edge.txt
+node_feat_path=../data/feats.npz
+num_nodes=232965
+server_list=./server.list
+
diff --git a/examples/distribute_graphsage/redis_setup/src/build_graph.py b/examples/distribute_graphsage/redis_setup/src/build_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..9fb1c6563bf24991bfd3dfa9bca78f513c9d21e5
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/build_graph.py
@@ -0,0 +1,275 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import json
+import logging
+from collections import defaultdict
+import tqdm
+import redis
+from redis._compat import b, unicode, bytes, long, basestring
+from rediscluster.nodemanager import NodeManager
+from rediscluster.crc import crc16
+import argparse
+import time
+import pickle
+import numpy as np
+import scipy.sparse as sp
+
+log = logging.getLogger(__name__)
+root = logging.getLogger()
+root.setLevel(logging.DEBUG)
+
+handler = logging.StreamHandler(sys.stdout)
+handler.setLevel(logging.DEBUG)
+formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
+handler.setFormatter(formatter)
+root.addHandler(handler)
+
+
+def encode(value):
+ """
+ Return a bytestring representation of the value.
+ This method is copied from Redis' connection.py:Connection.encode
+ """
+ if isinstance(value, bytes):
+ return value
+ elif isinstance(value, (int, long)):
+ value = b(str(value))
+ elif isinstance(value, float):
+ value = b(repr(value))
+ elif not isinstance(value, basestring):
+ value = unicode(value)
+ if isinstance(value, unicode):
+ value = value.encode('utf-8')
+ return value
+
+
+def crc16_hash(data):
+ return crc16(encode(data))
+
+
+def get_redis(startup_host, startup_port):
+ startup_nodes = [{"host": startup_host, "port": startup_port}, ]
+ nodemanager = NodeManager(startup_nodes=startup_nodes)
+ nodemanager.initialize()
+ rs = {}
+ for node, config in nodemanager.nodes.items():
+ rs[node] = redis.Redis(
+ host=config["host"], port=config["port"], decode_responses=False)
+ return rs, nodemanager
+
+
+def load_data(edge_path):
+ src, dst = [], []
+ with open(edge_path, "r") as f:
+ for i in tqdm.tqdm(f):
+ s, d, _ = i.split()
+ s = int(s)
+ d = int(d)
+ src.append(s)
+ dst.append(d)
+ dst.append(s)
+ src.append(d)
+ src = np.array(src, dtype="int64")
+ dst = np.array(dst, dtype="int64")
+ return src, dst
+
+
+def build_edge_index(edge_path, num_nodes, startup_host, startup_port,
+ num_bucket):
+ #src, dst = load_data(edge_path)
+ rs, nodemanager = get_redis(startup_host, startup_port)
+
+ dst_mp, edge_mp = defaultdict(list), defaultdict(list)
+ with open(edge_path) as f:
+ for l in tqdm.tqdm(f):
+ a, b, idx = l.rstrip().split('\t')
+ a, b, idx = int(a), int(b), int(idx)
+ dst_mp[a].append(b)
+ edge_mp[a].append(idx)
+ part_dst_dicts = {}
+ for i in tqdm.tqdm(range(num_nodes)):
+ #if len(edge_index.v[i]) == 0:
+ # continue
+ #v = edge_index.v[i].astype("int64").reshape([-1, 1])
+ #e = edge_index.eid[i].astype("int64").reshape([-1, 1])
+ if i not in dst_mp:
+ continue
+ v = np.array(dst_mp[i]).astype('int64').reshape([-1, 1])
+ e = np.array(edge_mp[i]).astype('int64').reshape([-1, 1])
+ o = np.hstack([v, e])
+ key = "d:%s" % i
+ part = crc16_hash(key) % num_bucket
+ if part not in part_dst_dicts:
+ part_dst_dicts[part] = {}
+ dst_dicts = part_dst_dicts[part]
+ dst_dicts["d:%s" % i] = o.tobytes()
+ if len(dst_dicts) > 10000:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, dst_dicts)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_dst_dicts[part] = {}
+
+ for part, dst_dicts in part_dst_dicts.items():
+ if len(dst_dicts) > 0:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, dst_dicts)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_dst_dicts[part] = {}
+ log.info("dst_dict Done")
+
+
+def build_edge_id(edge_path, num_nodes, startup_host, startup_port,
+ num_bucket):
+ src, dst = load_data(edge_path)
+ rs, nodemanager = get_redis(startup_host, startup_port)
+ part_edge_dict = {}
+ for i in tqdm.tqdm(range(len(src))):
+ key = "e:%s" % i
+ part = crc16_hash(key) % num_bucket
+ if part not in part_edge_dict:
+ part_edge_dict[part] = {}
+ edge_dict = part_edge_dict[part]
+ edge_dict["e:%s" % i] = int(src[i]) * num_nodes + int(dst[i])
+ if len(edge_dict) > 10000:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, edge_dict)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+
+ part_edge_dict[part] = {}
+
+ for part, edge_dict in part_edge_dict.items():
+ if len(edge_dict) > 0:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, edge_dict)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_edge_dict[part] = {}
+
+
+def build_infos(edge_path, num_nodes, startup_host, startup_port, num_bucket):
+ src, dst = load_data(edge_path)
+ rs, nodemanager = get_redis(startup_host, startup_port)
+ slot = nodemanager.keyslot("num_nodes")
+ node = nodemanager.slots[slot][0]['name']
+ res = rs[node].set("num_nodes", num_nodes)
+
+ slot = nodemanager.keyslot("num_edges")
+ node = nodemanager.slots[slot][0]['name']
+ rs[node].set("num_edges", len(src))
+
+ slot = nodemanager.keyslot("nf:infos")
+ node = nodemanager.slots[slot][0]['name']
+ rs[node].set("nf:infos", json.dumps([['feats', [-1, 602], 'float32'], ]))
+
+ slot = nodemanager.keyslot("ef:infos")
+ node = nodemanager.slots[slot][0]['name']
+ rs[node].set("ef:infos", json.dumps([]))
+
+
+def build_node_feat(node_feat_path, num_nodes, startup_host, startup_port, num_bucket):
+ assert node_feat_path != "", "node_feat_path empty!"
+ feat_dict = np.load(node_feat_path)
+ for k in feat_dict.keys():
+ feat = feat_dict[k]
+ assert feat.shape[0] == num_nodes, "num_nodes invalid"
+
+ rs, nodemanager = get_redis(startup_host, startup_port)
+ part_feat_dict = {}
+ for k in feat_dict.keys():
+ feat = feat_dict[k]
+ for i in tqdm.tqdm(range(num_nodes)):
+ key = "nf:%s:%i" % (k, i)
+ value = feat[i].tobytes()
+ part = crc16_hash(key) % num_bucket
+ if part not in part_feat_dict:
+ part_feat_dict[part] = {}
+ part_feat = part_feat_dict[part]
+ part_feat[key] = value
+ if len(part_feat) > 100:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, part_feat)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+
+ part_feat_dict[part] = {}
+
+ for part, part_feat in part_feat_dict.items():
+ if len(part_feat) > 0:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, part_feat)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_feat_dict[part] = {}
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='gen_redis_conf')
+ parser.add_argument('--startup_port', type=int, required=True)
+ parser.add_argument('--startup_host', type=str, required=True)
+ parser.add_argument('--edge_path', type=str, default="")
+ parser.add_argument('--node_feat_path', type=str, default="")
+ parser.add_argument('--num_nodes', type=int, default=0)
+ parser.add_argument('--num_bucket', type=int, default=64)
+ parser.add_argument(
+ '--mode',
+ type=str,
+ required=True,
+ help="choose one of the following modes (clear, edge_index, edge_id, graph_attr)"
+ )
+ args = parser.parse_args()
+ log.info("Mode: {}".format(args.mode))
+ if args.mode == 'edge_index':
+ build_edge_index(args.edge_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ elif args.mode == 'edge_id':
+ build_edge_id(args.edge_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ elif args.mode == 'graph_attr':
+ build_infos(args.edge_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ elif args.mode == 'node_feat':
+ build_node_feat(args.node_feat_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ else:
+ raise ValueError("%s mode not found" % args.mode)
+
diff --git a/examples/distribute_graphsage/redis_setup/src/dump_data.sh b/examples/distribute_graphsage/redis_setup/src/dump_data.sh
new file mode 100644
index 0000000000000000000000000000000000000000..052064b5ac5ae61d0270691726d299796fe2393a
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/dump_data.sh
@@ -0,0 +1,63 @@
+filter(){
+ lines=`cat $1`
+ rm $1
+ for line in $lines; do
+ remote_host=`echo $line | cut -d":" -f1`
+ remote_port=`echo $line | cut -d":" -f2`
+ nc -z $remote_host $remote_port
+ if [[ $? == 0 ]]; then
+ echo $line >> $1
+ fi
+ done
+}
+
+dump_data(){
+ filter $server_list
+
+ python ./src/start_cluster.py --server_list $server_list --replicas 0
+
+ address=`head -n 1 $server_list`
+
+ ip=`echo $address | cut -d":" -f1`
+ port=`echo $address | cut -d":" -f2`
+
+ python ./src/build_graph.py --startup_host $ip \
+ --startup_port $port \
+ --mode node_feat \
+ --node_feat_path $feat_fn \
+ --num_nodes $num_nodes
+
+ # build edge index
+ python ./src/build_graph.py --startup_host $ip \
+ --startup_port $port \
+ --mode edge_index \
+ --edge_path $edge_path \
+ --num_nodes $num_nodes
+
+ # build edge id
+ #python ./src/build_graph.py --startup_host $ip \
+ # --startup_port $port \
+ # --mode edge_id \
+ # --edge_path $edge_path \
+ # --num_nodes $num_nodes
+
+ # build graph attr
+ python ./src/build_graph.py --startup_host $ip \
+ --startup_port $port \
+ --mode graph_attr \
+ --edge_path $edge_path \
+ --num_nodes $num_nodes
+
+}
+
+if [ $# -ne 4 ]; then
+ echo 'sh edge_path server_list num_nodes feat_fn'
+ exit
+fi
+num_nodes=$3
+server_list=$2
+edge_path=$1
+feat_fn=$4
+
+dump_data
+
diff --git a/examples/distribute_graphsage/redis_setup/src/gen_redis_conf.py b/examples/distribute_graphsage/redis_setup/src/gen_redis_conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ded1f3d79d0d2d64071d6936d38e4514c28b453
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/gen_redis_conf.py
@@ -0,0 +1,72 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import socket
+import argparse
+import os
+temp = """port %s
+bind %s
+daemonize yes
+pidfile /var/run/redis_%s.pid
+cluster-enabled yes
+cluster-config-file nodes.conf
+cluster-node-timeout 50000
+logfile "redis.log"
+appendonly yes"""
+
+
+def gen_config(ports):
+ if len(ports) == 0:
+ raise ValueError("No ports")
+ ip = socket.gethostbyname(socket.gethostname())
+ print("Generate redis conf")
+ for port in ports:
+ try:
+ os.mkdir("%s" % port)
+ except:
+ print("port %s directory already exists" % port)
+ pass
+ with open("%s/redis.conf" % port, 'w') as f:
+ f.write(temp % (port, ip, port))
+
+ print("Generate Start Server Scripts")
+ with open("start_server.sh", "w") as f:
+ f.write("set -x\n")
+ for ind, port in enumerate(ports):
+ f.write("# %s %s start\n" % (ip, port))
+ if ind > 0:
+ f.write("cd ..\n")
+ f.write("cd %s\n" % port)
+ f.write("redis-server redis.conf\n")
+ f.write("\n")
+
+ print("Generate Stop Server Scripts")
+ with open("stop_server.sh", "w") as f:
+ f.write("set -x\n")
+ for ind, port in enumerate(ports):
+ f.write("# %s %s shutdown\n" % (ip, port))
+ f.write("redis-cli -h %s -p %s shutdown\n" % (ip, port))
+ f.write("\n")
+
+ with open("server.list", "w") as f:
+ for ind, port in enumerate(ports):
+ f.write("%s:%s\n" % (ip, port))
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='gen_redis_conf')
+ parser.add_argument('--ports', nargs='+', type=int, default=[])
+ args = parser.parse_args()
+ gen_config(args.ports)
diff --git a/examples/distribute_graphsage/redis_setup/src/preprocess.py b/examples/distribute_graphsage/redis_setup/src/preprocess.py
new file mode 100644
index 0000000000000000000000000000000000000000..42c641ccbf9bf8b623b8e3be159c37d2dffd9ebd
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/preprocess.py
@@ -0,0 +1,35 @@
+import os
+import sys
+
+import numpy as np
+import scipy.sparse as sp
+
+def _load_config(fn):
+ ret = {}
+ with open(fn) as f:
+ for l in f:
+ if l.strip() == '' or l.startswith('#'):
+ continue
+ k, v = l.strip().split('=')
+ ret[k] = v
+ return ret
+
+def _prepro(config):
+ data = np.load("../data/reddit.npz")
+ adj = sp.load_npz("../data/reddit_adj.npz")
+ adj = adj.tocoo()
+ src = adj.row
+ dst = adj.col
+
+ with open(config['edge_path'], 'w') as f:
+ for idx, e in enumerate(zip(src, dst)):
+ s, d = e
+ l = "{}\t{}\t{}\n".format(s, d, idx)
+ f.write(l)
+ feats = data['feats'].astype(np.float32)
+ np.savez(config['node_feat_path'], feats=feats)
+
+if __name__ == '__main__':
+ config = _load_config('./redis_graph.cfg')
+ _prepro(config)
+
diff --git a/examples/distribute_graphsage/redis_setup/src/requirements.txt b/examples/distribute_graphsage/redis_setup/src/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..2f955a8c35414405c0ef4bebd459d96d7934ab62
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/requirements.txt
@@ -0,0 +1,6 @@
+numpy
+scipy
+tqdm
+redis==2.10.6
+redis-py-cluster==1.3.6
+
diff --git a/examples/distribute_graphsage/redis_setup/src/run_server.sh b/examples/distribute_graphsage/redis_setup/src/run_server.sh
new file mode 100644
index 0000000000000000000000000000000000000000..e1268ad60df82c283d0e8d7cfc1e9ca6f7126b6f
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/run_server.sh
@@ -0,0 +1,14 @@
+start_server(){
+ ports=""
+ for i in {7430..7439}; do
+ nc -z localhost $i
+ if [[ $? != 0 ]]; then
+ ports="$ports $i"
+ fi
+ done
+ python ./src/gen_redis_conf.py --ports $ports
+ bash ./start_server.sh #启动服务器
+}
+
+start_server
+
diff --git a/examples/distribute_graphsage/redis_setup/src/start_cluster.py b/examples/distribute_graphsage/redis_setup/src/start_cluster.py
new file mode 100644
index 0000000000000000000000000000000000000000..570765d3696a4eafa924efe8c9ba1787eff574d0
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/start_cluster.py
@@ -0,0 +1,37 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import argparse
+
+
+def build_clusters(server_list, replicas):
+ servers = []
+ with open(server_list) as f:
+ for line in f:
+ servers.append(line.strip())
+ cmd = "echo yes | redis-cli --cluster create"
+ for server in servers:
+ cmd += ' %s ' % server
+ cmd += '--cluster-replicas %s' % replicas
+ print(cmd)
+ os.system(cmd)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description='start_cluster')
+ parser.add_argument('--server_list', type=str, required=True)
+ parser.add_argument('--replicas', type=int, default=0)
+ args = parser.parse_args()
+ build_clusters(args.server_list, args.replicas)
diff --git a/examples/distribute_graphsage/redis_setup/test/test.sh b/examples/distribute_graphsage/redis_setup/test/test.sh
new file mode 100644
index 0000000000000000000000000000000000000000..ec8695b9c75c921bc03bf56a3c381bbd279b1532
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/test/test.sh
@@ -0,0 +1,7 @@
+#!/bin/bash
+
+source ./redis_graph.cfg
+
+url=`head -n1 $server_list`
+shuf $edge_path | head -n 1000 | python ./test/test_redis_graph.py $url
+
diff --git a/examples/distribute_graphsage/redis_setup/test/test_redis_graph.py b/examples/distribute_graphsage/redis_setup/test/test_redis_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..f4a3a2541bbd96210e8f9eaef5bf38a07cbd9e60
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/test/test_redis_graph.py
@@ -0,0 +1,40 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+########################################################################
+#
+# Copyright (c) 2019 Baidu.com, Inc. All Rights Reserved
+#
+# File: test_redis_graph.py
+# Author: suweiyue(suweiyue@baidu.com)
+# Date: 2019/08/19 16:28:18
+#
+########################################################################
+"""
+ Comment.
+"""
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import sys
+
+import numpy as np
+import tqdm
+from pgl.redis_graph import RedisGraph
+
+if __name__ == '__main__':
+ host, port = sys.argv[1].split(':')
+ port = int(port)
+ redis_configs = [{"host": host, "port": port}, ]
+ graph = RedisGraph("reddit-graph", redis_configs, num_parts=64)
+ #nodes = np.arange(0, 100)
+ #for i in range(0, 100):
+ for l in tqdm.tqdm(sys.stdin):
+ l_sp = l.rstrip().split('\t')
+ if len(l_sp) != 2:
+ continue
+ i, j = int(l_sp[0]), int(l_sp[1])
+ nodes = graph.sample_predecessor(np.array([i]), 10000)
+ assert j in nodes
+
diff --git a/examples/distribute_graphsage/requirements.txt b/examples/distribute_graphsage/requirements.txt
index 7bda67a20635218a8786cfb872cfd2da5b2ddbe1..e0d28f3b6ce2ab2cea5d9674b871cc8d3e7ac932 100644
--- a/examples/distribute_graphsage/requirements.txt
+++ b/examples/distribute_graphsage/requirements.txt
@@ -1,3 +1,7 @@
+pgl==1.1.0
+pyyaml
+paddlepaddle==1.6.1
+
scipy
redis==2.10.6
redis-py-cluster==1.3.6
diff --git a/examples/distribute_graphsage/train.py b/examples/distribute_graphsage/train.py
deleted file mode 100644
index 4faafdd504415efd954f09d6d54dc7b38e6287c5..0000000000000000000000000000000000000000
--- a/examples/distribute_graphsage/train.py
+++ /dev/null
@@ -1,263 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import os
-import argparse
-import time
-
-import numpy as np
-import scipy.sparse as sp
-from sklearn.preprocessing import StandardScaler
-
-import pgl
-from pgl.utils.logger import log
-from pgl.utils import paddle_helper
-import paddle
-import paddle.fluid as fluid
-import reader
-from model import graphsage_mean, graphsage_meanpool,\
- graphsage_maxpool, graphsage_lstm
-
-
-def load_data():
- """
- data from https://github.com/matenure/FastGCN/issues/8
- reddit.npz: https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J
- reddit_index_label is preprocess from reddit.npz without feats key.
- """
- data_dir = os.path.dirname(os.path.abspath(__file__))
- data = np.load(os.path.join(data_dir, "data/reddit_index_label.npz"))
-
- num_class = 41
-
- train_label = data['y_train']
- val_label = data['y_val']
- test_label = data['y_test']
-
- train_index = data['train_index']
- val_index = data['val_index']
- test_index = data['test_index']
-
- return {
- "train_index": train_index,
- "train_label": train_label,
- "val_label": val_label,
- "val_index": val_index,
- "test_index": test_index,
- "test_label": test_label,
- "num_class": 41
- }
-
-
-def build_graph_model(graph_wrapper, num_class, k_hop, graphsage_type,
- hidden_size):
- node_index = fluid.layers.data(
- "node_index", shape=[None], dtype="int64", append_batch_size=False)
-
- node_label = fluid.layers.data(
- "node_label", shape=[None, 1], dtype="int64", append_batch_size=False)
-
- #feature = fluid.layers.gather(feature, graph_wrapper.node_feat['feats'])
- feature = graph_wrapper.node_feat['feats']
- feature.stop_gradient = True
-
- for i in range(k_hop):
- if graphsage_type == 'graphsage_mean':
- feature = graphsage_mean(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_mean_%s" % i)
- elif graphsage_type == 'graphsage_meanpool':
- feature = graphsage_meanpool(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_meanpool_%s" % i)
- elif graphsage_type == 'graphsage_maxpool':
- feature = graphsage_maxpool(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_maxpool_%s" % i)
- elif graphsage_type == 'graphsage_lstm':
- feature = graphsage_lstm(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_maxpool_%s" % i)
- else:
- raise ValueError("graphsage type %s is not"
- " implemented" % graphsage_type)
-
- feature = fluid.layers.gather(feature, node_index)
- logits = fluid.layers.fc(feature,
- num_class,
- act=None,
- name='classification_layer')
- proba = fluid.layers.softmax(logits)
-
- loss = fluid.layers.softmax_with_cross_entropy(
- logits=logits, label=node_label)
- loss = fluid.layers.mean(loss)
- acc = fluid.layers.accuracy(input=proba, label=node_label, k=1)
- return loss, acc
-
-
-def run_epoch(batch_iter,
- exe,
- program,
- prefix,
- model_loss,
- model_acc,
- epoch,
- log_per_step=100):
- batch = 0
- total_loss = 0.
- total_acc = 0.
- total_sample = 0
- start = time.time()
- for batch_feed_dict in batch_iter():
- batch += 1
- batch_loss, batch_acc = exe.run(program,
- fetch_list=[model_loss, model_acc],
- feed=batch_feed_dict)
-
- if batch % log_per_step == 0:
- log.info("Batch %s %s-Loss %s %s-Acc %s" %
- (batch, prefix, batch_loss, prefix, batch_acc))
-
- num_samples = len(batch_feed_dict["node_index"])
- total_loss += batch_loss * num_samples
- total_acc += batch_acc * num_samples
- total_sample += num_samples
- end = time.time()
-
- log.info("%s Epoch %s Loss %.5lf Acc %.5lf Speed(per batch) %.5lf sec" %
- (prefix, epoch, total_loss / total_sample,
- total_acc / total_sample, (end - start) / batch))
-
-
-def main(args):
- data = load_data()
- log.info("preprocess finish")
- log.info("Train Examples: %s" % len(data["train_index"]))
- log.info("Val Examples: %s" % len(data["val_index"]))
- log.info("Test Examples: %s" % len(data["test_index"]))
-
- place = fluid.CUDAPlace(0) if args.use_cuda else fluid.CPUPlace()
- train_program = fluid.Program()
- startup_program = fluid.Program()
- samples = []
- if args.samples_1 > 0:
- samples.append(args.samples_1)
- if args.samples_2 > 0:
- samples.append(args.samples_2)
-
- with fluid.program_guard(train_program, startup_program):
- graph_wrapper = pgl.graph_wrapper.GraphWrapper(
- "sub_graph", node_feat=[('feats', [None, 602], np.dtype('float32'))])
- model_loss, model_acc = build_graph_model(
- graph_wrapper,
- num_class=data["num_class"],
- hidden_size=args.hidden_size,
- graphsage_type=args.graphsage_type,
- k_hop=len(samples))
-
- test_program = train_program.clone(for_test=True)
-
- with fluid.program_guard(train_program, startup_program):
- adam = fluid.optimizer.Adam(learning_rate=args.lr)
- adam.minimize(model_loss)
-
- exe = fluid.Executor(place)
- exe.run(startup_program)
-
- train_iter = reader.multiprocess_graph_reader(
- graph_wrapper,
- samples=samples,
- num_workers=args.sample_workers,
- batch_size=args.batch_size,
- node_index=data['train_index'],
- node_label=data["train_label"])
-
- val_iter = reader.multiprocess_graph_reader(
- graph_wrapper,
- samples=samples,
- num_workers=args.sample_workers,
- batch_size=args.batch_size,
- node_index=data['val_index'],
- node_label=data["val_label"])
-
- test_iter = reader.multiprocess_graph_reader(
- graph_wrapper,
- samples=samples,
- num_workers=args.sample_workers,
- batch_size=args.batch_size,
- node_index=data['test_index'],
- node_label=data["test_label"])
-
- for epoch in range(args.epoch):
- run_epoch(
- train_iter,
- program=train_program,
- exe=exe,
- prefix="train",
- model_loss=model_loss,
- model_acc=model_acc,
- log_per_step=1,
- epoch=epoch)
-
- run_epoch(
- val_iter,
- program=test_program,
- exe=exe,
- prefix="val",
- model_loss=model_loss,
- model_acc=model_acc,
- log_per_step=10000,
- epoch=epoch)
-
- run_epoch(
- test_iter,
- program=test_program,
- prefix="test",
- exe=exe,
- model_loss=model_loss,
- model_acc=model_acc,
- log_per_step=10000,
- epoch=epoch)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(description='graphsage')
- parser.add_argument("--use_cuda", action='store_true', help="use_cuda")
- parser.add_argument(
- "--normalize", action='store_true', help="normalize features")
- parser.add_argument(
- "--symmetry", action='store_true', help="undirect graph")
- parser.add_argument("--graphsage_type", type=str, default="graphsage_mean")
- parser.add_argument("--sample_workers", type=int, default=10)
- parser.add_argument("--epoch", type=int, default=10)
- parser.add_argument("--hidden_size", type=int, default=128)
- parser.add_argument("--batch_size", type=int, default=128)
- parser.add_argument("--lr", type=float, default=0.01)
- parser.add_argument("--samples_1", type=int, default=25)
- parser.add_argument("--samples_2", type=int, default=10)
- args = parser.parse_args()
- log.info(args)
- main(args)
diff --git a/examples/distribute_graphsage/utils.py b/examples/distribute_graphsage/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5810f7fdd7a99b034505feaddf51a962ca34ac1
--- /dev/null
+++ b/examples/distribute_graphsage/utils.py
@@ -0,0 +1,55 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Implementation of some helper functions"""
+
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import os
+import time
+import yaml
+import numpy as np
+
+from pgl.utils.logger import log
+
+
+class AttrDict(dict):
+ """Attr dict
+ """
+
+ def __init__(self, d):
+ self.dict = d
+
+ def __getattr__(self, attr):
+ value = self.dict[attr]
+ if isinstance(value, dict):
+ return AttrDict(value)
+ else:
+ return value
+
+ def __str__(self):
+ return str(self.dict)
+
+
+def load_config(config_file):
+ """Load config file"""
+ with open(config_file) as f:
+ if hasattr(yaml, 'FullLoader'):
+ config = yaml.load(f, Loader=yaml.FullLoader)
+ else:
+ config = yaml.load(f)
+
+ return AttrDict(config)
diff --git a/examples/distribute_graphsage/utils.sh b/examples/distribute_graphsage/utils.sh
new file mode 100644
index 0000000000000000000000000000000000000000..6f6daa846d600e0bcecd4ce64e04946dba0fdd51
--- /dev/null
+++ b/examples/distribute_graphsage/utils.sh
@@ -0,0 +1,20 @@
+
+# parse yaml file
+function parse_yaml {
+ local prefix=$2
+ local s='[[:space:]]*' w='[a-zA-Z0-9_]*' fs=$(echo @|tr @ '\034')
+ sed -ne "s|^\($s\):|\1|" \
+ -e "s|^\($s\)\($w\)$s:$s[\"']\(.*\)[\"']$s\$|\1$fs\2$fs\3|p" \
+ -e "s|^\($s\)\($w\)$s:$s\(.*\)$s\$|\1$fs\2$fs\3|p" $1 |
+ awk -F$fs '{
+ indent = length($1)/2;
+ vname[indent] = $2;
+ for (i in vname) {if (i > indent) {delete vname[i]}}
+ if (length($3) > 0) {
+ vn=""; for (i=0; i