diff --git a/.gitignore b/.gitignore
index a2958b8e3bbfbfe918b6597fc2c3362f6709e556..d7bedb5e5bd83e8b853b74ade36f9f77cb8cb1c2 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,3 +1,9 @@
+# data and log
+/examples/GaAN/dataset/
+/examples/GaAN/log/
+/examples/GaAN/__pycache__/
+/examples/GaAN/params/
+/DoorGod
# Virtualenv
/.venv/
/venv/
diff --git a/README.md b/README.md
index 5a5cd380601c82d028c4cc1a3ccd25c63ded1994..128cb90f8651f2e7616500fef8073906421c0fec 100644
--- a/README.md
+++ b/README.md
@@ -1,11 +1,28 @@
 +[](https://pypi.org/project/pgl/)
+[](./LICENSE)
+
[DOC](https://pgl.readthedocs.io/en/latest/) | [Quick Start](https://pgl.readthedocs.io/en/latest/quick_start/instruction.html) | [中文](./README.zh.md)
+## Breaking News !!
+
+PGL v1.1 2020.4.29
+
+- You can find **ERNIESage**, a novel model for modeling text and graph structures, and its introduction [here](./examples/erniesage/).
+
+- PGL for [Open Graph Benchmark](https://github.com/snap-stanford/ogb) examples can be find [here](./ogb_examples/).
+
+- We add newly graph level operators like **GraphPooling** and [**GraphNormalization**](https://arxiv.org/abs/2003.00982) for graph level predictions.
+
+- We relase a PGL-KE toolkit [here](./examples/pgl-ke) including classical knowledge graph embedding t algorithms like TransE, TransR, RotatE.
+
+------
+
Paddle Graph Learning (PGL) is an efficient and flexible graph learning framework based on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle).
-
+[](https://pypi.org/project/pgl/)
+[](./LICENSE)
+
[DOC](https://pgl.readthedocs.io/en/latest/) | [Quick Start](https://pgl.readthedocs.io/en/latest/quick_start/instruction.html) | [中文](./README.zh.md)
+## Breaking News !!
+
+PGL v1.1 2020.4.29
+
+- You can find **ERNIESage**, a novel model for modeling text and graph structures, and its introduction [here](./examples/erniesage/).
+
+- PGL for [Open Graph Benchmark](https://github.com/snap-stanford/ogb) examples can be find [here](./ogb_examples/).
+
+- We add newly graph level operators like **GraphPooling** and [**GraphNormalization**](https://arxiv.org/abs/2003.00982) for graph level predictions.
+
+- We relase a PGL-KE toolkit [here](./examples/pgl-ke) including classical knowledge graph embedding t algorithms like TransE, TransR, RotatE.
+
+------
+
Paddle Graph Learning (PGL) is an efficient and flexible graph learning framework based on [PaddlePaddle](https://github.com/PaddlePaddle/Paddle).
- +
+ The newly released PGL supports heterogeneous graph learning on both walk based paradigm and message-passing based paradigm by providing MetaPath sampling and Message Passing mechanism on heterogeneous graph. Furthermor, The newly released PGL also support distributed graph storage and some distributed training algorithms, such as distributed deep walk and distributed graphsage. Combined with the PaddlePaddle deep learning framework, we are able to support both graph representation learning models and graph neural networks, and thus our framework has a wide range of graph-based applications.
@@ -13,13 +30,13 @@ The newly released PGL supports heterogeneous graph learning on both walk based
## Highlight: Efficiency - Support Scatter-Gather and LodTensor Message Passing
-One of the most important benefits of graph neural networks compared to other models is the ability to use node-to-node connectivity information, but coding the communication between nodes is very cumbersome. At PGL we adopt **Message Passing Paradigm** similar to [DGL](https://github.com/dmlc/dgl) to help to build a customize graph neural network easily. Users only need to write ```send``` and ```recv``` functions to easily implement a simple GCN. As shown in the following figure, for the first step the send function is defined on the edges of the graph, and the user can customize the send function  to send the message from the source to the target node. For the second step, the recv function  is responsible for aggregating  messages together from different sources.
+One of the most important benefits of graph neural networks compared to other models is the ability to use node-to-node connectivity information, but coding the communication between nodes is very cumbersome. At PGL we adopt **Message Passing Paradigm** similar to [DGL](https://github.com/dmlc/dgl) to help to build a customize graph neural network easily. Users only need to write ```send``` and ```recv``` functions to easily implement a simple GCN. As shown in the following figure, for the first step the send function is defined on the edges of the graph, and the user can customize the send function 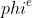 to send the message from the source to the target node. For the second step, the recv function 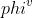 is responsible for aggregating  messages together from different sources.
The newly released PGL supports heterogeneous graph learning on both walk based paradigm and message-passing based paradigm by providing MetaPath sampling and Message Passing mechanism on heterogeneous graph. Furthermor, The newly released PGL also support distributed graph storage and some distributed training algorithms, such as distributed deep walk and distributed graphsage. Combined with the PaddlePaddle deep learning framework, we are able to support both graph representation learning models and graph neural networks, and thus our framework has a wide range of graph-based applications.
@@ -13,13 +30,13 @@ The newly released PGL supports heterogeneous graph learning on both walk based
## Highlight: Efficiency - Support Scatter-Gather and LodTensor Message Passing
-One of the most important benefits of graph neural networks compared to other models is the ability to use node-to-node connectivity information, but coding the communication between nodes is very cumbersome. At PGL we adopt **Message Passing Paradigm** similar to [DGL](https://github.com/dmlc/dgl) to help to build a customize graph neural network easily. Users only need to write ```send``` and ```recv``` functions to easily implement a simple GCN. As shown in the following figure, for the first step the send function is defined on the edges of the graph, and the user can customize the send function  to send the message from the source to the target node. For the second step, the recv function  is responsible for aggregating  messages together from different sources.
+One of the most important benefits of graph neural networks compared to other models is the ability to use node-to-node connectivity information, but coding the communication between nodes is very cumbersome. At PGL we adopt **Message Passing Paradigm** similar to [DGL](https://github.com/dmlc/dgl) to help to build a customize graph neural network easily. Users only need to write ```send``` and ```recv``` functions to easily implement a simple GCN. As shown in the following figure, for the first step the send function is defined on the edges of the graph, and the user can customize the send function 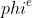 to send the message from the source to the target node. For the second step, the recv function 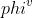 is responsible for aggregating  messages together from different sources.
 -As shown in the left of the following figure, to adapt general user-defined message aggregate functions, DGL uses the degree bucketing method to combine nodes with the same degree into a batch and then apply an aggregate function  on each batch serially. For our PGL UDF aggregate function, we organize the message as a [LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html) in [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) taking the message as variable length sequences. And we **utilize the features of LodTensor in Paddle to obtain fast parallel aggregation**.
+As shown in the left of the following figure, to adapt general user-defined message aggregate functions, DGL uses the degree bucketing method to combine nodes with the same degree into a batch and then apply an aggregate function  on each batch serially. For our PGL UDF aggregate function, we organize the message as a [LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html) in [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) taking the message as variable length sequences. And we **utilize the features of LodTensor in Paddle to obtain fast parallel aggregation**.
-As shown in the left of the following figure, to adapt general user-defined message aggregate functions, DGL uses the degree bucketing method to combine nodes with the same degree into a batch and then apply an aggregate function  on each batch serially. For our PGL UDF aggregate function, we organize the message as a [LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html) in [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) taking the message as variable length sequences. And we **utilize the features of LodTensor in Paddle to obtain fast parallel aggregation**.
+As shown in the left of the following figure, to adapt general user-defined message aggregate functions, DGL uses the degree bucketing method to combine nodes with the same degree into a batch and then apply an aggregate function  on each batch serially. For our PGL UDF aggregate function, we organize the message as a [LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html) in [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) taking the message as variable length sequences. And we **utilize the features of LodTensor in Paddle to obtain fast parallel aggregation**.
 @@ -82,10 +99,11 @@ In most cases of large-scale graph learning, we need distributed graph storage a
## Model Zoo
-The following are 13 graph learning models that have been implemented in the framework. See the details [here](https://pgl.readthedocs.io/en/latest/introduction.html#highlight-tons-of-models)
+The following graph learning models have been implemented in the framework. You can find more [examples](./examples) and the [details](https://pgl.readthedocs.io/en/latest/introduction.html#highlight-tons-of-models)
|Model | feature |
|---|---|
+| [**ERNIESage**](./examples/erniesage/) | ERNIE SAmple aggreGatE for Text and Graph |
| GCN | Graph Convolutional Neural Networks |
| GAT | Graph Attention Network |
| GraphSage |Large-scale graph convolution network based on neighborhood sampling|
diff --git a/README.zh.md b/README.zh.md
index e7996398a42a08c1dc1a5022d515ef472eb4382e..c41fdd485f8beda8569e7d70f3dc19670ed13673 100644
--- a/README.zh.md
+++ b/README.zh.md
@@ -1,7 +1,24 @@
+[](https://pypi.org/project/pgl/)
+[](./LICENSE)
+
[文档](https://pgl.readthedocs.io/en/latest/) | [快速开始](https://pgl.readthedocs.io/en/latest/quick_start/instruction.html) | [English](./README.md)
+## 最新消息
+
+PGL v1.1 2020.4.29
+
+- **ERNIESage**是PGL团队最新提出的模型,可以用于建模文本以及图结构信息。你可以在[这里](./examples/erniesage)看到详细的介绍。
+
+- PGL现在提供[Open Graph Benchmark](https://github.com/snap-stanford/ogb)的一些例子,你可以在[这里](./ogb_examples)找到。
+
+- 新增了图级别的算子包括**GraphPooling**以及[**GraphNormalization**](https://arxiv.org/abs/2003.00982),这样你就能实现更多复杂的图级别分类模型。
+
+- 新增PGL-KE工具包,里面包含许多经典知识图谱图嵌入算法,包括TransE, TransR, RotatE,详情可见[这里](./examples/pgl-ke)
+
+------
+
Paddle Graph Learning (PGL)是一个基于[PaddlePaddle](https://github.com/PaddlePaddle/Paddle)的高效易用的图学习框架
@@ -12,11 +29,11 @@ Paddle Graph Learning (PGL)是一个基于[PaddlePaddle](https://github.com/Padd
# 特色:高效性——支持Scatter-Gather及LodTensor消息传递
-对比于一般的模型,图神经网络模型最大的优势在于它利用了节点与节点之间连接的信息。但是,如何通过代码来实现建模这些节点连接十分的麻烦。PGL采用与[DGL](https://github.com/dmlc/dgl)相似的**消息传递范式**用于作为构建图神经网络的接口。用于只需要简单的编写```send```还有```recv```函数就能够轻松的实现一个简单的GCN网络。如下图所示,首先,send函数被定义在节点之间的边上,用户自定义send函数会把消息从源点发送到目标节点。然后,recv函数负责将这些消息用汇聚函数  汇聚起来。
+对比于一般的模型,图神经网络模型最大的优势在于它利用了节点与节点之间连接的信息。但是,如何通过代码来实现建模这些节点连接十分的麻烦。PGL采用与[DGL](https://github.com/dmlc/dgl)相似的**消息传递范式**用于作为构建图神经网络的接口。用于只需要简单的编写```send```还有```recv```函数就能够轻松的实现一个简单的GCN网络。如下图所示,首先,send函数被定义在节点之间的边上,用户自定义send函数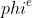会把消息从源点发送到目标节点。然后,recv函数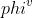负责将这些消息用汇聚函数  汇聚起来。
-如下面左图所示,为了去适配用户定义的汇聚函数,DGL使用了Degree Bucketing来将相同度的节点组合在一个块,然后将汇聚函数作用在每个块之上。而对于PGL的用户定义汇聚函数,我们则将消息以PaddlePaddle的[LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html)的形式处理,将若干消息看作一组变长的序列,然后利用**LodTensor在PaddlePaddle的特性进行快速平行的消息聚合**。
+如下面左图所示,为了去适配用户定义的汇聚函数,DGL使用了Degree Bucketing来将相同度的节点组合在一个块,然后将汇聚函数作用在每个块之上。而对于PGL的用户定义汇聚函数,我们则将消息以PaddlePaddle的[LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html)的形式处理,将若干消息看作一组变长的序列,然后利用**LodTensor在PaddlePaddle的特性进行快速平行的消息聚合**。
@@ -77,10 +94,11 @@ Paddle Graph Learning (PGL)是一个基于[PaddlePaddle](https://github.com/Padd
## 丰富性——覆盖业界大部分图学习网络
-下列是框架中已经自带实现的十三种图网络学习模型。详情请参考[这里](https://pgl.readthedocs.io/en/latest/introduction.html#highlight-tons-of-models)
+下列是框架中部分已经实现的图网络模型,更多的模型在[这里](./examples)可以找到。详情请参考[这里](https://pgl.readthedocs.io/en/latest/introduction.html#highlight-tons-of-models)
| 模型 | 特点 |
|---|---|
+| [**ERNIESage**](./examples/erniesage/) | 能同时建模文本以及图结构的ERNIE SAmple aggreGatE |
| GCN | 图卷积网络 |
| GAT | 基于Attention的图卷积网络 |
| GraphSage | 基于邻居采样的大规模图卷积网络 |
diff --git a/docs/source/_static/framework_of_pgl.png b/docs/source/_static/framework_of_pgl.png
index f8f6293a6821f7a13901f5b83d6d904a4f64ee0d..a054bd3438f60ca5e838d3e80ccdb567fddd23fd 100644
Binary files a/docs/source/_static/framework_of_pgl.png and b/docs/source/_static/framework_of_pgl.png differ
diff --git a/docs/source/_static/framework_of_pgl_en.png b/docs/source/_static/framework_of_pgl_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..04482775663088455fdd7020d8de5f7db663a177
Binary files /dev/null and b/docs/source/_static/framework_of_pgl_en.png differ
diff --git a/docs/source/_static/logo.png b/docs/source/_static/logo.png
index fc602ea6c020ee08116c7cd86411834741b5377e..48d5966bfa12d537b92b010a0f9e0c525d3350ae 100644
Binary files a/docs/source/_static/logo.png and b/docs/source/_static/logo.png differ
diff --git a/docs/source/api/pgl.contrib.heter_graph.rst b/docs/source/api/pgl.contrib.heter_graph.rst
deleted file mode 100644
index e1cc7ef4adeb943f352fad96781ef572606a6b96..0000000000000000000000000000000000000000
--- a/docs/source/api/pgl.contrib.heter_graph.rst
+++ /dev/null
@@ -1,7 +0,0 @@
-pgl.contrib.heter\_graph module: Heterogenous Graph Storage
-===============================
-
-.. automodule:: pgl.contrib.heter_graph
- :members:
- :undoc-members:
- :show-inheritance:
diff --git a/docs/source/api/pgl.contrib.heter_graph_wrapper.rst b/docs/source/api/pgl.contrib.heter_graph_wrapper.rst
deleted file mode 100644
index 74d9fe853df4639ee86470e67aa06c85c167cffe..0000000000000000000000000000000000000000
--- a/docs/source/api/pgl.contrib.heter_graph_wrapper.rst
+++ /dev/null
@@ -1,7 +0,0 @@
-pgl.contrib.heter\_graph\_wrapper module: Heterogenous Graph data holders for Paddle GNN.
-=========================
-
-.. automodule:: pgl.contrib.heter_graph_wrapper
- :members:
- :undoc-members:
- :show-inheritance:
diff --git a/docs/source/api/pgl.heter_graph.rst b/docs/source/api/pgl.heter_graph.rst
new file mode 100644
index 0000000000000000000000000000000000000000..f3d9091f2487533d54864f684bb1683a56d70f94
--- /dev/null
+++ b/docs/source/api/pgl.heter_graph.rst
@@ -0,0 +1,7 @@
+pgl.heter\_graph module: Heterogenous Graph Storage
+===============================
+
+.. automodule:: pgl.heter_graph
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/api/pgl.heter_graph_wrapper.rst b/docs/source/api/pgl.heter_graph_wrapper.rst
new file mode 100644
index 0000000000000000000000000000000000000000..63e364d9d2d02f2a52f4752ab017291624cdf40d
--- /dev/null
+++ b/docs/source/api/pgl.heter_graph_wrapper.rst
@@ -0,0 +1,7 @@
+pgl.heter\_graph\_wrapper module: Heterogenous Graph data holders for Paddle GNN.
+=========================
+
+.. automodule:: pgl.heter_graph_wrapper
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/api/pgl.rst b/docs/source/api/pgl.rst
index cc581c85b0298d3454bcbab0779427e2b25340d9..57034dabb67a995d46993e0218aaec76a1e897fa 100644
--- a/docs/source/api/pgl.rst
+++ b/docs/source/api/pgl.rst
@@ -9,5 +9,5 @@ API Reference
pgl.data_loader
pgl.utils.paddle_helper
pgl.utils.mp_reader
- pgl.contrib.heter_graph
- pgl.contrib.heter_graph_wrapper
+ pgl.heter_graph
+ pgl.heter_graph_wrapper
diff --git a/docs/source/quick_start/md/quick_start.md b/docs/source/quick_start/md/quick_start.md
index 7df4f48a997e35c001ae462b1f9d3052434eb443..afa8a22256a313f9f27b095d5c8eb9acc8f063c1 100644
--- a/docs/source/quick_start/md/quick_start.md
+++ b/docs/source/quick_start/md/quick_start.md
@@ -19,8 +19,8 @@ def build_graph():
# Each node can be represented by a d-dimensional feature vector, here for simple, the feature vectors are randomly generated.
d = 16
feature = np.random.randn(num_node, d).astype("float32")
- # each edge also can be represented by a feature vector
- edge_feature = np.random.randn(len(edge_list), d).astype("float32")
+ # each edge has it own weight
+ edge_feature = np.random.randn(len(edge_list), 1).astype("float32")
# create a graph
g = graph.Graph(num_nodes = num_node,
@@ -53,7 +53,6 @@ place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
# use GraphWrapper as a container for graph data to construct a graph neural network
gw = pgl.graph_wrapper.GraphWrapper(name='graph',
- place = place,
node_feat=g.node_feat_info())
```
@@ -67,13 +66,13 @@ In this tutorial, we use a simple Graph Convolutional Network(GCN) developed by
In PGL, we can easily implement a GCN layer as follows:
```python
# define GCN layer function
-def gcn_layer(gw, feature, hidden_size, name, activation):
+def gcn_layer(gw, nfeat, efeat, hidden_size, name, activation):
# gw is a GraphWrapper;feature is the feature vectors of nodes
# define message function
def send_func(src_feat, dst_feat, edge_feat):
# In this tutorial, we return the feature vector of the source node as message
- return src_feat['h']
+ return src_feat['h'] * edge_feat['e']
# define reduce function
def recv_func(feat):
@@ -81,7 +80,7 @@ def gcn_layer(gw, feature, hidden_size, name, activation):
return fluid.layers.sequence_pool(feat, pool_type='sum')
# trigger message to passing
- msg = gw.send(send_func, nfeat_list=[('h', feature)])
+ msg = gw.send(send_func, nfeat_list=[('h', nfeat)], efeat_list=[('e', efeat)])
# recv funciton receives message and trigger reduce funcition to handle message
output = gw.recv(msg, recv_func)
output = fluid.layers.fc(output,
@@ -93,10 +92,10 @@ def gcn_layer(gw, feature, hidden_size, name, activation):
```
After defining the GCN layer, we can construct a deeper GCN model with two GCN layers.
```python
-output = gcn_layer(gw, gw.node_feat['feature'],
+output = gcn_layer(gw, gw.node_feat['feature'], gw.edge_feat['edge_feature'],
hidden_size=8, name='gcn_layer_1', activation='relu')
-output = gcn_layer(gw, output, hidden_size=1,
- name='gcn_layer_2', activation=None)
+output = gcn_layer(gw, output, gw.edge_feat['edge_feature'],
+ hidden_size=1, name='gcn_layer_2', activation=None)
```
## Step 3: data preprocessing
diff --git a/docs/source/quick_start/md/quick_start_for_heterGraph.md b/docs/source/quick_start/md/quick_start_for_heterGraph.md
index 1be9cb228ce965cc8f0b6ae65ffc3738e08d0b2a..aae818c0be633a5708eb2ea29636077f3c919425 100644
--- a/docs/source/quick_start/md/quick_start_for_heterGraph.md
+++ b/docs/source/quick_start/md/quick_start_for_heterGraph.md
@@ -58,8 +58,8 @@ Now, we can build a heterogenous graph by using PGL.
import paddle.fluid as fluid
import paddle.fluid.layers as fl
import pgl
-from pgl.contrib import heter_graph
-from pgl.contrib import heter_graph_wrapper
+from pgl import heter_graph
+from pgl import heter_graph_wrapper
g = heter_graph.HeterGraph(num_nodes=num_nodes,
edges=edges,
@@ -77,7 +77,6 @@ place = fluid.CPUPlace()
# create a GraphWrapper as a container for graph data
gw = heter_graph_wrapper.HeterGraphWrapper(name='heter_graph',
- place = place,
edge_types = g.edge_types_info(),
node_feat=g.node_feat_info(),
edge_feat=g.edge_feat_info())
@@ -161,8 +160,3 @@ for epoch in range(30):
train_loss = exe.run(fluid.default_main_program(), feed=feed_dict, fetch_list=[loss], return_numpy=True)
print('Epoch %d | Loss: %f'%(epoch, train_loss[0]))
```
-
-
-
-
-
diff --git a/examples/GATNE/model.py b/examples/GATNE/model.py
index b193849e14d31eec7822fc65379a74c7cb2be38d..18f83c89a31324256f20ae118372828fe8be955d 100644
--- a/examples/GATNE/model.py
+++ b/examples/GATNE/model.py
@@ -53,7 +53,6 @@ class GATNE(object):
self.gw = heter_graph_wrapper.HeterGraphWrapper(
name="heter_graph",
- place=place,
edge_types=self.graph.edge_types_info(),
node_feat=self.graph.node_feat_info(),
edge_feat=self.graph.edge_feat_info())
diff --git a/examples/GaAN/README.md b/examples/GaAN/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a3b0981a63211fc2c2555d5942495ca849238e8c
--- /dev/null
+++ b/examples/GaAN/README.md
@@ -0,0 +1,41 @@
+# GaAN: Gated Attention Networks for Learning on Large and Spatiotemporal Graphs
+
+[GaAN](https://arxiv.org/abs/1803.07294) is a powerful neural network designed for machine learning on graph. It introduces an gated attention mechanism. Based on PGL, we reproduce the GaAN algorithm and train the model on [ogbn-proteins](https://ogb.stanford.edu/docs/nodeprop/#ogbn-proteins).
+
+## Datasets
+The ogbn-proteins dataset will be downloaded in directory ./dataset automatically.
+
+## Dependencies
+- [paddlepaddle >= 1.6](https://github.com/paddlepaddle/paddle)
+- [pgl 1.1](https://github.com/PaddlePaddle/PGL)
+- [ogb 1.1.1](https://github.com/snap-stanford/ogb)
+
+## How to run
+```bash
+python train.py --lr 1e-2 --rc 0 --batch_size 1024 --epochs 100
+```
+
+or
+```bash
+source main.sh
+```
+
+### Hyperparameters
+- use_gpu: whether to use gpu or not
+- mini_data: use a small dataset to test code
+- epochs: number of training epochs
+- lr: learning rate
+- rc: regularization coefficient
+- log_path: the path of log
+- batch_size: the number of batch size
+- heads: the number of heads of attention
+- hidden_size_a: the size of query and key vectors
+- hidden_size_v: the size of value vectors
+- hidden_size_m: the size of projection space for computing gates
+- hidden_size_o: the size of output of GaAN layer
+
+## Performance
+We train our models for 100 epochs and report the **rocauc** on the test dataset.
+|dataset|mean|std|#experiments|
+|-|-|-|-|
+|ogbn-proteins|0.7803|0.0073|10|
diff --git a/examples/GaAN/conv.py b/examples/GaAN/conv.py
new file mode 100644
index 0000000000000000000000000000000000000000..a9264d3c8cd475791d2e23097aaa4a94e7665d5a
--- /dev/null
+++ b/examples/GaAN/conv.py
@@ -0,0 +1,344 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""This package implements common layers to help building
+graph neural networks.
+"""
+import paddle.fluid as fluid
+from pgl import graph_wrapper
+from pgl.utils import paddle_helper
+
+__all__ = ['gcn', 'gat', 'gin', 'gaan']
+
+
+def gcn(gw, feature, hidden_size, activation, name, norm=None):
+ """Implementation of graph convolutional neural networks (GCN)
+
+ This is an implementation of the paper SEMI-SUPERVISED CLASSIFICATION
+ WITH GRAPH CONVOLUTIONAL NETWORKS (https://arxiv.org/pdf/1609.02907.pdf).
+
+ Args:
+ gw: Graph wrapper object (:code:`StaticGraphWrapper` or :code:`GraphWrapper`)
+
+ feature: A tensor with shape (num_nodes, feature_size).
+
+ hidden_size: The hidden size for gcn.
+
+ activation: The activation for the output.
+
+ name: Gcn layer names.
+
+ norm: If :code:`norm` is not None, then the feature will be normalized. Norm must
+ be tensor with shape (num_nodes,) and dtype float32.
+
+ Return:
+ A tensor with shape (num_nodes, hidden_size)
+ """
+
+ def send_src_copy(src_feat, dst_feat, edge_feat):
+ return src_feat["h"]
+
+ size = feature.shape[-1]
+ if size > hidden_size:
+ feature = fluid.layers.fc(feature,
+ size=hidden_size,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name))
+
+ if norm is not None:
+ feature = feature * norm
+
+ msg = gw.send(send_src_copy, nfeat_list=[("h", feature)])
+
+ if size > hidden_size:
+ output = gw.recv(msg, "sum")
+ else:
+ output = gw.recv(msg, "sum")
+ output = fluid.layers.fc(output,
+ size=hidden_size,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name))
+
+ if norm is not None:
+ output = output * norm
+
+ bias = fluid.layers.create_parameter(
+ shape=[hidden_size],
+ dtype='float32',
+ is_bias=True,
+ name=name + '_bias')
+ output = fluid.layers.elementwise_add(output, bias, act=activation)
+ return output
+
+
+def gat(gw,
+ feature,
+ hidden_size,
+ activation,
+ name,
+ num_heads=8,
+ feat_drop=0.6,
+ attn_drop=0.6,
+ is_test=False):
+ """Implementation of graph attention networks (GAT)
+
+ This is an implementation of the paper GRAPH ATTENTION NETWORKS
+ (https://arxiv.org/abs/1710.10903).
+
+ Args:
+ gw: Graph wrapper object (:code:`StaticGraphWrapper` or :code:`GraphWrapper`)
+
+ feature: A tensor with shape (num_nodes, feature_size).
+
+ hidden_size: The hidden size for gat.
+
+ activation: The activation for the output.
+
+ name: Gat layer names.
+
+ num_heads: The head number in gat.
+
+ feat_drop: Dropout rate for feature.
+
+ attn_drop: Dropout rate for attention.
+
+ is_test: Whether in test phrase.
+
+ Return:
+ A tensor with shape (num_nodes, hidden_size * num_heads)
+ """
+
+ def send_attention(src_feat, dst_feat, edge_feat):
+ output = src_feat["left_a"] + dst_feat["right_a"]
+ output = fluid.layers.leaky_relu(
+ output, alpha=0.2) # (num_edges, num_heads)
+ return {"alpha": output, "h": src_feat["h"]}
+
+ def reduce_attention(msg):
+ alpha = msg["alpha"] # lod-tensor (batch_size, seq_len, num_heads)
+ h = msg["h"]
+ alpha = paddle_helper.sequence_softmax(alpha)
+ old_h = h
+ h = fluid.layers.reshape(h, [-1, num_heads, hidden_size])
+ alpha = fluid.layers.reshape(alpha, [-1, num_heads, 1])
+ if attn_drop > 1e-15:
+ alpha = fluid.layers.dropout(
+ alpha,
+ dropout_prob=attn_drop,
+ is_test=is_test,
+ dropout_implementation="upscale_in_train")
+ h = h * alpha
+ h = fluid.layers.reshape(h, [-1, num_heads * hidden_size])
+ h = fluid.layers.lod_reset(h, old_h)
+ return fluid.layers.sequence_pool(h, "sum")
+
+ if feat_drop > 1e-15:
+ feature = fluid.layers.dropout(
+ feature,
+ dropout_prob=feat_drop,
+ is_test=is_test,
+ dropout_implementation='upscale_in_train')
+
+ ft = fluid.layers.fc(feature,
+ hidden_size * num_heads,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_weight'))
+ left_a = fluid.layers.create_parameter(
+ shape=[num_heads, hidden_size],
+ dtype='float32',
+ name=name + '_gat_l_A')
+ right_a = fluid.layers.create_parameter(
+ shape=[num_heads, hidden_size],
+ dtype='float32',
+ name=name + '_gat_r_A')
+ reshape_ft = fluid.layers.reshape(ft, [-1, num_heads, hidden_size])
+ left_a_value = fluid.layers.reduce_sum(reshape_ft * left_a, -1)
+ right_a_value = fluid.layers.reduce_sum(reshape_ft * right_a, -1)
+
+ msg = gw.send(
+ send_attention,
+ nfeat_list=[("h", ft), ("left_a", left_a_value),
+ ("right_a", right_a_value)])
+ output = gw.recv(msg, reduce_attention)
+ bias = fluid.layers.create_parameter(
+ shape=[hidden_size * num_heads],
+ dtype='float32',
+ is_bias=True,
+ name=name + '_bias')
+ bias.stop_gradient = True
+ output = fluid.layers.elementwise_add(output, bias, act=activation)
+ return output
+
+
+def gin(gw,
+ feature,
+ hidden_size,
+ activation,
+ name,
+ init_eps=0.0,
+ train_eps=False):
+ """Implementation of Graph Isomorphism Network (GIN) layer.
+
+ This is an implementation of the paper How Powerful are Graph Neural Networks?
+ (https://arxiv.org/pdf/1810.00826.pdf).
+
+ In their implementation, all MLPs have 2 layers. Batch normalization is applied
+ on every hidden layer.
+
+ Args:
+ gw: Graph wrapper object (:code:`StaticGraphWrapper` or :code:`GraphWrapper`)
+
+ feature: A tensor with shape (num_nodes, feature_size).
+
+ name: GIN layer names.
+
+ hidden_size: The hidden size for gin.
+
+ activation: The activation for the output.
+
+ init_eps: float, optional
+ Initial :math:`\epsilon` value, default is 0.
+
+ train_eps: bool, optional
+ if True, :math:`\epsilon` will be a learnable parameter.
+
+ Return:
+ A tensor with shape (num_nodes, hidden_size).
+ """
+
+ def send_src_copy(src_feat, dst_feat, edge_feat):
+ return src_feat["h"]
+
+ epsilon = fluid.layers.create_parameter(
+ shape=[1, 1],
+ dtype="float32",
+ attr=fluid.ParamAttr(name="%s_eps" % name),
+ default_initializer=fluid.initializer.ConstantInitializer(
+ value=init_eps))
+
+ if not train_eps:
+ epsilon.stop_gradient = True
+
+ msg = gw.send(send_src_copy, nfeat_list=[("h", feature)])
+ output = gw.recv(msg, "sum") + feature * (epsilon + 1.0)
+
+ output = fluid.layers.fc(output,
+ size=hidden_size,
+ act=None,
+ param_attr=fluid.ParamAttr(name="%s_w_0" % name),
+ bias_attr=fluid.ParamAttr(name="%s_b_0" % name))
+
+ output = fluid.layers.layer_norm(
+ output,
+ begin_norm_axis=1,
+ param_attr=fluid.ParamAttr(
+ name="norm_scale_%s" % (name),
+ initializer=fluid.initializer.Constant(1.0)),
+ bias_attr=fluid.ParamAttr(
+ name="norm_bias_%s" % (name),
+ initializer=fluid.initializer.Constant(0.0)), )
+
+ if activation is not None:
+ output = getattr(fluid.layers, activation)(output)
+
+ output = fluid.layers.fc(output,
+ size=hidden_size,
+ act=activation,
+ param_attr=fluid.ParamAttr(name="%s_w_1" % name),
+ bias_attr=fluid.ParamAttr(name="%s_b_1" % name))
+
+ return output
+
+
+def gaan(gw, feature, hidden_size_a, hidden_size_v, hidden_size_m, hidden_size_o, heads, name):
+ """Implementation of GaAN"""
+
+ def send_func(src_feat, dst_feat, edge_feat):
+ # attention score of each edge
+ # E * (M * D1)
+ feat_query, feat_key = dst_feat['feat_query'], src_feat['feat_key']
+ # E * M * D1
+ old = feat_query
+ feat_query = fluid.layers.reshape(feat_query, [-1, heads, hidden_size_a])
+ feat_key = fluid.layers.reshape(feat_key, [-1, heads, hidden_size_a])
+ # E * M
+ alpha = fluid.layers.reduce_sum(feat_key * feat_query, dim=-1)
+
+ return {'dst_node_feat': dst_feat['node_feat'],
+ 'src_node_feat': src_feat['node_feat'],
+ 'feat_value': src_feat['feat_value'],
+ 'alpha': alpha,
+ 'feat_gate': src_feat['feat_gate']}
+
+ def recv_func(message):
+ dst_feat = message['dst_node_feat']
+ src_feat = message['src_node_feat']
+ x = fluid.layers.sequence_pool(dst_feat, 'average')
+ z = fluid.layers.sequence_pool(src_feat, 'average')
+
+ feat_gate = message['feat_gate']
+ g_max = fluid.layers.sequence_pool(feat_gate, 'max')
+ g = fluid.layers.concat([x, g_max, z], axis=1)
+ g = fluid.layers.fc(g, heads, bias_attr=False, act="sigmoid")
+
+ # softmax
+ alpha = message['alpha']
+ alpha = paddle_helper.sequence_softmax(alpha) # E * M
+
+ feat_value = message['feat_value'] # E * (M * D2)
+ old = feat_value
+ feat_value = fluid.layers.reshape(feat_value, [-1, heads, hidden_size_v]) # E * M * D2
+ feat_value = fluid.layers.elementwise_mul(feat_value, alpha, axis=0)
+ feat_value = fluid.layers.reshape(feat_value, [-1, heads*hidden_size_v]) # E * (M * D2)
+ feat_value = fluid.layers.lod_reset(feat_value, old)
+
+ feat_value = fluid.layers.sequence_pool(feat_value, 'sum') # N * (M * D2)
+
+ feat_value = fluid.layers.reshape(feat_value, [-1, heads, hidden_size_v]) # N * M * D2
+
+ output = fluid.layers.elementwise_mul(feat_value, g, axis=0)
+ output = fluid.layers.reshape(output, [-1, heads * hidden_size_v]) # N * (M * D2)
+
+ output = fluid.layers.concat([x, output], axis=1)
+
+ return output
+
+ # N * (D1 * M)
+ feat_key = fluid.layers.fc(feature, hidden_size_a * heads, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_key'))
+ # N * (D2 * M)
+ feat_value = fluid.layers.fc(feature, hidden_size_v * heads, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_value'))
+ # N * (D1 * M)
+ feat_query = fluid.layers.fc(feature, hidden_size_a * heads, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_query'))
+ # N * Dm
+ feat_gate = fluid.layers.fc(feature, hidden_size_m, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_gate'))
+
+ # send stage
+ message = gw.send(
+ send_func,
+ nfeat_list=[('node_feat', feature), ('feat_key', feat_key), ('feat_value', feat_value),
+ ('feat_query', feat_query), ('feat_gate', feat_gate)],
+ efeat_list=None,
+ )
+
+ # recv stage
+ output = gw.recv(message, recv_func)
+ output = fluid.layers.fc(output, hidden_size_o, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_output'))
+ output = fluid.layers.leaky_relu(output, alpha=0.1)
+ output = fluid.layers.dropout(output, dropout_prob=0.1)
+
+ return output
diff --git a/examples/GaAN/main.sh b/examples/GaAN/main.sh
new file mode 100644
index 0000000000000000000000000000000000000000..338d977f3cba0705335888e173d34265611923a4
--- /dev/null
+++ b/examples/GaAN/main.sh
@@ -0,0 +1 @@
+python3 train.py --epochs 100 --lr 1e-2 --rc 0 --batch_size 1024 --gpu_id 0 --exp_id 0
\ No newline at end of file
diff --git a/examples/GaAN/model.py b/examples/GaAN/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..37b9f9bcd5dd4adf5e826ea9d47260d3208e22c3
--- /dev/null
+++ b/examples/GaAN/model.py
@@ -0,0 +1,51 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from paddle import fluid
+from pgl.utils import paddle_helper
+
+# from pgl.layers import gaan
+from conv import gaan
+
+class GaANModel(object):
+ def __init__(self, num_class, num_layers, hidden_size_a=24,
+ hidden_size_v=32, hidden_size_m=64, hidden_size_o=128,
+ heads=8, act='relu', name="GaAN"):
+ self.num_class = num_class
+ self.num_layers = num_layers
+ self.hidden_size_a = hidden_size_a
+ self.hidden_size_v = hidden_size_v
+ self.hidden_size_m = hidden_size_m
+ self.hidden_size_o = hidden_size_o
+ self.act = act
+ self.name = name
+ self.heads = heads
+
+ def forward(self, gw):
+ feature = gw.node_feat['node_feat']
+ for i in range(self.num_layers):
+ feature = gaan(gw, feature, self.hidden_size_a, self.hidden_size_v,
+ self.hidden_size_m, self.hidden_size_o, self.heads,
+ self.name+'_'+str(i))
+
+ pred = fluid.layers.fc(
+ feature, self.num_class, act=None, name=self.name + "_pred_output")
+
+ return pred
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/examples/GaAN/preprocess.py b/examples/GaAN/preprocess.py
new file mode 100644
index 0000000000000000000000000000000000000000..4357ee47cac919832530b94facb66a76e1470e49
--- /dev/null
+++ b/examples/GaAN/preprocess.py
@@ -0,0 +1,103 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+from ogb.nodeproppred import NodePropPredDataset, Evaluator
+
+import pgl
+import numpy as np
+import os
+import time
+
+
+def get_graph_data(d_name="ogbn-proteins", mini_data=False):
+ """
+ Param:
+ d_name: name of dataset
+ mini_data: if mini_data==True, only use a small dataset (for test)
+ """
+ # import ogb data
+ dataset = NodePropPredDataset(name = d_name)
+ num_tasks = dataset.num_tasks # obtaining the number of prediction tasks in a dataset
+
+ split_idx = dataset.get_idx_split()
+ train_idx, valid_idx, test_idx = split_idx["train"], split_idx["valid"], split_idx["test"]
+ graph, label = dataset[0]
+
+ # reshape
+ graph["edge_index"] = graph["edge_index"].T
+
+ # mini dataset
+ if mini_data:
+ graph['num_nodes'] = 500
+ mask = (graph['edge_index'][:, 0] < 500)*(graph['edge_index'][:, 1] < 500)
+ graph["edge_index"] = graph["edge_index"][mask]
+ graph["edge_feat"] = graph["edge_feat"][mask]
+ label = label[:500]
+ train_idx = np.arange(0,400)
+ valid_idx = np.arange(400,450)
+ test_idx = np.arange(450,500)
+
+
+
+ # read/compute node feature
+ if mini_data:
+ node_feat_path = './dataset/ogbn_proteins_node_feat_small.npy'
+ else:
+ node_feat_path = './dataset/ogbn_proteins_node_feat.npy'
+
+ new_node_feat = None
+ if os.path.exists(node_feat_path):
+ print("Begin: read node feature".center(50, '='))
+ new_node_feat = np.load(node_feat_path)
+ print("End: read node feature".center(50, '='))
+ else:
+ print("Begin: compute node feature".center(50, '='))
+ start = time.perf_counter()
+ for i in range(graph['num_nodes']):
+ if i % 100 == 0:
+ dur = time.perf_counter() - start
+ print("{}/{}({}%), times: {:.2f}s".format(
+ i, graph['num_nodes'], i/graph['num_nodes']*100, dur
+ ))
+ mask = (graph['edge_index'][:, 0] == i)
+
+ current_node_feat = np.mean(np.compress(mask, graph['edge_feat'], axis=0),
+ axis=0, keepdims=True)
+ if i == 0:
+ new_node_feat = [current_node_feat]
+ else:
+ new_node_feat.append(current_node_feat)
+
+ new_node_feat = np.concatenate(new_node_feat, axis=0)
+ print("End: compute node feature".center(50,'='))
+
+ print("Saving node feature in "+node_feat_path.center(50, '='))
+ np.save(node_feat_path, new_node_feat)
+ print("Saving finish".center(50,'='))
+
+ print(new_node_feat)
+
+
+ # create graph
+ g = pgl.graph.Graph(
+ num_nodes=graph["num_nodes"],
+ edges = graph["edge_index"],
+ node_feat = {'node_feat': new_node_feat},
+ edge_feat = None
+ )
+ print("Create graph")
+ print(g)
+ return g, label, train_idx, valid_idx, test_idx, Evaluator(d_name)
+
\ No newline at end of file
diff --git a/examples/GaAN/reader.py b/examples/GaAN/reader.py
new file mode 100644
index 0000000000000000000000000000000000000000..985600fbf914b4643858f320daf40d8fe78e4f94
--- /dev/null
+++ b/examples/GaAN/reader.py
@@ -0,0 +1,157 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import numpy as np
+import pickle as pkl
+import paddle
+import paddle.fluid as fluid
+import pgl
+import time
+from pgl.utils import mp_reader
+from pgl.utils.logger import log
+import time
+import copy
+
+
+def node_batch_iter(nodes, node_label, batch_size):
+ """node_batch_iter
+ """
+ perm = np.arange(len(nodes))
+ np.random.shuffle(perm)
+ start = 0
+ while start < len(nodes):
+ index = perm[start:start + batch_size]
+ start += batch_size
+ yield nodes[index], node_label[index]
+
+
+def traverse(item):
+ """traverse
+ """
+ if isinstance(item, list) or isinstance(item, np.ndarray):
+ for i in iter(item):
+ for j in traverse(i):
+ yield j
+ else:
+ yield item
+
+
+def flat_node_and_edge(nodes):
+ """flat_node_and_edge
+ """
+ nodes = list(set(traverse(nodes)))
+ return nodes
+
+
+def worker(batch_info, graph, graph_wrapper, samples):
+ """Worker
+ """
+
+ def work():
+ """work
+ """
+ _graph_wrapper = copy.copy(graph_wrapper)
+ _graph_wrapper.node_feat_tensor_dict = {}
+ for batch_train_samples, batch_train_labels in batch_info:
+ start_nodes = batch_train_samples
+ nodes = start_nodes
+ edges = []
+ for max_deg in samples:
+ pred_nodes = graph.sample_predecessor(
+ start_nodes, max_degree=max_deg)
+
+ for dst_node, src_nodes in zip(start_nodes, pred_nodes):
+ for src_node in src_nodes:
+ edges.append((src_node, dst_node))
+
+ last_nodes = nodes
+ nodes = [nodes, pred_nodes]
+ nodes = flat_node_and_edge(nodes)
+ # Find new nodes
+ start_nodes = list(set(nodes) - set(last_nodes))
+ if len(start_nodes) == 0:
+ break
+
+ subgraph = graph.subgraph(
+ nodes=nodes,
+ edges=edges,
+ with_node_feat=True,
+ with_edge_feat=True)
+
+ sub_node_index = subgraph.reindex_from_parrent_nodes(
+ batch_train_samples)
+
+ feed_dict = _graph_wrapper.to_feed(subgraph)
+
+ feed_dict["node_label"] = batch_train_labels
+ feed_dict["node_index"] = sub_node_index
+ feed_dict["parent_node_index"] = np.array(nodes, dtype="int64")
+ yield feed_dict
+
+ return work
+
+
+def multiprocess_graph_reader(graph,
+ graph_wrapper,
+ samples,
+ node_index,
+ batch_size,
+ node_label,
+ with_parent_node_index=False,
+ num_workers=4):
+ """multiprocess_graph_reader
+ """
+
+ def parse_to_subgraph(rd, prefix, node_feat, _with_parent_node_index):
+ """parse_to_subgraph
+ """
+
+ def work():
+ """work
+ """
+ for data in rd():
+ feed_dict = data
+ for key in node_feat:
+ feed_dict[prefix + '/node_feat/' + key] = node_feat[key][
+ feed_dict["parent_node_index"]]
+ if not _with_parent_node_index:
+ del feed_dict["parent_node_index"]
+ yield feed_dict
+
+ return work
+
+ def reader():
+ """reader"""
+ batch_info = list(
+ node_batch_iter(
+ node_index, node_label, batch_size=batch_size))
+ block_size = int(len(batch_info) / num_workers + 1)
+ reader_pool = []
+ for i in range(num_workers):
+ reader_pool.append(
+ worker(batch_info[block_size * i:block_size * (i + 1)], graph,
+ graph_wrapper, samples))
+
+ if len(reader_pool) == 1:
+ r = parse_to_subgraph(reader_pool[0],
+ repr(graph_wrapper), graph.node_feat,
+ with_parent_node_index)
+ else:
+ multi_process_sample = mp_reader.multiprocess_reader(
+ reader_pool, use_pipe=True, queue_size=1000)
+ r = parse_to_subgraph(multi_process_sample,
+ repr(graph_wrapper), graph.node_feat,
+ with_parent_node_index)
+ return paddle.reader.buffered(r, num_workers)
+
+ return reader()
diff --git a/examples/GaAN/train.py b/examples/GaAN/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c7a33929b05641f5943ff2d210dd4fd0a8b19e9
--- /dev/null
+++ b/examples/GaAN/train.py
@@ -0,0 +1,194 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from preprocess import get_graph_data
+import pgl
+import argparse
+import numpy as np
+import time
+from paddle import fluid
+
+import reader
+from train_tool import train_epoch, valid_epoch
+
+
+from model import GaANModel
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description="ogb Training")
+ parser.add_argument("--d_name", type=str, choices=["ogbn-proteins"], default="ogbn-proteins",
+ help="the name of dataset in ogb")
+ parser.add_argument("--model", type=str, choices=["GaAN"], default="GaAN",
+ help="the name of model")
+ parser.add_argument("--mini_data", type=str, choices=["True", "False"], default="False",
+ help="use a small dataset to test the code")
+ parser.add_argument("--use_gpu", type=bool, choices=[True, False], default=True,
+ help="use gpu")
+ parser.add_argument("--gpu_id", type=int, default=0,
+ help="the id of gpu")
+ parser.add_argument("--exp_id", type=int, default=0,
+ help="the id of experiment")
+ parser.add_argument("--epochs", type=int, default=100,
+ help="the number of training epochs")
+ parser.add_argument("--lr", type=float, default=1e-2,
+ help="learning rate of Adam")
+ parser.add_argument("--rc", type=float, default=0,
+ help="regularization coefficient")
+ parser.add_argument("--log_path", type=str, default="./log",
+ help="the path of log")
+ parser.add_argument("--batch_size", type=int, default=1024,
+ help="the number of batch size")
+ parser.add_argument("--heads", type=int, default=8,
+ help="the number of heads of attention")
+ parser.add_argument("--hidden_size_a", type=int, default=24,
+ help="the hidden size of query and key vectors")
+ parser.add_argument("--hidden_size_v", type=int, default=32,
+ help="the hidden size of value vectors")
+ parser.add_argument("--hidden_size_m", type=int, default=64,
+ help="the hidden size of projection for computing gates")
+ parser.add_argument("--hidden_size_o", type=int ,default=128,
+ help="the hidden size of each layer in GaAN")
+
+ args = parser.parse_args()
+
+ print("Parameters Setting".center(50, "="))
+ print("lr = {}, rc = {}, epochs = {}, batch_size = {}".format(args.lr, args.rc, args.epochs,
+ args.batch_size))
+ print("Experiment ID: {}".format(args.exp_id).center(50, "="))
+ print("training in GPU: {}".format(args.gpu_id).center(50, "="))
+ d_name = args.d_name
+
+ # get data
+ g, label, train_idx, valid_idx, test_idx, evaluator = get_graph_data(d_name=d_name,
+ mini_data=eval(args.mini_data))
+
+ if args.model == "GaAN":
+ graph_model = GaANModel(112, 3, args.hidden_size_a, args.hidden_size_v, args.hidden_size_m,
+ args.hidden_size_o, args.heads)
+
+ # training
+ samples = [25, 10] # 2-hop sample size
+ batch_size = args.batch_size
+ sample_workers = 1
+
+ place = fluid.CUDAPlace(args.gpu_id) if args.use_gpu else fluid.CPUPlace()
+ train_program = fluid.Program()
+ startup_program = fluid.Program()
+
+ with fluid.program_guard(train_program, startup_program):
+ gw = pgl.graph_wrapper.GraphWrapper(
+ name='graph',
+ place = place,
+ node_feat=g.node_feat_info(),
+ edge_feat=g.edge_feat_info()
+ )
+
+
+ node_index = fluid.layers.data('node_index', shape=[None, 1], dtype="int64",
+ append_batch_size=False)
+
+ node_label = fluid.layers.data('node_label', shape=[None, 112], dtype="float32",
+ append_batch_size=False)
+ parent_node_index = fluid.layers.data('parent_node_index', shape=[None, 1], dtype="int64",
+ append_batch_size=False)
+
+ output = graph_model.forward(gw)
+ output = fluid.layers.gather(output, node_index)
+ score = fluid.layers.sigmoid(output)
+
+ loss = fluid.layers.sigmoid_cross_entropy_with_logits(
+ x=output, label=node_label)
+ loss = fluid.layers.mean(loss)
+
+
+ val_program = train_program.clone(for_test=True)
+
+ with fluid.program_guard(train_program, startup_program):
+ lr = args.lr
+ adam = fluid.optimizer.Adam(
+ learning_rate=lr,
+ regularization=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=args.rc))
+ adam.minimize(loss)
+
+ exe = fluid.Executor(place)
+ exe.run(startup_program)
+
+ train_iter = reader.multiprocess_graph_reader(
+ g,
+ gw,
+ samples=samples,
+ num_workers=sample_workers,
+ batch_size=batch_size,
+ with_parent_node_index=True,
+ node_index=train_idx,
+ node_label=np.array(label[train_idx], dtype='float32'))
+
+ val_iter = reader.multiprocess_graph_reader(
+ g,
+ gw,
+ samples=samples,
+ num_workers=sample_workers,
+ batch_size=batch_size,
+ with_parent_node_index=True,
+ node_index=valid_idx,
+ node_label=np.array(label[valid_idx], dtype='float32'))
+
+ test_iter = reader.multiprocess_graph_reader(
+ g,
+ gw,
+ samples=samples,
+ num_workers=sample_workers,
+ batch_size=batch_size,
+ with_parent_node_index=True,
+ node_index=test_idx,
+ node_label=np.array(label[test_idx], dtype='float32'))
+
+
+ start = time.time()
+ print("Training Begin".center(50, "="))
+ best_valid = -1.0
+ for epoch in range(args.epochs):
+ start_e = time.time()
+ train_loss, train_rocauc = train_epoch(
+ train_iter, program=train_program, exe=exe, loss=loss, score=score,
+ evaluator=evaluator, epoch=epoch
+ )
+ valid_loss, valid_rocauc = valid_epoch(
+ val_iter, program=val_program, exe=exe, loss=loss, score=score,
+ evaluator=evaluator, epoch=epoch)
+ end_e = time.time()
+ print("Epoch {}: train_loss={:.4},val_loss={:.4}, train_rocauc={:.4}, val_rocauc={:.4}, s/epoch={:.3}".format(
+ epoch, train_loss, valid_loss, train_rocauc, valid_rocauc, end_e-start_e
+ ))
+
+ if valid_rocauc > best_valid:
+ print("Update: new {}, old {}".format(valid_rocauc, best_valid))
+ best_valid = valid_rocauc
+
+ fluid.io.save_params(executor=exe, dirname='./params/'+str(args.exp_id), main_program=val_program)
+
+
+ print("Test Stage".center(50, "="))
+
+ fluid.io.load_params(executor=exe, dirname='./params/'+str(args.exp_id), main_program=val_program)
+
+ test_loss, test_rocauc = valid_epoch(
+ test_iter, program=val_program, exe=exe, loss=loss, score=score,
+ evaluator=evaluator, epoch=epoch)
+ end = time.time()
+ print("test_loss={:.4},test_rocauc={:.4}, Total Time={:.3}".format(
+ test_loss, test_rocauc, end-start
+ ))
+ print("End".center(50, "="))
diff --git a/examples/GaAN/train_tool.py b/examples/GaAN/train_tool.py
new file mode 100644
index 0000000000000000000000000000000000000000..bdb1c928e6801f8b72cb076e7e4b353525d92303
--- /dev/null
+++ b/examples/GaAN/train_tool.py
@@ -0,0 +1,56 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import time
+from pgl.utils.logger import log
+
+def train_epoch(batch_iter, exe, program, loss, score, evaluator, epoch, log_per_step=1):
+ batch = 0
+ total_loss = 0.0
+ total_sample = 0
+ result = 0
+ for batch_feed_dict in batch_iter():
+ batch += 1
+ batch_loss, y_pred = exe.run(program, fetch_list=[loss, score], feed=batch_feed_dict)
+
+ num_samples = len(batch_feed_dict["node_index"])
+ total_loss += batch_loss * num_samples
+ total_sample += num_samples
+ input_dict = {
+ "y_true": batch_feed_dict["node_label"],
+ "y_pred": y_pred
+ }
+ result += evaluator.eval(input_dict)["rocauc"]
+
+ return total_loss.item()/total_sample, result/batch
+
+def valid_epoch(batch_iter, exe, program, loss, score, evaluator, epoch, log_per_step=1):
+ batch = 0
+ total_sample = 0
+ result = 0
+ total_loss = 0.0
+ for batch_feed_dict in batch_iter():
+ batch += 1
+ batch_loss, y_pred = exe.run(program, fetch_list=[loss, score], feed=batch_feed_dict)
+ input_dict = {
+ "y_true": batch_feed_dict["node_label"],
+ "y_pred": y_pred
+ }
+ result += evaluator.eval(input_dict)["rocauc"]
+
+
+ num_samples = len(batch_feed_dict["node_index"])
+ total_loss += batch_loss * num_samples
+ total_sample += num_samples
+
+ return total_loss.item()/total_sample, result/batch
diff --git a/examples/SAGPool/README.md b/examples/SAGPool/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..ebed2e7a4b4025a63e2e3f4538cd4a23739c0123
--- /dev/null
+++ b/examples/SAGPool/README.md
@@ -0,0 +1,53 @@
+# Self-Attention Graph Pooling
+
+SAGPool is a graph pooling method based on self-attention. Self-attention uses graph convolution, which allows the pooling method to consider both node features and graph topology. Based on PGL, we implement the SAGPool algorithm and train the model on five datasets.
+
+## Datasets
+
+There are five datasets, including D&D, PROTEINS, NCI1, NCI109 and FRANKENSTEIN. You can download the datasets from [here](https://bj.bcebos.com/paddle-pgl/SAGPool/data.zip), and unzip it directly. The pkl format datasets should be in directory ./data.
+
+## Dependencies
+
+- [paddlepaddle >= 1.8](https://github.com/PaddlePaddle/paddle)
+- [pgl 1.1](https://github.com/PaddlePaddle/PGL)
+
+## How to run
+
+```
+python main.py --dataset_name DD --learning_rate 0.005 --weight_decay 0.00001
+
+python main.py --dataset_name PROTEINS --learning_rate 0.001 --hidden_size 32 --weight_decay 0.00001
+
+python main.py --dataset_name NCI1 --learning_rate 0.001 --weight_decay 0.00001
+
+python main.py --dataset_name NCI109 --learning_rate 0.0005 --hidden_size 64 --weight_decay 0.0001 --patience 200
+
+python main.py --dataset_name FRANKENSTEIN --learning_rate 0.001 --weight_decay 0.0001
+```
+
+## Hyperparameters
+
+- seed: random seed
+- batch\_size: the number of batch size
+- learning\_rate: learning rate of optimizer
+- weight\_decay: the weight decay for L2 regularization
+- hidden\_size: the hidden size of gcn
+- pooling\_ratio: the pooling ratio of SAGPool
+- dropout\_ratio: the number of dropout ratio
+- dataset\_name: the name of datasets, including DD, PROTEINS, NCI1, NCI109, FRANKENSTEIN
+- epochs: maximum number of epochs
+- patience: patience for early stopping
+- use\_cuda: whether to use cuda
+- save\_model: the name for the best model
+
+## Performance
+
+We evaluate the implemented method for 20 random seeds using 10-fold cross validation, following the same training procedures as in the paper.
+
+| dataset | mean accuracy | standard deviation | mean accuracy(paper) | standard deviation(paper) |
+| ------------ | ------------- | ------------------ | -------------------- | ------------------------- |
+| DD | 74.4181 | 1.0244 | 76.19 | 0.94 |
+| PROTEINS | 72.7858 | 0.6617 | 70.04 | 1.47 |
+| NCI1 | 75.781 | 1.2125 | 74.18 | 1.2 |
+| NCI109 | 74.3156 | 1.3 | 74.06 | 0.78 |
+| FRANKENSTEIN | 60.7826 | 0.629 | 62.57 | 0.6 |
diff --git a/examples/SAGPool/args.py b/examples/SAGPool/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c6c44bc558638a5d6ec0a3c8c957a0730aa22a5
--- /dev/null
+++ b/examples/SAGPool/args.py
@@ -0,0 +1,43 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+
+parser = argparse.ArgumentParser()
+
+parser.add_argument('--seed', type=int, default=777,
+ help='seed')
+parser.add_argument('--batch_size', type=int, default=128,
+ help='batch size')
+parser.add_argument('--learning_rate', type=float, default=0.0005,
+ help='learning rate')
+parser.add_argument('--weight_decay', type=float, default=0.0001,
+ help='weight decay')
+parser.add_argument('--hidden_size', type=int, default=128,
+ help='gcn hidden size')
+parser.add_argument('--pooling_ratio', type=float, default=0.5,
+ help='pooling ratio of SAGPool')
+parser.add_argument('--dropout_ratio', type=float, default=0.5,
+ help='dropout ratio')
+parser.add_argument('--dataset_name', type=str, default='DD',
+ help='DD/PROTEINS/NCI1/NCI109/FRANKENSTEIN')
+parser.add_argument('--epochs', type=int, default=100000,
+ help='maximum number of epochs')
+parser.add_argument('--patience', type=int, default=50,
+ help='patience for early stopping')
+parser.add_argument('--use_cuda', type=bool, default=True,
+ help='use cuda or cpu')
+parser.add_argument('--save_model', type=str,
+ help='save model name')
+
diff --git a/examples/SAGPool/base_dataset.py b/examples/SAGPool/base_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..711e9203e311bb2c9cf5b6e9afc2834122a93a01
--- /dev/null
+++ b/examples/SAGPool/base_dataset.py
@@ -0,0 +1,96 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+import random
+import pgl
+from pgl.utils.logger import log
+from pgl.graph import Graph, MultiGraph
+import numpy as np
+import pickle
+
+class BaseDataset(object):
+ def __init__(self):
+ pass
+
+ def __getitem__(self, idx):
+ raise NotImplementedError
+
+ def __len__(self):
+ raise NotImplementedError
+
+
+class Subset(BaseDataset):
+ """Subset of a dataset at specified indices.
+
+ Args:
+ dataset (Dataset): The whole Dataset
+ indices (sequence): Indices in the whole set selected for subset
+ """
+
+ def __init__(self, dataset, indices):
+ self.dataset = dataset
+ self.indices = indices
+
+ def __getitem__(self, idx):
+ return self.dataset[self.indices[idx]]
+
+ def __len__(self):
+ return len(self.indices)
+
+
+class Dataset(BaseDataset):
+ def __init__(self, args):
+ self.args = args
+
+ with open('data/%s.pkl' % args.dataset_name, 'rb') as f:
+ graphs_info_list = pickle.load(f)
+
+ self.pgl_graph_list = []
+ self.graph_label_list = []
+ for i in range(len(graphs_info_list) - 1):
+ graph = graphs_info_list[i]
+ edges_l, edges_r = graph["edge_src"], graph["edge_dst"]
+
+ # add self-loops
+ if self.args.dataset_name != "FRANKENSTEIN":
+ num_nodes = graph["num_nodes"]
+ x = np.arange(0, num_nodes)
+ edges_l = np.append(edges_l, x)
+ edges_r = np.append(edges_r, x)
+
+ edges = list(zip(edges_l, edges_r))
+ g = pgl.graph.Graph(num_nodes=graph["num_nodes"], edges=edges)
+ g.node_feat["feat"] = graph["node_feat"]
+ self.pgl_graph_list.append(g)
+ self.graph_label_list.append(graph["label"])
+
+ self.num_classes = graphs_info_list[-1]["num_classes"]
+ self.num_features = graphs_info_list[-1]["num_features"]
+
+ def __getitem__(self, idx):
+ return self.pgl_graph_list[idx], self.graph_label_list[idx]
+
+ def shuffle(self):
+ """shuffle the dataset.
+ """
+ cc = list(zip(self.pgl_graph_list, self.graph_label_list))
+ random.seed(self.args.seed)
+ random.shuffle(cc)
+ a, b = zip(*cc)
+ self.pgl_graph_list[:], self.graph_label_list[:] = a, b
+
+ def __len__(self):
+ return len(self.pgl_graph_list)
diff --git a/examples/SAGPool/conv.py b/examples/SAGPool/conv.py
new file mode 100644
index 0000000000000000000000000000000000000000..5250f242b5bd5aff4f6fa9324a82a21e46302b6f
--- /dev/null
+++ b/examples/SAGPool/conv.py
@@ -0,0 +1,66 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+
+def norm_gcn(gw, feature, hidden_size, activation, name, norm=None):
+ """Implementation of graph convolutional neural networks(GCN), using different
+ normalization method.
+ Args:
+ gw: Graph wrapper object.
+
+ feature: A tensor with shape (num_nodes, feature_size).
+
+ hidden_size: The hidden size for norm gcn.
+
+ activation: The activation for the output.
+
+ name: Norm gcn layer names.
+
+ norm: If norm is not None, then the feature will be normalized. Norm must
+ be tensor with shape (num_nodes,) and dtype float32.
+
+ Return:
+ A tensor with shape (num_nodes, hidden_size)
+ """
+
+ size = feature.shape[-1]
+ feature = L.fc(feature,
+ size=hidden_size,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name))
+
+ if norm is not None:
+ src, dst = gw.edges
+ norm_src = L.gather(norm, src, overwrite=False)
+ norm_dst = L.gather(norm, dst, overwrite=False)
+ norm = norm_src * norm_dst
+
+ def send_src_copy(src_feat, dst_feat, edge_feat):
+ return src_feat["h"] * norm
+ else:
+ def send_src_copy(src_feat, dst_feat, edge_feat):
+ return src_feat["h"]
+
+ msg = gw.send(send_src_copy, nfeat_list=[("h", feature)])
+ output = gw.recv(msg, "sum")
+
+ bias = L.create_parameter(
+ shape=[hidden_size],
+ dtype='float32',
+ is_bias=True,
+ name=name + '_bias')
+ output = L.elementwise_add(output, bias, act=activation)
+ return output
diff --git a/examples/SAGPool/dataloader.py b/examples/SAGPool/dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..21ea7d43a64dbb3849afc8d5abf017a7bbac2661
--- /dev/null
+++ b/examples/SAGPool/dataloader.py
@@ -0,0 +1,143 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import numpy as np
+import collections
+import paddle
+import pgl
+from pgl.utils.logger import log
+from pgl.graph import Graph, MultiGraph
+
+def batch_iter(data, batch_size):
+ """node_batch_iter
+ """
+ size = len(data)
+ perm = np.arange(size)
+ np.random.shuffle(perm)
+ start = 0
+ while start < size:
+ index = perm[start:start + batch_size]
+ start += batch_size
+ yield data[index]
+
+
+def scan_batch_iter(data, batch_size):
+ """scan_batch_iter
+ """
+ batch = []
+ for example in data.scan():
+ batch.append(example)
+ if len(batch) == batch_size:
+ yield batch
+ batch = []
+
+ if len(batch) > 0:
+ yield batch
+
+
+def label_to_onehot(labels):
+ """Return one-hot representations of labels
+ """
+ onehot_labels = []
+ for label in labels:
+ if label == 0:
+ onehot_labels.append([1, 0])
+ else:
+ onehot_labels.append([0, 1])
+ onehot_labels = np.array(onehot_labels)
+ return onehot_labels
+
+
+class GraphDataloader(object):
+ """Graph Dataloader
+ """
+ def __init__(self,
+ dataset,
+ graph_wrapper,
+ batch_size,
+ seed=0,
+ buf_size=1000,
+ shuffle=True):
+
+ self.shuffle = shuffle
+ self.seed = seed
+ self.batch_size = batch_size
+ self.dataset = dataset
+ self.buf_size = buf_size
+ self.graph_wrapper = graph_wrapper
+
+ def batch_fn(self, batch_examples):
+ """ batch_fun batch producer """
+ graphs = [b[0] for b in batch_examples]
+ labels = [b[1] for b in batch_examples]
+ join_graph = MultiGraph(graphs)
+
+ # normalize
+ indegree = join_graph.indegree()
+ norm = np.zeros_like(indegree, dtype="float32")
+ norm[indegree > 0] = np.power(indegree[indegree > 0], -0.5)
+ join_graph.node_feat["norm"] = np.expand_dims(norm, -1)
+
+ feed_dict = self.graph_wrapper.to_feed(join_graph)
+ labels = np.array(labels)
+ feed_dict["labels_1dim"] = labels
+ labels = label_to_onehot(labels)
+ feed_dict["labels"] = labels
+
+ graph_lod = join_graph.graph_lod
+ graph_id = []
+ for i in range(1, len(graph_lod)):
+ graph_node_num = graph_lod[i] - graph_lod[i - 1]
+ graph_id += [i - 1] * graph_node_num
+ graph_id = np.array(graph_id, dtype="int32")
+ feed_dict["graph_id"] = graph_id
+
+ return feed_dict
+
+ def batch_iter(self):
+ """ batch_iter """
+ if self.shuffle:
+ for batch in batch_iter(self, self.batch_size):
+ yield batch
+ else:
+ for batch in scan_batch_iter(self, self.batch_size):
+ yield batch
+
+ def __len__(self):
+ """__len__"""
+ return len(self.dataset)
+
+ def __getitem__(self, idx):
+ """__getitem__"""
+ if isinstance(idx, collections.Iterable):
+ return [self.dataset[bidx] for bidx in idx]
+ else:
+ return self.dataset[idx]
+
+ def __iter__(self):
+ """__iter__"""
+ def func_run():
+ for batch_examples in self.batch_iter():
+ batch_dict = self.batch_fn(batch_examples)
+ yield batch_dict
+
+ r = paddle.reader.buffered(func_run, self.buf_size)
+
+ for batch in r():
+ yield batch
+
+ def scan(self):
+ """scan"""
+ for example in self.dataset:
+ yield example
diff --git a/examples/SAGPool/layers.py b/examples/SAGPool/layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..3dfa0822ece9e564adfbc9b15e0a62e1e1f4b08d
--- /dev/null
+++ b/examples/SAGPool/layers.py
@@ -0,0 +1,141 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import numpy as np
+import paddle
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+import pgl
+from pgl.graph_wrapper import GraphWrapper
+from pgl.utils.logger import log
+from conv import norm_gcn
+from pgl.layers.conv import gcn
+
+def topk_pool(gw, score, graph_id, ratio):
+ """Implementation of topk pooling, where k means pooling ratio.
+
+ Args:
+ gw: Graph wrapper object.
+
+ score: The attention score of all nodes, which is used to select
+ important nodes.
+
+ graph_id: The graphs that the nodes belong to.
+
+ ratio: The pooling ratio of nodes we want to select.
+
+ Return:
+ perm: The index of nodes we choose.
+
+ ratio_length: The selected node numbers of each graph.
+ """
+
+ graph_lod = gw.graph_lod
+ graph_nodes = gw.num_nodes
+ num_graph = gw.num_graph
+
+ num_nodes = L.ones(shape=[graph_nodes], dtype="float32")
+ num_nodes = L.lod_reset(num_nodes, graph_lod)
+ num_nodes_per_graph = L.sequence_pool(num_nodes, pool_type='sum')
+ max_num_nodes = L.reduce_max(num_nodes_per_graph, dim=0)
+ max_num_nodes = L.cast(max_num_nodes, dtype="int32")
+
+ index = L.arange(0, gw.num_nodes, dtype="int64")
+ offset = L.gather(graph_lod, graph_id, overwrite=False)
+ index = (index - offset) + (graph_id * max_num_nodes)
+ index.stop_gradient = True
+
+ # padding
+ dense_score = L.fill_constant(shape=[num_graph * max_num_nodes],
+ dtype="float32", value=-999999)
+ index = L.reshape(index, shape=[-1])
+ dense_score = L.scatter(dense_score, index, updates=score)
+ num_graph = L.cast(num_graph, dtype="int32")
+ dense_score = L.reshape(dense_score,
+ shape=[num_graph, max_num_nodes])
+
+ # record the sorted index
+ _, sort_index = L.argsort(dense_score, axis=-1, descending=True)
+
+ # recover the index range
+ graph_lod = graph_lod[:-1]
+ graph_lod = L.reshape(graph_lod, shape=[-1, 1])
+ graph_lod = L.cast(graph_lod, dtype="int64")
+ sort_index = L.elementwise_add(sort_index, graph_lod, axis=-1)
+ sort_index = L.reshape(sort_index, shape=[-1, 1])
+
+ # use sequence_slice to choose selected node index
+ pad_lod = L.arange(0, (num_graph + 1) * max_num_nodes, step=max_num_nodes, dtype="int32")
+ sort_index = L.lod_reset(sort_index, pad_lod)
+ ratio_length = L.ceil(num_nodes_per_graph * ratio)
+ ratio_length = L.cast(ratio_length, dtype="int64")
+ ratio_length = L.reshape(ratio_length, shape=[-1, 1])
+ offset = L.zeros(shape=[num_graph, 1], dtype="int64")
+ choose_index = L.sequence_slice(input=sort_index, offset=offset, length=ratio_length)
+
+ perm = L.reshape(choose_index, shape=[-1])
+ return perm, ratio_length
+
+
+def sag_pool(gw, feature, ratio, graph_id, dataset, name, activation=L.tanh):
+ """Implementation of self-attention graph pooling (SAGPool)
+
+ This is an implementation of the paper SELF-ATTENTION GRAPH POOLING
+ (https://arxiv.org/pdf/1904.08082.pdf)
+
+ Args:
+ gw: Graph wrapper object.
+
+ feature: A tensor with shape (num_nodes, feature_size).
+
+ ratio: The pooling ratio of nodes we want to select.
+
+ graph_id: The graphs that the nodes belong to.
+
+ dataset: To differentiate FRANKENSTEIN dataset and other datasets.
+
+ name: The name of SAGPool layer.
+
+ activation: The activation function.
+
+ Return:
+ new_feature: A tensor with shape (num_nodes, feature_size), and the unselected
+ nodes' feature is masked by zero.
+
+ ratio_length: The selected node numbers of each graph.
+
+ """
+ if dataset == "FRANKENSTEIN":
+ gcn_ = gcn
+ else:
+ gcn_ = norm_gcn
+
+ score = gcn_(gw=gw,
+ feature=feature,
+ hidden_size=1,
+ activation=None,
+ norm=gw.node_feat["norm"],
+ name=name)
+ score = L.squeeze(score, axes=[])
+ perm, ratio_length = topk_pool(gw, score, graph_id, ratio)
+
+ mask = L.zeros_like(score)
+ mask = L.cast(mask, dtype="float32")
+ updates = L.ones_like(perm)
+ updates = L.cast(updates, dtype="float32")
+ mask = L.scatter(mask, perm, updates)
+ new_feature = L.elementwise_mul(feature, mask, axis=0)
+ temp_score = activation(score)
+ new_feature = L.elementwise_mul(new_feature, temp_score, axis=0)
+ return new_feature, ratio_length
diff --git a/examples/SAGPool/main.py b/examples/SAGPool/main.py
new file mode 100644
index 0000000000000000000000000000000000000000..8895311e0f729bf572919faf07df50c7921cb545
--- /dev/null
+++ b/examples/SAGPool/main.py
@@ -0,0 +1,194 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+import argparse
+import pgl
+from pgl.utils.logger import log
+import paddle
+
+import re
+import time
+import random
+import numpy as np
+import math
+
+import paddle
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+import pgl
+from pgl.utils.logger import log
+
+from model import GlobalModel
+from base_dataset import Subset, Dataset
+from dataloader import GraphDataloader
+from args import parser
+import warnings
+from sklearn.model_selection import KFold
+
+warnings.filterwarnings("ignore")
+
+def main(args, train_dataset, val_dataset, test_dataset):
+ """main function for running one testing results.
+ """
+ log.info("Train Examples: %s" % len(train_dataset))
+ log.info("Val Examples: %s" % len(val_dataset))
+ log.info("Test Examples: %s" % len(test_dataset))
+
+ train_program = fluid.Program()
+ train_program.random_seed = args.seed
+ startup_program = fluid.Program()
+ startup_program.random_seed = args.seed
+
+ if args.use_cuda:
+ place = fluid.CUDAPlace(0)
+ else:
+ place = fluid.CPUPlace()
+ exe = fluid.Executor(place)
+
+ log.info("building model")
+
+ with fluid.program_guard(train_program, startup_program):
+ with fluid.unique_name.guard():
+ graph_model = GlobalModel(args, dataset)
+ train_loader = GraphDataloader(train_dataset,
+ graph_model.graph_wrapper,
+ batch_size=args.batch_size)
+ optimizer = fluid.optimizer.Adam(learning_rate=args.learning_rate,
+ regularization=fluid.regularizer.L2DecayRegularizer(args.weight_decay))
+ optimizer.minimize(graph_model.loss)
+
+ exe.run(startup_program)
+ test_program = fluid.Program()
+ test_program = train_program.clone(for_test=True)
+
+ val_loader = GraphDataloader(val_dataset,
+ graph_model.graph_wrapper,
+ batch_size=args.batch_size,
+ shuffle=False)
+ test_loader = GraphDataloader(test_dataset,
+ graph_model.graph_wrapper,
+ batch_size=args.batch_size,
+ shuffle=False)
+
+ min_loss = 1e10
+ global_step = 0
+ for epoch in range(args.epochs):
+ for feed_dict in train_loader:
+ loss, pred = exe.run(train_program,
+ feed=feed_dict,
+ fetch_list=[graph_model.loss, graph_model.pred])
+
+ log.info("Epoch: %d, global_step: %d, Training loss: %f" \
+ % (epoch, global_step, loss))
+ global_step += 1
+
+ # validation
+ valid_loss = 0.
+ correct = 0.
+ for feed_dict in val_loader:
+ valid_loss_, correct_ = exe.run(test_program,
+ feed=feed_dict,
+ fetch_list=[graph_model.loss, graph_model.correct])
+ valid_loss += valid_loss_
+ correct += correct_
+
+ if epoch % 50 == 0:
+ log.info("Epoch:%d, Validation loss: %f, Validation acc: %f" \
+ % (epoch, valid_loss, correct / len(val_loader)))
+
+ if valid_loss < min_loss:
+ min_loss = valid_loss
+ patience = 0
+ path = "./save/%s" % args.dataset_name
+ if not os.path.exists(path):
+ os.makedirs(path)
+ fluid.save(train_program, "%s/%s" \
+ % (path, args.save_model))
+ log.info("Model saved at epoch %d" % epoch)
+ else:
+ patience += 1
+ if patience > args.patience:
+ break
+
+ correct = 0.
+ new_test_program = fluid.Program()
+ fluid.load(new_test_program, "./save/%s/%s" \
+ % (args.dataset_name, args.save_model), exe)
+ for feed_dict in test_loader:
+ correct_ = exe.run(test_program,
+ feed=feed_dict,
+ fetch_list=[graph_model.correct])
+ correct += correct_[0]
+ log.info("Test acc: %f" % (correct / len(test_loader)))
+ return correct / len(test_loader)
+
+
+def split_10_cv(dataset, args):
+ """10 folds cross validation
+ """
+ dataset.shuffle()
+ X = np.array([0] * len(dataset))
+ y = X
+ kf = KFold(n_splits=10, shuffle=False)
+
+ i = 1
+ test_acc = []
+ for train_index, test_index in kf.split(X, y):
+ train_val_dataset = Subset(dataset, train_index)
+ test_dataset = Subset(dataset, test_index)
+ train_val_index_range = list(range(0, len(train_val_dataset)))
+ num_val = int(len(train_val_dataset) / 9)
+ val_dataset = Subset(train_val_dataset, train_val_index_range[:num_val])
+ train_dataset = Subset(train_val_dataset, train_val_index_range[num_val:])
+
+ log.info("######%d fold of 10-fold cross validation######" % i)
+ i += 1
+ test_acc_ = main(args, train_dataset, val_dataset, test_dataset)
+ test_acc.append(test_acc_)
+
+ mean_acc = sum(test_acc) / len(test_acc)
+ return mean_acc, test_acc
+
+
+def random_seed_20(args, dataset):
+ """run for 20 random seeds
+ """
+ alist = random.sample(range(1,1000),20)
+ test_acc_fold = []
+ for seed in alist:
+ log.info('############ Seed %d ############' % seed)
+ args.seed = seed
+
+ test_acc_fold_, _ = split_10_cv(dataset, args)
+ log.info('Mean test acc at seed %d: %f' % (seed, test_acc_fold_))
+ test_acc_fold.append(test_acc_fold_)
+
+ mean_acc = sum(test_acc_fold) / len(test_acc_fold)
+ temp = [(acc - mean_acc) * (acc - mean_acc) for acc in test_acc_fold]
+ standard_std = math.sqrt(sum(temp) / len(test_acc_fold))
+
+ log.info('Final mean test acc using 20 random seeds(mean for 10-fold): %f' % (mean_acc))
+ log.info('Final standard std using 20 random seeds(mean for 10-fold): %f' % (standard_std))
+
+
+if __name__ == "__main__":
+ args = parser.parse_args()
+ log.info('loading data...')
+ dataset = Dataset(args)
+ log.info("preprocess finish.")
+ args.num_classes = dataset.num_classes
+ args.num_features = dataset.num_features
+ random_seed_20(args, dataset)
diff --git a/examples/SAGPool/model.py b/examples/SAGPool/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..cdfbe6f4f2d911dff041522d3e75266b4867c5a3
--- /dev/null
+++ b/examples/SAGPool/model.py
@@ -0,0 +1,136 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from random import random
+import numpy as np
+
+import paddle
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+import pgl
+from pgl.graph import Graph, MultiGraph
+from pgl.graph_wrapper import GraphWrapper
+from pgl.utils.logger import log
+from pgl.layers.conv import gcn
+from layers import sag_pool
+from conv import norm_gcn
+
+class GlobalModel(object):
+ """Implementation of global pooling architecture with SAGPool.
+ """
+ def __init__(self, args, dataset):
+ self.args = args
+ self.dataset = dataset
+ self.hidden_size = args.hidden_size
+ self.num_classes = args.num_classes
+ self.num_features = args.num_features
+ self.pooling_ratio = args.pooling_ratio
+ self.dropout_ratio = args.dropout_ratio
+ self.batch_size = args.batch_size
+
+ graph_data = []
+ g, label = self.dataset[0]
+ graph_data.append(g)
+ g, label = self.dataset[1]
+ graph_data.append(g)
+
+ batch_graph = MultiGraph(graph_data)
+ indegree = batch_graph.indegree()
+ norm = np.zeros_like(indegree, dtype="float32")
+ norm[indegree > 0] = np.power(indegree[indegree > 0], -0.5)
+ batch_graph.node_feat["norm"] = np.expand_dims(norm, -1)
+ graph_data = batch_graph
+
+ self.graph_wrapper = GraphWrapper(
+ name="graph",
+ node_feat=graph_data.node_feat_info()
+ )
+ self.labels = L.data(
+ "labels",
+ shape=[None, self.args.num_classes],
+ dtype="int32",
+ append_batch_size=False)
+
+ self.labels_1dim = L.data(
+ "labels_1dim",
+ shape=[None],
+ dtype="int32",
+ append_batch_size=False)
+
+ self.graph_id = L.data(
+ "graph_id",
+ shape=[None],
+ dtype="int32",
+ append_batch_size=False)
+
+ if self.args.dataset_name == "FRANKENSTEIN":
+ self.gcn = gcn
+ else:
+ self.gcn = norm_gcn
+
+ self.build_model()
+
+ def build_model(self):
+ node_features = self.graph_wrapper.node_feat["feat"]
+
+ output = self.gcn(gw=self.graph_wrapper,
+ feature=node_features,
+ hidden_size=self.hidden_size,
+ activation="relu",
+ norm=self.graph_wrapper.node_feat["norm"],
+ name="gcn_layer_1")
+ output1 = output
+ output = self.gcn(gw=self.graph_wrapper,
+ feature=output,
+ hidden_size=self.hidden_size,
+ activation="relu",
+ norm=self.graph_wrapper.node_feat["norm"],
+ name="gcn_layer_2")
+ output2 = output
+ output = self.gcn(gw=self.graph_wrapper,
+ feature=output,
+ hidden_size=self.hidden_size,
+ activation="relu",
+ norm=self.graph_wrapper.node_feat["norm"],
+ name="gcn_layer_3")
+
+ output = L.concat(input=[output1, output2, output], axis=-1)
+
+ output, ratio_length = sag_pool(gw=self.graph_wrapper,
+ feature=output,
+ ratio=self.pooling_ratio,
+ graph_id=self.graph_id,
+ dataset=self.args.dataset_name,
+ name="sag_pool_1")
+ output = L.lod_reset(output, self.graph_wrapper.graph_lod)
+ cat1 = L.sequence_pool(output, "sum")
+ ratio_length = L.cast(ratio_length, dtype="float32")
+ cat1 = L.elementwise_div(cat1, ratio_length, axis=-1)
+ cat2 = L.sequence_pool(output, "max")
+ output = L.concat(input=[cat2, cat1], axis=-1)
+
+ output = L.fc(output, size=self.hidden_size, act="relu")
+ output = L.dropout(output, dropout_prob=self.dropout_ratio)
+ output = L.fc(output, size=self.hidden_size // 2, act="relu")
+ output = L.fc(output, size=self.num_classes, act=None,
+ param_attr=fluid.ParamAttr(name="final_fc"))
+
+ self.labels = L.cast(self.labels, dtype="float32")
+ loss = L.sigmoid_cross_entropy_with_logits(x=output, label=self.labels)
+ self.loss = L.mean(loss)
+ pred = L.sigmoid(output)
+ self.pred = L.argmax(x=pred, axis=-1)
+ correct = L.equal(self.pred, self.labels_1dim)
+ correct = L.cast(correct, dtype="int32")
+ self.correct = L.reduce_sum(correct)
diff --git a/examples/dgi/train.py b/examples/dgi/train.py
index 67742093486e9e391cea0d141d504580c2985df0..a23e4e7b8a154f706f9654a6aa69f131af922dde 100644
--- a/examples/dgi/train.py
+++ b/examples/dgi/train.py
@@ -65,7 +65,6 @@ def main(args):
with fluid.program_guard(train_program, startup_program):
gw = pgl.graph_wrapper.GraphWrapper(
name="graph",
- place=place,
node_feat=dataset.graph.node_feat_info())
output = pgl.layers.gcn(gw,
diff --git a/examples/distribute_graphsage/README.md b/examples/distribute_graphsage/README.md
index 0ce196f6417b676f8d1853f14c012bd86d5972ef..fcfe50a9bfecf258a7781b0ff158d3860cc85bc2 100644
--- a/examples/distribute_graphsage/README.md
+++ b/examples/distribute_graphsage/README.md
@@ -6,54 +6,32 @@ information (e.g., text attributes) to efficiently generate node embeddings for
For purpose of high scalability, we use redis as distribute graph storage solution and training graphsage against redis server.
### Datasets(Quickstart)
-The reddit dataset should be downloaded from [reddit_adj.npz](https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt) and [reddit.npz](https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2Jthe). The details for Reddit Dataset can be found [here](https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf).
+The reddit dataset should be downloaded from [reddit_adj.npz](https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt) and [reddit.npz](https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J). The details for Reddit Dataset can be found [here](https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf).
-Alternatively, reddit dataset has been preprocessed and packed into docker image, which can be instantly pulled using following commands.
+- reddit.npz: https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J
+- reddit_adj.npz: https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt
-```sh
-docker pull githubutilities/reddit_redis_demo:v0.1
-```
+Download `reddit.npz` and `reddit_adj.npz` into `data` directory for further preprocessing.
### Dependencies
-```txt
-- paddlepaddle>=1.6
-- pgl
-- scipy
-- redis==2.10.6
-- redis-py-cluster==1.3.6
+```sh
+pip install -r requirements.txt
```
### How to run
-#### 1. Start reddit data service
+#### 1. Preprocessing and start reddit data service
```sh
-docker run \
- --net=host \
- -d --rm \
- --name reddit_demo \
- -it githubutilities/reddit_redis_demo:v0.1 \
- /bin/bash -c "/bin/bash ./before_hook.sh && /bin/bash"
-docker logs -f `docker ps -aqf "name=reddit_demo"`
+pushd ./redis_setup
+ /bin/bash ./before_hook.sh
+popd
```
#### 2. training GraphSAGE model
```sh
-python train.py --use_cuda --epoch 10 --graphsage_type graphsage_mean --sample_workers 10
+sh ./cloud_run.sh
```
-#### Hyperparameters
-
-- epoch: Number of epochs default (10)
-- use_cuda: Use gpu if assign use_cuda.
-- graphsage_type: We support 4 aggregator types including "graphsage_mean", "graphsage_maxpool", "graphsage_meanpool" and "graphsage_lstm".
-- sample_workers: The number of workers for multiprocessing subgraph sample.
-- lr: Learning rate.
-- batch_size: Batch size.
-- samples_1: The max neighbors for the first hop neighbor sampling. (default: 25)
-- samples_2: The max neighbors for the second hop neighbor sampling. (default: 10)
-- hidden_size: The hidden size of the GraphSAGE models.
-
-
diff --git a/examples/distribute_graphsage/cloud_run.sh b/examples/distribute_graphsage/cloud_run.sh
new file mode 100755
index 0000000000000000000000000000000000000000..c5b5e45fe8990396da9e68cc68f7ebd5217dcbe7
--- /dev/null
+++ b/examples/distribute_graphsage/cloud_run.sh
@@ -0,0 +1,25 @@
+#!/bin/bash
+set -x
+mode=${1}
+
+source ./utils.sh
+unset http_proxy https_proxy
+
+source ./local_config
+if [ ! -d ${log_dir} ]; then
+ mkdir ${log_dir}
+fi
+
+for((i=0;i<${PADDLE_PSERVERS_NUM};i++))
+do
+ echo "start ps server: ${i}"
+ echo $log_dir
+ TRAINING_ROLE="PSERVER" PADDLE_TRAINER_ID=${i} sh job.sh &> $log_dir/pserver.$i.log &
+done
+sleep 10s
+for((j=0;j<${PADDLE_TRAINERS_NUM};j++))
+do
+ echo "start ps work: ${j}"
+ TRAINING_ROLE="TRAINER" PADDLE_TRAINER_ID=${j} sh job.sh &> $log_dir/worker.$j.log &
+done
+tail -f $log_dir/worker.0.log
diff --git a/examples/distribute_graphsage/cluster_train.py b/examples/distribute_graphsage/cluster_train.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ff2695bd5e09963bd497fadc8b5452cfe833288
--- /dev/null
+++ b/examples/distribute_graphsage/cluster_train.py
@@ -0,0 +1,191 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import time
+import os
+import math
+import numpy as np
+
+import paddle.fluid as F
+import paddle.fluid.layers as L
+from paddle.fluid.incubate.fleet.parameter_server.distribute_transpiler import fleet
+from paddle.fluid.transpiler.distribute_transpiler import DistributeTranspilerConfig
+import paddle.fluid.incubate.fleet.base.role_maker as role_maker
+from pgl.utils.logger import log
+
+from model import GraphsageModel
+from utils import load_config
+import reader
+
+
+def init_role():
+ # reset the place according to role of parameter server
+ training_role = os.getenv("TRAINING_ROLE", "TRAINER")
+ paddle_role = role_maker.Role.WORKER
+ place = F.CPUPlace()
+ if training_role == "PSERVER":
+ paddle_role = role_maker.Role.SERVER
+
+ # set the fleet runtime environment according to configure
+ ports = os.getenv("PADDLE_PORT", "6174").split(",")
+ pserver_ips = os.getenv("PADDLE_PSERVERS").split(",") # ip,ip...
+ eplist = []
+ if len(ports) > 1:
+ # local debug mode, multi port
+ for port in ports:
+ eplist.append(':'.join([pserver_ips[0], port]))
+ else:
+ # distributed mode, multi ip
+ for ip in pserver_ips:
+ eplist.append(':'.join([ip, ports[0]]))
+
+ pserver_endpoints = eplist # ip:port,ip:port...
+ worker_num = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ role = role_maker.UserDefinedRoleMaker(
+ current_id=trainer_id,
+ role=paddle_role,
+ worker_num=worker_num,
+ server_endpoints=pserver_endpoints)
+ fleet.init(role)
+
+
+def optimization(base_lr, loss, optimizer='adam'):
+ if optimizer == 'sgd':
+ optimizer = F.optimizer.SGD(base_lr)
+ elif optimizer == 'adam':
+ optimizer = F.optimizer.Adam(base_lr, lazy_mode=True)
+ else:
+ raise ValueError
+
+ log.info('learning rate:%f' % (base_lr))
+ #create the DistributeTranspiler configure
+ config = DistributeTranspilerConfig()
+ config.sync_mode = False
+ #config.runtime_split_send_recv = False
+
+ config.slice_var_up = False
+ #create the distributed optimizer
+ optimizer = fleet.distributed_optimizer(optimizer, config)
+ optimizer.minimize(loss)
+
+
+def build_complied_prog(train_program, model_loss):
+ num_threads = int(os.getenv("CPU_NUM", 10))
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", 0))
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = num_threads
+ #exec_strategy.use_experimental_executor = True
+ build_strategy = F.BuildStrategy()
+ build_strategy.enable_inplace = True
+ #build_strategy.memory_optimize = True
+ build_strategy.memory_optimize = False
+ build_strategy.remove_unnecessary_lock = False
+ if num_threads > 1:
+ build_strategy.reduce_strategy = F.BuildStrategy.ReduceStrategy.Reduce
+
+ compiled_prog = F.compiler.CompiledProgram(
+ train_program).with_data_parallel(loss_name=model_loss.name)
+ return compiled_prog
+
+
+def fake_py_reader(data_iter, num):
+ def fake_iter():
+ queue = []
+ for idx, data in enumerate(data_iter()):
+ queue.append(data)
+ if len(queue) == num:
+ yield queue
+ queue = []
+ if len(queue) > 0:
+ while len(queue) < num:
+ queue.append(queue[-1])
+ yield queue
+ return fake_iter
+
+def train_prog(exe, program, model, pyreader, args):
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ start = time.time()
+ batch = 0
+ total_loss = 0.
+ total_acc = 0.
+ total_sample = 0
+ for epoch_idx in range(args.num_epoch):
+ for step, batch_feed_dict in enumerate(pyreader()):
+ try:
+ cpu_time = time.time()
+ batch += 1
+ batch_loss, batch_acc = exe.run(
+ program,
+ feed=batch_feed_dict,
+ fetch_list=[model.loss, model.acc])
+
+ end = time.time()
+ if batch % args.log_per_step == 0:
+ log.info(
+ "Batch %s Loss %s Acc %s \t Speed(per batch) %.5lf/%.5lf sec"
+ % (batch, np.mean(batch_loss), np.mean(batch_acc), (end - start) /batch, (end - cpu_time)))
+
+ if step % args.steps_per_save == 0:
+ save_path = args.save_path
+ if trainer_id == 0:
+ model_path = os.path.join(save_path, "%s" % step)
+ fleet.save_persistables(exe, model_path)
+ except Exception as e:
+ log.info("Pyreader train error")
+ log.exception(e)
+
+def main(args):
+ log.info("start")
+
+ worker_num = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
+ num_devices = int(os.getenv("CPU_NUM", 10))
+
+ model = GraphsageModel(args)
+ loss = model.forward()
+ train_iter = reader.get_iter(args, model.graph_wrapper, 'train')
+ pyreader = fake_py_reader(train_iter, num_devices)
+
+ # init fleet
+ init_role()
+
+ optimization(args.lr, loss, args.optimizer)
+
+ # init and run server or worker
+ if fleet.is_server():
+ fleet.init_server(args.warm_start_from_dir)
+ fleet.run_server()
+
+ if fleet.is_worker():
+ log.info("start init worker done")
+ fleet.init_worker()
+ #just the worker, load the sample
+ log.info("init worker done")
+
+ exe = F.Executor(F.CPUPlace())
+ exe.run(fleet.startup_program)
+ log.info("Startup done")
+
+ compiled_prog = build_complied_prog(fleet.main_program, loss)
+ train_prog(exe, compiled_prog, model, pyreader, args)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='metapath2vec')
+ parser.add_argument("-c", "--config", type=str, default="./config.yaml")
+ args = parser.parse_args()
+ config = load_config(args.config)
+ log.info(config)
+ main(config)
+
diff --git a/examples/distribute_graphsage/config.yaml b/examples/distribute_graphsage/config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..915ef184c32db9ff6322ee9edc0cd57e1372b1f9
--- /dev/null
+++ b/examples/distribute_graphsage/config.yaml
@@ -0,0 +1,19 @@
+# model config
+hidden_size: 128
+num_class: 41
+samples: [25, 10]
+graphsage_type: "graphsage_mean"
+
+# trainging config
+num_epoch: 10
+batch_size: 128
+num_sample_workers: 10
+optimizer: "adam"
+lr: 0.01
+warm_start_from_dir: null
+steps_per_save: 1000
+log_per_step: 1
+save_path: "./checkpoints"
+log_dir: "./logs"
+CPU_NUM: 1
+
diff --git a/examples/distribute_graphsage/job.sh b/examples/distribute_graphsage/job.sh
new file mode 100644
index 0000000000000000000000000000000000000000..8b9ee4d1b5d981d9c4dfa920cffbb31723030dcc
--- /dev/null
+++ b/examples/distribute_graphsage/job.sh
@@ -0,0 +1,14 @@
+#!/bin/bash
+
+set -x
+source ./utils.sh
+
+export CPU_NUM=$CPU_NUM
+export FLAGS_rpc_deadline=3000000
+
+export FLAGS_communicator_send_queue_size=1
+export FLAGS_communicator_min_send_grad_num_before_recv=0
+export FLAGS_communicator_max_merge_var_num=1
+export FLAGS_communicator_merge_sparse_grad=0
+
+python -u cluster_train.py -c config.yaml
diff --git a/examples/distribute_graphsage/local_config b/examples/distribute_graphsage/local_config
new file mode 100644
index 0000000000000000000000000000000000000000..0e8ca14c66f40cfdc7beea1a0f0cd2f61b8a51ee
--- /dev/null
+++ b/examples/distribute_graphsage/local_config
@@ -0,0 +1,6 @@
+#!/bin/bash
+export PADDLE_TRAINERS_NUM=2
+export PADDLE_PSERVERS_NUM=2
+export PADDLE_PORT=6184,6185
+export PADDLE_PSERVERS="127.0.0.1"
+
diff --git a/examples/distribute_graphsage/model.py b/examples/distribute_graphsage/model.py
index 145a979e86951dc4b5a2522154a0dc0373eea065..7f5eb990fc9bad4f6475bb538b62266b6b5e7f41 100644
--- a/examples/distribute_graphsage/model.py
+++ b/examples/distribute_graphsage/model.py
@@ -11,10 +11,22 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+"""
+ graphsage model.
+"""
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+import math
+
+import pgl
+import numpy as np
import paddle
+import paddle.fluid.layers as L
+import paddle.fluid as F
import paddle.fluid as fluid
-
def copy_send(src_feat, dst_feat, edge_feat):
return src_feat["h"]
@@ -128,3 +140,87 @@ def graphsage_lstm(gw, feature, hidden_size, act, name):
output = fluid.layers.concat([self_feature, neigh_feature], axis=1)
output = fluid.layers.l2_normalize(output, axis=1)
return output
+
+
+def build_graph_model(graph_wrapper, num_class, k_hop, graphsage_type,
+ hidden_size):
+ node_index = fluid.layers.data(
+ "node_index", shape=[None], dtype="int64", append_batch_size=False)
+
+ node_label = fluid.layers.data(
+ "node_label", shape=[None, 1], dtype="int64", append_batch_size=False)
+
+ #feature = fluid.layers.gather(feature, graph_wrapper.node_feat['feats'])
+ feature = graph_wrapper.node_feat['feats']
+ feature.stop_gradient = True
+
+ for i in range(k_hop):
+ if graphsage_type == 'graphsage_mean':
+ feature = graphsage_mean(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_mean_%s" % i)
+ elif graphsage_type == 'graphsage_meanpool':
+ feature = graphsage_meanpool(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_meanpool_%s" % i)
+ elif graphsage_type == 'graphsage_maxpool':
+ feature = graphsage_maxpool(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_maxpool_%s" % i)
+ elif graphsage_type == 'graphsage_lstm':
+ feature = graphsage_lstm(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_maxpool_%s" % i)
+ else:
+ raise ValueError("graphsage type %s is not"
+ " implemented" % graphsage_type)
+
+ feature = fluid.layers.gather(feature, node_index)
+ logits = fluid.layers.fc(feature,
+ num_class,
+ act=None,
+ name='classification_layer')
+ proba = fluid.layers.softmax(logits)
+
+ loss = fluid.layers.softmax_with_cross_entropy(
+ logits=logits, label=node_label)
+ loss = fluid.layers.mean(loss)
+ acc = fluid.layers.accuracy(input=proba, label=node_label, k=1)
+ return loss, acc
+
+
+class GraphsageModel(object):
+ def __init__(self, args):
+ self.args = args
+
+ def forward(self):
+ args = self.args
+
+ graph_wrapper = pgl.graph_wrapper.GraphWrapper(
+ "sub_graph", node_feat=[('feats', [None, 602], np.dtype('float32'))])
+ loss, acc = build_graph_model(
+ graph_wrapper,
+ num_class=args.num_class,
+ hidden_size=args.hidden_size,
+ graphsage_type=args.graphsage_type,
+ k_hop=len(args.samples))
+
+ loss.persistable = True
+
+ self.graph_wrapper = graph_wrapper
+ self.loss = loss
+ self.acc = acc
+ return loss
+
diff --git a/examples/distribute_graphsage/reader.py b/examples/distribute_graphsage/reader.py
index 6617b6b86fe08facee1915edcd459a8c706c4191..88556d39a9d6c30e1b7c4e5e087e994de937566e 100644
--- a/examples/distribute_graphsage/reader.py
+++ b/examples/distribute_graphsage/reader.py
@@ -11,6 +11,8 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import os
+import sys
import numpy as np
import pickle as pkl
import paddle
@@ -147,3 +149,48 @@ def multiprocess_graph_reader(
return reader()
+
+def load_data():
+ """
+ data from https://github.com/matenure/FastGCN/issues/8
+ reddit.npz: https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J
+ reddit_index_label is preprocess from reddit.npz without feats key.
+ """
+ data_dir = os.path.dirname(os.path.abspath(__file__))
+ data = np.load(os.path.join(data_dir, "data/reddit_index_label.npz"))
+
+ num_class = 41
+
+ train_label = data['y_train']
+ val_label = data['y_val']
+ test_label = data['y_test']
+
+ train_index = data['train_index']
+ val_index = data['val_index']
+ test_index = data['test_index']
+
+ return {
+ "train_index": train_index,
+ "train_label": train_label,
+ "val_label": val_label,
+ "val_index": val_index,
+ "test_index": test_index,
+ "test_label": test_label,
+ "num_class": 41
+ }
+
+def get_iter(args, graph_wrapper, mode):
+ data = load_data()
+ train_iter = multiprocess_graph_reader(
+ graph_wrapper,
+ samples=args.samples,
+ num_workers=args.num_sample_workers,
+ batch_size=args.batch_size,
+ node_index=data['train_index'],
+ node_label=data["train_label"])
+ return train_iter
+
+if __name__ == '__main__':
+ for e in train_iter():
+ print(e)
+
diff --git a/examples/distribute_graphsage/redis_setup/before_hook.sh b/examples/distribute_graphsage/redis_setup/before_hook.sh
new file mode 100644
index 0000000000000000000000000000000000000000..1b5c101a2e77b7823b3d23a85a709e843812464c
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/before_hook.sh
@@ -0,0 +1,31 @@
+#!/bin/bash
+set -x
+
+srcdir=./src
+
+# Data preprocessing
+python ./src/preprocess.py
+
+# Download and compile redis
+export PATH=$PWD/redis-5.0.5/src:$PATH
+if [ ! -f ./redis.tar.gz ]; then
+ curl https://codeload.github.com/antirez/redis/tar.gz/5.0.5 -o ./redis.tar.gz
+fi
+tar -xzf ./redis.tar.gz
+cd ./redis-5.0.5/
+make
+cd -
+
+# Install python deps
+python -m pip install -U pip
+pip install -r ./src/requirements.txt -U
+
+# Run redis server
+sh ./src/run_server.sh
+
+# Dumping data into redis
+source ./redis_graph.cfg
+sh ./src/dump_data.sh $edge_path $server_list $num_nodes $node_feat_path
+
+exit 0
+
diff --git a/examples/distribute_graphsage/redis_setup/redis_graph.cfg b/examples/distribute_graphsage/redis_setup/redis_graph.cfg
new file mode 100644
index 0000000000000000000000000000000000000000..382ca1749082ecbec98f2666186d81c0534547b6
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/redis_graph.cfg
@@ -0,0 +1,6 @@
+# dump config
+edge_path=../data/edge.txt
+node_feat_path=../data/feats.npz
+num_nodes=232965
+server_list=./server.list
+
diff --git a/examples/distribute_graphsage/redis_setup/src/build_graph.py b/examples/distribute_graphsage/redis_setup/src/build_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..9fb1c6563bf24991bfd3dfa9bca78f513c9d21e5
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/build_graph.py
@@ -0,0 +1,275 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import json
+import logging
+from collections import defaultdict
+import tqdm
+import redis
+from redis._compat import b, unicode, bytes, long, basestring
+from rediscluster.nodemanager import NodeManager
+from rediscluster.crc import crc16
+import argparse
+import time
+import pickle
+import numpy as np
+import scipy.sparse as sp
+
+log = logging.getLogger(__name__)
+root = logging.getLogger()
+root.setLevel(logging.DEBUG)
+
+handler = logging.StreamHandler(sys.stdout)
+handler.setLevel(logging.DEBUG)
+formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
+handler.setFormatter(formatter)
+root.addHandler(handler)
+
+
+def encode(value):
+ """
+ Return a bytestring representation of the value.
+ This method is copied from Redis' connection.py:Connection.encode
+ """
+ if isinstance(value, bytes):
+ return value
+ elif isinstance(value, (int, long)):
+ value = b(str(value))
+ elif isinstance(value, float):
+ value = b(repr(value))
+ elif not isinstance(value, basestring):
+ value = unicode(value)
+ if isinstance(value, unicode):
+ value = value.encode('utf-8')
+ return value
+
+
+def crc16_hash(data):
+ return crc16(encode(data))
+
+
+def get_redis(startup_host, startup_port):
+ startup_nodes = [{"host": startup_host, "port": startup_port}, ]
+ nodemanager = NodeManager(startup_nodes=startup_nodes)
+ nodemanager.initialize()
+ rs = {}
+ for node, config in nodemanager.nodes.items():
+ rs[node] = redis.Redis(
+ host=config["host"], port=config["port"], decode_responses=False)
+ return rs, nodemanager
+
+
+def load_data(edge_path):
+ src, dst = [], []
+ with open(edge_path, "r") as f:
+ for i in tqdm.tqdm(f):
+ s, d, _ = i.split()
+ s = int(s)
+ d = int(d)
+ src.append(s)
+ dst.append(d)
+ dst.append(s)
+ src.append(d)
+ src = np.array(src, dtype="int64")
+ dst = np.array(dst, dtype="int64")
+ return src, dst
+
+
+def build_edge_index(edge_path, num_nodes, startup_host, startup_port,
+ num_bucket):
+ #src, dst = load_data(edge_path)
+ rs, nodemanager = get_redis(startup_host, startup_port)
+
+ dst_mp, edge_mp = defaultdict(list), defaultdict(list)
+ with open(edge_path) as f:
+ for l in tqdm.tqdm(f):
+ a, b, idx = l.rstrip().split('\t')
+ a, b, idx = int(a), int(b), int(idx)
+ dst_mp[a].append(b)
+ edge_mp[a].append(idx)
+ part_dst_dicts = {}
+ for i in tqdm.tqdm(range(num_nodes)):
+ #if len(edge_index.v[i]) == 0:
+ # continue
+ #v = edge_index.v[i].astype("int64").reshape([-1, 1])
+ #e = edge_index.eid[i].astype("int64").reshape([-1, 1])
+ if i not in dst_mp:
+ continue
+ v = np.array(dst_mp[i]).astype('int64').reshape([-1, 1])
+ e = np.array(edge_mp[i]).astype('int64').reshape([-1, 1])
+ o = np.hstack([v, e])
+ key = "d:%s" % i
+ part = crc16_hash(key) % num_bucket
+ if part not in part_dst_dicts:
+ part_dst_dicts[part] = {}
+ dst_dicts = part_dst_dicts[part]
+ dst_dicts["d:%s" % i] = o.tobytes()
+ if len(dst_dicts) > 10000:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, dst_dicts)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_dst_dicts[part] = {}
+
+ for part, dst_dicts in part_dst_dicts.items():
+ if len(dst_dicts) > 0:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, dst_dicts)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_dst_dicts[part] = {}
+ log.info("dst_dict Done")
+
+
+def build_edge_id(edge_path, num_nodes, startup_host, startup_port,
+ num_bucket):
+ src, dst = load_data(edge_path)
+ rs, nodemanager = get_redis(startup_host, startup_port)
+ part_edge_dict = {}
+ for i in tqdm.tqdm(range(len(src))):
+ key = "e:%s" % i
+ part = crc16_hash(key) % num_bucket
+ if part not in part_edge_dict:
+ part_edge_dict[part] = {}
+ edge_dict = part_edge_dict[part]
+ edge_dict["e:%s" % i] = int(src[i]) * num_nodes + int(dst[i])
+ if len(edge_dict) > 10000:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, edge_dict)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+
+ part_edge_dict[part] = {}
+
+ for part, edge_dict in part_edge_dict.items():
+ if len(edge_dict) > 0:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, edge_dict)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_edge_dict[part] = {}
+
+
+def build_infos(edge_path, num_nodes, startup_host, startup_port, num_bucket):
+ src, dst = load_data(edge_path)
+ rs, nodemanager = get_redis(startup_host, startup_port)
+ slot = nodemanager.keyslot("num_nodes")
+ node = nodemanager.slots[slot][0]['name']
+ res = rs[node].set("num_nodes", num_nodes)
+
+ slot = nodemanager.keyslot("num_edges")
+ node = nodemanager.slots[slot][0]['name']
+ rs[node].set("num_edges", len(src))
+
+ slot = nodemanager.keyslot("nf:infos")
+ node = nodemanager.slots[slot][0]['name']
+ rs[node].set("nf:infos", json.dumps([['feats', [-1, 602], 'float32'], ]))
+
+ slot = nodemanager.keyslot("ef:infos")
+ node = nodemanager.slots[slot][0]['name']
+ rs[node].set("ef:infos", json.dumps([]))
+
+
+def build_node_feat(node_feat_path, num_nodes, startup_host, startup_port, num_bucket):
+ assert node_feat_path != "", "node_feat_path empty!"
+ feat_dict = np.load(node_feat_path)
+ for k in feat_dict.keys():
+ feat = feat_dict[k]
+ assert feat.shape[0] == num_nodes, "num_nodes invalid"
+
+ rs, nodemanager = get_redis(startup_host, startup_port)
+ part_feat_dict = {}
+ for k in feat_dict.keys():
+ feat = feat_dict[k]
+ for i in tqdm.tqdm(range(num_nodes)):
+ key = "nf:%s:%i" % (k, i)
+ value = feat[i].tobytes()
+ part = crc16_hash(key) % num_bucket
+ if part not in part_feat_dict:
+ part_feat_dict[part] = {}
+ part_feat = part_feat_dict[part]
+ part_feat[key] = value
+ if len(part_feat) > 100:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, part_feat)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+
+ part_feat_dict[part] = {}
+
+ for part, part_feat in part_feat_dict.items():
+ if len(part_feat) > 0:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, part_feat)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_feat_dict[part] = {}
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='gen_redis_conf')
+ parser.add_argument('--startup_port', type=int, required=True)
+ parser.add_argument('--startup_host', type=str, required=True)
+ parser.add_argument('--edge_path', type=str, default="")
+ parser.add_argument('--node_feat_path', type=str, default="")
+ parser.add_argument('--num_nodes', type=int, default=0)
+ parser.add_argument('--num_bucket', type=int, default=64)
+ parser.add_argument(
+ '--mode',
+ type=str,
+ required=True,
+ help="choose one of the following modes (clear, edge_index, edge_id, graph_attr)"
+ )
+ args = parser.parse_args()
+ log.info("Mode: {}".format(args.mode))
+ if args.mode == 'edge_index':
+ build_edge_index(args.edge_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ elif args.mode == 'edge_id':
+ build_edge_id(args.edge_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ elif args.mode == 'graph_attr':
+ build_infos(args.edge_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ elif args.mode == 'node_feat':
+ build_node_feat(args.node_feat_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ else:
+ raise ValueError("%s mode not found" % args.mode)
+
diff --git a/examples/distribute_graphsage/redis_setup/src/dump_data.sh b/examples/distribute_graphsage/redis_setup/src/dump_data.sh
new file mode 100644
index 0000000000000000000000000000000000000000..052064b5ac5ae61d0270691726d299796fe2393a
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/dump_data.sh
@@ -0,0 +1,63 @@
+filter(){
+ lines=`cat $1`
+ rm $1
+ for line in $lines; do
+ remote_host=`echo $line | cut -d":" -f1`
+ remote_port=`echo $line | cut -d":" -f2`
+ nc -z $remote_host $remote_port
+ if [[ $? == 0 ]]; then
+ echo $line >> $1
+ fi
+ done
+}
+
+dump_data(){
+ filter $server_list
+
+ python ./src/start_cluster.py --server_list $server_list --replicas 0
+
+ address=`head -n 1 $server_list`
+
+ ip=`echo $address | cut -d":" -f1`
+ port=`echo $address | cut -d":" -f2`
+
+ python ./src/build_graph.py --startup_host $ip \
+ --startup_port $port \
+ --mode node_feat \
+ --node_feat_path $feat_fn \
+ --num_nodes $num_nodes
+
+ # build edge index
+ python ./src/build_graph.py --startup_host $ip \
+ --startup_port $port \
+ --mode edge_index \
+ --edge_path $edge_path \
+ --num_nodes $num_nodes
+
+ # build edge id
+ #python ./src/build_graph.py --startup_host $ip \
+ # --startup_port $port \
+ # --mode edge_id \
+ # --edge_path $edge_path \
+ # --num_nodes $num_nodes
+
+ # build graph attr
+ python ./src/build_graph.py --startup_host $ip \
+ --startup_port $port \
+ --mode graph_attr \
+ --edge_path $edge_path \
+ --num_nodes $num_nodes
+
+}
+
+if [ $# -ne 4 ]; then
+ echo 'sh edge_path server_list num_nodes feat_fn'
+ exit
+fi
+num_nodes=$3
+server_list=$2
+edge_path=$1
+feat_fn=$4
+
+dump_data
+
diff --git a/examples/distribute_graphsage/redis_setup/src/gen_redis_conf.py b/examples/distribute_graphsage/redis_setup/src/gen_redis_conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ded1f3d79d0d2d64071d6936d38e4514c28b453
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/gen_redis_conf.py
@@ -0,0 +1,72 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import socket
+import argparse
+import os
+temp = """port %s
+bind %s
+daemonize yes
+pidfile /var/run/redis_%s.pid
+cluster-enabled yes
+cluster-config-file nodes.conf
+cluster-node-timeout 50000
+logfile "redis.log"
+appendonly yes"""
+
+
+def gen_config(ports):
+ if len(ports) == 0:
+ raise ValueError("No ports")
+ ip = socket.gethostbyname(socket.gethostname())
+ print("Generate redis conf")
+ for port in ports:
+ try:
+ os.mkdir("%s" % port)
+ except:
+ print("port %s directory already exists" % port)
+ pass
+ with open("%s/redis.conf" % port, 'w') as f:
+ f.write(temp % (port, ip, port))
+
+ print("Generate Start Server Scripts")
+ with open("start_server.sh", "w") as f:
+ f.write("set -x\n")
+ for ind, port in enumerate(ports):
+ f.write("# %s %s start\n" % (ip, port))
+ if ind > 0:
+ f.write("cd ..\n")
+ f.write("cd %s\n" % port)
+ f.write("redis-server redis.conf\n")
+ f.write("\n")
+
+ print("Generate Stop Server Scripts")
+ with open("stop_server.sh", "w") as f:
+ f.write("set -x\n")
+ for ind, port in enumerate(ports):
+ f.write("# %s %s shutdown\n" % (ip, port))
+ f.write("redis-cli -h %s -p %s shutdown\n" % (ip, port))
+ f.write("\n")
+
+ with open("server.list", "w") as f:
+ for ind, port in enumerate(ports):
+ f.write("%s:%s\n" % (ip, port))
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='gen_redis_conf')
+ parser.add_argument('--ports', nargs='+', type=int, default=[])
+ args = parser.parse_args()
+ gen_config(args.ports)
diff --git a/examples/distribute_graphsage/redis_setup/src/preprocess.py b/examples/distribute_graphsage/redis_setup/src/preprocess.py
new file mode 100644
index 0000000000000000000000000000000000000000..42c641ccbf9bf8b623b8e3be159c37d2dffd9ebd
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/preprocess.py
@@ -0,0 +1,35 @@
+import os
+import sys
+
+import numpy as np
+import scipy.sparse as sp
+
+def _load_config(fn):
+ ret = {}
+ with open(fn) as f:
+ for l in f:
+ if l.strip() == '' or l.startswith('#'):
+ continue
+ k, v = l.strip().split('=')
+ ret[k] = v
+ return ret
+
+def _prepro(config):
+ data = np.load("../data/reddit.npz")
+ adj = sp.load_npz("../data/reddit_adj.npz")
+ adj = adj.tocoo()
+ src = adj.row
+ dst = adj.col
+
+ with open(config['edge_path'], 'w') as f:
+ for idx, e in enumerate(zip(src, dst)):
+ s, d = e
+ l = "{}\t{}\t{}\n".format(s, d, idx)
+ f.write(l)
+ feats = data['feats'].astype(np.float32)
+ np.savez(config['node_feat_path'], feats=feats)
+
+if __name__ == '__main__':
+ config = _load_config('./redis_graph.cfg')
+ _prepro(config)
+
diff --git a/examples/distribute_graphsage/redis_setup/src/requirements.txt b/examples/distribute_graphsage/redis_setup/src/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..2f955a8c35414405c0ef4bebd459d96d7934ab62
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/requirements.txt
@@ -0,0 +1,6 @@
+numpy
+scipy
+tqdm
+redis==2.10.6
+redis-py-cluster==1.3.6
+
diff --git a/examples/distribute_graphsage/redis_setup/src/run_server.sh b/examples/distribute_graphsage/redis_setup/src/run_server.sh
new file mode 100644
index 0000000000000000000000000000000000000000..e1268ad60df82c283d0e8d7cfc1e9ca6f7126b6f
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/run_server.sh
@@ -0,0 +1,14 @@
+start_server(){
+ ports=""
+ for i in {7430..7439}; do
+ nc -z localhost $i
+ if [[ $? != 0 ]]; then
+ ports="$ports $i"
+ fi
+ done
+ python ./src/gen_redis_conf.py --ports $ports
+ bash ./start_server.sh #启动服务器
+}
+
+start_server
+
diff --git a/examples/distribute_graphsage/redis_setup/src/start_cluster.py b/examples/distribute_graphsage/redis_setup/src/start_cluster.py
new file mode 100644
index 0000000000000000000000000000000000000000..570765d3696a4eafa924efe8c9ba1787eff574d0
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/start_cluster.py
@@ -0,0 +1,37 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import argparse
+
+
+def build_clusters(server_list, replicas):
+ servers = []
+ with open(server_list) as f:
+ for line in f:
+ servers.append(line.strip())
+ cmd = "echo yes | redis-cli --cluster create"
+ for server in servers:
+ cmd += ' %s ' % server
+ cmd += '--cluster-replicas %s' % replicas
+ print(cmd)
+ os.system(cmd)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description='start_cluster')
+ parser.add_argument('--server_list', type=str, required=True)
+ parser.add_argument('--replicas', type=int, default=0)
+ args = parser.parse_args()
+ build_clusters(args.server_list, args.replicas)
diff --git a/examples/distribute_graphsage/redis_setup/test/test.sh b/examples/distribute_graphsage/redis_setup/test/test.sh
new file mode 100644
index 0000000000000000000000000000000000000000..ec8695b9c75c921bc03bf56a3c381bbd279b1532
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/test/test.sh
@@ -0,0 +1,7 @@
+#!/bin/bash
+
+source ./redis_graph.cfg
+
+url=`head -n1 $server_list`
+shuf $edge_path | head -n 1000 | python ./test/test_redis_graph.py $url
+
diff --git a/examples/distribute_graphsage/redis_setup/test/test_redis_graph.py b/examples/distribute_graphsage/redis_setup/test/test_redis_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..f4a3a2541bbd96210e8f9eaef5bf38a07cbd9e60
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/test/test_redis_graph.py
@@ -0,0 +1,40 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+########################################################################
+#
+# Copyright (c) 2019 Baidu.com, Inc. All Rights Reserved
+#
+# File: test_redis_graph.py
+# Author: suweiyue(suweiyue@baidu.com)
+# Date: 2019/08/19 16:28:18
+#
+########################################################################
+"""
+ Comment.
+"""
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import sys
+
+import numpy as np
+import tqdm
+from pgl.redis_graph import RedisGraph
+
+if __name__ == '__main__':
+ host, port = sys.argv[1].split(':')
+ port = int(port)
+ redis_configs = [{"host": host, "port": port}, ]
+ graph = RedisGraph("reddit-graph", redis_configs, num_parts=64)
+ #nodes = np.arange(0, 100)
+ #for i in range(0, 100):
+ for l in tqdm.tqdm(sys.stdin):
+ l_sp = l.rstrip().split('\t')
+ if len(l_sp) != 2:
+ continue
+ i, j = int(l_sp[0]), int(l_sp[1])
+ nodes = graph.sample_predecessor(np.array([i]), 10000)
+ assert j in nodes
+
diff --git a/examples/distribute_graphsage/requirements.txt b/examples/distribute_graphsage/requirements.txt
index 7bda67a20635218a8786cfb872cfd2da5b2ddbe1..e0d28f3b6ce2ab2cea5d9674b871cc8d3e7ac932 100644
--- a/examples/distribute_graphsage/requirements.txt
+++ b/examples/distribute_graphsage/requirements.txt
@@ -1,3 +1,7 @@
+pgl==1.1.0
+pyyaml
+paddlepaddle==1.6.1
+
scipy
redis==2.10.6
redis-py-cluster==1.3.6
diff --git a/examples/distribute_graphsage/train.py b/examples/distribute_graphsage/train.py
deleted file mode 100644
index fa52e3e002b52e14db5ea4e893377476eada41ef..0000000000000000000000000000000000000000
--- a/examples/distribute_graphsage/train.py
+++ /dev/null
@@ -1,263 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import os
-import argparse
-import time
-
-import numpy as np
-import scipy.sparse as sp
-from sklearn.preprocessing import StandardScaler
-
-import pgl
-from pgl.utils.logger import log
-from pgl.utils import paddle_helper
-import paddle
-import paddle.fluid as fluid
-import reader
-from model import graphsage_mean, graphsage_meanpool,\
- graphsage_maxpool, graphsage_lstm
-
-
-def load_data():
- """
- data from https://github.com/matenure/FastGCN/issues/8
- reddit.npz: https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J
- reddit_index_label is preprocess from reddit.npz without feats key.
- """
- data_dir = os.path.dirname(os.path.abspath(__file__))
- data = np.load(os.path.join(data_dir, "data/reddit_index_label.npz"))
-
- num_class = 41
-
- train_label = data['y_train']
- val_label = data['y_val']
- test_label = data['y_test']
-
- train_index = data['train_index']
- val_index = data['val_index']
- test_index = data['test_index']
-
- return {
- "train_index": train_index,
- "train_label": train_label,
- "val_label": val_label,
- "val_index": val_index,
- "test_index": test_index,
- "test_label": test_label,
- "num_class": 41
- }
-
-
-def build_graph_model(graph_wrapper, num_class, k_hop, graphsage_type,
- hidden_size):
- node_index = fluid.layers.data(
- "node_index", shape=[None], dtype="int64", append_batch_size=False)
-
- node_label = fluid.layers.data(
- "node_label", shape=[None, 1], dtype="int64", append_batch_size=False)
-
- #feature = fluid.layers.gather(feature, graph_wrapper.node_feat['feats'])
- feature = graph_wrapper.node_feat['feats']
- feature.stop_gradient = True
-
- for i in range(k_hop):
- if graphsage_type == 'graphsage_mean':
- feature = graphsage_mean(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_mean_%s" % i)
- elif graphsage_type == 'graphsage_meanpool':
- feature = graphsage_meanpool(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_meanpool_%s" % i)
- elif graphsage_type == 'graphsage_maxpool':
- feature = graphsage_maxpool(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_maxpool_%s" % i)
- elif graphsage_type == 'graphsage_lstm':
- feature = graphsage_lstm(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_maxpool_%s" % i)
- else:
- raise ValueError("graphsage type %s is not"
- " implemented" % graphsage_type)
-
- feature = fluid.layers.gather(feature, node_index)
- logits = fluid.layers.fc(feature,
- num_class,
- act=None,
- name='classification_layer')
- proba = fluid.layers.softmax(logits)
-
- loss = fluid.layers.softmax_with_cross_entropy(
- logits=logits, label=node_label)
- loss = fluid.layers.mean(loss)
- acc = fluid.layers.accuracy(input=proba, label=node_label, k=1)
- return loss, acc
-
-
-def run_epoch(batch_iter,
- exe,
- program,
- prefix,
- model_loss,
- model_acc,
- epoch,
- log_per_step=100):
- batch = 0
- total_loss = 0.
- total_acc = 0.
- total_sample = 0
- start = time.time()
- for batch_feed_dict in batch_iter():
- batch += 1
- batch_loss, batch_acc = exe.run(program,
- fetch_list=[model_loss, model_acc],
- feed=batch_feed_dict)
-
- if batch % log_per_step == 0:
- log.info("Batch %s %s-Loss %s %s-Acc %s" %
- (batch, prefix, batch_loss, prefix, batch_acc))
-
- num_samples = len(batch_feed_dict["node_index"])
- total_loss += batch_loss * num_samples
- total_acc += batch_acc * num_samples
- total_sample += num_samples
- end = time.time()
-
- log.info("%s Epoch %s Loss %.5lf Acc %.5lf Speed(per batch) %.5lf sec" %
- (prefix, epoch, total_loss / total_sample,
- total_acc / total_sample, (end - start) / batch))
-
-
-def main(args):
- data = load_data()
- log.info("preprocess finish")
- log.info("Train Examples: %s" % len(data["train_index"]))
- log.info("Val Examples: %s" % len(data["val_index"]))
- log.info("Test Examples: %s" % len(data["test_index"]))
-
- place = fluid.CUDAPlace(0) if args.use_cuda else fluid.CPUPlace()
- train_program = fluid.Program()
- startup_program = fluid.Program()
- samples = []
- if args.samples_1 > 0:
- samples.append(args.samples_1)
- if args.samples_2 > 0:
- samples.append(args.samples_2)
-
- with fluid.program_guard(train_program, startup_program):
- graph_wrapper = pgl.graph_wrapper.GraphWrapper(
- "sub_graph", fluid.CPUPlace(), node_feat=[('feats', [None, 602], np.dtype('float32'))])
- model_loss, model_acc = build_graph_model(
- graph_wrapper,
- num_class=data["num_class"],
- hidden_size=args.hidden_size,
- graphsage_type=args.graphsage_type,
- k_hop=len(samples))
-
- test_program = train_program.clone(for_test=True)
-
- with fluid.program_guard(train_program, startup_program):
- adam = fluid.optimizer.Adam(learning_rate=args.lr)
- adam.minimize(model_loss)
-
- exe = fluid.Executor(place)
- exe.run(startup_program)
-
- train_iter = reader.multiprocess_graph_reader(
- graph_wrapper,
- samples=samples,
- num_workers=args.sample_workers,
- batch_size=args.batch_size,
- node_index=data['train_index'],
- node_label=data["train_label"])
-
- val_iter = reader.multiprocess_graph_reader(
- graph_wrapper,
- samples=samples,
- num_workers=args.sample_workers,
- batch_size=args.batch_size,
- node_index=data['val_index'],
- node_label=data["val_label"])
-
- test_iter = reader.multiprocess_graph_reader(
- graph_wrapper,
- samples=samples,
- num_workers=args.sample_workers,
- batch_size=args.batch_size,
- node_index=data['test_index'],
- node_label=data["test_label"])
-
- for epoch in range(args.epoch):
- run_epoch(
- train_iter,
- program=train_program,
- exe=exe,
- prefix="train",
- model_loss=model_loss,
- model_acc=model_acc,
- log_per_step=1,
- epoch=epoch)
-
- run_epoch(
- val_iter,
- program=test_program,
- exe=exe,
- prefix="val",
- model_loss=model_loss,
- model_acc=model_acc,
- log_per_step=10000,
- epoch=epoch)
-
- run_epoch(
- test_iter,
- program=test_program,
- prefix="test",
- exe=exe,
- model_loss=model_loss,
- model_acc=model_acc,
- log_per_step=10000,
- epoch=epoch)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(description='graphsage')
- parser.add_argument("--use_cuda", action='store_true', help="use_cuda")
- parser.add_argument(
- "--normalize", action='store_true', help="normalize features")
- parser.add_argument(
- "--symmetry", action='store_true', help="undirect graph")
- parser.add_argument("--graphsage_type", type=str, default="graphsage_mean")
- parser.add_argument("--sample_workers", type=int, default=10)
- parser.add_argument("--epoch", type=int, default=10)
- parser.add_argument("--hidden_size", type=int, default=128)
- parser.add_argument("--batch_size", type=int, default=128)
- parser.add_argument("--lr", type=float, default=0.01)
- parser.add_argument("--samples_1", type=int, default=25)
- parser.add_argument("--samples_2", type=int, default=10)
- args = parser.parse_args()
- log.info(args)
- main(args)
diff --git a/examples/distribute_graphsage/utils.py b/examples/distribute_graphsage/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5810f7fdd7a99b034505feaddf51a962ca34ac1
--- /dev/null
+++ b/examples/distribute_graphsage/utils.py
@@ -0,0 +1,55 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Implementation of some helper functions"""
+
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import os
+import time
+import yaml
+import numpy as np
+
+from pgl.utils.logger import log
+
+
+class AttrDict(dict):
+ """Attr dict
+ """
+
+ def __init__(self, d):
+ self.dict = d
+
+ def __getattr__(self, attr):
+ value = self.dict[attr]
+ if isinstance(value, dict):
+ return AttrDict(value)
+ else:
+ return value
+
+ def __str__(self):
+ return str(self.dict)
+
+
+def load_config(config_file):
+ """Load config file"""
+ with open(config_file) as f:
+ if hasattr(yaml, 'FullLoader'):
+ config = yaml.load(f, Loader=yaml.FullLoader)
+ else:
+ config = yaml.load(f)
+
+ return AttrDict(config)
diff --git a/examples/distribute_graphsage/utils.sh b/examples/distribute_graphsage/utils.sh
new file mode 100644
index 0000000000000000000000000000000000000000..6f6daa846d600e0bcecd4ce64e04946dba0fdd51
--- /dev/null
+++ b/examples/distribute_graphsage/utils.sh
@@ -0,0 +1,20 @@
+
+# parse yaml file
+function parse_yaml {
+ local prefix=$2
+ local s='[[:space:]]*' w='[a-zA-Z0-9_]*' fs=$(echo @|tr @ '\034')
+ sed -ne "s|^\($s\):|\1|" \
+ -e "s|^\($s\)\($w\)$s:$s[\"']\(.*\)[\"']$s\$|\1$fs\2$fs\3|p" \
+ -e "s|^\($s\)\($w\)$s:$s\(.*\)$s\$|\1$fs\2$fs\3|p" $1 |
+ awk -F$fs '{
+ indent = length($1)/2;
+ vname[indent] = $2;
+ for (i in vname) {if (i > indent) {delete vname[i]}}
+ if (length($3) > 0) {
+ vn=""; for (i=0; i
+
+**ERNIESage** (abbreviation of ERNIE SAmple aggreGatE), a model proposed by the PGL team, effectively improves the performance on text graph by simultaneously modeling text semantics and graph structure information. It's worth mentioning that [**ERNIE**](https://github.com/PaddlePaddle/ERNIE) in **ERNIESage** is a continual pre-training framework for language understanding launched by Baidu.
+
+**ERNIESage** is an aggregation of ERNIE and GraphSAGE. Its structure is shown in the figure below. The main idea is to use ERNIE as an aggregation function (Aggregators) to model the semantic and structural relationship between its own nodes and neighbor nodes. In addition, for the position-independent characteristics of neighbor nodes, attention mask and independent position embedding mechanism for neighbor blindness are designed.
+
+
@@ -82,10 +99,11 @@ In most cases of large-scale graph learning, we need distributed graph storage a
## Model Zoo
-The following are 13 graph learning models that have been implemented in the framework. See the details [here](https://pgl.readthedocs.io/en/latest/introduction.html#highlight-tons-of-models)
+The following graph learning models have been implemented in the framework. You can find more [examples](./examples) and the [details](https://pgl.readthedocs.io/en/latest/introduction.html#highlight-tons-of-models)
|Model | feature |
|---|---|
+| [**ERNIESage**](./examples/erniesage/) | ERNIE SAmple aggreGatE for Text and Graph |
| GCN | Graph Convolutional Neural Networks |
| GAT | Graph Attention Network |
| GraphSage |Large-scale graph convolution network based on neighborhood sampling|
diff --git a/README.zh.md b/README.zh.md
index e7996398a42a08c1dc1a5022d515ef472eb4382e..c41fdd485f8beda8569e7d70f3dc19670ed13673 100644
--- a/README.zh.md
+++ b/README.zh.md
@@ -1,7 +1,24 @@
+[](https://pypi.org/project/pgl/)
+[](./LICENSE)
+
[文档](https://pgl.readthedocs.io/en/latest/) | [快速开始](https://pgl.readthedocs.io/en/latest/quick_start/instruction.html) | [English](./README.md)
+## 最新消息
+
+PGL v1.1 2020.4.29
+
+- **ERNIESage**是PGL团队最新提出的模型,可以用于建模文本以及图结构信息。你可以在[这里](./examples/erniesage)看到详细的介绍。
+
+- PGL现在提供[Open Graph Benchmark](https://github.com/snap-stanford/ogb)的一些例子,你可以在[这里](./ogb_examples)找到。
+
+- 新增了图级别的算子包括**GraphPooling**以及[**GraphNormalization**](https://arxiv.org/abs/2003.00982),这样你就能实现更多复杂的图级别分类模型。
+
+- 新增PGL-KE工具包,里面包含许多经典知识图谱图嵌入算法,包括TransE, TransR, RotatE,详情可见[这里](./examples/pgl-ke)
+
+------
+
Paddle Graph Learning (PGL)是一个基于[PaddlePaddle](https://github.com/PaddlePaddle/Paddle)的高效易用的图学习框架
@@ -12,11 +29,11 @@ Paddle Graph Learning (PGL)是一个基于[PaddlePaddle](https://github.com/Padd
# 特色:高效性——支持Scatter-Gather及LodTensor消息传递
-对比于一般的模型,图神经网络模型最大的优势在于它利用了节点与节点之间连接的信息。但是,如何通过代码来实现建模这些节点连接十分的麻烦。PGL采用与[DGL](https://github.com/dmlc/dgl)相似的**消息传递范式**用于作为构建图神经网络的接口。用于只需要简单的编写```send```还有```recv```函数就能够轻松的实现一个简单的GCN网络。如下图所示,首先,send函数被定义在节点之间的边上,用户自定义send函数会把消息从源点发送到目标节点。然后,recv函数负责将这些消息用汇聚函数  汇聚起来。
+对比于一般的模型,图神经网络模型最大的优势在于它利用了节点与节点之间连接的信息。但是,如何通过代码来实现建模这些节点连接十分的麻烦。PGL采用与[DGL](https://github.com/dmlc/dgl)相似的**消息传递范式**用于作为构建图神经网络的接口。用于只需要简单的编写```send```还有```recv```函数就能够轻松的实现一个简单的GCN网络。如下图所示,首先,send函数被定义在节点之间的边上,用户自定义send函数会把消息从源点发送到目标节点。然后,recv函数负责将这些消息用汇聚函数  汇聚起来。
-如下面左图所示,为了去适配用户定义的汇聚函数,DGL使用了Degree Bucketing来将相同度的节点组合在一个块,然后将汇聚函数作用在每个块之上。而对于PGL的用户定义汇聚函数,我们则将消息以PaddlePaddle的[LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html)的形式处理,将若干消息看作一组变长的序列,然后利用**LodTensor在PaddlePaddle的特性进行快速平行的消息聚合**。
+如下面左图所示,为了去适配用户定义的汇聚函数,DGL使用了Degree Bucketing来将相同度的节点组合在一个块,然后将汇聚函数作用在每个块之上。而对于PGL的用户定义汇聚函数,我们则将消息以PaddlePaddle的[LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html)的形式处理,将若干消息看作一组变长的序列,然后利用**LodTensor在PaddlePaddle的特性进行快速平行的消息聚合**。
@@ -77,10 +94,11 @@ Paddle Graph Learning (PGL)是一个基于[PaddlePaddle](https://github.com/Padd
## 丰富性——覆盖业界大部分图学习网络
-下列是框架中已经自带实现的十三种图网络学习模型。详情请参考[这里](https://pgl.readthedocs.io/en/latest/introduction.html#highlight-tons-of-models)
+下列是框架中部分已经实现的图网络模型,更多的模型在[这里](./examples)可以找到。详情请参考[这里](https://pgl.readthedocs.io/en/latest/introduction.html#highlight-tons-of-models)
| 模型 | 特点 |
|---|---|
+| [**ERNIESage**](./examples/erniesage/) | 能同时建模文本以及图结构的ERNIE SAmple aggreGatE |
| GCN | 图卷积网络 |
| GAT | 基于Attention的图卷积网络 |
| GraphSage | 基于邻居采样的大规模图卷积网络 |
diff --git a/docs/source/_static/framework_of_pgl.png b/docs/source/_static/framework_of_pgl.png
index f8f6293a6821f7a13901f5b83d6d904a4f64ee0d..a054bd3438f60ca5e838d3e80ccdb567fddd23fd 100644
Binary files a/docs/source/_static/framework_of_pgl.png and b/docs/source/_static/framework_of_pgl.png differ
diff --git a/docs/source/_static/framework_of_pgl_en.png b/docs/source/_static/framework_of_pgl_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..04482775663088455fdd7020d8de5f7db663a177
Binary files /dev/null and b/docs/source/_static/framework_of_pgl_en.png differ
diff --git a/docs/source/_static/logo.png b/docs/source/_static/logo.png
index fc602ea6c020ee08116c7cd86411834741b5377e..48d5966bfa12d537b92b010a0f9e0c525d3350ae 100644
Binary files a/docs/source/_static/logo.png and b/docs/source/_static/logo.png differ
diff --git a/docs/source/api/pgl.contrib.heter_graph.rst b/docs/source/api/pgl.contrib.heter_graph.rst
deleted file mode 100644
index e1cc7ef4adeb943f352fad96781ef572606a6b96..0000000000000000000000000000000000000000
--- a/docs/source/api/pgl.contrib.heter_graph.rst
+++ /dev/null
@@ -1,7 +0,0 @@
-pgl.contrib.heter\_graph module: Heterogenous Graph Storage
-===============================
-
-.. automodule:: pgl.contrib.heter_graph
- :members:
- :undoc-members:
- :show-inheritance:
diff --git a/docs/source/api/pgl.contrib.heter_graph_wrapper.rst b/docs/source/api/pgl.contrib.heter_graph_wrapper.rst
deleted file mode 100644
index 74d9fe853df4639ee86470e67aa06c85c167cffe..0000000000000000000000000000000000000000
--- a/docs/source/api/pgl.contrib.heter_graph_wrapper.rst
+++ /dev/null
@@ -1,7 +0,0 @@
-pgl.contrib.heter\_graph\_wrapper module: Heterogenous Graph data holders for Paddle GNN.
-=========================
-
-.. automodule:: pgl.contrib.heter_graph_wrapper
- :members:
- :undoc-members:
- :show-inheritance:
diff --git a/docs/source/api/pgl.heter_graph.rst b/docs/source/api/pgl.heter_graph.rst
new file mode 100644
index 0000000000000000000000000000000000000000..f3d9091f2487533d54864f684bb1683a56d70f94
--- /dev/null
+++ b/docs/source/api/pgl.heter_graph.rst
@@ -0,0 +1,7 @@
+pgl.heter\_graph module: Heterogenous Graph Storage
+===============================
+
+.. automodule:: pgl.heter_graph
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/api/pgl.heter_graph_wrapper.rst b/docs/source/api/pgl.heter_graph_wrapper.rst
new file mode 100644
index 0000000000000000000000000000000000000000..63e364d9d2d02f2a52f4752ab017291624cdf40d
--- /dev/null
+++ b/docs/source/api/pgl.heter_graph_wrapper.rst
@@ -0,0 +1,7 @@
+pgl.heter\_graph\_wrapper module: Heterogenous Graph data holders for Paddle GNN.
+=========================
+
+.. automodule:: pgl.heter_graph_wrapper
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/docs/source/api/pgl.rst b/docs/source/api/pgl.rst
index cc581c85b0298d3454bcbab0779427e2b25340d9..57034dabb67a995d46993e0218aaec76a1e897fa 100644
--- a/docs/source/api/pgl.rst
+++ b/docs/source/api/pgl.rst
@@ -9,5 +9,5 @@ API Reference
pgl.data_loader
pgl.utils.paddle_helper
pgl.utils.mp_reader
- pgl.contrib.heter_graph
- pgl.contrib.heter_graph_wrapper
+ pgl.heter_graph
+ pgl.heter_graph_wrapper
diff --git a/docs/source/quick_start/md/quick_start.md b/docs/source/quick_start/md/quick_start.md
index 7df4f48a997e35c001ae462b1f9d3052434eb443..afa8a22256a313f9f27b095d5c8eb9acc8f063c1 100644
--- a/docs/source/quick_start/md/quick_start.md
+++ b/docs/source/quick_start/md/quick_start.md
@@ -19,8 +19,8 @@ def build_graph():
# Each node can be represented by a d-dimensional feature vector, here for simple, the feature vectors are randomly generated.
d = 16
feature = np.random.randn(num_node, d).astype("float32")
- # each edge also can be represented by a feature vector
- edge_feature = np.random.randn(len(edge_list), d).astype("float32")
+ # each edge has it own weight
+ edge_feature = np.random.randn(len(edge_list), 1).astype("float32")
# create a graph
g = graph.Graph(num_nodes = num_node,
@@ -53,7 +53,6 @@ place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
# use GraphWrapper as a container for graph data to construct a graph neural network
gw = pgl.graph_wrapper.GraphWrapper(name='graph',
- place = place,
node_feat=g.node_feat_info())
```
@@ -67,13 +66,13 @@ In this tutorial, we use a simple Graph Convolutional Network(GCN) developed by
In PGL, we can easily implement a GCN layer as follows:
```python
# define GCN layer function
-def gcn_layer(gw, feature, hidden_size, name, activation):
+def gcn_layer(gw, nfeat, efeat, hidden_size, name, activation):
# gw is a GraphWrapper;feature is the feature vectors of nodes
# define message function
def send_func(src_feat, dst_feat, edge_feat):
# In this tutorial, we return the feature vector of the source node as message
- return src_feat['h']
+ return src_feat['h'] * edge_feat['e']
# define reduce function
def recv_func(feat):
@@ -81,7 +80,7 @@ def gcn_layer(gw, feature, hidden_size, name, activation):
return fluid.layers.sequence_pool(feat, pool_type='sum')
# trigger message to passing
- msg = gw.send(send_func, nfeat_list=[('h', feature)])
+ msg = gw.send(send_func, nfeat_list=[('h', nfeat)], efeat_list=[('e', efeat)])
# recv funciton receives message and trigger reduce funcition to handle message
output = gw.recv(msg, recv_func)
output = fluid.layers.fc(output,
@@ -93,10 +92,10 @@ def gcn_layer(gw, feature, hidden_size, name, activation):
```
After defining the GCN layer, we can construct a deeper GCN model with two GCN layers.
```python
-output = gcn_layer(gw, gw.node_feat['feature'],
+output = gcn_layer(gw, gw.node_feat['feature'], gw.edge_feat['edge_feature'],
hidden_size=8, name='gcn_layer_1', activation='relu')
-output = gcn_layer(gw, output, hidden_size=1,
- name='gcn_layer_2', activation=None)
+output = gcn_layer(gw, output, gw.edge_feat['edge_feature'],
+ hidden_size=1, name='gcn_layer_2', activation=None)
```
## Step 3: data preprocessing
diff --git a/docs/source/quick_start/md/quick_start_for_heterGraph.md b/docs/source/quick_start/md/quick_start_for_heterGraph.md
index 1be9cb228ce965cc8f0b6ae65ffc3738e08d0b2a..aae818c0be633a5708eb2ea29636077f3c919425 100644
--- a/docs/source/quick_start/md/quick_start_for_heterGraph.md
+++ b/docs/source/quick_start/md/quick_start_for_heterGraph.md
@@ -58,8 +58,8 @@ Now, we can build a heterogenous graph by using PGL.
import paddle.fluid as fluid
import paddle.fluid.layers as fl
import pgl
-from pgl.contrib import heter_graph
-from pgl.contrib import heter_graph_wrapper
+from pgl import heter_graph
+from pgl import heter_graph_wrapper
g = heter_graph.HeterGraph(num_nodes=num_nodes,
edges=edges,
@@ -77,7 +77,6 @@ place = fluid.CPUPlace()
# create a GraphWrapper as a container for graph data
gw = heter_graph_wrapper.HeterGraphWrapper(name='heter_graph',
- place = place,
edge_types = g.edge_types_info(),
node_feat=g.node_feat_info(),
edge_feat=g.edge_feat_info())
@@ -161,8 +160,3 @@ for epoch in range(30):
train_loss = exe.run(fluid.default_main_program(), feed=feed_dict, fetch_list=[loss], return_numpy=True)
print('Epoch %d | Loss: %f'%(epoch, train_loss[0]))
```
-
-
-
-
-
diff --git a/examples/GATNE/model.py b/examples/GATNE/model.py
index b193849e14d31eec7822fc65379a74c7cb2be38d..18f83c89a31324256f20ae118372828fe8be955d 100644
--- a/examples/GATNE/model.py
+++ b/examples/GATNE/model.py
@@ -53,7 +53,6 @@ class GATNE(object):
self.gw = heter_graph_wrapper.HeterGraphWrapper(
name="heter_graph",
- place=place,
edge_types=self.graph.edge_types_info(),
node_feat=self.graph.node_feat_info(),
edge_feat=self.graph.edge_feat_info())
diff --git a/examples/GaAN/README.md b/examples/GaAN/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a3b0981a63211fc2c2555d5942495ca849238e8c
--- /dev/null
+++ b/examples/GaAN/README.md
@@ -0,0 +1,41 @@
+# GaAN: Gated Attention Networks for Learning on Large and Spatiotemporal Graphs
+
+[GaAN](https://arxiv.org/abs/1803.07294) is a powerful neural network designed for machine learning on graph. It introduces an gated attention mechanism. Based on PGL, we reproduce the GaAN algorithm and train the model on [ogbn-proteins](https://ogb.stanford.edu/docs/nodeprop/#ogbn-proteins).
+
+## Datasets
+The ogbn-proteins dataset will be downloaded in directory ./dataset automatically.
+
+## Dependencies
+- [paddlepaddle >= 1.6](https://github.com/paddlepaddle/paddle)
+- [pgl 1.1](https://github.com/PaddlePaddle/PGL)
+- [ogb 1.1.1](https://github.com/snap-stanford/ogb)
+
+## How to run
+```bash
+python train.py --lr 1e-2 --rc 0 --batch_size 1024 --epochs 100
+```
+
+or
+```bash
+source main.sh
+```
+
+### Hyperparameters
+- use_gpu: whether to use gpu or not
+- mini_data: use a small dataset to test code
+- epochs: number of training epochs
+- lr: learning rate
+- rc: regularization coefficient
+- log_path: the path of log
+- batch_size: the number of batch size
+- heads: the number of heads of attention
+- hidden_size_a: the size of query and key vectors
+- hidden_size_v: the size of value vectors
+- hidden_size_m: the size of projection space for computing gates
+- hidden_size_o: the size of output of GaAN layer
+
+## Performance
+We train our models for 100 epochs and report the **rocauc** on the test dataset.
+|dataset|mean|std|#experiments|
+|-|-|-|-|
+|ogbn-proteins|0.7803|0.0073|10|
diff --git a/examples/GaAN/conv.py b/examples/GaAN/conv.py
new file mode 100644
index 0000000000000000000000000000000000000000..a9264d3c8cd475791d2e23097aaa4a94e7665d5a
--- /dev/null
+++ b/examples/GaAN/conv.py
@@ -0,0 +1,344 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""This package implements common layers to help building
+graph neural networks.
+"""
+import paddle.fluid as fluid
+from pgl import graph_wrapper
+from pgl.utils import paddle_helper
+
+__all__ = ['gcn', 'gat', 'gin', 'gaan']
+
+
+def gcn(gw, feature, hidden_size, activation, name, norm=None):
+ """Implementation of graph convolutional neural networks (GCN)
+
+ This is an implementation of the paper SEMI-SUPERVISED CLASSIFICATION
+ WITH GRAPH CONVOLUTIONAL NETWORKS (https://arxiv.org/pdf/1609.02907.pdf).
+
+ Args:
+ gw: Graph wrapper object (:code:`StaticGraphWrapper` or :code:`GraphWrapper`)
+
+ feature: A tensor with shape (num_nodes, feature_size).
+
+ hidden_size: The hidden size for gcn.
+
+ activation: The activation for the output.
+
+ name: Gcn layer names.
+
+ norm: If :code:`norm` is not None, then the feature will be normalized. Norm must
+ be tensor with shape (num_nodes,) and dtype float32.
+
+ Return:
+ A tensor with shape (num_nodes, hidden_size)
+ """
+
+ def send_src_copy(src_feat, dst_feat, edge_feat):
+ return src_feat["h"]
+
+ size = feature.shape[-1]
+ if size > hidden_size:
+ feature = fluid.layers.fc(feature,
+ size=hidden_size,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name))
+
+ if norm is not None:
+ feature = feature * norm
+
+ msg = gw.send(send_src_copy, nfeat_list=[("h", feature)])
+
+ if size > hidden_size:
+ output = gw.recv(msg, "sum")
+ else:
+ output = gw.recv(msg, "sum")
+ output = fluid.layers.fc(output,
+ size=hidden_size,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name))
+
+ if norm is not None:
+ output = output * norm
+
+ bias = fluid.layers.create_parameter(
+ shape=[hidden_size],
+ dtype='float32',
+ is_bias=True,
+ name=name + '_bias')
+ output = fluid.layers.elementwise_add(output, bias, act=activation)
+ return output
+
+
+def gat(gw,
+ feature,
+ hidden_size,
+ activation,
+ name,
+ num_heads=8,
+ feat_drop=0.6,
+ attn_drop=0.6,
+ is_test=False):
+ """Implementation of graph attention networks (GAT)
+
+ This is an implementation of the paper GRAPH ATTENTION NETWORKS
+ (https://arxiv.org/abs/1710.10903).
+
+ Args:
+ gw: Graph wrapper object (:code:`StaticGraphWrapper` or :code:`GraphWrapper`)
+
+ feature: A tensor with shape (num_nodes, feature_size).
+
+ hidden_size: The hidden size for gat.
+
+ activation: The activation for the output.
+
+ name: Gat layer names.
+
+ num_heads: The head number in gat.
+
+ feat_drop: Dropout rate for feature.
+
+ attn_drop: Dropout rate for attention.
+
+ is_test: Whether in test phrase.
+
+ Return:
+ A tensor with shape (num_nodes, hidden_size * num_heads)
+ """
+
+ def send_attention(src_feat, dst_feat, edge_feat):
+ output = src_feat["left_a"] + dst_feat["right_a"]
+ output = fluid.layers.leaky_relu(
+ output, alpha=0.2) # (num_edges, num_heads)
+ return {"alpha": output, "h": src_feat["h"]}
+
+ def reduce_attention(msg):
+ alpha = msg["alpha"] # lod-tensor (batch_size, seq_len, num_heads)
+ h = msg["h"]
+ alpha = paddle_helper.sequence_softmax(alpha)
+ old_h = h
+ h = fluid.layers.reshape(h, [-1, num_heads, hidden_size])
+ alpha = fluid.layers.reshape(alpha, [-1, num_heads, 1])
+ if attn_drop > 1e-15:
+ alpha = fluid.layers.dropout(
+ alpha,
+ dropout_prob=attn_drop,
+ is_test=is_test,
+ dropout_implementation="upscale_in_train")
+ h = h * alpha
+ h = fluid.layers.reshape(h, [-1, num_heads * hidden_size])
+ h = fluid.layers.lod_reset(h, old_h)
+ return fluid.layers.sequence_pool(h, "sum")
+
+ if feat_drop > 1e-15:
+ feature = fluid.layers.dropout(
+ feature,
+ dropout_prob=feat_drop,
+ is_test=is_test,
+ dropout_implementation='upscale_in_train')
+
+ ft = fluid.layers.fc(feature,
+ hidden_size * num_heads,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_weight'))
+ left_a = fluid.layers.create_parameter(
+ shape=[num_heads, hidden_size],
+ dtype='float32',
+ name=name + '_gat_l_A')
+ right_a = fluid.layers.create_parameter(
+ shape=[num_heads, hidden_size],
+ dtype='float32',
+ name=name + '_gat_r_A')
+ reshape_ft = fluid.layers.reshape(ft, [-1, num_heads, hidden_size])
+ left_a_value = fluid.layers.reduce_sum(reshape_ft * left_a, -1)
+ right_a_value = fluid.layers.reduce_sum(reshape_ft * right_a, -1)
+
+ msg = gw.send(
+ send_attention,
+ nfeat_list=[("h", ft), ("left_a", left_a_value),
+ ("right_a", right_a_value)])
+ output = gw.recv(msg, reduce_attention)
+ bias = fluid.layers.create_parameter(
+ shape=[hidden_size * num_heads],
+ dtype='float32',
+ is_bias=True,
+ name=name + '_bias')
+ bias.stop_gradient = True
+ output = fluid.layers.elementwise_add(output, bias, act=activation)
+ return output
+
+
+def gin(gw,
+ feature,
+ hidden_size,
+ activation,
+ name,
+ init_eps=0.0,
+ train_eps=False):
+ """Implementation of Graph Isomorphism Network (GIN) layer.
+
+ This is an implementation of the paper How Powerful are Graph Neural Networks?
+ (https://arxiv.org/pdf/1810.00826.pdf).
+
+ In their implementation, all MLPs have 2 layers. Batch normalization is applied
+ on every hidden layer.
+
+ Args:
+ gw: Graph wrapper object (:code:`StaticGraphWrapper` or :code:`GraphWrapper`)
+
+ feature: A tensor with shape (num_nodes, feature_size).
+
+ name: GIN layer names.
+
+ hidden_size: The hidden size for gin.
+
+ activation: The activation for the output.
+
+ init_eps: float, optional
+ Initial :math:`\epsilon` value, default is 0.
+
+ train_eps: bool, optional
+ if True, :math:`\epsilon` will be a learnable parameter.
+
+ Return:
+ A tensor with shape (num_nodes, hidden_size).
+ """
+
+ def send_src_copy(src_feat, dst_feat, edge_feat):
+ return src_feat["h"]
+
+ epsilon = fluid.layers.create_parameter(
+ shape=[1, 1],
+ dtype="float32",
+ attr=fluid.ParamAttr(name="%s_eps" % name),
+ default_initializer=fluid.initializer.ConstantInitializer(
+ value=init_eps))
+
+ if not train_eps:
+ epsilon.stop_gradient = True
+
+ msg = gw.send(send_src_copy, nfeat_list=[("h", feature)])
+ output = gw.recv(msg, "sum") + feature * (epsilon + 1.0)
+
+ output = fluid.layers.fc(output,
+ size=hidden_size,
+ act=None,
+ param_attr=fluid.ParamAttr(name="%s_w_0" % name),
+ bias_attr=fluid.ParamAttr(name="%s_b_0" % name))
+
+ output = fluid.layers.layer_norm(
+ output,
+ begin_norm_axis=1,
+ param_attr=fluid.ParamAttr(
+ name="norm_scale_%s" % (name),
+ initializer=fluid.initializer.Constant(1.0)),
+ bias_attr=fluid.ParamAttr(
+ name="norm_bias_%s" % (name),
+ initializer=fluid.initializer.Constant(0.0)), )
+
+ if activation is not None:
+ output = getattr(fluid.layers, activation)(output)
+
+ output = fluid.layers.fc(output,
+ size=hidden_size,
+ act=activation,
+ param_attr=fluid.ParamAttr(name="%s_w_1" % name),
+ bias_attr=fluid.ParamAttr(name="%s_b_1" % name))
+
+ return output
+
+
+def gaan(gw, feature, hidden_size_a, hidden_size_v, hidden_size_m, hidden_size_o, heads, name):
+ """Implementation of GaAN"""
+
+ def send_func(src_feat, dst_feat, edge_feat):
+ # attention score of each edge
+ # E * (M * D1)
+ feat_query, feat_key = dst_feat['feat_query'], src_feat['feat_key']
+ # E * M * D1
+ old = feat_query
+ feat_query = fluid.layers.reshape(feat_query, [-1, heads, hidden_size_a])
+ feat_key = fluid.layers.reshape(feat_key, [-1, heads, hidden_size_a])
+ # E * M
+ alpha = fluid.layers.reduce_sum(feat_key * feat_query, dim=-1)
+
+ return {'dst_node_feat': dst_feat['node_feat'],
+ 'src_node_feat': src_feat['node_feat'],
+ 'feat_value': src_feat['feat_value'],
+ 'alpha': alpha,
+ 'feat_gate': src_feat['feat_gate']}
+
+ def recv_func(message):
+ dst_feat = message['dst_node_feat']
+ src_feat = message['src_node_feat']
+ x = fluid.layers.sequence_pool(dst_feat, 'average')
+ z = fluid.layers.sequence_pool(src_feat, 'average')
+
+ feat_gate = message['feat_gate']
+ g_max = fluid.layers.sequence_pool(feat_gate, 'max')
+ g = fluid.layers.concat([x, g_max, z], axis=1)
+ g = fluid.layers.fc(g, heads, bias_attr=False, act="sigmoid")
+
+ # softmax
+ alpha = message['alpha']
+ alpha = paddle_helper.sequence_softmax(alpha) # E * M
+
+ feat_value = message['feat_value'] # E * (M * D2)
+ old = feat_value
+ feat_value = fluid.layers.reshape(feat_value, [-1, heads, hidden_size_v]) # E * M * D2
+ feat_value = fluid.layers.elementwise_mul(feat_value, alpha, axis=0)
+ feat_value = fluid.layers.reshape(feat_value, [-1, heads*hidden_size_v]) # E * (M * D2)
+ feat_value = fluid.layers.lod_reset(feat_value, old)
+
+ feat_value = fluid.layers.sequence_pool(feat_value, 'sum') # N * (M * D2)
+
+ feat_value = fluid.layers.reshape(feat_value, [-1, heads, hidden_size_v]) # N * M * D2
+
+ output = fluid.layers.elementwise_mul(feat_value, g, axis=0)
+ output = fluid.layers.reshape(output, [-1, heads * hidden_size_v]) # N * (M * D2)
+
+ output = fluid.layers.concat([x, output], axis=1)
+
+ return output
+
+ # N * (D1 * M)
+ feat_key = fluid.layers.fc(feature, hidden_size_a * heads, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_key'))
+ # N * (D2 * M)
+ feat_value = fluid.layers.fc(feature, hidden_size_v * heads, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_value'))
+ # N * (D1 * M)
+ feat_query = fluid.layers.fc(feature, hidden_size_a * heads, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_query'))
+ # N * Dm
+ feat_gate = fluid.layers.fc(feature, hidden_size_m, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_gate'))
+
+ # send stage
+ message = gw.send(
+ send_func,
+ nfeat_list=[('node_feat', feature), ('feat_key', feat_key), ('feat_value', feat_value),
+ ('feat_query', feat_query), ('feat_gate', feat_gate)],
+ efeat_list=None,
+ )
+
+ # recv stage
+ output = gw.recv(message, recv_func)
+ output = fluid.layers.fc(output, hidden_size_o, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_output'))
+ output = fluid.layers.leaky_relu(output, alpha=0.1)
+ output = fluid.layers.dropout(output, dropout_prob=0.1)
+
+ return output
diff --git a/examples/GaAN/main.sh b/examples/GaAN/main.sh
new file mode 100644
index 0000000000000000000000000000000000000000..338d977f3cba0705335888e173d34265611923a4
--- /dev/null
+++ b/examples/GaAN/main.sh
@@ -0,0 +1 @@
+python3 train.py --epochs 100 --lr 1e-2 --rc 0 --batch_size 1024 --gpu_id 0 --exp_id 0
\ No newline at end of file
diff --git a/examples/GaAN/model.py b/examples/GaAN/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..37b9f9bcd5dd4adf5e826ea9d47260d3208e22c3
--- /dev/null
+++ b/examples/GaAN/model.py
@@ -0,0 +1,51 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from paddle import fluid
+from pgl.utils import paddle_helper
+
+# from pgl.layers import gaan
+from conv import gaan
+
+class GaANModel(object):
+ def __init__(self, num_class, num_layers, hidden_size_a=24,
+ hidden_size_v=32, hidden_size_m=64, hidden_size_o=128,
+ heads=8, act='relu', name="GaAN"):
+ self.num_class = num_class
+ self.num_layers = num_layers
+ self.hidden_size_a = hidden_size_a
+ self.hidden_size_v = hidden_size_v
+ self.hidden_size_m = hidden_size_m
+ self.hidden_size_o = hidden_size_o
+ self.act = act
+ self.name = name
+ self.heads = heads
+
+ def forward(self, gw):
+ feature = gw.node_feat['node_feat']
+ for i in range(self.num_layers):
+ feature = gaan(gw, feature, self.hidden_size_a, self.hidden_size_v,
+ self.hidden_size_m, self.hidden_size_o, self.heads,
+ self.name+'_'+str(i))
+
+ pred = fluid.layers.fc(
+ feature, self.num_class, act=None, name=self.name + "_pred_output")
+
+ return pred
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/examples/GaAN/preprocess.py b/examples/GaAN/preprocess.py
new file mode 100644
index 0000000000000000000000000000000000000000..4357ee47cac919832530b94facb66a76e1470e49
--- /dev/null
+++ b/examples/GaAN/preprocess.py
@@ -0,0 +1,103 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+from ogb.nodeproppred import NodePropPredDataset, Evaluator
+
+import pgl
+import numpy as np
+import os
+import time
+
+
+def get_graph_data(d_name="ogbn-proteins", mini_data=False):
+ """
+ Param:
+ d_name: name of dataset
+ mini_data: if mini_data==True, only use a small dataset (for test)
+ """
+ # import ogb data
+ dataset = NodePropPredDataset(name = d_name)
+ num_tasks = dataset.num_tasks # obtaining the number of prediction tasks in a dataset
+
+ split_idx = dataset.get_idx_split()
+ train_idx, valid_idx, test_idx = split_idx["train"], split_idx["valid"], split_idx["test"]
+ graph, label = dataset[0]
+
+ # reshape
+ graph["edge_index"] = graph["edge_index"].T
+
+ # mini dataset
+ if mini_data:
+ graph['num_nodes'] = 500
+ mask = (graph['edge_index'][:, 0] < 500)*(graph['edge_index'][:, 1] < 500)
+ graph["edge_index"] = graph["edge_index"][mask]
+ graph["edge_feat"] = graph["edge_feat"][mask]
+ label = label[:500]
+ train_idx = np.arange(0,400)
+ valid_idx = np.arange(400,450)
+ test_idx = np.arange(450,500)
+
+
+
+ # read/compute node feature
+ if mini_data:
+ node_feat_path = './dataset/ogbn_proteins_node_feat_small.npy'
+ else:
+ node_feat_path = './dataset/ogbn_proteins_node_feat.npy'
+
+ new_node_feat = None
+ if os.path.exists(node_feat_path):
+ print("Begin: read node feature".center(50, '='))
+ new_node_feat = np.load(node_feat_path)
+ print("End: read node feature".center(50, '='))
+ else:
+ print("Begin: compute node feature".center(50, '='))
+ start = time.perf_counter()
+ for i in range(graph['num_nodes']):
+ if i % 100 == 0:
+ dur = time.perf_counter() - start
+ print("{}/{}({}%), times: {:.2f}s".format(
+ i, graph['num_nodes'], i/graph['num_nodes']*100, dur
+ ))
+ mask = (graph['edge_index'][:, 0] == i)
+
+ current_node_feat = np.mean(np.compress(mask, graph['edge_feat'], axis=0),
+ axis=0, keepdims=True)
+ if i == 0:
+ new_node_feat = [current_node_feat]
+ else:
+ new_node_feat.append(current_node_feat)
+
+ new_node_feat = np.concatenate(new_node_feat, axis=0)
+ print("End: compute node feature".center(50,'='))
+
+ print("Saving node feature in "+node_feat_path.center(50, '='))
+ np.save(node_feat_path, new_node_feat)
+ print("Saving finish".center(50,'='))
+
+ print(new_node_feat)
+
+
+ # create graph
+ g = pgl.graph.Graph(
+ num_nodes=graph["num_nodes"],
+ edges = graph["edge_index"],
+ node_feat = {'node_feat': new_node_feat},
+ edge_feat = None
+ )
+ print("Create graph")
+ print(g)
+ return g, label, train_idx, valid_idx, test_idx, Evaluator(d_name)
+
\ No newline at end of file
diff --git a/examples/GaAN/reader.py b/examples/GaAN/reader.py
new file mode 100644
index 0000000000000000000000000000000000000000..985600fbf914b4643858f320daf40d8fe78e4f94
--- /dev/null
+++ b/examples/GaAN/reader.py
@@ -0,0 +1,157 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import numpy as np
+import pickle as pkl
+import paddle
+import paddle.fluid as fluid
+import pgl
+import time
+from pgl.utils import mp_reader
+from pgl.utils.logger import log
+import time
+import copy
+
+
+def node_batch_iter(nodes, node_label, batch_size):
+ """node_batch_iter
+ """
+ perm = np.arange(len(nodes))
+ np.random.shuffle(perm)
+ start = 0
+ while start < len(nodes):
+ index = perm[start:start + batch_size]
+ start += batch_size
+ yield nodes[index], node_label[index]
+
+
+def traverse(item):
+ """traverse
+ """
+ if isinstance(item, list) or isinstance(item, np.ndarray):
+ for i in iter(item):
+ for j in traverse(i):
+ yield j
+ else:
+ yield item
+
+
+def flat_node_and_edge(nodes):
+ """flat_node_and_edge
+ """
+ nodes = list(set(traverse(nodes)))
+ return nodes
+
+
+def worker(batch_info, graph, graph_wrapper, samples):
+ """Worker
+ """
+
+ def work():
+ """work
+ """
+ _graph_wrapper = copy.copy(graph_wrapper)
+ _graph_wrapper.node_feat_tensor_dict = {}
+ for batch_train_samples, batch_train_labels in batch_info:
+ start_nodes = batch_train_samples
+ nodes = start_nodes
+ edges = []
+ for max_deg in samples:
+ pred_nodes = graph.sample_predecessor(
+ start_nodes, max_degree=max_deg)
+
+ for dst_node, src_nodes in zip(start_nodes, pred_nodes):
+ for src_node in src_nodes:
+ edges.append((src_node, dst_node))
+
+ last_nodes = nodes
+ nodes = [nodes, pred_nodes]
+ nodes = flat_node_and_edge(nodes)
+ # Find new nodes
+ start_nodes = list(set(nodes) - set(last_nodes))
+ if len(start_nodes) == 0:
+ break
+
+ subgraph = graph.subgraph(
+ nodes=nodes,
+ edges=edges,
+ with_node_feat=True,
+ with_edge_feat=True)
+
+ sub_node_index = subgraph.reindex_from_parrent_nodes(
+ batch_train_samples)
+
+ feed_dict = _graph_wrapper.to_feed(subgraph)
+
+ feed_dict["node_label"] = batch_train_labels
+ feed_dict["node_index"] = sub_node_index
+ feed_dict["parent_node_index"] = np.array(nodes, dtype="int64")
+ yield feed_dict
+
+ return work
+
+
+def multiprocess_graph_reader(graph,
+ graph_wrapper,
+ samples,
+ node_index,
+ batch_size,
+ node_label,
+ with_parent_node_index=False,
+ num_workers=4):
+ """multiprocess_graph_reader
+ """
+
+ def parse_to_subgraph(rd, prefix, node_feat, _with_parent_node_index):
+ """parse_to_subgraph
+ """
+
+ def work():
+ """work
+ """
+ for data in rd():
+ feed_dict = data
+ for key in node_feat:
+ feed_dict[prefix + '/node_feat/' + key] = node_feat[key][
+ feed_dict["parent_node_index"]]
+ if not _with_parent_node_index:
+ del feed_dict["parent_node_index"]
+ yield feed_dict
+
+ return work
+
+ def reader():
+ """reader"""
+ batch_info = list(
+ node_batch_iter(
+ node_index, node_label, batch_size=batch_size))
+ block_size = int(len(batch_info) / num_workers + 1)
+ reader_pool = []
+ for i in range(num_workers):
+ reader_pool.append(
+ worker(batch_info[block_size * i:block_size * (i + 1)], graph,
+ graph_wrapper, samples))
+
+ if len(reader_pool) == 1:
+ r = parse_to_subgraph(reader_pool[0],
+ repr(graph_wrapper), graph.node_feat,
+ with_parent_node_index)
+ else:
+ multi_process_sample = mp_reader.multiprocess_reader(
+ reader_pool, use_pipe=True, queue_size=1000)
+ r = parse_to_subgraph(multi_process_sample,
+ repr(graph_wrapper), graph.node_feat,
+ with_parent_node_index)
+ return paddle.reader.buffered(r, num_workers)
+
+ return reader()
diff --git a/examples/GaAN/train.py b/examples/GaAN/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c7a33929b05641f5943ff2d210dd4fd0a8b19e9
--- /dev/null
+++ b/examples/GaAN/train.py
@@ -0,0 +1,194 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from preprocess import get_graph_data
+import pgl
+import argparse
+import numpy as np
+import time
+from paddle import fluid
+
+import reader
+from train_tool import train_epoch, valid_epoch
+
+
+from model import GaANModel
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description="ogb Training")
+ parser.add_argument("--d_name", type=str, choices=["ogbn-proteins"], default="ogbn-proteins",
+ help="the name of dataset in ogb")
+ parser.add_argument("--model", type=str, choices=["GaAN"], default="GaAN",
+ help="the name of model")
+ parser.add_argument("--mini_data", type=str, choices=["True", "False"], default="False",
+ help="use a small dataset to test the code")
+ parser.add_argument("--use_gpu", type=bool, choices=[True, False], default=True,
+ help="use gpu")
+ parser.add_argument("--gpu_id", type=int, default=0,
+ help="the id of gpu")
+ parser.add_argument("--exp_id", type=int, default=0,
+ help="the id of experiment")
+ parser.add_argument("--epochs", type=int, default=100,
+ help="the number of training epochs")
+ parser.add_argument("--lr", type=float, default=1e-2,
+ help="learning rate of Adam")
+ parser.add_argument("--rc", type=float, default=0,
+ help="regularization coefficient")
+ parser.add_argument("--log_path", type=str, default="./log",
+ help="the path of log")
+ parser.add_argument("--batch_size", type=int, default=1024,
+ help="the number of batch size")
+ parser.add_argument("--heads", type=int, default=8,
+ help="the number of heads of attention")
+ parser.add_argument("--hidden_size_a", type=int, default=24,
+ help="the hidden size of query and key vectors")
+ parser.add_argument("--hidden_size_v", type=int, default=32,
+ help="the hidden size of value vectors")
+ parser.add_argument("--hidden_size_m", type=int, default=64,
+ help="the hidden size of projection for computing gates")
+ parser.add_argument("--hidden_size_o", type=int ,default=128,
+ help="the hidden size of each layer in GaAN")
+
+ args = parser.parse_args()
+
+ print("Parameters Setting".center(50, "="))
+ print("lr = {}, rc = {}, epochs = {}, batch_size = {}".format(args.lr, args.rc, args.epochs,
+ args.batch_size))
+ print("Experiment ID: {}".format(args.exp_id).center(50, "="))
+ print("training in GPU: {}".format(args.gpu_id).center(50, "="))
+ d_name = args.d_name
+
+ # get data
+ g, label, train_idx, valid_idx, test_idx, evaluator = get_graph_data(d_name=d_name,
+ mini_data=eval(args.mini_data))
+
+ if args.model == "GaAN":
+ graph_model = GaANModel(112, 3, args.hidden_size_a, args.hidden_size_v, args.hidden_size_m,
+ args.hidden_size_o, args.heads)
+
+ # training
+ samples = [25, 10] # 2-hop sample size
+ batch_size = args.batch_size
+ sample_workers = 1
+
+ place = fluid.CUDAPlace(args.gpu_id) if args.use_gpu else fluid.CPUPlace()
+ train_program = fluid.Program()
+ startup_program = fluid.Program()
+
+ with fluid.program_guard(train_program, startup_program):
+ gw = pgl.graph_wrapper.GraphWrapper(
+ name='graph',
+ place = place,
+ node_feat=g.node_feat_info(),
+ edge_feat=g.edge_feat_info()
+ )
+
+
+ node_index = fluid.layers.data('node_index', shape=[None, 1], dtype="int64",
+ append_batch_size=False)
+
+ node_label = fluid.layers.data('node_label', shape=[None, 112], dtype="float32",
+ append_batch_size=False)
+ parent_node_index = fluid.layers.data('parent_node_index', shape=[None, 1], dtype="int64",
+ append_batch_size=False)
+
+ output = graph_model.forward(gw)
+ output = fluid.layers.gather(output, node_index)
+ score = fluid.layers.sigmoid(output)
+
+ loss = fluid.layers.sigmoid_cross_entropy_with_logits(
+ x=output, label=node_label)
+ loss = fluid.layers.mean(loss)
+
+
+ val_program = train_program.clone(for_test=True)
+
+ with fluid.program_guard(train_program, startup_program):
+ lr = args.lr
+ adam = fluid.optimizer.Adam(
+ learning_rate=lr,
+ regularization=fluid.regularizer.L2DecayRegularizer(
+ regularization_coeff=args.rc))
+ adam.minimize(loss)
+
+ exe = fluid.Executor(place)
+ exe.run(startup_program)
+
+ train_iter = reader.multiprocess_graph_reader(
+ g,
+ gw,
+ samples=samples,
+ num_workers=sample_workers,
+ batch_size=batch_size,
+ with_parent_node_index=True,
+ node_index=train_idx,
+ node_label=np.array(label[train_idx], dtype='float32'))
+
+ val_iter = reader.multiprocess_graph_reader(
+ g,
+ gw,
+ samples=samples,
+ num_workers=sample_workers,
+ batch_size=batch_size,
+ with_parent_node_index=True,
+ node_index=valid_idx,
+ node_label=np.array(label[valid_idx], dtype='float32'))
+
+ test_iter = reader.multiprocess_graph_reader(
+ g,
+ gw,
+ samples=samples,
+ num_workers=sample_workers,
+ batch_size=batch_size,
+ with_parent_node_index=True,
+ node_index=test_idx,
+ node_label=np.array(label[test_idx], dtype='float32'))
+
+
+ start = time.time()
+ print("Training Begin".center(50, "="))
+ best_valid = -1.0
+ for epoch in range(args.epochs):
+ start_e = time.time()
+ train_loss, train_rocauc = train_epoch(
+ train_iter, program=train_program, exe=exe, loss=loss, score=score,
+ evaluator=evaluator, epoch=epoch
+ )
+ valid_loss, valid_rocauc = valid_epoch(
+ val_iter, program=val_program, exe=exe, loss=loss, score=score,
+ evaluator=evaluator, epoch=epoch)
+ end_e = time.time()
+ print("Epoch {}: train_loss={:.4},val_loss={:.4}, train_rocauc={:.4}, val_rocauc={:.4}, s/epoch={:.3}".format(
+ epoch, train_loss, valid_loss, train_rocauc, valid_rocauc, end_e-start_e
+ ))
+
+ if valid_rocauc > best_valid:
+ print("Update: new {}, old {}".format(valid_rocauc, best_valid))
+ best_valid = valid_rocauc
+
+ fluid.io.save_params(executor=exe, dirname='./params/'+str(args.exp_id), main_program=val_program)
+
+
+ print("Test Stage".center(50, "="))
+
+ fluid.io.load_params(executor=exe, dirname='./params/'+str(args.exp_id), main_program=val_program)
+
+ test_loss, test_rocauc = valid_epoch(
+ test_iter, program=val_program, exe=exe, loss=loss, score=score,
+ evaluator=evaluator, epoch=epoch)
+ end = time.time()
+ print("test_loss={:.4},test_rocauc={:.4}, Total Time={:.3}".format(
+ test_loss, test_rocauc, end-start
+ ))
+ print("End".center(50, "="))
diff --git a/examples/GaAN/train_tool.py b/examples/GaAN/train_tool.py
new file mode 100644
index 0000000000000000000000000000000000000000..bdb1c928e6801f8b72cb076e7e4b353525d92303
--- /dev/null
+++ b/examples/GaAN/train_tool.py
@@ -0,0 +1,56 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import time
+from pgl.utils.logger import log
+
+def train_epoch(batch_iter, exe, program, loss, score, evaluator, epoch, log_per_step=1):
+ batch = 0
+ total_loss = 0.0
+ total_sample = 0
+ result = 0
+ for batch_feed_dict in batch_iter():
+ batch += 1
+ batch_loss, y_pred = exe.run(program, fetch_list=[loss, score], feed=batch_feed_dict)
+
+ num_samples = len(batch_feed_dict["node_index"])
+ total_loss += batch_loss * num_samples
+ total_sample += num_samples
+ input_dict = {
+ "y_true": batch_feed_dict["node_label"],
+ "y_pred": y_pred
+ }
+ result += evaluator.eval(input_dict)["rocauc"]
+
+ return total_loss.item()/total_sample, result/batch
+
+def valid_epoch(batch_iter, exe, program, loss, score, evaluator, epoch, log_per_step=1):
+ batch = 0
+ total_sample = 0
+ result = 0
+ total_loss = 0.0
+ for batch_feed_dict in batch_iter():
+ batch += 1
+ batch_loss, y_pred = exe.run(program, fetch_list=[loss, score], feed=batch_feed_dict)
+ input_dict = {
+ "y_true": batch_feed_dict["node_label"],
+ "y_pred": y_pred
+ }
+ result += evaluator.eval(input_dict)["rocauc"]
+
+
+ num_samples = len(batch_feed_dict["node_index"])
+ total_loss += batch_loss * num_samples
+ total_sample += num_samples
+
+ return total_loss.item()/total_sample, result/batch
diff --git a/examples/SAGPool/README.md b/examples/SAGPool/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..ebed2e7a4b4025a63e2e3f4538cd4a23739c0123
--- /dev/null
+++ b/examples/SAGPool/README.md
@@ -0,0 +1,53 @@
+# Self-Attention Graph Pooling
+
+SAGPool is a graph pooling method based on self-attention. Self-attention uses graph convolution, which allows the pooling method to consider both node features and graph topology. Based on PGL, we implement the SAGPool algorithm and train the model on five datasets.
+
+## Datasets
+
+There are five datasets, including D&D, PROTEINS, NCI1, NCI109 and FRANKENSTEIN. You can download the datasets from [here](https://bj.bcebos.com/paddle-pgl/SAGPool/data.zip), and unzip it directly. The pkl format datasets should be in directory ./data.
+
+## Dependencies
+
+- [paddlepaddle >= 1.8](https://github.com/PaddlePaddle/paddle)
+- [pgl 1.1](https://github.com/PaddlePaddle/PGL)
+
+## How to run
+
+```
+python main.py --dataset_name DD --learning_rate 0.005 --weight_decay 0.00001
+
+python main.py --dataset_name PROTEINS --learning_rate 0.001 --hidden_size 32 --weight_decay 0.00001
+
+python main.py --dataset_name NCI1 --learning_rate 0.001 --weight_decay 0.00001
+
+python main.py --dataset_name NCI109 --learning_rate 0.0005 --hidden_size 64 --weight_decay 0.0001 --patience 200
+
+python main.py --dataset_name FRANKENSTEIN --learning_rate 0.001 --weight_decay 0.0001
+```
+
+## Hyperparameters
+
+- seed: random seed
+- batch\_size: the number of batch size
+- learning\_rate: learning rate of optimizer
+- weight\_decay: the weight decay for L2 regularization
+- hidden\_size: the hidden size of gcn
+- pooling\_ratio: the pooling ratio of SAGPool
+- dropout\_ratio: the number of dropout ratio
+- dataset\_name: the name of datasets, including DD, PROTEINS, NCI1, NCI109, FRANKENSTEIN
+- epochs: maximum number of epochs
+- patience: patience for early stopping
+- use\_cuda: whether to use cuda
+- save\_model: the name for the best model
+
+## Performance
+
+We evaluate the implemented method for 20 random seeds using 10-fold cross validation, following the same training procedures as in the paper.
+
+| dataset | mean accuracy | standard deviation | mean accuracy(paper) | standard deviation(paper) |
+| ------------ | ------------- | ------------------ | -------------------- | ------------------------- |
+| DD | 74.4181 | 1.0244 | 76.19 | 0.94 |
+| PROTEINS | 72.7858 | 0.6617 | 70.04 | 1.47 |
+| NCI1 | 75.781 | 1.2125 | 74.18 | 1.2 |
+| NCI109 | 74.3156 | 1.3 | 74.06 | 0.78 |
+| FRANKENSTEIN | 60.7826 | 0.629 | 62.57 | 0.6 |
diff --git a/examples/SAGPool/args.py b/examples/SAGPool/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c6c44bc558638a5d6ec0a3c8c957a0730aa22a5
--- /dev/null
+++ b/examples/SAGPool/args.py
@@ -0,0 +1,43 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+
+parser = argparse.ArgumentParser()
+
+parser.add_argument('--seed', type=int, default=777,
+ help='seed')
+parser.add_argument('--batch_size', type=int, default=128,
+ help='batch size')
+parser.add_argument('--learning_rate', type=float, default=0.0005,
+ help='learning rate')
+parser.add_argument('--weight_decay', type=float, default=0.0001,
+ help='weight decay')
+parser.add_argument('--hidden_size', type=int, default=128,
+ help='gcn hidden size')
+parser.add_argument('--pooling_ratio', type=float, default=0.5,
+ help='pooling ratio of SAGPool')
+parser.add_argument('--dropout_ratio', type=float, default=0.5,
+ help='dropout ratio')
+parser.add_argument('--dataset_name', type=str, default='DD',
+ help='DD/PROTEINS/NCI1/NCI109/FRANKENSTEIN')
+parser.add_argument('--epochs', type=int, default=100000,
+ help='maximum number of epochs')
+parser.add_argument('--patience', type=int, default=50,
+ help='patience for early stopping')
+parser.add_argument('--use_cuda', type=bool, default=True,
+ help='use cuda or cpu')
+parser.add_argument('--save_model', type=str,
+ help='save model name')
+
diff --git a/examples/SAGPool/base_dataset.py b/examples/SAGPool/base_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..711e9203e311bb2c9cf5b6e9afc2834122a93a01
--- /dev/null
+++ b/examples/SAGPool/base_dataset.py
@@ -0,0 +1,96 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+import random
+import pgl
+from pgl.utils.logger import log
+from pgl.graph import Graph, MultiGraph
+import numpy as np
+import pickle
+
+class BaseDataset(object):
+ def __init__(self):
+ pass
+
+ def __getitem__(self, idx):
+ raise NotImplementedError
+
+ def __len__(self):
+ raise NotImplementedError
+
+
+class Subset(BaseDataset):
+ """Subset of a dataset at specified indices.
+
+ Args:
+ dataset (Dataset): The whole Dataset
+ indices (sequence): Indices in the whole set selected for subset
+ """
+
+ def __init__(self, dataset, indices):
+ self.dataset = dataset
+ self.indices = indices
+
+ def __getitem__(self, idx):
+ return self.dataset[self.indices[idx]]
+
+ def __len__(self):
+ return len(self.indices)
+
+
+class Dataset(BaseDataset):
+ def __init__(self, args):
+ self.args = args
+
+ with open('data/%s.pkl' % args.dataset_name, 'rb') as f:
+ graphs_info_list = pickle.load(f)
+
+ self.pgl_graph_list = []
+ self.graph_label_list = []
+ for i in range(len(graphs_info_list) - 1):
+ graph = graphs_info_list[i]
+ edges_l, edges_r = graph["edge_src"], graph["edge_dst"]
+
+ # add self-loops
+ if self.args.dataset_name != "FRANKENSTEIN":
+ num_nodes = graph["num_nodes"]
+ x = np.arange(0, num_nodes)
+ edges_l = np.append(edges_l, x)
+ edges_r = np.append(edges_r, x)
+
+ edges = list(zip(edges_l, edges_r))
+ g = pgl.graph.Graph(num_nodes=graph["num_nodes"], edges=edges)
+ g.node_feat["feat"] = graph["node_feat"]
+ self.pgl_graph_list.append(g)
+ self.graph_label_list.append(graph["label"])
+
+ self.num_classes = graphs_info_list[-1]["num_classes"]
+ self.num_features = graphs_info_list[-1]["num_features"]
+
+ def __getitem__(self, idx):
+ return self.pgl_graph_list[idx], self.graph_label_list[idx]
+
+ def shuffle(self):
+ """shuffle the dataset.
+ """
+ cc = list(zip(self.pgl_graph_list, self.graph_label_list))
+ random.seed(self.args.seed)
+ random.shuffle(cc)
+ a, b = zip(*cc)
+ self.pgl_graph_list[:], self.graph_label_list[:] = a, b
+
+ def __len__(self):
+ return len(self.pgl_graph_list)
diff --git a/examples/SAGPool/conv.py b/examples/SAGPool/conv.py
new file mode 100644
index 0000000000000000000000000000000000000000..5250f242b5bd5aff4f6fa9324a82a21e46302b6f
--- /dev/null
+++ b/examples/SAGPool/conv.py
@@ -0,0 +1,66 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+
+def norm_gcn(gw, feature, hidden_size, activation, name, norm=None):
+ """Implementation of graph convolutional neural networks(GCN), using different
+ normalization method.
+ Args:
+ gw: Graph wrapper object.
+
+ feature: A tensor with shape (num_nodes, feature_size).
+
+ hidden_size: The hidden size for norm gcn.
+
+ activation: The activation for the output.
+
+ name: Norm gcn layer names.
+
+ norm: If norm is not None, then the feature will be normalized. Norm must
+ be tensor with shape (num_nodes,) and dtype float32.
+
+ Return:
+ A tensor with shape (num_nodes, hidden_size)
+ """
+
+ size = feature.shape[-1]
+ feature = L.fc(feature,
+ size=hidden_size,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name))
+
+ if norm is not None:
+ src, dst = gw.edges
+ norm_src = L.gather(norm, src, overwrite=False)
+ norm_dst = L.gather(norm, dst, overwrite=False)
+ norm = norm_src * norm_dst
+
+ def send_src_copy(src_feat, dst_feat, edge_feat):
+ return src_feat["h"] * norm
+ else:
+ def send_src_copy(src_feat, dst_feat, edge_feat):
+ return src_feat["h"]
+
+ msg = gw.send(send_src_copy, nfeat_list=[("h", feature)])
+ output = gw.recv(msg, "sum")
+
+ bias = L.create_parameter(
+ shape=[hidden_size],
+ dtype='float32',
+ is_bias=True,
+ name=name + '_bias')
+ output = L.elementwise_add(output, bias, act=activation)
+ return output
diff --git a/examples/SAGPool/dataloader.py b/examples/SAGPool/dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..21ea7d43a64dbb3849afc8d5abf017a7bbac2661
--- /dev/null
+++ b/examples/SAGPool/dataloader.py
@@ -0,0 +1,143 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import numpy as np
+import collections
+import paddle
+import pgl
+from pgl.utils.logger import log
+from pgl.graph import Graph, MultiGraph
+
+def batch_iter(data, batch_size):
+ """node_batch_iter
+ """
+ size = len(data)
+ perm = np.arange(size)
+ np.random.shuffle(perm)
+ start = 0
+ while start < size:
+ index = perm[start:start + batch_size]
+ start += batch_size
+ yield data[index]
+
+
+def scan_batch_iter(data, batch_size):
+ """scan_batch_iter
+ """
+ batch = []
+ for example in data.scan():
+ batch.append(example)
+ if len(batch) == batch_size:
+ yield batch
+ batch = []
+
+ if len(batch) > 0:
+ yield batch
+
+
+def label_to_onehot(labels):
+ """Return one-hot representations of labels
+ """
+ onehot_labels = []
+ for label in labels:
+ if label == 0:
+ onehot_labels.append([1, 0])
+ else:
+ onehot_labels.append([0, 1])
+ onehot_labels = np.array(onehot_labels)
+ return onehot_labels
+
+
+class GraphDataloader(object):
+ """Graph Dataloader
+ """
+ def __init__(self,
+ dataset,
+ graph_wrapper,
+ batch_size,
+ seed=0,
+ buf_size=1000,
+ shuffle=True):
+
+ self.shuffle = shuffle
+ self.seed = seed
+ self.batch_size = batch_size
+ self.dataset = dataset
+ self.buf_size = buf_size
+ self.graph_wrapper = graph_wrapper
+
+ def batch_fn(self, batch_examples):
+ """ batch_fun batch producer """
+ graphs = [b[0] for b in batch_examples]
+ labels = [b[1] for b in batch_examples]
+ join_graph = MultiGraph(graphs)
+
+ # normalize
+ indegree = join_graph.indegree()
+ norm = np.zeros_like(indegree, dtype="float32")
+ norm[indegree > 0] = np.power(indegree[indegree > 0], -0.5)
+ join_graph.node_feat["norm"] = np.expand_dims(norm, -1)
+
+ feed_dict = self.graph_wrapper.to_feed(join_graph)
+ labels = np.array(labels)
+ feed_dict["labels_1dim"] = labels
+ labels = label_to_onehot(labels)
+ feed_dict["labels"] = labels
+
+ graph_lod = join_graph.graph_lod
+ graph_id = []
+ for i in range(1, len(graph_lod)):
+ graph_node_num = graph_lod[i] - graph_lod[i - 1]
+ graph_id += [i - 1] * graph_node_num
+ graph_id = np.array(graph_id, dtype="int32")
+ feed_dict["graph_id"] = graph_id
+
+ return feed_dict
+
+ def batch_iter(self):
+ """ batch_iter """
+ if self.shuffle:
+ for batch in batch_iter(self, self.batch_size):
+ yield batch
+ else:
+ for batch in scan_batch_iter(self, self.batch_size):
+ yield batch
+
+ def __len__(self):
+ """__len__"""
+ return len(self.dataset)
+
+ def __getitem__(self, idx):
+ """__getitem__"""
+ if isinstance(idx, collections.Iterable):
+ return [self.dataset[bidx] for bidx in idx]
+ else:
+ return self.dataset[idx]
+
+ def __iter__(self):
+ """__iter__"""
+ def func_run():
+ for batch_examples in self.batch_iter():
+ batch_dict = self.batch_fn(batch_examples)
+ yield batch_dict
+
+ r = paddle.reader.buffered(func_run, self.buf_size)
+
+ for batch in r():
+ yield batch
+
+ def scan(self):
+ """scan"""
+ for example in self.dataset:
+ yield example
diff --git a/examples/SAGPool/layers.py b/examples/SAGPool/layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..3dfa0822ece9e564adfbc9b15e0a62e1e1f4b08d
--- /dev/null
+++ b/examples/SAGPool/layers.py
@@ -0,0 +1,141 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import numpy as np
+import paddle
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+import pgl
+from pgl.graph_wrapper import GraphWrapper
+from pgl.utils.logger import log
+from conv import norm_gcn
+from pgl.layers.conv import gcn
+
+def topk_pool(gw, score, graph_id, ratio):
+ """Implementation of topk pooling, where k means pooling ratio.
+
+ Args:
+ gw: Graph wrapper object.
+
+ score: The attention score of all nodes, which is used to select
+ important nodes.
+
+ graph_id: The graphs that the nodes belong to.
+
+ ratio: The pooling ratio of nodes we want to select.
+
+ Return:
+ perm: The index of nodes we choose.
+
+ ratio_length: The selected node numbers of each graph.
+ """
+
+ graph_lod = gw.graph_lod
+ graph_nodes = gw.num_nodes
+ num_graph = gw.num_graph
+
+ num_nodes = L.ones(shape=[graph_nodes], dtype="float32")
+ num_nodes = L.lod_reset(num_nodes, graph_lod)
+ num_nodes_per_graph = L.sequence_pool(num_nodes, pool_type='sum')
+ max_num_nodes = L.reduce_max(num_nodes_per_graph, dim=0)
+ max_num_nodes = L.cast(max_num_nodes, dtype="int32")
+
+ index = L.arange(0, gw.num_nodes, dtype="int64")
+ offset = L.gather(graph_lod, graph_id, overwrite=False)
+ index = (index - offset) + (graph_id * max_num_nodes)
+ index.stop_gradient = True
+
+ # padding
+ dense_score = L.fill_constant(shape=[num_graph * max_num_nodes],
+ dtype="float32", value=-999999)
+ index = L.reshape(index, shape=[-1])
+ dense_score = L.scatter(dense_score, index, updates=score)
+ num_graph = L.cast(num_graph, dtype="int32")
+ dense_score = L.reshape(dense_score,
+ shape=[num_graph, max_num_nodes])
+
+ # record the sorted index
+ _, sort_index = L.argsort(dense_score, axis=-1, descending=True)
+
+ # recover the index range
+ graph_lod = graph_lod[:-1]
+ graph_lod = L.reshape(graph_lod, shape=[-1, 1])
+ graph_lod = L.cast(graph_lod, dtype="int64")
+ sort_index = L.elementwise_add(sort_index, graph_lod, axis=-1)
+ sort_index = L.reshape(sort_index, shape=[-1, 1])
+
+ # use sequence_slice to choose selected node index
+ pad_lod = L.arange(0, (num_graph + 1) * max_num_nodes, step=max_num_nodes, dtype="int32")
+ sort_index = L.lod_reset(sort_index, pad_lod)
+ ratio_length = L.ceil(num_nodes_per_graph * ratio)
+ ratio_length = L.cast(ratio_length, dtype="int64")
+ ratio_length = L.reshape(ratio_length, shape=[-1, 1])
+ offset = L.zeros(shape=[num_graph, 1], dtype="int64")
+ choose_index = L.sequence_slice(input=sort_index, offset=offset, length=ratio_length)
+
+ perm = L.reshape(choose_index, shape=[-1])
+ return perm, ratio_length
+
+
+def sag_pool(gw, feature, ratio, graph_id, dataset, name, activation=L.tanh):
+ """Implementation of self-attention graph pooling (SAGPool)
+
+ This is an implementation of the paper SELF-ATTENTION GRAPH POOLING
+ (https://arxiv.org/pdf/1904.08082.pdf)
+
+ Args:
+ gw: Graph wrapper object.
+
+ feature: A tensor with shape (num_nodes, feature_size).
+
+ ratio: The pooling ratio of nodes we want to select.
+
+ graph_id: The graphs that the nodes belong to.
+
+ dataset: To differentiate FRANKENSTEIN dataset and other datasets.
+
+ name: The name of SAGPool layer.
+
+ activation: The activation function.
+
+ Return:
+ new_feature: A tensor with shape (num_nodes, feature_size), and the unselected
+ nodes' feature is masked by zero.
+
+ ratio_length: The selected node numbers of each graph.
+
+ """
+ if dataset == "FRANKENSTEIN":
+ gcn_ = gcn
+ else:
+ gcn_ = norm_gcn
+
+ score = gcn_(gw=gw,
+ feature=feature,
+ hidden_size=1,
+ activation=None,
+ norm=gw.node_feat["norm"],
+ name=name)
+ score = L.squeeze(score, axes=[])
+ perm, ratio_length = topk_pool(gw, score, graph_id, ratio)
+
+ mask = L.zeros_like(score)
+ mask = L.cast(mask, dtype="float32")
+ updates = L.ones_like(perm)
+ updates = L.cast(updates, dtype="float32")
+ mask = L.scatter(mask, perm, updates)
+ new_feature = L.elementwise_mul(feature, mask, axis=0)
+ temp_score = activation(score)
+ new_feature = L.elementwise_mul(new_feature, temp_score, axis=0)
+ return new_feature, ratio_length
diff --git a/examples/SAGPool/main.py b/examples/SAGPool/main.py
new file mode 100644
index 0000000000000000000000000000000000000000..8895311e0f729bf572919faf07df50c7921cb545
--- /dev/null
+++ b/examples/SAGPool/main.py
@@ -0,0 +1,194 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+import argparse
+import pgl
+from pgl.utils.logger import log
+import paddle
+
+import re
+import time
+import random
+import numpy as np
+import math
+
+import paddle
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+import pgl
+from pgl.utils.logger import log
+
+from model import GlobalModel
+from base_dataset import Subset, Dataset
+from dataloader import GraphDataloader
+from args import parser
+import warnings
+from sklearn.model_selection import KFold
+
+warnings.filterwarnings("ignore")
+
+def main(args, train_dataset, val_dataset, test_dataset):
+ """main function for running one testing results.
+ """
+ log.info("Train Examples: %s" % len(train_dataset))
+ log.info("Val Examples: %s" % len(val_dataset))
+ log.info("Test Examples: %s" % len(test_dataset))
+
+ train_program = fluid.Program()
+ train_program.random_seed = args.seed
+ startup_program = fluid.Program()
+ startup_program.random_seed = args.seed
+
+ if args.use_cuda:
+ place = fluid.CUDAPlace(0)
+ else:
+ place = fluid.CPUPlace()
+ exe = fluid.Executor(place)
+
+ log.info("building model")
+
+ with fluid.program_guard(train_program, startup_program):
+ with fluid.unique_name.guard():
+ graph_model = GlobalModel(args, dataset)
+ train_loader = GraphDataloader(train_dataset,
+ graph_model.graph_wrapper,
+ batch_size=args.batch_size)
+ optimizer = fluid.optimizer.Adam(learning_rate=args.learning_rate,
+ regularization=fluid.regularizer.L2DecayRegularizer(args.weight_decay))
+ optimizer.minimize(graph_model.loss)
+
+ exe.run(startup_program)
+ test_program = fluid.Program()
+ test_program = train_program.clone(for_test=True)
+
+ val_loader = GraphDataloader(val_dataset,
+ graph_model.graph_wrapper,
+ batch_size=args.batch_size,
+ shuffle=False)
+ test_loader = GraphDataloader(test_dataset,
+ graph_model.graph_wrapper,
+ batch_size=args.batch_size,
+ shuffle=False)
+
+ min_loss = 1e10
+ global_step = 0
+ for epoch in range(args.epochs):
+ for feed_dict in train_loader:
+ loss, pred = exe.run(train_program,
+ feed=feed_dict,
+ fetch_list=[graph_model.loss, graph_model.pred])
+
+ log.info("Epoch: %d, global_step: %d, Training loss: %f" \
+ % (epoch, global_step, loss))
+ global_step += 1
+
+ # validation
+ valid_loss = 0.
+ correct = 0.
+ for feed_dict in val_loader:
+ valid_loss_, correct_ = exe.run(test_program,
+ feed=feed_dict,
+ fetch_list=[graph_model.loss, graph_model.correct])
+ valid_loss += valid_loss_
+ correct += correct_
+
+ if epoch % 50 == 0:
+ log.info("Epoch:%d, Validation loss: %f, Validation acc: %f" \
+ % (epoch, valid_loss, correct / len(val_loader)))
+
+ if valid_loss < min_loss:
+ min_loss = valid_loss
+ patience = 0
+ path = "./save/%s" % args.dataset_name
+ if not os.path.exists(path):
+ os.makedirs(path)
+ fluid.save(train_program, "%s/%s" \
+ % (path, args.save_model))
+ log.info("Model saved at epoch %d" % epoch)
+ else:
+ patience += 1
+ if patience > args.patience:
+ break
+
+ correct = 0.
+ new_test_program = fluid.Program()
+ fluid.load(new_test_program, "./save/%s/%s" \
+ % (args.dataset_name, args.save_model), exe)
+ for feed_dict in test_loader:
+ correct_ = exe.run(test_program,
+ feed=feed_dict,
+ fetch_list=[graph_model.correct])
+ correct += correct_[0]
+ log.info("Test acc: %f" % (correct / len(test_loader)))
+ return correct / len(test_loader)
+
+
+def split_10_cv(dataset, args):
+ """10 folds cross validation
+ """
+ dataset.shuffle()
+ X = np.array([0] * len(dataset))
+ y = X
+ kf = KFold(n_splits=10, shuffle=False)
+
+ i = 1
+ test_acc = []
+ for train_index, test_index in kf.split(X, y):
+ train_val_dataset = Subset(dataset, train_index)
+ test_dataset = Subset(dataset, test_index)
+ train_val_index_range = list(range(0, len(train_val_dataset)))
+ num_val = int(len(train_val_dataset) / 9)
+ val_dataset = Subset(train_val_dataset, train_val_index_range[:num_val])
+ train_dataset = Subset(train_val_dataset, train_val_index_range[num_val:])
+
+ log.info("######%d fold of 10-fold cross validation######" % i)
+ i += 1
+ test_acc_ = main(args, train_dataset, val_dataset, test_dataset)
+ test_acc.append(test_acc_)
+
+ mean_acc = sum(test_acc) / len(test_acc)
+ return mean_acc, test_acc
+
+
+def random_seed_20(args, dataset):
+ """run for 20 random seeds
+ """
+ alist = random.sample(range(1,1000),20)
+ test_acc_fold = []
+ for seed in alist:
+ log.info('############ Seed %d ############' % seed)
+ args.seed = seed
+
+ test_acc_fold_, _ = split_10_cv(dataset, args)
+ log.info('Mean test acc at seed %d: %f' % (seed, test_acc_fold_))
+ test_acc_fold.append(test_acc_fold_)
+
+ mean_acc = sum(test_acc_fold) / len(test_acc_fold)
+ temp = [(acc - mean_acc) * (acc - mean_acc) for acc in test_acc_fold]
+ standard_std = math.sqrt(sum(temp) / len(test_acc_fold))
+
+ log.info('Final mean test acc using 20 random seeds(mean for 10-fold): %f' % (mean_acc))
+ log.info('Final standard std using 20 random seeds(mean for 10-fold): %f' % (standard_std))
+
+
+if __name__ == "__main__":
+ args = parser.parse_args()
+ log.info('loading data...')
+ dataset = Dataset(args)
+ log.info("preprocess finish.")
+ args.num_classes = dataset.num_classes
+ args.num_features = dataset.num_features
+ random_seed_20(args, dataset)
diff --git a/examples/SAGPool/model.py b/examples/SAGPool/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..cdfbe6f4f2d911dff041522d3e75266b4867c5a3
--- /dev/null
+++ b/examples/SAGPool/model.py
@@ -0,0 +1,136 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from random import random
+import numpy as np
+
+import paddle
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+import pgl
+from pgl.graph import Graph, MultiGraph
+from pgl.graph_wrapper import GraphWrapper
+from pgl.utils.logger import log
+from pgl.layers.conv import gcn
+from layers import sag_pool
+from conv import norm_gcn
+
+class GlobalModel(object):
+ """Implementation of global pooling architecture with SAGPool.
+ """
+ def __init__(self, args, dataset):
+ self.args = args
+ self.dataset = dataset
+ self.hidden_size = args.hidden_size
+ self.num_classes = args.num_classes
+ self.num_features = args.num_features
+ self.pooling_ratio = args.pooling_ratio
+ self.dropout_ratio = args.dropout_ratio
+ self.batch_size = args.batch_size
+
+ graph_data = []
+ g, label = self.dataset[0]
+ graph_data.append(g)
+ g, label = self.dataset[1]
+ graph_data.append(g)
+
+ batch_graph = MultiGraph(graph_data)
+ indegree = batch_graph.indegree()
+ norm = np.zeros_like(indegree, dtype="float32")
+ norm[indegree > 0] = np.power(indegree[indegree > 0], -0.5)
+ batch_graph.node_feat["norm"] = np.expand_dims(norm, -1)
+ graph_data = batch_graph
+
+ self.graph_wrapper = GraphWrapper(
+ name="graph",
+ node_feat=graph_data.node_feat_info()
+ )
+ self.labels = L.data(
+ "labels",
+ shape=[None, self.args.num_classes],
+ dtype="int32",
+ append_batch_size=False)
+
+ self.labels_1dim = L.data(
+ "labels_1dim",
+ shape=[None],
+ dtype="int32",
+ append_batch_size=False)
+
+ self.graph_id = L.data(
+ "graph_id",
+ shape=[None],
+ dtype="int32",
+ append_batch_size=False)
+
+ if self.args.dataset_name == "FRANKENSTEIN":
+ self.gcn = gcn
+ else:
+ self.gcn = norm_gcn
+
+ self.build_model()
+
+ def build_model(self):
+ node_features = self.graph_wrapper.node_feat["feat"]
+
+ output = self.gcn(gw=self.graph_wrapper,
+ feature=node_features,
+ hidden_size=self.hidden_size,
+ activation="relu",
+ norm=self.graph_wrapper.node_feat["norm"],
+ name="gcn_layer_1")
+ output1 = output
+ output = self.gcn(gw=self.graph_wrapper,
+ feature=output,
+ hidden_size=self.hidden_size,
+ activation="relu",
+ norm=self.graph_wrapper.node_feat["norm"],
+ name="gcn_layer_2")
+ output2 = output
+ output = self.gcn(gw=self.graph_wrapper,
+ feature=output,
+ hidden_size=self.hidden_size,
+ activation="relu",
+ norm=self.graph_wrapper.node_feat["norm"],
+ name="gcn_layer_3")
+
+ output = L.concat(input=[output1, output2, output], axis=-1)
+
+ output, ratio_length = sag_pool(gw=self.graph_wrapper,
+ feature=output,
+ ratio=self.pooling_ratio,
+ graph_id=self.graph_id,
+ dataset=self.args.dataset_name,
+ name="sag_pool_1")
+ output = L.lod_reset(output, self.graph_wrapper.graph_lod)
+ cat1 = L.sequence_pool(output, "sum")
+ ratio_length = L.cast(ratio_length, dtype="float32")
+ cat1 = L.elementwise_div(cat1, ratio_length, axis=-1)
+ cat2 = L.sequence_pool(output, "max")
+ output = L.concat(input=[cat2, cat1], axis=-1)
+
+ output = L.fc(output, size=self.hidden_size, act="relu")
+ output = L.dropout(output, dropout_prob=self.dropout_ratio)
+ output = L.fc(output, size=self.hidden_size // 2, act="relu")
+ output = L.fc(output, size=self.num_classes, act=None,
+ param_attr=fluid.ParamAttr(name="final_fc"))
+
+ self.labels = L.cast(self.labels, dtype="float32")
+ loss = L.sigmoid_cross_entropy_with_logits(x=output, label=self.labels)
+ self.loss = L.mean(loss)
+ pred = L.sigmoid(output)
+ self.pred = L.argmax(x=pred, axis=-1)
+ correct = L.equal(self.pred, self.labels_1dim)
+ correct = L.cast(correct, dtype="int32")
+ self.correct = L.reduce_sum(correct)
diff --git a/examples/dgi/train.py b/examples/dgi/train.py
index 67742093486e9e391cea0d141d504580c2985df0..a23e4e7b8a154f706f9654a6aa69f131af922dde 100644
--- a/examples/dgi/train.py
+++ b/examples/dgi/train.py
@@ -65,7 +65,6 @@ def main(args):
with fluid.program_guard(train_program, startup_program):
gw = pgl.graph_wrapper.GraphWrapper(
name="graph",
- place=place,
node_feat=dataset.graph.node_feat_info())
output = pgl.layers.gcn(gw,
diff --git a/examples/distribute_graphsage/README.md b/examples/distribute_graphsage/README.md
index 0ce196f6417b676f8d1853f14c012bd86d5972ef..fcfe50a9bfecf258a7781b0ff158d3860cc85bc2 100644
--- a/examples/distribute_graphsage/README.md
+++ b/examples/distribute_graphsage/README.md
@@ -6,54 +6,32 @@ information (e.g., text attributes) to efficiently generate node embeddings for
For purpose of high scalability, we use redis as distribute graph storage solution and training graphsage against redis server.
### Datasets(Quickstart)
-The reddit dataset should be downloaded from [reddit_adj.npz](https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt) and [reddit.npz](https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2Jthe). The details for Reddit Dataset can be found [here](https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf).
+The reddit dataset should be downloaded from [reddit_adj.npz](https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt) and [reddit.npz](https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J). The details for Reddit Dataset can be found [here](https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf).
-Alternatively, reddit dataset has been preprocessed and packed into docker image, which can be instantly pulled using following commands.
+- reddit.npz: https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J
+- reddit_adj.npz: https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt
-```sh
-docker pull githubutilities/reddit_redis_demo:v0.1
-```
+Download `reddit.npz` and `reddit_adj.npz` into `data` directory for further preprocessing.
### Dependencies
-```txt
-- paddlepaddle>=1.6
-- pgl
-- scipy
-- redis==2.10.6
-- redis-py-cluster==1.3.6
+```sh
+pip install -r requirements.txt
```
### How to run
-#### 1. Start reddit data service
+#### 1. Preprocessing and start reddit data service
```sh
-docker run \
- --net=host \
- -d --rm \
- --name reddit_demo \
- -it githubutilities/reddit_redis_demo:v0.1 \
- /bin/bash -c "/bin/bash ./before_hook.sh && /bin/bash"
-docker logs -f `docker ps -aqf "name=reddit_demo"`
+pushd ./redis_setup
+ /bin/bash ./before_hook.sh
+popd
```
#### 2. training GraphSAGE model
```sh
-python train.py --use_cuda --epoch 10 --graphsage_type graphsage_mean --sample_workers 10
+sh ./cloud_run.sh
```
-#### Hyperparameters
-
-- epoch: Number of epochs default (10)
-- use_cuda: Use gpu if assign use_cuda.
-- graphsage_type: We support 4 aggregator types including "graphsage_mean", "graphsage_maxpool", "graphsage_meanpool" and "graphsage_lstm".
-- sample_workers: The number of workers for multiprocessing subgraph sample.
-- lr: Learning rate.
-- batch_size: Batch size.
-- samples_1: The max neighbors for the first hop neighbor sampling. (default: 25)
-- samples_2: The max neighbors for the second hop neighbor sampling. (default: 10)
-- hidden_size: The hidden size of the GraphSAGE models.
-
-
diff --git a/examples/distribute_graphsage/cloud_run.sh b/examples/distribute_graphsage/cloud_run.sh
new file mode 100755
index 0000000000000000000000000000000000000000..c5b5e45fe8990396da9e68cc68f7ebd5217dcbe7
--- /dev/null
+++ b/examples/distribute_graphsage/cloud_run.sh
@@ -0,0 +1,25 @@
+#!/bin/bash
+set -x
+mode=${1}
+
+source ./utils.sh
+unset http_proxy https_proxy
+
+source ./local_config
+if [ ! -d ${log_dir} ]; then
+ mkdir ${log_dir}
+fi
+
+for((i=0;i<${PADDLE_PSERVERS_NUM};i++))
+do
+ echo "start ps server: ${i}"
+ echo $log_dir
+ TRAINING_ROLE="PSERVER" PADDLE_TRAINER_ID=${i} sh job.sh &> $log_dir/pserver.$i.log &
+done
+sleep 10s
+for((j=0;j<${PADDLE_TRAINERS_NUM};j++))
+do
+ echo "start ps work: ${j}"
+ TRAINING_ROLE="TRAINER" PADDLE_TRAINER_ID=${j} sh job.sh &> $log_dir/worker.$j.log &
+done
+tail -f $log_dir/worker.0.log
diff --git a/examples/distribute_graphsage/cluster_train.py b/examples/distribute_graphsage/cluster_train.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ff2695bd5e09963bd497fadc8b5452cfe833288
--- /dev/null
+++ b/examples/distribute_graphsage/cluster_train.py
@@ -0,0 +1,191 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import time
+import os
+import math
+import numpy as np
+
+import paddle.fluid as F
+import paddle.fluid.layers as L
+from paddle.fluid.incubate.fleet.parameter_server.distribute_transpiler import fleet
+from paddle.fluid.transpiler.distribute_transpiler import DistributeTranspilerConfig
+import paddle.fluid.incubate.fleet.base.role_maker as role_maker
+from pgl.utils.logger import log
+
+from model import GraphsageModel
+from utils import load_config
+import reader
+
+
+def init_role():
+ # reset the place according to role of parameter server
+ training_role = os.getenv("TRAINING_ROLE", "TRAINER")
+ paddle_role = role_maker.Role.WORKER
+ place = F.CPUPlace()
+ if training_role == "PSERVER":
+ paddle_role = role_maker.Role.SERVER
+
+ # set the fleet runtime environment according to configure
+ ports = os.getenv("PADDLE_PORT", "6174").split(",")
+ pserver_ips = os.getenv("PADDLE_PSERVERS").split(",") # ip,ip...
+ eplist = []
+ if len(ports) > 1:
+ # local debug mode, multi port
+ for port in ports:
+ eplist.append(':'.join([pserver_ips[0], port]))
+ else:
+ # distributed mode, multi ip
+ for ip in pserver_ips:
+ eplist.append(':'.join([ip, ports[0]]))
+
+ pserver_endpoints = eplist # ip:port,ip:port...
+ worker_num = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ role = role_maker.UserDefinedRoleMaker(
+ current_id=trainer_id,
+ role=paddle_role,
+ worker_num=worker_num,
+ server_endpoints=pserver_endpoints)
+ fleet.init(role)
+
+
+def optimization(base_lr, loss, optimizer='adam'):
+ if optimizer == 'sgd':
+ optimizer = F.optimizer.SGD(base_lr)
+ elif optimizer == 'adam':
+ optimizer = F.optimizer.Adam(base_lr, lazy_mode=True)
+ else:
+ raise ValueError
+
+ log.info('learning rate:%f' % (base_lr))
+ #create the DistributeTranspiler configure
+ config = DistributeTranspilerConfig()
+ config.sync_mode = False
+ #config.runtime_split_send_recv = False
+
+ config.slice_var_up = False
+ #create the distributed optimizer
+ optimizer = fleet.distributed_optimizer(optimizer, config)
+ optimizer.minimize(loss)
+
+
+def build_complied_prog(train_program, model_loss):
+ num_threads = int(os.getenv("CPU_NUM", 10))
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", 0))
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = num_threads
+ #exec_strategy.use_experimental_executor = True
+ build_strategy = F.BuildStrategy()
+ build_strategy.enable_inplace = True
+ #build_strategy.memory_optimize = True
+ build_strategy.memory_optimize = False
+ build_strategy.remove_unnecessary_lock = False
+ if num_threads > 1:
+ build_strategy.reduce_strategy = F.BuildStrategy.ReduceStrategy.Reduce
+
+ compiled_prog = F.compiler.CompiledProgram(
+ train_program).with_data_parallel(loss_name=model_loss.name)
+ return compiled_prog
+
+
+def fake_py_reader(data_iter, num):
+ def fake_iter():
+ queue = []
+ for idx, data in enumerate(data_iter()):
+ queue.append(data)
+ if len(queue) == num:
+ yield queue
+ queue = []
+ if len(queue) > 0:
+ while len(queue) < num:
+ queue.append(queue[-1])
+ yield queue
+ return fake_iter
+
+def train_prog(exe, program, model, pyreader, args):
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ start = time.time()
+ batch = 0
+ total_loss = 0.
+ total_acc = 0.
+ total_sample = 0
+ for epoch_idx in range(args.num_epoch):
+ for step, batch_feed_dict in enumerate(pyreader()):
+ try:
+ cpu_time = time.time()
+ batch += 1
+ batch_loss, batch_acc = exe.run(
+ program,
+ feed=batch_feed_dict,
+ fetch_list=[model.loss, model.acc])
+
+ end = time.time()
+ if batch % args.log_per_step == 0:
+ log.info(
+ "Batch %s Loss %s Acc %s \t Speed(per batch) %.5lf/%.5lf sec"
+ % (batch, np.mean(batch_loss), np.mean(batch_acc), (end - start) /batch, (end - cpu_time)))
+
+ if step % args.steps_per_save == 0:
+ save_path = args.save_path
+ if trainer_id == 0:
+ model_path = os.path.join(save_path, "%s" % step)
+ fleet.save_persistables(exe, model_path)
+ except Exception as e:
+ log.info("Pyreader train error")
+ log.exception(e)
+
+def main(args):
+ log.info("start")
+
+ worker_num = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
+ num_devices = int(os.getenv("CPU_NUM", 10))
+
+ model = GraphsageModel(args)
+ loss = model.forward()
+ train_iter = reader.get_iter(args, model.graph_wrapper, 'train')
+ pyreader = fake_py_reader(train_iter, num_devices)
+
+ # init fleet
+ init_role()
+
+ optimization(args.lr, loss, args.optimizer)
+
+ # init and run server or worker
+ if fleet.is_server():
+ fleet.init_server(args.warm_start_from_dir)
+ fleet.run_server()
+
+ if fleet.is_worker():
+ log.info("start init worker done")
+ fleet.init_worker()
+ #just the worker, load the sample
+ log.info("init worker done")
+
+ exe = F.Executor(F.CPUPlace())
+ exe.run(fleet.startup_program)
+ log.info("Startup done")
+
+ compiled_prog = build_complied_prog(fleet.main_program, loss)
+ train_prog(exe, compiled_prog, model, pyreader, args)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='metapath2vec')
+ parser.add_argument("-c", "--config", type=str, default="./config.yaml")
+ args = parser.parse_args()
+ config = load_config(args.config)
+ log.info(config)
+ main(config)
+
diff --git a/examples/distribute_graphsage/config.yaml b/examples/distribute_graphsage/config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..915ef184c32db9ff6322ee9edc0cd57e1372b1f9
--- /dev/null
+++ b/examples/distribute_graphsage/config.yaml
@@ -0,0 +1,19 @@
+# model config
+hidden_size: 128
+num_class: 41
+samples: [25, 10]
+graphsage_type: "graphsage_mean"
+
+# trainging config
+num_epoch: 10
+batch_size: 128
+num_sample_workers: 10
+optimizer: "adam"
+lr: 0.01
+warm_start_from_dir: null
+steps_per_save: 1000
+log_per_step: 1
+save_path: "./checkpoints"
+log_dir: "./logs"
+CPU_NUM: 1
+
diff --git a/examples/distribute_graphsage/job.sh b/examples/distribute_graphsage/job.sh
new file mode 100644
index 0000000000000000000000000000000000000000..8b9ee4d1b5d981d9c4dfa920cffbb31723030dcc
--- /dev/null
+++ b/examples/distribute_graphsage/job.sh
@@ -0,0 +1,14 @@
+#!/bin/bash
+
+set -x
+source ./utils.sh
+
+export CPU_NUM=$CPU_NUM
+export FLAGS_rpc_deadline=3000000
+
+export FLAGS_communicator_send_queue_size=1
+export FLAGS_communicator_min_send_grad_num_before_recv=0
+export FLAGS_communicator_max_merge_var_num=1
+export FLAGS_communicator_merge_sparse_grad=0
+
+python -u cluster_train.py -c config.yaml
diff --git a/examples/distribute_graphsage/local_config b/examples/distribute_graphsage/local_config
new file mode 100644
index 0000000000000000000000000000000000000000..0e8ca14c66f40cfdc7beea1a0f0cd2f61b8a51ee
--- /dev/null
+++ b/examples/distribute_graphsage/local_config
@@ -0,0 +1,6 @@
+#!/bin/bash
+export PADDLE_TRAINERS_NUM=2
+export PADDLE_PSERVERS_NUM=2
+export PADDLE_PORT=6184,6185
+export PADDLE_PSERVERS="127.0.0.1"
+
diff --git a/examples/distribute_graphsage/model.py b/examples/distribute_graphsage/model.py
index 145a979e86951dc4b5a2522154a0dc0373eea065..7f5eb990fc9bad4f6475bb538b62266b6b5e7f41 100644
--- a/examples/distribute_graphsage/model.py
+++ b/examples/distribute_graphsage/model.py
@@ -11,10 +11,22 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+"""
+ graphsage model.
+"""
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+import math
+
+import pgl
+import numpy as np
import paddle
+import paddle.fluid.layers as L
+import paddle.fluid as F
import paddle.fluid as fluid
-
def copy_send(src_feat, dst_feat, edge_feat):
return src_feat["h"]
@@ -128,3 +140,87 @@ def graphsage_lstm(gw, feature, hidden_size, act, name):
output = fluid.layers.concat([self_feature, neigh_feature], axis=1)
output = fluid.layers.l2_normalize(output, axis=1)
return output
+
+
+def build_graph_model(graph_wrapper, num_class, k_hop, graphsage_type,
+ hidden_size):
+ node_index = fluid.layers.data(
+ "node_index", shape=[None], dtype="int64", append_batch_size=False)
+
+ node_label = fluid.layers.data(
+ "node_label", shape=[None, 1], dtype="int64", append_batch_size=False)
+
+ #feature = fluid.layers.gather(feature, graph_wrapper.node_feat['feats'])
+ feature = graph_wrapper.node_feat['feats']
+ feature.stop_gradient = True
+
+ for i in range(k_hop):
+ if graphsage_type == 'graphsage_mean':
+ feature = graphsage_mean(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_mean_%s" % i)
+ elif graphsage_type == 'graphsage_meanpool':
+ feature = graphsage_meanpool(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_meanpool_%s" % i)
+ elif graphsage_type == 'graphsage_maxpool':
+ feature = graphsage_maxpool(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_maxpool_%s" % i)
+ elif graphsage_type == 'graphsage_lstm':
+ feature = graphsage_lstm(
+ graph_wrapper,
+ feature,
+ hidden_size,
+ act="relu",
+ name="graphsage_maxpool_%s" % i)
+ else:
+ raise ValueError("graphsage type %s is not"
+ " implemented" % graphsage_type)
+
+ feature = fluid.layers.gather(feature, node_index)
+ logits = fluid.layers.fc(feature,
+ num_class,
+ act=None,
+ name='classification_layer')
+ proba = fluid.layers.softmax(logits)
+
+ loss = fluid.layers.softmax_with_cross_entropy(
+ logits=logits, label=node_label)
+ loss = fluid.layers.mean(loss)
+ acc = fluid.layers.accuracy(input=proba, label=node_label, k=1)
+ return loss, acc
+
+
+class GraphsageModel(object):
+ def __init__(self, args):
+ self.args = args
+
+ def forward(self):
+ args = self.args
+
+ graph_wrapper = pgl.graph_wrapper.GraphWrapper(
+ "sub_graph", node_feat=[('feats', [None, 602], np.dtype('float32'))])
+ loss, acc = build_graph_model(
+ graph_wrapper,
+ num_class=args.num_class,
+ hidden_size=args.hidden_size,
+ graphsage_type=args.graphsage_type,
+ k_hop=len(args.samples))
+
+ loss.persistable = True
+
+ self.graph_wrapper = graph_wrapper
+ self.loss = loss
+ self.acc = acc
+ return loss
+
diff --git a/examples/distribute_graphsage/reader.py b/examples/distribute_graphsage/reader.py
index 6617b6b86fe08facee1915edcd459a8c706c4191..88556d39a9d6c30e1b7c4e5e087e994de937566e 100644
--- a/examples/distribute_graphsage/reader.py
+++ b/examples/distribute_graphsage/reader.py
@@ -11,6 +11,8 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
+import os
+import sys
import numpy as np
import pickle as pkl
import paddle
@@ -147,3 +149,48 @@ def multiprocess_graph_reader(
return reader()
+
+def load_data():
+ """
+ data from https://github.com/matenure/FastGCN/issues/8
+ reddit.npz: https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J
+ reddit_index_label is preprocess from reddit.npz without feats key.
+ """
+ data_dir = os.path.dirname(os.path.abspath(__file__))
+ data = np.load(os.path.join(data_dir, "data/reddit_index_label.npz"))
+
+ num_class = 41
+
+ train_label = data['y_train']
+ val_label = data['y_val']
+ test_label = data['y_test']
+
+ train_index = data['train_index']
+ val_index = data['val_index']
+ test_index = data['test_index']
+
+ return {
+ "train_index": train_index,
+ "train_label": train_label,
+ "val_label": val_label,
+ "val_index": val_index,
+ "test_index": test_index,
+ "test_label": test_label,
+ "num_class": 41
+ }
+
+def get_iter(args, graph_wrapper, mode):
+ data = load_data()
+ train_iter = multiprocess_graph_reader(
+ graph_wrapper,
+ samples=args.samples,
+ num_workers=args.num_sample_workers,
+ batch_size=args.batch_size,
+ node_index=data['train_index'],
+ node_label=data["train_label"])
+ return train_iter
+
+if __name__ == '__main__':
+ for e in train_iter():
+ print(e)
+
diff --git a/examples/distribute_graphsage/redis_setup/before_hook.sh b/examples/distribute_graphsage/redis_setup/before_hook.sh
new file mode 100644
index 0000000000000000000000000000000000000000..1b5c101a2e77b7823b3d23a85a709e843812464c
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/before_hook.sh
@@ -0,0 +1,31 @@
+#!/bin/bash
+set -x
+
+srcdir=./src
+
+# Data preprocessing
+python ./src/preprocess.py
+
+# Download and compile redis
+export PATH=$PWD/redis-5.0.5/src:$PATH
+if [ ! -f ./redis.tar.gz ]; then
+ curl https://codeload.github.com/antirez/redis/tar.gz/5.0.5 -o ./redis.tar.gz
+fi
+tar -xzf ./redis.tar.gz
+cd ./redis-5.0.5/
+make
+cd -
+
+# Install python deps
+python -m pip install -U pip
+pip install -r ./src/requirements.txt -U
+
+# Run redis server
+sh ./src/run_server.sh
+
+# Dumping data into redis
+source ./redis_graph.cfg
+sh ./src/dump_data.sh $edge_path $server_list $num_nodes $node_feat_path
+
+exit 0
+
diff --git a/examples/distribute_graphsage/redis_setup/redis_graph.cfg b/examples/distribute_graphsage/redis_setup/redis_graph.cfg
new file mode 100644
index 0000000000000000000000000000000000000000..382ca1749082ecbec98f2666186d81c0534547b6
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/redis_graph.cfg
@@ -0,0 +1,6 @@
+# dump config
+edge_path=../data/edge.txt
+node_feat_path=../data/feats.npz
+num_nodes=232965
+server_list=./server.list
+
diff --git a/examples/distribute_graphsage/redis_setup/src/build_graph.py b/examples/distribute_graphsage/redis_setup/src/build_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..9fb1c6563bf24991bfd3dfa9bca78f513c9d21e5
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/build_graph.py
@@ -0,0 +1,275 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import json
+import logging
+from collections import defaultdict
+import tqdm
+import redis
+from redis._compat import b, unicode, bytes, long, basestring
+from rediscluster.nodemanager import NodeManager
+from rediscluster.crc import crc16
+import argparse
+import time
+import pickle
+import numpy as np
+import scipy.sparse as sp
+
+log = logging.getLogger(__name__)
+root = logging.getLogger()
+root.setLevel(logging.DEBUG)
+
+handler = logging.StreamHandler(sys.stdout)
+handler.setLevel(logging.DEBUG)
+formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
+handler.setFormatter(formatter)
+root.addHandler(handler)
+
+
+def encode(value):
+ """
+ Return a bytestring representation of the value.
+ This method is copied from Redis' connection.py:Connection.encode
+ """
+ if isinstance(value, bytes):
+ return value
+ elif isinstance(value, (int, long)):
+ value = b(str(value))
+ elif isinstance(value, float):
+ value = b(repr(value))
+ elif not isinstance(value, basestring):
+ value = unicode(value)
+ if isinstance(value, unicode):
+ value = value.encode('utf-8')
+ return value
+
+
+def crc16_hash(data):
+ return crc16(encode(data))
+
+
+def get_redis(startup_host, startup_port):
+ startup_nodes = [{"host": startup_host, "port": startup_port}, ]
+ nodemanager = NodeManager(startup_nodes=startup_nodes)
+ nodemanager.initialize()
+ rs = {}
+ for node, config in nodemanager.nodes.items():
+ rs[node] = redis.Redis(
+ host=config["host"], port=config["port"], decode_responses=False)
+ return rs, nodemanager
+
+
+def load_data(edge_path):
+ src, dst = [], []
+ with open(edge_path, "r") as f:
+ for i in tqdm.tqdm(f):
+ s, d, _ = i.split()
+ s = int(s)
+ d = int(d)
+ src.append(s)
+ dst.append(d)
+ dst.append(s)
+ src.append(d)
+ src = np.array(src, dtype="int64")
+ dst = np.array(dst, dtype="int64")
+ return src, dst
+
+
+def build_edge_index(edge_path, num_nodes, startup_host, startup_port,
+ num_bucket):
+ #src, dst = load_data(edge_path)
+ rs, nodemanager = get_redis(startup_host, startup_port)
+
+ dst_mp, edge_mp = defaultdict(list), defaultdict(list)
+ with open(edge_path) as f:
+ for l in tqdm.tqdm(f):
+ a, b, idx = l.rstrip().split('\t')
+ a, b, idx = int(a), int(b), int(idx)
+ dst_mp[a].append(b)
+ edge_mp[a].append(idx)
+ part_dst_dicts = {}
+ for i in tqdm.tqdm(range(num_nodes)):
+ #if len(edge_index.v[i]) == 0:
+ # continue
+ #v = edge_index.v[i].astype("int64").reshape([-1, 1])
+ #e = edge_index.eid[i].astype("int64").reshape([-1, 1])
+ if i not in dst_mp:
+ continue
+ v = np.array(dst_mp[i]).astype('int64').reshape([-1, 1])
+ e = np.array(edge_mp[i]).astype('int64').reshape([-1, 1])
+ o = np.hstack([v, e])
+ key = "d:%s" % i
+ part = crc16_hash(key) % num_bucket
+ if part not in part_dst_dicts:
+ part_dst_dicts[part] = {}
+ dst_dicts = part_dst_dicts[part]
+ dst_dicts["d:%s" % i] = o.tobytes()
+ if len(dst_dicts) > 10000:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, dst_dicts)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_dst_dicts[part] = {}
+
+ for part, dst_dicts in part_dst_dicts.items():
+ if len(dst_dicts) > 0:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, dst_dicts)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_dst_dicts[part] = {}
+ log.info("dst_dict Done")
+
+
+def build_edge_id(edge_path, num_nodes, startup_host, startup_port,
+ num_bucket):
+ src, dst = load_data(edge_path)
+ rs, nodemanager = get_redis(startup_host, startup_port)
+ part_edge_dict = {}
+ for i in tqdm.tqdm(range(len(src))):
+ key = "e:%s" % i
+ part = crc16_hash(key) % num_bucket
+ if part not in part_edge_dict:
+ part_edge_dict[part] = {}
+ edge_dict = part_edge_dict[part]
+ edge_dict["e:%s" % i] = int(src[i]) * num_nodes + int(dst[i])
+ if len(edge_dict) > 10000:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, edge_dict)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+
+ part_edge_dict[part] = {}
+
+ for part, edge_dict in part_edge_dict.items():
+ if len(edge_dict) > 0:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, edge_dict)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_edge_dict[part] = {}
+
+
+def build_infos(edge_path, num_nodes, startup_host, startup_port, num_bucket):
+ src, dst = load_data(edge_path)
+ rs, nodemanager = get_redis(startup_host, startup_port)
+ slot = nodemanager.keyslot("num_nodes")
+ node = nodemanager.slots[slot][0]['name']
+ res = rs[node].set("num_nodes", num_nodes)
+
+ slot = nodemanager.keyslot("num_edges")
+ node = nodemanager.slots[slot][0]['name']
+ rs[node].set("num_edges", len(src))
+
+ slot = nodemanager.keyslot("nf:infos")
+ node = nodemanager.slots[slot][0]['name']
+ rs[node].set("nf:infos", json.dumps([['feats', [-1, 602], 'float32'], ]))
+
+ slot = nodemanager.keyslot("ef:infos")
+ node = nodemanager.slots[slot][0]['name']
+ rs[node].set("ef:infos", json.dumps([]))
+
+
+def build_node_feat(node_feat_path, num_nodes, startup_host, startup_port, num_bucket):
+ assert node_feat_path != "", "node_feat_path empty!"
+ feat_dict = np.load(node_feat_path)
+ for k in feat_dict.keys():
+ feat = feat_dict[k]
+ assert feat.shape[0] == num_nodes, "num_nodes invalid"
+
+ rs, nodemanager = get_redis(startup_host, startup_port)
+ part_feat_dict = {}
+ for k in feat_dict.keys():
+ feat = feat_dict[k]
+ for i in tqdm.tqdm(range(num_nodes)):
+ key = "nf:%s:%i" % (k, i)
+ value = feat[i].tobytes()
+ part = crc16_hash(key) % num_bucket
+ if part not in part_feat_dict:
+ part_feat_dict[part] = {}
+ part_feat = part_feat_dict[part]
+ part_feat[key] = value
+ if len(part_feat) > 100:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, part_feat)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+
+ part_feat_dict[part] = {}
+
+ for part, part_feat in part_feat_dict.items():
+ if len(part_feat) > 0:
+ slot = nodemanager.keyslot("part-%s" % part)
+ node = nodemanager.slots[slot][0]['name']
+ while True:
+ res = rs[node].hmset("part-%s" % part, part_feat)
+ if res:
+ break
+ log.info("HMSET FAILED RETRY connected %s" % node)
+ time.sleep(1)
+ part_feat_dict[part] = {}
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='gen_redis_conf')
+ parser.add_argument('--startup_port', type=int, required=True)
+ parser.add_argument('--startup_host', type=str, required=True)
+ parser.add_argument('--edge_path', type=str, default="")
+ parser.add_argument('--node_feat_path', type=str, default="")
+ parser.add_argument('--num_nodes', type=int, default=0)
+ parser.add_argument('--num_bucket', type=int, default=64)
+ parser.add_argument(
+ '--mode',
+ type=str,
+ required=True,
+ help="choose one of the following modes (clear, edge_index, edge_id, graph_attr)"
+ )
+ args = parser.parse_args()
+ log.info("Mode: {}".format(args.mode))
+ if args.mode == 'edge_index':
+ build_edge_index(args.edge_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ elif args.mode == 'edge_id':
+ build_edge_id(args.edge_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ elif args.mode == 'graph_attr':
+ build_infos(args.edge_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ elif args.mode == 'node_feat':
+ build_node_feat(args.node_feat_path, args.num_nodes, args.startup_host,
+ args.startup_port, args.num_bucket)
+ else:
+ raise ValueError("%s mode not found" % args.mode)
+
diff --git a/examples/distribute_graphsage/redis_setup/src/dump_data.sh b/examples/distribute_graphsage/redis_setup/src/dump_data.sh
new file mode 100644
index 0000000000000000000000000000000000000000..052064b5ac5ae61d0270691726d299796fe2393a
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/dump_data.sh
@@ -0,0 +1,63 @@
+filter(){
+ lines=`cat $1`
+ rm $1
+ for line in $lines; do
+ remote_host=`echo $line | cut -d":" -f1`
+ remote_port=`echo $line | cut -d":" -f2`
+ nc -z $remote_host $remote_port
+ if [[ $? == 0 ]]; then
+ echo $line >> $1
+ fi
+ done
+}
+
+dump_data(){
+ filter $server_list
+
+ python ./src/start_cluster.py --server_list $server_list --replicas 0
+
+ address=`head -n 1 $server_list`
+
+ ip=`echo $address | cut -d":" -f1`
+ port=`echo $address | cut -d":" -f2`
+
+ python ./src/build_graph.py --startup_host $ip \
+ --startup_port $port \
+ --mode node_feat \
+ --node_feat_path $feat_fn \
+ --num_nodes $num_nodes
+
+ # build edge index
+ python ./src/build_graph.py --startup_host $ip \
+ --startup_port $port \
+ --mode edge_index \
+ --edge_path $edge_path \
+ --num_nodes $num_nodes
+
+ # build edge id
+ #python ./src/build_graph.py --startup_host $ip \
+ # --startup_port $port \
+ # --mode edge_id \
+ # --edge_path $edge_path \
+ # --num_nodes $num_nodes
+
+ # build graph attr
+ python ./src/build_graph.py --startup_host $ip \
+ --startup_port $port \
+ --mode graph_attr \
+ --edge_path $edge_path \
+ --num_nodes $num_nodes
+
+}
+
+if [ $# -ne 4 ]; then
+ echo 'sh edge_path server_list num_nodes feat_fn'
+ exit
+fi
+num_nodes=$3
+server_list=$2
+edge_path=$1
+feat_fn=$4
+
+dump_data
+
diff --git a/examples/distribute_graphsage/redis_setup/src/gen_redis_conf.py b/examples/distribute_graphsage/redis_setup/src/gen_redis_conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ded1f3d79d0d2d64071d6936d38e4514c28b453
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/gen_redis_conf.py
@@ -0,0 +1,72 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import socket
+import argparse
+import os
+temp = """port %s
+bind %s
+daemonize yes
+pidfile /var/run/redis_%s.pid
+cluster-enabled yes
+cluster-config-file nodes.conf
+cluster-node-timeout 50000
+logfile "redis.log"
+appendonly yes"""
+
+
+def gen_config(ports):
+ if len(ports) == 0:
+ raise ValueError("No ports")
+ ip = socket.gethostbyname(socket.gethostname())
+ print("Generate redis conf")
+ for port in ports:
+ try:
+ os.mkdir("%s" % port)
+ except:
+ print("port %s directory already exists" % port)
+ pass
+ with open("%s/redis.conf" % port, 'w') as f:
+ f.write(temp % (port, ip, port))
+
+ print("Generate Start Server Scripts")
+ with open("start_server.sh", "w") as f:
+ f.write("set -x\n")
+ for ind, port in enumerate(ports):
+ f.write("# %s %s start\n" % (ip, port))
+ if ind > 0:
+ f.write("cd ..\n")
+ f.write("cd %s\n" % port)
+ f.write("redis-server redis.conf\n")
+ f.write("\n")
+
+ print("Generate Stop Server Scripts")
+ with open("stop_server.sh", "w") as f:
+ f.write("set -x\n")
+ for ind, port in enumerate(ports):
+ f.write("# %s %s shutdown\n" % (ip, port))
+ f.write("redis-cli -h %s -p %s shutdown\n" % (ip, port))
+ f.write("\n")
+
+ with open("server.list", "w") as f:
+ for ind, port in enumerate(ports):
+ f.write("%s:%s\n" % (ip, port))
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='gen_redis_conf')
+ parser.add_argument('--ports', nargs='+', type=int, default=[])
+ args = parser.parse_args()
+ gen_config(args.ports)
diff --git a/examples/distribute_graphsage/redis_setup/src/preprocess.py b/examples/distribute_graphsage/redis_setup/src/preprocess.py
new file mode 100644
index 0000000000000000000000000000000000000000..42c641ccbf9bf8b623b8e3be159c37d2dffd9ebd
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/preprocess.py
@@ -0,0 +1,35 @@
+import os
+import sys
+
+import numpy as np
+import scipy.sparse as sp
+
+def _load_config(fn):
+ ret = {}
+ with open(fn) as f:
+ for l in f:
+ if l.strip() == '' or l.startswith('#'):
+ continue
+ k, v = l.strip().split('=')
+ ret[k] = v
+ return ret
+
+def _prepro(config):
+ data = np.load("../data/reddit.npz")
+ adj = sp.load_npz("../data/reddit_adj.npz")
+ adj = adj.tocoo()
+ src = adj.row
+ dst = adj.col
+
+ with open(config['edge_path'], 'w') as f:
+ for idx, e in enumerate(zip(src, dst)):
+ s, d = e
+ l = "{}\t{}\t{}\n".format(s, d, idx)
+ f.write(l)
+ feats = data['feats'].astype(np.float32)
+ np.savez(config['node_feat_path'], feats=feats)
+
+if __name__ == '__main__':
+ config = _load_config('./redis_graph.cfg')
+ _prepro(config)
+
diff --git a/examples/distribute_graphsage/redis_setup/src/requirements.txt b/examples/distribute_graphsage/redis_setup/src/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..2f955a8c35414405c0ef4bebd459d96d7934ab62
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/requirements.txt
@@ -0,0 +1,6 @@
+numpy
+scipy
+tqdm
+redis==2.10.6
+redis-py-cluster==1.3.6
+
diff --git a/examples/distribute_graphsage/redis_setup/src/run_server.sh b/examples/distribute_graphsage/redis_setup/src/run_server.sh
new file mode 100644
index 0000000000000000000000000000000000000000..e1268ad60df82c283d0e8d7cfc1e9ca6f7126b6f
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/run_server.sh
@@ -0,0 +1,14 @@
+start_server(){
+ ports=""
+ for i in {7430..7439}; do
+ nc -z localhost $i
+ if [[ $? != 0 ]]; then
+ ports="$ports $i"
+ fi
+ done
+ python ./src/gen_redis_conf.py --ports $ports
+ bash ./start_server.sh #启动服务器
+}
+
+start_server
+
diff --git a/examples/distribute_graphsage/redis_setup/src/start_cluster.py b/examples/distribute_graphsage/redis_setup/src/start_cluster.py
new file mode 100644
index 0000000000000000000000000000000000000000..570765d3696a4eafa924efe8c9ba1787eff574d0
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/src/start_cluster.py
@@ -0,0 +1,37 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import argparse
+
+
+def build_clusters(server_list, replicas):
+ servers = []
+ with open(server_list) as f:
+ for line in f:
+ servers.append(line.strip())
+ cmd = "echo yes | redis-cli --cluster create"
+ for server in servers:
+ cmd += ' %s ' % server
+ cmd += '--cluster-replicas %s' % replicas
+ print(cmd)
+ os.system(cmd)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description='start_cluster')
+ parser.add_argument('--server_list', type=str, required=True)
+ parser.add_argument('--replicas', type=int, default=0)
+ args = parser.parse_args()
+ build_clusters(args.server_list, args.replicas)
diff --git a/examples/distribute_graphsage/redis_setup/test/test.sh b/examples/distribute_graphsage/redis_setup/test/test.sh
new file mode 100644
index 0000000000000000000000000000000000000000..ec8695b9c75c921bc03bf56a3c381bbd279b1532
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/test/test.sh
@@ -0,0 +1,7 @@
+#!/bin/bash
+
+source ./redis_graph.cfg
+
+url=`head -n1 $server_list`
+shuf $edge_path | head -n 1000 | python ./test/test_redis_graph.py $url
+
diff --git a/examples/distribute_graphsage/redis_setup/test/test_redis_graph.py b/examples/distribute_graphsage/redis_setup/test/test_redis_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..f4a3a2541bbd96210e8f9eaef5bf38a07cbd9e60
--- /dev/null
+++ b/examples/distribute_graphsage/redis_setup/test/test_redis_graph.py
@@ -0,0 +1,40 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+########################################################################
+#
+# Copyright (c) 2019 Baidu.com, Inc. All Rights Reserved
+#
+# File: test_redis_graph.py
+# Author: suweiyue(suweiyue@baidu.com)
+# Date: 2019/08/19 16:28:18
+#
+########################################################################
+"""
+ Comment.
+"""
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import sys
+
+import numpy as np
+import tqdm
+from pgl.redis_graph import RedisGraph
+
+if __name__ == '__main__':
+ host, port = sys.argv[1].split(':')
+ port = int(port)
+ redis_configs = [{"host": host, "port": port}, ]
+ graph = RedisGraph("reddit-graph", redis_configs, num_parts=64)
+ #nodes = np.arange(0, 100)
+ #for i in range(0, 100):
+ for l in tqdm.tqdm(sys.stdin):
+ l_sp = l.rstrip().split('\t')
+ if len(l_sp) != 2:
+ continue
+ i, j = int(l_sp[0]), int(l_sp[1])
+ nodes = graph.sample_predecessor(np.array([i]), 10000)
+ assert j in nodes
+
diff --git a/examples/distribute_graphsage/requirements.txt b/examples/distribute_graphsage/requirements.txt
index 7bda67a20635218a8786cfb872cfd2da5b2ddbe1..e0d28f3b6ce2ab2cea5d9674b871cc8d3e7ac932 100644
--- a/examples/distribute_graphsage/requirements.txt
+++ b/examples/distribute_graphsage/requirements.txt
@@ -1,3 +1,7 @@
+pgl==1.1.0
+pyyaml
+paddlepaddle==1.6.1
+
scipy
redis==2.10.6
redis-py-cluster==1.3.6
diff --git a/examples/distribute_graphsage/train.py b/examples/distribute_graphsage/train.py
deleted file mode 100644
index fa52e3e002b52e14db5ea4e893377476eada41ef..0000000000000000000000000000000000000000
--- a/examples/distribute_graphsage/train.py
+++ /dev/null
@@ -1,263 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import os
-import argparse
-import time
-
-import numpy as np
-import scipy.sparse as sp
-from sklearn.preprocessing import StandardScaler
-
-import pgl
-from pgl.utils.logger import log
-from pgl.utils import paddle_helper
-import paddle
-import paddle.fluid as fluid
-import reader
-from model import graphsage_mean, graphsage_meanpool,\
- graphsage_maxpool, graphsage_lstm
-
-
-def load_data():
- """
- data from https://github.com/matenure/FastGCN/issues/8
- reddit.npz: https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J
- reddit_index_label is preprocess from reddit.npz without feats key.
- """
- data_dir = os.path.dirname(os.path.abspath(__file__))
- data = np.load(os.path.join(data_dir, "data/reddit_index_label.npz"))
-
- num_class = 41
-
- train_label = data['y_train']
- val_label = data['y_val']
- test_label = data['y_test']
-
- train_index = data['train_index']
- val_index = data['val_index']
- test_index = data['test_index']
-
- return {
- "train_index": train_index,
- "train_label": train_label,
- "val_label": val_label,
- "val_index": val_index,
- "test_index": test_index,
- "test_label": test_label,
- "num_class": 41
- }
-
-
-def build_graph_model(graph_wrapper, num_class, k_hop, graphsage_type,
- hidden_size):
- node_index = fluid.layers.data(
- "node_index", shape=[None], dtype="int64", append_batch_size=False)
-
- node_label = fluid.layers.data(
- "node_label", shape=[None, 1], dtype="int64", append_batch_size=False)
-
- #feature = fluid.layers.gather(feature, graph_wrapper.node_feat['feats'])
- feature = graph_wrapper.node_feat['feats']
- feature.stop_gradient = True
-
- for i in range(k_hop):
- if graphsage_type == 'graphsage_mean':
- feature = graphsage_mean(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_mean_%s" % i)
- elif graphsage_type == 'graphsage_meanpool':
- feature = graphsage_meanpool(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_meanpool_%s" % i)
- elif graphsage_type == 'graphsage_maxpool':
- feature = graphsage_maxpool(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_maxpool_%s" % i)
- elif graphsage_type == 'graphsage_lstm':
- feature = graphsage_lstm(
- graph_wrapper,
- feature,
- hidden_size,
- act="relu",
- name="graphsage_maxpool_%s" % i)
- else:
- raise ValueError("graphsage type %s is not"
- " implemented" % graphsage_type)
-
- feature = fluid.layers.gather(feature, node_index)
- logits = fluid.layers.fc(feature,
- num_class,
- act=None,
- name='classification_layer')
- proba = fluid.layers.softmax(logits)
-
- loss = fluid.layers.softmax_with_cross_entropy(
- logits=logits, label=node_label)
- loss = fluid.layers.mean(loss)
- acc = fluid.layers.accuracy(input=proba, label=node_label, k=1)
- return loss, acc
-
-
-def run_epoch(batch_iter,
- exe,
- program,
- prefix,
- model_loss,
- model_acc,
- epoch,
- log_per_step=100):
- batch = 0
- total_loss = 0.
- total_acc = 0.
- total_sample = 0
- start = time.time()
- for batch_feed_dict in batch_iter():
- batch += 1
- batch_loss, batch_acc = exe.run(program,
- fetch_list=[model_loss, model_acc],
- feed=batch_feed_dict)
-
- if batch % log_per_step == 0:
- log.info("Batch %s %s-Loss %s %s-Acc %s" %
- (batch, prefix, batch_loss, prefix, batch_acc))
-
- num_samples = len(batch_feed_dict["node_index"])
- total_loss += batch_loss * num_samples
- total_acc += batch_acc * num_samples
- total_sample += num_samples
- end = time.time()
-
- log.info("%s Epoch %s Loss %.5lf Acc %.5lf Speed(per batch) %.5lf sec" %
- (prefix, epoch, total_loss / total_sample,
- total_acc / total_sample, (end - start) / batch))
-
-
-def main(args):
- data = load_data()
- log.info("preprocess finish")
- log.info("Train Examples: %s" % len(data["train_index"]))
- log.info("Val Examples: %s" % len(data["val_index"]))
- log.info("Test Examples: %s" % len(data["test_index"]))
-
- place = fluid.CUDAPlace(0) if args.use_cuda else fluid.CPUPlace()
- train_program = fluid.Program()
- startup_program = fluid.Program()
- samples = []
- if args.samples_1 > 0:
- samples.append(args.samples_1)
- if args.samples_2 > 0:
- samples.append(args.samples_2)
-
- with fluid.program_guard(train_program, startup_program):
- graph_wrapper = pgl.graph_wrapper.GraphWrapper(
- "sub_graph", fluid.CPUPlace(), node_feat=[('feats', [None, 602], np.dtype('float32'))])
- model_loss, model_acc = build_graph_model(
- graph_wrapper,
- num_class=data["num_class"],
- hidden_size=args.hidden_size,
- graphsage_type=args.graphsage_type,
- k_hop=len(samples))
-
- test_program = train_program.clone(for_test=True)
-
- with fluid.program_guard(train_program, startup_program):
- adam = fluid.optimizer.Adam(learning_rate=args.lr)
- adam.minimize(model_loss)
-
- exe = fluid.Executor(place)
- exe.run(startup_program)
-
- train_iter = reader.multiprocess_graph_reader(
- graph_wrapper,
- samples=samples,
- num_workers=args.sample_workers,
- batch_size=args.batch_size,
- node_index=data['train_index'],
- node_label=data["train_label"])
-
- val_iter = reader.multiprocess_graph_reader(
- graph_wrapper,
- samples=samples,
- num_workers=args.sample_workers,
- batch_size=args.batch_size,
- node_index=data['val_index'],
- node_label=data["val_label"])
-
- test_iter = reader.multiprocess_graph_reader(
- graph_wrapper,
- samples=samples,
- num_workers=args.sample_workers,
- batch_size=args.batch_size,
- node_index=data['test_index'],
- node_label=data["test_label"])
-
- for epoch in range(args.epoch):
- run_epoch(
- train_iter,
- program=train_program,
- exe=exe,
- prefix="train",
- model_loss=model_loss,
- model_acc=model_acc,
- log_per_step=1,
- epoch=epoch)
-
- run_epoch(
- val_iter,
- program=test_program,
- exe=exe,
- prefix="val",
- model_loss=model_loss,
- model_acc=model_acc,
- log_per_step=10000,
- epoch=epoch)
-
- run_epoch(
- test_iter,
- program=test_program,
- prefix="test",
- exe=exe,
- model_loss=model_loss,
- model_acc=model_acc,
- log_per_step=10000,
- epoch=epoch)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(description='graphsage')
- parser.add_argument("--use_cuda", action='store_true', help="use_cuda")
- parser.add_argument(
- "--normalize", action='store_true', help="normalize features")
- parser.add_argument(
- "--symmetry", action='store_true', help="undirect graph")
- parser.add_argument("--graphsage_type", type=str, default="graphsage_mean")
- parser.add_argument("--sample_workers", type=int, default=10)
- parser.add_argument("--epoch", type=int, default=10)
- parser.add_argument("--hidden_size", type=int, default=128)
- parser.add_argument("--batch_size", type=int, default=128)
- parser.add_argument("--lr", type=float, default=0.01)
- parser.add_argument("--samples_1", type=int, default=25)
- parser.add_argument("--samples_2", type=int, default=10)
- args = parser.parse_args()
- log.info(args)
- main(args)
diff --git a/examples/distribute_graphsage/utils.py b/examples/distribute_graphsage/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5810f7fdd7a99b034505feaddf51a962ca34ac1
--- /dev/null
+++ b/examples/distribute_graphsage/utils.py
@@ -0,0 +1,55 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Implementation of some helper functions"""
+
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import os
+import time
+import yaml
+import numpy as np
+
+from pgl.utils.logger import log
+
+
+class AttrDict(dict):
+ """Attr dict
+ """
+
+ def __init__(self, d):
+ self.dict = d
+
+ def __getattr__(self, attr):
+ value = self.dict[attr]
+ if isinstance(value, dict):
+ return AttrDict(value)
+ else:
+ return value
+
+ def __str__(self):
+ return str(self.dict)
+
+
+def load_config(config_file):
+ """Load config file"""
+ with open(config_file) as f:
+ if hasattr(yaml, 'FullLoader'):
+ config = yaml.load(f, Loader=yaml.FullLoader)
+ else:
+ config = yaml.load(f)
+
+ return AttrDict(config)
diff --git a/examples/distribute_graphsage/utils.sh b/examples/distribute_graphsage/utils.sh
new file mode 100644
index 0000000000000000000000000000000000000000..6f6daa846d600e0bcecd4ce64e04946dba0fdd51
--- /dev/null
+++ b/examples/distribute_graphsage/utils.sh
@@ -0,0 +1,20 @@
+
+# parse yaml file
+function parse_yaml {
+ local prefix=$2
+ local s='[[:space:]]*' w='[a-zA-Z0-9_]*' fs=$(echo @|tr @ '\034')
+ sed -ne "s|^\($s\):|\1|" \
+ -e "s|^\($s\)\($w\)$s:$s[\"']\(.*\)[\"']$s\$|\1$fs\2$fs\3|p" \
+ -e "s|^\($s\)\($w\)$s:$s\(.*\)$s\$|\1$fs\2$fs\3|p" $1 |
+ awk -F$fs '{
+ indent = length($1)/2;
+ vname[indent] = $2;
+ for (i in vname) {if (i > indent) {delete vname[i]}}
+ if (length($3) > 0) {
+ vn=""; for (i=0; i
+
+**ERNIESage** (abbreviation of ERNIE SAmple aggreGatE), a model proposed by the PGL team, effectively improves the performance on text graph by simultaneously modeling text semantics and graph structure information. It's worth mentioning that [**ERNIE**](https://github.com/PaddlePaddle/ERNIE) in **ERNIESage** is a continual pre-training framework for language understanding launched by Baidu.
+
+**ERNIESage** is an aggregation of ERNIE and GraphSAGE. Its structure is shown in the figure below. The main idea is to use ERNIE as an aggregation function (Aggregators) to model the semantic and structural relationship between its own nodes and neighbor nodes. In addition, for the position-independent characteristics of neighbor nodes, attention mask and independent position embedding mechanism for neighbor blindness are designed.
+
+ +
+GraphSAGE with ID feature can only model the graph structure information, while ERNIE can only deal with the text. With the help of PGL, the proposed **ERNIESage** model can combine the advantages of both models. Take the following recommendation example of text graph, we can see that **ERNIESage** achieves the best performance when compared to single ERNIE model or GraphSAGE model.
+
+
+
+GraphSAGE with ID feature can only model the graph structure information, while ERNIE can only deal with the text. With the help of PGL, the proposed **ERNIESage** model can combine the advantages of both models. Take the following recommendation example of text graph, we can see that **ERNIESage** achieves the best performance when compared to single ERNIE model or GraphSAGE model.
+
+ +
+Thanks to the flexibility and usability of PGL, **ERNIESage** can be quickly implemented under PGL's Message Passing paradigm. Acutally, there are four PGL version of ERNIESage:
+
+- **ERNIESage v1**: ERNIE is applied to the NODE of the text graph;
+- **ERNIESage v2**: ERNIE is applied to the EDGE of the text graph;
+- **ERNIESage v3**: ERNIE is applied to the first order neighbors and center node;
+- **ERNIESage v4**: ERNIE is applied to the N-order neighbors and center node.
+
+
+
+Thanks to the flexibility and usability of PGL, **ERNIESage** can be quickly implemented under PGL's Message Passing paradigm. Acutally, there are four PGL version of ERNIESage:
+
+- **ERNIESage v1**: ERNIE is applied to the NODE of the text graph;
+- **ERNIESage v2**: ERNIE is applied to the EDGE of the text graph;
+- **ERNIESage v3**: ERNIE is applied to the first order neighbors and center node;
+- **ERNIESage v4**: ERNIE is applied to the N-order neighbors and center node.
+
+ +
+## Dependencies
+- paddlepaddle>=1.7
+- pgl>=1.1
+
+## Dataformat
+In the example data ```data.txt```, part of NLPCC2016-DBQA is used, and the format is "query \t answer" for each line.
+```text
+NLPCC2016-DBQA is a sub-task of NLPCC-ICCPOL 2016 Shared Task which is hosted by NLPCC(Natural Language Processing and Chinese Computing), this task targets on selecting documents from the candidates to answer the questions. [url: http://tcci.ccf.org.cn/conference/2016/dldoc/evagline2.pdf]
+```
+
+## How to run
+
+We adopt [PaddlePaddle Fleet](https://github.com/PaddlePaddle/Fleet) as our distributed training frameworks ```config/*.yaml``` are some example config files for hyperparameters. Among them, the ERNIE model checkpoint ```ckpt_path``` and the vocabulary ```ernie_vocab_file``` can be downloaded on the [ERNIE](https://github.com/PaddlePaddle/ERNIE) page.
+
+```sh
+# train ERNIESage in distributed gpu mode.
+sh local_run.sh config/enriesage_v1_gpu.yaml
+
+# train ERNIESage in distributed cpu mode.
+sh local_run.sh config/enriesage_v1_cpu.yaml
+```
+
+## Hyperparamters
+
+- learner_type: `gpu` or `cpu`; gpu use fleet Collective mode, cpu use fleet Transpiler mode.
+
+## Citation
+```
+@misc{ERNIESage,
+ author = {PGL Team},
+ title = {ERNIESage: ERNIE SAmple aggreGatE},
+ year = {2020},
+ publisher = {GitHub},
+ journal = {GitHub repository},
+ howpublished = {\url{https://github.com/PaddlePaddle/PGL/tree/master/examples/erniesage},
+}
+```
diff --git a/examples/erniesage/README.md b/examples/erniesage/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..78004852b9aa1f95b372f06d4104e7d65118f6e7
--- /dev/null
+++ b/examples/erniesage/README.md
@@ -0,0 +1,67 @@
+# 使用PGL实现ERNIESage
+
+[ENG Readme](./README.en.md)
+
+## 背景介绍
+
+在很多工业应用中,往往出现如下图所示的一种特殊的图:Text Graph。顾名思义,图的节点属性由文本构成,而边的构建提供了结构信息。如搜索场景下的Text Graph,节点可由搜索词、网页标题、网页正文来表达,用户反馈和超链信息则可构成边关系。
+
+
+
+## Dependencies
+- paddlepaddle>=1.7
+- pgl>=1.1
+
+## Dataformat
+In the example data ```data.txt```, part of NLPCC2016-DBQA is used, and the format is "query \t answer" for each line.
+```text
+NLPCC2016-DBQA is a sub-task of NLPCC-ICCPOL 2016 Shared Task which is hosted by NLPCC(Natural Language Processing and Chinese Computing), this task targets on selecting documents from the candidates to answer the questions. [url: http://tcci.ccf.org.cn/conference/2016/dldoc/evagline2.pdf]
+```
+
+## How to run
+
+We adopt [PaddlePaddle Fleet](https://github.com/PaddlePaddle/Fleet) as our distributed training frameworks ```config/*.yaml``` are some example config files for hyperparameters. Among them, the ERNIE model checkpoint ```ckpt_path``` and the vocabulary ```ernie_vocab_file``` can be downloaded on the [ERNIE](https://github.com/PaddlePaddle/ERNIE) page.
+
+```sh
+# train ERNIESage in distributed gpu mode.
+sh local_run.sh config/enriesage_v1_gpu.yaml
+
+# train ERNIESage in distributed cpu mode.
+sh local_run.sh config/enriesage_v1_cpu.yaml
+```
+
+## Hyperparamters
+
+- learner_type: `gpu` or `cpu`; gpu use fleet Collective mode, cpu use fleet Transpiler mode.
+
+## Citation
+```
+@misc{ERNIESage,
+ author = {PGL Team},
+ title = {ERNIESage: ERNIE SAmple aggreGatE},
+ year = {2020},
+ publisher = {GitHub},
+ journal = {GitHub repository},
+ howpublished = {\url{https://github.com/PaddlePaddle/PGL/tree/master/examples/erniesage},
+}
+```
diff --git a/examples/erniesage/README.md b/examples/erniesage/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..78004852b9aa1f95b372f06d4104e7d65118f6e7
--- /dev/null
+++ b/examples/erniesage/README.md
@@ -0,0 +1,67 @@
+# 使用PGL实现ERNIESage
+
+[ENG Readme](./README.en.md)
+
+## 背景介绍
+
+在很多工业应用中,往往出现如下图所示的一种特殊的图:Text Graph。顾名思义,图的节点属性由文本构成,而边的构建提供了结构信息。如搜索场景下的Text Graph,节点可由搜索词、网页标题、网页正文来表达,用户反馈和超链信息则可构成边关系。
+
+ +
+**ERNIESage** 由PGL团队提出,是ERNIE SAmple aggreGatE的简称,该模型可以同时建模文本语义与图结构信息,有效提升 Text Graph 的应用效果。其中 [**ERNIE**](https://github.com/PaddlePaddle/ERNIE) 是百度推出的基于知识增强的持续学习语义理解框架。
+
+**ERNIESage** 是 ERNIE 与 GraphSAGE 碰撞的结果,是 ERNIE SAmple aggreGatE 的简称,它的结构如下图所示,主要思想是通过 ERNIE 作为聚合函数(Aggregators),建模自身节点和邻居节点的语义与结构关系。ERNIESage 对于文本的建模是构建在邻居聚合的阶段,中心节点文本会与所有邻居节点文本进行拼接;然后通过预训练的 ERNIE 模型进行消息汇聚,捕捉中心节点以及邻居节点之间的相互关系;最后使用 ERNIESage 搭配独特的邻居互相看不见的 Attention Mask 和独立的 Position Embedding 体系,就可以轻松构建 TextGraph 中句子之间以及词之间的关系。
+
+
+
+使用ID特征的GraphSAGE只能够建模图的结构信息,而单独的ERNIE只能处理文本信息。通过PGL搭建的图与文本的桥梁,**ERNIESage**能够很简单的把GraphSAGE以及ERNIE的优点结合一起。以下面TextGraph的场景,**ERNIESage**的效果能够比单独的ERNIE以及GraphSAGE模型都要好。
+
+
+
+**ERNIESage**可以很轻松地在PGL中的消息传递范式中进行实现,目前PGL提供了4个版本的ERNIESage模型:
+
+- **ERNIESage v1**: ERNIE 作用于text graph节点上;
+- **ERNIESage v2**: ERNIE 作用在text graph的边上;
+- **ERNIESage v3**: ERNIE 作用于一阶邻居及起边上;
+- **ERNIESage v4**: ERNIE 作用于N阶邻居及边上;
+
+
+
+## 环境依赖
+- paddlepaddle>=1.7
+- pgl>=1.1
+
+## Dataformat
+示例数据```data.txt```中使用了NLPCC2016-DBQA的部分数据,格式为每行"query \t answer"。
+```text
+NLPCC2016-DBQA 是由国际自然语言处理和中文计算会议 NLPCC 于 2016 年举办的评测任务,其目标是从候选中找到合适的文档作为问题的答案。[链接: http://tcci.ccf.org.cn/conference/2016/dldoc/evagline2.pdf]
+```
+
+## How to run
+
+我们采用了[PaddlePaddle Fleet](https://github.com/PaddlePaddle/Fleet)作为我们的分布式训练框架,在```config/*.yaml```中,有部分用于训练ERNIESage的配置, 其中ERNIE模型```ckpt_path```以及词表```ernie_vocab_file```在[ERNIE](https://github.com/PaddlePaddle/ERNIE)下载。
+
+
+```sh
+# 分布式GPU模式或单机模式ERNIESage
+sh local_run.sh config/erniesage_v2_gpu.yaml
+
+# 分布式CPU模式训练ERNIESage
+sh local_run.sh config/erniesage_v2_cpu.yaml
+```
+
+## Hyperparamters
+
+- learner_type: `gpu` or `cpu`; gpu 使用fleet Collective 模式, cpu 使用fleet Transpiler 模式.
+
+## Citation
+```
+@misc{ERNIESage,
+ author = {PGL Team},
+ title = {ERNIESage: ERNIE SAmple aggreGatE},
+ year = {2020},
+ publisher = {GitHub},
+ journal = {GitHub repository},
+ howpublished = {\url{https://github.com/PaddlePaddle/PGL/tree/master/examples/erniesage},
+}
+```
diff --git a/examples/erniesage/config/erniesage_v1_cpu.yaml b/examples/erniesage/config/erniesage_v1_cpu.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..1f7e5eddc0b6bda5f8c3377c7320429d16b0718b
--- /dev/null
+++ b/examples/erniesage/config/erniesage_v1_cpu.yaml
@@ -0,0 +1,56 @@
+# Global Enviroment Settings
+#
+# trainer config ------
+learner_type: "cpu"
+optimizer_type: "adam"
+lr: 0.00005
+batch_size: 2
+CPU_NUM: 10
+epoch: 20
+log_per_step: 1
+save_per_step: 100
+output_path: "./output"
+ckpt_path: "./ernie_base_ckpt"
+
+# data config ------
+input_data: "./data.txt"
+graph_path: "./workdir"
+sample_workers: 1
+use_pyreader: true
+input_type: "text"
+
+# model config ------
+samples: [10]
+model_type: "ErnieSageModelV1"
+layer_type: "graphsage_sum"
+
+max_seqlen: 40
+
+num_layers: 1
+hidden_size: 128
+final_fc: true
+final_l2_norm: true
+loss_type: "hinge"
+margin: 0.3
+
+# infer config ------
+infer_model: "./output/last"
+infer_batch_size: 128
+
+# ernie config ------
+encoding: "utf8"
+ernie_vocab_file: "./vocab.txt"
+ernie_config:
+ attention_probs_dropout_prob: 0.1
+ hidden_act: "relu"
+ hidden_dropout_prob: 0.1
+ hidden_size: 768
+ initializer_range: 0.02
+ max_position_embeddings: 513
+ num_attention_heads: 12
+ num_hidden_layers: 12
+ sent_type_vocab_size: 4
+ task_type_vocab_size: 3
+ vocab_size: 18000
+ use_task_id: false
+ use_fp16: false
diff --git a/examples/erniesage/config/erniesage_v1_gpu.yaml b/examples/erniesage/config/erniesage_v1_gpu.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..7b883fe3fa06332cf196d5142c40acaee8b98259
--- /dev/null
+++ b/examples/erniesage/config/erniesage_v1_gpu.yaml
@@ -0,0 +1,56 @@
+# Global Enviroment Settings
+#
+# trainer config ------
+learner_type: "gpu"
+optimizer_type: "adam"
+lr: 0.00005
+batch_size: 32
+CPU_NUM: 10
+epoch: 20
+log_per_step: 1
+save_per_step: 100
+output_path: "./output"
+ckpt_path: "./ernie_base_ckpt"
+
+# data config ------
+input_data: "./data.txt"
+graph_path: "./workdir"
+sample_workers: 1
+use_pyreader: true
+input_type: "text"
+
+# model config ------
+samples: [10]
+model_type: "ErnieSageModelV1"
+layer_type: "graphsage_sum"
+
+max_seqlen: 40
+
+num_layers: 1
+hidden_size: 128
+final_fc: true
+final_l2_norm: true
+loss_type: "hinge"
+margin: 0.3
+
+# infer config ------
+infer_model: "./output/last"
+infer_batch_size: 128
+
+# ernie config ------
+encoding: "utf8"
+ernie_vocab_file: "./vocab.txt"
+ernie_config:
+ attention_probs_dropout_prob: 0.1
+ hidden_act: "relu"
+ hidden_dropout_prob: 0.1
+ hidden_size: 768
+ initializer_range: 0.02
+ max_position_embeddings: 513
+ num_attention_heads: 12
+ num_hidden_layers: 12
+ sent_type_vocab_size: 4
+ task_type_vocab_size: 3
+ vocab_size: 18000
+ use_task_id: false
+ use_fp16: false
diff --git a/examples/erniesage/config/erniesage_v2_cpu.yaml b/examples/erniesage/config/erniesage_v2_cpu.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..77b78052122448dd8ced0fe8518c8ae1de858a32
--- /dev/null
+++ b/examples/erniesage/config/erniesage_v2_cpu.yaml
@@ -0,0 +1,56 @@
+# Global Enviroment Settings
+#
+# trainer config ------
+learner_type: "cpu"
+optimizer_type: "adam"
+lr: 0.00005
+batch_size: 4
+CPU_NUM: 16
+epoch: 3
+log_per_step: 1
+save_per_step: 100
+output_path: "./output"
+ckpt_path: "./ernie_base_ckpt"
+
+# data config ------
+input_data: "./data.txt"
+graph_path: "./workdir"
+sample_workers: 1
+use_pyreader: true
+input_type: "text"
+
+# model config ------
+samples: [10]
+model_type: "ErnieSageModelV2"
+
+max_seqlen: 40
+
+num_layers: 1
+hidden_size: 128
+final_fc: true
+final_l2_norm: true
+loss_type: "hinge"
+margin: 0.3
+neg_type: "batch_neg"
+
+# infer config ------
+infer_model: "./output/last"
+infer_batch_size: 128
+
+# ernie config ------
+encoding: "utf8"
+ernie_vocab_file: "./vocab.txt"
+ernie_config:
+ attention_probs_dropout_prob: 0.1
+ hidden_act: "relu"
+ hidden_dropout_prob: 0.1
+ hidden_size: 768
+ initializer_range: 0.02
+ max_position_embeddings: 513
+ num_attention_heads: 12
+ num_hidden_layers: 12
+ sent_type_vocab_size: 2
+ task_type_vocab_size: 3
+ vocab_size: 18000
+ use_task_id: false
+ use_fp16: false
diff --git a/examples/erniesage/config/erniesage_v2_gpu.yaml b/examples/erniesage/config/erniesage_v2_gpu.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..7a9b4afa380904463b2b57e0944c3c29a14c77ff
--- /dev/null
+++ b/examples/erniesage/config/erniesage_v2_gpu.yaml
@@ -0,0 +1,56 @@
+# Global Enviroment Settings
+#
+# trainer config ------
+learner_type: "gpu"
+optimizer_type: "adam"
+lr: 0.00005
+batch_size: 32
+CPU_NUM: 10
+epoch: 3
+log_per_step: 10
+save_per_step: 1000
+output_path: "./output"
+ckpt_path: "./ernie_base_ckpt"
+
+# data config ------
+input_data: "./data.txt"
+graph_path: "./workdir"
+sample_workers: 1
+use_pyreader: true
+input_type: "text"
+
+# model config ------
+samples: [10]
+model_type: "ErnieSageModelV2"
+
+max_seqlen: 40
+
+num_layers: 1
+hidden_size: 128
+final_fc: true
+final_l2_norm: true
+loss_type: "hinge"
+margin: 0.3
+neg_type: "batch_neg"
+
+# infer config ------
+infer_model: "./output/last"
+infer_batch_size: 128
+
+# ernie config ------
+encoding: "utf8"
+ernie_vocab_file: "./vocab.txt"
+ernie_config:
+ attention_probs_dropout_prob: 0.1
+ hidden_act: "relu"
+ hidden_dropout_prob: 0.1
+ hidden_size: 768
+ initializer_range: 0.02
+ max_position_embeddings: 513
+ num_attention_heads: 12
+ num_hidden_layers: 12
+ sent_type_vocab_size: 2
+ task_type_vocab_size: 3
+ vocab_size: 18000
+ use_task_id: false
+ use_fp16: false
diff --git a/examples/erniesage/config/erniesage_v3_cpu.yaml b/examples/erniesage/config/erniesage_v3_cpu.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2172a26133c9718358163f4495133720dbeb9eff
--- /dev/null
+++ b/examples/erniesage/config/erniesage_v3_cpu.yaml
@@ -0,0 +1,55 @@
+# Global Enviroment Settings
+#
+# trainer config ------
+learner_type: "cpu"
+optimizer_type: "adam"
+lr: 0.00005
+batch_size: 2
+CPU_NUM: 10
+epoch: 20
+log_per_step: 1
+save_per_step: 100
+output_path: "./output"
+ckpt_path: "./ernie_base_ckpt"
+
+# data config ------
+input_data: "./data.txt"
+graph_path: "./workdir"
+sample_workers: 1
+use_pyreader: true
+input_type: "text"
+
+# model config ------
+samples: [10]
+model_type: "ErnieSageModelV3"
+
+max_seqlen: 40
+
+num_layers: 1
+hidden_size: 128
+final_fc: true
+final_l2_norm: true
+loss_type: "hinge"
+margin: 0.3
+
+# infer config ------
+infer_model: "./output/last"
+infer_batch_size: 128
+
+# ernie config ------
+encoding: "utf8"
+ernie_vocab_file: "./vocab.txt"
+ernie_config:
+ attention_probs_dropout_prob: 0.1
+ hidden_act: "relu"
+ hidden_dropout_prob: 0.1
+ hidden_size: 768
+ initializer_range: 0.02
+ max_position_embeddings: 513
+ num_attention_heads: 12
+ num_hidden_layers: 12
+ sent_type_vocab_size: 4
+ task_type_vocab_size: 3
+ vocab_size: 18000
+ use_task_id: false
+ use_fp16: false
diff --git a/examples/erniesage/config/erniesage_v3_gpu.yaml b/examples/erniesage/config/erniesage_v3_gpu.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..e53ab33c41f8b8760e75d602bf1b8ed9f1735fb8
--- /dev/null
+++ b/examples/erniesage/config/erniesage_v3_gpu.yaml
@@ -0,0 +1,55 @@
+# Global Enviroment Settings
+#
+# trainer config ------
+learner_type: "gpu"
+optimizer_type: "adam"
+lr: 0.00005
+batch_size: 32
+CPU_NUM: 10
+epoch: 20
+log_per_step: 1
+save_per_step: 100
+output_path: "./output"
+ckpt_path: "./ernie_base_ckpt"
+
+# data config ------
+input_data: "./data.txt"
+graph_path: "./workdir"
+sample_workers: 1
+use_pyreader: true
+input_type: "text"
+
+# model config ------
+samples: [10]
+model_type: "ErnieSageModelV3"
+
+max_seqlen: 40
+
+num_layers: 1
+hidden_size: 128
+final_fc: true
+final_l2_norm: true
+loss_type: "hinge"
+margin: 0.3
+
+# infer config ------
+infer_model: "./output/last"
+infer_batch_size: 128
+
+# ernie config ------
+encoding: "utf8"
+ernie_vocab_file: "./vocab.txt"
+ernie_config:
+ attention_probs_dropout_prob: 0.1
+ hidden_act: "relu"
+ hidden_dropout_prob: 0.1
+ hidden_size: 768
+ initializer_range: 0.02
+ max_position_embeddings: 513
+ num_attention_heads: 12
+ num_hidden_layers: 12
+ sent_type_vocab_size: 4
+ task_type_vocab_size: 3
+ vocab_size: 18000
+ use_task_id: false
+ use_fp16: false
diff --git a/examples/erniesage/data.txt b/examples/erniesage/data.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e9aead6c89fa2fdbed64e5dada352106a8deb349
--- /dev/null
+++ b/examples/erniesage/data.txt
@@ -0,0 +1,1000 @@
+黑缘粗角肖叶甲触角有多大? 体长卵形,棕红色;鞘翅棕黄或淡棕色,外缘和中缝黑色或黑褐色;触角基部3、4节棕黄,余节棕色。
+黑缘粗角肖叶甲触角有多大? 头部刻点粗大,分布不均匀,头顶刻点十分稀疏;触角基部的内侧有一个三角形光瘤,唇基前缘呈半圆形凹切。
+黑缘粗角肖叶甲触角有多大? 触角近于体长之半,第1节粗大,棒状,第2节短,椭圆形,3、4两节细长,稍短于第5节,第5节基细端粗,末端6节明显粗大。
+黑缘粗角肖叶甲触角有多大? 前胸背板横宽,宽约为长的两倍,侧缘敞出较宽,圆形,敞边与盘区之间有一条细纵沟;盘区刻点相当密,前半部刻点较大于后半部。
+黑缘粗角肖叶甲触角有多大? 小盾片舌形,光亮,末端圆钝。
+黑缘粗角肖叶甲触角有多大? 鞘翅刻点粗大,不规则排列,肩部之后的刻点更为粗大,具皱褶,近中缝的刻点较小,略呈纵行排列。
+黑缘粗角肖叶甲触角有多大? 前胸前侧片前缘直;前胸后侧片具粗大刻点。
+黑缘粗角肖叶甲触角有多大? 足粗壮;胫节具纵脊,外端角向外延伸,呈弯角状;爪具附齿。
+暮光闪闪的姐姐是谁? 暮光闪闪是一匹雌性独角兽,后来在神秘魔法的影响下变成了空角兽(公主),她是《我的小马驹:友情是魔法》(英文名:My Little Pony:Friendship is Magic)中的主角之一。
+暮光闪闪的姐姐是谁? 她是银甲闪闪(Shining Armor)的妹妹,同时也是韵律公主(Princess Cadance)的小姑子。
+暮光闪闪的姐姐是谁? 在该系列中,她与最好的朋友与助手斯派克(Spike)一起生活在小马镇(Ponyville)的金橡图书馆(Golden Oak Library),研究友谊的魔法。
+暮光闪闪的姐姐是谁? 在暮光闪闪成为天角兽之前(即S3E13前),常常给塞拉丝蒂娅公主(Princess Celestia)关于友谊的报告。[1]
+暮光闪闪的姐姐是谁? 《我的小马驹:友谊是魔法》(英文名称:My Little Pony:Friendship is Magic)(简称MLP)
+暮光闪闪的姐姐是谁? 动画讲述了一只名叫做暮光闪闪(Twilight Sparkle)的独角兽(在SE3E13
+暮光闪闪的姐姐是谁? My Little Pony:Friendship is Magic[2]
+暮光闪闪的姐姐是谁? 后成为了天角兽),执行她的导师塞拉斯蒂娅公主(PrincessCelestia)的任务,在小马镇(Ponyville)学习关于友谊的知识。
+暮光闪闪的姐姐是谁? 她与另外五只小马,苹果杰克(Applejack)、瑞瑞(Rarity)、云宝黛西(Rainbow Dash)、小蝶(Fluttershy)与萍琪派(Pinkie Pie),成为了最要好的朋友。
+暮光闪闪的姐姐是谁? 每匹小马都分别代表了协律精华的6个元素:诚实,慷慨,忠诚,善良,欢笑,魔法,各自扮演着属于自己的重要角色。
+暮光闪闪的姐姐是谁? 此后,暮光闪闪(Twilight Sparkle)便与她认识的新朋友们开始了有趣的日常生活。
+暮光闪闪的姐姐是谁? 在动画中,随时可见她们在小马镇(Ponyville)的种种冒险、奇遇、日常等等。
+暮光闪闪的姐姐是谁? 同时,也在她们之间的互动和冲突中,寻找着最适合最合理的完美解决方案。
+暮光闪闪的姐姐是谁? “尽管小马国并不太平,六位主角之间也常常有这样那样的问题,但是他们之间的真情对待,使得这个童话世界已经成为不少人心中理想的世外桃源。”
+暮光闪闪的姐姐是谁? 暮光闪闪在剧情刚开始的时候生活在中心城(Canterlot),后来在夏日
+暮光闪闪的姐姐是谁? 暮光闪闪与斯派克(Spike)
+暮光闪闪的姐姐是谁? 庆典的时候被塞拉丝蒂娅公主派遣到小马镇执行检查夏日庆典的准备工作的任务。
+暮光闪闪的姐姐是谁? 在小马镇交到了朋友(即其余5个主角),并和她们一起使用协律精华(Elements of harmony)击败了梦魇之月。
+暮光闪闪的姐姐是谁? 并在塞拉丝蒂亚公主的许可下,留在小马镇继续研究友谊的魔法。
+暮光闪闪的姐姐是谁? 暮光闪闪的知识基本来自于书本,并且她相当不相信书本以外的“迷信”,因为这样她在S1E15里吃足了苦头。
+暮光闪闪的姐姐是谁? 在这之后,她也开始慢慢学会相信一些书本以外的东西。
+暮光闪闪的姐姐是谁? 暮光闪闪热爱学习,并且学习成绩相当好(从她可以立刻算出
+暮光闪闪的姐姐是谁? 的结果可以看
+暮光闪闪的姐姐是谁? 暮光闪闪的原型
+暮光闪闪的姐姐是谁? 出)。
+暮光闪闪的姐姐是谁? 相当敬爱自己的老师塞拉丝蒂亚公主甚至到了精神失常的地步。
+暮光闪闪的姐姐是谁? 在第二季中,曾因为无法交出关于友谊的报告而做出了疯狂的行为,后来被塞拉丝蒂亚公主制止,在这之后,暮光闪闪得到了塞拉丝蒂亚公主“不用定期交友谊报告”的许可。
+暮光闪闪的姐姐是谁? 于是暮光闪闪在后面的剧情中的主角地位越来越得不到明显的体现。
+暮光闪闪的姐姐是谁? 在SE3E13中,因为破解了白胡子星璇留下的神秘魔法而被加冕成为了天角兽(公主),被尊称为“闪闪公主”。
+暮光闪闪的姐姐是谁? 当小星座熊在小马镇引起恐慌的时候,暮光闪闪运用了自身强大的魔法将水库举起后装满牛奶,用牛奶将小星座熊安抚后,连着巨型奶瓶和小星座熊一起送回了小星座熊居住的山洞。
+我想知道红谷十二庭有哪些金融机构? 红谷十二庭是由汪氏集团旗下子公司江西尤金房地产开发有限公司携手城发投资共同开发的精品社区,项目占地面积约380亩,总建筑面积约41万平方米。
+我想知道红谷十二庭有哪些金融机构? 项目以建设人文型、生态型居住环境为规划目标;创造一个布局合理、功能齐全、交通便捷、绿意盎然、生活方便,有文化内涵的居住区。
+我想知道红谷十二庭有哪些金融机构? 金融机构:工商银行、建设银行、农业银行、中国银行红谷滩支行、商业银行红谷滩支行等
+我想知道红谷十二庭有哪些金融机构? 周边公园:沿乌砂河50米宽绿化带、乌砂河水岸公园、秋水广场、赣江市民公园
+我想知道红谷十二庭有哪些金融机构? 周边医院:新建县人民医院、开心人药店、中寰医院
+我想知道红谷十二庭有哪些金融机构? 周边学校:育新小学红谷滩校区、南师附小红谷滩校区、实验小学红谷滩校区中学:南昌二中红谷滩校区、南昌五中、新建二中、竞秀贵族学校
+我想知道红谷十二庭有哪些金融机构? 周边公共交通:112、204、211、219、222、227、238、501等20多辆公交车在本项目社区门前停靠
+我想知道红谷十二庭有哪些金融机构? 红谷十二庭处在南昌一江两城中的西城中心,位属红谷滩CBD文化公园中心——马兰圩中心组团,红谷滩中心区、红角洲、新建县三区交汇处,南临南期友好路、东接红谷滩中心区、西靠乌砂河水岸公园(50米宽,1000米长)。
+我想知道红谷十二庭有哪些金融机构? 交通便捷,景观资源丰富,生活配套设施齐全,出则繁华,入则幽静,是现代人居的理想地段。
+我想知道红谷十二庭有哪些金融机构? 红谷十二庭户型图
+苏琳最开始进入智通实业是担任什么职位? 现任广东智通人才连锁股份有限公司总裁,清华大学高级工商管理硕士。
+苏琳最开始进入智通实业是担任什么职位? 1994年,加入智通实业,从总经理秘书做起。
+苏琳最开始进入智通实业是担任什么职位? 1995年,智通实业决定进入人才服务行业,被启用去负责新公司的筹建及运营工作,在苏琳的努力下,智通人才智力开发有限公司成立。
+苏琳最开始进入智通实业是担任什么职位? 2003年,面对同城对手的激烈竞争,苏琳冷静对待,领导智通先后接管、并购了同城的腾龙、安达盛人才市场,,“品牌运作,连锁经营,差异制胜”成为苏琳屡屡制胜的法宝。
+苏琳最开始进入智通实业是担任什么职位? 2006年,苏琳先是将智通人才升级为“东莞市智通人才连锁有限公司”,一举成为广东省人才市场目前惟一的连锁机构,随后在东莞同时开设长安、松山湖、清溪等镇区分部,至此智通在东莞共有6个分部。
+苏琳最开始进入智通实业是担任什么职位? 一番大刀阔斧完成东莞布局后,苏琳确定下一个更为高远的目标——进军珠三角,向全国发展连锁机构。
+苏琳最开始进入智通实业是担任什么职位? 到2011年末,苏琳领导的智通人才已在珠三角的东莞、佛山、江门、中山等地,长三角的南京、宁波、合肥等地,中西部的南昌、长沙、武汉、重庆、西安等地设立了20多家连锁经营网点。
+苏琳最开始进入智通实业是担任什么职位? 除了财务副总裁之外,苏琳是智通人才核心管理高层当中唯一的女性,不管是要约采访的记者还是刚刚加入智通的员工,见到苏琳的第一面,都会有一种惊艳的感觉,“一位女企业家居然非常美丽和时尚?!”
+苏琳最开始进入智通实业是担任什么职位? 智通管理高层的另外6位男性成员,有一次同时接受一家知名媒体采访时,共同表达了对自己老板的“爱慕”之情,苏琳听后莞尔一笑,指着在座的这几位高层说道“其实,我更爱他们!”
+苏琳最开始进入智通实业是担任什么职位? 这种具有独特领导魅力的表述让这位记者唏嘘不已,同时由这样的一个细节让他感受到了智通管理团队的协作力量。
+谁知道黄沙中心小学的邮政编码是多少? 学校于1954年始建于棕树湾村,当时借用一间民房做教室,取名为“黄沙小学”,只有教师1人,学生8人。
+谁知道黄沙中心小学的邮政编码是多少? 1958年在大跃进精神的指导下,实行大集体,全乡集中办学,发展到12个班,300多学生,20名教职工。
+谁知道黄沙中心小学的邮政编码是多少? 1959年解散。
+谁知道黄沙中心小学的邮政编码是多少? 1959年下半年,在上级的扶持下,建了6间木房,搬到1960年学校所在地,有6名教师,3个班,60名学生。
+谁知道黄沙中心小学的邮政编码是多少? 1968年,开始招收一个初中班,“黄沙小学”改名为 “附小”。
+谁知道黄沙中心小学的邮政编码是多少? 当时已发展到5个班,8名教师,110多名学生。
+谁知道黄沙中心小学的邮政编码是多少? 增建土木结构教室两间。
+谁知道黄沙中心小学的邮政编码是多少? 1986年,初中、小学分开办学。
+谁知道黄沙中心小学的邮政编码是多少? 增建部分教师宿舍和教室,办学条件稍有改善,学校初具规模。
+谁知道黄沙中心小学的邮政编码是多少? 1996年,我校在市、县领导及希望工程主管部门的关怀下,决定改为“黄沙希望小学”并拨款32万元,新建一栋4层,12间教室的教学楼,教学条件大有改善。
+谁知道黄沙中心小学的邮政编码是多少? 当时发展到10个班,学生300多人,教职工19人,小学高级教师3人,一级教师7人,二级教师9人。
+谁知道黄沙中心小学的邮政编码是多少? 2003年下半年由于农村教育体制改革,撤销教育组,更名为“黄沙中心小学”。
+谁知道黄沙中心小学的邮政编码是多少? 学校现有在校生177人(含学前42人),设有学前至六年级共7个教学班。
+谁知道黄沙中心小学的邮政编码是多少? 有教师19人,其中大专以上学历11人,中师6人;小学高级教师14人,一级教师5人。
+谁知道黄沙中心小学的邮政编码是多少? 学校校园占地面积2050平方米,生均达15.29平方米,校舍建筑面积1645平方米,生均12.27平方米;设有教师办公室、自然实验、电教室(合二为一)、微机室、图书阅览室(合二为一)、体育室、广播室、少先队活动室。
+谁知道黄沙中心小学的邮政编码是多少? 广西壮族自治区桂林市临桂县黄沙瑶族乡黄沙街 邮编:541113[1]
+伊藤实华的职业是什么? 伊藤实华(1984年3月25日-)是日本的女性声优。
+伊藤实华的职业是什么? THREE TREE所属,东京都出身,身长149cm,体重39kg,血型AB型。
+伊藤实华的职业是什么? ポルノグラフィティのLION(森男)
+伊藤实华的职业是什么? 2000年
+伊藤实华的职业是什么? 犬夜叉(枫(少女时代))
+伊藤实华的职业是什么? 幻影死神(西亚梨沙)
+伊藤实华的职业是什么? 2001年
+伊藤实华的职业是什么? NOIR(ロザリー)
+伊藤实华的职业是什么? 2002年
+伊藤实华的职业是什么? 水瓶战记(柠檬)
+伊藤实华的职业是什么? 返乡战士(エイファ)
+伊藤实华的职业是什么? 2003年
+伊藤实华的职业是什么? 奇诺之旅(女子A(悲しい国))
+伊藤实华的职业是什么? 2004年
+伊藤实华的职业是什么? 爱你宝贝(坂下ミキ)
+伊藤实华的职业是什么? Get Ride! アムドライバー(イヴァン・ニルギース幼少期)
+伊藤实华的职业是什么? スクールランブル(花井春树(幼少时代))
+伊藤实华的职业是什么? 2005年
+伊藤实华的职业是什么? 光速蒙面侠21(虎吉)
+伊藤实华的职业是什么? 搞笑漫画日和(男子トイレの精、パン美先生)
+伊藤实华的职业是什么? 银牙伝说WEED(テル)
+伊藤实华的职业是什么? 魔女的考验(真部カレン、守山太郎)
+伊藤实华的职业是什么? BUZZER BEATER(レニー)
+伊藤实华的职业是什么? 虫师(“眼福眼祸”さき、“草を踏む音”沢(幼少时代))
+伊藤实华的职业是什么? 2006年
+伊藤实华的职业是什么? 魔女之刃(娜梅)
+伊藤实华的职业是什么? 反斗小王子(远藤レイラ)
+伊藤实华的职业是什么? 搞笑漫画日和2(パン美先生、フグ子、ダンサー、ヤマトの妹、女性)
+伊藤实华的职业是什么? 人造昆虫カブトボーグ V×V(ベネチアンの弟、东ルリ、园儿A)
+伊藤实华的职业是什么? 2007年
+爆胎监测与安全控制系统英文是什么? 爆胎监测与安全控制系统(Blow-out Monitoring and Brake System),是吉利全球首创,并拥有自主知识产权及专利的一项安全技术。
+爆胎监测与安全控制系统英文是什么? 这项技术主要是出于防止高速爆胎所导致的车辆失控而设计。
+爆胎监测与安全控制系统英文是什么? BMBS爆胎监测与安全控制系统技术于2004年1月28日正式获得中国发明专利授权。
+爆胎监测与安全控制系统英文是什么? 2008年第一代BMBS系统正式与世人见面,BMBS汇集国内外汽车力学、控制学、人体生理学、电子信息学等方面的专家和工程技术人员经过一百余辆试验车累计行程超过五百万公里的可靠性验证,以确保产品的可靠性。
+爆胎监测与安全控制系统英文是什么? BMBS技术方案的核心即是采用智能化自动控制系统,弥补驾驶员生理局限,在爆胎后反应时间为0.5秒,替代驾驶员实施行车制动,保障行车安全。
+爆胎监测与安全控制系统英文是什么? BMBS系统由控制系统和显示系统两大部分组成,控制系统由BMBS开关、BMBS主机、BMBS分机、BMBS真空助力器四部分组成;显示系统由GPS显示、仪表指示灯、语言提示、制动双闪灯组成。
+爆胎监测与安全控制系统英文是什么? 当轮胎气压高于或低于限值时,控制器声光提示胎压异常。
+爆胎监测与安全控制系统英文是什么? 轮胎温度过高时,控制器发出信号提示轮胎温度过高。
+爆胎监测与安全控制系统英文是什么? 发射器电量不足时,控制器显示低电压报警。
+爆胎监测与安全控制系统英文是什么? 发射器受到干扰长期不发射信号时,控制器显示无信号报警。
+爆胎监测与安全控制系统英文是什么? 当汽车电门钥匙接通时,BMBS首先进入自检程序,检测系统各部分功能是否正常,如不正常,BMBS报警灯常亮。
+走读干部现象在哪里比较多? 走读干部一般是指县乡两级干部家住县城以上的城市,本人在县城或者乡镇工作,要么晚出早归,要么周一去单位上班、周五回家过周末。
+走读干部现象在哪里比较多? 对于这种现象,社会上的议论多是批评性的,认为这些干部脱离群众、作风漂浮、官僚主义,造成行政成本增加和腐败。
+走读干部现象在哪里比较多? 截至2014年10月,共有6484名“走读干部”在专项整治中被查处。
+走读干部现象在哪里比较多? 这是中央首次大规模集中处理这一长期遭诟病的干部作风问题。
+走读干部现象在哪里比较多? 干部“走读”问题主要在乡镇地区比较突出,城市地区则较少。
+走读干部现象在哪里比较多? 从历史成因和各地反映的情况来看,产生“走读”现象的主要原因大致有四种:
+走读干部现象在哪里比较多? 现今绝大多数乡村都有通往乡镇和县城的石子公路甚至柏油公路,这无疑为农村干部的出行创造了便利条件,为“干部像候鸟,频往家里跑”创造了客观条件。
+走读干部现象在哪里比较多? 选调生、公务员队伍大多是学历较高的大学毕业生,曾在高校所在地的城市生活,不少人向往城市生活,他们不安心长期扎根基层,而是将基层当作跳板,因此他们往往成为“走读”的主力军。
+走读干部现象在哪里比较多? 公仆意识、服务意识淡化,是“走读”现象滋生的主观原因。
+走读干部现象在哪里比较多? 有些党员干部感到自己长期在基层工作,该为自己和家庭想想了。
+走读干部现象在哪里比较多? 于是,不深入群众认真调查研究、认真听取群众意见、认真解决群众的实际困难,也就不难理解了。
+走读干部现象在哪里比较多? 县级党政组织对乡镇领导干部管理的弱化和为基层服务不到位,导致“走读”问题得不到应有的制度约束,是“走读”问题滋长的组织原因。[2]
+走读干部现象在哪里比较多? 近些年来,我国一些地方的“干部走读”现象较为普遍,社会上对此议走读干部论颇多。
+走读干部现象在哪里比较多? 所谓“干部走读”,一般是指县乡两级干部家住县城以上的城市,本人在县城或者乡镇工作,要么早出晚归,要么周一去单位上班、周五回家过周末。
+走读干部现象在哪里比较多? 对于这种现象,社会上的议论多是批评性的,认为这些干部脱离群众、作风漂浮、官僚主义,造成行政成本增加和腐败。
+走读干部现象在哪里比较多? 干部走读之所以成为“千夫所指”,是因为这种行为增加了行政成本。
+走读干部现象在哪里比较多? 从根子上说,干部走读是城乡发展不平衡的产物,“人往高处走,水往低处流”,有了更加舒适的生活环境,不管是为了自己生活条件改善也好,还是因为子女教育也好,农村人口向城镇转移,这是必然结果。
+走读干部现象在哪里比较多? “干部走读”的另一个重要原因,是干部人事制度改革。
+走读干部现象在哪里比较多? 目前公务员队伍“凡进必考”,考上公务员的大多是学历较高的大学毕业生,这些大学毕业生来自各个全国各地,一部分在本地结婚生子,沉淀下来;一部分把公务员作为跳板,到基层后或考研,或再参加省考、国考,或想办法调回原籍。
+走读干部现象在哪里比较多? 再加上一些下派干部、异地交流任职干部,构成了看似庞大的“走读”队伍。
+走读干部现象在哪里比较多? 那么,“干部走读”有哪些弊端呢?
+走读干部现象在哪里比较多? 一是这些干部人在基层,心在城市,缺乏长期作战的思想,工作不安心。
+走读干部现象在哪里比较多? 周一来上班,周五回家转,对基层工作缺乏热情和感情;二是长期在省市直机关工作,对基层工作不熟悉不了解,工作不热心;三是长期走读,基层干群有工作难汇报,有困难难解决,群众不开心;四是干部来回走读,公车私驾,私费公报,把大量的经济负担转嫁给基层;五是对这些走读干部,基层管不了,上级监督难,节假日期间到哪里去、做什么事,基本处于失控和真空状态,各级组织和基层干群不放心。
+走读干部现象在哪里比较多? 特别需要引起警觉的是,由于少数走读干部有临时思想,满足于“当维持会长”,得过且过混日子,热衷于做一些急功近利、砸锅求铁的短期行为和政绩工程,不愿做打基础、管长远的实事好事,甚至怠政、疏政和懒于理政,影响了党和政府各项方针政策措施的落实,导致基层无政府主义、自由主义抬头,削弱了党和政府的领导,等到矛盾激化甚至不可收拾的时候,处理已是来之不及。
+走读干部现象在哪里比较多? 权利要与义务相等,不能只有义务而没有权利,或是只有权利没有义务。
+走读干部现象在哪里比较多? 如何真正彻底解决乡镇干部“走读”的现象呢?
+走读干部现象在哪里比较多? 那就必须让乡镇基层干部义务与权利相等。
+走读干部现象在哪里比较多? 如果不能解决基层干部待遇等问题,即使干部住村,工作上也不会有什么进展的。
+走读干部现象在哪里比较多? 所以,在政治上关心,在生活上照顾,在待遇上提高。
+走读干部现象在哪里比较多? 如,提高基层干部的工资待遇,增加通讯、交通补助;帮助解决子女入学及老人赡养问题;提拔干部优先考虑基层干部;干部退休时的待遇至少不低于机关干部等等。
+化州市良光镇东岸小学学风是什么? 学校全体教职工爱岗敬业,团结拼搏,勇于开拓,大胆创新,进行教育教学改革,努力开辟第二课堂的教学路子,并开通了网络校校通的交流合作方式。
+化州市良光镇东岸小学学风是什么? 现学校教师正在为创建安全文明校园而努力。
+化州市良光镇东岸小学学风是什么? 东岸小学位置偏僻,地处贫穷落后,是良光镇最偏远的学校,学校,下辖分教点——东心埇小学,[1]?。
+化州市良光镇东岸小学学风是什么? 学校2011年有教师22人,学生231人。
+化州市良光镇东岸小学学风是什么? 小学高级教师8人,小学一级教师10人,未定级教师4人,大专学历的教师6人,其余的都具有中师学历。
+化州市良光镇东岸小学学风是什么? 全校共设12个班,学校课程按标准开设。
+化州市良光镇东岸小学学风是什么? 东岸小学原来是一所破旧不堪,教学质量非常差的薄弱学校。
+化州市良光镇东岸小学学风是什么? 近几年来,在各级政府、教育部门及社会各界热心人士鼎力支持下,学校领导大胆改革创新,致力提高教学质量和教师水平,并加大经费投入,大大改善了办学条件,使学校由差变好,实现了大跨越。
+化州市良光镇东岸小学学风是什么? 学校建设性方面。
+化州市良光镇东岸小学学风是什么? 东岸小学属于革命老区学校,始建于1980年,从东心埇村祠堂搬到这个校址,1990年建造一幢建筑面积为800平方米的南面教学楼, 1998年老促会支持从北面建造一幢1800平方米的教学大楼。
+化州市良光镇东岸小学学风是什么? 学校在管理方面表现方面颇具特色,实现了各项制度的日常化和规范化。
+化州市良光镇东岸小学学风是什么? 学校领导有较强的事业心和责任感,讲求民主与合作,勤政廉政,依法治校,树立了服务意识。
+化州市良光镇东岸小学学风是什么? 学校一贯实施“德育为先,以人为本”的教育方针,制定了“团结,律已,拼搏,创新”的校训。
+化州市良光镇东岸小学学风是什么? 教育风为“爱岗敬业,乐于奉献”,学风为“乐学,勤学,巧学,会学”。
+化州市良光镇东岸小学学风是什么? 校内营造了尊师重教的氛围,形成了良好的校风和学风。
+化州市良光镇东岸小学学风是什么? 教师们爱岗敬业,师德高尚,治学严谨,教研教改气氛浓厚,获得喜人的教研成果。
+化州市良光镇东岸小学学风是什么? 近几年来,教师撰写的教育教学论文共10篇获得县市级以上奖励,获了镇级以上奖励的有100人次。
+化州市良光镇东岸小学学风是什么? 学校德育工作成绩显著,多年被评为“安全事故为零”的学校,良光镇先进学校。
+化州市良光镇东岸小学学风是什么? 特别是教学质量大大提高了。
+化州市良光镇东岸小学学风是什么? 这些成绩得到了上级及群众的充分肯定。
+化州市良光镇东岸小学学风是什么? 1.学校环境欠美观有序,学校大门口及校道有待改造。
+化州市良光镇东岸小学学风是什么? 2.学校管理制度有待改进,部分教师业务水平有待提高。
+化州市良光镇东岸小学学风是什么? 3.教师宿舍、教室及学生宿舍欠缺。
+化州市良光镇东岸小学学风是什么? 4.运动场不够规范,各类体育器材及设施需要增加。
+化州市良光镇东岸小学学风是什么? 5.学生活动空间少,见识面窄,视野不够开阔。
+化州市良光镇东岸小学学风是什么? 1.努力营造和谐的教育教学新气氛。
+化州市良光镇东岸小学学风是什么? 建立科学的管理制度,坚持“与时俱进,以人为本”,真正实现领导对教师,教师对学生之间进行“德治与情治”;学校的人文环境做到“文明,和谐,清新”;德育环境做到“自尊,律已,律人”;心理环境做到“安全,谦虚,奋发”;交际环境做到“团结合作,真诚助人”;景物环境做到“宜人,有序。”
+化州市良光镇东岸小学学风是什么? 营造学校与育人的新特色。
+我很好奇发射管的输出功率怎么样? 产生或放大高频功率的静电控制电子管,有时也称振荡管。
+我很好奇发射管的输出功率怎么样? 用于音频或开关电路中的发射管称调制管。
+我很好奇发射管的输出功率怎么样? 发射管是无线电广播、通信、电视发射设备和工业高频设备中的主要电子器件。
+我很好奇发射管的输出功率怎么样? 输出功率和工作频率是发射管的基本技术指标。
+我很好奇发射管的输出功率怎么样? 广播、通信和工业设备的发射管,工作频率一般在30兆赫以下,输出功率在1919年为2千瓦以下,1930年达300千瓦,70年代初已超过1000千瓦,效率高达80%以上。
+我很好奇发射管的输出功率怎么样? 发射管工作频率提高时,输出功率和效率都会降低,因此1936年首次实用的脉冲雷达工作频率仅28兆赫,80年代则已达 400兆赫以上。
+我很好奇发射管的输出功率怎么样? 40年代电视发射管的工作频率为数十兆赫,而80年代初,优良的电视发射管可在1000兆赫下工作,输出功率达20千瓦,效率为40%。
+我很好奇发射管的输出功率怎么样? 平面电极结构的小功率发射三极管可在更高的频率下工作。
+我很好奇发射管的输出功率怎么样? 发射管多采用同心圆筒电极结构。
+我很好奇发射管的输出功率怎么样? 阴极在最内层,向外依次为各个栅极和阳极。
+我很好奇发射管的输出功率怎么样? 图中,自左至右为阴极、第一栅、第二栅、栅极阴极组装件和装入阳极后的整个管子。
+我很好奇发射管的输出功率怎么样? 发射管
+我很好奇发射管的输出功率怎么样? 中小功率发射管多采用间热式氧化物阴极。
+我很好奇发射管的输出功率怎么样? 大功率发射管一般采用碳化钍钨丝阴极,有螺旋、直条或网笼等结构形式。
+我很好奇发射管的输出功率怎么样? 图为网笼式阴极。
+我很好奇发射管的输出功率怎么样? 栅极多用钼丝或钨丝绕制,或用钼片经电加工等方法制造。
+我很好奇发射管的输出功率怎么样? 栅极表面经镀金(或铂)或涂敷锆粉等处理,以降低栅极电子发射,使发射管稳定工作。
+我很好奇发射管的输出功率怎么样? 用气相沉积方法制造的石墨栅极,具有良好的性能。
+我很好奇发射管的输出功率怎么样? 发射管阳极直流输入功率转化为高频输出功率的部分约为75%,其余25%成为阳极热损耗,因此对发射管的阳极必须进行冷却。
+我很好奇发射管的输出功率怎么样? 中小功率发射管的阳极采取自然冷却方式,用镍、钼或石墨等材料制造,装在管壳之内,工作温度可达 600℃。
+我很好奇发射管的输出功率怎么样? 大功率发射管的阳极都用铜制成,并作为真空密封管壳的一部分,采用各种强制冷却方式。
+我很好奇发射管的输出功率怎么样? 各种冷却方式下每平方厘米阳极内表面的散热能力为:水冷100瓦;风冷30瓦;蒸发冷却250瓦;超蒸发冷却1000瓦以上,80年代已制成阳极损耗功率为1250千瓦的超蒸发冷却发射管。
+我很好奇发射管的输出功率怎么样? 发射管也常以冷却方式命名,如风冷发射管、水冷发射管和蒸发冷却发射管。
+我很好奇发射管的输出功率怎么样? 发射管管壳用玻璃或陶瓷制造。
+我很好奇发射管的输出功率怎么样? 小功率发射管内使用含钡的吸气剂;大功率发射管则采用锆、钛、钽等吸气材料,管内压强约为10帕量级。
+我很好奇发射管的输出功率怎么样? 发射管寿命取决于阴极发射电子的能力。
+我很好奇发射管的输出功率怎么样? 大功率发射管寿命最高记录可达8万小时。
+我很好奇发射管的输出功率怎么样? 发射四极管的放大作用和输出输入电路间的隔离效果优于三极管,应用最广。
+我很好奇发射管的输出功率怎么样? 工业高频振荡器普遍采用三极管。
+我很好奇发射管的输出功率怎么样? 五极管多用在小功率范围中。
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 鲁能领秀城中央公园位于鲁能领秀城景观中轴之上,总占地161.55亩,总建筑面积约40万平米,容积率为2.70,由22栋小高层、高层组成;其绿地率高达35.2%,环境优美,产品更加注重品质化、人性化和自然生态化,是鲁能领秀城的生态人居典范。
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 中央公园[1] 学区准现房,坐享鲁能领秀城成熟配套,成熟生活一步到位。
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 经典板式小高层,103㎡2+1房仅22席,稀市推出,错过再无;92㎡经典两房、137㎡舒适三房压轴登场!
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 物业公司:
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 济南凯瑞物业公司;深圳长城物业公司;北京盛世物业有限公司
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 绿化率:
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 42%
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 容积率:
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 2.70
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 暖气:
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 集中供暖
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 楼座展示:中央公园由22栋小高层、高层组成,3、16、17号楼分别是11层小高层,18层和28层的高层。
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 4号楼是23层,2梯3户。
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 项目位置:
+鬼青蛙在哪里有收录详情? 鬼青蛙这张卡可以从手卡把这张卡以外的1只水属性怪兽丢弃,从手卡特殊召唤。
+鬼青蛙在哪里有收录详情? 这张卡召唤·反转召唤·特殊召唤成功时,可以从自己的卡组·场上选1只水族·水属性·2星以下的怪兽送去墓地。
+鬼青蛙在哪里有收录详情? 此外,1回合1次,可以通过让自己场上1只怪兽回到手卡,这个回合通常召唤外加上只有1次,自己可以把「鬼青蛙」以外的1只名字带有「青蛙」的怪兽召唤。[1]
+鬼青蛙在哪里有收录详情? 游戏王卡包收录详情
+鬼青蛙在哪里有收录详情? [09/09/18]
+西湖区有多大? 西湖区是江西省南昌市市辖区。
+西湖区有多大? 为南昌市中心城区之一,有着2200多年历史,是一个物华天宝、人杰地灵的古老城区。
+西湖区有多大? 2004年南昌市老城区区划调整后,西湖区东起京九铁路线与青山湖区毗邻,南以洪城路东段、抚河路南段、象湖以及南隔堤为界与青云谱区、南昌县接壤,西凭赣江中心线与红谷滩新区交界,北沿中山路、北京西路与东湖区相连,所辖面积34.5平方公里,常住人口43万,管辖1个镇、10个街道办事处,设12个行政村、100个社区。
+西湖区有多大? (图)西湖区[南昌市]
+西湖区有多大? 西湖原为汉代豫章群古太湖的一部分,唐贞元15年(公元799年)洪恩桥的架设将东太湖分隔成东西两部分,洪恩桥以西谓之西湖,西湖区由此而得名。
+西湖区有多大? 西湖区在1926年南昌设市后分别称第四、五部分,六、七部分。
+西湖区有多大? 1949年解放初期分别称第三、四区。
+西湖区有多大? 1955年分别称抚河区、西湖区。
+西湖区有多大? 1980年两区合并称西湖区。[1]
+西湖区有多大? 辖:西湖街道、丁公路街道、广外街道、系马桩街道、绳金塔街道、朝阳洲街道、禾草街街道、十字街街道、瓦子角街道、三眼井街道、上海路街道、筷子巷街道、南站街道。[1]
+西湖区有多大? 2002年9月,由原筷子巷街道和原禾草街街道合并设立南浦街道,原广外街道与瓦子角街道的一部分合并设立广润门街道。
+西湖区有多大? 2002年12月1日设立桃源街道。
+西湖区有多大? 2004年区划调整前的西湖区区域:东与青山湖区湖坊乡插花接壤;西临赣江与红谷滩新区隔江相望;南以建设路为界,和青云谱区毗邻;北连中山路,北京西路,与东湖区交界。[1]
+西湖区有多大? 2002年9月,由原筷子巷街道和原禾草街街道合并设立南浦街道,原广外街道与瓦子角街道的一部分合并设立广润门街道。
+西湖区有多大? 2002年12月1日设立桃源街道。
+西湖区有多大? 2004年区划调整前的西湖区区域:东与青山湖区湖坊乡插花接壤;西临赣江与红谷滩新区隔江相望;南以建设路为界,和青云谱区毗邻;北连中山路,北京西路,与东湖区交界。
+西湖区有多大? 2004年9月7日,国务院批准(国函[2004]70号)调整南昌市市辖区部分行政区划:将西湖区朝阳洲街道的西船居委会划归东湖区管辖。
+西湖区有多大? 将青山湖区的桃花镇和湖坊镇的同盟村划归西湖区管辖。
+西湖区有多大? 将西湖区十字街街道的谷市街、洪城路、南关口、九四、新丰5个居委会,上海路街道的草珊瑚集团、南昌肠衣厂、电子计算机厂、江西涤纶厂、江地基础公司、曙光、商标彩印厂、南昌市染整厂、江南蓄电池厂、四机床厂、二进、国乐新村12个居委会,南站街道的解放西路东居委会划归青云谱区管辖。
+西湖区有多大? 将西湖区上海路街道的轻化所、洪钢、省人民检察院、电信城东分局、安康、省机械施工公司、省水利设计院、省安装公司、南方电动工具厂、江西橡胶厂、上海路北、南昌电池厂、东华计量所、南昌搪瓷厂、上海路新村、华安针织总厂、江西五金厂、三波电机厂、水文地质大队、二六○厂、省卫生学校、新世纪、上海路住宅区北、塔子桥北、南航、上海路住宅区南、沿河、南昌阀门厂28个居委会,丁公路街道的新魏路、半边街、师大南路、顺化门、岔道口东路、师大、广电厅、手表厂、鸿顺9个居委会,南站街道的工人新村北、工人新村南、商苑、洪都中大道、铁路第三、铁路第四、铁路第六7个居委会划归青山湖区管辖。
+西湖区有多大? 调整后,西湖区辖绳金塔、桃源、朝阳洲、广润门、南浦、西湖、系马桩、十字街、丁公路、南站10个街道和桃花镇,区人民政府驻孺子路。
+西湖区有多大? 调整前,西湖区面积31平方千米,人口52万。
+西湖区有多大? (图)西湖区[南昌市]
+西湖区有多大? 西湖区位于江西省省会南昌市的中心地带,具有广阔的发展空间和庞大的消费群体,商贸旅游、娱乐服务业等到各个行业都蕴藏着无限商机,投资前景十分广阔。
+西湖区有多大? 不仅水、电价格低廉,劳动力资源丰富,人均工资和房产价格都比沿海城市低,城区拥有良好的人居环境、低廉的投资成本,巨大的发展潜力。
+西湖区有多大? 105、316、320国道和京九铁路贯穿全境,把南北东西交通连成一线;民航可与上海、北京、广州、深圳、厦门、温州等到地通航,并开通了南昌-新加坡第一条国际航线;水运依托赣江可直达长江各港口;邮电通讯便捷,程控电话、数字微波、图文传真进入国际通讯网络;商检、海关、口岸等涉外机构齐全;水、电、气供应充足。
+西湖区有多大? (图)西湖区[南昌市]
+西湖区有多大? 西湖区,是江西省省会南昌市的中心城区,面积34.8平方公里,常住人口51.9万人,辖桃花镇、朝农管理处及10个街道,设13个行政村,116个社区居委会,20个家委会。[2]
+西湖区有多大? 2005年11月16日,南昌市《关于同意西湖区桃花镇、桃源、十字街街道办事处行政区划进行调整的批复》
+西湖区有多大? 1、同意将桃花镇的三道闸居委会划归桃源街道办事处管辖。
+青藏虎耳草花期什么时候? 青藏虎耳草多年生草本,高4-11.5厘米,丛生。
+青藏虎耳草花期什么时候? 花期7-8月。
+青藏虎耳草花期什么时候? 分布于甘肃(祁连山地)、青海(黄南、海南、海北)和西藏(加查)。
+青藏虎耳草花期什么时候? 生于海拔3 700-4 250米的林下、高山草甸和高山碎石隙。[1]
+青藏虎耳草花期什么时候? 多年生草本,高4-11.5厘米,丛生。
+青藏虎耳草花期什么时候? 茎不分枝,具褐色卷曲柔毛。
+青藏虎耳草花期什么时候? 基生叶具柄,叶片卵形、椭圆形至长圆形,长15-25毫米,宽4-8毫米,腹面无毛,背面和边缘具褐色卷曲柔毛,叶柄长1-3厘米,基部扩大,边缘具褐色卷曲柔毛;茎生叶卵形至椭圆形,长1.5-2厘米,向上渐变小。
+青藏虎耳草花期什么时候? 聚伞花序伞房状,具2-6花;花梗长5-19毫米,密被褐色卷曲柔毛;萼片在花期反曲,卵形至狭卵形,长2.5-4.2毫米,宽1.5-2毫米,先端钝,两面无毛,边缘具褐色卷曲柔毛,3-5脉于先端不汇合;花瓣腹面淡黄色且其中下部具红色斑点,背面紫红色,卵形、狭卵形至近长圆形,长2.5-5.2毫米,宽1.5-2.1毫米,先端钝,基部具长0.5-1毫米之爪,3-5(-7)脉,具2痂体;雄蕊长2-3.6毫米,花丝钻形;子房半下位,周围具环状花盘,花柱长1-1.5毫米。
+青藏虎耳草花期什么时候? 生于高山草甸、碎石间。
+青藏虎耳草花期什么时候? 分布青海、西藏、甘肃、四川等地。
+青藏虎耳草花期什么时候? [1]
+青藏虎耳草花期什么时候? 顶峰虎耳草Saxifraga cacuminum Harry Sm.
+青藏虎耳草花期什么时候? 对叶虎耳Saxifraga contraria Harry Sm.
+青藏虎耳草花期什么时候? 狭瓣虎耳草Saxifraga pseudohirculus Engl.
+青藏虎耳草花期什么时候? 唐古特虎耳草Saxifraga tangutica Engl.
+青藏虎耳草花期什么时候? 宽叶虎耳草(变种)Saxifraga tangutica Engl. var. platyphylla (Harry Sm.) J. T. Pan
+青藏虎耳草花期什么时候? 唐古特虎耳草(原变种)Saxifraga tangutica Engl. var. tangutica
+青藏虎耳草花期什么时候? 西藏虎耳草Saxifraga tibetica Losinsk.[1]
+青藏虎耳草花期什么时候? Saxifraga przewalskii Engl. in Bull. Acad. Sci. St. -Petersb. 29:115. 1883: Engl et Irmsch. in Bot. Jahrb. 48:580. f. 5E-H. 1912 et in Engl. Pflanzenr. 67(IV. 117): 107. f. 21 E-H. 1916; J. T. Pan in Acta Phytotax. Sin. 16(2): 16. 1978;中国高等植物图鉴补编2: 30. 1983; 西藏植物志 2: 483. 1985. [1]
+生产一支欧文冲锋枪需要多少钱? 欧文冲锋枪 Owen Gun 1945年,在新不列颠手持欧文冲锋枪的澳大利亚士兵 类型 冲锋枪 原产国 ?澳大利亚 服役记录 服役期间 1941年-1960年代 用户 参见使用国 参与战役 第二次世界大战 马来亚紧急状态 朝鲜战争 越南战争 1964年罗德西亚布什战争 生产历史 研发者 伊夫林·欧文(Evelyn Owen) 研发日期 1931年-1939年 生产商 约翰·莱萨特工厂 利特高轻武器工厂 单位制造费用 $ 30/枝 生产日期 1941年-1945年 制造数量 45,000-50,000 枝 衍生型 Mk 1/42 Mk 1/43 Mk 2/43 基本规格 总重 空枪: Mk 1/42:4.24 千克(9.35 磅) Mk 1/43:3.99 千克(8.8 磅) Mk 2/43:3.47 千克(7.65 磅) 全长 806 毫米(31.73 英吋) 枪管长度 247 毫米(9.72 英吋) 弹药 制式:9 × 19 毫米 原型:.38/200 原型:.45 ACP 口径 9 × 19 毫米:9 毫米(.357 英吋) .38/200:9.65 毫米(.38 英吋) .45 ACP:11.43 毫米(.45 英吋) 枪管 1 根,膛线7 条,右旋 枪机种类 直接反冲作用 开放式枪机 发射速率 理论射速: Mk 1/42:700 发/分钟 Mk 1/43:680 发/分钟 Mk 2/43:600 发/分钟 实际射速:120 发/分钟 枪口初速 380-420 米/秒(1,246.72-1,377.95 英尺/秒) 有效射程 瞄具装定射程:91.44 米(100 码) 最大有效射程:123 米(134.51 码) 最大射程 200 米(218.72 码) 供弹方式 32/33 发可拆卸式弹匣 瞄准具型式 机械瞄具:向右偏置的觇孔式照门和片状准星 欧文冲锋枪(英语:Owen Gun,正式名称:Owen Machine Carbine,以下简称为“欧文枪”)是一枝由伊夫林·(埃沃)·欧文(英语:Evelyn (Evo) Owen)于1939年研制、澳大利亚的首枝冲锋枪,制式型发射9 × 19 毫米鲁格手枪子弹。
+生产一支欧文冲锋枪需要多少钱? 欧文冲锋枪是澳大利亚唯一设计和主要服役的二战冲锋枪,并从1943年由澳大利亚陆军所使用,直到1960年代中期。
+生产一支欧文冲锋枪需要多少钱? 由新南威尔士州卧龙岗市出身的欧文枪发明者,伊夫林·欧文,在24岁时于1939年7月向悉尼维多利亚军营的澳大利亚陆军军械官员展示了他所设计的.22 LR口径“卡宾机枪”原型枪。
+生产一支欧文冲锋枪需要多少钱? 该枪却被澳大利亚陆军所拒绝,因为澳大利亚陆军在当时没有承认冲锋枪的价值。
+生产一支欧文冲锋枪需要多少钱? 随着战争的爆发,欧文加入了澳大利亚军队,并且成为一名列兵。
+生产一支欧文冲锋枪需要多少钱? 1940年9月,欧文的邻居,文森特·沃德尔(英语:Vincent Wardell),看到欧文家楼梯后面搁著一个麻布袋,里面放著一枝欧文枪的原型枪。
+生产一支欧文冲锋枪需要多少钱? 而文森特·沃德尔是坎布拉港的大型钢制品厂莱萨特公司的经理,他向欧文的父亲表明了他对其儿子的粗心大意感到痛心,但无论如何仍然解释了这款武器的历史。
+生产一支欧文冲锋枪需要多少钱? 沃德尔对欧文枪的简洁的设计留下了深刻的印象。
+生产一支欧文冲锋枪需要多少钱? 沃德尔安排欧文转调到陆军发明部(英语:Army Inventions Board),并重新开始在枪上的工作。
+生产一支欧文冲锋枪需要多少钱? 军队仍然持续地从负面角度查看该武器,但同时政府开始采取越来越有利的观点。
+生产一支欧文冲锋枪需要多少钱? 该欧文枪原型配备了装在顶部的弹鼓,后来让位给装在顶部的弹匣使用。
+生产一支欧文冲锋枪需要多少钱? 口径的选择亦花了一些时间去解决。
+生产一支欧文冲锋枪需要多少钱? 由于陆军有大批量的柯尔特.45 ACP子弹,它们决定欧文枪需要采用这种口径。
+生产一支欧文冲锋枪需要多少钱? 直到在1941年9月19日官方举办试验时,约翰·莱萨特工厂制成了9 毫米、.38/200和.45 ACP三种口径版本。
+生产一支欧文冲锋枪需要多少钱? 而从美、英进口的斯登冲锋枪和汤普森冲锋枪在试验中作为基准使用。
+生产一支欧文冲锋枪需要多少钱? 作为测试的一部分,所有的枪支都浸没在泥浆里,并以沙土覆盖,以模拟他们将会被使用时最恶劣的环境。
+生产一支欧文冲锋枪需要多少钱? 欧文枪是唯一在这测试中这样对待以后仍可正常操作的冲锋枪。
+生产一支欧文冲锋枪需要多少钱? 虽然测试表现出欧文枪具有比汤普森冲锋枪和司登冲锋枪更优秀的可靠性,陆军没有对其口径作出决定。
+生产一支欧文冲锋枪需要多少钱? 结果它在上级政府干预以后,陆军才下令9 毫米的衍生型为正式口径,并在1941年11月20日正式被澳大利亚陆军采用。
+生产一支欧文冲锋枪需要多少钱? 在欧文枪的寿命期间,其可靠性在澳大利亚部队中赢得了“军人的至爱”(英语:Digger's Darling)的绰号,亦有人传言它受到美军高度青睐。
+生产一支欧文冲锋枪需要多少钱? 欧文枪是在1942年开始正式由坎布拉港和纽卡斯尔的约翰·莱萨特工厂投入生产,在生产高峰期每个星期生产800 支。
+生产一支欧文冲锋枪需要多少钱? 1942年3月至1943年2月之间,莱萨特生产了28,000 枝欧文枪。
+生产一支欧文冲锋枪需要多少钱? 然而,最初的一批弹药类型竟然是错误的,以至10,000 枝欧文枪无法提供弹药。
+生产一支欧文冲锋枪需要多少钱? 政府再一次推翻军方的官僚主义作风??,并让弹药通过其最后的生产阶段,以及运送到当时在新几内亚与日军战斗的澳大利亚部队的手中。
+生产一支欧文冲锋枪需要多少钱? 在1941年至1945年间生产了约50,000 枝欧文枪。
+生产一支欧文冲锋枪需要多少钱? 在战争期间,欧文枪的平均生产成本为$ 30。[1]
+生产一支欧文冲锋枪需要多少钱? 虽然它是有点笨重,因为其可靠性,欧文枪在士兵当中变得非常流行。
+生产一支欧文冲锋枪需要多少钱? 它是如此成功,它也被新西兰、英国和美国订购。[2]
+生产一支欧文冲锋枪需要多少钱? 欧文枪后来也被澳大利亚部队在朝鲜战争和越南战争,[3]特别是步兵组的侦察兵。
+生产一支欧文冲锋枪需要多少钱? 这仍然是一枝制式的澳大利亚陆军武器,直到1960年代中期,它被F1冲锋枪所取代。
+第二届中国光伏摄影大赛因为什么政策而开始的? 光伏发电不仅是全球能源科技和产业发展的重要方向,也是我国具有国际竞争优势的战略性新兴产业,是我国保障能源安全、治理环境污染、应对气候变化的战略性选择。
+第二届中国光伏摄影大赛因为什么政策而开始的? 2013年7月以来,国家出台了《关于促进光伏产业健康发展的若干意见》等一系列政策,大力推进分布式光伏发电的应用,光伏发电有望走进千家万户,融入百姓民生。
+第二届中国光伏摄影大赛因为什么政策而开始的? 大赛主办方以此为契机,开启了“第二届中国光伏摄影大赛”的征程。
+悬赏任务有哪些类型? 悬赏任务,威客网站上一种任务模式,由雇主在威客网站发布任务,提供一定数额的赏金,以吸引威客们参与。
+悬赏任务有哪些类型? 悬赏任务数额一般在几十到几千不等,但也有几万甚至几十万的任务。
+悬赏任务有哪些类型? 主要以提交的作品的质量好坏作为中标标准,当然其中也带有雇主的主观喜好,中标人数较少,多为一个或几个,因此竞争激烈。
+悬赏任务有哪些类型? 大型悬赏任务赏金数额巨大,中标者也较多,但参与人也很多,对于身有一技之长的威客来讲,悬赏任务十分适合。
+悬赏任务有哪些类型? 悬赏任务的类型主要包括:设计类、文案类、取名类、网站类、编程类、推广类等等。
+悬赏任务有哪些类型? 每一类所适合的威客人群不同,报酬的多少也不同,比如设计类的报酬就比较高,一般都几百到几千,而推广类的计件任务报酬比较少,一般也就几块钱,但花费的时间很少,技术要求也很低。
+悬赏任务有哪些类型? 1.注册—登陆
+悬赏任务有哪些类型? 2.点击“我要发悬赏”—按照发布流程及提示提交任务要求。
+悬赏任务有哪些类型? 悬赏模式选择->网站托管赏金模式。
+悬赏任务有哪些类型? 威客网站客服稍后会跟发布者联系确认任务要求。
+悬赏任务有哪些类型? 3.没有问题之后就可以预付赏金进行任务发布。
+悬赏任务有哪些类型? 4.会员参与并提交稿件。
+悬赏任务有哪些类型? 5.发布者需要跟会员互动(每个提交稿件的会员都可以),解决问题,完善稿件,初步筛选稿件。
+悬赏任务有哪些类型? 6.任务发布期结束,进入选稿期(在筛选的稿件中选择最后满意的)
+悬赏任务有哪些类型? 7.发布者不满意现有稿件可选定一个会员修改至满意为止,或者加价延期重新开放任务进行征稿。
+悬赏任务有哪些类型? (重复第六步)没有问题后进入下一步。
+悬赏任务有哪些类型? 8:中标会员交源文件给发布者—发布者确认—任务结束—网站将赏金付给中标会员。
+悬赏任务有哪些类型? 1、任务发布者自由定价,自由确定悬赏时间,自由发布任务要求,自主确定中标会员和中标方案。
+悬赏任务有哪些类型? 2、任务发布者100%预付任务赏金,让竞标者坚信您的诚意和诚信。
+悬赏任务有哪些类型? 3、任务赏金分配原则:任务一经发布,网站收取20%发布费,中标会员获得赏金的80%。
+悬赏任务有哪些类型? 4、每个任务最终都会选定至少一个作品中标,至少一个竞标者获得赏金。
+悬赏任务有哪些类型? 5、任务发布者若未征集到满意作品,可以加价延期征集,也可让会员修改,会员也可以删除任务。
+悬赏任务有哪些类型? 6、任务发布者自己所在组织的任何人均不能以任何形式参加自己所发布的任务,一经发现则视为任务发布者委托威客网按照网站规则选稿。
+悬赏任务有哪些类型? 7、任务悬赏总金额低于100元(含100元)的任务,悬赏时间最多为7天。
+悬赏任务有哪些类型? 所有任务最长时间不超过30天(特殊任务除外),任务总金额不得低于50元。
+悬赏任务有哪些类型? 8、网赚类、注册类任务总金额不能低于300元人民币,计件任务每个稿件的平均单价不能低于1元人民币。
+悬赏任务有哪些类型? 9、延期任务只有3次加价机会,第1次加价不得低于任务金额的10%,第2次加价不得低于任务总金额的20%,第3次不得低于任务总金额的50%。
+悬赏任务有哪些类型? 每次延期不能超过15天,加价金额不低于50元,特殊任务可以适当加长。
+悬赏任务有哪些类型? 如果为计件任务,且不是网赚类任务,将免费延期,直至征集完规定数量的作品为止。
+悬赏任务有哪些类型? 10、如果威客以交接源文件要挟任务发布者,威客网将扣除威客相关信用值,并取消其中标资格,同时任务将免费延长相应的时间继续征集作品 。
+江湖令由哪些平台运营? 《江湖令》是以隋唐时期为背景的RPG角色扮演类网页游戏。
+江湖令由哪些平台运营? 集角色扮演、策略、冒险等多种游戏元素为一体,画面精美犹如客户端游戏,融合历史、江湖、武功、恩仇多种特色元素,是款不可多得的精品游戏大作。
+江湖令由哪些平台运营? 由ya247平台、91wan游戏平台、2918、4399游戏平台、37wan、6711、兄弟玩网页游戏平台,49you、Y8Y9平台、8090游戏等平台运营的,由07177游戏网发布媒体资讯的网页游戏。
+江湖令由哪些平台运营? 网页游戏《江湖令》由51游戏社区运营,是以隋唐时期为背景的RPG角色扮演类网页游戏。
+江湖令由哪些平台运营? 集角色扮演、策略、冒险等多种游戏元素为一体,画面精美犹如客户端游戏,融合历史、江湖、武功、恩仇多种特色元素,是款不可多得的精品游戏大作…
+江湖令由哪些平台运营? 背景故事:
+江湖令由哪些平台运营? 隋朝末年,隋炀帝暴政,天下民不聊生,义军四起。
+江湖令由哪些平台运营? 在这动荡的时代中,百姓生活苦不堪言,多少人流离失所,家破人亡。
+江湖令由哪些平台运营? 天下三大势力---飞羽营、上清宫、侠隐岛,也值此机会扩张势力,派出弟子出来行走江湖。
+江湖令由哪些平台运营? 你便是这些弟子中的普通一员,在这群雄并起的年代,你将如何选择自己的未来。
+江湖令由哪些平台运营? 所有的故事,便从瓦岗寨/江都大营开始……
+江湖令由哪些平台运营? 势力:
+江湖令由哪些平台运营? ①、飞羽营:【外功、根骨】
+江湖令由哪些平台运营? 南北朝时期,由北方政权创立的一个民间军事团体,经过多年的发展,逐渐成为江湖一大势力。
+江湖令由哪些平台运营? ②、上清宫:【外功、身法】
+江湖令由哪些平台运营? 道家圣地,宫中弟子讲求清静无为,以一种隐世的方式修炼,但身在此乱世,亦也不能独善其身。
+江湖令由哪些平台运营? ③、侠隐岛:【根骨、内力】
+江湖令由哪些平台运营? 位于偏远海岛上的一个世家,岛内弟子大多武功高强,但从不进入江湖行走,适逢乱世,现今岛主也决意作一翻作为。
+江湖令由哪些平台运营? 两大阵营:
+江湖令由哪些平台运营? 义军:隋唐末期,百姓生活苦不堪言,有多个有志之士组成义军,对抗当朝暴君,希望建立一个适合百姓安居乐业的天地。
+江湖令由哪些平台运营? 隋军:战争一起即天下打乱,隋军首先要镇压四起的义军,同时在内部慢慢改变现有的朝廷,让天下再次恢复到昔日的安定。
+江湖令由哪些平台运营? 一、宠物品质
+江湖令由哪些平台运营? 宠物的品质分为:灵兽,妖兽,仙兽,圣兽,神兽
+江湖令由哪些平台运营? 二、宠物获取途径
+江湖令由哪些平台运营? 完成任务奖励宠物(其他途径待定)。
+江湖令由哪些平台运营? 三、宠物融合
+江湖令由哪些平台运营? 1、在主界面下方的【宠/骑】按钮进入宠物界面,再点击【融合】即可进入融合界面进行融合,在融合界面可选择要融合的宠物进行融合
+江湖令由哪些平台运营? 2、融合后主宠的形态不变;
+江湖令由哪些平台运营? 3、融合后宠物的成长,品质,技能,经验,成长经验,等级都继承成长高的宠物;
+江湖令由哪些平台运营? 4、融合宠物技能冲突,则保留成长值高的宠物技能,如果不冲突则叠加在空余的技能位置。
+请问土耳其足球超级联赛是什么时候成立的? 土耳其足球超级联赛(土耳其文:Türkiye 1. Süper Futbol Ligi)是土耳其足球协会管理的职业足球联赛,通常简称“土超”,也是土耳其足球联赛中最高级别。
+请问土耳其足球超级联赛是什么时候成立的? 目前,土超联赛队伍共有18支。
+请问土耳其足球超级联赛是什么时候成立的? 土耳其足球超级联赛
+请问土耳其足球超级联赛是什么时候成立的? 运动项目 足球
+请问土耳其足球超级联赛是什么时候成立的? 成立年份 1959年
+请问土耳其足球超级联赛是什么时候成立的? 参赛队数 18队
+请问土耳其足球超级联赛是什么时候成立的? 国家 土耳其
+请问土耳其足球超级联赛是什么时候成立的? 现任冠军 费内巴切足球俱乐部(2010-2011)
+请问土耳其足球超级联赛是什么时候成立的? 夺冠最多队伍 费内巴切足球俱乐部(18次)
+请问土耳其足球超级联赛是什么时候成立的? 土耳其足球超级联赛(Türkiye 1. Süper Futbol Ligi)是土耳其足球协会管理的职业足球联赛,通常简称「土超」,也是土耳其足球联赛中最高级别。
+请问土耳其足球超级联赛是什么时候成立的? 土超联赛队伍共有18支。
+请问土耳其足球超级联赛是什么时候成立的? 土超联赛成立于1959年,成立之前土耳其国有多个地区性联赛。
+请问土耳其足球超级联赛是什么时候成立的? 土超联赛成立后便把各地方联赛制度统一起来。
+请问土耳其足球超级联赛是什么时候成立的? 一般土超联赛由八月开始至五月结束,12月至1月会有歇冬期。
+请问土耳其足球超级联赛是什么时候成立的? 十八支球队会互相对叠,各有主场和作客两部分,采计分制。
+请问土耳其足球超级联赛是什么时候成立的? 联赛枋最底的三支球队会降到土耳其足球甲级联赛作赛。
+请问土耳其足球超级联赛是什么时候成立的? 由2005-06年球季起,土超联赛的冠、亚军会取得参加欧洲联赛冠军杯的资格。
+请问土耳其足球超级联赛是什么时候成立的? 成立至今土超联赛乃由两支著名球会所垄断──加拉塔萨雷足球俱乐部和费内巴切足球俱乐部,截至2009-2010赛季,双方各赢得冠军均为17次。
+请问土耳其足球超级联赛是什么时候成立的? 土超联赛共有18支球队,采取双循环得分制,每场比赛胜方得3分,负方0分,平局双方各得1分。
+请问土耳其足球超级联赛是什么时候成立的? 如果两支球队积分相同,对战成绩好的排名靠前,其次按照净胜球来决定;如果有三支以上的球队分数相同,则按照以下标准来确定排名:1、几支队伍间对战的得分,2、几支队伍间对战的净胜球数,3、总净胜球数。
+请问土耳其足球超级联赛是什么时候成立的? 联赛第1名直接参加下个赛季冠军杯小组赛,第2名参加下个赛季冠军杯资格赛第三轮,第3名进入下个赛季欧洲联赛资格赛第三轮,第4名进入下个赛季欧洲联赛资格赛第二轮,最后三名降入下个赛季的土甲联赛。
+请问土耳其足球超级联赛是什么时候成立的? 该赛季的土耳其杯冠军可参加下个赛季欧洲联赛资格赛第四轮,如果冠军已获得冠军杯资格,则亚军可参加下个赛季欧洲联赛资格赛第四轮,否则名额递补给联赛。
+请问土耳其足球超级联赛是什么时候成立的? 2010年/2011年 费内巴切
+请问土耳其足球超级联赛是什么时候成立的? 2009年/2010年 布尔萨体育(又译贝莎)
+请问土耳其足球超级联赛是什么时候成立的? 2008年/2009年 贝西克塔斯
+请问土耳其足球超级联赛是什么时候成立的? 2007年/2008年 加拉塔萨雷
+请问土耳其足球超级联赛是什么时候成立的? 2006年/2007年 费内巴切
+请问土耳其足球超级联赛是什么时候成立的? 2005年/2006年 加拉塔沙雷
+请问土耳其足球超级联赛是什么时候成立的? 2004年/2005年 费内巴切(又译费伦巴治)
+请问土耳其足球超级联赛是什么时候成立的? 2003年/2004年 费内巴切
+cid 作Customer IDentity解时是什么意思? ? CID 是 Customer IDentity 的简称,简单来说就是手机的平台版本. CID紧跟IMEI存储在手机的OTP(One Time Programmable)芯片中. CID 后面的数字代表的是索尼爱立信手机软件保护版本号,新的CID不断被使用,以用来防止手机被非索尼爱立信官方的维修程序拿来解锁/刷机/篡改
+cid 作Customer IDentity解时是什么意思? ? CID 是 Customer IDentity 的简称,简单来说就是手机的平台版本. CID紧跟IMEI存储在手机的OTP(One Time Programmable)芯片中. CID 后面的数字代表的是索尼爱立信手机软件保护版本号,新的CID不断被使用,以用来防止手机被非索尼爱立信官方的维修程序拿来解锁/刷机/篡改
+cid 作Customer IDentity解时是什么意思? ? (英)刑事调查局,香港警察的重案组
+cid 作Customer IDentity解时是什么意思? ? Criminal Investigation Department
+cid 作Customer IDentity解时是什么意思? ? 佩枪:
+cid 作Customer IDentity解时是什么意思? ? 香港警察的CID(刑事侦缉队),各区重案组的探员装备短管点38左轮手枪,其特点是便于收藏,而且不容易卡壳,重量轻,其缺点是装弹量少,只有6发,而且换子弹较慢,威力也一般,如果碰上54式手枪或者M9手枪明显处于下风。
+cid 作Customer IDentity解时是什么意思? ? 香港警察的“刑事侦查”(Criminal Investigation Department)部门,早于1983年起已经不叫做C.I.D.的了,1983年香港警察队的重整架构,撤销了C.I.D. ( Criminal Investigation Dept.) “刑事侦缉处”,将“刑事侦查”部门归入去“行动处”内,是“行动处”内的一个分支部门,叫“刑事部”( Crime Wing )。
+cid 作Customer IDentity解时是什么意思? ? 再于90年代的一次警队重整架构,香港警队成立了新的「刑事及保安处」,再将“刑事侦查”部门归入目前的「刑事及保安处」的“处”级单位,是归入这个“处”下的一个部门,亦叫“刑事部” ( Crime Wing ),由一个助理警务处长(刑事)领导。
+cid 作Customer IDentity解时是什么意思? ? 但是时至今天,CID虽已经是一个老旧的名称,香港市民、甚至香港警察都是习惯性的沿用这个历史上的叫法 .
+cid 作Customer IDentity解时是什么意思? ? CID格式是美国Adobe公司发表的最新字库格式,它具有易扩充、速度快、兼容性好、简便、灵活等特点,已成为国内开发中文字库的热点,也为用户使用字库提供质量更好,数量更多的字体。
+cid 作Customer IDentity解时是什么意思? ? CID (Character identifier)就是字符识别码,在组成方式上分成CIDFont,CMap表两部分。
+cid 作Customer IDentity解时是什么意思? ? CIDFont文件即总字符集,包括了一种特定语言中所有常用的字符,把这些字符排序,它们在总字符集中排列的次序号就是各个字符的CID标识码(Index);CMap(Character Map)表即字符映像文件,将字符的编码(Code)映像到字符的CID标识码(Index)。
+cid 作Customer IDentity解时是什么意思? ? CID字库完全针对大字符集市场设计,其基本过程为:先根据Code,在CMap表查到Index,然后在CIDFont文件找到相应的字形数据。
+本町位于什么地方? 本条目记述台湾日治时期,各都市之本町。
+本町位于什么地方? 为台湾日治时期台北市之行政区,共分一~四丁目,在表町之西。
+本町位于什么地方? 以现在的位置来看,本町位于现台北市中正区的西北角,约位于忠孝西路一段往西至台北邮局东侧。
+本町位于什么地方? 再向南至开封街一段,沿此路线向西至开封街一段60号,顺60号到汉口街一段向东到现在华南银行总行附近画一条直线到衡阳路。
+本町位于什么地方? 再向东至重庆南路一段,由重庆南路一段回到原点这个范围内。
+本町位于什么地方? 另外,重庆南路一段在当时名为“本町通”。
+本町位于什么地方? 此地方自日治时期起,就是繁华的商业地区,当时也有三和银行、台北专卖分局、日本石油等重要商业机构。
+本町位于什么地方? 其中,专卖分局是战后二二八事件的主要起始点。
+本町位于什么地方? 台湾贮蓄银行(一丁目)
+本町位于什么地方? 三和银行(二丁目)
+本町位于什么地方? 专卖局台北分局(三丁目)
+本町位于什么地方? 日本石油(四丁目)
+本町位于什么地方? 为台湾日治时期台南市之行政区。
+本町位于什么地方? 范围包括清代旧街名枋桥头前、枋桥头后、鞋、草花、天公埕、竹仔、下大埕、帽仔、武馆、统领巷、大井头、内宫后、内南町。
+本町位于什么地方? 为清代台南城最繁华的区域。
+本町位于什么地方? 台南公会堂
+本町位于什么地方? 北极殿
+本町位于什么地方? 开基武庙
+本町位于什么地方? 町名改正
+本町位于什么地方? 这是一个与台湾相关的小作品。
+本町位于什么地方? 你可以通过编辑或修订扩充其内容。
+《行走的观点:埃及》的条形码是多少? 出版社: 上海社会科学院出版社; 第1版 (2006年5月1日)
+《行走的观点:埃及》的条形码是多少? 丛书名: 时代建筑视觉旅行丛书
+《行走的观点:埃及》的条形码是多少? 条形码: 9787806818640
+《行走的观点:埃及》的条形码是多少? 尺寸: 18 x 13.1 x 0.7 cm
+《行走的观点:埃及》的条形码是多少? 重量: 181 g
+《行走的观点:埃及》的条形码是多少? 漂浮在沙与海市蜃楼之上的金字塔曾经是否是你的一个梦。
+《行走的观点:埃及》的条形码是多少? 埃及,这片蕴蓄了5000年文明的土地,本书为你撩开它神秘的纱。
+《行走的观点:埃及》的条形码是多少? 诸神、金字塔、神庙、狮身人面像、法老、艳后吸引着我们的注意力;缠绵悱恻的象形文字、医学、雕刻等留给我们的文明,不断引发我们对古代文明的惊喜和赞叹。
+《行走的观点:埃及》的条形码是多少? 尼罗河畔的奇异之旅,数千年的古老文明,尽收在你的眼底……
+《行走的观点:埃及》的条形码是多少? 本书集历史、文化、地理等知识于一体,并以优美、流畅文笔,简明扼要地阐述了埃及的地理环境、政治经济、历史沿革、文化艺术,以大量富有艺术感染力的彩色照片,生动形象地展示了埃及最具特色的名胜古迹、风土人情和自然风光。
+《行走的观点:埃及》的条形码是多少? 古埃及历史
+老挝人民军的工兵部队有几个营? 老挝人民军前身为老挝爱国战线领导的“寮国战斗部队”(即“巴特寮”),始建于1949年1月20日,1965年10月改名为老挝人民解放军,1982年7月改称现名。
+老挝人民军的工兵部队有几个营? 最高领导机构是中央国防和治安委员会,朱马里·赛雅颂任主席,隆再·皮吉任国防部长。
+老挝人民军的工兵部队有几个营? 实行义务兵役制,服役期最少18个月。[1]
+老挝人民军的工兵部队有几个营? ?老挝军队在老挝社会中有较好的地位和保障,工资待遇比地方政府工作人员略高。
+老挝人民军的工兵部队有几个营? 武装部队总兵力约6万人,其中陆军约5万人,主力部队编为5个步兵师;空军2000多人;海军(内河巡逻部队)1000多人;部队机关院校5000人。[1]
+老挝人民军的工兵部队有几个营? 老挝人民军军旗
+老挝人民军的工兵部队有几个营? 1991年8月14日通过的《老挝人民民主共和国宪法》第11条规定:国家执行保卫国防和维护社会安宁的政策。
+老挝人民军的工兵部队有几个营? 全体公民和国防力量、治安力量必须发扬忠于祖国、忠于人民的精神,履行保卫革命成果、保卫人民生命财产及和平劳动的任务,积极参加国家建设事业。
+老挝人民军的工兵部队有几个营? 最高领导机构是中央国防和治安委员会。
+老挝人民军的工兵部队有几个营? 主席由老挝人民革命党中央委员会总书记兼任。
+老挝人民军的工兵部队有几个营? 老挝陆军成立最早,兵力最多,约有5万人。
+老挝人民军的工兵部队有几个营? 其中主力部队步兵师5个、7个独立团、30多个营、65个独立连。
+老挝人民军的工兵部队有几个营? 地方部队30余个营及县属部队。
+老挝人民军的工兵部队有几个营? 地面炮兵2个团,10多个营。
+老挝人民军的工兵部队有几个营? 高射炮兵1个团9个营。
+老挝人民军的工兵部队有几个营? 导弹部队2个营。
+老挝人民军的工兵部队有几个营? 装甲兵7个营。
+老挝人民军的工兵部队有几个营? 特工部队6个营。
+老挝人民军的工兵部队有几个营? 通讯部队9个营。
+老挝人民军的工兵部队有几个营? 工兵部队6个营。
+老挝人民军的工兵部队有几个营? 基建工程兵2个团13个营。
+老挝人民军的工兵部队有几个营? 运输部队7个营。
+老挝人民军的工兵部队有几个营? 陆军的装备基本是中国和前苏联援助的装备和部分从抗美战争中缴获的美式装备。
+老挝人民军的工兵部队有几个营? 老挝内河部队总兵力约1700人,装备有内河船艇110多艘,编成4个艇队。
+老挝人民军的工兵部队有几个营? 有芒宽、巴能、纳坎、他曲、南盖、巴色等8个基地。
+老挝人民军的工兵部队有几个营? 空军于1975年8月组建,现有2个团、11个飞行大队,总兵力约2000人。
+老挝人民军的工兵部队有几个营? 装备有各种飞机140架,其中主要由前苏联提供和从万象政权的皇家空军手中接管。
+老挝人民军的工兵部队有几个营? 随着军队建设质量的提高,老挝人民军对外军事合作步伐也日益扩大,近年来先后与俄罗斯、印度、马来西亚、越南、菲律宾等国拓展了军事交流与合作的内容。
+老挝人民军的工兵部队有几个营? 2003年1月,印度决定向老挝援助一批军事装备和物资,并承诺提供技术帮助。
+老挝人民军的工兵部队有几个营? 2003年6月,老挝向俄罗斯订购了一批新式防空武器;2003年4月,老挝与越南签署了越南帮助老挝培训军事指挥干部和特种部队以及完成军队通信系统改造等多项协议。
+《焚心之城》的主角是谁? 《焚心之城》[1] 为网络作家老子扛过枪创作的一部都市类小说,目前正在创世中文网连载中。
+《焚心之城》的主角是谁? 乡下大男孩薛城,是一个不甘于生活现状的混混,他混过、爱过、也深深地被伤害过。
+《焚心之城》的主角是谁? 本料此生当浑浑噩噩,拼搏街头。
+《焚心之城》的主角是谁? 高考的成绩却给了他一点渺茫的希望,二月后,大学如期吹响了他进城的号角。
+《焚心之城》的主角是谁? 繁华的都市,热血的人生,冷眼嘲笑中,他发誓再不做一个平常人!
+《焚心之城》的主角是谁? 江北小城,黑河大地,他要行走过的每一个角落都有他的传说。
+《焚心之城》的主角是谁? 扯出一面旗,拉一帮兄弟,做男人,就要多一份担当,活一口傲气。
+《焚心之城》的主角是谁? (日期截止到2014年10月23日凌晨)
+请问香港利丰集团是什么时候成立的? 香港利丰集团前身是广州的华资贸易 (1906 - 1949) ,利丰是香港历史最悠久的出口贸易商号之一。
+请问香港利丰集团是什么时候成立的? 于1906年,冯柏燎先生和李道明先生在广州创立了利丰贸易公司;是当时中国第一家华资的对外贸易出口商。
+请问香港利丰集团是什么时候成立的? 利丰于1906年创立,初时只从事瓷器及丝绸生意;一年之后,增添了其它的货品,包括竹器、藤器、玉石、象牙及其它手工艺品,包括烟花爆竹类别。
+请问香港利丰集团是什么时候成立的? 在早期的对外贸易,中国南方内河港因水深不足不能行驶远洋船,反之香港港口水深岸阔,占尽地利。
+请问香港利丰集团是什么时候成立的? 因此,在香港成立分公司的责任,落在冯柏燎先生的三子冯汉柱先生身上。
+请问香港利丰集团是什么时候成立的? 1937年12月28日,利丰(1937)有限公司正式在香港创立。
+请问香港利丰集团是什么时候成立的? 第二次世界大战期间,利丰暂停贸易业务。
+请问香港利丰集团是什么时候成立的? 1943年,随着创办人冯柏燎先生去世后,业务移交给冯氏家族第二代。
+请问香港利丰集团是什么时候成立的? 之后,向来不参与业务管理的合伙人李道明先生宣布退休,将所拥有的利丰股权全部卖给冯氏家族。
+请问香港利丰集团是什么时候成立的? 目前由哈佛冯家两兄弟William Fung , Victor Fung和CEO Bruce Rockowitz 管理。
+请问香港利丰集团是什么时候成立的? 截止到2012年,集团旗下有利亚﹝零售﹞有限公司、利和集团、利邦时装有限公司、利越时装有限公司、利丰贸易有限公司。
+请问香港利丰集团是什么时候成立的? 利亚(零售)连锁,业务包括大家所熟悉的:OK便利店、玩具〝反〞斗城和圣安娜饼屋;范围包括香港、台湾、新加坡、马来西亚、至中国大陆及东南亚其它市场逾600多家店
+请问香港利丰集团是什么时候成立的? 利和集团,IDS以专业物流服务为根基,为客户提供经销,物流,制造服务领域内的一系列服务项目。
+请问香港利丰集团是什么时候成立的? 业务网络覆盖大中华区,东盟,美国及英国,经营着90多个经销中心,在中国设有18个经销公司,10,000家现代经销门店。
+请问香港利丰集团是什么时候成立的? 利邦(上海)时装贸易有限公司为大中华区其中一家大型男士服装零售集团。
+请问香港利丰集团是什么时候成立的? 现在在中国大陆、香港、台湾和澳门收购经营11个包括Cerruti 1881,Gieves & Hawkes,Kent & curwen和D’urban 等中档到高档的男士服装品牌,全国有超过350间门店设于各一线城市之高级商场及百货公司。
+请问香港利丰集团是什么时候成立的? 利越(上海)服装商贸有限公司隶属于Branded Lifestyle,负责中国大陆地区LEO里奥(意大利)、GIBO捷宝(意大利)、UFFIZI古杰师(意大利)、OVVIO奥维路(意大利)、Roots绿适(加拿大,全球服装排名第四)品牌销售业务
+请问香港利丰集团是什么时候成立的? 利丰(贸易)1995年收购了英之杰采购服务,1999年收购太古贸易有限公司(Swire & Maclain) 和金巴莉有限公司(Camberley),2000年和2002年分别收购香港采购出口集团Colby Group及Janco Oversea Limited,大大扩张了在美国及欧洲的顾客群,自2008年经济危机起一直到现在,收购多家欧、美、印、非等地区的时尚品牌,如英国品牌Visage,仅2011年上半年6个月就完成26个品牌的收购。
+请问香港利丰集团是什么时候成立的? 2004年利丰与Levi Strauss & Co.签订特许经营协议
+请问香港利丰集团是什么时候成立的? 2005年利丰伙拍Daymon Worldwide为全球供应私有品牌和特许品牌
+请问香港利丰集团是什么时候成立的? 2006年收购Rossetti手袋业务及Oxford Womenswear Group 强化美国批发业务
+请问香港利丰集团是什么时候成立的? 2007年收购Tommy Hilfiher全球采购业务,收购CGroup、Peter Black International LTD、Regetta USA LLC和American Marketing Enterprice
+请问香港利丰集团是什么时候成立的? 2008年收购Kent&Curwen全球特许经营权,收购Van Zeeland,Inc和Miles Fashion Group
+请问香港利丰集团是什么时候成立的? 2009年收购加拿大休闲品牌Roots ,收购Wear Me Appearl,LLC。
+请问香港利丰集团是什么时候成立的? 与Hudson's Bay、Wolverine Worldwide Inc、Talbots、Liz Claiborne达成了采购协议
+请问香港利丰集团是什么时候成立的? 2010年收购Oxford apparel Visage Group LTD
+请问香港利丰集团是什么时候成立的? 2011年一月收购土耳其Modium、美国女性时尚Beyond Productions,三月收购贸易公司Celissa 、玩具公司Techno Source USA, Inc.、卡通品牌产品TVMania和法国著名时装一线品牌Cerruti 1881,五月收购Loyaltex Apparel Ltd.、女装Hampshire Designers和英国彩妆Collection 2000,六月收购家私贸易Exim Designs Co., Ltd.,七月收购家庭旅行产业Union Rich USA, LLC和设计公司Lloyd Textile Fashion Company Limited,八月收购童装Fishman & Tobin和Crimzon Rose,九月收购家私贸易True Innovations, LLC、日用品企业Midway Enterprises和Wonderful World。
+请问香港利丰集团是什么时候成立的? 十二月与USPA – U.S. Polo Association签署授权协议。
+请问香港利丰集团是什么时候成立的? 利丰的精神:积极进取,不断认识并争取有利于客户和自身进步的机会;以行动为主导,对客户、供应商及职工的需求作出快速的决定。
+请问香港利丰集团是什么时候成立的? 利丰的最终目标:在产品采购、销售、流转的各环节建立全球性队伍提供多元化服务,利丰成员有效合作,共达目标。
+如何使魔兽变种akt不被查杀? Trojan/PSW.Moshou.akt“魔兽”变种akt是“魔兽”木马家族的最新成员之一,采用Delphi 6.0-7.0编写,并经过加壳处理。
+如何使魔兽变种akt不被查杀? “魔兽”变种akt运行后,自我复制到被感染计算机的指定目录下。
+如何使魔兽变种akt不被查杀? 修改注册表,实现木马开机自动运行。
+如何使魔兽变种akt不被查杀? 自我注入到被感染计算机的“explorer.exe”、“notepad.exe”等用户级权限的进程中加载运行,隐藏自我,防止被查杀。
+如何使魔兽变种akt不被查杀? 在后台秘密监视用户打开的窗口标题,盗取网络游戏《魔兽世界》玩家的游戏帐号、游戏密码、角色等级、装备信息、金钱数量等信息,并在后台将窃取到的玩家信息发送到骇客指定的远程服务器上,致使玩家游戏帐号、装备物品、金钱等丢失,给游戏玩家造成非常大的损失。
+丙种球蛋白能预防什么病情? 丙种球蛋白预防传染性肝炎,预防麻疹等病毒性疾病感染,治疗先天性丙种球蛋白缺乏症 ,与抗生素合并使用,可提高对某些严重细菌性和病毒性疾病感染的疗效。
+丙种球蛋白能预防什么病情? 中文简称:“丙球”
+丙种球蛋白能预防什么病情? 英文名称:γ-globulin、gamma globulin
+丙种球蛋白能预防什么病情? 【别名】 免疫血清球蛋白,普通免疫球蛋白,人血丙种球蛋白,丙种球蛋白,静脉注射用人免疫球蛋白(pH4)
+丙种球蛋白能预防什么病情? 注:由于人血中的免疫球蛋白大多数为丙种球蛋白(γ-球蛋白),有时丙种球蛋白也被混称为“免疫球蛋白”(immunoglobulin) 。
+丙种球蛋白能预防什么病情? 冻干制剂应为白色或灰白色的疏松体,液体制剂和冻干制剂溶解后,溶液应为接近无色或淡黄色的澄明液体,微带乳光。
+丙种球蛋白能预防什么病情? 但不应含有异物或摇不散的沉淀。
+丙种球蛋白能预防什么病情? 注射丙种球蛋白是一种被动免疫疗法。
+丙种球蛋白能预防什么病情? 它是把免疫球蛋白内含有的大量抗体输给受者,使之从低或无免疫状态很快达到暂时免疫保护状态。
+丙种球蛋白能预防什么病情? 由于抗体与抗原相互作用起到直接中和毒素与杀死细菌和病毒。
+丙种球蛋白能预防什么病情? 因此免疫球蛋白制品对预防细菌、病毒性感染有一定的作用[1]。
+丙种球蛋白能预防什么病情? 人免疫球蛋白的生物半衰期为16~24天。
+丙种球蛋白能预防什么病情? 1、丙种球蛋白[2]含有健康人群血清所具有的各种抗体,因而有增强机体抵抗力以预防感染的作用。
+丙种球蛋白能预防什么病情? 2、主要治疗先天性丙种球蛋白缺乏症和免疫缺陷病
+丙种球蛋白能预防什么病情? 3、预防传染性肝炎,如甲型肝炎和乙型肝炎等。
+丙种球蛋白能预防什么病情? 4、用于麻疹、水痘、腮腺炎、带状疱疹等病毒感染和细菌感染的防治
+丙种球蛋白能预防什么病情? 5、也可用于哮喘、过敏性鼻炎、湿疹等内源性过敏性疾病。
+丙种球蛋白能预防什么病情? 6、与抗生素合并使用,可提高对某些严重细菌性和病毒性疾病感染的疗效。
+丙种球蛋白能预防什么病情? 7、川崎病,又称皮肤粘膜淋巴结综合征,常见于儿童,丙种球蛋白是主要的治疗药物。
+丙种球蛋白能预防什么病情? 1、对免疫球蛋白过敏或有其他严重过敏史者。
+丙种球蛋白能预防什么病情? 2、有IgA抗体的选择性IgA缺乏者。
+丙种球蛋白能预防什么病情? 3、发烧患者禁用或慎用。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (1997年9月1日浙江省第八届人民代表大会常务委员会第三十九次会议通过 1997年9月9日浙江省第八届人民代表大会常务委员会公告第六十九号公布自公布之日起施行)
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 为了保护人的生命和健康,发扬人道主义精神,促进社会发展与和平进步事业,根据《中华人民共和国红十字会法》,结合本省实际,制定本办法。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 本省县级以上按行政区域建立的红十字会,是中国红十字会的地方组织,是从事人道主义工作的社会救助团体,依法取得社会团体法人资格,设置工作机构,配备专职工作人员,依照《中国红十字会章程》独立自主地开展工作。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 全省性行业根据需要可以建立行业红十字会,配备专职或兼职工作人员。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 街道、乡(镇)、机关、团体、学校、企业、事业单位根据需要,可以依照《中国红十字会章程》建立红十字会的基层组织。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 上级红十字会指导下级红十字会的工作。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 县级以上地方红十字会指导所在行政区域行业红十字会和基层红十字会的工作。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 人民政府对红十字会给予支持和资助,保障红十字会依法履行职责,并对其活动进行监督;红十字会协助人民政府开展与其职责有关的活动。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 全社会都应当关心和支持红十字事业。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 本省公民和单位承认《中国红十字会章程》并缴纳会费的,可以自愿参加红十字会,成为红十字会的个人会员或团体会员。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 个人会员由本人申请,基层红十字会批准,发给会员证;团体会员由单位申请,县级以上红十字会批准,发给团体会员证。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 个人会员和团体会员应当遵守《中华人民共和国红十字会法》和《中国红十字会章程》,热心红十字事业,履行会员的义务,并享有会员的权利。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 县级以上红十字会理事会由会员代表大会民主选举产生。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 理事会民主选举产生会长和副会长;根据会长提名,决定秘书长、副秘书长人选。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 县级以上红十字会可以设名誉会长、名誉副会长和名誉理事,由同级红十字会理事会聘请。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 省、市(地)红十字会根据独立、平等、互相尊重的原则,发展同境外、国外地方红十字会和红新月会的友好往来和合作关系。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 红十字会履行下列职责:
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (一)宣传、贯彻《中华人民共和国红十字会法》和本办法;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (二)开展救灾的准备工作,筹措救灾款物;在自然灾害和突发事件中,对伤病人员和其他受害者进行救助;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (三)普及卫生救护和防病知识,进行初级卫生救护培训,对交通、电力、建筑、矿山等容易发生意外伤害的单位进行现场救护培训;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (四)组织群众参加现场救护;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (五)参与输血献血工作,推动无偿献血;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (六)开展红十字青少年活动;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (七)根据中国红十字会总会部署,参加国际人道主义救援工作;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (八)依照国际红十字和红新月运动的基本原则,完成同级人民政府和上级红十字会委托的有关事宜;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (九)《中华人民共和国红十宇会法》和《中国红十字会章程》规定的其他职责。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 第八条 红十字会经费的主要来源:
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (一)红十字会会员缴纳的会费;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (二)接受国内外组织和个人捐赠的款物;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (三)红十字会的动产、不动产以及兴办社会福利事业和经济实体的收入;
+宝湖庭院绿化率多少? 建发·宝湖庭院位于银川市金凤区核心地带—正源南街与长城中路交汇处向东500米。
+宝湖庭院绿化率多少? 项目已于2012年4月开工建设,总占地约4.2万平方米,总建筑面积约11.2万平方米,容积率2.14,绿化率35%,预计可入住630户。
+宝湖庭院绿化率多少? “建发·宝湖庭院”是银川建发集团股份有限公司继“建发·宝湖湾”之后,在宝湖湖区的又一力作。
+宝湖庭院绿化率多少? 项目周边发展成熟,东有唐徕渠景观水道,西临银川市交通主干道正源街;南侧与宝湖湿地公园遥相呼应。
+宝湖庭院绿化率多少? “宝湖庭院”项目公共交通资源丰富:15路、21路、35路、38路、43路公交车贯穿银川市各地,出行便利。
+宝湖庭院绿化率多少? 距离新百良田购物广场约1公里,工人疗养院600米,宝湖公园1公里,唐徕渠景观水道500米。
+宝湖庭院绿化率多少? 项目位置优越,购物、餐饮、医疗、交通、休闲等生活资源丰富。[1]
+宝湖庭院绿化率多少? 建发·宝湖庭院建筑及景观设置传承建发一贯“简约、大气”的风格:搂间距宽广,确保每一座楼宇视野开阔通透。
+宝湖庭院绿化率多少? 楼宇位置错落有置,外立面设计大气沉稳别致。
+宝湖庭院绿化率多少? 项目内部休闲绿地、景观小品点缀其中,道路及停车系统设计合理,停车及通行条件便利。
+宝湖庭院绿化率多少? 社区会所、幼儿园、活动室、医疗服务中心等生活配套一应俱全。
+宝湖庭院绿化率多少? 行政区域:金凤区
+大月兔(中秋艺术作品)的作者还有哪些代表作? 大月兔是荷兰“大黄鸭”之父弗洛伦泰因·霍夫曼打造的大型装置艺术作品,该作品首次亮相于台湾桃园大园乡海军基地,为了迎接中秋节的到来;在展览期间,海军基地也首次对外开放。
+大月兔(中秋艺术作品)的作者还有哪些代表作? 霍夫曼觉得中国神话中捣杵的玉兔很有想象力,于是特别创作了“月兔”,这也是“月兔”新作第一次展出。[1]
+大月兔(中秋艺术作品)的作者还有哪些代表作? ?2014年9月15日因工人施工不慎,遭火烧毁。[2]
+大月兔(中秋艺术作品)的作者还有哪些代表作? “大月兔”外表采用的杜邦防水纸、会随风飘动,内部以木材加保丽龙框架支撑做成。
+大月兔(中秋艺术作品)的作者还有哪些代表作? 兔毛用防水纸做成,材质完全防水,不怕日晒雨淋。[3
+大月兔(中秋艺术作品)的作者还有哪些代表作? -4]
+大月兔(中秋艺术作品)的作者还有哪些代表作? 25米的“月兔”倚靠在机
+大月兔(中秋艺术作品)的作者还有哪些代表作? 堡上望着天空,像在思考又像赏月。
+大月兔(中秋艺术作品)的作者还有哪些代表作? 月兔斜躺在机堡上,意在思考生命、边做白日梦,编织自己的故事。[3]
+大月兔(中秋艺术作品)的作者还有哪些代表作? 台湾桃园大园乡海军基地也首度对外开放。
+大月兔(中秋艺术作品)的作者还有哪些代表作? 428公顷的海军基地中,地景艺术节使用约40公顷,展场包括过去军机机堡、跑道等,由于这处基地过去警备森严,不对外开放,这次结合地景艺术展出,也可一窥过去是黑猫中队基地的神秘面纱。
+大月兔(中秋艺术作品)的作者还有哪些代表作? 2014年9月2日,桃园县政府文化局举行“踩线团”,让
+大月兔(中秋艺术作品)的作者还有哪些代表作? 大月兔
+大月兔(中秋艺术作品)的作者还有哪些代表作? 各项地景艺术作品呈现在媒体眼中,虽然“月兔”仍在进行最后的细节赶工,但横躺在机堡上的“月兔”雏形已经完工。[5]
+大月兔(中秋艺术作品)的作者还有哪些代表作? “这么大”、“好可爱呦”是不少踩线团成员对“月兔”的直觉;尤其在蓝天的衬托及前方绿草的组合下,呈现犹如真实版的爱丽丝梦游仙境。[6]
+大月兔(中秋艺术作品)的作者还有哪些代表作? 霍夫曼的作品大月兔,“从平凡中,创作出不平凡的视觉”,创造出观赏者打从心中油然而生的幸福感,拉近观赏者的距离。[6]
+大月兔(中秋艺术作品)的作者还有哪些代表作? 2014年9月15日早
+大月兔(中秋艺术作品)的作者还有哪些代表作? 上,施工人员要将月兔拆解,搬离海军基地草皮时,疑施工拆除的卡车,在拆除过程,故障起火,起火的卡车不慎延烧到兔子,造成兔子起火燃烧,消防队员即刻抢救,白色的大月兔立即变成焦黑的火烧兔。[7]
+大月兔(中秋艺术作品)的作者还有哪些代表作? 桃园县府表示相当遗憾及难过,也不排除向包商求偿,也已将此事告知霍夫曼。[2]
+大月兔(中秋艺术作品)的作者还有哪些代表作? ?[8]
+大月兔(中秋艺术作品)的作者还有哪些代表作? 弗洛伦泰因·霍夫曼,荷兰艺术家,以在公共空间创作巨大造型
+大月兔(中秋艺术作品)的作者还有哪些代表作? 物的艺术项目见长。
+大月兔(中秋艺术作品)的作者还有哪些代表作? 代表作品包括“胖猴子”(2010年在巴西圣保罗展出)、“大黄兔”(2011年在瑞典厄勒布鲁展出)、粉红猫(2014年5月在上海亮相)、大黄鸭(Rubber Duck)、月兔等。
+英国耆卫保险公司有多少保险客户? 英国耆卫保险公司(Old Mutual plc)成立于1845年,一直在伦敦证券交易所(伦敦证券交易所:OML)作第一上市,也是全球排名第32位(按营业收入排名)的保险公司(人寿/健康)。
+英国耆卫保险公司有多少保险客户? 公司是全球财富500强公司之一,也是被列入英国金融时报100指数的金融服务集团之一。
+英国耆卫保险公司有多少保险客户? Old Mutual 是一家国际金融服务公司,拥有近320万个保险客户,240万个银行储户,270,000个短期保险客户以及700,000个信托客户
+英国耆卫保险公司有多少保险客户? 英国耆卫保险公司(Old Mutual)是一家国际金融服务公司,总部设在伦敦,主要为全球客户提供长期储蓄的解决方案、资产管理、短期保险和金融服务等,目前业务遍及全球34个国家。[1]
+英国耆卫保险公司有多少保险客户? 主要包括人寿保险,资产管理,银行等。
+英国耆卫保险公司有多少保险客户? 1845年,Old Mutual在好望角成立。
+英国耆卫保险公司有多少保险客户? 1870年,董事长Charles Bell设计了Old Mutual公司的标记。
+英国耆卫保险公司有多少保险客户? 1910年,南非从英联邦独立出来。
+英国耆卫保险公司有多少保险客户? Old Mutual的董事长John X. Merriman被选为国家总理。
+英国耆卫保险公司有多少保险客户? 1927年,Old Mutual在Harare成立它的第一个事务所。
+英国耆卫保险公司有多少保险客户? 1960年,Old Mutual在南非成立了Mutual Unit信托公司,用来管理公司的信托业务。
+英国耆卫保险公司有多少保险客户? 1970年,Old Mutual的收入超过100百万R。
+英国耆卫保险公司有多少保险客户? 1980年,Old Mutual成为南非第一大人寿保险公司,年收入达10亿R。
+英国耆卫保险公司有多少保险客户? 1991年,Old Mutual在美国财富周刊上评选的全球保险公司中名列第38位。
+英国耆卫保险公司有多少保险客户? 1995年,Old Mutual在美国波士顿建立投资顾问公司,同年、又在香港和Guernsey建立事务所。
+英国耆卫保险公司有多少保险客户? 作为一项加强与其母公司联系的举措,OMNIA公司(百慕大)荣幸的更名为Old Mutual 公司(百慕大) 。
+英国耆卫保险公司有多少保险客户? 这一新的名称和企业识别清晰地展示出公司成为其世界金融机构合作伙伴强有力支持的决心。
+英国耆卫保险公司有多少保险客户? 2003 年4月,该公司被Old Mutual plc公司收购,更名为Sage Life(百慕大)公司并闻名于世,公司为Old Mutual公司提供了一个新的销售渠道,补充了其现有的以美元计价的产品线和分销系统。
+英国耆卫保险公司有多少保险客户? 达到了一个重要里程碑是公司成功的一个例证: 2005年6月3日公司资产超过10亿美元成为公司的一个主要里程碑,也是公司成功的一个例证。
+英国耆卫保险公司有多少保险客户? Old Mutual (百慕大)为客户提供一系列的投资产品。
+英国耆卫保险公司有多少保险客户? 在其开放的结构下,客户除了能够参与由Old Mutual会员管理的方案外,还能够参与由一些世界顶尖投资机构提供的投资选择。
+英国耆卫保险公司有多少保险客户? 首席执行官John Clifford对此发表评论说:“过去的两年对于Old Mutual家族来说是稳固发展的两年,更名是迫在眉睫的事情。
+英国耆卫保险公司有多少保险客户? 通过采用其名字和形象上的相似,Old Mutual (百慕大)进一步强化了与母公司的联系。”
+英国耆卫保险公司有多少保险客户? Clifford补充道:“我相信Old Mutual全球品牌认可度和Old Mutual(百慕大)产品专业知识的结合将在未来的日子里进一步推动公司的成功。”
+英国耆卫保险公司有多少保险客户? 随着公司更名而来的是公司网站的全新改版,设计投资选择信息、陈述、销售方案、营销材料和公告板块。
+英国耆卫保险公司有多少保险客户? 在美国购买不到OMNIA投资产品,该产品也不向美国公民或居民以及百慕大居民提供。
+英国耆卫保险公司有多少保险客户? 这些产品不对任何要约未得到批准的区域中的任何人,以及进行此要约或询价为非法行为的个人构成要约或询价。
+英国耆卫保险公司有多少保险客户? 关于Old Mutual(百慕大)公司
+英国耆卫保险公司有多少保险客户? Old Mutual(百慕大)公司总部位于百慕大,公司面向非美国居民及公民以及非百慕大居民,通过遍布世界的各个市场的金融机构开发和销售保险和投资方案。
+英国耆卫保险公司有多少保险客户? 这些方案由Old Mutual(百慕大)公司直接做出,向投资者提供各种投资选择和战略,同时提供死亡和其他受益保证。
+谁知道北京的淡定哥做了什么? 尼日利亚足球队守门员恩耶马被封淡定哥,原因是2010年南非世界杯上1:2落后希腊队时,对方前锋已经突破到禁区,其仍头依门柱发呆,其从容淡定令人吃惊。
+谁知道北京的淡定哥做了什么? 淡定哥
+谁知道北京的淡定哥做了什么? 在2010年6月17日的世界杯赛场上,尼日利亚1比2不敌希腊队,但尼日利亚门将恩耶马(英文名:Vincent Enyeama)在赛场上的“淡定”表现令人惊奇。
+谁知道北京的淡定哥做了什么? 随后,网友将赛场照片发布于各大论坛,恩耶马迅速窜红,并被网友称为“淡定哥”。
+谁知道北京的淡定哥做了什么? 淡定哥
+谁知道北京的淡定哥做了什么? 从网友上传得照片中可以看到,“淡定哥”在面临对方前锋突袭至小禁区之时,还靠在球门柱上发呆,其“淡定”程度的确非一般人所能及。
+谁知道北京的淡定哥做了什么? 恩耶马是尼日利亚国家队的主力守门员,目前效力于以色列的特拉维夫哈普尔队。
+谁知道北京的淡定哥做了什么? 1999年,恩耶马在尼日利亚国内的伊波姆星队开始职业生涯,后辗转恩伊姆巴、Iwuanyanwu民族等队,从07年开始,他为特拉维夫效力。
+谁知道北京的淡定哥做了什么? 恩耶马的尼日利亚国脚生涯始于2002年,截至2010年1月底,他为国家队出场已超过50次。
+谁知道北京的淡定哥做了什么? 当地时间2011年1月4日,国际足球历史与统计协会(IFFHS)公布了2010年度世界最佳门将,恩耶马(尼日利亚,特拉维夫夏普尔)10票排第十一
+谁知道北京的淡定哥做了什么? 此词经国家语言资源监测与研究中心等机构专家审定入选2010年年度新词语,并收录到《中国语言生活状况报告》中。
+谁知道北京的淡定哥做了什么? 提示性释义:对遇事从容镇定、处变不惊的男性的戏称。
+谁知道北京的淡定哥做了什么? 例句:上海现“淡定哥”:百米外爆炸他仍专注垂钓(2010年10月20日腾讯网http://news.qq.com/a/20101020/000646.htm)
+谁知道北京的淡定哥做了什么? 2011年度新人物
+谁知道北京的淡定哥做了什么? 1、淡定哥(北京)
+谁知道北京的淡定哥做了什么? 7月24日傍晚,北京市出现大范围降雨天气,位于通州北苑路出现积水,公交车也难逃被淹。
+谁知道北京的淡定哥做了什么? 李欣摄图片来源:新华网一辆私家车深陷积水,车主索性盘坐在自己的汽车上抽烟等待救援。
+谁知道北京的淡定哥做了什么? 私家车主索性盘坐在自己的车上抽烟等待救援,被网友称“淡定哥”
+谁知道北京的淡定哥做了什么? 2、淡定哥——林峰
+谁知道北京的淡定哥做了什么? 在2011年7月23日的动车追尾事故中,绍兴人杨峰(@杨峰特快)在事故中失去了5位亲人:怀孕7个月的妻子、未出世的孩子、岳母、妻姐和外甥女,他的岳父也在事故中受伤正在治疗。
+谁知道北京的淡定哥做了什么? 他披麻戴孝出现在事故现场,要求将家人的死因弄个明白。
+谁知道北京的淡定哥做了什么? 但在第一轮谈判过后,表示:“请原谅我,如果我再坚持,我将失去我最后的第六个亲人。”
+谁知道北京的淡定哥做了什么? 如果他继续“纠缠”铁道部,他治疗中的岳父将会“被死亡”。
+谁知道北京的淡定哥做了什么? 很多博友就此批评杨峰,并讽刺其为“淡定哥”。
+071型船坞登陆舰的北约代号是什么? 071型船坞登陆舰(英语:Type 071 Amphibious Transport Dock,北约代号:Yuzhao-class,中文:玉昭级,或以首舰昆仑山号称之为昆仑山级船坞登陆舰),是中国人民解放军海军隶下的大型多功能两栖船坞登陆舰,可作为登陆艇的母舰,用以运送士兵、步兵战车、主战坦克等展开登陆作战,也可搭载两栖车辆,具备大型直升机起降甲板及操作设施。
+071型船坞登陆舰的北约代号是什么? 071型两栖登陆舰是中国首次建造的万吨级作战舰艇,亦为中国大型多功能两栖舰船的开山之作,也可以说是中国万吨级以上大型作战舰艇的试验之作,该舰的建造使中国海军的两栖舰船实力有了质的提升。
+071型船坞登陆舰的北约代号是什么? 在本世纪以前中国海军原有的两栖舰队以一
+071型船坞登陆舰的北约代号是什么? 早期071模型
+071型船坞登陆舰的北约代号是什么? 千至四千吨级登陆舰为主要骨干,这些舰艇吨位小、筹载量有限,直升机操作能力非常欠缺,舰上自卫武装普遍老旧,对于现代化两栖登陆作战可说有很多不足。
+071型船坞登陆舰的北约代号是什么? 为了应对新时期的国际国内形势,中国在本世纪初期紧急强化两栖作战能力,包括短时间内密集建造072、074系列登陆舰,同时也首度设计一种新型船坞登陆舰,型号为071。[1]
+071型船坞登陆舰的北约代号是什么? 在两栖作战行动中,这些舰只不得不采取最危险的
+071型船坞登陆舰的北约代号是什么? 舾装中的昆仑山号
+071型船坞登陆舰的北约代号是什么? 敌前登陆方式实施两栖作战行动,必须与敌人预定阻击力量进行面对面的战斗,在台湾地区或者亚洲其他国家的沿海,几乎没有可用而不设防的海滩登陆地带,并且各国或者地区的陆军在战时,可能会很快控制这些易于登陆的海难和港口,这样就限制住了中国海军两栖登陆部队的实际登陆作战能力。
+071型船坞登陆舰的北约代号是什么? 071型登陆舰正是为了更快和更多样化的登陆作战而开发的新型登陆舰艇。[2]
+071型船坞登陆舰的北约代号是什么? 071型两栖船坞登陆舰具有十分良好的整体隐身能力,
+071型船坞登陆舰的北约代号是什么? 071型概念图
+071型船坞登陆舰的北约代号是什么? 该舰外部线条简洁干练,而且舰体外形下部外倾、上部带有一定角度的内倾,从而形成雷达隐身性能良好的菱形横剖面。
+071型船坞登陆舰的北约代号是什么? 舰体为高干舷平甲板型,长宽比较小,舰身宽满,采用大飞剪型舰首及楔形舰尾,舰的上层建筑位于舰体中间部位,后部是大型直升机甲板,适航性能非常突出。
+071型船坞登陆舰的北约代号是什么? 顶甲板上各类电子设备和武器系统布局十分简洁干净,各系统的突出物很少。
+071型船坞登陆舰的北约代号是什么? 该舰的两座烟囱实行左右分布式设置在舰体两侧,既考虑了隐身特点,也十分新颖。[3]
+071型船坞登陆舰的北约代号是什么? 1号甲板及上层建筑物主要设置有指挥室、控
+071型船坞登陆舰的北约代号是什么? 舰尾俯视
+071型船坞登陆舰的北约代号是什么? 制舱、医疗救护舱及一些居住舱,其中医疗救护舱设置有完备的战场救护设施,可以在舰上为伤病员提供紧急手术和野战救护能力。
+071型船坞登陆舰的北约代号是什么? 2号甲板主要是舰员和部分登陆人员的居住舱、办公室及厨房。
+071型船坞登陆舰的北约代号是什么? 主甲板以下则是登陆舱,分前后两段,前段是装甲车辆储存舱,共两层,可以储存登陆装甲车辆和一些其它物资,在进出口处还设有一小型升降机,用于两层之间的移动装卸用。
+071型船坞登陆舰的北约代号是什么? 前段车辆储存舱外壁左右各设有一折叠式装载舱门,所有装载车辆在码头可通过该门直接装载或者登陆上岸。
+071型船坞登陆舰的北约代号是什么? 后段是一个巨型船坞登陆舱,总长约70米,主要用来停泊大小型气垫登陆艇、机械登陆艇或车辆人员登陆艇。[4]
+071型船坞登陆舰的北约代号是什么? 自卫武装方面,舰艏设有一门PJ-26型76mm舰炮(
+071型船坞登陆舰的北约代号是什么? 井冈山号舰首主炮
+071型船坞登陆舰的北约代号是什么? 俄罗斯AK-176M的中国仿制版,亦被054A采用) , 四具与052B/C相同的726-4 18联装干扰弹发射器分置于舰首两侧以及上层结构两侧,近迫防御则依赖四座布置于上层结构的AK-630 30mm防空机炮 。
+071型船坞登陆舰的北约代号是什么? 原本071模型的舰桥前方设有一座八联装海红-7短程防空导弹发射器,不过071首舰直到出海试航与2009年4月下旬的海上阅兵式中,都未装上此一武器。
+071型船坞登陆舰的北约代号是什么? 电子装备方面, 舰桥后方主桅杆顶配置一具363S型E/F频2D对空/平面搜索雷达 、一具Racal Decca RM-1290 I频导航雷达,后桅杆顶装备一具拥有球型外罩的364型(SR-64)X频2D对空/对海搜索雷达,此外还有一具LR-66C舰炮射控雷达、一具负责导引AK-630机炮的TR-47C型火炮射控雷达等。[5]
+071型船坞登陆舰的北约代号是什么? 071型自卫武装布置
+071型船坞登陆舰的北约代号是什么? 071首舰昆仑山号于2006年6月开
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 竹溪县人大常委会办公室:承担人民代表大会会议、常委会会议、主任会议和常委会党组会议(简称“四会”)的筹备和服务工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责常委会组成人员视察活动的联系服务工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 受主任会议委托,拟定有关议案草案。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承担常委会人事任免的具体工作,负责机关人事管理和离退休干部的管理与服务。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承担县人大机关的行政事务和后勤保障工作,负责机关的安全保卫、文电处理、档案、保密、文印工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承担县人大常委会同市人大常委会及乡镇人大的工作联系。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责信息反馈工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 了解宪法、法律、法规和本级人大及其常委会的决议、决定实施情况及常委会成员提出建议办理情况,及时向常委会和主任会议报告。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承担人大宣传工作,负责人大常委会会议宣传的组织和联系。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 组织协调各专门工作委员会开展工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承办上级交办的其他工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 办公室下设五个科,即秘书科、调研科、人事任免科、综合科、老干部科。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 教科文卫工作委员会:负责人大教科文卫工作的日常联系、督办、信息收集反馈和业务指导工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责教科文卫方面法律法规贯彻和人大工作情况的宣传、调研工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承担人大常委会教科文卫方面会议议题调查的组织联系和调研材料的起草工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承担教科文卫方面规范性备案文件的初审工作,侧重对教科文卫行政执法个案监督业务承办工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责常委会组成人员和人大代表对教科文卫工作方面检查、视察的组织联系工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承办上级交办的其他工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 代表工作委员会:负责与县人大代表和上级人大代表的联系、情况收集交流工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责《代表法》的宣传贯彻和贯彻实施情况的调查研究工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责县人大代表法律法规和人民代表大会制度知识学习的组织和指导工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责常委会主任、副主任和委员走访联系人大代表的组织、联系工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责组织人大系统的干部培训。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责乡镇人大主席团工作的联系和指导。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责人大代表建议、批评和意见办理工作的联系和督办落实。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责人大代表开展活动的组织、联系工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承办上级交办的其他工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 财政经济工作委员会:负责人大财政经济工作的日常联系、督办、信息收集反馈和业务指导工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责财政经济方面法律法规贯彻和人大工作情况的宣传、调研工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 对国民经济计划和财政预算编制情况进行初审。
+我想知道武汉常住人口有多少? 武汉,简称“汉”,湖北省省会。
+我想知道武汉常住人口有多少? 它是武昌、汉口、汉阳三镇统称。
+我想知道武汉常住人口有多少? 世界第三大河长江及其最长支流汉江横贯市区,将武汉一分为三,形成武昌、汉口、汉阳,三镇跨江鼎立的格局。
+我想知道武汉常住人口有多少? 唐朝诗人李白在此写下“黄鹤楼中吹玉笛,江城五月落梅花”,因此武汉自古又称“江城”。
+我想知道武汉常住人口有多少? 武汉是中国15个副省级城市之一,全国七大中心城市之一,全市常住人口858万人。
+我想知道武汉常住人口有多少? 华中地区最大都市,华中金融中心、交通中心、文化中心,长江中下游特大城市。
+我想知道武汉常住人口有多少? 武汉城市圈的中心城市。
+我想知道武汉常住人口有多少? [3]武昌、汉口、汉阳三地被俗称武汉三镇。
+我想知道武汉常住人口有多少? 武汉西与仙桃市、洪湖市相接,东与鄂州市、黄石市接壤,南与咸宁市相连,北与孝感市相接,形似一只自西向东的蝴蝶形状。
+我想知道武汉常住人口有多少? 在中国经济地理圈内,武汉处于优越的中心位置是中国地理上的“心脏”,故被称为“九省通衢”之地。
+我想知道武汉常住人口有多少? 武汉市历史悠久,古有夏汭、鄂渚之名。
+我想知道武汉常住人口有多少? 武汉地区考古发现的历史可以上溯距今6000年的新石器时代,其考古发现有东湖放鹰台遗址的含有稻壳的红烧土、石斧、石锛以及鱼叉。
+我想知道武汉常住人口有多少? 市郊黄陂区境内的盘龙城遗址是距今约3500年前的商朝方国宫城,是迄今中国发现及保存最完整的商代古城之一。
+我想知道武汉常住人口有多少? 现代武汉的城市起源,是东汉末年的位于今汉阳的卻月城、鲁山城,和在今武昌蛇山的夏口城。
+我想知道武汉常住人口有多少? 东汉末年,地方军阀刘表派黄祖为江夏太守,将郡治设在位于今汉阳龟山的卻月城中。
+我想知道武汉常住人口有多少? 卻月城是武汉市区内已知的最早城堡。
+我想知道武汉常住人口有多少? 223年,东吴孙权在武昌蛇山修筑夏口城,同时在城内的黄鹄矶上修筑了一座瞭望塔——黄鹤楼。
+我想知道武汉常住人口有多少? 苏轼在《前赤壁赋》中说的“西望夏口,东望武昌”中的夏口就是指武汉(而当时的武昌则是今天的鄂州)。
+我想知道武汉常住人口有多少? 南朝时,夏口扩建为郢州,成为郢州的治所。
+我想知道武汉常住人口有多少? 隋置江夏县和汉阳县,分别以武昌,汉阳为治所。
+我想知道武汉常住人口有多少? 唐时江夏和汉阳分别升为鄂州和沔州的州治,成为长江沿岸的商业重镇。
+我想知道武汉常住人口有多少? 江城之称亦始于隋唐。
+我想知道武汉常住人口有多少? 两宋时武昌属鄂州,汉阳汉口属汉阳郡。
+我想知道武汉常住人口有多少? 经过发掘,武汉出土了大量唐朝墓葬,在武昌马房山和岳家咀出土了灰陶四神砖以及灰陶十二生肖俑等。
+我想知道武汉常住人口有多少? 宋代武汉的制瓷业发达。
+我想知道武汉常住人口有多少? 在市郊江夏区梁子湖旁发现了宋代瓷窑群100多座,烧制的瓷器品种很多,釉色以青白瓷为主。
+我想知道武汉常住人口有多少? 南宋诗人陆游在经过武昌时,写下“市邑雄富,列肆繁错,城外南市亦数里,虽钱塘、建康不能过,隐然一大都会也”来描写武昌的繁华。
+我想知道武汉常住人口有多少? 南宋抗金将领岳飞驻防鄂州(今武昌)8年,在此兴师北伐。
+我想知道武汉常住人口有多少? 元世祖至元十八年(1281年),武昌成为湖广行省的省治。
+我想知道武汉常住人口有多少? 这是武汉第一次成为一级行政单位(相当于现代的省一级)的治所。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 列夫·达维多维奇,托洛茨基是联共(布)党内和第三国际时期反对派的领导人,托派"第四国际"的创始人和领导人。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 列夫·达维多维奇·托洛茨基
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 列夫·达维多维奇·托洛茨基(俄国与国际历史上最重要的无产阶级革命家之一,二十世纪国际共产主义运动中最具争议的、也是备受污蔑的左翼反对派领袖,他以对古典马克思主义“不断革命论”的独创性发展闻名于世,第三共产国际和第四国际的主要缔造者之一(第三国际前三次代表大会的宣言执笔人)。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 在1905年俄国革命中被工人群众推举为彼得堡苏维埃主席(而当时布尔什维克多数干部却还在讨论是否支持苏维埃,这些干部后来被赶回俄国的列宁痛击)。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 1917年革命托洛茨基率领“区联派”与列宁派联合,并再次被工人推举为彼得格勒苏维埃主席。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 对于十月革命这场20世纪最重大的社会革命,托洛茨基赢得了不朽的历史地位。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 后来成了托洛茨基死敌的斯大林,当时作为革命组织领导者之一却写道:“起义的一切实际组织工作是在彼得格勒苏维埃主席托洛茨基同志直接指挥之下完成的。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 我们可以确切地说,卫戍部队之迅速站在苏维埃方面来,革命军事委员会的工作之所以搞得这样好,党认为这首先要归功于托洛茨基同志。”
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? (值得一提的是,若干年后,当反托成为政治需要时,此类评价都从斯大林文章中删掉了。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? )甚至连后来狂热的斯大林派雅克·沙杜尔,当时却也写道:“托洛茨基在十月起义中居支配地位,是起义的钢铁灵魂。”
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? (苏汉诺夫《革命札记》第6卷P76。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? )不仅在起义中,而且在无产阶级政权的捍卫、巩固方面和国际共产主义革命方面,托洛茨基也作出了极其卓越的贡献(外交官-苏联国际革命政策的负责人、苏联红军缔造者以及共产国际缔造者)。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 革命后若干年里,托洛茨基与列宁的画像时常双双并列挂在一起;十月革命之后到列宁病逝之前,布尔什维克历次全国代表大会上,代表大会发言结束均高呼口号:“我们的领袖列宁和托洛茨基万岁!”
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 在欧美共运中托洛茨基的威望非常高。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 后人常常认为托洛茨基只是一个知识分子文人,实际上他文武双全,而且谙熟军事指挥艺术,并且亲临战场。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 正是他作为十月革命的最高军事领袖(在十月革命期间他与士兵一起在战壕里作战),并且在1918年缔造并指挥苏联红军,是一个杰出的军事家(列宁曾对朋友说,除了托洛茨基,谁还能给我迅速地造成一支上百万人的强大军队?
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? )。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 在内战期间,他甚至坐装甲列车冒着枪林弹雨亲临战场指挥作战,差点挨炸死;当反革命军队进攻彼得堡时,当时的彼得堡领导人季诺维也夫吓得半死,托洛茨基却从容不迫指挥作战。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 同时托洛茨基又是一个高明的外交家,他曾强硬地要求英国政府释放因反战宣传被囚禁在英国的俄国流亡革命者,否则就不许英国公民离开俄国,连英国政府方面都觉得此举无懈可击;他并且把居高临下的法国到访者当场轰出他的办公室(革命前法国一直是俄国的头号债主与政治操纵者),却彬彬有礼地欢迎前来缓和冲突的法国大使;而在十月革命前夕,他对工人代表议会质询的答复既保守了即将起义的军事秘密,又鼓舞了革命者的战斗意志,同时严格遵循现代民主与公开原则,这些政治答复被波兰人多伊彻誉为“外交辞令的杰作”(伊·多伊彻的托氏传记<先知三部曲·武装的先知>第九章P335,第十一章P390)。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 托洛茨基在国民经济管理与研究工作中颇有创造:是苏俄新经济政策的首先提议者以及社会主义计划经济的首先实践者。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 1928年斯大林迟迟开始的计划经济实验,是对1923年以托洛茨基为首的左翼反对派经济纲领的拙劣剽窃和粗暴翻版。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 因为统治者的政策迟到,使得新经济政策到1928年已产生了一个威胁政权生存的农村资产阶级,而苏俄工人阶级国家不得不强力解决——而且是不得不借助已蜕化为官僚集团的强力来解决冲突——结果导致了1929年到30年代初的大饥荒和对农民的大量冤枉错杀。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 另外,他还对文学理论有很高的造诣,其著作<文学与革命>甚至影响了整整一代的国际左翼知识分子(包括中国的鲁迅、王实味等人)。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 他在哈佛大学图书馆留下了100多卷的<托洛茨基全集>,其生动而真诚的自传和大量私人日记、信件,给人留下了研究人类生活各个方面的宝贵财富,更是追求社会进步与解放的历史道路上的重要知识库之一。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 托洛茨基1879年10月26日生于乌克兰赫尔松县富裕农民家庭,祖籍是犹太人。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 原姓布隆施泰因。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 1896年开始参加工人运动。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 1897年 ,参加建立南俄工人协会 ,反对沙皇专制制度。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 1898年 在尼古拉也夫组织工人团体,被流放至西伯利亚。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 1902年秋以署名托洛茨基之假护照逃到伦敦,参加V.I.列宁、G.V.普列汉诺夫等人主编的<火星报>的工作。
+谁知道洞庭湖大桥有多长? 洞庭湖大桥,位于洞庭湖与长江交汇处,东接岳阳市区洞庭大道和107国道、京珠高速公路,西连省道306线,是国内目前最长的内河公路桥。
+谁知道洞庭湖大桥有多长? 路桥全长10173.82m,其中桥长5747.82m,桥宽20m,西双向四车道,是我国第一座三塔双索面斜拉大桥,亚洲首座不等高三塔双斜索面预应力混凝土漂浮体系斜拉桥。
+谁知道洞庭湖大桥有多长? 洞庭湖大桥是我国最长的内河公路桥,大桥横跨东洞庭湖区,全长10174.2米,主桥梁长5747.8米。
+谁知道洞庭湖大桥有多长? 大桥的通车使湘、鄂间公路干线大为畅通,并为洞庭湖区运输抗洪抢险物资提供了一条快速通道该桥设计先进,新颖,造型美观,各项技求指标先进,且为首次在国内特大型桥梁中采用主塔斜拉桥结构体系。
+谁知道洞庭湖大桥有多长? 洞庭湖大桥是湖区人民的造福桥,装点湘北门户的形象桥,对优化交通网络绪构,发展区域经济,保障防汛救灾,缩短鄂、豫、陕等省、市西部车辆南下的运距,拓展岳阳城区的主骨架,提升岳阳城市品位,增强城市辐射力,有着十分重要的意义。
+谁知道洞庭湖大桥有多长? 自1996年12月开工以来,共有10支施工队伍和两支监理队伍参与了大桥的建设。
+谁知道洞庭湖大桥有多长? 主桥桥面高52米(黄海),设计通航等级Ⅲ级。
+谁知道洞庭湖大桥有多长? 主桥桥型为不等高三塔、双索面空间索、全飘浮体系的预应力钢筋混凝土肋板梁式结构的斜拉桥,跨径为130+310+310+130米。
+谁知道洞庭湖大桥有多长? 索塔为双室宝石型断面,中塔高为125.684米,两边塔高为99.311米。
+谁知道洞庭湖大桥有多长? 三塔基础为3米和3.2米大直径钻孔灌注桩。
+谁知道洞庭湖大桥有多长? 引桥为连续梁桥,跨径20至50米,基础直径为1.8和2.5米钻孔灌注桩。
+谁知道洞庭湖大桥有多长? 该桥设计先进、新颖、造型美观,各项技求指标先进,且为首次在国内特大型桥梁中采用主塔斜拉桥结构体系,岳阳洞庭湖大桥是我国首次采用不等高三塔斜拉桥桥型的特大桥,设计先进,施工难度大位居亚洲之首,是湖南省桥梁界的一大科研项目。
+谁知道洞庭湖大桥有多长? 洞庭湖大桥设计为三塔斜拉桥,空间双斜面索,主梁采用前支点挂篮施工,并按各种工况模拟挂篮受力进行现场试验,获得了大量有关挂篮受力性能和实际刚度的计算参数,作为施工控制参数。
+谁知道洞庭湖大桥有多长? 利用组合式模型单元,推导了斜拉桥分离式双肋平板主梁的单元刚度矩阵,并进行了岳阳洞庭湖大桥的空间受力分析,结果表明此种单元精度满足工程要求,同时在施工工艺方面也积累了成功经验。
+谁知道洞庭湖大桥有多长? 洞庭湖大桥的通车使湘、鄂间公路干线大为畅通,并为洞庭湖区抗洪抢险物资运输提供了一条快速通道。
+谁知道洞庭湖大桥有多长? 湖大桥设计先进,造型美丽,科技含量高。
+谁知道洞庭湖大桥有多长? 洞庭大桥还是一道美丽的风景线,大桥沿岸风景与岳阳楼,君山岛、洞庭湖等风景名胜融为一体,交相辉映,成为世人了解岳阳的又一崭新窗口,也具有特别旅游资源。
+谁知道洞庭湖大桥有多长? 洞庭湖大桥多塔斜拉桥新技术研究荣获国家科学技术进步二等奖、湖南省科学技术进步一等奖,并获第五届詹天佑大奖。
+谁知道洞庭湖大桥有多长? 大桥在中国土木工程学会2004年第16届年会上入选首届《中国十佳桥梁》,名列斜拉桥第二位。
+谁知道洞庭湖大桥有多长? 2001年荣获湖南省建设厅优秀设计一等奖,省优秀勘察一等奖。
+谁知道洞庭湖大桥有多长? 2003年荣获国家优秀工程设计金奖, "十佳学术活动"奖。
+天气预报员的布景师是谁? 芝加哥天气预报员大卫(尼古拉斯·凯奇),被他的粉丝们热爱,也被诅咒--这些人在天气不好的时候会迁怒于他,而大部分时候,大卫都是在预报坏天气。
+天气预报员的布景师是谁? ?不过,这也没什么,当一家国家早间新闻节目叫他去面试的时候,大卫的事业似乎又将再创新高。
+天气预报员的布景师是谁? 芝加哥天气预报员大卫(尼古拉斯·凯奇),被他的粉丝们热爱,也被诅咒--这些人在天气不好的时候会迁怒于他,而大部分时候,大卫都是在预报坏天气。
+天气预报员的布景师是谁? 不过,这也没什么,当一家国家早间新闻节目叫他去面试的时候,大卫的事业似乎又将再创新高。
+天气预报员的布景师是谁? 在电视节目上,大卫永远微笑,自信而光鲜,就像每一个成功的电视人一样,说起收入,他也绝对不落人后。
+天气预报员的布景师是谁? 不过,大卫的个人生活可就不那么如意了。
+天气预报员的布景师是谁? 与妻子劳伦(霍普·戴维斯)的离婚一直让他痛苦;儿子迈克吸大麻上瘾,正在进行戒毒,可戒毒顾问却对迈克有着异样的感情;女儿雪莉则体重惊人,总是愁眉苦脸、孤独寂寞;大卫的父亲罗伯特(迈克尔·凯恩),一个世界著名的小说家,虽然罗伯特不想再让大卫觉得负担过重,可正是他的名声让大卫的一生都仿佛处在他的阴影之下,更何况,罗伯特就快重病死了。
+天气预报员的布景师是谁? 和妻子的离婚、父亲的疾病、和孩子之间完全不和谐的关系,都让大卫每天头疼,而每次当他越想控制局面,一切就越加复杂。
+天气预报员的布景师是谁? 然而就在最后人们再也不会向他扔快餐,或许是因为他总是背着弓箭在大街上走。
+天气预报员的布景师是谁? 最后,面对那份高额工作的接受意味着又一个新生活的开始。
+天气预报员的布景师是谁? 也许,生活就像天气,想怎么样就怎么样,完全不可预料。
+天气预报员的布景师是谁? 导 演:戈尔·维宾斯基 Gore Verbinski
+天气预报员的布景师是谁? 编 剧:Steve Conrad .....(written by)
+天气预报员的布景师是谁? 演 员:尼古拉斯·凯奇 Nicolas Cage .....David Spritz
+天气预报员的布景师是谁? 尼古拉斯·霍尔特 Nicholas Hoult .....Mike
+天气预报员的布景师是谁? 迈克尔·凯恩 Michael Caine .....Robert Spritzel
+天气预报员的布景师是谁? 杰蒙妮·德拉佩纳 Gemmenne de la Peña .....Shelly
+天气预报员的布景师是谁? 霍普·戴维斯 Hope Davis .....Noreen
+天气预报员的布景师是谁? 迈克尔·瑞斯玻利 Michael Rispoli .....Russ
+天气预报员的布景师是谁? 原创音乐:James S. Levine .....(co-composer) (as James Levine)
+天气预报员的布景师是谁? 汉斯·兹米尔 Hans Zimmer
+天气预报员的布景师是谁? 摄 影:Phedon Papamichael
+天气预报员的布景师是谁? 剪 辑:Craig Wood
+天气预报员的布景师是谁? 选角导演:Denise Chamian
+天气预报员的布景师是谁? 艺术指导:Tom Duffield
+天气预报员的布景师是谁? 美术设计:Patrick M. Sullivan Jr. .....(as Patrick Sullivan)
+天气预报员的布景师是谁? 布景师 :Rosemary Brandenburg
+天气预报员的布景师是谁? 服装设计:Penny Rose
+天气预报员的布景师是谁? 视觉特效:Charles Gibson
+天气预报员的布景师是谁? David Sosalla .....Pacific Title & Art Studio
+韩国国家男子足球队教练是谁? 韩国国家足球队,全名大韩民国足球国家代表队(???? ?? ?????),为韩国足球协会所于1928年成立,并于1948年加入国际足球协会。
+韩国国家男子足球队教练是谁? 韩国队自1986年世界杯开始,从未缺席任何一届决赛周。
+韩国国家男子足球队教练是谁? 在2002年世界杯,韩国在主场之利淘汰了葡萄牙、意大利及西班牙三支欧洲强队,最后夺得了殿军,是亚洲球队有史以来最好成绩。
+韩国国家男子足球队教练是谁? 在2010年世界杯,韩国也在首圈分组赛压倒希腊及尼日利亚出线次圈,再次晋身十六强,但以1-2败给乌拉圭出局。
+韩国国家男子足球队教练是谁? 北京时间2014年6月27日3时,巴西世界杯小组赛H组最后一轮赛事韩国对阵比利时,韩国队0-1不敌比利时,3场1平2负积1分垫底出局。
+韩国国家男子足球队教练是谁? 球队教练:洪明甫
+韩国国家男子足球队教练是谁? 韩国国家足球队,全名大韩民国足球国家代表队(韩国国家男子足球队???? ?? ?????),为韩国足球协会所于1928年成立,并于1948年加入国际足联。
+韩国国家男子足球队教练是谁? 韩国队是众多亚洲球队中,在世界杯表现最好,他们自1986年世界杯开始,从未缺席任何一届决赛周。
+韩国国家男子足球队教练是谁? 在2002年世界杯,韩国在主场之利淘汰了葡萄牙、意大利及西班牙三支欧洲强队,最后夺得了殿军,是亚洲球队有史以来最好成绩。
+韩国国家男子足球队教练是谁? 在2010年世界杯,韩国也在首圈分组赛压倒希腊及尼日利亚出线次圈,再次晋身十六强,但以1-2败给乌拉圭出局。
+韩国国家男子足球队教练是谁? 2014年世界杯外围赛,韩国在首轮分组赛以首名出线次轮分组赛,与伊朗、卡塔尔、乌兹别克以及黎巴嫩争逐两个直接出线决赛周资格,最后韩国仅以较佳的得失球差压倒乌兹别克,以小组次名取得2014年世界杯决赛周参赛资格,也是韩国连续八次晋身世界杯决赛周。
+韩国国家男子足球队教练是谁? 虽然韩国队在世界杯成绩为亚洲之冠,但在亚洲杯足球赛的成绩却远不及世界杯。
+韩国国家男子足球队教练是谁? 韩国只在首两届亚洲杯(1956年及1960年)夺冠,之后五十多年未能再度称霸亚洲杯,而自1992年更从未打入过决赛,与另一支东亚强队日本近二十年来四度在亚洲杯夺冠成强烈对比。[1]
+韩国国家男子足球队教练是谁? 人物简介
+韩国国家男子足球队教练是谁? 车范根(1953年5月22日-)曾是大韩民国有名的锋线选手,他被欧洲媒体喻为亚洲最佳输出球员之一,他也被认为是世界最佳足球员之一。
+韩国国家男子足球队教练是谁? 他被国际足球史料与数据协会评选为20世纪亚洲最佳球员。
+韩国国家男子足球队教练是谁? 他在85-86赛季是德甲的最有价值球员,直到1999年为止他都是德甲外国球员入球纪录保持者。
+韩国国家男子足球队教练是谁? 德国的球迷一直没办法正确说出他名字的发音,所以球车范根(左)迷都以炸弹车(Cha Boom)称呼他。
+韩国国家男子足球队教练是谁? 这也代表了他强大的禁区得分能力。
+韩国国家男子足球队教练是谁? 职业生涯
+韩国国家男子足球队教练是谁? 车范根生于大韩民国京畿道的华城市,他在1971年于韩国空军俱乐部开始了他的足球员生涯;同年他入选了韩国19岁以下国家足球队(U-19)。
+韩国国家男子足球队教练是谁? 隔年他就加入了韩国国家足球队,他是有史以来加入国家队最年轻的球员。
+韩国国家男子足球队教练是谁? 车范根在27岁时前往德国发展,当时德甲被认为是世界上最好的足球联赛。
+韩国国家男子足球队教练是谁? 他在1978年12月加入了达姆施塔特,不过他在那里只待了不到一年就转到当时的德甲巨人法兰克福。
+韩国国家男子足球队教练是谁? 车范根很快在新俱乐部立足,他帮助球队赢得79-80赛季的欧洲足协杯。
+韩国国家男子足球队教练是谁? 在那个赛季过后,他成为德甲薪水第三高的球员,不过在1981年对上勒沃库森的一场比赛上,他的膝盖严重受伤,几乎毁了他的足球生涯。
+韩国国家男子足球队教练是谁? 在1983年车范根转投勒沃库森;他在这取得很高的成就,他成为85-86赛季德甲的最有价值球员,并且在1988年帮助球队拿下欧洲足协杯,也是他个人第二个欧洲足协杯。
+韩国国家男子足球队教练是谁? 他在决赛对垒西班牙人扮演追平比分的关键角色,而球会才在点球大战上胜出。
+韩国国家男子足球队教练是谁? 车范根在1989年退休,他在308场的德甲比赛中进了98球,一度是德甲外国球员的入球纪录。
+韩国国家男子足球队教练是谁? 执教生涯
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 国立台湾科技大学,简称台湾科大、台科大或台科,是位于台湾台北市大安区的台湾第一所高等技职体系大专院校,现为台湾最知名的科技大学,校本部比邻国立台湾大学。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 该校已于2005年、2008年持续入选教育部的“发展国际一流大学及顶尖研究中心计划”。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? “国立”台湾工业技术学院成立于“民国”六十三年(1974)八月一日,为台湾地区第一所技术职业教育高等学府。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 建校之目的,在因应台湾地区经济与工业迅速发展之需求,以培养高级工程技术及管理人才为目标,同时建立完整之技术职业教育体系。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? “国立”台湾工业技术学院成立于“民国”六十三年(1974)八月一日,为台湾地区第一所技术职业教育高等学府。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 建校之目的,在因应台湾地区经济与工业迅速发展之需求,以培养高级工程技术及管理人才为目标,同时建立完整之技术职业教育体系。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 本校校地约44.5公顷,校本部位于台北市基隆路四段四十三号,。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 民国68年成立硕士班,民国71年成立博士班,现有大学部学生5,664人,研究生4,458人,专任教师451位。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 2001年在台湾地区教育部筹划之研究型大学(“国立”大学研究所基础教育重点改善计画)中,成为全台首批之9所大学之一 。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 自2005年更在“教育部”所推动“五年五百亿 顶尖大学”计划下,遴选为适合发展成“顶尖研究中心”的11所研究型大学之一。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 国立台湾科技大学部设有二年制、四年制及工程在职人员进修班等三种学制;凡二专、三专及五专等专科学校以上之毕业生,皆可以报考本校大学部二年制,而高职、高中毕业生,可以报考本校大学部四年制。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 工业管理、电子工程、机械工程、营建工程及应用外语系等,则设有在职人员进修班学制,其招生对象为在职人员,利用夜间及暑假期间上课。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 凡在本校大学部修毕应修学分且成绩及格者皆授予学士学位。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 国立台湾科技大学目前设有工程、电资、管理、设计、人文社会及精诚荣誉等六个学院,分别有机械、材料科学与工程、营建、化工、电子、电机、资工、工管、企管、资管、建筑、工商业设计、应用外语等13个系及校内招生之财务金融学士学位学程、科技管理学士学位学程;全校、工程、电资、管理、创意设计等五个不分系菁英班及光电研究所、管理研究所、财务金融研究所、科技管理研究所、管理学院MBA、数位学习教育研究所、医学工程研究所、自动化及控制研究所、工程技术研究所、专利研究所等独立研究所,此外尚有人文学科负责人文及社会类等课程之教学,通识学科负责法律、音乐、环保类等课程之教学,以及师资培育中心专以培养学生未来担任中等学校工、商、管理、设计等科之合格教师,合计23个独立系所、师资培育中心、人文学科及通识学科等教学单位。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 国立台湾科技大学至今各系所毕业校友已达约56,456位,毕业生出路包含出国继续深造、在台深造以及投身于产业界。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 由于实作经验丰富,理论基础完备,工作态度认真,毕业校友担任政府要职、大学教授、大学校长及企业主管者众多,深受各界的肯定。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 工商业设计系副教授孙春望与硕一生全明远耗时两个月自制之三分钟动画短片“立体悲剧”。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 本片入选有“动画奥斯卡”之称的“ACM SIGGRAPH”国际动画展,并获得观众票选第一名,这也是台湾首次入选及获奖的短片。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 击败了好莱坞知名导演史蒂芬·史匹柏的“世界大战”、乔治卢卡斯的“星际大战三部曲”、梦工厂出品的动画“马达加斯加”、军机缠斗片“机战未来”及美国太空总署、柏克莱加州大学等好莱坞名片及顶尖学术单位制作的短片。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 2009年荣获有工业设计界奥斯卡奖之称的“德国iF设计大奖”国立台湾科技大学设计学院获得大学排名的全球第二,仅次于韩国三星美术设计学院“SADI”。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 总体排名 依据《泰晤士高等教育》(THES-QS)在2009年的世界大学排名调查,台科大排名全世界第351名,在台湾所有大学中排名第五,仅次于台大,清大,成大及阳明,并且是台湾唯一进入世界四百大名校的科技大学。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 依据在欧洲拥有广大声誉的“Eduniversal商学院排名网”2008年的资料,台湾有七所大学的商管学院被分别列入世界1000大商学院,其中台科大位在“卓越商学院”(EXCELLENT Business Schools,国内主要)之列,“推荐程度”(Recommendation Rate)为全台第四,仅次于台大、政大、中山,与交大并列。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 目前设有工程、电资、管理、设计、人文社会及精诚荣誉学院等六个学院。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 预计于竹北新校区设立产学合作学院及应用理学院。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? ●台湾建筑科技中心
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? ●智慧型机械人研究中心科技成果展示(15张)
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? ●台湾彩卷与博彩研究中心
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? ●电力电子技术研发中心
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? ●NCP-Taiwan办公室
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? ●资通安全研究与教学中心
+在日本,神道最初属于什么信仰? 神道又称天道,语出《易经》“大观在上,顺而巽,中正以观天下。
+在日本,神道最初属于什么信仰? 观,盥而不荐,有孚顒若,下观而化也。
+在日本,神道最初属于什么信仰? 观天之神道,而四时不忒,圣人以神道设教,而天下服矣”。
+在日本,神道最初属于什么信仰? 自汉以降,神道又指“墓前开道,建石柱以为标”。
+在日本,神道最初属于什么信仰? 在中医中,神道,经穴名。
+在日本,神道最初属于什么信仰? 出《针灸甲乙经》。
+在日本,神道最初属于什么信仰? 别名冲道。
+在日本,神道最初属于什么信仰? 属督脉。
+在日本,神道最初属于什么信仰? 宗教中,神道是日本的本土传统民族宗教,最初以自然崇拜为主,属于泛灵多神信仰(精灵崇拜),视自然界各种动植物为神祇。
+在日本,神道最初属于什么信仰? 神道又称天道,语出《易经》“大观在上,顺而巽,中正以观天下。
+在日本,神道最初属于什么信仰? 观,盥而不荐,有孚顒若,下观而化也。
+在日本,神道最初属于什么信仰? 观天之神道,而四时不忒,圣人以神道设教,而天下服矣”。
+在日本,神道最初属于什么信仰? 自汉以降,神道又指“墓前开道,建石柱以为标”。
+在日本,神道最初属于什么信仰? 在中医中,神道,经穴名。
+在日本,神道最初属于什么信仰? 出《针灸甲乙经》。
+在日本,神道最初属于什么信仰? 别名冲道。
+在日本,神道最初属于什么信仰? 属督脉。
+在日本,神道最初属于什么信仰? 宗教中,神道是日本的本土传统民族宗教,最初以自然崇拜为主,属于泛灵多神信仰(精灵崇拜),视自然界各种动植物为神祇。
+在日本,神道最初属于什么信仰? 谓鬼神赐福降灾神妙莫测之道。
+在日本,神道最初属于什么信仰? 《易·观》:“观天之神道,而四时不忒,圣人以神道设教,而天下服矣。”
+在日本,神道最初属于什么信仰? 孔颖达 疏:“微妙无方,理不可知,目不可见,不知所以然而然,谓之神道。”
+在日本,神道最初属于什么信仰? 《文选·王延寿<鲁灵光殿赋>》:“敷皇极以创业,协神道而大宁。”
+在日本,神道最初属于什么信仰? 张载 注:“协和神明之道,而天下大宁。”
+在日本,神道最初属于什么信仰? 南朝 梁 刘勰 《文心雕龙·正纬》:“夫神道阐幽,天命微显。”
+在日本,神道最初属于什么信仰? 鲁迅 《中国小说史略》第五篇:“﹝ 干宝 ﹞尝感於其父婢死而再生,及其兄气绝复苏,自言见天神事,乃撰《搜神记》二十卷,以‘发明神道之不诬’。”
+在日本,神道最初属于什么信仰? 神道设教 观卦里面蕴含着《易经》固有的诸如神道设教、用舍行藏、以德化民等思想,是孔子把这些思想发掘出来。
+在日本,神道最初属于什么信仰? 「据此是孔子见当时之人,惑于吉凶祸福,而卜筮之史,加以穿凿傅会,故演易系辞,明义理,切人事,借卜筮以教后人,所谓以神道设教,其所发明者,实即羲文之义理,而非别有义理,亦非羲文并无义理,至孔子始言义理也,当即朱子之言而小变之曰,易为卜筮作,实为义理作,伏羲文王之易,有占而无文,与今人用火珠林起课者相似,孔子加卦爻辞如签辞,纯以理言,实即羲文本意,则其说分明无误矣。」
+在日本,神道最初属于什么信仰? 孔子所发掘的《易经》思想与孔子在《论语》书中表现出来的思想完全一致。
+在日本,神道最初属于什么信仰? 《易传》的思想反映了孔子的思想,这个思想是《周易》的,也是孔子的。
+在日本,神道最初属于什么信仰? 在《周易》和孔子看来,神不是有意识的人格化的上帝。
+奥林匹克里昂获得了几连霸? 里昂 Lyon 全名 Olympique lyonnais 绰号 Les Gones、OL 成立 1950年 城市 法国,里昂 主场 热尔兰球场(Stade Gerland) 容纳人数 41,044人 主席 奥拉斯 主教练 雷米·加尔德 联赛 法国足球甲级联赛 2013–14 法甲,第 5 位 网站 官方网站 主场球衣 客场球衣 第三球衣 日尔兰体育场 奥林匹克里昂(Olympique lyonnais,简称:OL及Lyon,中文简称里昂)是一间位于法国东南部罗纳-阿尔卑斯区的里昂市的足球会,成立于1950年8月3日,前身为里昂·奥林匹克(Lyon Olympique)体育俱乐部其中一个分支的足球队,1889年离开体育俱乐部自立门户成立新俱乐部,但官方网站表示俱乐部于1950年正式成立。
+奥林匹克里昂获得了几连霸? 现时在法国足球甲级联赛比赛,俱乐部同时设立男子及女子足球队。
+奥林匹克里昂获得了几连霸? 里昂是首届法国足球甲级联赛成员之一,可惜名列第十五位而降落乙组,1951年以乙级联赛冠军获得创会后首次锦标。
+奥林匹克里昂获得了几连霸? 球队在法国足球史上没有取得辉煌成绩,比较优异的算是六十年代曾杀入欧洲杯赛冠军杯四强,及3度晋身法国杯决赛并2次成功获冠。
+奥林匹克里昂获得了几连霸? 直至九十年代末里昂由辛天尼带领,先连续取得联赛头三名,到2002年终于首次登上法国顶级联赛冠军宝座,同年勒冈(Paul Le Guen)接替执教法国国家足球队的辛天尼,他其后继续带领里昂保持气势,加上队中球员小儒尼尼奧、迪亚拉、克里斯蒂亞諾·馬克斯·戈麥斯、迈克尔·埃辛、西德尼·戈武及门将格雷戈里·库佩表现突出,2003年至2005年横扫3届联赛冠军,创下连续四年夺得联赛锦标,平了1960年代末圣艾蒂安及1990年代初马赛的四连冠纪录。
+奥林匹克里昂获得了几连霸? 2005年前利物浦主教练热拉尔·霍利尔重返法国担任新任主教练,并加入葡萄牙中场蒂亚戈,和前巴伦西亚前锋约翰·卡鲁。
+奥林匹克里昂获得了几连霸? 他亦成功带领里昂赢得一届法甲冠军。
+奥林匹克里昂获得了几连霸? 2007年里昂成为首支上市的法国足球俱乐部,招股价21至24.4欧元,发行370万股,集资8400万欧元[1]。
+奥林匹克里昂获得了几连霸? 2007年4月21日,联赛次名图卢兹二比三不敌雷恩,令处于榜首的里昂领先次席多达17分距离,里昂因此提前六轮联赛庆祝俱乐部连续第六年夺得联赛冠军,亦是欧洲五大联赛(英格兰、德国、西班牙、意大利及法国)历史上首支联赛六连冠队伍[2]。
+奥林匹克里昂获得了几连霸? 在2007-08年赛季,里昂再一次成功卫冕联赛锦标,达成七连霸伟业。
+奥林匹克里昂获得了几连霸? 不过在2008-09赛季,里昂排名法甲第三位,联赛冠军被波尔多所获得。
+奥林匹克里昂获得了几连霸? 于2010年4月,里昂以两回合3比2的比分于欧洲冠军联赛击败波尔多跻身四强,此乃里昂首次晋级此项顶级杯赛的四强阶段。
+奥林匹克里昂获得了几连霸? 粗体字为新加盟球员
+奥林匹克里昂获得了几连霸? 以下球员名单更新于2014年8月27日,球员编号参照 官方网站,夏季转会窗为6月9日至8月31日
+火柴人刺杀行动怎么才能过关? 移动鼠标控制瞄准,点击鼠标左键进行射击。
+火柴人刺杀行动怎么才能过关? 游戏加载完成后点击STARTGAME-然后点击STARTMISSION即可开始游戏。
+火柴人刺杀行动怎么才能过关? 这里不仅仅考验的是你的枪法而且最重要的是你的智慧,喜欢火柴人类型游戏的玩家可以进来小试身手。
+火柴人刺杀行动怎么才能过关? 控制瞄准,刺杀游戏中的目标人物即可过关哦。
+你知道2月14日西方情人节是因何起源的吗? 情人节(英语:Valentine's Day),情人节的起源有多个版本,其中一个说法是在公元三世纪,古罗马暴君为了征召更多士兵,禁止婚礼,一名叫瓦伦丁Valentine的修士不理禁令,秘密替人主持婚礼,结果被收监,最后处死。
+你知道2月14日西方情人节是因何起源的吗? 而他死的那天就是2月14日,为纪念Valentine的勇敢精神,人们将每年的2月14日定为Valentine的纪念日。
+你知道2月14日西方情人节是因何起源的吗? 因此成了后来的“情人节”。
+你知道2月14日西方情人节是因何起源的吗? 另外,据记载,教宗在公元496年废除牧神节,把2月14日定为圣瓦伦丁日,即是St.Valentine's Day,后来成为是西方的节日之一。
+你知道2月14日西方情人节是因何起源的吗? 中文名称:情人节
+你知道2月14日西方情人节是因何起源的吗? 外文名称:Valentine‘s Day
+你知道2月14日西方情人节是因何起源的吗? 别名:情人节圣瓦伦丁节
+你知道2月14日西方情人节是因何起源的吗? 公历日期:2月14日
+你知道2月14日西方情人节是因何起源的吗? 起源时间:公元270年2月14日
+你知道2月14日西方情人节是因何起源的吗? 起源事件:人们为了纪念为情人做主而牺牲的瓦伦丁神父,把他遇害的那一天(2月14日)称为情人节。
+你知道2月14日西方情人节是因何起源的吗? 地区:欧美地区
+你知道2月14日西方情人节是因何起源的吗? 宗教:基督教
+你知道2月14日西方情人节是因何起源的吗? 其他信息:西方的传统节日之一。
+你知道2月14日西方情人节是因何起源的吗? 男女在这一天互送礼物(如贺卡和玫瑰花等)用以表达爱意或友好。
+你知道2月14日西方情人节是因何起源的吗? 据台湾“今日台湾人讨厌情人节新闻网”报道,西洋情人节即将来到,求职网进行“办公室恋情及情人节调查”发现,在目前全台上班族的感情状态中,有情人相伴的比率约5成5,4成5的上班族单身;较出乎意料的结果是,情人节以近3成(28%)的占比,登上最讨厌的节日第一名,端午节以24.3%居第二;农历年则以18.2%居第三;第四名是圣诞节,占12.4%。
+你知道2月14日西方情人节是因何起源的吗? 调查指出,情人节对单身族来说,不仅成为压力,也显得更加孤单,在情人节当天,单身的上班族有将近4成(39.1%)的人在家看电视度过,近两成(18.7%)上网聊天,有1成4(14.8%)的人,不畏满街闪光,勇气十足出门看电影,近1成(9.7%)的上班族选择留在公司加班;另外有 5.4%的人,会在情人节当天积极参加联谊,希望能改变自己的感情状态。
+你知道2月14日西方情人节是因何起源的吗? 情侣们在情人节当天,庆祝方式以吃浪漫大餐最多(37.1%),不过有近3成(27%)的情侣,在情人节当天不会特别庆祝情人节,且这个比率远比第三名的旅游(占比11.5%)高出1倍以上。
+你知道2月14日西方情人节是因何起源的吗? 在情人节当天庆祝的开销上,可以说是小资男女当道,选择1000元(新台币,下同)以内的上班族最多占33.1%,情人节当天的花费上班族的平均花费是2473元,大手笔花费上万元以上庆祝情人节的,占比只有2.5%。
+你知道2月14日西方情人节是因何起源的吗? 情人节的起源众说纷纭,而为纪念罗马教士瓦伦丁是其中一个普遍的说法。
+你知道2月14日西方情人节是因何起源的吗? 据《世界图书百科全书》(World Book Encyclopedia)数据指出:“在公元200年时期,罗马皇帝克劳狄二世禁止年轻男子结婚。
+你知道2月14日西方情人节是因何起源的吗? 他认为未婚男子可以成为更优良的士兵。
+你知道2月14日西方情人节是因何起源的吗? 一位名叫瓦伦丁的教士违反了皇帝的命令,秘密为年轻男子主持婚礼,引起皇帝不满,结果被收监,据说瓦伦丁于公元269年2月14日被处决。
+你知道2月14日西方情人节是因何起源的吗? 另外,据《天主教百科全书》(The Catholic情人节 Encyclopedia)指出,公元496年,教宗圣基拉西乌斯一世在公元第五世纪末叶废除了牧神节,把2月14日定为圣瓦伦丁日。”
+你知道2月14日西方情人节是因何起源的吗? 这个节日现今以“圣瓦伦丁节”——亦即情人节的姿态盛行起来。
+你知道2月14日西方情人节是因何起源的吗? 但是在第2次梵蒂冈大公会议后,1969年的典礼改革上,整理了一堆在史实上不确定是否真实存在的人物以后,圣瓦伦丁日就被废除了。
+你知道2月14日西方情人节是因何起源的吗? 现在天主教圣人历已经没有圣瓦伦丁日(St. Valentine's Day)。
+你知道2月14日西方情人节是因何起源的吗? 根据《布卢姆尔的警句与寓言辞典》记载:“圣瓦伦丁是个罗马教士,由于援助受逼害的基督徒而身陷险境,后来他归信基督教,最后被处死,卒于二月十四日”古代庆祝情人节的习俗与瓦伦丁拉上关系,可能是纯属巧合而已。
+你知道2月14日西方情人节是因何起源的吗? 事实上,这个节日很可能与古罗马的牧神节或雀鸟交配的季节有关。
+你知道2月14日西方情人节是因何起源的吗? 情人节的特色是情侣互相馈赠礼物。
+你知道2月14日西方情人节是因何起源的吗? 时至今日,人们则喜欢以情人卡向爱人表达情意。
+防卫大学每年招收多少学生? 防卫大学的前身是保安大学。
+防卫大学每年招收多少学生? 防卫大学是日本自卫队培养陆、海、空三军初级军官的学校,被称为日军"军官的摇篮"。
+防卫大学每年招收多少学生? 防卫大学是日军的重点院校。
+防卫大学每年招收多少学生? 日本历届内阁首相都要到防卫大学视察"训示",并亲自向学生颁发毕业证书。
+防卫大学每年招收多少学生? 日军四分之一的军官、三分之一的将官从这里走出。
+防卫大学每年招收多少学生? 防卫大学毕业生已成为日军军官的中坚力量。
+防卫大学每年招收多少学生? 防卫大学每年从地方招收18岁至21岁的应届高中毕业生和同等学历的青年。
+防卫大学每年招收多少学生? 每年招生名额为530名。
+防卫大学每年招收多少学生? 1950年 8月,日本组建警察预备队,1952年改为保安队。
+防卫大学每年招收多少学生? 为了充实保安队干部队伍,提高干部军政素质,1953年4月成立了保安大学,校址设在三浦半岛的久里滨。
+防卫大学每年招收多少学生? 1954年7月1日保安厅改为防卫厅。
+防卫大学每年招收多少学生? 在保安队基础上,日本建立了陆、海、空三军自卫队,保安大学遂改名为防卫大学,1955年迁至三浦半岛东南方的小原台。
+防卫大学每年招收多少学生? 学校直属防卫厅领导。
+防卫大学每年招收多少学生? 防卫大学的教育方针是:要求学生德智体全面发展,倡导学生崇尚知识和正义,培养学生具有指挥各种部队的能力。
+防卫大学每年招收多少学生? 防卫大学每年招生名额为530名,其中陆军300名,海军100名,空军130名。
+防卫大学每年招收多少学生? 根据自卫队向妇女敞开军官大门的决定,防卫大学1992年首次招收女学员35名。
+防卫大学每年招收多少学生? 考试分两次进行。
+防卫大学每年招收多少学生? 第一次,每年11月份进行学科考试;第二次,12月份进行口试和体检。
+防卫大学每年招收多少学生? 学校按陆、海、空三军分别设大学本科班和理工科研究生班。
+防卫大学每年招收多少学生? 本科班学制4年,又分为理工和人文社会学两大科。
+防卫大学每年招收多少学生? 学员入学后先分科,530人中有460人专攻理科,70人专攻文科。
+防卫大学每年招收多少学生? 第1学年按专科学习一般大学课程和一般军事知识。
+防卫大学每年招收多少学生? 第2学年以后在军事上开始区分军种,学员分别学习陆、海、空军的专门课程。
+防卫大学每年招收多少学生? 文化课和军事课的比例是6:l。
+防卫大学每年招收多少学生? 文化课程有人文、社会、自然、外语、电气工程、机械工程、土木建筑工程、应用化学、应用物理、航空、航海等。
+防卫大学每年招收多少学生? 军事训练课每学年6周,按一年四季有比例地安排教学内容,对学生进行军事技术和体能训练。
+防卫大学每年招收多少学生? 理工科研究生班,每年招生1期,学制2年,每期招收90人,设电子工程、航空工程、兵器制造等7个专业,课程按一般大学硕士课程标准设置。
+防卫大学每年招收多少学生? 防卫大学的课程和训练都十分紧张。
+防卫大学每年招收多少学生? 近年来,为了增强防卫大学的吸引力,克服考生逐年减少的倾向广泛征集优秀人才,学校进行了一些改革,改变入学考试办法,各高中校长以内部呈报的形式向防卫大学推荐品学兼优的学生;减少学生入学考试科目,放宽对报考防卫大学的学生的视力要求;降低学分数(大约降低30学分);改善学生宿舍条件。
+防卫大学每年招收多少学生? 防卫大学的学生生活紧张而愉快。
+《威鲁贝鲁的物语》官网是什么? 10年前大战后,威鲁贝鲁国一致辛勤的保护着得来不易的和平,但是与邻国圣卡特拉斯国的关系却不断的紧张,战争即将爆发。
+《威鲁贝鲁的物语》官网是什么? 为了避免战争,威鲁贝鲁国王海特鲁王决定将自己最大的女儿公主莉塔嫁给圣卡特拉斯国的王子格鲁尼亚。
+《威鲁贝鲁的物语》官网是什么? 但是莉塔却刺伤了政治婚姻的对象格鲁尼亚王子逃了出去,这事激怒了圣卡特拉斯国的国王兰帕诺夫王,并下令14天之内抓到王女并执行公开处刑来谢罪,不然两国就要开战。
+《威鲁贝鲁的物语》官网是什么? 《威鲁贝鲁的物语~Sisters of Wellber~》
+《威鲁贝鲁的物语》官网是什么? (Sisters of Wellber)
+《威鲁贝鲁的物语》官网是什么? 日文名 ウエルベールの物语
+《威鲁贝鲁的物语》官网是什么? 官方网站 http://www.avexmovie.jp/lineup/wellber/
+《威鲁贝鲁的物语》官网是什么? 为了回避发生战争这个最坏的结果,莉塔下定决心去中立国古利达姆。
diff --git a/examples/erniesage/dataset/__init__.py b/examples/erniesage/dataset/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/examples/erniesage/dataset/base_dataset.py b/examples/erniesage/dataset/base_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b29b5761769e9be9e62fb4536e41d43f9c9abb4
--- /dev/null
+++ b/examples/erniesage/dataset/base_dataset.py
@@ -0,0 +1,158 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Base DataLoader
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import sys
+import six
+from io import open
+from collections import namedtuple
+import numpy as np
+import tqdm
+import paddle
+from pgl.utils import mp_reader
+import collections
+import time
+from pgl.utils.logger import log
+import traceback
+
+
+if six.PY3:
+ import io
+ sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
+ sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
+
+
+def batch_iter(data, perm, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ size = len(data)
+ start = 0
+ cc = 0
+ while start < size:
+ index = perm[start:start + batch_size]
+ start += batch_size
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ yield data[index]
+
+
+def scan_batch_iter(data, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ batch = []
+ cc = 0
+ for line_example in data.scan():
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ batch.append(line_example)
+ if len(batch) == batch_size:
+ yield batch
+ batch = []
+
+ if len(batch) > 0:
+ yield batch
+
+
+class BaseDataGenerator(object):
+ """Base Data Geneartor"""
+
+ def __init__(self, buf_size, batch_size, num_workers, shuffle=True):
+ self.num_workers = num_workers
+ self.batch_size = batch_size
+ self.line_examples = []
+ self.buf_size = buf_size
+ self.shuffle = shuffle
+
+ def batch_fn(self, batch_examples):
+ """ batch_fn batch producer"""
+ raise NotImplementedError("No defined Batch Fn")
+
+ def batch_iter(self, fid, perm):
+ """ batch iterator"""
+ if self.shuffle:
+ for batch in batch_iter(self, perm, self.batch_size, fid, self.num_workers):
+ yield batch
+ else:
+ for batch in scan_batch_iter(self, self.batch_size, fid, self.num_workers):
+ yield batch
+
+ def __len__(self):
+ return len(self.line_examples)
+
+ def __getitem__(self, idx):
+ if isinstance(idx, collections.Iterable):
+ return [self[bidx] for bidx in idx]
+ else:
+ return self.line_examples[idx]
+
+ def generator(self):
+ """batch dict generator"""
+
+ def worker(filter_id, perm):
+ """ multiprocess worker"""
+
+ def func_run():
+ """ func_run """
+ pid = os.getpid()
+ np.random.seed(pid + int(time.time()))
+ for batch_examples in self.batch_iter(filter_id, perm):
+ try:
+ batch_dict = self.batch_fn(batch_examples)
+ except Exception as e:
+ traceback.print_exc()
+ log.info(traceback.format_exc())
+ log.info(str(e))
+ continue
+
+ if batch_dict is None:
+ continue
+ yield batch_dict
+
+
+
+ return func_run
+
+ # consume a seed
+ np.random.rand()
+
+ if self.shuffle:
+ perm = np.arange(0, len(self))
+ np.random.shuffle(perm)
+ else:
+ perm = None
+
+ if self.num_workers == 1:
+ r = paddle.reader.buffered(worker(0, perm), self.buf_size)
+ else:
+ worker_pool = [worker(wid, perm) for wid in range(self.num_workers)]
+ worker = mp_reader.multiprocess_reader(
+ worker_pool, use_pipe=True, queue_size=1000)
+ r = paddle.reader.buffered(worker, self.buf_size)
+
+ for batch in r():
+ yield batch
+
+ def scan(self):
+ for line_example in self.line_examples:
+ yield line_example
diff --git a/examples/erniesage/dataset/graph_reader.py b/examples/erniesage/dataset/graph_reader.py
new file mode 100644
index 0000000000000000000000000000000000000000..c811b56b1273377d476d8b6f0e53ac23ffdefca8
--- /dev/null
+++ b/examples/erniesage/dataset/graph_reader.py
@@ -0,0 +1,126 @@
+"""Graph Dataset
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import pgl
+import sys
+
+import numpy as np
+
+from pgl.utils.logger import log
+from dataset.base_dataset import BaseDataGenerator
+from pgl.sample import alias_sample
+from pgl.sample import pinsage_sample
+from pgl.sample import graphsage_sample
+from pgl.sample import edge_hash
+
+
+class GraphGenerator(BaseDataGenerator):
+ def __init__(self, graph_wrappers, data, batch_size, samples,
+ num_workers, feed_name_list, use_pyreader,
+ phase, graph_data_path, shuffle=True, buf_size=1000, neg_type="batch_neg"):
+
+ super(GraphGenerator, self).__init__(
+ buf_size=buf_size,
+ num_workers=num_workers,
+ batch_size=batch_size, shuffle=shuffle)
+ # For iteration
+ self.line_examples = data
+
+ self.graph_wrappers = graph_wrappers
+ self.samples = samples
+ self.feed_name_list = feed_name_list
+ self.use_pyreader = use_pyreader
+ self.phase = phase
+ self.load_graph(graph_data_path)
+ self.num_layers = len(graph_wrappers)
+ self.neg_type= neg_type
+
+ def load_graph(self, graph_data_path):
+ self.graph = pgl.graph.MemmapGraph(graph_data_path)
+ self.alias = np.load(os.path.join(graph_data_path, "alias.npy"), mmap_mode="r")
+ self.events = np.load(os.path.join(graph_data_path, "events.npy"), mmap_mode="r")
+ self.term_ids = np.load(os.path.join(graph_data_path, "term_ids.npy"), mmap_mode="r")
+
+ def batch_fn(self, batch_ex):
+ # batch_ex = [
+ # (src, dst, neg),
+ # (src, dst, neg),
+ # (src, dst, neg),
+ # ]
+ #
+ batch_src = []
+ batch_dst = []
+ batch_neg = []
+ for batch in batch_ex:
+ batch_src.append(batch[0])
+ batch_dst.append(batch[1])
+ if len(batch) == 3: # default neg samples
+ batch_neg.append(batch[2])
+
+ if len(batch_src) != self.batch_size:
+ if self.phase == "train":
+ return None #Skip
+
+ if len(batch_neg) > 0:
+ batch_neg = np.unique(np.concatenate(batch_neg))
+ batch_src = np.array(batch_src, dtype="int64")
+ batch_dst = np.array(batch_dst, dtype="int64")
+
+ if self.neg_type == "batch_neg":
+ neg_shape = [1]
+ else:
+ neg_shape = batch_dst.shape
+ sampled_batch_neg = alias_sample(neg_shape, self.alias, self.events)
+
+ if len(batch_neg) > 0:
+ batch_neg = np.concatenate([batch_neg, sampled_batch_neg], 0)
+ else:
+ batch_neg = sampled_batch_neg
+
+ if self.phase == "train":
+ #ignore_edges = np.concatenate([np.stack([batch_src, batch_dst], 1), np.stack([batch_dst, batch_src], 1)], 0)
+ ignore_edges = set()
+ else:
+ ignore_edges = set()
+
+ nodes = np.unique(np.concatenate([batch_src, batch_dst, batch_neg], 0))
+ subgraphs = graphsage_sample(self.graph, nodes, self.samples, ignore_edges=ignore_edges)
+ #subgraphs[0].reindex_to_parrent_nodes(subgraphs[0].nodes)
+ feed_dict = {}
+ for i in range(self.num_layers):
+ feed_dict.update(self.graph_wrappers[i].to_feed(subgraphs[i]))
+
+ # only reindex from first subgraph
+ sub_src_idx = subgraphs[0].reindex_from_parrent_nodes(batch_src)
+ sub_dst_idx = subgraphs[0].reindex_from_parrent_nodes(batch_dst)
+ sub_neg_idx = subgraphs[0].reindex_from_parrent_nodes(batch_neg)
+
+ feed_dict["user_index"] = np.array(sub_src_idx, dtype="int64")
+ feed_dict["item_index"] = np.array(sub_dst_idx, dtype="int64")
+ feed_dict["neg_item_index"] = np.array(sub_neg_idx, dtype="int64")
+ feed_dict["term_ids"] = self.term_ids[subgraphs[0].node_feat["index"]].astype(np.int64)
+ return feed_dict
+
+ def __call__(self):
+ return self.generator()
+
+ def generator(self):
+ try:
+ for feed_dict in super(GraphGenerator, self).generator():
+ if self.use_pyreader:
+ yield [feed_dict[name] for name in self.feed_name_list]
+ else:
+ yield feed_dict
+
+ except Exception as e:
+ log.exception(e)
+
+
+
diff --git a/examples/erniesage/docs/source/_static/ERNIESage_result.png b/examples/erniesage/docs/source/_static/ERNIESage_result.png
new file mode 100644
index 0000000000000000000000000000000000000000..75c28240e1ec58e1603583df465a73815c97a2f8
Binary files /dev/null and b/examples/erniesage/docs/source/_static/ERNIESage_result.png differ
diff --git a/examples/erniesage/docs/source/_static/ERNIESage_v1_4.png b/examples/erniesage/docs/source/_static/ERNIESage_v1_4.png
new file mode 100644
index 0000000000000000000000000000000000000000..2b5869ab33464eb23511b759e2bb3263d8297004
Binary files /dev/null and b/examples/erniesage/docs/source/_static/ERNIESage_v1_4.png differ
diff --git a/examples/erniesage/docs/source/_static/ernie_aggregator.png b/examples/erniesage/docs/source/_static/ernie_aggregator.png
new file mode 100644
index 0000000000000000000000000000000000000000..206a0673d76e97bcc6a47108df683583e4a0b240
Binary files /dev/null and b/examples/erniesage/docs/source/_static/ernie_aggregator.png differ
diff --git a/examples/erniesage/docs/source/_static/text_graph.png b/examples/erniesage/docs/source/_static/text_graph.png
new file mode 100644
index 0000000000000000000000000000000000000000..26f89eb124f272acee2b097f39cb310416de45e1
Binary files /dev/null and b/examples/erniesage/docs/source/_static/text_graph.png differ
diff --git a/examples/erniesage/infer.py b/examples/erniesage/infer.py
new file mode 100644
index 0000000000000000000000000000000000000000..9fc4aeee96f84e4ac8e3b88351d8ec92083701df
--- /dev/null
+++ b/examples/erniesage/infer.py
@@ -0,0 +1,187 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+import argparse
+import pickle
+import time
+import glob
+import os
+import io
+import traceback
+import pickle as pkl
+role = os.getenv("TRAINING_ROLE", "TRAINER")
+
+import numpy as np
+import yaml
+from easydict import EasyDict as edict
+import pgl
+from pgl.utils.logger import log
+from pgl.utils import paddle_helper
+import paddle
+import paddle.fluid as F
+
+from models.model_factory import Model
+from dataset.graph_reader import GraphGenerator
+
+
+class PredictData(object):
+ def __init__(self, num_nodes):
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ trainer_count = int(os.getenv("PADDLE_TRAINERS_NUM", "1"))
+ train_usr = np.arange(trainer_id, num_nodes, trainer_count)
+ #self.data = (train_usr, train_usr)
+ self.data = train_usr
+
+ def __getitem__(self, index):
+ return [self.data[index], self.data[index]]
+
+def tostr(data_array):
+ return " ".join(["%.5lf" % d for d in data_array])
+
+def run_predict(py_reader,
+ exe,
+ program,
+ model_dict,
+ log_per_step=1,
+ args=None):
+
+ id2str = io.open(os.path.join(args.graph_path, "terms.txt"), encoding=args.encoding).readlines()
+
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ trainer_count = int(os.getenv("PADDLE_TRAINERS_NUM", "1"))
+ if not os.path.exists(args.output_path):
+ os.mkdir(args.output_path)
+
+ fout = io.open("%s/part-%s" % (args.output_path, trainer_id), "w", encoding="utf8")
+ batch = 0
+
+ for batch_feed_dict in py_reader():
+ batch += 1
+ batch_usr_feat, batch_ad_feat, _, batch_src_real_index = exe.run(
+ program,
+ feed=batch_feed_dict,
+ fetch_list=model_dict.outputs)
+
+ if batch % log_per_step == 0:
+ log.info("Predict %s finished" % batch)
+
+ for ufs, _, sri in zip(batch_usr_feat, batch_ad_feat, batch_src_real_index):
+ if args.input_type == "text":
+ sri = id2str[int(sri)].strip("\n")
+ line = "{}\t{}\n".format(sri, tostr(ufs))
+ fout.write(line)
+
+ fout.close()
+
+def _warmstart(exe, program, path='params'):
+ def _existed_persitables(var):
+ #if not isinstance(var, fluid.framework.Parameter):
+ # return False
+ if not F.io.is_persistable(var):
+ return False
+ param_path = os.path.join(path, var.name)
+ log.info("Loading parameter: {} persistable: {} exists: {}".format(
+ param_path,
+ F.io.is_persistable(var),
+ os.path.exists(param_path),
+ ))
+ return os.path.exists(param_path)
+ F.io.load_vars(
+ exe,
+ path,
+ main_program=program,
+ predicate=_existed_persitables
+ )
+
+def main(config):
+ model = Model.factory(config)
+
+ if config.learner_type == "cpu":
+ place = F.CPUPlace()
+ elif config.learner_type == "gpu":
+ gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
+ place = F.CUDAPlace(gpu_id)
+ else:
+ raise ValueError
+
+ exe = F.Executor(place)
+
+ val_program = F.default_main_program().clone(for_test=True)
+ exe.run(F.default_startup_program())
+ _warmstart(exe, F.default_startup_program(), path=config.infer_model)
+
+ num_threads = int(os.getenv("CPU_NUM", 1))
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", 0))
+
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = num_threads
+ build_strategy = F.BuildStrategy()
+ build_strategy.enable_inplace = True
+ build_strategy.memory_optimize = True
+ build_strategy.remove_unnecessary_lock = False
+ build_strategy.memory_optimize = False
+
+ if num_threads > 1:
+ build_strategy.reduce_strategy = F.BuildStrategy.ReduceStrategy.Reduce
+
+ val_compiled_prog = F.compiler.CompiledProgram(
+ val_program).with_data_parallel(
+ build_strategy=build_strategy,
+ exec_strategy=exec_strategy)
+
+ num_nodes = int(np.load(os.path.join(config.graph_path, "num_nodes.npy")))
+
+ predict_data = PredictData(num_nodes)
+
+ predict_iter = GraphGenerator(
+ graph_wrappers=model.graph_wrappers,
+ batch_size=config.infer_batch_size,
+ data=predict_data,
+ samples=config.samples,
+ num_workers=config.sample_workers,
+ feed_name_list=[var.name for var in model.feed_list],
+ use_pyreader=config.use_pyreader,
+ phase="predict",
+ graph_data_path=config.graph_path,
+ shuffle=False)
+
+ if config.learner_type == "cpu":
+ model.data_loader.decorate_batch_generator(
+ predict_iter, places=F.cpu_places())
+ elif config.learner_type == "gpu":
+ gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
+ place = F.CUDAPlace(gpu_id)
+ model.data_loader.decorate_batch_generator(
+ predict_iter, places=place)
+ else:
+ raise ValueError
+
+ run_predict(model.data_loader,
+ program=val_compiled_prog,
+ exe=exe,
+ model_dict=model,
+ args=config)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description='main')
+ parser.add_argument("--conf", type=str, default="./config.yaml")
+ args = parser.parse_args()
+ config = edict(yaml.load(open(args.conf), Loader=yaml.FullLoader))
+ config.loss_type = "hinge"
+ print(config)
+ main(config)
diff --git a/examples/erniesage/learner.py b/examples/erniesage/learner.py
new file mode 100644
index 0000000000000000000000000000000000000000..43db90623d59c03fcfa16260476c5eacd94be436
--- /dev/null
+++ b/examples/erniesage/learner.py
@@ -0,0 +1,222 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import time
+import os
+role = os.getenv("TRAINING_ROLE", "TRAINER")
+
+import numpy as np
+from pgl.utils.logger import log
+from pgl.utils.log_writer import LogWriter
+import paddle.fluid as F
+import paddle.fluid.layers as L
+from paddle.fluid.incubate.fleet.parameter_server.distribute_transpiler import StrategyFactory
+from paddle.fluid.incubate.fleet.collective import DistributedStrategy
+from paddle.fluid.transpiler.distribute_transpiler import DistributeTranspilerConfig
+from paddle.fluid.incubate.fleet.collective import fleet as cfleet
+from paddle.fluid.incubate.fleet.parameter_server.distribute_transpiler import fleet as tfleet
+import paddle.fluid.incubate.fleet.base.role_maker as role_maker
+from paddle.fluid.transpiler.distribute_transpiler import DistributedMode
+from paddle.fluid.incubate.fleet.parameter_server.distribute_transpiler.distributed_strategy import TrainerRuntimeConfig
+
+# hack it!
+base_get_communicator_flags = TrainerRuntimeConfig.get_communicator_flags
+def get_communicator_flags(self):
+ flag_dict = base_get_communicator_flags(self)
+ flag_dict['communicator_max_merge_var_num'] = str(1)
+ flag_dict['communicator_send_queue_size'] = str(1)
+ return flag_dict
+TrainerRuntimeConfig.get_communicator_flags = get_communicator_flags
+
+
+class Learner(object):
+ @classmethod
+ def factory(cls, name):
+ if name == "cpu":
+ return TranspilerLearner()
+ elif name == "gpu":
+ return CollectiveLearner()
+ else:
+ raise ValueError
+
+ def build(self, model, data_gen, config):
+ raise NotImplementedError
+
+ def warmstart(self, program, path='./checkpoints'):
+ def _existed_persitables(var):
+ #if not isinstance(var, fluid.framework.Parameter):
+ # return False
+ if not F.io.is_persistable(var):
+ return False
+ param_path = os.path.join(path, var.name)
+ log.info("Loading parameter: {} persistable: {} exists: {}".format(
+ param_path,
+ F.io.is_persistable(var),
+ os.path.exists(param_path),
+ ))
+ return os.path.exists(param_path)
+ F.io.load_vars(
+ self.exe,
+ path,
+ main_program=program,
+ predicate=_existed_persitables
+ )
+
+ def start(self):
+ batch = 0
+ start = time.time()
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ if trainer_id == 0:
+ writer = LogWriter(os.path.join(self.config.output_path, "train_history"))
+
+ for epoch_idx in range(self.config.epoch):
+ for idx, batch_feed_dict in enumerate(self.model.data_loader()):
+ try:
+ cpu_time = time.time()
+ batch += 1
+ batch_loss = self.exe.run(
+ self.program,
+ feed=batch_feed_dict,
+ fetch_list=[self.model.loss])
+ end = time.time()
+ if trainer_id == 0:
+ writer.add_scalar("loss", np.mean(batch_loss), batch)
+ if batch % self.config.log_per_step == 0:
+ log.info(
+ "Epoch %s Batch %s %s-Loss %s \t Speed(per batch) %.5lf/%.5lf sec"
+ % (epoch_idx, batch, "train", np.mean(batch_loss), (end - start) /batch, (end - cpu_time)))
+ writer.flush()
+ if batch % self.config.save_per_step == 0:
+ self.fleet.save_persistables(self.exe, os.path.join(self.config.output_path, str(batch)))
+ except Exception as e:
+ log.info("Pyreader train error")
+ log.exception(e)
+ log.info("epcoh %s done." % epoch_idx)
+
+ def stop(self):
+ self.fleet.save_persistables(self.exe, os.path.join(self.config.output_path, "last"))
+
+
+class TranspilerLearner(Learner):
+ def __init__(self):
+ training_role = os.getenv("TRAINING_ROLE", "TRAINER")
+ paddle_role = role_maker.Role.WORKER
+ place = F.CPUPlace()
+ if training_role == "PSERVER":
+ paddle_role = role_maker.Role.SERVER
+
+ # set the fleet runtime environment according to configure
+ port = os.getenv("PADDLE_PORT", "6174")
+ pserver_ips = os.getenv("PADDLE_PSERVERS") # ip,ip...
+ eplist = []
+ for ip in pserver_ips.split(","):
+ eplist.append(':'.join([ip, port]))
+ pserver_endpoints = eplist # ip:port,ip:port...
+ worker_num = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ role = role_maker.UserDefinedRoleMaker(
+ current_id=trainer_id,
+ role=paddle_role,
+ worker_num=worker_num,
+ server_endpoints=pserver_endpoints)
+ tfleet.init(role)
+ tfleet.save_on_pserver = True
+
+ def build(self, model, data_gen, config):
+ self.optimize(model.loss, config.optimizer_type, config.lr)
+ self.init_and_run_ps_worker(config.ckpt_path)
+ self.program = self.complie_program(model.loss)
+ self.fleet = tfleet
+ model.data_loader.decorate_batch_generator(
+ data_gen, places=F.cpu_places())
+ self.config = config
+ self.model = model
+
+ def optimize(self, loss, optimizer_type, lr):
+ log.info('learning rate:%f' % lr)
+ if optimizer_type == "sgd":
+ optimizer = F.optimizer.SGD(learning_rate=lr)
+ elif optimizer_type == "adam":
+ # Don't slice tensor ensure convergence
+ optimizer = F.optimizer.Adam(learning_rate=lr, lazy_mode=True)
+ else:
+ raise ValueError("Unknown Optimizer %s" % optimizer_type)
+ #create the DistributeTranspiler configure
+ self.strategy = StrategyFactory.create_sync_strategy()
+ optimizer = tfleet.distributed_optimizer(optimizer, self.strategy)
+ optimizer.minimize(loss)
+
+ def init_and_run_ps_worker(self, ckpt_path):
+ # init and run server or worker
+ self.exe = F.Executor(F.CPUPlace())
+ if tfleet.is_server():
+ tfleet.init_server()
+ self.warmstart(tfleet.startup_program, path=ckpt_path)
+ tfleet.run_server()
+ exit()
+
+ if tfleet.is_worker():
+ log.info("start init worker done")
+ tfleet.init_worker()
+ self.exe.run(tfleet.startup_program)
+
+ def complie_program(self, loss):
+ num_threads = int(os.getenv("CPU_NUM", 1))
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = num_threads
+ exec_strategy.use_thread_barrier = False
+ build_strategy = F.BuildStrategy()
+ build_strategy.enable_inplace = True
+ build_strategy.memory_optimize = True
+ build_strategy.remove_unnecessary_lock = False
+ build_strategy.memory_optimize = False
+ build_strategy.async_mode = False
+
+ if num_threads > 1:
+ build_strategy.reduce_strategy = F.BuildStrategy.ReduceStrategy.Reduce
+
+ log.info("start build compile program...")
+ compiled_prog = F.compiler.CompiledProgram(tfleet.main_program
+ ).with_data_parallel(
+ loss_name=loss.name,
+ build_strategy=build_strategy,
+ exec_strategy=exec_strategy)
+
+ return compiled_prog
+
+
+class CollectiveLearner(Learner):
+ def __init__(self):
+ role = role_maker.PaddleCloudRoleMaker(is_collective=True)
+ cfleet.init(role)
+
+ def optimize(self, loss, optimizer_type, lr):
+ optimizer = F.optimizer.Adam(learning_rate=lr)
+ dist_strategy = DistributedStrategy()
+ dist_strategy.enable_sequential_execution = True
+ optimizer = cfleet.distributed_optimizer(optimizer, strategy=dist_strategy)
+ _, param_grads = optimizer.minimize(loss, F.default_startup_program())
+
+ def build(self, model, data_gen, config):
+ self.optimize(model.loss, config.optimizer_type, config.lr)
+ self.program = cfleet.main_program
+ gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
+ place = F.CUDAPlace(gpu_id)
+ self.exe = F.Executor(place)
+ self.exe.run(F.default_startup_program())
+ self.warmstart(F.default_startup_program(), config.ckpt_path)
+ self.fleet = cfleet
+ model.data_loader.decorate_batch_generator(
+ data_gen, places=place)
+ self.config = config
+ self.model = model
diff --git a/examples/erniesage/local_run.sh b/examples/erniesage/local_run.sh
new file mode 100644
index 0000000000000000000000000000000000000000..6a11daf87014458228cad6d32dd8f87e5bb342a8
--- /dev/null
+++ b/examples/erniesage/local_run.sh
@@ -0,0 +1,67 @@
+#!/bin/bash
+
+set -x
+config=${1:-"./config.yaml"}
+unset http_proxy https_proxy
+
+function parse_yaml {
+ local prefix=$2
+ local s='[[:space:]]*' w='[a-zA-Z0-9_]*' fs=$(echo @|tr @ '\034')
+ sed -ne "s|^\($s\):|\1|" \
+ -e "s|^\($s\)\($w\)$s:$s[\"']\(.*\)[\"']$s\$|\1$fs\2$fs\3|p" \
+ -e "s|^\($s\)\($w\)$s:$s\(.*\)$s\$|\1$fs\2$fs\3|p" $1 |
+ awk -F$fs '{
+ indent = length($1)/2;
+ vname[indent] = $2;
+ for (i in vname) {if (i > indent) {delete vname[i]}}
+ if (length($3) > 0) {
+ vn=""; for (i=0; i $BASE/pserver.$i.log &
+ echo $! >> job_id
+ done
+ sleep 3s
+ for((j=0;j<${PADDLE_TRAINERS_NUM};j++))
+ do
+ echo "start ps work: ${j}"
+ TRAINING_ROLE="TRAINER" PADDLE_TRAINER_ID=${j} python ./train.py --conf $config
+ TRAINING_ROLE="TRAINER" PADDLE_TRAINER_ID=${j} python ./infer.py --conf $config
+ done
+}
+
+collective_local_train(){
+ echo `which python`
+ python -m paddle.distributed.launch train.py --conf $config
+ python -m paddle.distributed.launch infer.py --conf $config
+}
+
+eval $(parse_yaml $config)
+
+python ./preprocessing/dump_graph.py -i $input_data -o $graph_path --encoding $encoding -l $max_seqlen --vocab_file $ernie_vocab_file
+
+if [[ $learner_type == "cpu" ]];then
+ transpiler_local_train
+fi
+if [[ $learner_type == "gpu" ]];then
+ collective_local_train
+fi
diff --git a/examples/erniesage/models/__init__.py b/examples/erniesage/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/examples/erniesage/models/base.py b/examples/erniesage/models/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..e93fd5ffbb00de1da1612b0945cdba682909f164
--- /dev/null
+++ b/examples/erniesage/models/base.py
@@ -0,0 +1,244 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import time
+import glob
+import os
+
+import numpy as np
+
+import pgl
+import paddle.fluid as F
+import paddle.fluid.layers as L
+
+from models import message_passing
+
+def get_layer(layer_type, gw, feature, hidden_size, act, initializer, learning_rate, name, is_test=False):
+ return getattr(message_passing, layer_type)(gw, feature, hidden_size, act, initializer, learning_rate, name)
+
+
+class BaseGraphWrapperBuilder(object):
+ def __init__(self, config):
+ self.config = config
+ self.node_feature_info = []
+ self.edge_feature_info = []
+
+ def __call__(self):
+ place = F.CPUPlace()
+ graph_wrappers = []
+ for i in range(self.config.num_layers):
+ # all graph have same node_feat_info
+ graph_wrappers.append(
+ pgl.graph_wrapper.GraphWrapper(
+ "layer_%s" % i, node_feat=self.node_feature_info, edge_feat=self.edge_feature_info))
+ return graph_wrappers
+
+
+class GraphsageGraphWrapperBuilder(BaseGraphWrapperBuilder):
+ def __init__(self, config):
+ super(GraphsageGraphWrapperBuilder, self).__init__(config)
+ self.node_feature_info.append(('index', [None], np.dtype('int64')))
+
+
+class BaseGNNModel(object):
+ def __init__(self, config):
+ self.config = config
+ self.graph_wrapper_builder = self.gen_graph_wrapper_builder(config)
+ self.net_fn = self.gen_net_fn(config)
+ self.feed_list_builder = self.gen_feed_list_builder(config)
+ self.data_loader_builder = self.gen_data_loader_builder(config)
+ self.loss_fn = self.gen_loss_fn(config)
+ self.build()
+
+
+ def gen_graph_wrapper_builder(self, config):
+ return GraphsageGraphWrapperBuilder(config)
+
+ def gen_net_fn(self, config):
+ return BaseNet(config)
+
+ def gen_feed_list_builder(self, config):
+ return BaseFeedListBuilder(config)
+
+ def gen_data_loader_builder(self, config):
+ return BaseDataLoaderBuilder(config)
+
+ def gen_loss_fn(self, config):
+ return BaseLoss(config)
+
+ def build(self):
+ self.graph_wrappers = self.graph_wrapper_builder()
+ self.inputs, self.outputs = self.net_fn(self.graph_wrappers)
+ self.feed_list = self.feed_list_builder(self.inputs, self.graph_wrappers)
+ self.data_loader = self.data_loader_builder(self.feed_list)
+ self.loss = self.loss_fn(self.outputs)
+
+class BaseFeedListBuilder(object):
+ def __init__(self, config):
+ self.config = config
+
+ def __call__(self, inputs, graph_wrappers):
+ feed_list = []
+ for i in range(len(graph_wrappers)):
+ feed_list.extend(graph_wrappers[i].holder_list)
+ feed_list.extend(inputs)
+ return feed_list
+
+
+class BaseDataLoaderBuilder(object):
+ def __init__(self, config):
+ self.config = config
+
+ def __call__(self, feed_list):
+ data_loader = F.io.PyReader(
+ feed_list=feed_list, capacity=20, use_double_buffer=True, iterable=True)
+ return data_loader
+
+
+
+class BaseNet(object):
+ def __init__(self, config):
+ self.config = config
+
+ def take_final_feature(self, feature, index, name):
+ """take final feature"""
+ feat = L.gather(feature, index, overwrite=False)
+
+ if self.config.final_fc:
+ feat = L.fc(feat,
+ self.config.hidden_size,
+ param_attr=F.ParamAttr(name=name + '_w'),
+ bias_attr=F.ParamAttr(name=name + '_b'))
+
+ if self.config.final_l2_norm:
+ feat = L.l2_normalize(feat, axis=1)
+ return feat
+
+ def build_inputs(self):
+ user_index = L.data(
+ "user_index", shape=[None], dtype="int64", append_batch_size=False)
+ item_index = L.data(
+ "item_index", shape=[None], dtype="int64", append_batch_size=False)
+ neg_item_index = L.data(
+ "neg_item_index", shape=[None], dtype="int64", append_batch_size=False)
+ return [user_index, item_index, neg_item_index]
+
+ def build_embedding(self, graph_wrappers, inputs=None):
+ num_embed = int(np.load(os.path.join(self.config.graph_path, "num_nodes.npy")))
+ is_sparse = self.config.trainer_type == "Transpiler"
+
+ embed = L.embedding(
+ input=L.reshape(graph_wrappers[0].node_feat['index'], [-1, 1]),
+ size=[num_embed, self.config.hidden_size],
+ is_sparse=is_sparse,
+ param_attr=F.ParamAttr(name="node_embedding", initializer=F.initializer.Uniform(
+ low=-1. / self.config.hidden_size,
+ high=1. / self.config.hidden_size)))
+ return embed
+
+ def gnn_layers(self, graph_wrappers, feature):
+ features = [feature]
+
+ initializer = None
+ fc_lr = self.config.lr / 0.001
+
+ for i in range(self.config.num_layers):
+ if i == self.config.num_layers - 1:
+ act = None
+ else:
+ act = "leaky_relu"
+
+ feature = get_layer(
+ self.config.layer_type,
+ graph_wrappers[i],
+ feature,
+ self.config.hidden_size,
+ act,
+ initializer,
+ learning_rate=fc_lr,
+ name="%s_%s" % (self.config.layer_type, i))
+ features.append(feature)
+ return features
+
+ def __call__(self, graph_wrappers):
+ inputs = self.build_inputs()
+ feature = self.build_embedding(graph_wrappers, inputs)
+ features = self.gnn_layers(graph_wrappers, feature)
+ outputs = [self.take_final_feature(features[-1], i, "final_fc") for i in inputs]
+ src_real_index = L.gather(graph_wrappers[0].node_feat['index'], inputs[0])
+ outputs.append(src_real_index)
+ return inputs, outputs
+
+def all_gather(X):
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ trainer_num = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
+ if trainer_num == 1:
+ copy_X = X * 1
+ copy_X.stop_gradients=True
+ return copy_X
+
+ Xs = []
+ for i in range(trainer_num):
+ copy_X = X * 1
+ copy_X = L.collective._broadcast(copy_X, i, True)
+ copy_X.stop_gradient=True
+ Xs.append(copy_X)
+
+ if len(Xs) > 1:
+ Xs=L.concat(Xs, 0)
+ Xs.stop_gradient=True
+ else:
+ Xs = Xs[0]
+ return Xs
+
+class BaseLoss(object):
+ def __init__(self, config):
+ self.config = config
+
+ def __call__(self, outputs):
+ user_feat, item_feat, neg_item_feat = outputs[0], outputs[1], outputs[2]
+ loss_type = self.config.loss_type
+
+ if self.config.neg_type == "batch_neg":
+ neg_item_feat = item_feat
+ # Calc Loss
+ if self.config.loss_type == "hinge":
+ pos = L.reduce_sum(user_feat * item_feat, -1, keep_dim=True) # [B, 1]
+ neg = L.matmul(user_feat, neg_item_feat, transpose_y=True) # [B, B]
+ loss = L.reduce_mean(L.relu(neg - pos + self.config.margin))
+ elif self.config.loss_type == "all_hinge":
+ pos = L.reduce_sum(user_feat * item_feat, -1, keep_dim=True) # [B, 1]
+ all_pos = all_gather(pos) # [B * n, 1]
+ all_neg_item_feat = all_gather(neg_item_feat) # [B * n, 1]
+ all_user_feat = all_gather(user_feat) # [B * n, 1]
+
+ neg1 = L.matmul(user_feat, all_neg_item_feat, transpose_y=True) # [B, B * n]
+ neg2 = L.matmul(all_user_feat, neg_item_feat, transpose_y=True) # [B *n, B]
+
+ loss1 = L.reduce_mean(L.relu(neg1 - pos + self.config.margin))
+ loss2 = L.reduce_mean(L.relu(neg2 - all_pos + self.config.margin))
+
+ #loss = (loss1 + loss2) / 2
+ loss = loss1 + loss2
+
+ elif self.config.loss_type == "softmax":
+ pass
+ # TODO
+ # pos = L.reduce_sum(user_feat * item_feat, -1, keep_dim=True) # [B, 1]
+ # neg = L.matmul(user_feat, neg_feat, transpose_y=True) # [B, B]
+ # logits = L.concat([pos, neg], -1) # [B, 1+B]
+ # labels = L.fill_constant_batch_size_like(logits, [-1, 1], "int64", 0)
+ # loss = L.reduce_mean(L.softmax_with_cross_entropy(logits, labels))
+ else:
+ raise ValueError
+ return loss
diff --git a/examples/erniesage/models/ernie.py b/examples/erniesage/models/ernie.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b53ebd439713f7f249c21ad96cafa0b2ae84f06
--- /dev/null
+++ b/examples/erniesage/models/ernie.py
@@ -0,0 +1,40 @@
+"""Ernie
+"""
+from models.base import BaseNet, BaseGNNModel
+
+class Ernie(BaseNet):
+
+ def build_inputs(self):
+ inputs = super(Ernie, self).build_inputs()
+ term_ids = L.data(
+ "term_ids", shape=[None, self.config.max_seqlen], dtype="int64", append_batch_size=False)
+ return inputs + [term_ids]
+
+ def build_embedding(self, graph_wrappers, term_ids):
+ term_ids = L.unsqueeze(term_ids, [-1])
+ ernie_config = self.config.ernie_config
+ ernie = ErnieModel(
+ src_ids=term_ids,
+ sentence_ids=L.zeros_like(term_ids),
+ task_ids=None,
+ config=ernie_config,
+ use_fp16=False,
+ name="student_")
+ feature = ernie.get_pooled_output()
+ return feature
+
+ def __call__(self, graph_wrappers):
+ inputs = self.build_inputs()
+ feature = self.build_embedding(graph_wrappers, inputs[-1])
+ features = [feature]
+ outputs = [self.take_final_feature(features[-1], i, "final_fc") for i in inputs[:-1]]
+ src_real_index = L.gather(graph_wrappers[0].node_feat['index'], inputs[0])
+ outputs.append(src_real_index)
+ return inputs, outputs
+
+
+class ErnieModel(BaseGNNModel):
+ def gen_net_fn(self, config):
+ return Ernie(config)
+
+
diff --git a/examples/erniesage/models/ernie_model/__init__.py b/examples/erniesage/models/ernie_model/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/examples/erniesage/models/ernie_model/ernie.py b/examples/erniesage/models/ernie_model/ernie.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a8b4650bd9a77882e458677215525940a3d7df2
--- /dev/null
+++ b/examples/erniesage/models/ernie_model/ernie.py
@@ -0,0 +1,403 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Ernie model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import json
+import six
+import logging
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+
+from io import open
+
+from models.ernie_model.transformer_encoder import encoder, pre_process_layer
+from models.ernie_model.transformer_encoder import graph_encoder
+
+log = logging.getLogger(__name__)
+
+
+class ErnieConfig(object):
+ def __init__(self, config_path):
+ self._config_dict = self._parse(config_path)
+
+ def _parse(self, config_path):
+ try:
+ with open(config_path, 'r', encoding='utf8') as json_file:
+ config_dict = json.load(json_file)
+ except Exception:
+ raise IOError("Error in parsing Ernie model config file '%s'" %
+ config_path)
+ else:
+ return config_dict
+
+ def __getitem__(self, key):
+ return self._config_dict.get(key, None)
+
+ def print_config(self):
+ for arg, value in sorted(six.iteritems(self._config_dict)):
+ log.info('%s: %s' % (arg, value))
+ log.info('------------------------------------------------')
+
+
+class ErnieModel(object):
+ def __init__(self,
+ src_ids,
+ sentence_ids,
+ position_ids=None,
+ input_mask=None,
+ task_ids=None,
+ config=None,
+ weight_sharing=True,
+ use_fp16=False,
+ name=""):
+
+ self._set_config(config, name, weight_sharing)
+ if position_ids is None:
+ position_ids = self._build_position_ids(src_ids)
+ if input_mask is None:
+ input_mask = self._build_input_mask(src_ids)
+ self._build_model(src_ids, position_ids, sentence_ids, task_ids,
+ input_mask)
+ self._debug_summary(input_mask)
+
+ def _debug_summary(self, input_mask):
+ #histogram
+ seqlen_before_pad = L.cast(
+ L.reduce_sum(
+ input_mask, dim=1), dtype='float32')
+ seqlen_after_pad = L.reduce_sum(
+ L.cast(
+ L.zeros_like(input_mask), dtype='float32') + 1.0, dim=1)
+ pad_num = seqlen_after_pad - seqlen_before_pad
+ pad_rate = pad_num / seqlen_after_pad
+
+ def _build_position_ids(self, src_ids):
+ d_shape = L.shape(src_ids)
+ d_seqlen = d_shape[1]
+ d_batch = d_shape[0]
+ position_ids = L.reshape(
+ L.range(
+ 0, d_seqlen, 1, dtype='int32'), [1, d_seqlen, 1],
+ inplace=True)
+ position_ids = L.expand(position_ids, [d_batch, 1, 1])
+ position_ids = L.cast(position_ids, 'int64')
+ position_ids.stop_gradient = True
+ return position_ids
+
+ def _build_input_mask(self, src_ids):
+ zero = L.fill_constant([1], dtype='int64', value=0)
+ input_mask = L.logical_not(L.equal(src_ids,
+ zero)) # assume pad id == 0
+ input_mask = L.cast(input_mask, 'float32')
+ input_mask.stop_gradient = True
+ return input_mask
+
+ def _set_config(self, config, name, weight_sharing):
+ self._emb_size = config['hidden_size']
+ self._n_layer = config['num_hidden_layers']
+ self._n_head = config['num_attention_heads']
+ self._voc_size = config['vocab_size']
+ self._max_position_seq_len = config['max_position_embeddings']
+ if config.get('sent_type_vocab_size'):
+ self._sent_types = config['sent_type_vocab_size']
+ else:
+ self._sent_types = config['type_vocab_size']
+
+ self._use_task_id = config['use_task_id']
+ if self._use_task_id:
+ self._task_types = config['task_type_vocab_size']
+ self._hidden_act = config['hidden_act']
+ self._postprocess_cmd = config.get('postprocess_cmd', 'dan')
+ self._preprocess_cmd = config.get('preprocess_cmd', '')
+ self._prepostprocess_dropout = config['hidden_dropout_prob']
+ self._attention_dropout = config['attention_probs_dropout_prob']
+ self._weight_sharing = weight_sharing
+ self.name = name
+
+ self._word_emb_name = self.name + "word_embedding"
+ self._pos_emb_name = self.name + "pos_embedding"
+ self._sent_emb_name = self.name + "sent_embedding"
+ self._task_emb_name = self.name + "task_embedding"
+ self._dtype = "float16" if config['use_fp16'] else "float32"
+ self._emb_dtype = "float32"
+
+ # Initialize all weigths by truncated normal initializer, and all biases
+ # will be initialized by constant zero by default.
+ self._param_initializer = fluid.initializer.TruncatedNormal(
+ scale=config['initializer_range'])
+
+ def _build_model(self, src_ids, position_ids, sentence_ids, task_ids,
+ input_mask):
+
+ emb_out = self._build_embedding(src_ids, position_ids, sentence_ids,
+ task_ids)
+ self.input_mask = input_mask
+ self._enc_out, self.all_hidden, self.all_attn, self.all_ffn = encoder(
+ enc_input=emb_out,
+ input_mask=input_mask,
+ n_layer=self._n_layer,
+ n_head=self._n_head,
+ d_key=self._emb_size // self._n_head,
+ d_value=self._emb_size // self._n_head,
+ d_model=self._emb_size,
+ d_inner_hid=self._emb_size * 4,
+ prepostprocess_dropout=self._prepostprocess_dropout,
+ attention_dropout=self._attention_dropout,
+ relu_dropout=0,
+ hidden_act=self._hidden_act,
+ preprocess_cmd=self._preprocess_cmd,
+ postprocess_cmd=self._postprocess_cmd,
+ param_initializer=self._param_initializer,
+ name=self.name + 'encoder')
+ if self._dtype == "float16":
+ self._enc_out = fluid.layers.cast(
+ x=self._enc_out, dtype=self._emb_dtype)
+
+ def _build_embedding(self, src_ids, position_ids, sentence_ids, task_ids):
+ # padding id in vocabulary must be set to 0
+ emb_out = fluid.layers.embedding(
+ input=src_ids,
+ size=[self._voc_size, self._emb_size],
+ dtype=self._emb_dtype,
+ param_attr=fluid.ParamAttr(
+ name=self._word_emb_name, initializer=self._param_initializer),
+ is_sparse=False)
+
+ position_emb_out = fluid.layers.embedding(
+ input=position_ids,
+ size=[self._max_position_seq_len, self._emb_size],
+ dtype=self._emb_dtype,
+ param_attr=fluid.ParamAttr(
+ name=self._pos_emb_name, initializer=self._param_initializer))
+
+ sent_emb_out = fluid.layers.embedding(
+ sentence_ids,
+ size=[self._sent_types, self._emb_size],
+ dtype=self._emb_dtype,
+ param_attr=fluid.ParamAttr(
+ name=self._sent_emb_name, initializer=self._param_initializer))
+
+ self.all_emb = [emb_out, position_emb_out, sent_emb_out]
+ emb_out = emb_out + position_emb_out
+ emb_out = emb_out + sent_emb_out
+
+ if self._use_task_id:
+ task_emb_out = fluid.layers.embedding(
+ task_ids,
+ size=[self._task_types, self._emb_size],
+ dtype=self._emb_dtype,
+ param_attr=fluid.ParamAttr(
+ name=self._task_emb_name,
+ initializer=self._param_initializer))
+
+ emb_out = emb_out + task_emb_out
+
+ emb_out = pre_process_layer(
+ emb_out,
+ 'nd',
+ self._prepostprocess_dropout,
+ name=self.name + 'pre_encoder')
+
+ if self._dtype == "float16":
+ emb_out = fluid.layers.cast(x=emb_out, dtype=self._dtype)
+ return emb_out
+
+ def get_sequence_output(self):
+ return self._enc_out
+
+ def get_pooled_output(self):
+ """Get the first feature of each sequence for classification"""
+ next_sent_feat = self._enc_out[:, 0, :]
+ #next_sent_feat = fluid.layers.slice(input=self._enc_out, axes=[1], starts=[0], ends=[1])
+ next_sent_feat = fluid.layers.fc(
+ input=next_sent_feat,
+ size=self._emb_size,
+ act="tanh",
+ param_attr=fluid.ParamAttr(
+ name=self.name + "pooled_fc.w_0",
+ initializer=self._param_initializer),
+ bias_attr=self.name + "pooled_fc.b_0")
+ return next_sent_feat
+
+ def get_lm_output(self, mask_label, mask_pos):
+ """Get the loss & accuracy for pretraining"""
+
+ mask_pos = fluid.layers.cast(x=mask_pos, dtype='int32')
+
+ # extract the first token feature in each sentence
+ self.next_sent_feat = self.get_pooled_output()
+ reshaped_emb_out = fluid.layers.reshape(
+ x=self._enc_out, shape=[-1, self._emb_size])
+ # extract masked tokens' feature
+ mask_feat = fluid.layers.gather(input=reshaped_emb_out, index=mask_pos)
+
+ # transform: fc
+ mask_trans_feat = fluid.layers.fc(
+ input=mask_feat,
+ size=self._emb_size,
+ act=self._hidden_act,
+ param_attr=fluid.ParamAttr(
+ name=self.name + 'mask_lm_trans_fc.w_0',
+ initializer=self._param_initializer),
+ bias_attr=fluid.ParamAttr(name=self.name + 'mask_lm_trans_fc.b_0'))
+
+ # transform: layer norm
+ mask_trans_feat = fluid.layers.layer_norm(
+ mask_trans_feat,
+ begin_norm_axis=len(mask_trans_feat.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=self.name + 'mask_lm_trans_layer_norm_scale',
+ initializer=fluid.initializer.Constant(1.)),
+ bias_attr=fluid.ParamAttr(
+ name=self.name + 'mask_lm_trans_layer_norm_bias',
+ initializer=fluid.initializer.Constant(0.)))
+ # transform: layer norm
+ #mask_trans_feat = pre_process_layer(
+ # mask_trans_feat, 'n', name=self.name + 'mask_lm_trans')
+
+ mask_lm_out_bias_attr = fluid.ParamAttr(
+ name=self.name + "mask_lm_out_fc.b_0",
+ initializer=fluid.initializer.Constant(value=0.0))
+ if self._weight_sharing:
+ fc_out = fluid.layers.matmul(
+ x=mask_trans_feat,
+ y=fluid.default_main_program().global_block().var(
+ self._word_emb_name),
+ transpose_y=True)
+ fc_out += fluid.layers.create_parameter(
+ shape=[self._voc_size],
+ dtype=self._emb_dtype,
+ attr=mask_lm_out_bias_attr,
+ is_bias=True)
+
+ else:
+ fc_out = fluid.layers.fc(input=mask_trans_feat,
+ size=self._voc_size,
+ param_attr=fluid.ParamAttr(
+ name=self.name + "mask_lm_out_fc.w_0",
+ initializer=self._param_initializer),
+ bias_attr=mask_lm_out_bias_attr)
+
+ mask_lm_loss = fluid.layers.softmax_with_cross_entropy(
+ logits=fc_out, label=mask_label)
+ return mask_lm_loss
+
+ def get_task_output(self, task, task_labels):
+ task_fc_out = fluid.layers.fc(
+ input=self.next_sent_feat,
+ size=task["num_labels"],
+ param_attr=fluid.ParamAttr(
+ name=self.name + task["task_name"] + "_fc.w_0",
+ initializer=self._param_initializer),
+ bias_attr=self.name + task["task_name"] + "_fc.b_0")
+ task_loss, task_softmax = fluid.layers.softmax_with_cross_entropy(
+ logits=task_fc_out, label=task_labels, return_softmax=True)
+ task_acc = fluid.layers.accuracy(input=task_softmax, label=task_labels)
+ return task_loss, task_acc
+
+
+class ErnieGraphModel(ErnieModel):
+ def __init__(self,
+ src_ids,
+ task_ids=None,
+ config=None,
+ weight_sharing=True,
+ use_fp16=False,
+ slot_seqlen=40,
+ name=""):
+ self.slot_seqlen = slot_seqlen
+ self._set_config(config, name, weight_sharing)
+ input_mask = self._build_input_mask(src_ids)
+ position_ids = self._build_position_ids(src_ids)
+ sentence_ids = self._build_sentence_ids(src_ids)
+ self._build_model(src_ids, position_ids, sentence_ids, task_ids,
+ input_mask)
+ self._debug_summary(input_mask)
+
+ def _build_position_ids(self, src_ids):
+ src_shape = L.shape(src_ids)
+ src_seqlen = src_shape[1]
+ src_batch = src_shape[0]
+
+ slot_seqlen = self.slot_seqlen
+
+ num_b = (src_seqlen / slot_seqlen) - 1
+ a_position_ids = L.reshape(
+ L.range(
+ 0, slot_seqlen, 1, dtype='int32'), [1, slot_seqlen, 1],
+ inplace=True) # [1, slot_seqlen, 1]
+ a_position_ids = L.expand(a_position_ids, [src_batch, 1, 1]) # [B, slot_seqlen, 1]
+
+ zero = L.fill_constant([1], dtype='int64', value=0)
+ input_mask = L.cast(L.equal(src_ids[:, :slot_seqlen], zero), "int32") # assume pad id == 0 [B, slot_seqlen, 1]
+ a_pad_len = L.reduce_sum(input_mask, 1) # [B, 1, 1]
+
+ b_position_ids = L.reshape(
+ L.range(
+ slot_seqlen, 2*slot_seqlen, 1, dtype='int32'), [1, slot_seqlen, 1],
+ inplace=True) # [1, slot_seqlen, 1]
+ b_position_ids = L.expand(b_position_ids, [src_batch, num_b, 1]) # [B, slot_seqlen * num_b, 1]
+ b_position_ids = b_position_ids - a_pad_len # [B, slot_seqlen * num_b, 1]
+
+ position_ids = L.concat([a_position_ids, b_position_ids], 1)
+ position_ids = L.cast(position_ids, 'int64')
+ position_ids.stop_gradient = True
+ return position_ids
+
+ def _build_sentence_ids(self, src_ids):
+ src_shape = L.shape(src_ids)
+ src_seqlen = src_shape[1]
+ src_batch = src_shape[0]
+
+ slot_seqlen = self.slot_seqlen
+
+ zeros = L.zeros([src_batch, slot_seqlen, 1], "int64")
+ ones = L.ones([src_batch, src_seqlen-slot_seqlen, 1], "int64")
+
+ sentence_ids = L.concat([zeros, ones], 1)
+ sentence_ids.stop_gradient = True
+ return sentence_ids
+
+ def _build_model(self, src_ids, position_ids, sentence_ids, task_ids,
+ input_mask):
+
+ emb_out = self._build_embedding(src_ids, position_ids, sentence_ids,
+ task_ids)
+ self.input_mask = input_mask
+ self._enc_out, self.all_hidden, self.all_attn, self.all_ffn = graph_encoder(
+ enc_input=emb_out,
+ input_mask=input_mask,
+ n_layer=self._n_layer,
+ n_head=self._n_head,
+ d_key=self._emb_size // self._n_head,
+ d_value=self._emb_size // self._n_head,
+ d_model=self._emb_size,
+ d_inner_hid=self._emb_size * 4,
+ prepostprocess_dropout=self._prepostprocess_dropout,
+ attention_dropout=self._attention_dropout,
+ relu_dropout=0,
+ hidden_act=self._hidden_act,
+ preprocess_cmd=self._preprocess_cmd,
+ postprocess_cmd=self._postprocess_cmd,
+ param_initializer=self._param_initializer,
+ slot_seqlen=self.slot_seqlen,
+ name=self.name + 'encoder')
+ if self._dtype == "float16":
+ self._enc_out = fluid.layers.cast(
+ x=self._enc_out, dtype=self._emb_dtype)
diff --git a/examples/erniesage/models/ernie_model/transformer_encoder.py b/examples/erniesage/models/ernie_model/transformer_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..e6a95e1f6b4bcd61dc700d23b454346e973d0002
--- /dev/null
+++ b/examples/erniesage/models/ernie_model/transformer_encoder.py
@@ -0,0 +1,499 @@
+# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from functools import partial
+import numpy as np
+from contextlib import contextmanager
+
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+import paddle.fluid.layers as layers
+
+#determin this at the begining
+to_3d = lambda a: a # will change later
+to_2d = lambda a: a
+
+
+def multi_head_attention(queries,
+ keys,
+ values,
+ attn_bias,
+ d_key,
+ d_value,
+ d_model,
+ n_head=1,
+ dropout_rate=0.,
+ cache=None,
+ param_initializer=None,
+ name='multi_head_att'):
+ """
+ Multi-Head Attention. Note that attn_bias is added to the logit before
+ computing softmax activiation to mask certain selected positions so that
+ they will not considered in attention weights.
+ """
+ keys = queries if keys is None else keys
+ values = keys if values is None else values
+
+ def __compute_qkv(queries, keys, values, n_head, d_key, d_value):
+ """
+ Add linear projection to queries, keys, and values.
+ """
+ q = layers.fc(input=queries,
+ size=d_key * n_head,
+ num_flatten_dims=len(queries.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=name + '_query_fc.w_0',
+ initializer=param_initializer),
+ bias_attr=name + '_query_fc.b_0')
+ k = layers.fc(input=keys,
+ size=d_key * n_head,
+ num_flatten_dims=len(keys.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=name + '_key_fc.w_0',
+ initializer=param_initializer),
+ bias_attr=name + '_key_fc.b_0')
+ v = layers.fc(input=values,
+ size=d_value * n_head,
+ num_flatten_dims=len(values.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=name + '_value_fc.w_0',
+ initializer=param_initializer),
+ bias_attr=name + '_value_fc.b_0')
+ return q, k, v
+
+ def __split_heads(x, n_head):
+ """
+ Reshape the last dimension of inpunt tensor x so that it becomes two
+ dimensions and then transpose. Specifically, input a tensor with shape
+ [bs, max_sequence_length, n_head * hidden_dim] then output a tensor
+ with shape [bs, n_head, max_sequence_length, hidden_dim].
+ """
+ hidden_size = x.shape[-1]
+ # The value 0 in shape attr means copying the corresponding dimension
+ # size of the input as the output dimension size.
+ reshaped = layers.reshape(
+ x=x, shape=[0, 0, n_head, hidden_size // n_head], inplace=True)
+
+ # permuate the dimensions into:
+ # [batch_size, n_head, max_sequence_len, hidden_size_per_head]
+ return layers.transpose(x=reshaped, perm=[0, 2, 1, 3])
+
+ def __combine_heads(x):
+ """
+ Transpose and then reshape the last two dimensions of inpunt tensor x
+ so that it becomes one dimension, which is reverse to __split_heads.
+ """
+ if len(x.shape) == 3: return x
+ if len(x.shape) != 4:
+ raise ValueError("Input(x) should be a 4-D Tensor.")
+ trans_x = layers.transpose(x, perm=[0, 2, 1, 3])
+ # The value 0 in shape attr means copying the corresponding dimension
+ # size of the input as the output dimension size.
+ #trans_x.desc.set_shape((-1, 1, n_head, d_value))
+ return layers.reshape(x=trans_x, shape=[0, 0, d_model], inplace=True)
+
+ def scaled_dot_product_attention(q, k, v, attn_bias, d_key, dropout_rate):
+ """
+ Scaled Dot-Product Attention
+ """
+ scaled_q = layers.scale(x=q, scale=d_key**-0.5)
+ product = layers.matmul(x=scaled_q, y=k, transpose_y=True)
+ if attn_bias:
+ product += attn_bias
+ weights = layers.softmax(product)
+ if dropout_rate:
+ weights = layers.dropout(
+ weights,
+ dropout_prob=dropout_rate,
+ dropout_implementation="upscale_in_train",
+ is_test=False)
+ out = layers.matmul(weights, v)
+ #return out, product
+ return out, weights
+
+ q, k, v = __compute_qkv(queries, keys, values, n_head, d_key, d_value)
+ q = to_3d(q)
+ k = to_3d(k)
+ v = to_3d(v)
+
+ if cache is not None: # use cache and concat time steps
+ # Since the inplace reshape in __split_heads changes the shape of k and
+ # v, which is the cache input for next time step, reshape the cache
+ # input from the previous time step first.
+ k = cache["k"] = layers.concat(
+ [layers.reshape(
+ cache["k"], shape=[0, 0, d_model]), k], axis=1)
+ v = cache["v"] = layers.concat(
+ [layers.reshape(
+ cache["v"], shape=[0, 0, d_model]), v], axis=1)
+
+ q = __split_heads(q, n_head)
+ k = __split_heads(k, n_head)
+ v = __split_heads(v, n_head)
+
+ ctx_multiheads, ctx_multiheads_attn = scaled_dot_product_attention(
+ q, k, v, attn_bias, d_key, dropout_rate)
+
+ out = __combine_heads(ctx_multiheads)
+
+ out = to_2d(out)
+
+ # Project back to the model size.
+ proj_out = layers.fc(input=out,
+ size=d_model,
+ num_flatten_dims=len(out.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=name + '_output_fc.w_0',
+ initializer=param_initializer),
+ bias_attr=name + '_output_fc.b_0')
+ return proj_out, ctx_multiheads_attn
+
+
+def positionwise_feed_forward(x,
+ d_inner_hid,
+ d_hid,
+ dropout_rate,
+ hidden_act,
+ param_initializer=None,
+ name='ffn'):
+ """
+ Position-wise Feed-Forward Networks.
+ This module consists of two linear transformations with a ReLU activation
+ in between, which is applied to each position separately and identically.
+ """
+ hidden = layers.fc(input=x,
+ size=d_inner_hid,
+ num_flatten_dims=len(x.shape) - 1,
+ act=hidden_act,
+ param_attr=fluid.ParamAttr(
+ name=name + '_fc_0.w_0',
+ initializer=param_initializer),
+ bias_attr=name + '_fc_0.b_0')
+ if dropout_rate:
+ hidden = layers.dropout(
+ hidden,
+ dropout_prob=dropout_rate,
+ dropout_implementation="upscale_in_train",
+ is_test=False)
+ out = layers.fc(input=hidden,
+ size=d_hid,
+ num_flatten_dims=len(hidden.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=name + '_fc_1.w_0',
+ initializer=param_initializer),
+ bias_attr=name + '_fc_1.b_0')
+ return out
+
+
+def pre_post_process_layer(prev_out,
+ out,
+ process_cmd,
+ dropout_rate=0.,
+ name=''):
+ """
+ Add residual connection, layer normalization and droput to the out tensor
+ optionally according to the value of process_cmd.
+ This will be used before or after multi-head attention and position-wise
+ feed-forward networks.
+ """
+ for cmd in process_cmd:
+ if cmd == "a": # add residual connection
+ out = out + prev_out if prev_out else out
+ elif cmd == "n": # add layer normalization
+ out_dtype = out.dtype
+ if out_dtype == fluid.core.VarDesc.VarType.FP16:
+ out = layers.cast(x=out, dtype="float32")
+ out = layers.layer_norm(
+ out,
+ begin_norm_axis=len(out.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=name + '_layer_norm_scale',
+ initializer=fluid.initializer.Constant(1.)),
+ bias_attr=fluid.ParamAttr(
+ name=name + '_layer_norm_bias',
+ initializer=fluid.initializer.Constant(0.)))
+ if out_dtype == fluid.core.VarDesc.VarType.FP16:
+ out = layers.cast(x=out, dtype="float16")
+ elif cmd == "d": # add dropout
+ if dropout_rate:
+ out = layers.dropout(
+ out,
+ dropout_prob=dropout_rate,
+ dropout_implementation="upscale_in_train",
+ is_test=False)
+ return out
+
+
+pre_process_layer = partial(pre_post_process_layer, None)
+post_process_layer = pre_post_process_layer
+
+
+def encoder_layer(enc_input,
+ attn_bias,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd="n",
+ postprocess_cmd="da",
+ param_initializer=None,
+ name=''):
+ """The encoder layers that can be stacked to form a deep encoder.
+ This module consits of a multi-head (self) attention followed by
+ position-wise feed-forward networks and both the two components companied
+ with the post_process_layer to add residual connection, layer normalization
+ and droput.
+ """
+ attn_output, ctx_multiheads_attn = multi_head_attention(
+ pre_process_layer(
+ enc_input,
+ preprocess_cmd,
+ prepostprocess_dropout,
+ name=name + '_pre_att'),
+ None,
+ None,
+ attn_bias,
+ d_key,
+ d_value,
+ d_model,
+ n_head,
+ attention_dropout,
+ param_initializer=param_initializer,
+ name=name + '_multi_head_att')
+ attn_output = post_process_layer(
+ enc_input,
+ attn_output,
+ postprocess_cmd,
+ prepostprocess_dropout,
+ name=name + '_post_att')
+
+ ffd_output = positionwise_feed_forward(
+ pre_process_layer(
+ attn_output,
+ preprocess_cmd,
+ prepostprocess_dropout,
+ name=name + '_pre_ffn'),
+ d_inner_hid,
+ d_model,
+ relu_dropout,
+ hidden_act,
+ param_initializer=param_initializer,
+ name=name + '_ffn')
+ ret = post_process_layer(
+ attn_output,
+ ffd_output,
+ postprocess_cmd,
+ prepostprocess_dropout,
+ name=name + '_post_ffn')
+ return ret, ctx_multiheads_attn, ffd_output
+
+
+def build_pad_idx(input_mask):
+ pad_idx = L.where(L.cast(L.squeeze(input_mask, [2]), 'bool'))
+ return pad_idx
+
+
+def build_attn_bias(input_mask, n_head, dtype):
+ attn_bias = L.matmul(
+ input_mask, input_mask, transpose_y=True) # [batch, seq, seq]
+ attn_bias = (1. - attn_bias) * -10000.
+ attn_bias = L.stack([attn_bias] * n_head, 1) # [batch, n_head, seq, seq]
+ if attn_bias.dtype != dtype:
+ attn_bias = L.cast(attn_bias, dtype)
+ return attn_bias
+
+
+def build_graph_attn_bias(input_mask, n_head, dtype, slot_seqlen):
+
+ input_shape = L.shape(input_mask)
+ input_batch = input_shape[0]
+ input_seqlen = input_shape[1]
+ num_slot = input_seqlen / slot_seqlen
+ num_b = num_slot - 1
+ ones = L.ones([num_b], dtype="float32") # [num_b]
+ diag_ones = L.diag(ones) # [num_b, num_b]
+ diag_ones = L.unsqueeze(diag_ones, [1, -1]) # [num_b, 1, num_b, 1]
+ diag_ones = L.expand(diag_ones, [1, slot_seqlen, 1, slot_seqlen]) # [num_b, seqlen, num_b, seqlen]
+ diag_ones = L.reshape(diag_ones, [1, num_b*slot_seqlen, num_b*slot_seqlen]) # [1, num_b*seqlen, num_b*seqlen]
+
+ graph_attn_bias = L.concat([L.ones([1, num_b*slot_seqlen, slot_seqlen], dtype="float32"), diag_ones], 2)
+ graph_attn_bias = L.concat([L.ones([1, slot_seqlen, num_slot*slot_seqlen], dtype="float32"), graph_attn_bias], 1) # [1, seq, seq]
+
+ pad_attn_bias = L.matmul(
+ input_mask, input_mask, transpose_y=True) # [batch, seq, seq]
+ attn_bias = graph_attn_bias * pad_attn_bias
+
+ attn_bias = (1. - attn_bias) * -10000.
+ attn_bias = L.stack([attn_bias] * n_head, 1) # [batch, n_head, seq, seq]
+ if attn_bias.dtype != dtype:
+ attn_bias = L.cast(attn_bias, dtype)
+ return attn_bias
+
+
+def encoder(enc_input,
+ input_mask,
+ n_layer,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd="n",
+ postprocess_cmd="da",
+ param_initializer=None,
+ name=''):
+ """
+ The encoder is composed of a stack of identical layers returned by calling
+ encoder_layer.
+ """
+
+ global to_2d, to_3d #, batch, seqlen, dynamic_dim
+ d_shape = L.shape(input_mask)
+ pad_idx = build_pad_idx(input_mask)
+ attn_bias = build_attn_bias(input_mask, n_head, enc_input.dtype)
+
+ # d_batch = d_shape[0]
+ # d_seqlen = d_shape[1]
+ # pad_idx = L.where(
+ # L.cast(L.reshape(input_mask, [d_batch, d_seqlen]), 'bool'))
+
+ # attn_bias = L.matmul(
+ # input_mask, input_mask, transpose_y=True) # [batch, seq, seq]
+ # attn_bias = (1. - attn_bias) * -10000.
+ # attn_bias = L.stack([attn_bias] * n_head, 1)
+ # if attn_bias.dtype != enc_input.dtype:
+ # attn_bias = L.cast(attn_bias, enc_input.dtype)
+
+ def to_2d(t_3d):
+ t_2d = L.gather_nd(t_3d, pad_idx)
+ return t_2d
+
+ def to_3d(t_2d):
+ t_3d = L.scatter_nd(
+ pad_idx, t_2d, shape=[d_shape[0], d_shape[1], d_model])
+ return t_3d
+
+ enc_input = to_2d(enc_input)
+ all_hidden = []
+ all_attn = []
+ all_ffn = []
+ for i in range(n_layer):
+ enc_output, ctx_multiheads_attn, ffn_output = encoder_layer(
+ enc_input,
+ attn_bias,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd,
+ postprocess_cmd,
+ param_initializer=param_initializer,
+ name=name + '_layer_' + str(i))
+ all_hidden.append(enc_output)
+ all_attn.append(ctx_multiheads_attn)
+ all_ffn.append(ffn_output)
+ enc_input = enc_output
+ enc_output = pre_process_layer(
+ enc_output,
+ preprocess_cmd,
+ prepostprocess_dropout,
+ name="post_encoder")
+ enc_output = to_3d(enc_output)
+ #enc_output.desc.set_shape((-1, 1, final_dim))
+ return enc_output, all_hidden, all_attn, all_ffn
+
+def graph_encoder(enc_input,
+ input_mask,
+ n_layer,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd="n",
+ postprocess_cmd="da",
+ param_initializer=None,
+ slot_seqlen=40,
+ name=''):
+ """
+ The encoder is composed of a stack of identical layers returned by calling
+ encoder_layer.
+ """
+
+ global to_2d, to_3d #, batch, seqlen, dynamic_dim
+ d_shape = L.shape(input_mask)
+ pad_idx = build_pad_idx(input_mask)
+ attn_bias = build_graph_attn_bias(input_mask, n_head, enc_input.dtype, slot_seqlen)
+ #attn_bias = build_attn_bias(input_mask, n_head, enc_input.dtype)
+
+ def to_2d(t_3d):
+ t_2d = L.gather_nd(t_3d, pad_idx)
+ return t_2d
+
+ def to_3d(t_2d):
+ t_3d = L.scatter_nd(
+ pad_idx, t_2d, shape=[d_shape[0], d_shape[1], d_model])
+ return t_3d
+
+ enc_input = to_2d(enc_input)
+ all_hidden = []
+ all_attn = []
+ all_ffn = []
+ for i in range(n_layer):
+ enc_output, ctx_multiheads_attn, ffn_output = encoder_layer(
+ enc_input,
+ attn_bias,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd,
+ postprocess_cmd,
+ param_initializer=param_initializer,
+ name=name + '_layer_' + str(i))
+ all_hidden.append(enc_output)
+ all_attn.append(ctx_multiheads_attn)
+ all_ffn.append(ffn_output)
+ enc_input = enc_output
+ enc_output = pre_process_layer(
+ enc_output,
+ preprocess_cmd,
+ prepostprocess_dropout,
+ name="post_encoder")
+ enc_output = to_3d(enc_output)
+ #enc_output.desc.set_shape((-1, 1, final_dim))
+ return enc_output, all_hidden, all_attn, all_ffn
diff --git a/examples/erniesage/models/erniesage_v1.py b/examples/erniesage/models/erniesage_v1.py
new file mode 100644
index 0000000000000000000000000000000000000000..696231a785ffecb8098c3379c7a7b0f4ee935e33
--- /dev/null
+++ b/examples/erniesage/models/erniesage_v1.py
@@ -0,0 +1,42 @@
+import pgl
+import paddle.fluid as F
+import paddle.fluid.layers as L
+from models.base import BaseNet, BaseGNNModel
+from models.ernie_model.ernie import ErnieModel
+from models.ernie_model.ernie import ErnieGraphModel
+from models.ernie_model.ernie import ErnieConfig
+
+class ErnieSageV1(BaseNet):
+
+ def build_inputs(self):
+ inputs = super(ErnieSageV1, self).build_inputs()
+ term_ids = L.data(
+ "term_ids", shape=[None, self.config.max_seqlen], dtype="int64", append_batch_size=False)
+ return inputs + [term_ids]
+
+ def build_embedding(self, graph_wrappers, term_ids):
+ term_ids = L.unsqueeze(term_ids, [-1])
+ ernie_config = self.config.ernie_config
+ ernie = ErnieModel(
+ src_ids=term_ids,
+ sentence_ids=L.zeros_like(term_ids),
+ task_ids=None,
+ config=ernie_config,
+ use_fp16=False,
+ name="student_")
+ feature = ernie.get_pooled_output()
+ return feature
+
+ def __call__(self, graph_wrappers):
+ inputs = self.build_inputs()
+ feature = self.build_embedding(graph_wrappers, inputs[-1])
+ features = self.gnn_layers(graph_wrappers, feature)
+ outputs = [self.take_final_feature(features[-1], i, "final_fc") for i in inputs[:-1]]
+ src_real_index = L.gather(graph_wrappers[0].node_feat['index'], inputs[0])
+ outputs.append(src_real_index)
+ return inputs, outputs
+
+
+class ErnieSageModelV1(BaseGNNModel):
+ def gen_net_fn(self, config):
+ return ErnieSageV1(config)
diff --git a/examples/erniesage/models/erniesage_v2.py b/examples/erniesage/models/erniesage_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..7ad9a26caf87d7ed79fe55584f21fe8d4f46dd2d
--- /dev/null
+++ b/examples/erniesage/models/erniesage_v2.py
@@ -0,0 +1,135 @@
+import pgl
+import paddle.fluid as F
+import paddle.fluid.layers as L
+from models.base import BaseNet, BaseGNNModel
+from models.ernie_model.ernie import ErnieModel
+
+
+class ErnieSageV2(BaseNet):
+
+ def build_inputs(self):
+ inputs = super(ErnieSageV2, self).build_inputs()
+ term_ids = L.data(
+ "term_ids", shape=[None, self.config.max_seqlen], dtype="int64", append_batch_size=False)
+ return inputs + [term_ids]
+
+ def gnn_layer(self, gw, feature, hidden_size, act, initializer, learning_rate, name):
+ def build_position_ids(src_ids, dst_ids):
+ src_shape = L.shape(src_ids)
+ src_batch = src_shape[0]
+ src_seqlen = src_shape[1]
+ dst_seqlen = src_seqlen - 1 # without cls
+
+ src_position_ids = L.reshape(
+ L.range(
+ 0, src_seqlen, 1, dtype='int32'), [1, src_seqlen, 1],
+ inplace=True) # [1, slot_seqlen, 1]
+ src_position_ids = L.expand(src_position_ids, [src_batch, 1, 1]) # [B, slot_seqlen * num_b, 1]
+ zero = L.fill_constant([1], dtype='int64', value=0)
+ input_mask = L.cast(L.equal(src_ids, zero), "int32") # assume pad id == 0 [B, slot_seqlen, 1]
+ src_pad_len = L.reduce_sum(input_mask, 1, keep_dim=True) # [B, 1, 1]
+
+ dst_position_ids = L.reshape(
+ L.range(
+ src_seqlen, src_seqlen+dst_seqlen, 1, dtype='int32'), [1, dst_seqlen, 1],
+ inplace=True) # [1, slot_seqlen, 1]
+ dst_position_ids = L.expand(dst_position_ids, [src_batch, 1, 1]) # [B, slot_seqlen, 1]
+ dst_position_ids = dst_position_ids - src_pad_len # [B, slot_seqlen, 1]
+
+ position_ids = L.concat([src_position_ids, dst_position_ids], 1)
+ position_ids = L.cast(position_ids, 'int64')
+ position_ids.stop_gradient = True
+ return position_ids
+
+
+ def ernie_send(src_feat, dst_feat, edge_feat):
+ """doc"""
+ # input_ids
+ cls = L.fill_constant_batch_size_like(src_feat["term_ids"], [-1, 1, 1], "int64", 1)
+ src_ids = L.concat([cls, src_feat["term_ids"]], 1)
+ dst_ids = dst_feat["term_ids"]
+
+ # sent_ids
+ sent_ids = L.concat([L.zeros_like(src_ids), L.ones_like(dst_ids)], 1)
+ term_ids = L.concat([src_ids, dst_ids], 1)
+
+ # position_ids
+ position_ids = build_position_ids(src_ids, dst_ids)
+
+ term_ids.stop_gradient = True
+ sent_ids.stop_gradient = True
+ ernie = ErnieModel(
+ term_ids, sent_ids, position_ids,
+ config=self.config.ernie_config)
+ feature = ernie.get_pooled_output()
+ return feature
+
+ def erniesage_v2_aggregator(gw, feature, hidden_size, act, initializer, learning_rate, name):
+ feature = L.unsqueeze(feature, [-1])
+ msg = gw.send(ernie_send, nfeat_list=[("term_ids", feature)])
+ neigh_feature = gw.recv(msg, lambda feat: F.layers.sequence_pool(feat, pool_type="sum"))
+
+ term_ids = feature
+ cls = L.fill_constant_batch_size_like(term_ids, [-1, 1, 1], "int64", 1)
+ term_ids = L.concat([cls, term_ids], 1)
+ term_ids.stop_gradient = True
+ ernie = ErnieModel(
+ term_ids, L.zeros_like(term_ids),
+ config=self.config.ernie_config)
+ self_feature = ernie.get_pooled_output()
+
+ self_feature = L.fc(self_feature,
+ hidden_size,
+ act=act,
+ param_attr=F.ParamAttr(name=name + "_l.w_0",
+ learning_rate=learning_rate),
+ bias_attr=name+"_l.b_0"
+ )
+ neigh_feature = L.fc(neigh_feature,
+ hidden_size,
+ act=act,
+ param_attr=F.ParamAttr(name=name + "_r.w_0",
+ learning_rate=learning_rate),
+ bias_attr=name+"_r.b_0"
+ )
+ output = L.concat([self_feature, neigh_feature], axis=1)
+ output = L.l2_normalize(output, axis=1)
+ return output
+ return erniesage_v2_aggregator(gw, feature, hidden_size, act, initializer, learning_rate, name)
+
+ def gnn_layers(self, graph_wrappers, feature):
+ features = [feature]
+
+ initializer = None
+ fc_lr = self.config.lr / 0.001
+
+ for i in range(self.config.num_layers):
+ if i == self.config.num_layers - 1:
+ act = None
+ else:
+ act = "leaky_relu"
+
+ feature = self.gnn_layer(
+ graph_wrappers[i],
+ feature,
+ self.config.hidden_size,
+ act,
+ initializer,
+ learning_rate=fc_lr,
+ name="%s_%s" % ("erniesage_v2", i))
+ features.append(feature)
+ return features
+
+ def __call__(self, graph_wrappers):
+ inputs = self.build_inputs()
+ feature = inputs[-1]
+ features = self.gnn_layers(graph_wrappers, feature)
+ outputs = [self.take_final_feature(features[-1], i, "final_fc") for i in inputs[:-1]]
+ src_real_index = L.gather(graph_wrappers[0].node_feat['index'], inputs[0])
+ outputs.append(src_real_index)
+ return inputs, outputs
+
+
+class ErnieSageModelV2(BaseGNNModel):
+ def gen_net_fn(self, config):
+ return ErnieSageV2(config)
diff --git a/examples/erniesage/models/erniesage_v3.py b/examples/erniesage/models/erniesage_v3.py
new file mode 100644
index 0000000000000000000000000000000000000000..44c3ae8b967df10af4c6a74425e3a43490eab25e
--- /dev/null
+++ b/examples/erniesage/models/erniesage_v3.py
@@ -0,0 +1,119 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import pgl
+import paddle.fluid as F
+import paddle.fluid.layers as L
+
+from models.base import BaseNet, BaseGNNModel
+from models.ernie_model.ernie import ErnieModel
+from models.ernie_model.ernie import ErnieGraphModel
+from models.message_passing import copy_send
+
+
+class ErnieSageV3(BaseNet):
+ def __init__(self, config):
+ super(ErnieSageV3, self).__init__(config)
+
+ def build_inputs(self):
+ inputs = super(ErnieSageV3, self).build_inputs()
+ term_ids = L.data(
+ "term_ids", shape=[None, self.config.max_seqlen], dtype="int64", append_batch_size=False)
+ return inputs + [term_ids]
+
+ def gnn_layer(self, gw, feature, hidden_size, act, initializer, learning_rate, name):
+ def ernie_recv(feat):
+ """doc"""
+ num_neighbor = self.config.samples[0]
+ pad_value = L.zeros([1], "int64")
+ out, _ = L.sequence_pad(feat, pad_value=pad_value, maxlen=num_neighbor)
+ out = L.reshape(out, [0, self.config.max_seqlen*num_neighbor])
+ return out
+
+ def erniesage_v3_aggregator(gw, feature, hidden_size, act, initializer, learning_rate, name):
+ msg = gw.send(copy_send, nfeat_list=[("h", feature)])
+ neigh_feature = gw.recv(msg, ernie_recv)
+ neigh_feature = L.cast(L.unsqueeze(neigh_feature, [-1]), "int64")
+
+ feature = L.unsqueeze(feature, [-1])
+ cls = L.fill_constant_batch_size_like(feature, [-1, 1, 1], "int64", 1)
+ term_ids = L.concat([cls, feature[:, :-1], neigh_feature], 1)
+ term_ids.stop_gradient = True
+ return term_ids
+ return erniesage_v3_aggregator(gw, feature, hidden_size, act, initializer, learning_rate, name)
+
+ def gnn_layers(self, graph_wrappers, feature):
+ features = [feature]
+
+ initializer = None
+ fc_lr = self.config.lr / 0.001
+
+ for i in range(self.config.num_layers):
+ if i == self.config.num_layers - 1:
+ act = None
+ else:
+ act = "leaky_relu"
+
+ feature = self.gnn_layer(
+ graph_wrappers[i],
+ feature,
+ self.config.hidden_size,
+ act,
+ initializer,
+ learning_rate=fc_lr,
+ name="%s_%s" % ("erniesage_v3", i))
+ features.append(feature)
+ return features
+
+ def take_final_feature(self, feature, index, name):
+ """take final feature"""
+ feat = L.gather(feature, index, overwrite=False)
+
+ ernie_config = self.config.ernie_config
+ ernie = ErnieGraphModel(
+ src_ids=feat,
+ config=ernie_config,
+ slot_seqlen=self.config.max_seqlen)
+ feat = ernie.get_pooled_output()
+ fc_lr = self.config.lr / 0.001
+ # feat = L.fc(feat,
+ # self.config.hidden_size,
+ # act="relu",
+ # param_attr=F.ParamAttr(name=name + "_l",
+ # learning_rate=fc_lr),
+ # )
+ #feat = L.l2_normalize(feat, axis=1)
+
+ if self.config.final_fc:
+ feat = L.fc(feat,
+ self.config.hidden_size,
+ param_attr=F.ParamAttr(name=name + '_w'),
+ bias_attr=F.ParamAttr(name=name + '_b'))
+
+ if self.config.final_l2_norm:
+ feat = L.l2_normalize(feat, axis=1)
+ return feat
+
+ def __call__(self, graph_wrappers):
+ inputs = self.build_inputs()
+ feature = inputs[-1]
+ features = self.gnn_layers(graph_wrappers, feature)
+ outputs = [self.take_final_feature(features[-1], i, "final_fc") for i in inputs[:-1]]
+ src_real_index = L.gather(graph_wrappers[0].node_feat['index'], inputs[0])
+ outputs.append(src_real_index)
+ return inputs, outputs
+
+
+class ErnieSageModelV3(BaseGNNModel):
+ def gen_net_fn(self, config):
+ return ErnieSageV3(config)
diff --git a/examples/erniesage/models/message_passing.py b/examples/erniesage/models/message_passing.py
new file mode 100644
index 0000000000000000000000000000000000000000..f45e4be000a17348664486f627f74934c81add1a
--- /dev/null
+++ b/examples/erniesage/models/message_passing.py
@@ -0,0 +1,145 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import numpy as np
+import paddle
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+
+
+def copy_send(src_feat, dst_feat, edge_feat):
+ """doc"""
+ return src_feat["h"]
+
+def weighted_copy_send(src_feat, dst_feat, edge_feat):
+ """doc"""
+ return src_feat["h"] * edge_feat["weight"]
+
+def mean_recv(feat):
+ """doc"""
+ return fluid.layers.sequence_pool(feat, pool_type="average")
+
+
+def sum_recv(feat):
+ """doc"""
+ return fluid.layers.sequence_pool(feat, pool_type="sum")
+
+
+def max_recv(feat):
+ """doc"""
+ return fluid.layers.sequence_pool(feat, pool_type="max")
+
+
+def lstm_recv(feat):
+ """doc"""
+ hidden_dim = 128
+ forward, _ = fluid.layers.dynamic_lstm(
+ input=feat, size=hidden_dim * 4, use_peepholes=False)
+ output = fluid.layers.sequence_last_step(forward)
+ return output
+
+
+def graphsage_sum(gw, feature, hidden_size, act, initializer, learning_rate, name):
+ """doc"""
+ msg = gw.send(copy_send, nfeat_list=[("h", feature)])
+ neigh_feature = gw.recv(msg, sum_recv)
+ self_feature = feature
+ self_feature = fluid.layers.fc(self_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_l.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_l.b_0"
+ )
+ neigh_feature = fluid.layers.fc(neigh_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_r.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_r.b_0"
+ )
+ output = fluid.layers.concat([self_feature, neigh_feature], axis=1)
+ output = fluid.layers.l2_normalize(output, axis=1)
+ return output
+
+
+def graphsage_mean(gw, feature, hidden_size, act, initializer, learning_rate, name):
+ """doc"""
+ msg = gw.send(copy_send, nfeat_list=[("h", feature)])
+ neigh_feature = gw.recv(msg, mean_recv)
+ self_feature = feature
+ self_feature = fluid.layers.fc(self_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_l.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_l.b_0"
+ )
+ neigh_feature = fluid.layers.fc(neigh_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_r.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_r.b_0"
+ )
+ output = fluid.layers.concat([self_feature, neigh_feature], axis=1)
+ output = fluid.layers.l2_normalize(output, axis=1)
+ return output
+
+
+def pinsage_mean(gw, feature, hidden_size, act, initializer, learning_rate, name):
+ """doc"""
+ msg = gw.send(weighted_copy_send, nfeat_list=[("h", feature)], efeat_list=["weight"])
+ neigh_feature = gw.recv(msg, mean_recv)
+ self_feature = feature
+ self_feature = fluid.layers.fc(self_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_l.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_l.b_0"
+ )
+ neigh_feature = fluid.layers.fc(neigh_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_r.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_r.b_0"
+ )
+ output = fluid.layers.concat([self_feature, neigh_feature], axis=1)
+ output = fluid.layers.l2_normalize(output, axis=1)
+ return output
+
+
+def pinsage_sum(gw, feature, hidden_size, act, initializer, learning_rate, name):
+ """doc"""
+ msg = gw.send(weighted_copy_send, nfeat_list=[("h", feature)], efeat_list=["weight"])
+ neigh_feature = gw.recv(msg, sum_recv)
+ self_feature = feature
+ self_feature = fluid.layers.fc(self_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_l.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_l.b_0"
+ )
+ neigh_feature = fluid.layers.fc(neigh_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_r.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_r.b_0"
+ )
+ output = fluid.layers.concat([self_feature, neigh_feature], axis=1)
+ output = fluid.layers.l2_normalize(output, axis=1)
+ return output
diff --git a/examples/erniesage/models/model_factory.py b/examples/erniesage/models/model_factory.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f69bb1f6932a219f4a41faee9cf5bf6c3f947a8
--- /dev/null
+++ b/examples/erniesage/models/model_factory.py
@@ -0,0 +1,24 @@
+from models.base import BaseGNNModel
+from models.ernie import ErnieModel
+from models.erniesage_v1 import ErnieSageModelV1
+from models.erniesage_v2 import ErnieSageModelV2
+from models.erniesage_v3 import ErnieSageModelV3
+
+class Model(object):
+ @classmethod
+ def factory(cls, config):
+ name = config.model_type
+ if name == "BaseGNNModel":
+ return BaseGNNModel(config)
+ if name == "ErnieModel":
+ return ErnieModel(config)
+ if name == "ErnieSageModelV1":
+ return ErnieSageModelV1(config)
+ if name == "ErnieSageModelV2":
+ return ErnieSageModelV2(config)
+ if name == "ErnieSageModelV3":
+ return ErnieSageModelV3(config)
+ else:
+ raise ValueError
+
+
diff --git a/examples/erniesage/preprocessing/dump_graph.py b/examples/erniesage/preprocessing/dump_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..d1558b39a9f95424140b9661732cfa27dccd730a
--- /dev/null
+++ b/examples/erniesage/preprocessing/dump_graph.py
@@ -0,0 +1,121 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+########################################################################
+#
+# Copyright (c) 2020 Baidu.com, Inc. All Rights Reserved
+#
+# File: dump_graph.py
+# Author: suweiyue(suweiyue@baidu.com)
+# Date: 2020/03/01 22:17:13
+#
+########################################################################
+"""
+ Comment.
+"""
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+#from __future__ import unicode_literals
+
+import io
+import os
+import sys
+import argparse
+import logging
+import multiprocessing
+from functools import partial
+from io import open
+
+import numpy as np
+import tqdm
+import pgl
+from pgl.graph_kernel import alias_sample_build_table
+from pgl.utils.logger import log
+
+from tokenization import FullTokenizer
+
+
+def term2id(string, tokenizer, max_seqlen):
+ #string = string.split("\t")[1]
+ tokens = tokenizer.tokenize(string)
+ ids = tokenizer.convert_tokens_to_ids(tokens)
+ ids = ids[:max_seqlen-1]
+ ids = ids + [2] # ids + [sep]
+ ids = ids + [0] * (max_seqlen - len(ids))
+ return ids
+
+
+def dump_graph(args):
+ if not os.path.exists(args.outpath):
+ os.makedirs(args.outpath)
+ neg_samples = []
+ str2id = dict()
+ term_file = io.open(os.path.join(args.outpath, "terms.txt"), "w", encoding=args.encoding)
+ terms = []
+ count = 0
+ item_distribution = []
+
+ with io.open(args.inpath, encoding=args.encoding) as f:
+ edges = []
+ for idx, line in enumerate(f):
+ if idx % 100000 == 0:
+ log.info("%s readed %s lines" % (args.inpath, idx))
+ slots = []
+ for col_idx, col in enumerate(line.strip("\n").split("\t")):
+ s = col[:args.max_seqlen]
+ if s not in str2id:
+ str2id[s] = count
+ count += 1
+ term_file.write(str(col_idx) + "\t" + col + "\n")
+ item_distribution.append(0)
+
+ slots.append(str2id[s])
+
+ src = slots[0]
+ dst = slots[1]
+ neg_samples.append(slots[2:])
+ edges.append((src, dst))
+ edges.append((dst, src))
+ item_distribution[dst] += 1
+
+ term_file.close()
+ edges = np.array(edges, dtype="int64")
+ num_nodes = len(str2id)
+ str2id.clear()
+ log.info("building graph...")
+ graph = pgl.graph.Graph(num_nodes=num_nodes, edges=edges)
+ indegree = graph.indegree()
+ graph.indegree()
+ graph.outdegree()
+ graph.dump(args.outpath)
+
+ # dump alias sample table
+ item_distribution = np.array(item_distribution)
+ item_distribution = np.sqrt(item_distribution)
+ distribution = 1. * item_distribution / item_distribution.sum()
+ alias, events = alias_sample_build_table(distribution)
+ np.save(os.path.join(args.outpath, "alias.npy"), alias)
+ np.save(os.path.join(args.outpath, "events.npy"), events)
+ np.save(os.path.join(args.outpath, "neg_samples.npy"), np.array(neg_samples))
+ log.info("End Build Graph")
+
+def dump_node_feat(args):
+ log.info("Dump node feat starting...")
+ id2str = [line.strip("\n").split("\t")[1] for line in io.open(os.path.join(args.outpath, "terms.txt"), encoding=args.encoding)]
+ pool = multiprocessing.Pool()
+ tokenizer = FullTokenizer(args.vocab_file)
+ term_ids = pool.map(partial(term2id, tokenizer=tokenizer, max_seqlen=args.max_seqlen), id2str)
+ np.save(os.path.join(args.outpath, "term_ids.npy"), np.array(term_ids, np.uint16))
+ log.info("Dump node feat done.")
+ pool.terminate()
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description='main')
+ parser.add_argument("-i", "--inpath", type=str, default=None)
+ parser.add_argument("-l", "--max_seqlen", type=int, default=30)
+ parser.add_argument("--vocab_file", type=str, default="./vocab.txt")
+ parser.add_argument("--encoding", type=str, default="utf8")
+ parser.add_argument("-o", "--outpath", type=str, default=None)
+ args = parser.parse_args()
+ dump_graph(args)
+ dump_node_feat(args)
diff --git a/examples/erniesage/preprocessing/tokenization.py b/examples/erniesage/preprocessing/tokenization.py
new file mode 100644
index 0000000000000000000000000000000000000000..975bb26a531e655bcfa4744f8ebc81fc01c68d9c
--- /dev/null
+++ b/examples/erniesage/preprocessing/tokenization.py
@@ -0,0 +1,461 @@
+# coding=utf-8
+# Copyright 2018 The Google AI Language Team Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Tokenization classes."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import collections
+import unicodedata
+import six
+import sentencepiece as sp
+
+def convert_to_unicode(text):
+ """Converts `text` to Unicode (if it's not already), assuming utf-8 input."""
+ if six.PY3:
+ if isinstance(text, str):
+ return text
+ elif isinstance(text, bytes):
+ return text.decode("utf-8", "ignore")
+ else:
+ raise ValueError("Unsupported string type: %s" % (type(text)))
+ elif six.PY2:
+ if isinstance(text, str):
+ return text.decode("utf-8", "ignore")
+ elif isinstance(text, unicode):
+ return text
+ else:
+ raise ValueError("Unsupported string type: %s" % (type(text)))
+ else:
+ raise ValueError("Not running on Python2 or Python 3?")
+
+
+def printable_text(text):
+ """Returns text encoded in a way suitable for print or `tf.logging`."""
+
+ # These functions want `str` for both Python2 and Python3, but in one case
+ # it's a Unicode string and in the other it's a byte string.
+ if six.PY3:
+ if isinstance(text, str):
+ return text
+ elif isinstance(text, bytes):
+ return text.decode("utf-8", "ignore")
+ else:
+ raise ValueError("Unsupported string type: %s" % (type(text)))
+ elif six.PY2:
+ if isinstance(text, str):
+ return text
+ elif isinstance(text, unicode):
+ return text.encode("utf-8")
+ else:
+ raise ValueError("Unsupported string type: %s" % (type(text)))
+ else:
+ raise ValueError("Not running on Python2 or Python 3?")
+
+
+def load_vocab(vocab_file):
+ """Loads a vocabulary file into a dictionary."""
+ vocab = collections.OrderedDict()
+ fin = open(vocab_file, 'rb')
+ for num, line in enumerate(fin):
+ items = convert_to_unicode(line.strip()).split("\t")
+ if len(items) > 2:
+ break
+ token = items[0]
+ index = items[1] if len(items) == 2 else num
+ token = token.strip()
+ vocab[token] = int(index)
+ return vocab
+
+
+def convert_by_vocab(vocab, items):
+ """Converts a sequence of [tokens|ids] using the vocab."""
+ output = []
+ for item in items:
+ output.append(vocab[item])
+ return output
+
+
+def convert_tokens_to_ids_include_unk(vocab, tokens, unk_token="[UNK]"):
+ output = []
+ for token in tokens:
+ if token in vocab:
+ output.append(vocab[token])
+ else:
+ output.append(vocab[unk_token])
+ return output
+
+
+def convert_tokens_to_ids(vocab, tokens):
+ return convert_by_vocab(vocab, tokens)
+
+
+def convert_ids_to_tokens(inv_vocab, ids):
+ return convert_by_vocab(inv_vocab, ids)
+
+
+def whitespace_tokenize(text):
+ """Runs basic whitespace cleaning and splitting on a peice of text."""
+ text = text.strip()
+ if not text:
+ return []
+ tokens = text.split()
+ return tokens
+
+
+class FullTokenizer(object):
+ """Runs end-to-end tokenziation."""
+
+ def __init__(self, vocab_file, do_lower_case=True):
+ self.vocab = load_vocab(vocab_file)
+ self.inv_vocab = {v: k for k, v in self.vocab.items()}
+ self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case)
+ self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab)
+
+ def tokenize(self, text):
+ split_tokens = []
+ for token in self.basic_tokenizer.tokenize(text):
+ for sub_token in self.wordpiece_tokenizer.tokenize(token):
+ split_tokens.append(sub_token)
+
+ return split_tokens
+
+ def convert_tokens_to_ids(self, tokens):
+ return convert_by_vocab(self.vocab, tokens)
+
+ def convert_ids_to_tokens(self, ids):
+ return convert_by_vocab(self.inv_vocab, ids)
+
+
+class CharTokenizer(object):
+ """Runs end-to-end tokenziation."""
+
+ def __init__(self, vocab_file, do_lower_case=True):
+ self.vocab = load_vocab(vocab_file)
+ self.inv_vocab = {v: k for k, v in self.vocab.items()}
+ self.tokenizer = WordpieceTokenizer(vocab=self.vocab)
+
+ def tokenize(self, text):
+ split_tokens = []
+ for token in text.lower().split(" "):
+ for sub_token in self.tokenizer.tokenize(token):
+ split_tokens.append(sub_token)
+ return split_tokens
+
+ def convert_tokens_to_ids(self, tokens):
+ return convert_by_vocab(self.vocab, tokens)
+
+ def convert_ids_to_tokens(self, ids):
+ return convert_by_vocab(self.inv_vocab, ids)
+
+
+class BasicTokenizer(object):
+ """Runs basic tokenization (punctuation splitting, lower casing, etc.)."""
+
+ def __init__(self, do_lower_case=True):
+ """Constructs a BasicTokenizer.
+
+ Args:
+ do_lower_case: Whether to lower case the input.
+ """
+ self.do_lower_case = do_lower_case
+
+ def tokenize(self, text):
+ """Tokenizes a piece of text."""
+ text = convert_to_unicode(text)
+ text = self._clean_text(text)
+
+ # This was added on November 1st, 2018 for the multilingual and Chinese
+ # models. This is also applied to the English models now, but it doesn't
+ # matter since the English models were not trained on any Chinese data
+ # and generally don't have any Chinese data in them (there are Chinese
+ # characters in the vocabulary because Wikipedia does have some Chinese
+ # words in the English Wikipedia.).
+ text = self._tokenize_chinese_chars(text)
+
+ orig_tokens = whitespace_tokenize(text)
+ split_tokens = []
+ for token in orig_tokens:
+ if self.do_lower_case:
+ token = token.lower()
+ token = self._run_strip_accents(token)
+ split_tokens.extend(self._run_split_on_punc(token))
+
+ output_tokens = whitespace_tokenize(" ".join(split_tokens))
+ return output_tokens
+
+ def _run_strip_accents(self, text):
+ """Strips accents from a piece of text."""
+ text = unicodedata.normalize("NFD", text)
+ output = []
+ for char in text:
+ cat = unicodedata.category(char)
+ if cat == "Mn":
+ continue
+ output.append(char)
+ return "".join(output)
+
+ def _run_split_on_punc(self, text):
+ """Splits punctuation on a piece of text."""
+ chars = list(text)
+ i = 0
+ start_new_word = True
+ output = []
+ while i < len(chars):
+ char = chars[i]
+ if _is_punctuation(char):
+ output.append([char])
+ start_new_word = True
+ else:
+ if start_new_word:
+ output.append([])
+ start_new_word = False
+ output[-1].append(char)
+ i += 1
+
+ return ["".join(x) for x in output]
+
+ def _tokenize_chinese_chars(self, text):
+ """Adds whitespace around any CJK character."""
+ output = []
+ for char in text:
+ cp = ord(char)
+ if self._is_chinese_char(cp):
+ output.append(" ")
+ output.append(char)
+ output.append(" ")
+ else:
+ output.append(char)
+ return "".join(output)
+
+ def _is_chinese_char(self, cp):
+ """Checks whether CP is the codepoint of a CJK character."""
+ # This defines a "chinese character" as anything in the CJK Unicode block:
+ # https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
+ #
+ # Note that the CJK Unicode block is NOT all Japanese and Korean characters,
+ # despite its name. The modern Korean Hangul alphabet is a different block,
+ # as is Japanese Hiragana and Katakana. Those alphabets are used to write
+ # space-separated words, so they are not treated specially and handled
+ # like the all of the other languages.
+ if ((cp >= 0x4E00 and cp <= 0x9FFF) or #
+ (cp >= 0x3400 and cp <= 0x4DBF) or #
+ (cp >= 0x20000 and cp <= 0x2A6DF) or #
+ (cp >= 0x2A700 and cp <= 0x2B73F) or #
+ (cp >= 0x2B740 and cp <= 0x2B81F) or #
+ (cp >= 0x2B820 and cp <= 0x2CEAF) or
+ (cp >= 0xF900 and cp <= 0xFAFF) or #
+ (cp >= 0x2F800 and cp <= 0x2FA1F)): #
+ return True
+
+ return False
+
+ def _clean_text(self, text):
+ """Performs invalid character removal and whitespace cleanup on text."""
+ output = []
+ for char in text:
+ cp = ord(char)
+ if cp == 0 or cp == 0xfffd or _is_control(char):
+ continue
+ if _is_whitespace(char):
+ output.append(" ")
+ else:
+ output.append(char)
+ return "".join(output)
+
+
+class SentencepieceTokenizer(object):
+ """Runs SentencePiece tokenziation."""
+
+ def __init__(self, vocab_file, do_lower_case=True, unk_token="[UNK]"):
+ self.vocab = load_vocab(vocab_file)
+ self.inv_vocab = {v: k for k, v in self.vocab.items()}
+ self.do_lower_case = do_lower_case
+ self.tokenizer = sp.SentencePieceProcessor()
+ self.tokenizer.Load(vocab_file + ".model")
+ self.sp_unk_token = ""
+ self.unk_token = unk_token
+
+ def tokenize(self, text):
+ """Tokenizes a piece of text into its word pieces.
+
+ Returns:
+ A list of wordpiece tokens.
+ """
+ text = text.lower() if self.do_lower_case else text
+ text = convert_to_unicode(text.replace("\1", " "))
+ tokens = self.tokenizer.EncodeAsPieces(text)
+
+ output_tokens = []
+ for token in tokens:
+ if token == self.sp_unk_token:
+ token = self.unk_token
+
+ if token in self.vocab:
+ output_tokens.append(token)
+ else:
+ output_tokens.append(self.unk_token)
+
+ return output_tokens
+
+ def convert_tokens_to_ids(self, tokens):
+ return convert_by_vocab(self.vocab, tokens)
+
+ def convert_ids_to_tokens(self, ids):
+ return convert_by_vocab(self.inv_vocab, ids)
+
+
+class WordsegTokenizer(object):
+ """Runs Wordseg tokenziation."""
+
+ def __init__(self, vocab_file, do_lower_case=True, unk_token="[UNK]",
+ split_token="\1"):
+ self.vocab = load_vocab(vocab_file)
+ self.inv_vocab = {v: k for k, v in self.vocab.items()}
+ self.tokenizer = sp.SentencePieceProcessor()
+ self.tokenizer.Load(vocab_file + ".model")
+
+ self.do_lower_case = do_lower_case
+ self.unk_token = unk_token
+ self.split_token = split_token
+
+ def tokenize(self, text):
+ """Tokenizes a piece of text into its word pieces.
+
+ Returns:
+ A list of wordpiece tokens.
+ """
+ text = text.lower() if self.do_lower_case else text
+ text = convert_to_unicode(text)
+
+ output_tokens = []
+ for token in text.split(self.split_token):
+ if token in self.vocab:
+ output_tokens.append(token)
+ else:
+ sp_tokens = self.tokenizer.EncodeAsPieces(token)
+ for sp_token in sp_tokens:
+ if sp_token in self.vocab:
+ output_tokens.append(sp_token)
+ return output_tokens
+
+ def convert_tokens_to_ids(self, tokens):
+ return convert_by_vocab(self.vocab, tokens)
+
+ def convert_ids_to_tokens(self, ids):
+ return convert_by_vocab(self.inv_vocab, ids)
+
+
+class WordpieceTokenizer(object):
+ """Runs WordPiece tokenziation."""
+
+ def __init__(self, vocab, unk_token="[UNK]", max_input_chars_per_word=100):
+ self.vocab = vocab
+ self.unk_token = unk_token
+ self.max_input_chars_per_word = max_input_chars_per_word
+
+ def tokenize(self, text):
+ """Tokenizes a piece of text into its word pieces.
+
+ This uses a greedy longest-match-first algorithm to perform tokenization
+ using the given vocabulary.
+
+ For example:
+ input = "unaffable"
+ output = ["un", "##aff", "##able"]
+
+ Args:
+ text: A single token or whitespace separated tokens. This should have
+ already been passed through `BasicTokenizer.
+
+ Returns:
+ A list of wordpiece tokens.
+ """
+
+ text = convert_to_unicode(text)
+
+ output_tokens = []
+ for token in whitespace_tokenize(text):
+ chars = list(token)
+ if len(chars) > self.max_input_chars_per_word:
+ output_tokens.append(self.unk_token)
+ continue
+
+ is_bad = False
+ start = 0
+ sub_tokens = []
+ while start < len(chars):
+ end = len(chars)
+ cur_substr = None
+ while start < end:
+ substr = "".join(chars[start:end])
+ if start > 0:
+ substr = "##" + substr
+ if substr in self.vocab:
+ cur_substr = substr
+ break
+ end -= 1
+ if cur_substr is None:
+ is_bad = True
+ break
+ sub_tokens.append(cur_substr)
+ start = end
+
+ if is_bad:
+ output_tokens.append(self.unk_token)
+ else:
+ output_tokens.extend(sub_tokens)
+ return output_tokens
+
+
+def _is_whitespace(char):
+ """Checks whether `chars` is a whitespace character."""
+ # \t, \n, and \r are technically contorl characters but we treat them
+ # as whitespace since they are generally considered as such.
+ if char == " " or char == "\t" or char == "\n" or char == "\r":
+ return True
+ cat = unicodedata.category(char)
+ if cat == "Zs":
+ return True
+ return False
+
+
+def _is_control(char):
+ """Checks whether `chars` is a control character."""
+ # These are technically control characters but we count them as whitespace
+ # characters.
+ if char == "\t" or char == "\n" or char == "\r":
+ return False
+ cat = unicodedata.category(char)
+ if cat.startswith("C"):
+ return True
+ return False
+
+
+def _is_punctuation(char):
+ """Checks whether `chars` is a punctuation character."""
+ cp = ord(char)
+ # We treat all non-letter/number ASCII as punctuation.
+ # Characters such as "^", "$", and "`" are not in the Unicode
+ # Punctuation class but we treat them as punctuation anyways, for
+ # consistency.
+ if ((cp >= 33 and cp <= 47) or (cp >= 58 and cp <= 64) or
+ (cp >= 91 and cp <= 96) or (cp >= 123 and cp <= 126)):
+ return True
+ cat = unicodedata.category(char)
+ if cat.startswith("P"):
+ return True
+ return False
diff --git a/examples/erniesage/train.py b/examples/erniesage/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..cc3255c9949ca3812637b07c2b10acb190c38462
--- /dev/null
+++ b/examples/erniesage/train.py
@@ -0,0 +1,95 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import argparse
+import traceback
+
+import yaml
+import numpy as np
+from easydict import EasyDict as edict
+from pgl.utils.logger import log
+from pgl.utils import paddle_helper
+
+from learner import Learner
+from models.model_factory import Model
+from dataset.graph_reader import GraphGenerator
+
+
+class TrainData(object):
+ def __init__(self, graph_path):
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ trainer_count = int(os.getenv("PADDLE_TRAINERS_NUM", "1"))
+ log.info("trainer_id: %s, trainer_count: %s." % (trainer_id, trainer_count))
+
+ bidirectional_edges = np.load(os.path.join(graph_path, "edges.npy"), allow_pickle=True)
+ # edges is bidirectional.
+ edges = bidirectional_edges[0::2]
+ train_usr = edges[trainer_id::trainer_count, 0]
+ train_ad = edges[trainer_id::trainer_count, 1]
+ returns = {
+ "train_data": [train_usr, train_ad]
+ }
+
+ if os.path.exists(os.path.join(graph_path, "neg_samples.npy")):
+ neg_samples = np.load(os.path.join(graph_path, "neg_samples.npy"), allow_pickle=True)
+ if neg_samples.size != 0:
+ train_negs = neg_samples[trainer_id::trainer_count]
+ returns["train_data"].append(train_negs)
+ log.info("Load train_data done.")
+ self.data = returns
+
+ def __getitem__(self, index):
+ return [ data[index] for data in self.data["train_data"]]
+
+ def __len__(self):
+ return len(self.data["train_data"][0])
+
+
+def main(config):
+ # Select Model
+ model = Model.factory(config)
+
+ # Build Train Edges
+ data = TrainData(config.graph_path)
+
+ # Build Train Data
+ train_iter = GraphGenerator(
+ graph_wrappers=model.graph_wrappers,
+ batch_size=config.batch_size,
+ data=data,
+ samples=config.samples,
+ num_workers=config.sample_workers,
+ feed_name_list=[var.name for var in model.feed_list],
+ use_pyreader=config.use_pyreader,
+ phase="train",
+ graph_data_path=config.graph_path,
+ shuffle=True,
+ neg_type=config.neg_type)
+
+ log.info("build graph reader done.")
+
+ learner = Learner.factory(config.learner_type)
+ learner.build(model, train_iter, config)
+
+ learner.start()
+ learner.stop()
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description='main')
+ parser.add_argument("--conf", type=str, default="./config.yaml")
+ args = parser.parse_args()
+ config = edict(yaml.load(open(args.conf), Loader=yaml.FullLoader))
+ print(config)
+ main(config)
diff --git a/examples/gat/train.py b/examples/gat/train.py
index 344948803539f260bbe7288a4ee16a423c5c5f8a..438565baad16780ad0c57ae1833db1301160500f 100644
--- a/examples/gat/train.py
+++ b/examples/gat/train.py
@@ -44,7 +44,6 @@ def main(args):
with fluid.program_guard(train_program, startup_program):
gw = pgl.graph_wrapper.GraphWrapper(
name="graph",
- place=place,
node_feat=dataset.graph.node_feat_info())
output = pgl.layers.gat(gw,
diff --git a/examples/gin/README.md b/examples/gin/README.md
index 22145cb04236c2522e7e1d6be8e5b8b6e1bd913a..e35eef7fae1feaa22508a313b35b2103695fc3aa 100644
--- a/examples/gin/README.md
+++ b/examples/gin/README.md
@@ -4,18 +4,19 @@
### Datasets
-The dataset can be downloaded from [here](https://github.com/weihua916/powerful-gnns/blob/master/dataset.zip)
+The dataset can be downloaded from [here](https://github.com/weihua916/powerful-gnns/blob/master/dataset.zip).
+After downloading the data,uncompress them, then a directory named `./dataset/` can be found in current directory. Note that the current directory is the root directory of GIN model.
### Dependencies
-- paddlepaddle 1.6
+- paddlepaddle >= 1.6
- pgl 1.0.2
### How to run
For examples, use GPU to train GIN model on MUTAG dataset.
```
-python main.py --use_cuda --dataset_name MUTAG
+python main.py --use_cuda --dataset_name MUTAG --data_path ./dataset
```
### Hyperparameters
diff --git a/examples/gin/model.py b/examples/gin/model.py
index 2380ddde8990fa68987bc41e4774a87247c8e3cc..45548f37121afe7fc0945246c415b42df4c9d2c7 100644
--- a/examples/gin/model.py
+++ b/examples/gin/model.py
@@ -50,7 +50,16 @@ class GINModel(object):
init_eps=0.0,
train_eps=self.train_eps)
- h = fl.batch_norm(h)
+ h = fl.layer_norm(
+ h,
+ begin_norm_axis=1,
+ param_attr=fluid.ParamAttr(
+ name="norm_scale_%s" % (i),
+ initializer=fluid.initializer.Constant(1.0)),
+ bias_attr=fluid.ParamAttr(
+ name="norm_bias_%s" % (i),
+ initializer=fluid.initializer.Constant(0.0)), )
+
h = fl.relu(h)
features_list.append(h)
diff --git a/examples/graphsage/train.py b/examples/graphsage/train.py
index da20f6e9643b25b800b87d3935feedaf3ec2a62b..463e0b6d4d6457d0307223e21dc79d246a2ef656 100644
--- a/examples/graphsage/train.py
+++ b/examples/graphsage/train.py
@@ -204,8 +204,8 @@ def main(args):
graph_wrapper = pgl.graph_wrapper.GraphWrapper(
"sub_graph",
- fluid.CPUPlace(),
node_feat=data['graph'].node_feat_info())
+
model_loss, model_acc = build_graph_model(
graph_wrapper,
num_class=data["num_class"],
diff --git a/examples/graphsage/train_multi.py b/examples/graphsage/train_multi.py
index eda3a341c99e4f4b7123dc3eebf0f7f2f79617ad..1f8fe69c6496c2a6f4e933d3ea6aa7da01c50571 100644
--- a/examples/graphsage/train_multi.py
+++ b/examples/graphsage/train_multi.py
@@ -231,7 +231,6 @@ def main(args):
with fluid.program_guard(train_program, startup_program):
graph_wrapper = pgl.graph_wrapper.GraphWrapper(
"sub_graph",
- fluid.CPUPlace(),
node_feat=data['graph'].node_feat_info())
model_loss, model_acc = build_graph_model(
diff --git a/examples/graphsage/train_scale.py b/examples/graphsage/train_scale.py
index f0625d0202b37ca4153b3077451b5032edaf0fbf..c6fce995246e0244badf51e6bc3583d9fc7be9c7 100644
--- a/examples/graphsage/train_scale.py
+++ b/examples/graphsage/train_scale.py
@@ -227,7 +227,6 @@ def main(args):
with fluid.program_guard(train_program, startup_program):
graph_wrapper = pgl.graph_wrapper.GraphWrapper(
"sub_graph",
- fluid.CPUPlace(),
node_feat=data['graph'].node_feat_info())
model_loss, model_acc = build_graph_model(
diff --git a/examples/stgcn/main.py b/examples/stgcn/main.py
index 6be8df9991177daf2ba9fed1f39eebbb8e8ad83f..26adb6a4e6f3c81b4e4e2d35e3f049d0d80f03f5 100644
--- a/examples/stgcn/main.py
+++ b/examples/stgcn/main.py
@@ -49,7 +49,6 @@ def main(args):
with fluid.program_guard(train_program, startup_program):
gw = pgl.graph_wrapper.GraphWrapper(
"gw",
- place,
node_feat=[('norm', [None, 1], "float32")],
edge_feat=[('weights', [None, 1], "float32")])
diff --git a/examples/unsup_graphsage/train.py b/examples/unsup_graphsage/train.py
index a53ffdcb042e74ed262b10a44e0b5c36fad3b1ef..cc7351bb58a05eed05b6f020fc87d41bf1ce6ef9 100644
--- a/examples/unsup_graphsage/train.py
+++ b/examples/unsup_graphsage/train.py
@@ -88,7 +88,7 @@ def build_graph_model(args):
graph_wrappers.append(
pgl.graph_wrapper.GraphWrapper(
- "layer_0", fluid.CPUPlace(), node_feat=node_feature_info))
+ "layer_0", node_feat=node_feature_info))
#edge_feat=[("f", [None, 1], "float32")]))
num_embed = args.num_nodes
diff --git a/ogb_examples/graphproppred/main_pgl.py b/ogb_examples/graphproppred/main_pgl.py
deleted file mode 100644
index ef7c112e5a364db8d26d297d5b4f297e2b6ef7ad..0000000000000000000000000000000000000000
--- a/ogb_examples/graphproppred/main_pgl.py
+++ /dev/null
@@ -1,189 +0,0 @@
-# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""test ogb
-"""
-import argparse
-
-import pgl
-import numpy as np
-import paddle.fluid as fluid
-from pgl.contrib.ogb.graphproppred.dataset_pgl import PglGraphPropPredDataset
-from pgl.utils import paddle_helper
-from ogb.graphproppred import Evaluator
-from pgl.contrib.ogb.graphproppred.mol_encoder import AtomEncoder, BondEncoder
-
-
-def train(exe, batch_size, graph_wrapper, train_program, splitted_idx, dataset,
- evaluator, fetch_loss, fetch_pred):
- """Train"""
- graphs, labels = dataset[splitted_idx["train"]]
- perm = np.arange(0, len(graphs))
- np.random.shuffle(perm)
- start_batch = 0
- batch_no = 0
- pred_output = np.zeros_like(labels, dtype="float32")
- while start_batch < len(perm):
- batch_index = perm[start_batch:start_batch + batch_size]
- start_batch += batch_size
- batch_graph = pgl.graph.MultiGraph(graphs[batch_index])
- batch_label = labels[batch_index]
- batch_valid = (batch_label == batch_label).astype("float32")
- batch_label = np.nan_to_num(batch_label).astype("float32")
- feed_dict = graph_wrapper.to_feed(batch_graph)
- feed_dict["label"] = batch_label
- feed_dict["weight"] = batch_valid
- loss, pred = exe.run(train_program,
- feed=feed_dict,
- fetch_list=[fetch_loss, fetch_pred])
- pred_output[batch_index] = pred
- batch_no += 1
- print("train", evaluator.eval({"y_true": labels, "y_pred": pred_output}))
-
-
-def evaluate(exe, batch_size, graph_wrapper, val_program, splitted_idx,
- dataset, mode, evaluator, fetch_pred):
- """Eval"""
- graphs, labels = dataset[splitted_idx[mode]]
- perm = np.arange(0, len(graphs))
- start_batch = 0
- batch_no = 0
- pred_output = np.zeros_like(labels, dtype="float32")
- while start_batch < len(perm):
- batch_index = perm[start_batch:start_batch + batch_size]
- start_batch += batch_size
- batch_graph = pgl.graph.MultiGraph(graphs[batch_index])
- feed_dict = graph_wrapper.to_feed(batch_graph)
- pred = exe.run(val_program, feed=feed_dict, fetch_list=[fetch_pred])
- pred_output[batch_index] = pred[0]
- batch_no += 1
- print(mode, evaluator.eval({"y_true": labels, "y_pred": pred_output}))
-
-
-def send_func(src_feat, dst_feat, edge_feat):
- """Send"""
- return src_feat["h"] + edge_feat["h"]
-
-
-class GNNModel(object):
- """GNNModel"""
-
- def __init__(self, name, emb_dim, num_task, num_layers):
- self.num_task = num_task
- self.emb_dim = emb_dim
- self.num_layers = num_layers
- self.name = name
- self.atom_encoder = AtomEncoder(name=name, emb_dim=emb_dim)
- self.bond_encoder = BondEncoder(name=name, emb_dim=emb_dim)
-
- def forward(self, graph):
- """foward"""
- h_node = self.atom_encoder(graph.node_feat['feat'])
- h_edge = self.bond_encoder(graph.edge_feat['feat'])
- for layer in range(self.num_layers):
- msg = graph.send(
- send_func,
- nfeat_list=[("h", h_node)],
- efeat_list=[("h", h_edge)])
- h_node = graph.recv(msg, 'sum') + h_node
- h_node = fluid.layers.fc(h_node,
- size=self.emb_dim,
- name=self.name + '_%s' % layer,
- act="relu")
- graph_nodes = pgl.layers.graph_pooling(graph, h_node, "average")
- graph_pred = fluid.layers.fc(graph_nodes, self.num_task, name="final")
- return graph_pred
-
-
-def main():
- """main
- """
- # Training settings
- parser = argparse.ArgumentParser(description='Graph Dataset')
- parser.add_argument(
- '--epochs',
- type=int,
- default=100,
- help='number of epochs to train (default: 100)')
- parser.add_argument(
- '--dataset',
- type=str,
- default="ogbg-mol-tox21",
- help='dataset name (default: proteinfunc)')
- args = parser.parse_args()
-
- place = fluid.CPUPlace() # Dataset too big to use GPU
-
- ### automatic dataloading and splitting
- dataset = PglGraphPropPredDataset(name=args.dataset)
- splitted_idx = dataset.get_idx_split()
-
- ### automatic evaluator. takes dataset name as input
- evaluator = Evaluator(args.dataset)
-
- graph_data, label = dataset[:2]
- batch_graph = pgl.graph.MultiGraph(graph_data)
- graph_data = batch_graph
-
- train_program = fluid.Program()
- startup_program = fluid.Program()
- test_program = fluid.Program()
- # degree normalize
- graph_data.edge_feat["feat"] = graph_data.edge_feat["feat"].astype("int64")
- graph_data.node_feat["feat"] = graph_data.node_feat["feat"].astype("int64")
-
- model = GNNModel(
- name="gnn", num_task=dataset.num_tasks, emb_dim=64, num_layers=2)
-
- with fluid.program_guard(train_program, startup_program):
- gw = pgl.graph_wrapper.GraphWrapper(
- "graph",
- place=place,
- node_feat=graph_data.node_feat_info(),
- edge_feat=graph_data.edge_feat_info())
- pred = model.forward(gw)
- sigmoid_pred = fluid.layers.sigmoid(pred)
-
- val_program = train_program.clone(for_test=True)
-
- initializer = []
- with fluid.program_guard(train_program, startup_program):
- train_label = fluid.layers.data(
- name="label", dtype="float32", shape=[None, dataset.num_tasks])
- train_weight = fluid.layers.data(
- name="weight", dtype="float32", shape=[None, dataset.num_tasks])
- train_loss_t = fluid.layers.sigmoid_cross_entropy_with_logits(
- x=pred, label=train_label) * train_weight
- train_loss_t = fluid.layers.reduce_sum(train_loss_t)
-
- adam = fluid.optimizer.Adam(
- learning_rate=1e-2,
- regularization=fluid.regularizer.L2DecayRegularizer(
- regularization_coeff=0.0005))
- adam.minimize(train_loss_t)
-
- exe = fluid.Executor(place)
- exe.run(startup_program)
-
- for epoch in range(1, args.epochs + 1):
- print("Epoch", epoch)
- train(exe, 128, gw, train_program, splitted_idx, dataset, evaluator,
- train_loss_t, sigmoid_pred)
- evaluate(exe, 128, gw, val_program, splitted_idx, dataset, "valid",
- evaluator, sigmoid_pred)
- evaluate(exe, 128, gw, val_program, splitted_idx, dataset, "test",
- evaluator, sigmoid_pred)
-
-
-if __name__ == "__main__":
- main()
diff --git a/ogb_examples/graphproppred/mol/README.md b/ogb_examples/graphproppred/mol/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..d1f4da579a7ce909bfa00f6d41cb2470ca64df93
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/README.md
@@ -0,0 +1,37 @@
+# Graph Property Prediction for Open Graph Benchmark (OGB)
+
+[The Open Graph Benchmark (OGB)](https://ogb.stanford.edu/) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. Here we complete the Graph Property Prediction task based on PGL.
+
+### Requirements
+
+- paddlpaddle >= 1.7.1
+- pgl 1.0.2
+- ogb
+
+NOTE: To install ogb that is fited for this project, run below command to install ogb
+```
+git clone https://github.com/snap-stanford/ogb.git
+git checkout 482c40bc9f31fe25f9df5aa11c8fb657bd2b1621
+python setup.py install
+```
+
+### How to run
+For example, use GPU to train model on ogbg-molhiv dataset and ogb-molpcba dataset.
+```
+CUDA_VISIBLE_DEVICES=1 python -u main.py --config hiv_config.yaml --use_cuda
+
+CUDA_VISIBLE_DEVICES=2 python -u main.py --config pcba_config.yaml --use_cuda
+```
+
+If you want to use CPU to train model, environment variables `CPU_NUM` should be specified and should be in the range of 1 to N, where N is the total CPU number on your machine.
+```
+CPU_NUM=1 python -u main.py --config hiv_config.yaml
+
+CPU_NUM=1 python -u main.py --config pcba_config.yaml
+```
+
+### Experiment results
+
+| model | hiv (rocauc)| pcba (prcauc)|
+|-------|-------------|--------------|
+| GIN |0.7719 (0.0079) | 0.2232 (0.0018) |
diff --git a/ogb_examples/graphproppred/mol/args.py b/ogb_examples/graphproppred/mol/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..b637a5ad41471032268e6a00b3e759d1e27dec4b
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/args.py
@@ -0,0 +1,104 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import time
+import argparse
+
+from utils.args import ArgumentGroup
+
+# yapf: disable
+parser = argparse.ArgumentParser(__doc__)
+parser.add_argument('--use_cuda', action='store_true')
+model_g = ArgumentGroup(parser, "model", "model configuration and paths.")
+model_g.add_arg("init_checkpoint", str, None, "Init checkpoint to resume training from.")
+model_g.add_arg("init_pretraining_params", str, None,
+ "Init pre-training params which preforms fine-tuning from. If the "
+ "arg 'init_checkpoint' has been set, this argument wouldn't be valid.")
+model_g.add_arg("./save_dir", str, "./checkpoints", "Path to save checkpoints.")
+model_g.add_arg("hidden_size", int, 128, "hidden size.")
+
+
+train_g = ArgumentGroup(parser, "training", "training options.")
+train_g.add_arg("epoch", int, 3, "Number of epoches for fine-tuning.")
+train_g.add_arg("learning_rate", float, 5e-5, "Learning rate used to train with warmup.")
+train_g.add_arg("lr_scheduler", str, "linear_warmup_decay",
+ "scheduler of learning rate.", choices=['linear_warmup_decay', 'noam_decay'])
+train_g.add_arg("weight_decay", float, 0.01, "Weight decay rate for L2 regularizer.")
+train_g.add_arg("warmup_proportion", float, 0.1,
+ "Proportion of training steps to perform linear learning rate warmup for.")
+train_g.add_arg("save_steps", int, 10000, "The steps interval to save checkpoints.")
+train_g.add_arg("validation_steps", int, 1000, "The steps interval to evaluate model performance.")
+train_g.add_arg("use_dynamic_loss_scaling", bool, True, "Whether to use dynamic loss scaling.")
+train_g.add_arg("init_loss_scaling", float, 102400,
+ "Loss scaling factor for mixed precision training, only valid when use_fp16 is enabled.")
+
+train_g.add_arg("test_save", str, "./checkpoints/test_result", "test_save")
+train_g.add_arg("metric", str, "simple_accuracy", "metric")
+train_g.add_arg("incr_every_n_steps", int, 100, "Increases loss scaling every n consecutive.")
+train_g.add_arg("decr_every_n_nan_or_inf", int, 2,
+ "Decreases loss scaling every n accumulated steps with nan or inf gradients.")
+train_g.add_arg("incr_ratio", float, 2.0,
+ "The multiplier to use when increasing the loss scaling.")
+train_g.add_arg("decr_ratio", float, 0.8,
+ "The less-than-one-multiplier to use when decreasing.")
+
+
+
+
+log_g = ArgumentGroup(parser, "logging", "logging related.")
+log_g.add_arg("skip_steps", int, 10, "The steps interval to print loss.")
+log_g.add_arg("verbose", bool, False, "Whether to output verbose log.")
+log_g.add_arg("log_dir", str, './logs/', "Whether to output verbose log.")
+
+data_g = ArgumentGroup(parser, "data", "Data paths, vocab paths and data processing options")
+data_g.add_arg("tokenizer", str, "FullTokenizer",
+ "ATTENTION: the INPUT must be splited by Word with blank while using SentencepieceTokenizer or WordsegTokenizer")
+data_g.add_arg("train_set", str, None, "Path to training data.")
+data_g.add_arg("test_set", str, None, "Path to test data.")
+data_g.add_arg("dev_set", str, None, "Path to validation data.")
+data_g.add_arg("aug1_type", str, "scheme1", "augment type")
+data_g.add_arg("aug2_type", str, "scheme1", "augment type")
+data_g.add_arg("batch_size", int, 32, "Total examples' number in batch for training. see also --in_tokens.")
+data_g.add_arg("predict_batch_size", int, None, "Total examples' number in batch for predict. see also --in_tokens.")
+data_g.add_arg("random_seed", int, None, "Random seed.")
+data_g.add_arg("buf_size", int, 1000, "Random seed.")
+
+run_type_g = ArgumentGroup(parser, "run_type", "running type options.")
+run_type_g.add_arg("num_iteration_per_drop_scope", int, 10, "Iteration intervals to drop scope.")
+run_type_g.add_arg("do_train", bool, True, "Whether to perform training.")
+run_type_g.add_arg("do_val", bool, True, "Whether to perform evaluation on dev data set.")
+run_type_g.add_arg("do_test", bool, True, "Whether to perform evaluation on test data set.")
+run_type_g.add_arg("metrics", bool, True, "Whether to perform evaluation on test data set.")
+run_type_g.add_arg("shuffle", bool, True, "")
+run_type_g.add_arg("for_cn", bool, True, "model train for cn or for other langs.")
+run_type_g.add_arg("num_workers", int, 1, "use multiprocess to generate graph")
+run_type_g.add_arg("output_dir", str, None, "path to save model")
+run_type_g.add_arg("config", str, None, "configure yaml file")
+run_type_g.add_arg("n", str, None, "task name")
+run_type_g.add_arg("task_name", str, None, "task name")
+run_type_g.add_arg("pretrain", bool, False, "Whether do pretrian")
+run_type_g.add_arg("pretrain_name", str, None, "pretrain task name")
+run_type_g.add_arg("pretrain_config", str, None, "pretrain config.yaml file")
+run_type_g.add_arg("pretrain_model_step", str, None, "pretrain model step")
+run_type_g.add_arg("model_type", str, "BaseLineModel", "pretrain model step")
+run_type_g.add_arg("num_class", int, 1, "number class")
+run_type_g.add_arg("dataset_name", str, None, "finetune dataset name")
+run_type_g.add_arg("eval_metrics", str, None, "evaluate metrics")
+run_type_g.add_arg("task_type", str, None, "regression or classification")
diff --git a/ogb_examples/graphproppred/mol/data/__init__.py b/ogb_examples/graphproppred/mol/data/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..abf198b97e6e818e1fbe59006f98492640bcee54
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/data/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/ogb_examples/graphproppred/mol/data/base_dataset.py b/ogb_examples/graphproppred/mol/data/base_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..e802ea5254100c121a216d9cb4f1cd0c1f264d9d
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/data/base_dataset.py
@@ -0,0 +1,83 @@
+# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import sys
+import os
+
+from ogb.graphproppred import GraphPropPredDataset
+import pgl
+from pgl.utils.logger import log
+
+
+class BaseDataset(object):
+ def __init__(self):
+ pass
+
+ def __getitem__(self, idx):
+ raise NotImplementedError
+
+ def __len__(self):
+ raise NotImplementedError
+
+
+class Subset(BaseDataset):
+ r"""
+ Subset of a dataset at specified indices.
+ Arguments:
+ dataset (Dataset): The whole Dataset
+ indices (sequence): Indices in the whole set selected for subset
+ """
+
+ def __init__(self, dataset, indices):
+ self.dataset = dataset
+ self.indices = indices
+
+ def __getitem__(self, idx):
+ return self.dataset[self.indices[idx]]
+
+ def __len__(self):
+ return len(self.indices)
+
+
+class Dataset(BaseDataset):
+ def __init__(self, args):
+ self.args = args
+ self.raw_dataset = GraphPropPredDataset(name=args.dataset_name)
+ self.num_tasks = self.raw_dataset.num_tasks
+ self.eval_metrics = self.raw_dataset.eval_metric
+ self.task_type = self.raw_dataset.task_type
+
+ self.pgl_graph_list = []
+ self.graph_label_list = []
+ for i in range(len(self.raw_dataset)):
+ graph, label = self.raw_dataset[i]
+ edges = list(zip(graph["edge_index"][0], graph["edge_index"][1]))
+ g = pgl.graph.Graph(num_nodes=graph["num_nodes"], edges=edges)
+
+ if graph["edge_feat"] is not None:
+ g.edge_feat["feat"] = graph["edge_feat"]
+
+ if graph["node_feat"] is not None:
+ g.node_feat["feat"] = graph["node_feat"]
+
+ self.pgl_graph_list.append(g)
+ self.graph_label_list.append(label)
+
+ def __getitem__(self, idx):
+ return self.pgl_graph_list[idx], self.graph_label_list[idx]
+
+ def __len__(self):
+ return len(slef.pgl_graph_list)
+
+ def get_idx_split(self):
+ return self.raw_dataset.get_idx_split()
diff --git a/ogb_examples/graphproppred/mol/data/dataloader.py b/ogb_examples/graphproppred/mol/data/dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..66023d0971f74121ee1cae8711c50a11ba6f9536
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/data/dataloader.py
@@ -0,0 +1,183 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This file implement the graph dataloader.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+# SSL
+
+import torch
+import sys
+import six
+from io import open
+import collections
+from collections import namedtuple
+import numpy as np
+import tqdm
+import time
+
+import paddle
+import paddle.fluid as fluid
+import paddle.fluid.layers as fl
+import pgl
+from pgl.utils import mp_reader
+from pgl.utils.logger import log
+
+from ogb.graphproppred import GraphPropPredDataset
+
+
+def batch_iter(data, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ size = len(data)
+ perm = np.arange(size)
+ np.random.shuffle(perm)
+ start = 0
+ cc = 0
+ while start < size:
+ index = perm[start:start + batch_size]
+ start += batch_size
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ yield data[index]
+
+
+def scan_batch_iter(data, batch_size, fid, num_workers):
+ """scan_batch_iter
+ """
+ batch = []
+ cc = 0
+ for line_example in data.scan():
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ batch.append(line_example)
+ if len(batch) == batch_size:
+ yield batch
+ batch = []
+
+ if len(batch) > 0:
+ yield batch
+
+
+class GraphDataloader(object):
+ """Graph Dataloader
+ """
+
+ def __init__(self,
+ dataset,
+ graph_wrapper,
+ batch_size,
+ seed=0,
+ num_workers=1,
+ buf_size=1000,
+ shuffle=True):
+
+ self.shuffle = shuffle
+ self.seed = seed
+ self.num_workers = num_workers
+ self.buf_size = buf_size
+ self.batch_size = batch_size
+ self.dataset = dataset
+ self.graph_wrapper = graph_wrapper
+
+ def batch_fn(self, batch_examples):
+ """ batch_fn batch producer"""
+ graphs = [b[0] for b in batch_examples]
+ labels = [b[1] for b in batch_examples]
+ join_graph = pgl.graph.MultiGraph(graphs)
+ labels = np.array(labels)
+
+ feed_dict = self.graph_wrapper.to_feed(join_graph)
+ batch_valid = (labels == labels).astype("float32")
+ labels = np.nan_to_num(labels).astype("float32")
+ feed_dict['labels'] = labels
+ feed_dict['unmask'] = batch_valid
+ return feed_dict
+
+ def batch_iter(self, fid):
+ """batch_iter"""
+ if self.shuffle:
+ for batch in batch_iter(self, self.batch_size, fid,
+ self.num_workers):
+ yield batch
+ else:
+ for batch in scan_batch_iter(self, self.batch_size, fid,
+ self.num_workers):
+ yield batch
+
+ def __len__(self):
+ """__len__"""
+ return len(self.dataset)
+
+ def __getitem__(self, idx):
+ """__getitem__"""
+ if isinstance(idx, collections.Iterable):
+ return [self[bidx] for bidx in idx]
+ else:
+ return self.dataset[idx]
+
+ def __iter__(self):
+ """__iter__"""
+
+ def worker(filter_id):
+ def func_run():
+ for batch_examples in self.batch_iter(filter_id):
+ batch_dict = self.batch_fn(batch_examples)
+ yield batch_dict
+
+ return func_run
+
+ if self.num_workers == 1:
+ r = paddle.reader.buffered(worker(0), self.buf_size)
+ else:
+ worker_pool = [worker(wid) for wid in range(self.num_workers)]
+ worker = mp_reader.multiprocess_reader(
+ worker_pool, use_pipe=True, queue_size=1000)
+ r = paddle.reader.buffered(worker, self.buf_size)
+
+ for batch in r():
+ yield batch
+
+ def scan(self):
+ """scan"""
+ for example in self.dataset:
+ yield example
+
+
+if __name__ == "__main__":
+ from base_dataset import BaseDataset, Subset
+ dataset = GraphPropPredDataset(name="ogbg-molhiv")
+ splitted_index = dataset.get_idx_split()
+ train_dataset = Subset(dataset, splitted_index['train'])
+ valid_dataset = Subset(dataset, splitted_index['valid'])
+ test_dataset = Subset(dataset, splitted_index['test'])
+ log.info("Train Examples: %s" % len(train_dataset))
+ log.info("Val Examples: %s" % len(valid_dataset))
+ log.info("Test Examples: %s" % len(test_dataset))
+
+ # train_loader = GraphDataloader(train_dataset, batch_size=3)
+ # for batch_data in train_loader:
+ # graphs, labels = batch_data
+ # print(labels.shape)
+ # time.sleep(4)
diff --git a/ogb_examples/graphproppred/mol/data/splitters.py b/ogb_examples/graphproppred/mol/data/splitters.py
new file mode 100644
index 0000000000000000000000000000000000000000..be1f1c1d94b16bfe17346eabeee553f8c3e1965a
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/data/splitters.py
@@ -0,0 +1,153 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+import logging
+from random import random
+import pandas as pd
+import numpy as np
+from itertools import compress
+
+import scipy.sparse as sp
+from sklearn.model_selection import StratifiedKFold
+from sklearn.preprocessing import StandardScaler
+from rdkit.Chem.Scaffolds import MurckoScaffold
+
+import pgl
+from pgl.utils import paddle_helper
+try:
+ from dataset.Dataset import Subset
+ from dataset.Dataset import ChemDataset
+except:
+ from Dataset import Subset
+ from Dataset import ChemDataset
+
+log = logging.getLogger("logger")
+
+
+def random_split(dataset, args):
+ total_precent = args.frac_train + args.frac_valid + args.frac_test
+ np.testing.assert_almost_equal(total_precent, 1.0)
+
+ length = len(dataset)
+ perm = list(range(length))
+ np.random.shuffle(perm)
+ num_train = int(args.frac_train * length)
+ num_valid = int(args.frac_valid * length)
+ num_test = int(args.frac_test * length)
+
+ train_indices = perm[0:num_train]
+ valid_indices = perm[num_train:(num_train + num_valid)]
+ test_indices = perm[(num_train + num_valid):]
+ assert (len(train_indices) + len(valid_indices) + len(test_indices)
+ ) == length
+
+ train_dataset = Subset(dataset, train_indices)
+ valid_dataset = Subset(dataset, valid_indices)
+ test_dataset = Subset(dataset, test_indices)
+ return train_dataset, valid_dataset, test_dataset
+
+
+def scaffold_split(dataset, args, return_smiles=False):
+ total_precent = args.frac_train + args.frac_valid + args.frac_test
+ np.testing.assert_almost_equal(total_precent, 1.0)
+
+ smiles_list_file = os.path.join(args.data_dir, "smiles.csv")
+ smiles_list = pd.read_csv(smiles_list_file, header=None)[0].tolist()
+
+ non_null = np.ones(len(dataset)) == 1
+ smiles_list = list(compress(enumerate(smiles_list), non_null))
+
+ # create dict of the form {scaffold_i: [idx1, idx....]}
+ all_scaffolds = {}
+ for i, smiles in smiles_list:
+ scaffold = MurckoScaffold.MurckoScaffoldSmiles(
+ smiles=smiles, includeChirality=True)
+ # scaffold = generate_scaffold(smiles, include_chirality=True)
+ if scaffold not in all_scaffolds:
+ all_scaffolds[scaffold] = [i]
+ else:
+ all_scaffolds[scaffold].append(i)
+
+ # sort from largest to smallest sets
+ all_scaffolds = {
+ key: sorted(value)
+ for key, value in all_scaffolds.items()
+ }
+ all_scaffold_sets = [
+ scaffold_set
+ for (scaffold, scaffold_set) in sorted(
+ all_scaffolds.items(),
+ key=lambda x: (len(x[1]), x[1][0]),
+ reverse=True)
+ ]
+
+ # get train, valid test indices
+ train_cutoff = args.frac_train * len(smiles_list)
+ valid_cutoff = (args.frac_train + args.frac_valid) * len(smiles_list)
+ train_idx, valid_idx, test_idx = [], [], []
+ for scaffold_set in all_scaffold_sets:
+ if len(train_idx) + len(scaffold_set) > train_cutoff:
+ if len(train_idx) + len(valid_idx) + len(
+ scaffold_set) > valid_cutoff:
+ test_idx.extend(scaffold_set)
+ else:
+ valid_idx.extend(scaffold_set)
+ else:
+ train_idx.extend(scaffold_set)
+
+ assert len(set(train_idx).intersection(set(valid_idx))) == 0
+ assert len(set(test_idx).intersection(set(valid_idx))) == 0
+ # log.info(len(scaffold_set))
+ # log.info(["train_idx", train_idx])
+ # log.info(["valid_idx", valid_idx])
+ # log.info(["test_idx", test_idx])
+
+ train_dataset = Subset(dataset, train_idx)
+ valid_dataset = Subset(dataset, valid_idx)
+ test_dataset = Subset(dataset, test_idx)
+
+ if return_smiles:
+ train_smiles = [smiles_list[i][1] for i in train_idx]
+ valid_smiles = [smiles_list[i][1] for i in valid_idx]
+ test_smiles = [smiles_list[i][1] for i in test_idx]
+
+ return train_dataset, valid_dataset, test_dataset, (
+ train_smiles, valid_smiles, test_smiles)
+
+ return train_dataset, valid_dataset, test_dataset
+
+
+if __name__ == "__main__":
+ file_path = os.path.dirname(os.path.realpath(__file__))
+ proj_path = os.path.join(file_path, '../')
+ sys.path.append(proj_path)
+ from utils.config import Config
+ from dataset.Dataset import Subset
+ from dataset.Dataset import ChemDataset
+
+ config_file = "./finetune_config.yaml"
+ args = Config(config_file)
+ log.info("loading dataset")
+ dataset = ChemDataset(args)
+
+ train_dataset, valid_dataset, test_dataset = scaffold_split(dataset, args)
+
+ log.info("Train Examples: %s" % len(train_dataset))
+ log.info("Val Examples: %s" % len(valid_dataset))
+ log.info("Test Examples: %s" % len(test_dataset))
+ import ipdb
+ ipdb.set_trace()
+ log.info("preprocess finish")
diff --git a/ogb_examples/graphproppred/mol/hiv_config.yaml b/ogb_examples/graphproppred/mol/hiv_config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..ee0afbbb2af1b3315569e87ab09cad9f451120d8
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/hiv_config.yaml
@@ -0,0 +1,53 @@
+task_name: hiv
+seed: 15391
+dataset_name: ogbg-molhiv
+eval_metrics: null
+task_type: null
+num_class: null
+pool_type: average
+train_eps: True
+norm_type: layer_norm
+
+model_type: GNNModel
+embed_dim: 128
+num_layers: 5
+hidden_size: 256
+save_dir: ./checkpoints
+
+
+# finetune model config
+init_checkpoint: null
+init_pretraining_params: null
+
+# data config
+data_dir: ./dataset/
+symmetry: True
+batch_size: 32
+buf_size: 1000
+metrics: True
+shuffle: True
+num_workers: 12
+output_dir: ./outputs/
+
+# trainging config
+epoch: 50
+learning_rate: 0.0001
+lr_scheduler: linear_warmup_decay
+weight_decay: 0.01
+warmup_proportion: 0.1
+save_steps: 10000
+validation_steps: 1000
+use_dynamic_loss_scaling: True
+init_loss_scaling: 102400
+metric: simple_accuracy
+incr_every_n_steps: 100
+decr_every_n_nan_or_inf: 2
+incr_ratio: 2.0
+decr_ratio: 0.8
+log_dir: ./logs
+eval_step: 400
+train_log_step: 20
+
+# log config
+skip_steps: 10
+verbose: False
diff --git a/ogb_examples/graphproppred/mol/main.py b/ogb_examples/graphproppred/mol/main.py
new file mode 100644
index 0000000000000000000000000000000000000000..bbc4dc4600524c2e3c6b804d2d9a5dd6be17c27c
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/main.py
@@ -0,0 +1,180 @@
+# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+# SSL
+
+import torch
+import os
+import re
+import time
+from random import random
+from functools import reduce, partial
+import numpy as np
+import multiprocessing
+
+from ogb.graphproppred import Evaluator
+import paddle
+import paddle.fluid as F
+import paddle.fluid.layers as L
+import pgl
+from pgl.utils import paddle_helper
+from pgl.utils.logger import log
+
+from utils.args import print_arguments, check_cuda, prepare_logger
+from utils.init import init_checkpoint, init_pretraining_params
+from utils.config import Config
+from optimization import optimization
+from monitor.train_monitor import train_and_evaluate
+from args import parser
+
+import model as Model
+from data.base_dataset import Subset, Dataset
+from data.dataloader import GraphDataloader
+
+
+def main(args):
+ log.info('loading data')
+ dataset = Dataset(args)
+ args.num_class = dataset.num_tasks
+ args.eval_metrics = dataset.eval_metrics
+ args.task_type = dataset.task_type
+ splitted_index = dataset.get_idx_split()
+ train_dataset = Subset(dataset, splitted_index['train'])
+ valid_dataset = Subset(dataset, splitted_index['valid'])
+ test_dataset = Subset(dataset, splitted_index['test'])
+
+ log.info("preprocess finish")
+ log.info("Train Examples: %s" % len(train_dataset))
+ log.info("Val Examples: %s" % len(valid_dataset))
+ log.info("Test Examples: %s" % len(test_dataset))
+
+ train_prog = F.Program()
+ startup_prog = F.Program()
+
+ if args.use_cuda:
+ dev_list = F.cuda_places()
+ place = dev_list[0]
+ dev_count = len(dev_list)
+ else:
+ place = F.CPUPlace()
+ dev_count = int(os.environ.get('CPU_NUM', multiprocessing.cpu_count()))
+ # dev_count = args.cpu_num
+
+ log.info("building model")
+ with F.program_guard(train_prog, startup_prog):
+ with F.unique_name.guard():
+ graph_model = getattr(Model, args.model_type)(args, dataset)
+ train_ds = GraphDataloader(
+ train_dataset,
+ graph_model.graph_wrapper,
+ batch_size=args.batch_size)
+
+ num_train_examples = len(train_dataset)
+ max_train_steps = args.epoch * num_train_examples // args.batch_size // dev_count
+ warmup_steps = int(max_train_steps * args.warmup_proportion)
+
+ scheduled_lr, loss_scaling = optimization(
+ loss=graph_model.loss,
+ warmup_steps=warmup_steps,
+ num_train_steps=max_train_steps,
+ learning_rate=args.learning_rate,
+ train_program=train_prog,
+ startup_prog=startup_prog,
+ weight_decay=args.weight_decay,
+ scheduler=args.lr_scheduler,
+ use_fp16=False,
+ use_dynamic_loss_scaling=args.use_dynamic_loss_scaling,
+ init_loss_scaling=args.init_loss_scaling,
+ incr_every_n_steps=args.incr_every_n_steps,
+ decr_every_n_nan_or_inf=args.decr_every_n_nan_or_inf,
+ incr_ratio=args.incr_ratio,
+ decr_ratio=args.decr_ratio)
+
+ test_prog = F.Program()
+ with F.program_guard(test_prog, startup_prog):
+ with F.unique_name.guard():
+ _graph_model = getattr(Model, args.model_type)(args, dataset)
+
+ test_prog = test_prog.clone(for_test=True)
+
+ valid_ds = GraphDataloader(
+ valid_dataset,
+ graph_model.graph_wrapper,
+ batch_size=args.batch_size,
+ shuffle=False)
+ test_ds = GraphDataloader(
+ test_dataset,
+ graph_model.graph_wrapper,
+ batch_size=args.batch_size,
+ shuffle=False)
+
+ exe = F.Executor(place)
+ exe.run(startup_prog)
+ for init in graph_model.init_vars:
+ init(place)
+ for init in _graph_model.init_vars:
+ init(place)
+
+ if args.init_pretraining_params is not None:
+ init_pretraining_params(
+ exe, args.init_pretraining_params, main_program=startup_prog)
+
+ nccl2_num_trainers = 1
+ nccl2_trainer_id = 0
+ if dev_count > 1:
+
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = dev_count
+
+ train_exe = F.ParallelExecutor(
+ use_cuda=args.use_cuda,
+ loss_name=graph_model.loss.name,
+ exec_strategy=exec_strategy,
+ main_program=train_prog,
+ num_trainers=nccl2_num_trainers,
+ trainer_id=nccl2_trainer_id)
+
+ test_exe = exe
+ else:
+ train_exe, test_exe = exe, exe
+
+ evaluator = Evaluator(args.dataset_name)
+
+ train_and_evaluate(
+ exe=exe,
+ train_exe=train_exe,
+ valid_exe=test_exe,
+ train_ds=train_ds,
+ valid_ds=valid_ds,
+ test_ds=test_ds,
+ train_prog=train_prog,
+ valid_prog=test_prog,
+ args=args,
+ dev_count=dev_count,
+ evaluator=evaluator,
+ model=graph_model)
+
+
+if __name__ == "__main__":
+ args = parser.parse_args()
+ if args.config is not None:
+ config = Config(args.config, isCreate=True, isSave=True)
+
+ config['use_cuda'] = args.use_cuda
+
+ log.info(config)
+
+ main(config)
diff --git a/ogb_examples/graphproppred/mol/model.py b/ogb_examples/graphproppred/mol/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..f9e89c8942a52c3f46c79966d5e26bd3d9cbf311
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/model.py
@@ -0,0 +1,210 @@
+#-*- coding: utf-8 -*-
+import os
+import re
+import time
+import logging
+from random import random
+from functools import reduce, partial
+
+import numpy as np
+import multiprocessing
+
+import paddle
+import paddle.fluid as F
+import paddle.fluid.layers as L
+import pgl
+from pgl.graph_wrapper import GraphWrapper
+from pgl.layers.conv import gcn, gat
+from pgl.utils import paddle_helper
+from pgl.utils.logger import log
+
+from utils.args import print_arguments, check_cuda, prepare_logger
+from utils.init import init_checkpoint, init_pretraining_params
+
+from mol_encoder import AtomEncoder, BondEncoder
+
+
+def copy_send(src_feat, dst_feat, edge_feat):
+ return src_feat["h"]
+
+
+def mean_recv(feat):
+ return L.sequence_pool(feat, pool_type="average")
+
+
+def sum_recv(feat):
+ return L.sequence_pool(feat, pool_type="sum")
+
+
+def max_recv(feat):
+ return L.sequence_pool(feat, pool_type="max")
+
+
+def unsqueeze(tensor):
+ tensor = L.unsqueeze(tensor, axes=-1)
+ tensor.stop_gradient = True
+ return tensor
+
+
+class Metric:
+ def __init__(self, **args):
+ self.args = args
+
+ @property
+ def vars(self):
+ values = [self.args[k] for k in self.args.keys()]
+ return values
+
+ def parse(self, fetch_list):
+ tup = list(zip(self.args.keys(), [float(v[0]) for v in fetch_list]))
+ return dict(tup)
+
+
+def gin_layer(gw, node_features, edge_features, train_eps, name):
+ def send_func(src_feat, dst_feat, edge_feat):
+ """Send"""
+ return src_feat["h"] + edge_feat["h"]
+
+ epsilon = L.create_parameter(
+ shape=[1, 1],
+ dtype="float32",
+ attr=F.ParamAttr(name="%s_eps" % name),
+ default_initializer=F.initializer.ConstantInitializer(value=0.0))
+ if not train_eps:
+ epsilon.stop_gradient = True
+
+ msg = gw.send(
+ send_func,
+ nfeat_list=[("h", node_features)],
+ efeat_list=[("h", edge_features)])
+
+ node_feat = gw.recv(msg, "sum") + node_features * (epsilon + 1.0)
+
+ # if apply_func is not None:
+ # node_feat = apply_func(node_feat, name)
+ return node_feat
+
+
+class GNNModel(object):
+ def __init__(self, args, dataset):
+ self.args = args
+ self.dataset = dataset
+ self.hidden_size = self.args.hidden_size
+ self.embed_dim = self.args.embed_dim
+ self.dropout_prob = self.args.dropout_rate
+ self.pool_type = self.args.pool_type
+ self._init_vars = []
+
+ graph_data = []
+ g, label = self.dataset[0]
+ graph_data.append(g)
+ g, label = self.dataset[1]
+ graph_data.append(g)
+
+ batch_graph = pgl.graph.MultiGraph(graph_data)
+ graph_data = batch_graph
+ graph_data.edge_feat["feat"] = graph_data.edge_feat["feat"].astype(
+ "int64")
+ graph_data.node_feat["feat"] = graph_data.node_feat["feat"].astype(
+ "int64")
+ self.graph_wrapper = GraphWrapper(
+ name="graph",
+ place=F.CPUPlace(),
+ node_feat=graph_data.node_feat_info(),
+ edge_feat=graph_data.edge_feat_info())
+
+ self.atom_encoder = AtomEncoder(name="atom", emb_dim=self.embed_dim)
+ self.bond_encoder = BondEncoder(name="bond", emb_dim=self.embed_dim)
+
+ self.labels = L.data(
+ "labels",
+ shape=[None, self.args.num_class],
+ dtype="float32",
+ append_batch_size=False)
+
+ self.unmask = L.data(
+ "unmask",
+ shape=[None, self.args.num_class],
+ dtype="float32",
+ append_batch_size=False)
+
+ self.build_model()
+
+ def build_model(self):
+ node_features = self.atom_encoder(self.graph_wrapper.node_feat['feat'])
+ edge_features = self.bond_encoder(self.graph_wrapper.edge_feat['feat'])
+
+ self._enc_out = self.node_repr_encode(node_features, edge_features)
+
+ logits = L.fc(self._enc_out,
+ self.args.num_class,
+ act=None,
+ param_attr=F.ParamAttr(name="final_fc"))
+
+ # L.Print(self.labels, message="labels")
+ # L.Print(self.unmask, message="unmask")
+ loss = L.sigmoid_cross_entropy_with_logits(x=logits, label=self.labels)
+ loss = loss * self.unmask
+ self.loss = L.reduce_sum(loss) / L.reduce_sum(self.unmask)
+ self.pred = L.sigmoid(logits)
+
+ self._metrics = Metric(loss=self.loss)
+
+ def node_repr_encode(self, node_features, edge_features):
+ features_list = [node_features]
+ for layer in range(self.args.num_layers):
+ feat = gin_layer(
+ self.graph_wrapper,
+ features_list[layer],
+ edge_features,
+ train_eps=self.args.train_eps,
+ name="gin_%s" % layer, )
+
+ feat = self.mlp(feat, name="mlp_%s" % layer)
+
+ feat = feat + features_list[layer] # residual
+
+ features_list.append(feat)
+
+ output = pgl.layers.graph_pooling(
+ self.graph_wrapper, features_list[-1], self.args.pool_type)
+
+ return output
+
+ def mlp(self, features, name):
+ h = features
+ dim = features.shape[-1]
+ dim_list = [dim * 2, dim]
+ for i in range(2):
+ h = L.fc(h,
+ size=dim_list[i],
+ name="%s_fc_%s" % (name, i),
+ act=None)
+ if self.args.norm_type == "layer_norm":
+ log.info("norm_type is %s" % self.args.norm_type)
+ h = L.layer_norm(
+ h,
+ begin_norm_axis=1,
+ param_attr=F.ParamAttr(
+ name="norm_scale_%s_%s" % (name, i),
+ initializer=F.initializer.Constant(1.0)),
+ bias_attr=F.ParamAttr(
+ name="norm_bias_%s_%s" % (name, i),
+ initializer=F.initializer.Constant(0.0)), )
+ else:
+ log.info("using batch_norm")
+ h = L.batch_norm(h)
+ h = pgl.layers.graph_norm(self.graph_wrapper, h)
+ h = L.relu(h)
+ return h
+
+ def get_enc_output(self):
+ return self._enc_out
+
+ @property
+ def init_vars(self):
+ return self._init_vars
+
+ @property
+ def metrics(self):
+ return self._metrics
diff --git a/ogb_examples/graphproppred/mol/mol_encoder.py b/ogb_examples/graphproppred/mol/mol_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..2662d141532dc58925f30e0973d5d85bb4953bd3
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/mol_encoder.py
@@ -0,0 +1,71 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""MolEncoder for ogb
+"""
+import paddle.fluid as fluid
+from ogb.utils.features import get_atom_feature_dims, get_bond_feature_dims
+
+
+class AtomEncoder(object):
+ """AtomEncoder for encoding node features"""
+
+ def __init__(self, name, emb_dim):
+ self.emb_dim = emb_dim
+ self.name = name
+
+ def __call__(self, x):
+ atom_feature = get_atom_feature_dims()
+ atom_input = fluid.layers.split(
+ x, num_or_sections=len(atom_feature), dim=-1)
+ outputs = None
+ count = 0
+ for _x, _atom_input_dim in zip(atom_input, atom_feature):
+ count += 1
+ emb = fluid.layers.embedding(
+ _x,
+ size=(_atom_input_dim, self.emb_dim),
+ param_attr=fluid.ParamAttr(
+ name=self.name + '_atom_feat_%s' % count))
+ if outputs is None:
+ outputs = emb
+ else:
+ outputs = outputs + emb
+ return outputs
+
+
+class BondEncoder(object):
+ """Bond for encoding edge features"""
+
+ def __init__(self, name, emb_dim):
+ self.emb_dim = emb_dim
+ self.name = name
+
+ def __call__(self, x):
+ bond_feature = get_bond_feature_dims()
+ bond_input = fluid.layers.split(
+ x, num_or_sections=len(bond_feature), dim=-1)
+ outputs = None
+ count = 0
+ for _x, _bond_input_dim in zip(bond_input, bond_feature):
+ count += 1
+ emb = fluid.layers.embedding(
+ _x,
+ size=(_bond_input_dim, self.emb_dim),
+ param_attr=fluid.ParamAttr(
+ name=self.name + '_bond_feat_%s' % count))
+ if outputs is None:
+ outputs = emb
+ else:
+ outputs = outputs + emb
+ return outputs
diff --git a/ogb_examples/graphproppred/mol/monitor/train_monitor.py b/ogb_examples/graphproppred/mol/monitor/train_monitor.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c9892c117f766aa1219deacbd7456ea5c47e25c
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/monitor/train_monitor.py
@@ -0,0 +1,154 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import tqdm
+import json
+import numpy as np
+import os
+from datetime import datetime
+import logging
+from collections import defaultdict
+
+import paddle.fluid as F
+from pgl.utils.logger import log
+from pgl.utils.log_writer import LogWriter
+
+
+def multi_device(reader, dev_count):
+ if dev_count == 1:
+ for batch in reader:
+ yield batch
+ else:
+ batches = []
+ for batch in reader:
+ batches.append(batch)
+ if len(batches) == dev_count:
+ yield batches
+ batches = []
+
+
+def evaluate(exe, loader, prog, model, evaluator):
+ total_labels = []
+ for i in range(len(loader.dataset)):
+ g, l = loader.dataset[i]
+ total_labels.append(l)
+ total_labels = np.vstack(total_labels)
+
+ pred_output = []
+ for feed_dict in loader:
+ ret = exe.run(prog, feed=feed_dict, fetch_list=model.pred)
+ pred_output.append(ret[0])
+
+ pred_output = np.vstack(pred_output)
+
+ result = evaluator.eval({"y_true": total_labels, "y_pred": pred_output})
+
+ return result
+
+
+def _create_if_not_exist(path):
+ basedir = os.path.dirname(path)
+ if not os.path.exists(basedir):
+ os.makedirs(basedir)
+
+
+def train_and_evaluate(exe,
+ train_exe,
+ valid_exe,
+ train_ds,
+ valid_ds,
+ test_ds,
+ train_prog,
+ valid_prog,
+ args,
+ model,
+ evaluator,
+ dev_count=1):
+
+ global_step = 0
+
+ timestamp = datetime.now().strftime("%Hh%Mm%Ss")
+ log_path = os.path.join(args.log_dir, "log_%s" % timestamp)
+ _create_if_not_exist(log_path)
+
+ writer = LogWriter(log_path)
+
+ best_valid_score = 0.0
+ for e in range(args.epoch):
+ for feed_dict in multi_device(train_ds, dev_count):
+ if dev_count > 1:
+ ret = train_exe.run(feed=feed_dict,
+ fetch_list=model.metrics.vars)
+ ret = [[np.mean(v)] for v in ret]
+ else:
+ ret = train_exe.run(train_prog,
+ feed=feed_dict,
+ fetch_list=model.metrics.vars)
+
+ ret = model.metrics.parse(ret)
+ if global_step % args.train_log_step == 0:
+ writer.add_scalar(
+ "batch_loss", ret['loss'], global_step)
+ log.info("epoch: %d | step: %d | loss: %.4f " %
+ (e, global_step, ret['loss']))
+
+ global_step += 1
+ if global_step % args.eval_step == 0:
+ valid_ret = evaluate(exe, valid_ds, valid_prog, model,
+ evaluator)
+ message = "valid: "
+ for key, value in valid_ret.items():
+ message += "%s %.4f | " % (key, value)
+ writer.add_scalar(
+ "eval_%s" % key, value, global_step)
+ log.info(message)
+
+ # testing
+ test_ret = evaluate(exe, test_ds, valid_prog, model, evaluator)
+ message = "test: "
+ for key, value in test_ret.items():
+ message += "%s %.4f | " % (key, value)
+ writer.add_scalar(
+ "test_%s" % key, value, global_step)
+ log.info(message)
+
+ # evaluate after one epoch
+ valid_ret = evaluate(exe, valid_ds, valid_prog, model, evaluator)
+ message = "epoch %s valid: " % e
+ for key, value in valid_ret.items():
+ message += "%s %.4f | " % (key, value)
+ writer.add_scalar("eval_%s" % key, value, global_step)
+ log.info(message)
+
+ # testing
+ test_ret = evaluate(exe, test_ds, valid_prog, model, evaluator)
+ message = "epoch %s test: " % e
+ for key, value in test_ret.items():
+ message += "%s %.4f | " % (key, value)
+ writer.add_scalar("test_%s" % key, value, global_step)
+ log.info(message)
+
+ message = "epoch %s best %s result | " % (e, args.eval_metrics)
+ if valid_ret[args.eval_metrics] > best_valid_score:
+ best_valid_score = valid_ret[args.eval_metrics]
+ best_test_score = test_ret[args.eval_metrics]
+
+ message += "valid %.4f | test %.4f" % (best_valid_score,
+ best_test_score)
+ log.info(message)
+
+ # if global_step % args.save_step == 0:
+ # F.io.save_persistables(exe, os.path.join(args.save_dir, "%s" % global_step), train_prog)
+
+ writer.close()
diff --git a/ogb_examples/graphproppred/mol/optimization.py b/ogb_examples/graphproppred/mol/optimization.py
new file mode 100644
index 0000000000000000000000000000000000000000..23a958f30459143d9ac581a26c9bf7690452bb69
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/optimization.py
@@ -0,0 +1,163 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Optimization and learning rate scheduling."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import numpy as np
+import paddle.fluid as fluid
+from utils.fp16 import create_master_params_grads, master_param_to_train_param, apply_dynamic_loss_scaling
+
+
+def linear_warmup_decay(learning_rate, warmup_steps, num_train_steps):
+ """ Applies linear warmup of learning rate from 0 and decay to 0."""
+ with fluid.default_main_program()._lr_schedule_guard():
+ lr = fluid.layers.tensor.create_global_var(
+ shape=[1],
+ value=0.0,
+ dtype='float32',
+ persistable=True,
+ name="scheduled_learning_rate")
+
+ global_step = fluid.layers.learning_rate_scheduler._decay_step_counter(
+ )
+
+ with fluid.layers.control_flow.Switch() as switch:
+ with switch.case(global_step < warmup_steps):
+ warmup_lr = learning_rate * (global_step / warmup_steps)
+ fluid.layers.tensor.assign(warmup_lr, lr)
+ with switch.default():
+ decayed_lr = fluid.layers.learning_rate_scheduler.polynomial_decay(
+ learning_rate=learning_rate,
+ decay_steps=num_train_steps,
+ end_learning_rate=0.0,
+ power=1.0,
+ cycle=False)
+ fluid.layers.tensor.assign(decayed_lr, lr)
+
+ return lr
+
+
+def optimization(loss,
+ warmup_steps,
+ num_train_steps,
+ learning_rate,
+ train_program,
+ startup_prog,
+ weight_decay,
+ scheduler='linear_warmup_decay',
+ use_fp16=False,
+ use_dynamic_loss_scaling=False,
+ init_loss_scaling=1.0,
+ incr_every_n_steps=1000,
+ decr_every_n_nan_or_inf=2,
+ incr_ratio=2.0,
+ decr_ratio=0.8):
+ if warmup_steps > 0:
+ if scheduler == 'noam_decay':
+ scheduled_lr = fluid.layers.learning_rate_scheduler\
+ .noam_decay(1/(warmup_steps *(learning_rate ** 2)),
+ warmup_steps)
+ elif scheduler == 'linear_warmup_decay':
+ scheduled_lr = linear_warmup_decay(learning_rate, warmup_steps,
+ num_train_steps)
+ else:
+ raise ValueError("Unkown learning rate scheduler, should be "
+ "'noam_decay' or 'linear_warmup_decay'")
+ optimizer = fluid.optimizer.Adam(learning_rate=scheduled_lr)
+ else:
+ scheduled_lr = fluid.layers.create_global_var(
+ name=fluid.unique_name.generate("learning_rate"),
+ shape=[1],
+ value=learning_rate,
+ dtype='float32',
+ persistable=True)
+ optimizer = fluid.optimizer.Adam(learning_rate=scheduled_lr)
+ optimizer._learning_rate_map[fluid.default_main_program(
+ )] = scheduled_lr
+
+ fluid.clip.set_gradient_clip(
+ clip=fluid.clip.GradientClipByGlobalNorm(clip_norm=1.0))
+
+ def exclude_from_weight_decay(name):
+ if name.find("layer_norm") > -1:
+ return True
+ bias_suffix = ["_bias", "_b", ".b_0"]
+ for suffix in bias_suffix:
+ if name.endswith(suffix):
+ return True
+ return False
+
+ param_list = dict()
+
+ loss_scaling = fluid.layers.create_global_var(
+ name=fluid.unique_name.generate("loss_scaling"),
+ shape=[1],
+ value=init_loss_scaling,
+ dtype='float32',
+ persistable=True)
+
+ if use_fp16:
+ loss *= loss_scaling
+ param_grads = optimizer.backward(loss)
+
+ master_param_grads = create_master_params_grads(
+ param_grads, train_program, startup_prog, loss_scaling)
+
+ for param, _ in master_param_grads:
+ param_list[param.name] = param * 1.0
+ param_list[param.name].stop_gradient = True
+
+ if use_dynamic_loss_scaling:
+ apply_dynamic_loss_scaling(
+ loss_scaling, master_param_grads, incr_every_n_steps,
+ decr_every_n_nan_or_inf, incr_ratio, decr_ratio)
+
+ optimizer.apply_gradients(master_param_grads)
+
+ if weight_decay > 0:
+ for param, grad in master_param_grads:
+ if exclude_from_weight_decay(param.name.rstrip(".master")):
+ continue
+ with param.block.program._optimized_guard(
+ [param, grad]), fluid.framework.name_scope("weight_decay"):
+ updated_param = param - param_list[
+ param.name] * weight_decay * scheduled_lr
+ fluid.layers.assign(output=param, input=updated_param)
+
+ master_param_to_train_param(master_param_grads, param_grads,
+ train_program)
+
+ else:
+ for param in train_program.global_block().all_parameters():
+ param_list[param.name] = param * 1.0
+ param_list[param.name].stop_gradient = True
+
+ _, param_grads = optimizer.minimize(loss)
+
+ if weight_decay > 0:
+ for param, grad in param_grads:
+ if exclude_from_weight_decay(param.name):
+ continue
+ with param.block.program._optimized_guard(
+ [param, grad]), fluid.framework.name_scope("weight_decay"):
+ updated_param = param - param_list[
+ param.name] * weight_decay * scheduled_lr
+ fluid.layers.assign(output=param, input=updated_param)
+
+ return scheduled_lr, loss_scaling
diff --git a/ogb_examples/graphproppred/mol/pcba_config.yaml b/ogb_examples/graphproppred/mol/pcba_config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..e39eadecf21987b38d2bba10c5b0efa019e144e0
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/pcba_config.yaml
@@ -0,0 +1,53 @@
+task_name: pcba
+seed: 28994
+dataset_name: ogbg-molpcba
+eval_metrics: null
+task_type: null
+num_class: null
+pool_type: average
+train_eps: True
+norm_type: layer_norm
+
+model_type: GNNModel
+embed_dim: 128
+num_layers: 5
+hidden_size: 256
+save_dir: ./checkpoints
+
+
+# finetune model config
+init_checkpoint: null
+init_pretraining_params: null
+
+# data config
+data_dir: ./dataset/
+symmetry: True
+batch_size: 256
+buf_size: 1000
+metrics: True
+shuffle: True
+num_workers: 12
+output_dir: ./outputs/
+
+# trainging config
+epoch: 50
+learning_rate: 0.005
+lr_scheduler: linear_warmup_decay
+weight_decay: 0.01
+warmup_proportion: 0.1
+save_steps: 10000
+validation_steps: 1000
+use_dynamic_loss_scaling: True
+init_loss_scaling: 102400
+metric: simple_accuracy
+incr_every_n_steps: 100
+decr_every_n_nan_or_inf: 2
+incr_ratio: 2.0
+decr_ratio: 0.8
+log_dir: ./logs
+eval_step: 1000
+train_log_step: 20
+
+# log config
+skip_steps: 10
+verbose: False
diff --git a/ogb_examples/graphproppred/mol/utils/__init__.py b/ogb_examples/graphproppred/mol/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..abf198b97e6e818e1fbe59006f98492640bcee54
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/utils/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/ogb_examples/graphproppred/mol/utils/args.py b/ogb_examples/graphproppred/mol/utils/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..2de3d0da17519f091079aa963aad743fa4095941
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/utils/args.py
@@ -0,0 +1,94 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Arguments for configuration."""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import six
+import os
+import sys
+import argparse
+import logging
+
+import paddle.fluid as fluid
+
+log = logging.getLogger("logger")
+
+
+def prepare_logger(logger, debug=False, save_to_file=None):
+ formatter = logging.Formatter(
+ fmt='[%(levelname)s] %(asctime)s [%(filename)12s:%(lineno)5d]:\t%(message)s'
+ )
+ # console_hdl = logging.StreamHandler()
+ # console_hdl.setFormatter(formatter)
+ # logger.addHandler(console_hdl)
+ if save_to_file is not None: #and not os.path.exists(save_to_file):
+ if os.path.isdir(save_to_file):
+ file_hdl = logging.FileHandler(
+ os.path.join(save_to_file, 'log.txt'))
+ else:
+ file_hdl = logging.FileHandler(save_to_file)
+ file_hdl.setFormatter(formatter)
+ logger.addHandler(file_hdl)
+ logger.setLevel(logging.DEBUG)
+ logger.propagate = False
+
+
+def str2bool(v):
+ # because argparse does not support to parse "true, False" as python
+ # boolean directly
+ return v.lower() in ("true", "t", "1")
+
+
+class ArgumentGroup(object):
+ def __init__(self, parser, title, des):
+ self._group = parser.add_argument_group(title=title, description=des)
+
+ def add_arg(self,
+ name,
+ type,
+ default,
+ help,
+ positional_arg=False,
+ **kwargs):
+ prefix = "" if positional_arg else "--"
+ type = str2bool if type == bool else type
+ self._group.add_argument(
+ prefix + name,
+ default=default,
+ type=type,
+ help=help + ' Default: %(default)s.',
+ **kwargs)
+
+
+def print_arguments(args):
+ log.info('----------- Configuration Arguments -----------')
+ for arg, value in sorted(six.iteritems(vars(args))):
+ log.info('%s: %s' % (arg, value))
+ log.info('------------------------------------------------')
+
+
+def check_cuda(use_cuda, err = \
+ "\nYou can not set use_cuda = True in the model because you are using paddlepaddle-cpu.\n \
+ Please: 1. Install paddlepaddle-gpu to run your models on GPU or 2. Set use_cuda = False to run models on CPU.\n"
+ ):
+ try:
+ if use_cuda == True and fluid.is_compiled_with_cuda() == False:
+ log.error(err)
+ sys.exit(1)
+ except Exception as e:
+ pass
diff --git a/ogb_examples/graphproppred/mol/utils/cards.py b/ogb_examples/graphproppred/mol/utils/cards.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c9c6709f71edd692c81d5fed8bfb87e9afd596f
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/utils/cards.py
@@ -0,0 +1,30 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+import os
+
+
+def get_cards():
+ """
+ get gpu cards number
+ """
+ num = 0
+ cards = os.environ.get('CUDA_VISIBLE_DEVICES', '')
+ if cards != '':
+ num = len(cards.split(","))
+ return num
diff --git a/ogb_examples/graphproppred/mol/utils/config.py b/ogb_examples/graphproppred/mol/utils/config.py
new file mode 100644
index 0000000000000000000000000000000000000000..62d2847c357c3c0d28f1ed57e4430a766c7dfebc
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/utils/config.py
@@ -0,0 +1,136 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This file implement a class for model configure.
+"""
+
+import datetime
+import os
+import yaml
+import random
+import shutil
+import six
+import logging
+
+log = logging.getLogger("logger")
+
+
+class AttrDict(dict):
+ """Attr dict
+ """
+
+ def __init__(self, d):
+ self.dict = d
+
+ def __getattr__(self, attr):
+ value = self.dict[attr]
+ if isinstance(value, dict):
+ return AttrDict(value)
+ else:
+ return value
+
+ def __str__(self):
+ return str(self.dict)
+
+
+class Config(object):
+ """Implementation of Config class for model configure.
+
+ Args:
+ config_file(str): configure filename, which is a yaml file.
+ isCreate(bool): if true, create some neccessary directories to save models, log file and other outputs.
+ isSave(bool): if true, save config_file in order to record the configure message.
+ """
+
+ def __init__(self, config_file, isCreate=False, isSave=False):
+ self.config_file = config_file
+ # self.config = self.get_config_from_yaml(config_file)
+ self.config = self.load_config(config_file)
+
+ if isCreate:
+ self.create_necessary_dirs()
+
+ if isSave:
+ self.save_config_file()
+
+ def load_config(self, config_file):
+ """Load config file"""
+ with open(config_file) as f:
+ if hasattr(yaml, 'FullLoader'):
+ config = yaml.load(f, Loader=yaml.FullLoader)
+ else:
+ config = yaml.load(f)
+ return config
+
+ def create_necessary_dirs(self):
+ """Create some necessary directories to save some important files.
+ """
+
+ self.config['log_dir'] = os.path.join(self.config['log_dir'],
+ self.config['task_name'])
+ self.config['save_dir'] = os.path.join(self.config['save_dir'],
+ self.config['task_name'])
+ self.config['output_dir'] = os.path.join(self.config['output_dir'],
+ self.config['task_name'])
+
+ self.make_dir(self.config['log_dir'])
+ self.make_dir(self.config['save_dir'])
+ self.make_dir(self.config['output_dir'])
+
+ def save_config_file(self):
+ """Save config file so that we can know the config when we look back
+ """
+ filename = self.config_file.split('/')[-1]
+ targetpath = os.path.join(self.config['save_dir'], filename)
+ try:
+ shutil.copyfile(self.config_file, targetpath)
+ except shutil.SameFileError:
+ log.info("%s and %s are the same file, did not copy by shutil"\
+ % (self.config_file, targetpath))
+
+ def make_dir(self, path):
+ """Build directory"""
+ if not os.path.exists(path):
+ os.makedirs(path)
+
+ def __getitem__(self, key):
+ return self.config[key]
+
+ def __call__(self):
+ """__call__"""
+ return self.config
+
+ def __getattr__(self, attr):
+ try:
+ result = self.config[attr]
+ except KeyError:
+ log.warn("%s attribute is not existed, return None" % attr)
+ result = None
+ return result
+
+ def __setitem__(self, key, value):
+ self.config[key] = value
+
+ def __str__(self):
+ return str(self.config)
+
+ def pretty_print(self):
+ log.info(
+ "-----------------------------------------------------------------")
+ log.info("config file: %s" % self.config_file)
+ for key, value in sorted(
+ self.config.items(), key=lambda item: item[0]):
+ log.info("%s: %s" % (key, value))
+ log.info(
+ "-----------------------------------------------------------------")
diff --git a/ogb_examples/graphproppred/mol/utils/fp16.py b/ogb_examples/graphproppred/mol/utils/fp16.py
new file mode 100644
index 0000000000000000000000000000000000000000..740add267dff2dbf463032bcc47a6741ca9f7c43
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/utils/fp16.py
@@ -0,0 +1,201 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import print_function
+import paddle
+import paddle.fluid as fluid
+
+
+def append_cast_op(i, o, prog):
+ """
+ Append a cast op in a given Program to cast input `i` to data type `o.dtype`.
+ Args:
+ i (Variable): The input Variable.
+ o (Variable): The output Variable.
+ prog (Program): The Program to append cast op.
+ """
+ prog.global_block().append_op(
+ type="cast",
+ inputs={"X": i},
+ outputs={"Out": o},
+ attrs={"in_dtype": i.dtype,
+ "out_dtype": o.dtype})
+
+
+def copy_to_master_param(p, block):
+ v = block.vars.get(p.name, None)
+ if v is None:
+ raise ValueError("no param name %s found!" % p.name)
+ new_p = fluid.framework.Parameter(
+ block=block,
+ shape=v.shape,
+ dtype=fluid.core.VarDesc.VarType.FP32,
+ type=v.type,
+ lod_level=v.lod_level,
+ stop_gradient=p.stop_gradient,
+ trainable=p.trainable,
+ optimize_attr=p.optimize_attr,
+ regularizer=p.regularizer,
+ gradient_clip_attr=p.gradient_clip_attr,
+ error_clip=p.error_clip,
+ name=v.name + ".master")
+ return new_p
+
+
+def apply_dynamic_loss_scaling(loss_scaling, master_params_grads,
+ incr_every_n_steps, decr_every_n_nan_or_inf,
+ incr_ratio, decr_ratio):
+ _incr_every_n_steps = fluid.layers.fill_constant(
+ shape=[1], dtype='int32', value=incr_every_n_steps)
+ _decr_every_n_nan_or_inf = fluid.layers.fill_constant(
+ shape=[1], dtype='int32', value=decr_every_n_nan_or_inf)
+
+ _num_good_steps = fluid.layers.create_global_var(
+ name=fluid.unique_name.generate("num_good_steps"),
+ shape=[1],
+ value=0,
+ dtype='int32',
+ persistable=True)
+ _num_bad_steps = fluid.layers.create_global_var(
+ name=fluid.unique_name.generate("num_bad_steps"),
+ shape=[1],
+ value=0,
+ dtype='int32',
+ persistable=True)
+
+ grads = [fluid.layers.reduce_sum(g) for [_, g] in master_params_grads]
+ all_grads = fluid.layers.concat(grads)
+ all_grads_sum = fluid.layers.reduce_sum(all_grads)
+ is_overall_finite = fluid.layers.isfinite(all_grads_sum)
+
+ update_loss_scaling(is_overall_finite, loss_scaling, _num_good_steps,
+ _num_bad_steps, _incr_every_n_steps,
+ _decr_every_n_nan_or_inf, incr_ratio, decr_ratio)
+
+ # apply_gradient append all ops in global block, thus we shouldn't
+ # apply gradient in the switch branch.
+ with fluid.layers.Switch() as switch:
+ with switch.case(is_overall_finite):
+ pass
+ with switch.default():
+ for _, g in master_params_grads:
+ fluid.layers.assign(fluid.layers.zeros_like(g), g)
+
+
+def create_master_params_grads(params_grads, main_prog, startup_prog,
+ loss_scaling):
+ master_params_grads = []
+ for p, g in params_grads:
+ with main_prog._optimized_guard([p, g]):
+ # create master parameters
+ master_param = copy_to_master_param(p, main_prog.global_block())
+ startup_master_param = startup_prog.global_block()._clone_variable(
+ master_param)
+ startup_p = startup_prog.global_block().var(p.name)
+ append_cast_op(startup_p, startup_master_param, startup_prog)
+ # cast fp16 gradients to fp32 before apply gradients
+ if g.name.find("layer_norm") > -1:
+ scaled_g = g / loss_scaling
+ master_params_grads.append([p, scaled_g])
+ continue
+ master_grad = fluid.layers.cast(g, "float32")
+ master_grad = master_grad / loss_scaling
+ master_params_grads.append([master_param, master_grad])
+
+ return master_params_grads
+
+
+def master_param_to_train_param(master_params_grads, params_grads, main_prog):
+ for idx, m_p_g in enumerate(master_params_grads):
+ train_p, _ = params_grads[idx]
+ if train_p.name.find("layer_norm") > -1:
+ continue
+ with main_prog._optimized_guard([m_p_g[0], m_p_g[1]]):
+ append_cast_op(m_p_g[0], train_p, main_prog)
+
+
+def update_loss_scaling(is_overall_finite, prev_loss_scaling, num_good_steps,
+ num_bad_steps, incr_every_n_steps,
+ decr_every_n_nan_or_inf, incr_ratio, decr_ratio):
+ """
+ Update loss scaling according to overall gradients. If all gradients is
+ finite after incr_every_n_steps, loss scaling will increase by incr_ratio.
+ Otherwisw, loss scaling will decrease by decr_ratio after
+ decr_every_n_nan_or_inf steps and each step some gradients are infinite.
+ Args:
+ is_overall_finite (Variable): A boolean variable indicates whether
+ all gradients are finite.
+ prev_loss_scaling (Variable): Previous loss scaling.
+ num_good_steps (Variable): A variable accumulates good steps in which
+ all gradients are finite.
+ num_bad_steps (Variable): A variable accumulates bad steps in which
+ some gradients are infinite.
+ incr_every_n_steps (Variable): A variable represents increasing loss
+ scaling every n consecutive steps with
+ finite gradients.
+ decr_every_n_nan_or_inf (Variable): A variable represents decreasing
+ loss scaling every n accumulated
+ steps with nan or inf gradients.
+ incr_ratio(float): The multiplier to use when increasing the loss
+ scaling.
+ decr_ratio(float): The less-than-one-multiplier to use when decreasing
+ loss scaling.
+ """
+ zero_steps = fluid.layers.fill_constant(shape=[1], dtype='int32', value=0)
+ with fluid.layers.Switch() as switch:
+ with switch.case(is_overall_finite):
+ should_incr_loss_scaling = fluid.layers.less_than(
+ incr_every_n_steps, num_good_steps + 1)
+ with fluid.layers.Switch() as switch1:
+ with switch1.case(should_incr_loss_scaling):
+ new_loss_scaling = prev_loss_scaling * incr_ratio
+ loss_scaling_is_finite = fluid.layers.isfinite(
+ new_loss_scaling)
+ with fluid.layers.Switch() as switch2:
+ with switch2.case(loss_scaling_is_finite):
+ fluid.layers.assign(new_loss_scaling,
+ prev_loss_scaling)
+ with switch2.default():
+ pass
+ fluid.layers.assign(zero_steps, num_good_steps)
+ fluid.layers.assign(zero_steps, num_bad_steps)
+
+ with switch1.default():
+ fluid.layers.increment(num_good_steps)
+ fluid.layers.assign(zero_steps, num_bad_steps)
+
+ with switch.default():
+ should_decr_loss_scaling = fluid.layers.less_than(
+ decr_every_n_nan_or_inf, num_bad_steps + 1)
+ with fluid.layers.Switch() as switch3:
+ with switch3.case(should_decr_loss_scaling):
+ new_loss_scaling = prev_loss_scaling * decr_ratio
+ static_loss_scaling = \
+ fluid.layers.fill_constant(shape=[1],
+ dtype='float32',
+ value=1.0)
+ less_than_one = fluid.layers.less_than(new_loss_scaling,
+ static_loss_scaling)
+ with fluid.layers.Switch() as switch4:
+ with switch4.case(less_than_one):
+ fluid.layers.assign(static_loss_scaling,
+ prev_loss_scaling)
+ with switch4.default():
+ fluid.layers.assign(new_loss_scaling,
+ prev_loss_scaling)
+ fluid.layers.assign(zero_steps, num_good_steps)
+ fluid.layers.assign(zero_steps, num_bad_steps)
+ with switch3.default():
+ fluid.layers.assign(zero_steps, num_good_steps)
+ fluid.layers.increment(num_bad_steps)
diff --git a/ogb_examples/graphproppred/mol/utils/init.py b/ogb_examples/graphproppred/mol/utils/init.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f54a185ac80ec2308c9f8effe59148547b2548d
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/utils/init.py
@@ -0,0 +1,91 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import six
+import ast
+import copy
+import logging
+
+import numpy as np
+import paddle.fluid as fluid
+
+log = logging.getLogger("logger")
+
+
+def cast_fp32_to_fp16(exe, main_program):
+ log.info("Cast parameters to float16 data format.")
+ for param in main_program.global_block().all_parameters():
+ if not param.name.endswith(".master"):
+ param_t = fluid.global_scope().find_var(param.name).get_tensor()
+ data = np.array(param_t)
+ if param.name.startswith("encoder_layer") \
+ and "layer_norm" not in param.name:
+ param_t.set(np.float16(data).view(np.uint16), exe.place)
+
+ #load fp32
+ master_param_var = fluid.global_scope().find_var(param.name +
+ ".master")
+ if master_param_var is not None:
+ master_param_var.get_tensor().set(data, exe.place)
+
+
+def init_checkpoint(exe, init_checkpoint_path, main_program, use_fp16=False):
+ assert os.path.exists(
+ init_checkpoint_path), "[%s] cann't be found." % init_checkpoint_path
+
+ def existed_persitables(var):
+ if not fluid.io.is_persistable(var):
+ return False
+ return os.path.exists(os.path.join(init_checkpoint_path, var.name))
+
+ fluid.io.load_vars(
+ exe,
+ init_checkpoint_path,
+ main_program=main_program,
+ predicate=existed_persitables)
+ log.info("Load model from {}".format(init_checkpoint_path))
+
+ if use_fp16:
+ cast_fp32_to_fp16(exe, main_program)
+
+
+def init_pretraining_params(exe,
+ pretraining_params_path,
+ main_program,
+ use_fp16=False):
+ assert os.path.exists(pretraining_params_path
+ ), "[%s] cann't be found." % pretraining_params_path
+
+ def existed_params(var):
+ if not isinstance(var, fluid.framework.Parameter):
+ return False
+ return os.path.exists(os.path.join(pretraining_params_path, var.name))
+
+ fluid.io.load_vars(
+ exe,
+ pretraining_params_path,
+ main_program=main_program,
+ predicate=existed_params)
+ log.info("Load pretraining parameters from {}.".format(
+ pretraining_params_path))
+
+ if use_fp16:
+ cast_fp32_to_fp16(exe, main_program)
diff --git a/ogb_examples/linkproppred/main_pgl.py b/ogb_examples/linkproppred/main_pgl.py
deleted file mode 100644
index bb81a248c98fe03dcc44037d211e5e2af06a0716..0000000000000000000000000000000000000000
--- a/ogb_examples/linkproppred/main_pgl.py
+++ /dev/null
@@ -1,276 +0,0 @@
-# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""test ogb
-"""
-import argparse
-import time
-import logging
-import numpy as np
-
-import paddle.fluid as fluid
-
-import pgl
-from pgl.contrib.ogb.linkproppred.dataset_pgl import PglLinkPropPredDataset
-from pgl.utils import paddle_helper
-from ogb.linkproppred import Evaluator
-
-
-def send_func(src_feat, dst_feat, edge_feat):
- """send_func"""
- return src_feat["h"]
-
-
-def recv_func(feat):
- """recv_func"""
- return fluid.layers.sequence_pool(feat, pool_type="sum")
-
-
-class GNNModel(object):
- """GNNModel"""
-
- def __init__(self, name, num_nodes, emb_dim, num_layers):
- self.num_nodes = num_nodes
- self.emb_dim = emb_dim
- self.num_layers = num_layers
- self.name = name
-
- self.src_nodes = fluid.layers.data(
- name='src_nodes',
- shape=[None],
- dtype='int64', )
-
- self.dst_nodes = fluid.layers.data(
- name='dst_nodes',
- shape=[None],
- dtype='int64', )
-
- self.edge_label = fluid.layers.data(
- name='edge_label',
- shape=[None, 1],
- dtype='float32', )
-
- def forward(self, graph):
- """forward"""
- h = fluid.layers.create_parameter(
- shape=[self.num_nodes, self.emb_dim],
- dtype="float32",
- name=self.name + "_embedding")
-
- for layer in range(self.num_layers):
- msg = graph.send(
- send_func,
- nfeat_list=[("h", h)], )
- h = graph.recv(msg, recv_func)
- h = fluid.layers.fc(
- h,
- size=self.emb_dim,
- bias_attr=False,
- param_attr=fluid.ParamAttr(name=self.name + '_%s' % layer))
- h = h * graph.node_feat["norm"]
- bias = fluid.layers.create_parameter(
- shape=[self.emb_dim],
- dtype='float32',
- is_bias=True,
- name=self.name + '_bias_%s' % layer)
- h = fluid.layers.elementwise_add(h, bias, act="relu")
-
- src = fluid.layers.gather(h, self.src_nodes, overwrite=False)
- dst = fluid.layers.gather(h, self.dst_nodes, overwrite=False)
- edge_embed = src * dst
- pred = fluid.layers.fc(input=edge_embed,
- size=1,
- name=self.name + "_pred_output")
-
- prob = fluid.layers.sigmoid(pred)
-
- loss = fluid.layers.sigmoid_cross_entropy_with_logits(pred,
- self.edge_label)
- loss = fluid.layers.reduce_sum(loss)
-
- return pred, prob, loss
-
-
-def main():
- """main
- """
- # Training settings
- parser = argparse.ArgumentParser(description='Graph Dataset')
- parser.add_argument(
- '--epochs',
- type=int,
- default=4,
- help='number of epochs to train (default: 100)')
- parser.add_argument(
- '--dataset',
- type=str,
- default="ogbl-ppa",
- help='dataset name (default: protein protein associations)')
- parser.add_argument('--use_cuda', action='store_true')
- parser.add_argument('--batch_size', type=int, default=5120)
- parser.add_argument('--embed_dim', type=int, default=64)
- parser.add_argument('--num_layers', type=int, default=2)
- parser.add_argument('--lr', type=float, default=0.001)
- args = parser.parse_args()
- print(args)
-
- place = fluid.CUDAPlace(0) if args.use_cuda else fluid.CPUPlace()
-
- ### automatic dataloading and splitting
- print("loadding dataset")
- dataset = PglLinkPropPredDataset(name=args.dataset)
- splitted_edge = dataset.get_edge_split()
- print(splitted_edge['train_edge'].shape)
- print(splitted_edge['train_edge_label'].shape)
-
- print("building evaluator")
- ### automatic evaluator. takes dataset name as input
- evaluator = Evaluator(args.dataset)
-
- graph_data = dataset[0]
- print("num_nodes: %d" % graph_data.num_nodes)
-
- train_program = fluid.Program()
- startup_program = fluid.Program()
-
- # degree normalize
- indegree = graph_data.indegree()
- norm = np.zeros_like(indegree, dtype="float32")
- norm[indegree > 0] = np.power(indegree[indegree > 0], -0.5)
- graph_data.node_feat["norm"] = np.expand_dims(norm, -1).astype("float32")
- # graph_data.node_feat["index"] = np.array([i for i in range(graph_data.num_nodes)], dtype=np.int64).reshape(-1,1)
-
- with fluid.program_guard(train_program, startup_program):
- model = GNNModel(
- name="gnn",
- num_nodes=graph_data.num_nodes,
- emb_dim=args.embed_dim,
- num_layers=args.num_layers)
- gw = pgl.graph_wrapper.GraphWrapper(
- "graph",
- place,
- node_feat=graph_data.node_feat_info(),
- edge_feat=graph_data.edge_feat_info())
- pred, prob, loss = model.forward(gw)
-
- val_program = train_program.clone(for_test=True)
-
- with fluid.program_guard(train_program, startup_program):
- global_steps = int(splitted_edge['train_edge'].shape[0] /
- args.batch_size * 2)
- learning_rate = fluid.layers.polynomial_decay(args.lr, global_steps,
- 0.00005)
-
- adam = fluid.optimizer.Adam(
- learning_rate=learning_rate,
- regularization=fluid.regularizer.L2DecayRegularizer(
- regularization_coeff=0.0005))
- adam.minimize(loss)
-
- exe = fluid.Executor(place)
- exe.run(startup_program)
- feed = gw.to_feed(graph_data)
-
- print("evaluate result before training: ")
- result = test(exe, val_program, prob, evaluator, feed, splitted_edge)
- print(result)
-
- print("training")
- cc = 0
- for epoch in range(1, args.epochs + 1):
- for batch_data, batch_label in data_generator(
- graph_data,
- splitted_edge["train_edge"],
- splitted_edge["train_edge_label"],
- batch_size=args.batch_size):
- feed['src_nodes'] = batch_data[:, 0].reshape(-1, 1)
- feed['dst_nodes'] = batch_data[:, 1].reshape(-1, 1)
- feed['edge_label'] = batch_label.astype("float32")
-
- res_loss, y_pred, b_lr = exe.run(
- train_program,
- feed=feed,
- fetch_list=[loss, prob, learning_rate])
- if cc % 1 == 0:
- print("epoch %d | step %d | lr %s | Loss %s" %
- (epoch, cc, b_lr[0], res_loss[0]))
- cc += 1
-
- if cc % 20 == 0:
- print("Evaluating...")
- result = test(exe, val_program, prob, evaluator, feed,
- splitted_edge)
- print("epoch %d | step %d" % (epoch, cc))
- print(result)
-
-
-def test(exe, val_program, prob, evaluator, feed, splitted_edge):
- """Evaluation"""
- result = {}
- feed['src_nodes'] = splitted_edge["valid_edge"][:, 0].reshape(-1, 1)
- feed['dst_nodes'] = splitted_edge["valid_edge"][:, 1].reshape(-1, 1)
- feed['edge_label'] = splitted_edge["valid_edge_label"].astype(
- "float32").reshape(-1, 1)
- y_pred = exe.run(val_program, feed=feed, fetch_list=[prob])[0]
- input_dict = {
- "y_pred_pos":
- y_pred[splitted_edge["valid_edge_label"] == 1].reshape(-1, ),
- "y_pred_neg":
- y_pred[splitted_edge["valid_edge_label"] == 0].reshape(-1, )
- }
- result["valid"] = evaluator.eval(input_dict)
-
- feed['src_nodes'] = splitted_edge["test_edge"][:, 0].reshape(-1, 1)
- feed['dst_nodes'] = splitted_edge["test_edge"][:, 1].reshape(-1, 1)
- feed['edge_label'] = splitted_edge["test_edge_label"].astype(
- "float32").reshape(-1, 1)
- y_pred = exe.run(val_program, feed=feed, fetch_list=[prob])[0]
- input_dict = {
- "y_pred_pos":
- y_pred[splitted_edge["test_edge_label"] == 1].reshape(-1, ),
- "y_pred_neg":
- y_pred[splitted_edge["test_edge_label"] == 0].reshape(-1, )
- }
- result["test"] = evaluator.eval(input_dict)
- return result
-
-
-def data_generator(graph, data, label_data, batch_size, shuffle=True):
- """Data Generator"""
- perm = np.arange(0, len(data))
- if shuffle:
- np.random.shuffle(perm)
-
- offset = 0
- while offset < len(perm):
- batch_index = perm[offset:(offset + batch_size)]
- offset += batch_size
- pos_data = data[batch_index]
- pos_label = label_data[batch_index]
-
- neg_src_node = pos_data[:, 0]
- neg_dst_node = np.random.choice(
- pos_data.reshape(-1, ), size=len(neg_src_node))
- neg_data = np.hstack(
- [neg_src_node.reshape(-1, 1), neg_dst_node.reshape(-1, 1)])
- exists = graph.has_edges_between(neg_src_node, neg_dst_node)
- neg_data = neg_data[np.invert(exists)]
- neg_label = np.zeros(shape=len(neg_data), dtype=np.int64)
-
- batch_data = np.vstack([pos_data, neg_data])
- label = np.vstack([pos_label.reshape(-1, 1), neg_label.reshape(-1, 1)])
- yield batch_data, label
-
-
-if __name__ == "__main__":
- main()
diff --git a/ogb_examples/linkproppred/ogbl-ppa/README.md b/ogb_examples/linkproppred/ogbl-ppa/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..f06b3bc2be13dca9548491c5a152841fd4bb034f
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/README.md
@@ -0,0 +1,21 @@
+# Graph Link Prediction for Open Graph Benchmark (OGB) PPA dataset
+
+[The Open Graph Benchmark (OGB)](https://ogb.stanford.edu/) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. Here we complete the Graph Link Prediction task based on PGL.
+
+
+### Requirements
+
+paddlpaddle >= 1.7.1
+
+pgl 1.0.2
+
+ogb
+
+
+### How to Run
+
+```
+CUDA_VISIBLE_DEVICES=0,1,2,3 python train.py --use_cuda 1 --num_workers 4 --output_path ./output/model_1 --batch_size 65536 --epoch 1000 --learning_rate 0.005 --hidden_size 256
+```
+
+The best record will be saved in ./output/model_1/best.txt.
diff --git a/ogb_examples/linkproppred/ogbl-ppa/args.py b/ogb_examples/linkproppred/ogbl-ppa/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..5fc51d37f9774fbf50fb7bbb5aa700b9f8aaff7f
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/args.py
@@ -0,0 +1,44 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""finetune args"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import time
+import argparse
+
+from utils.args import ArgumentGroup
+
+# yapf: disable
+parser = argparse.ArgumentParser(__doc__)
+model_g = ArgumentGroup(parser, "model", "model configuration and paths.")
+model_g.add_arg("init_checkpoint", str, None, "Init checkpoint to resume training from.")
+model_g.add_arg("init_pretraining_params", str, None,
+ "Init pre-training params which preforms fine-tuning from. If the "
+ "arg 'init_checkpoint' has been set, this argument wouldn't be valid.")
+
+train_g = ArgumentGroup(parser, "training", "training options.")
+train_g.add_arg("epoch", int, 3, "Number of epoches for fine-tuning.")
+train_g.add_arg("learning_rate", float, 5e-5, "Learning rate used to train with warmup.")
+
+run_type_g = ArgumentGroup(parser, "run_type", "running type options.")
+run_type_g.add_arg("use_cuda", bool, True, "If set, use GPU for training.")
+run_type_g.add_arg("num_workers", int, 1, "use multiprocess to generate graph")
+run_type_g.add_arg("output_path", str, None, "path to save model")
+run_type_g.add_arg("hidden_size", int, 128, "model hidden-size")
+run_type_g.add_arg("batch_size", int, 128, "batch_size")
diff --git a/ogb_examples/linkproppred/ogbl-ppa/dataloader/__init__.py b/ogb_examples/linkproppred/ogbl-ppa/dataloader/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..abf198b97e6e818e1fbe59006f98492640bcee54
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/dataloader/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/ogb_examples/linkproppred/ogbl-ppa/dataloader/base_dataloader.py b/ogb_examples/linkproppred/ogbl-ppa/dataloader/base_dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..d04f9fd521602bf67f950b3e72ba021fd09c298f
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/dataloader/base_dataloader.py
@@ -0,0 +1,148 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Base DataLoader
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import sys
+import six
+from io import open
+from collections import namedtuple
+import numpy as np
+import tqdm
+import paddle
+from pgl.utils import mp_reader
+import collections
+import time
+
+import pgl
+
+if six.PY3:
+ import io
+ sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
+ sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
+
+
+def batch_iter(data, perm, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ size = len(data)
+ start = 0
+ cc = 0
+ while start < size:
+ index = perm[start:start + batch_size]
+ start += batch_size
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ yield data[index]
+
+
+def scan_batch_iter(data, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ batch = []
+ cc = 0
+ for line_example in data.scan():
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ batch.append(line_example)
+ if len(batch) == batch_size:
+ yield batch
+ batch = []
+
+ if len(batch) > 0:
+ yield batch
+
+
+class BaseDataGenerator(object):
+ """Base Data Geneartor"""
+
+ def __init__(self, buf_size, batch_size, num_workers, shuffle=True):
+ self.num_workers = num_workers
+ self.batch_size = batch_size
+ self.line_examples = []
+ self.buf_size = buf_size
+ self.shuffle = shuffle
+
+ def batch_fn(self, batch_examples):
+ """ batch_fn batch producer"""
+ raise NotImplementedError("No defined Batch Fn")
+
+ def batch_iter(self, fid, perm):
+ """ batch iterator"""
+ if self.shuffle:
+ for batch in batch_iter(self, perm, self.batch_size, fid,
+ self.num_workers):
+ yield batch
+ else:
+ for batch in scan_batch_iter(self, self.batch_size, fid,
+ self.num_workers):
+ yield batch
+
+ def __len__(self):
+ return len(self.line_examples)
+
+ def __getitem__(self, idx):
+ if isinstance(idx, collections.Iterable):
+ return [self[bidx] for bidx in idx]
+ else:
+ return self.line_examples[idx]
+
+ def generator(self):
+ """batch dict generator"""
+
+ def worker(filter_id, perm):
+ """ multiprocess worker"""
+
+ def func_run():
+ """ func_run """
+ pid = os.getpid()
+ np.random.seed(pid + int(time.time()))
+ for batch_examples in self.batch_iter(filter_id, perm):
+ batch_dict = self.batch_fn(batch_examples)
+ yield batch_dict
+
+ return func_run
+
+ # consume a seed
+ np.random.rand()
+ if self.shuffle:
+ perm = np.arange(0, len(self))
+ np.random.shuffle(perm)
+ else:
+ perm = None
+ if self.num_workers == 1:
+ r = paddle.reader.buffered(worker(0, perm), self.buf_size)
+ else:
+ worker_pool = [
+ worker(wid, perm) for wid in range(self.num_workers)
+ ]
+ worker = mp_reader.multiprocess_reader(
+ worker_pool, use_pipe=True, queue_size=1000)
+ r = paddle.reader.buffered(worker, self.buf_size)
+
+ for batch in r():
+ yield batch
+
+ def scan(self):
+ for line_example in self.line_examples:
+ yield line_example
diff --git a/ogb_examples/linkproppred/ogbl-ppa/dataloader/ogbl_ppa_dataloader.py b/ogb_examples/linkproppred/ogbl-ppa/dataloader/ogbl_ppa_dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..621db215a6924de338a7dd881ddc54ac82290a33
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/dataloader/ogbl_ppa_dataloader.py
@@ -0,0 +1,118 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+from dataloader.base_dataloader import BaseDataGenerator
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+
+from ogb.linkproppred import LinkPropPredDataset
+from ogb.linkproppred import Evaluator
+import tqdm
+from collections import namedtuple
+import pgl
+import numpy as np
+
+
+class PPADataGenerator(BaseDataGenerator):
+ def __init__(self,
+ graph_wrapper=None,
+ buf_size=1000,
+ batch_size=128,
+ num_workers=1,
+ shuffle=True,
+ phase="train"):
+ super(PPADataGenerator, self).__init__(
+ buf_size=buf_size,
+ num_workers=num_workers,
+ batch_size=batch_size,
+ shuffle=shuffle)
+
+ self.d_name = "ogbl-ppa"
+ self.graph_wrapper = graph_wrapper
+ dataset = LinkPropPredDataset(name=self.d_name)
+ splitted_edge = dataset.get_edge_split()
+ self.phase = phase
+ graph = dataset[0]
+ edges = graph["edge_index"].T
+ #self.graph = pgl.graph.Graph(num_nodes=graph["num_nodes"],
+ # edges=edges,
+ # node_feat={"nfeat": graph["node_feat"],
+ # "node_id": np.arange(0, graph["num_nodes"], dtype="int64").reshape(-1, 1) })
+
+ #self.graph.indegree()
+ self.num_nodes = graph["num_nodes"]
+ if self.phase == 'train':
+ edges = splitted_edge["train"]["edge"]
+ labels = np.ones(len(edges))
+ elif self.phase == "valid":
+ # Compute the embedding for all the nodes
+ pos_edges = splitted_edge["valid"]["edge"]
+ neg_edges = splitted_edge["valid"]["edge_neg"]
+ pos_labels = np.ones(len(pos_edges))
+ neg_labels = np.zeros(len(neg_edges))
+ edges = np.vstack([pos_edges, neg_edges])
+ labels = pos_labels.tolist() + neg_labels.tolist()
+ elif self.phase == "test":
+ # Compute the embedding for all the nodes
+ pos_edges = splitted_edge["test"]["edge"]
+ neg_edges = splitted_edge["test"]["edge_neg"]
+ pos_labels = np.ones(len(pos_edges))
+ neg_labels = np.zeros(len(neg_edges))
+ edges = np.vstack([pos_edges, neg_edges])
+ labels = pos_labels.tolist() + neg_labels.tolist()
+
+ self.line_examples = []
+ Example = namedtuple('Example', ['src', "dst", "label"])
+ for edge, label in zip(edges, labels):
+ self.line_examples.append(
+ Example(
+ src=edge[0], dst=edge[1], label=label))
+ print("Phase", self.phase)
+ print("Len Examples", len(self.line_examples))
+
+ def batch_fn(self, batch_ex):
+ batch_src = []
+ batch_dst = []
+ join_graph = []
+ cc = 0
+ batch_node_id = []
+ batch_labels = []
+ for ex in batch_ex:
+ batch_src.append(ex.src)
+ batch_dst.append(ex.dst)
+ batch_labels.append(ex.label)
+
+ if self.phase == "train":
+ for num in range(1):
+ rand_src = np.random.randint(
+ low=0, high=self.num_nodes, size=len(batch_ex))
+ rand_dst = np.random.randint(
+ low=0, high=self.num_nodes, size=len(batch_ex))
+ batch_src = batch_src + rand_src.tolist()
+ batch_dst = batch_dst + rand_dst.tolist()
+ batch_labels = batch_labels + np.zeros_like(
+ rand_src, dtype="int64").tolist()
+
+ feed_dict = {}
+
+ feed_dict["batch_src"] = np.array(batch_src, dtype="int64")
+ feed_dict["batch_dst"] = np.array(batch_dst, dtype="int64")
+ feed_dict["labels"] = np.array(batch_labels, dtype="int64")
+ return feed_dict
diff --git a/ogb_examples/linkproppred/ogbl-ppa/model.py b/ogb_examples/linkproppred/ogbl-ppa/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..9429ea39a900488e1ab65c084e4b133079c56dcb
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/model.py
@@ -0,0 +1,108 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""lbs_model"""
+import os
+import re
+import time
+from random import random
+from functools import reduce, partial
+
+import numpy as np
+import multiprocessing
+
+import paddle
+import paddle.fluid as F
+import paddle.fluid.layers as L
+from pgl.graph_wrapper import GraphWrapper
+from pgl.layers.conv import gcn, gat
+
+
+class BaseGraph(object):
+ """Base Graph Model"""
+
+ def __init__(self, args):
+ node_feature = [('nfeat', [None, 58], "float32"),
+ ('node_id', [None, 1], "int64")]
+ self.hidden_size = args.hidden_size
+ self.num_nodes = args.num_nodes
+
+ self.graph_wrapper = None # GraphWrapper(
+ #name="graph", place=F.CPUPlace(), node_feat=node_feature)
+
+ self.build_model(args)
+
+ def build_model(self, args):
+ """ build graph model"""
+ self.batch_src = L.data(name="batch_src", shape=[-1], dtype="int64")
+ self.batch_src = L.reshape(self.batch_src, [-1, 1])
+ self.batch_dst = L.data(name="batch_dst", shape=[-1], dtype="int64")
+ self.batch_dst = L.reshape(self.batch_dst, [-1, 1])
+ self.labels = L.data(name="labels", shape=[-1], dtype="int64")
+ self.labels = L.reshape(self.labels, [-1, 1])
+ self.labels.stop_gradients = True
+ self.src_repr = L.embedding(
+ self.batch_src,
+ size=(self.num_nodes, self.hidden_size),
+ param_attr=F.ParamAttr(
+ name="node_embeddings",
+ initializer=F.initializer.NormalInitializer(
+ loc=0.0, scale=1.0)))
+
+ self.dst_repr = L.embedding(
+ self.batch_dst,
+ size=(self.num_nodes, self.hidden_size),
+ param_attr=F.ParamAttr(
+ name="node_embeddings",
+ initializer=F.initializer.NormalInitializer(
+ loc=0.0, scale=1.0)))
+
+ self.link_predictor(self.src_repr, self.dst_repr)
+
+ self.bce_loss()
+
+ def link_predictor(self, x, y):
+ """ siamese network"""
+ feat = x * y
+
+ feat = L.fc(feat, size=self.hidden_size, name="link_predictor_1")
+ feat = L.relu(feat)
+
+ feat = L.fc(feat, size=self.hidden_size, name="link_predictor_2")
+ feat = L.relu(feat)
+
+ self.logits = L.fc(feat,
+ size=1,
+ act="sigmoid",
+ name="link_predictor_logits")
+
+ def bce_loss(self):
+ """listwise model"""
+ mask = L.cast(self.labels > 0.5, dtype="float32")
+ mask.stop_gradients = True
+
+ self.loss = L.log_loss(self.logits, mask, epsilon=1e-15)
+ self.loss = L.reduce_mean(self.loss) * 2
+ proba = L.sigmoid(self.logits)
+ proba = L.concat([proba * -1 + 1, proba], axis=1)
+ auc_out, batch_auc_out, _ = \
+ L.auc(input=proba, label=self.labels, curve='ROC', slide_steps=1)
+
+ self.metrics = {
+ "loss": self.loss,
+ "auc": batch_auc_out,
+ }
+
+ def neighbor_aggregator(self, node_repr):
+ """neighbor aggregation"""
+ return node_repr
diff --git a/ogb_examples/linkproppred/ogbl-ppa/monitor/__init__.py b/ogb_examples/linkproppred/ogbl-ppa/monitor/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d814437561c253c97a95e31187e63a554476364f
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/monitor/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""init"""
diff --git a/ogb_examples/linkproppred/ogbl-ppa/monitor/train_monitor.py b/ogb_examples/linkproppred/ogbl-ppa/monitor/train_monitor.py
new file mode 100644
index 0000000000000000000000000000000000000000..a377135a23ad50ce0cc195bdd4dff3ff3b1e8d44
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/monitor/train_monitor.py
@@ -0,0 +1,184 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""train and evaluate"""
+import tqdm
+import json
+import numpy as np
+import sys
+import os
+import paddle.fluid as F
+from pgl.utils.log_writer import LogWriter
+from ogb.linkproppred import Evaluator
+from ogb.linkproppred import LinkPropPredDataset
+
+
+def multi_device(reader, dev_count):
+ """multi device"""
+ if dev_count == 1:
+ for batch in reader:
+ yield batch
+ else:
+ batches = []
+ for batch in reader:
+ batches.append(batch)
+ if len(batches) == dev_count:
+ yield batches
+ batches = []
+
+
+class OgbEvaluator(object):
+ def __init__(self):
+ d_name = "ogbl-ppa"
+ dataset = LinkPropPredDataset(name=d_name)
+ splitted_edge = dataset.get_edge_split()
+ graph = dataset[0]
+ self.num_nodes = graph["num_nodes"]
+ self.ogb_evaluator = Evaluator(name="ogbl-ppa")
+
+ def eval(self, scores, labels, phase):
+ labels = np.reshape(labels, [-1])
+ ret = {}
+ pos = scores[labels > 0.5].squeeze(-1)
+ neg = scores[labels < 0.5].squeeze(-1)
+ for K in [10, 50, 100]:
+ self.ogb_evaluator.K = K
+ ret['%s_hits@%s' % (phase, K)] = self.ogb_evaluator.eval({
+ 'y_pred_pos': pos,
+ 'y_pred_neg': neg,
+ })[f'hits@{K}']
+ return ret
+
+
+def evaluate(model, valid_exe, valid_ds, valid_prog, dev_count, evaluator,
+ phase):
+ """evaluate """
+ cc = 0
+ scores = []
+ labels = []
+
+ for feed_dict in tqdm.tqdm(
+ multi_device(valid_ds.generator(), dev_count), desc='evaluating'):
+
+ if dev_count > 1:
+ output = valid_exe.run(feed=feed_dict,
+ fetch_list=[model.logits, model.labels])
+ else:
+ output = valid_exe.run(valid_prog,
+ feed=feed_dict,
+ fetch_list=[model.logits, model.labels])
+ scores.append(output[0])
+ labels.append(output[1])
+
+ scores = np.vstack(scores)
+ labels = np.vstack(labels)
+ ret = evaluator.eval(scores, labels, phase)
+ return ret
+
+
+def _create_if_not_exist(path):
+ basedir = os.path.dirname(path)
+ if not os.path.exists(basedir):
+ os.makedirs(basedir)
+
+
+def train_and_evaluate(exe,
+ train_exe,
+ valid_exe,
+ train_ds,
+ valid_ds,
+ test_ds,
+ train_prog,
+ valid_prog,
+ model,
+ metric,
+ epoch=20,
+ dev_count=1,
+ train_log_step=5,
+ eval_step=10000,
+ evaluator=None,
+ output_path=None):
+ """train and evaluate"""
+
+ global_step = 0
+
+ log_path = os.path.join(output_path, "log")
+ _create_if_not_exist(log_path)
+
+ writer = LogWriter(log_path)
+
+ best_model = 0
+ for e in range(epoch):
+ for feed_dict in tqdm.tqdm(
+ multi_device(train_ds.generator(), dev_count),
+ desc='Epoch %s' % e):
+ if dev_count > 1:
+ ret = train_exe.run(feed=feed_dict, fetch_list=metric.vars)
+ ret = [[np.mean(v)] for v in ret]
+ else:
+ ret = train_exe.run(train_prog,
+ feed=feed_dict,
+ fetch_list=metric.vars)
+
+ ret = metric.parse(ret)
+ if global_step % train_log_step == 0:
+ for key, value in ret.items():
+ writer.add_scalar(
+ 'train_' + key, value, global_step)
+
+ global_step += 1
+ if global_step % eval_step == 0:
+ eval_ret = evaluate(model, exe, valid_ds, valid_prog, 1,
+ evaluator, "valid")
+
+ test_eval_ret = evaluate(model, exe, test_ds, valid_prog, 1,
+ evaluator, "test")
+
+ eval_ret.update(test_eval_ret)
+
+ sys.stderr.write(json.dumps(eval_ret, indent=4) + "\n")
+
+ for key, value in eval_ret.items():
+ writer.add_scalar(key, value, global_step)
+
+ if eval_ret["valid_hits@100"] > best_model:
+ F.io.save_persistables(
+ exe,
+ os.path.join(output_path, "checkpoint"), train_prog)
+ eval_ret["step"] = global_step
+ with open(os.path.join(output_path, "best.txt"), "w") as f:
+ f.write(json.dumps(eval_ret, indent=2) + '\n')
+ best_model = eval_ret["valid_hits@100"]
+ # Epoch End
+ eval_ret = evaluate(model, exe, valid_ds, valid_prog, 1, evaluator,
+ "valid")
+
+ test_eval_ret = evaluate(model, exe, test_ds, valid_prog, 1, evaluator,
+ "test")
+
+ eval_ret.update(test_eval_ret)
+ sys.stderr.write(json.dumps(eval_ret, indent=4) + "\n")
+
+ for key, value in eval_ret.items():
+ writer.add_scalar(key, value, global_step)
+
+ if eval_ret["valid_hits@100"] > best_model:
+ F.io.save_persistables(exe,
+ os.path.join(output_path, "checkpoint"),
+ train_prog)
+ eval_ret["step"] = global_step
+ with open(os.path.join(output_path, "best.txt"), "w") as f:
+ f.write(json.dumps(eval_ret, indent=2) + '\n')
+ best_model = eval_ret["valid_hits@100"]
+
+ writer.close()
diff --git a/ogb_examples/linkproppred/ogbl-ppa/train.py b/ogb_examples/linkproppred/ogbl-ppa/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..c70fa4f9dd4987e615f6f935b5108c727fe7abee
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/train.py
@@ -0,0 +1,157 @@
+# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""listwise model
+"""
+
+import torch
+import os
+import re
+import time
+import logging
+from random import random
+from functools import reduce, partial
+
+# For downloading ogb
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+# SSL
+
+import numpy as np
+import multiprocessing
+
+import pgl
+import paddle
+import paddle.fluid as F
+import paddle.fluid.layers as L
+
+from args import parser
+from utils.args import print_arguments, check_cuda
+from utils.init import init_checkpoint, init_pretraining_params
+from model import BaseGraph
+from dataloader.ogbl_ppa_dataloader import PPADataGenerator
+from monitor.train_monitor import train_and_evaluate, OgbEvaluator
+
+log = logging.getLogger(__name__)
+
+
+class Metric(object):
+ """Metric"""
+
+ def __init__(self, **args):
+ self.args = args
+
+ @property
+ def vars(self):
+ """ fetch metric vars"""
+ values = [self.args[k] for k in self.args.keys()]
+ return values
+
+ def parse(self, fetch_list):
+ """parse"""
+ tup = list(zip(self.args.keys(), [float(v[0]) for v in fetch_list]))
+ return dict(tup)
+
+
+if __name__ == '__main__':
+ args = parser.parse_args()
+ print_arguments(args)
+ evaluator = OgbEvaluator()
+
+ train_prog = F.Program()
+ startup_prog = F.Program()
+ args.num_nodes = evaluator.num_nodes
+
+ if args.use_cuda:
+ dev_list = F.cuda_places()
+ place = dev_list[0]
+ dev_count = len(dev_list)
+ else:
+ place = F.CPUPlace()
+ dev_count = int(os.environ.get('CPU_NUM', multiprocessing.cpu_count()))
+
+ with F.program_guard(train_prog, startup_prog):
+ with F.unique_name.guard():
+ graph_model = BaseGraph(args)
+ test_prog = train_prog.clone(for_test=True)
+ opt = F.optimizer.Adam(learning_rate=args.learning_rate)
+ opt.minimize(graph_model.loss)
+
+ #test_prog = F.Program()
+ #with F.program_guard(test_prog, startup_prog):
+ # with F.unique_name.guard():
+ # _graph_model = BaseGraph(args)
+
+ train_ds = PPADataGenerator(
+ phase="train",
+ graph_wrapper=graph_model.graph_wrapper,
+ num_workers=args.num_workers,
+ batch_size=args.batch_size)
+
+ valid_ds = PPADataGenerator(
+ phase="valid",
+ graph_wrapper=graph_model.graph_wrapper,
+ num_workers=args.num_workers,
+ batch_size=args.batch_size)
+
+ test_ds = PPADataGenerator(
+ phase="test",
+ graph_wrapper=graph_model.graph_wrapper,
+ num_workers=args.num_workers,
+ batch_size=args.batch_size)
+
+ exe = F.Executor(place)
+ exe.run(startup_prog)
+
+ if args.init_pretraining_params is not None:
+ init_pretraining_params(
+ exe, args.init_pretraining_params, main_program=startup_prog)
+
+ metric = Metric(**graph_model.metrics)
+
+ nccl2_num_trainers = 1
+ nccl2_trainer_id = 0
+ if dev_count > 1:
+
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = dev_count
+
+ train_exe = F.ParallelExecutor(
+ use_cuda=args.use_cuda,
+ loss_name=graph_model.loss.name,
+ exec_strategy=exec_strategy,
+ main_program=train_prog,
+ num_trainers=nccl2_num_trainers,
+ trainer_id=nccl2_trainer_id)
+
+ test_exe = exe
+ else:
+ train_exe, test_exe = exe, exe
+
+ train_and_evaluate(
+ exe=exe,
+ train_exe=train_exe,
+ valid_exe=test_exe,
+ train_ds=train_ds,
+ valid_ds=valid_ds,
+ test_ds=test_ds,
+ train_prog=train_prog,
+ valid_prog=test_prog,
+ train_log_step=5,
+ output_path=args.output_path,
+ dev_count=dev_count,
+ model=graph_model,
+ epoch=args.epoch,
+ eval_step=1000000,
+ evaluator=evaluator,
+ metric=metric)
diff --git a/ogb_examples/linkproppred/ogbl-ppa/utils/__init__.py b/ogb_examples/linkproppred/ogbl-ppa/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1333621cf62da67fcf10016fc848c503f7c254fa
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/utils/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""utils"""
diff --git a/ogb_examples/linkproppred/ogbl-ppa/utils/args.py b/ogb_examples/linkproppred/ogbl-ppa/utils/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..5131f2ceb88775f12e886402ef205735a1ac1d77
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/utils/args.py
@@ -0,0 +1,97 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Arguments for configuration."""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import six
+import os
+import sys
+import argparse
+import logging
+
+import paddle.fluid as fluid
+
+log = logging.getLogger(__name__)
+
+
+def prepare_logger(logger, debug=False, save_to_file=None):
+ """doc"""
+ formatter = logging.Formatter(
+ fmt='[%(levelname)s] %(asctime)s [%(filename)12s:%(lineno)5d]:\t%(message)s'
+ )
+ #console_hdl = logging.StreamHandler()
+ #console_hdl.setFormatter(formatter)
+ #logger.addHandler(console_hdl)
+ if save_to_file is not None and not os.path.exists(save_to_file):
+ file_hdl = logging.FileHandler(save_to_file)
+ file_hdl.setFormatter(formatter)
+ logger.addHandler(file_hdl)
+ logger.setLevel(logging.DEBUG)
+ logger.propagate = False
+
+
+def str2bool(v):
+ """doc"""
+ # because argparse does not support to parse "true, False" as python
+ # boolean directly
+ return v.lower() in ("true", "t", "1")
+
+
+class ArgumentGroup(object):
+ """doc"""
+
+ def __init__(self, parser, title, des):
+ self._group = parser.add_argument_group(title=title, description=des)
+
+ def add_arg(self,
+ name,
+ type,
+ default,
+ help,
+ positional_arg=False,
+ **kwargs):
+ """doc"""
+ prefix = "" if positional_arg else "--"
+ type = str2bool if type == bool else type
+ self._group.add_argument(
+ prefix + name,
+ default=default,
+ type=type,
+ help=help + ' Default: %(default)s.',
+ **kwargs)
+
+
+def print_arguments(args):
+ """doc"""
+ log.info('----------- Configuration Arguments -----------')
+ for arg, value in sorted(six.iteritems(vars(args))):
+ log.info('%s: %s' % (arg, value))
+ log.info('------------------------------------------------')
+
+
+def check_cuda(use_cuda, err= \
+ "\nYou can not set use_cuda=True in the model because you are using paddlepaddle-cpu.\n \
+ Please: 1. Install paddlepaddle-gpu to run your models on GPU or 2. Set use_cuda=False to run models on CPU.\n"
+ ):
+ """doc"""
+ try:
+ if use_cuda == True and fluid.is_compiled_with_cuda() == False:
+ log.error(err)
+ sys.exit(1)
+ except Exception as e:
+ pass
diff --git a/ogb_examples/linkproppred/ogbl-ppa/utils/cards.py b/ogb_examples/linkproppred/ogbl-ppa/utils/cards.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b658a4bf6272f00f48ff447caaaa580189afe60
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/utils/cards.py
@@ -0,0 +1,31 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""cards"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+import os
+
+
+def get_cards():
+ """
+ get gpu cards number
+ """
+ num = 0
+ cards = os.environ.get('CUDA_VISIBLE_DEVICES', '')
+ if cards != '':
+ num = len(cards.split(","))
+ return num
diff --git a/ogb_examples/linkproppred/ogbl-ppa/utils/fp16.py b/ogb_examples/linkproppred/ogbl-ppa/utils/fp16.py
new file mode 100644
index 0000000000000000000000000000000000000000..740add267dff2dbf463032bcc47a6741ca9f7c43
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/utils/fp16.py
@@ -0,0 +1,201 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import print_function
+import paddle
+import paddle.fluid as fluid
+
+
+def append_cast_op(i, o, prog):
+ """
+ Append a cast op in a given Program to cast input `i` to data type `o.dtype`.
+ Args:
+ i (Variable): The input Variable.
+ o (Variable): The output Variable.
+ prog (Program): The Program to append cast op.
+ """
+ prog.global_block().append_op(
+ type="cast",
+ inputs={"X": i},
+ outputs={"Out": o},
+ attrs={"in_dtype": i.dtype,
+ "out_dtype": o.dtype})
+
+
+def copy_to_master_param(p, block):
+ v = block.vars.get(p.name, None)
+ if v is None:
+ raise ValueError("no param name %s found!" % p.name)
+ new_p = fluid.framework.Parameter(
+ block=block,
+ shape=v.shape,
+ dtype=fluid.core.VarDesc.VarType.FP32,
+ type=v.type,
+ lod_level=v.lod_level,
+ stop_gradient=p.stop_gradient,
+ trainable=p.trainable,
+ optimize_attr=p.optimize_attr,
+ regularizer=p.regularizer,
+ gradient_clip_attr=p.gradient_clip_attr,
+ error_clip=p.error_clip,
+ name=v.name + ".master")
+ return new_p
+
+
+def apply_dynamic_loss_scaling(loss_scaling, master_params_grads,
+ incr_every_n_steps, decr_every_n_nan_or_inf,
+ incr_ratio, decr_ratio):
+ _incr_every_n_steps = fluid.layers.fill_constant(
+ shape=[1], dtype='int32', value=incr_every_n_steps)
+ _decr_every_n_nan_or_inf = fluid.layers.fill_constant(
+ shape=[1], dtype='int32', value=decr_every_n_nan_or_inf)
+
+ _num_good_steps = fluid.layers.create_global_var(
+ name=fluid.unique_name.generate("num_good_steps"),
+ shape=[1],
+ value=0,
+ dtype='int32',
+ persistable=True)
+ _num_bad_steps = fluid.layers.create_global_var(
+ name=fluid.unique_name.generate("num_bad_steps"),
+ shape=[1],
+ value=0,
+ dtype='int32',
+ persistable=True)
+
+ grads = [fluid.layers.reduce_sum(g) for [_, g] in master_params_grads]
+ all_grads = fluid.layers.concat(grads)
+ all_grads_sum = fluid.layers.reduce_sum(all_grads)
+ is_overall_finite = fluid.layers.isfinite(all_grads_sum)
+
+ update_loss_scaling(is_overall_finite, loss_scaling, _num_good_steps,
+ _num_bad_steps, _incr_every_n_steps,
+ _decr_every_n_nan_or_inf, incr_ratio, decr_ratio)
+
+ # apply_gradient append all ops in global block, thus we shouldn't
+ # apply gradient in the switch branch.
+ with fluid.layers.Switch() as switch:
+ with switch.case(is_overall_finite):
+ pass
+ with switch.default():
+ for _, g in master_params_grads:
+ fluid.layers.assign(fluid.layers.zeros_like(g), g)
+
+
+def create_master_params_grads(params_grads, main_prog, startup_prog,
+ loss_scaling):
+ master_params_grads = []
+ for p, g in params_grads:
+ with main_prog._optimized_guard([p, g]):
+ # create master parameters
+ master_param = copy_to_master_param(p, main_prog.global_block())
+ startup_master_param = startup_prog.global_block()._clone_variable(
+ master_param)
+ startup_p = startup_prog.global_block().var(p.name)
+ append_cast_op(startup_p, startup_master_param, startup_prog)
+ # cast fp16 gradients to fp32 before apply gradients
+ if g.name.find("layer_norm") > -1:
+ scaled_g = g / loss_scaling
+ master_params_grads.append([p, scaled_g])
+ continue
+ master_grad = fluid.layers.cast(g, "float32")
+ master_grad = master_grad / loss_scaling
+ master_params_grads.append([master_param, master_grad])
+
+ return master_params_grads
+
+
+def master_param_to_train_param(master_params_grads, params_grads, main_prog):
+ for idx, m_p_g in enumerate(master_params_grads):
+ train_p, _ = params_grads[idx]
+ if train_p.name.find("layer_norm") > -1:
+ continue
+ with main_prog._optimized_guard([m_p_g[0], m_p_g[1]]):
+ append_cast_op(m_p_g[0], train_p, main_prog)
+
+
+def update_loss_scaling(is_overall_finite, prev_loss_scaling, num_good_steps,
+ num_bad_steps, incr_every_n_steps,
+ decr_every_n_nan_or_inf, incr_ratio, decr_ratio):
+ """
+ Update loss scaling according to overall gradients. If all gradients is
+ finite after incr_every_n_steps, loss scaling will increase by incr_ratio.
+ Otherwisw, loss scaling will decrease by decr_ratio after
+ decr_every_n_nan_or_inf steps and each step some gradients are infinite.
+ Args:
+ is_overall_finite (Variable): A boolean variable indicates whether
+ all gradients are finite.
+ prev_loss_scaling (Variable): Previous loss scaling.
+ num_good_steps (Variable): A variable accumulates good steps in which
+ all gradients are finite.
+ num_bad_steps (Variable): A variable accumulates bad steps in which
+ some gradients are infinite.
+ incr_every_n_steps (Variable): A variable represents increasing loss
+ scaling every n consecutive steps with
+ finite gradients.
+ decr_every_n_nan_or_inf (Variable): A variable represents decreasing
+ loss scaling every n accumulated
+ steps with nan or inf gradients.
+ incr_ratio(float): The multiplier to use when increasing the loss
+ scaling.
+ decr_ratio(float): The less-than-one-multiplier to use when decreasing
+ loss scaling.
+ """
+ zero_steps = fluid.layers.fill_constant(shape=[1], dtype='int32', value=0)
+ with fluid.layers.Switch() as switch:
+ with switch.case(is_overall_finite):
+ should_incr_loss_scaling = fluid.layers.less_than(
+ incr_every_n_steps, num_good_steps + 1)
+ with fluid.layers.Switch() as switch1:
+ with switch1.case(should_incr_loss_scaling):
+ new_loss_scaling = prev_loss_scaling * incr_ratio
+ loss_scaling_is_finite = fluid.layers.isfinite(
+ new_loss_scaling)
+ with fluid.layers.Switch() as switch2:
+ with switch2.case(loss_scaling_is_finite):
+ fluid.layers.assign(new_loss_scaling,
+ prev_loss_scaling)
+ with switch2.default():
+ pass
+ fluid.layers.assign(zero_steps, num_good_steps)
+ fluid.layers.assign(zero_steps, num_bad_steps)
+
+ with switch1.default():
+ fluid.layers.increment(num_good_steps)
+ fluid.layers.assign(zero_steps, num_bad_steps)
+
+ with switch.default():
+ should_decr_loss_scaling = fluid.layers.less_than(
+ decr_every_n_nan_or_inf, num_bad_steps + 1)
+ with fluid.layers.Switch() as switch3:
+ with switch3.case(should_decr_loss_scaling):
+ new_loss_scaling = prev_loss_scaling * decr_ratio
+ static_loss_scaling = \
+ fluid.layers.fill_constant(shape=[1],
+ dtype='float32',
+ value=1.0)
+ less_than_one = fluid.layers.less_than(new_loss_scaling,
+ static_loss_scaling)
+ with fluid.layers.Switch() as switch4:
+ with switch4.case(less_than_one):
+ fluid.layers.assign(static_loss_scaling,
+ prev_loss_scaling)
+ with switch4.default():
+ fluid.layers.assign(new_loss_scaling,
+ prev_loss_scaling)
+ fluid.layers.assign(zero_steps, num_good_steps)
+ fluid.layers.assign(zero_steps, num_bad_steps)
+ with switch3.default():
+ fluid.layers.assign(zero_steps, num_good_steps)
+ fluid.layers.increment(num_bad_steps)
diff --git a/ogb_examples/linkproppred/ogbl-ppa/utils/init.py b/ogb_examples/linkproppred/ogbl-ppa/utils/init.py
new file mode 100644
index 0000000000000000000000000000000000000000..baa3ba5987cf1cbae20a60ea88e3f3bf0e389f43
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/utils/init.py
@@ -0,0 +1,97 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""paddle init"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import six
+import ast
+import copy
+import logging
+
+import numpy as np
+import paddle.fluid as fluid
+
+log = logging.getLogger(__name__)
+
+
+def cast_fp32_to_fp16(exe, main_program):
+ """doc"""
+ log.info("Cast parameters to float16 data format.")
+ for param in main_program.global_block().all_parameters():
+ if not param.name.endswith(".master"):
+ param_t = fluid.global_scope().find_var(param.name).get_tensor()
+ data = np.array(param_t)
+ if param.name.startswith("encoder_layer") \
+ and "layer_norm" not in param.name:
+ param_t.set(np.float16(data).view(np.uint16), exe.place)
+
+ #load fp32
+ master_param_var = fluid.global_scope().find_var(param.name +
+ ".master")
+ if master_param_var is not None:
+ master_param_var.get_tensor().set(data, exe.place)
+
+
+def init_checkpoint(exe, init_checkpoint_path, main_program, use_fp16=False):
+ """init"""
+ assert os.path.exists(
+ init_checkpoint_path), "[%s] cann't be found." % init_checkpoint_path
+
+ def existed_persitables(var):
+ """existed"""
+ if not fluid.io.is_persistable(var):
+ return False
+ return os.path.exists(os.path.join(init_checkpoint_path, var.name))
+
+ fluid.io.load_vars(
+ exe,
+ init_checkpoint_path,
+ main_program=main_program,
+ predicate=existed_persitables)
+ log.info("Load model from {}".format(init_checkpoint_path))
+
+ if use_fp16:
+ cast_fp32_to_fp16(exe, main_program)
+
+
+def init_pretraining_params(exe,
+ pretraining_params_path,
+ main_program,
+ use_fp16=False):
+ """init"""
+ assert os.path.exists(pretraining_params_path
+ ), "[%s] cann't be found." % pretraining_params_path
+
+ def existed_params(var):
+ """doc"""
+ if not isinstance(var, fluid.framework.Parameter):
+ return False
+ return os.path.exists(os.path.join(pretraining_params_path, var.name))
+
+ fluid.io.load_vars(
+ exe,
+ pretraining_params_path,
+ main_program=main_program,
+ predicate=existed_params)
+ log.info("Load pretraining parameters from {}.".format(
+ pretraining_params_path))
+
+ if use_fp16:
+ cast_fp32_to_fp16(exe, main_program)
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/README.md b/ogb_examples/nodeproppred/ogbn-arxiv/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..123deb80fa337081cbe389dd1d97049ecd3764d8
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/README.md
@@ -0,0 +1,59 @@
+# Graph Node Prediction for Open Graph Benchmark (OGB) Arxiv dataset
+
+[The Open Graph Benchmark (OGB)](https://ogb.stanford.edu/) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. Here we complete the Graph Node Prediction task based on PGL.
+
+
+### Requirements
+
+paddlpaddle >= 1.7.1
+
+pgl 1.0.2
+
+ogb 1.1.1
+
+
+### How to Run
+
+```
+CUDA_VISIBLE_DEVICES=0 python train.py \
+ --use_cuda 1 \
+ --num_workers 4 \
+ --output_path ./output/model_1 \
+ --batch_size 1024 \
+ --test_batch_size 512 \
+ --epoch 100 \
+ --learning_rate 0.001 \
+ --full_batch 0 \
+ --model gaan \
+ --drop_rate 0.5 \
+ --samples 8 8 8 \
+ --test_samples 20 20 20 \
+ --hidden_size 256
+```
+or
+
+```
+sh run.sh
+```
+
+The best record will be saved in ./output/model_1/best.txt.
+
+
+### Hyperparameters
+- use_cuda: whether to use gpu or not
+- num_workers: the nums of sample workers
+- output_path: path to save the model
+- batch_size: batch size
+- epoch: number of training epochs
+- learning_rate: learning rate
+- full_batch: run full batch of graph
+- model: model to run, now gaan, sage, gcn, eta are available
+- drop_rate: drop rate of the feature layers
+- samples: the sample nums of each GNN layers
+- hidden_size: the hidden size
+
+### Performance
+We train our models for 100 epochs and report the **acc** on the test dataset.
+|dataset|mean|std|#experiments|
+|-|-|-|-|
+|ogbn-arxiv|0.7197|0.0024|16|
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/args.py b/ogb_examples/nodeproppred/ogbn-arxiv/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..638a2ca4db636c86e9383b5c8f260e725962a400
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/args.py
@@ -0,0 +1,50 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""finetune args"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import time
+import argparse
+
+from utils.args import ArgumentGroup
+
+# yapf: disable
+parser = argparse.ArgumentParser(__doc__)
+model_g = ArgumentGroup(parser, "model", "model configuration and paths.")
+model_g.add_arg("init_checkpoint", str, None, "Init checkpoint to resume training from.")
+model_g.add_arg("init_pretraining_params", str, None,
+ "Init pre-training params which preforms fine-tuning from. If the "
+ "arg 'init_checkpoint' has been set, this argument wouldn't be valid.")
+
+train_g = ArgumentGroup(parser, "training", "training options.")
+train_g.add_arg("epoch", int, 3, "Number of epoches for fine-tuning.")
+train_g.add_arg("learning_rate", float, 5e-5, "Learning rate used to train with warmup.")
+
+run_type_g = ArgumentGroup(parser, "run_type", "running type options.")
+run_type_g.add_arg("use_cuda", bool, True, "If set, use GPU for training.")
+run_type_g.add_arg("num_workers", int, 4, "use multiprocess to generate graph")
+run_type_g.add_arg("output_path", str, None, "path to save model")
+run_type_g.add_arg("model", str, None, "model to run")
+run_type_g.add_arg("hidden_size", int, 256, "model hidden-size")
+run_type_g.add_arg("drop_rate", float, 0.5, "Dropout rate")
+run_type_g.add_arg("batch_size", int, 1024, "batch_size")
+run_type_g.add_arg("full_batch", bool, False, "use static graph wrapper, if full_batch is true, batch_size will take no effect.")
+run_type_g.add_arg("samples", type=int, nargs='+', default=[30, 30], help="sample nums of k-hop.")
+run_type_g.add_arg("test_batch_size", int, 512, help="sample nums of k-hop of test phase.")
+run_type_g.add_arg("test_samples", type=int, nargs='+', default=[30, 30], help="sample nums of k-hop.")
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/__init__.py b/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..abf198b97e6e818e1fbe59006f98492640bcee54
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/base_dataloader.py b/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/base_dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..d04f9fd521602bf67f950b3e72ba021fd09c298f
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/base_dataloader.py
@@ -0,0 +1,148 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Base DataLoader
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import sys
+import six
+from io import open
+from collections import namedtuple
+import numpy as np
+import tqdm
+import paddle
+from pgl.utils import mp_reader
+import collections
+import time
+
+import pgl
+
+if six.PY3:
+ import io
+ sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
+ sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
+
+
+def batch_iter(data, perm, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ size = len(data)
+ start = 0
+ cc = 0
+ while start < size:
+ index = perm[start:start + batch_size]
+ start += batch_size
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ yield data[index]
+
+
+def scan_batch_iter(data, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ batch = []
+ cc = 0
+ for line_example in data.scan():
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ batch.append(line_example)
+ if len(batch) == batch_size:
+ yield batch
+ batch = []
+
+ if len(batch) > 0:
+ yield batch
+
+
+class BaseDataGenerator(object):
+ """Base Data Geneartor"""
+
+ def __init__(self, buf_size, batch_size, num_workers, shuffle=True):
+ self.num_workers = num_workers
+ self.batch_size = batch_size
+ self.line_examples = []
+ self.buf_size = buf_size
+ self.shuffle = shuffle
+
+ def batch_fn(self, batch_examples):
+ """ batch_fn batch producer"""
+ raise NotImplementedError("No defined Batch Fn")
+
+ def batch_iter(self, fid, perm):
+ """ batch iterator"""
+ if self.shuffle:
+ for batch in batch_iter(self, perm, self.batch_size, fid,
+ self.num_workers):
+ yield batch
+ else:
+ for batch in scan_batch_iter(self, self.batch_size, fid,
+ self.num_workers):
+ yield batch
+
+ def __len__(self):
+ return len(self.line_examples)
+
+ def __getitem__(self, idx):
+ if isinstance(idx, collections.Iterable):
+ return [self[bidx] for bidx in idx]
+ else:
+ return self.line_examples[idx]
+
+ def generator(self):
+ """batch dict generator"""
+
+ def worker(filter_id, perm):
+ """ multiprocess worker"""
+
+ def func_run():
+ """ func_run """
+ pid = os.getpid()
+ np.random.seed(pid + int(time.time()))
+ for batch_examples in self.batch_iter(filter_id, perm):
+ batch_dict = self.batch_fn(batch_examples)
+ yield batch_dict
+
+ return func_run
+
+ # consume a seed
+ np.random.rand()
+ if self.shuffle:
+ perm = np.arange(0, len(self))
+ np.random.shuffle(perm)
+ else:
+ perm = None
+ if self.num_workers == 1:
+ r = paddle.reader.buffered(worker(0, perm), self.buf_size)
+ else:
+ worker_pool = [
+ worker(wid, perm) for wid in range(self.num_workers)
+ ]
+ worker = mp_reader.multiprocess_reader(
+ worker_pool, use_pipe=True, queue_size=1000)
+ r = paddle.reader.buffered(worker, self.buf_size)
+
+ for batch in r():
+ yield batch
+
+ def scan(self):
+ for line_example in self.line_examples:
+ yield line_example
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/ogbn_arxiv_dataloader.py b/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/ogbn_arxiv_dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..48529c6a39f1bbf861765e21bed82fe0185dc27e
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/ogbn_arxiv_dataloader.py
@@ -0,0 +1,151 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+from dataloader.base_dataloader import BaseDataGenerator
+from utils.to_undirected import to_undirected
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+
+from pgl.contrib.ogb.nodeproppred.dataset_pgl import PglNodePropPredDataset
+#from pgl.sample import graph_saint_random_walk_sample
+from ogb.nodeproppred import Evaluator
+import tqdm
+from collections import namedtuple
+import pgl
+import numpy as np
+import copy
+
+
+def traverse(item):
+ """traverse
+ """
+ if isinstance(item, list) or isinstance(item, np.ndarray):
+ for i in iter(item):
+ for j in traverse(i):
+ yield j
+ else:
+ yield item
+
+
+def flat_node_and_edge(nodes):
+ """flat_node_and_edge
+ """
+ nodes = list(set(traverse(nodes)))
+ return nodes
+
+
+def k_hop_sampler(graph, samples, batch_nodes):
+ # for batch_train_samples, batch_train_labels in batch_info:
+ start_nodes = copy.deepcopy(batch_nodes)
+ nodes = start_nodes
+ edges = []
+ for max_deg in samples:
+ pred_nodes = graph.sample_predecessor(start_nodes, max_degree=max_deg)
+
+ for dst_node, src_nodes in zip(start_nodes, pred_nodes):
+ for src_node in src_nodes:
+ edges.append((src_node, dst_node))
+
+ last_nodes = nodes
+ nodes = [nodes, pred_nodes]
+ nodes = flat_node_and_edge(nodes)
+ # Find new nodes
+ start_nodes = list(set(nodes) - set(last_nodes))
+ if len(start_nodes) == 0:
+ break
+
+ subgraph = graph.subgraph(
+ nodes=nodes, edges=edges, with_node_feat=True, with_edge_feat=True)
+ sub_node_index = subgraph.reindex_from_parrent_nodes(batch_nodes)
+
+ return subgraph, sub_node_index
+
+
+#def graph_saint_randomwalk_sampler(graph, batch_nodes, max_depth=3):
+# subgraph = graph_saint_random_walk_sample(graph, batch_nodes, max_depth)
+# sub_node_index = subgraph.reindex_from_parrent_nodes(batch_nodes)
+# return subgraph, sub_node_index
+
+
+class ArxivDataGenerator(BaseDataGenerator):
+ def __init__(self,
+ graph_wrapper=None,
+ buf_size=1000,
+ batch_size=128,
+ num_workers=1,
+ samples=[30, 30],
+ shuffle=True,
+ phase="train"):
+ super(ArxivDataGenerator, self).__init__(
+ buf_size=buf_size,
+ num_workers=num_workers,
+ batch_size=batch_size,
+ shuffle=shuffle)
+ self.samples = samples
+ self.d_name = "ogbn-arxiv"
+ self.graph_wrapper = graph_wrapper
+ dataset = PglNodePropPredDataset(name=self.d_name)
+ splitted_idx = dataset.get_idx_split()
+ self.phase = phase
+ graph, label = dataset[0]
+ graph = to_undirected(graph)
+ self.graph = graph
+ self.num_nodes = graph.num_nodes
+ if self.phase == 'train':
+ nodes_idx = splitted_idx["train"]
+ labels = label[nodes_idx]
+ elif self.phase == "valid":
+ nodes_idx = splitted_idx["valid"]
+ labels = label[nodes_idx]
+ elif self.phase == "test":
+ nodes_idx = splitted_idx["test"]
+ labels = label[nodes_idx]
+ self.nodes_idx = nodes_idx
+ self.labels = labels
+ self.sample_based_line_example(nodes_idx, labels)
+
+ def sample_based_line_example(self, nodes_idx, labels):
+ self.line_examples = []
+ Example = namedtuple('Example', ["node", "label"])
+ for node, label in zip(nodes_idx, labels):
+ self.line_examples.append(Example(node=node, label=label))
+ print("Phase", self.phase)
+ print("Len Examples", len(self.line_examples))
+
+ def batch_fn(self, batch_ex):
+ batch_nodes = []
+ cc = 0
+ batch_node_id = []
+ batch_labels = []
+ for ex in batch_ex:
+ batch_nodes.append(ex.node)
+ batch_labels.append(ex.label)
+
+ _graph_wrapper = copy.copy(self.graph_wrapper)
+ #if self.phase == "train":
+ # subgraph, sub_node_index = graph_saint_randomwalk_sampler(self.graph, batch_nodes)
+ #else:
+ subgraph, sub_node_index = k_hop_sampler(self.graph, self.samples,
+ batch_nodes)
+
+ feed_dict = _graph_wrapper.to_feed(subgraph)
+ feed_dict["batch_nodes"] = sub_node_index
+ feed_dict["labels"] = np.array(batch_labels, dtype="int64")
+ return feed_dict
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/model.py b/ogb_examples/nodeproppred/ogbn-arxiv/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..1bfa50b1c31b7effdf2573025a1e8e04ee4ec739
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/model.py
@@ -0,0 +1,416 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# encoding=utf-8
+"""lbs_model"""
+import os
+import re
+import time
+from random import random
+from functools import reduce, partial
+
+import numpy as np
+import multiprocessing
+
+import paddle
+import paddle.fluid as F
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+from pgl.graph_wrapper import GraphWrapper
+from pgl.layers.conv import gcn, gat
+from pgl.utils import paddle_helper
+
+
+class BaseGraph(object):
+ """Base Graph Model"""
+
+ def __init__(self, args, graph_wrapper=None):
+ self.hidden_size = args.hidden_size
+ self.num_nodes = args.num_nodes
+ self.drop_rate = args.drop_rate
+ node_feature = [('feat', [None, 128], "float32")]
+ if graph_wrapper is None:
+ self.graph_wrapper = GraphWrapper(
+ name="graph", place=F.CPUPlace(), node_feat=node_feature)
+ else:
+ self.graph_wrapper = graph_wrapper
+ self.build_model(args)
+
+ def build_model(self, args):
+ """ build graph model"""
+ self.batch_nodes = L.data(
+ name="batch_nodes", shape=[-1], dtype="int64")
+ self.labels = L.data(name="labels", shape=[-1], dtype="int64")
+
+ self.batch_nodes = L.reshape(self.batch_nodes, [-1, 1])
+ self.labels = L.reshape(self.labels, [-1, 1])
+
+ self.batch_nodes.stop_gradients = True
+ self.labels.stop_gradients = True
+
+ feat = self.graph_wrapper.node_feat['feat']
+ if self.graph_wrapper is not None:
+ feat = self.neighbor_aggregator(feat)
+
+ assert feat is not None
+ feat = L.gather(feat, self.batch_nodes)
+ self.logits = L.fc(feat,
+ size=40,
+ act=None,
+ name="node_predictor_logits")
+ self.loss()
+
+ def mlp(self, feat):
+ for i in range(3):
+ feat = L.fc(node,
+ size=self.hidden_size,
+ name="simple_mlp_{}".format(i))
+ feat = L.batch_norm(feat)
+ feat = L.relu(feat)
+ feat = L.dropout(feat, dropout_prob=0.5)
+ return feat
+
+ def loss(self):
+ self.loss = L.softmax_with_cross_entropy(self.logits, self.labels)
+ self.loss = L.reduce_mean(self.loss)
+ self.metrics = {"loss": self.loss, }
+
+ def neighbor_aggregator(self, feature):
+ """neighbor aggregation"""
+ raise NotImplementedError(
+ "Please implement this method when you using graph wrapper for GNNs."
+ )
+
+
+class MLPModel(BaseGraph):
+ def __init__(self, args, gw):
+ super(MLPModel, self).__init__(args, gw)
+
+ def neighbor_aggregator(self, feature):
+ for i in range(3):
+ feature = L.fc(feature,
+ size=self.hidden_size,
+ name="simple_mlp_{}".format(i))
+ #feature = L.batch_norm(feature)
+ feature = L.relu(feature)
+ feature = L.dropout(feature, dropout_prob=self.drop_rate)
+ return feature
+
+
+class SAGEModel(BaseGraph):
+ def __init__(self, args, gw):
+ super(SAGEModel, self).__init__(args, gw)
+
+ def neighbor_aggregator(self, feature):
+ sage = GraphSageModel(40, 3, 256)
+ feature = sage.forward(self.graph_wrapper, feature, self.drop_rate)
+ return feature
+
+
+class GAANModel(BaseGraph):
+ def __init__(self, args, gw):
+ super(GAANModel, self).__init__(args, gw)
+
+ def neighbor_aggregator(self, feature):
+ gaan = GaANModel(
+ 40,
+ 3,
+ hidden_size_a=48,
+ hidden_size_v=64,
+ hidden_size_m=128,
+ hidden_size_o=256)
+ feature = gaan.forward(self.graph_wrapper, feature, self.drop_rate)
+ return feature
+
+
+class GINModel(BaseGraph):
+ def __init__(self, args, gw):
+ super(GINModel, self).__init__(args, gw)
+
+ def neighbor_aggregator(self, feature):
+ gin = GinModel(40, 2, 256)
+ feature = gin.forward(self.graph_wrapper, feature, self.drop_rate)
+ return feature
+
+
+class GATModel(BaseGraph):
+ def __init__(self, args, gw):
+ super(GATModel, self).__init__(args, gw)
+
+ def neighbor_aggregator(self, feature):
+ feature = gat(self.graph_wrapper,
+ feature,
+ hidden_size=self.hidden_size,
+ activation='relu',
+ name="GAT_1")
+ feature = gat(self.graph_wrapper,
+ feature,
+ hidden_size=self.hidden_size,
+ activation='relu',
+ name="GAT_2")
+ return feature
+
+
+class GCNModel(BaseGraph):
+ def __init__(self, args, gw):
+ super(GCNModel, self).__init__(args, gw)
+
+ def neighbor_aggregator(self, feature):
+ feature = gcn(
+ self.graph_wrapper,
+ feature,
+ hidden_size=self.hidden_size,
+ activation='relu',
+ name="GCN_1", )
+ feature = fluid.layers.dropout(feature, dropout_prob=self.drop_rate)
+ feature = gcn(self.graph_wrapper,
+ feature,
+ hidden_size=self.hidden_size,
+ activation='relu',
+ name="GCN_2")
+ feature = fluid.layers.dropout(feature, dropout_prob=self.drop_rate)
+ return feature
+
+
+class GinModel(object):
+ def __init__(self,
+ num_class,
+ num_layers,
+ hidden_size,
+ act='relu',
+ name="GINModel"):
+ self.num_class = num_class
+ self.num_layers = num_layers
+ self.hidden_size = hidden_size
+ self.act = act
+ self.name = name
+
+ def forward(self, gw, feature):
+ for i in range(self.num_layers):
+ feature = gin(gw, feature, self.hidden_size, self.act,
+ self.name + '_' + str(i))
+ feature = fluid.layers.layer_norm(
+ feature,
+ begin_norm_axis=1,
+ param_attr=fluid.ParamAttr(
+ name="norm_scale_%s" % (i),
+ initializer=fluid.initializer.Constant(1.0)),
+ bias_attr=fluid.ParamAttr(
+ name="norm_bias_%s" % (i),
+ initializer=fluid.initializer.Constant(0.0)), )
+
+ feature = fluid.layers.relu(feature)
+ return feature
+
+
+class GaANModel(object):
+ def __init__(self,
+ num_class,
+ num_layers,
+ hidden_size_a=24,
+ hidden_size_v=32,
+ hidden_size_m=64,
+ hidden_size_o=128,
+ heads=8,
+ act='relu',
+ name="GaAN"):
+ self.num_class = num_class
+ self.num_layers = num_layers
+ self.hidden_size_a = hidden_size_a
+ self.hidden_size_v = hidden_size_v
+ self.hidden_size_m = hidden_size_m
+ self.hidden_size_o = hidden_size_o
+ self.act = act
+ self.name = name
+ self.heads = heads
+
+ def GaANConv(self, gw, feature, name):
+ feat_key = fluid.layers.fc(
+ feature,
+ self.hidden_size_a * self.heads,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_key'))
+ # N * (D2 * M)
+ feat_value = fluid.layers.fc(
+ feature,
+ self.hidden_size_v * self.heads,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_value'))
+ # N * (D1 * M)
+ feat_query = fluid.layers.fc(
+ feature,
+ self.hidden_size_a * self.heads,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_query'))
+ # N * Dm
+ feat_gate = fluid.layers.fc(
+ feature,
+ self.hidden_size_m,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_gate'))
+
+ # send
+ message = gw.send(
+ self.send_func,
+ nfeat_list=[('node_feat', feature), ('feat_key', feat_key),
+ ('feat_value', feat_value), ('feat_query', feat_query),
+ ('feat_gate', feat_gate)],
+ efeat_list=None, )
+
+ # recv
+ output = gw.recv(message, self.recv_func)
+ output = fluid.layers.fc(
+ output,
+ self.hidden_size_o,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_output'))
+ output = fluid.layers.leaky_relu(output, alpha=0.1)
+ output = fluid.layers.dropout(output, dropout_prob=0.1)
+ return output
+
+ def forward(self, gw, feature, drop_rate):
+ for i in range(self.num_layers):
+ feature = self.GaANConv(gw, feature, self.name + '_' + str(i))
+ feature = fluid.layers.dropout(feature, dropout_prob=drop_rate)
+ return feature
+
+ def send_func(self, src_feat, dst_feat, edge_feat):
+ # E * (M * D1)
+ feat_query, feat_key = dst_feat['feat_query'], src_feat['feat_key']
+ # E * M * D1
+ old = feat_query
+ feat_query = fluid.layers.reshape(
+ feat_query, [-1, self.heads, self.hidden_size_a])
+ feat_key = fluid.layers.reshape(feat_key,
+ [-1, self.heads, self.hidden_size_a])
+ # E * M
+ alpha = fluid.layers.reduce_sum(feat_key * feat_query, dim=-1)
+
+ return {
+ 'dst_node_feat': dst_feat['node_feat'],
+ 'src_node_feat': src_feat['node_feat'],
+ 'feat_value': src_feat['feat_value'],
+ 'alpha': alpha,
+ 'feat_gate': src_feat['feat_gate']
+ }
+
+ def recv_func(self, message):
+ dst_feat = message['dst_node_feat']
+ src_feat = message['src_node_feat']
+ x = fluid.layers.sequence_pool(dst_feat, 'average')
+ z = fluid.layers.sequence_pool(src_feat, 'average')
+
+ feat_gate = message['feat_gate']
+ g_max = fluid.layers.sequence_pool(feat_gate, 'max')
+
+ g = fluid.layers.concat([x, g_max, z], axis=1)
+ g = fluid.layers.fc(g, self.heads, bias_attr=False, act="sigmoid")
+
+ # softmax
+ alpha = message['alpha']
+ alpha = paddle_helper.sequence_softmax(alpha) # E * M
+
+ feat_value = message['feat_value'] # E * (M * D2)
+ old = feat_value
+ feat_value = fluid.layers.reshape(
+ feat_value, [-1, self.heads, self.hidden_size_v]) # E * M * D2
+ feat_value = fluid.layers.elementwise_mul(feat_value, alpha, axis=0)
+ feat_value = fluid.layers.reshape(
+ feat_value, [-1, self.heads * self.hidden_size_v]) # E * (M * D2)
+ feat_value = fluid.layers.lod_reset(feat_value, old)
+
+ feat_value = fluid.layers.sequence_pool(feat_value,
+ 'sum') # N * (M * D2)
+ feat_value = fluid.layers.reshape(
+ feat_value, [-1, self.heads, self.hidden_size_v]) # N * M * D2
+ output = fluid.layers.elementwise_mul(feat_value, g, axis=0)
+ output = fluid.layers.reshape(
+ output, [-1, self.heads * self.hidden_size_v]) # N * (M * D2)
+ output = fluid.layers.concat([x, output], axis=1)
+
+ return output
+
+
+class GraphSageModel(object):
+ def __init__(self,
+ num_class,
+ num_layers,
+ hidden_size,
+ act='relu',
+ name="GraphSage"):
+ self.num_class = num_class
+ self.num_layers = num_layers
+ self.hidden_size = hidden_size
+ self.act = act
+ self.name = name
+
+ def GraphSageConv(self, gw, feature, name):
+ message = gw.send(
+ self.send_func,
+ nfeat_list=[('node_feat', feature)],
+ efeat_list=None, )
+ neighbor_feat = gw.recv(message, self.recv_func)
+ neighbor_feat = fluid.layers.fc(neighbor_feat,
+ self.hidden_size,
+ act=self.act,
+ name=name + '_n')
+ self_feature = fluid.layers.fc(feature,
+ self.hidden_size,
+ act=self.act,
+ name=name + '_s')
+ output = self_feature + neighbor_feat
+ output = fluid.layers.l2_normalize(output, axis=1)
+
+ return output
+
+ def SageConv(self, gw, feature, name, hidden_size, act):
+ message = gw.send(
+ self.send_func,
+ nfeat_list=[('node_feat', feature)],
+ efeat_list=None, )
+ neighbor_feat = gw.recv(message, self.recv_func)
+ neighbor_feat = fluid.layers.fc(neighbor_feat,
+ hidden_size,
+ act=None,
+ name=name + '_n')
+ self_feature = fluid.layers.fc(feature,
+ hidden_size,
+ act=None,
+ name=name + '_s')
+ output = self_feature + neighbor_feat
+ # output = fluid.layers.concat([self_feature, neighbor_feat], axis=1)
+ output = fluid.layers.l2_normalize(output, axis=1)
+ if act is not None:
+ ouput = L.relu(output)
+ return output
+
+ def bn_drop(self, feat, drop_rate):
+ #feat = L.batch_norm(feat)
+ feat = L.dropout(feat, dropout_prob=drop_rate)
+ return feat
+
+ def forward(self, gw, feature, drop_rate):
+ for i in range(self.num_layers):
+ final = (i == (self.num_layers - 1))
+ feature = self.SageConv(gw, feature, self.name + '_' + str(i),
+ self.hidden_size, None
+ if final else self.act)
+ if not final:
+ feature = self.bn_drop(feature, drop_rate)
+ return feature
+
+ def send_func(self, src_feat, dst_feat, edge_feat):
+ return src_feat["node_feat"]
+
+ def recv_func(self, feat):
+ return fluid.layers.sequence_pool(feat, pool_type="average")
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/monitor/__init__.py b/ogb_examples/nodeproppred/ogbn-arxiv/monitor/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d814437561c253c97a95e31187e63a554476364f
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/monitor/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""init"""
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/monitor/train_monitor.py b/ogb_examples/nodeproppred/ogbn-arxiv/monitor/train_monitor.py
new file mode 100644
index 0000000000000000000000000000000000000000..b73cfd061863167ac9d0d1cffcecba9f78797424
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/monitor/train_monitor.py
@@ -0,0 +1,213 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""train and evaluate"""
+import tqdm
+import json
+import numpy as np
+import sys
+import os
+import paddle.fluid as F
+from tensorboardX import SummaryWriter
+from ogb.nodeproppred import Evaluator
+from ogb.nodeproppred import NodePropPredDataset
+
+
+def multi_device(reader, dev_count):
+ """multi device"""
+ if dev_count == 1:
+ for batch in reader:
+ yield batch
+ else:
+ batches = []
+ for batch in reader:
+ batches.append(batch)
+ if len(batches) == dev_count:
+ yield batches
+ batches = []
+
+
+class OgbEvaluator(object):
+ def __init__(self):
+ d_name = "ogbn-arxiv"
+ dataset = NodePropPredDataset(name=d_name)
+ graph, label = dataset[0]
+ self.num_nodes = graph["num_nodes"]
+ self.ogb_evaluator = Evaluator(name="ogbn-arxiv")
+
+ def eval(self, scores, labels, phase):
+ pred = (np.argmax(scores, axis=1)).reshape([-1, 1])
+ ret = {}
+ ret['%s_acc' % (phase)] = self.ogb_evaluator.eval({
+ 'y_true': labels,
+ 'y_pred': pred,
+ })['acc']
+ return ret
+
+
+def evaluate(model, valid_exe, valid_ds, valid_prog, dev_count, evaluator,
+ phase, full_batch):
+ """evaluate """
+ cc = 0
+ scores = []
+ labels = []
+ if full_batch:
+ valid_iter = _full_batch_wapper(valid_ds)
+ else:
+ valid_iter = valid_ds.generator
+
+ for feed_dict in tqdm.tqdm(
+ multi_device(valid_iter(), dev_count), desc='evaluating'):
+ if dev_count > 1:
+ output = valid_exe.run(feed=feed_dict,
+ fetch_list=[model.logits, model.labels])
+ else:
+ output = valid_exe.run(valid_prog,
+ feed=feed_dict,
+ fetch_list=[model.logits, model.labels])
+ scores.append(output[0])
+ labels.append(output[1])
+
+ scores = np.vstack(scores)
+ labels = np.vstack(labels)
+ ret = evaluator.eval(scores, labels, phase)
+ return ret
+
+
+def _create_if_not_exist(path):
+ basedir = os.path.dirname(path)
+ if not os.path.exists(basedir):
+ os.makedirs(basedir)
+
+
+def _full_batch_wapper(ds):
+ feed_dict = {}
+ feed_dict["batch_nodes"] = np.array(ds.nodes_idx, dtype="int64")
+ feed_dict["labels"] = np.array(ds.labels, dtype="int64")
+
+ def r():
+ yield feed_dict
+
+ return r
+
+
+def train_and_evaluate(exe,
+ train_exe,
+ valid_exe,
+ train_ds,
+ valid_ds,
+ test_ds,
+ train_prog,
+ valid_prog,
+ full_batch,
+ model,
+ metric,
+ epoch=20,
+ dev_count=1,
+ train_log_step=5,
+ eval_step=10000,
+ evaluator=None,
+ output_path=None):
+ """train and evaluate"""
+
+ global_step = 0
+
+ log_path = os.path.join(output_path, "log")
+ _create_if_not_exist(log_path)
+
+ writer = SummaryWriter(log_path)
+
+ best_model = 0
+
+ if full_batch:
+ train_iter = _full_batch_wapper(train_ds)
+ else:
+ train_iter = train_ds.generator
+
+ for e in range(epoch):
+ ret_sum_loss = 0
+ per_step = 0
+ scores = []
+ labels = []
+ for feed_dict in tqdm.tqdm(
+ multi_device(train_iter(), dev_count), desc='Epoch %s' % e):
+ if dev_count > 1:
+ ret = train_exe.run(feed=feed_dict, fetch_list=metric.vars)
+ ret = [[np.mean(v)] for v in ret]
+ else:
+ ret = train_exe.run(
+ train_prog,
+ feed=feed_dict,
+ fetch_list=[model.loss, model.logits, model.labels]
+ #fetch_list=metric.vars
+ )
+ scores.append(ret[1])
+ labels.append(ret[2])
+ ret = [ret[0]]
+
+ ret = metric.parse(ret)
+ if global_step % train_log_step == 0:
+ for key, value in ret.items():
+ writer.add_scalar(
+ 'train_' + key, value, global_step=global_step)
+ ret_sum_loss += ret['loss']
+ per_step += 1
+ global_step += 1
+ if global_step % eval_step == 0:
+ eval_ret = evaluate(model, exe, valid_ds, valid_prog, 1,
+ evaluator, "valid", full_batch)
+ test_eval_ret = evaluate(model, exe, test_ds, valid_prog, 1,
+ evaluator, "test", full_batch)
+ eval_ret.update(test_eval_ret)
+ sys.stderr.write(json.dumps(eval_ret, indent=4) + "\n")
+ for key, value in eval_ret.items():
+ writer.add_scalar(key, value, global_step=global_step)
+ if eval_ret["valid_acc"] > best_model:
+ F.io.save_persistables(
+ exe,
+ os.path.join(output_path, "checkpoint"), train_prog)
+ eval_ret["epoch"] = e
+ #eval_ret["step"] = global_step
+ with open(os.path.join(output_path, "best.txt"), "w") as f:
+ f.write(json.dumps(eval_ret, indent=2) + '\n')
+ best_model = eval_ret["valid_acc"]
+ scores = np.vstack(scores)
+ labels = np.vstack(labels)
+
+ ret = evaluator.eval(scores, labels, "train")
+ sys.stderr.write(json.dumps(ret, indent=4) + "\n")
+ #print(json.dumps(ret, indent=4) + "\n")
+ # Epoch End
+ sys.stderr.write("epoch:{}, average loss {}\n".format(e, ret_sum_loss /
+ per_step))
+ eval_ret = evaluate(model, exe, valid_ds, valid_prog, 1, evaluator,
+ "valid", full_batch)
+ test_eval_ret = evaluate(model, exe, test_ds, valid_prog, 1, evaluator,
+ "test", full_batch)
+ eval_ret.update(test_eval_ret)
+ sys.stderr.write(json.dumps(eval_ret, indent=4) + "\n")
+
+ for key, value in eval_ret.items():
+ writer.add_scalar(key, value, global_step=global_step)
+
+ if eval_ret["valid_acc"] > best_model:
+ F.io.save_persistables(exe,
+ os.path.join(output_path, "checkpoint"),
+ train_prog)
+ #eval_ret["step"] = global_step
+ eval_ret["epoch"] = e
+ with open(os.path.join(output_path, "best.txt"), "w") as f:
+ f.write(json.dumps(eval_ret, indent=2) + '\n')
+ best_model = eval_ret["valid_acc"]
+
+ writer.close()
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/run.sh b/ogb_examples/nodeproppred/ogbn-arxiv/run.sh
new file mode 100644
index 0000000000000000000000000000000000000000..70599681ba252b72a2ce6c1fc178e55bbee6fa69
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/run.sh
@@ -0,0 +1,20 @@
+device=0
+model='gaan'
+lr=0.001
+drop=0.5
+
+CUDA_VISIBLE_DEVICES=${device} \
+ python -u train.py \
+ --use_cuda 1 \
+ --num_workers 4 \
+ --output_path ./output/model \
+ --batch_size 1024 \
+ --test_batch_size 512 \
+ --epoch 100 \
+ --learning_rate ${lr} \
+ --full_batch 0 \
+ --model ${model} \
+ --drop_rate ${drop} \
+ --samples 8 8 8 \
+ --test_samples 20 20 20 \
+ --hidden_size 256
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/train.py b/ogb_examples/nodeproppred/ogbn-arxiv/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..99ba18cdca2b7791aeab74a75692326f3bdabaac
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/train.py
@@ -0,0 +1,191 @@
+# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""listwise model
+"""
+
+import torch
+import os
+import re
+import time
+import logging
+from random import random
+from functools import reduce, partial
+
+# For downloading ogb
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+# SSL
+
+import numpy as np
+import multiprocessing
+
+import pgl
+import paddle
+import paddle.fluid as F
+import paddle.fluid.layers as L
+
+from args import parser
+from utils.args import print_arguments, check_cuda
+from utils.init import init_checkpoint, init_pretraining_params
+from utils.to_undirected import to_undirected
+from model import BaseGraph, MLPModel, SAGEModel, GAANModel, GATModel, GCNModel, GINModel
+from dataloader.ogbn_arxiv_dataloader import ArxivDataGenerator
+from monitor.train_monitor import train_and_evaluate, OgbEvaluator
+from pgl.contrib.ogb.nodeproppred.dataset_pgl import PglNodePropPredDataset
+
+log = logging.getLogger(__name__)
+
+
+class Metric(object):
+ """Metric"""
+
+ def __init__(self, **args):
+ self.args = args
+
+ @property
+ def vars(self):
+ """ fetch metric vars"""
+ values = [self.args[k] for k in self.args.keys()]
+ return values
+
+ def parse(self, fetch_list):
+ """parse"""
+ tup = list(zip(self.args.keys(), [float(v[0]) for v in fetch_list]))
+ return dict(tup)
+
+
+if __name__ == '__main__':
+ args = parser.parse_args()
+ print_arguments(args)
+ evaluator = OgbEvaluator()
+
+ train_prog = F.Program()
+ startup_prog = F.Program()
+ args.num_nodes = evaluator.num_nodes
+
+ if args.use_cuda:
+ dev_list = F.cuda_places()
+ place = dev_list[0]
+ dev_count = len(dev_list)
+ else:
+ place = F.CPUPlace()
+ dev_count = int(os.environ.get('CPU_NUM', multiprocessing.cpu_count()))
+ assert dev_count == 1, "The program not support multi devices now!"
+
+ dataset = PglNodePropPredDataset(name="ogbn-arxiv")
+ graph, label = dataset[0]
+ graph = to_undirected(graph)
+
+ if args.model is None:
+ Model = BaseGraph
+ elif args.model.upper() == "MLP":
+ Model = MLPModel
+ elif args.model.upper() == "SAGE":
+ Model = SAGEModel
+ elif args.model.upper() == "GAT":
+ Model = GATModel
+ elif args.model.upper() == "GCN":
+ Model = GCNModel
+ elif args.model.upper() == "GAAN":
+ Model = GAANModel
+ elif args.model.upper() == "GIN":
+ Model = GINModel
+ else:
+ raise ValueError("Not support {} model!".format(args.model))
+
+ with F.program_guard(train_prog, startup_prog):
+ with F.unique_name.guard():
+ if args.full_batch:
+ gw = pgl.graph_wrapper.StaticGraphWrapper(
+ name="graph", graph=graph, place=place)
+ else:
+ gw = pgl.graph_wrapper.GraphWrapper(
+ name="graph",
+ node_feat=graph.node_feat_info(),
+ edge_feat=graph.edge_feat_info())
+ log.info(gw.node_feat.keys())
+ graph_model = Model(args, gw)
+ test_prog = train_prog.clone(for_test=True)
+ opt = F.optimizer.Adam(learning_rate=args.learning_rate)
+ opt.minimize(graph_model.loss)
+
+ train_ds = ArxivDataGenerator(
+ phase="train",
+ graph_wrapper=graph_model.graph_wrapper,
+ num_workers=args.num_workers,
+ batch_size=args.batch_size,
+ samples=args.samples)
+
+ valid_ds = ArxivDataGenerator(
+ phase="valid",
+ graph_wrapper=graph_model.graph_wrapper,
+ num_workers=args.num_workers,
+ batch_size=args.test_batch_size,
+ samples=args.test_samples)
+
+ test_ds = ArxivDataGenerator(
+ phase="test",
+ graph_wrapper=graph_model.graph_wrapper,
+ num_workers=args.num_workers,
+ batch_size=args.test_batch_size,
+ samples=args.test_samples)
+
+ exe = F.Executor(place)
+ exe.run(startup_prog)
+ if args.full_batch:
+ gw.initialize(place)
+
+ if args.init_pretraining_params is not None:
+ init_pretraining_params(
+ exe, args.init_pretraining_params, main_program=startup_prog)
+
+ metric = Metric(**graph_model.metrics)
+
+ nccl2_num_trainers = 1
+ nccl2_trainer_id = 0
+ if dev_count > 1:
+
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = dev_count
+
+ train_exe = F.ParallelExecutor(
+ use_cuda=args.use_cuda,
+ loss_name=graph_model.loss.name,
+ exec_strategy=exec_strategy,
+ main_program=train_prog,
+ num_trainers=nccl2_num_trainers,
+ trainer_id=nccl2_trainer_id)
+
+ test_exe = exe
+ else:
+ train_exe, test_exe = exe, exe
+
+ train_and_evaluate(
+ exe=exe,
+ train_exe=train_exe,
+ valid_exe=test_exe,
+ train_ds=train_ds,
+ valid_ds=valid_ds,
+ test_ds=test_ds,
+ train_prog=train_prog,
+ valid_prog=test_prog,
+ full_batch=args.full_batch,
+ train_log_step=5,
+ output_path=args.output_path,
+ dev_count=dev_count,
+ model=graph_model,
+ epoch=args.epoch,
+ eval_step=1000000,
+ evaluator=evaluator,
+ metric=metric)
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/utils/__init__.py b/ogb_examples/nodeproppred/ogbn-arxiv/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1333621cf62da67fcf10016fc848c503f7c254fa
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/utils/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""utils"""
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/utils/args.py b/ogb_examples/nodeproppred/ogbn-arxiv/utils/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..5131f2ceb88775f12e886402ef205735a1ac1d77
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/utils/args.py
@@ -0,0 +1,97 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Arguments for configuration."""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import six
+import os
+import sys
+import argparse
+import logging
+
+import paddle.fluid as fluid
+
+log = logging.getLogger(__name__)
+
+
+def prepare_logger(logger, debug=False, save_to_file=None):
+ """doc"""
+ formatter = logging.Formatter(
+ fmt='[%(levelname)s] %(asctime)s [%(filename)12s:%(lineno)5d]:\t%(message)s'
+ )
+ #console_hdl = logging.StreamHandler()
+ #console_hdl.setFormatter(formatter)
+ #logger.addHandler(console_hdl)
+ if save_to_file is not None and not os.path.exists(save_to_file):
+ file_hdl = logging.FileHandler(save_to_file)
+ file_hdl.setFormatter(formatter)
+ logger.addHandler(file_hdl)
+ logger.setLevel(logging.DEBUG)
+ logger.propagate = False
+
+
+def str2bool(v):
+ """doc"""
+ # because argparse does not support to parse "true, False" as python
+ # boolean directly
+ return v.lower() in ("true", "t", "1")
+
+
+class ArgumentGroup(object):
+ """doc"""
+
+ def __init__(self, parser, title, des):
+ self._group = parser.add_argument_group(title=title, description=des)
+
+ def add_arg(self,
+ name,
+ type,
+ default,
+ help,
+ positional_arg=False,
+ **kwargs):
+ """doc"""
+ prefix = "" if positional_arg else "--"
+ type = str2bool if type == bool else type
+ self._group.add_argument(
+ prefix + name,
+ default=default,
+ type=type,
+ help=help + ' Default: %(default)s.',
+ **kwargs)
+
+
+def print_arguments(args):
+ """doc"""
+ log.info('----------- Configuration Arguments -----------')
+ for arg, value in sorted(six.iteritems(vars(args))):
+ log.info('%s: %s' % (arg, value))
+ log.info('------------------------------------------------')
+
+
+def check_cuda(use_cuda, err= \
+ "\nYou can not set use_cuda=True in the model because you are using paddlepaddle-cpu.\n \
+ Please: 1. Install paddlepaddle-gpu to run your models on GPU or 2. Set use_cuda=False to run models on CPU.\n"
+ ):
+ """doc"""
+ try:
+ if use_cuda == True and fluid.is_compiled_with_cuda() == False:
+ log.error(err)
+ sys.exit(1)
+ except Exception as e:
+ pass
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/utils/init.py b/ogb_examples/nodeproppred/ogbn-arxiv/utils/init.py
new file mode 100644
index 0000000000000000000000000000000000000000..baa3ba5987cf1cbae20a60ea88e3f3bf0e389f43
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/utils/init.py
@@ -0,0 +1,97 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""paddle init"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import six
+import ast
+import copy
+import logging
+
+import numpy as np
+import paddle.fluid as fluid
+
+log = logging.getLogger(__name__)
+
+
+def cast_fp32_to_fp16(exe, main_program):
+ """doc"""
+ log.info("Cast parameters to float16 data format.")
+ for param in main_program.global_block().all_parameters():
+ if not param.name.endswith(".master"):
+ param_t = fluid.global_scope().find_var(param.name).get_tensor()
+ data = np.array(param_t)
+ if param.name.startswith("encoder_layer") \
+ and "layer_norm" not in param.name:
+ param_t.set(np.float16(data).view(np.uint16), exe.place)
+
+ #load fp32
+ master_param_var = fluid.global_scope().find_var(param.name +
+ ".master")
+ if master_param_var is not None:
+ master_param_var.get_tensor().set(data, exe.place)
+
+
+def init_checkpoint(exe, init_checkpoint_path, main_program, use_fp16=False):
+ """init"""
+ assert os.path.exists(
+ init_checkpoint_path), "[%s] cann't be found." % init_checkpoint_path
+
+ def existed_persitables(var):
+ """existed"""
+ if not fluid.io.is_persistable(var):
+ return False
+ return os.path.exists(os.path.join(init_checkpoint_path, var.name))
+
+ fluid.io.load_vars(
+ exe,
+ init_checkpoint_path,
+ main_program=main_program,
+ predicate=existed_persitables)
+ log.info("Load model from {}".format(init_checkpoint_path))
+
+ if use_fp16:
+ cast_fp32_to_fp16(exe, main_program)
+
+
+def init_pretraining_params(exe,
+ pretraining_params_path,
+ main_program,
+ use_fp16=False):
+ """init"""
+ assert os.path.exists(pretraining_params_path
+ ), "[%s] cann't be found." % pretraining_params_path
+
+ def existed_params(var):
+ """doc"""
+ if not isinstance(var, fluid.framework.Parameter):
+ return False
+ return os.path.exists(os.path.join(pretraining_params_path, var.name))
+
+ fluid.io.load_vars(
+ exe,
+ pretraining_params_path,
+ main_program=main_program,
+ predicate=existed_params)
+ log.info("Load pretraining parameters from {}.".format(
+ pretraining_params_path))
+
+ if use_fp16:
+ cast_fp32_to_fp16(exe, main_program)
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/utils/to_undirected.py b/ogb_examples/nodeproppred/ogbn-arxiv/utils/to_undirected.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a9715d5b37dcb6495012dde17e13446d4af26b8
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/utils/to_undirected.py
@@ -0,0 +1,33 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Arguments for configuration."""
+from __future__ import absolute_import
+from __future__ import unicode_literals
+
+import paddle.fluid as fluid
+import pgl
+import numpy as np
+
+
+def to_undirected(graph):
+ inv_edges = np.zeros(graph.edges.shape)
+ inv_edges[:, 0] = graph.edges[:, 1]
+ inv_edges[:, 1] = graph.edges[:, 0]
+ edges = np.vstack((graph.edges, inv_edges))
+ g = pgl.graph.Graph(num_nodes=graph.num_nodes, edges=edges)
+ for k, v in graph._edge_feat.items():
+ g._edge_feat[k] = np.vstack((v, v))
+ for k, v in graph._node_feat.items():
+ g._node_feat[k] = v
+ return g
diff --git a/pgl/__init__.py b/pgl/__init__.py
index 535632ea7afb3a157a4d92bbb08cb6445b21a125..93375e9ec5c7913334b02a05f6681de3f1ee4069 100644
--- a/pgl/__init__.py
+++ b/pgl/__init__.py
@@ -13,7 +13,7 @@
# limitations under the License.
"""Generate pgl apis
"""
-__version__ = "1.0.2"
+__version__ = "1.1.0"
from pgl import layers
from pgl import graph_wrapper
from pgl import graph
diff --git a/pgl/graph.py b/pgl/graph.py
index 30a147566821f3a2b76e2ae5976cfce5b0782e0c..85ec4060fe726333b62bc2c38c3966397ddcd9c4 100644
--- a/pgl/graph.py
+++ b/pgl/graph.py
@@ -593,7 +593,7 @@ class Graph(object):
edges = self._edges[eid]
else:
edges = np.array(edges, dtype="int64")
-
+
sub_edges = graph_kernel.map_edges(
np.arange(
len(edges), dtype="int64"), edges, reindex)
diff --git a/pgl/graph_wrapper.py b/pgl/graph_wrapper.py
index 3f30da477a5e97287315efc4e693eaa022399d84..91dda8f78796aedd493b37e85a92ad9ecb1c6664 100644
--- a/pgl/graph_wrapper.py
+++ b/pgl/graph_wrapper.py
@@ -40,7 +40,6 @@ def recv(dst, uniq_dst, bucketing_index, msg, reduce_function, num_nodes,
num_edges):
"""Recv message from given msg to dst nodes.
"""
- empty_msg_flag = fluid.layers.cast(num_edges > 0, dtype="float32")
if reduce_function == "sum":
if isinstance(msg, dict):
raise TypeError("The message for build-in function"
@@ -49,8 +48,9 @@ def recv(dst, uniq_dst, bucketing_index, msg, reduce_function, num_nodes,
try:
out_dim = msg.shape[-1]
init_output = fluid.layers.fill_constant(
- shape=[num_nodes, out_dim], value=0, dtype="float32")
+ shape=[num_nodes, out_dim], value=0, dtype=msg.dtype)
init_output.stop_gradient = False
+ empty_msg_flag = fluid.layers.cast(num_edges > 0, dtype=msg.dtype)
msg = msg * empty_msg_flag
output = paddle_helper.scatter_add(init_output, dst, msg)
return output
@@ -66,10 +66,12 @@ def recv(dst, uniq_dst, bucketing_index, msg, reduce_function, num_nodes,
bucketed_msg = op.nested_lod_reset(msg, bucketing_index)
output = reduce_function(bucketed_msg)
output_dim = output.shape[-1]
+
+ empty_msg_flag = fluid.layers.cast(num_edges > 0, dtype=output.dtype)
output = output * empty_msg_flag
init_output = fluid.layers.fill_constant(
- shape=[num_nodes, output_dim], value=0, dtype="float32")
+ shape=[num_nodes, output_dim], value=0, dtype=output.dtype)
init_output.stop_gradient = True
final_output = fluid.layers.scatter(init_output, uniq_dst, output)
return final_output
@@ -475,9 +477,6 @@ class GraphWrapper(BaseGraphWrapper):
Args:
name: The graph data prefix
- place: fluid.CPUPlace or fluid.CUDAPlace(n) indicating the
- device to hold the graph data.
-
node_feat: A list of tuples that decribe the details of node
feature tenosr. Each tuple mush be (name, shape, dtype)
and the first dimension of the shape must be set unknown
@@ -516,7 +515,6 @@ class GraphWrapper(BaseGraphWrapper):
})
graph_wrapper = GraphWrapper(name="graph",
- place=place,
node_feat=graph.node_feat_info(),
edge_feat=graph.edge_feat_info())
@@ -531,12 +529,11 @@ class GraphWrapper(BaseGraphWrapper):
ret = exe.run(fetch_list=[...], feed=feed_dict )
"""
- def __init__(self, name, place, node_feat=[], edge_feat=[]):
+ def __init__(self, name, node_feat=[], edge_feat=[], **kwargs):
super(GraphWrapper, self).__init__()
# collect holders for PyReader
self._data_name_prefix = name
self._holder_list = []
- self._place = place
self.__create_graph_attr_holders()
for node_feat_name, node_feat_shape, node_feat_dtype in node_feat:
self.__create_graph_node_feat_holders(
diff --git a/pgl/heter_graph_wrapper.py b/pgl/heter_graph_wrapper.py
index a56bc4e3151b1ab0a136e939e4b736cb8bc32742..bd786c7f459cae6a191a913904202a50e86b3e04 100644
--- a/pgl/heter_graph_wrapper.py
+++ b/pgl/heter_graph_wrapper.py
@@ -44,9 +44,6 @@ class HeterGraphWrapper(object):
Args:
name: The heterogeneous graph data prefix
- place: fluid.CPUPlace or fluid.CUDAPlace(n) indicating the
- device to hold the graph data.
-
node_feat: A dict of list of tuples that decribe the details of node
feature tenosr. Each tuple mush be (name, shape, dtype)
and the first dimension of the shape must be set unknown
@@ -85,19 +82,15 @@ class HeterGraphWrapper(object):
node_feat=node_feat,
edge_feat=edges_feat)
- place = fluid.CPUPlace()
-
gw = heter_graph_wrapper.HeterGraphWrapper(
name='heter_graph',
- place = place,
edge_types = g.edge_types_info(),
node_feat=g.node_feat_info(),
edge_feat=g.edge_feat_info())
"""
- def __init__(self, name, place, edge_types, node_feat={}, edge_feat={}):
+ def __init__(self, name, edge_types, node_feat={}, edge_feat={}, **kwargs):
self.__data_name_prefix = name
- self._place = place
self._edge_types = edge_types
self._multi_gw = {}
for edge_type in self._edge_types:
@@ -114,7 +107,6 @@ class HeterGraphWrapper(object):
self._multi_gw[edge_type] = GraphWrapper(
name=type_name,
- place=self._place,
node_feat=n_feat,
edge_feat=e_feat)
diff --git a/pgl/layers/conv.py b/pgl/layers/conv.py
index bbb364ab64a89f8ee3ee002cd8a9294a1710f804..68a1d733ed1d297e7a20daa1fb7c14828ff8722b 100644
--- a/pgl/layers/conv.py
+++ b/pgl/layers/conv.py
@@ -18,7 +18,7 @@ import paddle.fluid as fluid
from pgl import graph_wrapper
from pgl.utils import paddle_helper
-__all__ = ['gcn', 'gat', 'gin']
+__all__ = ['gcn', 'gat', 'gin', 'gaan']
def gcn(gw, feature, hidden_size, activation, name, norm=None):
@@ -238,8 +238,18 @@ def gin(gw,
param_attr=fluid.ParamAttr(name="%s_w_0" % name),
bias_attr=fluid.ParamAttr(name="%s_b_0" % name))
- output = fluid.layers.batch_norm(output)
- output = getattr(fluid.layers, activation)(output)
+ output = fluid.layers.layer_norm(
+ output,
+ begin_norm_axis=1,
+ param_attr=fluid.ParamAttr(
+ name="norm_scale_%s" % (name),
+ initializer=fluid.initializer.Constant(1.0)),
+ bias_attr=fluid.ParamAttr(
+ name="norm_bias_%s" % (name),
+ initializer=fluid.initializer.Constant(0.0)), )
+
+ if activation is not None:
+ output = getattr(fluid.layers, activation)(output)
output = fluid.layers.fc(output,
size=hidden_size,
@@ -248,3 +258,97 @@ def gin(gw,
bias_attr=fluid.ParamAttr(name="%s_b_1" % name))
return output
+
+
+def gaan(gw, feature, hidden_size_a, hidden_size_v, hidden_size_m, hidden_size_o, heads, name):
+ """Implementation of GaAN"""
+
+ def send_func(src_feat, dst_feat, edge_feat):
+ # 计算每条边上的注意力分数
+ # E * (M * D1), 每个 dst 点都查询它的全部邻边的 src 点
+ feat_query, feat_key = dst_feat['feat_query'], src_feat['feat_key']
+ # E * M * D1
+ old = feat_query
+ feat_query = fluid.layers.reshape(feat_query, [-1, heads, hidden_size_a])
+ feat_key = fluid.layers.reshape(feat_key, [-1, heads, hidden_size_a])
+ # E * M
+ alpha = fluid.layers.reduce_sum(feat_key * feat_query, dim=-1)
+
+ return {'dst_node_feat': dst_feat['node_feat'],
+ 'src_node_feat': src_feat['node_feat'],
+ 'feat_value': src_feat['feat_value'],
+ 'alpha': alpha,
+ 'feat_gate': src_feat['feat_gate']}
+
+ def recv_func(message):
+ # 每条边的终点的特征
+ dst_feat = message['dst_node_feat']
+ # 每条边的出发点的特征
+ src_feat = message['src_node_feat']
+ # 每个中心点自己的特征
+ x = fluid.layers.sequence_pool(dst_feat, 'average')
+ # 每个中心点的邻居的特征的平均值
+ z = fluid.layers.sequence_pool(src_feat, 'average')
+
+ # 计算 gate
+ feat_gate = message['feat_gate']
+ g_max = fluid.layers.sequence_pool(feat_gate, 'max')
+ g = fluid.layers.concat([x, g_max, z], axis=1)
+ g = fluid.layers.fc(g, heads, bias_attr=False, act="sigmoid")
+
+ # softmax
+ alpha = message['alpha']
+ alpha = paddle_helper.sequence_softmax(alpha) # E * M
+
+ feat_value = message['feat_value'] # E * (M * D2)
+ old = feat_value
+ feat_value = fluid.layers.reshape(feat_value, [-1, heads, hidden_size_v]) # E * M * D2
+ feat_value = fluid.layers.elementwise_mul(feat_value, alpha, axis=0)
+ feat_value = fluid.layers.reshape(feat_value, [-1, heads*hidden_size_v]) # E * (M * D2)
+ feat_value = fluid.layers.lod_reset(feat_value, old)
+
+ feat_value = fluid.layers.sequence_pool(feat_value, 'sum') # N * (M * D2)
+
+ feat_value = fluid.layers.reshape(feat_value, [-1, heads, hidden_size_v]) # N * M * D2
+
+ output = fluid.layers.elementwise_mul(feat_value, g, axis=0)
+ output = fluid.layers.reshape(output, [-1, heads * hidden_size_v]) # N * (M * D2)
+
+ output = fluid.layers.concat([x, output], axis=1)
+
+ return output
+
+ # feature N * D
+
+ # 计算每个点自己需要发送出去的内容
+ # 投影后的特征向量
+ # N * (D1 * M)
+ feat_key = fluid.layers.fc(feature, hidden_size_a * heads, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_key'))
+ # N * (D2 * M)
+ feat_value = fluid.layers.fc(feature, hidden_size_v * heads, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_value'))
+ # N * (D1 * M)
+ feat_query = fluid.layers.fc(feature, hidden_size_a * heads, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_query'))
+ # N * Dm
+ feat_gate = fluid.layers.fc(feature, hidden_size_m, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_gate'))
+
+ # send 阶段
+
+ message = gw.send(
+ send_func,
+ nfeat_list=[('node_feat', feature), ('feat_key', feat_key), ('feat_value', feat_value),
+ ('feat_query', feat_query), ('feat_gate', feat_gate)],
+ efeat_list=None,
+ )
+
+ # 聚合邻居特征
+ output = gw.recv(message, recv_func)
+ output = fluid.layers.fc(output, hidden_size_o, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_output'))
+ output = fluid.layers.leaky_relu(output, alpha=0.1)
+ output = fluid.layers.dropout(output, dropout_prob=0.1)
+
+ return output
diff --git a/pgl/utils/log_writer.py b/pgl/utils/log_writer.py
new file mode 100644
index 0000000000000000000000000000000000000000..a4c718cc528f1f1978b7709d5b8a5a12ef9d4cb0
--- /dev/null
+++ b/pgl/utils/log_writer.py
@@ -0,0 +1,29 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Log writer setup: interface for training visualization.
+"""
+import six
+
+LogWriter = None
+
+if six.PY3:
+ # We highly recommend using VisualDL (https://github.com/PaddlePaddle/VisualDL)
+ # for training visualization in Python 3.
+ from visualdl import LogWriter
+ LogWriter = LogWriter
+elif six.PY2:
+ from tensorboardX import SummaryWriter
+ LogWriter = SummaryWriter
+else:
+ raise ValueError("Not running on Python2 or Python3 ?")
diff --git a/pgl/utils/mp_reader.py b/pgl/utils/mp_reader.py
index b7aec4d268e13d282c8420d80628f975e5472499..a7962830031c3aeede2b780104dacf936d62a120 100644
--- a/pgl/utils/mp_reader.py
+++ b/pgl/utils/mp_reader.py
@@ -25,7 +25,7 @@ except:
import numpy as np
import time
import paddle.fluid as fluid
-from queue import Queue
+from multiprocessing import Queue
import threading
diff --git a/requirements.txt b/requirements.txt
index 4a13b16b9df0af570752f5dac9857fa7e496d3db..acd3de6d9108ea1eb40b14d01951ad33ff1378e4 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -4,3 +4,5 @@ cython >= 0.25.2
#paddlepaddle
redis-py-cluster
+
+visualdl >= 2.0.0b ; python_version >= "3"
diff --git a/tutorials/1-Introduction.ipynb b/tutorials/1-Introduction.ipynb
index 9d849a015e855b072f634d15c8084e07520831af..7c2e4134381b5ceb8abb25f1bd3a54b0bde6a956 100644
--- a/tutorials/1-Introduction.ipynb
+++ b/tutorials/1-Introduction.ipynb
@@ -42,8 +42,8 @@
" d = 16\n",
" feature = np.random.randn(num_node, d).astype(\"float32\")\n",
" #feature = np.array(feature, dtype=\"float32\")\n",
- " # 对于边,也同样可以用一个特征向量表示。\n",
- " edge_feature = np.random.randn(len(edge_list), d).astype(\"float32\")\n",
+ " # 对于边,也同样可以用边的权重作为边特征\n",
+ " edge_feature = np.random.randn(len(edge_list), 1).astype(\"float32\")\n",
" \n",
" # 根据节点,边以及对应的特征向量,创建一个完整的图网络。\n",
" # 在PGL中,节点特征和边特征都是存储在一个dict中。\n",
@@ -99,7 +99,7 @@
"outputs": [
{
"data": {
- "image/png": "iVBORw0KGgoAAAANSUhEUgAAAcUAAAE1CAYAAACWU/udAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMi4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvIxREBQAAIABJREFUeJzs3Xd8zWf/x/HXOScnO6GEGiElxApBEkQitbporVaHlppVWru2Wylt1S5qtkRbe7WUalUQMxJbiMbeI4iMk7O/vz9Cfh1ozsnZuZ73I4/eJd/r+ijyznV9ryGTJElCEARBEATk9i5AEARBEByFCEVBEARBeEiEoiAIgiA8JEJREARBEB4SoSgIgiAID4lQFARBEISHRCgKgiAIwkMiFAVBEAThIRGKgiAIgvCQCEVBEARBeEiEoiAIgiA8JEJREARBEB4SoSgIgiAID4lQFARBEISHRCgKgiAIwkMiFAVBEAThITd7FyAIgmAvOoOOU3dOkXInhRxtDhISvu6+1CxVk1qlaqFUKO1domBjIhQFQShSMjWZLD26lPmH5pN2Nw1PN08ADJIBALlMjgwZar2aKiWq0Du8N+/XfZ/insXtWbZgIzJJkiR7FyEIgmBt93LvMWzbMJafWI5cJidHl1Og53yUPhgkA2/VeoupL04lwDvAypUK9iRCURAEl/dz6s90/bkrubpcNAaNWW24K9zxcvNicdvFdKjRwcIVCo5ChKIgCC7LYDTQ+5ferDi5ApVOZZE2vZXevF7jdZa0XYJCrrBIm4LjEKEoCIJLMkpG3lrzFlvObrFYID7irfTmhcovsO7NdSIYXYzYkiEIgkv6aPNHVglEAJVOxbbz2+i1qZfF2xbsS4SiIAgu5/dzv/P98e+tEoiPqHQqVqWsYkvaFqv1IdiemD4VBMGlZGoyCZ4VTLoq3Sb9lfAqwbn+58SWDRchRoqCILiUCQkTyNZm26y/HG0OY3eMtVl/gnWJkaIgCC5Do9dQakopsrRZNu3XR+nDnaF38FJ62bRfwfLESFEQBJex9tRaJGz/fb5MJmNVyiqb9ytYnghFQRBcxrdHvjVv6jQRWABMADaY/ni2NptFhxeZ/qDgcMTZp4IguIyjN4+a96AfEAucA3TmNXH81nEkSUImk5nXgOAQRCgKguASbmbfJFeXa97DNR/+8zpmh6LBaOBK5hUqFqtoXgMOTKPXcPjGYQ7dOETCpQQuZFxAo9fgrnCnnF85YoNiCS8bTkS5CPw8/OxdbqGIUBQEwSWkpqfi6eZp9tmmheWucCc1PdWlQvH8/fPMSpzFd0e+Qy6TozVoUevVf/ucQzcO8du53/B080Rr0NKxZkeGRA0hrEyYnaouHBGKgiC4BGtu1C8ICcnuNVhKhjqDvpv7siF1AwajAZ3x6cNnrUGL1qAFYPmJ5aw7vY4G5RrwQ4cfCPQPtEXJFiMW2giC4BJk2P9dnlzm/F9St57dSvCsYNafXo9ar/7PQPwng2RApVOx58oeasypwXdHvsOZdv45/++gIAgC4O/hb5ftGI/IkOHn7tzv074+8DWvr36de7n3Cj0NrTfqydZl0//X/ny85WOnCUYxfSoIgksILR1q/kIbA2AEpIcfOvKGDCZcgJGpymT+Z/M5HHqYOnXqEBYWRunSpc2rxw5mJc5iVPwoi08Bq3Qq4o7FYZSMzG091+FX54oTbQRBcBllp5blZs5N0x/cAez6x489DzQreBPFlcWZVmYax44d4/jx4xw7dgx3d3fq1KmT/xEWFkb16tXx8PAwvUYr+v3c77Rf1d6q70S9ld5MajmJfg36Wa0PSxChKAiCy2i/sj0/nfnJLn2/UuUVtrz7/zdmSJLE9evX80Py0ce5c+eoUqVKfkg+CsyyZcvaZRT1QP2A4FnB3M29a/W+vJXenOhzgsrPVLZ6X+YSoSgIgsv4/dzvvL76dZseCA7g5+7HitdX0Dqk9X9+rlqt5vTp0/mjyUf/lCTpbyFZp04datWqhaenp1Vr77KhC2tOrfnXVgtrUMgU1C9bn8SeiQ47jSpCURAEl2GUjAROD+RG9g2b9lvKuxQ3htxAITfhJeRfSJLErVu3/jWq/PPPP6lUqdK/pmADAwMtEioXMy5S45saNgnER3zdfdn49kaaVTJhbtqGxEIbQRBchlwm5/3g95l8eDJGhdEmfXorvRnaeKjZgQh5B4qXKVOGMmXK8NJLL+X/uFarJTU1NT8kZ8+ezfHjx1Gr1X8LyUejSh8fH5P6/SbpG4ySbf47PZKtzWbKvikOG4pipCgIgkvIyMhg3Lhx/Lj8R5T9lNwy3rL6Fg0ZMqqWrMrJPidRKpRW7euvbt++zYkTJ/42skxNTSUwMPBfU7DPPffcY0eVWoOWgMkB5l2ztQ64AGgBXyAaCC/4454KT84NOEc5v3Km921lYqQoCIJTMxqNLFmyhNGjR9OmTRtOp5zmDneIWBhBrt7MLRoF5OnmyZqOa2waiAClS5emRYsWtGjRIv/HdDodf/75Z35ILly4kGPHjpGVlUXt2rX/NrIMDQ3lTNYZ8wtoArQlL0HuAHFAWaCAGadUKNl1cRfv1H7H/BqsRIwUBUFwWomJifTr1w+FQsHs2bOJiIjI/7n5yfMZ/NtgqwWjt9KbSS0m0a+hY28xuHv3LidOnPjbwp5Tp07h3cSb+w3uY1AYCtdBOnmh+DIQWrBHZMj4uMHHzHplVuH6tgIRioIgOJ1bt24xYsQIfvvtNyZNmsR7772HXP7vA7om753M+F3jLb7/zlvpzciYkYyJHWPRdm3FYDDQ4YcObLy00fxGfgGOAnqgDNANMGH7Zb0y9Tjc+7D5/VuJOOZNEASnodPpmD59OrVq1SIgIIDU1FS6dOny2EAEGBY9jK9f/hovNy+LnEsql8nxcvNi6gtTnTYQARQKBXeNhdyX+CowirwwrIHJL+NsvUK4oMQ7RUEQnMK2bdsYMGAAFSpUYM+ePVSvXr1Az/Ws35Png57nrbVv8efdP8nR5ZjVv4/Sh+BnglndcTXVAqqZ1YYjscg2DDkQBBwHkoBGBX9UZzDz4korE6EoCIJDu3DhAkOGDOHo0aPMmDGDNm3amLxHr2rJqiT1SuL7Y9/zxZ4vuJF1g1x97n9uR5Ahw1vpzbM+zzIiZgTd63Uv1NYLR+KhsOBRc0bgvmmPuMkdM37E9KkgCA5JpVLx6aefEhERQf369Tl16hRt27Y1e9O6Qq6gW71u/Pnxn/zR5Q961OtBcLFgMORtKPf38Mffwx9fd1+UciXVSlajW71u/N75d872P0uv8F4uE4gAFYpVMO/BbOAEoCEvDM8CJ4FKpjVTyruUef1bmWNGtSAIRZYkSaxbt44hQ4bQqFEjjhw5QsWKlrvNXiaT0SiwEY0CG7F582ZmzprJN8u/IUebg4SEj9KHys9Utvk2C1uLqRjDxjMbTV+dKwOSyVtoIwHFyVt5WrDZ7HzRFaNNe8BGRCgKguAwUlJS6N+/P7dv3yYuLo5mzax76klKSgq1a9UmpGSIVftxROFlw1EqlKaHog95i2sKwdfdl8YVGheuESsR06eCINhdRkYGAwcOpGnTprRr144jR45YPRAhLxRr1apl9X4cUb2y9dAb9XbpW2/UExsUa5e+/4sIRUEQ7MZoNPLdd99RvXp1VCoVp06dol+/fri52WYSqyiHoqebJ13qdLHLgpfIcpE8V/w5m/dbEGLzviAIdpGYmMjHH3+Mm5vbv06jsQWj0Yi/vz/Xr1/H39/fpn07ijPpZ6i3oJ7Vj8P7K193X1a+vrJA12zZgxgpCoJgU7du3aJbt260b9+efv36sXfvXpsHIsDFixcpUaJEkQ1EgGoB1WheqTnucneb9CdDRnm/8rxc5WWb9GcOEYqCINiEqafRWFtRnjr9q8VtF+PpZt2LjB95dIC6I29tEatPBUGwum3bttG/f3+CgoJMOo3Gmk6ePClCEXDTuFHpZCVOBJ+w6h2Uj+6drP1sbav1YQlipCgIgtVcuHCBDh060Lt3byZNmsSvv/7qEIEIYqQIcOzYMSIjI2n+bHOGxAzBW+ltlX683bx5Kfglxj4/1irtW5IIRUEQLM7Sp9FYQ0pKCqGhBbzryAWtWLGCli1bMmHCBKZPn85XL3zFR5EfWTwYvZXevFTlJVa9scoih7Jbm1h9KgiCxfzzNJqpU6dSoYKZx4lZkcFgwM/Pj9u3b+Pr62vvcmxKr9czfPhwfvrpJ9avX09YWNjffj7uaBz9tvRDbVAXah+jDBmebp6MjBnJ6NjRThGIIN4pCoJgIX89jWbp0qU0bdrU3iU90fnz53n22WeLXCDeuXOHt956C3d3d5KSkihRosS/Pqdr3a60rNySd9e/y6Hrhwp0cPo/+bn7EegfyOqOqwkt7VyjceeIbkEQHNbjTqNx5ECEovk+MSkpiYiICKKioti8efNjA/GRQP9Adr6/kz+6/EH76u3xUHjg7+GP/AmRIUOGn7sfnm6eNHuuGWs6ruFk35NOF4ggRoqCIJjJaDSyZMkSRo8eTdu2bTl16hSlSjnmzQf/VNRCcfHixQwfPpwFCxbQoUOHAj3z6OD0tW+uJV2Vzu5Lu0m8lkjCpQSuZV1Da9CilCsp5V2KmIoxNApsREzFGPNv33AQIhQFQTDZgQMH6NevH0qlks2bNxMeHm7vkkySkpLCyy877gZyS9FqtQwYMID4+Hh27dpFzZo1zWonwDuA9jXa075GewtX6HjE9KkgCAV28+ZNunbtSocOHejfvz979uxxukCEojFSvH79Os2aNeP69escPHjQ7EAsakQoCoLwnx6dRhMaGkqpUqVITU2lc+fOdjuNpjD0ej1paWnUqFHD3qVYzd69e2nQoAGvvPIKGzZsoFixYvYuyWmI6VNBcAI6g44Tt09w6Poh9lzZw8X7F9EYNLgr3KlQrAIxFWIILxdO2LNheLh5WLRvRzyNpjDOnTtH2bJl8fa2zkZ1e5IkiXnz5jF+/HiWLFlCq1at7F2S0xGhKAgO7PKDy8w5OIcFhxYgSRIGyYBKp/rX5204vQGlQonBaKBb3W70b9ifqiWrFqrvCxcuMGTIEI4dO8aMGTN47bXXHGrzvblc9Xi33Nxc+vbtS3JyMnv37qVKlSr2LskpOd/chyAUAZmaTLps6EK1OdX4OvFrMjWZZGmzHhuIALn6XDI1meToclhwaAF15teh3cp2pKvSTe5bpVIxduxYIiIiCA8PJyUlhTZt2rhEIIJrnmRz6dIlmjRpgkqlYv/+/SIQC0GEoiA4mG3nthE8K5g1KWtQ69VoDVqTntcZdaj1an49+ytVZlVh/en1BXpOkiTWrl1LjRo1OHPmDEePHmX06NF4etrmBgVbcbVFNvHx8TRs2JC3336blStXFrkDCSxNTJ8KggOZlTiLEX+MsMilr1qDFq1BS+cNnTl68yjjm45/4mjv0Wk0d+7ccfjTaAorJSWFkSNH2ruMQpMkienTpzNlyhSWLVtGixYt7F2SSxBnnwqCg5iVOIuR20c+cYq0MLyV3gxqNIiJzSf+7cczMjL49NNPWb58OZ9++ikffvghbm6u+72yTqfD39+f+/fvO/UIOCcnh549e5KWlsa6desICgqyd0kuQ0yfCoID+DXtV0b8McIqgQig0qmYcWAGPx7/Ecg7jebbb7+levXqqNVqTp06xccff+zSgQiQlpZGhQoVnDoQz507R1RUFB4eHuzevVsEooW59t8AQXACGeoM3tvwnkWmTJ9GpVPRZ3Mfit8vzvhPxjvtaTSF4ezvE3/99Ve6du3K2LFj6du3r8ssfnIkIhQFwc76bu5LjjbHJn3laHJ4/cfX+bb/t7z77rtOufm+MJw1FI1GI59//jnz589n3bp1xMTE2LsklyVCURDs6Ny9c2xI3YDGoLFJf5JMwu05N6o3r17kAhHyQrGgB2I7iszMTLp06cLt27dJSkqiXLly9i7JpRW9vxWC4EBmJc7CYDTYtE+1Qc20/dNs2qejcLaR4unTp2nQoAFly5Zl586dIhBtwKVWn0qSkdzcNNTqK0iSBplMiVJZCh+fWsjl7vYuTxD+Rq1XU2pKKbK12aY9qAc2A+eBXOAZoCVgwgE2nm6eXBt8jRJeT75Tz9VoNBqKFy9ORkYGHh6WPQrPGjZs2EDv3r2ZNGkS3bt3t3c5RYbTT59qtbe4fn0Rd+6sQ6U6jUzmhkz211+WEaNRjadnEM888xLly3+Mj49zn90ouIZD1w8hl5kxWWME/IGuQDEgDVgD9CEvIAvAXeHO7ku7aVu9ren9O6k///yToKAghw9Eg8HA2LFj+eGHH9i8eTORkZH2LqlIcdpQzMk5zfnzI7h373dAhiTlrdyTpMe/m8nNPUtu7kVu3lyMj08olSp9QYkSLW1YsSD83aEbh0w+rQYAd6DZX/69GlAcuEGBQzFHm8PBaweLVCg6w/Fu9+7do1OnTmg0GpKTkyldurS9SypynO6doiQZuHTpCw4dCufu3U1Ikjo/EP+bHqMxl6ysJE6ebMupU53R6x9YtV5BeJKESwmo9erCN5QN3AVMuPTeIBnYdWlX4ft2Io7+PvHYsWNERkZSs2ZNtm3bJgLRTpwqFLXaOyQn1+fSpS8wGnMB81+HGo0q0tPXkphYhaysI5YrUhAK6ELGhcI3YgDWAXUxKRQBrmVeK3z/TsSRQ3HFihW0bNmSCRMmMH36dJc/RMGROc1/eY3mJocPN0SrvYEk6SzSptGoxmhUc/RoLGFhf+Dv39Ai7QpCQWj0hdyGYQTWAwrAjGvzzJq6dWKOGIp6vZ5hw4bx888/88cffxAWFmbvkoo8pxgp6vVZHDkSjVZ73WKB+FcGQzbHjr1ATs5pi7ctCE/irijEimgJ2AjkAG+RF4wmclM4zffEhaZWq7l8+TJVqxbujklLun37Ni+88AKnTp0iKSlJBKKDcIpQTEvrh0ZzHUnSW60PgyGbkyc7YDRaPnQF4XHK+JYx/+FfgDvAO4DSvCZKeZs43+rEzpw5Q+XKlXF3d4ytWUlJSURGRtK4cWM2b95MiRJFZ2uMo3P4ULx37w/u3FmDJFlgQcJTSWg0l7l06Usr9yMIeWKDYs0bLWYAh4CbwFTg84cfxwvehAwZTYKamN63k3KkqdPFixfTqlUrZs6cyeeff45CYcYwX7Aah54/kSQDqaldMBqtc3PAPxmNKq5cmUTZst3w9Kxgkz6FoiuyXCSebp6mv9srDowrXN++7r40Kt+ocI04EUcIRa1Wy4ABA9ixYwcJCQnUqFHDrvUIj+fQI8W7d3/FYDDxtI9CkiQD1659Y9M+haIpsnyk3Ra76Iw6YioWnUOl7R2K169fp2nTpty4cYODBw+KQHRgDh2KV65MxmDIsmmfkqTl+vX5GI1Fa2WeYHv+Hv60r97evFNtCim6QjTl/cvbvF97OXnypN1Ccc+ePURGRtKqVSvWr1+Pv7+/XeoQCsZhQ1Gnu0tmZqJZzw4cCC++CK+8kvfRpYupLUjcv7/drL4FwRSfNP4ETzcbX3irhYpXK5KVZdtvOO1FpVJx7do1qlSpYtN+JUnim2++oUOHDixatIgxY8YUyZtJnI3DvlPMyjqEXO6FwczppQEDoHVr8/o2GFRkZiZSsuQr5jUgCAVUv2x96petz4GrB9Abrbe6+hEZMiqVrIQqSUWVKlUYPHgwH330Eb6+vlbv215SU1OpWrUqSqWZy3TNkJubS58+fTh8+DD79u2zeSAL5nPYb1uyspIxGGxz8eq/6XnwoGgdgSXYz7IOy/BQ2OaQak83Tza+t5GVK1YSHx/PkSNHCA4OZvLkyWRn2/b9va3Y+n3ipUuXiImJQa1Ws3//fhGITsZhQzEz8yB5d+SYZ9EiaNsWPv4Yjh41/XmxkV+wlYrFKjKp+SQURusuzfdWejMyZiS1SucFRK1atVi5ciXbt2/n0KFDBAcHM2XKFHJy7PXNqHXYMhTj4+Np2LAhnTp1YsWKFfj4+NikX8FyHDYUDQbzD+r+4ANYvhzWrIFXX4VRo+Caicc85p2tKgjWd//+fdaNWkfgvUC83byt0oeXmxcvBb/E6NjR//q50NBQVq1axfbt20lKSiI4OJipU6e6TDjaIhQlSWLq1Kl06tSJ5cuXM2TIEGQymVX7FKzDYUOxMGrWBG9vcHeHl1+G0FBING/NjiBY1cWLF4mOjiasThhpM9J4p/Y7eCstG4zeSm9ervIyq95Y9dSVrqGhoaxevZpt27aRmJhIcHAw06ZNQ6WyzT5ha7F2KObk5PDOO++wcuVKEhMTad68udX6EqzPYUNRobDcsmWZDCQTL9SQy228IlAocpKTk4mOjqZ3797MnDkTpZuSRa8tYmKziXi5eRV6q4YMGV5uXnwS9Qlr31yLUlGwhSa1a9dmzZo1/P777+zfv5/g4GCmT5/ulOGYk5PDzZs3CQ4Otkr7Z8+epVGjRnh5ebF7926CgoKs0o9gOw4bin5+kZhzqGN2Nhw8CFotGAywbRscPw4NGpjWjre32FwrWM+mTZto1aoVc+fOZcCAAfk/LpPJGBQ1iGMfHiPs2TB83c1bFerr7kvVklU50PMA45uNNytg69Spw9q1a9m6dSt79+4lODiYGTNmOFU4nj59mpCQEKscpbZlyxYaN25Mnz59WLx4MV5eXhbvQ7A9hw1Ff/9IFArTp5H0eli8GNq1y1tos2EDTJgAFUw6tU1B8eLPm9y3IBTEnDlz6N27N5s3b6Zt27aP/ZyqJauS/EEyG97aQMvKLfFQeODn7vfUdn2Vvni6eRJdIZrlHZZzqu8p6jxbp9D1hoWFsW7dOn799Vd2795NlSpVmDlzJrm5jv/e3RpTp0ajkQkTJtCrVy82bNhA3759xftDFyKTJFMnFm1Dq01n//5AJKmQd86ZQaHwp2bNFZQsacYldYLwBAaDgaFDh7J161Y2b95MpUqVCvzs1cyr7Ly4k/1X9rPn8h5u5txEZ9ChVCgJ8A4gukI0jSs0JjYolsrPVLbirwKOHDnCZ599RmJiIsOHD+eDDz5w2FHSsGHDKF68OKNGjbJIew8ePOD999/nzp07rFmzhnLlylmkXcFxOGwoAhw+HE1m5j6b96tQ+BMdfRu53DZ7xwTXp1KpeO+997h//z7r16/nmWeesXdJhXbkyBHGjx9PUlJSfjh6ejrWu/hWrVrRu3fvJ47ITXH69GnatWtHixYtmDlzpsNcQyVYlsNOnwJUrDgcheLpU0aWJpO5U65cbxGIgsXcvn2bZs2a4ePjw9atW10iEAHq1avHTz/9xKZNm9i+fTvBwcHMnj0btdra17wVnKWmT9evX09sbCzDhw9n7ty5IhBdmEOPFCXJwL595dDpbtusT7nciwYNTuPpKVaRCYWXmppK69atee+99xg3bpxLv3s6dOgQ48eP5/Dhw4wYMYKePXvaZOQoSRIXMi5w6Pohzt8/j8agwU3uhrfMmxFdR5B+Mh1fT/MWLBkMBv73v/+xbNky1q5dS2RkpIWrFxyNQ4ciwL17v3HyZAeb3KmoVoNG05Y2bTa49BcvwTYSEhLo2LEjX331FV27drV3OTaTnJzM+PHjOXLkCCNHjqRnz554eFh25kWSJBKvJTJ131R+PfsrAAqZglx9LnqjHjlylHIlOo0OuYec4GeCGdRoEO/WebfAK3rv3btHp06d0Gg0rFq1itKlS1v01yA4JocPRYBTp97lzp11Vl50I0MmC6R/f3+eey6Y+fPnU7ZsWSv2J7iy5cuXM3DgQFasWEGLFi3sXY5dJCUlMX78eI4dO8bIkSPp0aOHRcJx+/nt9Nnch+tZ18nV52KUjAV6zkfpg4TEh+EfMrH5RLyUT14cdOzYMTp06EC7du346quvcHNz2LsTBAtz6HeKj4SEzMXDoywymfX+YCoUPoSHb+HgwUPUqVOHsLAwfvjhB5zgewbBgUiSxOeff87IkSOJj48vsoEIEBkZyS+//MK6devYvHkzVatWZd68eWg05n1zm6XJottP3XhtxWuk3UsjR5dT4EAEyNHloNKpmJc8j6qzq7L/yv7Hft7y5ctp2bIlEydOZNq0aSIQixinGCkCaDTXOXSoATrdbSRJZ9G25XIfwsJ+o1ix6PwfO3z4MF27diUoKIgFCxaIpdfCf9LpdHz44YccPXqUTZs2iT8z/5CYmMj48eM5efIko0aNonv37gVesHLh/gVilsRwL/cear1lFvJ4uXnxeYvPGdRoEJD3+zds2DA2btzI+vXrCQsLs0g/gnNxipEigIdHOcLDk/HyqopcbpmzIWUyD9zcSlC37o6/BSJA/fr1SU5Opn79+tStW5elS5eKUaPwRA8ePKB169bcunWLXbt2iUB8jIYNG7JlyxZWr17Nzz//TNWqVVmwYAFa7dPvTD1//zyRiyK5mX3TYoEIkKvPZUz8GD7f/Tm3b9/mhRde4PTp0yQlJYlALMKcZqT4iNGo49KlL7hy5SuMRjVgXvlyuTclS7YmJGQBSuXTl8gfOXKErl27EhgYyMKFCylfvrxZfQqu6cqVK7Ru3ZqYmBhmzZolptsKaP/+/YwfP57U1FRGjRpF165d/zVyzFBnUOObGtzOuW3SVKkpPOWeeO/wpk/jPowfP94qR8IJzsNpRoqPyOVKKlX6lPr1EylR4mXkck9ksoK9vJfJ3JDLvfD1rUutWmupVWv1fwYi5O3HSkpKIjIykrp16xIXFydGjQKQ9w1TVFQU77//Pt98840IRBNERUWxdetWli9fzrp16wgJCWHRokXodP//euTDXz7kfu59qwUigNqoJqdZDr2H9haBKDjfSPGfNJrrXLs2lz17JlGxohyFwgNQkDeClAESRqMKD49AnnmmJeXLD8DXN9Ts/o4ePUrXrl0pV64cCxcuJDAw0EK/EsHZbNmyhffff5958+bxxhtv2Lscp7d3717Gjx9PWloao0ePpnR0ad7Z8A4qnfW3Y7nJ3WgU2IiErgliO1YR5/ShCHlB9dZbb3H6dAoqVSoazRWMRjVyuTtKZSl8fGqjUFjubEatVsuXX37JnDlz+Oqrr+jWrZv4i1TELFiwgHHjxrF+/XqioqLsXY5L2bMDPIXIAAAgAElEQVRnD+PGj2Nn/Z0YvA0269fX3ZdVb6yiVVVx5nFR5hKhOH36dNLS0pg3b55N+z127Bhdu3alTJkyLFy4kAqmXcUhOCGj0cjIkSP56aef2LJli9Xu6Svqtp3bRtsVbck12PYmjueDnmdn15027VNwLE73TvFx7LUfLCwsjIMHD9K4cWPq16/Pd999J941ujC1Ws3bb7/Nvn372LdvnwhEK5q8b7LNAxEg8VoiF+5fsHm/guNw+pGiTqcjICCAc+fOERAQYLc6jh8/Trdu3QgICGDRokVUrFjRbrUIlpeenk7btm2pWLEiS5YscbjbIFyJRq/B70s/dEYT9yN//o9/1wORgAmzoR4KDya1nMTARgNN61twGU4/UkxOTqZSpUp2DUTIu6X8wIEDxMbGEh4ezqJFi8So0UWkpaURFRXF888/z7Jly0QgWtmJ2yfwcjNjDcDov3x8ArgBNU1rQmPQsOvSLtP7FlyG04eiIx2lpVQqGT16NPHx8cyfP5+XXnqJS5cu2bssoRD27t1LkyZNGDZsGF988QVyudP/lXF4ydeTTR8l/tNpwAcw47KbpGtJhetbcGpO/zd8+/btNG/e3N5l/E3t2rU5cOAATZs2JSIigoULF4pRoxNavXo17du3Z+nSpfTq1cve5RQZp+6cIldfyPeJR4Ew8nZlmehG9o3C9S04NacOxdzcXA4ePEhsbKy9S/kXpVLJqFGj2LFjB4sWLeLFF18Uo0YnIUkSkydPZsiQIWzbto2XXnrJ3iUVKVmarMI1kAFcAuqa97gkSegMlj1fWXAeTh2K+/bto06dOvj5+dm7lCcKDQ1l//79tGjRgvDwcObPny9GjQ5Mr9fTt29fli1bxv79+8UZmHbgJi/kqUDHgIrAfx9W9VgSEgq5ONmmqHLqUIyPj3e4qdPHcXNzY8SIESQkJLB48WJatmzJxYsX7V2W8A9ZWVm0adOGCxcusHv3bnFakZ2U8imFzJx5z0eOkTd1aiYPhQdymVN/aRQKwal/5x1pkU1B1KxZk3379vHiiy8SERHBvHnzMBqtd6ajUHDXrl0jNjaW8uXLs2nTJvz9/e1dUpFVv2x9fN19zXv4MpAF1DK//5CSIeY/LDg9pw3FzMxMTp486XRHbLm5uTF8+HASEhKIi4ujZcuWXLggNgvb0/Hjx4mKiuKtt95i4cKFKJVKe5dUJKnVanbu3MmulbvIyc0xr5FjQA2gYHcEPFZMxRjzHxacntOGYkJCAg0bNnTaPWM1a9Zk7969vPLKK0RGRjJ37lwxarSD33//nZYtWzJ58mRGjBghzrC1Ib1eT2JiIl9++SUvvPACpUqVYsSIEfjqffF0N/Pv9WtAB/Nr8nP3IzbI8RbuCbbjtCfaDBo0iFKlSjFq1Ch7l1Jop0+fplu3bnh5efHdd99RuXJle5dUJCxevJhRo0axZs0amjRpYu9yXJ7RaOTkyZPEx8cTHx9PQkICQUFBNG/enObNmxMbG0uxYsUA+OT3T5h9cDZaw9MvILY0X6Uvt4fexktpuQsEBOfitKEYFhbGggULaNSokb1LsQiDwcCMGTOYNGkS48aNo2/fvmKjuJVIksT//vc/Vq5cyebNm6lWrZq9S3JJkiRx9uzZ/BDcsWMHxYsXzw/BZs2aUapUqcc+ezHjIjW+qYFar7ZZvUq5kg8jPmTWK7Ns1qfgeJwyFO/cuUPVqlVJT093uUtdU1NT6d69O0qlksWLF4tDpy1Mo9HQvXt3zp8/z8aNG5/4RVkwz9WrV/NDMD4+HqPRSIsWLfJD0JQzgVsta8W289vQG/VWrPj/yfQyFkcspmvbrjbpT3BMTjkU2bFjB02aNHG5QASoXr06u3fvpm3btjRs2JBZs2aJd40Wcu/ePV588UU0Gg3x8fEiEC0gPT2dNWvW0KdPH6pVq0a9evX45ZdfaNSoEX/88QdXrlxh6dKlvP/++yYfkv9tm2/xdLPNmgEfpQ/vBL7DxCETefXVVzlz5oxN+hUcj1OGorNtxTCVQqFg8ODB7Nu3j1WrVtG0aVPOnj1r77Kc2vnz52ncuDENGjRg9erVeHmJd0bmyMzM5JdffmHw4MHUrVuXKlWq8P333xMSEsLq1au5desWq1ev5sMPPyQkJKRQC5fK+ZVjzitz8FH6WPBX8G9ymZyg4kEs7bWUlJQUmjZtSnR0NIMHDyYjI8OqfQuOx2lD0Rk27RdWSEgICQkJtG/fnkaNGvH111+LUaMZEhMTiYmJoX///kyZMkW8qzVBbm4u27dvZ/To0URFRVG+fHlmzpxJQEAA8+fPJz09nU2bNjFo0CDCwsIs/t+2S1gX2ldvj7fS26Lt/lUxj2JsfHsjbnI3PDw8+OSTT0hJSSE7O5vq1aszf/58DAaD1foXHIvTvVO8cuUK4eHh3Lx5s0h9cUtLS6Nbt27IZDIWL15M1apV7V2SU9iwYQMffPABS5Ys4dVXX7V3OQ5Pp9ORlJSU/04wKSmJOnXq5C+OiYqKsvk2KIPRwNvr3mZL2hZUOpXF2pUho7hncXZ13UXtZ2s/9nOOHDnCwIEDuX//PjNnziwS34wXdU4XikuXLmXLli2sWrXK3qXYnMFgYM6cOUyYMIExY8bQr18/FApxRuPjSJLEzJkzmTZtGj///DPh4eH2LskhGY1Gjh07lh+Ce/bsoXLlyvmLY5o0aeIQZwsbJSNDtw1lXtK8wt+gAXgrvSnnV45f3/2VKiWqPPVzJUli3bp1DB06lLp16zJ16lSxAM6FOV0odunShejoaHr37m3vUuwmLS2N7t27I0kSixcvJiREHEv1VwaDgUGDBhEfH8+WLVtMXuDhyiRJ4s8//2T79u3Ex8ezc+dOAgICaN68OS1atOD555+3+4XdT7P/yn7eXPMm99T3zBo1KmQK3BXuDGo0iE+bfoq7wr3Az6rVaqZPn8706dPp2bMno0aNEscBuiCnCkVJkqhQoQI7d+6kSpWnf3fn6oxGI3PmzOGzzz5j1KhRDBgwQIwagZycHN555x1UKhXr1q3L3wxelF2+fDk/BOPj41EoFLRo0YIWLVrQrFkzypcvb+8STZKry+Xbw98yZd8U7qvvk6PNQeLpX8a8ld4YJSMda3ZkePRwapU2/3DU69evM2rUKH7//XcmTJhA165dxd89F+JUofjnn3/SsmVLLl26JI7jeujcuXN0794dnU7HkiVLivRG9Js3b/Lqq69Su3ZtFixYgLt7wUcBruT27dvs2LEjPwgzMzPzR4LNmzencuXKLvH3R5Ikdl7cyfrU9ey5vIfU9FQkKe/aJ0mS0Bl1lPEpQ2T5SF6o/ALv1H6H4p7FLdZ/UlISAwcOJDc3l6+//lqciuQinCoU582bR2JiInFxcfYuxaEYjUbmzp3LuHHjGDFiBIMGDSpy37mmpKTQunVrevTowZgxY1zii35BZWRkkJCQkB+CV69eJTY2Nj8Ea9WqVST+exglI3dVd1Hr1SgVSvw9/K26ahXygnnlypUMHz6cqKgoJk+eTFBQkFX7FKzLqUKxY8eOtGnThs6dO9u7FId0/vx5unfvjkajYcmSJVSvXt3eJdlEfHw8b7/9NtOmTSsSfzZUKhV79+4lPj6e7du3c/r0aaKiovJHg/Xq1XPJgy0cmUqlYsqUKcyaNYu+ffsyfPhwfH3NvP5KsC/JSRgMBqlkyZLS1atX7V2KQzMYDNKcOXOkkiVLSpMnT5b0er29S7KqpUuXSqVLl5bi4+PtXYrVaDQaaffu3dL48eOl2NhYycfHR4qJiZHGjh0r7dy5U1Kr1fYuUXjo8uXLUqdOnaTy5ctL33//vWQwGOxdkmAipxkpHj16lLfffpvU1FR7l+IUzp8/T48ePcjNzWXJkiXUqFHD3iVZlCRJfPbZZ8TFxbF582Zq1qxp75IsxmAwcPTo0fyR4L59+wgJCcnfKxgTEyNGIQ5u//79DBgwAJlMxtdff+0yFxcUBU4TitOnT+fs2bPMnTvX3qU4DaPRyIIFCxg7dixDhw5l8ODBLjGtptVq+eCDD0hJSWHTpk2UKVPG3iUViiRJnD59Oj8Ed+3aRdmyZfNDsGnTpjzzzDP2LlMwkdFo5Mcff2TUqFE0bdqUSZMmERgYaO+yhP/gNKHYunVrunXrxhtvvGHvUpzOxYsX6dGjB9nZ2SxZssSpR1UZGRm8/vrr+Pn5sWzZMnx8rHsuprVcuHAhPwTj4+Px9vb+25VKZcuWtXeJgoVkZ2czadIk5s2bx4ABA/jkk0/w9rbuAiDBfE4RijqdjoCAAM6fP0/JkiXtXY5TkiSJhQsXMmbMGIYMGcInn3zidKPGS5cu0apVK1q2bMn06dOdaoXtjRs32LFjR34QqtXq/BBs3rw5lSpVsneJgpVduHCB4cOHk5iYyFdffcVbb71VJFYFOxunCMX9+/fTt29fjhw5Yu9SnN7Fixfp2bMnDx48IC4ujlq1zN/EbEvJycm0bduWYcOGMWDAAHuX85/u3bvHrl278kPw5s2bNG3aND8Ea9SoIb4gFlEJCQkMHDgQb29vZs6cSUREhL1LEv7CoUJRkiQMhmyMRjUymRsKhS9yuZKJEyeSkZHB1KlT7V2iS5AkiUWLFjF69GgGDRrEsGHDLDJq1Ouzyc4+QlbWIbKzj2AwZAMylMqS+PlF4ucXjo9PLeRy0zbVb9q0iR49erBw4ULatWtX6DqtITs7mz179uSHYFpaGtHR0fkhWLduXaca2QrWZTAYiIuLY8yYMbz88st88cUXYsrcQdg1FCVJIjNzP+npP5GRkUBOzkkkSYtMpkCSjIARD48gDh7Mplq1TrRsOQGFwjnfITmiS5cu0atXL+7du0dcXByhoaEmtyFJBu7d+43LlyeTmbkPudwLo1GDJGn+9nlyuTcymQKjUUupUm9QocIQ/Pzq/Wf733zzDZ9//jk//fQTDRo0MLk+a9FoNBw4cCA/BI8ePUpERER+CDZo0KDInqgjFFxmZiYTJ05k8eLFDBkyhEGDBtn8FhLh7+wSikajhhs34rhyZTJa7S2Mxlzg6fcEyuU+gMSzz3ahYsVP8PISp9RbgiRJfPvtt4waNYqBAwcybNgwlEplgZ69e3cLqandMRpzHo4KC0qBXO6Bt3d1atT4ER+ff28XMRqNDB06lC1btrBlyxa7v3PT6/UcPnw4//zQ/fv3U6NGjfxTY6Kjo8XiCcFsZ8+e5ZNPPuH48eNMmTKFDh06iOl1O7F5KGZmJpGS0hGdLh2jMceMFtyQy5UEBY2lYsWhyGRiSsoSLl++TK9evUhPTycuLo7atR9/vxyATpfBn39+yN27mzAaC3O/nQy53JOgoDFUrDg8//dSpVLRuXNn7t69y4YNG+yyHUGSJE6ePJkfggkJCQQGBuafGhMbG0vx4pY7R1MQALZv387AgQMJCAhgxowZ1K1b194lFTk2C0VJMnL+/CiuXZv1cGRYOHK5D15elald+xc8PcXVQJYgPbyKasSIEQwYMIDhw4f/a9SoVl/i8OFodLr0f02Rmksu98bfvyG1a2/m7t0s2rRpQ9WqVfn222/x8PCwSB//RZIkzp07lx+CO3bswM/PLz8EmzZtyrPPPmuTWoSiTa/Xs2jRIsaNG0fbtm2ZOHEipUuXtndZRYZNQlGSDJw69a4FRhb/pECpfIZ69fbh7S1uoreUK1eu8MEHH3Dr1i3i4uKoU6cOAGr1ZQ4dikCnuwcYLNqnXO6JQlGd7t0f8Oab7/LZZ59Zffro2rVr+SEYHx+PXq/PD8FmzZqJg50Fu7p//z6fffYZP/zwAyNHjqRfv37iPbUNWD0UJUkiNbUbd+6ssXAgPiJDqQwgPPwQnp4VrNB+0SRJEnFxcQwbNox+/foxbNhAjhypg0ZzFUsH4iMaDeh04bz6arJV2r97927+XsH4+Hju3LlDs2bN8oMwJCREvMcRHE5qaipDhgwhLS2NadOm8eqrr4o/p1Zk9VC8cWMpaWkfmfn+sKAU+PrWJTz8IDKZ3Ir9FD1Xr17lgw8+oFGjJGJjswDLTJk+iVzuTY0ayyhVqvBbL7KyskhISMgPwfPnzxMTE5MfgnXq1EEuF39eBOewdetWBg0aRIUKFZgxY4bT7DF2NlYNRY3mOgcPVjNxZaJ55HIfKlWaSIUKA63eV1GTkbGXw4ebI5drbdKfm1txGjY8i1Jp2ulFarWaffv25Yfg8ePHadCgQX4IRkREFHhlrSA4Ip1Ox7x585g4cSJvvvkm48ePF6d8WZhVQ/HYsVe4f/8PQG+tLv5GLvemQYMzeHqKQ3ctKTk5nOzswzbrTybzIDBwAMHBXz318/R6PUlJSfkhePDgQUJDQ/P3CjZu3BgvLy8bVS0ItnP37l0+/fRTVq9ezZgxY+jTp4/4hs9CrBaKubnnSUqqhdGotkbzj5X3xXQgwcGTbNanq8vJSeHQoUiLrBg2hUJRjOjo2387/cZoNHLixIn8Q7R3795NpUqV8kMwNjYWf39/m9YpCPaUkpLCoEGDuHr1KtOnT+fll1+2d0lOz2qhmJY2iOvX5yJJtplye+RxX0wF86Wm9uTmzTistbjmSRQKP0JCFvLgQf38ENyxYwclS5b825VKpUqVsmldguBoJEnil19+YfDgwYSEhDB9+nSqVatm77KcllVCUZKM7NlTHIMhy6zn4+Nh6VK4fRtKlIDhw+HhroD/pFD4Ub369xZZqCHA3r2l0enumPxcZiZMmQLJyVCsGPTsCS1bmtbGwYOezJ4dkH9qTLNmzahQQawwFoTH0Wq1zJ49m0mTJvHee+8xduxYcQ+nGayy9C4399zDs0tNl5wMCxfmBeHmzTBzJphyTq7BkM2DB7vN6lv4O53uLnr9A7Oe/fprcHOD9eth9Oi838cLF0xrIyqqOJcvXyYuLo4uXbqIQBSEp3B3d2fIkCGkpKSgUqmoXr068+bNQ6+3zZoOV2GVUMzKOmT21oi4OOjcGWrWBLkcSpXK+yg4iYyMBLP6Fv4uK+swcrnphxPn5kJCAnTvDl5eULs2NG4M27aZ1o7RmG6lva2C4LpKly7NggUL+O2331i1ahX16tVj+/bt9i7LaVgtFM3ZhmEwwJkz8OABvPsudOyYN+LQmLg1TqU6bXLfwr+p1ReRJNO/y7x6FRQK+OvALjgYLl40rR253Au1+orJ/QuCAHXr1mXHjh2MGzeOXr160a5dO86ePWvvshyeVa5e1+luA6a/qrx/H/R62LULZs3Km34bPRp++CHvnVRBGQwqfvjhByRJyv8wGo1P/feCfI412rBXvwVpIyLiCi++mIupK71zc+GfF0b4+IDK5EGfzKarlwXB1chkMl5//XVat27NjBkzaNSoEd27d2fMmDFipfYTWCUUzRldADw6+7l9e3i0H7VjR/jxR9NCUSaT+O23rchkcmQyGXJ53j8fffzz3wvyOQVtQ6FQmPyMJfq1ThubgLmYeoqNl9e/A1Cl+ndQ/jcJuVzsvRKEwvL09GTkyJF07dqVUaNGUa1aNSZMmEC3bt3E5df/YJVQNPciYD+/vPeHfz3Wz5wj/mQyN378cZlZNQj/7/btdM6c+Q6DwbRQDAzMmwq/ejXv/wOcPQvPPWda/5Kkw81NnNYhCJZStmxZlixZQnJyMgMHDmTu3LnMnDmT2NhYe5fmMKzyTtHHp5ZZCzQAXn4ZNmzIm0rNyoK1ayEqyrQ23N3LmdW38He+vvWQJNP3J3p5QZMmsGRJ3lTqiROwbx+88IJp7chkHnh4lDG5f0EQni4iIoLdu3czbNgwOnfuzJtvvslFU1/6uyirjBR9fcORydwB098HdemSt9Cmc2dwd4emTeG990xrw8+vgcn9Cv/m5RUMmLe1ZuBAmDwZOnQAf/+8f69UybQ2fH3DzOpbEIT/JpPJePvtt2nTpg1Tp04lPDycPn36MGLECHx9fS3e3/3c+xy+cZjk68mcTj9Nri4XpUJJGd8yRJaLJLxcOMHPBNv9BhCrbN7X67PZu/cZs98tFoZM5klw8GQCA/vZvG9XdOTI8zx4YPstLjKZJ889N5agoJE271sQiqKrV68yYsQIduzYwRdffEHnzp0LfYuM1qBl3al1fLX3K07dOYWX0gu1Xo3W8P8nncmQ4evui0EyoJQr+TDiQz6K/IgKxeyzL9lqx7wdPhxNZuY+azT9VDKZJw0anMbL6zmb9+2K0tM3cvr0e2afTmQumcyTRo0uiOlTQbCxAwcOMGDAACRJ4uuvvybK1PdX5B09t+jwIoZuG4okSWRpC/71w0PhgUwm45Uqr7Dg1QWU8rHtUY5Wu0yuYsXhKBR+1mr+iYoVixKBaEElS7Z+OBVuSzJKlHhRBKIg2EGjRo3Yv38//fr1o2PHjrz77rtcuVLw/cKXH1ymyZImDP5tMJmaTJMCEUBj0KDWq9mctpmqs6uy7tQ6U38JhWK1UCxZsjVyuYe1mn8sudyXChWG2bRPVyeTKQgKGgOYt3DKHHK5J0FB/7NZf4Ig/J1cLqdz586kpqZSuXJl6taty/jx41H9x2bjxKuJ1J5Xm8RrieToCnexvNag5YHmAV1+6sKArXkjV1uwWijKZAqqVp2LXG7y5jQz+3PDz68uJUq8ZJP+igqVSsXXX1/m4kU9kmT9F+ByuTdly36Av3+E1fsSBOHpfH19mTBhAocPH+bUqVNUr16dFStWPDagEq8m0uL7FmRqMtEbLbeeRKVT8e3hb+m7ua9NgtFqoQhQunRHihdvZpPpN5nMgxo1ltt95ZIr2bVrF2FhYVy/fpOWLXejUFh7tChDqSxJ5cpfWrkfQRBMERQUxKpVq1i2bBlTp04lJiaGpKSk/J+/8uAKL/74YqFHh0+i0qn44fgPTN0/1Srt/5VVQxGgevUlD98tWi+s5HJvQkK+wdNT3KJgCZmZmfTp04d3332XadOmsXz5cgIDG1G9+lLkcuvdZK9Q+FOnzm8oFNbrQxAE8zVp0oSDBw/So0cP2rRpQ9euXbl27Rqd1ndCpbPu4f05uhzG7RhHanqqVfuxeii6u5eiXr3dKBT+WCMY5XJvKlYcQZky71u87aLo119/JTQ0FL1ez8mTJ2nTpk3+z5Uu3ZGQkAVWCEYZCkUx6tbdiY9PDQu3LQiCJSkUCrp3786ZM2d49tlnCXk7hMTLiRadMn0StUHNm2vexGC03qXnVtuS8U85OakcPdoEvT4LSTLx2osnkMu9eO658VSsONQi7RVld+/eZdCgQezZs4dFixbRokWLJ37uvXu/c+rU2xgMqkL/Xsrl3nh6Pkdo6E94e1ctVFuCINiW1qAl4KsAsnS227Ll6+7LkrZLeKPmG1Zp3+ojxUd8fKrToMEZSpZ8tdCLb+RyL9zdy1Knzm8iEC1g7dq11K5dmxIlSnDixImnBiJAiRIv0rDhOQIC2jz8vTT9j5FM5o5c7kXFiiOJiDgmAlEQnNBPqT8hyWyzKvSRbG02k/dOtlr7Nhsp/lV6+kbS0j5Cr88w6d5FudwHMFK2bE8qV56EQmGbla2u6ubNm3z00UecOnWK7777jsaNG5vcRmZmIleuTOXu3V8ABUbj0160y/MPiy9bthfly/cTe0oFwYmFLwjn8M3DNu/Xy82LQx8cokYpy79usUsoQt6JBxkZO7l8eTIZGTvyrwj6a0jKZB4YDHIkSY2PTyUCAwdRpkwX3NzEPWCFIUkS33//PUOHDqVXr17873//w9OzcCtLtdp07t79hQcP9pKZuRe1+iJGoxZJAr1eTokSdSlWLJZixaIpWbKVzfewCoJgWZmaTAImB6Az6kx/+A6wGbgBeAMvAibkm7vCnS+af8GQxkNM7/s/2C0U/0qSDKhUZ8jKSkatvojBkI1M5oFSWRK1OpAWLT7k0qU7YruFBVy+fJnevXtz8+ZNFi9eTL169aza35o1a1i1ahVr1661aj+CINjWrou7aLOyDZmaTNMeNADfABFAI+AisALoDQQUvJnXQl5j4zsbTeu7AKxyS4apZDIFPj418fGp+YTPGMzZs2epWlW8dzKX0Whk/vz5fPrppwwaNIihQ4eiVFr/At+AgADS09Ot3o8gCLaVfD0Zjd6MhXbpQBYQRd6GhMpABeA40Ny0/q3BIULxv0RHR7Nv3z4RimZKS0ujZ8+e6HQ6EhISqFHDdtseRCgKgms6c/cMGhMvIH+q2yZ+eo6JDxSQzVafFkbjxo3Zt8/2N244O71ez5QpU4iKiqJDhw7s3r3bpoEIULJkSe7evWvTPgVBsD6zN+sHAD7AXvKmUs+SN4Vq4qtJg2TAKJl33+vTOMVIsXHjxixYsMDeZTiVEydO0L17d/z9/Tl48CCVK1e2Sx2PQlGSJPFOWBBciFJu5usXBfA28Ct5wVgOqIXJaSR7+D9Lc4qRYlhYGJcuXSIjI8PepTg8rVbLuHHjaN68Ob179+aPP/6wWyACeHh44OnpSWamiS/jBUFwaGX9yiI3N0LKAN2A4UBn4D5Q3rQmfN19rfKNtlOEopubG5GRkRw4cMDepTi0pKQkwsPDOXToEEeOHKFnz54OMToTU6iC4HoiykXg6+Fr3sM3yZsu1ZI3WswG6prWRM1ST1qYWThOEYqQN4W6d+9ee5fhkFQqFUOHDuW1115j1KhRbNy4kcDAQHuXlU8sthEE1xNeNhydwYw9ipC30nQaMAW4QN5o0YTpUzlyYoNizev7PzjFO0XIW4E6dar1rw1xNgkJCfTo0YOIiAiOHz9O6dKl7V3Sv4hQFATXU7FYRbyUXuTqc01/+MWHH2bycfeh6XNNzW/gKZxmpNioUSOSkpLQ661/ErszyMzMpG/fvnTq1Ilp06axYsUKhwxEENOnguCKZDIZH0V+hIfC9qdTuSvceTG4EKn6FE4Tis888wwVKlTg+PHj9i7F7rZu3Urt2rXRarX/ut7JEYmRoiC4pg8jPrR5n55unvRv2I2pOE8AABBxSURBVB83uXUmOp0mFOH/N/EXVffu3eP999+nT58+fPfdd3z77bcUL17c3mX9JxGKguCayvmVo131djYdLbrJ3awaxk4VikV5E/+6desIDQ2lWLFinDhxgpYtW9q7pAIT06eC4Lrmtp6Ll9LSF48/no/Sh9mvzKa0j/VeFTldKBa1Fag3b97kjTfeYPTo0axZs4ZZs2bh62vmMmg7ESNFQXBdJbxK8H277/FWWvcqP6VcSYPyDXg/7H2r9uNUoVi1alVUKhVXr161dylW9+h6pzp16hASEsLRo0eJjo62d1lmEaEoCK7ttWqv0a9BP6sFo5vcjXJ+5VjdcbXV9147zZYMyFvt1LhxY/bv30/Hjh3tXY7VPLre6caNG2zdupX69evbu6RCEdOnguD6vmzxJVqDlgWHFph/LupjKOVKyvmVY1+PfQR4m3C3lJmcaqQIrj2FajQamTdvHuHh4cTExJCUlOT0gQhipCgIRYFMJmP6S9OZ1HIS3m7eyGWFjxcfpQ8xFWNI/iCZcn7lLFDlf3OIS4ZNsWfPHgYPHszBgwftXYpFPbreSaPRsHjxYmrWtM4RRvag0Wjw8/NDo9E4xLFzgiBY19l7Z3lr7Vv8efdPsrXZJj/v5eaFQq7gm1bf0LlOZ5t+3XC6kWJ4eDgpKSmoVJYbntuTXq9n6tSpREVF0a5dO/bu3etSgQh5h4J7eHiQlZVl71IEQbCBKiWqkNQriWUdlhFdIRpPN088FZ5PfUYuk+Pn7keAdwCjm4zmfP/zdAnrYvNvpJ3qnSKAl5cXtWvXJjk5mdhY65x9ZysnT56ke/fu+Pr6kpiYSHBwsL1LsppHU6j+/v72LkUQBBuQy+S0qdaGNtXacPbeWbakbSHhUgIHrx3kZvZN9EY9CrkCH6UPoaVDeT7oeWKDYmlZuSUKucJudTtdKML/v1d01lDUarV8+eWXzJkzhy+++MJhbrOwpkehaM9rrARBsI8qJarQv2F/+jfsb+9S/pNThmJ0dDRxcXH2LsMsSUlJ9OjRg4oVK3LkyBGHus3CmsQKVEEQnIHTvVMEiIqKYt++fTjTGqHc3FyGDRvGa6+9xogRI9i0aVORCUQQK1AFQXAOThmK5cqVw9/fnzNnzti7lAJJSEggLCyMy5cvc/z4cTp16uTy06X/JEJREARn4JShCM5xOHhWVhYfffQR77zzDpMnT2blypUOe72TtYnpU0EQnIHThqKjHw7+22+/ERoaSm5uLidPnqRdu3b2LsmuxEhREARn4JQLbSAvFGfPnm3vMv7l3r17DB48mJ07d7Jo0SJefNE6F2E6GxGKgiA4A6cdKdauXZvr16871JTc+vXrCQ0Nxd/fn5MnT4pA/AsxfSoIgjNw2pGiQqGgQYMGHDhwgNatW9u1llu3bvHxxx9z/PhxVq9eTUxMjF3rcURipCgIgjNw2pEi2P9wcEmS+OGHH6hTpw7BwcEcPXpUBOITiFAUBMEZOO1IEfJWoH7xxRd26fvKlSv07t2ba9eusWXLFsLDw/+vvbuNjau68zj+u/faM5PxOB4cJ87YMUKWE7wJIjThKRJNSF7QLUFVUSq6u2lRi4OWEiroSiUS+6Kr7CKW7gNB2wVSdanKbqtWaiTERi2ogoXtSpCEZB0gD9BQkjgb7MRBsT0zHj/MOfvCU4hKCJ47T8fM9yPxIpHP+Z+gSL/8z73n3JqsY674w/aptbbujqMAmDvmdKd4ww03aP/+/ZqamqpaTWOMnnrqKa1atUpr1qzRvn37CMRZ4FJwAHPBnO4UE4mI1q9v1759f61k8pQmJk7L2in5/jzF48s0f/4aNTevVjzeK68M3/Y6duyYtmzZolwup5dfflkrVqwow5+ifnApOADXzbnvKUpSJnNIAwOP6cyZnymXm1ZDg+T7H+8WgyAha62CoElLljygVOpuRSLFf7k5n89rx44deuSRR/TQQw/p/vvvVxDU7hb3ueraa6/Vk08+qeuuu67WSwGAi5pTneLExP/pyJE7NTr6qoyZlJRXJPLJP5/Pz3zc0piMTpz4W504sV0dHfepu/vv5PvRWdV866231NfXp3g8rtdee009PT1l+JPUJ162AeC6OfFM0Vqr999/Wnv29Gpk5L9lzLikfFFzGDMuY3I6ffoJ7d3bq9HR1y/585OTk9q+fbvWr1+vvr4+vfjiiwRiiQhFAK5zvlO01uidd76loaGfyphMyfMZk1Uud1z9/evU2/uMFi3a9LGfef3113XXXXepq6tLBw4cUFdXV8l1wQF+AO5zulO01urtt+/W0NB/lCUQL2RMVkePfl1nzuz68PfGx8e1bds2bdy4UQ8++KB2795NIJYRnSIA1zndKQ4M/IPOnPm5jMlWZH5jxnX06J2aN69b/f1p9fX16ZprrtEbb7yh9vb2itSsZ21tbTp48GCtlwEAn8jZUMxkjur48b8pPD+sHGOyeuWVm3XvvU16/PF/1e23317RevWM7VMArnMyFK3N6/DhO2TMRFXqRaMZPf/8N7V8OYFYSWyfAnCdk88Uz537lXK59ySZqtRrbMxreHinpqbOV6VevSIUAbjOyVA8efLvPzxjWD2+BgefrnLN+sL2KQDXOReK4+PvKp0+EHr8qVPSLbdIDz9c3DhjshoY+CfNwQt+5owFCxZoeHiY/8cAnOVcKH7wwW9UyrIef1zq7Q03dnr6vHK5E6Fr49JisRiXggNwmnOhODLy29BHMF56SWpqklatClfb8xqUTu8PNxizwhYqAJc5F4qjo3tCjctkpB//WNq6NXztfH4sdH3MDi/bAHCZc6E4NTUUatzTT0u33iotXFhKdats9nelTIBPQSgCcJlzoWhM8R8MPnZM2r9f+spXylG/spcF1Du2TwG4zLnD+57XIGuLO7Tf3y8NDUlf/erMr8fHJWOkEyekH/6wuPqz/aQUwqFTBOAy50KxoSGpycniLv++7TZpw4aPfv2LX0iDg9J3vlN8/Wh0SfGDMGuEIgCXObd92ty8uugxsZjU2vrRf/PmSZGIlEwWN08QJDR//o1F18fssX0KwGXOdYrJ5Dp98MELRW+hXugb3whfP0woY/boFAG4zLlOMZlcJ8+rVVb7isevrFHt+kAoAnCZc6GYSKxSNNpZ9bqeF1FHxz3yvKDqtesJ26cAXOZcKHqep8sv3ybfb6pyXV+dnSWc/Mes0CkCcJlzoShJixb9uYIgUbV6nhfVggVfUix2edVq1isuBQfgMidDMQjmafnyn8n351Wt3rJlT1alVr2LxWKKRCJKp6v9aTAA+HROhqIkXXbZBi1a9GcVD0bfj6u39ydqbGytaB18hC1UAK5yNhQlaenSJ5RIrJTnVeaWGd+Pq6vru2pr+1JF5sfFEYoAXOV0KAZBTFdf/Rs1N3+u7B2j78e1ZMkDuuKK75V1Xnw63kAF4CqnQ1GSGhoSWrnyv9Te/vWyBKPnNcj3m7R06Q/U3f2wPM8rwypRDDpFAK5yPhSlmY7xyit36uqrn1ckkpLvh3kz1ZPvN2n+/DW6/vqjSqW+WfZ1YnYIRQCucu6at0tJJtfqxhvf09mzv9TJk49qfPxdSfYSn3vyFARNMmZKra23qKvru2ppuYnusMbYPgXgqjkVitLMp53a2zervX2z0um3NDLyPxoZ+a1GR/doevq8rJ2W7zcqEulUS8vn1dKyRsnkBkWji2u9dBS0tbXpzTffrPUyAOBj5lwoXiiRuEqJxFXq7Lyn1ktBEdg+BeCqOfFMEZ8tbJ8CcBWhiKqjUwTgKkIRVUcoAnCVZ7mZGVWWy+XU0tKiXC7Hm8AAnEKniKqLxWJqbGzkUnAAziEUURNsoQJwEaGImuANVAAuIhRRE3SKAFxEKKImCEUALiIUURNsnwJwEaGImqBTBOAiQhE1QSgCcBGhiJpg+xSAiwhF1ASdIgAXEYqoCUIRgIsIRdQE26cAXDSnPzKMuWd6ekzp9P9qcvJVbd48qMOH/0KeF1EksljNzdequXm1YrEruCgcQE3wlQxUnDFTGh5+VgMD31c6fVC+H5cxOVk7ccFP+QqChKydlu9HlErdo87OrYrFltRs3QDqD6GIirHWanDwJ3r33b+StdPK58dmPdbzopKkBQs2atmynYpE2iq1TAD4EKGIipiYOK0jR76m0dG9MiYTeh7Pi8j356m399+0cOGmMq4QAD6OUETZjY0dUH//BuXzGUnTZZnT95uUSm1RT89jPG8EUDGEIspqJhDXKZ8v/weEfT+u9vY7tWzZEwQjgIrgSAbKZmLidKFDLH8gSpIxWQ0NPaOBgX+syPwAQCiiLKy1OnLka4Ut08oxJqvjx7+nTOZIResAqE+EIspiaOjfNTq6V+V6hngpxuR06NAdsjZf8VoA6guhiJIZM61jxx4o6S3T4ljlcu/p7NldVaoHoF4QiijZuXPPydrKd4gXMiajkye/X9WaAD77CEWU7OTJR4s6mF8u2exhZTKHq14XwGcXd5+iJPl8Run0gVBjBwelHTukQ4ekxkZp3TrpvvukIJjdeGvzGh7+TzU1LQ9VHwD+GJ0iSpJO98v346HG7tghJZPSrl3Sj34kHTwoPfvs7MdbO6mRkVdC1QaAiyEUUZKxsf2ydjLU2Pffl26+WYpEpNZW6frrpePHi60frksFgIshFFGSbPZtGZMLNXbTJumll6RcTjp7VtqzZyYYizE1dUZcygSgXHimiJLk89nQY1eulHbvljZulIyRvvAF6aabip/H2ml5XmPodQDAH9ApoiS+Hy6MjJG2bZPWrpV+/euZZ4ljY9LOncXOZOV5/NsOQHkQiihJY+NihflrNDYmDQ1JX/7yzDPFlhbpi1+c2UIthu/HuRwcQNkQiijJ/PmrFQSJose1tEiplPTcc1I+L6XT0gsvSN3dxc0Tj/9J0bUB4JMQiihJIrFa1k6FGrt9u7R370y3uHnzzPnErVuLmcFTMvn5ULUB4GJ4GIOSRKOdCoImGTNe9NienpmzimEFQULJ5M3hJwCAP0KniJJ4nqeOjq3y/VgNagdqbb216nUBfHYRiihZR8c9VT8r6HlRdXTcF/rtVwC4GEIRJYtGF2vhwk3yvGjVanpegzo7761aPQD1gVBEWSxd+gMFQbg7UIvl+03q6flnRaOpqtQDUD8IRZRFY+Nl6u19JvTl4LPXoETiGqVSd1e4DoB6RCiibNrablNn57crGIyBIpF2XXXVLg7sA6gIQhFl1d39iDo6/rICwdioSCSlVateVSTSXua5AWCGZ/nEACrg1Kl/0e9/v03GTEgyJc3l+01qbv6cVqz4JYEIoKIIRVRMNntMhw/fofHx3ymfTxc9fubsY6CenseUSm1hyxRAxRGKqChrjYaHn9PAwKNKpw/KWiNrJy4xwlcQNBWOXHxbHR3fUjS6uGrrBVDfCEVUTTb7js6d+5XOn39FY2P7NDU1JGunNROEccXjK5RMrlVLy1q1tv6pfJ9bCAFUF6GImrLWsi0KwBm8fYqaIhABuIRQBACggFAEAKCAUAQAoIBQBACggFAEAKCAUAQAoIBQBACggFAEAKCAUAQAoIBQBACggFAEAKCAUAQAoIBQBACggFAEAKCAUAQAoIBQBACg4P8BE44yWQnzR6QAAAAASUVORK5CYII=\n",
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAcUAAAE1CAYAAACWU/udAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMi4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvIxREBQAAIABJREFUeJzs3Xd4VNXWx/HvnCnJpJCE3kMNJCA1BEEpigUUpGuiIoKCvCqKBAtXLNer2BARFJEiqGACAakWQGlKCwQInQBKDSUQSG8zc94/gAhSzEymZWZ97pPnGsjea6mYX/Ype2tUVVURQgghBIqrGxBCCCHchYSiEEIIcZmEohBCCHGZhKIQQghxmYSiEEIIcZmEohBCCHGZhKIQQghxmYSiEEIIcZmEohBCCHGZhKIQQghxmYSiEEIIcZmEohBCCHGZhKIQQghxmc7VDQjhDlRVZffZ3WxJ3cL64+tJSk0ipygHVVXx1/vTslpL7qh1B21qtKF5leZoNBpXtyyEcACNHB0lvFl2YTbfJX/Hxxs+5mzOWQByinJu+LV+ej80aChvLM/L7V/mieZPEOQb5Mx2hRAOJqEovJKqqnyb/C3Dfx6ORbXcNAhvxl/vD8C4+8bxTOtnZOUohIeQUBRe53T2aR5d8CiJJxOtDsN/8tf707xqc+L7xlMrqJadOhRCuIqEovAqB88f5M6Zd5Kel47JYrLLnDpFRzlDOdYNWkeTyk3sMqcQwjUkFIXXOHLxCJFTI0nPS0fFvn/sNWgI8gli85DNhFUIs+vcQgjnkVAUXiHflE/4F+EcyziGRbU4pIYGDVUDqnJw+EH8Df4OqSGEcCx5T1F4hTGrxnA256zDAhFAReVi/kVGLh/psBpCCMeSlaLweFtTt9JxZkfyTHlOqWfUGVn++HI6hHZwSj0hhP3ISlF4vP/89h+nBSJAnimPV3991Wn1hBD2I6EoPNqJzBOsO7rO6XW3n97OwfMHnV5XCFE6EorCo03eMtm2gWnALOB94DNgn3XDzRYzExMn2lZbCOEyEorCoy1LWUaBucC6QWYgDggDXgV6AD8A50o+RZGliJ8P/mxdXSGEy0koCo9ltphJOZ9i/cBzQBbQjkv/hdQDagE7rZvmWMYx8k351tcXQriMhKLwWCnnU9Br9fab8Kx1X27UG9l1Zpf96gshHE5CUXisU9mn0Gq01g+sCPgD67l0KfUQcAQosm4aDRpOZ5+2vr4QwmXkPEXhsQrNhbYN1ALRwM9cCsbqQBOs/q9FRbX+fqYQwqUkFIXHMmgNtg+uCgy66vPpQAvrptCgwUfrY3sPQgink8unwmNVC6iGWTXbNvg0ly6XFnJptZiN1aGoolI1oKpt9YUQLiErReGxwiqEUWS28kbgFTuBbVy6pxgKDMDq/1ryivJoVqWZbfWFEC4hoSg8llbRElYhjF1nbXgC9L7LH6VQO6g2Pjq5fCpEWSKXT4VHe6jRQy65r6dX9HRr2M3pdYUQpSOhKDzasMhhLqmrVbS8EPWCS2oLIWwnoSg8Ws1yNekY2tHpdVtWbUnDCg2dXlcIUToSisLjvd/lfYw6o9PqGXVGPrr3I6fVE0LYj4Si8Hitq7fmuajn8NP7ObyWUWdkYPOB3Fn7TofXEkLYn0ZVVdXVTQjhaAWmAsK/COdoxlEsqsUhNTRoqBZYjZTnU/A3+DukhhDCsWSlKLyCj86HVQNXEeIbgqKx/x97DRqCfIJYPXC1BKIQZZiEovAadYLrsOnpTVT0q4hesd/pGTpFR4gxhPVPrSesQpjd5hVCOJ+EovAqDco3IHlYMp1CO+GvL/2Kzl/vz+01byd5WDIRlSLs0KEQwpXknqLwSqqq8l3ydwxaMAi9Xk+Bat1pFlcCdfz94xnSaggajcYRbQohnExWisIraTQaKpysQKMljZjQbQL1Qurhr/e/5erxyu+HBoXy4T0fkhqbytDWQyUQhfAgslIUXslisRAZGcmYMWPo06cPqqqyN20vW1K3sOH4BrambiWnMAcVFX+9Py2rteSOWncQWT2SZlWaSRAK4aEkFIVXWrBgAWPHjmXr1q0ScEKIYm4biqp66dRyRaOgV/TyjUvYjdlsplmzZowbN45u3WTTbiHE39zm6Ki/LvzFwv0LWXNkDVtTt3I6+zSKRkFFRdEo1A2uS/ta7elcpzN9wvtQzqecq1sWZVRcXBzBwcF07drV1a0IIdyMS1eKqqqy/PByPvjjAzaf3Fy8OryVAH0AZtVMdNNoRrUfJY/BC6sUFRURHh7OtGnTuOuuu1zdjhDCzbgsFE9mnmTAwgFsObmF7KJsq8frFB16Rc9zUc/x7l3vymGuokSmT59OXFwcv/32m6tbEUK4IZeEYvzueIYsHUK+KR+TxVSqufx0flQOqMzSmKU0rdzUTh0KT1RQUEDDhg2ZO3cu7dq1c3U7Qgg35PT3FD/d9CmDFw8muzC71IEIkGvK5cjFI7Sf0Z7Ek4l26FB4qmnTptGsWTMJRCHETTl1pThl6xRiV8SSW5TrkPkDDYH8Puh3mldt7pD5RdmVm5tLgwYNWLZsGa1atXJ1O0IIN+W0leL2U9sZuXykwwIRIKswi25zujm0hiibvvjiC9q3by+BKIS4JaesFAvNhUR8EcHhC4cdXar4kNcvu3/p8FqibMjMzKRBgwasWbOGiAh5WlkIcXNOWSm+t+49TmWfckYp8kx5fJP8DZtPbHZKPeH+PvvsM+6//34JRCHEv3L4SrHAVECljyuRVZjlyDLX0KDhwbAHWRqz1Gk1hXtKT08nLCyMTZs20aBBA1e3I4Rwcw5fKS7YtwAV5771oaKy8vBKTmU5Z3Uq3Ne4cePo3bu3BKIQokQcvs3b+I3jyS60/uV8FgB/AYVAAHAH0LrkwzVomLVjFqM7jLa+tvAIZ8+e5auvvmL79u2ubkUIUUY4dKVospjYdXaXbYM7ACOA/wAxwCogteTD8835rPhzhW21hUf44IMPeOyxx6hdu7arWxFClBEOXSnuP7cfg9ZAobnQ+sGVr/przeWPdKB6yadIPp1sfV3hEU6cOMGsWbPYs2ePq1sRQpQhDg3FHad3lG6CZcAOwARUBRpaNzy3KJe0nDQq+VcqXR+izHnvvfd4+umnqVatmqtbEUKUIQ4NxQt5FygyF9k+QXfgAeA4cASru9Vr9VzMvyih6GX++usv5s2bR0pKiqtbEUKUMQ6/p1jqJ08VIBTIBLZYN1SDhiJLKUJZlEnvvPMOzz//PBUqVHB1K0KIMsahK0VfnS9ajdY+k1mAC1YOUS346nztU1+UCQcOHGDZsmUcPHjQ1a0IIcogh64U64XUQ6/VWz8wG9gFFHApDA8Bu4G61k1TaC6kRmAN6+uLMuutt95i5MiRBAcHu7oVIUQZ5NCVYuvqrck35Vs/UANs5dKDNioQDHQFGls3TWhwqBw+7EV27tzJmjVrmDFjhqtbEUKUUQ4NxYp+FQk0BHI+77x1A/2BQaWv37Jiy9JPIsqMN998k9deew1/f39XtyKEKKMcvs1b3/C+6DQO3zjnOjqzjh8/+pG77rqLyZMnc/r0aaf3IJxny5YtbN26lWHDhrm6FSFEGebwUBxx+wjb7iuWUkhgCGf+OMOLL77Ihg0bCA8Pp1OnTnz++eecOiV7onqaMWPGMGbMGHx95cEqIYTtHB6K4ZXCaVK5iaPLXMOoMzLi9hEE+AfQq1cvZs+ezalTp4iNjWXz5s1ERETQsWNHJk2aRGqqFXvHCbe0bt06Dh48yODBg13dihCijHPKIcNbTm6h06xO5JnyHF0KgCr+VTj0wiECDAE3/P2CggJWrFjB/PnzWbp0KREREfTv359+/fpRo4Y8rVqWqKpKp06deOqppxg4cKCr2xFClHFOCUWA2BWxTNkyhVxTrkPrGHVGfnz0R+6qe1eJvr6goIBff/2VhIQElixZQnh4eHFA1qxZ06G9itJbuXIlw4cPZ/fu3eh0zr93LYTwLE4LxQJTAU2/bMqRi0cwWUwOqeGn92NAswFM6T7FpvGFhYXXBGSjRo3o378/ffv2lZMW3JCqqrRt25bY2FgeeeQRV7cjhPAATgtFgFNZp4icGsnZ3LN2D0ajzsjdde9mcfRitErpd9EpLCxk1apVJCQksHjxYho0aFC8ggwNDbVDx6K0lixZwhtvvMH27dtRFIffHhdCeAGnhiJAalYqd359J6ezT9vtHqO/3p9uDbsR1zcOnWL/S2hFRUXFAblo0SLq169fHJB16tSxez3x7ywWCy1btuR///sfDz30kKvbEUJ4CKeHIkBOYQ4jV4zku+TvShWMOkWHj9aHCV0n8FTLp9BoNHbs8saKiopYvXo18+fPZ+HChdSpU4f+/fvTv39/6ta1ch86YbN58+Yxbtw4Nm/e7JR/70II7+CSULxi3dF1DFo8iDPZZ8gtyi3xiRoGrQFFo9CxdkemPzSdWkG1HNzpjZlMJtasWUNCQgILFy6kdu3axQFZr149l/TkDUwmE02bNmXixIncd999rm5HCOFBXBqKcOlhiQ3HN/Dxho/56eBPxXuVZhdmF3+NggJFoPfR46P3YUirITzX5jnqhrjPysxkMrF27Vrmz5/PDz/8QI0aNYoDskGDBq5uz6N88803zJgxg7Vr18oqUQhhVy4PxauZLCb2pu0lKTWJvWl7ySrMQqfoCPENYdOiTXRs2JExz49x+2+EZrOZdevWkZCQwA8//EC1atWKA7Jhw4aubq9MKywspHHjxsyaNYuOHTu6uh0hhIdxq1C8lcmTJ7Njxw6mTp3q6lasYjab+f3334sDskqVKsUP6TRq1MjV7ZU5X331FT/88APLly93dStCCA9UZkJxw4YNjBgxgsTERFe3YjOz2cz69etJSEhgwYIFVKxYsXgF2bixledieaH8/HwaNmzIggULiIqKcnU7QggPVGZCMSsri6pVq5KRkeERO5dYLJZrArJ8+fLFARkeHu7q9tzShAkTWL16NYsXL3Z1K0IID1VmQhEgLCyMRYsWERER4epW7MpisbBhwwbmz5/P/PnzCQoKKg7IJk2cu5m6u8rOzqZBgwasWLGCZs2aubodIYSHKlPbgLRo0YIdO3a4ug27UxSFO++8kwkTJnDs2DGmTZtGRkYGXbt2JSIigrfeeovdu3dThn5+sbvPP/+czp07SyAKIRyqTK0Ux44dy8WLF/noo49c3YpTWCwWNm/eTEJCAvPnz8ff359+/frRv39/brvtNrd/CtdeMjIyaNCgAb///rvcexVCOJSsFN2Yoii0a9eO8ePHc/ToUWbNmkVeXh49evSgcePGjBkzhuTkZI9fQY4fP54HH3xQAlEI4XBlaqWYmppK8+bNOXv2rNeskm5EVVW2bNlSvILU6/XFK8gWLVq49T+b1KxUNp3YxOYTm1l/fD3peemYLCZ8db6EVQijY2hHIqtHElk9EoPWwLlz52jUqBFbt26VbfSEEA5XpkJRVVWqVKnC9u3b5TDgy1RVJSkpiYSEBBISEtBqtcUB2bJlS7cISItqYfmh5Xy0/iM2ndyEQWsguyAbC5brvtZX54tBa0CDhmGRw8j4NQMy4Msvv3RB50IIb1OmQhHgvvvu48UXX+TBBx90dStuR1VVtm3bVhyQQPFTrK1atXJJQCalJvHw/Ic5m3P2mq37SsKgNVBYUMjA2wYyufdk/PR+DupSCCEuKXOh+MorrxAUFMTrr7/u6lbcmqqqbN++nfnz55OQkIDZbC5eQUZGRjo8IAvNhYxZNYbPEz8v9RFhRp2R8sbyJPRPoF2tdnbqUAghrlfmQvH7779n4cKFxSsh8e9UVSU5Obl4BVlUVFQckG3atLF7QOYW5dJtdje2ntpKblGu3eb10/sxq+cs+jfpb7c5hRDiamUuFPfu3UvPnj05ePCgq1spk1RVZefOncUBmZ+fXxyQbdu2LXVAFpgK6PJtF5JOJZFvyrdT138z6ox83/d7ejXuZfe5hRCizIWiyWQiKCiI06dPExgY6Op2yjRVVdm9e3dxQObk5FwTkIpi/Rs7gxYNYu6euaW+ZHorfno/Nj+9maaVmzqshhDCO5W5UASIiori9Q9eJ7heMHmmPLQaLeV8ytG0clP8Df6ubq9MUlWVPXv2FAdkVlYWffv2pX///rRr165EAbny8Ep6ze1l10umN6JBQ6OKjdg5bCd6rd6htYQQ3qXMhGJeUR7xu+OZlTyLjX9tRFVU/H3+DkAVldyiXKoFVKND7Q482+ZZ2tdq7xavJJRFe/fuLQ7IixcvFgdk+/btbxiQ2YXZ1P2sLudyzzmlPz+9H6/e8SpvdnrTKfWEEN7B7UPxfO553l77NjO3z0Sj0ZTosX4NGvz0flT2r8wbHd9gYIuBKJoytXmPW9m3b19xQKanp18TkFqtFoBJmyfx2m+vOXyVeDV/vT9nXz4rr2oIIezGrUNx8f7FPLnoSXJNuRSaC22aw1/vT9PKTYnvF0+d4Dr2bdAL7d+/v/g1j7S0NPr06UO/fv0YsH0AJzJPOLUXf70/n3X9jKdaPeXUukIIz+WWoVhkLuLJRU+y6MAiu6w8tBotPjofvun1Df0i+tmhQwGQkpJCQkICM1fN5M/b/0Q1WPFH6b1/fG4C2gAPWNdDWIUwDjx/wLpBQghxE24XioXmQrp/350/jv1h9ycYjTojkx+YzJMtn7TrvN7u9d9e54M/Prjhtm0lUgCMAx4D6lg3VK/oSXs5jSDfINtqCyHEVdzqRpuqqkTPj2b9sfUOeaQ/z5THsz89y6L9i+w+tzdbe3St7YEIsA/wB0KtH2rUG9l2apvttYUQ4ipuFYozd8xkxeEV5Joc97BGnimPJxY+wens0w6r4W12nd1Vugl2AM0BGx4UzjflszV1a+nqCyHEZW4TiiczT/LiLy+SU5Tj8Fr5pnwGLBzg8ecQOoNFtZBZkGn7BBeBo0AL24YXmgs5lnHM9vpCCHEVtwnFZ3981iHbgt1IkaWIjcc38uPBH51Sz5MVmYvQarS2T5AM1AZCbJ/CkbvnCCG8i87VDcClg2eXH16OyWJyWs2cohzG/j6W7mHdnVbT3ZnNZjIyMkhPT+fChQv/+pGenk76hXTMT5ptuvQJXArFO0vXt1FnLN0EQghxmVuE4pStU1yy88z209s5eP4gDSs0dHptR7kSbDcLsVuFXHZ2NoGBgYSEhNzwo3z58tSvX5/y5ctf8+vN45uTXWTdWYkAHAOygCa2//0atAZqBdWyfQIhhLiKW4TijG0zrL90uplLD2icBZoCva2va7KY+G7nd7xz1zvWD3Ygi8Vi9Yrtyl9nZWVdE2z/DLArwXaj0AsKCireocYazao2Y8PxDdb/jSYD4YCP9UOvMOqMRFaPtH0CIYS4istD8WL+RdJy06wfGAh0BA4DRbbVNllMrD6y2rbB/+JKsNmyYsvKyiIgIOCWK7Z69erZNdhKo1NoJzad2IRFtfK1jB6lr51blEuraq1KP5EQQuAGobjt1Db89H5kFGRYNzDi8v+nYnMoAuw6c/PXCSwWC5mZmSUKsn9+TWZm5i0vRYaEhFC3bt0bruhcEWylcW+9e5mUOKlE+9LaW2hwKMG+wU6vK4TwTC4PxT1n91BgLnBZ/ez8bAYOG0heet51IZeZmYm/v/91q7SrP69Tp84NAy84OLhMBVtpdK7TmSCfIKeHYoA+gJfbv+zUmkIIz+byUMwuzKbIXIqlXikpGoWwpmE0qNTghpcidTqX/yNyexqNhlHtR/H6qtedekqGBQuP3faY0+oJITyfy7/jq5f/5yoGvYHHH3+c0GAb9hgTxQa3HMy76951Wij66f2IbRcrh0oLIezK5S/vBxgC0CuuOz3dZDHJN1Y7KOdTjtl9ZjvlbEMNGmoE1uCNjm84vJYQwru4PBQjKkXgo7PhmXwzlx6wUS9/FF3+NSsZtAYqGCtYP1Bcp2uDrvRu3NvhL9OrRSqDAwej17ruhykhhGdy+eXTVtVa2ba92zpg7VWf7wQ6AXdZN81tVW5zycYBnmr6Q9M5lH6I5NPJ5Jvtv22fUWfkv23+y+TnJpNxIIN3333Xax5oEkI4nlucp1h1XFXO5Jxxel2douOV9q/wXpd/nngrSiO7MJv7v7uf7ae323VfUj+dH9Mfmk7MbTGcO3eO/v374+/vz5w5cwgKkvMUhRCl5/LLpwCDWgzCR1uKbU1spFN0DGg+wOl1PV2AIYBVA1cxtPVQu1xK9dX5UtW/Kj8//jMxt8UAULFiRVasWEFoaCi33347Bw8eLHUdIYRwi1B8Luo5l9Q1nTQRNymOs2fPuqS+J/PR+TCh6wRWDVxFrXK18NNa/wCOQWvAV+fLgGYDOPTCITqGdrzm9/V6PV988QUvvfQSd955J8uXL7dX+0IIL+UWoVizXE3uqnMXOsV5tzj99f582vdTzpw5Q+PGjRkyZAj79u1zWn1vcXvN2/nzxT9pe7ItoZpQfHW+BBoC0dzkWA2D1kA5n3IEGAJ4rs1z7H12L1N7TL3lE8JDhw5l/vz5DBo0iPHjx8s5mUIIm7nFPUWAoxeP0mRyE6ccMqxTdLSv1Z41A9eg0WhIS0tjypQpTJ48mZYtWxIbG8vdd98tD+DYSVpaGmFhYRw6dIgcXQ4bj29k08lNrD+2ngv5FzCZTfjofGhYviEdQzsSWT2SdrXa4avztarOsWPH6NmzJ82aNeOrr77C19e68UII4TahCPDlli95eeXLDg/GAH0A+57fR81yNa/59fz8fObMmcP48ePR6/WMHDmS6OhoDAaDQ/vxdGPHjuXw4cPMmDHD4bVycnIYPHgwR44cYeHChVSvXt3hNYUQnsOtQlFVVbrN6ca6o+scdpq6n86PGT1nEN00+pZ9LF++nE8++YS9e/cyfPhwnnnmGUJCSnE8vJcymUzUrVuXJUuW0LJlS6fUVFWV999/n8mTJ7NgwQLatm3rlLpCiLLPLe4pXqHRaFgUvYjW1Vo75AVwP70fH9/78S0D8UofXbt2ZeXKlfz000/s37+f+vXrM3z4cA4fPmz3vjzZ4sWLCQ0NdVogwqV/f//5z3/48ssv6dGjB99++63Tagshyja3CkW49Pj9r0/8yn3177PblmGKRsGoMzL5wck8G/WsVWObN2/OrFmz2L17N4GBgdx+++307duX9evXywMdJfD5558zfPhwl9Tu0aMHa9as4Z133iE2NhaTyeSSPoQQZYdbXT69mqqqxO2OY9iyYeSb8imy2HaShr/enwblGzC331waVWxU6r5ycnKYNWsWn376KRUrViQ2NpbevXvLaRo3sGvXLrp27cqRI0fQ6123JVt6ejqPPPIIiqIQHx8vl8GFEDfltqF4xZnsM4z+bTTxu+NRNEqJH8IJMAQQaAjkPx3+w/9F/h9axb5bgZnNZpYsWcL48eM5ceIEL774Ik899RSBgYF2rVOWPfPMM9SoUYM333zT1a1gMpl4+eWXWbZsGUuWLCE8PNzVLQkh3JDbh+IVmQWZfJv8LbN2zGJv2l40Gg16RV987JQGDXmmPIJ8gri95u0MjxpOl3pdUDSOv0KcmJjIJ598wm+//cbgwYMZPnw4tWrVcnhdd3bhwgXq1avHvn37qFq1qqvbKTZr1ixeeeUVvv76a7p37+7qdoQQbqbMhOLVVFXlzwt/knI+hTxTHlqNlnI+5WhetTnljeVd1teRI0eYOHEi33zzDV27diU2NpZWrVq5rB9XGj9+PElJScyZM8fVrVxn48aN9OvXj+eff57XXntN3kcVQhQrk6Ho7jIyMpg2bRoTJ06kfv36jBw5kgcffBBFcbvnmhzCYrHQsGFD5syZw+233+7qdm7o5MmT9O7dm/r16zNjxgz8/Bx/DqQQwv15x3dpJwsKCmLUqFEcPnyYoUOH8t///peIiAi++uorcnOdczK9K/3888+EhIS49fuBNWrUYO3ateh0Ojp06MDx48dd3ZIQwg1IKDqQXq8nJiaGLVu28NVXX/HTTz9Rp04d3nzzTc6ccf5RWc4yadIkhg8f7vaXJY1GI99++y0xMTG0bduW9evXu7olIYSLSSg6gUajoVOnTixevJg//viDtLQ0wsPDefrpp9mzZ4+r27OrlJQUtm3bxiOPPOLqVkpEo9EwatQovv76a3r37s306dNd3ZIQwoUkFJ0sLCyML7/8kpSUFOrUqcM999xDt27d+PXXXz1iM4AvvviCp59+usxtxt21a1d+//13xo0bx/Dhwykqsu29WCFE2SYP2rhYfn4+33//PePHj0er1TJy5EhiYmLK5CbkWVlZhIaGkpycXGZfSbl48SKPPvoo+fn5JCQkUKFCBVe3JIRwIlkpupivry+DBw9m165dfPTRR8yZM4e6devy/vvvk56e7ur2rPLdd99x1113ldlABAgODmbp0qW0adOGNm3asGvXLle3JIRwIlkpuqGdO3fy6aefsnjxYh599FFGjBhBgwYNXNpTobmQszlnyTflo1f0lDeWJ9Dn7917VFWlSZMmTJ48mc6dO7uuUTuaM2cOI0aMYOrUqfTu3dvV7QghnEBC0Y2dOnWKzz//nKlTp9KhQwdGjhzJHXfc4ZSnOk0WEz+m/MgP+39g4/GNHLl4BL1Wj6JRUFWVQnMhFf0qElk9km4NulE9vTpjRo1h586dbv/UqTW2bt1K7969GTJkCGPGjPGad02F8FYSimVATk4O33zzDZ9++inly5cnNjaWPn36OGQT8ov5F5m4eSITN0+k0FxIVmHWv47x0/uRX5BPlF8UM5+aSeOKje3elyudOnWKvn37Ur16dWbNmkVAQICrWxJCOIiEYhliNptZunQp48eP59ixY8WbkJcrV84u8/908CcGLBxAblEu+aZ8q8drNVoMWgOj7xzN6A6j0Smec3JIQUEBzz77LFu3bmXx4sXUqVPH1S0JIRxAQrGMSkxMZPz48axcuZLBgwfzwgsv2PyAS4GpgMGLB7PowCJyi0q/446/3p/aQbX55fFfqB1Uu9TzuQtVVZk0aRJjx44lPj7eY+6dCiH+JjdIyqioqCji4+PZtm0bFouFFi1a8Oijj5KUlGTVPPmmfO797l4W7l9ol0AEyCnKIeWuKmHNAAAgAElEQVR8Cq2ntubg+YN2mdMdaDQaXnjhBWbPns0jjzzC5MmTPeLdUiHE32Sl6CEyMjKYPn06n332GXXr1iU2Npbu3bvf8sEQk8VEt9nd+OP4HzZdLv03GjRU9KvItme2UbNcTbvP70qHDx+mZ8+e3HHHHUyaNKlMvlcqhLiehKKHKSoqYsGCBXzyySdkZmby0ksv8cQTT9zwFIixv4/lvd/fs9sK8Ua0Gi2R1SPZ8NQGp5xt6UxZWVk8/vjjXLhwgfnz51O5cmVXtySEKCXP+i4l0Ov1REdHk5iYyLRp0/jll1+oU6cOb7zxBqdPny7+un1p+3h33bsODUQAs2pm99ndTNk6xaF1XCEwMJCFCxfSqVMnoqKi2L59u6tbEkKUkqwUvUBKSgoTJkwgPj6e3r1789JLLzHgjwEkn0lGxTn/+v30fvz5wp9UCajilHrOlpCQwLPPPsvnn39eZjZDF0JcT1aKXiAsLIzJkydz8OBB6tWrR+dHO7MzdafTAhHAolr4Kukrp9Vztv79+7Ny5UpeffVVxowZg8VicXVLQggbyErRCz0872Hm75vv1FAEqGCswOlRpz3q/cV/Onv2LP369SM4OJjZs2fb7R1SIYRzyErRy+QV5bEkZYn1gWgCFgOfAmOBLwEr37YoNBey6q9V1g0qYypXrsyvv/5K9erVadeuHYcOHXJ1S0IIK0goepmdZ3bio/OxfqAFKAc8CbwG3A0kABdKPkVeUR4bj2+0vnYZYzAYmDJlCsOHD+eOO+7g119/dXVLQogSklD0Mkmnkigy23CArgG4Cwjh0p+aRkAwcKrkU5hUE2uOrrG+dhk1bNgw5s2bx4ABA5gwYYK86C9EGSCh6GU2n9xMnimv9BNlA+eBStYN231md+lrlyGdOnVi48aNzJw5k8GDB1NQUODqloQQtyCh6GXO5Z4r/SRmYAHQAqtDMdfk2Pci3VGdOnXYsGED2dnZdO7cmVOnrFheCyGcSkLRy5T6VQEL8AOgBR6wYbjqna8q+Pv7M2/ePB544AGioqLYsmWLq1sSQtyAhKKX8Tf42z5YBZYAOcAjXApGKxm03rtHqEaj4Y033mDSpEk88MADzJ4929UtCSH+QULRyzSv0tz29wSXAWlADKC3bYo6wXVsG+hBevXqxerVq3nrrbd45ZVXMJvNrm5JCHGZhKKXaVOjDX766zcH/1cXgSTgNDAOeO/yx07rpulQu4P1tT1Q06ZNSUxMJCkpiR49enDx4kVXtySEQHa08TppOWnU/LQmheZCp9fWFGronN2Zl+55iS5dutzw5A5vU1RURGxsLMuXL2fJkiU0atTI1S0J4dVkpehlKvlXokmlJi6pbfA1cHftuxk/fjxVq1alR48eTJ06lZMnT7qkH3eg1+uZOHEir7zyCh06dOCnn35ydUtCeDVZKXqhubvnMmTpELIKs5xWU9EoPBzxMHH94gC4cOECv/zyC0uXLuWXX36hbt269OjRgx49etCyZctbHo7sqdavX0///v0ZMWIEL7/8MhqNxtUtCeF1JBS9UKG5kCrjqnAx33n3sfz0fqx9ci2R1SOv+z2TycT69etZunQpS5cuJTs7mwcffJAePXp43WXW48eP06tXL8LDw5k2bRpGo9HVLQnhVbzvx3GBQWvgiwe+wF9fitczrOCj9aF7WPcbBiKATqejU6dOjBs3jgMHDrB69WoaN27slZdZa9Wqxe+//47FYqFjx46cOHHC1S0J4VVkpeilVFWl25xurPprFUUWG/ZCtUKIbwiHXzhMiDHE6rG3uszaqlUrj73EqKoqH330ERMnTmT+/Pm0a9fO1S0J4RUkFL3YmewzNJnchPS8dIedrWjUGVn4yELub3B/qefyxsusP/74I4MGDeLDDz9k0KBBrm5HCI8noejl9qbtpf2M9mQWZNo9GI06I5MfnMyTLZ6067xXpKSksGzZMpYuXUpSUhKdOnWiR48ePPjgg9SoUcMhNV1h37599OzZkwceeIBx48ah03nuIc1CuJqEomD/uf10nNmRzIJMCsylP8VBgwZfnS9f9/ya6KbRdujw33n6ZdYLFy4QExOD2Wxm7ty5lC9f3tUtCeGRJBQFABfzL/Lsj8+y+MBicotsP8nCT+9HneA6JPRPIKJShB07LLkbXWbt3r073bt3L9OXWc1mM6+++iqLFi1i8eLFNGnimvdNhfBkEoriGj8f/JnhPw/ndPZpcotyS3xJNdAQiKJReO3O1xjVfpTt+6s6gKddZv3222+JjY1l+vTp9OzZ09XtCOFRJBTFdVRVZdOJTXyy8RN+OfQLFtWCXqsn35SP2WJG0Sj4aH1AAwWmAlpUbcGo9qPo1biX25+C4SmXWRMTE+nTpw/Dhg3j9ddfLzN9C+HuJBTFLamqyrGMYySdSuLoxaMUmAvQK3oq+lWkVbVWhFcKd6tVoTXK+mXW1NRUevfuTWhoKDNnzsTf3znvnQphC1VVsVjyUdVCNBoDiuLrlj/MSSgKcVlKSgpLly5l2bJl11xm7d69O9WrV3d1ezeUn5/PM888w86dO1m0aBGhoaGubkkIAFTVwoULq0hP/4WMjHXk5OzBYilAo9ECFjQaHX5+4QQFdaB8+fsoX77r5d9zLQlFIW6gLF1mVVWVCRMm8NFHHzF37lw6duzo6paEFzOZMjl1ahrHj3+C2ZyF2ZwLWG4xQoNWG4BG40PNmi9So8b/oddXcFa713cjoSjErZWVy6wrVqxgwIABvPPOOzzzzDOubkd4ofT05ezb9zhmcw4WS57V4zUaXxTFh8aNZ1CpUl8HdFiCHiQUhbCOO19mPXjwID179qRz58589tln6PV6l/YjvIPFUsCBA0+TlvYDFovtr3RdoSh+hIR0ITz8e3S6ADt0WHISikKUwj8vs9arV4/u3bu79DJrZmYmjz32GJmZmcyfP59KlSqVar4rD0hYLAUoigFFMbrV5WPhWmZzLsnJ95Kdvd2m1eHNaDQ++PmF0aLFOvT6YLvN+691JRSFsA93usxqNpt54403iIuLY9GiRTRv3rzEY1XVwsWLqzl//ucbPiABWvz8GhMUdOflByQeQCmjTyCL0rFYCklOvpesrEQslny7z6/RGPDzC6dVq/Votc55ulpCUQgHcYfLrPHx8QwfPpwpU6bQt++t79GYTFlXPSCRacUDEgZq1nyB6tWfxWCoaNf+hXs7fPg1Tp6cZJdLpjejKL5UrhxD48ZfO6zG1SQUhXACV15m3bZtG71792bgwIG8/fbbKMr1x6imp69k375HMZtzbfoGd+kBCQONGk2lUqWH5fKqF8jK2sb27Xfa9ZLpzSiKH7fdtpSQkLsdXktCUQgnKyoqYsOGDdddZu3Rowd33323Qy6znjlzhr59+1KpUiW+/fZbAgMDgUuXvw4ceIa0tHl2e0AiOLgzERFx6HTlSj2fcE+qamHz5kbk5x9yWk29vgrt2h1DURy7a5aEohAu5qzLrIWFhTz33HNs2rSJxYsXExpajZ077ycra6vdH5AwGuvRsuUf6PVymocnSk9fyZ49fTCbs51WU6sNJCxsKlWqOPbkHQlFIdyIoy+zqqrK5MmTGTv2HWbPro5Wu9+BD0iE0bLlRqc/Ui8cLzn5Xi5c+NXpdQMCWhAZud2hNSQUhXBTRUVFrF+/vviEj6svs3bp0gWj0Wjz3KtXD6CwcDY+PnZs+B80Gl8qV+5PePi3jisinK6w8CwbN9ZGVW07e/XECRg8GDp1gtdft26sohiJjNyBn1+YTbVLVMNhMwshSkWv19O5c2fGjRvHgQMHWL16NWFhYXzyySdUqVKFHj16MHXqVFJTU62aNzs7Ga12gUMDEUBV80lLW0B6+grHFhJOlZm5GUWx/Q/PZ59B48a2jtaSmbnR5tolIaEoRBkRFhZGbGwsq1ev5ujRozz66KOsWbOGpk2bEhkZydtvv01SUhK3uvijqip79kQ75JLpjVgsuezb9xhms3PqCcfLzEzEbM6xaeyqVeDvD61a2VbbYskmI2ODbYNLSEJRiDIoJCSEmJgYvv/+e86cOcO4cePIzs7m0UcfpWbNmjzzzDMsW7aMvLxrH6C5eHENhYUnoISHR9uDxZJPWlqC0+oJx8rMXA+YrR6XkwMzZ8Jzz5W2vqwUhRC3YM1l1uPHP7b5p3xbmc3ZHDv2oVNrCscpKkq3adzXX8MDD0Apdx3EZMoo3QT/Qh60EcKDXf006x9//MSMGZno9db/J5+ZCR9/DFu3QlAQPP003HNPyccrih+tWyfi79/E6trCdqqqUlRURF5eHnl5eeTn5xf/9Y0+L8nXREevoFIl617FOHQI3n0Xpk0DvR5mzYKTJ61/0AbAYKhB+/YnrB9YQrJhoRAe7Mpl1piYGM6eXcbevdGA9SvFzz4DnQ5++OHSN7jRo6F+fahbt6QzaMjI2OjVoaiqKgUFBSUKHlvC6mZjFEXBaDQWf/j6+pb48woVKlz3+yEhOwHrXtrfsQPOnIFHHrn0eV4eWCxw9ChMnWrdP0dHv7wvoSiEl8jN3Q4UWj0uLw/Wrbt0+ctohNtug/btYeVKGDq0ZHNYLDlkZKynevWnra7vCBaLhfz8fKeE05XP8/Pz0ev1JQ6nf/5auXLlrAq0K5/rdPb9Nr9v3xLOnLEuFLt3h7uv2qFt7lw4fRpeesn6+kZjQ+sHWUFCUQgvkZGxHiiyetyJE6DVQq1af/9a/fqQnGzdPFlZm2/462az2eagsXVMYWEhPj4+Nq2eLq2WQqwe4+Pjg1artfqfv7sJCrqTtLQFVm0L6Ot76eMKoxEMBgi28kQojUZPcHBn6wZZSUJRCC9RVHTOpnF5efDP7Vj9/SHXyq1ST506SHh4+HVhZTKZbL68FxAQQMWKFa1acV0JKNm03DaBga0vHyNmuyeftG2cohgJDIwsVe1/I6EohNew/jF6uPRT/T8DMDf3+qD8N8HB5ViwYMF1YWUwGCSgypCAgBZoND5AltNrq6qZoKA7HVpDXskQwksoim3bwtWsCWbzpcuoVxw6BHXqWDePwRBAREQEdevWpWrVqgQFBcmKrQzSaLTUrPkiGo3vv3+xXevqqVZtMFqt7dsbloSEohBews8vwqZxRiN06HDpxeu8PNi1CzZsgHvvtXae+jbVF+6nevWhOPtnGY1GS40aLzi8joSiEF4iKOgOFMXfprEjRkBBAfTpc+l9sxEjrHkdA0BHcHAnm2oL92MwVKZmzZdQFPuf/XkjiuJL5cqP4efXwOG15OV9IbxEdvZOtm+/w6ln4F2h0QTQtOlcKlR4wOm1hWNYLIX8/nt9zOYTKA5eXun1VWjb9pBTjiGTlaIQXsLfv6nNK8XSysvLpk+f/zJx4kROnz7tkh6EfX377feMGpUNOPa4FUUx0qTJXKedyymhKISX0GiUy5e8HPugwvV0hIYOYfTo/5KUlER4eDhdunRh+vTppKfbto+mcJ2CggL+7//+j/fff59Zs/6gefNFDvszpShGGjWa4dRL73L5VAgvUlR0no0bazrt6Ci49I2tdett+PtfOkQvPz+fn376ifj4eFasWEGHDh2Ijo6mZ8+eBAQ4ZzUgbHPixAn69etHtWrVmDVrFkFBQQCkp69g9+4+WCx5gMUOlTQoipHGjWdRuXJ/O8xXcrJSFMKL6PUVqFXrVac9IKHR+FKp0sPFgQjg6+tLnz59mDdvHsePHyc6Opq4uDhq1KjBww8/zMKFC8nPl/MX3c2aNWuIioqiZ8+eLFiwoDgQAcqXv4/IyB0EBLQo9SV6RfHDaAyjVatNTg9EkJWiEF7HYiliy5bbyMtLwdHnKur1lS4/IFHuX782PT2dBQsWEB8fz/bt23nooYeIjo6mS5cu6PV6h/Ypbk5VVcaPH8/HH3/Md999x723eBdHVS2cODGRI0feAixWPdSlKAGASq1arxAaOhpFcc2/cwlFIbxQdvYutm273ar9K62lKEZuu20ZISF3//sX/8OpU6dISEggLi6Ow4cP07dvX6Kjo+nQoQOKox91FMWys7N56qmnOHz4MAsWLCA0NLRE4yyWQtLSfuD48Y/IydmFovhhsRShqn8feq3R+KAoPlgseRiNDahV6xUqV37E4S/n/xsJRSG8VHr6r+ze3dMhwagoRsLCplC16hOlnuuvv/5i7ty5xMfHc+7cOR5++GFiYmKIjIyU3XAc6MCBA/Tp04fbb7+dL774Al9f23awMZtzyc5OJisriYKC45jNuWi1fhgM1QgMjCQgoIXTniwtCQlFIbzYhQur2LXrocsP3ti2N+q1NCiKL40afU2VKtF2mO9a+/btIz4+nri4OCwWC9HR0URHR9O0aVO71/JmixYtYujQobz77rsMGTLEq374kFAUwsvl5f3J3r3R5OTsxWKx/gDiKwoKFIKD69OkyXwCAprZscPrqarK9u3biYuLY+7cuQQFBRUHZP36sp2crcxmM2+88QazZ89m/vz5REVFubolp5NQFEKgqhZOnvyCv/56EzBjNpf8BIQrD0isXBlMvXpvMWjQEIf1eSMWi4WNGzcSFxdHQkICoaGhxMTE8PDDD1OjRg2n9lKWnTt3jkcffRSTyUR8fDyVK1d2dUsuIaEohChmsRRy7twijh37kJycnSiKH7m5mfhctWnJ1Q9I+PrWp3btl6lcOZpt2/bQs2dP9u/fT7ly//60qSOYTCZWr15NXFwcixYtolmzZkRHR9OvXz8qVqzokp7KgqSkJPr27csjjzzCe++9h07nvacKSigKIW7IbM4jLW0jL7zQlfffH4nFkoei+F5+QKL15QckAq8ZM2jQICpXrsyHH37ooq7/VlBQwPLly4mLi+Pnn3+mXbt2xMTE0KtXL5eFtjv6+uuvefXVV5kyZQp9+/Z1dTsuJ6EohLipnTt3EhMTw549e0r09adOneK2225j48aNNGzY0MHdlVxOTg5Lly4lLi6ONWvWcM899xAdHU337t0xGl37CsCtmEzZZGdvJysricLCk5jN+Wi1vvj41CQgoHWpntwsKCjghRdeYO3atSxcuJDw8HA7d182SSgKIW5q8eLFTJs2jWXLlpV4zIcffsiGDRtYvHixAzuz3YULF1i0aBFxcXEkJibSvXt3YmJiuPfeezEYDK5u7/IKfR7Hjn1EXl7K5Xf8ClDVguKvURRfNBoDFksufn6NqVXrFSpV6o9WW7LXJo4fP06/fv2oWbMmM2fOlJXzVeQtWCHETf3111/Ute7gREaMGMGePXtYsWKFg7oqnZCQEAYNGsSKFSs4cOAA7dq144MPPqB69eoMHTqUVatWYTbb4/UU61gsJo4eHcuGDZU5ePB5cnP3oqomzObMawLx0tfmX/51Ezk5uzl48Fk2bKjMsWMfoqq37n3VqlVERUXRp08f5s+fL4H4D7JSFELc1IsvvkhoaCgjR460atySJUsYPXo0O3bsKDNbtB07dox58+YRFxdHampq8SYBbdu2dfh7ejk5e9iz52Hy84+W6rUYRfHHaKxHRMS8a/abhUuvsYwbN45PPvmEOXPm0KVLl9K27ZFkpSiEuClbVooAPXr0oEaNGkyZMsUBXTlG7dq1GTVqFElJSaxdu5YKFSowaNAg6tWrx+jRo0lOTsYRa4i0tEUkJUWRm7uvVIEIYLHkkJOzh6Sk1pw79/cl76ysLB5++GHmzZtHYmKiBOItyEpRCHFTt912G9999x0tWrSweuyePXu466672Lt3b5l9HUJVVXbu3El8fDzx8fH4+voSExNDdHQ0YWFhpZ7/7Nn57N//xOUjl+xLUYxERMRz7lwYffr04Y477mDSpEk2b9fmLSQUhRA3pKoqgYGBnDx58ppjgqzxwgsvYDKZmDx5sp27cz5VVdm8eTNxcXHMmzeP6tWrF28SULt2bavny8jYQHLyPQ4JxCtU1cB//mPkqafG8fTTTzusjieRUBRC3FBaWhqNGzfm/PnzNs+Rnp5OeHg4K1eupFkzx2795kxms5m1a9cSHx/PDz/8QOPGjYmJiaFfv35UqVKlBONz2by5IYWFqQ7vVaOpwp13Hinxk6neTu4pCiFuyNb7iVcrX748b731FiNGjHDI/ThX0Wq13H333UydOpXU1FRGjx7Nxo0badSoEffddx9ff/01Fy9evOn4w4dHYTJdcEqvGk0mf/452im1PIGEohDihuwRigBDhw4lLS2NhQsX2qEr92MwGHjwwQeZPXs2qampDBkyhB9//JHQ0FB69uxJfHw8OTl/P0CTn3+U06dnOvSy6dUsljxOnZpCQcFJp9Qr6yQUhRA3ZK9Q1Ol0TJgwgdjYWPLz8+3Qmfvy8/Ojf//+LFiwgGPHjtG3b1+++eYbatSoQUxMDIsXL+bo0c9QVYtT+1JVlZMnv3RqzbJKQlEIcUP2CkWALl260LJlS8aPH2+X+cqCoKAgnnjiCX7++WcOHTpEp06dmDjxEw4f/hRVLXRqL6paQGrqF1gsRU6tWxZJKAohbsieoQgUvzh+8qT3XcarWLEiw4YNY8GC/xEQEPjvA25i1SoYOBC6dYPHHoOdO0s+VlUtZGVttbm2t5BQFELc0J9//mnXUKxXrx7PPPMMo0d770MfWVlJNq8St26FqVPh1Vfhxx9hwgSoVq3k4y2WIrKykmyq7U0kFIUQ1zGbzRw/fpzQ0FC7zjt69Gh+++03Nm3aZNd5y4qLF9det49pSc2aBQMGQEQEKApUqnTpo6RUNY+MjHU21fYmEopCiOucPHmSihUr2n33k8DAQN5//31efPFFLBbnPmziDvLyUmwaZzbDgQOQkXHpsmn//vDZZ1BgZb7m5u63qb43kVAUQlzH3vcTr/b4448DMHv2bIfM784sFtuevr1wAUwmWLsWJk6E6dPh4EH47jtr69u2SvUmEopCiOs4MhQVRWHixImMHj2arKwsh9RwXzqbRvn4XPr/3r2hQgUICrq0Wty82bp5NBqtTfW9iYSiEOI6jgxFgLZt23LPPfcwduxYh9VwRzpdsE3jAgMv3T+8+gQrW06z0ulCbKrvTSQUhRDXcXQoArz//vtMmzaNw4cPO7SOOzCZTCQnJ3P8eDlsvZXatSssXHjpUmpWFsyfD+3aWTODQlDQHbYV9yISikKI6zgjFKtXr05sbCyjRo1yaB1nU1WVv/76i7lz5xIbG0uHDh0IDg4mOjqa5OQiVNXHpnmfeAIaNbr0BOrAgdCgAVy+PVsiWm0A5cq1tam2N5FTMoQQ16lZsybr16+3+ysZ/5Sfn09ERARTp07lnnvucWgtR0lLS2PLli0kJiaSmJjIli1bMBgMREVFFX9ERkYSFBREXt4RtmwJt/mBm9LQaHxp2/Ygvr41nV67LLHtrq8QosxTVZX8/L/IykoiMzORwsITWCyFgIH77juFn99OCgt9MRj+/SgkW/n6+vLJJ58wYsQIduzYgU7n3t+ScnNz2bZtW3EAJiYmcv78edq0aUNUVBRDhw5l2rRp1KhR44bjjcY6+Ps3Iysr0cmdQ7lybSQQS0BWikJ4mYKC06SmTuHkyc+xWPLQaHSYzdnA3ze7TCbw8SmHxVKAj08NatV6hSpVHkOnC7B7P6qqcs8999CnTx+ee+45u89vK5PJxN69e68JwJSUFJo2bXrNKjAsLAxFKfmdqLS0hezfPxCz2XlP3mq1gURExFGhwoNOq1lWSSgK4SVMpkwOHhzO2bNz0Wg0Vl3CUxR/QKV27dHUrv0aimLfFd2uXbvo0qUL+/bto0KFCnaduyRUVeXIkSPXBOD27dupVasWUVFRxSvB5s2b4+Nj2z3BKywWE5s21aGw0Hl7wPr4hHL77YfllYwSkFAUwgukp69g377HMJuzS3U/S1H88fUNpUmTBPz9I+zYITz33HMoisKkSZPsOu+NnDt37pr7gImJiej1etq2bVu8AmzdujXBwba9QvFvMjLWk5x8r1POVFQUIy1arKFcuSiH1/IEEopCeLijR8dy9Oh7WCy5dppRg6IYadJkPhUqdLPTnHD+/HnCw8NZtWoVTZs2tdu8V98HvBKE586dIzIy8prLoDe7D+goKSnPOfywYUUxUr36MBo08J4ju0pLQlEID3bkyDscO/ahHQPxb38H4wN2m3PSpEksXryYlStXorHh7XRH3Qd0BLM5nx07OpCdvcvmTcJvRaPxJTCwFS1arEJRSnfJ15tIKArhoU6fnkNKylCHBOIViuJHq1YbCQhoZpf5ioqKaNGiBWPHjqVnz563/FpVVTl69Oh19wFr1KhxTQDa4z6go5hMmezYcRe5uXvt+pqGovji79+M5s1/c8jDUZ5MQlEID1RQkEpiYqPLT5U6kgajsSFt2uxGUfR2mXHlypUMGzaMvXv3XhNm/7wPuGXLFnQ6XfF9wDZt2hAZGemw+4COYjbnsm/fQNLTf7LLDzCK4kfFig/RqNFMtFr7nnLiDSQUhfAwqqqSnHwPFy+uA0wOr6coftSsOZJ69f5ntzm7d+9OrVq1CAsLKw5Bd7gP6Ejnzi1h//4nsVjybbrPqChGFMVIePh3dr2k7W0kFIXwMBcv/sHOnV2xWHKcVlNRfGnXLhW93voNp81m83X3AQ8cOEBhYSGPP/44d911F1FRUTRq1Mjl9wEdrajoIqmpUzlxYjwWS+7llf6tvkVr0Gr90WoDqFkzlurVh6DTBTmrXY8koSiEh9m1qyfnzy/l1t9M7UtR/Khb93/UqjXyll9nzX3At956i9OnTzNr1izn/E24EVW1cOHCStLTl3Px4u/k5u7BYilEo1FQVQuK4oO/fxOCgjpSvvz9hIR0QaPx7B8YnEVCUQgPUlh4lo0bQ1FV5++taTBUp127E9c8NXr+/Pnr3gfUarXXvA94s/uAWVlZNGrUiEWLFhEV5d3v2KmqiqoWYrEUoCg+aDQGm57OFf9OQlEID3LmzBxSUobZ9IDNiPkvwb0AAAldSURBVBGwdy9oL296UqkSfPttyccrih9a7dds2XKqOADT0tKuuQ/Ypk0batSoUeJv6LNmzWLKlCls2LDB4y+dCvcgoSiEB0lJeZ7U1MnYcul0xAi491540MbtMXNz4Ycf6uHj07U4BEt7H9BisdC2bVtefPFFHrfmnCQhbOTeW9ILIaySkfEHzryXeDU/Pw2vvtqdhg0/s9uciqIwceJE+vfvT69evQgIkHfuhGPJ9QghPEhBwYlSjZ82DXr2hOefhx07rB2tkpu7r1T1b6Rdu3Z07tyZDz74wO5zC/FPcvlUCA/y++9BmM2ZNo3duxfq1AGdDlatgokTL4WkNa8CBgV1oGXLdTbVv5UTJ07QvHlztm7dSt26de0+vxBXyEpRCA9SmsfyIyLAzw8MBujaFZo2hc2bra1vn11t/qlmzZq89NJLvPzyyw6ZX4grJBSF8CA6nf22ONNowNrrSAZDFbvV/6fY2Fi2bt3K6tWrHVZDCAlFITxIQECkTeOysyExEQoLwWyGlSth506w5vVARTESFHSnTfVLwmg0Mm7cOEaMGIHJ5Pjt64R3klAUwoMEB3dEUazfBNpkgq+/hl69Lj1os3Ah/O9/UKtWyefQaPQEBra2urY1+vbtS0hICNOnT3doHeG95EEbITxIVtYOtm+/06n7nl6hKEbuuOM8Wq3RoXWSk5O577772L9/PyEh1u+1KsStyEpRCA8SGNgCH5+aLqispXLlGIcHIkDz5s3p06cPb7/9tsNrCe8jK0UhPMypUzM5ePAFLBZHn6X4N0Ux0qpVIgEBTZ1SLy0tjYiICNauXUtERIRTagrvICtFITxM5crRTlmxXaHR6AgMjHJaIAJUqlSJMWPGMGLECOTnemFPEopCeBit1kh4+BwUxc8p9TQaH8LDrdg53E6effZZjh8/zrJly5xeW3guCUUhPFD58vdSqVI/m55EtYai+NOgwXh8fWs7tM6N6PV6JkyYwMiRIykoKHB6feGZJBSF8FBhYV/i59cYjcbHIfMrih+VKvWjWrUhDpm/JO6//34aN27MxIkTXdaD8CzyoI0QHsxkymD79k7k5h6w68HDiuJHxYq9CQ//Bo1Ga7d5bZGSkkL79u3ZvXs3VatWdWkvouyTUBTCw5nNOezf/xTnzy/FYskt5WwaFMWXWrVepU6dN93m9PeXX36Z9PR0ZsyY4epWRBknoSiElzh//if27RuAxZJvUzhqtQEYDDVo0mQeAQHNHNCh7TIyMmjcuDFLly4lMvL6re5UVSU//ygm0wVU1YxWa8TXty5arXMeRhJlh4SiEF7EZMri9OlvOH78Y0ymdMzmfODm+4hqNP/f3v2FSFUFcBz/nXN3x9nZGV1t0xZ1NfFPrcUKxfZQlEQgUdFmFIXUc2QFRaQIUfgSPQQKZVjqU1AQglQgiv2R7C/9k1YQDRGz1nXF2WHGXXd27j097O0hyHJmd+7s2f1+3s/53af97Z17/sySMVaZTJc6Ozepvb1X1tbnJoyJ2r17t/bs2aMjR47IGKPh4d/U3/+u8vlD8T2PRsb8fa+6UxSNKJXqUC53mxYs2KBrrrlf1nLv+kxHKQIzkHNOhcIRDQ19oaGhwyqVjioMC3IulDHNam5uVy53q9ra7tK8eevU2jr1N8iHYaienh5t2bJO119/WKXST3IulHNj/zs2CHIyplkLFz6nxYtfUFNTLoEnxlREKQKYFsbG8vr66/UaGTmsdLq2P2vWphUEs9XV9b7mzr17kp8QPqAUAXhvaOhL9fU9qDAclnMT37NobYsWLHhSK1e+1fDVtUgWpQjAaxcvHlRf30OTsLL2n6zNaO7ce7R69V6+Nc4gbN4H4K1C4Zu6FKIkRdGw8vlDOn78Cc5XnUEoRQBeqlSK6ut7sC6F+LcoGtaFCx9rYOC9umVgaqEUAXjp5MlnVakU654TRZd08uTTGh3tr3sWGo9SBOCdQuFbDQ5+OKlH1/2XMBzViRNPJZKFxqIUAXjnzJnXFEUjCSaOKZ8/qNHRPxPMRCNQigC8Ui4P6OLFg5KSXfzinNMff7ydaCaSRykC8Mr58x/UdBD5uXPS5s3SAw9I69dL27dLYXj1450bVX//O1Xnwi+UIgCv5POf1vTT6bZtUlubtHevtGuXdPSotG9fdXNUKkMqlwerzoY/KEUAXikWf6hpXH+/tHatlEpJ8+ZJPT3S6dPVzWFti4rFH2vKhx8oRQDeCMPLKpfP1zT24Yelzz6TLl+WBgel774bL8ZqRNGwLl36taZ8+IGziwB4IwxLMqZJzlXxMTDW3S198ol0331SFEnr1kl33FHdHM6NqVIpVJ0Nf/CmCMAjrqZFNlEkbdok3XmntH//+LfEYlHaubOWZ6i+kOEPShGAN6xtkXNXvhT5SopFaWBA6u0d/6Y4Z450773jP6FWJ1AQcNfidEYpAvBGU1O2plKaM0fq6JA++mh8G0apJB04IC1bVt08QdCqTOaGqvPhD0oRgFey2e6axm3dKn3//fjb4oYNUhBIGzdWN4dzFeVyt9SUDz+w0AaAV9ra1qpQ+ErOjVU1bvny8b2KE2GM1axZnRObBFMab4oAvDJ//mMyphH/zwe69tpHa1roA39QigC8ksmsUmvrzYnnWpvSokXPJ56LZFGKALzT2blZ1rYmmGiUyXQpm70pwUw0AqUIwDvt7b3KZrsT+xnV2rRWrdqVSBYai1IE4B1jjLq63pcxs+qeZW1Gixa9oFxuTd2z0HiUIgAvpdOdWrlyh6zN1C3DmJRaWlZo6dJX6paBqYVSBOCt6657UkuXvlqXYjQmpXR6idas+VzWNk/6/JiajHMu2eurAWCSnT27Q6dOvVjTPYv/xtqMMpkb1d19SM3NbZMyJ/xAKQKYForFX3Ts2CMql/9UFA3XOIuRtWktWfKyOjtfkjHBpD4jpj5KEcC0EUVlnTnzun7//Q1JocKwdFXjjEnJGKvZs2/XihVvqrWV801nKkoRwLQTRWO6cGGfzp7dplLpZ0kmvoexIslJsjImUBQNK5Xq0Pz5j2vhwmeUTi9u8JOj0ShFANOac5FGRk6pVPpFlcqQnKsoCFrU0rJC2Wy3giDJQwAw1VGKAADE2JIBAECMUgQAIEYpAgAQoxQBAIhRigAAxChFAABilCIAADFKEQCAGKUIAECMUgQAIEYpAgAQoxQBAIhRigAAxP4CFbmhaac9TskAAAAASUVORK5CYII=\n",
"text/plain": [
""
]
@@ -176,14 +176,14 @@
"outputs": [],
"source": [
"# 自定义GCN层函数\n",
- "def gcn_layer(gw, feature, hidden_size, name, activation):\n",
+ "def gcn_layer(gw, nfeat, efeat, hidden_size, name, activation):\n",
" # gw是一个GraphWrapper;feature是节点的特征向量。\n",
" \n",
" # 定义message函数,\n",
" def send_func(src_feat, dst_feat, edge_feat): \n",
" # 注意: 这里三个参数是固定的,虽然我们只用到了第一个参数。\n",
" # 在本教程中,我们直接返回源节点的特征向量作为message。用户也可以自定义message函数的内容。\n",
- " return src_feat['h']\n",
+ " return src_feat['h'] * edge_feat['e']\n",
"\n",
" # 定义reduce函数,参数feat其实是从message函数那里获得的。\n",
" def recv_func(feat):\n",
@@ -192,7 +192,7 @@
" return fluid.layers.sequence_pool(feat, pool_type='sum')\n",
"\n",
" # send函数触发message函数,发送消息,并将返回消息。\n",
- " msg = gw.send(send_func, nfeat_list=[('h', feature)])\n",
+ " msg = gw.send(send_func, nfeat_list=[('h', nfeat)], efeat_list=[('e', efeat)])\n",
" # recv函数接收消息,并触发reduce函数,对消息进行处理。\n",
" output = gw.recv(msg, recv_func) \n",
" # 以activation为激活函数的全连接输出层。\n",
@@ -211,21 +211,14 @@
"cell_type": "code",
"execution_count": 7,
"metadata": {},
- "outputs": [
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "/Users/huangzhengjie/Workspace/baidu/nlp-gnn/pgl/pgl/utils/paddle_helper.py:48: UserWarning: Your paddle version is less than 1.5 gather may be slower.\n",
- " warnings.warn(\"Your paddle version is less than 1.5\"\n"
- ]
- }
- ],
+ "outputs": [],
"source": [
"# 第一层GCN将特征向量从16维映射到8维,激活函数使用relu。\n",
- "output = gcn_layer(gw, gw.node_feat['feature'], hidden_size=8, name='gcn_layer_1', activation='relu')\n",
+ "output = gcn_layer(gw, gw.node_feat['feature'], gw.edge_feat['edge_feature'], \n",
+ " hidden_size=8, name='gcn_layer_1', activation='relu')\n",
"# 第二层GCN将特征向量从8维映射导2维,对应我们的二分类。不使用激活函数。\n",
- "output = gcn_layer(gw, output, hidden_size=1, name='gcn_layer_2', activation=None)"
+ "output = gcn_layer(gw, output, gw.edge_feat['edge_feature'], \n",
+ " hidden_size=1, name='gcn_layer_2', activation=None)"
]
},
{
@@ -268,36 +261,36 @@
"name": "stdout",
"output_type": "stream",
"text": [
- "Epoch 0 | Loss: 0.712927\n",
- "Epoch 1 | Loss: 0.665513\n",
- "Epoch 2 | Loss: 0.625431\n",
- "Epoch 3 | Loss: 0.591621\n",
- "Epoch 4 | Loss: 0.563292\n",
- "Epoch 5 | Loss: 0.539553\n",
- "Epoch 6 | Loss: 0.519604\n",
- "Epoch 7 | Loss: 0.502797\n",
- "Epoch 8 | Loss: 0.488625\n",
- "Epoch 9 | Loss: 0.476778\n",
- "Epoch 10 | Loss: 0.466839\n",
- "Epoch 11 | Loss: 0.458521\n",
- "Epoch 12 | Loss: 0.451596\n",
- "Epoch 13 | Loss: 0.445855\n",
- "Epoch 14 | Loss: 0.441109\n",
- "Epoch 15 | Loss: 0.437194\n",
- "Epoch 16 | Loss: 0.434423\n",
- "Epoch 17 | Loss: 0.432126\n",
- "Epoch 18 | Loss: 0.430175\n",
- "Epoch 19 | Loss: 0.428500\n",
- "Epoch 20 | Loss: 0.427060\n",
- "Epoch 21 | Loss: 0.425821\n",
- "Epoch 22 | Loss: 0.424751\n",
- "Epoch 23 | Loss: 0.423827\n",
- "Epoch 24 | Loss: 0.423026\n",
- "Epoch 25 | Loss: 0.422332\n",
- "Epoch 26 | Loss: 0.421729\n",
- "Epoch 27 | Loss: 0.421204\n",
- "Epoch 28 | Loss: 0.420746\n",
- "Epoch 29 | Loss: 0.420345\n"
+ "Epoch 0 | Loss: 0.629119\n",
+ "Epoch 1 | Loss: 0.614591\n",
+ "Epoch 2 | Loss: 0.602767\n",
+ "Epoch 3 | Loss: 0.593824\n",
+ "Epoch 4 | Loss: 0.587454\n",
+ "Epoch 5 | Loss: 0.581866\n",
+ "Epoch 6 | Loss: 0.576963\n",
+ "Epoch 7 | Loss: 0.572337\n",
+ "Epoch 8 | Loss: 0.567905\n",
+ "Epoch 9 | Loss: 0.563806\n",
+ "Epoch 10 | Loss: 0.559831\n",
+ "Epoch 11 | Loss: 0.555969\n",
+ "Epoch 12 | Loss: 0.552211\n",
+ "Epoch 13 | Loss: 0.548553\n",
+ "Epoch 14 | Loss: 0.544992\n",
+ "Epoch 15 | Loss: 0.541524\n",
+ "Epoch 16 | Loss: 0.538145\n",
+ "Epoch 17 | Loss: 0.534852\n",
+ "Epoch 18 | Loss: 0.531641\n",
+ "Epoch 19 | Loss: 0.528505\n",
+ "Epoch 20 | Loss: 0.525442\n",
+ "Epoch 21 | Loss: 0.522446\n",
+ "Epoch 22 | Loss: 0.519513\n",
+ "Epoch 23 | Loss: 0.516638\n",
+ "Epoch 24 | Loss: 0.513819\n",
+ "Epoch 25 | Loss: 0.511053\n",
+ "Epoch 26 | Loss: 0.508336\n",
+ "Epoch 27 | Loss: 0.505668\n",
+ "Epoch 28 | Loss: 0.503046\n",
+ "Epoch 29 | Loss: 0.500472\n"
]
}
],
@@ -349,9 +342,9 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.6.7"
+ "version": "3.6.5"
}
},
"nbformat": 4,
- "nbformat_minor": 2
+ "nbformat_minor": 4
}
+
+**ERNIESage** 由PGL团队提出,是ERNIE SAmple aggreGatE的简称,该模型可以同时建模文本语义与图结构信息,有效提升 Text Graph 的应用效果。其中 [**ERNIE**](https://github.com/PaddlePaddle/ERNIE) 是百度推出的基于知识增强的持续学习语义理解框架。
+
+**ERNIESage** 是 ERNIE 与 GraphSAGE 碰撞的结果,是 ERNIE SAmple aggreGatE 的简称,它的结构如下图所示,主要思想是通过 ERNIE 作为聚合函数(Aggregators),建模自身节点和邻居节点的语义与结构关系。ERNIESage 对于文本的建模是构建在邻居聚合的阶段,中心节点文本会与所有邻居节点文本进行拼接;然后通过预训练的 ERNIE 模型进行消息汇聚,捕捉中心节点以及邻居节点之间的相互关系;最后使用 ERNIESage 搭配独特的邻居互相看不见的 Attention Mask 和独立的 Position Embedding 体系,就可以轻松构建 TextGraph 中句子之间以及词之间的关系。
+
+
+
+使用ID特征的GraphSAGE只能够建模图的结构信息,而单独的ERNIE只能处理文本信息。通过PGL搭建的图与文本的桥梁,**ERNIESage**能够很简单的把GraphSAGE以及ERNIE的优点结合一起。以下面TextGraph的场景,**ERNIESage**的效果能够比单独的ERNIE以及GraphSAGE模型都要好。
+
+
+
+**ERNIESage**可以很轻松地在PGL中的消息传递范式中进行实现,目前PGL提供了4个版本的ERNIESage模型:
+
+- **ERNIESage v1**: ERNIE 作用于text graph节点上;
+- **ERNIESage v2**: ERNIE 作用在text graph的边上;
+- **ERNIESage v3**: ERNIE 作用于一阶邻居及起边上;
+- **ERNIESage v4**: ERNIE 作用于N阶邻居及边上;
+
+
+
+## 环境依赖
+- paddlepaddle>=1.7
+- pgl>=1.1
+
+## Dataformat
+示例数据```data.txt```中使用了NLPCC2016-DBQA的部分数据,格式为每行"query \t answer"。
+```text
+NLPCC2016-DBQA 是由国际自然语言处理和中文计算会议 NLPCC 于 2016 年举办的评测任务,其目标是从候选中找到合适的文档作为问题的答案。[链接: http://tcci.ccf.org.cn/conference/2016/dldoc/evagline2.pdf]
+```
+
+## How to run
+
+我们采用了[PaddlePaddle Fleet](https://github.com/PaddlePaddle/Fleet)作为我们的分布式训练框架,在```config/*.yaml```中,有部分用于训练ERNIESage的配置, 其中ERNIE模型```ckpt_path```以及词表```ernie_vocab_file```在[ERNIE](https://github.com/PaddlePaddle/ERNIE)下载。
+
+
+```sh
+# 分布式GPU模式或单机模式ERNIESage
+sh local_run.sh config/erniesage_v2_gpu.yaml
+
+# 分布式CPU模式训练ERNIESage
+sh local_run.sh config/erniesage_v2_cpu.yaml
+```
+
+## Hyperparamters
+
+- learner_type: `gpu` or `cpu`; gpu 使用fleet Collective 模式, cpu 使用fleet Transpiler 模式.
+
+## Citation
+```
+@misc{ERNIESage,
+ author = {PGL Team},
+ title = {ERNIESage: ERNIE SAmple aggreGatE},
+ year = {2020},
+ publisher = {GitHub},
+ journal = {GitHub repository},
+ howpublished = {\url{https://github.com/PaddlePaddle/PGL/tree/master/examples/erniesage},
+}
+```
diff --git a/examples/erniesage/config/erniesage_v1_cpu.yaml b/examples/erniesage/config/erniesage_v1_cpu.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..1f7e5eddc0b6bda5f8c3377c7320429d16b0718b
--- /dev/null
+++ b/examples/erniesage/config/erniesage_v1_cpu.yaml
@@ -0,0 +1,56 @@
+# Global Enviroment Settings
+#
+# trainer config ------
+learner_type: "cpu"
+optimizer_type: "adam"
+lr: 0.00005
+batch_size: 2
+CPU_NUM: 10
+epoch: 20
+log_per_step: 1
+save_per_step: 100
+output_path: "./output"
+ckpt_path: "./ernie_base_ckpt"
+
+# data config ------
+input_data: "./data.txt"
+graph_path: "./workdir"
+sample_workers: 1
+use_pyreader: true
+input_type: "text"
+
+# model config ------
+samples: [10]
+model_type: "ErnieSageModelV1"
+layer_type: "graphsage_sum"
+
+max_seqlen: 40
+
+num_layers: 1
+hidden_size: 128
+final_fc: true
+final_l2_norm: true
+loss_type: "hinge"
+margin: 0.3
+
+# infer config ------
+infer_model: "./output/last"
+infer_batch_size: 128
+
+# ernie config ------
+encoding: "utf8"
+ernie_vocab_file: "./vocab.txt"
+ernie_config:
+ attention_probs_dropout_prob: 0.1
+ hidden_act: "relu"
+ hidden_dropout_prob: 0.1
+ hidden_size: 768
+ initializer_range: 0.02
+ max_position_embeddings: 513
+ num_attention_heads: 12
+ num_hidden_layers: 12
+ sent_type_vocab_size: 4
+ task_type_vocab_size: 3
+ vocab_size: 18000
+ use_task_id: false
+ use_fp16: false
diff --git a/examples/erniesage/config/erniesage_v1_gpu.yaml b/examples/erniesage/config/erniesage_v1_gpu.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..7b883fe3fa06332cf196d5142c40acaee8b98259
--- /dev/null
+++ b/examples/erniesage/config/erniesage_v1_gpu.yaml
@@ -0,0 +1,56 @@
+# Global Enviroment Settings
+#
+# trainer config ------
+learner_type: "gpu"
+optimizer_type: "adam"
+lr: 0.00005
+batch_size: 32
+CPU_NUM: 10
+epoch: 20
+log_per_step: 1
+save_per_step: 100
+output_path: "./output"
+ckpt_path: "./ernie_base_ckpt"
+
+# data config ------
+input_data: "./data.txt"
+graph_path: "./workdir"
+sample_workers: 1
+use_pyreader: true
+input_type: "text"
+
+# model config ------
+samples: [10]
+model_type: "ErnieSageModelV1"
+layer_type: "graphsage_sum"
+
+max_seqlen: 40
+
+num_layers: 1
+hidden_size: 128
+final_fc: true
+final_l2_norm: true
+loss_type: "hinge"
+margin: 0.3
+
+# infer config ------
+infer_model: "./output/last"
+infer_batch_size: 128
+
+# ernie config ------
+encoding: "utf8"
+ernie_vocab_file: "./vocab.txt"
+ernie_config:
+ attention_probs_dropout_prob: 0.1
+ hidden_act: "relu"
+ hidden_dropout_prob: 0.1
+ hidden_size: 768
+ initializer_range: 0.02
+ max_position_embeddings: 513
+ num_attention_heads: 12
+ num_hidden_layers: 12
+ sent_type_vocab_size: 4
+ task_type_vocab_size: 3
+ vocab_size: 18000
+ use_task_id: false
+ use_fp16: false
diff --git a/examples/erniesage/config/erniesage_v2_cpu.yaml b/examples/erniesage/config/erniesage_v2_cpu.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..77b78052122448dd8ced0fe8518c8ae1de858a32
--- /dev/null
+++ b/examples/erniesage/config/erniesage_v2_cpu.yaml
@@ -0,0 +1,56 @@
+# Global Enviroment Settings
+#
+# trainer config ------
+learner_type: "cpu"
+optimizer_type: "adam"
+lr: 0.00005
+batch_size: 4
+CPU_NUM: 16
+epoch: 3
+log_per_step: 1
+save_per_step: 100
+output_path: "./output"
+ckpt_path: "./ernie_base_ckpt"
+
+# data config ------
+input_data: "./data.txt"
+graph_path: "./workdir"
+sample_workers: 1
+use_pyreader: true
+input_type: "text"
+
+# model config ------
+samples: [10]
+model_type: "ErnieSageModelV2"
+
+max_seqlen: 40
+
+num_layers: 1
+hidden_size: 128
+final_fc: true
+final_l2_norm: true
+loss_type: "hinge"
+margin: 0.3
+neg_type: "batch_neg"
+
+# infer config ------
+infer_model: "./output/last"
+infer_batch_size: 128
+
+# ernie config ------
+encoding: "utf8"
+ernie_vocab_file: "./vocab.txt"
+ernie_config:
+ attention_probs_dropout_prob: 0.1
+ hidden_act: "relu"
+ hidden_dropout_prob: 0.1
+ hidden_size: 768
+ initializer_range: 0.02
+ max_position_embeddings: 513
+ num_attention_heads: 12
+ num_hidden_layers: 12
+ sent_type_vocab_size: 2
+ task_type_vocab_size: 3
+ vocab_size: 18000
+ use_task_id: false
+ use_fp16: false
diff --git a/examples/erniesage/config/erniesage_v2_gpu.yaml b/examples/erniesage/config/erniesage_v2_gpu.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..7a9b4afa380904463b2b57e0944c3c29a14c77ff
--- /dev/null
+++ b/examples/erniesage/config/erniesage_v2_gpu.yaml
@@ -0,0 +1,56 @@
+# Global Enviroment Settings
+#
+# trainer config ------
+learner_type: "gpu"
+optimizer_type: "adam"
+lr: 0.00005
+batch_size: 32
+CPU_NUM: 10
+epoch: 3
+log_per_step: 10
+save_per_step: 1000
+output_path: "./output"
+ckpt_path: "./ernie_base_ckpt"
+
+# data config ------
+input_data: "./data.txt"
+graph_path: "./workdir"
+sample_workers: 1
+use_pyreader: true
+input_type: "text"
+
+# model config ------
+samples: [10]
+model_type: "ErnieSageModelV2"
+
+max_seqlen: 40
+
+num_layers: 1
+hidden_size: 128
+final_fc: true
+final_l2_norm: true
+loss_type: "hinge"
+margin: 0.3
+neg_type: "batch_neg"
+
+# infer config ------
+infer_model: "./output/last"
+infer_batch_size: 128
+
+# ernie config ------
+encoding: "utf8"
+ernie_vocab_file: "./vocab.txt"
+ernie_config:
+ attention_probs_dropout_prob: 0.1
+ hidden_act: "relu"
+ hidden_dropout_prob: 0.1
+ hidden_size: 768
+ initializer_range: 0.02
+ max_position_embeddings: 513
+ num_attention_heads: 12
+ num_hidden_layers: 12
+ sent_type_vocab_size: 2
+ task_type_vocab_size: 3
+ vocab_size: 18000
+ use_task_id: false
+ use_fp16: false
diff --git a/examples/erniesage/config/erniesage_v3_cpu.yaml b/examples/erniesage/config/erniesage_v3_cpu.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2172a26133c9718358163f4495133720dbeb9eff
--- /dev/null
+++ b/examples/erniesage/config/erniesage_v3_cpu.yaml
@@ -0,0 +1,55 @@
+# Global Enviroment Settings
+#
+# trainer config ------
+learner_type: "cpu"
+optimizer_type: "adam"
+lr: 0.00005
+batch_size: 2
+CPU_NUM: 10
+epoch: 20
+log_per_step: 1
+save_per_step: 100
+output_path: "./output"
+ckpt_path: "./ernie_base_ckpt"
+
+# data config ------
+input_data: "./data.txt"
+graph_path: "./workdir"
+sample_workers: 1
+use_pyreader: true
+input_type: "text"
+
+# model config ------
+samples: [10]
+model_type: "ErnieSageModelV3"
+
+max_seqlen: 40
+
+num_layers: 1
+hidden_size: 128
+final_fc: true
+final_l2_norm: true
+loss_type: "hinge"
+margin: 0.3
+
+# infer config ------
+infer_model: "./output/last"
+infer_batch_size: 128
+
+# ernie config ------
+encoding: "utf8"
+ernie_vocab_file: "./vocab.txt"
+ernie_config:
+ attention_probs_dropout_prob: 0.1
+ hidden_act: "relu"
+ hidden_dropout_prob: 0.1
+ hidden_size: 768
+ initializer_range: 0.02
+ max_position_embeddings: 513
+ num_attention_heads: 12
+ num_hidden_layers: 12
+ sent_type_vocab_size: 4
+ task_type_vocab_size: 3
+ vocab_size: 18000
+ use_task_id: false
+ use_fp16: false
diff --git a/examples/erniesage/config/erniesage_v3_gpu.yaml b/examples/erniesage/config/erniesage_v3_gpu.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..e53ab33c41f8b8760e75d602bf1b8ed9f1735fb8
--- /dev/null
+++ b/examples/erniesage/config/erniesage_v3_gpu.yaml
@@ -0,0 +1,55 @@
+# Global Enviroment Settings
+#
+# trainer config ------
+learner_type: "gpu"
+optimizer_type: "adam"
+lr: 0.00005
+batch_size: 32
+CPU_NUM: 10
+epoch: 20
+log_per_step: 1
+save_per_step: 100
+output_path: "./output"
+ckpt_path: "./ernie_base_ckpt"
+
+# data config ------
+input_data: "./data.txt"
+graph_path: "./workdir"
+sample_workers: 1
+use_pyreader: true
+input_type: "text"
+
+# model config ------
+samples: [10]
+model_type: "ErnieSageModelV3"
+
+max_seqlen: 40
+
+num_layers: 1
+hidden_size: 128
+final_fc: true
+final_l2_norm: true
+loss_type: "hinge"
+margin: 0.3
+
+# infer config ------
+infer_model: "./output/last"
+infer_batch_size: 128
+
+# ernie config ------
+encoding: "utf8"
+ernie_vocab_file: "./vocab.txt"
+ernie_config:
+ attention_probs_dropout_prob: 0.1
+ hidden_act: "relu"
+ hidden_dropout_prob: 0.1
+ hidden_size: 768
+ initializer_range: 0.02
+ max_position_embeddings: 513
+ num_attention_heads: 12
+ num_hidden_layers: 12
+ sent_type_vocab_size: 4
+ task_type_vocab_size: 3
+ vocab_size: 18000
+ use_task_id: false
+ use_fp16: false
diff --git a/examples/erniesage/data.txt b/examples/erniesage/data.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e9aead6c89fa2fdbed64e5dada352106a8deb349
--- /dev/null
+++ b/examples/erniesage/data.txt
@@ -0,0 +1,1000 @@
+黑缘粗角肖叶甲触角有多大? 体长卵形,棕红色;鞘翅棕黄或淡棕色,外缘和中缝黑色或黑褐色;触角基部3、4节棕黄,余节棕色。
+黑缘粗角肖叶甲触角有多大? 头部刻点粗大,分布不均匀,头顶刻点十分稀疏;触角基部的内侧有一个三角形光瘤,唇基前缘呈半圆形凹切。
+黑缘粗角肖叶甲触角有多大? 触角近于体长之半,第1节粗大,棒状,第2节短,椭圆形,3、4两节细长,稍短于第5节,第5节基细端粗,末端6节明显粗大。
+黑缘粗角肖叶甲触角有多大? 前胸背板横宽,宽约为长的两倍,侧缘敞出较宽,圆形,敞边与盘区之间有一条细纵沟;盘区刻点相当密,前半部刻点较大于后半部。
+黑缘粗角肖叶甲触角有多大? 小盾片舌形,光亮,末端圆钝。
+黑缘粗角肖叶甲触角有多大? 鞘翅刻点粗大,不规则排列,肩部之后的刻点更为粗大,具皱褶,近中缝的刻点较小,略呈纵行排列。
+黑缘粗角肖叶甲触角有多大? 前胸前侧片前缘直;前胸后侧片具粗大刻点。
+黑缘粗角肖叶甲触角有多大? 足粗壮;胫节具纵脊,外端角向外延伸,呈弯角状;爪具附齿。
+暮光闪闪的姐姐是谁? 暮光闪闪是一匹雌性独角兽,后来在神秘魔法的影响下变成了空角兽(公主),她是《我的小马驹:友情是魔法》(英文名:My Little Pony:Friendship is Magic)中的主角之一。
+暮光闪闪的姐姐是谁? 她是银甲闪闪(Shining Armor)的妹妹,同时也是韵律公主(Princess Cadance)的小姑子。
+暮光闪闪的姐姐是谁? 在该系列中,她与最好的朋友与助手斯派克(Spike)一起生活在小马镇(Ponyville)的金橡图书馆(Golden Oak Library),研究友谊的魔法。
+暮光闪闪的姐姐是谁? 在暮光闪闪成为天角兽之前(即S3E13前),常常给塞拉丝蒂娅公主(Princess Celestia)关于友谊的报告。[1]
+暮光闪闪的姐姐是谁? 《我的小马驹:友谊是魔法》(英文名称:My Little Pony:Friendship is Magic)(简称MLP)
+暮光闪闪的姐姐是谁? 动画讲述了一只名叫做暮光闪闪(Twilight Sparkle)的独角兽(在SE3E13
+暮光闪闪的姐姐是谁? My Little Pony:Friendship is Magic[2]
+暮光闪闪的姐姐是谁? 后成为了天角兽),执行她的导师塞拉斯蒂娅公主(PrincessCelestia)的任务,在小马镇(Ponyville)学习关于友谊的知识。
+暮光闪闪的姐姐是谁? 她与另外五只小马,苹果杰克(Applejack)、瑞瑞(Rarity)、云宝黛西(Rainbow Dash)、小蝶(Fluttershy)与萍琪派(Pinkie Pie),成为了最要好的朋友。
+暮光闪闪的姐姐是谁? 每匹小马都分别代表了协律精华的6个元素:诚实,慷慨,忠诚,善良,欢笑,魔法,各自扮演着属于自己的重要角色。
+暮光闪闪的姐姐是谁? 此后,暮光闪闪(Twilight Sparkle)便与她认识的新朋友们开始了有趣的日常生活。
+暮光闪闪的姐姐是谁? 在动画中,随时可见她们在小马镇(Ponyville)的种种冒险、奇遇、日常等等。
+暮光闪闪的姐姐是谁? 同时,也在她们之间的互动和冲突中,寻找着最适合最合理的完美解决方案。
+暮光闪闪的姐姐是谁? “尽管小马国并不太平,六位主角之间也常常有这样那样的问题,但是他们之间的真情对待,使得这个童话世界已经成为不少人心中理想的世外桃源。”
+暮光闪闪的姐姐是谁? 暮光闪闪在剧情刚开始的时候生活在中心城(Canterlot),后来在夏日
+暮光闪闪的姐姐是谁? 暮光闪闪与斯派克(Spike)
+暮光闪闪的姐姐是谁? 庆典的时候被塞拉丝蒂娅公主派遣到小马镇执行检查夏日庆典的准备工作的任务。
+暮光闪闪的姐姐是谁? 在小马镇交到了朋友(即其余5个主角),并和她们一起使用协律精华(Elements of harmony)击败了梦魇之月。
+暮光闪闪的姐姐是谁? 并在塞拉丝蒂亚公主的许可下,留在小马镇继续研究友谊的魔法。
+暮光闪闪的姐姐是谁? 暮光闪闪的知识基本来自于书本,并且她相当不相信书本以外的“迷信”,因为这样她在S1E15里吃足了苦头。
+暮光闪闪的姐姐是谁? 在这之后,她也开始慢慢学会相信一些书本以外的东西。
+暮光闪闪的姐姐是谁? 暮光闪闪热爱学习,并且学习成绩相当好(从她可以立刻算出
+暮光闪闪的姐姐是谁? 的结果可以看
+暮光闪闪的姐姐是谁? 暮光闪闪的原型
+暮光闪闪的姐姐是谁? 出)。
+暮光闪闪的姐姐是谁? 相当敬爱自己的老师塞拉丝蒂亚公主甚至到了精神失常的地步。
+暮光闪闪的姐姐是谁? 在第二季中,曾因为无法交出关于友谊的报告而做出了疯狂的行为,后来被塞拉丝蒂亚公主制止,在这之后,暮光闪闪得到了塞拉丝蒂亚公主“不用定期交友谊报告”的许可。
+暮光闪闪的姐姐是谁? 于是暮光闪闪在后面的剧情中的主角地位越来越得不到明显的体现。
+暮光闪闪的姐姐是谁? 在SE3E13中,因为破解了白胡子星璇留下的神秘魔法而被加冕成为了天角兽(公主),被尊称为“闪闪公主”。
+暮光闪闪的姐姐是谁? 当小星座熊在小马镇引起恐慌的时候,暮光闪闪运用了自身强大的魔法将水库举起后装满牛奶,用牛奶将小星座熊安抚后,连着巨型奶瓶和小星座熊一起送回了小星座熊居住的山洞。
+我想知道红谷十二庭有哪些金融机构? 红谷十二庭是由汪氏集团旗下子公司江西尤金房地产开发有限公司携手城发投资共同开发的精品社区,项目占地面积约380亩,总建筑面积约41万平方米。
+我想知道红谷十二庭有哪些金融机构? 项目以建设人文型、生态型居住环境为规划目标;创造一个布局合理、功能齐全、交通便捷、绿意盎然、生活方便,有文化内涵的居住区。
+我想知道红谷十二庭有哪些金融机构? 金融机构:工商银行、建设银行、农业银行、中国银行红谷滩支行、商业银行红谷滩支行等
+我想知道红谷十二庭有哪些金融机构? 周边公园:沿乌砂河50米宽绿化带、乌砂河水岸公园、秋水广场、赣江市民公园
+我想知道红谷十二庭有哪些金融机构? 周边医院:新建县人民医院、开心人药店、中寰医院
+我想知道红谷十二庭有哪些金融机构? 周边学校:育新小学红谷滩校区、南师附小红谷滩校区、实验小学红谷滩校区中学:南昌二中红谷滩校区、南昌五中、新建二中、竞秀贵族学校
+我想知道红谷十二庭有哪些金融机构? 周边公共交通:112、204、211、219、222、227、238、501等20多辆公交车在本项目社区门前停靠
+我想知道红谷十二庭有哪些金融机构? 红谷十二庭处在南昌一江两城中的西城中心,位属红谷滩CBD文化公园中心——马兰圩中心组团,红谷滩中心区、红角洲、新建县三区交汇处,南临南期友好路、东接红谷滩中心区、西靠乌砂河水岸公园(50米宽,1000米长)。
+我想知道红谷十二庭有哪些金融机构? 交通便捷,景观资源丰富,生活配套设施齐全,出则繁华,入则幽静,是现代人居的理想地段。
+我想知道红谷十二庭有哪些金融机构? 红谷十二庭户型图
+苏琳最开始进入智通实业是担任什么职位? 现任广东智通人才连锁股份有限公司总裁,清华大学高级工商管理硕士。
+苏琳最开始进入智通实业是担任什么职位? 1994年,加入智通实业,从总经理秘书做起。
+苏琳最开始进入智通实业是担任什么职位? 1995年,智通实业决定进入人才服务行业,被启用去负责新公司的筹建及运营工作,在苏琳的努力下,智通人才智力开发有限公司成立。
+苏琳最开始进入智通实业是担任什么职位? 2003年,面对同城对手的激烈竞争,苏琳冷静对待,领导智通先后接管、并购了同城的腾龙、安达盛人才市场,,“品牌运作,连锁经营,差异制胜”成为苏琳屡屡制胜的法宝。
+苏琳最开始进入智通实业是担任什么职位? 2006年,苏琳先是将智通人才升级为“东莞市智通人才连锁有限公司”,一举成为广东省人才市场目前惟一的连锁机构,随后在东莞同时开设长安、松山湖、清溪等镇区分部,至此智通在东莞共有6个分部。
+苏琳最开始进入智通实业是担任什么职位? 一番大刀阔斧完成东莞布局后,苏琳确定下一个更为高远的目标——进军珠三角,向全国发展连锁机构。
+苏琳最开始进入智通实业是担任什么职位? 到2011年末,苏琳领导的智通人才已在珠三角的东莞、佛山、江门、中山等地,长三角的南京、宁波、合肥等地,中西部的南昌、长沙、武汉、重庆、西安等地设立了20多家连锁经营网点。
+苏琳最开始进入智通实业是担任什么职位? 除了财务副总裁之外,苏琳是智通人才核心管理高层当中唯一的女性,不管是要约采访的记者还是刚刚加入智通的员工,见到苏琳的第一面,都会有一种惊艳的感觉,“一位女企业家居然非常美丽和时尚?!”
+苏琳最开始进入智通实业是担任什么职位? 智通管理高层的另外6位男性成员,有一次同时接受一家知名媒体采访时,共同表达了对自己老板的“爱慕”之情,苏琳听后莞尔一笑,指着在座的这几位高层说道“其实,我更爱他们!”
+苏琳最开始进入智通实业是担任什么职位? 这种具有独特领导魅力的表述让这位记者唏嘘不已,同时由这样的一个细节让他感受到了智通管理团队的协作力量。
+谁知道黄沙中心小学的邮政编码是多少? 学校于1954年始建于棕树湾村,当时借用一间民房做教室,取名为“黄沙小学”,只有教师1人,学生8人。
+谁知道黄沙中心小学的邮政编码是多少? 1958年在大跃进精神的指导下,实行大集体,全乡集中办学,发展到12个班,300多学生,20名教职工。
+谁知道黄沙中心小学的邮政编码是多少? 1959年解散。
+谁知道黄沙中心小学的邮政编码是多少? 1959年下半年,在上级的扶持下,建了6间木房,搬到1960年学校所在地,有6名教师,3个班,60名学生。
+谁知道黄沙中心小学的邮政编码是多少? 1968年,开始招收一个初中班,“黄沙小学”改名为 “附小”。
+谁知道黄沙中心小学的邮政编码是多少? 当时已发展到5个班,8名教师,110多名学生。
+谁知道黄沙中心小学的邮政编码是多少? 增建土木结构教室两间。
+谁知道黄沙中心小学的邮政编码是多少? 1986年,初中、小学分开办学。
+谁知道黄沙中心小学的邮政编码是多少? 增建部分教师宿舍和教室,办学条件稍有改善,学校初具规模。
+谁知道黄沙中心小学的邮政编码是多少? 1996年,我校在市、县领导及希望工程主管部门的关怀下,决定改为“黄沙希望小学”并拨款32万元,新建一栋4层,12间教室的教学楼,教学条件大有改善。
+谁知道黄沙中心小学的邮政编码是多少? 当时发展到10个班,学生300多人,教职工19人,小学高级教师3人,一级教师7人,二级教师9人。
+谁知道黄沙中心小学的邮政编码是多少? 2003年下半年由于农村教育体制改革,撤销教育组,更名为“黄沙中心小学”。
+谁知道黄沙中心小学的邮政编码是多少? 学校现有在校生177人(含学前42人),设有学前至六年级共7个教学班。
+谁知道黄沙中心小学的邮政编码是多少? 有教师19人,其中大专以上学历11人,中师6人;小学高级教师14人,一级教师5人。
+谁知道黄沙中心小学的邮政编码是多少? 学校校园占地面积2050平方米,生均达15.29平方米,校舍建筑面积1645平方米,生均12.27平方米;设有教师办公室、自然实验、电教室(合二为一)、微机室、图书阅览室(合二为一)、体育室、广播室、少先队活动室。
+谁知道黄沙中心小学的邮政编码是多少? 广西壮族自治区桂林市临桂县黄沙瑶族乡黄沙街 邮编:541113[1]
+伊藤实华的职业是什么? 伊藤实华(1984年3月25日-)是日本的女性声优。
+伊藤实华的职业是什么? THREE TREE所属,东京都出身,身长149cm,体重39kg,血型AB型。
+伊藤实华的职业是什么? ポルノグラフィティのLION(森男)
+伊藤实华的职业是什么? 2000年
+伊藤实华的职业是什么? 犬夜叉(枫(少女时代))
+伊藤实华的职业是什么? 幻影死神(西亚梨沙)
+伊藤实华的职业是什么? 2001年
+伊藤实华的职业是什么? NOIR(ロザリー)
+伊藤实华的职业是什么? 2002年
+伊藤实华的职业是什么? 水瓶战记(柠檬)
+伊藤实华的职业是什么? 返乡战士(エイファ)
+伊藤实华的职业是什么? 2003年
+伊藤实华的职业是什么? 奇诺之旅(女子A(悲しい国))
+伊藤实华的职业是什么? 2004年
+伊藤实华的职业是什么? 爱你宝贝(坂下ミキ)
+伊藤实华的职业是什么? Get Ride! アムドライバー(イヴァン・ニルギース幼少期)
+伊藤实华的职业是什么? スクールランブル(花井春树(幼少时代))
+伊藤实华的职业是什么? 2005年
+伊藤实华的职业是什么? 光速蒙面侠21(虎吉)
+伊藤实华的职业是什么? 搞笑漫画日和(男子トイレの精、パン美先生)
+伊藤实华的职业是什么? 银牙伝说WEED(テル)
+伊藤实华的职业是什么? 魔女的考验(真部カレン、守山太郎)
+伊藤实华的职业是什么? BUZZER BEATER(レニー)
+伊藤实华的职业是什么? 虫师(“眼福眼祸”さき、“草を踏む音”沢(幼少时代))
+伊藤实华的职业是什么? 2006年
+伊藤实华的职业是什么? 魔女之刃(娜梅)
+伊藤实华的职业是什么? 反斗小王子(远藤レイラ)
+伊藤实华的职业是什么? 搞笑漫画日和2(パン美先生、フグ子、ダンサー、ヤマトの妹、女性)
+伊藤实华的职业是什么? 人造昆虫カブトボーグ V×V(ベネチアンの弟、东ルリ、园儿A)
+伊藤实华的职业是什么? 2007年
+爆胎监测与安全控制系统英文是什么? 爆胎监测与安全控制系统(Blow-out Monitoring and Brake System),是吉利全球首创,并拥有自主知识产权及专利的一项安全技术。
+爆胎监测与安全控制系统英文是什么? 这项技术主要是出于防止高速爆胎所导致的车辆失控而设计。
+爆胎监测与安全控制系统英文是什么? BMBS爆胎监测与安全控制系统技术于2004年1月28日正式获得中国发明专利授权。
+爆胎监测与安全控制系统英文是什么? 2008年第一代BMBS系统正式与世人见面,BMBS汇集国内外汽车力学、控制学、人体生理学、电子信息学等方面的专家和工程技术人员经过一百余辆试验车累计行程超过五百万公里的可靠性验证,以确保产品的可靠性。
+爆胎监测与安全控制系统英文是什么? BMBS技术方案的核心即是采用智能化自动控制系统,弥补驾驶员生理局限,在爆胎后反应时间为0.5秒,替代驾驶员实施行车制动,保障行车安全。
+爆胎监测与安全控制系统英文是什么? BMBS系统由控制系统和显示系统两大部分组成,控制系统由BMBS开关、BMBS主机、BMBS分机、BMBS真空助力器四部分组成;显示系统由GPS显示、仪表指示灯、语言提示、制动双闪灯组成。
+爆胎监测与安全控制系统英文是什么? 当轮胎气压高于或低于限值时,控制器声光提示胎压异常。
+爆胎监测与安全控制系统英文是什么? 轮胎温度过高时,控制器发出信号提示轮胎温度过高。
+爆胎监测与安全控制系统英文是什么? 发射器电量不足时,控制器显示低电压报警。
+爆胎监测与安全控制系统英文是什么? 发射器受到干扰长期不发射信号时,控制器显示无信号报警。
+爆胎监测与安全控制系统英文是什么? 当汽车电门钥匙接通时,BMBS首先进入自检程序,检测系统各部分功能是否正常,如不正常,BMBS报警灯常亮。
+走读干部现象在哪里比较多? 走读干部一般是指县乡两级干部家住县城以上的城市,本人在县城或者乡镇工作,要么晚出早归,要么周一去单位上班、周五回家过周末。
+走读干部现象在哪里比较多? 对于这种现象,社会上的议论多是批评性的,认为这些干部脱离群众、作风漂浮、官僚主义,造成行政成本增加和腐败。
+走读干部现象在哪里比较多? 截至2014年10月,共有6484名“走读干部”在专项整治中被查处。
+走读干部现象在哪里比较多? 这是中央首次大规模集中处理这一长期遭诟病的干部作风问题。
+走读干部现象在哪里比较多? 干部“走读”问题主要在乡镇地区比较突出,城市地区则较少。
+走读干部现象在哪里比较多? 从历史成因和各地反映的情况来看,产生“走读”现象的主要原因大致有四种:
+走读干部现象在哪里比较多? 现今绝大多数乡村都有通往乡镇和县城的石子公路甚至柏油公路,这无疑为农村干部的出行创造了便利条件,为“干部像候鸟,频往家里跑”创造了客观条件。
+走读干部现象在哪里比较多? 选调生、公务员队伍大多是学历较高的大学毕业生,曾在高校所在地的城市生活,不少人向往城市生活,他们不安心长期扎根基层,而是将基层当作跳板,因此他们往往成为“走读”的主力军。
+走读干部现象在哪里比较多? 公仆意识、服务意识淡化,是“走读”现象滋生的主观原因。
+走读干部现象在哪里比较多? 有些党员干部感到自己长期在基层工作,该为自己和家庭想想了。
+走读干部现象在哪里比较多? 于是,不深入群众认真调查研究、认真听取群众意见、认真解决群众的实际困难,也就不难理解了。
+走读干部现象在哪里比较多? 县级党政组织对乡镇领导干部管理的弱化和为基层服务不到位,导致“走读”问题得不到应有的制度约束,是“走读”问题滋长的组织原因。[2]
+走读干部现象在哪里比较多? 近些年来,我国一些地方的“干部走读”现象较为普遍,社会上对此议走读干部论颇多。
+走读干部现象在哪里比较多? 所谓“干部走读”,一般是指县乡两级干部家住县城以上的城市,本人在县城或者乡镇工作,要么早出晚归,要么周一去单位上班、周五回家过周末。
+走读干部现象在哪里比较多? 对于这种现象,社会上的议论多是批评性的,认为这些干部脱离群众、作风漂浮、官僚主义,造成行政成本增加和腐败。
+走读干部现象在哪里比较多? 干部走读之所以成为“千夫所指”,是因为这种行为增加了行政成本。
+走读干部现象在哪里比较多? 从根子上说,干部走读是城乡发展不平衡的产物,“人往高处走,水往低处流”,有了更加舒适的生活环境,不管是为了自己生活条件改善也好,还是因为子女教育也好,农村人口向城镇转移,这是必然结果。
+走读干部现象在哪里比较多? “干部走读”的另一个重要原因,是干部人事制度改革。
+走读干部现象在哪里比较多? 目前公务员队伍“凡进必考”,考上公务员的大多是学历较高的大学毕业生,这些大学毕业生来自各个全国各地,一部分在本地结婚生子,沉淀下来;一部分把公务员作为跳板,到基层后或考研,或再参加省考、国考,或想办法调回原籍。
+走读干部现象在哪里比较多? 再加上一些下派干部、异地交流任职干部,构成了看似庞大的“走读”队伍。
+走读干部现象在哪里比较多? 那么,“干部走读”有哪些弊端呢?
+走读干部现象在哪里比较多? 一是这些干部人在基层,心在城市,缺乏长期作战的思想,工作不安心。
+走读干部现象在哪里比较多? 周一来上班,周五回家转,对基层工作缺乏热情和感情;二是长期在省市直机关工作,对基层工作不熟悉不了解,工作不热心;三是长期走读,基层干群有工作难汇报,有困难难解决,群众不开心;四是干部来回走读,公车私驾,私费公报,把大量的经济负担转嫁给基层;五是对这些走读干部,基层管不了,上级监督难,节假日期间到哪里去、做什么事,基本处于失控和真空状态,各级组织和基层干群不放心。
+走读干部现象在哪里比较多? 特别需要引起警觉的是,由于少数走读干部有临时思想,满足于“当维持会长”,得过且过混日子,热衷于做一些急功近利、砸锅求铁的短期行为和政绩工程,不愿做打基础、管长远的实事好事,甚至怠政、疏政和懒于理政,影响了党和政府各项方针政策措施的落实,导致基层无政府主义、自由主义抬头,削弱了党和政府的领导,等到矛盾激化甚至不可收拾的时候,处理已是来之不及。
+走读干部现象在哪里比较多? 权利要与义务相等,不能只有义务而没有权利,或是只有权利没有义务。
+走读干部现象在哪里比较多? 如何真正彻底解决乡镇干部“走读”的现象呢?
+走读干部现象在哪里比较多? 那就必须让乡镇基层干部义务与权利相等。
+走读干部现象在哪里比较多? 如果不能解决基层干部待遇等问题,即使干部住村,工作上也不会有什么进展的。
+走读干部现象在哪里比较多? 所以,在政治上关心,在生活上照顾,在待遇上提高。
+走读干部现象在哪里比较多? 如,提高基层干部的工资待遇,增加通讯、交通补助;帮助解决子女入学及老人赡养问题;提拔干部优先考虑基层干部;干部退休时的待遇至少不低于机关干部等等。
+化州市良光镇东岸小学学风是什么? 学校全体教职工爱岗敬业,团结拼搏,勇于开拓,大胆创新,进行教育教学改革,努力开辟第二课堂的教学路子,并开通了网络校校通的交流合作方式。
+化州市良光镇东岸小学学风是什么? 现学校教师正在为创建安全文明校园而努力。
+化州市良光镇东岸小学学风是什么? 东岸小学位置偏僻,地处贫穷落后,是良光镇最偏远的学校,学校,下辖分教点——东心埇小学,[1]?。
+化州市良光镇东岸小学学风是什么? 学校2011年有教师22人,学生231人。
+化州市良光镇东岸小学学风是什么? 小学高级教师8人,小学一级教师10人,未定级教师4人,大专学历的教师6人,其余的都具有中师学历。
+化州市良光镇东岸小学学风是什么? 全校共设12个班,学校课程按标准开设。
+化州市良光镇东岸小学学风是什么? 东岸小学原来是一所破旧不堪,教学质量非常差的薄弱学校。
+化州市良光镇东岸小学学风是什么? 近几年来,在各级政府、教育部门及社会各界热心人士鼎力支持下,学校领导大胆改革创新,致力提高教学质量和教师水平,并加大经费投入,大大改善了办学条件,使学校由差变好,实现了大跨越。
+化州市良光镇东岸小学学风是什么? 学校建设性方面。
+化州市良光镇东岸小学学风是什么? 东岸小学属于革命老区学校,始建于1980年,从东心埇村祠堂搬到这个校址,1990年建造一幢建筑面积为800平方米的南面教学楼, 1998年老促会支持从北面建造一幢1800平方米的教学大楼。
+化州市良光镇东岸小学学风是什么? 学校在管理方面表现方面颇具特色,实现了各项制度的日常化和规范化。
+化州市良光镇东岸小学学风是什么? 学校领导有较强的事业心和责任感,讲求民主与合作,勤政廉政,依法治校,树立了服务意识。
+化州市良光镇东岸小学学风是什么? 学校一贯实施“德育为先,以人为本”的教育方针,制定了“团结,律已,拼搏,创新”的校训。
+化州市良光镇东岸小学学风是什么? 教育风为“爱岗敬业,乐于奉献”,学风为“乐学,勤学,巧学,会学”。
+化州市良光镇东岸小学学风是什么? 校内营造了尊师重教的氛围,形成了良好的校风和学风。
+化州市良光镇东岸小学学风是什么? 教师们爱岗敬业,师德高尚,治学严谨,教研教改气氛浓厚,获得喜人的教研成果。
+化州市良光镇东岸小学学风是什么? 近几年来,教师撰写的教育教学论文共10篇获得县市级以上奖励,获了镇级以上奖励的有100人次。
+化州市良光镇东岸小学学风是什么? 学校德育工作成绩显著,多年被评为“安全事故为零”的学校,良光镇先进学校。
+化州市良光镇东岸小学学风是什么? 特别是教学质量大大提高了。
+化州市良光镇东岸小学学风是什么? 这些成绩得到了上级及群众的充分肯定。
+化州市良光镇东岸小学学风是什么? 1.学校环境欠美观有序,学校大门口及校道有待改造。
+化州市良光镇东岸小学学风是什么? 2.学校管理制度有待改进,部分教师业务水平有待提高。
+化州市良光镇东岸小学学风是什么? 3.教师宿舍、教室及学生宿舍欠缺。
+化州市良光镇东岸小学学风是什么? 4.运动场不够规范,各类体育器材及设施需要增加。
+化州市良光镇东岸小学学风是什么? 5.学生活动空间少,见识面窄,视野不够开阔。
+化州市良光镇东岸小学学风是什么? 1.努力营造和谐的教育教学新气氛。
+化州市良光镇东岸小学学风是什么? 建立科学的管理制度,坚持“与时俱进,以人为本”,真正实现领导对教师,教师对学生之间进行“德治与情治”;学校的人文环境做到“文明,和谐,清新”;德育环境做到“自尊,律已,律人”;心理环境做到“安全,谦虚,奋发”;交际环境做到“团结合作,真诚助人”;景物环境做到“宜人,有序。”
+化州市良光镇东岸小学学风是什么? 营造学校与育人的新特色。
+我很好奇发射管的输出功率怎么样? 产生或放大高频功率的静电控制电子管,有时也称振荡管。
+我很好奇发射管的输出功率怎么样? 用于音频或开关电路中的发射管称调制管。
+我很好奇发射管的输出功率怎么样? 发射管是无线电广播、通信、电视发射设备和工业高频设备中的主要电子器件。
+我很好奇发射管的输出功率怎么样? 输出功率和工作频率是发射管的基本技术指标。
+我很好奇发射管的输出功率怎么样? 广播、通信和工业设备的发射管,工作频率一般在30兆赫以下,输出功率在1919年为2千瓦以下,1930年达300千瓦,70年代初已超过1000千瓦,效率高达80%以上。
+我很好奇发射管的输出功率怎么样? 发射管工作频率提高时,输出功率和效率都会降低,因此1936年首次实用的脉冲雷达工作频率仅28兆赫,80年代则已达 400兆赫以上。
+我很好奇发射管的输出功率怎么样? 40年代电视发射管的工作频率为数十兆赫,而80年代初,优良的电视发射管可在1000兆赫下工作,输出功率达20千瓦,效率为40%。
+我很好奇发射管的输出功率怎么样? 平面电极结构的小功率发射三极管可在更高的频率下工作。
+我很好奇发射管的输出功率怎么样? 发射管多采用同心圆筒电极结构。
+我很好奇发射管的输出功率怎么样? 阴极在最内层,向外依次为各个栅极和阳极。
+我很好奇发射管的输出功率怎么样? 图中,自左至右为阴极、第一栅、第二栅、栅极阴极组装件和装入阳极后的整个管子。
+我很好奇发射管的输出功率怎么样? 发射管
+我很好奇发射管的输出功率怎么样? 中小功率发射管多采用间热式氧化物阴极。
+我很好奇发射管的输出功率怎么样? 大功率发射管一般采用碳化钍钨丝阴极,有螺旋、直条或网笼等结构形式。
+我很好奇发射管的输出功率怎么样? 图为网笼式阴极。
+我很好奇发射管的输出功率怎么样? 栅极多用钼丝或钨丝绕制,或用钼片经电加工等方法制造。
+我很好奇发射管的输出功率怎么样? 栅极表面经镀金(或铂)或涂敷锆粉等处理,以降低栅极电子发射,使发射管稳定工作。
+我很好奇发射管的输出功率怎么样? 用气相沉积方法制造的石墨栅极,具有良好的性能。
+我很好奇发射管的输出功率怎么样? 发射管阳极直流输入功率转化为高频输出功率的部分约为75%,其余25%成为阳极热损耗,因此对发射管的阳极必须进行冷却。
+我很好奇发射管的输出功率怎么样? 中小功率发射管的阳极采取自然冷却方式,用镍、钼或石墨等材料制造,装在管壳之内,工作温度可达 600℃。
+我很好奇发射管的输出功率怎么样? 大功率发射管的阳极都用铜制成,并作为真空密封管壳的一部分,采用各种强制冷却方式。
+我很好奇发射管的输出功率怎么样? 各种冷却方式下每平方厘米阳极内表面的散热能力为:水冷100瓦;风冷30瓦;蒸发冷却250瓦;超蒸发冷却1000瓦以上,80年代已制成阳极损耗功率为1250千瓦的超蒸发冷却发射管。
+我很好奇发射管的输出功率怎么样? 发射管也常以冷却方式命名,如风冷发射管、水冷发射管和蒸发冷却发射管。
+我很好奇发射管的输出功率怎么样? 发射管管壳用玻璃或陶瓷制造。
+我很好奇发射管的输出功率怎么样? 小功率发射管内使用含钡的吸气剂;大功率发射管则采用锆、钛、钽等吸气材料,管内压强约为10帕量级。
+我很好奇发射管的输出功率怎么样? 发射管寿命取决于阴极发射电子的能力。
+我很好奇发射管的输出功率怎么样? 大功率发射管寿命最高记录可达8万小时。
+我很好奇发射管的输出功率怎么样? 发射四极管的放大作用和输出输入电路间的隔离效果优于三极管,应用最广。
+我很好奇发射管的输出功率怎么样? 工业高频振荡器普遍采用三极管。
+我很好奇发射管的输出功率怎么样? 五极管多用在小功率范围中。
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 鲁能领秀城中央公园位于鲁能领秀城景观中轴之上,总占地161.55亩,总建筑面积约40万平米,容积率为2.70,由22栋小高层、高层组成;其绿地率高达35.2%,环境优美,产品更加注重品质化、人性化和自然生态化,是鲁能领秀城的生态人居典范。
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 中央公园[1] 学区准现房,坐享鲁能领秀城成熟配套,成熟生活一步到位。
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 经典板式小高层,103㎡2+1房仅22席,稀市推出,错过再无;92㎡经典两房、137㎡舒适三房压轴登场!
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 物业公司:
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 济南凯瑞物业公司;深圳长城物业公司;北京盛世物业有限公司
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 绿化率:
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 42%
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 容积率:
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 2.70
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 暖气:
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 集中供暖
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 楼座展示:中央公园由22栋小高层、高层组成,3、16、17号楼分别是11层小高层,18层和28层的高层。
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 4号楼是23层,2梯3户。
+鲁能领秀城中央公园有23层,2梯3户的是几号楼? 项目位置:
+鬼青蛙在哪里有收录详情? 鬼青蛙这张卡可以从手卡把这张卡以外的1只水属性怪兽丢弃,从手卡特殊召唤。
+鬼青蛙在哪里有收录详情? 这张卡召唤·反转召唤·特殊召唤成功时,可以从自己的卡组·场上选1只水族·水属性·2星以下的怪兽送去墓地。
+鬼青蛙在哪里有收录详情? 此外,1回合1次,可以通过让自己场上1只怪兽回到手卡,这个回合通常召唤外加上只有1次,自己可以把「鬼青蛙」以外的1只名字带有「青蛙」的怪兽召唤。[1]
+鬼青蛙在哪里有收录详情? 游戏王卡包收录详情
+鬼青蛙在哪里有收录详情? [09/09/18]
+西湖区有多大? 西湖区是江西省南昌市市辖区。
+西湖区有多大? 为南昌市中心城区之一,有着2200多年历史,是一个物华天宝、人杰地灵的古老城区。
+西湖区有多大? 2004年南昌市老城区区划调整后,西湖区东起京九铁路线与青山湖区毗邻,南以洪城路东段、抚河路南段、象湖以及南隔堤为界与青云谱区、南昌县接壤,西凭赣江中心线与红谷滩新区交界,北沿中山路、北京西路与东湖区相连,所辖面积34.5平方公里,常住人口43万,管辖1个镇、10个街道办事处,设12个行政村、100个社区。
+西湖区有多大? (图)西湖区[南昌市]
+西湖区有多大? 西湖原为汉代豫章群古太湖的一部分,唐贞元15年(公元799年)洪恩桥的架设将东太湖分隔成东西两部分,洪恩桥以西谓之西湖,西湖区由此而得名。
+西湖区有多大? 西湖区在1926年南昌设市后分别称第四、五部分,六、七部分。
+西湖区有多大? 1949年解放初期分别称第三、四区。
+西湖区有多大? 1955年分别称抚河区、西湖区。
+西湖区有多大? 1980年两区合并称西湖区。[1]
+西湖区有多大? 辖:西湖街道、丁公路街道、广外街道、系马桩街道、绳金塔街道、朝阳洲街道、禾草街街道、十字街街道、瓦子角街道、三眼井街道、上海路街道、筷子巷街道、南站街道。[1]
+西湖区有多大? 2002年9月,由原筷子巷街道和原禾草街街道合并设立南浦街道,原广外街道与瓦子角街道的一部分合并设立广润门街道。
+西湖区有多大? 2002年12月1日设立桃源街道。
+西湖区有多大? 2004年区划调整前的西湖区区域:东与青山湖区湖坊乡插花接壤;西临赣江与红谷滩新区隔江相望;南以建设路为界,和青云谱区毗邻;北连中山路,北京西路,与东湖区交界。[1]
+西湖区有多大? 2002年9月,由原筷子巷街道和原禾草街街道合并设立南浦街道,原广外街道与瓦子角街道的一部分合并设立广润门街道。
+西湖区有多大? 2002年12月1日设立桃源街道。
+西湖区有多大? 2004年区划调整前的西湖区区域:东与青山湖区湖坊乡插花接壤;西临赣江与红谷滩新区隔江相望;南以建设路为界,和青云谱区毗邻;北连中山路,北京西路,与东湖区交界。
+西湖区有多大? 2004年9月7日,国务院批准(国函[2004]70号)调整南昌市市辖区部分行政区划:将西湖区朝阳洲街道的西船居委会划归东湖区管辖。
+西湖区有多大? 将青山湖区的桃花镇和湖坊镇的同盟村划归西湖区管辖。
+西湖区有多大? 将西湖区十字街街道的谷市街、洪城路、南关口、九四、新丰5个居委会,上海路街道的草珊瑚集团、南昌肠衣厂、电子计算机厂、江西涤纶厂、江地基础公司、曙光、商标彩印厂、南昌市染整厂、江南蓄电池厂、四机床厂、二进、国乐新村12个居委会,南站街道的解放西路东居委会划归青云谱区管辖。
+西湖区有多大? 将西湖区上海路街道的轻化所、洪钢、省人民检察院、电信城东分局、安康、省机械施工公司、省水利设计院、省安装公司、南方电动工具厂、江西橡胶厂、上海路北、南昌电池厂、东华计量所、南昌搪瓷厂、上海路新村、华安针织总厂、江西五金厂、三波电机厂、水文地质大队、二六○厂、省卫生学校、新世纪、上海路住宅区北、塔子桥北、南航、上海路住宅区南、沿河、南昌阀门厂28个居委会,丁公路街道的新魏路、半边街、师大南路、顺化门、岔道口东路、师大、广电厅、手表厂、鸿顺9个居委会,南站街道的工人新村北、工人新村南、商苑、洪都中大道、铁路第三、铁路第四、铁路第六7个居委会划归青山湖区管辖。
+西湖区有多大? 调整后,西湖区辖绳金塔、桃源、朝阳洲、广润门、南浦、西湖、系马桩、十字街、丁公路、南站10个街道和桃花镇,区人民政府驻孺子路。
+西湖区有多大? 调整前,西湖区面积31平方千米,人口52万。
+西湖区有多大? (图)西湖区[南昌市]
+西湖区有多大? 西湖区位于江西省省会南昌市的中心地带,具有广阔的发展空间和庞大的消费群体,商贸旅游、娱乐服务业等到各个行业都蕴藏着无限商机,投资前景十分广阔。
+西湖区有多大? 不仅水、电价格低廉,劳动力资源丰富,人均工资和房产价格都比沿海城市低,城区拥有良好的人居环境、低廉的投资成本,巨大的发展潜力。
+西湖区有多大? 105、316、320国道和京九铁路贯穿全境,把南北东西交通连成一线;民航可与上海、北京、广州、深圳、厦门、温州等到地通航,并开通了南昌-新加坡第一条国际航线;水运依托赣江可直达长江各港口;邮电通讯便捷,程控电话、数字微波、图文传真进入国际通讯网络;商检、海关、口岸等涉外机构齐全;水、电、气供应充足。
+西湖区有多大? (图)西湖区[南昌市]
+西湖区有多大? 西湖区,是江西省省会南昌市的中心城区,面积34.8平方公里,常住人口51.9万人,辖桃花镇、朝农管理处及10个街道,设13个行政村,116个社区居委会,20个家委会。[2]
+西湖区有多大? 2005年11月16日,南昌市《关于同意西湖区桃花镇、桃源、十字街街道办事处行政区划进行调整的批复》
+西湖区有多大? 1、同意将桃花镇的三道闸居委会划归桃源街道办事处管辖。
+青藏虎耳草花期什么时候? 青藏虎耳草多年生草本,高4-11.5厘米,丛生。
+青藏虎耳草花期什么时候? 花期7-8月。
+青藏虎耳草花期什么时候? 分布于甘肃(祁连山地)、青海(黄南、海南、海北)和西藏(加查)。
+青藏虎耳草花期什么时候? 生于海拔3 700-4 250米的林下、高山草甸和高山碎石隙。[1]
+青藏虎耳草花期什么时候? 多年生草本,高4-11.5厘米,丛生。
+青藏虎耳草花期什么时候? 茎不分枝,具褐色卷曲柔毛。
+青藏虎耳草花期什么时候? 基生叶具柄,叶片卵形、椭圆形至长圆形,长15-25毫米,宽4-8毫米,腹面无毛,背面和边缘具褐色卷曲柔毛,叶柄长1-3厘米,基部扩大,边缘具褐色卷曲柔毛;茎生叶卵形至椭圆形,长1.5-2厘米,向上渐变小。
+青藏虎耳草花期什么时候? 聚伞花序伞房状,具2-6花;花梗长5-19毫米,密被褐色卷曲柔毛;萼片在花期反曲,卵形至狭卵形,长2.5-4.2毫米,宽1.5-2毫米,先端钝,两面无毛,边缘具褐色卷曲柔毛,3-5脉于先端不汇合;花瓣腹面淡黄色且其中下部具红色斑点,背面紫红色,卵形、狭卵形至近长圆形,长2.5-5.2毫米,宽1.5-2.1毫米,先端钝,基部具长0.5-1毫米之爪,3-5(-7)脉,具2痂体;雄蕊长2-3.6毫米,花丝钻形;子房半下位,周围具环状花盘,花柱长1-1.5毫米。
+青藏虎耳草花期什么时候? 生于高山草甸、碎石间。
+青藏虎耳草花期什么时候? 分布青海、西藏、甘肃、四川等地。
+青藏虎耳草花期什么时候? [1]
+青藏虎耳草花期什么时候? 顶峰虎耳草Saxifraga cacuminum Harry Sm.
+青藏虎耳草花期什么时候? 对叶虎耳Saxifraga contraria Harry Sm.
+青藏虎耳草花期什么时候? 狭瓣虎耳草Saxifraga pseudohirculus Engl.
+青藏虎耳草花期什么时候? 唐古特虎耳草Saxifraga tangutica Engl.
+青藏虎耳草花期什么时候? 宽叶虎耳草(变种)Saxifraga tangutica Engl. var. platyphylla (Harry Sm.) J. T. Pan
+青藏虎耳草花期什么时候? 唐古特虎耳草(原变种)Saxifraga tangutica Engl. var. tangutica
+青藏虎耳草花期什么时候? 西藏虎耳草Saxifraga tibetica Losinsk.[1]
+青藏虎耳草花期什么时候? Saxifraga przewalskii Engl. in Bull. Acad. Sci. St. -Petersb. 29:115. 1883: Engl et Irmsch. in Bot. Jahrb. 48:580. f. 5E-H. 1912 et in Engl. Pflanzenr. 67(IV. 117): 107. f. 21 E-H. 1916; J. T. Pan in Acta Phytotax. Sin. 16(2): 16. 1978;中国高等植物图鉴补编2: 30. 1983; 西藏植物志 2: 483. 1985. [1]
+生产一支欧文冲锋枪需要多少钱? 欧文冲锋枪 Owen Gun 1945年,在新不列颠手持欧文冲锋枪的澳大利亚士兵 类型 冲锋枪 原产国 ?澳大利亚 服役记录 服役期间 1941年-1960年代 用户 参见使用国 参与战役 第二次世界大战 马来亚紧急状态 朝鲜战争 越南战争 1964年罗德西亚布什战争 生产历史 研发者 伊夫林·欧文(Evelyn Owen) 研发日期 1931年-1939年 生产商 约翰·莱萨特工厂 利特高轻武器工厂 单位制造费用 $ 30/枝 生产日期 1941年-1945年 制造数量 45,000-50,000 枝 衍生型 Mk 1/42 Mk 1/43 Mk 2/43 基本规格 总重 空枪: Mk 1/42:4.24 千克(9.35 磅) Mk 1/43:3.99 千克(8.8 磅) Mk 2/43:3.47 千克(7.65 磅) 全长 806 毫米(31.73 英吋) 枪管长度 247 毫米(9.72 英吋) 弹药 制式:9 × 19 毫米 原型:.38/200 原型:.45 ACP 口径 9 × 19 毫米:9 毫米(.357 英吋) .38/200:9.65 毫米(.38 英吋) .45 ACP:11.43 毫米(.45 英吋) 枪管 1 根,膛线7 条,右旋 枪机种类 直接反冲作用 开放式枪机 发射速率 理论射速: Mk 1/42:700 发/分钟 Mk 1/43:680 发/分钟 Mk 2/43:600 发/分钟 实际射速:120 发/分钟 枪口初速 380-420 米/秒(1,246.72-1,377.95 英尺/秒) 有效射程 瞄具装定射程:91.44 米(100 码) 最大有效射程:123 米(134.51 码) 最大射程 200 米(218.72 码) 供弹方式 32/33 发可拆卸式弹匣 瞄准具型式 机械瞄具:向右偏置的觇孔式照门和片状准星 欧文冲锋枪(英语:Owen Gun,正式名称:Owen Machine Carbine,以下简称为“欧文枪”)是一枝由伊夫林·(埃沃)·欧文(英语:Evelyn (Evo) Owen)于1939年研制、澳大利亚的首枝冲锋枪,制式型发射9 × 19 毫米鲁格手枪子弹。
+生产一支欧文冲锋枪需要多少钱? 欧文冲锋枪是澳大利亚唯一设计和主要服役的二战冲锋枪,并从1943年由澳大利亚陆军所使用,直到1960年代中期。
+生产一支欧文冲锋枪需要多少钱? 由新南威尔士州卧龙岗市出身的欧文枪发明者,伊夫林·欧文,在24岁时于1939年7月向悉尼维多利亚军营的澳大利亚陆军军械官员展示了他所设计的.22 LR口径“卡宾机枪”原型枪。
+生产一支欧文冲锋枪需要多少钱? 该枪却被澳大利亚陆军所拒绝,因为澳大利亚陆军在当时没有承认冲锋枪的价值。
+生产一支欧文冲锋枪需要多少钱? 随着战争的爆发,欧文加入了澳大利亚军队,并且成为一名列兵。
+生产一支欧文冲锋枪需要多少钱? 1940年9月,欧文的邻居,文森特·沃德尔(英语:Vincent Wardell),看到欧文家楼梯后面搁著一个麻布袋,里面放著一枝欧文枪的原型枪。
+生产一支欧文冲锋枪需要多少钱? 而文森特·沃德尔是坎布拉港的大型钢制品厂莱萨特公司的经理,他向欧文的父亲表明了他对其儿子的粗心大意感到痛心,但无论如何仍然解释了这款武器的历史。
+生产一支欧文冲锋枪需要多少钱? 沃德尔对欧文枪的简洁的设计留下了深刻的印象。
+生产一支欧文冲锋枪需要多少钱? 沃德尔安排欧文转调到陆军发明部(英语:Army Inventions Board),并重新开始在枪上的工作。
+生产一支欧文冲锋枪需要多少钱? 军队仍然持续地从负面角度查看该武器,但同时政府开始采取越来越有利的观点。
+生产一支欧文冲锋枪需要多少钱? 该欧文枪原型配备了装在顶部的弹鼓,后来让位给装在顶部的弹匣使用。
+生产一支欧文冲锋枪需要多少钱? 口径的选择亦花了一些时间去解决。
+生产一支欧文冲锋枪需要多少钱? 由于陆军有大批量的柯尔特.45 ACP子弹,它们决定欧文枪需要采用这种口径。
+生产一支欧文冲锋枪需要多少钱? 直到在1941年9月19日官方举办试验时,约翰·莱萨特工厂制成了9 毫米、.38/200和.45 ACP三种口径版本。
+生产一支欧文冲锋枪需要多少钱? 而从美、英进口的斯登冲锋枪和汤普森冲锋枪在试验中作为基准使用。
+生产一支欧文冲锋枪需要多少钱? 作为测试的一部分,所有的枪支都浸没在泥浆里,并以沙土覆盖,以模拟他们将会被使用时最恶劣的环境。
+生产一支欧文冲锋枪需要多少钱? 欧文枪是唯一在这测试中这样对待以后仍可正常操作的冲锋枪。
+生产一支欧文冲锋枪需要多少钱? 虽然测试表现出欧文枪具有比汤普森冲锋枪和司登冲锋枪更优秀的可靠性,陆军没有对其口径作出决定。
+生产一支欧文冲锋枪需要多少钱? 结果它在上级政府干预以后,陆军才下令9 毫米的衍生型为正式口径,并在1941年11月20日正式被澳大利亚陆军采用。
+生产一支欧文冲锋枪需要多少钱? 在欧文枪的寿命期间,其可靠性在澳大利亚部队中赢得了“军人的至爱”(英语:Digger's Darling)的绰号,亦有人传言它受到美军高度青睐。
+生产一支欧文冲锋枪需要多少钱? 欧文枪是在1942年开始正式由坎布拉港和纽卡斯尔的约翰·莱萨特工厂投入生产,在生产高峰期每个星期生产800 支。
+生产一支欧文冲锋枪需要多少钱? 1942年3月至1943年2月之间,莱萨特生产了28,000 枝欧文枪。
+生产一支欧文冲锋枪需要多少钱? 然而,最初的一批弹药类型竟然是错误的,以至10,000 枝欧文枪无法提供弹药。
+生产一支欧文冲锋枪需要多少钱? 政府再一次推翻军方的官僚主义作风??,并让弹药通过其最后的生产阶段,以及运送到当时在新几内亚与日军战斗的澳大利亚部队的手中。
+生产一支欧文冲锋枪需要多少钱? 在1941年至1945年间生产了约50,000 枝欧文枪。
+生产一支欧文冲锋枪需要多少钱? 在战争期间,欧文枪的平均生产成本为$ 30。[1]
+生产一支欧文冲锋枪需要多少钱? 虽然它是有点笨重,因为其可靠性,欧文枪在士兵当中变得非常流行。
+生产一支欧文冲锋枪需要多少钱? 它是如此成功,它也被新西兰、英国和美国订购。[2]
+生产一支欧文冲锋枪需要多少钱? 欧文枪后来也被澳大利亚部队在朝鲜战争和越南战争,[3]特别是步兵组的侦察兵。
+生产一支欧文冲锋枪需要多少钱? 这仍然是一枝制式的澳大利亚陆军武器,直到1960年代中期,它被F1冲锋枪所取代。
+第二届中国光伏摄影大赛因为什么政策而开始的? 光伏发电不仅是全球能源科技和产业发展的重要方向,也是我国具有国际竞争优势的战略性新兴产业,是我国保障能源安全、治理环境污染、应对气候变化的战略性选择。
+第二届中国光伏摄影大赛因为什么政策而开始的? 2013年7月以来,国家出台了《关于促进光伏产业健康发展的若干意见》等一系列政策,大力推进分布式光伏发电的应用,光伏发电有望走进千家万户,融入百姓民生。
+第二届中国光伏摄影大赛因为什么政策而开始的? 大赛主办方以此为契机,开启了“第二届中国光伏摄影大赛”的征程。
+悬赏任务有哪些类型? 悬赏任务,威客网站上一种任务模式,由雇主在威客网站发布任务,提供一定数额的赏金,以吸引威客们参与。
+悬赏任务有哪些类型? 悬赏任务数额一般在几十到几千不等,但也有几万甚至几十万的任务。
+悬赏任务有哪些类型? 主要以提交的作品的质量好坏作为中标标准,当然其中也带有雇主的主观喜好,中标人数较少,多为一个或几个,因此竞争激烈。
+悬赏任务有哪些类型? 大型悬赏任务赏金数额巨大,中标者也较多,但参与人也很多,对于身有一技之长的威客来讲,悬赏任务十分适合。
+悬赏任务有哪些类型? 悬赏任务的类型主要包括:设计类、文案类、取名类、网站类、编程类、推广类等等。
+悬赏任务有哪些类型? 每一类所适合的威客人群不同,报酬的多少也不同,比如设计类的报酬就比较高,一般都几百到几千,而推广类的计件任务报酬比较少,一般也就几块钱,但花费的时间很少,技术要求也很低。
+悬赏任务有哪些类型? 1.注册—登陆
+悬赏任务有哪些类型? 2.点击“我要发悬赏”—按照发布流程及提示提交任务要求。
+悬赏任务有哪些类型? 悬赏模式选择->网站托管赏金模式。
+悬赏任务有哪些类型? 威客网站客服稍后会跟发布者联系确认任务要求。
+悬赏任务有哪些类型? 3.没有问题之后就可以预付赏金进行任务发布。
+悬赏任务有哪些类型? 4.会员参与并提交稿件。
+悬赏任务有哪些类型? 5.发布者需要跟会员互动(每个提交稿件的会员都可以),解决问题,完善稿件,初步筛选稿件。
+悬赏任务有哪些类型? 6.任务发布期结束,进入选稿期(在筛选的稿件中选择最后满意的)
+悬赏任务有哪些类型? 7.发布者不满意现有稿件可选定一个会员修改至满意为止,或者加价延期重新开放任务进行征稿。
+悬赏任务有哪些类型? (重复第六步)没有问题后进入下一步。
+悬赏任务有哪些类型? 8:中标会员交源文件给发布者—发布者确认—任务结束—网站将赏金付给中标会员。
+悬赏任务有哪些类型? 1、任务发布者自由定价,自由确定悬赏时间,自由发布任务要求,自主确定中标会员和中标方案。
+悬赏任务有哪些类型? 2、任务发布者100%预付任务赏金,让竞标者坚信您的诚意和诚信。
+悬赏任务有哪些类型? 3、任务赏金分配原则:任务一经发布,网站收取20%发布费,中标会员获得赏金的80%。
+悬赏任务有哪些类型? 4、每个任务最终都会选定至少一个作品中标,至少一个竞标者获得赏金。
+悬赏任务有哪些类型? 5、任务发布者若未征集到满意作品,可以加价延期征集,也可让会员修改,会员也可以删除任务。
+悬赏任务有哪些类型? 6、任务发布者自己所在组织的任何人均不能以任何形式参加自己所发布的任务,一经发现则视为任务发布者委托威客网按照网站规则选稿。
+悬赏任务有哪些类型? 7、任务悬赏总金额低于100元(含100元)的任务,悬赏时间最多为7天。
+悬赏任务有哪些类型? 所有任务最长时间不超过30天(特殊任务除外),任务总金额不得低于50元。
+悬赏任务有哪些类型? 8、网赚类、注册类任务总金额不能低于300元人民币,计件任务每个稿件的平均单价不能低于1元人民币。
+悬赏任务有哪些类型? 9、延期任务只有3次加价机会,第1次加价不得低于任务金额的10%,第2次加价不得低于任务总金额的20%,第3次不得低于任务总金额的50%。
+悬赏任务有哪些类型? 每次延期不能超过15天,加价金额不低于50元,特殊任务可以适当加长。
+悬赏任务有哪些类型? 如果为计件任务,且不是网赚类任务,将免费延期,直至征集完规定数量的作品为止。
+悬赏任务有哪些类型? 10、如果威客以交接源文件要挟任务发布者,威客网将扣除威客相关信用值,并取消其中标资格,同时任务将免费延长相应的时间继续征集作品 。
+江湖令由哪些平台运营? 《江湖令》是以隋唐时期为背景的RPG角色扮演类网页游戏。
+江湖令由哪些平台运营? 集角色扮演、策略、冒险等多种游戏元素为一体,画面精美犹如客户端游戏,融合历史、江湖、武功、恩仇多种特色元素,是款不可多得的精品游戏大作。
+江湖令由哪些平台运营? 由ya247平台、91wan游戏平台、2918、4399游戏平台、37wan、6711、兄弟玩网页游戏平台,49you、Y8Y9平台、8090游戏等平台运营的,由07177游戏网发布媒体资讯的网页游戏。
+江湖令由哪些平台运营? 网页游戏《江湖令》由51游戏社区运营,是以隋唐时期为背景的RPG角色扮演类网页游戏。
+江湖令由哪些平台运营? 集角色扮演、策略、冒险等多种游戏元素为一体,画面精美犹如客户端游戏,融合历史、江湖、武功、恩仇多种特色元素,是款不可多得的精品游戏大作…
+江湖令由哪些平台运营? 背景故事:
+江湖令由哪些平台运营? 隋朝末年,隋炀帝暴政,天下民不聊生,义军四起。
+江湖令由哪些平台运营? 在这动荡的时代中,百姓生活苦不堪言,多少人流离失所,家破人亡。
+江湖令由哪些平台运营? 天下三大势力---飞羽营、上清宫、侠隐岛,也值此机会扩张势力,派出弟子出来行走江湖。
+江湖令由哪些平台运营? 你便是这些弟子中的普通一员,在这群雄并起的年代,你将如何选择自己的未来。
+江湖令由哪些平台运营? 所有的故事,便从瓦岗寨/江都大营开始……
+江湖令由哪些平台运营? 势力:
+江湖令由哪些平台运营? ①、飞羽营:【外功、根骨】
+江湖令由哪些平台运营? 南北朝时期,由北方政权创立的一个民间军事团体,经过多年的发展,逐渐成为江湖一大势力。
+江湖令由哪些平台运营? ②、上清宫:【外功、身法】
+江湖令由哪些平台运营? 道家圣地,宫中弟子讲求清静无为,以一种隐世的方式修炼,但身在此乱世,亦也不能独善其身。
+江湖令由哪些平台运营? ③、侠隐岛:【根骨、内力】
+江湖令由哪些平台运营? 位于偏远海岛上的一个世家,岛内弟子大多武功高强,但从不进入江湖行走,适逢乱世,现今岛主也决意作一翻作为。
+江湖令由哪些平台运营? 两大阵营:
+江湖令由哪些平台运营? 义军:隋唐末期,百姓生活苦不堪言,有多个有志之士组成义军,对抗当朝暴君,希望建立一个适合百姓安居乐业的天地。
+江湖令由哪些平台运营? 隋军:战争一起即天下打乱,隋军首先要镇压四起的义军,同时在内部慢慢改变现有的朝廷,让天下再次恢复到昔日的安定。
+江湖令由哪些平台运营? 一、宠物品质
+江湖令由哪些平台运营? 宠物的品质分为:灵兽,妖兽,仙兽,圣兽,神兽
+江湖令由哪些平台运营? 二、宠物获取途径
+江湖令由哪些平台运营? 完成任务奖励宠物(其他途径待定)。
+江湖令由哪些平台运营? 三、宠物融合
+江湖令由哪些平台运营? 1、在主界面下方的【宠/骑】按钮进入宠物界面,再点击【融合】即可进入融合界面进行融合,在融合界面可选择要融合的宠物进行融合
+江湖令由哪些平台运营? 2、融合后主宠的形态不变;
+江湖令由哪些平台运营? 3、融合后宠物的成长,品质,技能,经验,成长经验,等级都继承成长高的宠物;
+江湖令由哪些平台运营? 4、融合宠物技能冲突,则保留成长值高的宠物技能,如果不冲突则叠加在空余的技能位置。
+请问土耳其足球超级联赛是什么时候成立的? 土耳其足球超级联赛(土耳其文:Türkiye 1. Süper Futbol Ligi)是土耳其足球协会管理的职业足球联赛,通常简称“土超”,也是土耳其足球联赛中最高级别。
+请问土耳其足球超级联赛是什么时候成立的? 目前,土超联赛队伍共有18支。
+请问土耳其足球超级联赛是什么时候成立的? 土耳其足球超级联赛
+请问土耳其足球超级联赛是什么时候成立的? 运动项目 足球
+请问土耳其足球超级联赛是什么时候成立的? 成立年份 1959年
+请问土耳其足球超级联赛是什么时候成立的? 参赛队数 18队
+请问土耳其足球超级联赛是什么时候成立的? 国家 土耳其
+请问土耳其足球超级联赛是什么时候成立的? 现任冠军 费内巴切足球俱乐部(2010-2011)
+请问土耳其足球超级联赛是什么时候成立的? 夺冠最多队伍 费内巴切足球俱乐部(18次)
+请问土耳其足球超级联赛是什么时候成立的? 土耳其足球超级联赛(Türkiye 1. Süper Futbol Ligi)是土耳其足球协会管理的职业足球联赛,通常简称「土超」,也是土耳其足球联赛中最高级别。
+请问土耳其足球超级联赛是什么时候成立的? 土超联赛队伍共有18支。
+请问土耳其足球超级联赛是什么时候成立的? 土超联赛成立于1959年,成立之前土耳其国有多个地区性联赛。
+请问土耳其足球超级联赛是什么时候成立的? 土超联赛成立后便把各地方联赛制度统一起来。
+请问土耳其足球超级联赛是什么时候成立的? 一般土超联赛由八月开始至五月结束,12月至1月会有歇冬期。
+请问土耳其足球超级联赛是什么时候成立的? 十八支球队会互相对叠,各有主场和作客两部分,采计分制。
+请问土耳其足球超级联赛是什么时候成立的? 联赛枋最底的三支球队会降到土耳其足球甲级联赛作赛。
+请问土耳其足球超级联赛是什么时候成立的? 由2005-06年球季起,土超联赛的冠、亚军会取得参加欧洲联赛冠军杯的资格。
+请问土耳其足球超级联赛是什么时候成立的? 成立至今土超联赛乃由两支著名球会所垄断──加拉塔萨雷足球俱乐部和费内巴切足球俱乐部,截至2009-2010赛季,双方各赢得冠军均为17次。
+请问土耳其足球超级联赛是什么时候成立的? 土超联赛共有18支球队,采取双循环得分制,每场比赛胜方得3分,负方0分,平局双方各得1分。
+请问土耳其足球超级联赛是什么时候成立的? 如果两支球队积分相同,对战成绩好的排名靠前,其次按照净胜球来决定;如果有三支以上的球队分数相同,则按照以下标准来确定排名:1、几支队伍间对战的得分,2、几支队伍间对战的净胜球数,3、总净胜球数。
+请问土耳其足球超级联赛是什么时候成立的? 联赛第1名直接参加下个赛季冠军杯小组赛,第2名参加下个赛季冠军杯资格赛第三轮,第3名进入下个赛季欧洲联赛资格赛第三轮,第4名进入下个赛季欧洲联赛资格赛第二轮,最后三名降入下个赛季的土甲联赛。
+请问土耳其足球超级联赛是什么时候成立的? 该赛季的土耳其杯冠军可参加下个赛季欧洲联赛资格赛第四轮,如果冠军已获得冠军杯资格,则亚军可参加下个赛季欧洲联赛资格赛第四轮,否则名额递补给联赛。
+请问土耳其足球超级联赛是什么时候成立的? 2010年/2011年 费内巴切
+请问土耳其足球超级联赛是什么时候成立的? 2009年/2010年 布尔萨体育(又译贝莎)
+请问土耳其足球超级联赛是什么时候成立的? 2008年/2009年 贝西克塔斯
+请问土耳其足球超级联赛是什么时候成立的? 2007年/2008年 加拉塔萨雷
+请问土耳其足球超级联赛是什么时候成立的? 2006年/2007年 费内巴切
+请问土耳其足球超级联赛是什么时候成立的? 2005年/2006年 加拉塔沙雷
+请问土耳其足球超级联赛是什么时候成立的? 2004年/2005年 费内巴切(又译费伦巴治)
+请问土耳其足球超级联赛是什么时候成立的? 2003年/2004年 费内巴切
+cid 作Customer IDentity解时是什么意思? ? CID 是 Customer IDentity 的简称,简单来说就是手机的平台版本. CID紧跟IMEI存储在手机的OTP(One Time Programmable)芯片中. CID 后面的数字代表的是索尼爱立信手机软件保护版本号,新的CID不断被使用,以用来防止手机被非索尼爱立信官方的维修程序拿来解锁/刷机/篡改
+cid 作Customer IDentity解时是什么意思? ? CID 是 Customer IDentity 的简称,简单来说就是手机的平台版本. CID紧跟IMEI存储在手机的OTP(One Time Programmable)芯片中. CID 后面的数字代表的是索尼爱立信手机软件保护版本号,新的CID不断被使用,以用来防止手机被非索尼爱立信官方的维修程序拿来解锁/刷机/篡改
+cid 作Customer IDentity解时是什么意思? ? (英)刑事调查局,香港警察的重案组
+cid 作Customer IDentity解时是什么意思? ? Criminal Investigation Department
+cid 作Customer IDentity解时是什么意思? ? 佩枪:
+cid 作Customer IDentity解时是什么意思? ? 香港警察的CID(刑事侦缉队),各区重案组的探员装备短管点38左轮手枪,其特点是便于收藏,而且不容易卡壳,重量轻,其缺点是装弹量少,只有6发,而且换子弹较慢,威力也一般,如果碰上54式手枪或者M9手枪明显处于下风。
+cid 作Customer IDentity解时是什么意思? ? 香港警察的“刑事侦查”(Criminal Investigation Department)部门,早于1983年起已经不叫做C.I.D.的了,1983年香港警察队的重整架构,撤销了C.I.D. ( Criminal Investigation Dept.) “刑事侦缉处”,将“刑事侦查”部门归入去“行动处”内,是“行动处”内的一个分支部门,叫“刑事部”( Crime Wing )。
+cid 作Customer IDentity解时是什么意思? ? 再于90年代的一次警队重整架构,香港警队成立了新的「刑事及保安处」,再将“刑事侦查”部门归入目前的「刑事及保安处」的“处”级单位,是归入这个“处”下的一个部门,亦叫“刑事部” ( Crime Wing ),由一个助理警务处长(刑事)领导。
+cid 作Customer IDentity解时是什么意思? ? 但是时至今天,CID虽已经是一个老旧的名称,香港市民、甚至香港警察都是习惯性的沿用这个历史上的叫法 .
+cid 作Customer IDentity解时是什么意思? ? CID格式是美国Adobe公司发表的最新字库格式,它具有易扩充、速度快、兼容性好、简便、灵活等特点,已成为国内开发中文字库的热点,也为用户使用字库提供质量更好,数量更多的字体。
+cid 作Customer IDentity解时是什么意思? ? CID (Character identifier)就是字符识别码,在组成方式上分成CIDFont,CMap表两部分。
+cid 作Customer IDentity解时是什么意思? ? CIDFont文件即总字符集,包括了一种特定语言中所有常用的字符,把这些字符排序,它们在总字符集中排列的次序号就是各个字符的CID标识码(Index);CMap(Character Map)表即字符映像文件,将字符的编码(Code)映像到字符的CID标识码(Index)。
+cid 作Customer IDentity解时是什么意思? ? CID字库完全针对大字符集市场设计,其基本过程为:先根据Code,在CMap表查到Index,然后在CIDFont文件找到相应的字形数据。
+本町位于什么地方? 本条目记述台湾日治时期,各都市之本町。
+本町位于什么地方? 为台湾日治时期台北市之行政区,共分一~四丁目,在表町之西。
+本町位于什么地方? 以现在的位置来看,本町位于现台北市中正区的西北角,约位于忠孝西路一段往西至台北邮局东侧。
+本町位于什么地方? 再向南至开封街一段,沿此路线向西至开封街一段60号,顺60号到汉口街一段向东到现在华南银行总行附近画一条直线到衡阳路。
+本町位于什么地方? 再向东至重庆南路一段,由重庆南路一段回到原点这个范围内。
+本町位于什么地方? 另外,重庆南路一段在当时名为“本町通”。
+本町位于什么地方? 此地方自日治时期起,就是繁华的商业地区,当时也有三和银行、台北专卖分局、日本石油等重要商业机构。
+本町位于什么地方? 其中,专卖分局是战后二二八事件的主要起始点。
+本町位于什么地方? 台湾贮蓄银行(一丁目)
+本町位于什么地方? 三和银行(二丁目)
+本町位于什么地方? 专卖局台北分局(三丁目)
+本町位于什么地方? 日本石油(四丁目)
+本町位于什么地方? 为台湾日治时期台南市之行政区。
+本町位于什么地方? 范围包括清代旧街名枋桥头前、枋桥头后、鞋、草花、天公埕、竹仔、下大埕、帽仔、武馆、统领巷、大井头、内宫后、内南町。
+本町位于什么地方? 为清代台南城最繁华的区域。
+本町位于什么地方? 台南公会堂
+本町位于什么地方? 北极殿
+本町位于什么地方? 开基武庙
+本町位于什么地方? 町名改正
+本町位于什么地方? 这是一个与台湾相关的小作品。
+本町位于什么地方? 你可以通过编辑或修订扩充其内容。
+《行走的观点:埃及》的条形码是多少? 出版社: 上海社会科学院出版社; 第1版 (2006年5月1日)
+《行走的观点:埃及》的条形码是多少? 丛书名: 时代建筑视觉旅行丛书
+《行走的观点:埃及》的条形码是多少? 条形码: 9787806818640
+《行走的观点:埃及》的条形码是多少? 尺寸: 18 x 13.1 x 0.7 cm
+《行走的观点:埃及》的条形码是多少? 重量: 181 g
+《行走的观点:埃及》的条形码是多少? 漂浮在沙与海市蜃楼之上的金字塔曾经是否是你的一个梦。
+《行走的观点:埃及》的条形码是多少? 埃及,这片蕴蓄了5000年文明的土地,本书为你撩开它神秘的纱。
+《行走的观点:埃及》的条形码是多少? 诸神、金字塔、神庙、狮身人面像、法老、艳后吸引着我们的注意力;缠绵悱恻的象形文字、医学、雕刻等留给我们的文明,不断引发我们对古代文明的惊喜和赞叹。
+《行走的观点:埃及》的条形码是多少? 尼罗河畔的奇异之旅,数千年的古老文明,尽收在你的眼底……
+《行走的观点:埃及》的条形码是多少? 本书集历史、文化、地理等知识于一体,并以优美、流畅文笔,简明扼要地阐述了埃及的地理环境、政治经济、历史沿革、文化艺术,以大量富有艺术感染力的彩色照片,生动形象地展示了埃及最具特色的名胜古迹、风土人情和自然风光。
+《行走的观点:埃及》的条形码是多少? 古埃及历史
+老挝人民军的工兵部队有几个营? 老挝人民军前身为老挝爱国战线领导的“寮国战斗部队”(即“巴特寮”),始建于1949年1月20日,1965年10月改名为老挝人民解放军,1982年7月改称现名。
+老挝人民军的工兵部队有几个营? 最高领导机构是中央国防和治安委员会,朱马里·赛雅颂任主席,隆再·皮吉任国防部长。
+老挝人民军的工兵部队有几个营? 实行义务兵役制,服役期最少18个月。[1]
+老挝人民军的工兵部队有几个营? ?老挝军队在老挝社会中有较好的地位和保障,工资待遇比地方政府工作人员略高。
+老挝人民军的工兵部队有几个营? 武装部队总兵力约6万人,其中陆军约5万人,主力部队编为5个步兵师;空军2000多人;海军(内河巡逻部队)1000多人;部队机关院校5000人。[1]
+老挝人民军的工兵部队有几个营? 老挝人民军军旗
+老挝人民军的工兵部队有几个营? 1991年8月14日通过的《老挝人民民主共和国宪法》第11条规定:国家执行保卫国防和维护社会安宁的政策。
+老挝人民军的工兵部队有几个营? 全体公民和国防力量、治安力量必须发扬忠于祖国、忠于人民的精神,履行保卫革命成果、保卫人民生命财产及和平劳动的任务,积极参加国家建设事业。
+老挝人民军的工兵部队有几个营? 最高领导机构是中央国防和治安委员会。
+老挝人民军的工兵部队有几个营? 主席由老挝人民革命党中央委员会总书记兼任。
+老挝人民军的工兵部队有几个营? 老挝陆军成立最早,兵力最多,约有5万人。
+老挝人民军的工兵部队有几个营? 其中主力部队步兵师5个、7个独立团、30多个营、65个独立连。
+老挝人民军的工兵部队有几个营? 地方部队30余个营及县属部队。
+老挝人民军的工兵部队有几个营? 地面炮兵2个团,10多个营。
+老挝人民军的工兵部队有几个营? 高射炮兵1个团9个营。
+老挝人民军的工兵部队有几个营? 导弹部队2个营。
+老挝人民军的工兵部队有几个营? 装甲兵7个营。
+老挝人民军的工兵部队有几个营? 特工部队6个营。
+老挝人民军的工兵部队有几个营? 通讯部队9个营。
+老挝人民军的工兵部队有几个营? 工兵部队6个营。
+老挝人民军的工兵部队有几个营? 基建工程兵2个团13个营。
+老挝人民军的工兵部队有几个营? 运输部队7个营。
+老挝人民军的工兵部队有几个营? 陆军的装备基本是中国和前苏联援助的装备和部分从抗美战争中缴获的美式装备。
+老挝人民军的工兵部队有几个营? 老挝内河部队总兵力约1700人,装备有内河船艇110多艘,编成4个艇队。
+老挝人民军的工兵部队有几个营? 有芒宽、巴能、纳坎、他曲、南盖、巴色等8个基地。
+老挝人民军的工兵部队有几个营? 空军于1975年8月组建,现有2个团、11个飞行大队,总兵力约2000人。
+老挝人民军的工兵部队有几个营? 装备有各种飞机140架,其中主要由前苏联提供和从万象政权的皇家空军手中接管。
+老挝人民军的工兵部队有几个营? 随着军队建设质量的提高,老挝人民军对外军事合作步伐也日益扩大,近年来先后与俄罗斯、印度、马来西亚、越南、菲律宾等国拓展了军事交流与合作的内容。
+老挝人民军的工兵部队有几个营? 2003年1月,印度决定向老挝援助一批军事装备和物资,并承诺提供技术帮助。
+老挝人民军的工兵部队有几个营? 2003年6月,老挝向俄罗斯订购了一批新式防空武器;2003年4月,老挝与越南签署了越南帮助老挝培训军事指挥干部和特种部队以及完成军队通信系统改造等多项协议。
+《焚心之城》的主角是谁? 《焚心之城》[1] 为网络作家老子扛过枪创作的一部都市类小说,目前正在创世中文网连载中。
+《焚心之城》的主角是谁? 乡下大男孩薛城,是一个不甘于生活现状的混混,他混过、爱过、也深深地被伤害过。
+《焚心之城》的主角是谁? 本料此生当浑浑噩噩,拼搏街头。
+《焚心之城》的主角是谁? 高考的成绩却给了他一点渺茫的希望,二月后,大学如期吹响了他进城的号角。
+《焚心之城》的主角是谁? 繁华的都市,热血的人生,冷眼嘲笑中,他发誓再不做一个平常人!
+《焚心之城》的主角是谁? 江北小城,黑河大地,他要行走过的每一个角落都有他的传说。
+《焚心之城》的主角是谁? 扯出一面旗,拉一帮兄弟,做男人,就要多一份担当,活一口傲气。
+《焚心之城》的主角是谁? (日期截止到2014年10月23日凌晨)
+请问香港利丰集团是什么时候成立的? 香港利丰集团前身是广州的华资贸易 (1906 - 1949) ,利丰是香港历史最悠久的出口贸易商号之一。
+请问香港利丰集团是什么时候成立的? 于1906年,冯柏燎先生和李道明先生在广州创立了利丰贸易公司;是当时中国第一家华资的对外贸易出口商。
+请问香港利丰集团是什么时候成立的? 利丰于1906年创立,初时只从事瓷器及丝绸生意;一年之后,增添了其它的货品,包括竹器、藤器、玉石、象牙及其它手工艺品,包括烟花爆竹类别。
+请问香港利丰集团是什么时候成立的? 在早期的对外贸易,中国南方内河港因水深不足不能行驶远洋船,反之香港港口水深岸阔,占尽地利。
+请问香港利丰集团是什么时候成立的? 因此,在香港成立分公司的责任,落在冯柏燎先生的三子冯汉柱先生身上。
+请问香港利丰集团是什么时候成立的? 1937年12月28日,利丰(1937)有限公司正式在香港创立。
+请问香港利丰集团是什么时候成立的? 第二次世界大战期间,利丰暂停贸易业务。
+请问香港利丰集团是什么时候成立的? 1943年,随着创办人冯柏燎先生去世后,业务移交给冯氏家族第二代。
+请问香港利丰集团是什么时候成立的? 之后,向来不参与业务管理的合伙人李道明先生宣布退休,将所拥有的利丰股权全部卖给冯氏家族。
+请问香港利丰集团是什么时候成立的? 目前由哈佛冯家两兄弟William Fung , Victor Fung和CEO Bruce Rockowitz 管理。
+请问香港利丰集团是什么时候成立的? 截止到2012年,集团旗下有利亚﹝零售﹞有限公司、利和集团、利邦时装有限公司、利越时装有限公司、利丰贸易有限公司。
+请问香港利丰集团是什么时候成立的? 利亚(零售)连锁,业务包括大家所熟悉的:OK便利店、玩具〝反〞斗城和圣安娜饼屋;范围包括香港、台湾、新加坡、马来西亚、至中国大陆及东南亚其它市场逾600多家店
+请问香港利丰集团是什么时候成立的? 利和集团,IDS以专业物流服务为根基,为客户提供经销,物流,制造服务领域内的一系列服务项目。
+请问香港利丰集团是什么时候成立的? 业务网络覆盖大中华区,东盟,美国及英国,经营着90多个经销中心,在中国设有18个经销公司,10,000家现代经销门店。
+请问香港利丰集团是什么时候成立的? 利邦(上海)时装贸易有限公司为大中华区其中一家大型男士服装零售集团。
+请问香港利丰集团是什么时候成立的? 现在在中国大陆、香港、台湾和澳门收购经营11个包括Cerruti 1881,Gieves & Hawkes,Kent & curwen和D’urban 等中档到高档的男士服装品牌,全国有超过350间门店设于各一线城市之高级商场及百货公司。
+请问香港利丰集团是什么时候成立的? 利越(上海)服装商贸有限公司隶属于Branded Lifestyle,负责中国大陆地区LEO里奥(意大利)、GIBO捷宝(意大利)、UFFIZI古杰师(意大利)、OVVIO奥维路(意大利)、Roots绿适(加拿大,全球服装排名第四)品牌销售业务
+请问香港利丰集团是什么时候成立的? 利丰(贸易)1995年收购了英之杰采购服务,1999年收购太古贸易有限公司(Swire & Maclain) 和金巴莉有限公司(Camberley),2000年和2002年分别收购香港采购出口集团Colby Group及Janco Oversea Limited,大大扩张了在美国及欧洲的顾客群,自2008年经济危机起一直到现在,收购多家欧、美、印、非等地区的时尚品牌,如英国品牌Visage,仅2011年上半年6个月就完成26个品牌的收购。
+请问香港利丰集团是什么时候成立的? 2004年利丰与Levi Strauss & Co.签订特许经营协议
+请问香港利丰集团是什么时候成立的? 2005年利丰伙拍Daymon Worldwide为全球供应私有品牌和特许品牌
+请问香港利丰集团是什么时候成立的? 2006年收购Rossetti手袋业务及Oxford Womenswear Group 强化美国批发业务
+请问香港利丰集团是什么时候成立的? 2007年收购Tommy Hilfiher全球采购业务,收购CGroup、Peter Black International LTD、Regetta USA LLC和American Marketing Enterprice
+请问香港利丰集团是什么时候成立的? 2008年收购Kent&Curwen全球特许经营权,收购Van Zeeland,Inc和Miles Fashion Group
+请问香港利丰集团是什么时候成立的? 2009年收购加拿大休闲品牌Roots ,收购Wear Me Appearl,LLC。
+请问香港利丰集团是什么时候成立的? 与Hudson's Bay、Wolverine Worldwide Inc、Talbots、Liz Claiborne达成了采购协议
+请问香港利丰集团是什么时候成立的? 2010年收购Oxford apparel Visage Group LTD
+请问香港利丰集团是什么时候成立的? 2011年一月收购土耳其Modium、美国女性时尚Beyond Productions,三月收购贸易公司Celissa 、玩具公司Techno Source USA, Inc.、卡通品牌产品TVMania和法国著名时装一线品牌Cerruti 1881,五月收购Loyaltex Apparel Ltd.、女装Hampshire Designers和英国彩妆Collection 2000,六月收购家私贸易Exim Designs Co., Ltd.,七月收购家庭旅行产业Union Rich USA, LLC和设计公司Lloyd Textile Fashion Company Limited,八月收购童装Fishman & Tobin和Crimzon Rose,九月收购家私贸易True Innovations, LLC、日用品企业Midway Enterprises和Wonderful World。
+请问香港利丰集团是什么时候成立的? 十二月与USPA – U.S. Polo Association签署授权协议。
+请问香港利丰集团是什么时候成立的? 利丰的精神:积极进取,不断认识并争取有利于客户和自身进步的机会;以行动为主导,对客户、供应商及职工的需求作出快速的决定。
+请问香港利丰集团是什么时候成立的? 利丰的最终目标:在产品采购、销售、流转的各环节建立全球性队伍提供多元化服务,利丰成员有效合作,共达目标。
+如何使魔兽变种akt不被查杀? Trojan/PSW.Moshou.akt“魔兽”变种akt是“魔兽”木马家族的最新成员之一,采用Delphi 6.0-7.0编写,并经过加壳处理。
+如何使魔兽变种akt不被查杀? “魔兽”变种akt运行后,自我复制到被感染计算机的指定目录下。
+如何使魔兽变种akt不被查杀? 修改注册表,实现木马开机自动运行。
+如何使魔兽变种akt不被查杀? 自我注入到被感染计算机的“explorer.exe”、“notepad.exe”等用户级权限的进程中加载运行,隐藏自我,防止被查杀。
+如何使魔兽变种akt不被查杀? 在后台秘密监视用户打开的窗口标题,盗取网络游戏《魔兽世界》玩家的游戏帐号、游戏密码、角色等级、装备信息、金钱数量等信息,并在后台将窃取到的玩家信息发送到骇客指定的远程服务器上,致使玩家游戏帐号、装备物品、金钱等丢失,给游戏玩家造成非常大的损失。
+丙种球蛋白能预防什么病情? 丙种球蛋白预防传染性肝炎,预防麻疹等病毒性疾病感染,治疗先天性丙种球蛋白缺乏症 ,与抗生素合并使用,可提高对某些严重细菌性和病毒性疾病感染的疗效。
+丙种球蛋白能预防什么病情? 中文简称:“丙球”
+丙种球蛋白能预防什么病情? 英文名称:γ-globulin、gamma globulin
+丙种球蛋白能预防什么病情? 【别名】 免疫血清球蛋白,普通免疫球蛋白,人血丙种球蛋白,丙种球蛋白,静脉注射用人免疫球蛋白(pH4)
+丙种球蛋白能预防什么病情? 注:由于人血中的免疫球蛋白大多数为丙种球蛋白(γ-球蛋白),有时丙种球蛋白也被混称为“免疫球蛋白”(immunoglobulin) 。
+丙种球蛋白能预防什么病情? 冻干制剂应为白色或灰白色的疏松体,液体制剂和冻干制剂溶解后,溶液应为接近无色或淡黄色的澄明液体,微带乳光。
+丙种球蛋白能预防什么病情? 但不应含有异物或摇不散的沉淀。
+丙种球蛋白能预防什么病情? 注射丙种球蛋白是一种被动免疫疗法。
+丙种球蛋白能预防什么病情? 它是把免疫球蛋白内含有的大量抗体输给受者,使之从低或无免疫状态很快达到暂时免疫保护状态。
+丙种球蛋白能预防什么病情? 由于抗体与抗原相互作用起到直接中和毒素与杀死细菌和病毒。
+丙种球蛋白能预防什么病情? 因此免疫球蛋白制品对预防细菌、病毒性感染有一定的作用[1]。
+丙种球蛋白能预防什么病情? 人免疫球蛋白的生物半衰期为16~24天。
+丙种球蛋白能预防什么病情? 1、丙种球蛋白[2]含有健康人群血清所具有的各种抗体,因而有增强机体抵抗力以预防感染的作用。
+丙种球蛋白能预防什么病情? 2、主要治疗先天性丙种球蛋白缺乏症和免疫缺陷病
+丙种球蛋白能预防什么病情? 3、预防传染性肝炎,如甲型肝炎和乙型肝炎等。
+丙种球蛋白能预防什么病情? 4、用于麻疹、水痘、腮腺炎、带状疱疹等病毒感染和细菌感染的防治
+丙种球蛋白能预防什么病情? 5、也可用于哮喘、过敏性鼻炎、湿疹等内源性过敏性疾病。
+丙种球蛋白能预防什么病情? 6、与抗生素合并使用,可提高对某些严重细菌性和病毒性疾病感染的疗效。
+丙种球蛋白能预防什么病情? 7、川崎病,又称皮肤粘膜淋巴结综合征,常见于儿童,丙种球蛋白是主要的治疗药物。
+丙种球蛋白能预防什么病情? 1、对免疫球蛋白过敏或有其他严重过敏史者。
+丙种球蛋白能预防什么病情? 2、有IgA抗体的选择性IgA缺乏者。
+丙种球蛋白能预防什么病情? 3、发烧患者禁用或慎用。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (1997年9月1日浙江省第八届人民代表大会常务委员会第三十九次会议通过 1997年9月9日浙江省第八届人民代表大会常务委员会公告第六十九号公布自公布之日起施行)
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 为了保护人的生命和健康,发扬人道主义精神,促进社会发展与和平进步事业,根据《中华人民共和国红十字会法》,结合本省实际,制定本办法。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 本省县级以上按行政区域建立的红十字会,是中国红十字会的地方组织,是从事人道主义工作的社会救助团体,依法取得社会团体法人资格,设置工作机构,配备专职工作人员,依照《中国红十字会章程》独立自主地开展工作。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 全省性行业根据需要可以建立行业红十字会,配备专职或兼职工作人员。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 街道、乡(镇)、机关、团体、学校、企业、事业单位根据需要,可以依照《中国红十字会章程》建立红十字会的基层组织。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 上级红十字会指导下级红十字会的工作。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 县级以上地方红十字会指导所在行政区域行业红十字会和基层红十字会的工作。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 人民政府对红十字会给予支持和资助,保障红十字会依法履行职责,并对其活动进行监督;红十字会协助人民政府开展与其职责有关的活动。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 全社会都应当关心和支持红十字事业。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 本省公民和单位承认《中国红十字会章程》并缴纳会费的,可以自愿参加红十字会,成为红十字会的个人会员或团体会员。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 个人会员由本人申请,基层红十字会批准,发给会员证;团体会员由单位申请,县级以上红十字会批准,发给团体会员证。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 个人会员和团体会员应当遵守《中华人民共和国红十字会法》和《中国红十字会章程》,热心红十字事业,履行会员的义务,并享有会员的权利。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 县级以上红十字会理事会由会员代表大会民主选举产生。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 理事会民主选举产生会长和副会长;根据会长提名,决定秘书长、副秘书长人选。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 县级以上红十字会可以设名誉会长、名誉副会长和名誉理事,由同级红十字会理事会聘请。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 省、市(地)红十字会根据独立、平等、互相尊重的原则,发展同境外、国外地方红十字会和红新月会的友好往来和合作关系。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 红十字会履行下列职责:
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (一)宣传、贯彻《中华人民共和国红十字会法》和本办法;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (二)开展救灾的准备工作,筹措救灾款物;在自然灾害和突发事件中,对伤病人员和其他受害者进行救助;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (三)普及卫生救护和防病知识,进行初级卫生救护培训,对交通、电力、建筑、矿山等容易发生意外伤害的单位进行现场救护培训;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (四)组织群众参加现场救护;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (五)参与输血献血工作,推动无偿献血;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (六)开展红十字青少年活动;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (七)根据中国红十字会总会部署,参加国际人道主义救援工作;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (八)依照国际红十字和红新月运动的基本原则,完成同级人民政府和上级红十字会委托的有关事宜;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (九)《中华人民共和国红十宇会法》和《中国红十字会章程》规定的其他职责。
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? 第八条 红十字会经费的主要来源:
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (一)红十字会会员缴纳的会费;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (二)接受国内外组织和个人捐赠的款物;
+浙江省实施《中华人民共和国红十字会法》办法在浙江省第八届人民代表大会常务委员会第几次会议通过的? (三)红十字会的动产、不动产以及兴办社会福利事业和经济实体的收入;
+宝湖庭院绿化率多少? 建发·宝湖庭院位于银川市金凤区核心地带—正源南街与长城中路交汇处向东500米。
+宝湖庭院绿化率多少? 项目已于2012年4月开工建设,总占地约4.2万平方米,总建筑面积约11.2万平方米,容积率2.14,绿化率35%,预计可入住630户。
+宝湖庭院绿化率多少? “建发·宝湖庭院”是银川建发集团股份有限公司继“建发·宝湖湾”之后,在宝湖湖区的又一力作。
+宝湖庭院绿化率多少? 项目周边发展成熟,东有唐徕渠景观水道,西临银川市交通主干道正源街;南侧与宝湖湿地公园遥相呼应。
+宝湖庭院绿化率多少? “宝湖庭院”项目公共交通资源丰富:15路、21路、35路、38路、43路公交车贯穿银川市各地,出行便利。
+宝湖庭院绿化率多少? 距离新百良田购物广场约1公里,工人疗养院600米,宝湖公园1公里,唐徕渠景观水道500米。
+宝湖庭院绿化率多少? 项目位置优越,购物、餐饮、医疗、交通、休闲等生活资源丰富。[1]
+宝湖庭院绿化率多少? 建发·宝湖庭院建筑及景观设置传承建发一贯“简约、大气”的风格:搂间距宽广,确保每一座楼宇视野开阔通透。
+宝湖庭院绿化率多少? 楼宇位置错落有置,外立面设计大气沉稳别致。
+宝湖庭院绿化率多少? 项目内部休闲绿地、景观小品点缀其中,道路及停车系统设计合理,停车及通行条件便利。
+宝湖庭院绿化率多少? 社区会所、幼儿园、活动室、医疗服务中心等生活配套一应俱全。
+宝湖庭院绿化率多少? 行政区域:金凤区
+大月兔(中秋艺术作品)的作者还有哪些代表作? 大月兔是荷兰“大黄鸭”之父弗洛伦泰因·霍夫曼打造的大型装置艺术作品,该作品首次亮相于台湾桃园大园乡海军基地,为了迎接中秋节的到来;在展览期间,海军基地也首次对外开放。
+大月兔(中秋艺术作品)的作者还有哪些代表作? 霍夫曼觉得中国神话中捣杵的玉兔很有想象力,于是特别创作了“月兔”,这也是“月兔”新作第一次展出。[1]
+大月兔(中秋艺术作品)的作者还有哪些代表作? ?2014年9月15日因工人施工不慎,遭火烧毁。[2]
+大月兔(中秋艺术作品)的作者还有哪些代表作? “大月兔”外表采用的杜邦防水纸、会随风飘动,内部以木材加保丽龙框架支撑做成。
+大月兔(中秋艺术作品)的作者还有哪些代表作? 兔毛用防水纸做成,材质完全防水,不怕日晒雨淋。[3
+大月兔(中秋艺术作品)的作者还有哪些代表作? -4]
+大月兔(中秋艺术作品)的作者还有哪些代表作? 25米的“月兔”倚靠在机
+大月兔(中秋艺术作品)的作者还有哪些代表作? 堡上望着天空,像在思考又像赏月。
+大月兔(中秋艺术作品)的作者还有哪些代表作? 月兔斜躺在机堡上,意在思考生命、边做白日梦,编织自己的故事。[3]
+大月兔(中秋艺术作品)的作者还有哪些代表作? 台湾桃园大园乡海军基地也首度对外开放。
+大月兔(中秋艺术作品)的作者还有哪些代表作? 428公顷的海军基地中,地景艺术节使用约40公顷,展场包括过去军机机堡、跑道等,由于这处基地过去警备森严,不对外开放,这次结合地景艺术展出,也可一窥过去是黑猫中队基地的神秘面纱。
+大月兔(中秋艺术作品)的作者还有哪些代表作? 2014年9月2日,桃园县政府文化局举行“踩线团”,让
+大月兔(中秋艺术作品)的作者还有哪些代表作? 大月兔
+大月兔(中秋艺术作品)的作者还有哪些代表作? 各项地景艺术作品呈现在媒体眼中,虽然“月兔”仍在进行最后的细节赶工,但横躺在机堡上的“月兔”雏形已经完工。[5]
+大月兔(中秋艺术作品)的作者还有哪些代表作? “这么大”、“好可爱呦”是不少踩线团成员对“月兔”的直觉;尤其在蓝天的衬托及前方绿草的组合下,呈现犹如真实版的爱丽丝梦游仙境。[6]
+大月兔(中秋艺术作品)的作者还有哪些代表作? 霍夫曼的作品大月兔,“从平凡中,创作出不平凡的视觉”,创造出观赏者打从心中油然而生的幸福感,拉近观赏者的距离。[6]
+大月兔(中秋艺术作品)的作者还有哪些代表作? 2014年9月15日早
+大月兔(中秋艺术作品)的作者还有哪些代表作? 上,施工人员要将月兔拆解,搬离海军基地草皮时,疑施工拆除的卡车,在拆除过程,故障起火,起火的卡车不慎延烧到兔子,造成兔子起火燃烧,消防队员即刻抢救,白色的大月兔立即变成焦黑的火烧兔。[7]
+大月兔(中秋艺术作品)的作者还有哪些代表作? 桃园县府表示相当遗憾及难过,也不排除向包商求偿,也已将此事告知霍夫曼。[2]
+大月兔(中秋艺术作品)的作者还有哪些代表作? ?[8]
+大月兔(中秋艺术作品)的作者还有哪些代表作? 弗洛伦泰因·霍夫曼,荷兰艺术家,以在公共空间创作巨大造型
+大月兔(中秋艺术作品)的作者还有哪些代表作? 物的艺术项目见长。
+大月兔(中秋艺术作品)的作者还有哪些代表作? 代表作品包括“胖猴子”(2010年在巴西圣保罗展出)、“大黄兔”(2011年在瑞典厄勒布鲁展出)、粉红猫(2014年5月在上海亮相)、大黄鸭(Rubber Duck)、月兔等。
+英国耆卫保险公司有多少保险客户? 英国耆卫保险公司(Old Mutual plc)成立于1845年,一直在伦敦证券交易所(伦敦证券交易所:OML)作第一上市,也是全球排名第32位(按营业收入排名)的保险公司(人寿/健康)。
+英国耆卫保险公司有多少保险客户? 公司是全球财富500强公司之一,也是被列入英国金融时报100指数的金融服务集团之一。
+英国耆卫保险公司有多少保险客户? Old Mutual 是一家国际金融服务公司,拥有近320万个保险客户,240万个银行储户,270,000个短期保险客户以及700,000个信托客户
+英国耆卫保险公司有多少保险客户? 英国耆卫保险公司(Old Mutual)是一家国际金融服务公司,总部设在伦敦,主要为全球客户提供长期储蓄的解决方案、资产管理、短期保险和金融服务等,目前业务遍及全球34个国家。[1]
+英国耆卫保险公司有多少保险客户? 主要包括人寿保险,资产管理,银行等。
+英国耆卫保险公司有多少保险客户? 1845年,Old Mutual在好望角成立。
+英国耆卫保险公司有多少保险客户? 1870年,董事长Charles Bell设计了Old Mutual公司的标记。
+英国耆卫保险公司有多少保险客户? 1910年,南非从英联邦独立出来。
+英国耆卫保险公司有多少保险客户? Old Mutual的董事长John X. Merriman被选为国家总理。
+英国耆卫保险公司有多少保险客户? 1927年,Old Mutual在Harare成立它的第一个事务所。
+英国耆卫保险公司有多少保险客户? 1960年,Old Mutual在南非成立了Mutual Unit信托公司,用来管理公司的信托业务。
+英国耆卫保险公司有多少保险客户? 1970年,Old Mutual的收入超过100百万R。
+英国耆卫保险公司有多少保险客户? 1980年,Old Mutual成为南非第一大人寿保险公司,年收入达10亿R。
+英国耆卫保险公司有多少保险客户? 1991年,Old Mutual在美国财富周刊上评选的全球保险公司中名列第38位。
+英国耆卫保险公司有多少保险客户? 1995年,Old Mutual在美国波士顿建立投资顾问公司,同年、又在香港和Guernsey建立事务所。
+英国耆卫保险公司有多少保险客户? 作为一项加强与其母公司联系的举措,OMNIA公司(百慕大)荣幸的更名为Old Mutual 公司(百慕大) 。
+英国耆卫保险公司有多少保险客户? 这一新的名称和企业识别清晰地展示出公司成为其世界金融机构合作伙伴强有力支持的决心。
+英国耆卫保险公司有多少保险客户? 2003 年4月,该公司被Old Mutual plc公司收购,更名为Sage Life(百慕大)公司并闻名于世,公司为Old Mutual公司提供了一个新的销售渠道,补充了其现有的以美元计价的产品线和分销系统。
+英国耆卫保险公司有多少保险客户? 达到了一个重要里程碑是公司成功的一个例证: 2005年6月3日公司资产超过10亿美元成为公司的一个主要里程碑,也是公司成功的一个例证。
+英国耆卫保险公司有多少保险客户? Old Mutual (百慕大)为客户提供一系列的投资产品。
+英国耆卫保险公司有多少保险客户? 在其开放的结构下,客户除了能够参与由Old Mutual会员管理的方案外,还能够参与由一些世界顶尖投资机构提供的投资选择。
+英国耆卫保险公司有多少保险客户? 首席执行官John Clifford对此发表评论说:“过去的两年对于Old Mutual家族来说是稳固发展的两年,更名是迫在眉睫的事情。
+英国耆卫保险公司有多少保险客户? 通过采用其名字和形象上的相似,Old Mutual (百慕大)进一步强化了与母公司的联系。”
+英国耆卫保险公司有多少保险客户? Clifford补充道:“我相信Old Mutual全球品牌认可度和Old Mutual(百慕大)产品专业知识的结合将在未来的日子里进一步推动公司的成功。”
+英国耆卫保险公司有多少保险客户? 随着公司更名而来的是公司网站的全新改版,设计投资选择信息、陈述、销售方案、营销材料和公告板块。
+英国耆卫保险公司有多少保险客户? 在美国购买不到OMNIA投资产品,该产品也不向美国公民或居民以及百慕大居民提供。
+英国耆卫保险公司有多少保险客户? 这些产品不对任何要约未得到批准的区域中的任何人,以及进行此要约或询价为非法行为的个人构成要约或询价。
+英国耆卫保险公司有多少保险客户? 关于Old Mutual(百慕大)公司
+英国耆卫保险公司有多少保险客户? Old Mutual(百慕大)公司总部位于百慕大,公司面向非美国居民及公民以及非百慕大居民,通过遍布世界的各个市场的金融机构开发和销售保险和投资方案。
+英国耆卫保险公司有多少保险客户? 这些方案由Old Mutual(百慕大)公司直接做出,向投资者提供各种投资选择和战略,同时提供死亡和其他受益保证。
+谁知道北京的淡定哥做了什么? 尼日利亚足球队守门员恩耶马被封淡定哥,原因是2010年南非世界杯上1:2落后希腊队时,对方前锋已经突破到禁区,其仍头依门柱发呆,其从容淡定令人吃惊。
+谁知道北京的淡定哥做了什么? 淡定哥
+谁知道北京的淡定哥做了什么? 在2010年6月17日的世界杯赛场上,尼日利亚1比2不敌希腊队,但尼日利亚门将恩耶马(英文名:Vincent Enyeama)在赛场上的“淡定”表现令人惊奇。
+谁知道北京的淡定哥做了什么? 随后,网友将赛场照片发布于各大论坛,恩耶马迅速窜红,并被网友称为“淡定哥”。
+谁知道北京的淡定哥做了什么? 淡定哥
+谁知道北京的淡定哥做了什么? 从网友上传得照片中可以看到,“淡定哥”在面临对方前锋突袭至小禁区之时,还靠在球门柱上发呆,其“淡定”程度的确非一般人所能及。
+谁知道北京的淡定哥做了什么? 恩耶马是尼日利亚国家队的主力守门员,目前效力于以色列的特拉维夫哈普尔队。
+谁知道北京的淡定哥做了什么? 1999年,恩耶马在尼日利亚国内的伊波姆星队开始职业生涯,后辗转恩伊姆巴、Iwuanyanwu民族等队,从07年开始,他为特拉维夫效力。
+谁知道北京的淡定哥做了什么? 恩耶马的尼日利亚国脚生涯始于2002年,截至2010年1月底,他为国家队出场已超过50次。
+谁知道北京的淡定哥做了什么? 当地时间2011年1月4日,国际足球历史与统计协会(IFFHS)公布了2010年度世界最佳门将,恩耶马(尼日利亚,特拉维夫夏普尔)10票排第十一
+谁知道北京的淡定哥做了什么? 此词经国家语言资源监测与研究中心等机构专家审定入选2010年年度新词语,并收录到《中国语言生活状况报告》中。
+谁知道北京的淡定哥做了什么? 提示性释义:对遇事从容镇定、处变不惊的男性的戏称。
+谁知道北京的淡定哥做了什么? 例句:上海现“淡定哥”:百米外爆炸他仍专注垂钓(2010年10月20日腾讯网http://news.qq.com/a/20101020/000646.htm)
+谁知道北京的淡定哥做了什么? 2011年度新人物
+谁知道北京的淡定哥做了什么? 1、淡定哥(北京)
+谁知道北京的淡定哥做了什么? 7月24日傍晚,北京市出现大范围降雨天气,位于通州北苑路出现积水,公交车也难逃被淹。
+谁知道北京的淡定哥做了什么? 李欣摄图片来源:新华网一辆私家车深陷积水,车主索性盘坐在自己的汽车上抽烟等待救援。
+谁知道北京的淡定哥做了什么? 私家车主索性盘坐在自己的车上抽烟等待救援,被网友称“淡定哥”
+谁知道北京的淡定哥做了什么? 2、淡定哥——林峰
+谁知道北京的淡定哥做了什么? 在2011年7月23日的动车追尾事故中,绍兴人杨峰(@杨峰特快)在事故中失去了5位亲人:怀孕7个月的妻子、未出世的孩子、岳母、妻姐和外甥女,他的岳父也在事故中受伤正在治疗。
+谁知道北京的淡定哥做了什么? 他披麻戴孝出现在事故现场,要求将家人的死因弄个明白。
+谁知道北京的淡定哥做了什么? 但在第一轮谈判过后,表示:“请原谅我,如果我再坚持,我将失去我最后的第六个亲人。”
+谁知道北京的淡定哥做了什么? 如果他继续“纠缠”铁道部,他治疗中的岳父将会“被死亡”。
+谁知道北京的淡定哥做了什么? 很多博友就此批评杨峰,并讽刺其为“淡定哥”。
+071型船坞登陆舰的北约代号是什么? 071型船坞登陆舰(英语:Type 071 Amphibious Transport Dock,北约代号:Yuzhao-class,中文:玉昭级,或以首舰昆仑山号称之为昆仑山级船坞登陆舰),是中国人民解放军海军隶下的大型多功能两栖船坞登陆舰,可作为登陆艇的母舰,用以运送士兵、步兵战车、主战坦克等展开登陆作战,也可搭载两栖车辆,具备大型直升机起降甲板及操作设施。
+071型船坞登陆舰的北约代号是什么? 071型两栖登陆舰是中国首次建造的万吨级作战舰艇,亦为中国大型多功能两栖舰船的开山之作,也可以说是中国万吨级以上大型作战舰艇的试验之作,该舰的建造使中国海军的两栖舰船实力有了质的提升。
+071型船坞登陆舰的北约代号是什么? 在本世纪以前中国海军原有的两栖舰队以一
+071型船坞登陆舰的北约代号是什么? 早期071模型
+071型船坞登陆舰的北约代号是什么? 千至四千吨级登陆舰为主要骨干,这些舰艇吨位小、筹载量有限,直升机操作能力非常欠缺,舰上自卫武装普遍老旧,对于现代化两栖登陆作战可说有很多不足。
+071型船坞登陆舰的北约代号是什么? 为了应对新时期的国际国内形势,中国在本世纪初期紧急强化两栖作战能力,包括短时间内密集建造072、074系列登陆舰,同时也首度设计一种新型船坞登陆舰,型号为071。[1]
+071型船坞登陆舰的北约代号是什么? 在两栖作战行动中,这些舰只不得不采取最危险的
+071型船坞登陆舰的北约代号是什么? 舾装中的昆仑山号
+071型船坞登陆舰的北约代号是什么? 敌前登陆方式实施两栖作战行动,必须与敌人预定阻击力量进行面对面的战斗,在台湾地区或者亚洲其他国家的沿海,几乎没有可用而不设防的海滩登陆地带,并且各国或者地区的陆军在战时,可能会很快控制这些易于登陆的海难和港口,这样就限制住了中国海军两栖登陆部队的实际登陆作战能力。
+071型船坞登陆舰的北约代号是什么? 071型登陆舰正是为了更快和更多样化的登陆作战而开发的新型登陆舰艇。[2]
+071型船坞登陆舰的北约代号是什么? 071型两栖船坞登陆舰具有十分良好的整体隐身能力,
+071型船坞登陆舰的北约代号是什么? 071型概念图
+071型船坞登陆舰的北约代号是什么? 该舰外部线条简洁干练,而且舰体外形下部外倾、上部带有一定角度的内倾,从而形成雷达隐身性能良好的菱形横剖面。
+071型船坞登陆舰的北约代号是什么? 舰体为高干舷平甲板型,长宽比较小,舰身宽满,采用大飞剪型舰首及楔形舰尾,舰的上层建筑位于舰体中间部位,后部是大型直升机甲板,适航性能非常突出。
+071型船坞登陆舰的北约代号是什么? 顶甲板上各类电子设备和武器系统布局十分简洁干净,各系统的突出物很少。
+071型船坞登陆舰的北约代号是什么? 该舰的两座烟囱实行左右分布式设置在舰体两侧,既考虑了隐身特点,也十分新颖。[3]
+071型船坞登陆舰的北约代号是什么? 1号甲板及上层建筑物主要设置有指挥室、控
+071型船坞登陆舰的北约代号是什么? 舰尾俯视
+071型船坞登陆舰的北约代号是什么? 制舱、医疗救护舱及一些居住舱,其中医疗救护舱设置有完备的战场救护设施,可以在舰上为伤病员提供紧急手术和野战救护能力。
+071型船坞登陆舰的北约代号是什么? 2号甲板主要是舰员和部分登陆人员的居住舱、办公室及厨房。
+071型船坞登陆舰的北约代号是什么? 主甲板以下则是登陆舱,分前后两段,前段是装甲车辆储存舱,共两层,可以储存登陆装甲车辆和一些其它物资,在进出口处还设有一小型升降机,用于两层之间的移动装卸用。
+071型船坞登陆舰的北约代号是什么? 前段车辆储存舱外壁左右各设有一折叠式装载舱门,所有装载车辆在码头可通过该门直接装载或者登陆上岸。
+071型船坞登陆舰的北约代号是什么? 后段是一个巨型船坞登陆舱,总长约70米,主要用来停泊大小型气垫登陆艇、机械登陆艇或车辆人员登陆艇。[4]
+071型船坞登陆舰的北约代号是什么? 自卫武装方面,舰艏设有一门PJ-26型76mm舰炮(
+071型船坞登陆舰的北约代号是什么? 井冈山号舰首主炮
+071型船坞登陆舰的北约代号是什么? 俄罗斯AK-176M的中国仿制版,亦被054A采用) , 四具与052B/C相同的726-4 18联装干扰弹发射器分置于舰首两侧以及上层结构两侧,近迫防御则依赖四座布置于上层结构的AK-630 30mm防空机炮 。
+071型船坞登陆舰的北约代号是什么? 原本071模型的舰桥前方设有一座八联装海红-7短程防空导弹发射器,不过071首舰直到出海试航与2009年4月下旬的海上阅兵式中,都未装上此一武器。
+071型船坞登陆舰的北约代号是什么? 电子装备方面, 舰桥后方主桅杆顶配置一具363S型E/F频2D对空/平面搜索雷达 、一具Racal Decca RM-1290 I频导航雷达,后桅杆顶装备一具拥有球型外罩的364型(SR-64)X频2D对空/对海搜索雷达,此外还有一具LR-66C舰炮射控雷达、一具负责导引AK-630机炮的TR-47C型火炮射控雷达等。[5]
+071型船坞登陆舰的北约代号是什么? 071型自卫武装布置
+071型船坞登陆舰的北约代号是什么? 071首舰昆仑山号于2006年6月开
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 竹溪县人大常委会办公室:承担人民代表大会会议、常委会会议、主任会议和常委会党组会议(简称“四会”)的筹备和服务工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责常委会组成人员视察活动的联系服务工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 受主任会议委托,拟定有关议案草案。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承担常委会人事任免的具体工作,负责机关人事管理和离退休干部的管理与服务。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承担县人大机关的行政事务和后勤保障工作,负责机关的安全保卫、文电处理、档案、保密、文印工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承担县人大常委会同市人大常委会及乡镇人大的工作联系。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责信息反馈工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 了解宪法、法律、法规和本级人大及其常委会的决议、决定实施情况及常委会成员提出建议办理情况,及时向常委会和主任会议报告。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承担人大宣传工作,负责人大常委会会议宣传的组织和联系。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 组织协调各专门工作委员会开展工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承办上级交办的其他工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 办公室下设五个科,即秘书科、调研科、人事任免科、综合科、老干部科。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 教科文卫工作委员会:负责人大教科文卫工作的日常联系、督办、信息收集反馈和业务指导工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责教科文卫方面法律法规贯彻和人大工作情况的宣传、调研工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承担人大常委会教科文卫方面会议议题调查的组织联系和调研材料的起草工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承担教科文卫方面规范性备案文件的初审工作,侧重对教科文卫行政执法个案监督业务承办工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责常委会组成人员和人大代表对教科文卫工作方面检查、视察的组织联系工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承办上级交办的其他工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 代表工作委员会:负责与县人大代表和上级人大代表的联系、情况收集交流工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责《代表法》的宣传贯彻和贯彻实施情况的调查研究工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责县人大代表法律法规和人民代表大会制度知识学习的组织和指导工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责常委会主任、副主任和委员走访联系人大代表的组织、联系工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责组织人大系统的干部培训。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责乡镇人大主席团工作的联系和指导。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责人大代表建议、批评和意见办理工作的联系和督办落实。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责人大代表开展活动的组织、联系工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 承办上级交办的其他工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 财政经济工作委员会:负责人大财政经济工作的日常联系、督办、信息收集反馈和业务指导工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 负责财政经济方面法律法规贯彻和人大工作情况的宣传、调研工作。
+我很好奇竹溪县人大常委会财政经济工作委员会是负责做什么的? 对国民经济计划和财政预算编制情况进行初审。
+我想知道武汉常住人口有多少? 武汉,简称“汉”,湖北省省会。
+我想知道武汉常住人口有多少? 它是武昌、汉口、汉阳三镇统称。
+我想知道武汉常住人口有多少? 世界第三大河长江及其最长支流汉江横贯市区,将武汉一分为三,形成武昌、汉口、汉阳,三镇跨江鼎立的格局。
+我想知道武汉常住人口有多少? 唐朝诗人李白在此写下“黄鹤楼中吹玉笛,江城五月落梅花”,因此武汉自古又称“江城”。
+我想知道武汉常住人口有多少? 武汉是中国15个副省级城市之一,全国七大中心城市之一,全市常住人口858万人。
+我想知道武汉常住人口有多少? 华中地区最大都市,华中金融中心、交通中心、文化中心,长江中下游特大城市。
+我想知道武汉常住人口有多少? 武汉城市圈的中心城市。
+我想知道武汉常住人口有多少? [3]武昌、汉口、汉阳三地被俗称武汉三镇。
+我想知道武汉常住人口有多少? 武汉西与仙桃市、洪湖市相接,东与鄂州市、黄石市接壤,南与咸宁市相连,北与孝感市相接,形似一只自西向东的蝴蝶形状。
+我想知道武汉常住人口有多少? 在中国经济地理圈内,武汉处于优越的中心位置是中国地理上的“心脏”,故被称为“九省通衢”之地。
+我想知道武汉常住人口有多少? 武汉市历史悠久,古有夏汭、鄂渚之名。
+我想知道武汉常住人口有多少? 武汉地区考古发现的历史可以上溯距今6000年的新石器时代,其考古发现有东湖放鹰台遗址的含有稻壳的红烧土、石斧、石锛以及鱼叉。
+我想知道武汉常住人口有多少? 市郊黄陂区境内的盘龙城遗址是距今约3500年前的商朝方国宫城,是迄今中国发现及保存最完整的商代古城之一。
+我想知道武汉常住人口有多少? 现代武汉的城市起源,是东汉末年的位于今汉阳的卻月城、鲁山城,和在今武昌蛇山的夏口城。
+我想知道武汉常住人口有多少? 东汉末年,地方军阀刘表派黄祖为江夏太守,将郡治设在位于今汉阳龟山的卻月城中。
+我想知道武汉常住人口有多少? 卻月城是武汉市区内已知的最早城堡。
+我想知道武汉常住人口有多少? 223年,东吴孙权在武昌蛇山修筑夏口城,同时在城内的黄鹄矶上修筑了一座瞭望塔——黄鹤楼。
+我想知道武汉常住人口有多少? 苏轼在《前赤壁赋》中说的“西望夏口,东望武昌”中的夏口就是指武汉(而当时的武昌则是今天的鄂州)。
+我想知道武汉常住人口有多少? 南朝时,夏口扩建为郢州,成为郢州的治所。
+我想知道武汉常住人口有多少? 隋置江夏县和汉阳县,分别以武昌,汉阳为治所。
+我想知道武汉常住人口有多少? 唐时江夏和汉阳分别升为鄂州和沔州的州治,成为长江沿岸的商业重镇。
+我想知道武汉常住人口有多少? 江城之称亦始于隋唐。
+我想知道武汉常住人口有多少? 两宋时武昌属鄂州,汉阳汉口属汉阳郡。
+我想知道武汉常住人口有多少? 经过发掘,武汉出土了大量唐朝墓葬,在武昌马房山和岳家咀出土了灰陶四神砖以及灰陶十二生肖俑等。
+我想知道武汉常住人口有多少? 宋代武汉的制瓷业发达。
+我想知道武汉常住人口有多少? 在市郊江夏区梁子湖旁发现了宋代瓷窑群100多座,烧制的瓷器品种很多,釉色以青白瓷为主。
+我想知道武汉常住人口有多少? 南宋诗人陆游在经过武昌时,写下“市邑雄富,列肆繁错,城外南市亦数里,虽钱塘、建康不能过,隐然一大都会也”来描写武昌的繁华。
+我想知道武汉常住人口有多少? 南宋抗金将领岳飞驻防鄂州(今武昌)8年,在此兴师北伐。
+我想知道武汉常住人口有多少? 元世祖至元十八年(1281年),武昌成为湖广行省的省治。
+我想知道武汉常住人口有多少? 这是武汉第一次成为一级行政单位(相当于现代的省一级)的治所。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 列夫·达维多维奇,托洛茨基是联共(布)党内和第三国际时期反对派的领导人,托派"第四国际"的创始人和领导人。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 列夫·达维多维奇·托洛茨基
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 列夫·达维多维奇·托洛茨基(俄国与国际历史上最重要的无产阶级革命家之一,二十世纪国际共产主义运动中最具争议的、也是备受污蔑的左翼反对派领袖,他以对古典马克思主义“不断革命论”的独创性发展闻名于世,第三共产国际和第四国际的主要缔造者之一(第三国际前三次代表大会的宣言执笔人)。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 在1905年俄国革命中被工人群众推举为彼得堡苏维埃主席(而当时布尔什维克多数干部却还在讨论是否支持苏维埃,这些干部后来被赶回俄国的列宁痛击)。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 1917年革命托洛茨基率领“区联派”与列宁派联合,并再次被工人推举为彼得格勒苏维埃主席。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 对于十月革命这场20世纪最重大的社会革命,托洛茨基赢得了不朽的历史地位。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 后来成了托洛茨基死敌的斯大林,当时作为革命组织领导者之一却写道:“起义的一切实际组织工作是在彼得格勒苏维埃主席托洛茨基同志直接指挥之下完成的。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 我们可以确切地说,卫戍部队之迅速站在苏维埃方面来,革命军事委员会的工作之所以搞得这样好,党认为这首先要归功于托洛茨基同志。”
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? (值得一提的是,若干年后,当反托成为政治需要时,此类评价都从斯大林文章中删掉了。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? )甚至连后来狂热的斯大林派雅克·沙杜尔,当时却也写道:“托洛茨基在十月起义中居支配地位,是起义的钢铁灵魂。”
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? (苏汉诺夫《革命札记》第6卷P76。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? )不仅在起义中,而且在无产阶级政权的捍卫、巩固方面和国际共产主义革命方面,托洛茨基也作出了极其卓越的贡献(外交官-苏联国际革命政策的负责人、苏联红军缔造者以及共产国际缔造者)。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 革命后若干年里,托洛茨基与列宁的画像时常双双并列挂在一起;十月革命之后到列宁病逝之前,布尔什维克历次全国代表大会上,代表大会发言结束均高呼口号:“我们的领袖列宁和托洛茨基万岁!”
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 在欧美共运中托洛茨基的威望非常高。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 后人常常认为托洛茨基只是一个知识分子文人,实际上他文武双全,而且谙熟军事指挥艺术,并且亲临战场。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 正是他作为十月革命的最高军事领袖(在十月革命期间他与士兵一起在战壕里作战),并且在1918年缔造并指挥苏联红军,是一个杰出的军事家(列宁曾对朋友说,除了托洛茨基,谁还能给我迅速地造成一支上百万人的强大军队?
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? )。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 在内战期间,他甚至坐装甲列车冒着枪林弹雨亲临战场指挥作战,差点挨炸死;当反革命军队进攻彼得堡时,当时的彼得堡领导人季诺维也夫吓得半死,托洛茨基却从容不迫指挥作战。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 同时托洛茨基又是一个高明的外交家,他曾强硬地要求英国政府释放因反战宣传被囚禁在英国的俄国流亡革命者,否则就不许英国公民离开俄国,连英国政府方面都觉得此举无懈可击;他并且把居高临下的法国到访者当场轰出他的办公室(革命前法国一直是俄国的头号债主与政治操纵者),却彬彬有礼地欢迎前来缓和冲突的法国大使;而在十月革命前夕,他对工人代表议会质询的答复既保守了即将起义的军事秘密,又鼓舞了革命者的战斗意志,同时严格遵循现代民主与公开原则,这些政治答复被波兰人多伊彻誉为“外交辞令的杰作”(伊·多伊彻的托氏传记<先知三部曲·武装的先知>第九章P335,第十一章P390)。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 托洛茨基在国民经济管理与研究工作中颇有创造:是苏俄新经济政策的首先提议者以及社会主义计划经济的首先实践者。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 1928年斯大林迟迟开始的计划经济实验,是对1923年以托洛茨基为首的左翼反对派经济纲领的拙劣剽窃和粗暴翻版。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 因为统治者的政策迟到,使得新经济政策到1928年已产生了一个威胁政权生存的农村资产阶级,而苏俄工人阶级国家不得不强力解决——而且是不得不借助已蜕化为官僚集团的强力来解决冲突——结果导致了1929年到30年代初的大饥荒和对农民的大量冤枉错杀。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 另外,他还对文学理论有很高的造诣,其著作<文学与革命>甚至影响了整整一代的国际左翼知识分子(包括中国的鲁迅、王实味等人)。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 他在哈佛大学图书馆留下了100多卷的<托洛茨基全集>,其生动而真诚的自传和大量私人日记、信件,给人留下了研究人类生活各个方面的宝贵财富,更是追求社会进步与解放的历史道路上的重要知识库之一。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 托洛茨基1879年10月26日生于乌克兰赫尔松县富裕农民家庭,祖籍是犹太人。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 原姓布隆施泰因。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 1896年开始参加工人运动。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 1897年 ,参加建立南俄工人协会 ,反对沙皇专制制度。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 1898年 在尼古拉也夫组织工人团体,被流放至西伯利亚。
+列夫·达维多维奇·托洛茨基是什么时候开始参加工人运动的? 1902年秋以署名托洛茨基之假护照逃到伦敦,参加V.I.列宁、G.V.普列汉诺夫等人主编的<火星报>的工作。
+谁知道洞庭湖大桥有多长? 洞庭湖大桥,位于洞庭湖与长江交汇处,东接岳阳市区洞庭大道和107国道、京珠高速公路,西连省道306线,是国内目前最长的内河公路桥。
+谁知道洞庭湖大桥有多长? 路桥全长10173.82m,其中桥长5747.82m,桥宽20m,西双向四车道,是我国第一座三塔双索面斜拉大桥,亚洲首座不等高三塔双斜索面预应力混凝土漂浮体系斜拉桥。
+谁知道洞庭湖大桥有多长? 洞庭湖大桥是我国最长的内河公路桥,大桥横跨东洞庭湖区,全长10174.2米,主桥梁长5747.8米。
+谁知道洞庭湖大桥有多长? 大桥的通车使湘、鄂间公路干线大为畅通,并为洞庭湖区运输抗洪抢险物资提供了一条快速通道该桥设计先进,新颖,造型美观,各项技求指标先进,且为首次在国内特大型桥梁中采用主塔斜拉桥结构体系。
+谁知道洞庭湖大桥有多长? 洞庭湖大桥是湖区人民的造福桥,装点湘北门户的形象桥,对优化交通网络绪构,发展区域经济,保障防汛救灾,缩短鄂、豫、陕等省、市西部车辆南下的运距,拓展岳阳城区的主骨架,提升岳阳城市品位,增强城市辐射力,有着十分重要的意义。
+谁知道洞庭湖大桥有多长? 自1996年12月开工以来,共有10支施工队伍和两支监理队伍参与了大桥的建设。
+谁知道洞庭湖大桥有多长? 主桥桥面高52米(黄海),设计通航等级Ⅲ级。
+谁知道洞庭湖大桥有多长? 主桥桥型为不等高三塔、双索面空间索、全飘浮体系的预应力钢筋混凝土肋板梁式结构的斜拉桥,跨径为130+310+310+130米。
+谁知道洞庭湖大桥有多长? 索塔为双室宝石型断面,中塔高为125.684米,两边塔高为99.311米。
+谁知道洞庭湖大桥有多长? 三塔基础为3米和3.2米大直径钻孔灌注桩。
+谁知道洞庭湖大桥有多长? 引桥为连续梁桥,跨径20至50米,基础直径为1.8和2.5米钻孔灌注桩。
+谁知道洞庭湖大桥有多长? 该桥设计先进、新颖、造型美观,各项技求指标先进,且为首次在国内特大型桥梁中采用主塔斜拉桥结构体系,岳阳洞庭湖大桥是我国首次采用不等高三塔斜拉桥桥型的特大桥,设计先进,施工难度大位居亚洲之首,是湖南省桥梁界的一大科研项目。
+谁知道洞庭湖大桥有多长? 洞庭湖大桥设计为三塔斜拉桥,空间双斜面索,主梁采用前支点挂篮施工,并按各种工况模拟挂篮受力进行现场试验,获得了大量有关挂篮受力性能和实际刚度的计算参数,作为施工控制参数。
+谁知道洞庭湖大桥有多长? 利用组合式模型单元,推导了斜拉桥分离式双肋平板主梁的单元刚度矩阵,并进行了岳阳洞庭湖大桥的空间受力分析,结果表明此种单元精度满足工程要求,同时在施工工艺方面也积累了成功经验。
+谁知道洞庭湖大桥有多长? 洞庭湖大桥的通车使湘、鄂间公路干线大为畅通,并为洞庭湖区抗洪抢险物资运输提供了一条快速通道。
+谁知道洞庭湖大桥有多长? 湖大桥设计先进,造型美丽,科技含量高。
+谁知道洞庭湖大桥有多长? 洞庭大桥还是一道美丽的风景线,大桥沿岸风景与岳阳楼,君山岛、洞庭湖等风景名胜融为一体,交相辉映,成为世人了解岳阳的又一崭新窗口,也具有特别旅游资源。
+谁知道洞庭湖大桥有多长? 洞庭湖大桥多塔斜拉桥新技术研究荣获国家科学技术进步二等奖、湖南省科学技术进步一等奖,并获第五届詹天佑大奖。
+谁知道洞庭湖大桥有多长? 大桥在中国土木工程学会2004年第16届年会上入选首届《中国十佳桥梁》,名列斜拉桥第二位。
+谁知道洞庭湖大桥有多长? 2001年荣获湖南省建设厅优秀设计一等奖,省优秀勘察一等奖。
+谁知道洞庭湖大桥有多长? 2003年荣获国家优秀工程设计金奖, "十佳学术活动"奖。
+天气预报员的布景师是谁? 芝加哥天气预报员大卫(尼古拉斯·凯奇),被他的粉丝们热爱,也被诅咒--这些人在天气不好的时候会迁怒于他,而大部分时候,大卫都是在预报坏天气。
+天气预报员的布景师是谁? ?不过,这也没什么,当一家国家早间新闻节目叫他去面试的时候,大卫的事业似乎又将再创新高。
+天气预报员的布景师是谁? 芝加哥天气预报员大卫(尼古拉斯·凯奇),被他的粉丝们热爱,也被诅咒--这些人在天气不好的时候会迁怒于他,而大部分时候,大卫都是在预报坏天气。
+天气预报员的布景师是谁? 不过,这也没什么,当一家国家早间新闻节目叫他去面试的时候,大卫的事业似乎又将再创新高。
+天气预报员的布景师是谁? 在电视节目上,大卫永远微笑,自信而光鲜,就像每一个成功的电视人一样,说起收入,他也绝对不落人后。
+天气预报员的布景师是谁? 不过,大卫的个人生活可就不那么如意了。
+天气预报员的布景师是谁? 与妻子劳伦(霍普·戴维斯)的离婚一直让他痛苦;儿子迈克吸大麻上瘾,正在进行戒毒,可戒毒顾问却对迈克有着异样的感情;女儿雪莉则体重惊人,总是愁眉苦脸、孤独寂寞;大卫的父亲罗伯特(迈克尔·凯恩),一个世界著名的小说家,虽然罗伯特不想再让大卫觉得负担过重,可正是他的名声让大卫的一生都仿佛处在他的阴影之下,更何况,罗伯特就快重病死了。
+天气预报员的布景师是谁? 和妻子的离婚、父亲的疾病、和孩子之间完全不和谐的关系,都让大卫每天头疼,而每次当他越想控制局面,一切就越加复杂。
+天气预报员的布景师是谁? 然而就在最后人们再也不会向他扔快餐,或许是因为他总是背着弓箭在大街上走。
+天气预报员的布景师是谁? 最后,面对那份高额工作的接受意味着又一个新生活的开始。
+天气预报员的布景师是谁? 也许,生活就像天气,想怎么样就怎么样,完全不可预料。
+天气预报员的布景师是谁? 导 演:戈尔·维宾斯基 Gore Verbinski
+天气预报员的布景师是谁? 编 剧:Steve Conrad .....(written by)
+天气预报员的布景师是谁? 演 员:尼古拉斯·凯奇 Nicolas Cage .....David Spritz
+天气预报员的布景师是谁? 尼古拉斯·霍尔特 Nicholas Hoult .....Mike
+天气预报员的布景师是谁? 迈克尔·凯恩 Michael Caine .....Robert Spritzel
+天气预报员的布景师是谁? 杰蒙妮·德拉佩纳 Gemmenne de la Peña .....Shelly
+天气预报员的布景师是谁? 霍普·戴维斯 Hope Davis .....Noreen
+天气预报员的布景师是谁? 迈克尔·瑞斯玻利 Michael Rispoli .....Russ
+天气预报员的布景师是谁? 原创音乐:James S. Levine .....(co-composer) (as James Levine)
+天气预报员的布景师是谁? 汉斯·兹米尔 Hans Zimmer
+天气预报员的布景师是谁? 摄 影:Phedon Papamichael
+天气预报员的布景师是谁? 剪 辑:Craig Wood
+天气预报员的布景师是谁? 选角导演:Denise Chamian
+天气预报员的布景师是谁? 艺术指导:Tom Duffield
+天气预报员的布景师是谁? 美术设计:Patrick M. Sullivan Jr. .....(as Patrick Sullivan)
+天气预报员的布景师是谁? 布景师 :Rosemary Brandenburg
+天气预报员的布景师是谁? 服装设计:Penny Rose
+天气预报员的布景师是谁? 视觉特效:Charles Gibson
+天气预报员的布景师是谁? David Sosalla .....Pacific Title & Art Studio
+韩国国家男子足球队教练是谁? 韩国国家足球队,全名大韩民国足球国家代表队(???? ?? ?????),为韩国足球协会所于1928年成立,并于1948年加入国际足球协会。
+韩国国家男子足球队教练是谁? 韩国队自1986年世界杯开始,从未缺席任何一届决赛周。
+韩国国家男子足球队教练是谁? 在2002年世界杯,韩国在主场之利淘汰了葡萄牙、意大利及西班牙三支欧洲强队,最后夺得了殿军,是亚洲球队有史以来最好成绩。
+韩国国家男子足球队教练是谁? 在2010年世界杯,韩国也在首圈分组赛压倒希腊及尼日利亚出线次圈,再次晋身十六强,但以1-2败给乌拉圭出局。
+韩国国家男子足球队教练是谁? 北京时间2014年6月27日3时,巴西世界杯小组赛H组最后一轮赛事韩国对阵比利时,韩国队0-1不敌比利时,3场1平2负积1分垫底出局。
+韩国国家男子足球队教练是谁? 球队教练:洪明甫
+韩国国家男子足球队教练是谁? 韩国国家足球队,全名大韩民国足球国家代表队(韩国国家男子足球队???? ?? ?????),为韩国足球协会所于1928年成立,并于1948年加入国际足联。
+韩国国家男子足球队教练是谁? 韩国队是众多亚洲球队中,在世界杯表现最好,他们自1986年世界杯开始,从未缺席任何一届决赛周。
+韩国国家男子足球队教练是谁? 在2002年世界杯,韩国在主场之利淘汰了葡萄牙、意大利及西班牙三支欧洲强队,最后夺得了殿军,是亚洲球队有史以来最好成绩。
+韩国国家男子足球队教练是谁? 在2010年世界杯,韩国也在首圈分组赛压倒希腊及尼日利亚出线次圈,再次晋身十六强,但以1-2败给乌拉圭出局。
+韩国国家男子足球队教练是谁? 2014年世界杯外围赛,韩国在首轮分组赛以首名出线次轮分组赛,与伊朗、卡塔尔、乌兹别克以及黎巴嫩争逐两个直接出线决赛周资格,最后韩国仅以较佳的得失球差压倒乌兹别克,以小组次名取得2014年世界杯决赛周参赛资格,也是韩国连续八次晋身世界杯决赛周。
+韩国国家男子足球队教练是谁? 虽然韩国队在世界杯成绩为亚洲之冠,但在亚洲杯足球赛的成绩却远不及世界杯。
+韩国国家男子足球队教练是谁? 韩国只在首两届亚洲杯(1956年及1960年)夺冠,之后五十多年未能再度称霸亚洲杯,而自1992年更从未打入过决赛,与另一支东亚强队日本近二十年来四度在亚洲杯夺冠成强烈对比。[1]
+韩国国家男子足球队教练是谁? 人物简介
+韩国国家男子足球队教练是谁? 车范根(1953年5月22日-)曾是大韩民国有名的锋线选手,他被欧洲媒体喻为亚洲最佳输出球员之一,他也被认为是世界最佳足球员之一。
+韩国国家男子足球队教练是谁? 他被国际足球史料与数据协会评选为20世纪亚洲最佳球员。
+韩国国家男子足球队教练是谁? 他在85-86赛季是德甲的最有价值球员,直到1999年为止他都是德甲外国球员入球纪录保持者。
+韩国国家男子足球队教练是谁? 德国的球迷一直没办法正确说出他名字的发音,所以球车范根(左)迷都以炸弹车(Cha Boom)称呼他。
+韩国国家男子足球队教练是谁? 这也代表了他强大的禁区得分能力。
+韩国国家男子足球队教练是谁? 职业生涯
+韩国国家男子足球队教练是谁? 车范根生于大韩民国京畿道的华城市,他在1971年于韩国空军俱乐部开始了他的足球员生涯;同年他入选了韩国19岁以下国家足球队(U-19)。
+韩国国家男子足球队教练是谁? 隔年他就加入了韩国国家足球队,他是有史以来加入国家队最年轻的球员。
+韩国国家男子足球队教练是谁? 车范根在27岁时前往德国发展,当时德甲被认为是世界上最好的足球联赛。
+韩国国家男子足球队教练是谁? 他在1978年12月加入了达姆施塔特,不过他在那里只待了不到一年就转到当时的德甲巨人法兰克福。
+韩国国家男子足球队教练是谁? 车范根很快在新俱乐部立足,他帮助球队赢得79-80赛季的欧洲足协杯。
+韩国国家男子足球队教练是谁? 在那个赛季过后,他成为德甲薪水第三高的球员,不过在1981年对上勒沃库森的一场比赛上,他的膝盖严重受伤,几乎毁了他的足球生涯。
+韩国国家男子足球队教练是谁? 在1983年车范根转投勒沃库森;他在这取得很高的成就,他成为85-86赛季德甲的最有价值球员,并且在1988年帮助球队拿下欧洲足协杯,也是他个人第二个欧洲足协杯。
+韩国国家男子足球队教练是谁? 他在决赛对垒西班牙人扮演追平比分的关键角色,而球会才在点球大战上胜出。
+韩国国家男子足球队教练是谁? 车范根在1989年退休,他在308场的德甲比赛中进了98球,一度是德甲外国球员的入球纪录。
+韩国国家男子足球队教练是谁? 执教生涯
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 国立台湾科技大学,简称台湾科大、台科大或台科,是位于台湾台北市大安区的台湾第一所高等技职体系大专院校,现为台湾最知名的科技大学,校本部比邻国立台湾大学。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 该校已于2005年、2008年持续入选教育部的“发展国际一流大学及顶尖研究中心计划”。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? “国立”台湾工业技术学院成立于“民国”六十三年(1974)八月一日,为台湾地区第一所技术职业教育高等学府。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 建校之目的,在因应台湾地区经济与工业迅速发展之需求,以培养高级工程技术及管理人才为目标,同时建立完整之技术职业教育体系。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? “国立”台湾工业技术学院成立于“民国”六十三年(1974)八月一日,为台湾地区第一所技术职业教育高等学府。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 建校之目的,在因应台湾地区经济与工业迅速发展之需求,以培养高级工程技术及管理人才为目标,同时建立完整之技术职业教育体系。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 本校校地约44.5公顷,校本部位于台北市基隆路四段四十三号,。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 民国68年成立硕士班,民国71年成立博士班,现有大学部学生5,664人,研究生4,458人,专任教师451位。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 2001年在台湾地区教育部筹划之研究型大学(“国立”大学研究所基础教育重点改善计画)中,成为全台首批之9所大学之一 。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 自2005年更在“教育部”所推动“五年五百亿 顶尖大学”计划下,遴选为适合发展成“顶尖研究中心”的11所研究型大学之一。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 国立台湾科技大学部设有二年制、四年制及工程在职人员进修班等三种学制;凡二专、三专及五专等专科学校以上之毕业生,皆可以报考本校大学部二年制,而高职、高中毕业生,可以报考本校大学部四年制。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 工业管理、电子工程、机械工程、营建工程及应用外语系等,则设有在职人员进修班学制,其招生对象为在职人员,利用夜间及暑假期间上课。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 凡在本校大学部修毕应修学分且成绩及格者皆授予学士学位。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 国立台湾科技大学目前设有工程、电资、管理、设计、人文社会及精诚荣誉等六个学院,分别有机械、材料科学与工程、营建、化工、电子、电机、资工、工管、企管、资管、建筑、工商业设计、应用外语等13个系及校内招生之财务金融学士学位学程、科技管理学士学位学程;全校、工程、电资、管理、创意设计等五个不分系菁英班及光电研究所、管理研究所、财务金融研究所、科技管理研究所、管理学院MBA、数位学习教育研究所、医学工程研究所、自动化及控制研究所、工程技术研究所、专利研究所等独立研究所,此外尚有人文学科负责人文及社会类等课程之教学,通识学科负责法律、音乐、环保类等课程之教学,以及师资培育中心专以培养学生未来担任中等学校工、商、管理、设计等科之合格教师,合计23个独立系所、师资培育中心、人文学科及通识学科等教学单位。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 国立台湾科技大学至今各系所毕业校友已达约56,456位,毕业生出路包含出国继续深造、在台深造以及投身于产业界。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 由于实作经验丰富,理论基础完备,工作态度认真,毕业校友担任政府要职、大学教授、大学校长及企业主管者众多,深受各界的肯定。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 工商业设计系副教授孙春望与硕一生全明远耗时两个月自制之三分钟动画短片“立体悲剧”。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 本片入选有“动画奥斯卡”之称的“ACM SIGGRAPH”国际动画展,并获得观众票选第一名,这也是台湾首次入选及获奖的短片。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 击败了好莱坞知名导演史蒂芬·史匹柏的“世界大战”、乔治卢卡斯的“星际大战三部曲”、梦工厂出品的动画“马达加斯加”、军机缠斗片“机战未来”及美国太空总署、柏克莱加州大学等好莱坞名片及顶尖学术单位制作的短片。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 2009年荣获有工业设计界奥斯卡奖之称的“德国iF设计大奖”国立台湾科技大学设计学院获得大学排名的全球第二,仅次于韩国三星美术设计学院“SADI”。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 总体排名 依据《泰晤士高等教育》(THES-QS)在2009年的世界大学排名调查,台科大排名全世界第351名,在台湾所有大学中排名第五,仅次于台大,清大,成大及阳明,并且是台湾唯一进入世界四百大名校的科技大学。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 依据在欧洲拥有广大声誉的“Eduniversal商学院排名网”2008年的资料,台湾有七所大学的商管学院被分别列入世界1000大商学院,其中台科大位在“卓越商学院”(EXCELLENT Business Schools,国内主要)之列,“推荐程度”(Recommendation Rate)为全台第四,仅次于台大、政大、中山,与交大并列。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 目前设有工程、电资、管理、设计、人文社会及精诚荣誉学院等六个学院。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? 预计于竹北新校区设立产学合作学院及应用理学院。
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? ●台湾建筑科技中心
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? ●智慧型机械人研究中心科技成果展示(15张)
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? ●台湾彩卷与博彩研究中心
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? ●电力电子技术研发中心
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? ●NCP-Taiwan办公室
+国立台湾科技大学副教授自制的动画“立体悲剧”入选的“ACM SIGGRAPH”国际动画展还有什么别称? ●资通安全研究与教学中心
+在日本,神道最初属于什么信仰? 神道又称天道,语出《易经》“大观在上,顺而巽,中正以观天下。
+在日本,神道最初属于什么信仰? 观,盥而不荐,有孚顒若,下观而化也。
+在日本,神道最初属于什么信仰? 观天之神道,而四时不忒,圣人以神道设教,而天下服矣”。
+在日本,神道最初属于什么信仰? 自汉以降,神道又指“墓前开道,建石柱以为标”。
+在日本,神道最初属于什么信仰? 在中医中,神道,经穴名。
+在日本,神道最初属于什么信仰? 出《针灸甲乙经》。
+在日本,神道最初属于什么信仰? 别名冲道。
+在日本,神道最初属于什么信仰? 属督脉。
+在日本,神道最初属于什么信仰? 宗教中,神道是日本的本土传统民族宗教,最初以自然崇拜为主,属于泛灵多神信仰(精灵崇拜),视自然界各种动植物为神祇。
+在日本,神道最初属于什么信仰? 神道又称天道,语出《易经》“大观在上,顺而巽,中正以观天下。
+在日本,神道最初属于什么信仰? 观,盥而不荐,有孚顒若,下观而化也。
+在日本,神道最初属于什么信仰? 观天之神道,而四时不忒,圣人以神道设教,而天下服矣”。
+在日本,神道最初属于什么信仰? 自汉以降,神道又指“墓前开道,建石柱以为标”。
+在日本,神道最初属于什么信仰? 在中医中,神道,经穴名。
+在日本,神道最初属于什么信仰? 出《针灸甲乙经》。
+在日本,神道最初属于什么信仰? 别名冲道。
+在日本,神道最初属于什么信仰? 属督脉。
+在日本,神道最初属于什么信仰? 宗教中,神道是日本的本土传统民族宗教,最初以自然崇拜为主,属于泛灵多神信仰(精灵崇拜),视自然界各种动植物为神祇。
+在日本,神道最初属于什么信仰? 谓鬼神赐福降灾神妙莫测之道。
+在日本,神道最初属于什么信仰? 《易·观》:“观天之神道,而四时不忒,圣人以神道设教,而天下服矣。”
+在日本,神道最初属于什么信仰? 孔颖达 疏:“微妙无方,理不可知,目不可见,不知所以然而然,谓之神道。”
+在日本,神道最初属于什么信仰? 《文选·王延寿<鲁灵光殿赋>》:“敷皇极以创业,协神道而大宁。”
+在日本,神道最初属于什么信仰? 张载 注:“协和神明之道,而天下大宁。”
+在日本,神道最初属于什么信仰? 南朝 梁 刘勰 《文心雕龙·正纬》:“夫神道阐幽,天命微显。”
+在日本,神道最初属于什么信仰? 鲁迅 《中国小说史略》第五篇:“﹝ 干宝 ﹞尝感於其父婢死而再生,及其兄气绝复苏,自言见天神事,乃撰《搜神记》二十卷,以‘发明神道之不诬’。”
+在日本,神道最初属于什么信仰? 神道设教 观卦里面蕴含着《易经》固有的诸如神道设教、用舍行藏、以德化民等思想,是孔子把这些思想发掘出来。
+在日本,神道最初属于什么信仰? 「据此是孔子见当时之人,惑于吉凶祸福,而卜筮之史,加以穿凿傅会,故演易系辞,明义理,切人事,借卜筮以教后人,所谓以神道设教,其所发明者,实即羲文之义理,而非别有义理,亦非羲文并无义理,至孔子始言义理也,当即朱子之言而小变之曰,易为卜筮作,实为义理作,伏羲文王之易,有占而无文,与今人用火珠林起课者相似,孔子加卦爻辞如签辞,纯以理言,实即羲文本意,则其说分明无误矣。」
+在日本,神道最初属于什么信仰? 孔子所发掘的《易经》思想与孔子在《论语》书中表现出来的思想完全一致。
+在日本,神道最初属于什么信仰? 《易传》的思想反映了孔子的思想,这个思想是《周易》的,也是孔子的。
+在日本,神道最初属于什么信仰? 在《周易》和孔子看来,神不是有意识的人格化的上帝。
+奥林匹克里昂获得了几连霸? 里昂 Lyon 全名 Olympique lyonnais 绰号 Les Gones、OL 成立 1950年 城市 法国,里昂 主场 热尔兰球场(Stade Gerland) 容纳人数 41,044人 主席 奥拉斯 主教练 雷米·加尔德 联赛 法国足球甲级联赛 2013–14 法甲,第 5 位 网站 官方网站 主场球衣 客场球衣 第三球衣 日尔兰体育场 奥林匹克里昂(Olympique lyonnais,简称:OL及Lyon,中文简称里昂)是一间位于法国东南部罗纳-阿尔卑斯区的里昂市的足球会,成立于1950年8月3日,前身为里昂·奥林匹克(Lyon Olympique)体育俱乐部其中一个分支的足球队,1889年离开体育俱乐部自立门户成立新俱乐部,但官方网站表示俱乐部于1950年正式成立。
+奥林匹克里昂获得了几连霸? 现时在法国足球甲级联赛比赛,俱乐部同时设立男子及女子足球队。
+奥林匹克里昂获得了几连霸? 里昂是首届法国足球甲级联赛成员之一,可惜名列第十五位而降落乙组,1951年以乙级联赛冠军获得创会后首次锦标。
+奥林匹克里昂获得了几连霸? 球队在法国足球史上没有取得辉煌成绩,比较优异的算是六十年代曾杀入欧洲杯赛冠军杯四强,及3度晋身法国杯决赛并2次成功获冠。
+奥林匹克里昂获得了几连霸? 直至九十年代末里昂由辛天尼带领,先连续取得联赛头三名,到2002年终于首次登上法国顶级联赛冠军宝座,同年勒冈(Paul Le Guen)接替执教法国国家足球队的辛天尼,他其后继续带领里昂保持气势,加上队中球员小儒尼尼奧、迪亚拉、克里斯蒂亞諾·馬克斯·戈麥斯、迈克尔·埃辛、西德尼·戈武及门将格雷戈里·库佩表现突出,2003年至2005年横扫3届联赛冠军,创下连续四年夺得联赛锦标,平了1960年代末圣艾蒂安及1990年代初马赛的四连冠纪录。
+奥林匹克里昂获得了几连霸? 2005年前利物浦主教练热拉尔·霍利尔重返法国担任新任主教练,并加入葡萄牙中场蒂亚戈,和前巴伦西亚前锋约翰·卡鲁。
+奥林匹克里昂获得了几连霸? 他亦成功带领里昂赢得一届法甲冠军。
+奥林匹克里昂获得了几连霸? 2007年里昂成为首支上市的法国足球俱乐部,招股价21至24.4欧元,发行370万股,集资8400万欧元[1]。
+奥林匹克里昂获得了几连霸? 2007年4月21日,联赛次名图卢兹二比三不敌雷恩,令处于榜首的里昂领先次席多达17分距离,里昂因此提前六轮联赛庆祝俱乐部连续第六年夺得联赛冠军,亦是欧洲五大联赛(英格兰、德国、西班牙、意大利及法国)历史上首支联赛六连冠队伍[2]。
+奥林匹克里昂获得了几连霸? 在2007-08年赛季,里昂再一次成功卫冕联赛锦标,达成七连霸伟业。
+奥林匹克里昂获得了几连霸? 不过在2008-09赛季,里昂排名法甲第三位,联赛冠军被波尔多所获得。
+奥林匹克里昂获得了几连霸? 于2010年4月,里昂以两回合3比2的比分于欧洲冠军联赛击败波尔多跻身四强,此乃里昂首次晋级此项顶级杯赛的四强阶段。
+奥林匹克里昂获得了几连霸? 粗体字为新加盟球员
+奥林匹克里昂获得了几连霸? 以下球员名单更新于2014年8月27日,球员编号参照 官方网站,夏季转会窗为6月9日至8月31日
+火柴人刺杀行动怎么才能过关? 移动鼠标控制瞄准,点击鼠标左键进行射击。
+火柴人刺杀行动怎么才能过关? 游戏加载完成后点击STARTGAME-然后点击STARTMISSION即可开始游戏。
+火柴人刺杀行动怎么才能过关? 这里不仅仅考验的是你的枪法而且最重要的是你的智慧,喜欢火柴人类型游戏的玩家可以进来小试身手。
+火柴人刺杀行动怎么才能过关? 控制瞄准,刺杀游戏中的目标人物即可过关哦。
+你知道2月14日西方情人节是因何起源的吗? 情人节(英语:Valentine's Day),情人节的起源有多个版本,其中一个说法是在公元三世纪,古罗马暴君为了征召更多士兵,禁止婚礼,一名叫瓦伦丁Valentine的修士不理禁令,秘密替人主持婚礼,结果被收监,最后处死。
+你知道2月14日西方情人节是因何起源的吗? 而他死的那天就是2月14日,为纪念Valentine的勇敢精神,人们将每年的2月14日定为Valentine的纪念日。
+你知道2月14日西方情人节是因何起源的吗? 因此成了后来的“情人节”。
+你知道2月14日西方情人节是因何起源的吗? 另外,据记载,教宗在公元496年废除牧神节,把2月14日定为圣瓦伦丁日,即是St.Valentine's Day,后来成为是西方的节日之一。
+你知道2月14日西方情人节是因何起源的吗? 中文名称:情人节
+你知道2月14日西方情人节是因何起源的吗? 外文名称:Valentine‘s Day
+你知道2月14日西方情人节是因何起源的吗? 别名:情人节圣瓦伦丁节
+你知道2月14日西方情人节是因何起源的吗? 公历日期:2月14日
+你知道2月14日西方情人节是因何起源的吗? 起源时间:公元270年2月14日
+你知道2月14日西方情人节是因何起源的吗? 起源事件:人们为了纪念为情人做主而牺牲的瓦伦丁神父,把他遇害的那一天(2月14日)称为情人节。
+你知道2月14日西方情人节是因何起源的吗? 地区:欧美地区
+你知道2月14日西方情人节是因何起源的吗? 宗教:基督教
+你知道2月14日西方情人节是因何起源的吗? 其他信息:西方的传统节日之一。
+你知道2月14日西方情人节是因何起源的吗? 男女在这一天互送礼物(如贺卡和玫瑰花等)用以表达爱意或友好。
+你知道2月14日西方情人节是因何起源的吗? 据台湾“今日台湾人讨厌情人节新闻网”报道,西洋情人节即将来到,求职网进行“办公室恋情及情人节调查”发现,在目前全台上班族的感情状态中,有情人相伴的比率约5成5,4成5的上班族单身;较出乎意料的结果是,情人节以近3成(28%)的占比,登上最讨厌的节日第一名,端午节以24.3%居第二;农历年则以18.2%居第三;第四名是圣诞节,占12.4%。
+你知道2月14日西方情人节是因何起源的吗? 调查指出,情人节对单身族来说,不仅成为压力,也显得更加孤单,在情人节当天,单身的上班族有将近4成(39.1%)的人在家看电视度过,近两成(18.7%)上网聊天,有1成4(14.8%)的人,不畏满街闪光,勇气十足出门看电影,近1成(9.7%)的上班族选择留在公司加班;另外有 5.4%的人,会在情人节当天积极参加联谊,希望能改变自己的感情状态。
+你知道2月14日西方情人节是因何起源的吗? 情侣们在情人节当天,庆祝方式以吃浪漫大餐最多(37.1%),不过有近3成(27%)的情侣,在情人节当天不会特别庆祝情人节,且这个比率远比第三名的旅游(占比11.5%)高出1倍以上。
+你知道2月14日西方情人节是因何起源的吗? 在情人节当天庆祝的开销上,可以说是小资男女当道,选择1000元(新台币,下同)以内的上班族最多占33.1%,情人节当天的花费上班族的平均花费是2473元,大手笔花费上万元以上庆祝情人节的,占比只有2.5%。
+你知道2月14日西方情人节是因何起源的吗? 情人节的起源众说纷纭,而为纪念罗马教士瓦伦丁是其中一个普遍的说法。
+你知道2月14日西方情人节是因何起源的吗? 据《世界图书百科全书》(World Book Encyclopedia)数据指出:“在公元200年时期,罗马皇帝克劳狄二世禁止年轻男子结婚。
+你知道2月14日西方情人节是因何起源的吗? 他认为未婚男子可以成为更优良的士兵。
+你知道2月14日西方情人节是因何起源的吗? 一位名叫瓦伦丁的教士违反了皇帝的命令,秘密为年轻男子主持婚礼,引起皇帝不满,结果被收监,据说瓦伦丁于公元269年2月14日被处决。
+你知道2月14日西方情人节是因何起源的吗? 另外,据《天主教百科全书》(The Catholic情人节 Encyclopedia)指出,公元496年,教宗圣基拉西乌斯一世在公元第五世纪末叶废除了牧神节,把2月14日定为圣瓦伦丁日。”
+你知道2月14日西方情人节是因何起源的吗? 这个节日现今以“圣瓦伦丁节”——亦即情人节的姿态盛行起来。
+你知道2月14日西方情人节是因何起源的吗? 但是在第2次梵蒂冈大公会议后,1969年的典礼改革上,整理了一堆在史实上不确定是否真实存在的人物以后,圣瓦伦丁日就被废除了。
+你知道2月14日西方情人节是因何起源的吗? 现在天主教圣人历已经没有圣瓦伦丁日(St. Valentine's Day)。
+你知道2月14日西方情人节是因何起源的吗? 根据《布卢姆尔的警句与寓言辞典》记载:“圣瓦伦丁是个罗马教士,由于援助受逼害的基督徒而身陷险境,后来他归信基督教,最后被处死,卒于二月十四日”古代庆祝情人节的习俗与瓦伦丁拉上关系,可能是纯属巧合而已。
+你知道2月14日西方情人节是因何起源的吗? 事实上,这个节日很可能与古罗马的牧神节或雀鸟交配的季节有关。
+你知道2月14日西方情人节是因何起源的吗? 情人节的特色是情侣互相馈赠礼物。
+你知道2月14日西方情人节是因何起源的吗? 时至今日,人们则喜欢以情人卡向爱人表达情意。
+防卫大学每年招收多少学生? 防卫大学的前身是保安大学。
+防卫大学每年招收多少学生? 防卫大学是日本自卫队培养陆、海、空三军初级军官的学校,被称为日军"军官的摇篮"。
+防卫大学每年招收多少学生? 防卫大学是日军的重点院校。
+防卫大学每年招收多少学生? 日本历届内阁首相都要到防卫大学视察"训示",并亲自向学生颁发毕业证书。
+防卫大学每年招收多少学生? 日军四分之一的军官、三分之一的将官从这里走出。
+防卫大学每年招收多少学生? 防卫大学毕业生已成为日军军官的中坚力量。
+防卫大学每年招收多少学生? 防卫大学每年从地方招收18岁至21岁的应届高中毕业生和同等学历的青年。
+防卫大学每年招收多少学生? 每年招生名额为530名。
+防卫大学每年招收多少学生? 1950年 8月,日本组建警察预备队,1952年改为保安队。
+防卫大学每年招收多少学生? 为了充实保安队干部队伍,提高干部军政素质,1953年4月成立了保安大学,校址设在三浦半岛的久里滨。
+防卫大学每年招收多少学生? 1954年7月1日保安厅改为防卫厅。
+防卫大学每年招收多少学生? 在保安队基础上,日本建立了陆、海、空三军自卫队,保安大学遂改名为防卫大学,1955年迁至三浦半岛东南方的小原台。
+防卫大学每年招收多少学生? 学校直属防卫厅领导。
+防卫大学每年招收多少学生? 防卫大学的教育方针是:要求学生德智体全面发展,倡导学生崇尚知识和正义,培养学生具有指挥各种部队的能力。
+防卫大学每年招收多少学生? 防卫大学每年招生名额为530名,其中陆军300名,海军100名,空军130名。
+防卫大学每年招收多少学生? 根据自卫队向妇女敞开军官大门的决定,防卫大学1992年首次招收女学员35名。
+防卫大学每年招收多少学生? 考试分两次进行。
+防卫大学每年招收多少学生? 第一次,每年11月份进行学科考试;第二次,12月份进行口试和体检。
+防卫大学每年招收多少学生? 学校按陆、海、空三军分别设大学本科班和理工科研究生班。
+防卫大学每年招收多少学生? 本科班学制4年,又分为理工和人文社会学两大科。
+防卫大学每年招收多少学生? 学员入学后先分科,530人中有460人专攻理科,70人专攻文科。
+防卫大学每年招收多少学生? 第1学年按专科学习一般大学课程和一般军事知识。
+防卫大学每年招收多少学生? 第2学年以后在军事上开始区分军种,学员分别学习陆、海、空军的专门课程。
+防卫大学每年招收多少学生? 文化课和军事课的比例是6:l。
+防卫大学每年招收多少学生? 文化课程有人文、社会、自然、外语、电气工程、机械工程、土木建筑工程、应用化学、应用物理、航空、航海等。
+防卫大学每年招收多少学生? 军事训练课每学年6周,按一年四季有比例地安排教学内容,对学生进行军事技术和体能训练。
+防卫大学每年招收多少学生? 理工科研究生班,每年招生1期,学制2年,每期招收90人,设电子工程、航空工程、兵器制造等7个专业,课程按一般大学硕士课程标准设置。
+防卫大学每年招收多少学生? 防卫大学的课程和训练都十分紧张。
+防卫大学每年招收多少学生? 近年来,为了增强防卫大学的吸引力,克服考生逐年减少的倾向广泛征集优秀人才,学校进行了一些改革,改变入学考试办法,各高中校长以内部呈报的形式向防卫大学推荐品学兼优的学生;减少学生入学考试科目,放宽对报考防卫大学的学生的视力要求;降低学分数(大约降低30学分);改善学生宿舍条件。
+防卫大学每年招收多少学生? 防卫大学的学生生活紧张而愉快。
+《威鲁贝鲁的物语》官网是什么? 10年前大战后,威鲁贝鲁国一致辛勤的保护着得来不易的和平,但是与邻国圣卡特拉斯国的关系却不断的紧张,战争即将爆发。
+《威鲁贝鲁的物语》官网是什么? 为了避免战争,威鲁贝鲁国王海特鲁王决定将自己最大的女儿公主莉塔嫁给圣卡特拉斯国的王子格鲁尼亚。
+《威鲁贝鲁的物语》官网是什么? 但是莉塔却刺伤了政治婚姻的对象格鲁尼亚王子逃了出去,这事激怒了圣卡特拉斯国的国王兰帕诺夫王,并下令14天之内抓到王女并执行公开处刑来谢罪,不然两国就要开战。
+《威鲁贝鲁的物语》官网是什么? 《威鲁贝鲁的物语~Sisters of Wellber~》
+《威鲁贝鲁的物语》官网是什么? (Sisters of Wellber)
+《威鲁贝鲁的物语》官网是什么? 日文名 ウエルベールの物语
+《威鲁贝鲁的物语》官网是什么? 官方网站 http://www.avexmovie.jp/lineup/wellber/
+《威鲁贝鲁的物语》官网是什么? 为了回避发生战争这个最坏的结果,莉塔下定决心去中立国古利达姆。
diff --git a/examples/erniesage/dataset/__init__.py b/examples/erniesage/dataset/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/examples/erniesage/dataset/base_dataset.py b/examples/erniesage/dataset/base_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b29b5761769e9be9e62fb4536e41d43f9c9abb4
--- /dev/null
+++ b/examples/erniesage/dataset/base_dataset.py
@@ -0,0 +1,158 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Base DataLoader
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import sys
+import six
+from io import open
+from collections import namedtuple
+import numpy as np
+import tqdm
+import paddle
+from pgl.utils import mp_reader
+import collections
+import time
+from pgl.utils.logger import log
+import traceback
+
+
+if six.PY3:
+ import io
+ sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
+ sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
+
+
+def batch_iter(data, perm, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ size = len(data)
+ start = 0
+ cc = 0
+ while start < size:
+ index = perm[start:start + batch_size]
+ start += batch_size
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ yield data[index]
+
+
+def scan_batch_iter(data, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ batch = []
+ cc = 0
+ for line_example in data.scan():
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ batch.append(line_example)
+ if len(batch) == batch_size:
+ yield batch
+ batch = []
+
+ if len(batch) > 0:
+ yield batch
+
+
+class BaseDataGenerator(object):
+ """Base Data Geneartor"""
+
+ def __init__(self, buf_size, batch_size, num_workers, shuffle=True):
+ self.num_workers = num_workers
+ self.batch_size = batch_size
+ self.line_examples = []
+ self.buf_size = buf_size
+ self.shuffle = shuffle
+
+ def batch_fn(self, batch_examples):
+ """ batch_fn batch producer"""
+ raise NotImplementedError("No defined Batch Fn")
+
+ def batch_iter(self, fid, perm):
+ """ batch iterator"""
+ if self.shuffle:
+ for batch in batch_iter(self, perm, self.batch_size, fid, self.num_workers):
+ yield batch
+ else:
+ for batch in scan_batch_iter(self, self.batch_size, fid, self.num_workers):
+ yield batch
+
+ def __len__(self):
+ return len(self.line_examples)
+
+ def __getitem__(self, idx):
+ if isinstance(idx, collections.Iterable):
+ return [self[bidx] for bidx in idx]
+ else:
+ return self.line_examples[idx]
+
+ def generator(self):
+ """batch dict generator"""
+
+ def worker(filter_id, perm):
+ """ multiprocess worker"""
+
+ def func_run():
+ """ func_run """
+ pid = os.getpid()
+ np.random.seed(pid + int(time.time()))
+ for batch_examples in self.batch_iter(filter_id, perm):
+ try:
+ batch_dict = self.batch_fn(batch_examples)
+ except Exception as e:
+ traceback.print_exc()
+ log.info(traceback.format_exc())
+ log.info(str(e))
+ continue
+
+ if batch_dict is None:
+ continue
+ yield batch_dict
+
+
+
+ return func_run
+
+ # consume a seed
+ np.random.rand()
+
+ if self.shuffle:
+ perm = np.arange(0, len(self))
+ np.random.shuffle(perm)
+ else:
+ perm = None
+
+ if self.num_workers == 1:
+ r = paddle.reader.buffered(worker(0, perm), self.buf_size)
+ else:
+ worker_pool = [worker(wid, perm) for wid in range(self.num_workers)]
+ worker = mp_reader.multiprocess_reader(
+ worker_pool, use_pipe=True, queue_size=1000)
+ r = paddle.reader.buffered(worker, self.buf_size)
+
+ for batch in r():
+ yield batch
+
+ def scan(self):
+ for line_example in self.line_examples:
+ yield line_example
diff --git a/examples/erniesage/dataset/graph_reader.py b/examples/erniesage/dataset/graph_reader.py
new file mode 100644
index 0000000000000000000000000000000000000000..c811b56b1273377d476d8b6f0e53ac23ffdefca8
--- /dev/null
+++ b/examples/erniesage/dataset/graph_reader.py
@@ -0,0 +1,126 @@
+"""Graph Dataset
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import pgl
+import sys
+
+import numpy as np
+
+from pgl.utils.logger import log
+from dataset.base_dataset import BaseDataGenerator
+from pgl.sample import alias_sample
+from pgl.sample import pinsage_sample
+from pgl.sample import graphsage_sample
+from pgl.sample import edge_hash
+
+
+class GraphGenerator(BaseDataGenerator):
+ def __init__(self, graph_wrappers, data, batch_size, samples,
+ num_workers, feed_name_list, use_pyreader,
+ phase, graph_data_path, shuffle=True, buf_size=1000, neg_type="batch_neg"):
+
+ super(GraphGenerator, self).__init__(
+ buf_size=buf_size,
+ num_workers=num_workers,
+ batch_size=batch_size, shuffle=shuffle)
+ # For iteration
+ self.line_examples = data
+
+ self.graph_wrappers = graph_wrappers
+ self.samples = samples
+ self.feed_name_list = feed_name_list
+ self.use_pyreader = use_pyreader
+ self.phase = phase
+ self.load_graph(graph_data_path)
+ self.num_layers = len(graph_wrappers)
+ self.neg_type= neg_type
+
+ def load_graph(self, graph_data_path):
+ self.graph = pgl.graph.MemmapGraph(graph_data_path)
+ self.alias = np.load(os.path.join(graph_data_path, "alias.npy"), mmap_mode="r")
+ self.events = np.load(os.path.join(graph_data_path, "events.npy"), mmap_mode="r")
+ self.term_ids = np.load(os.path.join(graph_data_path, "term_ids.npy"), mmap_mode="r")
+
+ def batch_fn(self, batch_ex):
+ # batch_ex = [
+ # (src, dst, neg),
+ # (src, dst, neg),
+ # (src, dst, neg),
+ # ]
+ #
+ batch_src = []
+ batch_dst = []
+ batch_neg = []
+ for batch in batch_ex:
+ batch_src.append(batch[0])
+ batch_dst.append(batch[1])
+ if len(batch) == 3: # default neg samples
+ batch_neg.append(batch[2])
+
+ if len(batch_src) != self.batch_size:
+ if self.phase == "train":
+ return None #Skip
+
+ if len(batch_neg) > 0:
+ batch_neg = np.unique(np.concatenate(batch_neg))
+ batch_src = np.array(batch_src, dtype="int64")
+ batch_dst = np.array(batch_dst, dtype="int64")
+
+ if self.neg_type == "batch_neg":
+ neg_shape = [1]
+ else:
+ neg_shape = batch_dst.shape
+ sampled_batch_neg = alias_sample(neg_shape, self.alias, self.events)
+
+ if len(batch_neg) > 0:
+ batch_neg = np.concatenate([batch_neg, sampled_batch_neg], 0)
+ else:
+ batch_neg = sampled_batch_neg
+
+ if self.phase == "train":
+ #ignore_edges = np.concatenate([np.stack([batch_src, batch_dst], 1), np.stack([batch_dst, batch_src], 1)], 0)
+ ignore_edges = set()
+ else:
+ ignore_edges = set()
+
+ nodes = np.unique(np.concatenate([batch_src, batch_dst, batch_neg], 0))
+ subgraphs = graphsage_sample(self.graph, nodes, self.samples, ignore_edges=ignore_edges)
+ #subgraphs[0].reindex_to_parrent_nodes(subgraphs[0].nodes)
+ feed_dict = {}
+ for i in range(self.num_layers):
+ feed_dict.update(self.graph_wrappers[i].to_feed(subgraphs[i]))
+
+ # only reindex from first subgraph
+ sub_src_idx = subgraphs[0].reindex_from_parrent_nodes(batch_src)
+ sub_dst_idx = subgraphs[0].reindex_from_parrent_nodes(batch_dst)
+ sub_neg_idx = subgraphs[0].reindex_from_parrent_nodes(batch_neg)
+
+ feed_dict["user_index"] = np.array(sub_src_idx, dtype="int64")
+ feed_dict["item_index"] = np.array(sub_dst_idx, dtype="int64")
+ feed_dict["neg_item_index"] = np.array(sub_neg_idx, dtype="int64")
+ feed_dict["term_ids"] = self.term_ids[subgraphs[0].node_feat["index"]].astype(np.int64)
+ return feed_dict
+
+ def __call__(self):
+ return self.generator()
+
+ def generator(self):
+ try:
+ for feed_dict in super(GraphGenerator, self).generator():
+ if self.use_pyreader:
+ yield [feed_dict[name] for name in self.feed_name_list]
+ else:
+ yield feed_dict
+
+ except Exception as e:
+ log.exception(e)
+
+
+
diff --git a/examples/erniesage/docs/source/_static/ERNIESage_result.png b/examples/erniesage/docs/source/_static/ERNIESage_result.png
new file mode 100644
index 0000000000000000000000000000000000000000..75c28240e1ec58e1603583df465a73815c97a2f8
Binary files /dev/null and b/examples/erniesage/docs/source/_static/ERNIESage_result.png differ
diff --git a/examples/erniesage/docs/source/_static/ERNIESage_v1_4.png b/examples/erniesage/docs/source/_static/ERNIESage_v1_4.png
new file mode 100644
index 0000000000000000000000000000000000000000..2b5869ab33464eb23511b759e2bb3263d8297004
Binary files /dev/null and b/examples/erniesage/docs/source/_static/ERNIESage_v1_4.png differ
diff --git a/examples/erniesage/docs/source/_static/ernie_aggregator.png b/examples/erniesage/docs/source/_static/ernie_aggregator.png
new file mode 100644
index 0000000000000000000000000000000000000000..206a0673d76e97bcc6a47108df683583e4a0b240
Binary files /dev/null and b/examples/erniesage/docs/source/_static/ernie_aggregator.png differ
diff --git a/examples/erniesage/docs/source/_static/text_graph.png b/examples/erniesage/docs/source/_static/text_graph.png
new file mode 100644
index 0000000000000000000000000000000000000000..26f89eb124f272acee2b097f39cb310416de45e1
Binary files /dev/null and b/examples/erniesage/docs/source/_static/text_graph.png differ
diff --git a/examples/erniesage/infer.py b/examples/erniesage/infer.py
new file mode 100644
index 0000000000000000000000000000000000000000..9fc4aeee96f84e4ac8e3b88351d8ec92083701df
--- /dev/null
+++ b/examples/erniesage/infer.py
@@ -0,0 +1,187 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+import argparse
+import pickle
+import time
+import glob
+import os
+import io
+import traceback
+import pickle as pkl
+role = os.getenv("TRAINING_ROLE", "TRAINER")
+
+import numpy as np
+import yaml
+from easydict import EasyDict as edict
+import pgl
+from pgl.utils.logger import log
+from pgl.utils import paddle_helper
+import paddle
+import paddle.fluid as F
+
+from models.model_factory import Model
+from dataset.graph_reader import GraphGenerator
+
+
+class PredictData(object):
+ def __init__(self, num_nodes):
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ trainer_count = int(os.getenv("PADDLE_TRAINERS_NUM", "1"))
+ train_usr = np.arange(trainer_id, num_nodes, trainer_count)
+ #self.data = (train_usr, train_usr)
+ self.data = train_usr
+
+ def __getitem__(self, index):
+ return [self.data[index], self.data[index]]
+
+def tostr(data_array):
+ return " ".join(["%.5lf" % d for d in data_array])
+
+def run_predict(py_reader,
+ exe,
+ program,
+ model_dict,
+ log_per_step=1,
+ args=None):
+
+ id2str = io.open(os.path.join(args.graph_path, "terms.txt"), encoding=args.encoding).readlines()
+
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ trainer_count = int(os.getenv("PADDLE_TRAINERS_NUM", "1"))
+ if not os.path.exists(args.output_path):
+ os.mkdir(args.output_path)
+
+ fout = io.open("%s/part-%s" % (args.output_path, trainer_id), "w", encoding="utf8")
+ batch = 0
+
+ for batch_feed_dict in py_reader():
+ batch += 1
+ batch_usr_feat, batch_ad_feat, _, batch_src_real_index = exe.run(
+ program,
+ feed=batch_feed_dict,
+ fetch_list=model_dict.outputs)
+
+ if batch % log_per_step == 0:
+ log.info("Predict %s finished" % batch)
+
+ for ufs, _, sri in zip(batch_usr_feat, batch_ad_feat, batch_src_real_index):
+ if args.input_type == "text":
+ sri = id2str[int(sri)].strip("\n")
+ line = "{}\t{}\n".format(sri, tostr(ufs))
+ fout.write(line)
+
+ fout.close()
+
+def _warmstart(exe, program, path='params'):
+ def _existed_persitables(var):
+ #if not isinstance(var, fluid.framework.Parameter):
+ # return False
+ if not F.io.is_persistable(var):
+ return False
+ param_path = os.path.join(path, var.name)
+ log.info("Loading parameter: {} persistable: {} exists: {}".format(
+ param_path,
+ F.io.is_persistable(var),
+ os.path.exists(param_path),
+ ))
+ return os.path.exists(param_path)
+ F.io.load_vars(
+ exe,
+ path,
+ main_program=program,
+ predicate=_existed_persitables
+ )
+
+def main(config):
+ model = Model.factory(config)
+
+ if config.learner_type == "cpu":
+ place = F.CPUPlace()
+ elif config.learner_type == "gpu":
+ gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
+ place = F.CUDAPlace(gpu_id)
+ else:
+ raise ValueError
+
+ exe = F.Executor(place)
+
+ val_program = F.default_main_program().clone(for_test=True)
+ exe.run(F.default_startup_program())
+ _warmstart(exe, F.default_startup_program(), path=config.infer_model)
+
+ num_threads = int(os.getenv("CPU_NUM", 1))
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", 0))
+
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = num_threads
+ build_strategy = F.BuildStrategy()
+ build_strategy.enable_inplace = True
+ build_strategy.memory_optimize = True
+ build_strategy.remove_unnecessary_lock = False
+ build_strategy.memory_optimize = False
+
+ if num_threads > 1:
+ build_strategy.reduce_strategy = F.BuildStrategy.ReduceStrategy.Reduce
+
+ val_compiled_prog = F.compiler.CompiledProgram(
+ val_program).with_data_parallel(
+ build_strategy=build_strategy,
+ exec_strategy=exec_strategy)
+
+ num_nodes = int(np.load(os.path.join(config.graph_path, "num_nodes.npy")))
+
+ predict_data = PredictData(num_nodes)
+
+ predict_iter = GraphGenerator(
+ graph_wrappers=model.graph_wrappers,
+ batch_size=config.infer_batch_size,
+ data=predict_data,
+ samples=config.samples,
+ num_workers=config.sample_workers,
+ feed_name_list=[var.name for var in model.feed_list],
+ use_pyreader=config.use_pyreader,
+ phase="predict",
+ graph_data_path=config.graph_path,
+ shuffle=False)
+
+ if config.learner_type == "cpu":
+ model.data_loader.decorate_batch_generator(
+ predict_iter, places=F.cpu_places())
+ elif config.learner_type == "gpu":
+ gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
+ place = F.CUDAPlace(gpu_id)
+ model.data_loader.decorate_batch_generator(
+ predict_iter, places=place)
+ else:
+ raise ValueError
+
+ run_predict(model.data_loader,
+ program=val_compiled_prog,
+ exe=exe,
+ model_dict=model,
+ args=config)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description='main')
+ parser.add_argument("--conf", type=str, default="./config.yaml")
+ args = parser.parse_args()
+ config = edict(yaml.load(open(args.conf), Loader=yaml.FullLoader))
+ config.loss_type = "hinge"
+ print(config)
+ main(config)
diff --git a/examples/erniesage/learner.py b/examples/erniesage/learner.py
new file mode 100644
index 0000000000000000000000000000000000000000..43db90623d59c03fcfa16260476c5eacd94be436
--- /dev/null
+++ b/examples/erniesage/learner.py
@@ -0,0 +1,222 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import time
+import os
+role = os.getenv("TRAINING_ROLE", "TRAINER")
+
+import numpy as np
+from pgl.utils.logger import log
+from pgl.utils.log_writer import LogWriter
+import paddle.fluid as F
+import paddle.fluid.layers as L
+from paddle.fluid.incubate.fleet.parameter_server.distribute_transpiler import StrategyFactory
+from paddle.fluid.incubate.fleet.collective import DistributedStrategy
+from paddle.fluid.transpiler.distribute_transpiler import DistributeTranspilerConfig
+from paddle.fluid.incubate.fleet.collective import fleet as cfleet
+from paddle.fluid.incubate.fleet.parameter_server.distribute_transpiler import fleet as tfleet
+import paddle.fluid.incubate.fleet.base.role_maker as role_maker
+from paddle.fluid.transpiler.distribute_transpiler import DistributedMode
+from paddle.fluid.incubate.fleet.parameter_server.distribute_transpiler.distributed_strategy import TrainerRuntimeConfig
+
+# hack it!
+base_get_communicator_flags = TrainerRuntimeConfig.get_communicator_flags
+def get_communicator_flags(self):
+ flag_dict = base_get_communicator_flags(self)
+ flag_dict['communicator_max_merge_var_num'] = str(1)
+ flag_dict['communicator_send_queue_size'] = str(1)
+ return flag_dict
+TrainerRuntimeConfig.get_communicator_flags = get_communicator_flags
+
+
+class Learner(object):
+ @classmethod
+ def factory(cls, name):
+ if name == "cpu":
+ return TranspilerLearner()
+ elif name == "gpu":
+ return CollectiveLearner()
+ else:
+ raise ValueError
+
+ def build(self, model, data_gen, config):
+ raise NotImplementedError
+
+ def warmstart(self, program, path='./checkpoints'):
+ def _existed_persitables(var):
+ #if not isinstance(var, fluid.framework.Parameter):
+ # return False
+ if not F.io.is_persistable(var):
+ return False
+ param_path = os.path.join(path, var.name)
+ log.info("Loading parameter: {} persistable: {} exists: {}".format(
+ param_path,
+ F.io.is_persistable(var),
+ os.path.exists(param_path),
+ ))
+ return os.path.exists(param_path)
+ F.io.load_vars(
+ self.exe,
+ path,
+ main_program=program,
+ predicate=_existed_persitables
+ )
+
+ def start(self):
+ batch = 0
+ start = time.time()
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ if trainer_id == 0:
+ writer = LogWriter(os.path.join(self.config.output_path, "train_history"))
+
+ for epoch_idx in range(self.config.epoch):
+ for idx, batch_feed_dict in enumerate(self.model.data_loader()):
+ try:
+ cpu_time = time.time()
+ batch += 1
+ batch_loss = self.exe.run(
+ self.program,
+ feed=batch_feed_dict,
+ fetch_list=[self.model.loss])
+ end = time.time()
+ if trainer_id == 0:
+ writer.add_scalar("loss", np.mean(batch_loss), batch)
+ if batch % self.config.log_per_step == 0:
+ log.info(
+ "Epoch %s Batch %s %s-Loss %s \t Speed(per batch) %.5lf/%.5lf sec"
+ % (epoch_idx, batch, "train", np.mean(batch_loss), (end - start) /batch, (end - cpu_time)))
+ writer.flush()
+ if batch % self.config.save_per_step == 0:
+ self.fleet.save_persistables(self.exe, os.path.join(self.config.output_path, str(batch)))
+ except Exception as e:
+ log.info("Pyreader train error")
+ log.exception(e)
+ log.info("epcoh %s done." % epoch_idx)
+
+ def stop(self):
+ self.fleet.save_persistables(self.exe, os.path.join(self.config.output_path, "last"))
+
+
+class TranspilerLearner(Learner):
+ def __init__(self):
+ training_role = os.getenv("TRAINING_ROLE", "TRAINER")
+ paddle_role = role_maker.Role.WORKER
+ place = F.CPUPlace()
+ if training_role == "PSERVER":
+ paddle_role = role_maker.Role.SERVER
+
+ # set the fleet runtime environment according to configure
+ port = os.getenv("PADDLE_PORT", "6174")
+ pserver_ips = os.getenv("PADDLE_PSERVERS") # ip,ip...
+ eplist = []
+ for ip in pserver_ips.split(","):
+ eplist.append(':'.join([ip, port]))
+ pserver_endpoints = eplist # ip:port,ip:port...
+ worker_num = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ role = role_maker.UserDefinedRoleMaker(
+ current_id=trainer_id,
+ role=paddle_role,
+ worker_num=worker_num,
+ server_endpoints=pserver_endpoints)
+ tfleet.init(role)
+ tfleet.save_on_pserver = True
+
+ def build(self, model, data_gen, config):
+ self.optimize(model.loss, config.optimizer_type, config.lr)
+ self.init_and_run_ps_worker(config.ckpt_path)
+ self.program = self.complie_program(model.loss)
+ self.fleet = tfleet
+ model.data_loader.decorate_batch_generator(
+ data_gen, places=F.cpu_places())
+ self.config = config
+ self.model = model
+
+ def optimize(self, loss, optimizer_type, lr):
+ log.info('learning rate:%f' % lr)
+ if optimizer_type == "sgd":
+ optimizer = F.optimizer.SGD(learning_rate=lr)
+ elif optimizer_type == "adam":
+ # Don't slice tensor ensure convergence
+ optimizer = F.optimizer.Adam(learning_rate=lr, lazy_mode=True)
+ else:
+ raise ValueError("Unknown Optimizer %s" % optimizer_type)
+ #create the DistributeTranspiler configure
+ self.strategy = StrategyFactory.create_sync_strategy()
+ optimizer = tfleet.distributed_optimizer(optimizer, self.strategy)
+ optimizer.minimize(loss)
+
+ def init_and_run_ps_worker(self, ckpt_path):
+ # init and run server or worker
+ self.exe = F.Executor(F.CPUPlace())
+ if tfleet.is_server():
+ tfleet.init_server()
+ self.warmstart(tfleet.startup_program, path=ckpt_path)
+ tfleet.run_server()
+ exit()
+
+ if tfleet.is_worker():
+ log.info("start init worker done")
+ tfleet.init_worker()
+ self.exe.run(tfleet.startup_program)
+
+ def complie_program(self, loss):
+ num_threads = int(os.getenv("CPU_NUM", 1))
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = num_threads
+ exec_strategy.use_thread_barrier = False
+ build_strategy = F.BuildStrategy()
+ build_strategy.enable_inplace = True
+ build_strategy.memory_optimize = True
+ build_strategy.remove_unnecessary_lock = False
+ build_strategy.memory_optimize = False
+ build_strategy.async_mode = False
+
+ if num_threads > 1:
+ build_strategy.reduce_strategy = F.BuildStrategy.ReduceStrategy.Reduce
+
+ log.info("start build compile program...")
+ compiled_prog = F.compiler.CompiledProgram(tfleet.main_program
+ ).with_data_parallel(
+ loss_name=loss.name,
+ build_strategy=build_strategy,
+ exec_strategy=exec_strategy)
+
+ return compiled_prog
+
+
+class CollectiveLearner(Learner):
+ def __init__(self):
+ role = role_maker.PaddleCloudRoleMaker(is_collective=True)
+ cfleet.init(role)
+
+ def optimize(self, loss, optimizer_type, lr):
+ optimizer = F.optimizer.Adam(learning_rate=lr)
+ dist_strategy = DistributedStrategy()
+ dist_strategy.enable_sequential_execution = True
+ optimizer = cfleet.distributed_optimizer(optimizer, strategy=dist_strategy)
+ _, param_grads = optimizer.minimize(loss, F.default_startup_program())
+
+ def build(self, model, data_gen, config):
+ self.optimize(model.loss, config.optimizer_type, config.lr)
+ self.program = cfleet.main_program
+ gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
+ place = F.CUDAPlace(gpu_id)
+ self.exe = F.Executor(place)
+ self.exe.run(F.default_startup_program())
+ self.warmstart(F.default_startup_program(), config.ckpt_path)
+ self.fleet = cfleet
+ model.data_loader.decorate_batch_generator(
+ data_gen, places=place)
+ self.config = config
+ self.model = model
diff --git a/examples/erniesage/local_run.sh b/examples/erniesage/local_run.sh
new file mode 100644
index 0000000000000000000000000000000000000000..6a11daf87014458228cad6d32dd8f87e5bb342a8
--- /dev/null
+++ b/examples/erniesage/local_run.sh
@@ -0,0 +1,67 @@
+#!/bin/bash
+
+set -x
+config=${1:-"./config.yaml"}
+unset http_proxy https_proxy
+
+function parse_yaml {
+ local prefix=$2
+ local s='[[:space:]]*' w='[a-zA-Z0-9_]*' fs=$(echo @|tr @ '\034')
+ sed -ne "s|^\($s\):|\1|" \
+ -e "s|^\($s\)\($w\)$s:$s[\"']\(.*\)[\"']$s\$|\1$fs\2$fs\3|p" \
+ -e "s|^\($s\)\($w\)$s:$s\(.*\)$s\$|\1$fs\2$fs\3|p" $1 |
+ awk -F$fs '{
+ indent = length($1)/2;
+ vname[indent] = $2;
+ for (i in vname) {if (i > indent) {delete vname[i]}}
+ if (length($3) > 0) {
+ vn=""; for (i=0; i $BASE/pserver.$i.log &
+ echo $! >> job_id
+ done
+ sleep 3s
+ for((j=0;j<${PADDLE_TRAINERS_NUM};j++))
+ do
+ echo "start ps work: ${j}"
+ TRAINING_ROLE="TRAINER" PADDLE_TRAINER_ID=${j} python ./train.py --conf $config
+ TRAINING_ROLE="TRAINER" PADDLE_TRAINER_ID=${j} python ./infer.py --conf $config
+ done
+}
+
+collective_local_train(){
+ echo `which python`
+ python -m paddle.distributed.launch train.py --conf $config
+ python -m paddle.distributed.launch infer.py --conf $config
+}
+
+eval $(parse_yaml $config)
+
+python ./preprocessing/dump_graph.py -i $input_data -o $graph_path --encoding $encoding -l $max_seqlen --vocab_file $ernie_vocab_file
+
+if [[ $learner_type == "cpu" ]];then
+ transpiler_local_train
+fi
+if [[ $learner_type == "gpu" ]];then
+ collective_local_train
+fi
diff --git a/examples/erniesage/models/__init__.py b/examples/erniesage/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/examples/erniesage/models/base.py b/examples/erniesage/models/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..e93fd5ffbb00de1da1612b0945cdba682909f164
--- /dev/null
+++ b/examples/erniesage/models/base.py
@@ -0,0 +1,244 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import time
+import glob
+import os
+
+import numpy as np
+
+import pgl
+import paddle.fluid as F
+import paddle.fluid.layers as L
+
+from models import message_passing
+
+def get_layer(layer_type, gw, feature, hidden_size, act, initializer, learning_rate, name, is_test=False):
+ return getattr(message_passing, layer_type)(gw, feature, hidden_size, act, initializer, learning_rate, name)
+
+
+class BaseGraphWrapperBuilder(object):
+ def __init__(self, config):
+ self.config = config
+ self.node_feature_info = []
+ self.edge_feature_info = []
+
+ def __call__(self):
+ place = F.CPUPlace()
+ graph_wrappers = []
+ for i in range(self.config.num_layers):
+ # all graph have same node_feat_info
+ graph_wrappers.append(
+ pgl.graph_wrapper.GraphWrapper(
+ "layer_%s" % i, node_feat=self.node_feature_info, edge_feat=self.edge_feature_info))
+ return graph_wrappers
+
+
+class GraphsageGraphWrapperBuilder(BaseGraphWrapperBuilder):
+ def __init__(self, config):
+ super(GraphsageGraphWrapperBuilder, self).__init__(config)
+ self.node_feature_info.append(('index', [None], np.dtype('int64')))
+
+
+class BaseGNNModel(object):
+ def __init__(self, config):
+ self.config = config
+ self.graph_wrapper_builder = self.gen_graph_wrapper_builder(config)
+ self.net_fn = self.gen_net_fn(config)
+ self.feed_list_builder = self.gen_feed_list_builder(config)
+ self.data_loader_builder = self.gen_data_loader_builder(config)
+ self.loss_fn = self.gen_loss_fn(config)
+ self.build()
+
+
+ def gen_graph_wrapper_builder(self, config):
+ return GraphsageGraphWrapperBuilder(config)
+
+ def gen_net_fn(self, config):
+ return BaseNet(config)
+
+ def gen_feed_list_builder(self, config):
+ return BaseFeedListBuilder(config)
+
+ def gen_data_loader_builder(self, config):
+ return BaseDataLoaderBuilder(config)
+
+ def gen_loss_fn(self, config):
+ return BaseLoss(config)
+
+ def build(self):
+ self.graph_wrappers = self.graph_wrapper_builder()
+ self.inputs, self.outputs = self.net_fn(self.graph_wrappers)
+ self.feed_list = self.feed_list_builder(self.inputs, self.graph_wrappers)
+ self.data_loader = self.data_loader_builder(self.feed_list)
+ self.loss = self.loss_fn(self.outputs)
+
+class BaseFeedListBuilder(object):
+ def __init__(self, config):
+ self.config = config
+
+ def __call__(self, inputs, graph_wrappers):
+ feed_list = []
+ for i in range(len(graph_wrappers)):
+ feed_list.extend(graph_wrappers[i].holder_list)
+ feed_list.extend(inputs)
+ return feed_list
+
+
+class BaseDataLoaderBuilder(object):
+ def __init__(self, config):
+ self.config = config
+
+ def __call__(self, feed_list):
+ data_loader = F.io.PyReader(
+ feed_list=feed_list, capacity=20, use_double_buffer=True, iterable=True)
+ return data_loader
+
+
+
+class BaseNet(object):
+ def __init__(self, config):
+ self.config = config
+
+ def take_final_feature(self, feature, index, name):
+ """take final feature"""
+ feat = L.gather(feature, index, overwrite=False)
+
+ if self.config.final_fc:
+ feat = L.fc(feat,
+ self.config.hidden_size,
+ param_attr=F.ParamAttr(name=name + '_w'),
+ bias_attr=F.ParamAttr(name=name + '_b'))
+
+ if self.config.final_l2_norm:
+ feat = L.l2_normalize(feat, axis=1)
+ return feat
+
+ def build_inputs(self):
+ user_index = L.data(
+ "user_index", shape=[None], dtype="int64", append_batch_size=False)
+ item_index = L.data(
+ "item_index", shape=[None], dtype="int64", append_batch_size=False)
+ neg_item_index = L.data(
+ "neg_item_index", shape=[None], dtype="int64", append_batch_size=False)
+ return [user_index, item_index, neg_item_index]
+
+ def build_embedding(self, graph_wrappers, inputs=None):
+ num_embed = int(np.load(os.path.join(self.config.graph_path, "num_nodes.npy")))
+ is_sparse = self.config.trainer_type == "Transpiler"
+
+ embed = L.embedding(
+ input=L.reshape(graph_wrappers[0].node_feat['index'], [-1, 1]),
+ size=[num_embed, self.config.hidden_size],
+ is_sparse=is_sparse,
+ param_attr=F.ParamAttr(name="node_embedding", initializer=F.initializer.Uniform(
+ low=-1. / self.config.hidden_size,
+ high=1. / self.config.hidden_size)))
+ return embed
+
+ def gnn_layers(self, graph_wrappers, feature):
+ features = [feature]
+
+ initializer = None
+ fc_lr = self.config.lr / 0.001
+
+ for i in range(self.config.num_layers):
+ if i == self.config.num_layers - 1:
+ act = None
+ else:
+ act = "leaky_relu"
+
+ feature = get_layer(
+ self.config.layer_type,
+ graph_wrappers[i],
+ feature,
+ self.config.hidden_size,
+ act,
+ initializer,
+ learning_rate=fc_lr,
+ name="%s_%s" % (self.config.layer_type, i))
+ features.append(feature)
+ return features
+
+ def __call__(self, graph_wrappers):
+ inputs = self.build_inputs()
+ feature = self.build_embedding(graph_wrappers, inputs)
+ features = self.gnn_layers(graph_wrappers, feature)
+ outputs = [self.take_final_feature(features[-1], i, "final_fc") for i in inputs]
+ src_real_index = L.gather(graph_wrappers[0].node_feat['index'], inputs[0])
+ outputs.append(src_real_index)
+ return inputs, outputs
+
+def all_gather(X):
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ trainer_num = int(os.getenv("PADDLE_TRAINERS_NUM", "0"))
+ if trainer_num == 1:
+ copy_X = X * 1
+ copy_X.stop_gradients=True
+ return copy_X
+
+ Xs = []
+ for i in range(trainer_num):
+ copy_X = X * 1
+ copy_X = L.collective._broadcast(copy_X, i, True)
+ copy_X.stop_gradient=True
+ Xs.append(copy_X)
+
+ if len(Xs) > 1:
+ Xs=L.concat(Xs, 0)
+ Xs.stop_gradient=True
+ else:
+ Xs = Xs[0]
+ return Xs
+
+class BaseLoss(object):
+ def __init__(self, config):
+ self.config = config
+
+ def __call__(self, outputs):
+ user_feat, item_feat, neg_item_feat = outputs[0], outputs[1], outputs[2]
+ loss_type = self.config.loss_type
+
+ if self.config.neg_type == "batch_neg":
+ neg_item_feat = item_feat
+ # Calc Loss
+ if self.config.loss_type == "hinge":
+ pos = L.reduce_sum(user_feat * item_feat, -1, keep_dim=True) # [B, 1]
+ neg = L.matmul(user_feat, neg_item_feat, transpose_y=True) # [B, B]
+ loss = L.reduce_mean(L.relu(neg - pos + self.config.margin))
+ elif self.config.loss_type == "all_hinge":
+ pos = L.reduce_sum(user_feat * item_feat, -1, keep_dim=True) # [B, 1]
+ all_pos = all_gather(pos) # [B * n, 1]
+ all_neg_item_feat = all_gather(neg_item_feat) # [B * n, 1]
+ all_user_feat = all_gather(user_feat) # [B * n, 1]
+
+ neg1 = L.matmul(user_feat, all_neg_item_feat, transpose_y=True) # [B, B * n]
+ neg2 = L.matmul(all_user_feat, neg_item_feat, transpose_y=True) # [B *n, B]
+
+ loss1 = L.reduce_mean(L.relu(neg1 - pos + self.config.margin))
+ loss2 = L.reduce_mean(L.relu(neg2 - all_pos + self.config.margin))
+
+ #loss = (loss1 + loss2) / 2
+ loss = loss1 + loss2
+
+ elif self.config.loss_type == "softmax":
+ pass
+ # TODO
+ # pos = L.reduce_sum(user_feat * item_feat, -1, keep_dim=True) # [B, 1]
+ # neg = L.matmul(user_feat, neg_feat, transpose_y=True) # [B, B]
+ # logits = L.concat([pos, neg], -1) # [B, 1+B]
+ # labels = L.fill_constant_batch_size_like(logits, [-1, 1], "int64", 0)
+ # loss = L.reduce_mean(L.softmax_with_cross_entropy(logits, labels))
+ else:
+ raise ValueError
+ return loss
diff --git a/examples/erniesage/models/ernie.py b/examples/erniesage/models/ernie.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b53ebd439713f7f249c21ad96cafa0b2ae84f06
--- /dev/null
+++ b/examples/erniesage/models/ernie.py
@@ -0,0 +1,40 @@
+"""Ernie
+"""
+from models.base import BaseNet, BaseGNNModel
+
+class Ernie(BaseNet):
+
+ def build_inputs(self):
+ inputs = super(Ernie, self).build_inputs()
+ term_ids = L.data(
+ "term_ids", shape=[None, self.config.max_seqlen], dtype="int64", append_batch_size=False)
+ return inputs + [term_ids]
+
+ def build_embedding(self, graph_wrappers, term_ids):
+ term_ids = L.unsqueeze(term_ids, [-1])
+ ernie_config = self.config.ernie_config
+ ernie = ErnieModel(
+ src_ids=term_ids,
+ sentence_ids=L.zeros_like(term_ids),
+ task_ids=None,
+ config=ernie_config,
+ use_fp16=False,
+ name="student_")
+ feature = ernie.get_pooled_output()
+ return feature
+
+ def __call__(self, graph_wrappers):
+ inputs = self.build_inputs()
+ feature = self.build_embedding(graph_wrappers, inputs[-1])
+ features = [feature]
+ outputs = [self.take_final_feature(features[-1], i, "final_fc") for i in inputs[:-1]]
+ src_real_index = L.gather(graph_wrappers[0].node_feat['index'], inputs[0])
+ outputs.append(src_real_index)
+ return inputs, outputs
+
+
+class ErnieModel(BaseGNNModel):
+ def gen_net_fn(self, config):
+ return Ernie(config)
+
+
diff --git a/examples/erniesage/models/ernie_model/__init__.py b/examples/erniesage/models/ernie_model/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/examples/erniesage/models/ernie_model/ernie.py b/examples/erniesage/models/ernie_model/ernie.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a8b4650bd9a77882e458677215525940a3d7df2
--- /dev/null
+++ b/examples/erniesage/models/ernie_model/ernie.py
@@ -0,0 +1,403 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Ernie model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import json
+import six
+import logging
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+
+from io import open
+
+from models.ernie_model.transformer_encoder import encoder, pre_process_layer
+from models.ernie_model.transformer_encoder import graph_encoder
+
+log = logging.getLogger(__name__)
+
+
+class ErnieConfig(object):
+ def __init__(self, config_path):
+ self._config_dict = self._parse(config_path)
+
+ def _parse(self, config_path):
+ try:
+ with open(config_path, 'r', encoding='utf8') as json_file:
+ config_dict = json.load(json_file)
+ except Exception:
+ raise IOError("Error in parsing Ernie model config file '%s'" %
+ config_path)
+ else:
+ return config_dict
+
+ def __getitem__(self, key):
+ return self._config_dict.get(key, None)
+
+ def print_config(self):
+ for arg, value in sorted(six.iteritems(self._config_dict)):
+ log.info('%s: %s' % (arg, value))
+ log.info('------------------------------------------------')
+
+
+class ErnieModel(object):
+ def __init__(self,
+ src_ids,
+ sentence_ids,
+ position_ids=None,
+ input_mask=None,
+ task_ids=None,
+ config=None,
+ weight_sharing=True,
+ use_fp16=False,
+ name=""):
+
+ self._set_config(config, name, weight_sharing)
+ if position_ids is None:
+ position_ids = self._build_position_ids(src_ids)
+ if input_mask is None:
+ input_mask = self._build_input_mask(src_ids)
+ self._build_model(src_ids, position_ids, sentence_ids, task_ids,
+ input_mask)
+ self._debug_summary(input_mask)
+
+ def _debug_summary(self, input_mask):
+ #histogram
+ seqlen_before_pad = L.cast(
+ L.reduce_sum(
+ input_mask, dim=1), dtype='float32')
+ seqlen_after_pad = L.reduce_sum(
+ L.cast(
+ L.zeros_like(input_mask), dtype='float32') + 1.0, dim=1)
+ pad_num = seqlen_after_pad - seqlen_before_pad
+ pad_rate = pad_num / seqlen_after_pad
+
+ def _build_position_ids(self, src_ids):
+ d_shape = L.shape(src_ids)
+ d_seqlen = d_shape[1]
+ d_batch = d_shape[0]
+ position_ids = L.reshape(
+ L.range(
+ 0, d_seqlen, 1, dtype='int32'), [1, d_seqlen, 1],
+ inplace=True)
+ position_ids = L.expand(position_ids, [d_batch, 1, 1])
+ position_ids = L.cast(position_ids, 'int64')
+ position_ids.stop_gradient = True
+ return position_ids
+
+ def _build_input_mask(self, src_ids):
+ zero = L.fill_constant([1], dtype='int64', value=0)
+ input_mask = L.logical_not(L.equal(src_ids,
+ zero)) # assume pad id == 0
+ input_mask = L.cast(input_mask, 'float32')
+ input_mask.stop_gradient = True
+ return input_mask
+
+ def _set_config(self, config, name, weight_sharing):
+ self._emb_size = config['hidden_size']
+ self._n_layer = config['num_hidden_layers']
+ self._n_head = config['num_attention_heads']
+ self._voc_size = config['vocab_size']
+ self._max_position_seq_len = config['max_position_embeddings']
+ if config.get('sent_type_vocab_size'):
+ self._sent_types = config['sent_type_vocab_size']
+ else:
+ self._sent_types = config['type_vocab_size']
+
+ self._use_task_id = config['use_task_id']
+ if self._use_task_id:
+ self._task_types = config['task_type_vocab_size']
+ self._hidden_act = config['hidden_act']
+ self._postprocess_cmd = config.get('postprocess_cmd', 'dan')
+ self._preprocess_cmd = config.get('preprocess_cmd', '')
+ self._prepostprocess_dropout = config['hidden_dropout_prob']
+ self._attention_dropout = config['attention_probs_dropout_prob']
+ self._weight_sharing = weight_sharing
+ self.name = name
+
+ self._word_emb_name = self.name + "word_embedding"
+ self._pos_emb_name = self.name + "pos_embedding"
+ self._sent_emb_name = self.name + "sent_embedding"
+ self._task_emb_name = self.name + "task_embedding"
+ self._dtype = "float16" if config['use_fp16'] else "float32"
+ self._emb_dtype = "float32"
+
+ # Initialize all weigths by truncated normal initializer, and all biases
+ # will be initialized by constant zero by default.
+ self._param_initializer = fluid.initializer.TruncatedNormal(
+ scale=config['initializer_range'])
+
+ def _build_model(self, src_ids, position_ids, sentence_ids, task_ids,
+ input_mask):
+
+ emb_out = self._build_embedding(src_ids, position_ids, sentence_ids,
+ task_ids)
+ self.input_mask = input_mask
+ self._enc_out, self.all_hidden, self.all_attn, self.all_ffn = encoder(
+ enc_input=emb_out,
+ input_mask=input_mask,
+ n_layer=self._n_layer,
+ n_head=self._n_head,
+ d_key=self._emb_size // self._n_head,
+ d_value=self._emb_size // self._n_head,
+ d_model=self._emb_size,
+ d_inner_hid=self._emb_size * 4,
+ prepostprocess_dropout=self._prepostprocess_dropout,
+ attention_dropout=self._attention_dropout,
+ relu_dropout=0,
+ hidden_act=self._hidden_act,
+ preprocess_cmd=self._preprocess_cmd,
+ postprocess_cmd=self._postprocess_cmd,
+ param_initializer=self._param_initializer,
+ name=self.name + 'encoder')
+ if self._dtype == "float16":
+ self._enc_out = fluid.layers.cast(
+ x=self._enc_out, dtype=self._emb_dtype)
+
+ def _build_embedding(self, src_ids, position_ids, sentence_ids, task_ids):
+ # padding id in vocabulary must be set to 0
+ emb_out = fluid.layers.embedding(
+ input=src_ids,
+ size=[self._voc_size, self._emb_size],
+ dtype=self._emb_dtype,
+ param_attr=fluid.ParamAttr(
+ name=self._word_emb_name, initializer=self._param_initializer),
+ is_sparse=False)
+
+ position_emb_out = fluid.layers.embedding(
+ input=position_ids,
+ size=[self._max_position_seq_len, self._emb_size],
+ dtype=self._emb_dtype,
+ param_attr=fluid.ParamAttr(
+ name=self._pos_emb_name, initializer=self._param_initializer))
+
+ sent_emb_out = fluid.layers.embedding(
+ sentence_ids,
+ size=[self._sent_types, self._emb_size],
+ dtype=self._emb_dtype,
+ param_attr=fluid.ParamAttr(
+ name=self._sent_emb_name, initializer=self._param_initializer))
+
+ self.all_emb = [emb_out, position_emb_out, sent_emb_out]
+ emb_out = emb_out + position_emb_out
+ emb_out = emb_out + sent_emb_out
+
+ if self._use_task_id:
+ task_emb_out = fluid.layers.embedding(
+ task_ids,
+ size=[self._task_types, self._emb_size],
+ dtype=self._emb_dtype,
+ param_attr=fluid.ParamAttr(
+ name=self._task_emb_name,
+ initializer=self._param_initializer))
+
+ emb_out = emb_out + task_emb_out
+
+ emb_out = pre_process_layer(
+ emb_out,
+ 'nd',
+ self._prepostprocess_dropout,
+ name=self.name + 'pre_encoder')
+
+ if self._dtype == "float16":
+ emb_out = fluid.layers.cast(x=emb_out, dtype=self._dtype)
+ return emb_out
+
+ def get_sequence_output(self):
+ return self._enc_out
+
+ def get_pooled_output(self):
+ """Get the first feature of each sequence for classification"""
+ next_sent_feat = self._enc_out[:, 0, :]
+ #next_sent_feat = fluid.layers.slice(input=self._enc_out, axes=[1], starts=[0], ends=[1])
+ next_sent_feat = fluid.layers.fc(
+ input=next_sent_feat,
+ size=self._emb_size,
+ act="tanh",
+ param_attr=fluid.ParamAttr(
+ name=self.name + "pooled_fc.w_0",
+ initializer=self._param_initializer),
+ bias_attr=self.name + "pooled_fc.b_0")
+ return next_sent_feat
+
+ def get_lm_output(self, mask_label, mask_pos):
+ """Get the loss & accuracy for pretraining"""
+
+ mask_pos = fluid.layers.cast(x=mask_pos, dtype='int32')
+
+ # extract the first token feature in each sentence
+ self.next_sent_feat = self.get_pooled_output()
+ reshaped_emb_out = fluid.layers.reshape(
+ x=self._enc_out, shape=[-1, self._emb_size])
+ # extract masked tokens' feature
+ mask_feat = fluid.layers.gather(input=reshaped_emb_out, index=mask_pos)
+
+ # transform: fc
+ mask_trans_feat = fluid.layers.fc(
+ input=mask_feat,
+ size=self._emb_size,
+ act=self._hidden_act,
+ param_attr=fluid.ParamAttr(
+ name=self.name + 'mask_lm_trans_fc.w_0',
+ initializer=self._param_initializer),
+ bias_attr=fluid.ParamAttr(name=self.name + 'mask_lm_trans_fc.b_0'))
+
+ # transform: layer norm
+ mask_trans_feat = fluid.layers.layer_norm(
+ mask_trans_feat,
+ begin_norm_axis=len(mask_trans_feat.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=self.name + 'mask_lm_trans_layer_norm_scale',
+ initializer=fluid.initializer.Constant(1.)),
+ bias_attr=fluid.ParamAttr(
+ name=self.name + 'mask_lm_trans_layer_norm_bias',
+ initializer=fluid.initializer.Constant(0.)))
+ # transform: layer norm
+ #mask_trans_feat = pre_process_layer(
+ # mask_trans_feat, 'n', name=self.name + 'mask_lm_trans')
+
+ mask_lm_out_bias_attr = fluid.ParamAttr(
+ name=self.name + "mask_lm_out_fc.b_0",
+ initializer=fluid.initializer.Constant(value=0.0))
+ if self._weight_sharing:
+ fc_out = fluid.layers.matmul(
+ x=mask_trans_feat,
+ y=fluid.default_main_program().global_block().var(
+ self._word_emb_name),
+ transpose_y=True)
+ fc_out += fluid.layers.create_parameter(
+ shape=[self._voc_size],
+ dtype=self._emb_dtype,
+ attr=mask_lm_out_bias_attr,
+ is_bias=True)
+
+ else:
+ fc_out = fluid.layers.fc(input=mask_trans_feat,
+ size=self._voc_size,
+ param_attr=fluid.ParamAttr(
+ name=self.name + "mask_lm_out_fc.w_0",
+ initializer=self._param_initializer),
+ bias_attr=mask_lm_out_bias_attr)
+
+ mask_lm_loss = fluid.layers.softmax_with_cross_entropy(
+ logits=fc_out, label=mask_label)
+ return mask_lm_loss
+
+ def get_task_output(self, task, task_labels):
+ task_fc_out = fluid.layers.fc(
+ input=self.next_sent_feat,
+ size=task["num_labels"],
+ param_attr=fluid.ParamAttr(
+ name=self.name + task["task_name"] + "_fc.w_0",
+ initializer=self._param_initializer),
+ bias_attr=self.name + task["task_name"] + "_fc.b_0")
+ task_loss, task_softmax = fluid.layers.softmax_with_cross_entropy(
+ logits=task_fc_out, label=task_labels, return_softmax=True)
+ task_acc = fluid.layers.accuracy(input=task_softmax, label=task_labels)
+ return task_loss, task_acc
+
+
+class ErnieGraphModel(ErnieModel):
+ def __init__(self,
+ src_ids,
+ task_ids=None,
+ config=None,
+ weight_sharing=True,
+ use_fp16=False,
+ slot_seqlen=40,
+ name=""):
+ self.slot_seqlen = slot_seqlen
+ self._set_config(config, name, weight_sharing)
+ input_mask = self._build_input_mask(src_ids)
+ position_ids = self._build_position_ids(src_ids)
+ sentence_ids = self._build_sentence_ids(src_ids)
+ self._build_model(src_ids, position_ids, sentence_ids, task_ids,
+ input_mask)
+ self._debug_summary(input_mask)
+
+ def _build_position_ids(self, src_ids):
+ src_shape = L.shape(src_ids)
+ src_seqlen = src_shape[1]
+ src_batch = src_shape[0]
+
+ slot_seqlen = self.slot_seqlen
+
+ num_b = (src_seqlen / slot_seqlen) - 1
+ a_position_ids = L.reshape(
+ L.range(
+ 0, slot_seqlen, 1, dtype='int32'), [1, slot_seqlen, 1],
+ inplace=True) # [1, slot_seqlen, 1]
+ a_position_ids = L.expand(a_position_ids, [src_batch, 1, 1]) # [B, slot_seqlen, 1]
+
+ zero = L.fill_constant([1], dtype='int64', value=0)
+ input_mask = L.cast(L.equal(src_ids[:, :slot_seqlen], zero), "int32") # assume pad id == 0 [B, slot_seqlen, 1]
+ a_pad_len = L.reduce_sum(input_mask, 1) # [B, 1, 1]
+
+ b_position_ids = L.reshape(
+ L.range(
+ slot_seqlen, 2*slot_seqlen, 1, dtype='int32'), [1, slot_seqlen, 1],
+ inplace=True) # [1, slot_seqlen, 1]
+ b_position_ids = L.expand(b_position_ids, [src_batch, num_b, 1]) # [B, slot_seqlen * num_b, 1]
+ b_position_ids = b_position_ids - a_pad_len # [B, slot_seqlen * num_b, 1]
+
+ position_ids = L.concat([a_position_ids, b_position_ids], 1)
+ position_ids = L.cast(position_ids, 'int64')
+ position_ids.stop_gradient = True
+ return position_ids
+
+ def _build_sentence_ids(self, src_ids):
+ src_shape = L.shape(src_ids)
+ src_seqlen = src_shape[1]
+ src_batch = src_shape[0]
+
+ slot_seqlen = self.slot_seqlen
+
+ zeros = L.zeros([src_batch, slot_seqlen, 1], "int64")
+ ones = L.ones([src_batch, src_seqlen-slot_seqlen, 1], "int64")
+
+ sentence_ids = L.concat([zeros, ones], 1)
+ sentence_ids.stop_gradient = True
+ return sentence_ids
+
+ def _build_model(self, src_ids, position_ids, sentence_ids, task_ids,
+ input_mask):
+
+ emb_out = self._build_embedding(src_ids, position_ids, sentence_ids,
+ task_ids)
+ self.input_mask = input_mask
+ self._enc_out, self.all_hidden, self.all_attn, self.all_ffn = graph_encoder(
+ enc_input=emb_out,
+ input_mask=input_mask,
+ n_layer=self._n_layer,
+ n_head=self._n_head,
+ d_key=self._emb_size // self._n_head,
+ d_value=self._emb_size // self._n_head,
+ d_model=self._emb_size,
+ d_inner_hid=self._emb_size * 4,
+ prepostprocess_dropout=self._prepostprocess_dropout,
+ attention_dropout=self._attention_dropout,
+ relu_dropout=0,
+ hidden_act=self._hidden_act,
+ preprocess_cmd=self._preprocess_cmd,
+ postprocess_cmd=self._postprocess_cmd,
+ param_initializer=self._param_initializer,
+ slot_seqlen=self.slot_seqlen,
+ name=self.name + 'encoder')
+ if self._dtype == "float16":
+ self._enc_out = fluid.layers.cast(
+ x=self._enc_out, dtype=self._emb_dtype)
diff --git a/examples/erniesage/models/ernie_model/transformer_encoder.py b/examples/erniesage/models/ernie_model/transformer_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..e6a95e1f6b4bcd61dc700d23b454346e973d0002
--- /dev/null
+++ b/examples/erniesage/models/ernie_model/transformer_encoder.py
@@ -0,0 +1,499 @@
+# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from functools import partial
+import numpy as np
+from contextlib import contextmanager
+
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+import paddle.fluid.layers as layers
+
+#determin this at the begining
+to_3d = lambda a: a # will change later
+to_2d = lambda a: a
+
+
+def multi_head_attention(queries,
+ keys,
+ values,
+ attn_bias,
+ d_key,
+ d_value,
+ d_model,
+ n_head=1,
+ dropout_rate=0.,
+ cache=None,
+ param_initializer=None,
+ name='multi_head_att'):
+ """
+ Multi-Head Attention. Note that attn_bias is added to the logit before
+ computing softmax activiation to mask certain selected positions so that
+ they will not considered in attention weights.
+ """
+ keys = queries if keys is None else keys
+ values = keys if values is None else values
+
+ def __compute_qkv(queries, keys, values, n_head, d_key, d_value):
+ """
+ Add linear projection to queries, keys, and values.
+ """
+ q = layers.fc(input=queries,
+ size=d_key * n_head,
+ num_flatten_dims=len(queries.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=name + '_query_fc.w_0',
+ initializer=param_initializer),
+ bias_attr=name + '_query_fc.b_0')
+ k = layers.fc(input=keys,
+ size=d_key * n_head,
+ num_flatten_dims=len(keys.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=name + '_key_fc.w_0',
+ initializer=param_initializer),
+ bias_attr=name + '_key_fc.b_0')
+ v = layers.fc(input=values,
+ size=d_value * n_head,
+ num_flatten_dims=len(values.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=name + '_value_fc.w_0',
+ initializer=param_initializer),
+ bias_attr=name + '_value_fc.b_0')
+ return q, k, v
+
+ def __split_heads(x, n_head):
+ """
+ Reshape the last dimension of inpunt tensor x so that it becomes two
+ dimensions and then transpose. Specifically, input a tensor with shape
+ [bs, max_sequence_length, n_head * hidden_dim] then output a tensor
+ with shape [bs, n_head, max_sequence_length, hidden_dim].
+ """
+ hidden_size = x.shape[-1]
+ # The value 0 in shape attr means copying the corresponding dimension
+ # size of the input as the output dimension size.
+ reshaped = layers.reshape(
+ x=x, shape=[0, 0, n_head, hidden_size // n_head], inplace=True)
+
+ # permuate the dimensions into:
+ # [batch_size, n_head, max_sequence_len, hidden_size_per_head]
+ return layers.transpose(x=reshaped, perm=[0, 2, 1, 3])
+
+ def __combine_heads(x):
+ """
+ Transpose and then reshape the last two dimensions of inpunt tensor x
+ so that it becomes one dimension, which is reverse to __split_heads.
+ """
+ if len(x.shape) == 3: return x
+ if len(x.shape) != 4:
+ raise ValueError("Input(x) should be a 4-D Tensor.")
+ trans_x = layers.transpose(x, perm=[0, 2, 1, 3])
+ # The value 0 in shape attr means copying the corresponding dimension
+ # size of the input as the output dimension size.
+ #trans_x.desc.set_shape((-1, 1, n_head, d_value))
+ return layers.reshape(x=trans_x, shape=[0, 0, d_model], inplace=True)
+
+ def scaled_dot_product_attention(q, k, v, attn_bias, d_key, dropout_rate):
+ """
+ Scaled Dot-Product Attention
+ """
+ scaled_q = layers.scale(x=q, scale=d_key**-0.5)
+ product = layers.matmul(x=scaled_q, y=k, transpose_y=True)
+ if attn_bias:
+ product += attn_bias
+ weights = layers.softmax(product)
+ if dropout_rate:
+ weights = layers.dropout(
+ weights,
+ dropout_prob=dropout_rate,
+ dropout_implementation="upscale_in_train",
+ is_test=False)
+ out = layers.matmul(weights, v)
+ #return out, product
+ return out, weights
+
+ q, k, v = __compute_qkv(queries, keys, values, n_head, d_key, d_value)
+ q = to_3d(q)
+ k = to_3d(k)
+ v = to_3d(v)
+
+ if cache is not None: # use cache and concat time steps
+ # Since the inplace reshape in __split_heads changes the shape of k and
+ # v, which is the cache input for next time step, reshape the cache
+ # input from the previous time step first.
+ k = cache["k"] = layers.concat(
+ [layers.reshape(
+ cache["k"], shape=[0, 0, d_model]), k], axis=1)
+ v = cache["v"] = layers.concat(
+ [layers.reshape(
+ cache["v"], shape=[0, 0, d_model]), v], axis=1)
+
+ q = __split_heads(q, n_head)
+ k = __split_heads(k, n_head)
+ v = __split_heads(v, n_head)
+
+ ctx_multiheads, ctx_multiheads_attn = scaled_dot_product_attention(
+ q, k, v, attn_bias, d_key, dropout_rate)
+
+ out = __combine_heads(ctx_multiheads)
+
+ out = to_2d(out)
+
+ # Project back to the model size.
+ proj_out = layers.fc(input=out,
+ size=d_model,
+ num_flatten_dims=len(out.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=name + '_output_fc.w_0',
+ initializer=param_initializer),
+ bias_attr=name + '_output_fc.b_0')
+ return proj_out, ctx_multiheads_attn
+
+
+def positionwise_feed_forward(x,
+ d_inner_hid,
+ d_hid,
+ dropout_rate,
+ hidden_act,
+ param_initializer=None,
+ name='ffn'):
+ """
+ Position-wise Feed-Forward Networks.
+ This module consists of two linear transformations with a ReLU activation
+ in between, which is applied to each position separately and identically.
+ """
+ hidden = layers.fc(input=x,
+ size=d_inner_hid,
+ num_flatten_dims=len(x.shape) - 1,
+ act=hidden_act,
+ param_attr=fluid.ParamAttr(
+ name=name + '_fc_0.w_0',
+ initializer=param_initializer),
+ bias_attr=name + '_fc_0.b_0')
+ if dropout_rate:
+ hidden = layers.dropout(
+ hidden,
+ dropout_prob=dropout_rate,
+ dropout_implementation="upscale_in_train",
+ is_test=False)
+ out = layers.fc(input=hidden,
+ size=d_hid,
+ num_flatten_dims=len(hidden.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=name + '_fc_1.w_0',
+ initializer=param_initializer),
+ bias_attr=name + '_fc_1.b_0')
+ return out
+
+
+def pre_post_process_layer(prev_out,
+ out,
+ process_cmd,
+ dropout_rate=0.,
+ name=''):
+ """
+ Add residual connection, layer normalization and droput to the out tensor
+ optionally according to the value of process_cmd.
+ This will be used before or after multi-head attention and position-wise
+ feed-forward networks.
+ """
+ for cmd in process_cmd:
+ if cmd == "a": # add residual connection
+ out = out + prev_out if prev_out else out
+ elif cmd == "n": # add layer normalization
+ out_dtype = out.dtype
+ if out_dtype == fluid.core.VarDesc.VarType.FP16:
+ out = layers.cast(x=out, dtype="float32")
+ out = layers.layer_norm(
+ out,
+ begin_norm_axis=len(out.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=name + '_layer_norm_scale',
+ initializer=fluid.initializer.Constant(1.)),
+ bias_attr=fluid.ParamAttr(
+ name=name + '_layer_norm_bias',
+ initializer=fluid.initializer.Constant(0.)))
+ if out_dtype == fluid.core.VarDesc.VarType.FP16:
+ out = layers.cast(x=out, dtype="float16")
+ elif cmd == "d": # add dropout
+ if dropout_rate:
+ out = layers.dropout(
+ out,
+ dropout_prob=dropout_rate,
+ dropout_implementation="upscale_in_train",
+ is_test=False)
+ return out
+
+
+pre_process_layer = partial(pre_post_process_layer, None)
+post_process_layer = pre_post_process_layer
+
+
+def encoder_layer(enc_input,
+ attn_bias,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd="n",
+ postprocess_cmd="da",
+ param_initializer=None,
+ name=''):
+ """The encoder layers that can be stacked to form a deep encoder.
+ This module consits of a multi-head (self) attention followed by
+ position-wise feed-forward networks and both the two components companied
+ with the post_process_layer to add residual connection, layer normalization
+ and droput.
+ """
+ attn_output, ctx_multiheads_attn = multi_head_attention(
+ pre_process_layer(
+ enc_input,
+ preprocess_cmd,
+ prepostprocess_dropout,
+ name=name + '_pre_att'),
+ None,
+ None,
+ attn_bias,
+ d_key,
+ d_value,
+ d_model,
+ n_head,
+ attention_dropout,
+ param_initializer=param_initializer,
+ name=name + '_multi_head_att')
+ attn_output = post_process_layer(
+ enc_input,
+ attn_output,
+ postprocess_cmd,
+ prepostprocess_dropout,
+ name=name + '_post_att')
+
+ ffd_output = positionwise_feed_forward(
+ pre_process_layer(
+ attn_output,
+ preprocess_cmd,
+ prepostprocess_dropout,
+ name=name + '_pre_ffn'),
+ d_inner_hid,
+ d_model,
+ relu_dropout,
+ hidden_act,
+ param_initializer=param_initializer,
+ name=name + '_ffn')
+ ret = post_process_layer(
+ attn_output,
+ ffd_output,
+ postprocess_cmd,
+ prepostprocess_dropout,
+ name=name + '_post_ffn')
+ return ret, ctx_multiheads_attn, ffd_output
+
+
+def build_pad_idx(input_mask):
+ pad_idx = L.where(L.cast(L.squeeze(input_mask, [2]), 'bool'))
+ return pad_idx
+
+
+def build_attn_bias(input_mask, n_head, dtype):
+ attn_bias = L.matmul(
+ input_mask, input_mask, transpose_y=True) # [batch, seq, seq]
+ attn_bias = (1. - attn_bias) * -10000.
+ attn_bias = L.stack([attn_bias] * n_head, 1) # [batch, n_head, seq, seq]
+ if attn_bias.dtype != dtype:
+ attn_bias = L.cast(attn_bias, dtype)
+ return attn_bias
+
+
+def build_graph_attn_bias(input_mask, n_head, dtype, slot_seqlen):
+
+ input_shape = L.shape(input_mask)
+ input_batch = input_shape[0]
+ input_seqlen = input_shape[1]
+ num_slot = input_seqlen / slot_seqlen
+ num_b = num_slot - 1
+ ones = L.ones([num_b], dtype="float32") # [num_b]
+ diag_ones = L.diag(ones) # [num_b, num_b]
+ diag_ones = L.unsqueeze(diag_ones, [1, -1]) # [num_b, 1, num_b, 1]
+ diag_ones = L.expand(diag_ones, [1, slot_seqlen, 1, slot_seqlen]) # [num_b, seqlen, num_b, seqlen]
+ diag_ones = L.reshape(diag_ones, [1, num_b*slot_seqlen, num_b*slot_seqlen]) # [1, num_b*seqlen, num_b*seqlen]
+
+ graph_attn_bias = L.concat([L.ones([1, num_b*slot_seqlen, slot_seqlen], dtype="float32"), diag_ones], 2)
+ graph_attn_bias = L.concat([L.ones([1, slot_seqlen, num_slot*slot_seqlen], dtype="float32"), graph_attn_bias], 1) # [1, seq, seq]
+
+ pad_attn_bias = L.matmul(
+ input_mask, input_mask, transpose_y=True) # [batch, seq, seq]
+ attn_bias = graph_attn_bias * pad_attn_bias
+
+ attn_bias = (1. - attn_bias) * -10000.
+ attn_bias = L.stack([attn_bias] * n_head, 1) # [batch, n_head, seq, seq]
+ if attn_bias.dtype != dtype:
+ attn_bias = L.cast(attn_bias, dtype)
+ return attn_bias
+
+
+def encoder(enc_input,
+ input_mask,
+ n_layer,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd="n",
+ postprocess_cmd="da",
+ param_initializer=None,
+ name=''):
+ """
+ The encoder is composed of a stack of identical layers returned by calling
+ encoder_layer.
+ """
+
+ global to_2d, to_3d #, batch, seqlen, dynamic_dim
+ d_shape = L.shape(input_mask)
+ pad_idx = build_pad_idx(input_mask)
+ attn_bias = build_attn_bias(input_mask, n_head, enc_input.dtype)
+
+ # d_batch = d_shape[0]
+ # d_seqlen = d_shape[1]
+ # pad_idx = L.where(
+ # L.cast(L.reshape(input_mask, [d_batch, d_seqlen]), 'bool'))
+
+ # attn_bias = L.matmul(
+ # input_mask, input_mask, transpose_y=True) # [batch, seq, seq]
+ # attn_bias = (1. - attn_bias) * -10000.
+ # attn_bias = L.stack([attn_bias] * n_head, 1)
+ # if attn_bias.dtype != enc_input.dtype:
+ # attn_bias = L.cast(attn_bias, enc_input.dtype)
+
+ def to_2d(t_3d):
+ t_2d = L.gather_nd(t_3d, pad_idx)
+ return t_2d
+
+ def to_3d(t_2d):
+ t_3d = L.scatter_nd(
+ pad_idx, t_2d, shape=[d_shape[0], d_shape[1], d_model])
+ return t_3d
+
+ enc_input = to_2d(enc_input)
+ all_hidden = []
+ all_attn = []
+ all_ffn = []
+ for i in range(n_layer):
+ enc_output, ctx_multiheads_attn, ffn_output = encoder_layer(
+ enc_input,
+ attn_bias,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd,
+ postprocess_cmd,
+ param_initializer=param_initializer,
+ name=name + '_layer_' + str(i))
+ all_hidden.append(enc_output)
+ all_attn.append(ctx_multiheads_attn)
+ all_ffn.append(ffn_output)
+ enc_input = enc_output
+ enc_output = pre_process_layer(
+ enc_output,
+ preprocess_cmd,
+ prepostprocess_dropout,
+ name="post_encoder")
+ enc_output = to_3d(enc_output)
+ #enc_output.desc.set_shape((-1, 1, final_dim))
+ return enc_output, all_hidden, all_attn, all_ffn
+
+def graph_encoder(enc_input,
+ input_mask,
+ n_layer,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd="n",
+ postprocess_cmd="da",
+ param_initializer=None,
+ slot_seqlen=40,
+ name=''):
+ """
+ The encoder is composed of a stack of identical layers returned by calling
+ encoder_layer.
+ """
+
+ global to_2d, to_3d #, batch, seqlen, dynamic_dim
+ d_shape = L.shape(input_mask)
+ pad_idx = build_pad_idx(input_mask)
+ attn_bias = build_graph_attn_bias(input_mask, n_head, enc_input.dtype, slot_seqlen)
+ #attn_bias = build_attn_bias(input_mask, n_head, enc_input.dtype)
+
+ def to_2d(t_3d):
+ t_2d = L.gather_nd(t_3d, pad_idx)
+ return t_2d
+
+ def to_3d(t_2d):
+ t_3d = L.scatter_nd(
+ pad_idx, t_2d, shape=[d_shape[0], d_shape[1], d_model])
+ return t_3d
+
+ enc_input = to_2d(enc_input)
+ all_hidden = []
+ all_attn = []
+ all_ffn = []
+ for i in range(n_layer):
+ enc_output, ctx_multiheads_attn, ffn_output = encoder_layer(
+ enc_input,
+ attn_bias,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd,
+ postprocess_cmd,
+ param_initializer=param_initializer,
+ name=name + '_layer_' + str(i))
+ all_hidden.append(enc_output)
+ all_attn.append(ctx_multiheads_attn)
+ all_ffn.append(ffn_output)
+ enc_input = enc_output
+ enc_output = pre_process_layer(
+ enc_output,
+ preprocess_cmd,
+ prepostprocess_dropout,
+ name="post_encoder")
+ enc_output = to_3d(enc_output)
+ #enc_output.desc.set_shape((-1, 1, final_dim))
+ return enc_output, all_hidden, all_attn, all_ffn
diff --git a/examples/erniesage/models/erniesage_v1.py b/examples/erniesage/models/erniesage_v1.py
new file mode 100644
index 0000000000000000000000000000000000000000..696231a785ffecb8098c3379c7a7b0f4ee935e33
--- /dev/null
+++ b/examples/erniesage/models/erniesage_v1.py
@@ -0,0 +1,42 @@
+import pgl
+import paddle.fluid as F
+import paddle.fluid.layers as L
+from models.base import BaseNet, BaseGNNModel
+from models.ernie_model.ernie import ErnieModel
+from models.ernie_model.ernie import ErnieGraphModel
+from models.ernie_model.ernie import ErnieConfig
+
+class ErnieSageV1(BaseNet):
+
+ def build_inputs(self):
+ inputs = super(ErnieSageV1, self).build_inputs()
+ term_ids = L.data(
+ "term_ids", shape=[None, self.config.max_seqlen], dtype="int64", append_batch_size=False)
+ return inputs + [term_ids]
+
+ def build_embedding(self, graph_wrappers, term_ids):
+ term_ids = L.unsqueeze(term_ids, [-1])
+ ernie_config = self.config.ernie_config
+ ernie = ErnieModel(
+ src_ids=term_ids,
+ sentence_ids=L.zeros_like(term_ids),
+ task_ids=None,
+ config=ernie_config,
+ use_fp16=False,
+ name="student_")
+ feature = ernie.get_pooled_output()
+ return feature
+
+ def __call__(self, graph_wrappers):
+ inputs = self.build_inputs()
+ feature = self.build_embedding(graph_wrappers, inputs[-1])
+ features = self.gnn_layers(graph_wrappers, feature)
+ outputs = [self.take_final_feature(features[-1], i, "final_fc") for i in inputs[:-1]]
+ src_real_index = L.gather(graph_wrappers[0].node_feat['index'], inputs[0])
+ outputs.append(src_real_index)
+ return inputs, outputs
+
+
+class ErnieSageModelV1(BaseGNNModel):
+ def gen_net_fn(self, config):
+ return ErnieSageV1(config)
diff --git a/examples/erniesage/models/erniesage_v2.py b/examples/erniesage/models/erniesage_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..7ad9a26caf87d7ed79fe55584f21fe8d4f46dd2d
--- /dev/null
+++ b/examples/erniesage/models/erniesage_v2.py
@@ -0,0 +1,135 @@
+import pgl
+import paddle.fluid as F
+import paddle.fluid.layers as L
+from models.base import BaseNet, BaseGNNModel
+from models.ernie_model.ernie import ErnieModel
+
+
+class ErnieSageV2(BaseNet):
+
+ def build_inputs(self):
+ inputs = super(ErnieSageV2, self).build_inputs()
+ term_ids = L.data(
+ "term_ids", shape=[None, self.config.max_seqlen], dtype="int64", append_batch_size=False)
+ return inputs + [term_ids]
+
+ def gnn_layer(self, gw, feature, hidden_size, act, initializer, learning_rate, name):
+ def build_position_ids(src_ids, dst_ids):
+ src_shape = L.shape(src_ids)
+ src_batch = src_shape[0]
+ src_seqlen = src_shape[1]
+ dst_seqlen = src_seqlen - 1 # without cls
+
+ src_position_ids = L.reshape(
+ L.range(
+ 0, src_seqlen, 1, dtype='int32'), [1, src_seqlen, 1],
+ inplace=True) # [1, slot_seqlen, 1]
+ src_position_ids = L.expand(src_position_ids, [src_batch, 1, 1]) # [B, slot_seqlen * num_b, 1]
+ zero = L.fill_constant([1], dtype='int64', value=0)
+ input_mask = L.cast(L.equal(src_ids, zero), "int32") # assume pad id == 0 [B, slot_seqlen, 1]
+ src_pad_len = L.reduce_sum(input_mask, 1, keep_dim=True) # [B, 1, 1]
+
+ dst_position_ids = L.reshape(
+ L.range(
+ src_seqlen, src_seqlen+dst_seqlen, 1, dtype='int32'), [1, dst_seqlen, 1],
+ inplace=True) # [1, slot_seqlen, 1]
+ dst_position_ids = L.expand(dst_position_ids, [src_batch, 1, 1]) # [B, slot_seqlen, 1]
+ dst_position_ids = dst_position_ids - src_pad_len # [B, slot_seqlen, 1]
+
+ position_ids = L.concat([src_position_ids, dst_position_ids], 1)
+ position_ids = L.cast(position_ids, 'int64')
+ position_ids.stop_gradient = True
+ return position_ids
+
+
+ def ernie_send(src_feat, dst_feat, edge_feat):
+ """doc"""
+ # input_ids
+ cls = L.fill_constant_batch_size_like(src_feat["term_ids"], [-1, 1, 1], "int64", 1)
+ src_ids = L.concat([cls, src_feat["term_ids"]], 1)
+ dst_ids = dst_feat["term_ids"]
+
+ # sent_ids
+ sent_ids = L.concat([L.zeros_like(src_ids), L.ones_like(dst_ids)], 1)
+ term_ids = L.concat([src_ids, dst_ids], 1)
+
+ # position_ids
+ position_ids = build_position_ids(src_ids, dst_ids)
+
+ term_ids.stop_gradient = True
+ sent_ids.stop_gradient = True
+ ernie = ErnieModel(
+ term_ids, sent_ids, position_ids,
+ config=self.config.ernie_config)
+ feature = ernie.get_pooled_output()
+ return feature
+
+ def erniesage_v2_aggregator(gw, feature, hidden_size, act, initializer, learning_rate, name):
+ feature = L.unsqueeze(feature, [-1])
+ msg = gw.send(ernie_send, nfeat_list=[("term_ids", feature)])
+ neigh_feature = gw.recv(msg, lambda feat: F.layers.sequence_pool(feat, pool_type="sum"))
+
+ term_ids = feature
+ cls = L.fill_constant_batch_size_like(term_ids, [-1, 1, 1], "int64", 1)
+ term_ids = L.concat([cls, term_ids], 1)
+ term_ids.stop_gradient = True
+ ernie = ErnieModel(
+ term_ids, L.zeros_like(term_ids),
+ config=self.config.ernie_config)
+ self_feature = ernie.get_pooled_output()
+
+ self_feature = L.fc(self_feature,
+ hidden_size,
+ act=act,
+ param_attr=F.ParamAttr(name=name + "_l.w_0",
+ learning_rate=learning_rate),
+ bias_attr=name+"_l.b_0"
+ )
+ neigh_feature = L.fc(neigh_feature,
+ hidden_size,
+ act=act,
+ param_attr=F.ParamAttr(name=name + "_r.w_0",
+ learning_rate=learning_rate),
+ bias_attr=name+"_r.b_0"
+ )
+ output = L.concat([self_feature, neigh_feature], axis=1)
+ output = L.l2_normalize(output, axis=1)
+ return output
+ return erniesage_v2_aggregator(gw, feature, hidden_size, act, initializer, learning_rate, name)
+
+ def gnn_layers(self, graph_wrappers, feature):
+ features = [feature]
+
+ initializer = None
+ fc_lr = self.config.lr / 0.001
+
+ for i in range(self.config.num_layers):
+ if i == self.config.num_layers - 1:
+ act = None
+ else:
+ act = "leaky_relu"
+
+ feature = self.gnn_layer(
+ graph_wrappers[i],
+ feature,
+ self.config.hidden_size,
+ act,
+ initializer,
+ learning_rate=fc_lr,
+ name="%s_%s" % ("erniesage_v2", i))
+ features.append(feature)
+ return features
+
+ def __call__(self, graph_wrappers):
+ inputs = self.build_inputs()
+ feature = inputs[-1]
+ features = self.gnn_layers(graph_wrappers, feature)
+ outputs = [self.take_final_feature(features[-1], i, "final_fc") for i in inputs[:-1]]
+ src_real_index = L.gather(graph_wrappers[0].node_feat['index'], inputs[0])
+ outputs.append(src_real_index)
+ return inputs, outputs
+
+
+class ErnieSageModelV2(BaseGNNModel):
+ def gen_net_fn(self, config):
+ return ErnieSageV2(config)
diff --git a/examples/erniesage/models/erniesage_v3.py b/examples/erniesage/models/erniesage_v3.py
new file mode 100644
index 0000000000000000000000000000000000000000..44c3ae8b967df10af4c6a74425e3a43490eab25e
--- /dev/null
+++ b/examples/erniesage/models/erniesage_v3.py
@@ -0,0 +1,119 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import pgl
+import paddle.fluid as F
+import paddle.fluid.layers as L
+
+from models.base import BaseNet, BaseGNNModel
+from models.ernie_model.ernie import ErnieModel
+from models.ernie_model.ernie import ErnieGraphModel
+from models.message_passing import copy_send
+
+
+class ErnieSageV3(BaseNet):
+ def __init__(self, config):
+ super(ErnieSageV3, self).__init__(config)
+
+ def build_inputs(self):
+ inputs = super(ErnieSageV3, self).build_inputs()
+ term_ids = L.data(
+ "term_ids", shape=[None, self.config.max_seqlen], dtype="int64", append_batch_size=False)
+ return inputs + [term_ids]
+
+ def gnn_layer(self, gw, feature, hidden_size, act, initializer, learning_rate, name):
+ def ernie_recv(feat):
+ """doc"""
+ num_neighbor = self.config.samples[0]
+ pad_value = L.zeros([1], "int64")
+ out, _ = L.sequence_pad(feat, pad_value=pad_value, maxlen=num_neighbor)
+ out = L.reshape(out, [0, self.config.max_seqlen*num_neighbor])
+ return out
+
+ def erniesage_v3_aggregator(gw, feature, hidden_size, act, initializer, learning_rate, name):
+ msg = gw.send(copy_send, nfeat_list=[("h", feature)])
+ neigh_feature = gw.recv(msg, ernie_recv)
+ neigh_feature = L.cast(L.unsqueeze(neigh_feature, [-1]), "int64")
+
+ feature = L.unsqueeze(feature, [-1])
+ cls = L.fill_constant_batch_size_like(feature, [-1, 1, 1], "int64", 1)
+ term_ids = L.concat([cls, feature[:, :-1], neigh_feature], 1)
+ term_ids.stop_gradient = True
+ return term_ids
+ return erniesage_v3_aggregator(gw, feature, hidden_size, act, initializer, learning_rate, name)
+
+ def gnn_layers(self, graph_wrappers, feature):
+ features = [feature]
+
+ initializer = None
+ fc_lr = self.config.lr / 0.001
+
+ for i in range(self.config.num_layers):
+ if i == self.config.num_layers - 1:
+ act = None
+ else:
+ act = "leaky_relu"
+
+ feature = self.gnn_layer(
+ graph_wrappers[i],
+ feature,
+ self.config.hidden_size,
+ act,
+ initializer,
+ learning_rate=fc_lr,
+ name="%s_%s" % ("erniesage_v3", i))
+ features.append(feature)
+ return features
+
+ def take_final_feature(self, feature, index, name):
+ """take final feature"""
+ feat = L.gather(feature, index, overwrite=False)
+
+ ernie_config = self.config.ernie_config
+ ernie = ErnieGraphModel(
+ src_ids=feat,
+ config=ernie_config,
+ slot_seqlen=self.config.max_seqlen)
+ feat = ernie.get_pooled_output()
+ fc_lr = self.config.lr / 0.001
+ # feat = L.fc(feat,
+ # self.config.hidden_size,
+ # act="relu",
+ # param_attr=F.ParamAttr(name=name + "_l",
+ # learning_rate=fc_lr),
+ # )
+ #feat = L.l2_normalize(feat, axis=1)
+
+ if self.config.final_fc:
+ feat = L.fc(feat,
+ self.config.hidden_size,
+ param_attr=F.ParamAttr(name=name + '_w'),
+ bias_attr=F.ParamAttr(name=name + '_b'))
+
+ if self.config.final_l2_norm:
+ feat = L.l2_normalize(feat, axis=1)
+ return feat
+
+ def __call__(self, graph_wrappers):
+ inputs = self.build_inputs()
+ feature = inputs[-1]
+ features = self.gnn_layers(graph_wrappers, feature)
+ outputs = [self.take_final_feature(features[-1], i, "final_fc") for i in inputs[:-1]]
+ src_real_index = L.gather(graph_wrappers[0].node_feat['index'], inputs[0])
+ outputs.append(src_real_index)
+ return inputs, outputs
+
+
+class ErnieSageModelV3(BaseGNNModel):
+ def gen_net_fn(self, config):
+ return ErnieSageV3(config)
diff --git a/examples/erniesage/models/message_passing.py b/examples/erniesage/models/message_passing.py
new file mode 100644
index 0000000000000000000000000000000000000000..f45e4be000a17348664486f627f74934c81add1a
--- /dev/null
+++ b/examples/erniesage/models/message_passing.py
@@ -0,0 +1,145 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import numpy as np
+import paddle
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+
+
+def copy_send(src_feat, dst_feat, edge_feat):
+ """doc"""
+ return src_feat["h"]
+
+def weighted_copy_send(src_feat, dst_feat, edge_feat):
+ """doc"""
+ return src_feat["h"] * edge_feat["weight"]
+
+def mean_recv(feat):
+ """doc"""
+ return fluid.layers.sequence_pool(feat, pool_type="average")
+
+
+def sum_recv(feat):
+ """doc"""
+ return fluid.layers.sequence_pool(feat, pool_type="sum")
+
+
+def max_recv(feat):
+ """doc"""
+ return fluid.layers.sequence_pool(feat, pool_type="max")
+
+
+def lstm_recv(feat):
+ """doc"""
+ hidden_dim = 128
+ forward, _ = fluid.layers.dynamic_lstm(
+ input=feat, size=hidden_dim * 4, use_peepholes=False)
+ output = fluid.layers.sequence_last_step(forward)
+ return output
+
+
+def graphsage_sum(gw, feature, hidden_size, act, initializer, learning_rate, name):
+ """doc"""
+ msg = gw.send(copy_send, nfeat_list=[("h", feature)])
+ neigh_feature = gw.recv(msg, sum_recv)
+ self_feature = feature
+ self_feature = fluid.layers.fc(self_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_l.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_l.b_0"
+ )
+ neigh_feature = fluid.layers.fc(neigh_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_r.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_r.b_0"
+ )
+ output = fluid.layers.concat([self_feature, neigh_feature], axis=1)
+ output = fluid.layers.l2_normalize(output, axis=1)
+ return output
+
+
+def graphsage_mean(gw, feature, hidden_size, act, initializer, learning_rate, name):
+ """doc"""
+ msg = gw.send(copy_send, nfeat_list=[("h", feature)])
+ neigh_feature = gw.recv(msg, mean_recv)
+ self_feature = feature
+ self_feature = fluid.layers.fc(self_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_l.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_l.b_0"
+ )
+ neigh_feature = fluid.layers.fc(neigh_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_r.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_r.b_0"
+ )
+ output = fluid.layers.concat([self_feature, neigh_feature], axis=1)
+ output = fluid.layers.l2_normalize(output, axis=1)
+ return output
+
+
+def pinsage_mean(gw, feature, hidden_size, act, initializer, learning_rate, name):
+ """doc"""
+ msg = gw.send(weighted_copy_send, nfeat_list=[("h", feature)], efeat_list=["weight"])
+ neigh_feature = gw.recv(msg, mean_recv)
+ self_feature = feature
+ self_feature = fluid.layers.fc(self_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_l.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_l.b_0"
+ )
+ neigh_feature = fluid.layers.fc(neigh_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_r.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_r.b_0"
+ )
+ output = fluid.layers.concat([self_feature, neigh_feature], axis=1)
+ output = fluid.layers.l2_normalize(output, axis=1)
+ return output
+
+
+def pinsage_sum(gw, feature, hidden_size, act, initializer, learning_rate, name):
+ """doc"""
+ msg = gw.send(weighted_copy_send, nfeat_list=[("h", feature)], efeat_list=["weight"])
+ neigh_feature = gw.recv(msg, sum_recv)
+ self_feature = feature
+ self_feature = fluid.layers.fc(self_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_l.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_l.b_0"
+ )
+ neigh_feature = fluid.layers.fc(neigh_feature,
+ hidden_size,
+ act=act,
+ param_attr=fluid.ParamAttr(name=name + "_r.w_0", initializer=initializer,
+ learning_rate=learning_rate),
+ bias_attr=name+"_r.b_0"
+ )
+ output = fluid.layers.concat([self_feature, neigh_feature], axis=1)
+ output = fluid.layers.l2_normalize(output, axis=1)
+ return output
diff --git a/examples/erniesage/models/model_factory.py b/examples/erniesage/models/model_factory.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f69bb1f6932a219f4a41faee9cf5bf6c3f947a8
--- /dev/null
+++ b/examples/erniesage/models/model_factory.py
@@ -0,0 +1,24 @@
+from models.base import BaseGNNModel
+from models.ernie import ErnieModel
+from models.erniesage_v1 import ErnieSageModelV1
+from models.erniesage_v2 import ErnieSageModelV2
+from models.erniesage_v3 import ErnieSageModelV3
+
+class Model(object):
+ @classmethod
+ def factory(cls, config):
+ name = config.model_type
+ if name == "BaseGNNModel":
+ return BaseGNNModel(config)
+ if name == "ErnieModel":
+ return ErnieModel(config)
+ if name == "ErnieSageModelV1":
+ return ErnieSageModelV1(config)
+ if name == "ErnieSageModelV2":
+ return ErnieSageModelV2(config)
+ if name == "ErnieSageModelV3":
+ return ErnieSageModelV3(config)
+ else:
+ raise ValueError
+
+
diff --git a/examples/erniesage/preprocessing/dump_graph.py b/examples/erniesage/preprocessing/dump_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..d1558b39a9f95424140b9661732cfa27dccd730a
--- /dev/null
+++ b/examples/erniesage/preprocessing/dump_graph.py
@@ -0,0 +1,121 @@
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+########################################################################
+#
+# Copyright (c) 2020 Baidu.com, Inc. All Rights Reserved
+#
+# File: dump_graph.py
+# Author: suweiyue(suweiyue@baidu.com)
+# Date: 2020/03/01 22:17:13
+#
+########################################################################
+"""
+ Comment.
+"""
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+#from __future__ import unicode_literals
+
+import io
+import os
+import sys
+import argparse
+import logging
+import multiprocessing
+from functools import partial
+from io import open
+
+import numpy as np
+import tqdm
+import pgl
+from pgl.graph_kernel import alias_sample_build_table
+from pgl.utils.logger import log
+
+from tokenization import FullTokenizer
+
+
+def term2id(string, tokenizer, max_seqlen):
+ #string = string.split("\t")[1]
+ tokens = tokenizer.tokenize(string)
+ ids = tokenizer.convert_tokens_to_ids(tokens)
+ ids = ids[:max_seqlen-1]
+ ids = ids + [2] # ids + [sep]
+ ids = ids + [0] * (max_seqlen - len(ids))
+ return ids
+
+
+def dump_graph(args):
+ if not os.path.exists(args.outpath):
+ os.makedirs(args.outpath)
+ neg_samples = []
+ str2id = dict()
+ term_file = io.open(os.path.join(args.outpath, "terms.txt"), "w", encoding=args.encoding)
+ terms = []
+ count = 0
+ item_distribution = []
+
+ with io.open(args.inpath, encoding=args.encoding) as f:
+ edges = []
+ for idx, line in enumerate(f):
+ if idx % 100000 == 0:
+ log.info("%s readed %s lines" % (args.inpath, idx))
+ slots = []
+ for col_idx, col in enumerate(line.strip("\n").split("\t")):
+ s = col[:args.max_seqlen]
+ if s not in str2id:
+ str2id[s] = count
+ count += 1
+ term_file.write(str(col_idx) + "\t" + col + "\n")
+ item_distribution.append(0)
+
+ slots.append(str2id[s])
+
+ src = slots[0]
+ dst = slots[1]
+ neg_samples.append(slots[2:])
+ edges.append((src, dst))
+ edges.append((dst, src))
+ item_distribution[dst] += 1
+
+ term_file.close()
+ edges = np.array(edges, dtype="int64")
+ num_nodes = len(str2id)
+ str2id.clear()
+ log.info("building graph...")
+ graph = pgl.graph.Graph(num_nodes=num_nodes, edges=edges)
+ indegree = graph.indegree()
+ graph.indegree()
+ graph.outdegree()
+ graph.dump(args.outpath)
+
+ # dump alias sample table
+ item_distribution = np.array(item_distribution)
+ item_distribution = np.sqrt(item_distribution)
+ distribution = 1. * item_distribution / item_distribution.sum()
+ alias, events = alias_sample_build_table(distribution)
+ np.save(os.path.join(args.outpath, "alias.npy"), alias)
+ np.save(os.path.join(args.outpath, "events.npy"), events)
+ np.save(os.path.join(args.outpath, "neg_samples.npy"), np.array(neg_samples))
+ log.info("End Build Graph")
+
+def dump_node_feat(args):
+ log.info("Dump node feat starting...")
+ id2str = [line.strip("\n").split("\t")[1] for line in io.open(os.path.join(args.outpath, "terms.txt"), encoding=args.encoding)]
+ pool = multiprocessing.Pool()
+ tokenizer = FullTokenizer(args.vocab_file)
+ term_ids = pool.map(partial(term2id, tokenizer=tokenizer, max_seqlen=args.max_seqlen), id2str)
+ np.save(os.path.join(args.outpath, "term_ids.npy"), np.array(term_ids, np.uint16))
+ log.info("Dump node feat done.")
+ pool.terminate()
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description='main')
+ parser.add_argument("-i", "--inpath", type=str, default=None)
+ parser.add_argument("-l", "--max_seqlen", type=int, default=30)
+ parser.add_argument("--vocab_file", type=str, default="./vocab.txt")
+ parser.add_argument("--encoding", type=str, default="utf8")
+ parser.add_argument("-o", "--outpath", type=str, default=None)
+ args = parser.parse_args()
+ dump_graph(args)
+ dump_node_feat(args)
diff --git a/examples/erniesage/preprocessing/tokenization.py b/examples/erniesage/preprocessing/tokenization.py
new file mode 100644
index 0000000000000000000000000000000000000000..975bb26a531e655bcfa4744f8ebc81fc01c68d9c
--- /dev/null
+++ b/examples/erniesage/preprocessing/tokenization.py
@@ -0,0 +1,461 @@
+# coding=utf-8
+# Copyright 2018 The Google AI Language Team Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Tokenization classes."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import collections
+import unicodedata
+import six
+import sentencepiece as sp
+
+def convert_to_unicode(text):
+ """Converts `text` to Unicode (if it's not already), assuming utf-8 input."""
+ if six.PY3:
+ if isinstance(text, str):
+ return text
+ elif isinstance(text, bytes):
+ return text.decode("utf-8", "ignore")
+ else:
+ raise ValueError("Unsupported string type: %s" % (type(text)))
+ elif six.PY2:
+ if isinstance(text, str):
+ return text.decode("utf-8", "ignore")
+ elif isinstance(text, unicode):
+ return text
+ else:
+ raise ValueError("Unsupported string type: %s" % (type(text)))
+ else:
+ raise ValueError("Not running on Python2 or Python 3?")
+
+
+def printable_text(text):
+ """Returns text encoded in a way suitable for print or `tf.logging`."""
+
+ # These functions want `str` for both Python2 and Python3, but in one case
+ # it's a Unicode string and in the other it's a byte string.
+ if six.PY3:
+ if isinstance(text, str):
+ return text
+ elif isinstance(text, bytes):
+ return text.decode("utf-8", "ignore")
+ else:
+ raise ValueError("Unsupported string type: %s" % (type(text)))
+ elif six.PY2:
+ if isinstance(text, str):
+ return text
+ elif isinstance(text, unicode):
+ return text.encode("utf-8")
+ else:
+ raise ValueError("Unsupported string type: %s" % (type(text)))
+ else:
+ raise ValueError("Not running on Python2 or Python 3?")
+
+
+def load_vocab(vocab_file):
+ """Loads a vocabulary file into a dictionary."""
+ vocab = collections.OrderedDict()
+ fin = open(vocab_file, 'rb')
+ for num, line in enumerate(fin):
+ items = convert_to_unicode(line.strip()).split("\t")
+ if len(items) > 2:
+ break
+ token = items[0]
+ index = items[1] if len(items) == 2 else num
+ token = token.strip()
+ vocab[token] = int(index)
+ return vocab
+
+
+def convert_by_vocab(vocab, items):
+ """Converts a sequence of [tokens|ids] using the vocab."""
+ output = []
+ for item in items:
+ output.append(vocab[item])
+ return output
+
+
+def convert_tokens_to_ids_include_unk(vocab, tokens, unk_token="[UNK]"):
+ output = []
+ for token in tokens:
+ if token in vocab:
+ output.append(vocab[token])
+ else:
+ output.append(vocab[unk_token])
+ return output
+
+
+def convert_tokens_to_ids(vocab, tokens):
+ return convert_by_vocab(vocab, tokens)
+
+
+def convert_ids_to_tokens(inv_vocab, ids):
+ return convert_by_vocab(inv_vocab, ids)
+
+
+def whitespace_tokenize(text):
+ """Runs basic whitespace cleaning and splitting on a peice of text."""
+ text = text.strip()
+ if not text:
+ return []
+ tokens = text.split()
+ return tokens
+
+
+class FullTokenizer(object):
+ """Runs end-to-end tokenziation."""
+
+ def __init__(self, vocab_file, do_lower_case=True):
+ self.vocab = load_vocab(vocab_file)
+ self.inv_vocab = {v: k for k, v in self.vocab.items()}
+ self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case)
+ self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab)
+
+ def tokenize(self, text):
+ split_tokens = []
+ for token in self.basic_tokenizer.tokenize(text):
+ for sub_token in self.wordpiece_tokenizer.tokenize(token):
+ split_tokens.append(sub_token)
+
+ return split_tokens
+
+ def convert_tokens_to_ids(self, tokens):
+ return convert_by_vocab(self.vocab, tokens)
+
+ def convert_ids_to_tokens(self, ids):
+ return convert_by_vocab(self.inv_vocab, ids)
+
+
+class CharTokenizer(object):
+ """Runs end-to-end tokenziation."""
+
+ def __init__(self, vocab_file, do_lower_case=True):
+ self.vocab = load_vocab(vocab_file)
+ self.inv_vocab = {v: k for k, v in self.vocab.items()}
+ self.tokenizer = WordpieceTokenizer(vocab=self.vocab)
+
+ def tokenize(self, text):
+ split_tokens = []
+ for token in text.lower().split(" "):
+ for sub_token in self.tokenizer.tokenize(token):
+ split_tokens.append(sub_token)
+ return split_tokens
+
+ def convert_tokens_to_ids(self, tokens):
+ return convert_by_vocab(self.vocab, tokens)
+
+ def convert_ids_to_tokens(self, ids):
+ return convert_by_vocab(self.inv_vocab, ids)
+
+
+class BasicTokenizer(object):
+ """Runs basic tokenization (punctuation splitting, lower casing, etc.)."""
+
+ def __init__(self, do_lower_case=True):
+ """Constructs a BasicTokenizer.
+
+ Args:
+ do_lower_case: Whether to lower case the input.
+ """
+ self.do_lower_case = do_lower_case
+
+ def tokenize(self, text):
+ """Tokenizes a piece of text."""
+ text = convert_to_unicode(text)
+ text = self._clean_text(text)
+
+ # This was added on November 1st, 2018 for the multilingual and Chinese
+ # models. This is also applied to the English models now, but it doesn't
+ # matter since the English models were not trained on any Chinese data
+ # and generally don't have any Chinese data in them (there are Chinese
+ # characters in the vocabulary because Wikipedia does have some Chinese
+ # words in the English Wikipedia.).
+ text = self._tokenize_chinese_chars(text)
+
+ orig_tokens = whitespace_tokenize(text)
+ split_tokens = []
+ for token in orig_tokens:
+ if self.do_lower_case:
+ token = token.lower()
+ token = self._run_strip_accents(token)
+ split_tokens.extend(self._run_split_on_punc(token))
+
+ output_tokens = whitespace_tokenize(" ".join(split_tokens))
+ return output_tokens
+
+ def _run_strip_accents(self, text):
+ """Strips accents from a piece of text."""
+ text = unicodedata.normalize("NFD", text)
+ output = []
+ for char in text:
+ cat = unicodedata.category(char)
+ if cat == "Mn":
+ continue
+ output.append(char)
+ return "".join(output)
+
+ def _run_split_on_punc(self, text):
+ """Splits punctuation on a piece of text."""
+ chars = list(text)
+ i = 0
+ start_new_word = True
+ output = []
+ while i < len(chars):
+ char = chars[i]
+ if _is_punctuation(char):
+ output.append([char])
+ start_new_word = True
+ else:
+ if start_new_word:
+ output.append([])
+ start_new_word = False
+ output[-1].append(char)
+ i += 1
+
+ return ["".join(x) for x in output]
+
+ def _tokenize_chinese_chars(self, text):
+ """Adds whitespace around any CJK character."""
+ output = []
+ for char in text:
+ cp = ord(char)
+ if self._is_chinese_char(cp):
+ output.append(" ")
+ output.append(char)
+ output.append(" ")
+ else:
+ output.append(char)
+ return "".join(output)
+
+ def _is_chinese_char(self, cp):
+ """Checks whether CP is the codepoint of a CJK character."""
+ # This defines a "chinese character" as anything in the CJK Unicode block:
+ # https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
+ #
+ # Note that the CJK Unicode block is NOT all Japanese and Korean characters,
+ # despite its name. The modern Korean Hangul alphabet is a different block,
+ # as is Japanese Hiragana and Katakana. Those alphabets are used to write
+ # space-separated words, so they are not treated specially and handled
+ # like the all of the other languages.
+ if ((cp >= 0x4E00 and cp <= 0x9FFF) or #
+ (cp >= 0x3400 and cp <= 0x4DBF) or #
+ (cp >= 0x20000 and cp <= 0x2A6DF) or #
+ (cp >= 0x2A700 and cp <= 0x2B73F) or #
+ (cp >= 0x2B740 and cp <= 0x2B81F) or #
+ (cp >= 0x2B820 and cp <= 0x2CEAF) or
+ (cp >= 0xF900 and cp <= 0xFAFF) or #
+ (cp >= 0x2F800 and cp <= 0x2FA1F)): #
+ return True
+
+ return False
+
+ def _clean_text(self, text):
+ """Performs invalid character removal and whitespace cleanup on text."""
+ output = []
+ for char in text:
+ cp = ord(char)
+ if cp == 0 or cp == 0xfffd or _is_control(char):
+ continue
+ if _is_whitespace(char):
+ output.append(" ")
+ else:
+ output.append(char)
+ return "".join(output)
+
+
+class SentencepieceTokenizer(object):
+ """Runs SentencePiece tokenziation."""
+
+ def __init__(self, vocab_file, do_lower_case=True, unk_token="[UNK]"):
+ self.vocab = load_vocab(vocab_file)
+ self.inv_vocab = {v: k for k, v in self.vocab.items()}
+ self.do_lower_case = do_lower_case
+ self.tokenizer = sp.SentencePieceProcessor()
+ self.tokenizer.Load(vocab_file + ".model")
+ self.sp_unk_token = ""
+ self.unk_token = unk_token
+
+ def tokenize(self, text):
+ """Tokenizes a piece of text into its word pieces.
+
+ Returns:
+ A list of wordpiece tokens.
+ """
+ text = text.lower() if self.do_lower_case else text
+ text = convert_to_unicode(text.replace("\1", " "))
+ tokens = self.tokenizer.EncodeAsPieces(text)
+
+ output_tokens = []
+ for token in tokens:
+ if token == self.sp_unk_token:
+ token = self.unk_token
+
+ if token in self.vocab:
+ output_tokens.append(token)
+ else:
+ output_tokens.append(self.unk_token)
+
+ return output_tokens
+
+ def convert_tokens_to_ids(self, tokens):
+ return convert_by_vocab(self.vocab, tokens)
+
+ def convert_ids_to_tokens(self, ids):
+ return convert_by_vocab(self.inv_vocab, ids)
+
+
+class WordsegTokenizer(object):
+ """Runs Wordseg tokenziation."""
+
+ def __init__(self, vocab_file, do_lower_case=True, unk_token="[UNK]",
+ split_token="\1"):
+ self.vocab = load_vocab(vocab_file)
+ self.inv_vocab = {v: k for k, v in self.vocab.items()}
+ self.tokenizer = sp.SentencePieceProcessor()
+ self.tokenizer.Load(vocab_file + ".model")
+
+ self.do_lower_case = do_lower_case
+ self.unk_token = unk_token
+ self.split_token = split_token
+
+ def tokenize(self, text):
+ """Tokenizes a piece of text into its word pieces.
+
+ Returns:
+ A list of wordpiece tokens.
+ """
+ text = text.lower() if self.do_lower_case else text
+ text = convert_to_unicode(text)
+
+ output_tokens = []
+ for token in text.split(self.split_token):
+ if token in self.vocab:
+ output_tokens.append(token)
+ else:
+ sp_tokens = self.tokenizer.EncodeAsPieces(token)
+ for sp_token in sp_tokens:
+ if sp_token in self.vocab:
+ output_tokens.append(sp_token)
+ return output_tokens
+
+ def convert_tokens_to_ids(self, tokens):
+ return convert_by_vocab(self.vocab, tokens)
+
+ def convert_ids_to_tokens(self, ids):
+ return convert_by_vocab(self.inv_vocab, ids)
+
+
+class WordpieceTokenizer(object):
+ """Runs WordPiece tokenziation."""
+
+ def __init__(self, vocab, unk_token="[UNK]", max_input_chars_per_word=100):
+ self.vocab = vocab
+ self.unk_token = unk_token
+ self.max_input_chars_per_word = max_input_chars_per_word
+
+ def tokenize(self, text):
+ """Tokenizes a piece of text into its word pieces.
+
+ This uses a greedy longest-match-first algorithm to perform tokenization
+ using the given vocabulary.
+
+ For example:
+ input = "unaffable"
+ output = ["un", "##aff", "##able"]
+
+ Args:
+ text: A single token or whitespace separated tokens. This should have
+ already been passed through `BasicTokenizer.
+
+ Returns:
+ A list of wordpiece tokens.
+ """
+
+ text = convert_to_unicode(text)
+
+ output_tokens = []
+ for token in whitespace_tokenize(text):
+ chars = list(token)
+ if len(chars) > self.max_input_chars_per_word:
+ output_tokens.append(self.unk_token)
+ continue
+
+ is_bad = False
+ start = 0
+ sub_tokens = []
+ while start < len(chars):
+ end = len(chars)
+ cur_substr = None
+ while start < end:
+ substr = "".join(chars[start:end])
+ if start > 0:
+ substr = "##" + substr
+ if substr in self.vocab:
+ cur_substr = substr
+ break
+ end -= 1
+ if cur_substr is None:
+ is_bad = True
+ break
+ sub_tokens.append(cur_substr)
+ start = end
+
+ if is_bad:
+ output_tokens.append(self.unk_token)
+ else:
+ output_tokens.extend(sub_tokens)
+ return output_tokens
+
+
+def _is_whitespace(char):
+ """Checks whether `chars` is a whitespace character."""
+ # \t, \n, and \r are technically contorl characters but we treat them
+ # as whitespace since they are generally considered as such.
+ if char == " " or char == "\t" or char == "\n" or char == "\r":
+ return True
+ cat = unicodedata.category(char)
+ if cat == "Zs":
+ return True
+ return False
+
+
+def _is_control(char):
+ """Checks whether `chars` is a control character."""
+ # These are technically control characters but we count them as whitespace
+ # characters.
+ if char == "\t" or char == "\n" or char == "\r":
+ return False
+ cat = unicodedata.category(char)
+ if cat.startswith("C"):
+ return True
+ return False
+
+
+def _is_punctuation(char):
+ """Checks whether `chars` is a punctuation character."""
+ cp = ord(char)
+ # We treat all non-letter/number ASCII as punctuation.
+ # Characters such as "^", "$", and "`" are not in the Unicode
+ # Punctuation class but we treat them as punctuation anyways, for
+ # consistency.
+ if ((cp >= 33 and cp <= 47) or (cp >= 58 and cp <= 64) or
+ (cp >= 91 and cp <= 96) or (cp >= 123 and cp <= 126)):
+ return True
+ cat = unicodedata.category(char)
+ if cat.startswith("P"):
+ return True
+ return False
diff --git a/examples/erniesage/train.py b/examples/erniesage/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..cc3255c9949ca3812637b07c2b10acb190c38462
--- /dev/null
+++ b/examples/erniesage/train.py
@@ -0,0 +1,95 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import argparse
+import traceback
+
+import yaml
+import numpy as np
+from easydict import EasyDict as edict
+from pgl.utils.logger import log
+from pgl.utils import paddle_helper
+
+from learner import Learner
+from models.model_factory import Model
+from dataset.graph_reader import GraphGenerator
+
+
+class TrainData(object):
+ def __init__(self, graph_path):
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
+ trainer_count = int(os.getenv("PADDLE_TRAINERS_NUM", "1"))
+ log.info("trainer_id: %s, trainer_count: %s." % (trainer_id, trainer_count))
+
+ bidirectional_edges = np.load(os.path.join(graph_path, "edges.npy"), allow_pickle=True)
+ # edges is bidirectional.
+ edges = bidirectional_edges[0::2]
+ train_usr = edges[trainer_id::trainer_count, 0]
+ train_ad = edges[trainer_id::trainer_count, 1]
+ returns = {
+ "train_data": [train_usr, train_ad]
+ }
+
+ if os.path.exists(os.path.join(graph_path, "neg_samples.npy")):
+ neg_samples = np.load(os.path.join(graph_path, "neg_samples.npy"), allow_pickle=True)
+ if neg_samples.size != 0:
+ train_negs = neg_samples[trainer_id::trainer_count]
+ returns["train_data"].append(train_negs)
+ log.info("Load train_data done.")
+ self.data = returns
+
+ def __getitem__(self, index):
+ return [ data[index] for data in self.data["train_data"]]
+
+ def __len__(self):
+ return len(self.data["train_data"][0])
+
+
+def main(config):
+ # Select Model
+ model = Model.factory(config)
+
+ # Build Train Edges
+ data = TrainData(config.graph_path)
+
+ # Build Train Data
+ train_iter = GraphGenerator(
+ graph_wrappers=model.graph_wrappers,
+ batch_size=config.batch_size,
+ data=data,
+ samples=config.samples,
+ num_workers=config.sample_workers,
+ feed_name_list=[var.name for var in model.feed_list],
+ use_pyreader=config.use_pyreader,
+ phase="train",
+ graph_data_path=config.graph_path,
+ shuffle=True,
+ neg_type=config.neg_type)
+
+ log.info("build graph reader done.")
+
+ learner = Learner.factory(config.learner_type)
+ learner.build(model, train_iter, config)
+
+ learner.start()
+ learner.stop()
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description='main')
+ parser.add_argument("--conf", type=str, default="./config.yaml")
+ args = parser.parse_args()
+ config = edict(yaml.load(open(args.conf), Loader=yaml.FullLoader))
+ print(config)
+ main(config)
diff --git a/examples/gat/train.py b/examples/gat/train.py
index 344948803539f260bbe7288a4ee16a423c5c5f8a..438565baad16780ad0c57ae1833db1301160500f 100644
--- a/examples/gat/train.py
+++ b/examples/gat/train.py
@@ -44,7 +44,6 @@ def main(args):
with fluid.program_guard(train_program, startup_program):
gw = pgl.graph_wrapper.GraphWrapper(
name="graph",
- place=place,
node_feat=dataset.graph.node_feat_info())
output = pgl.layers.gat(gw,
diff --git a/examples/gin/README.md b/examples/gin/README.md
index 22145cb04236c2522e7e1d6be8e5b8b6e1bd913a..e35eef7fae1feaa22508a313b35b2103695fc3aa 100644
--- a/examples/gin/README.md
+++ b/examples/gin/README.md
@@ -4,18 +4,19 @@
### Datasets
-The dataset can be downloaded from [here](https://github.com/weihua916/powerful-gnns/blob/master/dataset.zip)
+The dataset can be downloaded from [here](https://github.com/weihua916/powerful-gnns/blob/master/dataset.zip).
+After downloading the data,uncompress them, then a directory named `./dataset/` can be found in current directory. Note that the current directory is the root directory of GIN model.
### Dependencies
-- paddlepaddle 1.6
+- paddlepaddle >= 1.6
- pgl 1.0.2
### How to run
For examples, use GPU to train GIN model on MUTAG dataset.
```
-python main.py --use_cuda --dataset_name MUTAG
+python main.py --use_cuda --dataset_name MUTAG --data_path ./dataset
```
### Hyperparameters
diff --git a/examples/gin/model.py b/examples/gin/model.py
index 2380ddde8990fa68987bc41e4774a87247c8e3cc..45548f37121afe7fc0945246c415b42df4c9d2c7 100644
--- a/examples/gin/model.py
+++ b/examples/gin/model.py
@@ -50,7 +50,16 @@ class GINModel(object):
init_eps=0.0,
train_eps=self.train_eps)
- h = fl.batch_norm(h)
+ h = fl.layer_norm(
+ h,
+ begin_norm_axis=1,
+ param_attr=fluid.ParamAttr(
+ name="norm_scale_%s" % (i),
+ initializer=fluid.initializer.Constant(1.0)),
+ bias_attr=fluid.ParamAttr(
+ name="norm_bias_%s" % (i),
+ initializer=fluid.initializer.Constant(0.0)), )
+
h = fl.relu(h)
features_list.append(h)
diff --git a/examples/graphsage/train.py b/examples/graphsage/train.py
index da20f6e9643b25b800b87d3935feedaf3ec2a62b..463e0b6d4d6457d0307223e21dc79d246a2ef656 100644
--- a/examples/graphsage/train.py
+++ b/examples/graphsage/train.py
@@ -204,8 +204,8 @@ def main(args):
graph_wrapper = pgl.graph_wrapper.GraphWrapper(
"sub_graph",
- fluid.CPUPlace(),
node_feat=data['graph'].node_feat_info())
+
model_loss, model_acc = build_graph_model(
graph_wrapper,
num_class=data["num_class"],
diff --git a/examples/graphsage/train_multi.py b/examples/graphsage/train_multi.py
index eda3a341c99e4f4b7123dc3eebf0f7f2f79617ad..1f8fe69c6496c2a6f4e933d3ea6aa7da01c50571 100644
--- a/examples/graphsage/train_multi.py
+++ b/examples/graphsage/train_multi.py
@@ -231,7 +231,6 @@ def main(args):
with fluid.program_guard(train_program, startup_program):
graph_wrapper = pgl.graph_wrapper.GraphWrapper(
"sub_graph",
- fluid.CPUPlace(),
node_feat=data['graph'].node_feat_info())
model_loss, model_acc = build_graph_model(
diff --git a/examples/graphsage/train_scale.py b/examples/graphsage/train_scale.py
index f0625d0202b37ca4153b3077451b5032edaf0fbf..c6fce995246e0244badf51e6bc3583d9fc7be9c7 100644
--- a/examples/graphsage/train_scale.py
+++ b/examples/graphsage/train_scale.py
@@ -227,7 +227,6 @@ def main(args):
with fluid.program_guard(train_program, startup_program):
graph_wrapper = pgl.graph_wrapper.GraphWrapper(
"sub_graph",
- fluid.CPUPlace(),
node_feat=data['graph'].node_feat_info())
model_loss, model_acc = build_graph_model(
diff --git a/examples/stgcn/main.py b/examples/stgcn/main.py
index 6be8df9991177daf2ba9fed1f39eebbb8e8ad83f..26adb6a4e6f3c81b4e4e2d35e3f049d0d80f03f5 100644
--- a/examples/stgcn/main.py
+++ b/examples/stgcn/main.py
@@ -49,7 +49,6 @@ def main(args):
with fluid.program_guard(train_program, startup_program):
gw = pgl.graph_wrapper.GraphWrapper(
"gw",
- place,
node_feat=[('norm', [None, 1], "float32")],
edge_feat=[('weights', [None, 1], "float32")])
diff --git a/examples/unsup_graphsage/train.py b/examples/unsup_graphsage/train.py
index a53ffdcb042e74ed262b10a44e0b5c36fad3b1ef..cc7351bb58a05eed05b6f020fc87d41bf1ce6ef9 100644
--- a/examples/unsup_graphsage/train.py
+++ b/examples/unsup_graphsage/train.py
@@ -88,7 +88,7 @@ def build_graph_model(args):
graph_wrappers.append(
pgl.graph_wrapper.GraphWrapper(
- "layer_0", fluid.CPUPlace(), node_feat=node_feature_info))
+ "layer_0", node_feat=node_feature_info))
#edge_feat=[("f", [None, 1], "float32")]))
num_embed = args.num_nodes
diff --git a/ogb_examples/graphproppred/main_pgl.py b/ogb_examples/graphproppred/main_pgl.py
deleted file mode 100644
index ef7c112e5a364db8d26d297d5b4f297e2b6ef7ad..0000000000000000000000000000000000000000
--- a/ogb_examples/graphproppred/main_pgl.py
+++ /dev/null
@@ -1,189 +0,0 @@
-# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""test ogb
-"""
-import argparse
-
-import pgl
-import numpy as np
-import paddle.fluid as fluid
-from pgl.contrib.ogb.graphproppred.dataset_pgl import PglGraphPropPredDataset
-from pgl.utils import paddle_helper
-from ogb.graphproppred import Evaluator
-from pgl.contrib.ogb.graphproppred.mol_encoder import AtomEncoder, BondEncoder
-
-
-def train(exe, batch_size, graph_wrapper, train_program, splitted_idx, dataset,
- evaluator, fetch_loss, fetch_pred):
- """Train"""
- graphs, labels = dataset[splitted_idx["train"]]
- perm = np.arange(0, len(graphs))
- np.random.shuffle(perm)
- start_batch = 0
- batch_no = 0
- pred_output = np.zeros_like(labels, dtype="float32")
- while start_batch < len(perm):
- batch_index = perm[start_batch:start_batch + batch_size]
- start_batch += batch_size
- batch_graph = pgl.graph.MultiGraph(graphs[batch_index])
- batch_label = labels[batch_index]
- batch_valid = (batch_label == batch_label).astype("float32")
- batch_label = np.nan_to_num(batch_label).astype("float32")
- feed_dict = graph_wrapper.to_feed(batch_graph)
- feed_dict["label"] = batch_label
- feed_dict["weight"] = batch_valid
- loss, pred = exe.run(train_program,
- feed=feed_dict,
- fetch_list=[fetch_loss, fetch_pred])
- pred_output[batch_index] = pred
- batch_no += 1
- print("train", evaluator.eval({"y_true": labels, "y_pred": pred_output}))
-
-
-def evaluate(exe, batch_size, graph_wrapper, val_program, splitted_idx,
- dataset, mode, evaluator, fetch_pred):
- """Eval"""
- graphs, labels = dataset[splitted_idx[mode]]
- perm = np.arange(0, len(graphs))
- start_batch = 0
- batch_no = 0
- pred_output = np.zeros_like(labels, dtype="float32")
- while start_batch < len(perm):
- batch_index = perm[start_batch:start_batch + batch_size]
- start_batch += batch_size
- batch_graph = pgl.graph.MultiGraph(graphs[batch_index])
- feed_dict = graph_wrapper.to_feed(batch_graph)
- pred = exe.run(val_program, feed=feed_dict, fetch_list=[fetch_pred])
- pred_output[batch_index] = pred[0]
- batch_no += 1
- print(mode, evaluator.eval({"y_true": labels, "y_pred": pred_output}))
-
-
-def send_func(src_feat, dst_feat, edge_feat):
- """Send"""
- return src_feat["h"] + edge_feat["h"]
-
-
-class GNNModel(object):
- """GNNModel"""
-
- def __init__(self, name, emb_dim, num_task, num_layers):
- self.num_task = num_task
- self.emb_dim = emb_dim
- self.num_layers = num_layers
- self.name = name
- self.atom_encoder = AtomEncoder(name=name, emb_dim=emb_dim)
- self.bond_encoder = BondEncoder(name=name, emb_dim=emb_dim)
-
- def forward(self, graph):
- """foward"""
- h_node = self.atom_encoder(graph.node_feat['feat'])
- h_edge = self.bond_encoder(graph.edge_feat['feat'])
- for layer in range(self.num_layers):
- msg = graph.send(
- send_func,
- nfeat_list=[("h", h_node)],
- efeat_list=[("h", h_edge)])
- h_node = graph.recv(msg, 'sum') + h_node
- h_node = fluid.layers.fc(h_node,
- size=self.emb_dim,
- name=self.name + '_%s' % layer,
- act="relu")
- graph_nodes = pgl.layers.graph_pooling(graph, h_node, "average")
- graph_pred = fluid.layers.fc(graph_nodes, self.num_task, name="final")
- return graph_pred
-
-
-def main():
- """main
- """
- # Training settings
- parser = argparse.ArgumentParser(description='Graph Dataset')
- parser.add_argument(
- '--epochs',
- type=int,
- default=100,
- help='number of epochs to train (default: 100)')
- parser.add_argument(
- '--dataset',
- type=str,
- default="ogbg-mol-tox21",
- help='dataset name (default: proteinfunc)')
- args = parser.parse_args()
-
- place = fluid.CPUPlace() # Dataset too big to use GPU
-
- ### automatic dataloading and splitting
- dataset = PglGraphPropPredDataset(name=args.dataset)
- splitted_idx = dataset.get_idx_split()
-
- ### automatic evaluator. takes dataset name as input
- evaluator = Evaluator(args.dataset)
-
- graph_data, label = dataset[:2]
- batch_graph = pgl.graph.MultiGraph(graph_data)
- graph_data = batch_graph
-
- train_program = fluid.Program()
- startup_program = fluid.Program()
- test_program = fluid.Program()
- # degree normalize
- graph_data.edge_feat["feat"] = graph_data.edge_feat["feat"].astype("int64")
- graph_data.node_feat["feat"] = graph_data.node_feat["feat"].astype("int64")
-
- model = GNNModel(
- name="gnn", num_task=dataset.num_tasks, emb_dim=64, num_layers=2)
-
- with fluid.program_guard(train_program, startup_program):
- gw = pgl.graph_wrapper.GraphWrapper(
- "graph",
- place=place,
- node_feat=graph_data.node_feat_info(),
- edge_feat=graph_data.edge_feat_info())
- pred = model.forward(gw)
- sigmoid_pred = fluid.layers.sigmoid(pred)
-
- val_program = train_program.clone(for_test=True)
-
- initializer = []
- with fluid.program_guard(train_program, startup_program):
- train_label = fluid.layers.data(
- name="label", dtype="float32", shape=[None, dataset.num_tasks])
- train_weight = fluid.layers.data(
- name="weight", dtype="float32", shape=[None, dataset.num_tasks])
- train_loss_t = fluid.layers.sigmoid_cross_entropy_with_logits(
- x=pred, label=train_label) * train_weight
- train_loss_t = fluid.layers.reduce_sum(train_loss_t)
-
- adam = fluid.optimizer.Adam(
- learning_rate=1e-2,
- regularization=fluid.regularizer.L2DecayRegularizer(
- regularization_coeff=0.0005))
- adam.minimize(train_loss_t)
-
- exe = fluid.Executor(place)
- exe.run(startup_program)
-
- for epoch in range(1, args.epochs + 1):
- print("Epoch", epoch)
- train(exe, 128, gw, train_program, splitted_idx, dataset, evaluator,
- train_loss_t, sigmoid_pred)
- evaluate(exe, 128, gw, val_program, splitted_idx, dataset, "valid",
- evaluator, sigmoid_pred)
- evaluate(exe, 128, gw, val_program, splitted_idx, dataset, "test",
- evaluator, sigmoid_pred)
-
-
-if __name__ == "__main__":
- main()
diff --git a/ogb_examples/graphproppred/mol/README.md b/ogb_examples/graphproppred/mol/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..d1f4da579a7ce909bfa00f6d41cb2470ca64df93
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/README.md
@@ -0,0 +1,37 @@
+# Graph Property Prediction for Open Graph Benchmark (OGB)
+
+[The Open Graph Benchmark (OGB)](https://ogb.stanford.edu/) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. Here we complete the Graph Property Prediction task based on PGL.
+
+### Requirements
+
+- paddlpaddle >= 1.7.1
+- pgl 1.0.2
+- ogb
+
+NOTE: To install ogb that is fited for this project, run below command to install ogb
+```
+git clone https://github.com/snap-stanford/ogb.git
+git checkout 482c40bc9f31fe25f9df5aa11c8fb657bd2b1621
+python setup.py install
+```
+
+### How to run
+For example, use GPU to train model on ogbg-molhiv dataset and ogb-molpcba dataset.
+```
+CUDA_VISIBLE_DEVICES=1 python -u main.py --config hiv_config.yaml --use_cuda
+
+CUDA_VISIBLE_DEVICES=2 python -u main.py --config pcba_config.yaml --use_cuda
+```
+
+If you want to use CPU to train model, environment variables `CPU_NUM` should be specified and should be in the range of 1 to N, where N is the total CPU number on your machine.
+```
+CPU_NUM=1 python -u main.py --config hiv_config.yaml
+
+CPU_NUM=1 python -u main.py --config pcba_config.yaml
+```
+
+### Experiment results
+
+| model | hiv (rocauc)| pcba (prcauc)|
+|-------|-------------|--------------|
+| GIN |0.7719 (0.0079) | 0.2232 (0.0018) |
diff --git a/ogb_examples/graphproppred/mol/args.py b/ogb_examples/graphproppred/mol/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..b637a5ad41471032268e6a00b3e759d1e27dec4b
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/args.py
@@ -0,0 +1,104 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import time
+import argparse
+
+from utils.args import ArgumentGroup
+
+# yapf: disable
+parser = argparse.ArgumentParser(__doc__)
+parser.add_argument('--use_cuda', action='store_true')
+model_g = ArgumentGroup(parser, "model", "model configuration and paths.")
+model_g.add_arg("init_checkpoint", str, None, "Init checkpoint to resume training from.")
+model_g.add_arg("init_pretraining_params", str, None,
+ "Init pre-training params which preforms fine-tuning from. If the "
+ "arg 'init_checkpoint' has been set, this argument wouldn't be valid.")
+model_g.add_arg("./save_dir", str, "./checkpoints", "Path to save checkpoints.")
+model_g.add_arg("hidden_size", int, 128, "hidden size.")
+
+
+train_g = ArgumentGroup(parser, "training", "training options.")
+train_g.add_arg("epoch", int, 3, "Number of epoches for fine-tuning.")
+train_g.add_arg("learning_rate", float, 5e-5, "Learning rate used to train with warmup.")
+train_g.add_arg("lr_scheduler", str, "linear_warmup_decay",
+ "scheduler of learning rate.", choices=['linear_warmup_decay', 'noam_decay'])
+train_g.add_arg("weight_decay", float, 0.01, "Weight decay rate for L2 regularizer.")
+train_g.add_arg("warmup_proportion", float, 0.1,
+ "Proportion of training steps to perform linear learning rate warmup for.")
+train_g.add_arg("save_steps", int, 10000, "The steps interval to save checkpoints.")
+train_g.add_arg("validation_steps", int, 1000, "The steps interval to evaluate model performance.")
+train_g.add_arg("use_dynamic_loss_scaling", bool, True, "Whether to use dynamic loss scaling.")
+train_g.add_arg("init_loss_scaling", float, 102400,
+ "Loss scaling factor for mixed precision training, only valid when use_fp16 is enabled.")
+
+train_g.add_arg("test_save", str, "./checkpoints/test_result", "test_save")
+train_g.add_arg("metric", str, "simple_accuracy", "metric")
+train_g.add_arg("incr_every_n_steps", int, 100, "Increases loss scaling every n consecutive.")
+train_g.add_arg("decr_every_n_nan_or_inf", int, 2,
+ "Decreases loss scaling every n accumulated steps with nan or inf gradients.")
+train_g.add_arg("incr_ratio", float, 2.0,
+ "The multiplier to use when increasing the loss scaling.")
+train_g.add_arg("decr_ratio", float, 0.8,
+ "The less-than-one-multiplier to use when decreasing.")
+
+
+
+
+log_g = ArgumentGroup(parser, "logging", "logging related.")
+log_g.add_arg("skip_steps", int, 10, "The steps interval to print loss.")
+log_g.add_arg("verbose", bool, False, "Whether to output verbose log.")
+log_g.add_arg("log_dir", str, './logs/', "Whether to output verbose log.")
+
+data_g = ArgumentGroup(parser, "data", "Data paths, vocab paths and data processing options")
+data_g.add_arg("tokenizer", str, "FullTokenizer",
+ "ATTENTION: the INPUT must be splited by Word with blank while using SentencepieceTokenizer or WordsegTokenizer")
+data_g.add_arg("train_set", str, None, "Path to training data.")
+data_g.add_arg("test_set", str, None, "Path to test data.")
+data_g.add_arg("dev_set", str, None, "Path to validation data.")
+data_g.add_arg("aug1_type", str, "scheme1", "augment type")
+data_g.add_arg("aug2_type", str, "scheme1", "augment type")
+data_g.add_arg("batch_size", int, 32, "Total examples' number in batch for training. see also --in_tokens.")
+data_g.add_arg("predict_batch_size", int, None, "Total examples' number in batch for predict. see also --in_tokens.")
+data_g.add_arg("random_seed", int, None, "Random seed.")
+data_g.add_arg("buf_size", int, 1000, "Random seed.")
+
+run_type_g = ArgumentGroup(parser, "run_type", "running type options.")
+run_type_g.add_arg("num_iteration_per_drop_scope", int, 10, "Iteration intervals to drop scope.")
+run_type_g.add_arg("do_train", bool, True, "Whether to perform training.")
+run_type_g.add_arg("do_val", bool, True, "Whether to perform evaluation on dev data set.")
+run_type_g.add_arg("do_test", bool, True, "Whether to perform evaluation on test data set.")
+run_type_g.add_arg("metrics", bool, True, "Whether to perform evaluation on test data set.")
+run_type_g.add_arg("shuffle", bool, True, "")
+run_type_g.add_arg("for_cn", bool, True, "model train for cn or for other langs.")
+run_type_g.add_arg("num_workers", int, 1, "use multiprocess to generate graph")
+run_type_g.add_arg("output_dir", str, None, "path to save model")
+run_type_g.add_arg("config", str, None, "configure yaml file")
+run_type_g.add_arg("n", str, None, "task name")
+run_type_g.add_arg("task_name", str, None, "task name")
+run_type_g.add_arg("pretrain", bool, False, "Whether do pretrian")
+run_type_g.add_arg("pretrain_name", str, None, "pretrain task name")
+run_type_g.add_arg("pretrain_config", str, None, "pretrain config.yaml file")
+run_type_g.add_arg("pretrain_model_step", str, None, "pretrain model step")
+run_type_g.add_arg("model_type", str, "BaseLineModel", "pretrain model step")
+run_type_g.add_arg("num_class", int, 1, "number class")
+run_type_g.add_arg("dataset_name", str, None, "finetune dataset name")
+run_type_g.add_arg("eval_metrics", str, None, "evaluate metrics")
+run_type_g.add_arg("task_type", str, None, "regression or classification")
diff --git a/ogb_examples/graphproppred/mol/data/__init__.py b/ogb_examples/graphproppred/mol/data/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..abf198b97e6e818e1fbe59006f98492640bcee54
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/data/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/ogb_examples/graphproppred/mol/data/base_dataset.py b/ogb_examples/graphproppred/mol/data/base_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..e802ea5254100c121a216d9cb4f1cd0c1f264d9d
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/data/base_dataset.py
@@ -0,0 +1,83 @@
+# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import sys
+import os
+
+from ogb.graphproppred import GraphPropPredDataset
+import pgl
+from pgl.utils.logger import log
+
+
+class BaseDataset(object):
+ def __init__(self):
+ pass
+
+ def __getitem__(self, idx):
+ raise NotImplementedError
+
+ def __len__(self):
+ raise NotImplementedError
+
+
+class Subset(BaseDataset):
+ r"""
+ Subset of a dataset at specified indices.
+ Arguments:
+ dataset (Dataset): The whole Dataset
+ indices (sequence): Indices in the whole set selected for subset
+ """
+
+ def __init__(self, dataset, indices):
+ self.dataset = dataset
+ self.indices = indices
+
+ def __getitem__(self, idx):
+ return self.dataset[self.indices[idx]]
+
+ def __len__(self):
+ return len(self.indices)
+
+
+class Dataset(BaseDataset):
+ def __init__(self, args):
+ self.args = args
+ self.raw_dataset = GraphPropPredDataset(name=args.dataset_name)
+ self.num_tasks = self.raw_dataset.num_tasks
+ self.eval_metrics = self.raw_dataset.eval_metric
+ self.task_type = self.raw_dataset.task_type
+
+ self.pgl_graph_list = []
+ self.graph_label_list = []
+ for i in range(len(self.raw_dataset)):
+ graph, label = self.raw_dataset[i]
+ edges = list(zip(graph["edge_index"][0], graph["edge_index"][1]))
+ g = pgl.graph.Graph(num_nodes=graph["num_nodes"], edges=edges)
+
+ if graph["edge_feat"] is not None:
+ g.edge_feat["feat"] = graph["edge_feat"]
+
+ if graph["node_feat"] is not None:
+ g.node_feat["feat"] = graph["node_feat"]
+
+ self.pgl_graph_list.append(g)
+ self.graph_label_list.append(label)
+
+ def __getitem__(self, idx):
+ return self.pgl_graph_list[idx], self.graph_label_list[idx]
+
+ def __len__(self):
+ return len(slef.pgl_graph_list)
+
+ def get_idx_split(self):
+ return self.raw_dataset.get_idx_split()
diff --git a/ogb_examples/graphproppred/mol/data/dataloader.py b/ogb_examples/graphproppred/mol/data/dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..66023d0971f74121ee1cae8711c50a11ba6f9536
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/data/dataloader.py
@@ -0,0 +1,183 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This file implement the graph dataloader.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+# SSL
+
+import torch
+import sys
+import six
+from io import open
+import collections
+from collections import namedtuple
+import numpy as np
+import tqdm
+import time
+
+import paddle
+import paddle.fluid as fluid
+import paddle.fluid.layers as fl
+import pgl
+from pgl.utils import mp_reader
+from pgl.utils.logger import log
+
+from ogb.graphproppred import GraphPropPredDataset
+
+
+def batch_iter(data, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ size = len(data)
+ perm = np.arange(size)
+ np.random.shuffle(perm)
+ start = 0
+ cc = 0
+ while start < size:
+ index = perm[start:start + batch_size]
+ start += batch_size
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ yield data[index]
+
+
+def scan_batch_iter(data, batch_size, fid, num_workers):
+ """scan_batch_iter
+ """
+ batch = []
+ cc = 0
+ for line_example in data.scan():
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ batch.append(line_example)
+ if len(batch) == batch_size:
+ yield batch
+ batch = []
+
+ if len(batch) > 0:
+ yield batch
+
+
+class GraphDataloader(object):
+ """Graph Dataloader
+ """
+
+ def __init__(self,
+ dataset,
+ graph_wrapper,
+ batch_size,
+ seed=0,
+ num_workers=1,
+ buf_size=1000,
+ shuffle=True):
+
+ self.shuffle = shuffle
+ self.seed = seed
+ self.num_workers = num_workers
+ self.buf_size = buf_size
+ self.batch_size = batch_size
+ self.dataset = dataset
+ self.graph_wrapper = graph_wrapper
+
+ def batch_fn(self, batch_examples):
+ """ batch_fn batch producer"""
+ graphs = [b[0] for b in batch_examples]
+ labels = [b[1] for b in batch_examples]
+ join_graph = pgl.graph.MultiGraph(graphs)
+ labels = np.array(labels)
+
+ feed_dict = self.graph_wrapper.to_feed(join_graph)
+ batch_valid = (labels == labels).astype("float32")
+ labels = np.nan_to_num(labels).astype("float32")
+ feed_dict['labels'] = labels
+ feed_dict['unmask'] = batch_valid
+ return feed_dict
+
+ def batch_iter(self, fid):
+ """batch_iter"""
+ if self.shuffle:
+ for batch in batch_iter(self, self.batch_size, fid,
+ self.num_workers):
+ yield batch
+ else:
+ for batch in scan_batch_iter(self, self.batch_size, fid,
+ self.num_workers):
+ yield batch
+
+ def __len__(self):
+ """__len__"""
+ return len(self.dataset)
+
+ def __getitem__(self, idx):
+ """__getitem__"""
+ if isinstance(idx, collections.Iterable):
+ return [self[bidx] for bidx in idx]
+ else:
+ return self.dataset[idx]
+
+ def __iter__(self):
+ """__iter__"""
+
+ def worker(filter_id):
+ def func_run():
+ for batch_examples in self.batch_iter(filter_id):
+ batch_dict = self.batch_fn(batch_examples)
+ yield batch_dict
+
+ return func_run
+
+ if self.num_workers == 1:
+ r = paddle.reader.buffered(worker(0), self.buf_size)
+ else:
+ worker_pool = [worker(wid) for wid in range(self.num_workers)]
+ worker = mp_reader.multiprocess_reader(
+ worker_pool, use_pipe=True, queue_size=1000)
+ r = paddle.reader.buffered(worker, self.buf_size)
+
+ for batch in r():
+ yield batch
+
+ def scan(self):
+ """scan"""
+ for example in self.dataset:
+ yield example
+
+
+if __name__ == "__main__":
+ from base_dataset import BaseDataset, Subset
+ dataset = GraphPropPredDataset(name="ogbg-molhiv")
+ splitted_index = dataset.get_idx_split()
+ train_dataset = Subset(dataset, splitted_index['train'])
+ valid_dataset = Subset(dataset, splitted_index['valid'])
+ test_dataset = Subset(dataset, splitted_index['test'])
+ log.info("Train Examples: %s" % len(train_dataset))
+ log.info("Val Examples: %s" % len(valid_dataset))
+ log.info("Test Examples: %s" % len(test_dataset))
+
+ # train_loader = GraphDataloader(train_dataset, batch_size=3)
+ # for batch_data in train_loader:
+ # graphs, labels = batch_data
+ # print(labels.shape)
+ # time.sleep(4)
diff --git a/ogb_examples/graphproppred/mol/data/splitters.py b/ogb_examples/graphproppred/mol/data/splitters.py
new file mode 100644
index 0000000000000000000000000000000000000000..be1f1c1d94b16bfe17346eabeee553f8c3e1965a
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/data/splitters.py
@@ -0,0 +1,153 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import os
+import logging
+from random import random
+import pandas as pd
+import numpy as np
+from itertools import compress
+
+import scipy.sparse as sp
+from sklearn.model_selection import StratifiedKFold
+from sklearn.preprocessing import StandardScaler
+from rdkit.Chem.Scaffolds import MurckoScaffold
+
+import pgl
+from pgl.utils import paddle_helper
+try:
+ from dataset.Dataset import Subset
+ from dataset.Dataset import ChemDataset
+except:
+ from Dataset import Subset
+ from Dataset import ChemDataset
+
+log = logging.getLogger("logger")
+
+
+def random_split(dataset, args):
+ total_precent = args.frac_train + args.frac_valid + args.frac_test
+ np.testing.assert_almost_equal(total_precent, 1.0)
+
+ length = len(dataset)
+ perm = list(range(length))
+ np.random.shuffle(perm)
+ num_train = int(args.frac_train * length)
+ num_valid = int(args.frac_valid * length)
+ num_test = int(args.frac_test * length)
+
+ train_indices = perm[0:num_train]
+ valid_indices = perm[num_train:(num_train + num_valid)]
+ test_indices = perm[(num_train + num_valid):]
+ assert (len(train_indices) + len(valid_indices) + len(test_indices)
+ ) == length
+
+ train_dataset = Subset(dataset, train_indices)
+ valid_dataset = Subset(dataset, valid_indices)
+ test_dataset = Subset(dataset, test_indices)
+ return train_dataset, valid_dataset, test_dataset
+
+
+def scaffold_split(dataset, args, return_smiles=False):
+ total_precent = args.frac_train + args.frac_valid + args.frac_test
+ np.testing.assert_almost_equal(total_precent, 1.0)
+
+ smiles_list_file = os.path.join(args.data_dir, "smiles.csv")
+ smiles_list = pd.read_csv(smiles_list_file, header=None)[0].tolist()
+
+ non_null = np.ones(len(dataset)) == 1
+ smiles_list = list(compress(enumerate(smiles_list), non_null))
+
+ # create dict of the form {scaffold_i: [idx1, idx....]}
+ all_scaffolds = {}
+ for i, smiles in smiles_list:
+ scaffold = MurckoScaffold.MurckoScaffoldSmiles(
+ smiles=smiles, includeChirality=True)
+ # scaffold = generate_scaffold(smiles, include_chirality=True)
+ if scaffold not in all_scaffolds:
+ all_scaffolds[scaffold] = [i]
+ else:
+ all_scaffolds[scaffold].append(i)
+
+ # sort from largest to smallest sets
+ all_scaffolds = {
+ key: sorted(value)
+ for key, value in all_scaffolds.items()
+ }
+ all_scaffold_sets = [
+ scaffold_set
+ for (scaffold, scaffold_set) in sorted(
+ all_scaffolds.items(),
+ key=lambda x: (len(x[1]), x[1][0]),
+ reverse=True)
+ ]
+
+ # get train, valid test indices
+ train_cutoff = args.frac_train * len(smiles_list)
+ valid_cutoff = (args.frac_train + args.frac_valid) * len(smiles_list)
+ train_idx, valid_idx, test_idx = [], [], []
+ for scaffold_set in all_scaffold_sets:
+ if len(train_idx) + len(scaffold_set) > train_cutoff:
+ if len(train_idx) + len(valid_idx) + len(
+ scaffold_set) > valid_cutoff:
+ test_idx.extend(scaffold_set)
+ else:
+ valid_idx.extend(scaffold_set)
+ else:
+ train_idx.extend(scaffold_set)
+
+ assert len(set(train_idx).intersection(set(valid_idx))) == 0
+ assert len(set(test_idx).intersection(set(valid_idx))) == 0
+ # log.info(len(scaffold_set))
+ # log.info(["train_idx", train_idx])
+ # log.info(["valid_idx", valid_idx])
+ # log.info(["test_idx", test_idx])
+
+ train_dataset = Subset(dataset, train_idx)
+ valid_dataset = Subset(dataset, valid_idx)
+ test_dataset = Subset(dataset, test_idx)
+
+ if return_smiles:
+ train_smiles = [smiles_list[i][1] for i in train_idx]
+ valid_smiles = [smiles_list[i][1] for i in valid_idx]
+ test_smiles = [smiles_list[i][1] for i in test_idx]
+
+ return train_dataset, valid_dataset, test_dataset, (
+ train_smiles, valid_smiles, test_smiles)
+
+ return train_dataset, valid_dataset, test_dataset
+
+
+if __name__ == "__main__":
+ file_path = os.path.dirname(os.path.realpath(__file__))
+ proj_path = os.path.join(file_path, '../')
+ sys.path.append(proj_path)
+ from utils.config import Config
+ from dataset.Dataset import Subset
+ from dataset.Dataset import ChemDataset
+
+ config_file = "./finetune_config.yaml"
+ args = Config(config_file)
+ log.info("loading dataset")
+ dataset = ChemDataset(args)
+
+ train_dataset, valid_dataset, test_dataset = scaffold_split(dataset, args)
+
+ log.info("Train Examples: %s" % len(train_dataset))
+ log.info("Val Examples: %s" % len(valid_dataset))
+ log.info("Test Examples: %s" % len(test_dataset))
+ import ipdb
+ ipdb.set_trace()
+ log.info("preprocess finish")
diff --git a/ogb_examples/graphproppred/mol/hiv_config.yaml b/ogb_examples/graphproppred/mol/hiv_config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..ee0afbbb2af1b3315569e87ab09cad9f451120d8
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/hiv_config.yaml
@@ -0,0 +1,53 @@
+task_name: hiv
+seed: 15391
+dataset_name: ogbg-molhiv
+eval_metrics: null
+task_type: null
+num_class: null
+pool_type: average
+train_eps: True
+norm_type: layer_norm
+
+model_type: GNNModel
+embed_dim: 128
+num_layers: 5
+hidden_size: 256
+save_dir: ./checkpoints
+
+
+# finetune model config
+init_checkpoint: null
+init_pretraining_params: null
+
+# data config
+data_dir: ./dataset/
+symmetry: True
+batch_size: 32
+buf_size: 1000
+metrics: True
+shuffle: True
+num_workers: 12
+output_dir: ./outputs/
+
+# trainging config
+epoch: 50
+learning_rate: 0.0001
+lr_scheduler: linear_warmup_decay
+weight_decay: 0.01
+warmup_proportion: 0.1
+save_steps: 10000
+validation_steps: 1000
+use_dynamic_loss_scaling: True
+init_loss_scaling: 102400
+metric: simple_accuracy
+incr_every_n_steps: 100
+decr_every_n_nan_or_inf: 2
+incr_ratio: 2.0
+decr_ratio: 0.8
+log_dir: ./logs
+eval_step: 400
+train_log_step: 20
+
+# log config
+skip_steps: 10
+verbose: False
diff --git a/ogb_examples/graphproppred/mol/main.py b/ogb_examples/graphproppred/mol/main.py
new file mode 100644
index 0000000000000000000000000000000000000000..bbc4dc4600524c2e3c6b804d2d9a5dd6be17c27c
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/main.py
@@ -0,0 +1,180 @@
+# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+# SSL
+
+import torch
+import os
+import re
+import time
+from random import random
+from functools import reduce, partial
+import numpy as np
+import multiprocessing
+
+from ogb.graphproppred import Evaluator
+import paddle
+import paddle.fluid as F
+import paddle.fluid.layers as L
+import pgl
+from pgl.utils import paddle_helper
+from pgl.utils.logger import log
+
+from utils.args import print_arguments, check_cuda, prepare_logger
+from utils.init import init_checkpoint, init_pretraining_params
+from utils.config import Config
+from optimization import optimization
+from monitor.train_monitor import train_and_evaluate
+from args import parser
+
+import model as Model
+from data.base_dataset import Subset, Dataset
+from data.dataloader import GraphDataloader
+
+
+def main(args):
+ log.info('loading data')
+ dataset = Dataset(args)
+ args.num_class = dataset.num_tasks
+ args.eval_metrics = dataset.eval_metrics
+ args.task_type = dataset.task_type
+ splitted_index = dataset.get_idx_split()
+ train_dataset = Subset(dataset, splitted_index['train'])
+ valid_dataset = Subset(dataset, splitted_index['valid'])
+ test_dataset = Subset(dataset, splitted_index['test'])
+
+ log.info("preprocess finish")
+ log.info("Train Examples: %s" % len(train_dataset))
+ log.info("Val Examples: %s" % len(valid_dataset))
+ log.info("Test Examples: %s" % len(test_dataset))
+
+ train_prog = F.Program()
+ startup_prog = F.Program()
+
+ if args.use_cuda:
+ dev_list = F.cuda_places()
+ place = dev_list[0]
+ dev_count = len(dev_list)
+ else:
+ place = F.CPUPlace()
+ dev_count = int(os.environ.get('CPU_NUM', multiprocessing.cpu_count()))
+ # dev_count = args.cpu_num
+
+ log.info("building model")
+ with F.program_guard(train_prog, startup_prog):
+ with F.unique_name.guard():
+ graph_model = getattr(Model, args.model_type)(args, dataset)
+ train_ds = GraphDataloader(
+ train_dataset,
+ graph_model.graph_wrapper,
+ batch_size=args.batch_size)
+
+ num_train_examples = len(train_dataset)
+ max_train_steps = args.epoch * num_train_examples // args.batch_size // dev_count
+ warmup_steps = int(max_train_steps * args.warmup_proportion)
+
+ scheduled_lr, loss_scaling = optimization(
+ loss=graph_model.loss,
+ warmup_steps=warmup_steps,
+ num_train_steps=max_train_steps,
+ learning_rate=args.learning_rate,
+ train_program=train_prog,
+ startup_prog=startup_prog,
+ weight_decay=args.weight_decay,
+ scheduler=args.lr_scheduler,
+ use_fp16=False,
+ use_dynamic_loss_scaling=args.use_dynamic_loss_scaling,
+ init_loss_scaling=args.init_loss_scaling,
+ incr_every_n_steps=args.incr_every_n_steps,
+ decr_every_n_nan_or_inf=args.decr_every_n_nan_or_inf,
+ incr_ratio=args.incr_ratio,
+ decr_ratio=args.decr_ratio)
+
+ test_prog = F.Program()
+ with F.program_guard(test_prog, startup_prog):
+ with F.unique_name.guard():
+ _graph_model = getattr(Model, args.model_type)(args, dataset)
+
+ test_prog = test_prog.clone(for_test=True)
+
+ valid_ds = GraphDataloader(
+ valid_dataset,
+ graph_model.graph_wrapper,
+ batch_size=args.batch_size,
+ shuffle=False)
+ test_ds = GraphDataloader(
+ test_dataset,
+ graph_model.graph_wrapper,
+ batch_size=args.batch_size,
+ shuffle=False)
+
+ exe = F.Executor(place)
+ exe.run(startup_prog)
+ for init in graph_model.init_vars:
+ init(place)
+ for init in _graph_model.init_vars:
+ init(place)
+
+ if args.init_pretraining_params is not None:
+ init_pretraining_params(
+ exe, args.init_pretraining_params, main_program=startup_prog)
+
+ nccl2_num_trainers = 1
+ nccl2_trainer_id = 0
+ if dev_count > 1:
+
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = dev_count
+
+ train_exe = F.ParallelExecutor(
+ use_cuda=args.use_cuda,
+ loss_name=graph_model.loss.name,
+ exec_strategy=exec_strategy,
+ main_program=train_prog,
+ num_trainers=nccl2_num_trainers,
+ trainer_id=nccl2_trainer_id)
+
+ test_exe = exe
+ else:
+ train_exe, test_exe = exe, exe
+
+ evaluator = Evaluator(args.dataset_name)
+
+ train_and_evaluate(
+ exe=exe,
+ train_exe=train_exe,
+ valid_exe=test_exe,
+ train_ds=train_ds,
+ valid_ds=valid_ds,
+ test_ds=test_ds,
+ train_prog=train_prog,
+ valid_prog=test_prog,
+ args=args,
+ dev_count=dev_count,
+ evaluator=evaluator,
+ model=graph_model)
+
+
+if __name__ == "__main__":
+ args = parser.parse_args()
+ if args.config is not None:
+ config = Config(args.config, isCreate=True, isSave=True)
+
+ config['use_cuda'] = args.use_cuda
+
+ log.info(config)
+
+ main(config)
diff --git a/ogb_examples/graphproppred/mol/model.py b/ogb_examples/graphproppred/mol/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..f9e89c8942a52c3f46c79966d5e26bd3d9cbf311
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/model.py
@@ -0,0 +1,210 @@
+#-*- coding: utf-8 -*-
+import os
+import re
+import time
+import logging
+from random import random
+from functools import reduce, partial
+
+import numpy as np
+import multiprocessing
+
+import paddle
+import paddle.fluid as F
+import paddle.fluid.layers as L
+import pgl
+from pgl.graph_wrapper import GraphWrapper
+from pgl.layers.conv import gcn, gat
+from pgl.utils import paddle_helper
+from pgl.utils.logger import log
+
+from utils.args import print_arguments, check_cuda, prepare_logger
+from utils.init import init_checkpoint, init_pretraining_params
+
+from mol_encoder import AtomEncoder, BondEncoder
+
+
+def copy_send(src_feat, dst_feat, edge_feat):
+ return src_feat["h"]
+
+
+def mean_recv(feat):
+ return L.sequence_pool(feat, pool_type="average")
+
+
+def sum_recv(feat):
+ return L.sequence_pool(feat, pool_type="sum")
+
+
+def max_recv(feat):
+ return L.sequence_pool(feat, pool_type="max")
+
+
+def unsqueeze(tensor):
+ tensor = L.unsqueeze(tensor, axes=-1)
+ tensor.stop_gradient = True
+ return tensor
+
+
+class Metric:
+ def __init__(self, **args):
+ self.args = args
+
+ @property
+ def vars(self):
+ values = [self.args[k] for k in self.args.keys()]
+ return values
+
+ def parse(self, fetch_list):
+ tup = list(zip(self.args.keys(), [float(v[0]) for v in fetch_list]))
+ return dict(tup)
+
+
+def gin_layer(gw, node_features, edge_features, train_eps, name):
+ def send_func(src_feat, dst_feat, edge_feat):
+ """Send"""
+ return src_feat["h"] + edge_feat["h"]
+
+ epsilon = L.create_parameter(
+ shape=[1, 1],
+ dtype="float32",
+ attr=F.ParamAttr(name="%s_eps" % name),
+ default_initializer=F.initializer.ConstantInitializer(value=0.0))
+ if not train_eps:
+ epsilon.stop_gradient = True
+
+ msg = gw.send(
+ send_func,
+ nfeat_list=[("h", node_features)],
+ efeat_list=[("h", edge_features)])
+
+ node_feat = gw.recv(msg, "sum") + node_features * (epsilon + 1.0)
+
+ # if apply_func is not None:
+ # node_feat = apply_func(node_feat, name)
+ return node_feat
+
+
+class GNNModel(object):
+ def __init__(self, args, dataset):
+ self.args = args
+ self.dataset = dataset
+ self.hidden_size = self.args.hidden_size
+ self.embed_dim = self.args.embed_dim
+ self.dropout_prob = self.args.dropout_rate
+ self.pool_type = self.args.pool_type
+ self._init_vars = []
+
+ graph_data = []
+ g, label = self.dataset[0]
+ graph_data.append(g)
+ g, label = self.dataset[1]
+ graph_data.append(g)
+
+ batch_graph = pgl.graph.MultiGraph(graph_data)
+ graph_data = batch_graph
+ graph_data.edge_feat["feat"] = graph_data.edge_feat["feat"].astype(
+ "int64")
+ graph_data.node_feat["feat"] = graph_data.node_feat["feat"].astype(
+ "int64")
+ self.graph_wrapper = GraphWrapper(
+ name="graph",
+ place=F.CPUPlace(),
+ node_feat=graph_data.node_feat_info(),
+ edge_feat=graph_data.edge_feat_info())
+
+ self.atom_encoder = AtomEncoder(name="atom", emb_dim=self.embed_dim)
+ self.bond_encoder = BondEncoder(name="bond", emb_dim=self.embed_dim)
+
+ self.labels = L.data(
+ "labels",
+ shape=[None, self.args.num_class],
+ dtype="float32",
+ append_batch_size=False)
+
+ self.unmask = L.data(
+ "unmask",
+ shape=[None, self.args.num_class],
+ dtype="float32",
+ append_batch_size=False)
+
+ self.build_model()
+
+ def build_model(self):
+ node_features = self.atom_encoder(self.graph_wrapper.node_feat['feat'])
+ edge_features = self.bond_encoder(self.graph_wrapper.edge_feat['feat'])
+
+ self._enc_out = self.node_repr_encode(node_features, edge_features)
+
+ logits = L.fc(self._enc_out,
+ self.args.num_class,
+ act=None,
+ param_attr=F.ParamAttr(name="final_fc"))
+
+ # L.Print(self.labels, message="labels")
+ # L.Print(self.unmask, message="unmask")
+ loss = L.sigmoid_cross_entropy_with_logits(x=logits, label=self.labels)
+ loss = loss * self.unmask
+ self.loss = L.reduce_sum(loss) / L.reduce_sum(self.unmask)
+ self.pred = L.sigmoid(logits)
+
+ self._metrics = Metric(loss=self.loss)
+
+ def node_repr_encode(self, node_features, edge_features):
+ features_list = [node_features]
+ for layer in range(self.args.num_layers):
+ feat = gin_layer(
+ self.graph_wrapper,
+ features_list[layer],
+ edge_features,
+ train_eps=self.args.train_eps,
+ name="gin_%s" % layer, )
+
+ feat = self.mlp(feat, name="mlp_%s" % layer)
+
+ feat = feat + features_list[layer] # residual
+
+ features_list.append(feat)
+
+ output = pgl.layers.graph_pooling(
+ self.graph_wrapper, features_list[-1], self.args.pool_type)
+
+ return output
+
+ def mlp(self, features, name):
+ h = features
+ dim = features.shape[-1]
+ dim_list = [dim * 2, dim]
+ for i in range(2):
+ h = L.fc(h,
+ size=dim_list[i],
+ name="%s_fc_%s" % (name, i),
+ act=None)
+ if self.args.norm_type == "layer_norm":
+ log.info("norm_type is %s" % self.args.norm_type)
+ h = L.layer_norm(
+ h,
+ begin_norm_axis=1,
+ param_attr=F.ParamAttr(
+ name="norm_scale_%s_%s" % (name, i),
+ initializer=F.initializer.Constant(1.0)),
+ bias_attr=F.ParamAttr(
+ name="norm_bias_%s_%s" % (name, i),
+ initializer=F.initializer.Constant(0.0)), )
+ else:
+ log.info("using batch_norm")
+ h = L.batch_norm(h)
+ h = pgl.layers.graph_norm(self.graph_wrapper, h)
+ h = L.relu(h)
+ return h
+
+ def get_enc_output(self):
+ return self._enc_out
+
+ @property
+ def init_vars(self):
+ return self._init_vars
+
+ @property
+ def metrics(self):
+ return self._metrics
diff --git a/ogb_examples/graphproppred/mol/mol_encoder.py b/ogb_examples/graphproppred/mol/mol_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..2662d141532dc58925f30e0973d5d85bb4953bd3
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/mol_encoder.py
@@ -0,0 +1,71 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""MolEncoder for ogb
+"""
+import paddle.fluid as fluid
+from ogb.utils.features import get_atom_feature_dims, get_bond_feature_dims
+
+
+class AtomEncoder(object):
+ """AtomEncoder for encoding node features"""
+
+ def __init__(self, name, emb_dim):
+ self.emb_dim = emb_dim
+ self.name = name
+
+ def __call__(self, x):
+ atom_feature = get_atom_feature_dims()
+ atom_input = fluid.layers.split(
+ x, num_or_sections=len(atom_feature), dim=-1)
+ outputs = None
+ count = 0
+ for _x, _atom_input_dim in zip(atom_input, atom_feature):
+ count += 1
+ emb = fluid.layers.embedding(
+ _x,
+ size=(_atom_input_dim, self.emb_dim),
+ param_attr=fluid.ParamAttr(
+ name=self.name + '_atom_feat_%s' % count))
+ if outputs is None:
+ outputs = emb
+ else:
+ outputs = outputs + emb
+ return outputs
+
+
+class BondEncoder(object):
+ """Bond for encoding edge features"""
+
+ def __init__(self, name, emb_dim):
+ self.emb_dim = emb_dim
+ self.name = name
+
+ def __call__(self, x):
+ bond_feature = get_bond_feature_dims()
+ bond_input = fluid.layers.split(
+ x, num_or_sections=len(bond_feature), dim=-1)
+ outputs = None
+ count = 0
+ for _x, _bond_input_dim in zip(bond_input, bond_feature):
+ count += 1
+ emb = fluid.layers.embedding(
+ _x,
+ size=(_bond_input_dim, self.emb_dim),
+ param_attr=fluid.ParamAttr(
+ name=self.name + '_bond_feat_%s' % count))
+ if outputs is None:
+ outputs = emb
+ else:
+ outputs = outputs + emb
+ return outputs
diff --git a/ogb_examples/graphproppred/mol/monitor/train_monitor.py b/ogb_examples/graphproppred/mol/monitor/train_monitor.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c9892c117f766aa1219deacbd7456ea5c47e25c
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/monitor/train_monitor.py
@@ -0,0 +1,154 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import tqdm
+import json
+import numpy as np
+import os
+from datetime import datetime
+import logging
+from collections import defaultdict
+
+import paddle.fluid as F
+from pgl.utils.logger import log
+from pgl.utils.log_writer import LogWriter
+
+
+def multi_device(reader, dev_count):
+ if dev_count == 1:
+ for batch in reader:
+ yield batch
+ else:
+ batches = []
+ for batch in reader:
+ batches.append(batch)
+ if len(batches) == dev_count:
+ yield batches
+ batches = []
+
+
+def evaluate(exe, loader, prog, model, evaluator):
+ total_labels = []
+ for i in range(len(loader.dataset)):
+ g, l = loader.dataset[i]
+ total_labels.append(l)
+ total_labels = np.vstack(total_labels)
+
+ pred_output = []
+ for feed_dict in loader:
+ ret = exe.run(prog, feed=feed_dict, fetch_list=model.pred)
+ pred_output.append(ret[0])
+
+ pred_output = np.vstack(pred_output)
+
+ result = evaluator.eval({"y_true": total_labels, "y_pred": pred_output})
+
+ return result
+
+
+def _create_if_not_exist(path):
+ basedir = os.path.dirname(path)
+ if not os.path.exists(basedir):
+ os.makedirs(basedir)
+
+
+def train_and_evaluate(exe,
+ train_exe,
+ valid_exe,
+ train_ds,
+ valid_ds,
+ test_ds,
+ train_prog,
+ valid_prog,
+ args,
+ model,
+ evaluator,
+ dev_count=1):
+
+ global_step = 0
+
+ timestamp = datetime.now().strftime("%Hh%Mm%Ss")
+ log_path = os.path.join(args.log_dir, "log_%s" % timestamp)
+ _create_if_not_exist(log_path)
+
+ writer = LogWriter(log_path)
+
+ best_valid_score = 0.0
+ for e in range(args.epoch):
+ for feed_dict in multi_device(train_ds, dev_count):
+ if dev_count > 1:
+ ret = train_exe.run(feed=feed_dict,
+ fetch_list=model.metrics.vars)
+ ret = [[np.mean(v)] for v in ret]
+ else:
+ ret = train_exe.run(train_prog,
+ feed=feed_dict,
+ fetch_list=model.metrics.vars)
+
+ ret = model.metrics.parse(ret)
+ if global_step % args.train_log_step == 0:
+ writer.add_scalar(
+ "batch_loss", ret['loss'], global_step)
+ log.info("epoch: %d | step: %d | loss: %.4f " %
+ (e, global_step, ret['loss']))
+
+ global_step += 1
+ if global_step % args.eval_step == 0:
+ valid_ret = evaluate(exe, valid_ds, valid_prog, model,
+ evaluator)
+ message = "valid: "
+ for key, value in valid_ret.items():
+ message += "%s %.4f | " % (key, value)
+ writer.add_scalar(
+ "eval_%s" % key, value, global_step)
+ log.info(message)
+
+ # testing
+ test_ret = evaluate(exe, test_ds, valid_prog, model, evaluator)
+ message = "test: "
+ for key, value in test_ret.items():
+ message += "%s %.4f | " % (key, value)
+ writer.add_scalar(
+ "test_%s" % key, value, global_step)
+ log.info(message)
+
+ # evaluate after one epoch
+ valid_ret = evaluate(exe, valid_ds, valid_prog, model, evaluator)
+ message = "epoch %s valid: " % e
+ for key, value in valid_ret.items():
+ message += "%s %.4f | " % (key, value)
+ writer.add_scalar("eval_%s" % key, value, global_step)
+ log.info(message)
+
+ # testing
+ test_ret = evaluate(exe, test_ds, valid_prog, model, evaluator)
+ message = "epoch %s test: " % e
+ for key, value in test_ret.items():
+ message += "%s %.4f | " % (key, value)
+ writer.add_scalar("test_%s" % key, value, global_step)
+ log.info(message)
+
+ message = "epoch %s best %s result | " % (e, args.eval_metrics)
+ if valid_ret[args.eval_metrics] > best_valid_score:
+ best_valid_score = valid_ret[args.eval_metrics]
+ best_test_score = test_ret[args.eval_metrics]
+
+ message += "valid %.4f | test %.4f" % (best_valid_score,
+ best_test_score)
+ log.info(message)
+
+ # if global_step % args.save_step == 0:
+ # F.io.save_persistables(exe, os.path.join(args.save_dir, "%s" % global_step), train_prog)
+
+ writer.close()
diff --git a/ogb_examples/graphproppred/mol/optimization.py b/ogb_examples/graphproppred/mol/optimization.py
new file mode 100644
index 0000000000000000000000000000000000000000..23a958f30459143d9ac581a26c9bf7690452bb69
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/optimization.py
@@ -0,0 +1,163 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Optimization and learning rate scheduling."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import numpy as np
+import paddle.fluid as fluid
+from utils.fp16 import create_master_params_grads, master_param_to_train_param, apply_dynamic_loss_scaling
+
+
+def linear_warmup_decay(learning_rate, warmup_steps, num_train_steps):
+ """ Applies linear warmup of learning rate from 0 and decay to 0."""
+ with fluid.default_main_program()._lr_schedule_guard():
+ lr = fluid.layers.tensor.create_global_var(
+ shape=[1],
+ value=0.0,
+ dtype='float32',
+ persistable=True,
+ name="scheduled_learning_rate")
+
+ global_step = fluid.layers.learning_rate_scheduler._decay_step_counter(
+ )
+
+ with fluid.layers.control_flow.Switch() as switch:
+ with switch.case(global_step < warmup_steps):
+ warmup_lr = learning_rate * (global_step / warmup_steps)
+ fluid.layers.tensor.assign(warmup_lr, lr)
+ with switch.default():
+ decayed_lr = fluid.layers.learning_rate_scheduler.polynomial_decay(
+ learning_rate=learning_rate,
+ decay_steps=num_train_steps,
+ end_learning_rate=0.0,
+ power=1.0,
+ cycle=False)
+ fluid.layers.tensor.assign(decayed_lr, lr)
+
+ return lr
+
+
+def optimization(loss,
+ warmup_steps,
+ num_train_steps,
+ learning_rate,
+ train_program,
+ startup_prog,
+ weight_decay,
+ scheduler='linear_warmup_decay',
+ use_fp16=False,
+ use_dynamic_loss_scaling=False,
+ init_loss_scaling=1.0,
+ incr_every_n_steps=1000,
+ decr_every_n_nan_or_inf=2,
+ incr_ratio=2.0,
+ decr_ratio=0.8):
+ if warmup_steps > 0:
+ if scheduler == 'noam_decay':
+ scheduled_lr = fluid.layers.learning_rate_scheduler\
+ .noam_decay(1/(warmup_steps *(learning_rate ** 2)),
+ warmup_steps)
+ elif scheduler == 'linear_warmup_decay':
+ scheduled_lr = linear_warmup_decay(learning_rate, warmup_steps,
+ num_train_steps)
+ else:
+ raise ValueError("Unkown learning rate scheduler, should be "
+ "'noam_decay' or 'linear_warmup_decay'")
+ optimizer = fluid.optimizer.Adam(learning_rate=scheduled_lr)
+ else:
+ scheduled_lr = fluid.layers.create_global_var(
+ name=fluid.unique_name.generate("learning_rate"),
+ shape=[1],
+ value=learning_rate,
+ dtype='float32',
+ persistable=True)
+ optimizer = fluid.optimizer.Adam(learning_rate=scheduled_lr)
+ optimizer._learning_rate_map[fluid.default_main_program(
+ )] = scheduled_lr
+
+ fluid.clip.set_gradient_clip(
+ clip=fluid.clip.GradientClipByGlobalNorm(clip_norm=1.0))
+
+ def exclude_from_weight_decay(name):
+ if name.find("layer_norm") > -1:
+ return True
+ bias_suffix = ["_bias", "_b", ".b_0"]
+ for suffix in bias_suffix:
+ if name.endswith(suffix):
+ return True
+ return False
+
+ param_list = dict()
+
+ loss_scaling = fluid.layers.create_global_var(
+ name=fluid.unique_name.generate("loss_scaling"),
+ shape=[1],
+ value=init_loss_scaling,
+ dtype='float32',
+ persistable=True)
+
+ if use_fp16:
+ loss *= loss_scaling
+ param_grads = optimizer.backward(loss)
+
+ master_param_grads = create_master_params_grads(
+ param_grads, train_program, startup_prog, loss_scaling)
+
+ for param, _ in master_param_grads:
+ param_list[param.name] = param * 1.0
+ param_list[param.name].stop_gradient = True
+
+ if use_dynamic_loss_scaling:
+ apply_dynamic_loss_scaling(
+ loss_scaling, master_param_grads, incr_every_n_steps,
+ decr_every_n_nan_or_inf, incr_ratio, decr_ratio)
+
+ optimizer.apply_gradients(master_param_grads)
+
+ if weight_decay > 0:
+ for param, grad in master_param_grads:
+ if exclude_from_weight_decay(param.name.rstrip(".master")):
+ continue
+ with param.block.program._optimized_guard(
+ [param, grad]), fluid.framework.name_scope("weight_decay"):
+ updated_param = param - param_list[
+ param.name] * weight_decay * scheduled_lr
+ fluid.layers.assign(output=param, input=updated_param)
+
+ master_param_to_train_param(master_param_grads, param_grads,
+ train_program)
+
+ else:
+ for param in train_program.global_block().all_parameters():
+ param_list[param.name] = param * 1.0
+ param_list[param.name].stop_gradient = True
+
+ _, param_grads = optimizer.minimize(loss)
+
+ if weight_decay > 0:
+ for param, grad in param_grads:
+ if exclude_from_weight_decay(param.name):
+ continue
+ with param.block.program._optimized_guard(
+ [param, grad]), fluid.framework.name_scope("weight_decay"):
+ updated_param = param - param_list[
+ param.name] * weight_decay * scheduled_lr
+ fluid.layers.assign(output=param, input=updated_param)
+
+ return scheduled_lr, loss_scaling
diff --git a/ogb_examples/graphproppred/mol/pcba_config.yaml b/ogb_examples/graphproppred/mol/pcba_config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..e39eadecf21987b38d2bba10c5b0efa019e144e0
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/pcba_config.yaml
@@ -0,0 +1,53 @@
+task_name: pcba
+seed: 28994
+dataset_name: ogbg-molpcba
+eval_metrics: null
+task_type: null
+num_class: null
+pool_type: average
+train_eps: True
+norm_type: layer_norm
+
+model_type: GNNModel
+embed_dim: 128
+num_layers: 5
+hidden_size: 256
+save_dir: ./checkpoints
+
+
+# finetune model config
+init_checkpoint: null
+init_pretraining_params: null
+
+# data config
+data_dir: ./dataset/
+symmetry: True
+batch_size: 256
+buf_size: 1000
+metrics: True
+shuffle: True
+num_workers: 12
+output_dir: ./outputs/
+
+# trainging config
+epoch: 50
+learning_rate: 0.005
+lr_scheduler: linear_warmup_decay
+weight_decay: 0.01
+warmup_proportion: 0.1
+save_steps: 10000
+validation_steps: 1000
+use_dynamic_loss_scaling: True
+init_loss_scaling: 102400
+metric: simple_accuracy
+incr_every_n_steps: 100
+decr_every_n_nan_or_inf: 2
+incr_ratio: 2.0
+decr_ratio: 0.8
+log_dir: ./logs
+eval_step: 1000
+train_log_step: 20
+
+# log config
+skip_steps: 10
+verbose: False
diff --git a/ogb_examples/graphproppred/mol/utils/__init__.py b/ogb_examples/graphproppred/mol/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..abf198b97e6e818e1fbe59006f98492640bcee54
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/utils/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/ogb_examples/graphproppred/mol/utils/args.py b/ogb_examples/graphproppred/mol/utils/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..2de3d0da17519f091079aa963aad743fa4095941
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/utils/args.py
@@ -0,0 +1,94 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Arguments for configuration."""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import six
+import os
+import sys
+import argparse
+import logging
+
+import paddle.fluid as fluid
+
+log = logging.getLogger("logger")
+
+
+def prepare_logger(logger, debug=False, save_to_file=None):
+ formatter = logging.Formatter(
+ fmt='[%(levelname)s] %(asctime)s [%(filename)12s:%(lineno)5d]:\t%(message)s'
+ )
+ # console_hdl = logging.StreamHandler()
+ # console_hdl.setFormatter(formatter)
+ # logger.addHandler(console_hdl)
+ if save_to_file is not None: #and not os.path.exists(save_to_file):
+ if os.path.isdir(save_to_file):
+ file_hdl = logging.FileHandler(
+ os.path.join(save_to_file, 'log.txt'))
+ else:
+ file_hdl = logging.FileHandler(save_to_file)
+ file_hdl.setFormatter(formatter)
+ logger.addHandler(file_hdl)
+ logger.setLevel(logging.DEBUG)
+ logger.propagate = False
+
+
+def str2bool(v):
+ # because argparse does not support to parse "true, False" as python
+ # boolean directly
+ return v.lower() in ("true", "t", "1")
+
+
+class ArgumentGroup(object):
+ def __init__(self, parser, title, des):
+ self._group = parser.add_argument_group(title=title, description=des)
+
+ def add_arg(self,
+ name,
+ type,
+ default,
+ help,
+ positional_arg=False,
+ **kwargs):
+ prefix = "" if positional_arg else "--"
+ type = str2bool if type == bool else type
+ self._group.add_argument(
+ prefix + name,
+ default=default,
+ type=type,
+ help=help + ' Default: %(default)s.',
+ **kwargs)
+
+
+def print_arguments(args):
+ log.info('----------- Configuration Arguments -----------')
+ for arg, value in sorted(six.iteritems(vars(args))):
+ log.info('%s: %s' % (arg, value))
+ log.info('------------------------------------------------')
+
+
+def check_cuda(use_cuda, err = \
+ "\nYou can not set use_cuda = True in the model because you are using paddlepaddle-cpu.\n \
+ Please: 1. Install paddlepaddle-gpu to run your models on GPU or 2. Set use_cuda = False to run models on CPU.\n"
+ ):
+ try:
+ if use_cuda == True and fluid.is_compiled_with_cuda() == False:
+ log.error(err)
+ sys.exit(1)
+ except Exception as e:
+ pass
diff --git a/ogb_examples/graphproppred/mol/utils/cards.py b/ogb_examples/graphproppred/mol/utils/cards.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c9c6709f71edd692c81d5fed8bfb87e9afd596f
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/utils/cards.py
@@ -0,0 +1,30 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+import os
+
+
+def get_cards():
+ """
+ get gpu cards number
+ """
+ num = 0
+ cards = os.environ.get('CUDA_VISIBLE_DEVICES', '')
+ if cards != '':
+ num = len(cards.split(","))
+ return num
diff --git a/ogb_examples/graphproppred/mol/utils/config.py b/ogb_examples/graphproppred/mol/utils/config.py
new file mode 100644
index 0000000000000000000000000000000000000000..62d2847c357c3c0d28f1ed57e4430a766c7dfebc
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/utils/config.py
@@ -0,0 +1,136 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This file implement a class for model configure.
+"""
+
+import datetime
+import os
+import yaml
+import random
+import shutil
+import six
+import logging
+
+log = logging.getLogger("logger")
+
+
+class AttrDict(dict):
+ """Attr dict
+ """
+
+ def __init__(self, d):
+ self.dict = d
+
+ def __getattr__(self, attr):
+ value = self.dict[attr]
+ if isinstance(value, dict):
+ return AttrDict(value)
+ else:
+ return value
+
+ def __str__(self):
+ return str(self.dict)
+
+
+class Config(object):
+ """Implementation of Config class for model configure.
+
+ Args:
+ config_file(str): configure filename, which is a yaml file.
+ isCreate(bool): if true, create some neccessary directories to save models, log file and other outputs.
+ isSave(bool): if true, save config_file in order to record the configure message.
+ """
+
+ def __init__(self, config_file, isCreate=False, isSave=False):
+ self.config_file = config_file
+ # self.config = self.get_config_from_yaml(config_file)
+ self.config = self.load_config(config_file)
+
+ if isCreate:
+ self.create_necessary_dirs()
+
+ if isSave:
+ self.save_config_file()
+
+ def load_config(self, config_file):
+ """Load config file"""
+ with open(config_file) as f:
+ if hasattr(yaml, 'FullLoader'):
+ config = yaml.load(f, Loader=yaml.FullLoader)
+ else:
+ config = yaml.load(f)
+ return config
+
+ def create_necessary_dirs(self):
+ """Create some necessary directories to save some important files.
+ """
+
+ self.config['log_dir'] = os.path.join(self.config['log_dir'],
+ self.config['task_name'])
+ self.config['save_dir'] = os.path.join(self.config['save_dir'],
+ self.config['task_name'])
+ self.config['output_dir'] = os.path.join(self.config['output_dir'],
+ self.config['task_name'])
+
+ self.make_dir(self.config['log_dir'])
+ self.make_dir(self.config['save_dir'])
+ self.make_dir(self.config['output_dir'])
+
+ def save_config_file(self):
+ """Save config file so that we can know the config when we look back
+ """
+ filename = self.config_file.split('/')[-1]
+ targetpath = os.path.join(self.config['save_dir'], filename)
+ try:
+ shutil.copyfile(self.config_file, targetpath)
+ except shutil.SameFileError:
+ log.info("%s and %s are the same file, did not copy by shutil"\
+ % (self.config_file, targetpath))
+
+ def make_dir(self, path):
+ """Build directory"""
+ if not os.path.exists(path):
+ os.makedirs(path)
+
+ def __getitem__(self, key):
+ return self.config[key]
+
+ def __call__(self):
+ """__call__"""
+ return self.config
+
+ def __getattr__(self, attr):
+ try:
+ result = self.config[attr]
+ except KeyError:
+ log.warn("%s attribute is not existed, return None" % attr)
+ result = None
+ return result
+
+ def __setitem__(self, key, value):
+ self.config[key] = value
+
+ def __str__(self):
+ return str(self.config)
+
+ def pretty_print(self):
+ log.info(
+ "-----------------------------------------------------------------")
+ log.info("config file: %s" % self.config_file)
+ for key, value in sorted(
+ self.config.items(), key=lambda item: item[0]):
+ log.info("%s: %s" % (key, value))
+ log.info(
+ "-----------------------------------------------------------------")
diff --git a/ogb_examples/graphproppred/mol/utils/fp16.py b/ogb_examples/graphproppred/mol/utils/fp16.py
new file mode 100644
index 0000000000000000000000000000000000000000..740add267dff2dbf463032bcc47a6741ca9f7c43
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/utils/fp16.py
@@ -0,0 +1,201 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import print_function
+import paddle
+import paddle.fluid as fluid
+
+
+def append_cast_op(i, o, prog):
+ """
+ Append a cast op in a given Program to cast input `i` to data type `o.dtype`.
+ Args:
+ i (Variable): The input Variable.
+ o (Variable): The output Variable.
+ prog (Program): The Program to append cast op.
+ """
+ prog.global_block().append_op(
+ type="cast",
+ inputs={"X": i},
+ outputs={"Out": o},
+ attrs={"in_dtype": i.dtype,
+ "out_dtype": o.dtype})
+
+
+def copy_to_master_param(p, block):
+ v = block.vars.get(p.name, None)
+ if v is None:
+ raise ValueError("no param name %s found!" % p.name)
+ new_p = fluid.framework.Parameter(
+ block=block,
+ shape=v.shape,
+ dtype=fluid.core.VarDesc.VarType.FP32,
+ type=v.type,
+ lod_level=v.lod_level,
+ stop_gradient=p.stop_gradient,
+ trainable=p.trainable,
+ optimize_attr=p.optimize_attr,
+ regularizer=p.regularizer,
+ gradient_clip_attr=p.gradient_clip_attr,
+ error_clip=p.error_clip,
+ name=v.name + ".master")
+ return new_p
+
+
+def apply_dynamic_loss_scaling(loss_scaling, master_params_grads,
+ incr_every_n_steps, decr_every_n_nan_or_inf,
+ incr_ratio, decr_ratio):
+ _incr_every_n_steps = fluid.layers.fill_constant(
+ shape=[1], dtype='int32', value=incr_every_n_steps)
+ _decr_every_n_nan_or_inf = fluid.layers.fill_constant(
+ shape=[1], dtype='int32', value=decr_every_n_nan_or_inf)
+
+ _num_good_steps = fluid.layers.create_global_var(
+ name=fluid.unique_name.generate("num_good_steps"),
+ shape=[1],
+ value=0,
+ dtype='int32',
+ persistable=True)
+ _num_bad_steps = fluid.layers.create_global_var(
+ name=fluid.unique_name.generate("num_bad_steps"),
+ shape=[1],
+ value=0,
+ dtype='int32',
+ persistable=True)
+
+ grads = [fluid.layers.reduce_sum(g) for [_, g] in master_params_grads]
+ all_grads = fluid.layers.concat(grads)
+ all_grads_sum = fluid.layers.reduce_sum(all_grads)
+ is_overall_finite = fluid.layers.isfinite(all_grads_sum)
+
+ update_loss_scaling(is_overall_finite, loss_scaling, _num_good_steps,
+ _num_bad_steps, _incr_every_n_steps,
+ _decr_every_n_nan_or_inf, incr_ratio, decr_ratio)
+
+ # apply_gradient append all ops in global block, thus we shouldn't
+ # apply gradient in the switch branch.
+ with fluid.layers.Switch() as switch:
+ with switch.case(is_overall_finite):
+ pass
+ with switch.default():
+ for _, g in master_params_grads:
+ fluid.layers.assign(fluid.layers.zeros_like(g), g)
+
+
+def create_master_params_grads(params_grads, main_prog, startup_prog,
+ loss_scaling):
+ master_params_grads = []
+ for p, g in params_grads:
+ with main_prog._optimized_guard([p, g]):
+ # create master parameters
+ master_param = copy_to_master_param(p, main_prog.global_block())
+ startup_master_param = startup_prog.global_block()._clone_variable(
+ master_param)
+ startup_p = startup_prog.global_block().var(p.name)
+ append_cast_op(startup_p, startup_master_param, startup_prog)
+ # cast fp16 gradients to fp32 before apply gradients
+ if g.name.find("layer_norm") > -1:
+ scaled_g = g / loss_scaling
+ master_params_grads.append([p, scaled_g])
+ continue
+ master_grad = fluid.layers.cast(g, "float32")
+ master_grad = master_grad / loss_scaling
+ master_params_grads.append([master_param, master_grad])
+
+ return master_params_grads
+
+
+def master_param_to_train_param(master_params_grads, params_grads, main_prog):
+ for idx, m_p_g in enumerate(master_params_grads):
+ train_p, _ = params_grads[idx]
+ if train_p.name.find("layer_norm") > -1:
+ continue
+ with main_prog._optimized_guard([m_p_g[0], m_p_g[1]]):
+ append_cast_op(m_p_g[0], train_p, main_prog)
+
+
+def update_loss_scaling(is_overall_finite, prev_loss_scaling, num_good_steps,
+ num_bad_steps, incr_every_n_steps,
+ decr_every_n_nan_or_inf, incr_ratio, decr_ratio):
+ """
+ Update loss scaling according to overall gradients. If all gradients is
+ finite after incr_every_n_steps, loss scaling will increase by incr_ratio.
+ Otherwisw, loss scaling will decrease by decr_ratio after
+ decr_every_n_nan_or_inf steps and each step some gradients are infinite.
+ Args:
+ is_overall_finite (Variable): A boolean variable indicates whether
+ all gradients are finite.
+ prev_loss_scaling (Variable): Previous loss scaling.
+ num_good_steps (Variable): A variable accumulates good steps in which
+ all gradients are finite.
+ num_bad_steps (Variable): A variable accumulates bad steps in which
+ some gradients are infinite.
+ incr_every_n_steps (Variable): A variable represents increasing loss
+ scaling every n consecutive steps with
+ finite gradients.
+ decr_every_n_nan_or_inf (Variable): A variable represents decreasing
+ loss scaling every n accumulated
+ steps with nan or inf gradients.
+ incr_ratio(float): The multiplier to use when increasing the loss
+ scaling.
+ decr_ratio(float): The less-than-one-multiplier to use when decreasing
+ loss scaling.
+ """
+ zero_steps = fluid.layers.fill_constant(shape=[1], dtype='int32', value=0)
+ with fluid.layers.Switch() as switch:
+ with switch.case(is_overall_finite):
+ should_incr_loss_scaling = fluid.layers.less_than(
+ incr_every_n_steps, num_good_steps + 1)
+ with fluid.layers.Switch() as switch1:
+ with switch1.case(should_incr_loss_scaling):
+ new_loss_scaling = prev_loss_scaling * incr_ratio
+ loss_scaling_is_finite = fluid.layers.isfinite(
+ new_loss_scaling)
+ with fluid.layers.Switch() as switch2:
+ with switch2.case(loss_scaling_is_finite):
+ fluid.layers.assign(new_loss_scaling,
+ prev_loss_scaling)
+ with switch2.default():
+ pass
+ fluid.layers.assign(zero_steps, num_good_steps)
+ fluid.layers.assign(zero_steps, num_bad_steps)
+
+ with switch1.default():
+ fluid.layers.increment(num_good_steps)
+ fluid.layers.assign(zero_steps, num_bad_steps)
+
+ with switch.default():
+ should_decr_loss_scaling = fluid.layers.less_than(
+ decr_every_n_nan_or_inf, num_bad_steps + 1)
+ with fluid.layers.Switch() as switch3:
+ with switch3.case(should_decr_loss_scaling):
+ new_loss_scaling = prev_loss_scaling * decr_ratio
+ static_loss_scaling = \
+ fluid.layers.fill_constant(shape=[1],
+ dtype='float32',
+ value=1.0)
+ less_than_one = fluid.layers.less_than(new_loss_scaling,
+ static_loss_scaling)
+ with fluid.layers.Switch() as switch4:
+ with switch4.case(less_than_one):
+ fluid.layers.assign(static_loss_scaling,
+ prev_loss_scaling)
+ with switch4.default():
+ fluid.layers.assign(new_loss_scaling,
+ prev_loss_scaling)
+ fluid.layers.assign(zero_steps, num_good_steps)
+ fluid.layers.assign(zero_steps, num_bad_steps)
+ with switch3.default():
+ fluid.layers.assign(zero_steps, num_good_steps)
+ fluid.layers.increment(num_bad_steps)
diff --git a/ogb_examples/graphproppred/mol/utils/init.py b/ogb_examples/graphproppred/mol/utils/init.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f54a185ac80ec2308c9f8effe59148547b2548d
--- /dev/null
+++ b/ogb_examples/graphproppred/mol/utils/init.py
@@ -0,0 +1,91 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import six
+import ast
+import copy
+import logging
+
+import numpy as np
+import paddle.fluid as fluid
+
+log = logging.getLogger("logger")
+
+
+def cast_fp32_to_fp16(exe, main_program):
+ log.info("Cast parameters to float16 data format.")
+ for param in main_program.global_block().all_parameters():
+ if not param.name.endswith(".master"):
+ param_t = fluid.global_scope().find_var(param.name).get_tensor()
+ data = np.array(param_t)
+ if param.name.startswith("encoder_layer") \
+ and "layer_norm" not in param.name:
+ param_t.set(np.float16(data).view(np.uint16), exe.place)
+
+ #load fp32
+ master_param_var = fluid.global_scope().find_var(param.name +
+ ".master")
+ if master_param_var is not None:
+ master_param_var.get_tensor().set(data, exe.place)
+
+
+def init_checkpoint(exe, init_checkpoint_path, main_program, use_fp16=False):
+ assert os.path.exists(
+ init_checkpoint_path), "[%s] cann't be found." % init_checkpoint_path
+
+ def existed_persitables(var):
+ if not fluid.io.is_persistable(var):
+ return False
+ return os.path.exists(os.path.join(init_checkpoint_path, var.name))
+
+ fluid.io.load_vars(
+ exe,
+ init_checkpoint_path,
+ main_program=main_program,
+ predicate=existed_persitables)
+ log.info("Load model from {}".format(init_checkpoint_path))
+
+ if use_fp16:
+ cast_fp32_to_fp16(exe, main_program)
+
+
+def init_pretraining_params(exe,
+ pretraining_params_path,
+ main_program,
+ use_fp16=False):
+ assert os.path.exists(pretraining_params_path
+ ), "[%s] cann't be found." % pretraining_params_path
+
+ def existed_params(var):
+ if not isinstance(var, fluid.framework.Parameter):
+ return False
+ return os.path.exists(os.path.join(pretraining_params_path, var.name))
+
+ fluid.io.load_vars(
+ exe,
+ pretraining_params_path,
+ main_program=main_program,
+ predicate=existed_params)
+ log.info("Load pretraining parameters from {}.".format(
+ pretraining_params_path))
+
+ if use_fp16:
+ cast_fp32_to_fp16(exe, main_program)
diff --git a/ogb_examples/linkproppred/main_pgl.py b/ogb_examples/linkproppred/main_pgl.py
deleted file mode 100644
index bb81a248c98fe03dcc44037d211e5e2af06a0716..0000000000000000000000000000000000000000
--- a/ogb_examples/linkproppred/main_pgl.py
+++ /dev/null
@@ -1,276 +0,0 @@
-# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""test ogb
-"""
-import argparse
-import time
-import logging
-import numpy as np
-
-import paddle.fluid as fluid
-
-import pgl
-from pgl.contrib.ogb.linkproppred.dataset_pgl import PglLinkPropPredDataset
-from pgl.utils import paddle_helper
-from ogb.linkproppred import Evaluator
-
-
-def send_func(src_feat, dst_feat, edge_feat):
- """send_func"""
- return src_feat["h"]
-
-
-def recv_func(feat):
- """recv_func"""
- return fluid.layers.sequence_pool(feat, pool_type="sum")
-
-
-class GNNModel(object):
- """GNNModel"""
-
- def __init__(self, name, num_nodes, emb_dim, num_layers):
- self.num_nodes = num_nodes
- self.emb_dim = emb_dim
- self.num_layers = num_layers
- self.name = name
-
- self.src_nodes = fluid.layers.data(
- name='src_nodes',
- shape=[None],
- dtype='int64', )
-
- self.dst_nodes = fluid.layers.data(
- name='dst_nodes',
- shape=[None],
- dtype='int64', )
-
- self.edge_label = fluid.layers.data(
- name='edge_label',
- shape=[None, 1],
- dtype='float32', )
-
- def forward(self, graph):
- """forward"""
- h = fluid.layers.create_parameter(
- shape=[self.num_nodes, self.emb_dim],
- dtype="float32",
- name=self.name + "_embedding")
-
- for layer in range(self.num_layers):
- msg = graph.send(
- send_func,
- nfeat_list=[("h", h)], )
- h = graph.recv(msg, recv_func)
- h = fluid.layers.fc(
- h,
- size=self.emb_dim,
- bias_attr=False,
- param_attr=fluid.ParamAttr(name=self.name + '_%s' % layer))
- h = h * graph.node_feat["norm"]
- bias = fluid.layers.create_parameter(
- shape=[self.emb_dim],
- dtype='float32',
- is_bias=True,
- name=self.name + '_bias_%s' % layer)
- h = fluid.layers.elementwise_add(h, bias, act="relu")
-
- src = fluid.layers.gather(h, self.src_nodes, overwrite=False)
- dst = fluid.layers.gather(h, self.dst_nodes, overwrite=False)
- edge_embed = src * dst
- pred = fluid.layers.fc(input=edge_embed,
- size=1,
- name=self.name + "_pred_output")
-
- prob = fluid.layers.sigmoid(pred)
-
- loss = fluid.layers.sigmoid_cross_entropy_with_logits(pred,
- self.edge_label)
- loss = fluid.layers.reduce_sum(loss)
-
- return pred, prob, loss
-
-
-def main():
- """main
- """
- # Training settings
- parser = argparse.ArgumentParser(description='Graph Dataset')
- parser.add_argument(
- '--epochs',
- type=int,
- default=4,
- help='number of epochs to train (default: 100)')
- parser.add_argument(
- '--dataset',
- type=str,
- default="ogbl-ppa",
- help='dataset name (default: protein protein associations)')
- parser.add_argument('--use_cuda', action='store_true')
- parser.add_argument('--batch_size', type=int, default=5120)
- parser.add_argument('--embed_dim', type=int, default=64)
- parser.add_argument('--num_layers', type=int, default=2)
- parser.add_argument('--lr', type=float, default=0.001)
- args = parser.parse_args()
- print(args)
-
- place = fluid.CUDAPlace(0) if args.use_cuda else fluid.CPUPlace()
-
- ### automatic dataloading and splitting
- print("loadding dataset")
- dataset = PglLinkPropPredDataset(name=args.dataset)
- splitted_edge = dataset.get_edge_split()
- print(splitted_edge['train_edge'].shape)
- print(splitted_edge['train_edge_label'].shape)
-
- print("building evaluator")
- ### automatic evaluator. takes dataset name as input
- evaluator = Evaluator(args.dataset)
-
- graph_data = dataset[0]
- print("num_nodes: %d" % graph_data.num_nodes)
-
- train_program = fluid.Program()
- startup_program = fluid.Program()
-
- # degree normalize
- indegree = graph_data.indegree()
- norm = np.zeros_like(indegree, dtype="float32")
- norm[indegree > 0] = np.power(indegree[indegree > 0], -0.5)
- graph_data.node_feat["norm"] = np.expand_dims(norm, -1).astype("float32")
- # graph_data.node_feat["index"] = np.array([i for i in range(graph_data.num_nodes)], dtype=np.int64).reshape(-1,1)
-
- with fluid.program_guard(train_program, startup_program):
- model = GNNModel(
- name="gnn",
- num_nodes=graph_data.num_nodes,
- emb_dim=args.embed_dim,
- num_layers=args.num_layers)
- gw = pgl.graph_wrapper.GraphWrapper(
- "graph",
- place,
- node_feat=graph_data.node_feat_info(),
- edge_feat=graph_data.edge_feat_info())
- pred, prob, loss = model.forward(gw)
-
- val_program = train_program.clone(for_test=True)
-
- with fluid.program_guard(train_program, startup_program):
- global_steps = int(splitted_edge['train_edge'].shape[0] /
- args.batch_size * 2)
- learning_rate = fluid.layers.polynomial_decay(args.lr, global_steps,
- 0.00005)
-
- adam = fluid.optimizer.Adam(
- learning_rate=learning_rate,
- regularization=fluid.regularizer.L2DecayRegularizer(
- regularization_coeff=0.0005))
- adam.minimize(loss)
-
- exe = fluid.Executor(place)
- exe.run(startup_program)
- feed = gw.to_feed(graph_data)
-
- print("evaluate result before training: ")
- result = test(exe, val_program, prob, evaluator, feed, splitted_edge)
- print(result)
-
- print("training")
- cc = 0
- for epoch in range(1, args.epochs + 1):
- for batch_data, batch_label in data_generator(
- graph_data,
- splitted_edge["train_edge"],
- splitted_edge["train_edge_label"],
- batch_size=args.batch_size):
- feed['src_nodes'] = batch_data[:, 0].reshape(-1, 1)
- feed['dst_nodes'] = batch_data[:, 1].reshape(-1, 1)
- feed['edge_label'] = batch_label.astype("float32")
-
- res_loss, y_pred, b_lr = exe.run(
- train_program,
- feed=feed,
- fetch_list=[loss, prob, learning_rate])
- if cc % 1 == 0:
- print("epoch %d | step %d | lr %s | Loss %s" %
- (epoch, cc, b_lr[0], res_loss[0]))
- cc += 1
-
- if cc % 20 == 0:
- print("Evaluating...")
- result = test(exe, val_program, prob, evaluator, feed,
- splitted_edge)
- print("epoch %d | step %d" % (epoch, cc))
- print(result)
-
-
-def test(exe, val_program, prob, evaluator, feed, splitted_edge):
- """Evaluation"""
- result = {}
- feed['src_nodes'] = splitted_edge["valid_edge"][:, 0].reshape(-1, 1)
- feed['dst_nodes'] = splitted_edge["valid_edge"][:, 1].reshape(-1, 1)
- feed['edge_label'] = splitted_edge["valid_edge_label"].astype(
- "float32").reshape(-1, 1)
- y_pred = exe.run(val_program, feed=feed, fetch_list=[prob])[0]
- input_dict = {
- "y_pred_pos":
- y_pred[splitted_edge["valid_edge_label"] == 1].reshape(-1, ),
- "y_pred_neg":
- y_pred[splitted_edge["valid_edge_label"] == 0].reshape(-1, )
- }
- result["valid"] = evaluator.eval(input_dict)
-
- feed['src_nodes'] = splitted_edge["test_edge"][:, 0].reshape(-1, 1)
- feed['dst_nodes'] = splitted_edge["test_edge"][:, 1].reshape(-1, 1)
- feed['edge_label'] = splitted_edge["test_edge_label"].astype(
- "float32").reshape(-1, 1)
- y_pred = exe.run(val_program, feed=feed, fetch_list=[prob])[0]
- input_dict = {
- "y_pred_pos":
- y_pred[splitted_edge["test_edge_label"] == 1].reshape(-1, ),
- "y_pred_neg":
- y_pred[splitted_edge["test_edge_label"] == 0].reshape(-1, )
- }
- result["test"] = evaluator.eval(input_dict)
- return result
-
-
-def data_generator(graph, data, label_data, batch_size, shuffle=True):
- """Data Generator"""
- perm = np.arange(0, len(data))
- if shuffle:
- np.random.shuffle(perm)
-
- offset = 0
- while offset < len(perm):
- batch_index = perm[offset:(offset + batch_size)]
- offset += batch_size
- pos_data = data[batch_index]
- pos_label = label_data[batch_index]
-
- neg_src_node = pos_data[:, 0]
- neg_dst_node = np.random.choice(
- pos_data.reshape(-1, ), size=len(neg_src_node))
- neg_data = np.hstack(
- [neg_src_node.reshape(-1, 1), neg_dst_node.reshape(-1, 1)])
- exists = graph.has_edges_between(neg_src_node, neg_dst_node)
- neg_data = neg_data[np.invert(exists)]
- neg_label = np.zeros(shape=len(neg_data), dtype=np.int64)
-
- batch_data = np.vstack([pos_data, neg_data])
- label = np.vstack([pos_label.reshape(-1, 1), neg_label.reshape(-1, 1)])
- yield batch_data, label
-
-
-if __name__ == "__main__":
- main()
diff --git a/ogb_examples/linkproppred/ogbl-ppa/README.md b/ogb_examples/linkproppred/ogbl-ppa/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..f06b3bc2be13dca9548491c5a152841fd4bb034f
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/README.md
@@ -0,0 +1,21 @@
+# Graph Link Prediction for Open Graph Benchmark (OGB) PPA dataset
+
+[The Open Graph Benchmark (OGB)](https://ogb.stanford.edu/) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. Here we complete the Graph Link Prediction task based on PGL.
+
+
+### Requirements
+
+paddlpaddle >= 1.7.1
+
+pgl 1.0.2
+
+ogb
+
+
+### How to Run
+
+```
+CUDA_VISIBLE_DEVICES=0,1,2,3 python train.py --use_cuda 1 --num_workers 4 --output_path ./output/model_1 --batch_size 65536 --epoch 1000 --learning_rate 0.005 --hidden_size 256
+```
+
+The best record will be saved in ./output/model_1/best.txt.
diff --git a/ogb_examples/linkproppred/ogbl-ppa/args.py b/ogb_examples/linkproppred/ogbl-ppa/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..5fc51d37f9774fbf50fb7bbb5aa700b9f8aaff7f
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/args.py
@@ -0,0 +1,44 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""finetune args"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import time
+import argparse
+
+from utils.args import ArgumentGroup
+
+# yapf: disable
+parser = argparse.ArgumentParser(__doc__)
+model_g = ArgumentGroup(parser, "model", "model configuration and paths.")
+model_g.add_arg("init_checkpoint", str, None, "Init checkpoint to resume training from.")
+model_g.add_arg("init_pretraining_params", str, None,
+ "Init pre-training params which preforms fine-tuning from. If the "
+ "arg 'init_checkpoint' has been set, this argument wouldn't be valid.")
+
+train_g = ArgumentGroup(parser, "training", "training options.")
+train_g.add_arg("epoch", int, 3, "Number of epoches for fine-tuning.")
+train_g.add_arg("learning_rate", float, 5e-5, "Learning rate used to train with warmup.")
+
+run_type_g = ArgumentGroup(parser, "run_type", "running type options.")
+run_type_g.add_arg("use_cuda", bool, True, "If set, use GPU for training.")
+run_type_g.add_arg("num_workers", int, 1, "use multiprocess to generate graph")
+run_type_g.add_arg("output_path", str, None, "path to save model")
+run_type_g.add_arg("hidden_size", int, 128, "model hidden-size")
+run_type_g.add_arg("batch_size", int, 128, "batch_size")
diff --git a/ogb_examples/linkproppred/ogbl-ppa/dataloader/__init__.py b/ogb_examples/linkproppred/ogbl-ppa/dataloader/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..abf198b97e6e818e1fbe59006f98492640bcee54
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/dataloader/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/ogb_examples/linkproppred/ogbl-ppa/dataloader/base_dataloader.py b/ogb_examples/linkproppred/ogbl-ppa/dataloader/base_dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..d04f9fd521602bf67f950b3e72ba021fd09c298f
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/dataloader/base_dataloader.py
@@ -0,0 +1,148 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Base DataLoader
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import sys
+import six
+from io import open
+from collections import namedtuple
+import numpy as np
+import tqdm
+import paddle
+from pgl.utils import mp_reader
+import collections
+import time
+
+import pgl
+
+if six.PY3:
+ import io
+ sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
+ sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
+
+
+def batch_iter(data, perm, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ size = len(data)
+ start = 0
+ cc = 0
+ while start < size:
+ index = perm[start:start + batch_size]
+ start += batch_size
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ yield data[index]
+
+
+def scan_batch_iter(data, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ batch = []
+ cc = 0
+ for line_example in data.scan():
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ batch.append(line_example)
+ if len(batch) == batch_size:
+ yield batch
+ batch = []
+
+ if len(batch) > 0:
+ yield batch
+
+
+class BaseDataGenerator(object):
+ """Base Data Geneartor"""
+
+ def __init__(self, buf_size, batch_size, num_workers, shuffle=True):
+ self.num_workers = num_workers
+ self.batch_size = batch_size
+ self.line_examples = []
+ self.buf_size = buf_size
+ self.shuffle = shuffle
+
+ def batch_fn(self, batch_examples):
+ """ batch_fn batch producer"""
+ raise NotImplementedError("No defined Batch Fn")
+
+ def batch_iter(self, fid, perm):
+ """ batch iterator"""
+ if self.shuffle:
+ for batch in batch_iter(self, perm, self.batch_size, fid,
+ self.num_workers):
+ yield batch
+ else:
+ for batch in scan_batch_iter(self, self.batch_size, fid,
+ self.num_workers):
+ yield batch
+
+ def __len__(self):
+ return len(self.line_examples)
+
+ def __getitem__(self, idx):
+ if isinstance(idx, collections.Iterable):
+ return [self[bidx] for bidx in idx]
+ else:
+ return self.line_examples[idx]
+
+ def generator(self):
+ """batch dict generator"""
+
+ def worker(filter_id, perm):
+ """ multiprocess worker"""
+
+ def func_run():
+ """ func_run """
+ pid = os.getpid()
+ np.random.seed(pid + int(time.time()))
+ for batch_examples in self.batch_iter(filter_id, perm):
+ batch_dict = self.batch_fn(batch_examples)
+ yield batch_dict
+
+ return func_run
+
+ # consume a seed
+ np.random.rand()
+ if self.shuffle:
+ perm = np.arange(0, len(self))
+ np.random.shuffle(perm)
+ else:
+ perm = None
+ if self.num_workers == 1:
+ r = paddle.reader.buffered(worker(0, perm), self.buf_size)
+ else:
+ worker_pool = [
+ worker(wid, perm) for wid in range(self.num_workers)
+ ]
+ worker = mp_reader.multiprocess_reader(
+ worker_pool, use_pipe=True, queue_size=1000)
+ r = paddle.reader.buffered(worker, self.buf_size)
+
+ for batch in r():
+ yield batch
+
+ def scan(self):
+ for line_example in self.line_examples:
+ yield line_example
diff --git a/ogb_examples/linkproppred/ogbl-ppa/dataloader/ogbl_ppa_dataloader.py b/ogb_examples/linkproppred/ogbl-ppa/dataloader/ogbl_ppa_dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..621db215a6924de338a7dd881ddc54ac82290a33
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/dataloader/ogbl_ppa_dataloader.py
@@ -0,0 +1,118 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+from dataloader.base_dataloader import BaseDataGenerator
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+
+from ogb.linkproppred import LinkPropPredDataset
+from ogb.linkproppred import Evaluator
+import tqdm
+from collections import namedtuple
+import pgl
+import numpy as np
+
+
+class PPADataGenerator(BaseDataGenerator):
+ def __init__(self,
+ graph_wrapper=None,
+ buf_size=1000,
+ batch_size=128,
+ num_workers=1,
+ shuffle=True,
+ phase="train"):
+ super(PPADataGenerator, self).__init__(
+ buf_size=buf_size,
+ num_workers=num_workers,
+ batch_size=batch_size,
+ shuffle=shuffle)
+
+ self.d_name = "ogbl-ppa"
+ self.graph_wrapper = graph_wrapper
+ dataset = LinkPropPredDataset(name=self.d_name)
+ splitted_edge = dataset.get_edge_split()
+ self.phase = phase
+ graph = dataset[0]
+ edges = graph["edge_index"].T
+ #self.graph = pgl.graph.Graph(num_nodes=graph["num_nodes"],
+ # edges=edges,
+ # node_feat={"nfeat": graph["node_feat"],
+ # "node_id": np.arange(0, graph["num_nodes"], dtype="int64").reshape(-1, 1) })
+
+ #self.graph.indegree()
+ self.num_nodes = graph["num_nodes"]
+ if self.phase == 'train':
+ edges = splitted_edge["train"]["edge"]
+ labels = np.ones(len(edges))
+ elif self.phase == "valid":
+ # Compute the embedding for all the nodes
+ pos_edges = splitted_edge["valid"]["edge"]
+ neg_edges = splitted_edge["valid"]["edge_neg"]
+ pos_labels = np.ones(len(pos_edges))
+ neg_labels = np.zeros(len(neg_edges))
+ edges = np.vstack([pos_edges, neg_edges])
+ labels = pos_labels.tolist() + neg_labels.tolist()
+ elif self.phase == "test":
+ # Compute the embedding for all the nodes
+ pos_edges = splitted_edge["test"]["edge"]
+ neg_edges = splitted_edge["test"]["edge_neg"]
+ pos_labels = np.ones(len(pos_edges))
+ neg_labels = np.zeros(len(neg_edges))
+ edges = np.vstack([pos_edges, neg_edges])
+ labels = pos_labels.tolist() + neg_labels.tolist()
+
+ self.line_examples = []
+ Example = namedtuple('Example', ['src', "dst", "label"])
+ for edge, label in zip(edges, labels):
+ self.line_examples.append(
+ Example(
+ src=edge[0], dst=edge[1], label=label))
+ print("Phase", self.phase)
+ print("Len Examples", len(self.line_examples))
+
+ def batch_fn(self, batch_ex):
+ batch_src = []
+ batch_dst = []
+ join_graph = []
+ cc = 0
+ batch_node_id = []
+ batch_labels = []
+ for ex in batch_ex:
+ batch_src.append(ex.src)
+ batch_dst.append(ex.dst)
+ batch_labels.append(ex.label)
+
+ if self.phase == "train":
+ for num in range(1):
+ rand_src = np.random.randint(
+ low=0, high=self.num_nodes, size=len(batch_ex))
+ rand_dst = np.random.randint(
+ low=0, high=self.num_nodes, size=len(batch_ex))
+ batch_src = batch_src + rand_src.tolist()
+ batch_dst = batch_dst + rand_dst.tolist()
+ batch_labels = batch_labels + np.zeros_like(
+ rand_src, dtype="int64").tolist()
+
+ feed_dict = {}
+
+ feed_dict["batch_src"] = np.array(batch_src, dtype="int64")
+ feed_dict["batch_dst"] = np.array(batch_dst, dtype="int64")
+ feed_dict["labels"] = np.array(batch_labels, dtype="int64")
+ return feed_dict
diff --git a/ogb_examples/linkproppred/ogbl-ppa/model.py b/ogb_examples/linkproppred/ogbl-ppa/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..9429ea39a900488e1ab65c084e4b133079c56dcb
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/model.py
@@ -0,0 +1,108 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""lbs_model"""
+import os
+import re
+import time
+from random import random
+from functools import reduce, partial
+
+import numpy as np
+import multiprocessing
+
+import paddle
+import paddle.fluid as F
+import paddle.fluid.layers as L
+from pgl.graph_wrapper import GraphWrapper
+from pgl.layers.conv import gcn, gat
+
+
+class BaseGraph(object):
+ """Base Graph Model"""
+
+ def __init__(self, args):
+ node_feature = [('nfeat', [None, 58], "float32"),
+ ('node_id', [None, 1], "int64")]
+ self.hidden_size = args.hidden_size
+ self.num_nodes = args.num_nodes
+
+ self.graph_wrapper = None # GraphWrapper(
+ #name="graph", place=F.CPUPlace(), node_feat=node_feature)
+
+ self.build_model(args)
+
+ def build_model(self, args):
+ """ build graph model"""
+ self.batch_src = L.data(name="batch_src", shape=[-1], dtype="int64")
+ self.batch_src = L.reshape(self.batch_src, [-1, 1])
+ self.batch_dst = L.data(name="batch_dst", shape=[-1], dtype="int64")
+ self.batch_dst = L.reshape(self.batch_dst, [-1, 1])
+ self.labels = L.data(name="labels", shape=[-1], dtype="int64")
+ self.labels = L.reshape(self.labels, [-1, 1])
+ self.labels.stop_gradients = True
+ self.src_repr = L.embedding(
+ self.batch_src,
+ size=(self.num_nodes, self.hidden_size),
+ param_attr=F.ParamAttr(
+ name="node_embeddings",
+ initializer=F.initializer.NormalInitializer(
+ loc=0.0, scale=1.0)))
+
+ self.dst_repr = L.embedding(
+ self.batch_dst,
+ size=(self.num_nodes, self.hidden_size),
+ param_attr=F.ParamAttr(
+ name="node_embeddings",
+ initializer=F.initializer.NormalInitializer(
+ loc=0.0, scale=1.0)))
+
+ self.link_predictor(self.src_repr, self.dst_repr)
+
+ self.bce_loss()
+
+ def link_predictor(self, x, y):
+ """ siamese network"""
+ feat = x * y
+
+ feat = L.fc(feat, size=self.hidden_size, name="link_predictor_1")
+ feat = L.relu(feat)
+
+ feat = L.fc(feat, size=self.hidden_size, name="link_predictor_2")
+ feat = L.relu(feat)
+
+ self.logits = L.fc(feat,
+ size=1,
+ act="sigmoid",
+ name="link_predictor_logits")
+
+ def bce_loss(self):
+ """listwise model"""
+ mask = L.cast(self.labels > 0.5, dtype="float32")
+ mask.stop_gradients = True
+
+ self.loss = L.log_loss(self.logits, mask, epsilon=1e-15)
+ self.loss = L.reduce_mean(self.loss) * 2
+ proba = L.sigmoid(self.logits)
+ proba = L.concat([proba * -1 + 1, proba], axis=1)
+ auc_out, batch_auc_out, _ = \
+ L.auc(input=proba, label=self.labels, curve='ROC', slide_steps=1)
+
+ self.metrics = {
+ "loss": self.loss,
+ "auc": batch_auc_out,
+ }
+
+ def neighbor_aggregator(self, node_repr):
+ """neighbor aggregation"""
+ return node_repr
diff --git a/ogb_examples/linkproppred/ogbl-ppa/monitor/__init__.py b/ogb_examples/linkproppred/ogbl-ppa/monitor/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d814437561c253c97a95e31187e63a554476364f
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/monitor/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""init"""
diff --git a/ogb_examples/linkproppred/ogbl-ppa/monitor/train_monitor.py b/ogb_examples/linkproppred/ogbl-ppa/monitor/train_monitor.py
new file mode 100644
index 0000000000000000000000000000000000000000..a377135a23ad50ce0cc195bdd4dff3ff3b1e8d44
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/monitor/train_monitor.py
@@ -0,0 +1,184 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""train and evaluate"""
+import tqdm
+import json
+import numpy as np
+import sys
+import os
+import paddle.fluid as F
+from pgl.utils.log_writer import LogWriter
+from ogb.linkproppred import Evaluator
+from ogb.linkproppred import LinkPropPredDataset
+
+
+def multi_device(reader, dev_count):
+ """multi device"""
+ if dev_count == 1:
+ for batch in reader:
+ yield batch
+ else:
+ batches = []
+ for batch in reader:
+ batches.append(batch)
+ if len(batches) == dev_count:
+ yield batches
+ batches = []
+
+
+class OgbEvaluator(object):
+ def __init__(self):
+ d_name = "ogbl-ppa"
+ dataset = LinkPropPredDataset(name=d_name)
+ splitted_edge = dataset.get_edge_split()
+ graph = dataset[0]
+ self.num_nodes = graph["num_nodes"]
+ self.ogb_evaluator = Evaluator(name="ogbl-ppa")
+
+ def eval(self, scores, labels, phase):
+ labels = np.reshape(labels, [-1])
+ ret = {}
+ pos = scores[labels > 0.5].squeeze(-1)
+ neg = scores[labels < 0.5].squeeze(-1)
+ for K in [10, 50, 100]:
+ self.ogb_evaluator.K = K
+ ret['%s_hits@%s' % (phase, K)] = self.ogb_evaluator.eval({
+ 'y_pred_pos': pos,
+ 'y_pred_neg': neg,
+ })[f'hits@{K}']
+ return ret
+
+
+def evaluate(model, valid_exe, valid_ds, valid_prog, dev_count, evaluator,
+ phase):
+ """evaluate """
+ cc = 0
+ scores = []
+ labels = []
+
+ for feed_dict in tqdm.tqdm(
+ multi_device(valid_ds.generator(), dev_count), desc='evaluating'):
+
+ if dev_count > 1:
+ output = valid_exe.run(feed=feed_dict,
+ fetch_list=[model.logits, model.labels])
+ else:
+ output = valid_exe.run(valid_prog,
+ feed=feed_dict,
+ fetch_list=[model.logits, model.labels])
+ scores.append(output[0])
+ labels.append(output[1])
+
+ scores = np.vstack(scores)
+ labels = np.vstack(labels)
+ ret = evaluator.eval(scores, labels, phase)
+ return ret
+
+
+def _create_if_not_exist(path):
+ basedir = os.path.dirname(path)
+ if not os.path.exists(basedir):
+ os.makedirs(basedir)
+
+
+def train_and_evaluate(exe,
+ train_exe,
+ valid_exe,
+ train_ds,
+ valid_ds,
+ test_ds,
+ train_prog,
+ valid_prog,
+ model,
+ metric,
+ epoch=20,
+ dev_count=1,
+ train_log_step=5,
+ eval_step=10000,
+ evaluator=None,
+ output_path=None):
+ """train and evaluate"""
+
+ global_step = 0
+
+ log_path = os.path.join(output_path, "log")
+ _create_if_not_exist(log_path)
+
+ writer = LogWriter(log_path)
+
+ best_model = 0
+ for e in range(epoch):
+ for feed_dict in tqdm.tqdm(
+ multi_device(train_ds.generator(), dev_count),
+ desc='Epoch %s' % e):
+ if dev_count > 1:
+ ret = train_exe.run(feed=feed_dict, fetch_list=metric.vars)
+ ret = [[np.mean(v)] for v in ret]
+ else:
+ ret = train_exe.run(train_prog,
+ feed=feed_dict,
+ fetch_list=metric.vars)
+
+ ret = metric.parse(ret)
+ if global_step % train_log_step == 0:
+ for key, value in ret.items():
+ writer.add_scalar(
+ 'train_' + key, value, global_step)
+
+ global_step += 1
+ if global_step % eval_step == 0:
+ eval_ret = evaluate(model, exe, valid_ds, valid_prog, 1,
+ evaluator, "valid")
+
+ test_eval_ret = evaluate(model, exe, test_ds, valid_prog, 1,
+ evaluator, "test")
+
+ eval_ret.update(test_eval_ret)
+
+ sys.stderr.write(json.dumps(eval_ret, indent=4) + "\n")
+
+ for key, value in eval_ret.items():
+ writer.add_scalar(key, value, global_step)
+
+ if eval_ret["valid_hits@100"] > best_model:
+ F.io.save_persistables(
+ exe,
+ os.path.join(output_path, "checkpoint"), train_prog)
+ eval_ret["step"] = global_step
+ with open(os.path.join(output_path, "best.txt"), "w") as f:
+ f.write(json.dumps(eval_ret, indent=2) + '\n')
+ best_model = eval_ret["valid_hits@100"]
+ # Epoch End
+ eval_ret = evaluate(model, exe, valid_ds, valid_prog, 1, evaluator,
+ "valid")
+
+ test_eval_ret = evaluate(model, exe, test_ds, valid_prog, 1, evaluator,
+ "test")
+
+ eval_ret.update(test_eval_ret)
+ sys.stderr.write(json.dumps(eval_ret, indent=4) + "\n")
+
+ for key, value in eval_ret.items():
+ writer.add_scalar(key, value, global_step)
+
+ if eval_ret["valid_hits@100"] > best_model:
+ F.io.save_persistables(exe,
+ os.path.join(output_path, "checkpoint"),
+ train_prog)
+ eval_ret["step"] = global_step
+ with open(os.path.join(output_path, "best.txt"), "w") as f:
+ f.write(json.dumps(eval_ret, indent=2) + '\n')
+ best_model = eval_ret["valid_hits@100"]
+
+ writer.close()
diff --git a/ogb_examples/linkproppred/ogbl-ppa/train.py b/ogb_examples/linkproppred/ogbl-ppa/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..c70fa4f9dd4987e615f6f935b5108c727fe7abee
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/train.py
@@ -0,0 +1,157 @@
+# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""listwise model
+"""
+
+import torch
+import os
+import re
+import time
+import logging
+from random import random
+from functools import reduce, partial
+
+# For downloading ogb
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+# SSL
+
+import numpy as np
+import multiprocessing
+
+import pgl
+import paddle
+import paddle.fluid as F
+import paddle.fluid.layers as L
+
+from args import parser
+from utils.args import print_arguments, check_cuda
+from utils.init import init_checkpoint, init_pretraining_params
+from model import BaseGraph
+from dataloader.ogbl_ppa_dataloader import PPADataGenerator
+from monitor.train_monitor import train_and_evaluate, OgbEvaluator
+
+log = logging.getLogger(__name__)
+
+
+class Metric(object):
+ """Metric"""
+
+ def __init__(self, **args):
+ self.args = args
+
+ @property
+ def vars(self):
+ """ fetch metric vars"""
+ values = [self.args[k] for k in self.args.keys()]
+ return values
+
+ def parse(self, fetch_list):
+ """parse"""
+ tup = list(zip(self.args.keys(), [float(v[0]) for v in fetch_list]))
+ return dict(tup)
+
+
+if __name__ == '__main__':
+ args = parser.parse_args()
+ print_arguments(args)
+ evaluator = OgbEvaluator()
+
+ train_prog = F.Program()
+ startup_prog = F.Program()
+ args.num_nodes = evaluator.num_nodes
+
+ if args.use_cuda:
+ dev_list = F.cuda_places()
+ place = dev_list[0]
+ dev_count = len(dev_list)
+ else:
+ place = F.CPUPlace()
+ dev_count = int(os.environ.get('CPU_NUM', multiprocessing.cpu_count()))
+
+ with F.program_guard(train_prog, startup_prog):
+ with F.unique_name.guard():
+ graph_model = BaseGraph(args)
+ test_prog = train_prog.clone(for_test=True)
+ opt = F.optimizer.Adam(learning_rate=args.learning_rate)
+ opt.minimize(graph_model.loss)
+
+ #test_prog = F.Program()
+ #with F.program_guard(test_prog, startup_prog):
+ # with F.unique_name.guard():
+ # _graph_model = BaseGraph(args)
+
+ train_ds = PPADataGenerator(
+ phase="train",
+ graph_wrapper=graph_model.graph_wrapper,
+ num_workers=args.num_workers,
+ batch_size=args.batch_size)
+
+ valid_ds = PPADataGenerator(
+ phase="valid",
+ graph_wrapper=graph_model.graph_wrapper,
+ num_workers=args.num_workers,
+ batch_size=args.batch_size)
+
+ test_ds = PPADataGenerator(
+ phase="test",
+ graph_wrapper=graph_model.graph_wrapper,
+ num_workers=args.num_workers,
+ batch_size=args.batch_size)
+
+ exe = F.Executor(place)
+ exe.run(startup_prog)
+
+ if args.init_pretraining_params is not None:
+ init_pretraining_params(
+ exe, args.init_pretraining_params, main_program=startup_prog)
+
+ metric = Metric(**graph_model.metrics)
+
+ nccl2_num_trainers = 1
+ nccl2_trainer_id = 0
+ if dev_count > 1:
+
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = dev_count
+
+ train_exe = F.ParallelExecutor(
+ use_cuda=args.use_cuda,
+ loss_name=graph_model.loss.name,
+ exec_strategy=exec_strategy,
+ main_program=train_prog,
+ num_trainers=nccl2_num_trainers,
+ trainer_id=nccl2_trainer_id)
+
+ test_exe = exe
+ else:
+ train_exe, test_exe = exe, exe
+
+ train_and_evaluate(
+ exe=exe,
+ train_exe=train_exe,
+ valid_exe=test_exe,
+ train_ds=train_ds,
+ valid_ds=valid_ds,
+ test_ds=test_ds,
+ train_prog=train_prog,
+ valid_prog=test_prog,
+ train_log_step=5,
+ output_path=args.output_path,
+ dev_count=dev_count,
+ model=graph_model,
+ epoch=args.epoch,
+ eval_step=1000000,
+ evaluator=evaluator,
+ metric=metric)
diff --git a/ogb_examples/linkproppred/ogbl-ppa/utils/__init__.py b/ogb_examples/linkproppred/ogbl-ppa/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1333621cf62da67fcf10016fc848c503f7c254fa
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/utils/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""utils"""
diff --git a/ogb_examples/linkproppred/ogbl-ppa/utils/args.py b/ogb_examples/linkproppred/ogbl-ppa/utils/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..5131f2ceb88775f12e886402ef205735a1ac1d77
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/utils/args.py
@@ -0,0 +1,97 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Arguments for configuration."""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import six
+import os
+import sys
+import argparse
+import logging
+
+import paddle.fluid as fluid
+
+log = logging.getLogger(__name__)
+
+
+def prepare_logger(logger, debug=False, save_to_file=None):
+ """doc"""
+ formatter = logging.Formatter(
+ fmt='[%(levelname)s] %(asctime)s [%(filename)12s:%(lineno)5d]:\t%(message)s'
+ )
+ #console_hdl = logging.StreamHandler()
+ #console_hdl.setFormatter(formatter)
+ #logger.addHandler(console_hdl)
+ if save_to_file is not None and not os.path.exists(save_to_file):
+ file_hdl = logging.FileHandler(save_to_file)
+ file_hdl.setFormatter(formatter)
+ logger.addHandler(file_hdl)
+ logger.setLevel(logging.DEBUG)
+ logger.propagate = False
+
+
+def str2bool(v):
+ """doc"""
+ # because argparse does not support to parse "true, False" as python
+ # boolean directly
+ return v.lower() in ("true", "t", "1")
+
+
+class ArgumentGroup(object):
+ """doc"""
+
+ def __init__(self, parser, title, des):
+ self._group = parser.add_argument_group(title=title, description=des)
+
+ def add_arg(self,
+ name,
+ type,
+ default,
+ help,
+ positional_arg=False,
+ **kwargs):
+ """doc"""
+ prefix = "" if positional_arg else "--"
+ type = str2bool if type == bool else type
+ self._group.add_argument(
+ prefix + name,
+ default=default,
+ type=type,
+ help=help + ' Default: %(default)s.',
+ **kwargs)
+
+
+def print_arguments(args):
+ """doc"""
+ log.info('----------- Configuration Arguments -----------')
+ for arg, value in sorted(six.iteritems(vars(args))):
+ log.info('%s: %s' % (arg, value))
+ log.info('------------------------------------------------')
+
+
+def check_cuda(use_cuda, err= \
+ "\nYou can not set use_cuda=True in the model because you are using paddlepaddle-cpu.\n \
+ Please: 1. Install paddlepaddle-gpu to run your models on GPU or 2. Set use_cuda=False to run models on CPU.\n"
+ ):
+ """doc"""
+ try:
+ if use_cuda == True and fluid.is_compiled_with_cuda() == False:
+ log.error(err)
+ sys.exit(1)
+ except Exception as e:
+ pass
diff --git a/ogb_examples/linkproppred/ogbl-ppa/utils/cards.py b/ogb_examples/linkproppred/ogbl-ppa/utils/cards.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b658a4bf6272f00f48ff447caaaa580189afe60
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/utils/cards.py
@@ -0,0 +1,31 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""cards"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+import os
+
+
+def get_cards():
+ """
+ get gpu cards number
+ """
+ num = 0
+ cards = os.environ.get('CUDA_VISIBLE_DEVICES', '')
+ if cards != '':
+ num = len(cards.split(","))
+ return num
diff --git a/ogb_examples/linkproppred/ogbl-ppa/utils/fp16.py b/ogb_examples/linkproppred/ogbl-ppa/utils/fp16.py
new file mode 100644
index 0000000000000000000000000000000000000000..740add267dff2dbf463032bcc47a6741ca9f7c43
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/utils/fp16.py
@@ -0,0 +1,201 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import print_function
+import paddle
+import paddle.fluid as fluid
+
+
+def append_cast_op(i, o, prog):
+ """
+ Append a cast op in a given Program to cast input `i` to data type `o.dtype`.
+ Args:
+ i (Variable): The input Variable.
+ o (Variable): The output Variable.
+ prog (Program): The Program to append cast op.
+ """
+ prog.global_block().append_op(
+ type="cast",
+ inputs={"X": i},
+ outputs={"Out": o},
+ attrs={"in_dtype": i.dtype,
+ "out_dtype": o.dtype})
+
+
+def copy_to_master_param(p, block):
+ v = block.vars.get(p.name, None)
+ if v is None:
+ raise ValueError("no param name %s found!" % p.name)
+ new_p = fluid.framework.Parameter(
+ block=block,
+ shape=v.shape,
+ dtype=fluid.core.VarDesc.VarType.FP32,
+ type=v.type,
+ lod_level=v.lod_level,
+ stop_gradient=p.stop_gradient,
+ trainable=p.trainable,
+ optimize_attr=p.optimize_attr,
+ regularizer=p.regularizer,
+ gradient_clip_attr=p.gradient_clip_attr,
+ error_clip=p.error_clip,
+ name=v.name + ".master")
+ return new_p
+
+
+def apply_dynamic_loss_scaling(loss_scaling, master_params_grads,
+ incr_every_n_steps, decr_every_n_nan_or_inf,
+ incr_ratio, decr_ratio):
+ _incr_every_n_steps = fluid.layers.fill_constant(
+ shape=[1], dtype='int32', value=incr_every_n_steps)
+ _decr_every_n_nan_or_inf = fluid.layers.fill_constant(
+ shape=[1], dtype='int32', value=decr_every_n_nan_or_inf)
+
+ _num_good_steps = fluid.layers.create_global_var(
+ name=fluid.unique_name.generate("num_good_steps"),
+ shape=[1],
+ value=0,
+ dtype='int32',
+ persistable=True)
+ _num_bad_steps = fluid.layers.create_global_var(
+ name=fluid.unique_name.generate("num_bad_steps"),
+ shape=[1],
+ value=0,
+ dtype='int32',
+ persistable=True)
+
+ grads = [fluid.layers.reduce_sum(g) for [_, g] in master_params_grads]
+ all_grads = fluid.layers.concat(grads)
+ all_grads_sum = fluid.layers.reduce_sum(all_grads)
+ is_overall_finite = fluid.layers.isfinite(all_grads_sum)
+
+ update_loss_scaling(is_overall_finite, loss_scaling, _num_good_steps,
+ _num_bad_steps, _incr_every_n_steps,
+ _decr_every_n_nan_or_inf, incr_ratio, decr_ratio)
+
+ # apply_gradient append all ops in global block, thus we shouldn't
+ # apply gradient in the switch branch.
+ with fluid.layers.Switch() as switch:
+ with switch.case(is_overall_finite):
+ pass
+ with switch.default():
+ for _, g in master_params_grads:
+ fluid.layers.assign(fluid.layers.zeros_like(g), g)
+
+
+def create_master_params_grads(params_grads, main_prog, startup_prog,
+ loss_scaling):
+ master_params_grads = []
+ for p, g in params_grads:
+ with main_prog._optimized_guard([p, g]):
+ # create master parameters
+ master_param = copy_to_master_param(p, main_prog.global_block())
+ startup_master_param = startup_prog.global_block()._clone_variable(
+ master_param)
+ startup_p = startup_prog.global_block().var(p.name)
+ append_cast_op(startup_p, startup_master_param, startup_prog)
+ # cast fp16 gradients to fp32 before apply gradients
+ if g.name.find("layer_norm") > -1:
+ scaled_g = g / loss_scaling
+ master_params_grads.append([p, scaled_g])
+ continue
+ master_grad = fluid.layers.cast(g, "float32")
+ master_grad = master_grad / loss_scaling
+ master_params_grads.append([master_param, master_grad])
+
+ return master_params_grads
+
+
+def master_param_to_train_param(master_params_grads, params_grads, main_prog):
+ for idx, m_p_g in enumerate(master_params_grads):
+ train_p, _ = params_grads[idx]
+ if train_p.name.find("layer_norm") > -1:
+ continue
+ with main_prog._optimized_guard([m_p_g[0], m_p_g[1]]):
+ append_cast_op(m_p_g[0], train_p, main_prog)
+
+
+def update_loss_scaling(is_overall_finite, prev_loss_scaling, num_good_steps,
+ num_bad_steps, incr_every_n_steps,
+ decr_every_n_nan_or_inf, incr_ratio, decr_ratio):
+ """
+ Update loss scaling according to overall gradients. If all gradients is
+ finite after incr_every_n_steps, loss scaling will increase by incr_ratio.
+ Otherwisw, loss scaling will decrease by decr_ratio after
+ decr_every_n_nan_or_inf steps and each step some gradients are infinite.
+ Args:
+ is_overall_finite (Variable): A boolean variable indicates whether
+ all gradients are finite.
+ prev_loss_scaling (Variable): Previous loss scaling.
+ num_good_steps (Variable): A variable accumulates good steps in which
+ all gradients are finite.
+ num_bad_steps (Variable): A variable accumulates bad steps in which
+ some gradients are infinite.
+ incr_every_n_steps (Variable): A variable represents increasing loss
+ scaling every n consecutive steps with
+ finite gradients.
+ decr_every_n_nan_or_inf (Variable): A variable represents decreasing
+ loss scaling every n accumulated
+ steps with nan or inf gradients.
+ incr_ratio(float): The multiplier to use when increasing the loss
+ scaling.
+ decr_ratio(float): The less-than-one-multiplier to use when decreasing
+ loss scaling.
+ """
+ zero_steps = fluid.layers.fill_constant(shape=[1], dtype='int32', value=0)
+ with fluid.layers.Switch() as switch:
+ with switch.case(is_overall_finite):
+ should_incr_loss_scaling = fluid.layers.less_than(
+ incr_every_n_steps, num_good_steps + 1)
+ with fluid.layers.Switch() as switch1:
+ with switch1.case(should_incr_loss_scaling):
+ new_loss_scaling = prev_loss_scaling * incr_ratio
+ loss_scaling_is_finite = fluid.layers.isfinite(
+ new_loss_scaling)
+ with fluid.layers.Switch() as switch2:
+ with switch2.case(loss_scaling_is_finite):
+ fluid.layers.assign(new_loss_scaling,
+ prev_loss_scaling)
+ with switch2.default():
+ pass
+ fluid.layers.assign(zero_steps, num_good_steps)
+ fluid.layers.assign(zero_steps, num_bad_steps)
+
+ with switch1.default():
+ fluid.layers.increment(num_good_steps)
+ fluid.layers.assign(zero_steps, num_bad_steps)
+
+ with switch.default():
+ should_decr_loss_scaling = fluid.layers.less_than(
+ decr_every_n_nan_or_inf, num_bad_steps + 1)
+ with fluid.layers.Switch() as switch3:
+ with switch3.case(should_decr_loss_scaling):
+ new_loss_scaling = prev_loss_scaling * decr_ratio
+ static_loss_scaling = \
+ fluid.layers.fill_constant(shape=[1],
+ dtype='float32',
+ value=1.0)
+ less_than_one = fluid.layers.less_than(new_loss_scaling,
+ static_loss_scaling)
+ with fluid.layers.Switch() as switch4:
+ with switch4.case(less_than_one):
+ fluid.layers.assign(static_loss_scaling,
+ prev_loss_scaling)
+ with switch4.default():
+ fluid.layers.assign(new_loss_scaling,
+ prev_loss_scaling)
+ fluid.layers.assign(zero_steps, num_good_steps)
+ fluid.layers.assign(zero_steps, num_bad_steps)
+ with switch3.default():
+ fluid.layers.assign(zero_steps, num_good_steps)
+ fluid.layers.increment(num_bad_steps)
diff --git a/ogb_examples/linkproppred/ogbl-ppa/utils/init.py b/ogb_examples/linkproppred/ogbl-ppa/utils/init.py
new file mode 100644
index 0000000000000000000000000000000000000000..baa3ba5987cf1cbae20a60ea88e3f3bf0e389f43
--- /dev/null
+++ b/ogb_examples/linkproppred/ogbl-ppa/utils/init.py
@@ -0,0 +1,97 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""paddle init"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import six
+import ast
+import copy
+import logging
+
+import numpy as np
+import paddle.fluid as fluid
+
+log = logging.getLogger(__name__)
+
+
+def cast_fp32_to_fp16(exe, main_program):
+ """doc"""
+ log.info("Cast parameters to float16 data format.")
+ for param in main_program.global_block().all_parameters():
+ if not param.name.endswith(".master"):
+ param_t = fluid.global_scope().find_var(param.name).get_tensor()
+ data = np.array(param_t)
+ if param.name.startswith("encoder_layer") \
+ and "layer_norm" not in param.name:
+ param_t.set(np.float16(data).view(np.uint16), exe.place)
+
+ #load fp32
+ master_param_var = fluid.global_scope().find_var(param.name +
+ ".master")
+ if master_param_var is not None:
+ master_param_var.get_tensor().set(data, exe.place)
+
+
+def init_checkpoint(exe, init_checkpoint_path, main_program, use_fp16=False):
+ """init"""
+ assert os.path.exists(
+ init_checkpoint_path), "[%s] cann't be found." % init_checkpoint_path
+
+ def existed_persitables(var):
+ """existed"""
+ if not fluid.io.is_persistable(var):
+ return False
+ return os.path.exists(os.path.join(init_checkpoint_path, var.name))
+
+ fluid.io.load_vars(
+ exe,
+ init_checkpoint_path,
+ main_program=main_program,
+ predicate=existed_persitables)
+ log.info("Load model from {}".format(init_checkpoint_path))
+
+ if use_fp16:
+ cast_fp32_to_fp16(exe, main_program)
+
+
+def init_pretraining_params(exe,
+ pretraining_params_path,
+ main_program,
+ use_fp16=False):
+ """init"""
+ assert os.path.exists(pretraining_params_path
+ ), "[%s] cann't be found." % pretraining_params_path
+
+ def existed_params(var):
+ """doc"""
+ if not isinstance(var, fluid.framework.Parameter):
+ return False
+ return os.path.exists(os.path.join(pretraining_params_path, var.name))
+
+ fluid.io.load_vars(
+ exe,
+ pretraining_params_path,
+ main_program=main_program,
+ predicate=existed_params)
+ log.info("Load pretraining parameters from {}.".format(
+ pretraining_params_path))
+
+ if use_fp16:
+ cast_fp32_to_fp16(exe, main_program)
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/README.md b/ogb_examples/nodeproppred/ogbn-arxiv/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..123deb80fa337081cbe389dd1d97049ecd3764d8
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/README.md
@@ -0,0 +1,59 @@
+# Graph Node Prediction for Open Graph Benchmark (OGB) Arxiv dataset
+
+[The Open Graph Benchmark (OGB)](https://ogb.stanford.edu/) is a collection of benchmark datasets, data loaders, and evaluators for graph machine learning. Here we complete the Graph Node Prediction task based on PGL.
+
+
+### Requirements
+
+paddlpaddle >= 1.7.1
+
+pgl 1.0.2
+
+ogb 1.1.1
+
+
+### How to Run
+
+```
+CUDA_VISIBLE_DEVICES=0 python train.py \
+ --use_cuda 1 \
+ --num_workers 4 \
+ --output_path ./output/model_1 \
+ --batch_size 1024 \
+ --test_batch_size 512 \
+ --epoch 100 \
+ --learning_rate 0.001 \
+ --full_batch 0 \
+ --model gaan \
+ --drop_rate 0.5 \
+ --samples 8 8 8 \
+ --test_samples 20 20 20 \
+ --hidden_size 256
+```
+or
+
+```
+sh run.sh
+```
+
+The best record will be saved in ./output/model_1/best.txt.
+
+
+### Hyperparameters
+- use_cuda: whether to use gpu or not
+- num_workers: the nums of sample workers
+- output_path: path to save the model
+- batch_size: batch size
+- epoch: number of training epochs
+- learning_rate: learning rate
+- full_batch: run full batch of graph
+- model: model to run, now gaan, sage, gcn, eta are available
+- drop_rate: drop rate of the feature layers
+- samples: the sample nums of each GNN layers
+- hidden_size: the hidden size
+
+### Performance
+We train our models for 100 epochs and report the **acc** on the test dataset.
+|dataset|mean|std|#experiments|
+|-|-|-|-|
+|ogbn-arxiv|0.7197|0.0024|16|
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/args.py b/ogb_examples/nodeproppred/ogbn-arxiv/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..638a2ca4db636c86e9383b5c8f260e725962a400
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/args.py
@@ -0,0 +1,50 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""finetune args"""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import time
+import argparse
+
+from utils.args import ArgumentGroup
+
+# yapf: disable
+parser = argparse.ArgumentParser(__doc__)
+model_g = ArgumentGroup(parser, "model", "model configuration and paths.")
+model_g.add_arg("init_checkpoint", str, None, "Init checkpoint to resume training from.")
+model_g.add_arg("init_pretraining_params", str, None,
+ "Init pre-training params which preforms fine-tuning from. If the "
+ "arg 'init_checkpoint' has been set, this argument wouldn't be valid.")
+
+train_g = ArgumentGroup(parser, "training", "training options.")
+train_g.add_arg("epoch", int, 3, "Number of epoches for fine-tuning.")
+train_g.add_arg("learning_rate", float, 5e-5, "Learning rate used to train with warmup.")
+
+run_type_g = ArgumentGroup(parser, "run_type", "running type options.")
+run_type_g.add_arg("use_cuda", bool, True, "If set, use GPU for training.")
+run_type_g.add_arg("num_workers", int, 4, "use multiprocess to generate graph")
+run_type_g.add_arg("output_path", str, None, "path to save model")
+run_type_g.add_arg("model", str, None, "model to run")
+run_type_g.add_arg("hidden_size", int, 256, "model hidden-size")
+run_type_g.add_arg("drop_rate", float, 0.5, "Dropout rate")
+run_type_g.add_arg("batch_size", int, 1024, "batch_size")
+run_type_g.add_arg("full_batch", bool, False, "use static graph wrapper, if full_batch is true, batch_size will take no effect.")
+run_type_g.add_arg("samples", type=int, nargs='+', default=[30, 30], help="sample nums of k-hop.")
+run_type_g.add_arg("test_batch_size", int, 512, help="sample nums of k-hop of test phase.")
+run_type_g.add_arg("test_samples", type=int, nargs='+', default=[30, 30], help="sample nums of k-hop.")
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/__init__.py b/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..abf198b97e6e818e1fbe59006f98492640bcee54
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/__init__.py
@@ -0,0 +1,13 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/base_dataloader.py b/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/base_dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..d04f9fd521602bf67f950b3e72ba021fd09c298f
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/base_dataloader.py
@@ -0,0 +1,148 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Base DataLoader
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import sys
+import six
+from io import open
+from collections import namedtuple
+import numpy as np
+import tqdm
+import paddle
+from pgl.utils import mp_reader
+import collections
+import time
+
+import pgl
+
+if six.PY3:
+ import io
+ sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
+ sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
+
+
+def batch_iter(data, perm, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ size = len(data)
+ start = 0
+ cc = 0
+ while start < size:
+ index = perm[start:start + batch_size]
+ start += batch_size
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ yield data[index]
+
+
+def scan_batch_iter(data, batch_size, fid, num_workers):
+ """node_batch_iter
+ """
+ batch = []
+ cc = 0
+ for line_example in data.scan():
+ cc += 1
+ if cc % num_workers != fid:
+ continue
+ batch.append(line_example)
+ if len(batch) == batch_size:
+ yield batch
+ batch = []
+
+ if len(batch) > 0:
+ yield batch
+
+
+class BaseDataGenerator(object):
+ """Base Data Geneartor"""
+
+ def __init__(self, buf_size, batch_size, num_workers, shuffle=True):
+ self.num_workers = num_workers
+ self.batch_size = batch_size
+ self.line_examples = []
+ self.buf_size = buf_size
+ self.shuffle = shuffle
+
+ def batch_fn(self, batch_examples):
+ """ batch_fn batch producer"""
+ raise NotImplementedError("No defined Batch Fn")
+
+ def batch_iter(self, fid, perm):
+ """ batch iterator"""
+ if self.shuffle:
+ for batch in batch_iter(self, perm, self.batch_size, fid,
+ self.num_workers):
+ yield batch
+ else:
+ for batch in scan_batch_iter(self, self.batch_size, fid,
+ self.num_workers):
+ yield batch
+
+ def __len__(self):
+ return len(self.line_examples)
+
+ def __getitem__(self, idx):
+ if isinstance(idx, collections.Iterable):
+ return [self[bidx] for bidx in idx]
+ else:
+ return self.line_examples[idx]
+
+ def generator(self):
+ """batch dict generator"""
+
+ def worker(filter_id, perm):
+ """ multiprocess worker"""
+
+ def func_run():
+ """ func_run """
+ pid = os.getpid()
+ np.random.seed(pid + int(time.time()))
+ for batch_examples in self.batch_iter(filter_id, perm):
+ batch_dict = self.batch_fn(batch_examples)
+ yield batch_dict
+
+ return func_run
+
+ # consume a seed
+ np.random.rand()
+ if self.shuffle:
+ perm = np.arange(0, len(self))
+ np.random.shuffle(perm)
+ else:
+ perm = None
+ if self.num_workers == 1:
+ r = paddle.reader.buffered(worker(0, perm), self.buf_size)
+ else:
+ worker_pool = [
+ worker(wid, perm) for wid in range(self.num_workers)
+ ]
+ worker = mp_reader.multiprocess_reader(
+ worker_pool, use_pipe=True, queue_size=1000)
+ r = paddle.reader.buffered(worker, self.buf_size)
+
+ for batch in r():
+ yield batch
+
+ def scan(self):
+ for line_example in self.line_examples:
+ yield line_example
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/ogbn_arxiv_dataloader.py b/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/ogbn_arxiv_dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..48529c6a39f1bbf861765e21bed82fe0185dc27e
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/dataloader/ogbn_arxiv_dataloader.py
@@ -0,0 +1,151 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+from dataloader.base_dataloader import BaseDataGenerator
+from utils.to_undirected import to_undirected
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+
+from pgl.contrib.ogb.nodeproppred.dataset_pgl import PglNodePropPredDataset
+#from pgl.sample import graph_saint_random_walk_sample
+from ogb.nodeproppred import Evaluator
+import tqdm
+from collections import namedtuple
+import pgl
+import numpy as np
+import copy
+
+
+def traverse(item):
+ """traverse
+ """
+ if isinstance(item, list) or isinstance(item, np.ndarray):
+ for i in iter(item):
+ for j in traverse(i):
+ yield j
+ else:
+ yield item
+
+
+def flat_node_and_edge(nodes):
+ """flat_node_and_edge
+ """
+ nodes = list(set(traverse(nodes)))
+ return nodes
+
+
+def k_hop_sampler(graph, samples, batch_nodes):
+ # for batch_train_samples, batch_train_labels in batch_info:
+ start_nodes = copy.deepcopy(batch_nodes)
+ nodes = start_nodes
+ edges = []
+ for max_deg in samples:
+ pred_nodes = graph.sample_predecessor(start_nodes, max_degree=max_deg)
+
+ for dst_node, src_nodes in zip(start_nodes, pred_nodes):
+ for src_node in src_nodes:
+ edges.append((src_node, dst_node))
+
+ last_nodes = nodes
+ nodes = [nodes, pred_nodes]
+ nodes = flat_node_and_edge(nodes)
+ # Find new nodes
+ start_nodes = list(set(nodes) - set(last_nodes))
+ if len(start_nodes) == 0:
+ break
+
+ subgraph = graph.subgraph(
+ nodes=nodes, edges=edges, with_node_feat=True, with_edge_feat=True)
+ sub_node_index = subgraph.reindex_from_parrent_nodes(batch_nodes)
+
+ return subgraph, sub_node_index
+
+
+#def graph_saint_randomwalk_sampler(graph, batch_nodes, max_depth=3):
+# subgraph = graph_saint_random_walk_sample(graph, batch_nodes, max_depth)
+# sub_node_index = subgraph.reindex_from_parrent_nodes(batch_nodes)
+# return subgraph, sub_node_index
+
+
+class ArxivDataGenerator(BaseDataGenerator):
+ def __init__(self,
+ graph_wrapper=None,
+ buf_size=1000,
+ batch_size=128,
+ num_workers=1,
+ samples=[30, 30],
+ shuffle=True,
+ phase="train"):
+ super(ArxivDataGenerator, self).__init__(
+ buf_size=buf_size,
+ num_workers=num_workers,
+ batch_size=batch_size,
+ shuffle=shuffle)
+ self.samples = samples
+ self.d_name = "ogbn-arxiv"
+ self.graph_wrapper = graph_wrapper
+ dataset = PglNodePropPredDataset(name=self.d_name)
+ splitted_idx = dataset.get_idx_split()
+ self.phase = phase
+ graph, label = dataset[0]
+ graph = to_undirected(graph)
+ self.graph = graph
+ self.num_nodes = graph.num_nodes
+ if self.phase == 'train':
+ nodes_idx = splitted_idx["train"]
+ labels = label[nodes_idx]
+ elif self.phase == "valid":
+ nodes_idx = splitted_idx["valid"]
+ labels = label[nodes_idx]
+ elif self.phase == "test":
+ nodes_idx = splitted_idx["test"]
+ labels = label[nodes_idx]
+ self.nodes_idx = nodes_idx
+ self.labels = labels
+ self.sample_based_line_example(nodes_idx, labels)
+
+ def sample_based_line_example(self, nodes_idx, labels):
+ self.line_examples = []
+ Example = namedtuple('Example', ["node", "label"])
+ for node, label in zip(nodes_idx, labels):
+ self.line_examples.append(Example(node=node, label=label))
+ print("Phase", self.phase)
+ print("Len Examples", len(self.line_examples))
+
+ def batch_fn(self, batch_ex):
+ batch_nodes = []
+ cc = 0
+ batch_node_id = []
+ batch_labels = []
+ for ex in batch_ex:
+ batch_nodes.append(ex.node)
+ batch_labels.append(ex.label)
+
+ _graph_wrapper = copy.copy(self.graph_wrapper)
+ #if self.phase == "train":
+ # subgraph, sub_node_index = graph_saint_randomwalk_sampler(self.graph, batch_nodes)
+ #else:
+ subgraph, sub_node_index = k_hop_sampler(self.graph, self.samples,
+ batch_nodes)
+
+ feed_dict = _graph_wrapper.to_feed(subgraph)
+ feed_dict["batch_nodes"] = sub_node_index
+ feed_dict["labels"] = np.array(batch_labels, dtype="int64")
+ return feed_dict
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/model.py b/ogb_examples/nodeproppred/ogbn-arxiv/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..1bfa50b1c31b7effdf2573025a1e8e04ee4ec739
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/model.py
@@ -0,0 +1,416 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# encoding=utf-8
+"""lbs_model"""
+import os
+import re
+import time
+from random import random
+from functools import reduce, partial
+
+import numpy as np
+import multiprocessing
+
+import paddle
+import paddle.fluid as F
+import paddle.fluid as fluid
+import paddle.fluid.layers as L
+from pgl.graph_wrapper import GraphWrapper
+from pgl.layers.conv import gcn, gat
+from pgl.utils import paddle_helper
+
+
+class BaseGraph(object):
+ """Base Graph Model"""
+
+ def __init__(self, args, graph_wrapper=None):
+ self.hidden_size = args.hidden_size
+ self.num_nodes = args.num_nodes
+ self.drop_rate = args.drop_rate
+ node_feature = [('feat', [None, 128], "float32")]
+ if graph_wrapper is None:
+ self.graph_wrapper = GraphWrapper(
+ name="graph", place=F.CPUPlace(), node_feat=node_feature)
+ else:
+ self.graph_wrapper = graph_wrapper
+ self.build_model(args)
+
+ def build_model(self, args):
+ """ build graph model"""
+ self.batch_nodes = L.data(
+ name="batch_nodes", shape=[-1], dtype="int64")
+ self.labels = L.data(name="labels", shape=[-1], dtype="int64")
+
+ self.batch_nodes = L.reshape(self.batch_nodes, [-1, 1])
+ self.labels = L.reshape(self.labels, [-1, 1])
+
+ self.batch_nodes.stop_gradients = True
+ self.labels.stop_gradients = True
+
+ feat = self.graph_wrapper.node_feat['feat']
+ if self.graph_wrapper is not None:
+ feat = self.neighbor_aggregator(feat)
+
+ assert feat is not None
+ feat = L.gather(feat, self.batch_nodes)
+ self.logits = L.fc(feat,
+ size=40,
+ act=None,
+ name="node_predictor_logits")
+ self.loss()
+
+ def mlp(self, feat):
+ for i in range(3):
+ feat = L.fc(node,
+ size=self.hidden_size,
+ name="simple_mlp_{}".format(i))
+ feat = L.batch_norm(feat)
+ feat = L.relu(feat)
+ feat = L.dropout(feat, dropout_prob=0.5)
+ return feat
+
+ def loss(self):
+ self.loss = L.softmax_with_cross_entropy(self.logits, self.labels)
+ self.loss = L.reduce_mean(self.loss)
+ self.metrics = {"loss": self.loss, }
+
+ def neighbor_aggregator(self, feature):
+ """neighbor aggregation"""
+ raise NotImplementedError(
+ "Please implement this method when you using graph wrapper for GNNs."
+ )
+
+
+class MLPModel(BaseGraph):
+ def __init__(self, args, gw):
+ super(MLPModel, self).__init__(args, gw)
+
+ def neighbor_aggregator(self, feature):
+ for i in range(3):
+ feature = L.fc(feature,
+ size=self.hidden_size,
+ name="simple_mlp_{}".format(i))
+ #feature = L.batch_norm(feature)
+ feature = L.relu(feature)
+ feature = L.dropout(feature, dropout_prob=self.drop_rate)
+ return feature
+
+
+class SAGEModel(BaseGraph):
+ def __init__(self, args, gw):
+ super(SAGEModel, self).__init__(args, gw)
+
+ def neighbor_aggregator(self, feature):
+ sage = GraphSageModel(40, 3, 256)
+ feature = sage.forward(self.graph_wrapper, feature, self.drop_rate)
+ return feature
+
+
+class GAANModel(BaseGraph):
+ def __init__(self, args, gw):
+ super(GAANModel, self).__init__(args, gw)
+
+ def neighbor_aggregator(self, feature):
+ gaan = GaANModel(
+ 40,
+ 3,
+ hidden_size_a=48,
+ hidden_size_v=64,
+ hidden_size_m=128,
+ hidden_size_o=256)
+ feature = gaan.forward(self.graph_wrapper, feature, self.drop_rate)
+ return feature
+
+
+class GINModel(BaseGraph):
+ def __init__(self, args, gw):
+ super(GINModel, self).__init__(args, gw)
+
+ def neighbor_aggregator(self, feature):
+ gin = GinModel(40, 2, 256)
+ feature = gin.forward(self.graph_wrapper, feature, self.drop_rate)
+ return feature
+
+
+class GATModel(BaseGraph):
+ def __init__(self, args, gw):
+ super(GATModel, self).__init__(args, gw)
+
+ def neighbor_aggregator(self, feature):
+ feature = gat(self.graph_wrapper,
+ feature,
+ hidden_size=self.hidden_size,
+ activation='relu',
+ name="GAT_1")
+ feature = gat(self.graph_wrapper,
+ feature,
+ hidden_size=self.hidden_size,
+ activation='relu',
+ name="GAT_2")
+ return feature
+
+
+class GCNModel(BaseGraph):
+ def __init__(self, args, gw):
+ super(GCNModel, self).__init__(args, gw)
+
+ def neighbor_aggregator(self, feature):
+ feature = gcn(
+ self.graph_wrapper,
+ feature,
+ hidden_size=self.hidden_size,
+ activation='relu',
+ name="GCN_1", )
+ feature = fluid.layers.dropout(feature, dropout_prob=self.drop_rate)
+ feature = gcn(self.graph_wrapper,
+ feature,
+ hidden_size=self.hidden_size,
+ activation='relu',
+ name="GCN_2")
+ feature = fluid.layers.dropout(feature, dropout_prob=self.drop_rate)
+ return feature
+
+
+class GinModel(object):
+ def __init__(self,
+ num_class,
+ num_layers,
+ hidden_size,
+ act='relu',
+ name="GINModel"):
+ self.num_class = num_class
+ self.num_layers = num_layers
+ self.hidden_size = hidden_size
+ self.act = act
+ self.name = name
+
+ def forward(self, gw, feature):
+ for i in range(self.num_layers):
+ feature = gin(gw, feature, self.hidden_size, self.act,
+ self.name + '_' + str(i))
+ feature = fluid.layers.layer_norm(
+ feature,
+ begin_norm_axis=1,
+ param_attr=fluid.ParamAttr(
+ name="norm_scale_%s" % (i),
+ initializer=fluid.initializer.Constant(1.0)),
+ bias_attr=fluid.ParamAttr(
+ name="norm_bias_%s" % (i),
+ initializer=fluid.initializer.Constant(0.0)), )
+
+ feature = fluid.layers.relu(feature)
+ return feature
+
+
+class GaANModel(object):
+ def __init__(self,
+ num_class,
+ num_layers,
+ hidden_size_a=24,
+ hidden_size_v=32,
+ hidden_size_m=64,
+ hidden_size_o=128,
+ heads=8,
+ act='relu',
+ name="GaAN"):
+ self.num_class = num_class
+ self.num_layers = num_layers
+ self.hidden_size_a = hidden_size_a
+ self.hidden_size_v = hidden_size_v
+ self.hidden_size_m = hidden_size_m
+ self.hidden_size_o = hidden_size_o
+ self.act = act
+ self.name = name
+ self.heads = heads
+
+ def GaANConv(self, gw, feature, name):
+ feat_key = fluid.layers.fc(
+ feature,
+ self.hidden_size_a * self.heads,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_key'))
+ # N * (D2 * M)
+ feat_value = fluid.layers.fc(
+ feature,
+ self.hidden_size_v * self.heads,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_value'))
+ # N * (D1 * M)
+ feat_query = fluid.layers.fc(
+ feature,
+ self.hidden_size_a * self.heads,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_query'))
+ # N * Dm
+ feat_gate = fluid.layers.fc(
+ feature,
+ self.hidden_size_m,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_gate'))
+
+ # send
+ message = gw.send(
+ self.send_func,
+ nfeat_list=[('node_feat', feature), ('feat_key', feat_key),
+ ('feat_value', feat_value), ('feat_query', feat_query),
+ ('feat_gate', feat_gate)],
+ efeat_list=None, )
+
+ # recv
+ output = gw.recv(message, self.recv_func)
+ output = fluid.layers.fc(
+ output,
+ self.hidden_size_o,
+ bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_output'))
+ output = fluid.layers.leaky_relu(output, alpha=0.1)
+ output = fluid.layers.dropout(output, dropout_prob=0.1)
+ return output
+
+ def forward(self, gw, feature, drop_rate):
+ for i in range(self.num_layers):
+ feature = self.GaANConv(gw, feature, self.name + '_' + str(i))
+ feature = fluid.layers.dropout(feature, dropout_prob=drop_rate)
+ return feature
+
+ def send_func(self, src_feat, dst_feat, edge_feat):
+ # E * (M * D1)
+ feat_query, feat_key = dst_feat['feat_query'], src_feat['feat_key']
+ # E * M * D1
+ old = feat_query
+ feat_query = fluid.layers.reshape(
+ feat_query, [-1, self.heads, self.hidden_size_a])
+ feat_key = fluid.layers.reshape(feat_key,
+ [-1, self.heads, self.hidden_size_a])
+ # E * M
+ alpha = fluid.layers.reduce_sum(feat_key * feat_query, dim=-1)
+
+ return {
+ 'dst_node_feat': dst_feat['node_feat'],
+ 'src_node_feat': src_feat['node_feat'],
+ 'feat_value': src_feat['feat_value'],
+ 'alpha': alpha,
+ 'feat_gate': src_feat['feat_gate']
+ }
+
+ def recv_func(self, message):
+ dst_feat = message['dst_node_feat']
+ src_feat = message['src_node_feat']
+ x = fluid.layers.sequence_pool(dst_feat, 'average')
+ z = fluid.layers.sequence_pool(src_feat, 'average')
+
+ feat_gate = message['feat_gate']
+ g_max = fluid.layers.sequence_pool(feat_gate, 'max')
+
+ g = fluid.layers.concat([x, g_max, z], axis=1)
+ g = fluid.layers.fc(g, self.heads, bias_attr=False, act="sigmoid")
+
+ # softmax
+ alpha = message['alpha']
+ alpha = paddle_helper.sequence_softmax(alpha) # E * M
+
+ feat_value = message['feat_value'] # E * (M * D2)
+ old = feat_value
+ feat_value = fluid.layers.reshape(
+ feat_value, [-1, self.heads, self.hidden_size_v]) # E * M * D2
+ feat_value = fluid.layers.elementwise_mul(feat_value, alpha, axis=0)
+ feat_value = fluid.layers.reshape(
+ feat_value, [-1, self.heads * self.hidden_size_v]) # E * (M * D2)
+ feat_value = fluid.layers.lod_reset(feat_value, old)
+
+ feat_value = fluid.layers.sequence_pool(feat_value,
+ 'sum') # N * (M * D2)
+ feat_value = fluid.layers.reshape(
+ feat_value, [-1, self.heads, self.hidden_size_v]) # N * M * D2
+ output = fluid.layers.elementwise_mul(feat_value, g, axis=0)
+ output = fluid.layers.reshape(
+ output, [-1, self.heads * self.hidden_size_v]) # N * (M * D2)
+ output = fluid.layers.concat([x, output], axis=1)
+
+ return output
+
+
+class GraphSageModel(object):
+ def __init__(self,
+ num_class,
+ num_layers,
+ hidden_size,
+ act='relu',
+ name="GraphSage"):
+ self.num_class = num_class
+ self.num_layers = num_layers
+ self.hidden_size = hidden_size
+ self.act = act
+ self.name = name
+
+ def GraphSageConv(self, gw, feature, name):
+ message = gw.send(
+ self.send_func,
+ nfeat_list=[('node_feat', feature)],
+ efeat_list=None, )
+ neighbor_feat = gw.recv(message, self.recv_func)
+ neighbor_feat = fluid.layers.fc(neighbor_feat,
+ self.hidden_size,
+ act=self.act,
+ name=name + '_n')
+ self_feature = fluid.layers.fc(feature,
+ self.hidden_size,
+ act=self.act,
+ name=name + '_s')
+ output = self_feature + neighbor_feat
+ output = fluid.layers.l2_normalize(output, axis=1)
+
+ return output
+
+ def SageConv(self, gw, feature, name, hidden_size, act):
+ message = gw.send(
+ self.send_func,
+ nfeat_list=[('node_feat', feature)],
+ efeat_list=None, )
+ neighbor_feat = gw.recv(message, self.recv_func)
+ neighbor_feat = fluid.layers.fc(neighbor_feat,
+ hidden_size,
+ act=None,
+ name=name + '_n')
+ self_feature = fluid.layers.fc(feature,
+ hidden_size,
+ act=None,
+ name=name + '_s')
+ output = self_feature + neighbor_feat
+ # output = fluid.layers.concat([self_feature, neighbor_feat], axis=1)
+ output = fluid.layers.l2_normalize(output, axis=1)
+ if act is not None:
+ ouput = L.relu(output)
+ return output
+
+ def bn_drop(self, feat, drop_rate):
+ #feat = L.batch_norm(feat)
+ feat = L.dropout(feat, dropout_prob=drop_rate)
+ return feat
+
+ def forward(self, gw, feature, drop_rate):
+ for i in range(self.num_layers):
+ final = (i == (self.num_layers - 1))
+ feature = self.SageConv(gw, feature, self.name + '_' + str(i),
+ self.hidden_size, None
+ if final else self.act)
+ if not final:
+ feature = self.bn_drop(feature, drop_rate)
+ return feature
+
+ def send_func(self, src_feat, dst_feat, edge_feat):
+ return src_feat["node_feat"]
+
+ def recv_func(self, feat):
+ return fluid.layers.sequence_pool(feat, pool_type="average")
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/monitor/__init__.py b/ogb_examples/nodeproppred/ogbn-arxiv/monitor/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d814437561c253c97a95e31187e63a554476364f
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/monitor/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""init"""
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/monitor/train_monitor.py b/ogb_examples/nodeproppred/ogbn-arxiv/monitor/train_monitor.py
new file mode 100644
index 0000000000000000000000000000000000000000..b73cfd061863167ac9d0d1cffcecba9f78797424
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/monitor/train_monitor.py
@@ -0,0 +1,213 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""train and evaluate"""
+import tqdm
+import json
+import numpy as np
+import sys
+import os
+import paddle.fluid as F
+from tensorboardX import SummaryWriter
+from ogb.nodeproppred import Evaluator
+from ogb.nodeproppred import NodePropPredDataset
+
+
+def multi_device(reader, dev_count):
+ """multi device"""
+ if dev_count == 1:
+ for batch in reader:
+ yield batch
+ else:
+ batches = []
+ for batch in reader:
+ batches.append(batch)
+ if len(batches) == dev_count:
+ yield batches
+ batches = []
+
+
+class OgbEvaluator(object):
+ def __init__(self):
+ d_name = "ogbn-arxiv"
+ dataset = NodePropPredDataset(name=d_name)
+ graph, label = dataset[0]
+ self.num_nodes = graph["num_nodes"]
+ self.ogb_evaluator = Evaluator(name="ogbn-arxiv")
+
+ def eval(self, scores, labels, phase):
+ pred = (np.argmax(scores, axis=1)).reshape([-1, 1])
+ ret = {}
+ ret['%s_acc' % (phase)] = self.ogb_evaluator.eval({
+ 'y_true': labels,
+ 'y_pred': pred,
+ })['acc']
+ return ret
+
+
+def evaluate(model, valid_exe, valid_ds, valid_prog, dev_count, evaluator,
+ phase, full_batch):
+ """evaluate """
+ cc = 0
+ scores = []
+ labels = []
+ if full_batch:
+ valid_iter = _full_batch_wapper(valid_ds)
+ else:
+ valid_iter = valid_ds.generator
+
+ for feed_dict in tqdm.tqdm(
+ multi_device(valid_iter(), dev_count), desc='evaluating'):
+ if dev_count > 1:
+ output = valid_exe.run(feed=feed_dict,
+ fetch_list=[model.logits, model.labels])
+ else:
+ output = valid_exe.run(valid_prog,
+ feed=feed_dict,
+ fetch_list=[model.logits, model.labels])
+ scores.append(output[0])
+ labels.append(output[1])
+
+ scores = np.vstack(scores)
+ labels = np.vstack(labels)
+ ret = evaluator.eval(scores, labels, phase)
+ return ret
+
+
+def _create_if_not_exist(path):
+ basedir = os.path.dirname(path)
+ if not os.path.exists(basedir):
+ os.makedirs(basedir)
+
+
+def _full_batch_wapper(ds):
+ feed_dict = {}
+ feed_dict["batch_nodes"] = np.array(ds.nodes_idx, dtype="int64")
+ feed_dict["labels"] = np.array(ds.labels, dtype="int64")
+
+ def r():
+ yield feed_dict
+
+ return r
+
+
+def train_and_evaluate(exe,
+ train_exe,
+ valid_exe,
+ train_ds,
+ valid_ds,
+ test_ds,
+ train_prog,
+ valid_prog,
+ full_batch,
+ model,
+ metric,
+ epoch=20,
+ dev_count=1,
+ train_log_step=5,
+ eval_step=10000,
+ evaluator=None,
+ output_path=None):
+ """train and evaluate"""
+
+ global_step = 0
+
+ log_path = os.path.join(output_path, "log")
+ _create_if_not_exist(log_path)
+
+ writer = SummaryWriter(log_path)
+
+ best_model = 0
+
+ if full_batch:
+ train_iter = _full_batch_wapper(train_ds)
+ else:
+ train_iter = train_ds.generator
+
+ for e in range(epoch):
+ ret_sum_loss = 0
+ per_step = 0
+ scores = []
+ labels = []
+ for feed_dict in tqdm.tqdm(
+ multi_device(train_iter(), dev_count), desc='Epoch %s' % e):
+ if dev_count > 1:
+ ret = train_exe.run(feed=feed_dict, fetch_list=metric.vars)
+ ret = [[np.mean(v)] for v in ret]
+ else:
+ ret = train_exe.run(
+ train_prog,
+ feed=feed_dict,
+ fetch_list=[model.loss, model.logits, model.labels]
+ #fetch_list=metric.vars
+ )
+ scores.append(ret[1])
+ labels.append(ret[2])
+ ret = [ret[0]]
+
+ ret = metric.parse(ret)
+ if global_step % train_log_step == 0:
+ for key, value in ret.items():
+ writer.add_scalar(
+ 'train_' + key, value, global_step=global_step)
+ ret_sum_loss += ret['loss']
+ per_step += 1
+ global_step += 1
+ if global_step % eval_step == 0:
+ eval_ret = evaluate(model, exe, valid_ds, valid_prog, 1,
+ evaluator, "valid", full_batch)
+ test_eval_ret = evaluate(model, exe, test_ds, valid_prog, 1,
+ evaluator, "test", full_batch)
+ eval_ret.update(test_eval_ret)
+ sys.stderr.write(json.dumps(eval_ret, indent=4) + "\n")
+ for key, value in eval_ret.items():
+ writer.add_scalar(key, value, global_step=global_step)
+ if eval_ret["valid_acc"] > best_model:
+ F.io.save_persistables(
+ exe,
+ os.path.join(output_path, "checkpoint"), train_prog)
+ eval_ret["epoch"] = e
+ #eval_ret["step"] = global_step
+ with open(os.path.join(output_path, "best.txt"), "w") as f:
+ f.write(json.dumps(eval_ret, indent=2) + '\n')
+ best_model = eval_ret["valid_acc"]
+ scores = np.vstack(scores)
+ labels = np.vstack(labels)
+
+ ret = evaluator.eval(scores, labels, "train")
+ sys.stderr.write(json.dumps(ret, indent=4) + "\n")
+ #print(json.dumps(ret, indent=4) + "\n")
+ # Epoch End
+ sys.stderr.write("epoch:{}, average loss {}\n".format(e, ret_sum_loss /
+ per_step))
+ eval_ret = evaluate(model, exe, valid_ds, valid_prog, 1, evaluator,
+ "valid", full_batch)
+ test_eval_ret = evaluate(model, exe, test_ds, valid_prog, 1, evaluator,
+ "test", full_batch)
+ eval_ret.update(test_eval_ret)
+ sys.stderr.write(json.dumps(eval_ret, indent=4) + "\n")
+
+ for key, value in eval_ret.items():
+ writer.add_scalar(key, value, global_step=global_step)
+
+ if eval_ret["valid_acc"] > best_model:
+ F.io.save_persistables(exe,
+ os.path.join(output_path, "checkpoint"),
+ train_prog)
+ #eval_ret["step"] = global_step
+ eval_ret["epoch"] = e
+ with open(os.path.join(output_path, "best.txt"), "w") as f:
+ f.write(json.dumps(eval_ret, indent=2) + '\n')
+ best_model = eval_ret["valid_acc"]
+
+ writer.close()
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/run.sh b/ogb_examples/nodeproppred/ogbn-arxiv/run.sh
new file mode 100644
index 0000000000000000000000000000000000000000..70599681ba252b72a2ce6c1fc178e55bbee6fa69
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/run.sh
@@ -0,0 +1,20 @@
+device=0
+model='gaan'
+lr=0.001
+drop=0.5
+
+CUDA_VISIBLE_DEVICES=${device} \
+ python -u train.py \
+ --use_cuda 1 \
+ --num_workers 4 \
+ --output_path ./output/model \
+ --batch_size 1024 \
+ --test_batch_size 512 \
+ --epoch 100 \
+ --learning_rate ${lr} \
+ --full_batch 0 \
+ --model ${model} \
+ --drop_rate ${drop} \
+ --samples 8 8 8 \
+ --test_samples 20 20 20 \
+ --hidden_size 256
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/train.py b/ogb_examples/nodeproppred/ogbn-arxiv/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..99ba18cdca2b7791aeab74a75692326f3bdabaac
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/train.py
@@ -0,0 +1,191 @@
+# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""listwise model
+"""
+
+import torch
+import os
+import re
+import time
+import logging
+from random import random
+from functools import reduce, partial
+
+# For downloading ogb
+import ssl
+ssl._create_default_https_context = ssl._create_unverified_context
+# SSL
+
+import numpy as np
+import multiprocessing
+
+import pgl
+import paddle
+import paddle.fluid as F
+import paddle.fluid.layers as L
+
+from args import parser
+from utils.args import print_arguments, check_cuda
+from utils.init import init_checkpoint, init_pretraining_params
+from utils.to_undirected import to_undirected
+from model import BaseGraph, MLPModel, SAGEModel, GAANModel, GATModel, GCNModel, GINModel
+from dataloader.ogbn_arxiv_dataloader import ArxivDataGenerator
+from monitor.train_monitor import train_and_evaluate, OgbEvaluator
+from pgl.contrib.ogb.nodeproppred.dataset_pgl import PglNodePropPredDataset
+
+log = logging.getLogger(__name__)
+
+
+class Metric(object):
+ """Metric"""
+
+ def __init__(self, **args):
+ self.args = args
+
+ @property
+ def vars(self):
+ """ fetch metric vars"""
+ values = [self.args[k] for k in self.args.keys()]
+ return values
+
+ def parse(self, fetch_list):
+ """parse"""
+ tup = list(zip(self.args.keys(), [float(v[0]) for v in fetch_list]))
+ return dict(tup)
+
+
+if __name__ == '__main__':
+ args = parser.parse_args()
+ print_arguments(args)
+ evaluator = OgbEvaluator()
+
+ train_prog = F.Program()
+ startup_prog = F.Program()
+ args.num_nodes = evaluator.num_nodes
+
+ if args.use_cuda:
+ dev_list = F.cuda_places()
+ place = dev_list[0]
+ dev_count = len(dev_list)
+ else:
+ place = F.CPUPlace()
+ dev_count = int(os.environ.get('CPU_NUM', multiprocessing.cpu_count()))
+ assert dev_count == 1, "The program not support multi devices now!"
+
+ dataset = PglNodePropPredDataset(name="ogbn-arxiv")
+ graph, label = dataset[0]
+ graph = to_undirected(graph)
+
+ if args.model is None:
+ Model = BaseGraph
+ elif args.model.upper() == "MLP":
+ Model = MLPModel
+ elif args.model.upper() == "SAGE":
+ Model = SAGEModel
+ elif args.model.upper() == "GAT":
+ Model = GATModel
+ elif args.model.upper() == "GCN":
+ Model = GCNModel
+ elif args.model.upper() == "GAAN":
+ Model = GAANModel
+ elif args.model.upper() == "GIN":
+ Model = GINModel
+ else:
+ raise ValueError("Not support {} model!".format(args.model))
+
+ with F.program_guard(train_prog, startup_prog):
+ with F.unique_name.guard():
+ if args.full_batch:
+ gw = pgl.graph_wrapper.StaticGraphWrapper(
+ name="graph", graph=graph, place=place)
+ else:
+ gw = pgl.graph_wrapper.GraphWrapper(
+ name="graph",
+ node_feat=graph.node_feat_info(),
+ edge_feat=graph.edge_feat_info())
+ log.info(gw.node_feat.keys())
+ graph_model = Model(args, gw)
+ test_prog = train_prog.clone(for_test=True)
+ opt = F.optimizer.Adam(learning_rate=args.learning_rate)
+ opt.minimize(graph_model.loss)
+
+ train_ds = ArxivDataGenerator(
+ phase="train",
+ graph_wrapper=graph_model.graph_wrapper,
+ num_workers=args.num_workers,
+ batch_size=args.batch_size,
+ samples=args.samples)
+
+ valid_ds = ArxivDataGenerator(
+ phase="valid",
+ graph_wrapper=graph_model.graph_wrapper,
+ num_workers=args.num_workers,
+ batch_size=args.test_batch_size,
+ samples=args.test_samples)
+
+ test_ds = ArxivDataGenerator(
+ phase="test",
+ graph_wrapper=graph_model.graph_wrapper,
+ num_workers=args.num_workers,
+ batch_size=args.test_batch_size,
+ samples=args.test_samples)
+
+ exe = F.Executor(place)
+ exe.run(startup_prog)
+ if args.full_batch:
+ gw.initialize(place)
+
+ if args.init_pretraining_params is not None:
+ init_pretraining_params(
+ exe, args.init_pretraining_params, main_program=startup_prog)
+
+ metric = Metric(**graph_model.metrics)
+
+ nccl2_num_trainers = 1
+ nccl2_trainer_id = 0
+ if dev_count > 1:
+
+ exec_strategy = F.ExecutionStrategy()
+ exec_strategy.num_threads = dev_count
+
+ train_exe = F.ParallelExecutor(
+ use_cuda=args.use_cuda,
+ loss_name=graph_model.loss.name,
+ exec_strategy=exec_strategy,
+ main_program=train_prog,
+ num_trainers=nccl2_num_trainers,
+ trainer_id=nccl2_trainer_id)
+
+ test_exe = exe
+ else:
+ train_exe, test_exe = exe, exe
+
+ train_and_evaluate(
+ exe=exe,
+ train_exe=train_exe,
+ valid_exe=test_exe,
+ train_ds=train_ds,
+ valid_ds=valid_ds,
+ test_ds=test_ds,
+ train_prog=train_prog,
+ valid_prog=test_prog,
+ full_batch=args.full_batch,
+ train_log_step=5,
+ output_path=args.output_path,
+ dev_count=dev_count,
+ model=graph_model,
+ epoch=args.epoch,
+ eval_step=1000000,
+ evaluator=evaluator,
+ metric=metric)
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/utils/__init__.py b/ogb_examples/nodeproppred/ogbn-arxiv/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1333621cf62da67fcf10016fc848c503f7c254fa
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/utils/__init__.py
@@ -0,0 +1,14 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""utils"""
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/utils/args.py b/ogb_examples/nodeproppred/ogbn-arxiv/utils/args.py
new file mode 100644
index 0000000000000000000000000000000000000000..5131f2ceb88775f12e886402ef205735a1ac1d77
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/utils/args.py
@@ -0,0 +1,97 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Arguments for configuration."""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import six
+import os
+import sys
+import argparse
+import logging
+
+import paddle.fluid as fluid
+
+log = logging.getLogger(__name__)
+
+
+def prepare_logger(logger, debug=False, save_to_file=None):
+ """doc"""
+ formatter = logging.Formatter(
+ fmt='[%(levelname)s] %(asctime)s [%(filename)12s:%(lineno)5d]:\t%(message)s'
+ )
+ #console_hdl = logging.StreamHandler()
+ #console_hdl.setFormatter(formatter)
+ #logger.addHandler(console_hdl)
+ if save_to_file is not None and not os.path.exists(save_to_file):
+ file_hdl = logging.FileHandler(save_to_file)
+ file_hdl.setFormatter(formatter)
+ logger.addHandler(file_hdl)
+ logger.setLevel(logging.DEBUG)
+ logger.propagate = False
+
+
+def str2bool(v):
+ """doc"""
+ # because argparse does not support to parse "true, False" as python
+ # boolean directly
+ return v.lower() in ("true", "t", "1")
+
+
+class ArgumentGroup(object):
+ """doc"""
+
+ def __init__(self, parser, title, des):
+ self._group = parser.add_argument_group(title=title, description=des)
+
+ def add_arg(self,
+ name,
+ type,
+ default,
+ help,
+ positional_arg=False,
+ **kwargs):
+ """doc"""
+ prefix = "" if positional_arg else "--"
+ type = str2bool if type == bool else type
+ self._group.add_argument(
+ prefix + name,
+ default=default,
+ type=type,
+ help=help + ' Default: %(default)s.',
+ **kwargs)
+
+
+def print_arguments(args):
+ """doc"""
+ log.info('----------- Configuration Arguments -----------')
+ for arg, value in sorted(six.iteritems(vars(args))):
+ log.info('%s: %s' % (arg, value))
+ log.info('------------------------------------------------')
+
+
+def check_cuda(use_cuda, err= \
+ "\nYou can not set use_cuda=True in the model because you are using paddlepaddle-cpu.\n \
+ Please: 1. Install paddlepaddle-gpu to run your models on GPU or 2. Set use_cuda=False to run models on CPU.\n"
+ ):
+ """doc"""
+ try:
+ if use_cuda == True and fluid.is_compiled_with_cuda() == False:
+ log.error(err)
+ sys.exit(1)
+ except Exception as e:
+ pass
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/utils/init.py b/ogb_examples/nodeproppred/ogbn-arxiv/utils/init.py
new file mode 100644
index 0000000000000000000000000000000000000000..baa3ba5987cf1cbae20a60ea88e3f3bf0e389f43
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/utils/init.py
@@ -0,0 +1,97 @@
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""paddle init"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+from __future__ import absolute_import
+
+import os
+import six
+import ast
+import copy
+import logging
+
+import numpy as np
+import paddle.fluid as fluid
+
+log = logging.getLogger(__name__)
+
+
+def cast_fp32_to_fp16(exe, main_program):
+ """doc"""
+ log.info("Cast parameters to float16 data format.")
+ for param in main_program.global_block().all_parameters():
+ if not param.name.endswith(".master"):
+ param_t = fluid.global_scope().find_var(param.name).get_tensor()
+ data = np.array(param_t)
+ if param.name.startswith("encoder_layer") \
+ and "layer_norm" not in param.name:
+ param_t.set(np.float16(data).view(np.uint16), exe.place)
+
+ #load fp32
+ master_param_var = fluid.global_scope().find_var(param.name +
+ ".master")
+ if master_param_var is not None:
+ master_param_var.get_tensor().set(data, exe.place)
+
+
+def init_checkpoint(exe, init_checkpoint_path, main_program, use_fp16=False):
+ """init"""
+ assert os.path.exists(
+ init_checkpoint_path), "[%s] cann't be found." % init_checkpoint_path
+
+ def existed_persitables(var):
+ """existed"""
+ if not fluid.io.is_persistable(var):
+ return False
+ return os.path.exists(os.path.join(init_checkpoint_path, var.name))
+
+ fluid.io.load_vars(
+ exe,
+ init_checkpoint_path,
+ main_program=main_program,
+ predicate=existed_persitables)
+ log.info("Load model from {}".format(init_checkpoint_path))
+
+ if use_fp16:
+ cast_fp32_to_fp16(exe, main_program)
+
+
+def init_pretraining_params(exe,
+ pretraining_params_path,
+ main_program,
+ use_fp16=False):
+ """init"""
+ assert os.path.exists(pretraining_params_path
+ ), "[%s] cann't be found." % pretraining_params_path
+
+ def existed_params(var):
+ """doc"""
+ if not isinstance(var, fluid.framework.Parameter):
+ return False
+ return os.path.exists(os.path.join(pretraining_params_path, var.name))
+
+ fluid.io.load_vars(
+ exe,
+ pretraining_params_path,
+ main_program=main_program,
+ predicate=existed_params)
+ log.info("Load pretraining parameters from {}.".format(
+ pretraining_params_path))
+
+ if use_fp16:
+ cast_fp32_to_fp16(exe, main_program)
diff --git a/ogb_examples/nodeproppred/ogbn-arxiv/utils/to_undirected.py b/ogb_examples/nodeproppred/ogbn-arxiv/utils/to_undirected.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a9715d5b37dcb6495012dde17e13446d4af26b8
--- /dev/null
+++ b/ogb_examples/nodeproppred/ogbn-arxiv/utils/to_undirected.py
@@ -0,0 +1,33 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Arguments for configuration."""
+from __future__ import absolute_import
+from __future__ import unicode_literals
+
+import paddle.fluid as fluid
+import pgl
+import numpy as np
+
+
+def to_undirected(graph):
+ inv_edges = np.zeros(graph.edges.shape)
+ inv_edges[:, 0] = graph.edges[:, 1]
+ inv_edges[:, 1] = graph.edges[:, 0]
+ edges = np.vstack((graph.edges, inv_edges))
+ g = pgl.graph.Graph(num_nodes=graph.num_nodes, edges=edges)
+ for k, v in graph._edge_feat.items():
+ g._edge_feat[k] = np.vstack((v, v))
+ for k, v in graph._node_feat.items():
+ g._node_feat[k] = v
+ return g
diff --git a/pgl/__init__.py b/pgl/__init__.py
index 535632ea7afb3a157a4d92bbb08cb6445b21a125..93375e9ec5c7913334b02a05f6681de3f1ee4069 100644
--- a/pgl/__init__.py
+++ b/pgl/__init__.py
@@ -13,7 +13,7 @@
# limitations under the License.
"""Generate pgl apis
"""
-__version__ = "1.0.2"
+__version__ = "1.1.0"
from pgl import layers
from pgl import graph_wrapper
from pgl import graph
diff --git a/pgl/graph.py b/pgl/graph.py
index 30a147566821f3a2b76e2ae5976cfce5b0782e0c..85ec4060fe726333b62bc2c38c3966397ddcd9c4 100644
--- a/pgl/graph.py
+++ b/pgl/graph.py
@@ -593,7 +593,7 @@ class Graph(object):
edges = self._edges[eid]
else:
edges = np.array(edges, dtype="int64")
-
+
sub_edges = graph_kernel.map_edges(
np.arange(
len(edges), dtype="int64"), edges, reindex)
diff --git a/pgl/graph_wrapper.py b/pgl/graph_wrapper.py
index 3f30da477a5e97287315efc4e693eaa022399d84..91dda8f78796aedd493b37e85a92ad9ecb1c6664 100644
--- a/pgl/graph_wrapper.py
+++ b/pgl/graph_wrapper.py
@@ -40,7 +40,6 @@ def recv(dst, uniq_dst, bucketing_index, msg, reduce_function, num_nodes,
num_edges):
"""Recv message from given msg to dst nodes.
"""
- empty_msg_flag = fluid.layers.cast(num_edges > 0, dtype="float32")
if reduce_function == "sum":
if isinstance(msg, dict):
raise TypeError("The message for build-in function"
@@ -49,8 +48,9 @@ def recv(dst, uniq_dst, bucketing_index, msg, reduce_function, num_nodes,
try:
out_dim = msg.shape[-1]
init_output = fluid.layers.fill_constant(
- shape=[num_nodes, out_dim], value=0, dtype="float32")
+ shape=[num_nodes, out_dim], value=0, dtype=msg.dtype)
init_output.stop_gradient = False
+ empty_msg_flag = fluid.layers.cast(num_edges > 0, dtype=msg.dtype)
msg = msg * empty_msg_flag
output = paddle_helper.scatter_add(init_output, dst, msg)
return output
@@ -66,10 +66,12 @@ def recv(dst, uniq_dst, bucketing_index, msg, reduce_function, num_nodes,
bucketed_msg = op.nested_lod_reset(msg, bucketing_index)
output = reduce_function(bucketed_msg)
output_dim = output.shape[-1]
+
+ empty_msg_flag = fluid.layers.cast(num_edges > 0, dtype=output.dtype)
output = output * empty_msg_flag
init_output = fluid.layers.fill_constant(
- shape=[num_nodes, output_dim], value=0, dtype="float32")
+ shape=[num_nodes, output_dim], value=0, dtype=output.dtype)
init_output.stop_gradient = True
final_output = fluid.layers.scatter(init_output, uniq_dst, output)
return final_output
@@ -475,9 +477,6 @@ class GraphWrapper(BaseGraphWrapper):
Args:
name: The graph data prefix
- place: fluid.CPUPlace or fluid.CUDAPlace(n) indicating the
- device to hold the graph data.
-
node_feat: A list of tuples that decribe the details of node
feature tenosr. Each tuple mush be (name, shape, dtype)
and the first dimension of the shape must be set unknown
@@ -516,7 +515,6 @@ class GraphWrapper(BaseGraphWrapper):
})
graph_wrapper = GraphWrapper(name="graph",
- place=place,
node_feat=graph.node_feat_info(),
edge_feat=graph.edge_feat_info())
@@ -531,12 +529,11 @@ class GraphWrapper(BaseGraphWrapper):
ret = exe.run(fetch_list=[...], feed=feed_dict )
"""
- def __init__(self, name, place, node_feat=[], edge_feat=[]):
+ def __init__(self, name, node_feat=[], edge_feat=[], **kwargs):
super(GraphWrapper, self).__init__()
# collect holders for PyReader
self._data_name_prefix = name
self._holder_list = []
- self._place = place
self.__create_graph_attr_holders()
for node_feat_name, node_feat_shape, node_feat_dtype in node_feat:
self.__create_graph_node_feat_holders(
diff --git a/pgl/heter_graph_wrapper.py b/pgl/heter_graph_wrapper.py
index a56bc4e3151b1ab0a136e939e4b736cb8bc32742..bd786c7f459cae6a191a913904202a50e86b3e04 100644
--- a/pgl/heter_graph_wrapper.py
+++ b/pgl/heter_graph_wrapper.py
@@ -44,9 +44,6 @@ class HeterGraphWrapper(object):
Args:
name: The heterogeneous graph data prefix
- place: fluid.CPUPlace or fluid.CUDAPlace(n) indicating the
- device to hold the graph data.
-
node_feat: A dict of list of tuples that decribe the details of node
feature tenosr. Each tuple mush be (name, shape, dtype)
and the first dimension of the shape must be set unknown
@@ -85,19 +82,15 @@ class HeterGraphWrapper(object):
node_feat=node_feat,
edge_feat=edges_feat)
- place = fluid.CPUPlace()
-
gw = heter_graph_wrapper.HeterGraphWrapper(
name='heter_graph',
- place = place,
edge_types = g.edge_types_info(),
node_feat=g.node_feat_info(),
edge_feat=g.edge_feat_info())
"""
- def __init__(self, name, place, edge_types, node_feat={}, edge_feat={}):
+ def __init__(self, name, edge_types, node_feat={}, edge_feat={}, **kwargs):
self.__data_name_prefix = name
- self._place = place
self._edge_types = edge_types
self._multi_gw = {}
for edge_type in self._edge_types:
@@ -114,7 +107,6 @@ class HeterGraphWrapper(object):
self._multi_gw[edge_type] = GraphWrapper(
name=type_name,
- place=self._place,
node_feat=n_feat,
edge_feat=e_feat)
diff --git a/pgl/layers/conv.py b/pgl/layers/conv.py
index bbb364ab64a89f8ee3ee002cd8a9294a1710f804..68a1d733ed1d297e7a20daa1fb7c14828ff8722b 100644
--- a/pgl/layers/conv.py
+++ b/pgl/layers/conv.py
@@ -18,7 +18,7 @@ import paddle.fluid as fluid
from pgl import graph_wrapper
from pgl.utils import paddle_helper
-__all__ = ['gcn', 'gat', 'gin']
+__all__ = ['gcn', 'gat', 'gin', 'gaan']
def gcn(gw, feature, hidden_size, activation, name, norm=None):
@@ -238,8 +238,18 @@ def gin(gw,
param_attr=fluid.ParamAttr(name="%s_w_0" % name),
bias_attr=fluid.ParamAttr(name="%s_b_0" % name))
- output = fluid.layers.batch_norm(output)
- output = getattr(fluid.layers, activation)(output)
+ output = fluid.layers.layer_norm(
+ output,
+ begin_norm_axis=1,
+ param_attr=fluid.ParamAttr(
+ name="norm_scale_%s" % (name),
+ initializer=fluid.initializer.Constant(1.0)),
+ bias_attr=fluid.ParamAttr(
+ name="norm_bias_%s" % (name),
+ initializer=fluid.initializer.Constant(0.0)), )
+
+ if activation is not None:
+ output = getattr(fluid.layers, activation)(output)
output = fluid.layers.fc(output,
size=hidden_size,
@@ -248,3 +258,97 @@ def gin(gw,
bias_attr=fluid.ParamAttr(name="%s_b_1" % name))
return output
+
+
+def gaan(gw, feature, hidden_size_a, hidden_size_v, hidden_size_m, hidden_size_o, heads, name):
+ """Implementation of GaAN"""
+
+ def send_func(src_feat, dst_feat, edge_feat):
+ # 计算每条边上的注意力分数
+ # E * (M * D1), 每个 dst 点都查询它的全部邻边的 src 点
+ feat_query, feat_key = dst_feat['feat_query'], src_feat['feat_key']
+ # E * M * D1
+ old = feat_query
+ feat_query = fluid.layers.reshape(feat_query, [-1, heads, hidden_size_a])
+ feat_key = fluid.layers.reshape(feat_key, [-1, heads, hidden_size_a])
+ # E * M
+ alpha = fluid.layers.reduce_sum(feat_key * feat_query, dim=-1)
+
+ return {'dst_node_feat': dst_feat['node_feat'],
+ 'src_node_feat': src_feat['node_feat'],
+ 'feat_value': src_feat['feat_value'],
+ 'alpha': alpha,
+ 'feat_gate': src_feat['feat_gate']}
+
+ def recv_func(message):
+ # 每条边的终点的特征
+ dst_feat = message['dst_node_feat']
+ # 每条边的出发点的特征
+ src_feat = message['src_node_feat']
+ # 每个中心点自己的特征
+ x = fluid.layers.sequence_pool(dst_feat, 'average')
+ # 每个中心点的邻居的特征的平均值
+ z = fluid.layers.sequence_pool(src_feat, 'average')
+
+ # 计算 gate
+ feat_gate = message['feat_gate']
+ g_max = fluid.layers.sequence_pool(feat_gate, 'max')
+ g = fluid.layers.concat([x, g_max, z], axis=1)
+ g = fluid.layers.fc(g, heads, bias_attr=False, act="sigmoid")
+
+ # softmax
+ alpha = message['alpha']
+ alpha = paddle_helper.sequence_softmax(alpha) # E * M
+
+ feat_value = message['feat_value'] # E * (M * D2)
+ old = feat_value
+ feat_value = fluid.layers.reshape(feat_value, [-1, heads, hidden_size_v]) # E * M * D2
+ feat_value = fluid.layers.elementwise_mul(feat_value, alpha, axis=0)
+ feat_value = fluid.layers.reshape(feat_value, [-1, heads*hidden_size_v]) # E * (M * D2)
+ feat_value = fluid.layers.lod_reset(feat_value, old)
+
+ feat_value = fluid.layers.sequence_pool(feat_value, 'sum') # N * (M * D2)
+
+ feat_value = fluid.layers.reshape(feat_value, [-1, heads, hidden_size_v]) # N * M * D2
+
+ output = fluid.layers.elementwise_mul(feat_value, g, axis=0)
+ output = fluid.layers.reshape(output, [-1, heads * hidden_size_v]) # N * (M * D2)
+
+ output = fluid.layers.concat([x, output], axis=1)
+
+ return output
+
+ # feature N * D
+
+ # 计算每个点自己需要发送出去的内容
+ # 投影后的特征向量
+ # N * (D1 * M)
+ feat_key = fluid.layers.fc(feature, hidden_size_a * heads, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_key'))
+ # N * (D2 * M)
+ feat_value = fluid.layers.fc(feature, hidden_size_v * heads, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_value'))
+ # N * (D1 * M)
+ feat_query = fluid.layers.fc(feature, hidden_size_a * heads, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_query'))
+ # N * Dm
+ feat_gate = fluid.layers.fc(feature, hidden_size_m, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_gate'))
+
+ # send 阶段
+
+ message = gw.send(
+ send_func,
+ nfeat_list=[('node_feat', feature), ('feat_key', feat_key), ('feat_value', feat_value),
+ ('feat_query', feat_query), ('feat_gate', feat_gate)],
+ efeat_list=None,
+ )
+
+ # 聚合邻居特征
+ output = gw.recv(message, recv_func)
+ output = fluid.layers.fc(output, hidden_size_o, bias_attr=False,
+ param_attr=fluid.ParamAttr(name=name + '_project_output'))
+ output = fluid.layers.leaky_relu(output, alpha=0.1)
+ output = fluid.layers.dropout(output, dropout_prob=0.1)
+
+ return output
diff --git a/pgl/utils/log_writer.py b/pgl/utils/log_writer.py
new file mode 100644
index 0000000000000000000000000000000000000000..a4c718cc528f1f1978b7709d5b8a5a12ef9d4cb0
--- /dev/null
+++ b/pgl/utils/log_writer.py
@@ -0,0 +1,29 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Log writer setup: interface for training visualization.
+"""
+import six
+
+LogWriter = None
+
+if six.PY3:
+ # We highly recommend using VisualDL (https://github.com/PaddlePaddle/VisualDL)
+ # for training visualization in Python 3.
+ from visualdl import LogWriter
+ LogWriter = LogWriter
+elif six.PY2:
+ from tensorboardX import SummaryWriter
+ LogWriter = SummaryWriter
+else:
+ raise ValueError("Not running on Python2 or Python3 ?")
diff --git a/pgl/utils/mp_reader.py b/pgl/utils/mp_reader.py
index b7aec4d268e13d282c8420d80628f975e5472499..a7962830031c3aeede2b780104dacf936d62a120 100644
--- a/pgl/utils/mp_reader.py
+++ b/pgl/utils/mp_reader.py
@@ -25,7 +25,7 @@ except:
import numpy as np
import time
import paddle.fluid as fluid
-from queue import Queue
+from multiprocessing import Queue
import threading
diff --git a/requirements.txt b/requirements.txt
index 4a13b16b9df0af570752f5dac9857fa7e496d3db..acd3de6d9108ea1eb40b14d01951ad33ff1378e4 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -4,3 +4,5 @@ cython >= 0.25.2
#paddlepaddle
redis-py-cluster
+
+visualdl >= 2.0.0b ; python_version >= "3"
diff --git a/tutorials/1-Introduction.ipynb b/tutorials/1-Introduction.ipynb
index 9d849a015e855b072f634d15c8084e07520831af..7c2e4134381b5ceb8abb25f1bd3a54b0bde6a956 100644
--- a/tutorials/1-Introduction.ipynb
+++ b/tutorials/1-Introduction.ipynb
@@ -42,8 +42,8 @@
" d = 16\n",
" feature = np.random.randn(num_node, d).astype(\"float32\")\n",
" #feature = np.array(feature, dtype=\"float32\")\n",
- " # 对于边,也同样可以用一个特征向量表示。\n",
- " edge_feature = np.random.randn(len(edge_list), d).astype(\"float32\")\n",
+ " # 对于边,也同样可以用边的权重作为边特征\n",
+ " edge_feature = np.random.randn(len(edge_list), 1).astype(\"float32\")\n",
" \n",
" # 根据节点,边以及对应的特征向量,创建一个完整的图网络。\n",
" # 在PGL中,节点特征和边特征都是存储在一个dict中。\n",
@@ -99,7 +99,7 @@
"outputs": [
{
"data": {
- "image/png": "iVBORw0KGgoAAAANSUhEUgAAAcUAAAE1CAYAAACWU/udAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMi4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvIxREBQAAIABJREFUeJzs3Xd8zWf/x/HXOScnO6GEGiElxApBEkQitbporVaHlppVWru2Wylt1S5qtkRbe7WUalUQMxJbiMbeI4iMk7O/vz9Cfh1ozsnZuZ73I4/eJd/r+ijyznV9ryGTJElCEARBEATk9i5AEARBEByFCEVBEARBeEiEoiAIgiA8JEJREARBEB4SoSgIgiAID4lQFARBEISHRCgKgiAIwkMiFAVBEAThIRGKgiAIgvCQCEVBEARBeEiEoiAIgiA8JEJREARBEB4SoSgIgiAID4lQFARBEISHRCgKgiAIwkMiFAVBEAThITd7FyAIgmAvOoOOU3dOkXInhRxtDhISvu6+1CxVk1qlaqFUKO1domBjIhQFQShSMjWZLD26lPmH5pN2Nw1PN08ADJIBALlMjgwZar2aKiWq0Du8N+/XfZ/insXtWbZgIzJJkiR7FyEIgmBt93LvMWzbMJafWI5cJidHl1Og53yUPhgkA2/VeoupL04lwDvAypUK9iRCURAEl/dz6s90/bkrubpcNAaNWW24K9zxcvNicdvFdKjRwcIVCo5ChKIgCC7LYDTQ+5ferDi5ApVOZZE2vZXevF7jdZa0XYJCrrBIm4LjEKEoCIJLMkpG3lrzFlvObrFYID7irfTmhcovsO7NdSIYXYzYkiEIgkv6aPNHVglEAJVOxbbz2+i1qZfF2xbsS4SiIAgu5/dzv/P98e+tEoiPqHQqVqWsYkvaFqv1IdiemD4VBMGlZGoyCZ4VTLoq3Sb9lfAqwbn+58SWDRchRoqCILiUCQkTyNZm26y/HG0OY3eMtVl/gnWJkaIgCC5Do9dQakopsrRZNu3XR+nDnaF38FJ62bRfwfLESFEQBJex9tRaJGz/fb5MJmNVyiqb9ytYnghFQRBcxrdHvjVv6jQRWABMADaY/ni2NptFhxeZ/qDgcMTZp4IguIyjN4+a96AfEAucA3TmNXH81nEkSUImk5nXgOAQRCgKguASbmbfJFeXa97DNR/+8zpmh6LBaOBK5hUqFqtoXgMOTKPXcPjGYQ7dOETCpQQuZFxAo9fgrnCnnF85YoNiCS8bTkS5CPw8/OxdbqGIUBQEwSWkpqfi6eZp9tmmheWucCc1PdWlQvH8/fPMSpzFd0e+Qy6TozVoUevVf/ucQzcO8du53/B080Rr0NKxZkeGRA0hrEyYnaouHBGKgiC4BGtu1C8ICcnuNVhKhjqDvpv7siF1AwajAZ3x6cNnrUGL1qAFYPmJ5aw7vY4G5RrwQ4cfCPQPtEXJFiMW2giC4BJk2P9dnlzm/F9St57dSvCsYNafXo9ar/7PQPwng2RApVOx58oeasypwXdHvsOZdv45/++gIAgC4O/hb5ftGI/IkOHn7tzv074+8DWvr36de7n3Cj0NrTfqydZl0//X/ny85WOnCUYxfSoIgksILR1q/kIbA2AEpIcfOvKGDCZcgJGpymT+Z/M5HHqYOnXqEBYWRunSpc2rxw5mJc5iVPwoi08Bq3Qq4o7FYZSMzG091+FX54oTbQRBcBllp5blZs5N0x/cAez6x489DzQreBPFlcWZVmYax44d4/jx4xw7dgx3d3fq1KmT/xEWFkb16tXx8PAwvUYr+v3c77Rf1d6q70S9ld5MajmJfg36Wa0PSxChKAiCy2i/sj0/nfnJLn2/UuUVtrz7/zdmSJLE9evX80Py0ce5c+eoUqVKfkg+CsyyZcvaZRT1QP2A4FnB3M29a/W+vJXenOhzgsrPVLZ6X+YSoSgIgsv4/dzvvL76dZseCA7g5+7HitdX0Dqk9X9+rlqt5vTp0/mjyUf/lCTpbyFZp04datWqhaenp1Vr77KhC2tOrfnXVgtrUMgU1C9bn8SeiQ47jSpCURAEl2GUjAROD+RG9g2b9lvKuxQ3htxAITfhJeRfSJLErVu3/jWq/PPPP6lUqdK/pmADAwMtEioXMy5S45saNgnER3zdfdn49kaaVTJhbtqGxEIbQRBchlwm5/3g95l8eDJGhdEmfXorvRnaeKjZgQh5B4qXKVOGMmXK8NJLL+X/uFarJTU1NT8kZ8+ezfHjx1Gr1X8LyUejSh8fH5P6/SbpG4ySbf47PZKtzWbKvikOG4pipCgIgkvIyMhg3Lhx/Lj8R5T9lNwy3rL6Fg0ZMqqWrMrJPidRKpRW7euvbt++zYkTJ/42skxNTSUwMPBfU7DPPffcY0eVWoOWgMkB5l2ztQ64AGgBXyAaCC/4454KT84NOEc5v3Km921lYqQoCIJTMxqNLFmyhNGjR9OmTRtOp5zmDneIWBhBrt7MLRoF5OnmyZqOa2waiAClS5emRYsWtGjRIv/HdDodf/75Z35ILly4kGPHjpGVlUXt2rX/NrIMDQ3lTNYZ8wtoArQlL0HuAHFAWaCAGadUKNl1cRfv1H7H/BqsRIwUBUFwWomJifTr1w+FQsHs2bOJiIjI/7n5yfMZ/NtgqwWjt9KbSS0m0a+hY28xuHv3LidOnPjbwp5Tp07h3cSb+w3uY1AYCtdBOnmh+DIQWrBHZMj4uMHHzHplVuH6tgIRioIgOJ1bt24xYsQIfvvtNyZNmsR7772HXP7vA7om753M+F3jLb7/zlvpzciYkYyJHWPRdm3FYDDQ4YcObLy00fxGfgGOAnqgDNANMGH7Zb0y9Tjc+7D5/VuJOOZNEASnodPpmD59OrVq1SIgIIDU1FS6dOny2EAEGBY9jK9f/hovNy+LnEsql8nxcvNi6gtTnTYQARQKBXeNhdyX+CowirwwrIHJL+NsvUK4oMQ7RUEQnMK2bdsYMGAAFSpUYM+ePVSvXr1Az/Ws35Png57nrbVv8efdP8nR5ZjVv4/Sh+BnglndcTXVAqqZ1YYjscg2DDkQBBwHkoBGBX9UZzDz4korE6EoCIJDu3DhAkOGDOHo0aPMmDGDNm3amLxHr2rJqiT1SuL7Y9/zxZ4vuJF1g1x97n9uR5Ahw1vpzbM+zzIiZgTd63Uv1NYLR+KhsOBRc0bgvmmPuMkdM37E9KkgCA5JpVLx6aefEhERQf369Tl16hRt27Y1e9O6Qq6gW71u/Pnxn/zR5Q961OtBcLFgMORtKPf38Mffwx9fd1+UciXVSlajW71u/N75d872P0uv8F4uE4gAFYpVMO/BbOAEoCEvDM8CJ4FKpjVTyruUef1bmWNGtSAIRZYkSaxbt44hQ4bQqFEjjhw5QsWKlrvNXiaT0SiwEY0CG7F582ZmzprJN8u/IUebg4SEj9KHys9Utvk2C1uLqRjDxjMbTV+dKwOSyVtoIwHFyVt5WrDZ7HzRFaNNe8BGRCgKguAwUlJS6N+/P7dv3yYuLo5mzax76klKSgq1a9UmpGSIVftxROFlw1EqlKaHog95i2sKwdfdl8YVGheuESsR06eCINhdRkYGAwcOpGnTprRr144jR45YPRAhLxRr1apl9X4cUb2y9dAb9XbpW2/UExsUa5e+/4sIRUEQ7MZoNPLdd99RvXp1VCoVp06dol+/fri52WYSqyiHoqebJ13qdLHLgpfIcpE8V/w5m/dbEGLzviAIdpGYmMjHH3+Mm5vbv06jsQWj0Yi/vz/Xr1/H39/fpn07ijPpZ6i3oJ7Vj8P7K193X1a+vrJA12zZgxgpCoJgU7du3aJbt260b9+efv36sXfvXpsHIsDFixcpUaJEkQ1EgGoB1WheqTnucneb9CdDRnm/8rxc5WWb9GcOEYqCINiEqafRWFtRnjr9q8VtF+PpZt2LjB95dIC6I29tEatPBUGwum3bttG/f3+CgoJMOo3Gmk6ePClCEXDTuFHpZCVOBJ+w6h2Uj+6drP1sbav1YQlipCgIgtVcuHCBDh060Lt3byZNmsSvv/7qEIEIYqQIcOzYMSIjI2n+bHOGxAzBW+ltlX683bx5Kfglxj4/1irtW5IIRUEQLM7Sp9FYQ0pKCqGhBbzryAWtWLGCli1bMmHCBKZPn85XL3zFR5EfWTwYvZXevFTlJVa9scoih7Jbm1h9KgiCxfzzNJqpU6dSoYKZx4lZkcFgwM/Pj9u3b+Pr62vvcmxKr9czfPhwfvrpJ9avX09YWNjffj7uaBz9tvRDbVAXah+jDBmebp6MjBnJ6NjRThGIIN4pCoJgIX89jWbp0qU0bdrU3iU90fnz53n22WeLXCDeuXOHt956C3d3d5KSkihRosS/Pqdr3a60rNySd9e/y6Hrhwp0cPo/+bn7EegfyOqOqwkt7VyjceeIbkEQHNbjTqNx5ECEovk+MSkpiYiICKKioti8efNjA/GRQP9Adr6/kz+6/EH76u3xUHjg7+GP/AmRIUOGn7sfnm6eNHuuGWs6ruFk35NOF4ggRoqCIJjJaDSyZMkSRo8eTdu2bTl16hSlSjnmzQf/VNRCcfHixQwfPpwFCxbQoUOHAj3z6OD0tW+uJV2Vzu5Lu0m8lkjCpQSuZV1Da9CilCsp5V2KmIoxNApsREzFGPNv33AQIhQFQTDZgQMH6NevH0qlks2bNxMeHm7vkkySkpLCyy877gZyS9FqtQwYMID4+Hh27dpFzZo1zWonwDuA9jXa075GewtX6HjE9KkgCAV28+ZNunbtSocOHejfvz979uxxukCEojFSvH79Os2aNeP69escPHjQ7EAsakQoCoLwnx6dRhMaGkqpUqVITU2lc+fOdjuNpjD0ej1paWnUqFHD3qVYzd69e2nQoAGvvPIKGzZsoFixYvYuyWmI6VNBcAI6g44Tt09w6Poh9lzZw8X7F9EYNLgr3KlQrAIxFWIILxdO2LNheLh5WLRvRzyNpjDOnTtH2bJl8fa2zkZ1e5IkiXnz5jF+/HiWLFlCq1at7F2S0xGhKAgO7PKDy8w5OIcFhxYgSRIGyYBKp/rX5204vQGlQonBaKBb3W70b9ifqiWrFqrvCxcuMGTIEI4dO8aMGTN47bXXHGrzvblc9Xi33Nxc+vbtS3JyMnv37qVKlSr2LskpOd/chyAUAZmaTLps6EK1OdX4OvFrMjWZZGmzHhuIALn6XDI1meToclhwaAF15teh3cp2pKvSTe5bpVIxduxYIiIiCA8PJyUlhTZt2rhEIIJrnmRz6dIlmjRpgkqlYv/+/SIQC0GEoiA4mG3nthE8K5g1KWtQ69VoDVqTntcZdaj1an49+ytVZlVh/en1BXpOkiTWrl1LjRo1OHPmDEePHmX06NF4etrmBgVbcbVFNvHx8TRs2JC3336blStXFrkDCSxNTJ8KggOZlTiLEX+MsMilr1qDFq1BS+cNnTl68yjjm45/4mjv0Wk0d+7ccfjTaAorJSWFkSNH2ruMQpMkienTpzNlyhSWLVtGixYt7F2SSxBnnwqCg5iVOIuR20c+cYq0MLyV3gxqNIiJzSf+7cczMjL49NNPWb58OZ9++ikffvghbm6u+72yTqfD39+f+/fvO/UIOCcnh549e5KWlsa6desICgqyd0kuQ0yfCoID+DXtV0b8McIqgQig0qmYcWAGPx7/Ecg7jebbb7+levXqqNVqTp06xccff+zSgQiQlpZGhQoVnDoQz507R1RUFB4eHuzevVsEooW59t8AQXACGeoM3tvwnkWmTJ9GpVPRZ3Mfit8vzvhPxjvtaTSF4ezvE3/99Ve6du3K2LFj6du3r8ssfnIkIhQFwc76bu5LjjbHJn3laHJ4/cfX+bb/t7z77rtOufm+MJw1FI1GI59//jnz589n3bp1xMTE2LsklyVCURDs6Ny9c2xI3YDGoLFJf5JMwu05N6o3r17kAhHyQrGgB2I7iszMTLp06cLt27dJSkqiXLly9i7JpRW9vxWC4EBmJc7CYDTYtE+1Qc20/dNs2qejcLaR4unTp2nQoAFly5Zl586dIhBtwKVWn0qSkdzcNNTqK0iSBplMiVJZCh+fWsjl7vYuTxD+Rq1XU2pKKbK12aY9qAc2A+eBXOAZoCVgwgE2nm6eXBt8jRJeT75Tz9VoNBqKFy9ORkYGHh6WPQrPGjZs2EDv3r2ZNGkS3bt3t3c5RYbTT59qtbe4fn0Rd+6sQ6U6jUzmhkz211+WEaNRjadnEM888xLly3+Mj49zn90ouIZD1w8hl5kxWWME/IGuQDEgDVgD9CEvIAvAXeHO7ku7aVu9ren9O6k///yToKAghw9Eg8HA2LFj+eGHH9i8eTORkZH2LqlIcdpQzMk5zfnzI7h373dAhiTlrdyTpMe/m8nNPUtu7kVu3lyMj08olSp9QYkSLW1YsSD83aEbh0w+rQYAd6DZX/69GlAcuEGBQzFHm8PBaweLVCg6w/Fu9+7do1OnTmg0GpKTkyldurS9SypynO6doiQZuHTpCw4dCufu3U1Ikjo/EP+bHqMxl6ysJE6ebMupU53R6x9YtV5BeJKESwmo9erCN5QN3AVMuPTeIBnYdWlX4ft2Io7+PvHYsWNERkZSs2ZNtm3bJgLRTpwqFLXaOyQn1+fSpS8wGnMB81+HGo0q0tPXkphYhaysI5YrUhAK6ELGhcI3YgDWAXUxKRQBrmVeK3z/TsSRQ3HFihW0bNmSCRMmMH36dJc/RMGROc1/eY3mJocPN0SrvYEk6SzSptGoxmhUc/RoLGFhf+Dv39Ai7QpCQWj0hdyGYQTWAwrAjGvzzJq6dWKOGIp6vZ5hw4bx888/88cffxAWFmbvkoo8pxgp6vVZHDkSjVZ73WKB+FcGQzbHjr1ATs5pi7ctCE/irijEimgJ2AjkAG+RF4wmclM4zffEhaZWq7l8+TJVqxbujklLun37Ni+88AKnTp0iKSlJBKKDcIpQTEvrh0ZzHUnSW60PgyGbkyc7YDRaPnQF4XHK+JYx/+FfgDvAO4DSvCZKeZs43+rEzpw5Q+XKlXF3d4ytWUlJSURGRtK4cWM2b95MiRJFZ2uMo3P4ULx37w/u3FmDJFlgQcJTSWg0l7l06Usr9yMIeWKDYs0bLWYAh4CbwFTg84cfxwvehAwZTYKamN63k3KkqdPFixfTqlUrZs6cyeeff45CYcYwX7Aah54/kSQDqaldMBqtc3PAPxmNKq5cmUTZst3w9Kxgkz6FoiuyXCSebp6mv9srDowrXN++7r40Kt+ocI04EUcIRa1Wy4ABA9ixYwcJCQnUqFHDrvUIj+fQI8W7d3/FYDDxtI9CkiQD1659Y9M+haIpsnyk3Ra76Iw6YioWnUOl7R2K169fp2nTpty4cYODBw+KQHRgDh2KV65MxmDIsmmfkqTl+vX5GI1Fa2WeYHv+Hv60r97evFNtCim6QjTl/cvbvF97OXnypN1Ccc+ePURGRtKqVSvWr1+Pv7+/XeoQCsZhQ1Gnu0tmZqJZzw4cCC++CK+8kvfRpYupLUjcv7/drL4FwRSfNP4ETzcbX3irhYpXK5KVZdtvOO1FpVJx7do1qlSpYtN+JUnim2++oUOHDixatIgxY8YUyZtJnI3DvlPMyjqEXO6FwczppQEDoHVr8/o2GFRkZiZSsuQr5jUgCAVUv2x96petz4GrB9Abrbe6+hEZMiqVrIQqSUWVKlUYPHgwH330Eb6+vlbv215SU1OpWrUqSqWZy3TNkJubS58+fTh8+DD79u2zeSAL5nPYb1uyspIxGGxz8eq/6XnwoGgdgSXYz7IOy/BQ2OaQak83Tza+t5GVK1YSHx/PkSNHCA4OZvLkyWRn2/b9va3Y+n3ipUuXiImJQa1Ws3//fhGITsZhQzEz8yB5d+SYZ9EiaNsWPv4Yjh41/XmxkV+wlYrFKjKp+SQURusuzfdWejMyZiS1SucFRK1atVi5ciXbt2/n0KFDBAcHM2XKFHJy7PXNqHXYMhTj4+Np2LAhnTp1YsWKFfj4+NikX8FyHDYUDQbzD+r+4ANYvhzWrIFXX4VRo+Caicc85p2tKgjWd//+fdaNWkfgvUC83byt0oeXmxcvBb/E6NjR//q50NBQVq1axfbt20lKSiI4OJipU6e6TDjaIhQlSWLq1Kl06tSJ5cuXM2TIEGQymVX7FKzDYUOxMGrWBG9vcHeHl1+G0FBING/NjiBY1cWLF4mOjiasThhpM9J4p/Y7eCstG4zeSm9ervIyq95Y9dSVrqGhoaxevZpt27aRmJhIcHAw06ZNQ6WyzT5ha7F2KObk5PDOO++wcuVKEhMTad68udX6EqzPYUNRobDcsmWZDCQTL9SQy228IlAocpKTk4mOjqZ3797MnDkTpZuSRa8tYmKziXi5eRV6q4YMGV5uXnwS9Qlr31yLUlGwhSa1a9dmzZo1/P777+zfv5/g4GCmT5/ulOGYk5PDzZs3CQ4Otkr7Z8+epVGjRnh5ebF7926CgoKs0o9gOw4bin5+kZhzqGN2Nhw8CFotGAywbRscPw4NGpjWjre32FwrWM+mTZto1aoVc+fOZcCAAfk/LpPJGBQ1iGMfHiPs2TB83c1bFerr7kvVklU50PMA45uNNytg69Spw9q1a9m6dSt79+4lODiYGTNmOFU4nj59mpCQEKscpbZlyxYaN25Mnz59WLx4MV5eXhbvQ7A9hw1Ff/9IFArTp5H0eli8GNq1y1tos2EDTJgAFUw6tU1B8eLPm9y3IBTEnDlz6N27N5s3b6Zt27aP/ZyqJauS/EEyG97aQMvKLfFQeODn7vfUdn2Vvni6eRJdIZrlHZZzqu8p6jxbp9D1hoWFsW7dOn799Vd2795NlSpVmDlzJrm5jv/e3RpTp0ajkQkTJtCrVy82bNhA3759xftDFyKTJFMnFm1Dq01n//5AJKmQd86ZQaHwp2bNFZQsacYldYLwBAaDgaFDh7J161Y2b95MpUqVCvzs1cyr7Ly4k/1X9rPn8h5u5txEZ9ChVCgJ8A4gukI0jSs0JjYolsrPVLbirwKOHDnCZ599RmJiIsOHD+eDDz5w2FHSsGHDKF68OKNGjbJIew8ePOD999/nzp07rFmzhnLlylmkXcFxOGwoAhw+HE1m5j6b96tQ+BMdfRu53DZ7xwTXp1KpeO+997h//z7r16/nmWeesXdJhXbkyBHGjx9PUlJSfjh6ejrWu/hWrVrRu3fvJ47ITXH69GnatWtHixYtmDlzpsNcQyVYlsNOnwJUrDgcheLpU0aWJpO5U65cbxGIgsXcvn2bZs2a4ePjw9atW10iEAHq1avHTz/9xKZNm9i+fTvBwcHMnj0btdra17wVnKWmT9evX09sbCzDhw9n7ty5IhBdmEOPFCXJwL595dDpbtusT7nciwYNTuPpKVaRCYWXmppK69atee+99xg3bpxLv3s6dOgQ48eP5/Dhw4wYMYKePXvaZOQoSRIXMi5w6Pohzt8/j8agwU3uhrfMmxFdR5B+Mh1fT/MWLBkMBv73v/+xbNky1q5dS2RkpIWrFxyNQ4ciwL17v3HyZAeb3KmoVoNG05Y2bTa49BcvwTYSEhLo2LEjX331FV27drV3OTaTnJzM+PHjOXLkCCNHjqRnz554eFh25kWSJBKvJTJ131R+PfsrAAqZglx9LnqjHjlylHIlOo0OuYec4GeCGdRoEO/WebfAK3rv3btHp06d0Gg0rFq1itKlS1v01yA4JocPRYBTp97lzp11Vl50I0MmC6R/f3+eey6Y+fPnU7ZsWSv2J7iy5cuXM3DgQFasWEGLFi3sXY5dJCUlMX78eI4dO8bIkSPp0aOHRcJx+/nt9Nnch+tZ18nV52KUjAV6zkfpg4TEh+EfMrH5RLyUT14cdOzYMTp06EC7du346quvcHNz2LsTBAtz6HeKj4SEzMXDoywymfX+YCoUPoSHb+HgwUPUqVOHsLAwfvjhB5zgewbBgUiSxOeff87IkSOJj48vsoEIEBkZyS+//MK6devYvHkzVatWZd68eWg05n1zm6XJottP3XhtxWuk3UsjR5dT4EAEyNHloNKpmJc8j6qzq7L/yv7Hft7y5ctp2bIlEydOZNq0aSIQixinGCkCaDTXOXSoATrdbSRJZ9G25XIfwsJ+o1ix6PwfO3z4MF27diUoKIgFCxaIpdfCf9LpdHz44YccPXqUTZs2iT8z/5CYmMj48eM5efIko0aNonv37gVesHLh/gVilsRwL/cear1lFvJ4uXnxeYvPGdRoEJD3+zds2DA2btzI+vXrCQsLs0g/gnNxipEigIdHOcLDk/HyqopcbpmzIWUyD9zcSlC37o6/BSJA/fr1SU5Opn79+tStW5elS5eKUaPwRA8ePKB169bcunWLXbt2iUB8jIYNG7JlyxZWr17Nzz//TNWqVVmwYAFa7dPvTD1//zyRiyK5mX3TYoEIkKvPZUz8GD7f/Tm3b9/mhRde4PTp0yQlJYlALMKcZqT4iNGo49KlL7hy5SuMRjVgXvlyuTclS7YmJGQBSuXTl8gfOXKErl27EhgYyMKFCylfvrxZfQqu6cqVK7Ru3ZqYmBhmzZolptsKaP/+/YwfP57U1FRGjRpF165d/zVyzFBnUOObGtzOuW3SVKkpPOWeeO/wpk/jPowfP94qR8IJzsNpRoqPyOVKKlX6lPr1EylR4mXkck9ksoK9vJfJ3JDLvfD1rUutWmupVWv1fwYi5O3HSkpKIjIykrp16xIXFydGjQKQ9w1TVFQU77//Pt98840IRBNERUWxdetWli9fzrp16wgJCWHRokXodP//euTDXz7kfu59qwUigNqoJqdZDr2H9haBKDjfSPGfNJrrXLs2lz17JlGxohyFwgNQkDeClAESRqMKD49AnnmmJeXLD8DXN9Ts/o4ePUrXrl0pV64cCxcuJDAw0EK/EsHZbNmyhffff5958+bxxhtv2Lscp7d3717Gjx9PWloao0ePpnR0ad7Z8A4qnfW3Y7nJ3WgU2IiErgliO1YR5/ShCHlB9dZbb3H6dAoqVSoazRWMRjVyuTtKZSl8fGqjUFjubEatVsuXX37JnDlz+Oqrr+jWrZv4i1TELFiwgHHjxrF+/XqioqLsXY5L2bMDPIXIAAAgAElEQVRnD+PGj2Nn/Z0YvA0269fX3ZdVb6yiVVVx5nFR5hKhOH36dNLS0pg3b55N+z127Bhdu3alTJkyLFy4kAqmXcUhOCGj0cjIkSP56aef2LJli9Xu6Svqtp3bRtsVbck12PYmjueDnmdn15027VNwLE73TvFx7LUfLCwsjIMHD9K4cWPq16/Pd999J941ujC1Ws3bb7/Nvn372LdvnwhEK5q8b7LNAxEg8VoiF+5fsHm/guNw+pGiTqcjICCAc+fOERAQYLc6jh8/Trdu3QgICGDRokVUrFjRbrUIlpeenk7btm2pWLEiS5YscbjbIFyJRq/B70s/dEYT9yN//o9/1wORgAmzoR4KDya1nMTARgNN61twGU4/UkxOTqZSpUp2DUTIu6X8wIEDxMbGEh4ezqJFi8So0UWkpaURFRXF888/z7Jly0QgWtmJ2yfwcjNjDcDov3x8ArgBNU1rQmPQsOvSLtP7FlyG04eiIx2lpVQqGT16NPHx8cyfP5+XXnqJS5cu2bssoRD27t1LkyZNGDZsGF988QVyudP/lXF4ydeTTR8l/tNpwAcw47KbpGtJhetbcGpO/zd8+/btNG/e3N5l/E3t2rU5cOAATZs2JSIigoULF4pRoxNavXo17du3Z+nSpfTq1cve5RQZp+6cIldfyPeJR4Ew8nZlmehG9o3C9S04NacOxdzcXA4ePEhsbKy9S/kXpVLJqFGj2LFjB4sWLeLFF18Uo0YnIUkSkydPZsiQIWzbto2XXnrJ3iUVKVmarMI1kAFcAuqa97gkSegMlj1fWXAeTh2K+/bto06dOvj5+dm7lCcKDQ1l//79tGjRgvDwcObPny9GjQ5Mr9fTt29fli1bxv79+8UZmHbgJi/kqUDHgIrAfx9W9VgSEgq5ONmmqHLqUIyPj3e4qdPHcXNzY8SIESQkJLB48WJatmzJxYsX7V2W8A9ZWVm0adOGCxcusHv3bnFakZ2U8imFzJx5z0eOkTd1aiYPhQdymVN/aRQKwal/5x1pkU1B1KxZk3379vHiiy8SERHBvHnzMBqtd6ajUHDXrl0jNjaW8uXLs2nTJvz9/e1dUpFVv2x9fN19zXv4MpAF1DK//5CSIeY/LDg9pw3FzMxMTp486XRHbLm5uTF8+HASEhKIi4ujZcuWXLggNgvb0/Hjx4mKiuKtt95i4cKFKJVKe5dUJKnVanbu3MmulbvIyc0xr5FjQA2gYHcEPFZMxRjzHxacntOGYkJCAg0bNnTaPWM1a9Zk7969vPLKK0RGRjJ37lwxarSD33//nZYtWzJ58mRGjBghzrC1Ib1eT2JiIl9++SUvvPACpUqVYsSIEfjqffF0N/Pv9WtAB/Nr8nP3IzbI8RbuCbbjtCfaDBo0iFKlSjFq1Ch7l1Jop0+fplu3bnh5efHdd99RuXJle5dUJCxevJhRo0axZs0amjRpYu9yXJ7RaOTkyZPEx8cTHx9PQkICQUFBNG/enObNmxMbG0uxYsUA+OT3T5h9cDZaw9MvILY0X6Uvt4fexktpuQsEBOfitKEYFhbGggULaNSokb1LsQiDwcCMGTOYNGkS48aNo2/fvmKjuJVIksT//vc/Vq5cyebNm6lWrZq9S3JJkiRx9uzZ/BDcsWMHxYsXzw/BZs2aUapUqcc+ezHjIjW+qYFar7ZZvUq5kg8jPmTWK7Ns1qfgeJwyFO/cuUPVqlVJT093uUtdU1NT6d69O0qlksWLF4tDpy1Mo9HQvXt3zp8/z8aNG5/4RVkwz9WrV/NDMD4+HqPRSIsWLfJD0JQzgVsta8W289vQG/VWrPj/yfQyFkcspmvbrjbpT3BMTjkU2bFjB02aNHG5QASoXr06u3fvpm3btjRs2JBZs2aJd40Wcu/ePV588UU0Gg3x8fEiEC0gPT2dNWvW0KdPH6pVq0a9evX45ZdfaNSoEX/88QdXrlxh6dKlvP/++yYfkv9tm2/xdLPNmgEfpQ/vBL7DxCETefXVVzlz5oxN+hUcj1OGorNtxTCVQqFg8ODB7Nu3j1WrVtG0aVPOnj1r77Kc2vnz52ncuDENGjRg9erVeHmJd0bmyMzM5JdffmHw4MHUrVuXKlWq8P333xMSEsLq1au5desWq1ev5sMPPyQkJKRQC5fK+ZVjzitz8FH6WPBX8G9ymZyg4kEs7bWUlJQUmjZtSnR0NIMHDyYjI8OqfQuOx2lD0Rk27RdWSEgICQkJtG/fnkaNGvH111+LUaMZEhMTiYmJoX///kyZMkW8qzVBbm4u27dvZ/To0URFRVG+fHlmzpxJQEAA8+fPJz09nU2bNjFo0CDCwsIs/t+2S1gX2ldvj7fS26Lt/lUxj2JsfHsjbnI3PDw8+OSTT0hJSSE7O5vq1aszf/58DAaD1foXHIvTvVO8cuUK4eHh3Lx5s0h9cUtLS6Nbt27IZDIWL15M1apV7V2SU9iwYQMffPABS5Ys4dVXX7V3OQ5Pp9ORlJSU/04wKSmJOnXq5C+OiYqKsvk2KIPRwNvr3mZL2hZUOpXF2pUho7hncXZ13UXtZ2s/9nOOHDnCwIEDuX//PjNnziwS34wXdU4XikuXLmXLli2sWrXK3qXYnMFgYM6cOUyYMIExY8bQr18/FApxRuPjSJLEzJkzmTZtGj///DPh4eH2LskhGY1Gjh07lh+Ce/bsoXLlyvmLY5o0aeIQZwsbJSNDtw1lXtK8wt+gAXgrvSnnV45f3/2VKiWqPPVzJUli3bp1DB06lLp16zJ16lSxAM6FOV0odunShejoaHr37m3vUuwmLS2N7t27I0kSixcvJiREHEv1VwaDgUGDBhEfH8+WLVtMXuDhyiRJ4s8//2T79u3Ex8ezc+dOAgICaN68OS1atOD555+3+4XdT7P/yn7eXPMm99T3zBo1KmQK3BXuDGo0iE+bfoq7wr3Az6rVaqZPn8706dPp2bMno0aNEscBuiCnCkVJkqhQoQI7d+6kSpWnf3fn6oxGI3PmzOGzzz5j1KhRDBgwQIwagZycHN555x1UKhXr1q3L3wxelF2+fDk/BOPj41EoFLRo0YIWLVrQrFkzypcvb+8STZKry+Xbw98yZd8U7qvvk6PNQeLpX8a8ld4YJSMda3ZkePRwapU2/3DU69evM2rUKH7//XcmTJhA165dxd89F+JUofjnn3/SsmVLLl26JI7jeujcuXN0794dnU7HkiVLivRG9Js3b/Lqq69Su3ZtFixYgLt7wUcBruT27dvs2LEjPwgzMzPzR4LNmzencuXKLvH3R5Ikdl7cyfrU9ey5vIfU9FQkKe/aJ0mS0Bl1lPEpQ2T5SF6o/ALv1H6H4p7FLdZ/UlISAwcOJDc3l6+//lqciuQinCoU582bR2JiInFxcfYuxaEYjUbmzp3LuHHjGDFiBIMGDSpy37mmpKTQunVrevTowZgxY1zii35BZWRkkJCQkB+CV69eJTY2Nj8Ea9WqVST+exglI3dVd1Hr1SgVSvw9/K26ahXygnnlypUMHz6cqKgoJk+eTFBQkFX7FKzLqUKxY8eOtGnThs6dO9u7FId0/vx5unfvjkajYcmSJVSvXt3eJdlEfHw8b7/9NtOmTSsSfzZUKhV79+4lPj6e7du3c/r0aaKiovJHg/Xq1XPJgy0cmUqlYsqUKcyaNYu+ffsyfPhwfH3NvP5KsC/JSRgMBqlkyZLS1atX7V2KQzMYDNKcOXOkkiVLSpMnT5b0er29S7KqpUuXSqVLl5bi4+PtXYrVaDQaaffu3dL48eOl2NhYycfHR4qJiZHGjh0r7dy5U1Kr1fYuUXjo8uXLUqdOnaTy5ctL33//vWQwGOxdkmAipxkpHj16lLfffpvU1FR7l+IUzp8/T48ePcjNzWXJkiXUqFHD3iVZlCRJfPbZZ8TFxbF582Zq1qxp75IsxmAwcPTo0fyR4L59+wgJCcnfKxgTEyNGIQ5u//79DBgwAJlMxtdff+0yFxcUBU4TitOnT+fs2bPMnTvX3qU4DaPRyIIFCxg7dixDhw5l8ODBLjGtptVq+eCDD0hJSWHTpk2UKVPG3iUViiRJnD59Oj8Ed+3aRdmyZfNDsGnTpjzzzDP2LlMwkdFo5Mcff2TUqFE0bdqUSZMmERgYaO+yhP/gNKHYunVrunXrxhtvvGHvUpzOxYsX6dGjB9nZ2SxZssSpR1UZGRm8/vrr+Pn5sWzZMnx8rHsuprVcuHAhPwTj4+Px9vb+25VKZcuWtXeJgoVkZ2czadIk5s2bx4ABA/jkk0/w9rbuAiDBfE4RijqdjoCAAM6fP0/JkiXtXY5TkiSJhQsXMmbMGIYMGcInn3zidKPGS5cu0apVK1q2bMn06dOdaoXtjRs32LFjR34QqtXq/BBs3rw5lSpVsneJgpVduHCB4cOHk5iYyFdffcVbb71VJFYFOxunCMX9+/fTt29fjhw5Yu9SnN7Fixfp2bMnDx48IC4ujlq1zN/EbEvJycm0bduWYcOGMWDAAHuX85/u3bvHrl278kPw5s2bNG3aND8Ea9SoIb4gFlEJCQkMHDgQb29vZs6cSUREhL1LEv7CoUJRkiQMhmyMRjUymRsKhS9yuZKJEyeSkZHB1KlT7V2iS5AkiUWLFjF69GgGDRrEsGHDLDJq1Ouzyc4+QlbWIbKzj2AwZAMylMqS+PlF4ucXjo9PLeRy0zbVb9q0iR49erBw4ULatWtX6DqtITs7mz179uSHYFpaGtHR0fkhWLduXaca2QrWZTAYiIuLY8yYMbz88st88cUXYsrcQdg1FCVJIjNzP+npP5GRkUBOzkkkSYtMpkCSjIARD48gDh7Mplq1TrRsOQGFwjnfITmiS5cu0atXL+7du0dcXByhoaEmtyFJBu7d+43LlyeTmbkPudwLo1GDJGn+9nlyuTcymQKjUUupUm9QocIQ/Pzq/Wf733zzDZ9//jk//fQTDRo0MLk+a9FoNBw4cCA/BI8ePUpERER+CDZo0KDInqgjFFxmZiYTJ05k8eLFDBkyhEGDBtn8FhLh7+wSikajhhs34rhyZTJa7S2Mxlzg6fcEyuU+gMSzz3ahYsVP8PISp9RbgiRJfPvtt4waNYqBAwcybNgwlEplgZ69e3cLqandMRpzHo4KC0qBXO6Bt3d1atT4ER+ff28XMRqNDB06lC1btrBlyxa7v3PT6/UcPnw4//zQ/fv3U6NGjfxTY6Kjo8XiCcFsZ8+e5ZNPPuH48eNMmTKFDh06iOl1O7F5KGZmJpGS0hGdLh2jMceMFtyQy5UEBY2lYsWhyGRiSsoSLl++TK9evUhPTycuLo7atR9/vxyATpfBn39+yN27mzAaC3O/nQy53JOgoDFUrDg8//dSpVLRuXNn7t69y4YNG+yyHUGSJE6ePJkfggkJCQQGBuafGhMbG0vx4pY7R1MQALZv387AgQMJCAhgxowZ1K1b194lFTk2C0VJMnL+/CiuXZv1cGRYOHK5D15elald+xc8PcXVQJYgPbyKasSIEQwYMIDhw4f/a9SoVl/i8OFodLr0f02Rmksu98bfvyG1a2/m7t0s2rRpQ9WqVfn222/x8PCwSB//RZIkzp07lx+CO3bswM/PLz8EmzZtyrPPPmuTWoSiTa/Xs2jRIsaNG0fbtm2ZOHEipUuXtndZRYZNQlGSDJw69a4FRhb/pECpfIZ69fbh7S1uoreUK1eu8MEHH3Dr1i3i4uKoU6cOAGr1ZQ4dikCnuwcYLNqnXO6JQlGd7t0f8Oab7/LZZ59Zffro2rVr+SEYHx+PXq/PD8FmzZqJg50Fu7p//z6fffYZP/zwAyNHjqRfv37iPbUNWD0UJUkiNbUbd+6ssXAgPiJDqQwgPPwQnp4VrNB+0SRJEnFxcQwbNox+/foxbNhAjhypg0ZzFUsH4iMaDeh04bz6arJV2r97927+XsH4+Hju3LlDs2bN8oMwJCREvMcRHE5qaipDhgwhLS2NadOm8eqrr4o/p1Zk9VC8cWMpaWkfmfn+sKAU+PrWJTz8IDKZ3Ir9FD1Xr17lgw8+oFGjJGJjswDLTJk+iVzuTY0ayyhVqvBbL7KyskhISMgPwfPnzxMTE5MfgnXq1EEuF39eBOewdetWBg0aRIUKFZgxY4bT7DF2NlYNRY3mOgcPVjNxZaJ55HIfKlWaSIUKA63eV1GTkbGXw4ebI5drbdKfm1txGjY8i1Jp2ulFarWaffv25Yfg8ePHadCgQX4IRkREFHhlrSA4Ip1Ox7x585g4cSJvvvkm48ePF6d8WZhVQ/HYsVe4f/8PQG+tLv5GLvemQYMzeHqKQ3ctKTk5nOzswzbrTybzIDBwAMHBXz318/R6PUlJSfkhePDgQUJDQ/P3CjZu3BgvLy8bVS0ItnP37l0+/fRTVq9ezZgxY+jTp4/4hs9CrBaKubnnSUqqhdGotkbzj5X3xXQgwcGTbNanq8vJSeHQoUiLrBg2hUJRjOjo2387/cZoNHLixIn8Q7R3795NpUqV8kMwNjYWf39/m9YpCPaUkpLCoEGDuHr1KtOnT+fll1+2d0lOz2qhmJY2iOvX5yJJtplye+RxX0wF86Wm9uTmzTistbjmSRQKP0JCFvLgQf38ENyxYwclS5b825VKpUqVsmldguBoJEnil19+YfDgwYSEhDB9+nSqVatm77KcllVCUZKM7NlTHIMhy6zn4+Nh6VK4fRtKlIDhw+HhroD/pFD4Ub369xZZqCHA3r2l0enumPxcZiZMmQLJyVCsGPTsCS1bmtbGwYOezJ4dkH9qTLNmzahQQawwFoTH0Wq1zJ49m0mTJvHee+8xduxYcQ+nGayy9C4399zDs0tNl5wMCxfmBeHmzTBzJphyTq7BkM2DB7vN6lv4O53uLnr9A7Oe/fprcHOD9eth9Oi838cLF0xrIyqqOJcvXyYuLo4uXbqIQBSEp3B3d2fIkCGkpKSgUqmoXr068+bNQ6+3zZoOV2GVUMzKOmT21oi4OOjcGWrWBLkcSpXK+yg4iYyMBLP6Fv4uK+swcrnphxPn5kJCAnTvDl5eULs2NG4M27aZ1o7RmG6lva2C4LpKly7NggUL+O2331i1ahX16tVj+/bt9i7LaVgtFM3ZhmEwwJkz8OABvPsudOyYN+LQmLg1TqU6bXLfwr+p1ReRJNO/y7x6FRQK+OvALjgYLl40rR253Au1+orJ/QuCAHXr1mXHjh2MGzeOXr160a5dO86ePWvvshyeVa5e1+luA6a/qrx/H/R62LULZs3Km34bPRp++CHvnVRBGQwqfvjhByRJyv8wGo1P/feCfI412rBXvwVpIyLiCi++mIupK71zc+GfF0b4+IDK5EGfzKarlwXB1chkMl5//XVat27NjBkzaNSoEd27d2fMmDFipfYTWCUUzRldADw6+7l9e3i0H7VjR/jxR9NCUSaT+O23rchkcmQyGXJ53j8fffzz3wvyOQVtQ6FQmPyMJfq1ThubgLmYeoqNl9e/A1Cl+ndQ/jcJuVzsvRKEwvL09GTkyJF07dqVUaNGUa1aNSZMmEC3bt3E5df/YJVQNPciYD+/vPeHfz3Wz5wj/mQyN378cZlZNQj/7/btdM6c+Q6DwbRQDAzMmwq/ejXv/wOcPQvPPWda/5Kkw81NnNYhCJZStmxZlixZQnJyMgMHDmTu3LnMnDmT2NhYe5fmMKzyTtHHp5ZZCzQAXn4ZNmzIm0rNyoK1ayEqyrQ23N3LmdW38He+vvWQJNP3J3p5QZMmsGRJ3lTqiROwbx+88IJp7chkHnh4lDG5f0EQni4iIoLdu3czbNgwOnfuzJtvvslFU1/6uyirjBR9fcORydwB098HdemSt9Cmc2dwd4emTeG990xrw8+vgcn9Cv/m5RUMmLe1ZuBAmDwZOnQAf/+8f69UybQ2fH3DzOpbEIT/JpPJePvtt2nTpg1Tp04lPDycPn36MGLECHx9fS3e3/3c+xy+cZjk68mcTj9Nri4XpUJJGd8yRJaLJLxcOMHPBNv9BhCrbN7X67PZu/cZs98tFoZM5klw8GQCA/vZvG9XdOTI8zx4YPstLjKZJ889N5agoJE271sQiqKrV68yYsQIduzYwRdffEHnzp0LfYuM1qBl3al1fLX3K07dOYWX0gu1Xo3W8P8nncmQ4evui0EyoJQr+TDiQz6K/IgKxeyzL9lqx7wdPhxNZuY+azT9VDKZJw0anMbL6zmb9+2K0tM3cvr0e2afTmQumcyTRo0uiOlTQbCxAwcOMGDAACRJ4uuvvybK1PdX5B09t+jwIoZuG4okSWRpC/71w0PhgUwm45Uqr7Dg1QWU8rHtUY5Wu0yuYsXhKBR+1mr+iYoVixKBaEElS7Z+OBVuSzJKlHhRBKIg2EGjRo3Yv38//fr1o2PHjrz77rtcuVLw/cKXH1ymyZImDP5tMJmaTJMCEUBj0KDWq9mctpmqs6uy7tQ6U38JhWK1UCxZsjVyuYe1mn8sudyXChWG2bRPVyeTKQgKGgOYt3DKHHK5J0FB/7NZf4Ig/J1cLqdz586kpqZSuXJl6taty/jx41H9x2bjxKuJ1J5Xm8RrieToCnexvNag5YHmAV1+6sKArXkjV1uwWijKZAqqVp2LXG7y5jQz+3PDz68uJUq8ZJP+igqVSsXXX1/m4kU9kmT9F+ByuTdly36Av3+E1fsSBOHpfH19mTBhAocPH+bUqVNUr16dFStWPDagEq8m0uL7FmRqMtEbLbeeRKVT8e3hb+m7ua9NgtFqoQhQunRHihdvZpPpN5nMgxo1ltt95ZIr2bVrF2FhYVy/fpOWLXejUFh7tChDqSxJ5cpfWrkfQRBMERQUxKpVq1i2bBlTp04lJiaGpKSk/J+/8uAKL/74YqFHh0+i0qn44fgPTN0/1Srt/5VVQxGgevUlD98tWi+s5HJvQkK+wdNT3KJgCZmZmfTp04d3332XadOmsXz5cgIDG1G9+lLkcuvdZK9Q+FOnzm8oFNbrQxAE8zVp0oSDBw/So0cP2rRpQ9euXbl27Rqd1ndCpbPu4f05uhzG7RhHanqqVfuxeii6u5eiXr3dKBT+WCMY5XJvKlYcQZky71u87aLo119/JTQ0FL1ez8mTJ2nTpk3+z5Uu3ZGQkAVWCEYZCkUx6tbdiY9PDQu3LQiCJSkUCrp3786ZM2d49tlnCXk7hMTLiRadMn0StUHNm2vexGC03qXnVtuS8U85OakcPdoEvT4LSTLx2osnkMu9eO658VSsONQi7RVld+/eZdCgQezZs4dFixbRokWLJ37uvXu/c+rU2xgMqkL/Xsrl3nh6Pkdo6E94e1ctVFuCINiW1qAl4KsAsnS227Ll6+7LkrZLeKPmG1Zp3+ojxUd8fKrToMEZSpZ8tdCLb+RyL9zdy1Knzm8iEC1g7dq11K5dmxIlSnDixImnBiJAiRIv0rDhOQIC2jz8vTT9j5FM5o5c7kXFiiOJiDgmAlEQnNBPqT8hyWyzKvSRbG02k/dOtlr7Nhsp/lV6+kbS0j5Cr88w6d5FudwHMFK2bE8qV56EQmGbla2u6ubNm3z00UecOnWK7777jsaNG5vcRmZmIleuTOXu3V8ABUbj0160y/MPiy9bthfly/cTe0oFwYmFLwjn8M3DNu/Xy82LQx8cokYpy79usUsoQt6JBxkZO7l8eTIZGTvyrwj6a0jKZB4YDHIkSY2PTyUCAwdRpkwX3NzEPWCFIUkS33//PUOHDqVXr17873//w9OzcCtLtdp07t79hQcP9pKZuRe1+iJGoxZJAr1eTokSdSlWLJZixaIpWbKVzfewCoJgWZmaTAImB6Az6kx/+A6wGbgBeAMvAibkm7vCnS+af8GQxkNM7/s/2C0U/0qSDKhUZ8jKSkatvojBkI1M5oFSWRK1OpAWLT7k0qU7YruFBVy+fJnevXtz8+ZNFi9eTL169aza35o1a1i1ahVr1661aj+CINjWrou7aLOyDZmaTNMeNADfABFAI+AisALoDQQUvJnXQl5j4zsbTeu7AKxyS4apZDIFPj418fGp+YTPGMzZs2epWlW8dzKX0Whk/vz5fPrppwwaNIihQ4eiVFr/At+AgADS09Ot3o8gCLaVfD0Zjd6MhXbpQBYQRd6GhMpABeA40Ny0/q3BIULxv0RHR7Nv3z4RimZKS0ujZ8+e6HQ6EhISqFHDdtseRCgKgms6c/cMGhMvIH+q2yZ+eo6JDxSQzVafFkbjxo3Zt8/2N244O71ez5QpU4iKiqJDhw7s3r3bpoEIULJkSe7evWvTPgVBsD6zN+sHAD7AXvKmUs+SN4Vq4qtJg2TAKJl33+vTOMVIsXHjxixYsMDeZTiVEydO0L17d/z9/Tl48CCVK1e2Sx2PQlGSJPFOWBBciFJu5usXBfA28Ct5wVgOqIXJaSR7+D9Lc4qRYlhYGJcuXSIjI8PepTg8rVbLuHHjaN68Ob179+aPP/6wWyACeHh44OnpSWamiS/jBUFwaGX9yiI3N0LKAN2A4UBn4D5Q3rQmfN19rfKNtlOEopubG5GRkRw4cMDepTi0pKQkwsPDOXToEEeOHKFnz54OMToTU6iC4HoiykXg6+Fr3sM3yZsu1ZI3WswG6prWRM1ST1qYWThOEYqQN4W6d+9ee5fhkFQqFUOHDuW1115j1KhRbNy4kcDAQHuXlU8sthEE1xNeNhydwYw9ipC30nQaMAW4QN5o0YTpUzlyYoNizev7PzjFO0XIW4E6dar1rw1xNgkJCfTo0YOIiAiOHz9O6dKl7V3Sv4hQFATXU7FYRbyUXuTqc01/+MWHH2bycfeh6XNNzW/gKZxmpNioUSOSkpLQ661/ErszyMzMpG/fvnTq1Ilp06axYsUKhwxEENOnguCKZDIZH0V+hIfC9qdTuSvceTG4EKn6FE4Tis888wwVKlTg+PHj9i7F7rZu3Urt2rXRarX/ut7JEYmRoiC4pg8jPrR5n55unvRv2I2pOE8AABBxSURBVB83uXUmOp0mFOH/N/EXVffu3eP999+nT58+fPfdd3z77bcUL17c3mX9JxGKguCayvmVo131djYdLbrJ3awaxk4VikV5E/+6desIDQ2lWLFinDhxgpYtW9q7pAIT06eC4Lrmtp6Ll9LSF48/no/Sh9mvzKa0j/VeFTldKBa1Fag3b97kjTfeYPTo0axZs4ZZs2bh62vmMmg7ESNFQXBdJbxK8H277/FWWvcqP6VcSYPyDXg/7H2r9uNUoVi1alVUKhVXr161dylW9+h6pzp16hASEsLRo0eJjo62d1lmEaEoCK7ttWqv0a9BP6sFo5vcjXJ+5VjdcbXV9147zZYMyFvt1LhxY/bv30/Hjh3tXY7VPLre6caNG2zdupX69evbu6RCEdOnguD6vmzxJVqDlgWHFph/LupjKOVKyvmVY1+PfQR4m3C3lJmcaqQIrj2FajQamTdvHuHh4cTExJCUlOT0gQhipCgIRYFMJmP6S9OZ1HIS3m7eyGWFjxcfpQ8xFWNI/iCZcn7lLFDlf3OIS4ZNsWfPHgYPHszBgwftXYpFPbreSaPRsHjxYmrWtM4RRvag0Wjw8/NDo9E4xLFzgiBY19l7Z3lr7Vv8efdPsrXZJj/v5eaFQq7gm1bf0LlOZ5t+3XC6kWJ4eDgpKSmoVJYbntuTXq9n6tSpREVF0a5dO/bu3etSgQh5h4J7eHiQlZVl71IEQbCBKiWqkNQriWUdlhFdIRpPN088FZ5PfUYuk+Pn7keAdwCjm4zmfP/zdAnrYvNvpJ3qnSKAl5cXtWvXJjk5mdhY65x9ZysnT56ke/fu+Pr6kpiYSHBwsL1LsppHU6j+/v72LkUQBBuQy+S0qdaGNtXacPbeWbakbSHhUgIHrx3kZvZN9EY9CrkCH6UPoaVDeT7oeWKDYmlZuSUKucJudTtdKML/v1d01lDUarV8+eWXzJkzhy+++MJhbrOwpkehaM9rrARBsI8qJarQv2F/+jfsb+9S/pNThmJ0dDRxcXH2LsMsSUlJ9OjRg4oVK3LkyBGHus3CmsQKVEEQnIHTvVMEiIqKYt++fTjTGqHc3FyGDRvGa6+9xogRI9i0aVORCUQQK1AFQXAOThmK5cqVw9/fnzNnzti7lAJJSEggLCyMy5cvc/z4cTp16uTy06X/JEJREARn4JShCM5xOHhWVhYfffQR77zzDpMnT2blypUOe72TtYnpU0EQnIHThqKjHw7+22+/ERoaSm5uLidPnqRdu3b2LsmuxEhREARn4JQLbSAvFGfPnm3vMv7l3r17DB48mJ07d7Jo0SJefNE6F2E6GxGKgiA4A6cdKdauXZvr16871JTc+vXrCQ0Nxd/fn5MnT4pA/AsxfSoIgjNw2pGiQqGgQYMGHDhwgNatW9u1llu3bvHxxx9z/PhxVq9eTUxMjF3rcURipCgIgjNw2pEi2P9wcEmS+OGHH6hTpw7BwcEcPXpUBOITiFAUBMEZOO1IEfJWoH7xxRd26fvKlSv07t2ba9eusWXLFsLDw/+vvbuNjau68zj+u/faM5PxOB4cJ87YMUKWE7wJIjThKRJNSF7QLUFVUSq6u2lRi4OWEiroSiUS+6Kr7CKW7gNB2wVSdanKbqtWaiTERi2ogoXtSpCEZB0gD9BQkjgb7MRBsT0zHj/MOfvCU4hKCJ47T8fM9yPxIpHP+Z+gSL/8z73n3JqsY674w/aptbbujqMAmDvmdKd4ww03aP/+/ZqamqpaTWOMnnrqKa1atUpr1qzRvn37CMRZ4FJwAHPBnO4UE4mI1q9v1759f61k8pQmJk7L2in5/jzF48s0f/4aNTevVjzeK68M3/Y6duyYtmzZolwup5dfflkrVqwow5+ifnApOADXzbnvKUpSJnNIAwOP6cyZnymXm1ZDg+T7H+8WgyAha62CoElLljygVOpuRSLFf7k5n89rx44deuSRR/TQQw/p/vvvVxDU7hb3ueraa6/Vk08+qeuuu67WSwGAi5pTneLExP/pyJE7NTr6qoyZlJRXJPLJP5/Pz3zc0piMTpz4W504sV0dHfepu/vv5PvRWdV866231NfXp3g8rtdee009PT1l+JPUJ162AeC6OfFM0Vqr999/Wnv29Gpk5L9lzLikfFFzGDMuY3I6ffoJ7d3bq9HR1y/585OTk9q+fbvWr1+vvr4+vfjiiwRiiQhFAK5zvlO01uidd76loaGfyphMyfMZk1Uud1z9/evU2/uMFi3a9LGfef3113XXXXepq6tLBw4cUFdXV8l1wQF+AO5zulO01urtt+/W0NB/lCUQL2RMVkePfl1nzuz68PfGx8e1bds2bdy4UQ8++KB2795NIJYRnSIA1zndKQ4M/IPOnPm5jMlWZH5jxnX06J2aN69b/f1p9fX16ZprrtEbb7yh9vb2itSsZ21tbTp48GCtlwEAn8jZUMxkjur48b8pPD+sHGOyeuWVm3XvvU16/PF/1e23317RevWM7VMArnMyFK3N6/DhO2TMRFXqRaMZPf/8N7V8OYFYSWyfAnCdk88Uz537lXK59ySZqtRrbMxreHinpqbOV6VevSIUAbjOyVA8efLvPzxjWD2+BgefrnLN+sL2KQDXOReK4+PvKp0+EHr8qVPSLbdIDz9c3DhjshoY+CfNwQt+5owFCxZoeHiY/8cAnOVcKH7wwW9UyrIef1zq7Q03dnr6vHK5E6Fr49JisRiXggNwmnOhODLy29BHMF56SWpqklatClfb8xqUTu8PNxizwhYqAJc5F4qjo3tCjctkpB//WNq6NXztfH4sdH3MDi/bAHCZc6E4NTUUatzTT0u33iotXFhKdats9nelTIBPQSgCcJlzoWhM8R8MPnZM2r9f+spXylG/spcF1Du2TwG4zLnD+57XIGuLO7Tf3y8NDUlf/erMr8fHJWOkEyekH/6wuPqz/aQUwqFTBOAy50KxoSGpycniLv++7TZpw4aPfv2LX0iDg9J3vlN8/Wh0SfGDMGuEIgCXObd92ty8uugxsZjU2vrRf/PmSZGIlEwWN08QJDR//o1F18fssX0KwGXOdYrJ5Dp98MELRW+hXugb3whfP0woY/boFAG4zLlOMZlcJ8+rVVb7isevrFHt+kAoAnCZc6GYSKxSNNpZ9bqeF1FHxz3yvKDqtesJ26cAXOZcKHqep8sv3ybfb6pyXV+dnSWc/Mes0CkCcJlzoShJixb9uYIgUbV6nhfVggVfUix2edVq1isuBQfgMidDMQjmafnyn8n351Wt3rJlT1alVr2LxWKKRCJKp6v9aTAA+HROhqIkXXbZBi1a9GcVD0bfj6u39ydqbGytaB18hC1UAK5yNhQlaenSJ5RIrJTnVeaWGd+Pq6vru2pr+1JF5sfFEYoAXOV0KAZBTFdf/Rs1N3+u7B2j78e1ZMkDuuKK75V1Xnw63kAF4CqnQ1GSGhoSWrnyv9Te/vWyBKPnNcj3m7R06Q/U3f2wPM8rwypRDDpFAK5yPhSlmY7xyit36uqrn1ckkpLvh3kz1ZPvN2n+/DW6/vqjSqW+WfZ1YnYIRQCucu6at0tJJtfqxhvf09mzv9TJk49qfPxdSfYSn3vyFARNMmZKra23qKvru2ppuYnusMbYPgXgqjkVitLMp53a2zervX2z0um3NDLyPxoZ+a1GR/doevq8rJ2W7zcqEulUS8vn1dKyRsnkBkWji2u9dBS0tbXpzTffrPUyAOBj5lwoXiiRuEqJxFXq7Lyn1ktBEdg+BeCqOfFMEZ8tbJ8CcBWhiKqjUwTgKkIRVUcoAnCVZ7mZGVWWy+XU0tKiXC7Hm8AAnEKniKqLxWJqbGzkUnAAziEUURNsoQJwEaGImuANVAAuIhRRE3SKAFxEKKImCEUALiIUURNsnwJwEaGImqBTBOAiQhE1QSgCcBGhiJpg+xSAiwhF1ASdIgAXEYqoCUIRgIsIRdQE26cAXDSnPzKMuWd6ekzp9P9qcvJVbd48qMOH/0KeF1EksljNzdequXm1YrEruCgcQE3wlQxUnDFTGh5+VgMD31c6fVC+H5cxOVk7ccFP+QqChKydlu9HlErdo87OrYrFltRs3QDqD6GIirHWanDwJ3r33b+StdPK58dmPdbzopKkBQs2atmynYpE2iq1TAD4EKGIipiYOK0jR76m0dG9MiYTeh7Pi8j356m399+0cOGmMq4QAD6OUETZjY0dUH//BuXzGUnTZZnT95uUSm1RT89jPG8EUDGEIspqJhDXKZ8v/weEfT+u9vY7tWzZEwQjgIrgSAbKZmLidKFDLH8gSpIxWQ0NPaOBgX+syPwAQCiiLKy1OnLka4Ut08oxJqvjx7+nTOZIResAqE+EIspiaOjfNTq6V+V6hngpxuR06NAdsjZf8VoA6guhiJIZM61jxx4o6S3T4ljlcu/p7NldVaoHoF4QiijZuXPPydrKd4gXMiajkye/X9WaAD77CEWU7OTJR4s6mF8u2exhZTKHq14XwGcXd5+iJPl8Run0gVBjBwelHTukQ4ekxkZp3TrpvvukIJjdeGvzGh7+TzU1LQ9VHwD+GJ0iSpJO98v346HG7tghJZPSrl3Sj34kHTwoPfvs7MdbO6mRkVdC1QaAiyEUUZKxsf2ydjLU2Pffl26+WYpEpNZW6frrpePHi60frksFgIshFFGSbPZtGZMLNXbTJumll6RcTjp7VtqzZyYYizE1dUZcygSgXHimiJLk89nQY1eulHbvljZulIyRvvAF6aabip/H2ml5XmPodQDAH9ApoiS+Hy6MjJG2bZPWrpV+/euZZ4ljY9LOncXOZOV5/NsOQHkQiihJY+NihflrNDYmDQ1JX/7yzDPFlhbpi1+c2UIthu/HuRwcQNkQiijJ/PmrFQSJose1tEiplPTcc1I+L6XT0gsvSN3dxc0Tj/9J0bUB4JMQiihJIrFa1k6FGrt9u7R370y3uHnzzPnErVuLmcFTMvn5ULUB4GJ4GIOSRKOdCoImGTNe9NienpmzimEFQULJ5M3hJwCAP0KniJJ4nqeOjq3y/VgNagdqbb216nUBfHYRiihZR8c9VT8r6HlRdXTcF/rtVwC4GEIRJYtGF2vhwk3yvGjVanpegzo7761aPQD1gVBEWSxd+gMFQbg7UIvl+03q6flnRaOpqtQDUD8IRZRFY+Nl6u19JvTl4LPXoETiGqVSd1e4DoB6RCiibNrablNn57crGIyBIpF2XXXVLg7sA6gIQhFl1d39iDo6/rICwdioSCSlVateVSTSXua5AWCGZ/nEACrg1Kl/0e9/v03GTEgyJc3l+01qbv6cVqz4JYEIoKIIRVRMNntMhw/fofHx3ymfTxc9fubsY6CenseUSm1hyxRAxRGKqChrjYaHn9PAwKNKpw/KWiNrJy4xwlcQNBWOXHxbHR3fUjS6uGrrBVDfCEVUTTb7js6d+5XOn39FY2P7NDU1JGunNROEccXjK5RMrlVLy1q1tv6pfJ9bCAFUF6GImrLWsi0KwBm8fYqaIhABuIRQBACggFAEAKCAUAQAoIBQBACggFAEAKCAUAQAoIBQBACggFAEAKCAUAQAoIBQBACggFAEAKCAUAQAoIBQBACggFAEAKCAUAQAoIBQBACg4P8BE44yWQnzR6QAAAAASUVORK5CYII=\n",
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAcUAAAE1CAYAAACWU/udAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMi4zLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvIxREBQAAIABJREFUeJzs3Xd4VNXWx/HvnCnJpJCE3kMNJCA1BEEpigUUpGuiIoKCvCqKBAtXLNer2BARFJEiqGACAakWQGlKCwQInQBKDSUQSG8zc94/gAhSzEymZWZ97pPnGsjea6mYX/Ype2tUVVURQgghBIqrGxBCCCHchYSiEEIIcZmEohBCCHGZhKIQQghxmYSiEEIIcZmEohBCCHGZhKIQQghxmYSiEEIIcZmEohBCCHGZhKIQQghxmYSiEEIIcZmEohBCCHGZhKIQQghxmc7VDQjhDlRVZffZ3WxJ3cL64+tJSk0ipygHVVXx1/vTslpL7qh1B21qtKF5leZoNBpXtyyEcACNHB0lvFl2YTbfJX/Hxxs+5mzOWQByinJu+LV+ej80aChvLM/L7V/mieZPEOQb5Mx2hRAOJqEovJKqqnyb/C3Dfx6ORbXcNAhvxl/vD8C4+8bxTOtnZOUohIeQUBRe53T2aR5d8CiJJxOtDsN/8tf707xqc+L7xlMrqJadOhRCuIqEovAqB88f5M6Zd5Kel47JYrLLnDpFRzlDOdYNWkeTyk3sMqcQwjUkFIXXOHLxCJFTI0nPS0fFvn/sNWgI8gli85DNhFUIs+vcQgjnkVAUXiHflE/4F+EcyziGRbU4pIYGDVUDqnJw+EH8Df4OqSGEcCx5T1F4hTGrxnA256zDAhFAReVi/kVGLh/psBpCCMeSlaLweFtTt9JxZkfyTHlOqWfUGVn++HI6hHZwSj0hhP3ISlF4vP/89h+nBSJAnimPV3991Wn1hBD2I6EoPNqJzBOsO7rO6XW3n97OwfMHnV5XCFE6EorCo03eMtm2gWnALOB94DNgn3XDzRYzExMn2lZbCOEyEorCoy1LWUaBucC6QWYgDggDXgV6AD8A50o+RZGliJ8P/mxdXSGEy0koCo9ltphJOZ9i/cBzQBbQjkv/hdQDagE7rZvmWMYx8k351tcXQriMhKLwWCnnU9Br9fab8Kx1X27UG9l1Zpf96gshHE5CUXisU9mn0Gq01g+sCPgD67l0KfUQcAQosm4aDRpOZ5+2vr4QwmXkPEXhsQrNhbYN1ALRwM9cCsbqQBOs/q9FRbX+fqYQwqUkFIXHMmgNtg+uCgy66vPpQAvrptCgwUfrY3sPQgink8unwmNVC6iGWTXbNvg0ly6XFnJptZiN1aGoolI1oKpt9YUQLiErReGxwiqEUWS28kbgFTuBbVy6pxgKDMDq/1ryivJoVqWZbfWFEC4hoSg8llbRElYhjF1nbXgC9L7LH6VQO6g2Pjq5fCpEWSKXT4VHe6jRQy65r6dX9HRr2M3pdYUQpSOhKDzasMhhLqmrVbS8EPWCS2oLIWwnoSg8Ws1yNekY2tHpdVtWbUnDCg2dXlcIUToSisLjvd/lfYw6o9PqGXVGPrr3I6fVE0LYj4Si8Hitq7fmuajn8NP7ObyWUWdkYPOB3Fn7TofXEkLYn0ZVVdXVTQjhaAWmAsK/COdoxlEsqsUhNTRoqBZYjZTnU/A3+DukhhDCsWSlKLyCj86HVQNXEeIbgqKx/x97DRqCfIJYPXC1BKIQZZiEovAadYLrsOnpTVT0q4hesd/pGTpFR4gxhPVPrSesQpjd5hVCOJ+EovAqDco3IHlYMp1CO+GvL/2Kzl/vz+01byd5WDIRlSLs0KEQwpXknqLwSqqq8l3ydwxaMAi9Xk+Bat1pFlcCdfz94xnSaggajcYRbQohnExWisIraTQaKpysQKMljZjQbQL1Qurhr/e/5erxyu+HBoXy4T0fkhqbytDWQyUQhfAgslIUXslisRAZGcmYMWPo06cPqqqyN20vW1K3sOH4BrambiWnMAcVFX+9Py2rteSOWncQWT2SZlWaSRAK4aEkFIVXWrBgAWPHjmXr1q0ScEKIYm4biqp66dRyRaOgV/TyjUvYjdlsplmzZowbN45u3WTTbiHE39zm6Ki/LvzFwv0LWXNkDVtTt3I6+zSKRkFFRdEo1A2uS/ta7elcpzN9wvtQzqecq1sWZVRcXBzBwcF07drV1a0IIdyMS1eKqqqy/PByPvjjAzaf3Fy8OryVAH0AZtVMdNNoRrUfJY/BC6sUFRURHh7OtGnTuOuuu1zdjhDCzbgsFE9mnmTAwgFsObmF7KJsq8frFB16Rc9zUc/x7l3vymGuokSmT59OXFwcv/32m6tbEUK4IZeEYvzueIYsHUK+KR+TxVSqufx0flQOqMzSmKU0rdzUTh0KT1RQUEDDhg2ZO3cu7dq1c3U7Qgg35PT3FD/d9CmDFw8muzC71IEIkGvK5cjFI7Sf0Z7Ek4l26FB4qmnTptGsWTMJRCHETTl1pThl6xRiV8SSW5TrkPkDDYH8Puh3mldt7pD5RdmVm5tLgwYNWLZsGa1atXJ1O0IIN+W0leL2U9sZuXykwwIRIKswi25zujm0hiibvvjiC9q3by+BKIS4JaesFAvNhUR8EcHhC4cdXar4kNcvu3/p8FqibMjMzKRBgwasWbOGiAh5WlkIcXNOWSm+t+49TmWfckYp8kx5fJP8DZtPbHZKPeH+PvvsM+6//34JRCHEv3L4SrHAVECljyuRVZjlyDLX0KDhwbAHWRqz1Gk1hXtKT08nLCyMTZs20aBBA1e3I4Rwcw5fKS7YtwAV5771oaKy8vBKTmU5Z3Uq3Ne4cePo3bu3BKIQokQcvs3b+I3jyS60/uV8FgB/AYVAAHAH0LrkwzVomLVjFqM7jLa+tvAIZ8+e5auvvmL79u2ubkUIUUY4dKVospjYdXaXbYM7ACOA/wAxwCogteTD8835rPhzhW21hUf44IMPeOyxx6hdu7arWxFClBEOXSnuP7cfg9ZAobnQ+sGVr/przeWPdKB6yadIPp1sfV3hEU6cOMGsWbPYs2ePq1sRQpQhDg3FHad3lG6CZcAOwARUBRpaNzy3KJe0nDQq+VcqXR+izHnvvfd4+umnqVatmqtbEUKUIQ4NxQt5FygyF9k+QXfgAeA4cASru9Vr9VzMvyih6GX++usv5s2bR0pKiqtbEUKUMQ6/p1jqJ08VIBTIBLZYN1SDhiJLKUJZlEnvvPMOzz//PBUqVHB1K0KIMsahK0VfnS9ajdY+k1mAC1YOUS346nztU1+UCQcOHGDZsmUcPHjQ1a0IIcogh64U64XUQ6/VWz8wG9gFFHApDA8Bu4G61k1TaC6kRmAN6+uLMuutt95i5MiRBAcHu7oVIUQZ5NCVYuvqrck35Vs/UANs5dKDNioQDHQFGls3TWhwqBw+7EV27tzJmjVrmDFjhqtbEUKUUQ4NxYp+FQk0BHI+77x1A/2BQaWv37Jiy9JPIsqMN998k9deew1/f39XtyKEKKMcvs1b3/C+6DQO3zjnOjqzjh8/+pG77rqLyZMnc/r0aaf3IJxny5YtbN26lWHDhrm6FSFEGebwUBxx+wjb7iuWUkhgCGf+OMOLL77Ihg0bCA8Pp1OnTnz++eecOiV7onqaMWPGMGbMGHx95cEqIYTtHB6K4ZXCaVK5iaPLXMOoMzLi9hEE+AfQq1cvZs+ezalTp4iNjWXz5s1ERETQsWNHJk2aRGqqFXvHCbe0bt06Dh48yODBg13dihCijHPKIcNbTm6h06xO5JnyHF0KgCr+VTj0wiECDAE3/P2CggJWrFjB/PnzWbp0KREREfTv359+/fpRo4Y8rVqWqKpKp06deOqppxg4cKCr2xFClHFOCUWA2BWxTNkyhVxTrkPrGHVGfnz0R+6qe1eJvr6goIBff/2VhIQElixZQnh4eHFA1qxZ06G9itJbuXIlw4cPZ/fu3eh0zr93LYTwLE4LxQJTAU2/bMqRi0cwWUwOqeGn92NAswFM6T7FpvGFhYXXBGSjRo3o378/ffv2lZMW3JCqqrRt25bY2FgeeeQRV7cjhPAATgtFgFNZp4icGsnZ3LN2D0ajzsjdde9mcfRitErpd9EpLCxk1apVJCQksHjxYho0aFC8ggwNDbVDx6K0lixZwhtvvMH27dtRFIffHhdCeAGnhiJAalYqd359J6ezT9vtHqO/3p9uDbsR1zcOnWL/S2hFRUXFAblo0SLq169fHJB16tSxez3x7ywWCy1btuR///sfDz30kKvbEUJ4CKeHIkBOYQ4jV4zku+TvShWMOkWHj9aHCV0n8FTLp9BoNHbs8saKiopYvXo18+fPZ+HChdSpU4f+/fvTv39/6ta1ch86YbN58+Yxbtw4Nm/e7JR/70II7+CSULxi3dF1DFo8iDPZZ8gtyi3xiRoGrQFFo9CxdkemPzSdWkG1HNzpjZlMJtasWUNCQgILFy6kdu3axQFZr149l/TkDUwmE02bNmXixIncd999rm5HCOFBXBqKcOlhiQ3HN/Dxho/56eBPxXuVZhdmF3+NggJFoPfR46P3YUirITzX5jnqhrjPysxkMrF27Vrmz5/PDz/8QI0aNYoDskGDBq5uz6N88803zJgxg7Vr18oqUQhhVy4PxauZLCb2pu0lKTWJvWl7ySrMQqfoCPENYdOiTXRs2JExz49x+2+EZrOZdevWkZCQwA8//EC1atWKA7Jhw4aubq9MKywspHHjxsyaNYuOHTu6uh0hhIdxq1C8lcmTJ7Njxw6mTp3q6lasYjab+f3334sDskqVKsUP6TRq1MjV7ZU5X331FT/88APLly93dStCCA9UZkJxw4YNjBgxgsTERFe3YjOz2cz69etJSEhgwYIFVKxYsXgF2bixledieaH8/HwaNmzIggULiIqKcnU7QggPVGZCMSsri6pVq5KRkeERO5dYLJZrArJ8+fLFARkeHu7q9tzShAkTWL16NYsXL3Z1K0IID1VmQhEgLCyMRYsWERER4epW7MpisbBhwwbmz5/P/PnzCQoKKg7IJk2cu5m6u8rOzqZBgwasWLGCZs2aubodIYSHKlPbgLRo0YIdO3a4ug27UxSFO++8kwkTJnDs2DGmTZtGRkYGXbt2JSIigrfeeovdu3dThn5+sbvPP/+czp07SyAKIRyqTK0Ux44dy8WLF/noo49c3YpTWCwWNm/eTEJCAvPnz8ff359+/frRv39/brvtNrd/CtdeMjIyaNCgAb///rvcexVCOJSsFN2Yoii0a9eO8ePHc/ToUWbNmkVeXh49evSgcePGjBkzhuTkZI9fQY4fP54HH3xQAlEI4XBlaqWYmppK8+bNOXv2rNeskm5EVVW2bNlSvILU6/XFK8gWLVq49T+b1KxUNp3YxOYTm1l/fD3peemYLCZ8db6EVQijY2hHIqtHElk9EoPWwLlz52jUqBFbt26VbfSEEA5XpkJRVVWqVKnC9u3b5TDgy1RVJSkpiYSEBBISEtBqtcUB2bJlS7cISItqYfmh5Xy0/iM2ndyEQWsguyAbC5brvtZX54tBa0CDhmGRw8j4NQMy4Msvv3RB50IIb1OmQhHgvvvu48UXX+TBBx90dStuR1VVtm3bVhyQQPFTrK1atXJJQCalJvHw/Ic5m3P2mq37SsKgNVBYUMjA2wYyufdk/PR+DupSCCEuKXOh+MorrxAUFMTrr7/u6lbcmqqqbN++nfnz55OQkIDZbC5eQUZGRjo8IAvNhYxZNYbPEz8v9RFhRp2R8sbyJPRPoF2tdnbqUAghrlfmQvH7779n4cKFxSsh8e9UVSU5Obl4BVlUVFQckG3atLF7QOYW5dJtdje2ntpKblGu3eb10/sxq+cs+jfpb7c5hRDiamUuFPfu3UvPnj05ePCgq1spk1RVZefOncUBmZ+fXxyQbdu2LXVAFpgK6PJtF5JOJZFvyrdT138z6ox83/d7ejXuZfe5hRCizIWiyWQiKCiI06dPExgY6Op2yjRVVdm9e3dxQObk5FwTkIpi/Rs7gxYNYu6euaW+ZHorfno/Nj+9maaVmzqshhDCO5W5UASIiori9Q9eJ7heMHmmPLQaLeV8ytG0clP8Df6ubq9MUlWVPXv2FAdkVlYWffv2pX///rRr165EAbny8Ep6ze1l10umN6JBQ6OKjdg5bCd6rd6htYQQ3qXMhGJeUR7xu+OZlTyLjX9tRFVU/H3+DkAVldyiXKoFVKND7Q482+ZZ2tdq7xavJJRFe/fuLQ7IixcvFgdk+/btbxiQ2YXZ1P2sLudyzzmlPz+9H6/e8SpvdnrTKfWEEN7B7UPxfO553l77NjO3z0Sj0ZTosX4NGvz0flT2r8wbHd9gYIuBKJoytXmPW9m3b19xQKanp18TkFqtFoBJmyfx2m+vOXyVeDV/vT9nXz4rr2oIIezGrUNx8f7FPLnoSXJNuRSaC22aw1/vT9PKTYnvF0+d4Dr2bdAL7d+/v/g1j7S0NPr06UO/fv0YsH0AJzJPOLUXf70/n3X9jKdaPeXUukIIz+WWoVhkLuLJRU+y6MAiu6w8tBotPjofvun1Df0i+tmhQwGQkpJCQkICM1fN5M/b/0Q1WPFH6b1/fG4C2gAPWNdDWIUwDjx/wLpBQghxE24XioXmQrp/350/jv1h9ycYjTojkx+YzJMtn7TrvN7u9d9e54M/Prjhtm0lUgCMAx4D6lg3VK/oSXs5jSDfINtqCyHEVdzqRpuqqkTPj2b9sfUOeaQ/z5THsz89y6L9i+w+tzdbe3St7YEIsA/wB0KtH2rUG9l2apvttYUQ4ipuFYozd8xkxeEV5Joc97BGnimPJxY+wens0w6r4W12nd1Vugl2AM0BGx4UzjflszV1a+nqCyHEZW4TiiczT/LiLy+SU5Tj8Fr5pnwGLBzg8ecQOoNFtZBZkGn7BBeBo0AL24YXmgs5lnHM9vpCCHEVtwnFZ3981iHbgt1IkaWIjcc38uPBH51Sz5MVmYvQarS2T5AM1AZCbJ/CkbvnCCG8i87VDcClg2eXH16OyWJyWs2cohzG/j6W7mHdnVbT3ZnNZjIyMkhPT+fChQv/+pGenk76hXTMT5ptuvQJXArFO0vXt1FnLN0EQghxmVuE4pStU1yy88z209s5eP4gDSs0dHptR7kSbDcLsVuFXHZ2NoGBgYSEhNzwo3z58tSvX5/y5ctf8+vN45uTXWTdWYkAHAOygCa2//0atAZqBdWyfQIhhLiKW4TijG0zrL90uplLD2icBZoCva2va7KY+G7nd7xz1zvWD3Ygi8Vi9Yrtyl9nZWVdE2z/DLArwXaj0AsKCireocYazao2Y8PxDdb/jSYD4YCP9UOvMOqMRFaPtH0CIYS4istD8WL+RdJy06wfGAh0BA4DRbbVNllMrD6y2rbB/+JKsNmyYsvKyiIgIOCWK7Z69erZNdhKo1NoJzad2IRFtfK1jB6lr51blEuraq1KP5EQQuAGobjt1Db89H5kFGRYNzDi8v+nYnMoAuw6c/PXCSwWC5mZmSUKsn9+TWZm5i0vRYaEhFC3bt0bruhcEWylcW+9e5mUOKlE+9LaW2hwKMG+wU6vK4TwTC4PxT1n91BgLnBZ/ez8bAYOG0heet51IZeZmYm/v/91q7SrP69Tp84NAy84OLhMBVtpdK7TmSCfIKeHYoA+gJfbv+zUmkIIz+byUMwuzKbIXIqlXikpGoWwpmE0qNTghpcidTqX/yNyexqNhlHtR/H6qtedekqGBQuP3faY0+oJITyfy7/jq5f/5yoGvYHHH3+c0GAb9hgTxQa3HMy76951Wij66f2IbRcrh0oLIezK5S/vBxgC0CuuOz3dZDHJN1Y7KOdTjtl9ZjvlbEMNGmoE1uCNjm84vJYQwru4PBQjKkXgo7PhmXwzlx6wUS9/FF3+NSsZtAYqGCtYP1Bcp2uDrvRu3NvhL9OrRSqDAwej17ruhykhhGdy+eXTVtVa2ba92zpg7VWf7wQ6AXdZN81tVW5zycYBnmr6Q9M5lH6I5NPJ5Jvtv22fUWfkv23+y+TnJpNxIIN3333Xax5oEkI4nlucp1h1XFXO5Jxxel2douOV9q/wXpd/nngrSiO7MJv7v7uf7ae323VfUj+dH9Mfmk7MbTGcO3eO/v374+/vz5w5cwgKkvMUhRCl5/LLpwCDWgzCR1uKbU1spFN0DGg+wOl1PV2AIYBVA1cxtPVQu1xK9dX5UtW/Kj8//jMxt8UAULFiRVasWEFoaCi33347Bw8eLHUdIYRwi1B8Luo5l9Q1nTQRNymOs2fPuqS+J/PR+TCh6wRWDVxFrXK18NNa/wCOQWvAV+fLgGYDOPTCITqGdrzm9/V6PV988QUvvfQSd955J8uXL7dX+0IIL+UWoVizXE3uqnMXOsV5tzj99f582vdTzpw5Q+PGjRkyZAj79u1zWn1vcXvN2/nzxT9pe7ItoZpQfHW+BBoC0dzkWA2D1kA5n3IEGAJ4rs1z7H12L1N7TL3lE8JDhw5l/vz5DBo0iPHjx8s5mUIIm7nFPUWAoxeP0mRyE6ccMqxTdLSv1Z41A9eg0WhIS0tjypQpTJ48mZYtWxIbG8vdd98tD+DYSVpaGmFhYRw6dIgcXQ4bj29k08lNrD+2ngv5FzCZTfjofGhYviEdQzsSWT2SdrXa4avztarOsWPH6NmzJ82aNeOrr77C19e68UII4TahCPDlli95eeXLDg/GAH0A+57fR81yNa/59fz8fObMmcP48ePR6/WMHDmS6OhoDAaDQ/vxdGPHjuXw4cPMmDHD4bVycnIYPHgwR44cYeHChVSvXt3hNYUQnsOtQlFVVbrN6ca6o+scdpq6n86PGT1nEN00+pZ9LF++nE8++YS9e/cyfPhwnnnmGUJCSnE8vJcymUzUrVuXJUuW0LJlS6fUVFWV999/n8mTJ7NgwQLatm3rlLpCiLLPLe4pXqHRaFgUvYjW1Vo75AVwP70fH9/78S0D8UofXbt2ZeXKlfz000/s37+f+vXrM3z4cA4fPmz3vjzZ4sWLCQ0NdVogwqV/f//5z3/48ssv6dGjB99++63Tagshyja3CkW49Pj9r0/8yn3177PblmGKRsGoMzL5wck8G/WsVWObN2/OrFmz2L17N4GBgdx+++307duX9evXywMdJfD5558zfPhwl9Tu0aMHa9as4Z133iE2NhaTyeSSPoQQZYdbXT69mqqqxO2OY9iyYeSb8imy2HaShr/enwblGzC331waVWxU6r5ycnKYNWsWn376KRUrViQ2NpbevXvLaRo3sGvXLrp27cqRI0fQ6123JVt6ejqPPPIIiqIQHx8vl8GFEDfltqF4xZnsM4z+bTTxu+NRNEqJH8IJMAQQaAjkPx3+w/9F/h9axb5bgZnNZpYsWcL48eM5ceIEL774Ik899RSBgYF2rVOWPfPMM9SoUYM333zT1a1gMpl4+eWXWbZsGUuWLCE8PNzVLQkh3JDbh+IVmQWZfJv8LbN2zGJv2l40Gg16RV987JQGDXmmPIJ8gri95u0MjxpOl3pdUDSOv0KcmJjIJ598wm+//cbgwYMZPnw4tWrVcnhdd3bhwgXq1avHvn37qFq1qqvbKTZr1ixeeeUVvv76a7p37+7qdoQQbqbMhOLVVFXlzwt/knI+hTxTHlqNlnI+5WhetTnljeVd1teRI0eYOHEi33zzDV27diU2NpZWrVq5rB9XGj9+PElJScyZM8fVrVxn48aN9OvXj+eff57XXntN3kcVQhQrk6Ho7jIyMpg2bRoTJ06kfv36jBw5kgcffBBFcbvnmhzCYrHQsGFD5syZw+233+7qdm7o5MmT9O7dm/r16zNjxgz8/Bx/DqQQwv15x3dpJwsKCmLUqFEcPnyYoUOH8t///peIiAi++uorcnOdczK9K/3888+EhIS49fuBNWrUYO3ateh0Ojp06MDx48dd3ZIQwg1IKDqQXq8nJiaGLVu28NVXX/HTTz9Rp04d3nzzTc6ccf5RWc4yadIkhg8f7vaXJY1GI99++y0xMTG0bduW9evXu7olIYSLSSg6gUajoVOnTixevJg//viDtLQ0wsPDefrpp9mzZ4+r27OrlJQUtm3bxiOPPOLqVkpEo9EwatQovv76a3r37s306dNd3ZIQwoUkFJ0sLCyML7/8kpSUFOrUqcM999xDt27d+PXXXz1iM4AvvviCp59+usxtxt21a1d+//13xo0bx/Dhwykqsu29WCFE2SYP2rhYfn4+33//PePHj0er1TJy5EhiYmLK5CbkWVlZhIaGkpycXGZfSbl48SKPPvoo+fn5JCQkUKFCBVe3JIRwIlkpupivry+DBw9m165dfPTRR8yZM4e6devy/vvvk56e7ur2rPLdd99x1113ldlABAgODmbp0qW0adOGNm3asGvXLle3JIRwIlkpuqGdO3fy6aefsnjxYh599FFGjBhBgwYNXNpTobmQszlnyTflo1f0lDeWJ9Dn7917VFWlSZMmTJ48mc6dO7uuUTuaM2cOI0aMYOrUqfTu3dvV7QghnEBC0Y2dOnWKzz//nKlTp9KhQwdGjhzJHXfc4ZSnOk0WEz+m/MgP+39g4/GNHLl4BL1Wj6JRUFWVQnMhFf0qElk9km4NulE9vTpjRo1h586dbv/UqTW2bt1K7969GTJkCGPGjPGad02F8FYSimVATk4O33zzDZ9++inly5cnNjaWPn36OGQT8ov5F5m4eSITN0+k0FxIVmHWv47x0/uRX5BPlF8UM5+aSeOKje3elyudOnWKvn37Ur16dWbNmkVAQICrWxJCOIiEYhliNptZunQp48eP59ixY8WbkJcrV84u8/908CcGLBxAblEu+aZ8q8drNVoMWgOj7xzN6A6j0Smec3JIQUEBzz77LFu3bmXx4sXUqVPH1S0JIRxAQrGMSkxMZPz48axcuZLBgwfzwgsv2PyAS4GpgMGLB7PowCJyi0q/446/3p/aQbX55fFfqB1Uu9TzuQtVVZk0aRJjx44lPj7eY+6dCiH+JjdIyqioqCji4+PZtm0bFouFFi1a8Oijj5KUlGTVPPmmfO797l4W7l9ol0AEyCnKIeWuKmHNAAAgAElEQVR8Cq2ntubg+YN2mdMdaDQaXnjhBWbPns0jjzzC5MmTPeLdUiHE32Sl6CEyMjKYPn06n332GXXr1iU2Npbu3bvf8sEQk8VEt9nd+OP4HzZdLv03GjRU9KvItme2UbNcTbvP70qHDx+mZ8+e3HHHHUyaNKlMvlcqhLiehKKHKSoqYsGCBXzyySdkZmby0ksv8cQTT9zwFIixv4/lvd/fs9sK8Ua0Gi2R1SPZ8NQGp5xt6UxZWVk8/vjjXLhwgfnz51O5cmVXtySEKCXP+i4l0Ov1REdHk5iYyLRp0/jll1+oU6cOb7zxBqdPny7+un1p+3h33bsODUQAs2pm99ndTNk6xaF1XCEwMJCFCxfSqVMnoqKi2L59u6tbEkKUkqwUvUBKSgoTJkwgPj6e3r1789JLLzHgjwEkn0lGxTn/+v30fvz5wp9UCajilHrOlpCQwLPPPsvnn39eZjZDF0JcT1aKXiAsLIzJkydz8OBB6tWrR+dHO7MzdafTAhHAolr4Kukrp9Vztv79+7Ny5UpeffVVxowZg8VicXVLQggbyErRCz0872Hm75vv1FAEqGCswOlRpz3q/cV/Onv2LP369SM4OJjZs2fb7R1SIYRzyErRy+QV5bEkZYn1gWgCFgOfAmOBLwEr37YoNBey6q9V1g0qYypXrsyvv/5K9erVadeuHYcOHXJ1S0IIK0goepmdZ3bio/OxfqAFKAc8CbwG3A0kABdKPkVeUR4bj2+0vnYZYzAYmDJlCsOHD+eOO+7g119/dXVLQogSklD0Mkmnkigy23CArgG4Cwjh0p+aRkAwcKrkU5hUE2uOrrG+dhk1bNgw5s2bx4ABA5gwYYK86C9EGSCh6GU2n9xMnimv9BNlA+eBStYN231md+lrlyGdOnVi48aNzJw5k8GDB1NQUODqloQQtyCh6GXO5Z4r/SRmYAHQAqtDMdfk2Pci3VGdOnXYsGED2dnZdO7cmVOnrFheCyGcSkLRy5T6VQEL8AOgBR6wYbjqna8q+Pv7M2/ePB544AGioqLYsmWLq1sSQtyAhKKX8Tf42z5YBZYAOcAjXApGKxm03rtHqEaj4Y033mDSpEk88MADzJ4929UtCSH+QULRyzSv0tz29wSXAWlADKC3bYo6wXVsG+hBevXqxerVq3nrrbd45ZVXMJvNrm5JCHGZhKKXaVOjDX766zcH/1cXgSTgNDAOeO/yx07rpulQu4P1tT1Q06ZNSUxMJCkpiR49enDx4kVXtySEQHa08TppOWnU/LQmheZCp9fWFGronN2Zl+55iS5dutzw5A5vU1RURGxsLMuXL2fJkiU0atTI1S0J4dVkpehlKvlXokmlJi6pbfA1cHftuxk/fjxVq1alR48eTJ06lZMnT7qkH3eg1+uZOHEir7zyCh06dOCnn35ydUtCeDVZKXqhubvnMmTpELIKs5xWU9EoPBzxMHH94gC4cOECv/zyC0uXLuWXX36hbt269OjRgx49etCyZctbHo7sqdavX0///v0ZMWIEL7/8MhqNxtUtCeF1JBS9UKG5kCrjqnAx33n3sfz0fqx9ci2R1SOv+z2TycT69etZunQpS5cuJTs7mwcffJAePXp43WXW48eP06tXL8LDw5k2bRpGo9HVLQnhVbzvx3GBQWvgiwe+wF9fitczrOCj9aF7WPcbBiKATqejU6dOjBs3jgMHDrB69WoaN27slZdZa9Wqxe+//47FYqFjx46cOHHC1S0J4VVkpeilVFWl25xurPprFUUWG/ZCtUKIbwiHXzhMiDHE6rG3uszaqlUrj73EqKoqH330ERMnTmT+/Pm0a9fO1S0J4RUkFL3YmewzNJnchPS8dIedrWjUGVn4yELub3B/qefyxsusP/74I4MGDeLDDz9k0KBBrm5HCI8noejl9qbtpf2M9mQWZNo9GI06I5MfnMyTLZ6067xXpKSksGzZMpYuXUpSUhKdOnWiR48ePPjgg9SoUcMhNV1h37599OzZkwceeIBx48ah03nuIc1CuJqEomD/uf10nNmRzIJMCsylP8VBgwZfnS9f9/ya6KbRdujw33n6ZdYLFy4QExOD2Wxm7ty5lC9f3tUtCeGRJBQFABfzL/Lsj8+y+MBicotsP8nCT+9HneA6JPRPIKJShB07LLkbXWbt3r073bt3L9OXWc1mM6+++iqLFi1i8eLFNGnimvdNhfBkEoriGj8f/JnhPw/ndPZpcotyS3xJNdAQiKJReO3O1xjVfpTt+6s6gKddZv3222+JjY1l+vTp9OzZ09XtCOFRJBTFdVRVZdOJTXyy8RN+OfQLFtWCXqsn35SP2WJG0Sj4aH1AAwWmAlpUbcGo9qPo1biX25+C4SmXWRMTE+nTpw/Dhg3j9ddfLzN9C+HuJBTFLamqyrGMYySdSuLoxaMUmAvQK3oq+lWkVbVWhFcKd6tVoTXK+mXW1NRUevfuTWhoKDNnzsTf3znvnQphC1VVsVjyUdVCNBoDiuLrlj/MSSgKcVlKSgpLly5l2bJl11xm7d69O9WrV3d1ezeUn5/PM888w86dO1m0aBGhoaGubkkIAFTVwoULq0hP/4WMjHXk5OzBYilAo9ECFjQaHX5+4QQFdaB8+fsoX77r5d9zLQlFIW6gLF1mVVWVCRMm8NFHHzF37lw6duzo6paEFzOZMjl1ahrHj3+C2ZyF2ZwLWG4xQoNWG4BG40PNmi9So8b/oddXcFa713cjoSjErZWVy6wrVqxgwIABvPPOOzzzzDOubkd4ofT05ezb9zhmcw4WS57V4zUaXxTFh8aNZ1CpUl8HdFiCHiQUhbCOO19mPXjwID179qRz58589tln6PV6l/YjvIPFUsCBA0+TlvYDFovtr3RdoSh+hIR0ITz8e3S6ADt0WHISikKUwj8vs9arV4/u3bu79DJrZmYmjz32GJmZmcyfP59KlSqVar4rD0hYLAUoigFFMbrV5WPhWmZzLsnJ95Kdvd2m1eHNaDQ++PmF0aLFOvT6YLvN+691JRSFsA93usxqNpt54403iIuLY9GiRTRv3rzEY1XVwsWLqzl//ucbPiABWvz8GhMUdOflByQeQCmjTyCL0rFYCklOvpesrEQslny7z6/RGPDzC6dVq/Votc55ulpCUQgHcYfLrPHx8QwfPpwpU6bQt++t79GYTFlXPSCRacUDEgZq1nyB6tWfxWCoaNf+hXs7fPg1Tp6cZJdLpjejKL5UrhxD48ZfO6zG1SQUhXACV15m3bZtG71792bgwIG8/fbbKMr1x6imp69k375HMZtzbfoGd+kBCQONGk2lUqWH5fKqF8jK2sb27Xfa9ZLpzSiKH7fdtpSQkLsdXktCUQgnKyoqYsOGDdddZu3Rowd33323Qy6znjlzhr59+1KpUiW+/fZbAgMDgUuXvw4ceIa0tHl2e0AiOLgzERFx6HTlSj2fcE+qamHz5kbk5x9yWk29vgrt2h1DURy7a5aEohAu5qzLrIWFhTz33HNs2rSJxYsXExpajZ077ycra6vdH5AwGuvRsuUf6PVymocnSk9fyZ49fTCbs51WU6sNJCxsKlWqOPbkHQlFIdyIoy+zqqrK5MmTGTv2HWbPro5Wu9+BD0iE0bLlRqc/Ui8cLzn5Xi5c+NXpdQMCWhAZud2hNSQUhXBTRUVFrF+/vviEj6svs3bp0gWj0Wjz3KtXD6CwcDY+PnZs+B80Gl8qV+5PePi3jisinK6w8CwbN9ZGVW07e/XECRg8GDp1gtdft26sohiJjNyBn1+YTbVLVMNhMwshSkWv19O5c2fGjRvHgQMHWL16NWFhYXzyySdUqVKFHj16MHXqVFJTU62aNzs7Ga12gUMDEUBV80lLW0B6+grHFhJOlZm5GUWx/Q/PZ59B48a2jtaSmbnR5tolIaEoRBkRFhZGbGwsq1ev5ujRozz66KOsWbOGpk2bEhkZydtvv01SUhK3uvijqip79kQ75JLpjVgsuezb9xhms3PqCcfLzEzEbM6xaeyqVeDvD61a2VbbYskmI2ODbYNLSEJRiDIoJCSEmJgYvv/+e86cOcO4cePIzs7m0UcfpWbNmjzzzDMsW7aMvLxrH6C5eHENhYUnoISHR9uDxZJPWlqC0+oJx8rMXA+YrR6XkwMzZ8Jzz5W2vqwUhRC3YM1l1uPHP7b5p3xbmc3ZHDv2oVNrCscpKkq3adzXX8MDD0Apdx3EZMoo3QT/Qh60EcKDXf006x9//MSMGZno9db/J5+ZCR9/DFu3QlAQPP003HNPyccrih+tWyfi79/E6trCdqqqUlRURF5eHnl5eeTn5xf/9Y0+L8nXREevoFIl617FOHQI3n0Xpk0DvR5mzYKTJ61/0AbAYKhB+/YnrB9YQrJhoRAe7Mpl1piYGM6eXcbevdGA9SvFzz4DnQ5++OHSN7jRo6F+fahbt6QzaMjI2OjVoaiqKgUFBSUKHlvC6mZjFEXBaDQWf/j6+pb48woVKlz3+yEhOwHrXtrfsQPOnIFHHrn0eV4eWCxw9ChMnWrdP0dHv7wvoSiEl8jN3Q4UWj0uLw/Wrbt0+ctohNtug/btYeVKGDq0ZHNYLDlkZKynevWnra7vCBaLhfz8fKeE05XP8/Pz0ev1JQ6nf/5auXLlrAq0K5/rdPb9Nr9v3xLOnLEuFLt3h7uv2qFt7lw4fRpeesn6+kZjQ+sHWUFCUQgvkZGxHiiyetyJE6DVQq1af/9a/fqQnGzdPFlZm2/462az2eagsXVMYWEhPj4+Nq2eLq2WQqwe4+Pjg1artfqfv7sJCrqTtLQFVm0L6Ot76eMKoxEMBgi28kQojUZPcHBn6wZZSUJRCC9RVHTOpnF5efDP7Vj9/SHXyq1ST506SHh4+HVhZTKZbL68FxAQQMWKFa1acV0JKNm03DaBga0vHyNmuyeftG2cohgJDIwsVe1/I6EohNew/jF6uPRT/T8DMDf3+qD8N8HB5ViwYMF1YWUwGCSgypCAgBZoND5AltNrq6qZoKA7HVpDXskQwksoim3bwtWsCWbzpcuoVxw6BHXqWDePwRBAREQEdevWpWrVqgQFBcmKrQzSaLTUrPkiGo3vv3+xXevqqVZtMFqt7dsbloSEohBews8vwqZxRiN06HDpxeu8PNi1CzZsgHvvtXae+jbVF+6nevWhOPtnGY1GS40aLzi8joSiEF4iKOgOFMXfprEjRkBBAfTpc+l9sxEjrHkdA0BHcHAnm2oL92MwVKZmzZdQFPuf/XkjiuJL5cqP4efXwOG15OV9IbxEdvZOtm+/w6ln4F2h0QTQtOlcKlR4wOm1hWNYLIX8/nt9zOYTKA5eXun1VWjb9pBTjiGTlaIQXsLfv6nNK8XSysvLpk+f/zJx4kROnz7tkh6EfX377feMGpUNOPa4FUUx0qTJXKedyymhKISX0GiUy5e8HPugwvV0hIYOYfTo/5KUlER4eDhdunRh+vTppKfbto+mcJ2CggL+7//+j/fff59Zs/6gefNFDvszpShGGjWa4dRL73L5VAgvUlR0no0bazrt6Ci49I2tdett+PtfOkQvPz+fn376ifj4eFasWEGHDh2Ijo6mZ8+eBAQ4ZzUgbHPixAn69etHtWrVmDVrFkFBQQCkp69g9+4+WCx5gMUOlTQoipHGjWdRuXJ/O8xXcrJSFMKL6PUVqFXrVac9IKHR+FKp0sPFgQjg6+tLnz59mDdvHsePHyc6Opq4uDhq1KjBww8/zMKFC8nPl/MX3c2aNWuIioqiZ8+eLFiwoDgQAcqXv4/IyB0EBLQo9SV6RfHDaAyjVatNTg9EkJWiEF7HYiliy5bbyMtLwdHnKur1lS4/IFHuX782PT2dBQsWEB8fz/bt23nooYeIjo6mS5cu6PV6h/Ypbk5VVcaPH8/HH3/Md999x723eBdHVS2cODGRI0feAixWPdSlKAGASq1arxAaOhpFcc2/cwlFIbxQdvYutm273ar9K62lKEZuu20ZISF3//sX/8OpU6dISEggLi6Ow4cP07dvX6Kjo+nQoQOKox91FMWys7N56qmnOHz4MAsWLCA0NLRE4yyWQtLSfuD48Y/IydmFovhhsRShqn8feq3R+KAoPlgseRiNDahV6xUqV37E4S/n/xsJRSG8VHr6r+ze3dMhwagoRsLCplC16hOlnuuvv/5i7ty5xMfHc+7cOR5++GFiYmKIjIyU3XAc6MCBA/Tp04fbb7+dL774Al9f23awMZtzyc5OJisriYKC45jNuWi1fhgM1QgMjCQgoIXTniwtCQlFIbzYhQur2LXrocsP3ti2N+q1NCiKL40afU2VKtF2mO9a+/btIz4+nri4OCwWC9HR0URHR9O0aVO71/JmixYtYujQobz77rsMGTLEq374kFAUwsvl5f3J3r3R5OTsxWKx/gDiKwoKFIKD69OkyXwCAprZscPrqarK9u3biYuLY+7cuQQFBRUHZP36sp2crcxmM2+88QazZ89m/vz5REVFubolp5NQFEKgqhZOnvyCv/56EzBjNpf8BIQrD0isXBlMvXpvMWjQEIf1eSMWi4WNGzcSFxdHQkICoaGhxMTE8PDDD1OjRg2n9lKWnTt3jkcffRSTyUR8fDyVK1d2dUsuIaEohChmsRRy7twijh37kJycnSiKH7m5mfhctWnJ1Q9I+PrWp3btl6lcOZpt2/bQs2dP9u/fT7ly//60qSOYTCZWr15NXFwcixYtolmzZkRHR9OvXz8qVqzokp7KgqSkJPr27csjjzzCe++9h07nvacKSigKIW7IbM4jLW0jL7zQlfffH4nFkoei+F5+QKL15QckAq8ZM2jQICpXrsyHH37ooq7/VlBQwPLly4mLi+Pnn3+mXbt2xMTE0KtXL5eFtjv6+uuvefXVV5kyZQp9+/Z1dTsuJ6EohLipnTt3EhMTw549e0r09adOneK2225j48aNNGzY0MHdlVxOTg5Lly4lLi6ONWvWcM899xAdHU337t0xGl37CsCtmEzZZGdvJysricLCk5jN+Wi1vvj41CQgoHWpntwsKCjghRdeYO3atSxcuJDw8HA7d182SSgKIW5q8eLFTJs2jWXLlpV4zIcffsiGDRtYvHixAzuz3YULF1i0aBFxcXEkJibSvXt3YmJiuPfeezEYDK5u7/IKfR7Hjn1EXl7K5Xf8ClDVguKvURRfNBoDFksufn6NqVXrFSpV6o9WW7LXJo4fP06/fv2oWbMmM2fOlJXzVeQtWCHETf3111/Ute7gREaMGMGePXtYsWKFg7oqnZCQEAYNGsSKFSs4cOAA7dq144MPPqB69eoMHTqUVatWYTbb4/UU61gsJo4eHcuGDZU5ePB5cnP3oqomzObMawLx0tfmX/51Ezk5uzl48Fk2bKjMsWMfoqq37n3VqlVERUXRp08f5s+fL4H4D7JSFELc1IsvvkhoaCgjR460atySJUsYPXo0O3bsKDNbtB07dox58+YRFxdHampq8SYBbdu2dfh7ejk5e9iz52Hy84+W6rUYRfHHaKxHRMS8a/abhUuvsYwbN45PPvmEOXPm0KVLl9K27ZFkpSiEuClbVooAPXr0oEaNGkyZMsUBXTlG7dq1GTVqFElJSaxdu5YKFSowaNAg6tWrx+jRo0lOTsYRa4i0tEUkJUWRm7uvVIEIYLHkkJOzh6Sk1pw79/cl76ysLB5++GHmzZtHYmKiBOItyEpRCHFTt912G9999x0tWrSweuyePXu466672Lt3b5l9HUJVVXbu3El8fDzx8fH4+voSExNDdHQ0YWFhpZ7/7Nn57N//xOUjl+xLUYxERMRz7lwYffr04Y477mDSpEk2b9fmLSQUhRA3pKoqgYGBnDx58ppjgqzxwgsvYDKZmDx5sp27cz5VVdm8eTNxcXHMmzeP6tWrF28SULt2bavny8jYQHLyPQ4JxCtU1cB//mPkqafG8fTTTzusjieRUBRC3FBaWhqNGzfm/PnzNs+Rnp5OeHg4K1eupFkzx2795kxms5m1a9cSHx/PDz/8QOPGjYmJiaFfv35UqVKlBONz2by5IYWFqQ7vVaOpwp13Hinxk6neTu4pCiFuyNb7iVcrX748b731FiNGjHDI/ThX0Wq13H333UydOpXU1FRGjx7Nxo0badSoEffddx9ff/01Fy9evOn4w4dHYTJdcEqvGk0mf/452im1PIGEohDihuwRigBDhw4lLS2NhQsX2qEr92MwGHjwwQeZPXs2qampDBkyhB9//JHQ0FB69uxJfHw8OTl/P0CTn3+U06dnOvSy6dUsljxOnZpCQcFJp9Qr6yQUhRA3ZK9Q1Ol0TJgwgdjYWPLz8+3Qmfvy8/Ojf//+LFiwgGPHjtG3b1+++eYbatSoQUxMDIsXL+bo0c9QVYtT+1JVlZMnv3RqzbJKQlEIcUP2CkWALl260LJlS8aPH2+X+cqCoKAgnnjiCX7++WcOHTpEp06dmDjxEw4f/hRVLXRqL6paQGrqF1gsRU6tWxZJKAohbsieoQgUvzh+8qT3XcarWLEiw4YNY8GC/xEQEPjvA25i1SoYOBC6dYPHHoOdO0s+VlUtZGVttbm2t5BQFELc0J9//mnXUKxXrx7PPPMMo0d770MfWVlJNq8St26FqVPh1Vfhxx9hwgSoVq3k4y2WIrKykmyq7U0kFIUQ1zGbzRw/fpzQ0FC7zjt69Gh+++03Nm3aZNd5y4qLF9det49pSc2aBQMGQEQEKApUqnTpo6RUNY+MjHU21fYmEopCiOucPHmSihUr2n33k8DAQN5//31efPFFLBbnPmziDvLyUmwaZzbDgQOQkXHpsmn//vDZZ1BgZb7m5u63qb43kVAUQlzH3vcTr/b4448DMHv2bIfM784sFtuevr1wAUwmWLsWJk6E6dPh4EH47jtr69u2SvUmEopCiOs4MhQVRWHixImMHj2arKwsh9RwXzqbRvn4XPr/3r2hQgUICrq0Wty82bp5NBqtTfW9iYSiEOI6jgxFgLZt23LPPfcwduxYh9VwRzpdsE3jAgMv3T+8+gQrW06z0ulCbKrvTSQUhRDXcXQoArz//vtMmzaNw4cPO7SOOzCZTCQnJ3P8eDlsvZXatSssXHjpUmpWFsyfD+3aWTODQlDQHbYV9yISikKI6zgjFKtXr05sbCyjRo1yaB1nU1WVv/76i7lz5xIbG0uHDh0IDg4mOjqa5OQiVNXHpnmfeAIaNbr0BOrAgdCgAVy+PVsiWm0A5cq1tam2N5FTMoQQ16lZsybr16+3+ysZ/5Sfn09ERARTp07lnnvucWgtR0lLS2PLli0kJiaSmJjIli1bMBgMREVFFX9ERkYSFBREXt4RtmwJt/mBm9LQaHxp2/Ygvr41nV67LLHtrq8QosxTVZX8/L/IykoiMzORwsITWCyFgIH77juFn99OCgt9MRj+/SgkW/n6+vLJJ58wYsQIduzYgU7n3t+ScnNz2bZtW3EAJiYmcv78edq0aUNUVBRDhw5l2rRp1KhR44bjjcY6+Ps3Iysr0cmdQ7lybSQQS0BWikJ4mYKC06SmTuHkyc+xWPLQaHSYzdnA3ze7TCbw8SmHxVKAj08NatV6hSpVHkOnC7B7P6qqcs8999CnTx+ee+45u89vK5PJxN69e68JwJSUFJo2bXrNKjAsLAxFKfmdqLS0hezfPxCz2XlP3mq1gURExFGhwoNOq1lWSSgK4SVMpkwOHhzO2bNz0Wg0Vl3CUxR/QKV27dHUrv0aimLfFd2uXbvo0qUL+/bto0KFCnaduyRUVeXIkSPXBOD27dupVasWUVFRxSvB5s2b4+Nj2z3BKywWE5s21aGw0Hl7wPr4hHL77YfllYwSkFAUwgukp69g377HMJuzS3U/S1H88fUNpUmTBPz9I+zYITz33HMoisKkSZPsOu+NnDt37pr7gImJiej1etq2bVu8AmzdujXBwba9QvFvMjLWk5x8r1POVFQUIy1arKFcuSiH1/IEEopCeLijR8dy9Oh7WCy5dppRg6IYadJkPhUqdLPTnHD+/HnCw8NZtWoVTZs2tdu8V98HvBKE586dIzIy8prLoDe7D+goKSnPOfywYUUxUr36MBo08J4ju0pLQlEID3bkyDscO/ahHQPxb38H4wN2m3PSpEksXryYlStXorHh7XRH3Qd0BLM5nx07OpCdvcvmTcJvRaPxJTCwFS1arEJRSnfJ15tIKArhoU6fnkNKylCHBOIViuJHq1YbCQhoZpf5ioqKaNGiBWPHjqVnz563/FpVVTl69Oh19wFr1KhxTQDa4z6go5hMmezYcRe5uXvt+pqGovji79+M5s1/c8jDUZ5MQlEID1RQkEpiYqPLT5U6kgajsSFt2uxGUfR2mXHlypUMGzaMvXv3XhNm/7wPuGXLFnQ6XfF9wDZt2hAZGemw+4COYjbnsm/fQNLTf7LLDzCK4kfFig/RqNFMtFr7nnLiDSQUhfAwqqqSnHwPFy+uA0wOr6coftSsOZJ69f5ntzm7d+9OrVq1CAsLKw5Bd7gP6Ejnzi1h//4nsVjybbrPqChGFMVIePh3dr2k7W0kFIXwMBcv/sHOnV2xWHKcVlNRfGnXLhW93voNp81m83X3AQ8cOEBhYSGPP/44d911F1FRUTRq1Mjl9wEdrajoIqmpUzlxYjwWS+7llf6tvkVr0Gr90WoDqFkzlurVh6DTBTmrXY8koSiEh9m1qyfnzy/l1t9M7UtR/Khb93/UqjXyll9nzX3At956i9OnTzNr1izn/E24EVW1cOHCStLTl3Px4u/k5u7BYilEo1FQVQuK4oO/fxOCgjpSvvz9hIR0QaPx7B8YnEVCUQgPUlh4lo0bQ1FV5++taTBUp127E9c8NXr+/Pnr3gfUarXXvA94s/uAWVlZNGrUiEWLFhEV5d3v2KmqiqoWYrEUoCg+aDQGm57OFf9OQlEID3LmzBxSUobZ9IDNiPkvwb0AAAldSURBVBGwdy9oL296UqkSfPttyccrih9a7dds2XKqOADT0tKuuQ/Ypk0batSoUeJv6LNmzWLKlCls2LDB4y+dCvcgoSiEB0lJeZ7U1MnYcul0xAi491540MbtMXNz4Ycf6uHj07U4BEt7H9BisdC2bVtefPFFHrfmnCQhbOTeW9ILIaySkfEHzryXeDU/Pw2vvtqdhg0/s9uciqIwceJE+vfvT69evQgIkHfuhGPJ9QghPEhBwYlSjZ82DXr2hOefhx07rB2tkpu7r1T1b6Rdu3Z07tyZDz74wO5zC/FPcvlUCA/y++9BmM2ZNo3duxfq1AGdDlatgokTL4WkNa8CBgV1oGXLdTbVv5UTJ07QvHlztm7dSt26de0+vxBXyEpRCA9SmsfyIyLAzw8MBujaFZo2hc2bra1vn11t/qlmzZq89NJLvPzyyw6ZX4grJBSF8CA6nf22ONNowNrrSAZDFbvV/6fY2Fi2bt3K6tWrHVZDCAlFITxIQECkTeOysyExEQoLwWyGlSth506w5vVARTESFHSnTfVLwmg0Mm7cOEaMGIHJ5Pjt64R3klAUwoMEB3dEUazfBNpkgq+/hl69Lj1os3Ah/O9/UKtWyefQaPQEBra2urY1+vbtS0hICNOnT3doHeG95EEbITxIVtYOtm+/06n7nl6hKEbuuOM8Wq3RoXWSk5O577772L9/PyEh1u+1KsStyEpRCA8SGNgCH5+aLqispXLlGIcHIkDz5s3p06cPb7/9tsNrCe8jK0UhPMypUzM5ePAFLBZHn6X4N0Ux0qpVIgEBTZ1SLy0tjYiICNauXUtERIRTagrvICtFITxM5crRTlmxXaHR6AgMjHJaIAJUqlSJMWPGMGLECOTnemFPEopCeBit1kh4+BwUxc8p9TQaH8LDrdg53E6effZZjh8/zrJly5xeW3guCUUhPFD58vdSqVI/m55EtYai+NOgwXh8fWs7tM6N6PV6JkyYwMiRIykoKHB6feGZJBSF8FBhYV/i59cYjcbHIfMrih+VKvWjWrUhDpm/JO6//34aN27MxIkTXdaD8CzyoI0QHsxkymD79k7k5h6w68HDiuJHxYq9CQ//Bo1Ga7d5bZGSkkL79u3ZvXs3VatWdWkvouyTUBTCw5nNOezf/xTnzy/FYskt5WwaFMWXWrVepU6dN93m9PeXX36Z9PR0ZsyY4epWRBknoSiElzh//if27RuAxZJvUzhqtQEYDDVo0mQeAQHNHNCh7TIyMmjcuDFLly4lMvL6re5UVSU//ygm0wVU1YxWa8TXty5arXMeRhJlh4SiEF7EZMri9OlvOH78Y0ymdMzmfODm+4hqNP/f3v2FSFUFcBz/nXN3x9nZGV1t0xZ1NfFPrcUKxfZQlEQgUdFmFIXUc2QFRaQIUfgSPQQKZVjqU1AQglQgiv2R7C/9k1YQDRGz1nXF2WHGXXd27j097O0hyHJmd+7s2f1+3s/53af97Z17/sySMVaZTJc6Ozepvb1X1tbnJoyJ2r17t/bs2aMjR47IGKPh4d/U3/+u8vlD8T2PRsb8fa+6UxSNKJXqUC53mxYs2KBrrrlf1nLv+kxHKQIzkHNOhcIRDQ19oaGhwyqVjioMC3IulDHNam5uVy53q9ra7tK8eevU2jr1N8iHYaienh5t2bJO119/WKXST3IulHNj/zs2CHIyplkLFz6nxYtfUFNTLoEnxlREKQKYFsbG8vr66/UaGTmsdLq2P2vWphUEs9XV9b7mzr17kp8QPqAUAXhvaOhL9fU9qDAclnMT37NobYsWLHhSK1e+1fDVtUgWpQjAaxcvHlRf30OTsLL2n6zNaO7ce7R69V6+Nc4gbN4H4K1C4Zu6FKIkRdGw8vlDOn78Cc5XnUEoRQBeqlSK6ut7sC6F+LcoGtaFCx9rYOC9umVgaqEUAXjp5MlnVakU654TRZd08uTTGh3tr3sWGo9SBOCdQuFbDQ5+OKlH1/2XMBzViRNPJZKFxqIUAXjnzJnXFEUjCSaOKZ8/qNHRPxPMRCNQigC8Ui4P6OLFg5KSXfzinNMff7ydaCaSRykC8Mr58x/UdBD5uXPS5s3SAw9I69dL27dLYXj1450bVX//O1Xnwi+UIgCv5POf1vTT6bZtUlubtHevtGuXdPSotG9fdXNUKkMqlwerzoY/KEUAXikWf6hpXH+/tHatlEpJ8+ZJPT3S6dPVzWFti4rFH2vKhx8oRQDeCMPLKpfP1zT24Yelzz6TLl+WBgel774bL8ZqRNGwLl36taZ8+IGziwB4IwxLMqZJzlXxMTDW3S198ol0331SFEnr1kl33FHdHM6NqVIpVJ0Nf/CmCMAjrqZFNlEkbdok3XmntH//+LfEYlHaubOWZ6i+kOEPShGAN6xtkXNXvhT5SopFaWBA6u0d/6Y4Z450773jP6FWJ1AQcNfidEYpAvBGU1O2plKaM0fq6JA++mh8G0apJB04IC1bVt08QdCqTOaGqvPhD0oRgFey2e6axm3dKn3//fjb4oYNUhBIGzdWN4dzFeVyt9SUDz+w0AaAV9ra1qpQ+ErOjVU1bvny8b2KE2GM1axZnRObBFMab4oAvDJ//mMyphH/zwe69tpHa1roA39QigC8ksmsUmvrzYnnWpvSokXPJ56LZFGKALzT2blZ1rYmmGiUyXQpm70pwUw0AqUIwDvt7b3KZrsT+xnV2rRWrdqVSBYai1IE4B1jjLq63pcxs+qeZW1Gixa9oFxuTd2z0HiUIgAvpdOdWrlyh6zN1C3DmJRaWlZo6dJX6paBqYVSBOCt6657UkuXvlqXYjQmpXR6idas+VzWNk/6/JiajHMu2eurAWCSnT27Q6dOvVjTPYv/xtqMMpkb1d19SM3NbZMyJ/xAKQKYForFX3Ts2CMql/9UFA3XOIuRtWktWfKyOjtfkjHBpD4jpj5KEcC0EUVlnTnzun7//Q1JocKwdFXjjEnJGKvZs2/XihVvqrWV801nKkoRwLQTRWO6cGGfzp7dplLpZ0kmvoexIslJsjImUBQNK5Xq0Pz5j2vhwmeUTi9u8JOj0ShFANOac5FGRk6pVPpFlcqQnKsoCFrU0rJC2Wy3giDJQwAw1VGKAADE2JIBAECMUgQAIEYpAgAQoxQBAIhRigAAxChFAABilCIAADFKEQCAGKUIAECMUgQAIEYpAgAQoxQBAIhRigAAxP4CFbmhaac9TskAAAAASUVORK5CYII=\n",
"text/plain": [
""
]
@@ -176,14 +176,14 @@
"outputs": [],
"source": [
"# 自定义GCN层函数\n",
- "def gcn_layer(gw, feature, hidden_size, name, activation):\n",
+ "def gcn_layer(gw, nfeat, efeat, hidden_size, name, activation):\n",
" # gw是一个GraphWrapper;feature是节点的特征向量。\n",
" \n",
" # 定义message函数,\n",
" def send_func(src_feat, dst_feat, edge_feat): \n",
" # 注意: 这里三个参数是固定的,虽然我们只用到了第一个参数。\n",
" # 在本教程中,我们直接返回源节点的特征向量作为message。用户也可以自定义message函数的内容。\n",
- " return src_feat['h']\n",
+ " return src_feat['h'] * edge_feat['e']\n",
"\n",
" # 定义reduce函数,参数feat其实是从message函数那里获得的。\n",
" def recv_func(feat):\n",
@@ -192,7 +192,7 @@
" return fluid.layers.sequence_pool(feat, pool_type='sum')\n",
"\n",
" # send函数触发message函数,发送消息,并将返回消息。\n",
- " msg = gw.send(send_func, nfeat_list=[('h', feature)])\n",
+ " msg = gw.send(send_func, nfeat_list=[('h', nfeat)], efeat_list=[('e', efeat)])\n",
" # recv函数接收消息,并触发reduce函数,对消息进行处理。\n",
" output = gw.recv(msg, recv_func) \n",
" # 以activation为激活函数的全连接输出层。\n",
@@ -211,21 +211,14 @@
"cell_type": "code",
"execution_count": 7,
"metadata": {},
- "outputs": [
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "/Users/huangzhengjie/Workspace/baidu/nlp-gnn/pgl/pgl/utils/paddle_helper.py:48: UserWarning: Your paddle version is less than 1.5 gather may be slower.\n",
- " warnings.warn(\"Your paddle version is less than 1.5\"\n"
- ]
- }
- ],
+ "outputs": [],
"source": [
"# 第一层GCN将特征向量从16维映射到8维,激活函数使用relu。\n",
- "output = gcn_layer(gw, gw.node_feat['feature'], hidden_size=8, name='gcn_layer_1', activation='relu')\n",
+ "output = gcn_layer(gw, gw.node_feat['feature'], gw.edge_feat['edge_feature'], \n",
+ " hidden_size=8, name='gcn_layer_1', activation='relu')\n",
"# 第二层GCN将特征向量从8维映射导2维,对应我们的二分类。不使用激活函数。\n",
- "output = gcn_layer(gw, output, hidden_size=1, name='gcn_layer_2', activation=None)"
+ "output = gcn_layer(gw, output, gw.edge_feat['edge_feature'], \n",
+ " hidden_size=1, name='gcn_layer_2', activation=None)"
]
},
{
@@ -268,36 +261,36 @@
"name": "stdout",
"output_type": "stream",
"text": [
- "Epoch 0 | Loss: 0.712927\n",
- "Epoch 1 | Loss: 0.665513\n",
- "Epoch 2 | Loss: 0.625431\n",
- "Epoch 3 | Loss: 0.591621\n",
- "Epoch 4 | Loss: 0.563292\n",
- "Epoch 5 | Loss: 0.539553\n",
- "Epoch 6 | Loss: 0.519604\n",
- "Epoch 7 | Loss: 0.502797\n",
- "Epoch 8 | Loss: 0.488625\n",
- "Epoch 9 | Loss: 0.476778\n",
- "Epoch 10 | Loss: 0.466839\n",
- "Epoch 11 | Loss: 0.458521\n",
- "Epoch 12 | Loss: 0.451596\n",
- "Epoch 13 | Loss: 0.445855\n",
- "Epoch 14 | Loss: 0.441109\n",
- "Epoch 15 | Loss: 0.437194\n",
- "Epoch 16 | Loss: 0.434423\n",
- "Epoch 17 | Loss: 0.432126\n",
- "Epoch 18 | Loss: 0.430175\n",
- "Epoch 19 | Loss: 0.428500\n",
- "Epoch 20 | Loss: 0.427060\n",
- "Epoch 21 | Loss: 0.425821\n",
- "Epoch 22 | Loss: 0.424751\n",
- "Epoch 23 | Loss: 0.423827\n",
- "Epoch 24 | Loss: 0.423026\n",
- "Epoch 25 | Loss: 0.422332\n",
- "Epoch 26 | Loss: 0.421729\n",
- "Epoch 27 | Loss: 0.421204\n",
- "Epoch 28 | Loss: 0.420746\n",
- "Epoch 29 | Loss: 0.420345\n"
+ "Epoch 0 | Loss: 0.629119\n",
+ "Epoch 1 | Loss: 0.614591\n",
+ "Epoch 2 | Loss: 0.602767\n",
+ "Epoch 3 | Loss: 0.593824\n",
+ "Epoch 4 | Loss: 0.587454\n",
+ "Epoch 5 | Loss: 0.581866\n",
+ "Epoch 6 | Loss: 0.576963\n",
+ "Epoch 7 | Loss: 0.572337\n",
+ "Epoch 8 | Loss: 0.567905\n",
+ "Epoch 9 | Loss: 0.563806\n",
+ "Epoch 10 | Loss: 0.559831\n",
+ "Epoch 11 | Loss: 0.555969\n",
+ "Epoch 12 | Loss: 0.552211\n",
+ "Epoch 13 | Loss: 0.548553\n",
+ "Epoch 14 | Loss: 0.544992\n",
+ "Epoch 15 | Loss: 0.541524\n",
+ "Epoch 16 | Loss: 0.538145\n",
+ "Epoch 17 | Loss: 0.534852\n",
+ "Epoch 18 | Loss: 0.531641\n",
+ "Epoch 19 | Loss: 0.528505\n",
+ "Epoch 20 | Loss: 0.525442\n",
+ "Epoch 21 | Loss: 0.522446\n",
+ "Epoch 22 | Loss: 0.519513\n",
+ "Epoch 23 | Loss: 0.516638\n",
+ "Epoch 24 | Loss: 0.513819\n",
+ "Epoch 25 | Loss: 0.511053\n",
+ "Epoch 26 | Loss: 0.508336\n",
+ "Epoch 27 | Loss: 0.505668\n",
+ "Epoch 28 | Loss: 0.503046\n",
+ "Epoch 29 | Loss: 0.500472\n"
]
}
],
@@ -349,9 +342,9 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.6.7"
+ "version": "3.6.5"
}
},
"nbformat": 4,
- "nbformat_minor": 2
+ "nbformat_minor": 4
}