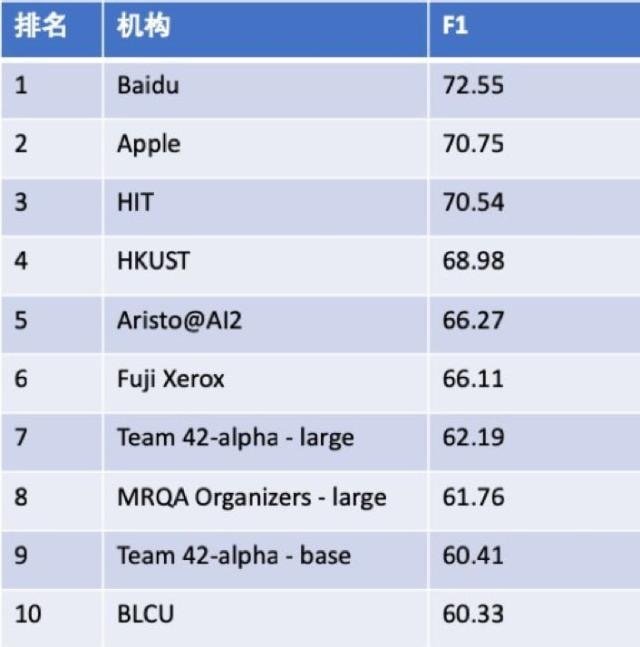
MRQA2019 排行榜
除了降低NLP研究成本以外,PaddlePALM已被应用于“百度搜索引擎”,有效地提高了用户查询的理解准确度和挖掘出的答案质量,具备高可靠性和高训练/推理性能。 #### 特点: - **易于使用**:使用PALM, *8个步骤*即可实现一个典型的NLP任务。此外,模型主干网络、数据集读取工具和任务输出层已经解耦,只需对代码进行相当小的更改,就可以将任何组件替换为其他候选组件。 - **支持多任务学习**:*6个步骤*即可实现多任务学习任务。 - **支持大规模任务和预训练**:可自动利用多gpu加速训练和推理。集群上的分布式训练需要较少代码。 - **流行的NLP骨架和预训练模型**:内置多种最先进的通用模型架构和预训练模型(如BERT、ERNIE、RoBERTa等)。 - **易于定制**:支持任何组件的定制开发(例如:主干网络,任务头,读取工具和优化器)与预定义组件的复用,这给了开发人员高度的灵活性和效率,以适应不同的NLP场景。 你可以很容易地用较少的代码复现出很好的性能,涵盖了大多数NLP任务,如分类、匹配、序列标记、阅读理解、对话理解等等。更多细节可以在`examples`中找到。| 数据集
|
MSRA-NER (SIGHAN2006) |
CMRC2018 | |||||
|---|---|---|---|---|---|---|---|
|
评价标准
|
|
f1-score
|
|
f1-score
|
f1-score
|
em
|
f1-score
|
|
test
|
test
|
test
|
dev
|
||||
| ERNIE Base | 95.8 | 95.8 | 86.2 | 82.2 | 99.2 | 64.3 | 85.2 |

PALM架构图
PaddlePALM是一个设计良好的高级NLP框架。基于PaddlePALM的轻量级代码可以高效实现**监督学习、非监督/自监督学习、多任务学习和迁移学习**。在PaddlePALM架构中有三层,从下到上依次是component层、trainer层、high-level trainer层。 在组件层,PaddlePALM提供了6个 **解耦的**组件来实现NLP任务。每个组件包含丰富的预定义类和一个基类。预定义类是针对典型的NLP任务的,而基类是帮助用户开发一个新类(基于预定义类或基类)。 训练器层是用选定的构件建立计算图,进行训练和预测。该层描述了训练策略、模型保存和加载、评估和预测过程。一个训练器只能处理一个任务。 高级训练器层用于复杂的学习和推理策略,如多任务学习。您可以添加辅助任务来训练健壮的NLP模型(提高模型的测试集和领域外的性能),或者联合训练多个相关任务来获得每个任务的更高性能。 | 模块 | 描述 | | - | - | | **paddlepalm** | 基于PaddlePaddle框架的high-level NLP预训练和多任务学习框架。 | | **paddlepalm.reader** | 预置的任务数据集读取与预处理工具。| | **paddlepalm.backbone** | 预置的主干网络,如BERT, ERNIE, RoBERTa。| | **paddlepalm.head** | 预置的任务输出层。| | **paddlepalm.lr_sched** | 预置的学习率规划策略。| | **paddlepalm.optimizer** | 预置的优化器。| | **paddlepalm.downloader** | 预训练模型管理与下载模块。| | **paddlepalm.Trainer** | 任务训练/预测单元。训练器用于建立计算图,管理训练和评估过程,实现模型/检查点保存和pretrain_model/检查点加载等。| | **paddlepalm.MultiHeadTrainer** | 完成多任务训练/预测的模块。一个MultiHeadTrainer建立在几个Trainer的基础上。实现了模型主干网络跨任务复用、多任务学习、多任务推理等。| ## 安装 PaddlePALM 支持 python2 和 python3, linux 和 windows, CPU 和 GPU。安装PaddlePALM的首选方法是通过`pip`。只需运行以下命令: ```bash pip install paddlepalm ``` ### 通过源码安装 ```shell git clone https://github.com/PaddlePaddle/PALM.git cd PALM && python setup.py install ``` ### 库依赖 - Python >= 2.7 - cuda >= 9.0 - cudnn >= 7.0 - PaddlePaddle >= 1.7.0 (请参考[安装指南](http://www.paddlepaddle.org/#quick-start)进行安装) ### 下载预训练模型 我们提供了许多预训练的模型来初始化模型主干网络参数。用预先训练好的模型训练大的NLP模型,如12层Transformer,实际上比用随机初始化的参数更有效。要查看所有可用的预训练模型并下载,请在python解释器中运行以下代码(在shell中输入命令`python`): ```python >>> from paddlepalm import downloader >>> downloader.ls('pretrain') Available pretrain items: => RoBERTa-zh-base => RoBERTa-zh-large => ERNIE-v2-en-base => ERNIE-v2-en-large => XLNet-cased-base => XLNet-cased-large => ERNIE-v1-zh-base => ERNIE-v1-zh-base-max-len-512 => BERT-en-uncased-large-whole-word-masking => BERT-en-cased-large-whole-word-masking => BERT-en-uncased-base => BERT-en-uncased-large => BERT-en-cased-base => BERT-en-cased-large => BERT-multilingual-uncased-base => BERT-multilingual-cased-base => BERT-zh-base >>> downloader.download('pretrain', 'BERT-en-uncased-base', './pretrain_models') ... ``` ## 使用 #### 快速开始 8个步骤开始一个典型的NLP训练任务。 1. 使用`paddlepalm.reader` 为数据集加载和输入特征生成创建一个`reader`,然后调用`reader.load_data`方法加载训练数据。 2. 使用`paddlepalm.load_data`创建一个模型*主干网络*来提取文本特征(例如,上下文单词嵌入,句子嵌入)。 3. 通过`reader.register_with`将`reader`注册到主干网络上。在这一步之后,reader能够使用主干网络产生的输入特征。 4. 使用`paddlepalm.head`。创建一个任务*head*,可以为训练提供任务损失,为模型推理提供预测结果。 5. 使用`paddlepalm.Trainer`创建一个任务`Trainer`,然后通过`Trainer.build_forward`构建包含主干网络和任务头的前向图(在步骤2和步骤4中创建)。 6. 使用`paddlepalm.optimizer`(如果需要,创建`paddlepalm.lr_sched`)来创建一个*优化器*,然后通过`train.build_back`向后构建。 7. 使用`trainer.fit_reader`将准备好的reader和数据(在步骤1中实现)给到trainer。 8. 使用`trainer.load_pretrain`加载预训练模型或使用 `trainer.load_pretrain`加载checkpoint,或不加载任何已训练好的参数,然后使用`trainer.train`进行训练。 更多实现细节请见示例: - [情感分析](https://github.com/PaddlePaddle/PALM/tree/master/examples/classification) - [Quora问题相似度匹配](https://github.com/PaddlePaddle/PALM/tree/master/examples/matching) - [命名实体识别](https://github.com/PaddlePaddle/PALM/tree/master/examples/tagging) - [类SQuAD机器阅读理解](https://github.com/PaddlePaddle/PALM/tree/master/examples/mrc) #### 多任务学习 多任务学习模式下运行: 1. 重复创建组件(每个任务按照上述第1~5步执行)。 2. 创建空的`Trainer`(每个`Trainer`对应一个任务),并通过它们创建一个`MultiHeadTrainer`。 3. 使用`multi_head_trainer.build_forward`构建多任务前向图。 4. 使用`paddlepalm.optimizer`(如果需要,创建`paddlepalm.lr_sched`)来创建一个*optimizer*,然后通过` multi_head_trainer.build_backward`创建反向。 5. 使用`multi_head_trainer.fit_readers`将所有准备好的读取器和数据放入`multi_head_trainer`中。 6. 使用`multi_head_trainer.load_pretrain`加载预训练模型或使用 `multi_head_trainer.load_pretrain`加载checkpoint,或不加载任何已经训练好的参数,然后使用`multi_head_trainer.train`进行训练。 multi_head_trainer的保存/加载和预测操作与trainer相同。 更多实现`multi_head_trainer`的细节,请见 - [ATIS: 对话意图识别和插槽填充的联合训练](https://github.com/PaddlePaddle/PALM/tree/master/examples/multi-task) #### 设置saver 在训练时保存 models/checkpoints 和 logs,调用 `trainer.set_saver` 方法。更多实现细节见[这里](https://github.com/PaddlePaddle/PALM/tree/master/examples)。 #### 评估/预测 训练结束后进行预测和评价, 只需创建额外的reader, backbone和head(重复上面1~4步骤),注意创建时需设`phase='predict'`。 然后使用trainer的`predict`方法进行预测(不需创建额外的trainer)。更多实现细节请见[这里](https://github.com/PaddlePaddle/PALM/tree/master/examples/predict)。 #### 使用多GPU 如果您的环境中存在多个GPU,您可以通过环境变量控制这些GPU的数量和索引[CUDA_VISIBLE_DEVICES](https://devblogs.nvidia.com/cuda-pro-tip-control-gpu-visibility-cuda_visible_devices/)。例如,如果您的环境中有4个gpu,索引为0、1、2、3,那么您可以运行以下命令来只使用GPU2: ```shell CUDA_VISIBLE_DEVICES=2 python run.py ``` 多GPU的使用需要 `,`作为分隔。例如,使用GPU2和GPU3,运行以下命令: ```shell CUDA_VISIBLE_DEVICES=2,3 python run.py ``` 在多GPU模式下,PaddlePALM会自动将每个batch数据分配到可用的GPU上。例如,如果`batch_size`设置为64,并且有4个GPU可以用于PaddlePALM,那么每个GPU中的batch_size实际上是64/4=16。因此,**当使用多个GPU时,您需要确保batch_size可以被暴露给PALM的GPU数量整除**。 ## 许可证书 此向导由[PaddlePaddle](https://github.com/PaddlePaddle/Paddle)贡献,受[Apache-2.0 license](https://github.com/PaddlePaddle/models/blob/develop/LICENSE)许可认证。