diff --git a/doc/fluid/advanced_guide/performance_improving/amp/amp.md b/doc/fluid/advanced_guide/performance_improving/amp/amp.md
new file mode 100644
index 0000000000000000000000000000000000000000..3a41a447f78cf3bc119abb7754292edbbc23050a
--- /dev/null
+++ b/doc/fluid/advanced_guide/performance_improving/amp/amp.md
@@ -0,0 +1,171 @@
+# 混合精度训练最佳实践
+
+Automatic Mixed Precision (AMP) 是一种自动混合使用半精度(FP16)和单精度(FP32)来加速模型训练的技术。AMP技术可方便用户快速将使用 FP32 训练的模型修改为使用混合精度训练,并通过黑白名单和动态`loss scaling`来保证训练时的数值稳定性进而避免梯度Infinite或者NaN(Not a Number)。借力于新一代NVIDIA GPU中Tensor Cores的计算性能,PaddlePaddle AMP技术在ResNet50、Transformer等模型上训练速度相对于FP32训练加速比可达1.5~2.9。
+
+### 半精度浮点类型FP16
+
+如图 1 所示,半精度(Float Precision16,FP16)是一种相对较新的浮点类型,在计算机中使用2字节(16位)存储。在IEEE 754-2008标准中,它亦被称作binary16。与计算中常用的单精度(FP32)和双精度(FP64)类型相比,FP16更适于在精度要求不高的场景中使用。
+
+
+ 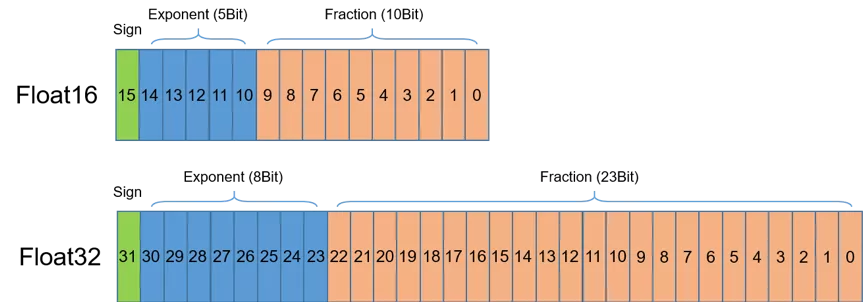 + 图 1. 半精度和单精度数据示意图
+
+
+### 英伟达GPU的FP16算力
+
+在使用相同的超参数下,混合精度训练使用半精度浮点(FP16)和单精度(FP32)浮点即可达到与使用纯单精度训练相同的准确率,并可加速模型的训练速度。这主要得益于英伟达推出的Volta及Turing架构GPU在使用FP16计算时具有如下特点:
+
+* FP16可降低一半的内存带宽和存储需求,这使得在相同的硬件条件下研究人员可使用更大更复杂的模型以及更大的batch size大小。
+* FP16可以充分利用英伟达Volta及Turing架构GPU提供的Tensor Cores技术。在相同的GPU硬件上,Tensor Cores的FP16计算吞吐量是FP32的8倍。
+
+### PaddlePaddle AMP功能——牛刀小试
+
+如前文所述,使用FP16数据类型可能会造成计算精度上的损失,但对深度学习领域而言,并不是所有计算都要求很高的精度,一些局部的精度损失对最终训练效果影响很微弱,却能使吞吐和训练速度带来大幅提升。因此,混合精度计算的需求应运而生。具体而言,训练过程中将一些对精度损失不敏感且能利用Tensor Cores进行加速的运算使用半精度处理,而对精度损失敏感部分依然保持FP32计算精度,用以最大限度提升访存和计算效率。
+
+为了避免对每个具体模型人工地去设计和尝试精度混合的方法,PaddlePaadle框架提供自动混合精度训练(AMP)功能,解放"炼丹师"的双手。在PaddlePaddle中使用AMP训练是一件十分容易的事情,用户只需要增加一行代码即可将原有的FP32训练转变为AMP训练。下面以`MNIST`为例介绍PaddlePaddle AMP功能的使用示例。
+
+**MNIST网络定义**
+
+```python
+import paddle.fluid as fluid
+
+def MNIST(data, class_dim):
+ conv1 = fluid.layers.conv2d(data, 16, 5, 1, act=None, data_format='NHWC')
+ bn1 = fluid.layers.batch_norm(conv1, act='relu', data_layout='NHWC')
+ pool1 = fluid.layers.pool2d(bn1, 2, 'max', 2, data_format='NHWC')
+ conv2 = fluid.layers.conv2d(pool1, 64, 5, 1, act=None, data_format='NHWC')
+ bn2 = fluid.layers.batch_norm(conv2, act='relu', data_layout='NHWC')
+ pool2 = fluid.layers.pool2d(bn2, 2, 'max', 2, data_format='NHWC')
+ fc1 = fluid.layers.fc(pool2, size=64, act='relu')
+ fc2 = fluid.layers.fc(fc1, size=class_dim, act='softmax')
+ return fc2
+```
+
+针对CV(Computer Vision)类模型组网,为获得更高的训练性能需要注意如下三点:
+
+* `conv2d`、`batch_norm`以及`pool2d`等需要将数据布局设置为`NHWC`,这样有助于使用TensorCore技术加速计算过程1。
+* Tensor Cores要求在使用FP16加速卷积运算时conv2d的输入/输出通道数为8的倍数2,因此设计网络时推荐将conv2d层的输入/输出通道数设置为8的倍数。
+* Tensor Cores要求在使用FP16加速矩阵乘运算时矩阵行数和列数均为8的倍数3,因此设计网络时推荐将fc层的size参数设置为8的倍数。
+
+
+**FP32 训练**
+
+为了训练 MNIST 网络,还需要定义损失函数来更新权重参数,此处使用的优化器是SGDOptimizer。为了简化说明,这里省略了迭代训练的相关代码,仅体现损失函数及优化器定义相关的内容。
+
+```python
+import paddle
+import numpy as np
+
+data = fluid.layers.data(
+ name='image', shape=[None, 28, 28, 1], dtype='float32')
+label = fluid.layers.data(name='label', shape=[None, 1], dtype='int64')
+
+out = MNIST(data, class_dim=10)
+loss = fluid.layers.cross_entropy(input=out, label=label)
+avg_loss = fluid.layers.mean(loss)
+
+sgd = fluid.optimizer.SGDOptimizer(learning_rate=1e-3)
+sgd.minimize(avg_loss)
+```
+
+**AMP训练**
+
+与FP32训练相比,用户仅需使用PaddlePaddle提供的`fluid.contrib.mixed_precision.decorate` 函数将原来的优化器SGDOptimizer进行封装,然后使用封装后的优化器(mp_sgd)更新参数梯度即可完成向AMP训练的转换,代码如下所示:
+
+```python
+sgd = SGDOptimizer(learning_rate=1e-3)
+# 此处只需要使用fluid.contrib.mixed_precision.decorate将sgd封装成AMP训练所需的
+# 优化器mp_sgd,并使用mp_sgd.minimize(avg_loss)代替原来的sgd.minimize(avg_loss)语句即可。
+mp_sgd = fluid.contrib.mixed_precision.decorator.decorate(sgd)
+mp_sgd.minimize(avg_loss)
+```
+
+运行上述混合精度训练python脚本时为得到更好的执行性能可配置如下环境参数,并保证cudnn版本在7.4.1及以上。
+
+```shell
+export FLAGS_conv_workspace_size_limit=1024 # MB,根据所使用的GPU显存容量及模型特点设置数值,值越大越有可能选择到更快的卷积算法
+export FLAGS_cudnn_exhaustive_search=1 # 使用穷举搜索方法来选择快速卷积算法
+export FLAGS_cudnn_batchnorm_spatial_persistent=1 # 用于触发batch_norm和relu的融合
+```
+
+上述即为最简单的PaddlePaddle AMP功能使用方法。ResNet50模型的AMP训练示例可[点击此处](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/README.md#%E6%B7%B7%E5%90%88%E7%B2%BE%E5%BA%A6%E8%AE%AD%E7%BB%83)查看,其他模型使用PaddlePaddle AMP的方法也与此类似。若AMP训练过程中出现连续的loss nan等不收敛现象,可尝试使用[check nan inf工具](https://www.paddlepaddle.org.cn/documentation/docs/zh/advanced_guide/flags/check_nan_inf_cn.html#span-id-speed-span)进行调试。
+
+
+### PaddlePaddle AMP功能——进阶使用
+
+上一小节所述均为默认AMP训练行为,用户当然也可以改变一些默认的参数设置来满足特定的模型训练场景需求。接下来的章节将介绍PaddlePaddle AMP功能使用中用户可配置的参数行为,即进阶使用技巧。
+
+#### 自定义黑白名单
+
+PaddlePaddle AMP功能实现中根据FP16数据类型计算稳定性和加速效果在框架内部定义了算子(Op)的黑白名单。具体来说,将对FP16计算友好且能利用Tensor Cores的Op归类于白名单,将使用FP16计算会导致数值不稳定的Op归类于黑名单,将对FP16计算没有多少影响的Op归类于灰名单。然而,框架开发人员不可能考虑到所有的网络模型情况,尤其是那些特殊场景中使用到的模型。用户可以在使用`fluid.contrib.mixed_precision.decorate` 函数时通过指定自定义的黑白名单列表来改变默认的FP16计算行为。
+
+```python
+sgd = SGDOptimizer(learning_rate=1e-3)
+# list1是白名单op列表,list2是黑名单op列表,list3是黑名单var_name列表(凡是以这些黑名单var_name为输入或输出的op均会被视为黑名单op)
+amp_list = AutoMixedPrecisionLists(custom_white_list=list1, custom_black_list=list2, custom_black_varnames=list3)
+mp_sgd = fluid.contrib.mixed_precision.decorator.decorate(sgd, amp_list)
+mp_sgd.minimize(avg_loss)
+```
+
+#### 自动loss scaling
+
+为了避免梯度Infinite或者NAN,PaddlePaddle AMP功能支持根据训练过程中梯度的数值自动调整loss scale值。用户在使用`fluid.contrib.mixed_precision.decorate` 函数时也可以改变与loss scaling相关的参数设置,示例如下:
+
+```python
+sgd = SGDOptimizer(learning_rate=1e-3)
+mp_sgd = fluid.contrib.mixed_precision.decorator.decorate(sgd,
+ amp_lists=None,
+ init_loss_scaling=2**8,
+ incr_every_n_steps=500,
+ decr_every_n_nan_or_inf=4,
+ incr_ratio=2.0,
+ decr_ratio=0.5,
+ use_dynamic_loss_scaling=True)
+mp_sgd.minimize(avg_loss)
+```
+
+`init_loss_scaling `、`incr_every_n_steps` 以及`decr_every_n_nan_or_inf`等参数控制着自动loss scaling的行为。它们仅当 `use_dynamic_loss_scaling`设置为True时有效。下面详述这些参数的意义:
+
+* init_loss_scaling(float):初始loss scaling值。
+* incr_every_n_steps(int):每经过incr_every_n_steps个连续的正常梯度值才会增大loss scaling值。
+* decr_every_n_nan_or_inf(int):每经过decr_every_n_nan_or_inf个连续的无效梯度值(nan或者inf)才会减小loss scaling值。
+* incr_ratio(float):每次增大loss scaling值的扩增倍数,其为大于1的浮点数。
+* decr_ratio(float):每次减小loss scaling值的比例系数,其为小于1的浮点数。
+
+### 多卡GPU训练的优化
+
+PaddlePaddle AMP功能对多卡GPU训练进行了深度优化。如图 2 所示,优化之前的参数梯度更新特点:梯度计算时虽然使用的是FP16数据类型,但是不同GPU卡之间的梯度传输数据类型仍为FP32。
+
+
+
+ 图 1. 半精度和单精度数据示意图
+
+
+### 英伟达GPU的FP16算力
+
+在使用相同的超参数下,混合精度训练使用半精度浮点(FP16)和单精度(FP32)浮点即可达到与使用纯单精度训练相同的准确率,并可加速模型的训练速度。这主要得益于英伟达推出的Volta及Turing架构GPU在使用FP16计算时具有如下特点:
+
+* FP16可降低一半的内存带宽和存储需求,这使得在相同的硬件条件下研究人员可使用更大更复杂的模型以及更大的batch size大小。
+* FP16可以充分利用英伟达Volta及Turing架构GPU提供的Tensor Cores技术。在相同的GPU硬件上,Tensor Cores的FP16计算吞吐量是FP32的8倍。
+
+### PaddlePaddle AMP功能——牛刀小试
+
+如前文所述,使用FP16数据类型可能会造成计算精度上的损失,但对深度学习领域而言,并不是所有计算都要求很高的精度,一些局部的精度损失对最终训练效果影响很微弱,却能使吞吐和训练速度带来大幅提升。因此,混合精度计算的需求应运而生。具体而言,训练过程中将一些对精度损失不敏感且能利用Tensor Cores进行加速的运算使用半精度处理,而对精度损失敏感部分依然保持FP32计算精度,用以最大限度提升访存和计算效率。
+
+为了避免对每个具体模型人工地去设计和尝试精度混合的方法,PaddlePaadle框架提供自动混合精度训练(AMP)功能,解放"炼丹师"的双手。在PaddlePaddle中使用AMP训练是一件十分容易的事情,用户只需要增加一行代码即可将原有的FP32训练转变为AMP训练。下面以`MNIST`为例介绍PaddlePaddle AMP功能的使用示例。
+
+**MNIST网络定义**
+
+```python
+import paddle.fluid as fluid
+
+def MNIST(data, class_dim):
+ conv1 = fluid.layers.conv2d(data, 16, 5, 1, act=None, data_format='NHWC')
+ bn1 = fluid.layers.batch_norm(conv1, act='relu', data_layout='NHWC')
+ pool1 = fluid.layers.pool2d(bn1, 2, 'max', 2, data_format='NHWC')
+ conv2 = fluid.layers.conv2d(pool1, 64, 5, 1, act=None, data_format='NHWC')
+ bn2 = fluid.layers.batch_norm(conv2, act='relu', data_layout='NHWC')
+ pool2 = fluid.layers.pool2d(bn2, 2, 'max', 2, data_format='NHWC')
+ fc1 = fluid.layers.fc(pool2, size=64, act='relu')
+ fc2 = fluid.layers.fc(fc1, size=class_dim, act='softmax')
+ return fc2
+```
+
+针对CV(Computer Vision)类模型组网,为获得更高的训练性能需要注意如下三点:
+
+* `conv2d`、`batch_norm`以及`pool2d`等需要将数据布局设置为`NHWC`,这样有助于使用TensorCore技术加速计算过程1。
+* Tensor Cores要求在使用FP16加速卷积运算时conv2d的输入/输出通道数为8的倍数2,因此设计网络时推荐将conv2d层的输入/输出通道数设置为8的倍数。
+* Tensor Cores要求在使用FP16加速矩阵乘运算时矩阵行数和列数均为8的倍数3,因此设计网络时推荐将fc层的size参数设置为8的倍数。
+
+
+**FP32 训练**
+
+为了训练 MNIST 网络,还需要定义损失函数来更新权重参数,此处使用的优化器是SGDOptimizer。为了简化说明,这里省略了迭代训练的相关代码,仅体现损失函数及优化器定义相关的内容。
+
+```python
+import paddle
+import numpy as np
+
+data = fluid.layers.data(
+ name='image', shape=[None, 28, 28, 1], dtype='float32')
+label = fluid.layers.data(name='label', shape=[None, 1], dtype='int64')
+
+out = MNIST(data, class_dim=10)
+loss = fluid.layers.cross_entropy(input=out, label=label)
+avg_loss = fluid.layers.mean(loss)
+
+sgd = fluid.optimizer.SGDOptimizer(learning_rate=1e-3)
+sgd.minimize(avg_loss)
+```
+
+**AMP训练**
+
+与FP32训练相比,用户仅需使用PaddlePaddle提供的`fluid.contrib.mixed_precision.decorate` 函数将原来的优化器SGDOptimizer进行封装,然后使用封装后的优化器(mp_sgd)更新参数梯度即可完成向AMP训练的转换,代码如下所示:
+
+```python
+sgd = SGDOptimizer(learning_rate=1e-3)
+# 此处只需要使用fluid.contrib.mixed_precision.decorate将sgd封装成AMP训练所需的
+# 优化器mp_sgd,并使用mp_sgd.minimize(avg_loss)代替原来的sgd.minimize(avg_loss)语句即可。
+mp_sgd = fluid.contrib.mixed_precision.decorator.decorate(sgd)
+mp_sgd.minimize(avg_loss)
+```
+
+运行上述混合精度训练python脚本时为得到更好的执行性能可配置如下环境参数,并保证cudnn版本在7.4.1及以上。
+
+```shell
+export FLAGS_conv_workspace_size_limit=1024 # MB,根据所使用的GPU显存容量及模型特点设置数值,值越大越有可能选择到更快的卷积算法
+export FLAGS_cudnn_exhaustive_search=1 # 使用穷举搜索方法来选择快速卷积算法
+export FLAGS_cudnn_batchnorm_spatial_persistent=1 # 用于触发batch_norm和relu的融合
+```
+
+上述即为最简单的PaddlePaddle AMP功能使用方法。ResNet50模型的AMP训练示例可[点击此处](https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/README.md#%E6%B7%B7%E5%90%88%E7%B2%BE%E5%BA%A6%E8%AE%AD%E7%BB%83)查看,其他模型使用PaddlePaddle AMP的方法也与此类似。若AMP训练过程中出现连续的loss nan等不收敛现象,可尝试使用[check nan inf工具](https://www.paddlepaddle.org.cn/documentation/docs/zh/advanced_guide/flags/check_nan_inf_cn.html#span-id-speed-span)进行调试。
+
+
+### PaddlePaddle AMP功能——进阶使用
+
+上一小节所述均为默认AMP训练行为,用户当然也可以改变一些默认的参数设置来满足特定的模型训练场景需求。接下来的章节将介绍PaddlePaddle AMP功能使用中用户可配置的参数行为,即进阶使用技巧。
+
+#### 自定义黑白名单
+
+PaddlePaddle AMP功能实现中根据FP16数据类型计算稳定性和加速效果在框架内部定义了算子(Op)的黑白名单。具体来说,将对FP16计算友好且能利用Tensor Cores的Op归类于白名单,将使用FP16计算会导致数值不稳定的Op归类于黑名单,将对FP16计算没有多少影响的Op归类于灰名单。然而,框架开发人员不可能考虑到所有的网络模型情况,尤其是那些特殊场景中使用到的模型。用户可以在使用`fluid.contrib.mixed_precision.decorate` 函数时通过指定自定义的黑白名单列表来改变默认的FP16计算行为。
+
+```python
+sgd = SGDOptimizer(learning_rate=1e-3)
+# list1是白名单op列表,list2是黑名单op列表,list3是黑名单var_name列表(凡是以这些黑名单var_name为输入或输出的op均会被视为黑名单op)
+amp_list = AutoMixedPrecisionLists(custom_white_list=list1, custom_black_list=list2, custom_black_varnames=list3)
+mp_sgd = fluid.contrib.mixed_precision.decorator.decorate(sgd, amp_list)
+mp_sgd.minimize(avg_loss)
+```
+
+#### 自动loss scaling
+
+为了避免梯度Infinite或者NAN,PaddlePaddle AMP功能支持根据训练过程中梯度的数值自动调整loss scale值。用户在使用`fluid.contrib.mixed_precision.decorate` 函数时也可以改变与loss scaling相关的参数设置,示例如下:
+
+```python
+sgd = SGDOptimizer(learning_rate=1e-3)
+mp_sgd = fluid.contrib.mixed_precision.decorator.decorate(sgd,
+ amp_lists=None,
+ init_loss_scaling=2**8,
+ incr_every_n_steps=500,
+ decr_every_n_nan_or_inf=4,
+ incr_ratio=2.0,
+ decr_ratio=0.5,
+ use_dynamic_loss_scaling=True)
+mp_sgd.minimize(avg_loss)
+```
+
+`init_loss_scaling `、`incr_every_n_steps` 以及`decr_every_n_nan_or_inf`等参数控制着自动loss scaling的行为。它们仅当 `use_dynamic_loss_scaling`设置为True时有效。下面详述这些参数的意义:
+
+* init_loss_scaling(float):初始loss scaling值。
+* incr_every_n_steps(int):每经过incr_every_n_steps个连续的正常梯度值才会增大loss scaling值。
+* decr_every_n_nan_or_inf(int):每经过decr_every_n_nan_or_inf个连续的无效梯度值(nan或者inf)才会减小loss scaling值。
+* incr_ratio(float):每次增大loss scaling值的扩增倍数,其为大于1的浮点数。
+* decr_ratio(float):每次减小loss scaling值的比例系数,其为小于1的浮点数。
+
+### 多卡GPU训练的优化
+
+PaddlePaddle AMP功能对多卡GPU训练进行了深度优化。如图 2 所示,优化之前的参数梯度更新特点:梯度计算时虽然使用的是FP16数据类型,但是不同GPU卡之间的梯度传输数据类型仍为FP32。
+
+
+ 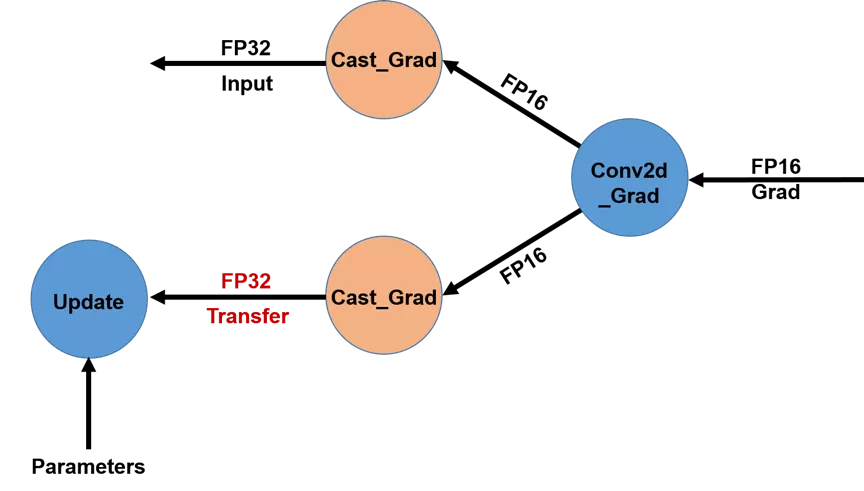 + 图 2. 不同GPU卡之间传输梯度使用FP32数据类型(优化前)
+
+
+为了降低GPU多卡之间的梯度传输带宽,我们将梯度传输提前至`Cast`操作之前,而每个GPU卡在得到对应的FP16梯度后再执行`Cast`操作将其转变为FP32类型,具体操作详见图2。这一优化在训练大模型时对减少带宽占用尤其有效,如多卡训练BERT-Large模型。
+
+
+
+ 图 2. 不同GPU卡之间传输梯度使用FP32数据类型(优化前)
+
+
+为了降低GPU多卡之间的梯度传输带宽,我们将梯度传输提前至`Cast`操作之前,而每个GPU卡在得到对应的FP16梯度后再执行`Cast`操作将其转变为FP32类型,具体操作详见图2。这一优化在训练大模型时对减少带宽占用尤其有效,如多卡训练BERT-Large模型。
+
+
+ 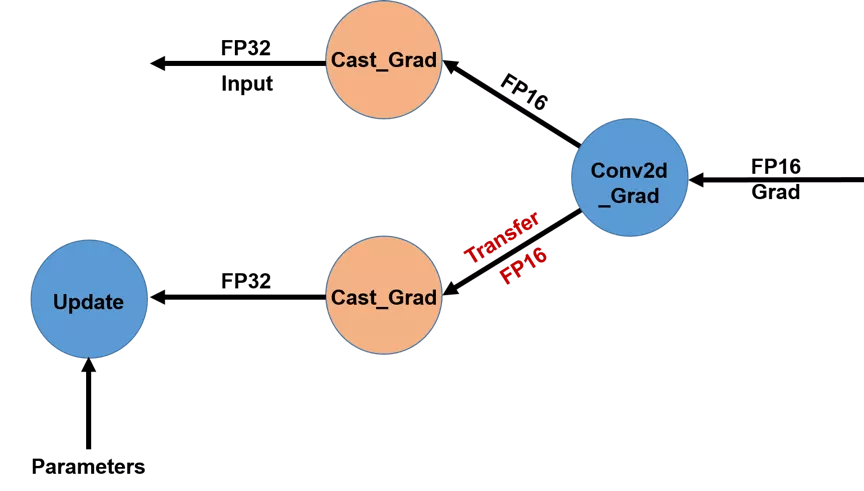 + 图 3. 不同GPU卡之间传输梯度使用FP16数据类型(优化后)
+
+
+### 训练性能对比(AMP VS FP32)
+
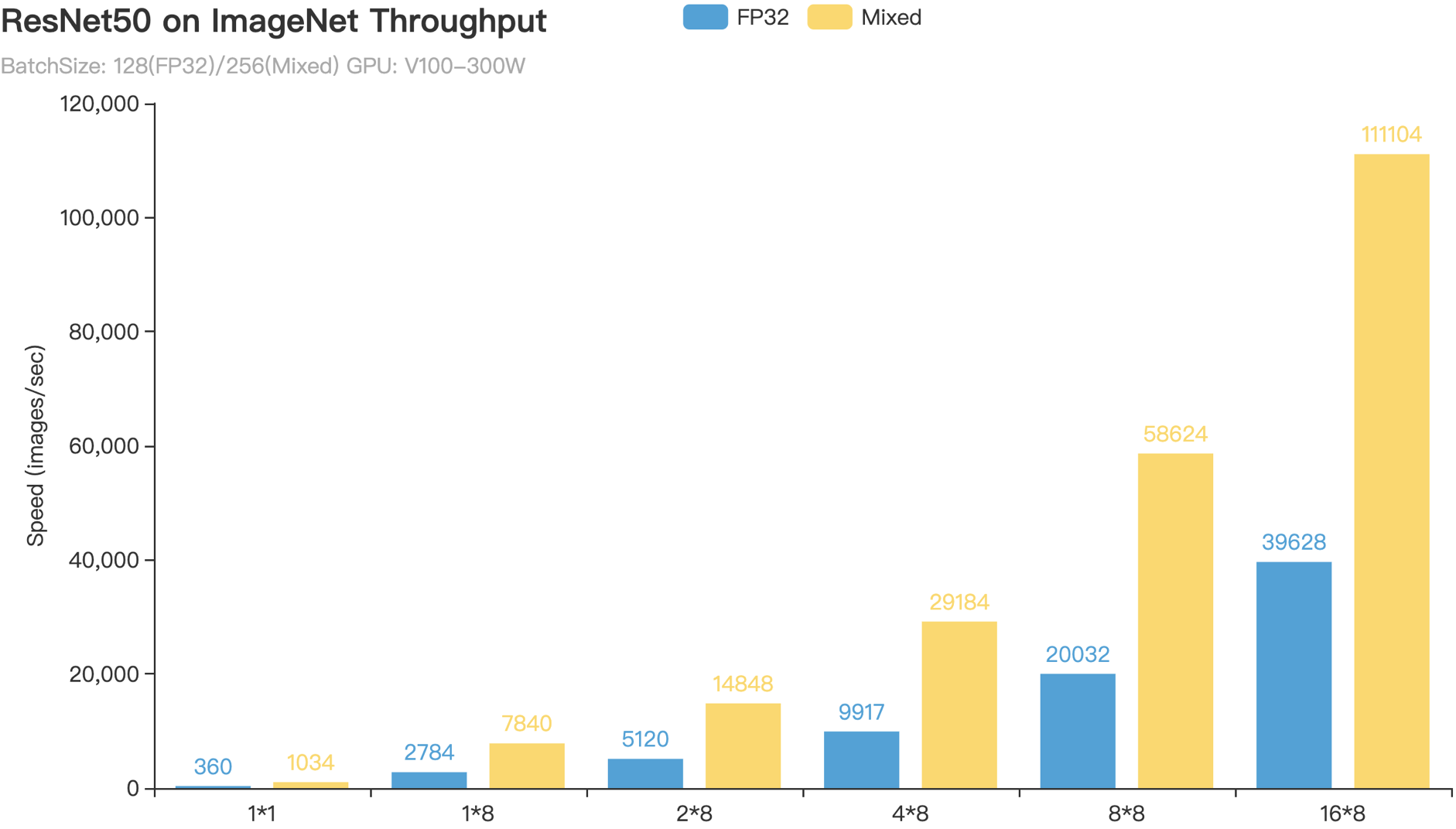
+PaddlePaddle AMP技术在ResNet50、Transformer等模型上训练速度相对于FP32训练上均有可观的加速比,下面是ResNet50和ERNIE Large模型的AMP训练相对于FP32训练的加速效果。
+
+
+ 图 3. 不同GPU卡之间传输梯度使用FP16数据类型(优化后)
+
+
+### 训练性能对比(AMP VS FP32)
+
+PaddlePaddle AMP技术在ResNet50、Transformer等模型上训练速度相对于FP32训练上均有可观的加速比,下面是ResNet50和ERNIE Large模型的AMP训练相对于FP32训练的加速效果。
+
+
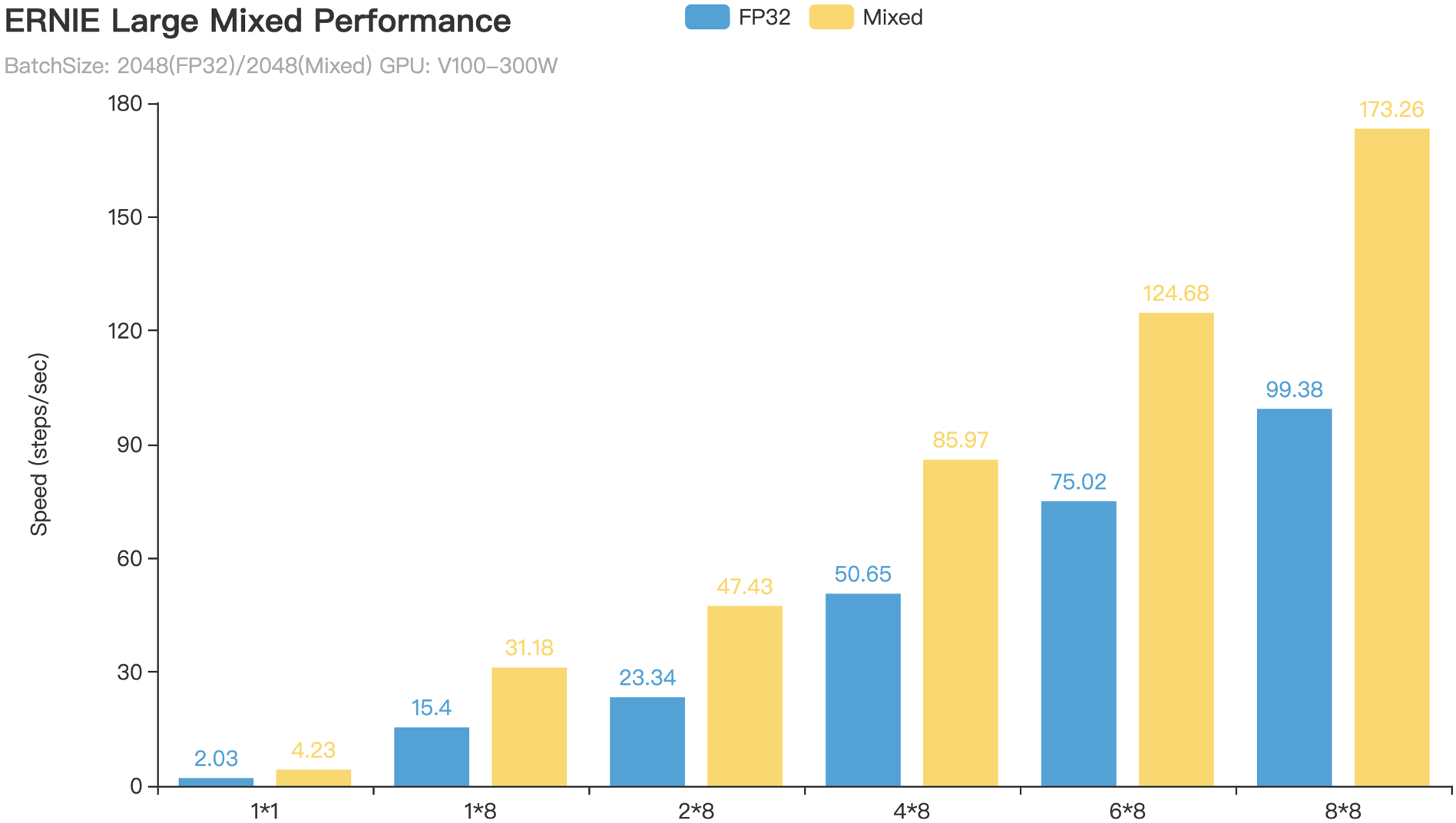
+图 4. Paddle AMP训练加速效果(横坐标为卡数,如8*8代表8机8卡)
+
+  |
+  |
+
+
+
+从图4所示的图表可以看出,ResNet50的AMP训练相对与FP32训练加速比可达$2.8 \times$以上,而ERNIE Large的AMP训练相对与FP32训练加速比亦可达 $1.7 \times -- 2.1 \times$ 。
+
+### 参考文献
+
+* Mixed Precision Training
+* 使用自动混合精度加速 PaddlePaddle 训练
+* Tensor Layouts In Memory: NCHW vs NHWC ↩
+* Channels In And Out Requirements ↩
+* Matrix-Matrix Multiplication Requirements ↩
diff --git a/doc/fluid/advanced_guide/performance_improving/index_cn.rst b/doc/fluid/advanced_guide/performance_improving/index_cn.rst
index a40594d13bf74398518f23ad923900ad1bed81d8..b50f091f8c70328d37c7cf3dc92a5b0f14a08f33 100644
--- a/doc/fluid/advanced_guide/performance_improving/index_cn.rst
+++ b/doc/fluid/advanced_guide/performance_improving/index_cn.rst
@@ -8,6 +8,7 @@
singlenode_training_improving/training_best_practice.rst
singlenode_training_improving/memory_optimize.rst
device_switching/device_switching.md
+ amp/amp.md
multinode_training_improving/cpu_train_best_practice.rst
multinode_training_improving/dist_training_gpu.rst
multinode_training_improving/gpu_training_with_recompute.rst