图3. 扰动图片展示[22]
@@ -139,7 +139,7 @@ ResNet(Residual Network) \[[15](#参考文献)\] 是2015年ImageNet图像分类
由于ImageNet数据集较大,下载和训练较慢,为了方便大家学习,我们使用[CIFAR10]()数据集。CIFAR10数据集包含60,000张32x32的彩色图片,10个类别,每个类包含6,000张。其中50,000张图片作为训练集,10000张作为测试集。图11从每个类别中随机抽取了10张图片,展示了所有的类别。
-
+
图11. CIFAR10数据集[21]
@@ -263,7 +263,7 @@ return tmp
2. 然后连接3组残差模块即下面配置3组 `layer_warp` ,每组采用图 10 左边残差模块组成。
3. 最后对网络做均值池化并返回该层。
-注意:除过第一层卷积层和最后一层全连接层之外,要求三组 `layer_warp` 总的含参层数能够被6整除,即 `resnet_cifar10` 的 depth 要满足 `$(depth - 2) % 6 == 0$` 。
+注意:除过第一层卷积层和最后一层全连接层之外,要求三组 `layer_warp` 总的含参层数能够被6整除,即 `resnet_cifar10` 的 depth 要满足 $(depth - 2) % 6 == 0$ 。
```python
def resnet_cifar10(ipt, depth=32):
diff --git a/source/beginners_guide/basics/label_semantic_roles/index.md b/source/beginners_guide/basics/label_semantic_roles/index.md
index 331c093d784d7c9ba23c571fee4955da3d7be22f..f77bfd1db652393f0f99d9d235a5192c51cf9cd3 100644
--- a/source/beginners_guide/basics/label_semantic_roles/index.md
+++ b/source/beginners_guide/basics/label_semantic_roles/index.md
@@ -1,6 +1,6 @@
# 语义角色标注
-本教程源代码目录在[book/label_semantic_roles](https://github.com/PaddlePaddle/book/tree/develop/07.label_semantic_roles), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/178.html)。
+本教程源代码目录在[book/label_semantic_roles](https://github.com/PaddlePaddle/book/tree/develop/07.label_semantic_roles), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
## 背景介绍
@@ -44,11 +44,11 @@ $$\mbox{[小明]}_{\mbox{Agent}}\mbox{[昨天]}_{\mbox{Time}}\mbox{[晚上]}_{\m
### 栈式循环神经网络(Stacked Recurrent Neural Network)
-深层网络有助于形成层次化特征,网络上层在下层已经学习到的初级特征基础上,形成更复杂的高级特征。尽管LSTM沿时间轴展开后等价于一个非常“深”的前馈网络,但由于LSTM各个时间步参数共享,`$t-1$`时刻状态到`$t$`时刻的映射,始终只经过了一次非线性映射,也就是说单层LSTM对状态转移的建模是 “浅” 的。堆叠多个LSTM单元,令前一个LSTM`$t$`时刻的输出,成为下一个LSTM单元`$t$`时刻的输入,帮助我们构建起一个深层网络,我们把它称为第一个版本的栈式循环神经网络。深层网络提高了模型拟合复杂模式的能力,能够更好地建模跨不同时间步的模式\[[2](#参考文献)\]。
+深层网络有助于形成层次化特征,网络上层在下层已经学习到的初级特征基础上,形成更复杂的高级特征。尽管LSTM沿时间轴展开后等价于一个非常“深”的前馈网络,但由于LSTM各个时间步参数共享,$t-1$时刻状态到$t$时刻的映射,始终只经过了一次非线性映射,也就是说单层LSTM对状态转移的建模是 “浅” 的。堆叠多个LSTM单元,令前一个LSTM$t$时刻的输出,成为下一个LSTM单元$t$时刻的输入,帮助我们构建起一个深层网络,我们把它称为第一个版本的栈式循环神经网络。深层网络提高了模型拟合复杂模式的能力,能够更好地建模跨不同时间步的模式\[[2](#参考文献)\]。
然而,训练一个深层LSTM网络并非易事。纵向堆叠多个LSTM单元可能遇到梯度在纵向深度上传播受阻的问题。通常,堆叠4层LSTM单元可以正常训练,当层数达到4~8层时,会出现性能衰减,这时必须考虑一些新的结构以保证梯度纵向顺畅传播,这是训练深层LSTM网络必须解决的问题。我们可以借鉴LSTM解决 “梯度消失梯度爆炸” 问题的智慧之一:在记忆单元(Memory Cell)这条信息传播的路线上没有非线性映射,当梯度反向传播时既不会衰减、也不会爆炸。因此,深层LSTM模型也可以在纵向上添加一条保证梯度顺畅传播的路径。
-一个LSTM单元完成的运算可以被分为三部分:(1)输入到隐层的映射(input-to-hidden) :每个时间步输入信息`$x$`会首先经过一个矩阵映射,再作为遗忘门,输入门,记忆单元,输出门的输入,注意,这一次映射没有引入非线性激活;(2)隐层到隐层的映射(hidden-to-hidden):这一步是LSTM计算的主体,包括遗忘门,输入门,记忆单元更新,输出门的计算;(3)隐层到输出的映射(hidden-to-output):通常是简单的对隐层向量进行激活。我们在第一个版本的栈式网络的基础上,加入一条新的路径:除上一层LSTM输出之外,将前层LSTM的输入到隐层的映射作为的一个新的输入,同时加入一个线性映射去学习一个新的变换。
+一个LSTM单元完成的运算可以被分为三部分:(1)输入到隐层的映射(input-to-hidden) :每个时间步输入信息$x$会首先经过一个矩阵映射,再作为遗忘门,输入门,记忆单元,输出门的输入,注意,这一次映射没有引入非线性激活;(2)隐层到隐层的映射(hidden-to-hidden):这一步是LSTM计算的主体,包括遗忘门,输入门,记忆单元更新,输出门的计算;(3)隐层到输出的映射(hidden-to-output):通常是简单的对隐层向量进行激活。我们在第一个版本的栈式网络的基础上,加入一条新的路径:除上一层LSTM输出之外,将前层LSTM的输入到隐层的映射作为的一个新的输入,同时加入一个线性映射去学习一个新的变换。
图3是最终得到的栈式循环神经网络结构示意图。
@@ -59,9 +59,9 @@ $$\mbox{[小明]}_{\mbox{Agent}}\mbox{[昨天]}_{\mbox{Time}}\mbox{[晚上]}_{\m
### 双向循环神经网络(Bidirectional Recurrent Neural Network)
-在LSTM中,`$t$`时刻的隐藏层向量编码了到`$t$`时刻为止所有输入的信息,但`$t$`时刻的LSTM可以看到历史,却无法看到未来。在绝大多数自然语言处理任务中,我们几乎总是能拿到整个句子。这种情况下,如果能够像获取历史信息一样,得到未来的信息,对序列学习任务会有很大的帮助。
+在LSTM中,$t$时刻的隐藏层向量编码了到$t$时刻为止所有输入的信息,但$t$时刻的LSTM可以看到历史,却无法看到未来。在绝大多数自然语言处理任务中,我们几乎总是能拿到整个句子。这种情况下,如果能够像获取历史信息一样,得到未来的信息,对序列学习任务会有很大的帮助。
-为了克服这一缺陷,我们可以设计一种双向循环网络单元,它的思想简单且直接:对上一节的栈式循环神经网络进行一个小小的修改,堆叠多个LSTM单元,让每一层LSTM单元分别以:正向、反向、正向 …… 的顺序学习上一层的输出序列。于是,从第2层开始,`$t$`时刻我们的LSTM单元便总是可以看到历史和未来的信息。图4是基于LSTM的双向循环神经网络结构示意图。
+为了克服这一缺陷,我们可以设计一种双向循环网络单元,它的思想简单且直接:对上一节的栈式循环神经网络进行一个小小的修改,堆叠多个LSTM单元,让每一层LSTM单元分别以:正向、反向、正向 …… 的顺序学习上一层的输出序列。于是,从第2层开始,$t$时刻我们的LSTM单元便总是可以看到历史和未来的信息。图4是基于LSTM的双向循环神经网络结构示意图。

@@ -74,7 +74,7 @@ $$\mbox{[小明]}_{\mbox{Agent}}\mbox{[昨天]}_{\mbox{Time}}\mbox{[晚上]}_{\m
使用神经网络模型解决问题的思路通常是:前层网络学习输入的特征表示,网络的最后一层在特征基础上完成最终的任务。在SRL任务中,深层LSTM网络学习输入的特征表示,条件随机场(Conditional Random Filed, CRF)在特征的基础上完成序列标注,处于整个网络的末端。
-CRF是一种概率化结构模型,可以看作是一个概率无向图模型,结点表示随机变量,边表示随机变量之间的概率依赖关系。简单来讲,CRF学习条件概率`$P(X|Y)$`,其中 `$X = (x_1, x_2, ... , x_n)$` 是输入序列,`$Y = (y_1, y_2, ... , y_n)$` 是标记序列;解码过程是给定 `$X$`序列求解令`$P(Y|X)$`最大的`$Y$`序列,即`$Y^* = \mbox{arg max}_{Y} P(Y | X)$`。
+CRF是一种概率化结构模型,可以看作是一个概率无向图模型,结点表示随机变量,边表示随机变量之间的概率依赖关系。简单来讲,CRF学习条件概率$P(X|Y)$,其中 $X = (x_1, x_2, ... , x_n)$ 是输入序列,$Y = (y_1, y_2, ... , y_n)$ 是标记序列;解码过程是给定 $X$序列求解令$P(Y|X)$最大的$Y$序列,即$Y^* = \mbox{arg max}_{Y} P(Y | X)$。
序列标注任务只需要考虑输入和输出都是一个线性序列,并且由于我们只是将输入序列作为条件,不做任何条件独立假设,因此输入序列的元素之间并不存在图结构。综上,在序列标注任务中使用的是如图5所示的定义在链式图上的CRF,称之为线性链条件随机场(Linear Chain Conditional Random Field)。
@@ -83,23 +83,23 @@ CRF是一种概率化结构模型,可以看作是一个概率无向图模型
图5. 序列标注任务中使用的线性链条件随机场
-根据线性链条件随机场上的因子分解定理\[[5](#参考文献)\],在给定观测序列`$X$`时,一个特定标记序列`$Y$`的概率可以定义为:
+根据线性链条件随机场上的因子分解定理\[[5](#参考文献)\],在给定观测序列$X$时,一个特定标记序列$Y$的概率可以定义为:
$$p(Y | X) = \frac{1}{Z(X)} \text{exp}\left(\sum_{i=1}^{n}\left(\sum_{j}\lambda_{j}t_{j} (y_{i - 1}, y_{i}, X, i) + \sum_{k} \mu_k s_k (y_i, X, i)\right)\right)$$
-其中`$Z(X)$`是归一化因子,`$t_j$` 是定义在边上的特征函数,依赖于当前和前一个位置,称为转移特征,表示对于输入序列`$X$`及其标注序列在 `$i$`及`$i - 1$`位置上标记的转移概率。`$s_k$`是定义在结点上的特征函数,称为状态特征,依赖于当前位置,表示对于观察序列`$X$`及其`$i$`位置的标记概率。`$\lambda_j$` 和 `$\mu_k$` 分别是转移特征函数和状态特征函数对应的权值。实际上,`$t$`和`$s$`可以用相同的数学形式表示,再对转移特征和状态特在各个位置`$i$`求和有:`$f_{k}(Y, X) = \sum_{i=1}^{n}f_k({y_{i - 1}, y_i, X, i})$`,把`$f$`统称为特征函数,于是`$P(Y|X)$`可表示为:
+其中$Z(X)$是归一化因子,$t_j$ 是定义在边上的特征函数,依赖于当前和前一个位置,称为转移特征,表示对于输入序列$X$及其标注序列在 $i$及$i - 1$位置上标记的转移概率。$s_k$是定义在结点上的特征函数,称为状态特征,依赖于当前位置,表示对于观察序列$X$及其$i$位置的标记概率。$\lambda_j$ 和 $\mu_k$ 分别是转移特征函数和状态特征函数对应的权值。实际上,$t$和$s$可以用相同的数学形式表示,再对转移特征和状态特在各个位置$i$求和有:$f_{k}(Y, X) = \sum_{i=1}^{n}f_k({y_{i - 1}, y_i, X, i})$,把$f$统称为特征函数,于是$P(Y|X)$可表示为:
$$p(Y|X, W) = \frac{1}{Z(X)}\text{exp}\sum_{k}\omega_{k}f_{k}(Y, X)$$
-`$\omega$`是特征函数对应的权值,是CRF模型要学习的参数。训练时,对于给定的输入序列和对应的标记序列集合`$D = \left[(X_1, Y_1), (X_2 , Y_2) , ... , (X_N, Y_N)\right]$` ,通过正则化的极大似然估计,求解如下优化目标:
+$\omega$是特征函数对应的权值,是CRF模型要学习的参数。训练时,对于给定的输入序列和对应的标记序列集合$D = \left[(X_1, Y_1), (X_2 , Y_2) , ... , (X_N, Y_N)\right]$ ,通过正则化的极大似然估计,求解如下优化目标:
$$\DeclareMathOperator*{\argmax}{arg\,max} L(\lambda, D) = - \text{log}\left(\prod_{m=1}^{N}p(Y_m|X_m, W)\right) + C \frac{1}{2}\lVert W\rVert^{2}$$
-这个优化目标可以通过反向传播算法和整个神经网络一起求解。解码时,对于给定的输入序列`$X$`,通过解码算法(通常有:维特比算法、Beam Search)求令出条件概率`$\bar{P}(Y|X)$`最大的输出序列 `$\bar{Y}$`。
+这个优化目标可以通过反向传播算法和整个神经网络一起求解。解码时,对于给定的输入序列$X$,通过解码算法(通常有:维特比算法、Beam Search)求令出条件概率$\bar{P}(Y|X)$最大的输出序列 $\bar{Y}$。
### 深度双向LSTM(DB-LSTM)SRL模型
-在SRL任务中,输入是 “谓词” 和 “一句话”,目标是从这句话中找到谓词的论元,并标注论元的语义角色。如果一个句子含有`$n$`个谓词,这个句子会被处理`$n$`次。一个最为直接的模型是下面这样:
+在SRL任务中,输入是 “谓词” 和 “一句话”,目标是从这句话中找到谓词的论元,并标注论元的语义角色。如果一个句子含有$n$个谓词,这个句子会被处理$n$次。一个最为直接的模型是下面这样:
1. 构造输入;
- 输入1是谓词,输入2是句子
@@ -110,13 +110,13 @@ $$\DeclareMathOperator*{\argmax}{arg\,max} L(\lambda, D) = - \text{log}\left(\pr
大家可以尝试上面这种方法。这里,我们提出一些改进,引入两个简单但对提高系统性能非常有效的特征:
-- 谓词上下文:上面的方法中,只用到了谓词的词向量表达谓词相关的所有信息,这种方法始终是非常弱的,特别是如果谓词在句子中出现多次,有可能引起一定的歧义。从经验出发,谓词前后若干个词的一个小片段,能够提供更丰富的信息,帮助消解歧义。于是,我们把这样的经验也添加到模型中,为每个谓词同时抽取一个“谓词上下文” 片段,也就是从这个谓词前后各取`$n$`个词构成的一个窗口片段;
+- 谓词上下文:上面的方法中,只用到了谓词的词向量表达谓词相关的所有信息,这种方法始终是非常弱的,特别是如果谓词在句子中出现多次,有可能引起一定的歧义。从经验出发,谓词前后若干个词的一个小片段,能够提供更丰富的信息,帮助消解歧义。于是,我们把这样的经验也添加到模型中,为每个谓词同时抽取一个“谓词上下文” 片段,也就是从这个谓词前后各取$n$个词构成的一个窗口片段;
- 谓词上下文区域标记:为句子中的每一个词引入一个0-1二值变量,表示它们是否在“谓词上下文”片段中;
修改后的模型如下(图6是一个深度为4的模型结构示意图):
1. 构造输入
-- 输入1是句子序列,输入2是谓词序列,输入3是谓词上下文,从句子中抽取这个谓词前后各`$n$`个词,构成谓词上下文,用one-hot方式表示,输入4是谓词上下文区域标记,标记了句子中每一个词是否在谓词上下文中;
+- 输入1是句子序列,输入2是谓词序列,输入3是谓词上下文,从句子中抽取这个谓词前后各$n$个词,构成谓词上下文,用one-hot方式表示,输入4是谓词上下文区域标记,标记了句子中每一个词是否在谓词上下文中;
- 将输入2~3均扩展为和输入1一样长的序列;
2. 输入1~4均通过词表取词向量转换为实向量表示的词向量序列;其中输入1、3共享同一个词表,输入2和4各自独有词表;
3. 第2步的4个词向量序列作为双向LSTM模型的输入;LSTM模型学习输入序列的特征表示,得到新的特性表示序列;
@@ -146,7 +146,7 @@ conll05st-release/
原始数据需要进行数据预处理才能被PaddlePaddle处理,预处理包括下面几个步骤:
1. 将文本序列和标记序列其合并到一条记录中;
-2. 一个句子如果含有`$n$`个谓词,这个句子会被处理`$n$`次,变成`$n$`条独立的训练样本,每个样本一个不同的谓词;
+2. 一个句子如果含有$n$个谓词,这个句子会被处理$n$次,变成$n$条独立的训练样本,每个样本一个不同的谓词;
3. 抽取谓词上下文和构造谓词上下文区域标记;
4. 构造以BIO法表示的标记;
5. 依据词典获取词对应的整数索引。
diff --git a/source/beginners_guide/basics/machine_translation/index.md b/source/beginners_guide/basics/machine_translation/index.md
index 06dc48bdb6860da582587b9e7b6f5ab580173ef3..5225758f349da22b807237b39fb88d156d241dba 100644
--- a/source/beginners_guide/basics/machine_translation/index.md
+++ b/source/beginners_guide/basics/machine_translation/index.md
@@ -1,6 +1,6 @@
# 机器翻译
-本教程源代码目录在[book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/08.machine_translation), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/179.html)。
+本教程源代码目录在[book/machine_translation](https://github.com/PaddlePaddle/book/tree/develop/08.machine_translation), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
## 背景介绍
@@ -41,7 +41,7 @@
我们已经在[语义角色标注](https://github.com/PaddlePaddle/book/blob/develop/07.label_semantic_roles/README.cn.md)一章中介绍了一种双向循环神经网络,这里介绍Bengio团队在论文\[[2](#参考文献),[4](#参考文献)\]中提出的另一种结构。该结构的目的是输入一个序列,得到其在每个时刻的特征表示,即输出的每个时刻都用定长向量表示到该时刻的上下文语义信息。
-具体来说,该双向循环神经网络分别在时间维以顺序和逆序——即前向(forward)和后向(backward)——依次处理输入序列,并将每个时间步RNN的输出拼接成为最终的输出层。这样每个时间步的输出节点,都包含了输入序列中当前时刻完整的过去和未来的上下文信息。下图展示的是一个按时间步展开的双向循环神经网络。该网络包含一个前向和一个后向RNN,其中有六个权重矩阵:输入到前向隐层和后向隐层的权重矩阵(`$W_1, W_3$`),隐层到隐层自己的权重矩阵(`$W_2,W_5$`),前向隐层和后向隐层到输出层的权重矩阵(`$W_4, W_6$`)。注意,该网络的前向隐层和后向隐层之间没有连接。
+具体来说,该双向循环神经网络分别在时间维以顺序和逆序——即前向(forward)和后向(backward)——依次处理输入序列,并将每个时间步RNN的输出拼接成为最终的输出层。这样每个时间步的输出节点,都包含了输入序列中当前时刻完整的过去和未来的上下文信息。下图展示的是一个按时间步展开的双向循环神经网络。该网络包含一个前向和一个后向RNN,其中有六个权重矩阵:输入到前向隐层和后向隐层的权重矩阵($W_1, W_3$),隐层到隐层自己的权重矩阵($W_2,W_5$),前向隐层和后向隐层到输出层的权重矩阵($W_4, W_6$)。注意,该网络的前向隐层和后向隐层之间没有连接。

@@ -60,13 +60,13 @@
编码阶段分为三步:
-1. one-hot vector表示:将源语言句子`$x=\left \{ x_1,x_2,...,x_T \right \}$`的每个词`$x_i$`表示成一个列向量`$w_i\epsilon \left \{ 0,1 \right \}^{\left | V \right |},i=1,2,...,T$`。这个向量`$w_i$`的维度与词汇表大小`$\left | V \right |$` 相同,并且只有一个维度上有值1(该位置对应该词在词汇表中的位置),其余全是0。
+1. one-hot vector表示:将源语言句子$x=\left \{ x_1,x_2,...,x_T \right \}$的每个词$x_i$表示成一个列向量$w_i\epsilon \left \{ 0,1 \right \}^{\left | V \right |},i=1,2,...,T$。这个向量$w_i$的维度与词汇表大小$\left | V \right |$ 相同,并且只有一个维度上有值1(该位置对应该词在词汇表中的位置),其余全是0。
-2. 映射到低维语义空间的词向量:one-hot vector表示存在两个问题,1)生成的向量维度往往很大,容易造成维数灾难;2)难以刻画词与词之间的关系(如语义相似性,也就是无法很好地表达语义)。因此,需再one-hot vector映射到低维的语义空间,由一个固定维度的稠密向量(称为词向量)表示。记映射矩阵为`$C\epsilon R^{K\times \left | V \right |}$`,用`$s_i=Cw_i$`表示第`$i$`个词的词向量,`$K$`为向量维度。
+2. 映射到低维语义空间的词向量:one-hot vector表示存在两个问题,1)生成的向量维度往往很大,容易造成维数灾难;2)难以刻画词与词之间的关系(如语义相似性,也就是无法很好地表达语义)。因此,需再one-hot vector映射到低维的语义空间,由一个固定维度的稠密向量(称为词向量)表示。记映射矩阵为$C\epsilon R^{K\times \left | V \right |}$,用$s_i=Cw_i$表示第$i$个词的词向量,$K$为向量维度。
-3. 用RNN编码源语言词序列:这一过程的计算公式为`$h_i=\varnothing _\theta \left ( h_{i-1}, s_i \right )$`,其中`$h_0$`是一个全零的向量,`$\varnothing _\theta$`是一个非线性激活函数,最后得到的`$\mathbf{h}=\left \{ h_1,..., h_T \right \}$`就是RNN依次读入源语言`$T$`个词的状态编码序列。整句话的向量表示可以采用`$\mathbf{h}$`在最后一个时间步`$T$`的状态编码,或使用时间维上的池化(pooling)结果。
+3. 用RNN编码源语言词序列:这一过程的计算公式为$h_i=\varnothing _\theta \left ( h_{i-1}, s_i \right )$,其中$h_0$是一个全零的向量,$\varnothing _\theta$是一个非线性激活函数,最后得到的$\mathbf{h}=\left \{ h_1,..., h_T \right \}$就是RNN依次读入源语言$T$个词的状态编码序列。整句话的向量表示可以采用$\mathbf{h}$在最后一个时间步$T$的状态编码,或使用时间维上的池化(pooling)结果。
-第3步也可以使用双向循环神经网络实现更复杂的句编码表示,具体可以用双向GRU实现。前向GRU按照词序列`$(x_1,x_2,...,x_T)$`的顺序依次编码源语言端词,并得到一系列隐层状态`$(\overrightarrow{h_1},\overrightarrow{h_2},...,\overrightarrow{h_T})$`。类似的,后向GRU按照`$(x_T,x_{T-1},...,x_1)$`的顺序依次编码源语言端词,得到`$(\overleftarrow{h_1},\overleftarrow{h_2},...,\overleftarrow{h_T})$`。最后对于词`$x_i$`,通过拼接两个GRU的结果得到它的隐层状态,即`$h_i=\left [ \overrightarrow{h_i^T},\overleftarrow{h_i^T} \right ]^{T}$`。
+第3步也可以使用双向循环神经网络实现更复杂的句编码表示,具体可以用双向GRU实现。前向GRU按照词序列$(x_1,x_2,...,x_T)$的顺序依次编码源语言端词,并得到一系列隐层状态$(\overrightarrow{h_1},\overrightarrow{h_2},...,\overrightarrow{h_T})$。类似的,后向GRU按照$(x_T,x_{T-1},...,x_1)$的顺序依次编码源语言端词,得到$(\overleftarrow{h_1},\overleftarrow{h_2},...,\overleftarrow{h_T})$。最后对于词$x_i$,通过拼接两个GRU的结果得到它的隐层状态,即$h_i=\left [ \overrightarrow{h_i^T},\overleftarrow{h_i^T} \right ]^{T}$。

@@ -77,19 +77,19 @@
机器翻译任务的训练过程中,解码阶段的目标是最大化下一个正确的目标语言词的概率。思路是:
-1. 每一个时刻,根据源语言句子的编码信息(又叫上下文向量,context vector)`$c$`、真实目标语言序列的第`$i$`个词`$u_i$`和`$i$`时刻RNN的隐层状态`$z_i$`,计算出下一个隐层状态`$z_{i+1}$`。计算公式如下:
+1. 每一个时刻,根据源语言句子的编码信息(又叫上下文向量,context vector)$c$、真实目标语言序列的第$i$个词$u_i$和$i$时刻RNN的隐层状态$z_i$,计算出下一个隐层状态$z_{i+1}$。计算公式如下:
$$z_{i+1}=\phi _{\theta '}\left ( c,u_i,z_i \right )$$
-其中`$\phi _{\theta '}$`是一个非线性激活函数;`$c=q\mathbf{h}$`是源语言句子的上下文向量,在不使用[注意力机制](#注意力机制)时,如果[编码器](#编码器)的输出是源语言句子编码后的最后一个元素,则可以定义`$c=h_T$`;`$u_i$`是目标语言序列的第`$i$`个单词,`$u_0$`是目标语言序列的开始标记``,表示解码开始;`$z_i$`是`$i$`时刻解码RNN的隐层状态,`$z_0$`是一个全零的向量。
+其中$\phi _{\theta '}$是一个非线性激活函数;$c=q\mathbf{h}$是源语言句子的上下文向量,在不使用[注意力机制](#注意力机制)时,如果[编码器](#编码器)的输出是源语言句子编码后的最后一个元素,则可以定义$c=h_T$;$u_i$是目标语言序列的第$i$个单词,$u_0$是目标语言序列的开始标记``,表示解码开始;$z_i$是$i$时刻解码RNN的隐层状态,$z_0$是一个全零的向量。
-2. 将`$z_{i+1}$`通过`softmax`归一化,得到目标语言序列的第`$i+1$`个单词的概率分布`$p_{i+1}$`。概率分布公式如下:
+2. 将$z_{i+1}$通过`softmax`归一化,得到目标语言序列的第$i+1$个单词的概率分布$p_{i+1}$。概率分布公式如下:
$$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
-其中`$W_sz_{i+1}+b_z$`是对每个可能的输出单词进行打分,再用softmax归一化就可以得到第`$i+1$`个词的概率`$p_{i+1}$`。
+其中$W_sz_{i+1}+b_z$是对每个可能的输出单词进行打分,再用softmax归一化就可以得到第$i+1$个词的概率$p_{i+1}$。
-3. 根据`$p_{i+1}$`和`$u_{i+1}$`计算代价。
+3. 根据$p_{i+1}$和$u_{i+1}$计算代价。
4. 重复步骤1~3,直到目标语言序列中的所有词处理完毕。
机器翻译任务的生成过程,通俗来讲就是根据预先训练的模型来翻译源语言句子。生成过程中的解码阶段和上述训练过程的有所差异,具体介绍请见[柱搜索算法](#柱搜索算法)。
@@ -102,12 +102,12 @@ $$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
使用柱搜索算法的解码阶段,目标是最大化生成序列的概率。思路是:
-1. 每一个时刻,根据源语言句子的编码信息`$c$`、生成的第`$i$`个目标语言序列单词`$u_i$`和`$i$`时刻RNN的隐层状态`$z_i$`,计算出下一个隐层状态`$z_{i+1}$`。
-2. 将`$z_{i+1}$`通过`softmax`归一化,得到目标语言序列的第`$i+1$`个单词的概率分布`$p_{i+1}$`。
-3. 根据`$p_{i+1}$`采样出单词`$u_{i+1}$`。
+1. 每一个时刻,根据源语言句子的编码信息$c$、生成的第$i$个目标语言序列单词$u_i$和$i$时刻RNN的隐层状态$z_i$,计算出下一个隐层状态$z_{i+1}$。
+2. 将$z_{i+1}$通过`softmax`归一化,得到目标语言序列的第$i+1$个单词的概率分布$p_{i+1}$。
+3. 根据$p_{i+1}$采样出单词$u_{i+1}$。
4. 重复步骤1~3,直到获得句子结束标记``或超过句子的最大生成长度为止。
-注意:`$z_{i+1}$`和`$p_{i+1}$`的计算公式同[解码器](#解码器)中的一样。且由于生成时的每一步都是通过贪心法实现的,因此并不能保证得到全局最优解。
+注意:$z_{i+1}$和$p_{i+1}$的计算公式同[解码器](#解码器)中的一样。且由于生成时的每一步都是通过贪心法实现的,因此并不能保证得到全局最优解。
## 数据介绍
@@ -118,7 +118,7 @@ $$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
我们的预处理流程包括两步:
- 将每个源语言到目标语言的平行语料库文件合并为一个文件:
- 合并每个`XXX.src`和`XXX.trg`文件为`XXX`。
-- `XXX`中的第`$i$`行内容为`XXX.src`中的第`$i$`行和`XXX.trg`中的第`$i$`行连接,用'\t'分隔。
+- `XXX`中的第$i$行内容为`XXX.src`中的第$i$行和`XXX.trg`中的第$i$行连接,用'\t'分隔。
- 创建训练数据的“源字典”和“目标字典”。每个字典都有**DICTSIZE**个单词,包括:语料中词频最高的(DICTSIZE - 3)个单词,和3个特殊符号``(序列的开始)、``(序列的结束)和``(未登录词)。
### 示例数据
diff --git a/source/beginners_guide/basics/recommender_system/index.md b/source/beginners_guide/basics/recommender_system/index.md
index b0845ca816ae650799015831b2c7c5888a5843c7..2c77613deffdab8da31408db875ec3928320b6d7 100644
--- a/source/beginners_guide/basics/recommender_system/index.md
+++ b/source/beginners_guide/basics/recommender_system/index.md
@@ -1,6 +1,6 @@
# 个性化推荐
-本教程源代码目录在[book/recommender_system](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/176.html)。
+本教程源代码目录在[book/recommender_system](https://github.com/PaddlePaddle/book/tree/develop/05.recommender_system), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
## 背景介绍
@@ -45,20 +45,20 @@ YouTube是世界上最大的视频上传、分享和发现网站,YouTube推荐
候选生成网络将推荐问题建模为一个类别数极大的多类分类问题:对于一个Youtube用户,使用其观看历史(视频ID)、搜索词记录(search tokens)、人口学信息(如地理位置、用户登录设备)、二值特征(如性别,是否登录)和连续特征(如用户年龄)等,对视频库中所有视频进行多分类,得到每一类别的分类结果(即每一个视频的推荐概率),最终输出概率较高的几百个视频。
-首先,将观看历史及搜索词记录这类历史信息,映射为向量后取平均值得到定长表示;同时,输入人口学特征以优化新用户的推荐效果,并将二值特征和连续特征归一化处理到[0, 1]范围。接下来,将所有特征表示拼接为一个向量,并输入给非线形多层感知器(MLP,详见[识别数字](https://github.com/PaddlePaddle/book/blob/develop/02.recognize_digits/README.cn.md)教程)处理。最后,训练时将MLP的输出给softmax做分类,预测时计算用户的综合特征(MLP的输出)与所有视频的相似度,取得分最高的`$k$`个作为候选生成网络的筛选结果。图2显示了候选生成网络结构。
+首先,将观看历史及搜索词记录这类历史信息,映射为向量后取平均值得到定长表示;同时,输入人口学特征以优化新用户的推荐效果,并将二值特征和连续特征归一化处理到[0, 1]范围。接下来,将所有特征表示拼接为一个向量,并输入给非线形多层感知器(MLP,详见[识别数字](https://github.com/PaddlePaddle/book/blob/develop/02.recognize_digits/README.cn.md)教程)处理。最后,训练时将MLP的输出给softmax做分类,预测时计算用户的综合特征(MLP的输出)与所有视频的相似度,取得分最高的$k$个作为候选生成网络的筛选结果。图2显示了候选生成网络结构。

图2. 候选生成网络结构
-对于一个用户`$U$`,预测此刻用户要观看的视频`$\omega$`为视频`$i$`的概率公式为:
+对于一个用户$U$,预测此刻用户要观看的视频$\omega$为视频$i$的概率公式为:
$$P(\omega=i|u)=\frac{e^{v_{i}u}}{\sum_{j \in V}e^{v_{j}u}}$$
-其中`$u$`为用户`$U$`的特征表示,`$V$`为视频库集合,`$v_i$`为视频库中第`$i$`个视频的特征表示。`$u$`和`$v_i$`为长度相等的向量,两者点积可以通过全连接层实现。
+其中$u$为用户$U$的特征表示,$V$为视频库集合,$v_i$为视频库中第$i$个视频的特征表示。$u$和$v_i$为长度相等的向量,两者点积可以通过全连接层实现。
-考虑到softmax分类的类别数非常多,为了保证一定的计算效率:1)训练阶段,使用负样本类别采样将实际计算的类别数缩小至数千;2)推荐(预测)阶段,忽略softmax的归一化计算(不影响结果),将类别打分问题简化为点积(dot product)空间中的最近邻(nearest neighbor)搜索问题,取与`$u$`最近的`$k$`个视频作为生成的候选。
+考虑到softmax分类的类别数非常多,为了保证一定的计算效率:1)训练阶段,使用负样本类别采样将实际计算的类别数缩小至数千;2)推荐(预测)阶段,忽略softmax的归一化计算(不影响结果),将类别打分问题简化为点积(dot product)空间中的最近邻(nearest neighbor)搜索问题,取与$u$最近的$k$个视频作为生成的候选。
#### 排序网络(Ranking Network)
排序网络的结构类似于候选生成网络,但是它的目标是对候选进行更细致的打分排序。和传统广告排序中的特征抽取方法类似,这里也构造了大量的用于视频排序的相关特征(如视频 ID、上次观看时间等)。这些特征的处理方式和候选生成网络类似,不同之处是排序网络的顶部是一个加权逻辑回归(weighted logistic regression),它对所有候选视频进行打分,从高到底排序后将分数较高的一些视频返回给用户。
@@ -77,15 +77,15 @@ $$P(\omega=i|u)=\frac{e^{v_{i}u}}{\sum_{j \in V}e^{v_{j}u}}$$
图3. 卷积神经网络文本分类模型
-假设待处理句子的长度为`$n$`,其中第`$i$`个词的词向量(word embedding)为`$x_i\in\mathbb{R}^k$`,`$k$`为维度大小。
+假设待处理句子的长度为$n$,其中第$i$个词的词向量(word embedding)为$x_i\in\mathbb{R}^k$,$k$为维度大小。
-首先,进行词向量的拼接操作:将每`$h$`个词拼接起来形成一个大小为`$h$`的词窗口,记为`$x_{i:i+h-1}$`,它表示词序列`$x_{i},x_{i+1},\ldots,x_{i+h-1}$`的拼接,其中,`$i$`表示词窗口中第一个词在整个句子中的位置,取值范围从`$1$`到`$n-h+1$`,`$x_{i:i+h-1}\in\mathbb{R}^{hk}$`。
+首先,进行词向量的拼接操作:将每$h$个词拼接起来形成一个大小为$h$的词窗口,记为$x_{i:i+h-1}$,它表示词序列$x_{i},x_{i+1},\ldots,x_{i+h-1}$的拼接,其中,$i$表示词窗口中第一个词在整个句子中的位置,取值范围从$1$到$n-h+1$,$x_{i:i+h-1}\in\mathbb{R}^{hk}$。
-其次,进行卷积操作:把卷积核(kernel)`$w\in\mathbb{R}^{hk}$`应用于包含`$h$`个词的窗口`$x_{i:i+h-1}$`,得到特征`$c_i=f(w\cdot x_{i:i+h-1}+b)$`,其中`$b\in\mathbb{R}$`为偏置项(bias),`$f$`为非线性激活函数,如`$sigmoid$`。将卷积核应用于句子中所有的词窗口`${x_{1:h},x_{2:h+1},\ldots,x_{n-h+1:n}}$`,产生一个特征图(feature map):
+其次,进行卷积操作:把卷积核(kernel)$w\in\mathbb{R}^{hk}$应用于包含$h$个词的窗口$x_{i:i+h-1}$,得到特征$c_i=f(w\cdot x_{i:i+h-1}+b)$,其中$b\in\mathbb{R}$为偏置项(bias),$f$为非线性激活函数,如$sigmoid$。将卷积核应用于句子中所有的词窗口${x_{1:h},x_{2:h+1},\ldots,x_{n-h+1:n}}$,产生一个特征图(feature map):
$$c=[c_1,c_2,\ldots,c_{n-h+1}], c \in \mathbb{R}^{n-h+1}$$
-接下来,对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征`$\hat c$`,它是特征图中所有元素的最大值:
+接下来,对特征图采用时间维度上的最大池化(max pooling over time)操作得到此卷积核对应的整句话的特征$\hat c$,它是特征图中所有元素的最大值:
$$\hat c=max(c)$$
diff --git a/source/beginners_guide/basics/understand_sentiment/index.md b/source/beginners_guide/basics/understand_sentiment/index.md
index 792781aed97285953214525bd98c4b7884103103..bbb065dfc7cc92504671911abdf8b49162b00313 100644
--- a/source/beginners_guide/basics/understand_sentiment/index.md
+++ b/source/beginners_guide/basics/understand_sentiment/index.md
@@ -1,6 +1,6 @@
# 情感分析
-本教程源代码目录在[book/understand_sentiment](https://github.com/PaddlePaddle/book/tree/develop/06.understand_sentiment), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/177.html)。
+本教程源代码目录在[book/understand_sentiment](https://github.com/PaddlePaddle/book/tree/develop/06.understand_sentiment), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
## 背景介绍
@@ -41,44 +41,44 @@
图1. 循环神经网络按时间展开的示意图
-循环神经网络按时间展开后如图1所示:在第`$t$`时刻,网络读入第`$t$`个输入`$x_t$`(向量表示)及前一时刻隐层的状态值`$h_{t-1}$`(向量表示,`$h_0$`一般初始化为`$0$`向量),计算得出本时刻隐层的状态值`$h_t$`,重复这一步骤直至读完所有输入。如果将循环神经网络所表示的函数记为`$f$`,则其公式可表示为:
+循环神经网络按时间展开后如图1所示:在第$t$时刻,网络读入第$t$个输入$x_t$(向量表示)及前一时刻隐层的状态值$h_{t-1}$(向量表示,$h_0$一般初始化为$0$向量),计算得出本时刻隐层的状态值$h_t$,重复这一步骤直至读完所有输入。如果将循环神经网络所表示的函数记为$f$,则其公式可表示为:
$$h_t=f(x_t,h_{t-1})=\sigma(W_{xh}x_t+W_{hh}h_{t-1}+b_h)$$
-其中`$W_{xh}$`是输入到隐层的矩阵参数,`$W_{hh}$`是隐层到隐层的矩阵参数,`$b_h$`为隐层的偏置向量(bias)参数,`$\sigma$`为`$sigmoid$`函数。
+其中$W_{xh}$是输入到隐层的矩阵参数,$W_{hh}$是隐层到隐层的矩阵参数,$b_h$为隐层的偏置向量(bias)参数,$\sigma$为$sigmoid$函数。
-在处理自然语言时,一般会先将词(one-hot表示)映射为其词向量(word embedding)表示,然后再作为循环神经网络每一时刻的输入`$x_t$`。此外,可以根据实际需要的不同在循环神经网络的隐层上连接其它层。如,可以把一个循环神经网络的隐层输出连接至下一个循环神经网络的输入构建深层(deep or stacked)循环神经网络,或者提取最后一个时刻的隐层状态作为句子表示进而使用分类模型等等。
+在处理自然语言时,一般会先将词(one-hot表示)映射为其词向量(word embedding)表示,然后再作为循环神经网络每一时刻的输入$x_t$。此外,可以根据实际需要的不同在循环神经网络的隐层上连接其它层。如,可以把一个循环神经网络的隐层输出连接至下一个循环神经网络的输入构建深层(deep or stacked)循环神经网络,或者提取最后一个时刻的隐层状态作为句子表示进而使用分类模型等等。
### 长短期记忆网络(LSTM)
对于较长的序列数据,循环神经网络的训练过程中容易出现梯度消失或爆炸现象\[[6](#参考文献)\]。为了解决这一问题,Hochreiter S, Schmidhuber J. (1997)提出了LSTM(long short term memory\[[5](#参考文献)\])。
-相比于简单的循环神经网络,LSTM增加了记忆单元`$c$`、输入门`$i$`、遗忘门`$f$`及输出门`$o$`。这些门及记忆单元组合起来大大提升了循环神经网络处理长序列数据的能力。若将基于LSTM的循环神经网络表示的函数记为`$F$`,则其公式为:
+相比于简单的循环神经网络,LSTM增加了记忆单元$c$、输入门$i$、遗忘门$f$及输出门$o$。这些门及记忆单元组合起来大大提升了循环神经网络处理长序列数据的能力。若将基于LSTM的循环神经网络表示的函数记为$F$,则其公式为:
$$ h_t=F(x_t,h_{t-1})$$
-`$F$`由下列公式组合而成\[[7](#参考文献)\]:
+$F$由下列公式组合而成\[[7](#参考文献)\]:
$$ i_t = \sigma{(W_{xi}x_t+W_{hi}h_{t-1}+W_{ci}c_{t-1}+b_i)} $$
$$ f_t = \sigma(W_{xf}x_t+W_{hf}h_{t-1}+W_{cf}c_{t-1}+b_f) $$
$$ c_t = f_t\odot c_{t-1}+i_t\odot tanh(W_{xc}x_t+W_{hc}h_{t-1}+b_c) $$
$$ o_t = \sigma(W_{xo}x_t+W_{ho}h_{t-1}+W_{co}c_{t}+b_o) $$
$$ h_t = o_t\odot tanh(c_t) $$
-其中,`$i_t, f_t, c_t, o_t$`分别表示输入门,遗忘门,记忆单元及输出门的向量值,带角标的`$W$`及`$b$`为模型参数,`$tanh$`为双曲正切函数,`$\odot$`表示逐元素(elementwise)的乘法操作。输入门控制着新输入进入记忆单元`$c$`的强度,遗忘门控制着记忆单元维持上一时刻值的强度,输出门控制着输出记忆单元的强度。三种门的计算方式类似,但有着完全不同的参数,它们各自以不同的方式控制着记忆单元`$c$`,如图2所示:
+其中,$i_t, f_t, c_t, o_t$分别表示输入门,遗忘门,记忆单元及输出门的向量值,带角标的$W$及$b$为模型参数,$tanh$为双曲正切函数,$\odot$表示逐元素(elementwise)的乘法操作。输入门控制着新输入进入记忆单元$c$的强度,遗忘门控制着记忆单元维持上一时刻值的强度,输出门控制着输出记忆单元的强度。三种门的计算方式类似,但有着完全不同的参数,它们各自以不同的方式控制着记忆单元$c$,如图2所示:

-图2. 时刻`$t$`的LSTM [7]
+图2. 时刻$t$的LSTM [7]
LSTM通过给简单的循环神经网络增加记忆及控制门的方式,增强了其处理远距离依赖问题的能力。类似原理的改进还有Gated Recurrent Unit (GRU)\[[8](#参考文献)\],其设计更为简洁一些。**这些改进虽然各有不同,但是它们的宏观描述却与简单的循环神经网络一样(如图2所示),即隐状态依据当前输入及前一时刻的隐状态来改变,不断地循环这一过程直至输入处理完毕:**
$$ h_t=Recrurent(x_t,h_{t-1})$$
-其中,`$Recrurent$`可以表示简单的循环神经网络、GRU或LSTM。
+其中,$Recrurent$可以表示简单的循环神经网络、GRU或LSTM。
### 栈式双向LSTM(Stacked Bidirectional LSTM)
-对于正常顺序的循环神经网络,`$h_t$`包含了`$t$`时刻之前的输入信息,也就是上文信息。同样,为了得到下文信息,我们可以使用反方向(将输入逆序处理)的循环神经网络。结合构建深层循环神经网络的方法(深层神经网络往往能得到更抽象和高级的特征表示),我们可以通过构建更加强有力的基于LSTM的栈式双向循环神经网络\[[9](#参考文献)\],来对时序数据进行建模。
+对于正常顺序的循环神经网络,$h_t$包含了$t$时刻之前的输入信息,也就是上文信息。同样,为了得到下文信息,我们可以使用反方向(将输入逆序处理)的循环神经网络。结合构建深层循环神经网络的方法(深层神经网络往往能得到更抽象和高级的特征表示),我们可以通过构建更加强有力的基于LSTM的栈式双向循环神经网络\[[9](#参考文献)\],来对时序数据进行建模。
如图3所示(以三层为例),奇数层LSTM正向,偶数层LSTM反向,高一层的LSTM使用低一层LSTM及之前所有层的信息作为输入,对最高层LSTM序列使用时间维度上的最大池化即可得到文本的定长向量表示(这一表示充分融合了文本的上下文信息,并且对文本进行了深层次抽象),最后我们将文本表示连接至softmax构建分类模型。
diff --git a/source/beginners_guide/basics/word2vec/index.md b/source/beginners_guide/basics/word2vec/index.md
index dff9471aa79a61f00515b5d3d4c364fd72707f9e..b0cc52978cb8c0aeebcd015da9e254fb9fd9944c 100644
--- a/source/beginners_guide/basics/word2vec/index.md
+++ b/source/beginners_guide/basics/word2vec/index.md
@@ -1,7 +1,7 @@
# 词向量
-本教程源代码目录在[book/word2vec](https://github.com/PaddlePaddle/book/tree/develop/04.word2vec), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/175.html)。
+本教程源代码目录在[book/word2vec](https://github.com/PaddlePaddle/book/tree/develop/04.word2vec), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
## 背景介绍
@@ -12,15 +12,15 @@
One-hot vector虽然自然,但是用处有限。比如,在互联网广告系统里,如果用户输入的query是“母亲节”,而有一个广告的关键词是“康乃馨”。虽然按照常理,我们知道这两个词之间是有联系的——母亲节通常应该送给母亲一束康乃馨;但是这两个词对应的one-hot vectors之间的距离度量,无论是欧氏距离还是余弦相似度(cosine similarity),由于其向量正交,都认为这两个词毫无相关性。 得出这种与我们相悖的结论的根本原因是:每个词本身的信息量都太小。所以,仅仅给定两个词,不足以让我们准确判别它们是否相关。要想精确计算相关性,我们还需要更多的信息——从大量数据里通过机器学习方法归纳出来的知识。
-在机器学习领域里,各种“知识”被各种模型表示,词向量模型(word embedding model)就是其中的一类。通过词向量模型可将一个 one-hot vector映射到一个维度更低的实数向量(embedding vector),如`$embedding(Mother's\ Day) = [0.3, 4.2, -1.5, ...], embedding(Carnation) = [0.2, 5.6, -2.3, ...]$`。在这个映射到的实数向量表示中,希望两个语义(或用法)上相似的词对应的词向量“更像”,这样如“母亲节”和“康乃馨”的对应词向量的余弦相似度就不再为零了。
+在机器学习领域里,各种“知识”被各种模型表示,词向量模型(word embedding model)就是其中的一类。通过词向量模型可将一个 one-hot vector映射到一个维度更低的实数向量(embedding vector),如$embedding(Mother's\ Day) = [0.3, 4.2, -1.5, ...], embedding(Carnation) = [0.2, 5.6, -2.3, ...]$。在这个映射到的实数向量表示中,希望两个语义(或用法)上相似的词对应的词向量“更像”,这样如“母亲节”和“康乃馨”的对应词向量的余弦相似度就不再为零了。
-词向量模型可以是概率模型、共生矩阵(co-occurrence matrix)模型或神经元网络模型。在用神经网络求词向量之前,传统做法是统计一个词语的共生矩阵`$X$`。`$X$`是一个`$|V| \times |V|$` 大小的矩阵,`$X_{ij}$`表示在所有语料中,词汇表`V`(vocabulary)中第i个词和第j个词同时出现的词数,`$|V|$`为词汇表的大小。对`$X$`做矩阵分解(如奇异值分解,Singular Value Decomposition \[[5](#参考文献)\]),得到的`$U$`即视为所有词的词向量:
+词向量模型可以是概率模型、共生矩阵(co-occurrence matrix)模型或神经元网络模型。在用神经网络求词向量之前,传统做法是统计一个词语的共生矩阵$X$。$X$是一个$|V| \times |V|$ 大小的矩阵,$X_{ij}$表示在所有语料中,词汇表`V`(vocabulary)中第i个词和第j个词同时出现的词数,$|V|$为词汇表的大小。对$X$做矩阵分解(如奇异值分解,Singular Value Decomposition \[[5](#参考文献)\]),得到的$U$即视为所有词的词向量:
$$X = USV^T$$
但这样的传统做法有很多问题:
1) 由于很多词没有出现,导致矩阵极其稀疏,因此需要对词频做额外处理来达到好的矩阵分解效果;
-2) 矩阵非常大,维度太高(通常达到`$10^6*10^6$`的数量级);
+2) 矩阵非常大,维度太高(通常达到$10^6*10^6$的数量级);
3) 需要手动去掉停用词(如although, a,...),不然这些频繁出现的词也会影响矩阵分解的效果。
@@ -36,7 +36,7 @@ $$X = USV^T$$
图1. 词向量的二维投影
-另一方面,我们知道两个向量的余弦值在`$[-1,1]$`的区间内:两个完全相同的向量余弦值为1, 两个相互垂直的向量之间余弦值为0,两个方向完全相反的向量余弦值为-1,即相关性和余弦值大小成正比。因此我们还可以计算两个词向量的余弦相似度:
+另一方面,我们知道两个向量的余弦值在$[-1,1]$的区间内:两个完全相同的向量余弦值为1, 两个相互垂直的向量之间余弦值为0,两个方向完全相反的向量余弦值为-1,即相关性和余弦值大小成正比。因此我们还可以计算两个词向量的余弦相似度:
```
similarity: 0.899180685161
@@ -56,10 +56,10 @@ similarity: -0.0997506977351
### 语言模型
在介绍词向量模型之前,我们先来引入一个概念:语言模型。
-语言模型旨在为语句的联合概率函数`$P(w_1, ..., w_T)$`建模, 其中`$w_i$`表示句子中的第i个词。语言模型的目标是,希望模型对有意义的句子赋予大概率,对没意义的句子赋予小概率。
+语言模型旨在为语句的联合概率函数$P(w_1, ..., w_T)$建模, 其中$w_i$表示句子中的第i个词。语言模型的目标是,希望模型对有意义的句子赋予大概率,对没意义的句子赋予小概率。
这样的模型可以应用于很多领域,如机器翻译、语音识别、信息检索、词性标注、手写识别等,它们都希望能得到一个连续序列的概率。 以信息检索为例,当你在搜索“how long is a football bame”时(bame是一个医学名词),搜索引擎会提示你是否希望搜索"how long is a football game", 这是因为根据语言模型计算出“how long is a football bame”的概率很低,而与bame近似的,可能引起错误的词中,game会使该句生成的概率最大。
-对语言模型的目标概率`$P(w_1, ..., w_T)$`,如果假设文本中每个词都是相互独立的,则整句话的联合概率可以表示为其中所有词语条件概率的乘积,即:
+对语言模型的目标概率$P(w_1, ..., w_T)$,如果假设文本中每个词都是相互独立的,则整句话的联合概率可以表示为其中所有词语条件概率的乘积,即:
$$P(w_1, ..., w_T) = \prod_{t=1}^TP(w_t)$$
@@ -75,7 +75,7 @@ $$P(w_1, ..., w_T) = \prod_{t=1}^TP(w_t | w_1, ... , w_{t-1})$$
Yoshua Bengio等科学家就于2003年在著名论文 Neural Probabilistic Language Models \[[1](#参考文献)\] 中介绍如何学习一个神经元网络表示的词向量模型。文中的神经概率语言模型(Neural Network Language Model,NNLM)通过一个线性映射和一个非线性隐层连接,同时学习了语言模型和词向量,即通过学习大量语料得到词语的向量表达,通过这些向量得到整个句子的概率。用这种方法学习语言模型可以克服维度灾难(curse of dimensionality),即训练和测试数据不同导致的模型不准。注意:由于“神经概率语言模型”说法较为泛泛,我们在这里不用其NNLM的本名,考虑到其具体做法,本文中称该模型为N-gram neural model。
-我们在上文中已经讲到用条件概率建模语言模型,即一句话中第`$t$`个词的概率和该句话的前`$t-1$`个词相关。可实际上越远的词语其实对该词的影响越小,那么如果考虑一个n-gram, 每个词都只受其前面`n-1`个词的影响,则有:
+我们在上文中已经讲到用条件概率建模语言模型,即一句话中第$t$个词的概率和该句话的前$t-1$个词相关。可实际上越远的词语其实对该词的影响越小,那么如果考虑一个n-gram, 每个词都只受其前面`n-1`个词的影响,则有:
$$P(w_1, ..., w_T) = \prod_{t=n}^TP(w_t|w_{t-1}, w_{t-2}, ..., w_{t-n+1})$$
@@ -83,7 +83,7 @@ $$P(w_1, ..., w_T) = \prod_{t=n}^TP(w_t|w_{t-1}, w_{t-2}, ..., w_{t-n+1})$$
$$\frac{1}{T}\sum_t f(w_t, w_{t-1}, ..., w_{t-n+1};\theta) + R(\theta)$$
-其中`$f(w_t, w_{t-1}, ..., w_{t-n+1})$`表示根据历史n-1个词得到当前词`$w_t$`的条件概率,`$R(\theta)$`表示参数正则项。
+其中$f(w_t, w_{t-1}, ..., w_{t-n+1})$表示根据历史n-1个词得到当前词$w_t$的条件概率,$R(\theta)$表示参数正则项。

@@ -91,17 +91,17 @@ $$\frac{1}{T}\sum_t f(w_t, w_{t-1}, ..., w_{t-n+1};\theta) + R(\theta)$$
图2展示了N-gram神经网络模型,从下往上看,该模型分为以下几个部分:
-- 对于每个样本,模型输入`$w_{t-n+1},...w_{t-1}$`, 输出句子第t个词为字典中`|V|`个词的概率。
+- 对于每个样本,模型输入$w_{t-n+1},...w_{t-1}$, 输出句子第t个词为字典中`|V|`个词的概率。
-每个输入词`$w_{t-n+1},...w_{t-1}$`首先通过映射矩阵映射到词向量`$C(w_{t-n+1}),...C(w_{t-1})$`。
+每个输入词$w_{t-n+1},...w_{t-1}$首先通过映射矩阵映射到词向量$C(w_{t-n+1}),...C(w_{t-1})$。
- 然后所有词语的词向量连接成一个大向量,并经过一个非线性映射得到历史词语的隐层表示:
$$g=Utanh(\theta^Tx + b_1) + Wx + b_2$$
-其中,`$x$`为所有词语的词向量连接成的大向量,表示文本历史特征;`$\theta$`、`$U$`、`$b_1$`、`$b_2$`和`$W$`分别为词向量层到隐层连接的参数。`$g$`表示未经归一化的所有输出单词概率,`$g_i$`表示未经归一化的字典中第`$i$`个单词的输出概率。
+其中,$x$为所有词语的词向量连接成的大向量,表示文本历史特征;$\theta$、$U$、$b_1$、$b_2$和$W$分别为词向量层到隐层连接的参数。$g$表示未经归一化的所有输出单词概率,$g_i$表示未经归一化的字典中第$i$个单词的输出概率。
-- 根据softmax的定义,通过归一化`$g_i$`, 生成目标词`$w_t$`的概率为:
+- 根据softmax的定义,通过归一化$g_i$, 生成目标词$w_t$的概率为:
$$P(w_t | w_1, ..., w_{t-n+1}) = \frac{e^{g_{w_t}}}{\sum_i^{|V|} e^{g_i}}$$
@@ -109,7 +109,7 @@ $$P(w_t | w_1, ..., w_{t-n+1}) = \frac{e^{g_{w_t}}}{\sum_i^{|V|} e^{g_i}}$$
$$J(\theta) = -\sum_{i=1}^N\sum_{c=1}^{|V|}y_k^{i}log(softmax(g_k^i))$$
-其中`$y_k^i$`表示第`$i$`个样本第`$k$`类的真实标签(0或1),`$softmax(g_k^i)$`表示第i个样本第k类softmax输出的概率。
+其中$y_k^i$表示第$i$个样本第$k$类的真实标签(0或1),$softmax(g_k^i)$表示第i个样本第k类softmax输出的概率。
@@ -126,7 +126,7 @@ CBOW模型通过一个词的上下文(各N个词)预测当前词。当N=2时
$$context = \frac{x_{t-1} + x_{t-2} + x_{t+1} + x_{t+2}}{4}$$
-其中`$x_t$`为第`$t$`个词的词向量,分类分数(score)向量 `$z=U*context$`,最终的分类`$y$`采用softmax,损失函数采用多类分类交叉熵。
+其中$x_t$为第$t$个词的词向量,分类分数(score)向量 $z=U*context$,最终的分类$y$采用softmax,损失函数采用多类分类交叉熵。
### Skip-gram model
@@ -137,7 +137,7 @@ CBOW的好处是对上下文词语的分布在词向量上进行了平滑,去
图4. Skip-gram模型
-如上图所示,Skip-gram模型的具体做法是,将一个词的词向量映射到`$2n$`个词的词向量(`$2n$`表示当前输入词的前后各`$n$`个词),然后分别通过softmax得到这`$2n$`个词的分类损失值之和。
+如上图所示,Skip-gram模型的具体做法是,将一个词的词向量映射到$2n$个词的词向量($2n$表示当前输入词的前后各$n$个词),然后分别通过softmax得到这$2n$个词的分类损失值之和。
## 数据准备
diff --git a/source/beginners_guide/install/install_doc.rst b/source/beginners_guide/install/install_doc.rst
index d862eded2ff9892f9d92469ff6fa7f54ad01fb3e..18788d2eae048ac5120b0b7afd63cd784a235798 100644
--- a/source/beginners_guide/install/install_doc.rst
+++ b/source/beginners_guide/install/install_doc.rst
@@ -3,7 +3,10 @@
安装说明
^^^^^^^^
-您可以使用我们提供的安装包,或使用源代码,安装PaddlePaddle。
+若您的系统为Linux或Windows,您可以使用我们提供的安装包来安装PaddlePaddle。
+
+对于MacOS系统,我们暂未提供安装包,您可以使用 **从源码编译** 的方式安装。
+
.. _install_linux:
@@ -23,11 +26,11 @@
pip install paddlepaddle
-当前的默认版本为0.13.0,cpu_avx_openblas,您可以通过指定版本号来安装其它版本,例如:
+您可以通过指定版本号来安装其它版本,例如:
.. code-block:: bash
- pip install paddlepaddle==0.12.0
+ pip install paddlepaddle==0.13.0
如果需要安装支持GPU的版本(cuda9.0_cudnn7_avx_openblas),需要执行:
@@ -36,11 +39,14 @@
pip install paddlepaddle-gpu
-当前的默认版本是0.13.0,PaddlePaddle针对不同需求提供了更多版本的安装包,部分列表如下:
+PaddlePaddle针对不同需求提供了更多版本的安装包,部分列表如下:
================================= ========================================
版本号 版本说明
================================= ========================================
+paddlepaddle-gpu==0.14.0 使用CUDA 9.0和cuDNN 7编译的0.14.0版本
+paddlepaddle-gpu==0.14.0.post87 使用CUDA 8.0和cuDNN 7编译的0.14.0版本
+paddlepaddle-gpu==0.14.0.post85 使用CUDA 8.0和cuDNN 5编译的0.14.0版本
paddlepaddle-gpu==0.13.0 使用CUDA 9.0和cuDNN 7编译的0.13.0版本
paddlepaddle-gpu==0.12.0 使用CUDA 8.0和cuDNN 5编译的0.12.0版本
paddlepaddle-gpu==0.11.0.post87 使用CUDA 8.0和cuDNN 7编译的0.11.0版本
@@ -64,12 +70,15 @@ paddlepaddle-gpu==0.11.0 使用CUDA 7.5和cuDNN 5编译的0.11.0版
:header: "版本说明", "cp27-cp27mu", "cp27-cp27m"
:widths: 1, 3, 3
- "cpu_avx_mkl", "`paddlepaddle-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle-latest-cp27-cp27m-linux_x86_64.whl `__"
- "cpu_avx_openblas", "`paddlepaddle-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle-latest-cp27-cp27m-linux_x86_64.whl `__"
- "cpu_noavx_openblas", "`paddlepaddle-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle-latest-cp27-cp27m-linux_x86_64.whl `_"
- "cuda8.0_cudnn5_avx_mkl", "`paddlepaddle_gpu-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle_gpu-latest-cp27-cp27m-linux_x86_64.whl `__"
- "cuda8.0_cudnn7_avx_mkl", "`paddlepaddle_gpu-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle_gpu-latest-cp27-cp27m-linux_x86_64.whl `__"
- "cuda9.0_cudnn7_avx_mkl", "`paddlepaddle_gpu-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle_gpu-latest-cp27-cp27m-linux_x86_64.whl `__"
+ "stable_cuda9.0_cudnn7", "`paddlepaddle_gpu-0.14.0-cp27-cp27mu-manylinux1_x86_64.whl `__", "`paddlepaddle_gpu-0.14.0-cp27-cp27m-manylinux1_x86_64.whl `__"
+ "stable_cuda8.0_cudnn7", "`paddlepaddle_gpu-0.14.0.post87-cp27-cp27mu-manylinux1_x86_64.whl `__", "`paddlepaddle_gpu-0.14.0.post87-cp27-cp27m-manylinux1_x86_64.whl `__"
+ "stable_cuda8.0_cudnn5", "`paddlepaddle_gpu-0.14.0.post85-cp27-cp27mu-manylinux1_x86_64.whl `__", "`paddlepaddle_gpu-0.14.0.post85-cp27-cp27m-manylinux1_x86_64.whl `__"
+ "cpu_avx_mkl", "`paddlepaddle-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle-latest-cp27-cp27m-linux_x86_64.whl `__"
+ "cpu_avx_openblas", "`paddlepaddle-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle-latest-cp27-cp27m-linux_x86_64.whl `__"
+ "cpu_noavx_openblas", "`paddlepaddle-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle-latest-cp27-cp27m-linux_x86_64.whl `_"
+ "cuda8.0_cudnn5_avx_mkl", "`paddlepaddle_gpu-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle_gpu-latest-cp27-cp27m-linux_x86_64.whl `__"
+ "cuda8.0_cudnn7_avx_mkl", "`paddlepaddle_gpu-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle_gpu-latest-cp27-cp27m-linux_x86_64.whl `__"
+ "cuda9.0_cudnn7_avx_mkl", "`paddlepaddle_gpu-latest-cp27-cp27mu-linux_x86_64.whl `__", "`paddlepaddle_gpu-latest-cp27-cp27m-linux_x86_64.whl `__"
.. _FAQ:
@@ -104,102 +113,127 @@ paddlepaddle-gpu==0.11.0 使用CUDA 7.5和cuDNN 5编译的0.11.0版
.. _install_windows:
-在windows安装PaddlePaddle
+在Windows安装PaddlePaddle
------------------------------
+Windows系统需要通过Docker来使用PaddleaPaddle。Docker是一个虚拟容器,使用Docker可以简化复杂的环境配置工作。
-若您的系统为windows,您可以通过Docker来使用PaddlePaddle。
+我们提供了 `PaddlePaddle_Windows快速安装包 `_,
+它能够帮助您安装Docker和PaddlePaddle。
-推荐您下载 `PaddlePaddle快速安装包 `_,
-该安装包能够帮助您判断、安装适合的Docker,并引导您在Docker中使用PaddlePaddle。
+* 安装包支持的系统:Windows7,Windows8的所有版本,Windows10的专业版、企业版。
-..
- todo: windows的安装包要放在百度云上
-
-注意事项:
+* 如果您希望使用GPU提升训练速度,请使用Linux系统安装,Windows系统暂不支持。
+
+.. _install_mac:
-* 系统要求:windows7&8&10。
+在MacOS安装PaddlePaddle
+--------
-* 下载安装包后,请您右键选择“以管理员身份运行”。
+对于MacOS系统,我们暂未提供pip安装方式,您可以使用 **源码编译** 的方式安装。
-* PaddlePaddle不支持在windows使用GPU。
+.. _others:
-Docker安装完成后,请您执行下面的步骤:
+其他安装方式
+-------------
-请您右键选择”以管理员身份运行“,来启动Docker客户端
+.. _source:
+源码编译(使用Docker镜像)
+==========
-获取Image ID
+.. _requirements:
-.. code-block:: bash
+需要的软硬件
+"""""""""""""
- docker images
+为了编译PaddlePaddle,我们需要
-启动Docker
+1. 一台电脑,可以装的是 Linux, Windows 或者 MacOS 操作系统
+2. Docker
-.. code-block:: bash
+不需要依赖其他任何软件了。即便是 Python 和 GCC 都不需要,因为我们会把所有编译工具都安装进一个 Docker 镜像里。
- docker run -d it -t imageid /bin/bash
+.. _build_step:
-获取Docker Container
+编译方法
+"""""""""""""
-.. code-block:: bash
+PaddlePaddle需要使用Docker环境完成编译,这样可以免去单独安装编译依赖的步骤,可选的不同编译环境Docker镜像可以在 `这里 `_ 找到。
- docker ps -a
-进入Container
+**I. 编译CPU-Only版本的PaddlePaddle,需要执行:**
.. code-block:: bash
- docker attach container
+ # 1. 获取源码
+ git clone https://github.com/PaddlePaddle/Paddle.git
+ cd Paddle
+ # 2. 执行如下命令下载最新版本的docker镜像
+ docker run --name paddle-test -v $PWD:/paddle --network=host -it docker.paddlepaddlehub.com/paddle:latest-dev /bin/bash
+ # 3. 进入docker内执行如下命令编译CPU-Only的二进制安装包
+ mkdir -p /paddle/build && cd /paddle/build
+ cmake .. -DWITH_FLUID_ONLY=ON -DWITH_GPU=OFF -DWITH_TESTING=OFF
+ make -j$(nproc)
-.. _others:
+**II. 编译GPU版本的PaddlePaddle,需要执行:**
-其他安装方式
--------------
+.. code-block:: bash
-.. _source:
-从源码编译
-==========
+ # 1. 获取源码
+ git clone https://github.com/PaddlePaddle/Paddle.git
+ cd Paddle
+ # 2. 安装nvidia-docker
+ apt-get install nvidia-docker
+ # 3. 执行如下命令下载支持GPU运行的docker容器
+ nvidia-docker run --name paddle-test-gpu -v $PWD:/paddle --network=host -it docker.paddlepaddlehub.com/paddle:latest-dev /bin/bash
+ # 4. 进入docker内执行如下命令编译GPU版本的PaddlePaddle
+ mkdir -p /paddle/build && cd /paddle/build
+ cmake .. -DWITH_FLUID_ONLY=ON -DWITH_GPU=ON -DWITH_TESTING=OFF
+ make -j$(nproc)
-.. _requirements:
+**注意事项:**
-需要的软硬件
-"""""""""""""
+* 上述有关 :code:`docker` 的命令把当前目录(源码树根目录)映射为 container 里的 :code:`/paddle` 目录。
+* 进入 :code:`docker` 后执行 :code:`cmake` 命令,若是出现 :code:`patchelf not found, please install it.` 错误,则执行 :code:`apt-get install -y patchelf` 命令即可解决问题。
+* 若您在使用Docker编译PaddlePaddle遇到问题时, `这个issue `_ 可能会对您有所帮助。
-为了编译PaddlePaddle,我们需要
-1. 一台电脑,可以装的是 Linux, Windows 或者 MacOS 操作系统
-2. Docker
+.. _source:
+源码编译(不使用Docker镜像)
+==========
-不需要依赖其他任何软件了。即便是 Python 和 GCC 都不需要,因为我们会把所有编译工具都安装进一个 Docker 镜像里。
+如果您选择不使用Docker镜像,则需要在本机安装下面章节列出的 `附录:编译依赖`_ 之后才能开始编译的步骤。
.. _build_step:
编译方法
"""""""""""""
-PaddlePaddle需要使用Docker环境完成编译,这样可以免去单独安装编译依赖的步骤,可选的不同编译环境Docker镜像
-可以在 `这里 `_ 找到。或者
-参考下述可选步骤,从源码中构建用于编译PaddlePaddle的Docker镜像。
-
-如果您选择不使用Docker镜像,则需要在本机安装下面章节列出的 `附录:编译依赖`_ 之后才能开始编译的步骤。
-
-编译PaddlePaddle,需要执行:
+在本机上编译CPU-Only版本的PaddlePaddle,需要执行如下命令:
.. code-block:: bash
- # 1. 获取源码
+ # 1. 使用virtualenvwrapper创建python虚环境并将工作空间切换到虚环境 [可选]
+ mkvirtualenv paddle-venv
+ workon paddle-venv
+ # 2. 获取源码
git clone https://github.com/PaddlePaddle/Paddle.git
cd Paddle
- # 2. 可选步骤:源码中构建用于编译PaddlePaddle的Docker镜像
- docker build -t paddle:dev .
# 3. 执行下面的命令编译CPU-Only的二进制
- docker run -it -v $PWD:/paddle -e "WITH_GPU=OFF" -e "WITH_TESTING=OFF" paddlepaddle/paddle_manylinux_devel:cuda8.0_cudnn5 bash -x /paddle/paddle/scripts/paddle_build.sh build
- # 4. 或者也可以使用为上述可选步骤构建的镜像(必须先执行第2步)
- docker run -it -v $PWD:/paddle -e "WITH_GPU=OFF" -e "WITH_TESTING=OFF" paddle:dev
+ mkdir build && cd build
+ cmake .. -DWITH_FLUID_ONLY=ON -DWITH_GPU=OFF -DWITH_TESTING=OFF
+ make -j4 # 根据机器配备CPU的核心数开启相应的多线程进行编译
+
-注:上述命令把当前目录(源码树根目录)映射为 container 里的 :code:`/paddle` 目录。如果使用自行
-构建的镜像(上述第4步)会执行 :code:`Dockerfile` 描述的默认入口程序 :code:`docker_build.sh` 可以省略步骤3中
-最后的执行脚本的命令。
+**注意事项:**
+
+* MacOS系统下因为默认安装了cblas库,所以编译时可能会遇到 :code:`use of undeclared identifier 'openblas_set_num_threads'` 错误。因此,在执行cmake命令时需要指定所使用openblas库的头文件路径,具体操作如下:
+
+ .. code-block:: bash
+
+ cd Paddle/build && rm -rf *
+ cmake .. -DWITH_FLUID_ONLY=ON -DWITH_GPU=OFF -DWITH_TESTING=OFF -DOPENBLAS_INC_DIR=/usr/local/Cellar/openblas/[本机所安装的openblas版本号]/include/
+ make -j4 # 根据机器配备CPU的核心数开启相应的多线程进行编译
+* 若您在MacOS系统下从源码编译PaddlePaddle遇到问题时, `这个issue `_ 可能会对您有所帮助。
编译完成后会在build/python/dist目录下生成输出的whl包,可以选在在当前机器安装也可以拷贝到目标机器安装:
@@ -230,13 +264,13 @@ PaddlePaddle需要使用Docker环境完成编译,这样可以免去单独安
.. code-block:: bash
- docker run -it -v $PWD:/paddle -e "WITH_GPU=OFF" -e "WITH_TESTING=ON" -e "RUN_TEST=ON" paddlepaddle/paddle_manylinux_devel:cuda8.0_cudnn5 bash -x /paddle/paddle/scripts/paddle_build.sh build
+ docker run -it -v $PWD:/paddle -e "WITH_GPU=OFF" -e "WITH_TESTING=ON" -e "RUN_TEST=ON" docker.paddlepaddlehub.com/paddle:latest-dev bash -x /paddle/paddle/scripts/paddle_build.sh build
如果期望执行其中一个单元测试,(比如 :code:`test_sum_op` ):
.. code-block:: bash
- docker run -it -v $PWD:/paddle -e "WITH_GPU=OFF" -e "WITH_TESTING=ON" -e "RUN_TEST=OFF" paddlepaddle/paddle_manylinux_devel:cuda8.0_cudnn5 bash -x /paddle/paddle/scripts/paddle_build.sh build
+ docker run -it -v $PWD:/paddle -e "WITH_GPU=OFF" -e "WITH_TESTING=ON" -e "RUN_TEST=OFF" docker.paddlepaddlehub.com/paddle:latest-dev bash -x /paddle/paddle/scripts/paddle_build.sh build
cd /paddle/build
ctest -R test_sum_op -V
@@ -310,12 +344,16 @@ PaddlePaddle编译需要使用到下面的依赖(包含但不限于),其
:header: "依赖", "版本", "说明"
:widths: 10, 15, 30
- "CMake", ">=3.2", ""
+ "CMake", "3.4", ""
"GCC", "4.8.2", "推荐使用CentOS的devtools2"
"Python", "2.7.x", "依赖libpython2.7.so"
+ "SWIG", ">=2.0", ""
+ "wget","",""
+ "openblas","",""
"pip", ">=9.0", ""
"numpy", "", ""
- "SWIG", ">=2.0", ""
+ "protobuf","3.1.0",""
+ "wheel","",""
"Go", ">=1.8", "可选"
@@ -378,7 +416,7 @@ PaddePaddle通过编译时指定路径来实现引用各种BLAS/CUDA/cuDNN库。
cmake .. -DWITH_GPU=ON -DWITH_TESTING=OFF -DCUDNN_ROOT=/opt/cudnnv5
-**注意:这几个编译选项的设置,只在第一次cmake的时候有效。如果之后想要重新设置,推荐清理整个编译目录(** :code:`rm -rf` )**后,再指定。**
+注意:这几个编译选项的设置,只在第一次cmake的时候有效。如果之后想要重新设置,推荐清理整个编译目录( :code:`rm -rf` )后,再指定。
.. _install_docker:
diff --git a/source/beginners_guide/quick_start/fit_a_line/README.cn.md b/source/beginners_guide/quick_start/fit_a_line/README.cn.md
index 89b3cea524c9250fcbe685a0b0a603abadd260c9..8886a8307c3e5baf2f6e1f4f1a60ca434c70945c 100644
--- a/source/beginners_guide/quick_start/fit_a_line/README.cn.md
+++ b/source/beginners_guide/quick_start/fit_a_line/README.cn.md
@@ -4,14 +4,14 @@
# 线性回归
让我们从经典的线性回归(Linear Regression \[[1](#参考文献)\])模型开始这份教程。在这一章里,你将使用真实的数据集建立起一个房价预测模型,并且了解到机器学习中的若干重要概念。
-本教程源代码目录在[book/fit_a_line](https://github.com/PaddlePaddle/book/tree/develop/01.fit_a_line), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/137.html)。
+本教程源代码目录在[book/fit_a_line](https://github.com/PaddlePaddle/book/tree/develop/01.fit_a_line), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
## 背景介绍
-给定一个大小为`$n$`的数据集 `${\{y_{i}, x_{i1}, ..., x_{id}\}}_{i=1}^{n}$`,其中`$x_{i1}, \ldots, x_{id}$`是第`$i$`个样本`$d$`个属性上的取值,`$y_i$`是该样本待预测的目标。线性回归模型假设目标`$y_i$`可以被属性间的线性组合描述,即
+给定一个大小为$n$的数据集 ${\{y_{i}, x_{i1}, ..., x_{id}\}}_{i=1}^{n}$,其中$x_{i1}, \ldots, x_{id}$是第$i$个样本$d$个属性上的取值,$y_i$是该样本待预测的目标。线性回归模型假设目标$y_i$可以被属性间的线性组合描述,即
$$y_i = \omega_1x_{i1} + \omega_2x_{i2} + \ldots + \omega_dx_{id} + b, i=1,\ldots,n$$
-例如,在我们将要建模的房价预测问题里,`$x_{ij}$`是描述房子`$i$`的各种属性(比如房间的个数、周围学校和医院的个数、交通状况等),而 `$y_i$`是房屋的价格。
+例如,在我们将要建模的房价预测问题里,$x_{ij}$是描述房子$i$的各种属性(比如房间的个数、周围学校和医院的个数、交通状况等),而 $y_i$是房屋的价格。
初看起来,这个假设实在过于简单了,变量间的真实关系很难是线性的。但由于线性回归模型有形式简单和易于建模分析的优点,它在实际问题中得到了大量的应用。很多经典的统计学习、机器学习书籍\[[2,3,4](#参考文献)\]也选择对线性模型独立成章重点讲解。
@@ -25,24 +25,24 @@ $$y_i = \omega_1x_{i1} + \omega_2x_{i2} + \ldots + \omega_dx_{id} + b, i=1,\ldo
### 模型定义
-在波士顿房价数据集中,和房屋相关的值共有14个:前13个用来描述房屋相关的各种信息,即模型中的 `$x_i$`;最后一个值为我们要预测的该类房屋价格的中位数,即模型中的 `$y_i$`。因此,我们的模型就可以表示成:
+在波士顿房价数据集中,和房屋相关的值共有14个:前13个用来描述房屋相关的各种信息,即模型中的 $x_i$;最后一个值为我们要预测的该类房屋价格的中位数,即模型中的 $y_i$。因此,我们的模型就可以表示成:
$$\hat{Y} = \omega_1X_{1} + \omega_2X_{2} + \ldots + \omega_{13}X_{13} + b$$
-`$\hat{Y}$` 表示模型的预测结果,用来和真实值`$Y$`区分。模型要学习的参数即:`$\omega_1, \ldots, \omega_{13}, b$`。
+$\hat{Y}$ 表示模型的预测结果,用来和真实值$Y$区分。模型要学习的参数即:$\omega_1, \ldots, \omega_{13}, b$。
-建立模型后,我们需要给模型一个优化目标,使得学到的参数能够让预测值`$\hat{Y}$`尽可能地接近真实值`$Y$`。这里我们引入损失函数([Loss Function](https://en.wikipedia.org/wiki/Loss_function),或Cost Function)这个概念。 输入任意一个数据样本的目标值`$y_{i}$`和模型给出的预测值`$\hat{y_{i}}$`,损失函数输出一个非负的实值。这个实值通常用来反映模型误差的大小。
+建立模型后,我们需要给模型一个优化目标,使得学到的参数能够让预测值$\hat{Y}$尽可能地接近真实值$Y$。这里我们引入损失函数([Loss Function](https://en.wikipedia.org/wiki/Loss_function),或Cost Function)这个概念。 输入任意一个数据样本的目标值$y_{i}$和模型给出的预测值$\hat{y_{i}}$,损失函数输出一个非负的实值。这个实值通常用来反映模型误差的大小。
对于线性回归模型来讲,最常见的损失函数就是均方误差(Mean Squared Error, [MSE](https://en.wikipedia.org/wiki/Mean_squared_error))了,它的形式是:
$$MSE=\frac{1}{n}\sum_{i=1}^{n}{(\hat{Y_i}-Y_i)}^2$$
-即对于一个大小为`$n$`的测试集,`$MSE$`是`$n$`个数据预测结果误差平方的均值。
+即对于一个大小为$n$的测试集,$MSE$是$n$个数据预测结果误差平方的均值。
### 训练过程
定义好模型结构之后,我们要通过以下几个步骤进行模型训练
-1. 初始化参数,其中包括权重`$\omega_i$`和偏置`$b$`,对其进行初始化(如0均值,1方差)。
+1. 初始化参数,其中包括权重$\omega_i$和偏置$b$,对其进行初始化(如0均值,1方差)。
2. 网络正向传播计算网络输出和损失函数。
3. 根据损失函数进行反向误差传播 ([backpropagation](https://en.wikipedia.org/wiki/Backpropagation)),将网络误差从输出层依次向前传递, 并更新网络中的参数。
4. 重复2~3步骤,直至网络训练误差达到规定的程度或训练轮次达到设定值。
@@ -52,26 +52,93 @@ $$MSE=\frac{1}{n}\sum_{i=1}^{n}{(\hat{Y_i}-Y_i)}^2$$
### 数据集介绍
这份数据集共506行,每行包含了波士顿郊区的一类房屋的相关信息及该类房屋价格的中位数。其各维属性的意义如下:
-| 属性名 | 解释 | 类型 |
-| ------| ------ | ------ |
-| CRIM | 该镇的人均犯罪率 | 连续值 |
-| ZN | 占地面积超过25,000平方呎的住宅用地比例 | 连续值 |
-| INDUS | 非零售商业用地比例 | 连续值 |
-| CHAS | 是否邻近 Charles River | 离散值,1=邻近;0=不邻近 |
-| NOX | 一氧化氮浓度 | 连续值 |
-| RM | 每栋房屋的平均客房数 | 连续值 |
-| AGE | 1940年之前建成的自用单位比例 | 连续值 |
-| DIS | 到波士顿5个就业中心的加权距离 | 连续值 |
-| RAD | 到径向公路的可达性指数 | 连续值 |
-| TAX | 全值财产税率 | 连续值 |
-| PTRATIO | 学生与教师的比例 | 连续值 |
-| B | 1000(BK - 0.63)^2,其中BK为黑人占比 | 连续值 |
-| LSTAT | 低收入人群占比 | 连续值 |
-| MEDV | 同类房屋价格的中位数 | 连续值 |
+
+
+
+
+ | 属性名 |
+ 解释 |
+ 类型 |
+
+
+
+
+ | CRIM |
+ 该镇的人均犯罪率 |
+ 连续值 |
+
+
+ | ZN |
+ 占地面积超过25,000平方呎的住宅用地比例 |
+ 连续值 |
+
+
+ | INDUS |
+ 非零售商业用地比例 |
+ 连续值 |
+
+
+ | CHAS |
+ 是否邻近 Charles River |
+ 离散值,1=邻近;0=不邻近 |
+
+
+ | NOX |
+ 一氧化氮浓度 |
+ 连续值 |
+
+
+ | RM |
+ 每栋房屋的平均客房数 |
+ 连续值 |
+
+
+ | AGE |
+ 1940年之前建成的自用单位比例 |
+ 连续值 |
+
+
+ | DIS |
+ 到波士顿5个就业中心的加权距离 |
+ 连续值 |
+
+
+ | RAD |
+ 到径向公路的可达性指数 |
+ 连续值 |
+
+
+ | TAX |
+ 全值财产税率 |
+ 连续值 |
+
+
+ | PTRATIO |
+ 学生与教师的比例 |
+ 连续值 |
+
+
+ | B |
+ 1000(BK - 0.63)^2,其中BK为黑人占比 |
+ 连续值 |
+
+
+ | LSTAT |
+ 低收入人群占比 |
+ 连续值 |
+
+
+ | MEDV |
+ 同类房屋价格的中位数 |
+ 连续值 |
+
+
+
+
### 数据预处理
#### 连续值与离散值
-观察一下数据,我们的第一个发现是:所有的13维属性中,有12维的连续值和1维的离散值(CHAS)。离散值虽然也常使用类似0、1、2这样的数字表示,但是其含义与连续值是不同的,因为这里的差值没有实际意义。例如,我们用0、1、2来分别表示红色、绿色和蓝色的话,我们并不能因此说“蓝色和红色”比“绿色和红色”的距离更远。所以通常对一个有`$d$`个可能取值的离散属性,我们会将它们转为`$d$`个取值为0或1的二值属性或者将每个可能取值映射为一个多维向量。不过就这里而言,因为CHAS本身就是一个二值属性,就省去了这个麻烦。
+观察一下数据,我们的第一个发现是:所有的13维属性中,有12维的连续值和1维的离散值(CHAS)。离散值虽然也常使用类似0、1、2这样的数字表示,但是其含义与连续值是不同的,因为这里的差值没有实际意义。例如,我们用0、1、2来分别表示红色、绿色和蓝色的话,我们并不能因此说“蓝色和红色”比“绿色和红色”的距离更远。所以通常对一个有$d$个可能取值的离散属性,我们会将它们转为$d$个取值为0或1的二值属性或者将每个可能取值映射为一个多维向量。不过就这里而言,因为CHAS本身就是一个二值属性,就省去了这个麻烦。
#### 属性的归一化
另外一个稍加观察即可发现的事实是,各维属性的取值范围差别很大(如图2所示)。例如,属性B的取值范围是[0.32, 396.90],而属性NOX的取值范围是[0.3850, 0.8170]。这里就要用到一个常见的操作-归一化(normalization)了。归一化的目标是把各位属性的取值范围放缩到差不多的区间,例如[-0.5,0.5]。这里我们使用一种很常见的操作方法:减掉均值,然后除以原取值范围。
@@ -85,7 +152,7 @@ $$MSE=\frac{1}{n}\sum_{i=1}^{n}{(\hat{Y_i}-Y_i)}^2$$
图2. 各维属性的取值范围
#### 整理训练集与测试集
-我们将数据集分割为两份:一份用于调整模型的参数,即进行模型的训练,模型在这份数据集上的误差被称为**训练误差**;另外一份被用来测试,模型在这份数据集上的误差被称为**测试误差**。我们训练模型的目的是为了通过从训练数据中找到规律来预测未知的新数据,所以测试误差是更能反映模型表现的指标。分割数据的比例要考虑到两个因素:更多的训练数据会降低参数估计的方差,从而得到更可信的模型;而更多的测试数据会降低测试误差的方差,从而得到更可信的测试误差。我们这个例子中设置的分割比例为`$8:2$`
+我们将数据集分割为两份:一份用于调整模型的参数,即进行模型的训练,模型在这份数据集上的误差被称为**训练误差**;另外一份被用来测试,模型在这份数据集上的误差被称为**测试误差**。我们训练模型的目的是为了通过从训练数据中找到规律来预测未知的新数据,所以测试误差是更能反映模型表现的指标。分割数据的比例要考虑到两个因素:更多的训练数据会降低参数估计的方差,从而得到更可信的模型;而更多的测试数据会降低测试误差的方差,从而得到更可信的测试误差。我们这个例子中设置的分割比例为$8:2$
在更复杂的模型训练过程中,我们往往还会多使用一种数据集:验证集。因为复杂的模型中常常还有一些超参数([Hyperparameter](https://en.wikipedia.org/wiki/Hyperparameter_optimization))需要调节,所以我们会尝试多种超参数的组合来分别训练多个模型,然后对比它们在验证集上的表现选择相对最好的一组超参数,最后才使用这组参数下训练的模型在测试集上评估测试误差。由于本章训练的模型比较简单,我们暂且忽略掉这个过程。
@@ -260,4 +327,3 @@ print("infer results: ", results[0])

本教程 由 PaddlePaddle 创作,采用 知识共享 署名-相同方式共享 4.0 国际 许可协议进行许可。
-
diff --git a/source/beginners_guide/quick_start/recognize_digits/README.cn.md b/source/beginners_guide/quick_start/recognize_digits/README.cn.md
index 71d64339d8633f7113df682e509b988ec06edf23..2996d3702c34867c150cd6d906081d57357dde62 100644
--- a/source/beginners_guide/quick_start/recognize_digits/README.cn.md
+++ b/source/beginners_guide/quick_start/recognize_digits/README.cn.md
@@ -1,6 +1,6 @@
# 识别数字
-本教程源代码目录在[book/recognize_digits](https://github.com/PaddlePaddle/book/tree/develop/02.recognize_digits), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书),更多内容请参考本教程的[视频课堂](http://bit.baidu.com/course/detail/id/167.html)。
+本教程源代码目录在[book/recognize_digits](https://github.com/PaddlePaddle/book/tree/develop/02.recognize_digits), 初次使用请参考PaddlePaddle[安装教程](https://github.com/PaddlePaddle/book/blob/develop/README.cn.md#运行这本书)。
## 背景介绍
当我们学习编程的时候,编写的第一个程序一般是实现打印"Hello World"。而机器学习(或深度学习)的入门教程,一般都是 [MNIST](http://yann.lecun.com/exdb/mnist/) 数据库上的手写识别问题。原因是手写识别属于典型的图像分类问题,比较简单,同时MNIST数据集也很完备。MNIST数据集作为一个简单的计算机视觉数据集,包含一系列如图1所示的手写数字图片和对应的标签。图片是28x28的像素矩阵,标签则对应着0~9的10个数字。每张图片都经过了大小归一化和居中处理。
@@ -20,21 +20,21 @@ Yann LeCun早先在手写字符识别上做了很多研究,并在研究过程
## 模型概览
基于MNIST数据训练一个分类器,在介绍本教程使用的三个基本图像分类网络前,我们先给出一些定义:
-- `$X$`是输入:MNIST图片是`$28\times28$` 的二维图像,为了进行计算,我们将其转化为`$784$`维向量,即`$X=\left ( x_0, x_1, \dots, x_{783} \right )$`。
-- `$Y$`是输出:分类器的输出是10类数字(0-9),即`$Y=\left ( y_0, y_1, \dots, y_9 \right )$`,每一维`$y_i$`代表图片分类为第`$i$`类数字的概率。
-- `$L$`是图片的真实标签:`$L=\left ( l_0, l_1, \dots, l_9 \right )$`也是10维,但只有一维为1,其他都为0。
+- $X$是输入:MNIST图片是$28\times28$ 的二维图像,为了进行计算,我们将其转化为$784$维向量,即$X=\left ( x_0, x_1, \dots, x_{783} \right )$。
+- $Y$是输出:分类器的输出是10类数字(0-9),即$Y=\left ( y_0, y_1, \dots, y_9 \right )$,每一维$y_i$代表图片分类为第$i$类数字的概率。
+- $L$是图片的真实标签:$L=\left ( l_0, l_1, \dots, l_9 \right )$也是10维,但只有一维为1,其他都为0。
### Softmax回归(Softmax Regression)
最简单的Softmax回归模型是先将输入层经过一个全连接层得到的特征,然后直接通过softmax 函数进行多分类\[[9](#参考文献)\]。
-输入层的数据`$X$`传到输出层,在激活操作之前,会乘以相应的权重 `$W$` ,并加上偏置变量 `$b$` ,具体如下:
+输入层的数据$X$传到输出层,在激活操作之前,会乘以相应的权重 $W$ ,并加上偏置变量 $b$ ,具体如下:
$$ y_i = \text{softmax}(\sum_j W_{i,j}x_j + b_i) $$
-其中 `$ \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} $`
+其中 $ \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} $
-对于有 `$N$` 个类别的多分类问题,指定 `$N$` 个输出节点,`$N$` 维结果向量经过softmax将归一化为 `$N$` 个[0,1]范围内的实数值,分别表示该样本属于这 `$N$` 个类别的概率。此处的 `$y_i$` 即对应该图片为数字 `$i$` 的预测概率。
+对于有 $N$ 个类别的多分类问题,指定 $N$ 个输出节点,$N$ 维结果向量经过softmax将归一化为 $N$ 个[0,1]范围内的实数值,分别表示该样本属于这 $N$ 个类别的概率。此处的 $y_i$ 即对应该图片为数字 $i$ 的预测概率。
在分类问题中,我们一般采用交叉熵代价损失函数(cross entropy),公式如下:
@@ -49,9 +49,9 @@ $$ \text{crossentropy}(label, y) = -\sum_i label_ilog(y_i) $$
Softmax回归模型采用了最简单的两层神经网络,即只有输入层和输出层,因此其拟合能力有限。为了达到更好的识别效果,我们考虑在输入层和输出层中间加上若干个隐藏层\[[10](#参考文献)\]。
-1. 经过第一个隐藏层,可以得到 `$ H_1 = \phi(W_1X + b_1) $`,其中`$\phi$`代表激活函数,常见的有sigmoid、tanh或ReLU等函数。
-2. 经过第二个隐藏层,可以得到 `$ H_2 = \phi(W_2H_1 + b_2) $`。
-3. 最后,再经过输出层,得到的`$Y=\text{softmax}(W_3H_2 + b_3)$`,即为最后的分类结果向量。
+1. 经过第一个隐藏层,可以得到 $ H_1 = \phi(W_1X + b_1) $,其中$\phi$代表激活函数,常见的有sigmoid、tanh或ReLU等函数。
+2. 经过第二个隐藏层,可以得到 $ H_2 = \phi(W_2H_1 + b_2) $。
+3. 最后,再经过输出层,得到的$Y=\text{softmax}(W_3H_2 + b_3)$,即为最后的分类结果向量。
图3为多层感知器的网络结构图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
@@ -70,16 +70,16 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
卷积层是卷积神经网络的核心基石。在图像识别里我们提到的卷积是二维卷积,即离散二维滤波器(也称作卷积核)与二维图像做卷积操作,简单的讲是二维滤波器滑动到二维图像上所有位置,并在每个位置上与该像素点及其领域像素点做内积。卷积操作被广泛应用与图像处理领域,不同卷积核可以提取不同的特征,例如边沿、线性、角等特征。在深层卷积神经网络中,通过卷积操作可以提取出图像低级到复杂的特征。
-
+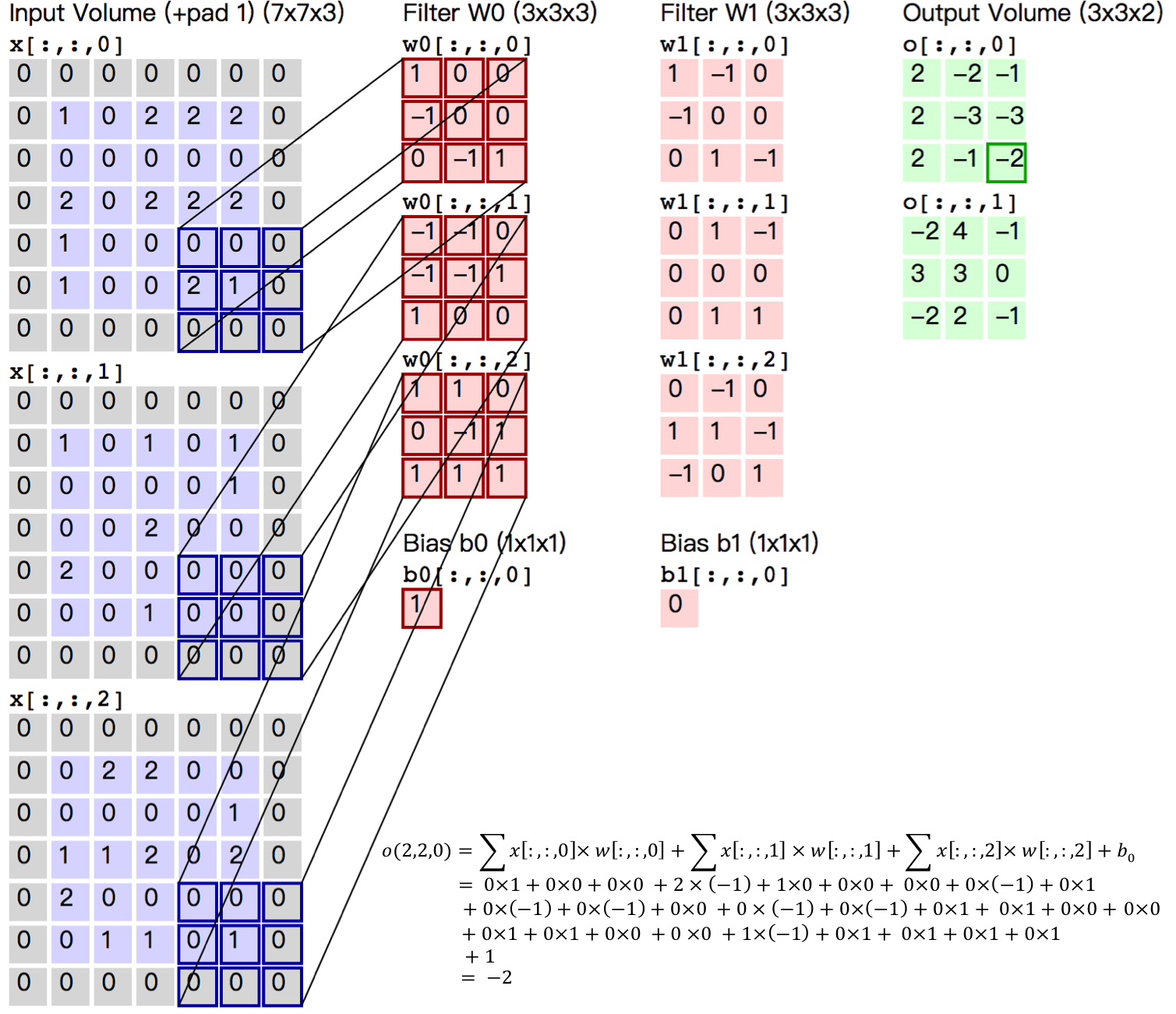
图5. 卷积层图片
-图5给出一个卷积计算过程的示例图,输入图像大小为`$H=5,W=5,D=3$`,即`$5 \times 5$`大小的3通道(RGB,也称作深度)彩色图像。这个示例图中包含两(用`$K$`表示)组卷积核,即图中滤波器`$W_0$`和`$W_1$`。在卷积计算中,通常对不同的输入通道采用不同的卷积核,如图示例中每组卷积核包含(`$D=3$`)个`$3 \times 3$`(用`$F \times F$`表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向(`$W$`方向)和垂直方向(`$H$`方向)的滑动步长为2(用`$S$`表示);对输入图像周围各填充1(用`$P$`表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为`$3 \times 3 \times 2$`(用`$H_{o} \times W_{o} \times K$`表示)大小的特征图,即`$3 \times 3$`大小的2通道特征图,其中`$H_o$`计算公式为:`$H_o = (H - F + 2 \times P)/S + 1$`,`$W_o$`同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置`$b_o$`,偏置通常对于每个输出特征图是共享的。输出特征图`$o[:,:,0]$`中的最后一个`$-2$`计算如图5右下角公式所示。
+图5给出一个卷积计算过程的示例图,输入图像大小为$H=5,W=5,D=3$,即$5 \times 5$大小的3通道(RGB,也称作深度)彩色图像。这个示例图中包含两(用$K$表示)组卷积核,即图中滤波器$W_0$和$W_1$。在卷积计算中,通常对不同的输入通道采用不同的卷积核,如图示例中每组卷积核包含($D=3$)个$3 \times 3$(用$F \times F$表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向($W$方向)和垂直方向($H$方向)的滑动步长为2(用$S$表示);对输入图像周围各填充1(用$P$表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为$3 \times 3 \times 2$(用$H_{o} \times W_{o} \times K$表示)大小的特征图,即$3 \times 3$大小的2通道特征图,其中$H_o$计算公式为:$H_o = (H - F + 2 \times P)/S + 1$,$W_o$同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置$b_o$,偏置通常对于每个输出特征图是共享的。输出特征图$o[:,:,0]$中的最后一个$-2$计算如图5右下角公式所示。
-在卷积操作中卷积核是可学习的参数,经过上面示例介绍,每层卷积的参数大小为`$D \times F \times F \times K$`。在多层感知器模型中,神经元通常是全部连接,参数较多。而卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
+在卷积操作中卷积核是可学习的参数,经过上面示例介绍,每层卷积的参数大小为$D \times F \times F \times K$。在多层感知器模型中,神经元通常是全部连接,参数较多。而卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
- 局部连接:每个神经元仅与输入神经元的一块区域连接,这块局部区域称作感受野(receptive field)。在图像卷积操作中,即神经元在空间维度(spatial dimension,即上图示例H和W所在的平面)是局部连接,但在深度上是全部连接。对于二维图像本身而言,也是局部像素关联较强。这种局部连接保证了学习后的过滤器能够对于局部的输入特征有最强的响应。局部连接的思想,也是受启发于生物学里面的视觉系统结构,视觉皮层的神经元就是局部接受信息的。
-- 权重共享:计算同一个深度切片的神经元时采用的滤波器是共享的。例如图4中计算`$o[:,:,0]$`的每个每个神经元的滤波器均相同,都为`$W_0$`,这样可以很大程度上减少参数。共享权重在一定程度上讲是有意义的,例如图片的底层边缘特征与特征在图中的具体位置无关。但是在一些场景中是无意的,比如输入的图片是人脸,眼睛和头发位于不同的位置,希望在不同的位置学到不同的特征 (参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/))。请注意权重只是对于同一深度切片的神经元是共享的,在卷积层,通常采用多组卷积核提取不同特征,即对应不同深度切片的特征,不同深度切片的神经元权重是不共享。另外,偏重对同一深度切片的所有神经元都是共享的。
+- 权重共享:计算同一个深度切片的神经元时采用的滤波器是共享的。例如图4中计算$o[:,:,0]$的每个每个神经元的滤波器均相同,都为$W_0$,这样可以很大程度上减少参数。共享权重在一定程度上讲是有意义的,例如图片的底层边缘特征与特征在图中的具体位置无关。但是在一些场景中是无意的,比如输入的图片是人脸,眼睛和头发位于不同的位置,希望在不同的位置学到不同的特征 (参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/))。请注意权重只是对于同一深度切片的神经元是共享的,在卷积层,通常采用多组卷积核提取不同特征,即对应不同深度切片的特征,不同深度切片的神经元权重是不共享。另外,偏重对同一深度切片的所有神经元都是共享的。
通过介绍卷积计算过程及其特性,可以看出卷积是线性操作,并具有平移不变性(shift-invariant),平移不变性即在图像每个位置执行相同的操作。卷积层的局部连接和权重共享使得需要学习的参数大大减小,这样也有利于训练较大卷积神经网络。
@@ -93,13 +93,13 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
更详细的关于卷积神经网络的具体知识可以参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/ )和[图像分类](https://github.com/PaddlePaddle/book/blob/develop/image_classification/README.md)教程。
### 常见激活函数介绍
-- sigmoid激活函数: `$ f(x) = sigmoid(x) = \frac{1}{1+e^{-x}} $`
+- sigmoid激活函数: $ f(x) = sigmoid(x) = \frac{1}{1+e^{-x}} $
-- tanh激活函数: `$ f(x) = tanh(x) = \frac{e^x-e^{-x}}{e^x+e^{-x}} $`
+- tanh激活函数: $ f(x) = tanh(x) = \frac{e^x-e^{-x}}{e^x+e^{-x}} $
实际上,tanh函数只是规模变化的sigmoid函数,将sigmoid函数值放大2倍之后再向下平移1个单位:tanh(x) = 2sigmoid(2x) - 1 。
-- ReLU激活函数: `$ f(x) = max(0, x) $`
+- ReLU激活函数: $ f(x) = max(0, x) $
更详细的介绍请参考[维基百科激活函数](https://en.wikipedia.org/wiki/Activation_function)。
@@ -107,12 +107,35 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
PaddlePaddle在API中提供了自动加载[MNIST](http://yann.lecun.com/exdb/mnist/)数据的模块`paddle.dataset.mnist`。加载后的数据位于`/home/username/.cache/paddle/dataset/mnist`下:
-| 文件名称 | 说明 |
-|-------------------------|----------------------------|
-| train-images-idx3-ubyte | 训练数据图片,60,000条数据 |
-| train-labels-idx1-ubyte | 训练数据标签,60,000条数据 |
-| t10k-images-idx3-ubyte | 测试数据图片,10,000条数据 |
-| t10k-labels-idx1-ubyte | 测试数据标签,10,000条数据 |
+
+
+
+
+ | 文件名称 |
+ 说明 |
+
+
+
+
+
+ | train-images-idx3-ubyte |
+ 训练数据图片,60,000条数据 |
+
+
+ | train-labels-idx1-ubyte |
+ 训练数据标签,60,000条数据 |
+
+
+ | t10k-images-idx3-ubyte |
+ 测试数据图片,10,000条数据 |
+
+
+ | t10k-labels-idx1-ubyte |
+ 测试数据标签,10,000条数据 |
+
+
+
+
## Fluid API 概述
diff --git a/source/faq/faq.rst b/source/faq/faq.rst
index 9d43c91a8544c3b281b2e8d556cb8b8e069d7e0a..3b4bd4f895162fa3b0ba12e785e38ad694590b25 100644
--- a/source/faq/faq.rst
+++ b/source/faq/faq.rst
@@ -1,3 +1,12 @@
-###
-FAQ
-###
+###################
+编译安装与单元测试
+###################
+
+1. 通过pip安装的PaddlePaddle在 :code:`import paddle.fluid` 报找不到 :code:`libmkldnn.so` 或 :code:`libmklml_intel.so`
+------------------------------------------------------------------------------------------
+出现这种问题的原因是在导入 :code:`paddle.fluid` 时需要加载 :code:`libmkldnn.so` 和 :code:`libmklml_intel.so`,
+但是系统没有找到该文件。一般通过pip安装PaddlePaddle时会将 :code:`libmkldnn.so` 和 :code:`libmklml_intel.so`
+拷贝到 :code:`/usr/local/lib` 路径下,所以解决办法是将该路径加到 :code:`LD_LIBRARY_PATH` 环境变量下,
+即: :code:`export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH` 。
+
+**注意**:如果是在虚拟环境中安装PaddlePaddle, :code:`libmkldnn.so` 和 :code:`libmklml_intel.so` 可能不在 :code:`/usr/local/lib` 路径下。
diff --git a/source/faq/index_cn.rst b/source/faq/index_cn.rst
new file mode 100644
index 0000000000000000000000000000000000000000..bb2ed99217609d3a9edd179d4f98ad5b8b649860
--- /dev/null
+++ b/source/faq/index_cn.rst
@@ -0,0 +1,9 @@
+FAQ
+====
+
+本文档对关于PaddlePaddle的一些常见问题提供了解答。如果您的问题未在此处,请您到 `PaddlePaddle社区 `_ 查找答案或直接提 `issue `_ ,我们会及时进行回复。
+
+.. toctree::
+ :maxdepth: 1
+
+ faq.rst
diff --git a/source/user_guides/howto/configure_simple_model/index.rst b/source/user_guides/howto/configure_simple_model/index.rst
index 9bed6fb9fe5476a33a8614be93dc76806521ee73..5946a2ccb7e43004eae39ec4b3c6112c66c1fd04 100644
--- a/source/user_guides/howto/configure_simple_model/index.rst
+++ b/source/user_guides/howto/configure_simple_model/index.rst
@@ -33,9 +33,9 @@
数据层
------
-PaddlePaddle提供了 :ref:`api_fluid_layers_data` 算子来描述输入数据的格式。
+PaddlePaddle提供了 :code:`fluid.layers.data()` 算子来描述输入数据的格式。
-:ref:`api_fluid_layers_data` 算子的输出是一个Variable。这个Variable的实际类型是Tensor。Tensor具有强大的表征能力,可以表示多维数据。为了精确描述数据结构,通常需要指定数据shape以及数值类型type。其中shape为一个整数向量,type可以是一个字符串类型。目前支持的数据类型参考 :ref:`user_guide_paddle_support_data_types` 。 模型训练一般会使用batch的方式读取数据,而batch的size在训练过程中可能不固定。data算子会依据实际数据来推断batch size,所以这里提供shape时不用关心batch size,只需关心一条样本的shape即可,更高级用法请参考 :ref:`user_guide_customize_batch_size_rank`。从上知,:math:`x` 为 :math:`13` 维的实数向量,:math:`y` 为实数,可使用下面代码定义数据层:
+:code:`fluid.layers.data()` 算子的输出是一个Variable。这个Variable的实际类型是Tensor。Tensor具有强大的表征能力,可以表示多维数据。为了精确描述数据结构,通常需要指定数据shape以及数值类型type。其中shape为一个整数向量,type可以是一个字符串类型。目前支持的数据类型参考 :ref:`user_guide_paddle_support_data_types` 。 模型训练一般会使用batch的方式读取数据,而batch的size在训练过程中可能不固定。data算子会依据实际数据来推断batch size,所以这里提供shape时不用关心batch size,只需关心一条样本的shape即可,更高级用法请参考 :ref:`user_guide_customize_batch_size_rank`。从上知,:math:`x` 为 :math:`13` 维的实数向量,:math:`y` 为实数,可使用下面代码定义数据层:
.. code-block:: python
@@ -55,7 +55,7 @@ PaddlePaddle提供了 :ref:`api_fluid_layers_data` 算子来描述输入数据
op_2_out = fluid.layers.op_2(input=op_1_out, ...)
...
-其中op_1和op_2表示算子类型,可以是fc来执行线性变换(全连接),也可以是conv来执行卷积变换等。通过算子的输入输出的连接来定义算子的计算顺序以及数据流方向。上面的例子中,op_1的输出是op_2的输入,那么在执行计算时,会先计算op_1,然后计算op_2。更复杂的模型可能需要使用控制流算子,依据输入数据来动态执行,针对这种情况,PaddlePaddle提供了IfElseOp和WhileOp等。算子的文档可参考 :ref:`api_fluid_layers`。具体到这个任务, 我们使用一个fc算子:
+其中op_1和op_2表示算子类型,可以是fc来执行线性变换(全连接),也可以是conv来执行卷积变换等。通过算子的输入输出的连接来定义算子的计算顺序以及数据流方向。上面的例子中,op_1的输出是op_2的输入,那么在执行计算时,会先计算op_1,然后计算op_2。更复杂的模型可能需要使用控制流算子,依据输入数据来动态执行,针对这种情况,PaddlePaddle提供了IfElseOp和WhileOp等。算子的文档可参考 :code:`fluid.layers`。具体到这个任务, 我们使用一个fc算子:
.. code-block:: python
@@ -80,7 +80,7 @@ PaddlePaddle提供了 :ref:`api_fluid_layers_data` 算子来描述输入数据
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001)
-更多优化算子可以参考 :ref:`api_fluid_optimizer` 。
+更多优化算子可以参考 :code:`fluid.optimizer()` 。
下一步做什么?
##############
diff --git a/source/user_guides/howto/inference/build_and_install_lib_cn.rst b/source/user_guides/howto/inference/build_and_install_lib_cn.rst
new file mode 100644
index 0000000000000000000000000000000000000000..3884284ea020fe94ed9c03ec84c856ee44aa8c3f
--- /dev/null
+++ b/source/user_guides/howto/inference/build_and_install_lib_cn.rst
@@ -0,0 +1,99 @@
+.. _install_or_build_cpp_inference_lib:
+
+安装与编译C++预测库
+===========================
+
+直接下载安装
+-------------
+
+====================== ========================================
+版本说明 C++预测库
+====================== ========================================
+cpu_avx_mkl `fluid.tgz `_
+cpu_avx_openblas `fluid.tgz `_
+cpu_noavx_openblas `fluid.tgz `_
+cuda7.5_cudnn5_avx_mkl `fluid.tgz `_
+cuda8.0_cudnn5_avx_mkl `fluid.tgz `_
+cuda8.0_cudnn7_avx_mkl `fluid.tgz `_
+cuda9.0_cudnn7_avx_mkl `fluid.tgz `_
+====================== ========================================
+
+从源码编译
+----------
+用户也可以从 PaddlePaddle 核心代码编译C++预测库,只需在编译时配制下面这些编译选项:
+
+================= =========
+选项 值
+================= =========
+CMAKE_BUILD_TYPE Release
+FLUID_INSTALL_DIR 安装路径
+WITH_FLUID_ONLY ON(推荐)
+WITH_SWIG_PY OFF(推荐
+WITH_PYTHON OFF(推荐)
+WITH_GPU ON/OFF
+WITH_MKL ON/OFF
+================= =========
+
+建议按照推荐值设置,以避免链接不必要的库。其它可选编译选项按需进行设定。
+
+下面的代码片段从github拉取最新代码,配制编译选项(需要将PADDLE_ROOT替换为PaddlePaddle预测库的安装路径):
+
+ .. code-block:: bash
+
+ pip install paddlepaddle-gpu
+ PADDLE_ROOT=/path/of/capi
+ git clone https://github.com/PaddlePaddle/Paddle.git
+ cd Paddle
+ mkdir build
+ cd build
+ cmake -DFLUID_INSTALL_DIR=$PADDLE_ROOT \
+ -DCMAKE_BUILD_TYPE=Release \
+ -DWITH_FLUID_ONLY=ON \
+ -DWITH_SWIG_PY=OFF \
+ -DWITH_PYTHON=OFF \
+ -DWITH_MKL=OFF \
+ -DWITH_GPU=OFF \
+ ..
+ make
+ make inference_lib_dist
+
+成功编译后,使用C++预测库所需的依赖(包括:(1)编译出的PaddlePaddle预测库和头文件;(2)第三方链接库和头文件;(3)版本信息与编译选项信息)
+均会存放于PADDLE_ROOT目录中。目录结构如下:
+
+ .. code-block:: text
+
+ PaddleRoot/
+ ├── CMakeCache.txt
+ ├── paddle
+ │ └── fluid
+ │ ├── framework
+ │ ├── inference
+ │ ├── memory
+ │ ├── platform
+ │ ├── pybind
+ │ └── string
+ ├── third_party
+ │ ├── boost
+ │ │ └── boost
+ │ ├── eigen3
+ │ │ ├── Eigen
+ │ │ └── unsupported
+ │ └── install
+ │ ├── gflags
+ │ ├── glog
+ │ ├── mklml
+ │ ├── protobuf
+ │ ├── snappy
+ │ ├── snappystream
+ │ └── zlib
+ └── version.txt
+
+version.txt 中记录了该预测库的版本信息,包括Git Commit ID、使用OpenBlas或MKL数学库、CUDA/CUDNN版本号,如:
+
+ .. code-block:: text
+
+ GIT COMMIT ID: c95cd4742f02bb009e651a00b07b21c979637dc8
+ WITH_MKL: ON
+ WITH_GPU: ON
+ CUDA version: 8.0
+ CUDNN version: v5
diff --git a/source/user_guides/howto/inference/index.rst b/source/user_guides/howto/inference/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..45e1a2883773b92ed47ef8d51417bbdcd060b4ec
--- /dev/null
+++ b/source/user_guides/howto/inference/index.rst
@@ -0,0 +1,11 @@
+############
+模型预测部署
+############
+
+PaddlePaddle Fluid 提供了 C++ API 来支持模型的部署上线
+
+.. toctree::
+ :maxdepth: 2
+
+ build_and_install_lib_cn.rst
+ native_infer.rst
diff --git a/source/user_guides/howto/inference/native_infer.rst b/source/user_guides/howto/inference/native_infer.rst
new file mode 100644
index 0000000000000000000000000000000000000000..e1eee3f818796e895362caab10846cf59b557162
--- /dev/null
+++ b/source/user_guides/howto/inference/native_infer.rst
@@ -0,0 +1,108 @@
+Paddle 预测 API
+===============
+
+为了更简单方便的预测部署,Fluid 提供了一套高层 API
+用来隐藏底层不同的优化实现。
+
+`预测库相关代码 `__
+包括
+
+- 头文件 ``paddle_inference_api.h`` 定义了所有的接口
+- 库文件\ ``libpaddle_fluid.so`` 或 ``libpaddle_fluid.a``
+- 库文件 ``libpaddle_inference_api.so`` 或
+ ``libpaddle_inference_api.a``
+
+编译和依赖可以参考 :ref:`install_or_build_cpp_inference_lib` 。
+
+下面是一些 API 概念的介绍
+
+PaddleTensor
+------------
+
+PaddleTensor 定义了预测最基本的输入输出的数据格式,其定义是
+
+.. code:: cpp
+
+ struct PaddleTensor {
+ std::string name; // variable name.
+ std::vector shape;
+ PaddleBuf data; // blob of data.
+ PaddleDType dtype;
+ };
+
+- ``name`` 用于指定输入数据对应的 模型中variable 的名字
+ (暂时没有用,但会在后续支持任意 target 时启用)
+- ``shape`` 表示一个 Tensor 的 shape
+- ``data`` 数据以连续内存的方式存储在\ ``PaddleBuf``
+ 中,\ ``PaddleBuf``
+ 可以接收外面的数据或者独立\ ``malloc``\ 内存,详细可以参考头文件中相关定义。
+- ``dtype`` 表示 Tensor 的数据类型
+
+engine
+------
+
+高层 API 底层有多种优化实现,我们称之为 engine,目前有三种 engine
+
+- 原生 engine,由 paddle 原生的 forward operator
+ 组成,可以天然支持所有paddle 训练出的模型,
+- Anakin engine,封装了
+ `Anakin `__
+ ,在某些模型上性能不错,但只能接受自带模型格式,无法支持所有 paddle
+ 模型,
+- TensorRT mixed engine,用子图的方式支持了
+ `TensorRT `__ ,支持所有paddle
+ 模型,并自动切割部分计算子图到 TensorRT 上加速(WIP)
+
+其实现为
+
+.. code:: cpp
+
+ enum class PaddleEngineKind {
+ kNative = 0, // Use the native Fluid facility.
+ kAnakin, // Use Anakin for inference.
+ kAutoMixedTensorRT // Automatically mixing TensorRT with the Fluid ops.
+ };
+
+预测部署过程
+------------
+
+总体上分为以下步骤
+
+1. 用合适的配置创建 ``PaddlePredictor``
+2. 创建输入用的 ``PaddleTensor``\ ,传入到 ``PaddlePredictor`` 中
+3. 获取输出的 ``PaddleTensor`` ,将结果取出
+
+下面完整演示一个简单的模型,部分细节代码隐去
+
+.. code:: cpp
+
+ #include "paddle_inference_api.h"
+
+ // 创建一个 config,并修改相关设置
+ paddle::NativeConfig config;
+ config.model_dir = "xxx";
+ config.use_gpu = false;
+ // 创建一个原生的 PaddlePredictor
+ auto predictor =
+ paddle::CreatePaddlePredictor(config);
+ // 创建输入 tensor
+ int64_t data[4] = {1, 2, 3, 4};
+ paddle::PaddleTensor tensor{.name = "",
+ .shape = std::vector({4, 1}),
+ .data = PaddleBuf(data, sizeof(data)),
+ .dtype = PaddleDType::INT64};
+ // 创建输出 tensor,输出 tensor 的内存可以复用
+ std::vector outputs;
+ // 执行预测
+ CHECK(predictor->Run(slots, &outputs));
+ // 获取 outputs ...
+
+编译时,联编 ``libpaddle_fluid.a/.so`` 和
+``libpaddle_inference_api.a/.so`` 便可。
+
+详细代码参考
+------------
+
+- `inference
+ demos `__
+- `复杂单线程/多线程例子 `__
diff --git a/source/user_guides/howto/prepare_data/feeding_data.rst b/source/user_guides/howto/prepare_data/feeding_data.rst
index 78f43338df02c503d6b46b93aaddb4d01a0f00ee..c3bf033bb8316eeb4901c0cdc61e0556c8816dac 100644
--- a/source/user_guides/howto/prepare_data/feeding_data.rst
+++ b/source/user_guides/howto/prepare_data/feeding_data.rst
@@ -4,15 +4,15 @@
使用Numpy Array作为训练数据
###########################
-PaddlePaddle Fluid支持使用 :ref:`api_fluid_layers_data` 配置数据层;
+PaddlePaddle Fluid支持使用 :code:`fluid.layers.data()` 配置数据层;
再使用 Numpy Array 或者直接使用Python创建C++的
-:ref:`api_guide_lod_tensor` , 通过 :code:`Executor.run(feed=...)` 传给
-:ref:`api_guide_executor` 或 :ref:`api_guide_parallel_executor` 。
+:code:`fluid.LoDTensor` , 通过 :code:`Executor.run(feed=...)` 传给
+:code:`fluid.Executor` 或 :code:`fluid.ParallelExecutor` 。
数据层配置
##########
-通过 :ref:`api_fluid_layers_data` 可以配置神经网络中需要的数据层。具体方法为:
+通过 :code:`fluid.layers.data()` 可以配置神经网络中需要的数据层。具体方法为:
.. code-block:: python
diff --git a/source/user_guides/howto/prepare_data/index.rst b/source/user_guides/howto/prepare_data/index.rst
index 643702e95ef6c245524fb7c54efd8d120da8c629..56fa928029903f1e3bd3e8064c146797f01b2b85 100644
--- a/source/user_guides/howto/prepare_data/index.rst
+++ b/source/user_guides/howto/prepare_data/index.rst
@@ -7,12 +7,12 @@
PaddlePaddle Fluid支持两种传入数据的方式:
1. 用户需要使用 :code:`fluid.layers.data`
-配置数据输入层,并在 :ref:`api_guide_executor` 或 :ref:`api_guide_parallel_executor`
+配置数据输入层,并在 :code:`fluid.Executor` 或 :code:`fluid.ParallelExecutor`
中,使用 :code:`executor.run(feed=...)` 传入训练数据。
2. 用户需要先将训练数据
-转换成 Paddle 识别的 :ref:`api_guide_recordio_file_format` , 再使用
-:code:`fluid.layers.open_files` 以及 :ref:`api_guide_reader` 配置数据读取。
+转换成 Paddle 识别的 :code:`fluid.recordio_writer` , 再使用
+:code:`fluid.layers.open_files` 以及 :code:`fluid.layers.reader` 配置数据读取。
这两种准备数据方法的比较如下:
@@ -21,9 +21,9 @@ PaddlePaddle Fluid支持两种传入数据的方式:
+------------+----------------------------------+---------------------------------------+
| | Feed数据 | 使用Reader |
+============+==================================+=======================================+
-| API接口 | :code:`executor.run(feed=...)` | :ref:`api_guide_reader` |
+| API接口 | :code:`executor.run(feed=...)` | :code:`fluid.layers.reader` |
+------------+----------------------------------+---------------------------------------+
-| 数据格式 | Numpy Array | :ref:`api_guide_recordio_file_format` |
+| 数据格式 | Numpy Array | :code:`fluid.recordio_writer` |
+------------+----------------------------------+---------------------------------------+
| 数据增强 | Python端使用其他库完成 | 使用Fluid中的Operator 完成 |
+------------+----------------------------------+---------------------------------------+
diff --git a/source/user_guides/howto/prepare_data/use_recordio_reader.rst b/source/user_guides/howto/prepare_data/use_recordio_reader.rst
index 3121ae74c4380b1ddfc4258f2a4f6be8782b306e..dfda33f1b03516fe2c704f55d095955282b19109 100644
--- a/source/user_guides/howto/prepare_data/use_recordio_reader.rst
+++ b/source/user_guides/howto/prepare_data/use_recordio_reader.rst
@@ -7,20 +7,20 @@
相比于 :ref:`user_guide_use_numpy_array_as_train_data`,
:ref:`user_guide_use_recordio_as_train_data` 的性能更好;
但是用户需要先将训练数据集转换成RecordIO文件格式,再使用
-:ref:`api_fluid_layers_open_files` 层在神经网络配置中导入 RecordIO 文件。
-用户还可以使用 :ref:`api_fluid_layers_double_buffer` 加速数据从内存到显存的拷贝,
-使用 :ref:`api_fluid_layers_Preprocessor` 工具进行数据增强。
+:code:`fluid.layers.open_files()` 层在神经网络配置中导入 RecordIO 文件。
+用户还可以使用 :code:`fluid.layers.double_buffer()` 加速数据从内存到显存的拷贝,
+使用 :code:`fluid.layers.Preprocessor` 工具进行数据增强。
将训练数据转换成RecordIO文件格式
################################
-:ref:`api_guide_recordio_file_format` 中,每个记录都是一个
+:code:`fluid.recordio_writer` 中,每个记录都是一个
:code:`vector`, 即一个支持序列信息的Tensor数组。这个数组包括训练所需
的所有特征。例如对于图像分类来说,这个数组可以包含图片和分类标签。
-用户可以使用 :ref:`api_fluid_recordio_writer_convert_reader_to_recordio_file` 可以将
+用户可以使用 :code:`fluid.recordio_writer.convert_reader_to_recordio_file()` 可以将
:ref:`user_guide_reader` 转换成一个RecordIO文件。或者可以使用
-:ref:`api_fluid_recordio_writer_convert_reader_to_recordio_files` 将一个
+:code:`fluid.recordio_writer.convert_reader_to_recordio_files()` 将一个
:ref:`user_guide_reader` 转换成多个RecordIO文件。
具体使用方法为:
@@ -62,8 +62,8 @@
配置神经网络, 打开RecordIO文件
##############################
-RecordIO文件转换好之后,用户可以使用 :ref:`api_fluid_layers_open_files`
-打开文件,并使用 :ref:`api_fluid_layers_read_file` 读取文件内容。
+RecordIO文件转换好之后,用户可以使用 :code:`fluid.layers.open_files()`
+打开文件,并使用 :code:`fluid.layers.read_file` 读取文件内容。
简单使用方法如下:
.. code-block:: python
@@ -89,11 +89,11 @@ RecordIO文件转换好之后,用户可以使用 :ref:`api_fluid_layers_open_f
########
-使用 :ref:`api_fluid_layers_double_buffer`
+使用 :code:`fluid.layers.double_buffer()`
------------------------------------------
:code:`Double buffer` 使用双缓冲技术,将训练数据从内存中复制到显存中。配置双缓冲
-需要使用 :ref:`api_fluid_layers_double_buffer` 修饰文件对象。 例如:
+需要使用 :code:`fluid.layers.double_buffer()` 修饰文件对象。 例如:
.. code-block:: python
@@ -109,7 +109,7 @@ RecordIO文件转换好之后,用户可以使用 :ref:`api_fluid_layers_open_f
配置数据增强
------------
-使用 :ref:`api_fluid_layers_Preprocessor` 可以配置文件的数据增强方法。例如
+使用 :code:`fluid.layers.Preprocessor` 可以配置文件的数据增强方法。例如
.. code-block:: python
@@ -132,7 +132,7 @@ RecordIO文件转换好之后,用户可以使用 :ref:`api_fluid_layers_open_f
使用Op组batch
-------------
-使用 :ref:`api_fluid_layers_batch` 可以在训练的过程中动态的组batch。例如
+使用 :code:`fluid.layers.batch()` 可以在训练的过程中动态的组batch。例如
.. code-block:: python
@@ -148,7 +148,7 @@ RecordIO文件转换好之后,用户可以使用 :ref:`api_fluid_layers_open_f
读入数据的shuffle
-----------------
-使用 :ref:`api_fluid_layers_shuffle` 可以在训练过程中动态重排训练数据。例如
+使用 :code:`fluid.layers.shuffle()` 可以在训练过程中动态重排训练数据。例如
.. code-block:: python
diff --git a/source/user_guides/howto/training/checkpoint_doc_cn.md b/source/user_guides/howto/training/checkpoint_doc_cn.md
index 51e07683f341059722f0d718d3fa4375ad551dfd..c4afd536c67b24a17e4437ecedf779ddcddcbc98 100644
--- a/source/user_guides/howto/training/checkpoint_doc_cn.md
+++ b/source/user_guides/howto/training/checkpoint_doc_cn.md
@@ -57,4 +57,4 @@ trainer = Trainer(..., checkpoint_config=config)
1. 保证每个训练的```checkpoint_dir``` 与其他训练独立。
2. 最大副本数量```max_num_checkpoints```需要根据磁盘容量以及模型的大小进行调整, 保证磁盘的可用性。
3. ```epoch_interval``` 和 ```step_interval``` 不宜过小, 频繁的进行checkpoint会拖慢训练速度。
-4. **分布式训练**的过程中:每个Trainer都会在```checkpoint_dir```目录中保存当前Trainer的参数(只有Trainer 0会保存模型的参数),需要**分布式文件系统(HDFS等)**将同```checkpoint_dir```目录的数据进行合并才能得到完整的数据,恢复训练的时候需要用完整的数据进行恢复。
\ No newline at end of file
+4. **分布式训练**的过程中:每个Trainer都会在```checkpoint_dir```目录中保存当前Trainer的参数(只有Trainer 0会保存模型的参数),需要**分布式文件系统(HDFS等)**将同```checkpoint_dir```目录的数据进行合并才能得到完整的数据,恢复训练的时候需要用完整的数据进行恢复。
diff --git a/source/user_guides/howto/training/checkpoint_doc_en.md b/source/user_guides/howto/training/checkpoint_doc_en.md
index 60524f64016e910768d0febed034717534f153ed..14d37246ca0cab8715e244fda9624d0d59f8ec5f 100644
--- a/source/user_guides/howto/training/checkpoint_doc_en.md
+++ b/source/user_guides/howto/training/checkpoint_doc_en.md
@@ -59,4 +59,4 @@ After all the things done, the train will save checkpoint at the specified epoch
1. Make the ```checkpoint_dir``` only be used by one train job.
2. The number of ```max_num_checkpoints``` need to be adjusted by the disk size and model size.
3. Too frequently to slow down the train speed, so too ```small epoch_interval``` and ```step_interval``` are not suitable.
-4. **In distributed train**, each Trainer will save arguments in its ```checkpoint_dir``` (Only Trainer 0 will save model variables). We need **distributed file system (HDFS, etc)** to merge all the ```checkpoint_dir``` to get the whole data.
\ No newline at end of file
+4. **In distributed train**, each Trainer will save arguments in its ```checkpoint_dir``` (Only Trainer 0 will save model variables). We need **distributed file system (HDFS, etc)** to merge all the ```checkpoint_dir``` to get the whole data.
diff --git a/source/user_guides/howto/training/save_load_variables.rst b/source/user_guides/howto/training/save_load_variables.rst
index 7d60231247357c5e7229f80e5653a1e7edbad8e3..a96776f4a17a1d6da170bdff9d81771c38912bb5 100644
--- a/source/user_guides/howto/training/save_load_variables.rst
+++ b/source/user_guides/howto/training/save_load_variables.rst
@@ -7,19 +7,19 @@
模型变量分类
############
-在PaddlePaddle Fluid中,所有的模型变量都用 :ref:`api_fluid_Variable` 作为基类进行表示。
+在PaddlePaddle Fluid中,所有的模型变量都用 :code:`fluid.Variable()` 作为基类进行表示。
在该基类之下,模型变量主要可以分为以下几种类别:
1. 模型参数
模型参数是深度学习模型中被训练和学习的变量,在训练过程中,训练框架根据反向传播算法计算出每一个模型参数当前的梯度,
并用优化器根据梯度对参数进行更新。模型的训练过程本质上可以看做是模型参数不断迭代更新的过程。
在PaddlePaddle Fluid中,模型参数用 :code:`fluid.framework.Parameter` 来表示,
- 这是一个 :ref:`api_fluid_Variable` 的派生类,除了 :ref:`api_fluid_Variable` 具有的各项性质以外,
+ 这是一个 :code:`fluid.Variable()` 的派生类,除了 :code:`fluid.Variable()` 具有的各项性质以外,
:code:`fluid.framework.Parameter` 还可以配置自身的初始化方法、更新率等属性。
2. 长期变量
长期变量指的是在整个训练过程中持续存在、不会因为一个迭代的结束而被销毁的变量,例如动态调节的全局学习率等。
- 在PaddlePaddle Fluid中,长期变量通过将 :ref:`api_fluid_Variable` 的 :code:`persistable`
+ 在PaddlePaddle Fluid中,长期变量通过将 :code:`fluid.Variable()` 的 :code:`persistable`
属性设置为 :code:`True` 来表示。所有的模型参数都是长期变量,但并非所有的长期变量都是模型参数。
3. 临时变量
@@ -43,7 +43,7 @@
==========================
如果我们保存模型的目的是用于对新样本的预测,那么只保存模型参数就足够了。我们可以使用
-:ref:`api_fluid_io_save_params` 接口来进行模型参数的保存。
+:code:`fluid.io.save_params()` 接口来进行模型参数的保存。
例如:
@@ -57,7 +57,7 @@
fluid.io.save_params(executor=exe, dirname=param_path, main_program=None)
上面的例子中,通过调用 :code:`fluid.io.save_params` 函数,PaddlePaddle Fluid会对默认
-:ref:`api_fluid_Program` 也就是 :code:`prog` 中的所有模型变量进行扫描,
+:code:`fluid.Program` 也就是 :code:`prog` 中的所有模型变量进行扫描,
筛选出其中所有的模型参数,并将这些模型参数保存到指定的 :code:`param_path` 之中。
@@ -66,7 +66,7 @@
在训练过程中,我们可能希望在一些节点上将当前的训练状态保存下来,
以便在将来需要的时候恢复训练环境继续进行训练。这一般被称作“checkpoint”。
-想要保存checkpoint,可以使用 :ref:`api_fluid_io_save_checkpoint` 接口。
+想要保存checkpoint,可以使用 :code:`fluid.io.save_checkpiont()` 接口。
例如:
@@ -87,7 +87,7 @@
max_num_checkpoints=3)
上面的例子中,通过调用 :code:`fluid.io.save_checkpoint` 函数,PaddlePaddle Fluid会对默认
-:ref:`api_fluid_Program` 也就是 :code:`prog` 中的所有模型变量进行扫描,
+:code:`fluid.Program` 也就是 :code:`prog` 中的所有模型变量进行扫描,
根据一系列内置的规则自动筛选出其中所有需要保存的变量,并将他们保存到指定的 :code:`path` 目录下。
:code:`fluid.io.save_checkpoint` 的各个参数中, :code:`trainer_id` 在单机情况下设置为0即可; :code:`trainer_args`
@@ -125,8 +125,8 @@
需要格外注意的是,这里的 :code:`prog` 必须和调用 :code:`fluid.io.save_params`
时所用的 :code:`prog` 中的前向部分完全一致,且不能包含任何参数更新的操作。如果两者存在不一致,
那么可能会导致一些变量未被正确加载;如果错误地包含了参数更新操作,那可能会导致正常预测过程中参数被更改。
-这两个 :ref:`api_fluid_Program` 之间的关系类似于训练 :ref:`api_fluid_Program`
-和测试 :ref:`api_fluid_Program` 之间的关系,详见: :ref:`user_guide_test_while_training`。
+这两个 :code:`fluid.Program` 之间的关系类似于训练 :code:`fluid.Program`
+和测试 :code:`fluid.Program` 之间的关系,详见: :ref:`user_guide_test_while_training`。
另外,需特别注意运行 :code:`fluid.default_startup_program()` 必须在调用 :code:`fluid.io.load_params`
之前。如果在之后运行,可能会覆盖已加载的模型参数导致错误。
diff --git a/source/user_guides/howto/training/single_node.rst b/source/user_guides/howto/training/single_node.rst
index 4282a39bc29681a028039948f1f2f9749c18cb0b..23eac0f831f2d6d052b7fc35b536d4ab633df851 100644
--- a/source/user_guides/howto/training/single_node.rst
+++ b/source/user_guides/howto/training/single_node.rst
@@ -8,8 +8,8 @@
要进行PaddlePaddle Fluid单机训练,需要先 :ref:`user_guide_prepare_data` 和
:ref:`user_guide_configure_simple_model` 。当\
:ref:`user_guide_configure_simple_model` 完毕后,可以得到两个\
-:ref:`api_fluid_Program`, :code:`startup_program` 和 :code:`main_program`。
-默认情况下,可以使用 :ref:`api_fluid_default_startup_program` 与\ :ref:`api_fluid_default_main_program` 获得全局的 :ref:`api_fluid_Program`。
+:code:`fluid.Program`, :code:`startup_program` 和 :code:`main_program`。
+默认情况下,可以使用 :code:`fluid.default_startup_program()` 与\ :code:`fluid.default_main_program()` 获得全局的 :code:`fluid.Program`。
例如:
@@ -44,8 +44,8 @@
==============
用户配置完模型后,参数初始化操作会被写入到\
-:code:`fluid.default_startup_program()` 中。使用 :ref:`api_fluid_Executor` 运行
-这一程序,即可在全局 :ref:`api_fluid_global_scope` 中随机初始化参数。例如:
+:code:`fluid.default_startup_program()` 中。使用 :code:`fluid.Executor()` 运行
+这一程序,即可在全局 :code:`fluid.global_scope()` 中随机初始化参数。例如:
.. code-block:: python
@@ -53,7 +53,7 @@
exe.run(program=fluid.default_startup_program())
值得注意的是: 如果使用多GPU训练,参数需要先在GPU0上初始化,再经由\
-:ref:`api_fluid_ParallelExecutor` 分发到多张显卡上。
+:code:`fluid.ParallelExecutor` 分发到多张显卡上。
载入预定义参数
@@ -66,8 +66,8 @@
单卡训练
########
-执行单卡训练可以使用 :ref:`api_fluid_Executor` 中的 :code:`run()` 方法,运行训练\
-:ref:`api_fluid_Program` 即可。在运行的时候,用户可以通过 :code:`run(feed=...)`\
+执行单卡训练可以使用 :code:`fluid.Executor()` 中的 :code:`run()` 方法,运行训练\
+:code:`fluid.Program` 即可。在运行的时候,用户可以通过 :code:`run(feed=...)`\
参数传入数据;用户可以通过 :code:`run(fetch=...)` 获取持久的数据。例如:\
.. code-block:: python
@@ -86,14 +86,14 @@
的Variable必须是persistable的。 :code:`fetch_list` 可以传入Variable的列表,\
也可以传入Variable的名字列表。:code:`Executor.run` 返回Fetch结果列表。
3. 如果需要取回的数据包含序列信息,可以设置
- :code:`exe.run(return_numpy=False, ...)` 直接返回 :ref:`api_guide_lod_tensor`
- 。用户可以直接访问 :ref:`api_guide_lod_tensor` 中的信息。
+ :code:`exe.run(return_numpy=False, ...)` 直接返回 :code:`fluid.LoDTensor`
+ 。用户可以直接访问 :code:`fluid.LoDTensor` 中的信息。
多卡训练
########
-执行多卡训练可以使用 :ref:`api_fluid_ParallelExecutor` 运行训练
-:ref:`api_fluid_Program`。例如:
+执行多卡训练可以使用 :code:`fluid.ParallelExecutor` 运行训练
+:code:`fluid.Program`。例如:
.. code-block:: python
@@ -103,8 +103,8 @@
这里有几点注意事项:
-1. :code:`ParallelExecutor` 的构造函数需要指明要执行的 :ref:`api_fluid_Program` ,
- 并在执行过程中不能修改。默认值是 :ref:`api_fluid_default_main_program` 。
+1. :code:`ParallelExecutor` 的构造函数需要指明要执行的 :code:`fluid.Program` ,
+ 并在执行过程中不能修改。默认值是 :code:`fluid.default_main_program()` 。
2. :code:`ParallelExecutor` 需要明确指定是否使用 CUDA 显卡进行训练。在显卡训练\
模式下会占用全部显卡。用户可以配置 `CUDA_VISIBLE_DEVICES `_ 来修改占用\
的显卡。
diff --git a/source/user_guides/howto/training/test_while_training.rst b/source/user_guides/howto/training/test_while_training.rst
index 665aa52ec581fcbb4a5799b49033f55ab82322f8..37d5c0d78179ccead7a81dffb4ae2f0d835a5949 100644
--- a/source/user_guides/howto/training/test_while_training.rst
+++ b/source/user_guides/howto/training/test_while_training.rst
@@ -4,7 +4,7 @@
训练过程中评测模型
##################
-模型的测试评价与训练的 :ref:`api_fluid_Program` 不同。在测试评价中:
+模型的测试评价与训练的 :code:`fluid.Program` 不同。在测试评价中:
1. 评价测试不进行反向传播,不优化更新参数。
2. 评价测试执行的操作可以不同。
@@ -13,13 +13,13 @@
* 评价模型与训练相比可以是完全不同的模型。
-生成测试 :ref:`api_fluid_Program`
+生成测试 :code:`fluid.Program`
#################################
-通过克隆训练 :ref:`api_fluid_Program` 生成测试 :ref:`api_fluid_Program`
+通过克隆训练 :code:`fluid.Program` 生成测试 :code:`fluid.Program`
=======================================================================
-:code:`Program.clone()` 方法可以复制出新的 :ref:`api_fluid_Program` 。 通过设置
+:code:`Program.clone()` 方法可以复制出新的 :code:`fluid.Program` 。 通过设置
:code:`Program.clone(for_test=True)` 复制含有用于测试的操作Program。简单的使用方法如下:
.. code-block:: python
@@ -45,11 +45,11 @@
成一个 :code:`test_program` 。之后使用测试数据运行 :code:`test_program`,\
就可以做到运行测试程序,而不影响训练结果。
-分别配置训练 :ref:`api_fluid_Program` 和测试 :ref:`api_fluid_Program`
+分别配置训练 :code:`fluid.Program` 和测试 :code:`fluid.Program`
=====================================================================
如果训练程序和测试程序相差较大时,用户也可以通过完全定义两个不同的
-:ref:`api_fluid_Program`,分别进行训练和测试。在PaddlePaddle Fluid中,\
+:code:`fluid.Program`,分别进行训练和测试。在PaddlePaddle Fluid中,\
所有的参数都有名字。如果两个不同的操作,甚至两个不同的网络使用了同样名字的参数,\
那么他们的值和内存空间都是共享的。
@@ -84,14 +84,14 @@ PaddlePaddle Fluid中使用 :code:`fluid.unique_name` 包来随机初始化用
# fluid.default_main_program() is the train program
# fluid.test_program is the test program
-执行测试 :ref:`api_fluid_Program`
+执行测试 :code:`fluid.Program`
#################################
-使用 :code:`Executor` 执行测试 :ref:`api_fluid_Program`
+使用 :code:`Executor` 执行测试 :code:`fluid.Program`
=======================================================
用户可以使用 :code:`Executor.run(program=...)` 来执行测试
-:ref:`api_fluid_Program`。
+:code:`fluid.Program`。
例如
@@ -101,10 +101,10 @@ PaddlePaddle Fluid中使用 :code:`fluid.unique_name` 包来随机初始化用
test_acc = exe.run(program=test_program, feed=test_data_batch, fetch_list=[acc])
print 'Test accuracy is ', test_acc
-使用 :code:`ParallelExecutor` 执行测试 :ref:`api_fluid_Program`
+使用 :code:`ParallelExecutor` 执行测试 :code:`fluid.Program`
===============================================================
-用户可以使用训练用的 :code:`ParallelExecutor` 与测试 :ref:`api_fluid_Program`
+用户可以使用训练用的 :code:`ParallelExecutor` 与测试 :code:`fluid.Program`
一起新建一个测试的 :code:`ParallelExecutor` ;再使用测试
:code:`ParallelExecutor.run` 来执行测试。
diff --git a/source/user_guides/index.rst b/source/user_guides/index.rst
index 453cb71cfdf72e031ce0f0517e2db936eca38dfc..377631109d8f65c149b12cd2a0e4da920fdf4def 100644
--- a/source/user_guides/index.rst
+++ b/source/user_guides/index.rst
@@ -15,4 +15,5 @@
howto/training/index
howto/debug/index
howto/evaluation/index
+ howto/inference/index
models/index.rst
diff --git a/source/user_guides/models/index.rst b/source/user_guides/models/index.rst
index 0eba1bcdd4c87d0e9e83eb0485fb2fe2febcc5f6..998e95c4885dc313d9449f5466f80c53d34fe82a 100644
--- a/source/user_guides/models/index.rst
+++ b/source/user_guides/models/index.rst
@@ -31,12 +31,13 @@ Fluid模型配置和参数文件的工具。
在目标检测任务中,我们介绍了如何基于\ `PASCAL
VOC `__\ 、\ `MS
-COCO `__\ 数据的训练目标检测算法SSD,SSD全称Single
-Shot MultiBox
-Detector,是目标检测领域较新且效果较好的检测算法之一,具有检测速度快且检测精度高的特点,并开源了训练好的\ `MobileNet-SSD模型 `__\ 。
+COCO `__\ 数据训练通用物体检测模型,当前介绍了SSD算法,SSD全称Single Shot MultiBox Detector,是目标检测领域较新且效果较好的检测算法之一,具有检测速度快且检测精度高的特点。
+
+开放环境中的检测人脸,尤其是小的、模糊的和部分遮挡的人脸也是一个具有挑战的任务。我们也介绍了如何基于 `WIDER FACE `_ 数据训练百度自研的人脸检测PyramidBox模型,该算法于2018年3月份在WIDER FACE的多项评测中均获得 `第一名 `_。
- `Single Shot MultiBox
Detector `__
+- `Face Detector: PyramidBox `_
图像语义分割
------------