Add Elastic CTR Document (#1502)
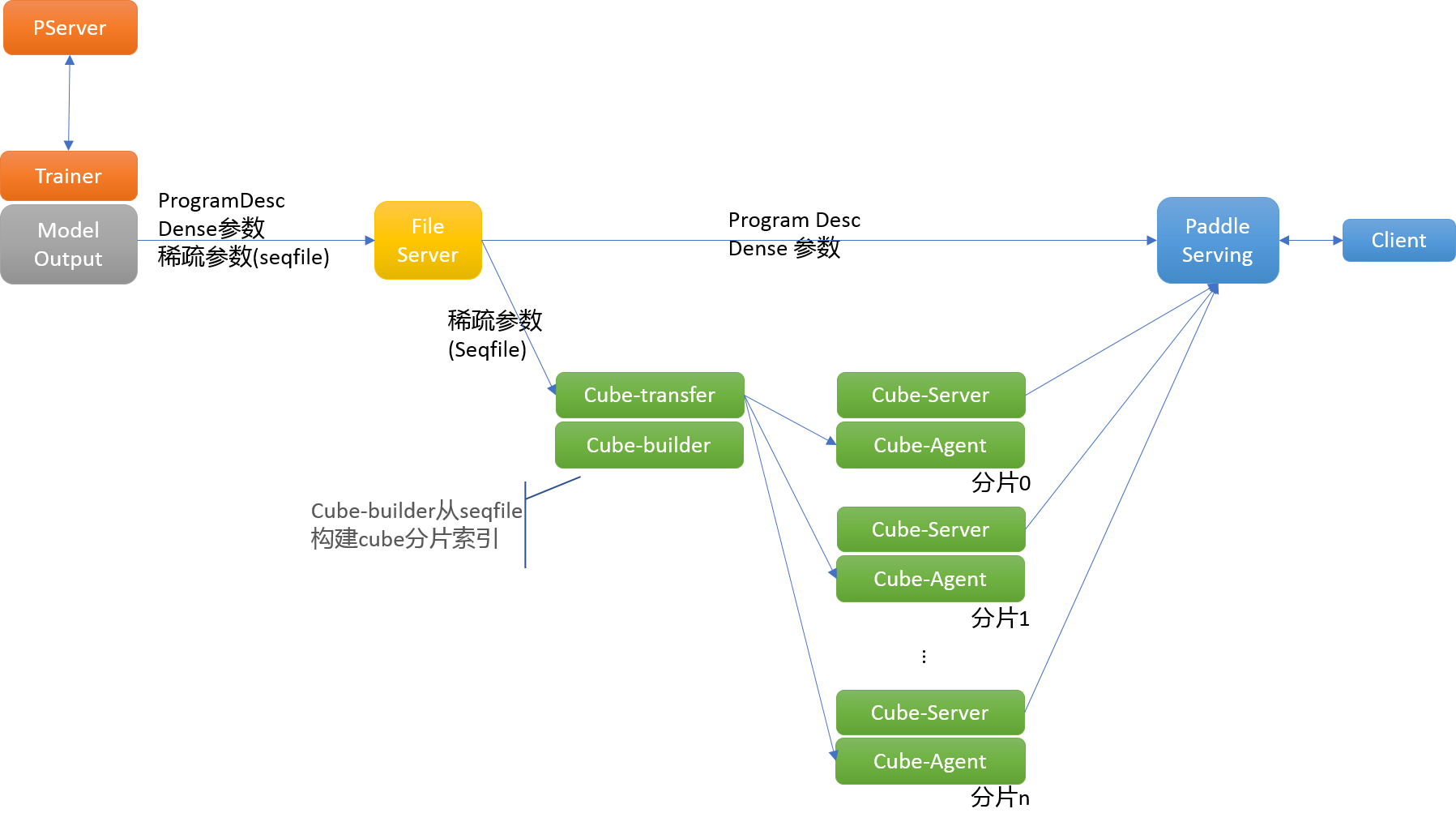
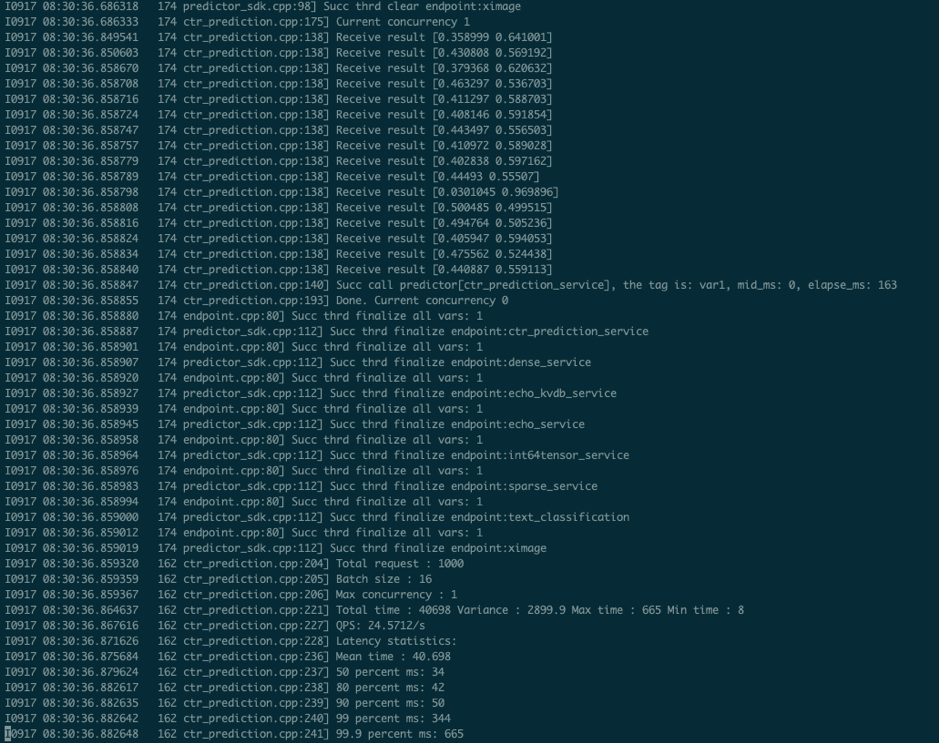
new document to upload in this PR the previous doc talks about how to run CTR training on Baidu Cloud K8S Cluster. the new doc are modified in following points. 1.Run CTR Training on Baidu Cloud K8S + Huawei Volcano 2.Auto Split CTR model into sparse ones and dense ones. 3.Cube auto fetch Sparse model, Serving auto fetch dense model. 4.provide paddle serving client to test the ctr prediction.
Showing
{kind=link}

98.2 KB
{kind=link}

109.7 KB
{kind=link}

70.9 KB
{kind=link}

320.5 KB
{kind=link}

42.5 KB
{kind=link}

75.6 KB
{kind=link}

39.1 KB
{kind=link}

13.9 KB
{kind=link}

24.7 KB
{kind=link}

45.3 KB
{kind=link}

22.6 KB
{kind=link}

23.7 KB
{kind=link}

163.6 KB
{kind=link}

138.9 KB
{kind=link}

33.9 KB
{kind=link}

39.3 KB
{kind=link}

125.1 KB
{kind=link}
164.3 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}

155.7 KB
{kind=link}
131.0 KB
{kind=link}
65.6 KB
{kind=link}
56.3 KB
{kind=link}

104.4 KB
{kind=link}
178.2 KB
{kind=link}
107.1 KB
{kind=link}

150.9 KB
{kind=link}

98.0 KB
{kind=link}
107.3 KB
{kind=link}
547.4 KB
{kind=link}
145.4 KB
{kind=link}

104.8 KB
{kind=link}
456.1 KB
{kind=link}
603.7 KB