Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
FluidDoc
提交
666b4079
F
FluidDoc
项目概览
PaddlePaddle
/
FluidDoc
通知
10
Star
2
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
23
列表
看板
标记
里程碑
合并请求
111
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
F
FluidDoc
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
23
Issue
23
列表
看板
标记
里程碑
合并请求
111
合并请求
111
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
666b4079
编写于
6月 27, 2018
作者:
T
typhoonzero
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update
上级
c4fd265a
变更
5
显示空白变更内容
内联
并排
Showing
5 changed file
with
57 addition
and
5 deletion
+57
-5
source/user_guides/howto/training/cluster_howto.rst
source/user_guides/howto/training/cluster_howto.rst
+57
-5
source/user_guides/howto/training/src/dist_train_nccl2.graffle
...e/user_guides/howto/training/src/dist_train_nccl2.graffle
+0
-0
source/user_guides/howto/training/src/dist_train_nccl2.png
source/user_guides/howto/training/src/dist_train_nccl2.png
+0
-0
source/user_guides/howto/training/src/dist_train_pserver.graffle
...user_guides/howto/training/src/dist_train_pserver.graffle
+0
-0
source/user_guides/howto/training/src/dist_train_pserver.png
source/user_guides/howto/training/src/dist_train_pserver.png
+0
-0
未找到文件。
source/user_guides/howto/training/cluster_howto.rst
浏览文件 @
666b4079
...
...
@@ -16,8 +16,8 @@ Fluid分布式训练使用手册
诸如模型并行的特例实现(超大稀疏模型训练)功能将在后续的文档中予以说明。
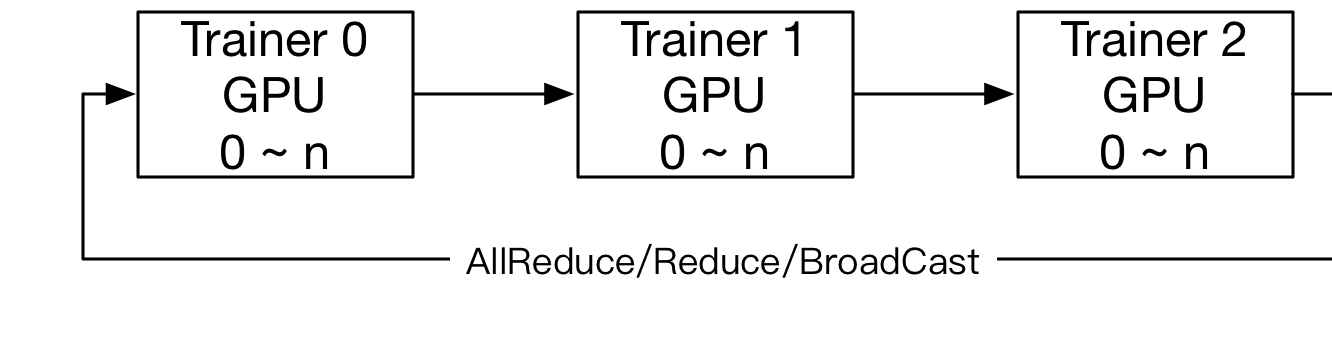
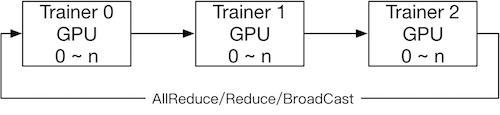
在数据并行模式的训练中,Fluid使用了两种通信模式,用于应对不同训练任务对分布式训练的要求,分别为RPC通信和Collective
通信。其中RPC通信方式使用 `gRPC<https://github.com/grpc/grpc/>`_ ,Collective通信方式使用
`NCCL2<https://developer.nvidia.com/nccl)`_ 。下面是一个RPC通信和Collective通信的横向对比:
通信。其中RPC通信方式使用 `gRPC
<https://github.com/grpc/grpc/>`_ ,Collective通信方式使用
`NCCL2
<https://developer.nvidia.com/nccl)`_ 。下面是一个RPC通信和Collective通信的横向对比:
.. csv-table:: 通信对比
:header: "Feature", "Coolective", "RPC"
...
...
@@ -31,13 +31,10 @@ Fluid分布式训练使用手册
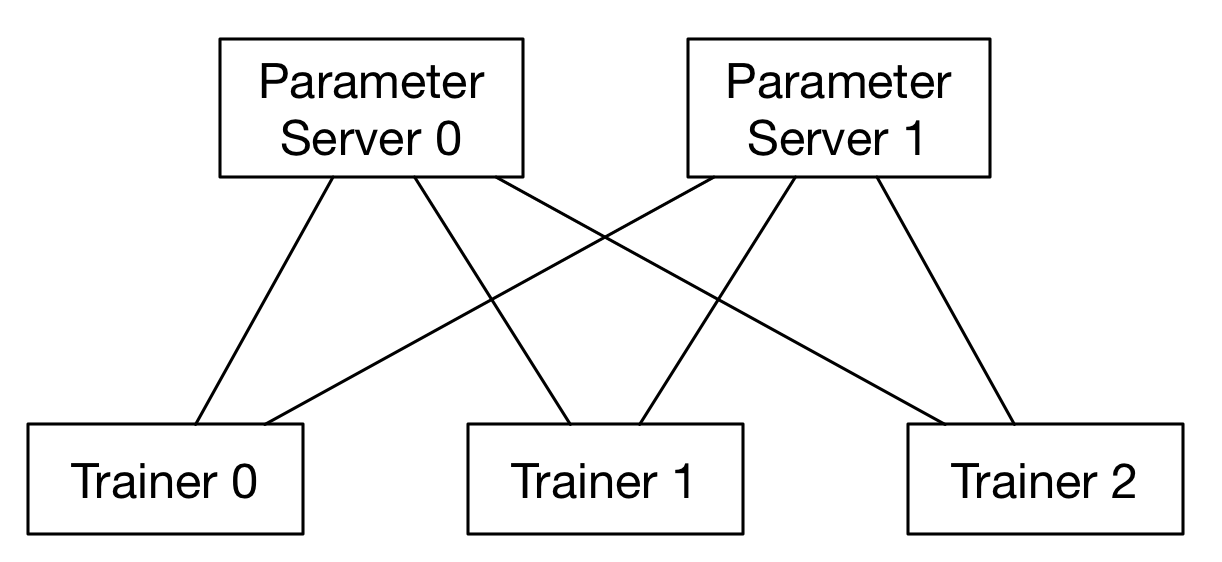
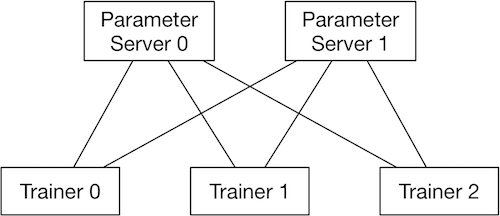
- RPC通信方式的结构:
.. image:: src/dist_train_pserver.png
:width: 500px
- NCCL2通信方式的结构:
.. image:: src/dist_train_nccl2.png
:width: 500px
使用parameter server方式的训练
---------------------------
...
...
@@ -76,6 +73,49 @@ Fluid分布式训练使用手册
train_loop(t.get_trainer_program())
选择同步或异步训练
+++++++++++++++
Fluid分布式任务可以支持同步训练或异步训练,在同步训练方式下,所有的trainer节点,会在每个mini-batch
同步地合并所有节点的梯度数据并发送给parameter server完成更新,在异步训练方式下,每个trainer没有相互
同步等待的过程,可以独立的parameter server的参数。通常情况下,使用异步训练方式,可以在trainer节点
更多的时候比同步训练方式有更高的总体吞吐量。
在调用 :code:`transpile` 函数时,默认会生成同步训练的分布式程序,通过指定 :code:`sync_mode=False`
参数即可生成异步训练的程序:
.. code-block:: python
t.transpile(trainer_id, pservers=pserver_endpoints, trainers=trainers, sync_mode=False)
选择参数分布方法
+++++++++++++
参数 :code:`split_method` 可以指定参数在parameter server上的分布方式。
Fluid默认使用 `RoundRobin <https://en.wikipedia.org/wiki/Round-robin_scheduling>`_
方式将参数分布在多个parameter server上。此方式在默认未关闭参数切分的情况下,参数会较平均的分布在所有的
parameter server上。如果需要使用其他,可以传入其他的方法,目前可选的方法有: :code:`RoundRobin` 和
:code:`HashName` 。也可以使用自定义的分布方式,只需要参考
`这里 <https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/fluid/transpiler/ps_dispatcher.py#L44>`_
编写自定义的分布函数。
关闭切分参数
++++++++++
参数 :code:`slice_var_up` 指定是否将较大(大于8192个元素)的参数切分到多个parameter server已均衡计算负载,默认为开启。
当模型中的可训练参数体积比较均匀或者使用自定义的参数分布方法是参数均匀分布在多个parameter server上,
可以选择关闭切分参数,这样可以降低切分和重组带来的计算和拷贝开销:
.. code-block:: python
t.transpile(trainer_id, pservers=pserver_endpoints, trainers=trainers, slice_var_up=False)
使用NCCL2通信方式的训练
--------------------
...
...
@@ -92,3 +132,15 @@ parameter server的进程,只需要启动多个trainer进程即可:
"PADDLE_PSERVER_PORT", "一个端口,用于在NCCL2初始化时,广播NCCL ID"
"PADDLE_CURRENT_IP", "当前节点的IP"
目前使用NCCL2进行分布式训练仅支持同步训练方式。使用NCCL2方式的分布式训练,更适合模型体积较大,并需要使用
同步训练和GPU训练,如果硬件设备支持RDMA和GPU Direct,可以达到很高的分布式训练性能。
注意如果系统中有多个网络设备,需要手动指定NCCL2使用的设备,
假设需要使用 :code:`eth2` 为通信设备,需要设定如下环境变量:
.. code-block:: bash
export NCCL_SOCKET_IFNAME=eth2
另外NCCL2提供了其他的开关环境变量,比如指定是否开启GPU Direct,是否使用RDMA等,详情可以参考
`ncclknobs <https://docs.nvidia.com/deeplearning/sdk/nccl-developer-guide/index.html#ncclknobs>`_ 。
source/user_guides/howto/training/src/dist_train_nccl2.graffle
浏览文件 @
666b4079
无法预览此类型文件
source/user_guides/howto/training/src/dist_train_nccl2.png
查看替换文件 @
c4fd265a
浏览文件 @
666b4079
30.1 KB
|
W:
|
H:
19.5 KB
|
W:
|
H:
2-up
Swipe
Onion skin
source/user_guides/howto/training/src/dist_train_pserver.graffle
浏览文件 @
666b4079
无法预览此类型文件
source/user_guides/howto/training/src/dist_train_pserver.png
查看替换文件 @
c4fd265a
浏览文件 @
666b4079
48.9 KB
|
W:
|
H:
31.8 KB
|
W:
|
H:
2-up
Swipe
Onion skin
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}
{kind=link}