 -
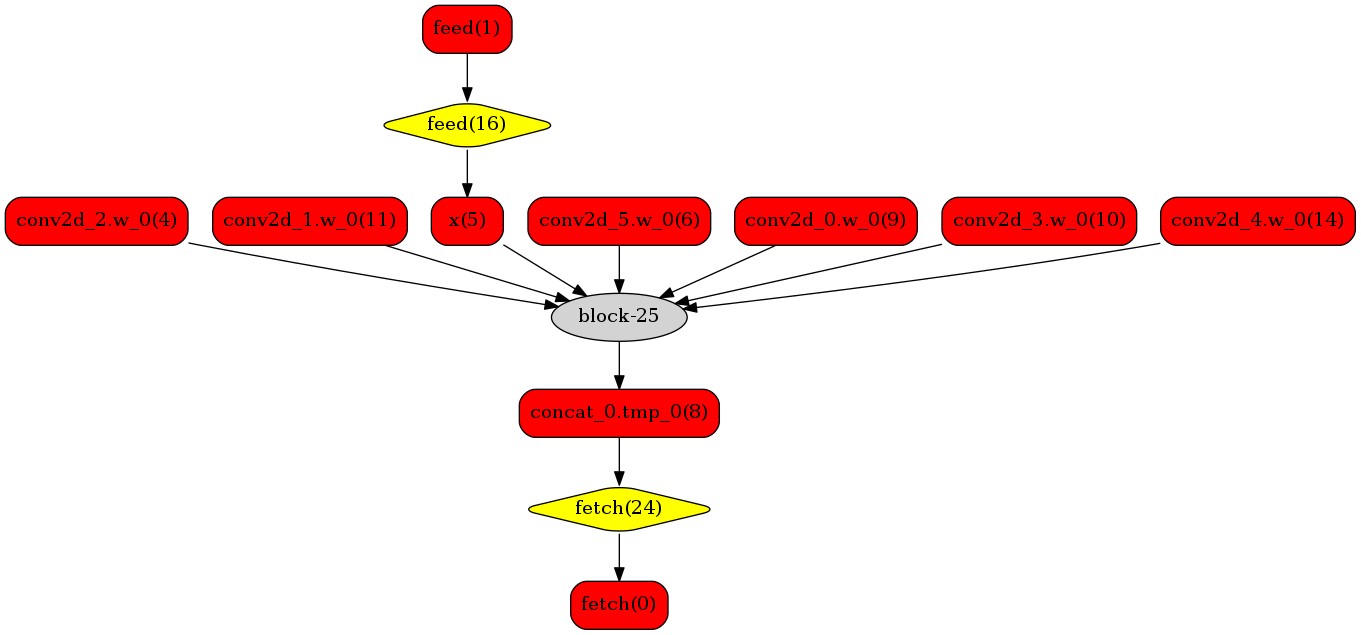
- 我们可以在原始模型网络中看到,绿色节点表示可以被TensorRT支持的节点,红色节点表示网络中的变量,黄色表示Paddle只能被Paddle原生实现执行的节点。那些在原始网络中的绿色节点被提取出来汇集成子图,并由一个TensorRT节点代替,成为转换网络中的`block-25` 节点。在网络运行过程中,如果遇到该节点,Paddle将调用TensorRT库来对其执行。
-
-
-
-
-
-
+ 我们可以在原始模型网络中看到,绿色节点表示可以被TensorRT支持的节点,红色节点表示网络中的变量,黄色表示Paddle只能被Paddle原生实现执行的节点。那些在原始网络中的绿色节点被提取出来汇集成子图,并由一个TensorRT节点代替,成为转换网络中的`block-25` 节点。在网络运行过程中,如果遇到该节点,Paddle将调用TensorRT库来对其执行。
diff --git a/doc/fluid/advanced_usage/deploy/inference/paddle_tensorrt_infer_en.md b/doc/fluid/advanced_usage/deploy/inference/paddle_tensorrt_infer_en.md
index 77f3b45d9..1480b2f2d 100755
--- a/doc/fluid/advanced_usage/deploy/inference/paddle_tensorrt_infer_en.md
+++ b/doc/fluid/advanced_usage/deploy/inference/paddle_tensorrt_infer_en.md
@@ -9,23 +9,25 @@ Subgraph is used in PaddlePaddle to preliminarily integrate TensorRT, which enab
- [Paddle-TRT example compiling test](#Paddle-TRT example compiling test)
- [Paddle-TRT INT8 usage](#Paddle-TRT_INT8 usage)
- [Paddle-TRT subgraph operation principle](#Paddle-TRT subgraph operation principle)
-
+
## compile Paddle-TRT inference libraries
-**Use Docker to build inference libraries**
+**Use Docker to build inference libraries**
+
+TRT inference libraries can only be compiled using GPU.
1. Download Paddle
-
+
```
git clone https://github.com/PaddlePaddle/Paddle.git
```
-
+
2. Get docker image
-
+
```
nvidia-docker run --name paddle_trt -v $PWD/Paddle:/Paddle -it hub.baidubce.com/paddlepaddle/paddle:latest-dev /bin/bash
```
-
+
3. Build Paddle TensorRT
```
@@ -41,16 +43,16 @@ Subgraph is used in PaddlePaddle to preliminarily integrate TensorRT, which enab
-DWITH_PYTHON=OFF \
-DTENSORRT_ROOT=/usr \
-DON_INFER=ON
-
+
# build
make -j
# generate inference library
make inference_lib_dist -j
```
-## Paddle-TRT interface usage
+## Paddle-TRT interface usage
-[`paddle_inference_api.h`]('https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/inference/api/paddle_inference_api.h') defines all APIs of TensorRT.
+[`paddle_inference_api.h`]('https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/inference/api/paddle_inference_api.h') defines all APIs of TensorRT.
General steps are as follows:
1. Create appropriate AnalysisConfig.
@@ -71,13 +73,13 @@ void RunTensorRT(int batch_size, std::string model_dirname) {
AnalysisConfig config(model_dirname);
// config->SetModel(model_dirname + "/model",
// model_dirname + "/params");
-
+
config->EnableUseGpu(100, 0 /*gpu_id*/);
config->EnableTensorRtEngine(1 << 20 /*work_space_size*/, batch_size /*max_batch_size*/);
-
+
// 2. Create predictor based on config
auto predictor = CreatePaddlePredictor(config);
- // 3. Create input tensor
+ // 3. Create input tensor
int height = 224;
int width = 224;
float data[batch_size * 3 * height * width] = {0};
@@ -96,13 +98,13 @@ void RunTensorRT(int batch_size, std::string model_dirname) {
const size_t num_elements = outputs.front().data.length() / sizeof(float);
auto *data = static_cast
-
- 我们可以在原始模型网络中看到,绿色节点表示可以被TensorRT支持的节点,红色节点表示网络中的变量,黄色表示Paddle只能被Paddle原生实现执行的节点。那些在原始网络中的绿色节点被提取出来汇集成子图,并由一个TensorRT节点代替,成为转换网络中的`block-25` 节点。在网络运行过程中,如果遇到该节点,Paddle将调用TensorRT库来对其执行。
-
-
-
-
-
-
+ 我们可以在原始模型网络中看到,绿色节点表示可以被TensorRT支持的节点,红色节点表示网络中的变量,黄色表示Paddle只能被Paddle原生实现执行的节点。那些在原始网络中的绿色节点被提取出来汇集成子图,并由一个TensorRT节点代替,成为转换网络中的`block-25` 节点。在网络运行过程中,如果遇到该节点,Paddle将调用TensorRT库来对其执行。
diff --git a/doc/fluid/advanced_usage/deploy/inference/paddle_tensorrt_infer_en.md b/doc/fluid/advanced_usage/deploy/inference/paddle_tensorrt_infer_en.md
index 77f3b45d9..1480b2f2d 100755
--- a/doc/fluid/advanced_usage/deploy/inference/paddle_tensorrt_infer_en.md
+++ b/doc/fluid/advanced_usage/deploy/inference/paddle_tensorrt_infer_en.md
@@ -9,23 +9,25 @@ Subgraph is used in PaddlePaddle to preliminarily integrate TensorRT, which enab
- [Paddle-TRT example compiling test](#Paddle-TRT example compiling test)
- [Paddle-TRT INT8 usage](#Paddle-TRT_INT8 usage)
- [Paddle-TRT subgraph operation principle](#Paddle-TRT subgraph operation principle)
-
+
## compile Paddle-TRT inference libraries
-**Use Docker to build inference libraries**
+**Use Docker to build inference libraries**
+
+TRT inference libraries can only be compiled using GPU.
1. Download Paddle
-
+
```
git clone https://github.com/PaddlePaddle/Paddle.git
```
-
+
2. Get docker image
-
+
```
nvidia-docker run --name paddle_trt -v $PWD/Paddle:/Paddle -it hub.baidubce.com/paddlepaddle/paddle:latest-dev /bin/bash
```
-
+
3. Build Paddle TensorRT
```
@@ -41,16 +43,16 @@ Subgraph is used in PaddlePaddle to preliminarily integrate TensorRT, which enab
-DWITH_PYTHON=OFF \
-DTENSORRT_ROOT=/usr \
-DON_INFER=ON
-
+
# build
make -j
# generate inference library
make inference_lib_dist -j
```
-## Paddle-TRT interface usage
+## Paddle-TRT interface usage
-[`paddle_inference_api.h`]('https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/inference/api/paddle_inference_api.h') defines all APIs of TensorRT.
+[`paddle_inference_api.h`]('https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/inference/api/paddle_inference_api.h') defines all APIs of TensorRT.
General steps are as follows:
1. Create appropriate AnalysisConfig.
@@ -71,13 +73,13 @@ void RunTensorRT(int batch_size, std::string model_dirname) {
AnalysisConfig config(model_dirname);
// config->SetModel(model_dirname + "/model",
// model_dirname + "/params");
-
+
config->EnableUseGpu(100, 0 /*gpu_id*/);
config->EnableTensorRtEngine(1 << 20 /*work_space_size*/, batch_size /*max_batch_size*/);
-
+
// 2. Create predictor based on config
auto predictor = CreatePaddlePredictor(config);
- // 3. Create input tensor
+ // 3. Create input tensor
int height = 224;
int width = 224;
float data[batch_size * 3 * height * width] = {0};
@@ -96,13 +98,13 @@ void RunTensorRT(int batch_size, std::string model_dirname) {
const size_t num_elements = outputs.front().data.length() / sizeof(float);
auto *data = static_cast@@ -151,5 +153,3 @@ A simple model expresses the process :
We can see in the Original Network that the green nodes represent nodes supported by TensorRT, the red nodes represent variables in network and yellow nodes represent nodes which can only be operated by native functions in Paddle. Green nodes in original network are extracted to compose subgraph which is replaced by a single TensorRT node to be transformed into `block-25` node in network. When such nodes are encountered during the runtime, TensorRT library will be called to execute them. - - diff --git a/doc/fluid/api_cn/fluid_cn.rst b/doc/fluid/api_cn/fluid_cn.rst index e0acc6ef3..e0ac4df79 100644 --- a/doc/fluid/api_cn/fluid_cn.rst +++ b/doc/fluid/api_cn/fluid_cn.rst @@ -62,7 +62,7 @@ BOOL类型。如果设置为True, GPU操作中的一些锁将被释放,Paralle 类型为bool,sync_batch_norm表示是否使用同步的批正则化,即在训练阶段通过多个设备同步均值和方差。 -当前的实现不支持FP16培训和CPU。仅在一台机器上进行同步式批正则,不适用于多台机器。 +当前的实现不支持FP16训练和CPU。仅在一台机器上进行同步式批正则,不适用于多台机器。 默认为 False。 @@ -1717,11 +1717,3 @@ WeightNormParamAttr param_attr=WeightNormParamAttr( dim=None, name='weight_norm_param')) - - - - - - - - diff --git a/doc/fluid/api_guides/low_level/inference.rst b/doc/fluid/api_guides/low_level/inference.rst index d33b0f6a7..84dfbacfc 100644 --- a/doc/fluid/api_guides/low_level/inference.rst +++ b/doc/fluid/api_guides/low_level/inference.rst @@ -28,15 +28,18 @@ 存储预测模型 =========== +存储预测模型时,一般通过 :code:`fluid.io.save_inference_model` 接口对默认的 :code:`fluid.Program` 进行裁剪,只保留预测 :code:`predict_var` 所需部分。 +裁剪后的 program 会保存在指定路径 ./infer_model/__model__ 下,参数会保存到 ./infer_model 下的各个独立文件。 + +示例代码如下: + .. code-block:: python exe = fluid.Executor(fluid.CPUPlace()) path = "./infer_model" - fluid.io.save_inference_model(dirname=path, feeded_var_names=['img'], + fluid.io.save_inference_model(dirname=path, feeded_var_names=['img'], target_vars=[predict_var], executor=exe) -在这个示例中,:code:`fluid.io.save_inference_model` 接口对默认的 :code:`fluid.Program` 进行裁剪,只保留预测 :code:`predict_var` 所需部分。 -裁剪后的 :code:`program` 会保存在 :code:`./infer_model/__model__` 下,参数会保存到 :code:`./infer_model` 下的各个独立文件。 加载预测模型 =========== @@ -45,11 +48,11 @@ exe = fluid.Executor(fluid.CPUPlace()) path = "./infer_model" - [inference_program, feed_target_names, fetch_targets] = + [inference_program, feed_target_names, fetch_targets] = fluid.io.load_inference_model(dirname=path, executor=exe) results = exe.run(inference_program, feed={feed_target_names[0]: tensor_img}, fetch_list=fetch_targets) -在这个示例中,首先调用 :code:`fluid.io.load_inference_model` 接口,获得预测的 :code:`program` 、输入数据的 :code:`variable` 名称和输出结果的 :code:`variable` ; -然后调用 :code:`executor` 执行预测的 :code:`program` 获得预测结果。 +在这个示例中,首先调用 :code:`fluid.io.load_inference_model` 接口,获得预测的 :code:`inference_program` 、输入数据的名称 :code:`feed_target_names` 和输出结果的 :code:`fetch_targets` ; +然后调用 :code:`executor` 执行预测的 :code:`inference_program` 获得预测结果。 diff --git a/doc/fluid/api_guides/low_level/inference_en.rst b/doc/fluid/api_guides/low_level/inference_en.rst index 956229375..33bd5d12a 100755 --- a/doc/fluid/api_guides/low_level/inference_en.rst +++ b/doc/fluid/api_guides/low_level/inference_en.rst @@ -28,15 +28,18 @@ There are two formats of saved inference model, which are controlled by :code:`m Save Inference model =============================== +To save an inference model, we normally use :code:`fluid.io.save_inference_model` to tailor the default :code:`fluid.Program` and only keep the parts useful for predicting :code:`predict_var`. +After being tailored, :code:`program` will be saved under :code:`./infer_model/__model__` while the parameters will be saved into independent files under :code:`./infer_model` . + +Sample Code: + .. code-block:: python exe = fluid.Executor(fluid.CPUPlace()) path = "./infer_model" - fluid.io.save_inference_model(dirname=path, feeded_var_names=['img'], + fluid.io.save_inference_model(dirname=path, feeded_var_names=['img'], target_vars=[predict_var], executor=exe) -In this example, :code:`fluid.io.save_inference_model` will tailor default :code:`fluid.Program` into useful parts for predicting :code:`predict_var` . -After being tailored, :code:`program` will be saved under :code:`./infer_model/__model__` while parameters will be saved into independent files under :code:`./infer_model` . Load Inference Model ===================== @@ -45,11 +48,11 @@ Load Inference Model exe = fluid.Executor(fluid.CPUPlace()) path = "./infer_model" - [inference_program, feed_target_names, fetch_targets] = + [inference_program, feed_target_names, fetch_targets] = fluid.io.load_inference_model(dirname=path, executor=exe) results = exe.run(inference_program, feed={feed_target_names[0]: tensor_img}, fetch_list=fetch_targets) -In this example, at first we call :code:`fluid.io.load_inference_model` to get inference :code:`program` , :code:`variable` name of input data and :code:`variable` of output; -then call :code:`executor` to run inference :code:`program` to get inferred result. \ No newline at end of file +In this example, at first we call :code:`fluid.io.load_inference_model` to get inference :code:`inference_program` , :code:`feed_target_names`-name of input data and :code:`fetch_targets` of output; +then call :code:`executor` to run inference :code:`inference_program` to get inferred result. diff --git a/doc/fluid/beginners_guide/install/install_Windows_en.md b/doc/fluid/beginners_guide/install/install_Windows_en.md index 2f60fff40..3e5e14a7a 100644 --- a/doc/fluid/beginners_guide/install/install_Windows_en.md +++ b/doc/fluid/beginners_guide/install/install_Windows_en.md @@ -1,48 +1,57 @@ -*** +# **Installation on Windows** -# **Install on Windows** +## Operating Environment -This instruction will show you how to install PaddlePaddle on Windows. The following conditions must be met before you begin to install: +* *64-bit operating system* +* *Windows 7/8, Windows 10 Pro/Enterprise* +* *Python 2.7/3.5/3.6/3.7* +* *pip or pip3 >= 9.0.1* -* *a 64-bit desktop or laptop* -* *Windows 7/8 , Windows 10 Professional/Enterprise Edition* +### Precautions -**Note** : +* The default installation package requires your computer to support AVX instruction set and MKL. If your environment doesn’t support AVX instruction set and MKL, please download [these](./Tables.html/#ciwhls-release) `no-avx`, `openblas` versions of installation package. +* The current version doesn’t support functions related to NCCL and distributed learning. -* The current version does not support NCCL, distributed training related functions. +## CPU or GPU +* If your computer doesn’t have NVIDIA® GPU, please install the CPU version of PaddlePaddle +* If your computer has NVIDIA® GPU, and it satisfies the following requirements, we recommend you to install the GPU version of PaddlePaddle + * *CUDA Toolkit 8.0 with cuDNN v7* + * *GPU's computing capability exceeds 1.0* +Please refer to the NVIDIA official documents for the installation process and the configuration methods of [CUDA](https://docs.nvidia.com/cuda/cuda-installation-guide-linux/) and [cuDNN](https://docs.nvidia.com/deeplearning/sdk/cudnn-install/). +## Installation Method -## Installation Steps +There are 3 ways to install PaddlePaddle on Windows: -### ***Install through pip*** +* pip installation (recommended) +* [Docker installation](./install_Docker.html) +* [source code compilation and installation](./compile/compile_Windows.html/#win_source) -* Check your Python versions +We would like to introduce the pip installation here. -Python2.7.15,Python3.5.x,Python3.6.x,Python3.7.x on [Official Python](https://www.python.org/downloads/) are supported. - -* Check your pip version +## Installation Process -Version of pip or pip3 should be equal to or above 9.0.1 . +* CPU version of PaddlePaddle: `pip install paddlepaddle` or `pip3 install paddlepaddle` +* GPU version of PaddlePaddle: `pip install paddlepaddle-gpu` or `pip3 install paddlepaddle-gpu` -* Install PaddlePaddle +There is a checking function below for [verifyig whether the installation is successful](#check). If you have any further questions, please check the [FAQ part](./FAQ.html). -* ***CPU version of PaddlePaddle***: -Execute `pip install paddlepaddle` or `pip3 install paddlepaddle` to download and install PaddlePaddle. +Notice: -* ***GPU version of PaddlePaddle***: -Execute `pip install paddlepaddle-gpu`(python2.7) or `pip3 install paddlepaddle-gpu`(python3.x) to download and install PaddlePaddle. - -## ***Verify installation*** +* The version of pip and the version of python should be corresponding: python2.7 corresponds to `pip`; python3.x corresponds to `pip3`. +* `pip install paddlepaddle-gpu` This command will install PaddlePaddle that supports CUDA 8.0 cuDNN v7. Currently, PaddlePaddle doesn't support any other version of CUDA or cuDNN on Windows. -After completing the installation, you can use `python` or `python3` to enter the python interpreter and then use `import paddle.fluid` to verify that the installation was successful. + +## Installation Verification +After completing the installation process, you can use `python` or `python3` to enter python interpreter and input `import paddle.fluid as fluid` and then `fluid.install_check.run_check()` to check whether the installation is successful. -## ***How to uninstall*** +If you see `Your Paddle Fluid is installed succesfully!`, your installation is verified successful. -* ***CPU version of PaddlePaddle***: -Use the following command to uninstall PaddlePaddle : `pip uninstallpaddlepaddle `or `pip3 uninstall paddlepaddle` +## Uninstall PaddlePaddle -* ***GPU version of PaddlePaddle***: -Use the following command to uninstall PaddlePaddle : `pip uninstall paddlepaddle-gpu` or `pip3 uninstall paddlepaddle-gpu` +* ***CPU version of PaddlePaddle***: `pip uninstall paddlepaddle` or `pip3 uninstall paddlepaddle` + +* ***GPU version of PaddlePaddle***: `pip uninstall paddlepaddle-gpu` or `pip3 uninstall paddlepaddle-gpu` -- GitLab