diff --git a/doc/fluid/beginners_guide/basic_concept/dygraph/DyGraph.md b/doc/fluid/beginners_guide/basic_concept/dygraph/DyGraph.md
index 89d96a2f197aef7face5c3042fbb8a9a7a68b21e..38e84d88cbd04de54ff6493cb0ce0647ab68b0c5 100644
--- a/doc/fluid/beginners_guide/basic_concept/dygraph/DyGraph.md
+++ b/doc/fluid/beginners_guide/basic_concept/dygraph/DyGraph.md
@@ -1,6 +1,6 @@
-# 动态图使用教程
+# 命令式编程模式使用教程
-从编程范式上说,飞桨兼容支持声明式编程和命令式编程,通俗地讲即动态图和静态图。其实飞桨本没有图的概念,在飞桨的设计中,把一个神经网络定义成一段类似程序的描述,也就是用户在写程序的过程中,就定义了模型表达及计算。在声明式编程模式的控制流实现方面,飞桨借助自己实现的控制流OP而不是python原生的if else和for循环,这使得在飞桨中的定义的program即一个网络模型,可以有一个内部的表达,是可以全局优化编译执行的。考虑对开发者来讲,更愿意使用python原生控制流,飞桨也做了支持,并通过解释方式执行,这就是命令式编程模式。但整体上,这两种编程范式是相对兼容统一的。飞桨将持续发布更完善的命令式编程模式功能,同时保持更强劲的性能。
+从编程范式上说,飞桨兼容支持声明式编程和命令式编程,通俗地讲即静态图和动态图。其实飞桨本没有图的概念,在飞桨的设计中,把一个神经网络定义成一段类似程序的描述,也就是用户在写程序的过程中,就定义了模型表达及计算。在声明式编程模式的控制流实现方面,飞桨借助自己实现的控制流OP而不是python原生的if else和for循环,这使得在飞桨中的定义的program即一个网络模型,可以有一个内部的表达,是可以全局优化编译执行的。考虑对开发者来讲,更愿意使用python原生控制流,飞桨也做了支持,并通过解释方式执行,这就是命令式编程模式。但整体上,这两种编程范式是相对兼容统一的。飞桨将持续发布更完善的命令式编程模式功能,同时保持更强劲的性能。
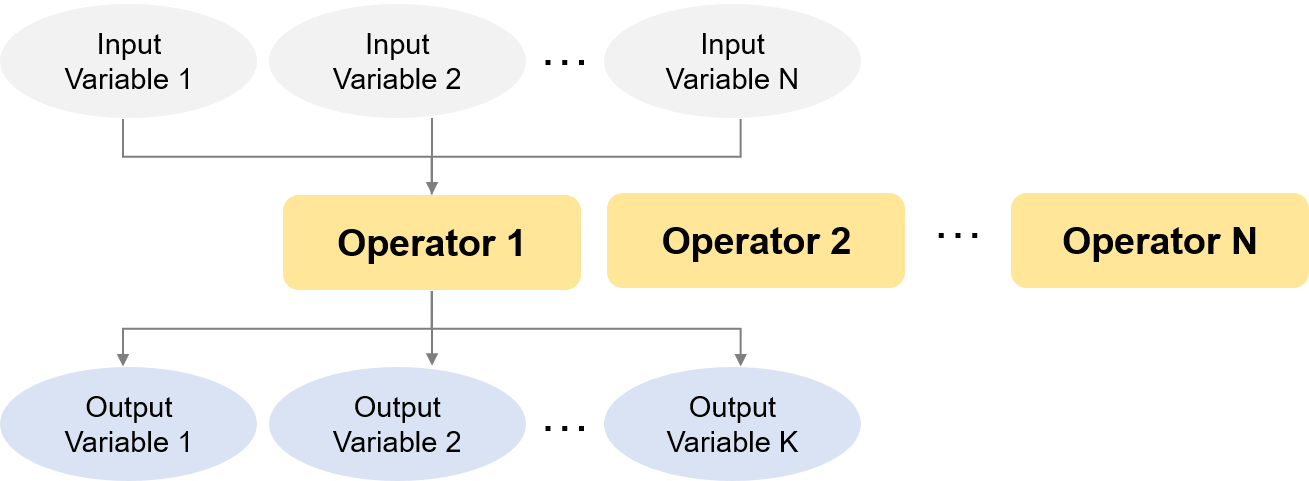
飞桨平台中,将神经网络抽象为计算表示**Operator**(算子,常简称OP)和数据表示**Variable**(变量),如 图1 所示。神经网络的每层操作均由一个或若干**Operator**组成,每个**Operator**接受一系列的**Variable**作为输入,经计算后输出一系列的**Variable**。
 @@ -8,14 +8,14 @@
图1 Operator和Variable关系示意图
根据**Operator**解析执行方式不同,飞桨支持如下两种编程范式:
-* **声明式编程模式模式(动态图)**:先编译后执行的方式。用户需预先定义完整的网络结构,再对网络结构进行编译优化后,才能执行获得计算结果。
-* **命令式编程模式模式(静态图)**:解析式的执行方式。用户无需预先定义完整的网络结构,每写一行网络代码,即可同时获得计算结果。
+* **声明式编程模式(静态图)**:先编译后执行的方式。用户需预先定义完整的网络结构,再对网络结构进行编译优化后,才能执行获得计算结果。
+* **命令式编程模式(动态图)**:解析式的执行方式。用户无需预先定义完整的网络结构,每写一行网络代码,即可同时获得计算结果。
-举例来说,假设用户写了一行代码:y=x+1,在声明式编程模式模式下,运行此代码只会往计算图中插入一个Tensor加1的**Operator**,此时**Operator**并未真正执行,无法获得y的计算结果。但在命令式编程模式模式下,所有**Operator**均是即时执行的,运行完此代码后**Operator**已经执行完毕,用户可直接获得y的计算结果。
+举例来说,假设用户写了一行代码:y=x+1,在声明式编程模式下,运行此代码只会往计算图中插入一个Tensor加1的**Operator**,此时**Operator**并未真正执行,无法获得y的计算结果。但在命令式编程模式下,所有**Operator**均是即时执行的,运行完此代码后**Operator**已经执行完毕,用户可直接获得y的计算结果。
-## 为什么命令式编程模式模式越来越流行?
+## 为什么命令式编程模式越来越流行?
-声明式编程模式模式作为较早提出的一种编程范式,提供丰富的 API ,能够快速的实现各种模型;并且可以利用全局的信息进行图优化,优化性能和显存占用;在预测部署方面也可以实现无缝衔接。 但具体实践中声明式编程模式模式存在如下问题:
+声明式编程模式作为较早提出的一种编程范式,提供丰富的 API ,能够快速的实现各种模型;并且可以利用全局的信息进行图优化,优化性能和显存占用;在预测部署方面也可以实现无缝衔接。 但具体实践中声明式编程模式存在如下问题:
1. 采用先编译后执行的方式,组网阶段和执行阶段割裂,导致调试不方便。
2. 属于一种符号化的编程方式,要学习新的编程方式,有一定的入门门槛。
3. 网络结构固定,对于一些树结构的任务支持的不够好。
@@ -26,22 +26,22 @@
3. 网络的结构在不同的层次中可以变化,使用更灵活。
-综合以上优势,使得命令式编程模式模式越来越受开发者的青睐,本章侧重介绍在飞桨中命令式编程模式的编程方法,包括如下几部分:
-1. 如何开启命令式编程模式模式
+综合以上优势,使得命令式编程模式越来越受开发者的青睐,本章侧重介绍在飞桨中命令式编程模式的编程方法,包括如下几部分:
+1. 如何开启命令式编程模式
2. 如何使用命令式编程模式进行模型训练
3. 如何基于命令式编程模式进行多卡训练
4. 如何部署命令式编程模式模型
-5. 命令式编程模式模式常见的使用技巧,如中间变量值/梯度打印、断点调试、阻断反向传递,以及某些场景下如何改写为声明式编程模式模式运行。
+5. 命令式编程模式常见的使用技巧,如中间变量值/梯度打印、断点调试、阻断反向传递,以及某些场景下如何改写为声明式编程模式运行。
-## 1. 开启命令式编程模式模式
+## 1. 开启命令式编程模式
-目前飞桨默认的模式是声明式编程模式,采用基于 context (上下文)的管理方式开启命令式编程模式模式:
+目前飞桨默认的模式是声明式编程模式,采用基于 context (上下文)的管理方式开启命令式编程模式:
```
with fluid.dygraph.guard()
```
-我们先通过一个实例,观察一下命令式编程模式模式开启前后执行方式的差别:
+我们先通过一个实例,观察一下命令式编程模式开启前后执行方式的差别:
```python
@@ -55,12 +55,12 @@ with fluid.program_guard(main_program=main_program, startup_program=startup_prog
# 利用np.ones函数构造出[2*2]的二维数组,值为1
data = np.ones([2, 2], np.float32)
- # 声明式编程模式模式下,使用layers.data构建占位符用于数据输入
+ # 声明式编程模式下,使用layers.data构建占位符用于数据输入
x = fluid.layers.data(name='x', shape=[2], dtype='float32')
print('In static mode, after calling layers.data, x = ', x)
- # 声明式编程模式模式下,对Variable类型的数据执行x=x+10操作
+ # 声明式编程模式下,对Variable类型的数据执行x=x+10操作
x += 10
- # 在声明式编程模式模式下,需要用户显示指定运行设备
+ # 在声明式编程模式下,需要用户显示指定运行设备
# 此处调用fluid.CPUPlace() API来指定在CPU设备上运行程序
place = fluid.CPUPlace()
# 创建“执行器”,并用place参数指明需要在何种设备上运行
@@ -74,14 +74,14 @@ with fluid.program_guard(main_program=main_program, startup_program=startup_prog
# 此时我们打印执行器返回的结果,可以看到“执行”后,Tensor中的数据已经被赋值并进行了运算,每个元素的值都是11
print('In static mode, data after run:', data_after_run)
-# 开启命令式编程模式模式
+# 开启命令式编程模式
with fluid.dygraph.guard():
- # 命令式编程模式模式下,将numpy的ndarray类型的数据转换为Variable类型
+ # 命令式编程模式下,将numpy的ndarray类型的数据转换为Variable类型
x = fluid.dygraph.to_variable(data)
print('In DyGraph mode, after calling dygraph.to_variable, x = ', x)
- # 命令式编程模式模式下,对Variable类型的数据执行x=x+10操作
+ # 命令式编程模式下,对Variable类型的数据执行x=x+10操作
x += 10
- # 命令式编程模式模式下,调用Variable的numpy函数将Variable类型的数据转换为numpy的ndarray类型的数据
+ # 命令式编程模式下,调用Variable的numpy函数将Variable类型的数据转换为numpy的ndarray类型的数据
print('In DyGraph mode, data after run:', x.numpy())
```
@@ -117,8 +117,8 @@ with fluid.dygraph.guard():
从以上输出结果可以看出:
-* 命令式编程模式模式下,所有操作在运行时就已经完成,更接近我们平时的编程方式,可以随时获取每一个操作的执行结果。
-* 声明式编程模式模式下,过程中并没有实际执行操作,上述例子中可以看到只能打印声明的类型,最后需要调用执行器来统一执行所有操作,计算结果需要通过执行器统一返回。
+* 命令式编程模式下,所有操作在运行时就已经完成,更接近我们平时的编程方式,可以随时获取每一个操作的执行结果。
+* 声明式编程模式下,过程中并没有实际执行操作,上述例子中可以看到只能打印声明的类型,最后需要调用执行器来统一执行所有操作,计算结果需要通过执行器统一返回。
## 2. 使用命令式编程模式进行模型训练
接下来我们以一个简单的手写体识别任务为例,说明如何使用飞桨的命令式编程模式来进行模型的训练。包括如下步骤:
@@ -181,9 +181,9 @@ test_reader = paddle.batch(
在开始构建网络模型前,需要了解如下信息:
-> 在命令式编程模式模式中,参数和变量的存储管理方式与声明式编程模式不同。命令式编程模式模式下,网络中学习的参数和中间变量,生命周期和 Python 对象的生命周期是一致的。简单来说,一个 Python 对象的生命周期结束,相应的存储空间就会释放。
+> 在命令式编程模式中,参数和变量的存储管理方式与声明式编程模式不同。命令式编程模式下,网络中学习的参数和中间变量,生命周期和 Python 对象的生命周期是一致的。简单来说,一个 Python 对象的生命周期结束,相应的存储空间就会释放。
-对于一个网络模型,在模型学习的过程中参数会不断更新,所以参数需要在整个学习周期内一直保持存在,因此需要一个机制来保持网络的所有的参数不被释放,飞桨的命令式编程模式模式采用了继承自 [fluid.dygraph.Layer](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/dygraph_cn/Layer_cn.html#layer) 的面向对象设计的方法来管理所有的参数,该方法也更容易模块化组织代码。
+对于一个网络模型,在模型学习的过程中参数会不断更新,所以参数需要在整个学习周期内一直保持存在,因此需要一个机制来保持网络的所有的参数不被释放,飞桨的命令式编程模式采用了继承自 [fluid.dygraph.Layer](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/dygraph_cn/Layer_cn.html#layer) 的面向对象设计的方法来管理所有的参数,该方法也更容易模块化组织代码。
下面介绍如何通过继承 fluid.dygraph.Layers 实现一个简单的ConvPool层;该层由一个 [卷积层](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/dygraph_cn/Conv2D_cn.html#conv2d) 和一个 [池化层](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/dygraph_cn/Pool2D_cn.html#pool2d) 组成。
@@ -314,7 +314,7 @@ with fluid.dygraph.guard():
# 定义MNIST类的对象
mnist = MNIST()
# 定义优化器为AdamOptimizer,学习旅learning_rate为0.001
- # 注意命令式编程模式模式下必须传入parameter_list参数,该参数为需要优化的网络参数,本例需要优化mnist网络中的所有参数
+ # 注意命令式编程模式下必须传入parameter_list参数,该参数为需要优化的网络参数,本例需要优化mnist网络中的所有参数
adam = AdamOptimizer(learning_rate=0.001, parameter_list=mnist.parameters())
```
@@ -341,7 +341,7 @@ with fluid.dygraph.guard():
# 定义MNIST类的对象
mnist = MNIST()
# 定义优化器为AdamOptimizer,学习旅learning_rate为0.001
- # 注意命令式编程模式模式下必须传入parameter_list参数,该参数为需要优化的网络参数,本例需要优化mnist网络中的所有参数
+ # 注意命令式编程模式下必须传入parameter_list参数,该参数为需要优化的网络参数,本例需要优化mnist网络中的所有参数
adam = AdamOptimizer(learning_rate=0.001, parameter_list=mnist.parameters())
# 设置全部样本的训练次数
@@ -466,7 +466,7 @@ with fluid.dygraph.guard():
### 2.5 模型参数的保存和加载
-在命令式编程模式模式下,模型和优化器在不同的模块中,所以模型和优化器分别在不同的对象中存储,使得模型参数和优化器信息需分别存储。
+在命令式编程模式下,模型和优化器在不同的模块中,所以模型和优化器分别在不同的对象中存储,使得模型参数和优化器信息需分别存储。
因此模型的保存需要单独调用模型和优化器中的 state_dict() 接口,同样模型的加载也需要单独进行处理。
保存模型 :
@@ -500,7 +500,7 @@ with fluid.dygraph.guard():
## 3. 多卡训练
-针对数据量、计算量较大的任务,我们需要多卡并行训练,以提高训练效率。目前命令式编程模式模式可支持GPU的单机多卡训练方式,在命令式编程模式中多卡的启动和单卡略有不同,命令式编程模式多卡通过 Python 基础库 subprocess.Popen 在每一张 GPU 上启动单独的 Python 程序的方式,每张卡的程序独立运行,只是在每一轮梯度计算完成之后,所有的程序进行梯度的同步,然后更新训练的参数。
+针对数据量、计算量较大的任务,我们需要多卡并行训练,以提高训练效率。目前命令式编程模式可支持GPU的单机多卡训练方式,在命令式编程模式中多卡的启动和单卡略有不同,命令式编程模式多卡通过 Python 基础库 subprocess.Popen 在每一张 GPU 上启动单独的 Python 程序的方式,每张卡的程序独立运行,只是在每一轮梯度计算完成之后,所有的程序进行梯度的同步,然后更新训练的参数。
我们通过一个实例了解如何进行多卡训练:
>由于AI Studio上未配置多卡环境,所以本实例需在本地构建多卡环境后运行。
@@ -818,16 +818,16 @@ print(y.gradient())
-### 5.3 使用声明式编程模式模式运行
+### 5.3 使用声明式编程模式运行
命令式编程模式虽然有友好编写、易于调试等功能,但是命令式编程模式中需要频繁进行 Python 与 C++ 交互,会导致一些任务在命令式编程模式中运行比声明式编程模式慢,根据经验,这类任务中包含了很多小粒度的 OP(指运算量相对比较小的 OP,如加减乘除、sigmoid 等,像 conv、matmul 等属于大粒度的 OP不在此列 )。
在实际任务中,如果发现这类任务运行较慢,有以下两种处理方式:
-* 1. 当用户使用的 if/else、switch、for/while 与输入(包括输入的值和 shape )无关时,可以在不改动模型定义的情况下使用声明式编程模式的模式运行。该方法将模型训练改为了声明式编程模式模式,区别于第4小节仅预测部署改为了声明式编程模式模式。
+* 1. 当用户使用的 if/else、switch、for/while 与输入(包括输入的值和 shape )无关时,可以在不改动模型定义的情况下使用声明式编程模式的模式运行。该方法将模型训练改为了声明式编程模式,区别于第4小节仅预测部署改为了声明式编程模式。
* 2. 如果使用了与输入相关的控制流,请参照[如何把命令式编程模式转写成声明式编程模式](https://www.paddlepaddle.org.cn/tutorials/projectdetail/360460#anchor-3)章节,将命令式编程模式代码进行转写。
-下面我们介绍上面的第一种方案,仍然以手写字体识别任务为例,在声明式编程模式模式下的实现如下:
+下面我们介绍上面的第一种方案,仍然以手写字体识别任务为例,在声明式编程模式下的实现如下:
```python
@@ -844,7 +844,7 @@ with fluid.program_guard(main_program=main_program, startup_program=startup_prog
# 定义MNIST类的对象,可以使用命令式编程模式定义好的网络结构
mnist_static = MNIST()
- # 定义优化器对象,声明式编程模式模式下不需要传入parameter_list参数
+ # 定义优化器对象,声明式编程模式下不需要传入parameter_list参数
sgd_static = fluid.optimizer.SGDOptimizer(learning_rate=1e-3)
# 通过调用paddle.dataset.mnist的train函数,直接获取处理好的MNIST训练集
@@ -897,7 +897,7 @@ with fluid.program_guard(main_program=main_program, startup_program=startup_prog
2. 组网
-* 优化器对象在声明式编程模式模式下不需要传入parameter_list参数。
+* 优化器对象在声明式编程模式下不需要传入parameter_list参数。
* 将定义的占位符,输入给模型执行正向,然后计算损失值,最后利用优化器将损失值做最小化优化,得到要训练的网络。
3. 执行
@@ -959,7 +959,7 @@ with fluid.dygraph.guard():
如果OP只要有一个输入需要梯度,那么该OP的输出也需要梯度。相反,只有当OP的所有输入都不需要梯度时,该OP的输出也不需要梯度。在所有的 Variable 都不需要梯度的子图中,反向计算就不会进行计算了。
-在命令式编程模式模式下,除参数以外的所有 Variable 的 stop_gradient 属性默认值都为 True,而参数的 stop_gradient 属性默认值为 False。 该属性用于自动剪枝,避免不必要的反向运算。
+在命令式编程模式下,除参数以外的所有 Variable 的 stop_gradient 属性默认值都为 True,而参数的 stop_gradient 属性默认值为 False。 该属性用于自动剪枝,避免不必要的反向运算。
使用方式如下:
@@ -8,14 +8,14 @@
图1 Operator和Variable关系示意图
根据**Operator**解析执行方式不同,飞桨支持如下两种编程范式:
-* **声明式编程模式模式(动态图)**:先编译后执行的方式。用户需预先定义完整的网络结构,再对网络结构进行编译优化后,才能执行获得计算结果。
-* **命令式编程模式模式(静态图)**:解析式的执行方式。用户无需预先定义完整的网络结构,每写一行网络代码,即可同时获得计算结果。
+* **声明式编程模式(静态图)**:先编译后执行的方式。用户需预先定义完整的网络结构,再对网络结构进行编译优化后,才能执行获得计算结果。
+* **命令式编程模式(动态图)**:解析式的执行方式。用户无需预先定义完整的网络结构,每写一行网络代码,即可同时获得计算结果。
-举例来说,假设用户写了一行代码:y=x+1,在声明式编程模式模式下,运行此代码只会往计算图中插入一个Tensor加1的**Operator**,此时**Operator**并未真正执行,无法获得y的计算结果。但在命令式编程模式模式下,所有**Operator**均是即时执行的,运行完此代码后**Operator**已经执行完毕,用户可直接获得y的计算结果。
+举例来说,假设用户写了一行代码:y=x+1,在声明式编程模式下,运行此代码只会往计算图中插入一个Tensor加1的**Operator**,此时**Operator**并未真正执行,无法获得y的计算结果。但在命令式编程模式下,所有**Operator**均是即时执行的,运行完此代码后**Operator**已经执行完毕,用户可直接获得y的计算结果。
-## 为什么命令式编程模式模式越来越流行?
+## 为什么命令式编程模式越来越流行?
-声明式编程模式模式作为较早提出的一种编程范式,提供丰富的 API ,能够快速的实现各种模型;并且可以利用全局的信息进行图优化,优化性能和显存占用;在预测部署方面也可以实现无缝衔接。 但具体实践中声明式编程模式模式存在如下问题:
+声明式编程模式作为较早提出的一种编程范式,提供丰富的 API ,能够快速的实现各种模型;并且可以利用全局的信息进行图优化,优化性能和显存占用;在预测部署方面也可以实现无缝衔接。 但具体实践中声明式编程模式存在如下问题:
1. 采用先编译后执行的方式,组网阶段和执行阶段割裂,导致调试不方便。
2. 属于一种符号化的编程方式,要学习新的编程方式,有一定的入门门槛。
3. 网络结构固定,对于一些树结构的任务支持的不够好。
@@ -26,22 +26,22 @@
3. 网络的结构在不同的层次中可以变化,使用更灵活。
-综合以上优势,使得命令式编程模式模式越来越受开发者的青睐,本章侧重介绍在飞桨中命令式编程模式的编程方法,包括如下几部分:
-1. 如何开启命令式编程模式模式
+综合以上优势,使得命令式编程模式越来越受开发者的青睐,本章侧重介绍在飞桨中命令式编程模式的编程方法,包括如下几部分:
+1. 如何开启命令式编程模式
2. 如何使用命令式编程模式进行模型训练
3. 如何基于命令式编程模式进行多卡训练
4. 如何部署命令式编程模式模型
-5. 命令式编程模式模式常见的使用技巧,如中间变量值/梯度打印、断点调试、阻断反向传递,以及某些场景下如何改写为声明式编程模式模式运行。
+5. 命令式编程模式常见的使用技巧,如中间变量值/梯度打印、断点调试、阻断反向传递,以及某些场景下如何改写为声明式编程模式运行。
-## 1. 开启命令式编程模式模式
+## 1. 开启命令式编程模式
-目前飞桨默认的模式是声明式编程模式,采用基于 context (上下文)的管理方式开启命令式编程模式模式:
+目前飞桨默认的模式是声明式编程模式,采用基于 context (上下文)的管理方式开启命令式编程模式:
```
with fluid.dygraph.guard()
```
-我们先通过一个实例,观察一下命令式编程模式模式开启前后执行方式的差别:
+我们先通过一个实例,观察一下命令式编程模式开启前后执行方式的差别:
```python
@@ -55,12 +55,12 @@ with fluid.program_guard(main_program=main_program, startup_program=startup_prog
# 利用np.ones函数构造出[2*2]的二维数组,值为1
data = np.ones([2, 2], np.float32)
- # 声明式编程模式模式下,使用layers.data构建占位符用于数据输入
+ # 声明式编程模式下,使用layers.data构建占位符用于数据输入
x = fluid.layers.data(name='x', shape=[2], dtype='float32')
print('In static mode, after calling layers.data, x = ', x)
- # 声明式编程模式模式下,对Variable类型的数据执行x=x+10操作
+ # 声明式编程模式下,对Variable类型的数据执行x=x+10操作
x += 10
- # 在声明式编程模式模式下,需要用户显示指定运行设备
+ # 在声明式编程模式下,需要用户显示指定运行设备
# 此处调用fluid.CPUPlace() API来指定在CPU设备上运行程序
place = fluid.CPUPlace()
# 创建“执行器”,并用place参数指明需要在何种设备上运行
@@ -74,14 +74,14 @@ with fluid.program_guard(main_program=main_program, startup_program=startup_prog
# 此时我们打印执行器返回的结果,可以看到“执行”后,Tensor中的数据已经被赋值并进行了运算,每个元素的值都是11
print('In static mode, data after run:', data_after_run)
-# 开启命令式编程模式模式
+# 开启命令式编程模式
with fluid.dygraph.guard():
- # 命令式编程模式模式下,将numpy的ndarray类型的数据转换为Variable类型
+ # 命令式编程模式下,将numpy的ndarray类型的数据转换为Variable类型
x = fluid.dygraph.to_variable(data)
print('In DyGraph mode, after calling dygraph.to_variable, x = ', x)
- # 命令式编程模式模式下,对Variable类型的数据执行x=x+10操作
+ # 命令式编程模式下,对Variable类型的数据执行x=x+10操作
x += 10
- # 命令式编程模式模式下,调用Variable的numpy函数将Variable类型的数据转换为numpy的ndarray类型的数据
+ # 命令式编程模式下,调用Variable的numpy函数将Variable类型的数据转换为numpy的ndarray类型的数据
print('In DyGraph mode, data after run:', x.numpy())
```
@@ -117,8 +117,8 @@ with fluid.dygraph.guard():
从以上输出结果可以看出:
-* 命令式编程模式模式下,所有操作在运行时就已经完成,更接近我们平时的编程方式,可以随时获取每一个操作的执行结果。
-* 声明式编程模式模式下,过程中并没有实际执行操作,上述例子中可以看到只能打印声明的类型,最后需要调用执行器来统一执行所有操作,计算结果需要通过执行器统一返回。
+* 命令式编程模式下,所有操作在运行时就已经完成,更接近我们平时的编程方式,可以随时获取每一个操作的执行结果。
+* 声明式编程模式下,过程中并没有实际执行操作,上述例子中可以看到只能打印声明的类型,最后需要调用执行器来统一执行所有操作,计算结果需要通过执行器统一返回。
## 2. 使用命令式编程模式进行模型训练
接下来我们以一个简单的手写体识别任务为例,说明如何使用飞桨的命令式编程模式来进行模型的训练。包括如下步骤:
@@ -181,9 +181,9 @@ test_reader = paddle.batch(
在开始构建网络模型前,需要了解如下信息:
-> 在命令式编程模式模式中,参数和变量的存储管理方式与声明式编程模式不同。命令式编程模式模式下,网络中学习的参数和中间变量,生命周期和 Python 对象的生命周期是一致的。简单来说,一个 Python 对象的生命周期结束,相应的存储空间就会释放。
+> 在命令式编程模式中,参数和变量的存储管理方式与声明式编程模式不同。命令式编程模式下,网络中学习的参数和中间变量,生命周期和 Python 对象的生命周期是一致的。简单来说,一个 Python 对象的生命周期结束,相应的存储空间就会释放。
-对于一个网络模型,在模型学习的过程中参数会不断更新,所以参数需要在整个学习周期内一直保持存在,因此需要一个机制来保持网络的所有的参数不被释放,飞桨的命令式编程模式模式采用了继承自 [fluid.dygraph.Layer](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/dygraph_cn/Layer_cn.html#layer) 的面向对象设计的方法来管理所有的参数,该方法也更容易模块化组织代码。
+对于一个网络模型,在模型学习的过程中参数会不断更新,所以参数需要在整个学习周期内一直保持存在,因此需要一个机制来保持网络的所有的参数不被释放,飞桨的命令式编程模式采用了继承自 [fluid.dygraph.Layer](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/dygraph_cn/Layer_cn.html#layer) 的面向对象设计的方法来管理所有的参数,该方法也更容易模块化组织代码。
下面介绍如何通过继承 fluid.dygraph.Layers 实现一个简单的ConvPool层;该层由一个 [卷积层](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/dygraph_cn/Conv2D_cn.html#conv2d) 和一个 [池化层](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/dygraph_cn/Pool2D_cn.html#pool2d) 组成。
@@ -314,7 +314,7 @@ with fluid.dygraph.guard():
# 定义MNIST类的对象
mnist = MNIST()
# 定义优化器为AdamOptimizer,学习旅learning_rate为0.001
- # 注意命令式编程模式模式下必须传入parameter_list参数,该参数为需要优化的网络参数,本例需要优化mnist网络中的所有参数
+ # 注意命令式编程模式下必须传入parameter_list参数,该参数为需要优化的网络参数,本例需要优化mnist网络中的所有参数
adam = AdamOptimizer(learning_rate=0.001, parameter_list=mnist.parameters())
```
@@ -341,7 +341,7 @@ with fluid.dygraph.guard():
# 定义MNIST类的对象
mnist = MNIST()
# 定义优化器为AdamOptimizer,学习旅learning_rate为0.001
- # 注意命令式编程模式模式下必须传入parameter_list参数,该参数为需要优化的网络参数,本例需要优化mnist网络中的所有参数
+ # 注意命令式编程模式下必须传入parameter_list参数,该参数为需要优化的网络参数,本例需要优化mnist网络中的所有参数
adam = AdamOptimizer(learning_rate=0.001, parameter_list=mnist.parameters())
# 设置全部样本的训练次数
@@ -466,7 +466,7 @@ with fluid.dygraph.guard():
### 2.5 模型参数的保存和加载
-在命令式编程模式模式下,模型和优化器在不同的模块中,所以模型和优化器分别在不同的对象中存储,使得模型参数和优化器信息需分别存储。
+在命令式编程模式下,模型和优化器在不同的模块中,所以模型和优化器分别在不同的对象中存储,使得模型参数和优化器信息需分别存储。
因此模型的保存需要单独调用模型和优化器中的 state_dict() 接口,同样模型的加载也需要单独进行处理。
保存模型 :
@@ -500,7 +500,7 @@ with fluid.dygraph.guard():
## 3. 多卡训练
-针对数据量、计算量较大的任务,我们需要多卡并行训练,以提高训练效率。目前命令式编程模式模式可支持GPU的单机多卡训练方式,在命令式编程模式中多卡的启动和单卡略有不同,命令式编程模式多卡通过 Python 基础库 subprocess.Popen 在每一张 GPU 上启动单独的 Python 程序的方式,每张卡的程序独立运行,只是在每一轮梯度计算完成之后,所有的程序进行梯度的同步,然后更新训练的参数。
+针对数据量、计算量较大的任务,我们需要多卡并行训练,以提高训练效率。目前命令式编程模式可支持GPU的单机多卡训练方式,在命令式编程模式中多卡的启动和单卡略有不同,命令式编程模式多卡通过 Python 基础库 subprocess.Popen 在每一张 GPU 上启动单独的 Python 程序的方式,每张卡的程序独立运行,只是在每一轮梯度计算完成之后,所有的程序进行梯度的同步,然后更新训练的参数。
我们通过一个实例了解如何进行多卡训练:
>由于AI Studio上未配置多卡环境,所以本实例需在本地构建多卡环境后运行。
@@ -818,16 +818,16 @@ print(y.gradient())
-### 5.3 使用声明式编程模式模式运行
+### 5.3 使用声明式编程模式运行
命令式编程模式虽然有友好编写、易于调试等功能,但是命令式编程模式中需要频繁进行 Python 与 C++ 交互,会导致一些任务在命令式编程模式中运行比声明式编程模式慢,根据经验,这类任务中包含了很多小粒度的 OP(指运算量相对比较小的 OP,如加减乘除、sigmoid 等,像 conv、matmul 等属于大粒度的 OP不在此列 )。
在实际任务中,如果发现这类任务运行较慢,有以下两种处理方式:
-* 1. 当用户使用的 if/else、switch、for/while 与输入(包括输入的值和 shape )无关时,可以在不改动模型定义的情况下使用声明式编程模式的模式运行。该方法将模型训练改为了声明式编程模式模式,区别于第4小节仅预测部署改为了声明式编程模式模式。
+* 1. 当用户使用的 if/else、switch、for/while 与输入(包括输入的值和 shape )无关时,可以在不改动模型定义的情况下使用声明式编程模式的模式运行。该方法将模型训练改为了声明式编程模式,区别于第4小节仅预测部署改为了声明式编程模式。
* 2. 如果使用了与输入相关的控制流,请参照[如何把命令式编程模式转写成声明式编程模式](https://www.paddlepaddle.org.cn/tutorials/projectdetail/360460#anchor-3)章节,将命令式编程模式代码进行转写。
-下面我们介绍上面的第一种方案,仍然以手写字体识别任务为例,在声明式编程模式模式下的实现如下:
+下面我们介绍上面的第一种方案,仍然以手写字体识别任务为例,在声明式编程模式下的实现如下:
```python
@@ -844,7 +844,7 @@ with fluid.program_guard(main_program=main_program, startup_program=startup_prog
# 定义MNIST类的对象,可以使用命令式编程模式定义好的网络结构
mnist_static = MNIST()
- # 定义优化器对象,声明式编程模式模式下不需要传入parameter_list参数
+ # 定义优化器对象,声明式编程模式下不需要传入parameter_list参数
sgd_static = fluid.optimizer.SGDOptimizer(learning_rate=1e-3)
# 通过调用paddle.dataset.mnist的train函数,直接获取处理好的MNIST训练集
@@ -897,7 +897,7 @@ with fluid.program_guard(main_program=main_program, startup_program=startup_prog
2. 组网
-* 优化器对象在声明式编程模式模式下不需要传入parameter_list参数。
+* 优化器对象在声明式编程模式下不需要传入parameter_list参数。
* 将定义的占位符,输入给模型执行正向,然后计算损失值,最后利用优化器将损失值做最小化优化,得到要训练的网络。
3. 执行
@@ -959,7 +959,7 @@ with fluid.dygraph.guard():
如果OP只要有一个输入需要梯度,那么该OP的输出也需要梯度。相反,只有当OP的所有输入都不需要梯度时,该OP的输出也不需要梯度。在所有的 Variable 都不需要梯度的子图中,反向计算就不会进行计算了。
-在命令式编程模式模式下,除参数以外的所有 Variable 的 stop_gradient 属性默认值都为 True,而参数的 stop_gradient 属性默认值为 False。 该属性用于自动剪枝,避免不必要的反向运算。
+在命令式编程模式下,除参数以外的所有 Variable 的 stop_gradient 属性默认值都为 True,而参数的 stop_gradient 属性默认值为 False。 该属性用于自动剪枝,避免不必要的反向运算。
使用方式如下: