Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
FluidDoc
提交
0ff489a9
F
FluidDoc
项目概览
PaddlePaddle
/
FluidDoc
通知
10
Star
2
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
23
列表
看板
标记
里程碑
合并请求
111
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
F
FluidDoc
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
23
Issue
23
列表
看板
标记
里程碑
合并请求
111
合并请求
111
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
0ff489a9
编写于
10月 11, 2018
作者:
Z
Zhaolong Xing
提交者:
GitHub
10月 11, 2018
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #131 from NHZlX/add_trt_doc
Add trt doc
上级
9b15d29c
a6c56a92
变更
4
显示空白变更内容
内联
并排
Showing
4 changed file
with
133 addition
and
0 deletion
+133
-0
doc/fluid/user_guides/howto/inference/image/model_graph_original.png
...ser_guides/howto/inference/image/model_graph_original.png
+0
-0
doc/fluid/user_guides/howto/inference/image/model_graph_trt.png
...uid/user_guides/howto/inference/image/model_graph_trt.png
+0
-0
doc/fluid/user_guides/howto/inference/index.rst
doc/fluid/user_guides/howto/inference/index.rst
+1
-0
doc/fluid/user_guides/howto/inference/paddle_tensorrt_infer.md
...luid/user_guides/howto/inference/paddle_tensorrt_infer.md
+132
-0
未找到文件。
doc/fluid/user_guides/howto/inference/image/model_graph_original.png
0 → 100644
浏览文件 @
0ff489a9
87.8 KB
doc/fluid/user_guides/howto/inference/image/model_graph_trt.png
0 → 100644
浏览文件 @
0ff489a9
46.2 KB
doc/fluid/user_guides/howto/inference/index.rst
浏览文件 @
0ff489a9
...
@@ -9,3 +9,4 @@ PaddlePaddle Fluid 提供了 C++ API 来支持模型的部署上线
...
@@ -9,3 +9,4 @@ PaddlePaddle Fluid 提供了 C++ API 来支持模型的部署上线
build_and_install_lib_cn.rst
build_and_install_lib_cn.rst
native_infer.md
native_infer.md
paddle_tensorrt_infer.md
doc/fluid/user_guides/howto/inference/paddle_tensorrt_infer.md
0 → 100644
浏览文件 @
0ff489a9
# 使用Paddle TensorRT预测
NVIDIA TensorRT 是一个高性能的深度学习预测库,可为深度学习推理应用程序提供低延迟和高吞吐量。Paddle 1.0 采用了子图的形式对TensorRT进行了初步集成,即我们可以使用该模块来提升Paddle模型的预测性能。该模块依旧在持续开发中,目前已支持的模型有:AlexNet, MobileNet, ResNet50, VGG19, ResNext, MobileNet-SSD等。在这篇文档中,我们将会对Paddle-TensorRT库的获取、使用和原理进行介绍。
## 编译带`TensorRT`的预测库
**使用Docker编译预测库**
1.
下载Paddle
```
git clone https://github.com/PaddlePaddle/Paddle.git
```
2.
获取docker镜像
```
nvidia-docker run --name paddle_trt -v $PWD/Paddle:/Paddle -it hub.baidubce.com/paddlepaddle/paddle:latest-dev /bin/bash
```
3.
编译Paddle TensorRT
```
# 在docker容器中执行以下操作
cd /Paddle
mkdir build
cd build
cmake .. \
-DWITH_FLUID_ONLY=ON \
-DWITH_CONTRIB=OFF \
-DWITH_MKL=OFF \
-DWITH_MKLDNN=OFF \
-DWITH_TESTING=ON \
-DCMAKE_BUILD_TYPE=Release \
-DWITH_PYTHON=OFF
# 编译
make -j 10
# 生成预测库
make inference_lib_dist -j
```
## Paddle TensorRT使用
[
`paddle_inference_api.h`
](
'https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/inference/api/paddle_inference_api.h'
)
定义了使用TensorRT的所有接口。
总体上分为以下步骤:
1.
创建合适的配置MixedRTConfig.
2.
根据配合创建
`PaddlePredictor`
.
3.
创建输入的tensor.
4.
获取输出的tensor,输出结果.
以下的代码展示了完整的过程:
```
c++
#include "paddle_inference_api.h"
using
paddle
::
contrib
::
MixedRTConfig
;
namespace
paddle
{
void
RunTensorRT
(
int
batch_size
,
std
::
string
model_dirname
)
{
// 1. 创建MixedRTConfig
MixedRTConfig
config
;
config
.
model_dir
=
model_dirname
;
config
.
use_gpu
=
true
;
// 此处必须为true
config
.
fraction_of_gpu_memory
=
0.2
;
config
.
device
=
0
;
// gpu id
// TensorRT 根据max batch size大小给op选择合适的实现,
// 因此max batch size大小和运行时batch的值最好相同。
config
.
max_batch_size
=
batch_size
;
// 2. 根据config 创建predictor
auto
predictor
=
CreatePaddlePredictor
<
MixedRTConfig
>
(
config
);
// 3. 创建输入 tensor
int
height
=
224
;
int
width
=
224
;
float
data
[
batch_size
*
3
*
height
*
width
]
=
{
0
};
PaddleTensor
tensor
;
tensor
.
shape
=
std
::
vector
<
int
>
({
batch_size
,
3
,
height
,
width
});
tensor
.
data
=
PaddleBuf
(
static_cast
<
void
*>
(
data
),
sizeof
(
float
)
*
(
batch_size
*
3
*
height
*
width
));
tensor
.
dtype
=
PaddleDType
::
FLOAT32
;
std
::
vector
<
PaddleTensor
>
paddle_tensor_feeds
(
1
,
tensor
);
// 4. 创建输出 tensor
std
::
vector
<
PaddleTensor
>
outputs
;
// 5. 预测
predictor
->
Run
(
paddle_tensor_feeds
,
&
outputs
,
batch_size
);
const
size_t
num_elements
=
outputs
.
front
().
data
.
length
()
/
sizeof
(
float
);
auto
*
data
=
static_cast
<
float
*>
(
outputs
.
front
().
data
.
data
());
for
(
size_t
i
=
0
;
i
<
num_elements
;
i
++
)
{
std
::
cout
<<
"output: "
<<
data
[
i
]
<<
std
::
endl
;
}
}
}
// namespace paddle
int
main
()
{
// 模型下载地址 http://paddle-inference-dist.cdn.bcebos.com/tensorrt_test/mobilenet.tar.gz
paddle
::
RunTensorRT
(
1
,
“
.
/
mobilenet
");
return 0;
}
```
编译过程可以参照
[
这里
](
https://github.com/PaddlePaddle/Paddle/tree/develop/paddle/fluid/inference/api/demo_ci
)
。
## 子图运行原理
PaddlePaddle采用子图的形式对TensorRT进行集成,当模型加载后,神经网络可以表示为由变量和运算节点组成的计算图。Paddle TensorRT实现的功能是能够对整个图进行扫描,发现图中可以使用TensorRT优化的子图,并使用TensorRT节点替换它们。在模型的推断期间,如果遇到TensorRT节点,Paddle会调用TensoRT库对该节点进行优化,其他的节点调用Paddle的原生实现。TensorRT在推断期间能够进行Op的横向和纵向融合,过滤掉冗余的Op,并对特定平台下的特定的Op选择合适的kenel等进行优化,能够加快模型的预测速度。
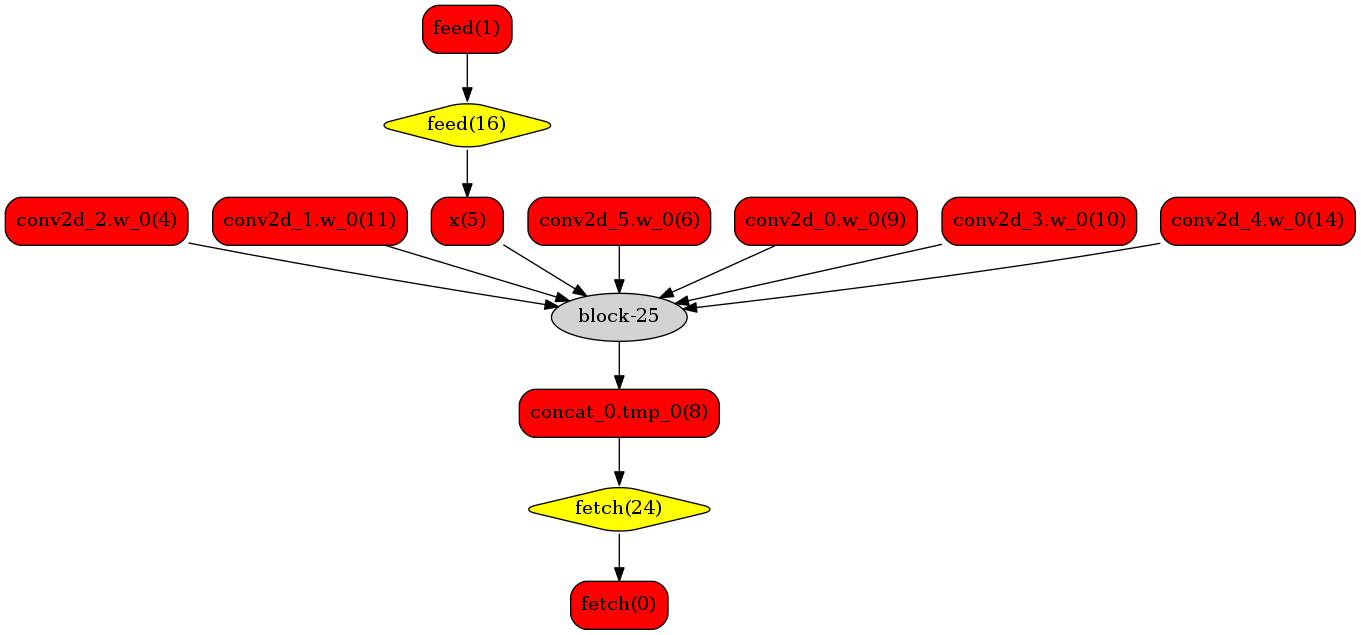
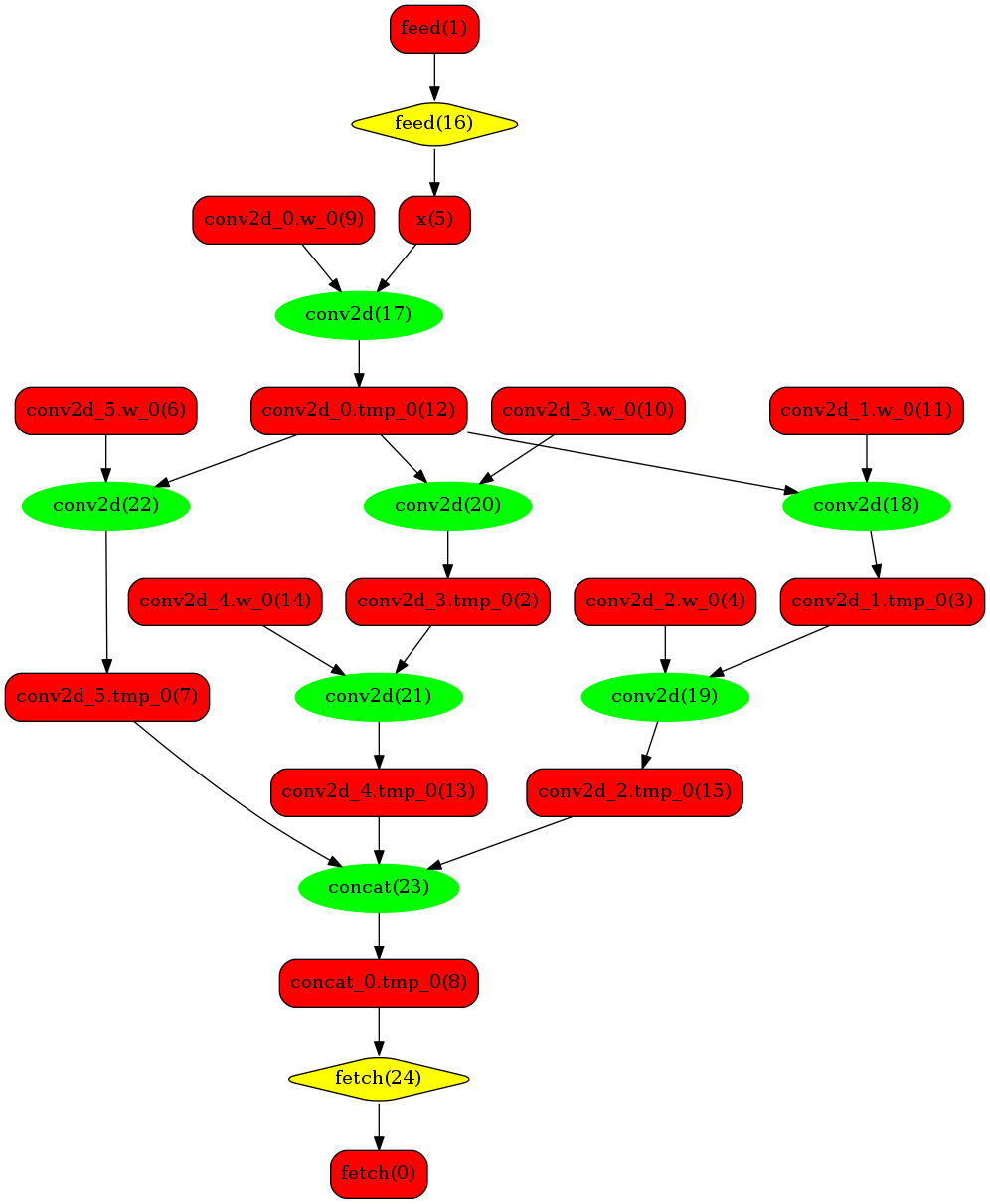
下图使用一个简单的模型展示了这个过程:
**原始网络**
<p
align=
"center"
>
<img
src=
"https://raw.githubusercontent.com/NHZlX/FluidDoc/add_trt_doc/doc/fluid/user_guides/howto/inference/image/model_graph_original.png"
width=
800
>
</p>
**转换的网络**
<p
align=
"center"
>
<img
src=
"https://raw.githubusercontent.com/NHZlX/FluidDoc/add_trt_doc/doc/fluid/user_guides/howto/inference/image/model_graph_trt.png"
width=
800
>
</p>
我们可以在原始模型网络中看到,绿色节点表示可以被TensorRT支持的节点,红色节点表示网络中的变量,黄色表示Paddle只能被Paddle原生实现执行的节点。那些在原始网络中的绿色节点被提取出来汇集成子图,并由一个TensorRT节点代替,成为转换网络中的
`block-25`
节点。在网络运行过程中,如果遇到该节点,Paddle将调用TensorRT库来对其执行。
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}