English| [简体中文](./README_zh.md)
## _ERNIE-ViL_: Knowledge Enhanced Vision-Language Representations Through Scene Graph
- [Framework](#framework)
- [Pre-trained models](#pre-trained-models)
- [Downstream tasks](#downstream-tasks)
* [VCR](#VCR)
* [VQA](#VQA)
* [IR&TR](#Retrieval)
* [RefCOCO+](#RefCOCO+)
- [Usage](#usage)
* [Install PaddlePaddle](#install-paddlepaddle)
* [Fine-tuning on ERNIE-ViL](#fine-tuning-on-ernie-vil)
* [Inference](#inference)
- [Citation](#citation)
For technical description of the algorithm, please see our paper:
>[_**ERNIE-ViL:Knowledge Enhanced Vision-Language Representations Through Scene Graph**_](https://arxiv.org/abs/2006.16934)
>
>Fei Yu\*, Jiji Tang\*, Weichong Yin, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang (\* : equal contribution)
>
>Preprint June 2020
>


 

**[ERNIE-ViL](https://arxiv.org/abs/2006.16934) is a knowledge-enhanced joint representations for vision-language tasks**, which is the first work that has **introduced structured knowledge to enhance vision-language pre-training**. Utilizing structured knowledge obtained
from scene graphs, ERNIE-ViL constructs three **Scene Graph Prediction tasks**, i.e., **Object Prediction**, **Attribute Prediction** and **Relationship Prediction** tasks.
Thus, ERNIE-ViL can learn the better joint vision-language representations characterizing the alignments of the detailed semantics across vision and language.
## Framework
Based on the scene graph parsed from the text using Scene Graph Parser, we construct Object Prediction, Attribute Prediction and Relationship Prediction tasks:
- **Object Prediction:** We randomly select a set of the objects in the scene graph, then mask and predict the corresponding words in the sentence.
- **Attribute Prediction:** For the object-attribute pairs in the scene graph, we randomly select a part of them to mask and predict the words related to the attribute nodes in the sentence.
- **Realtionship Prediction:** For the object-relationship-object triplets in the scene graph, we randomly select a part of realtionship nodes to mask and predict them.
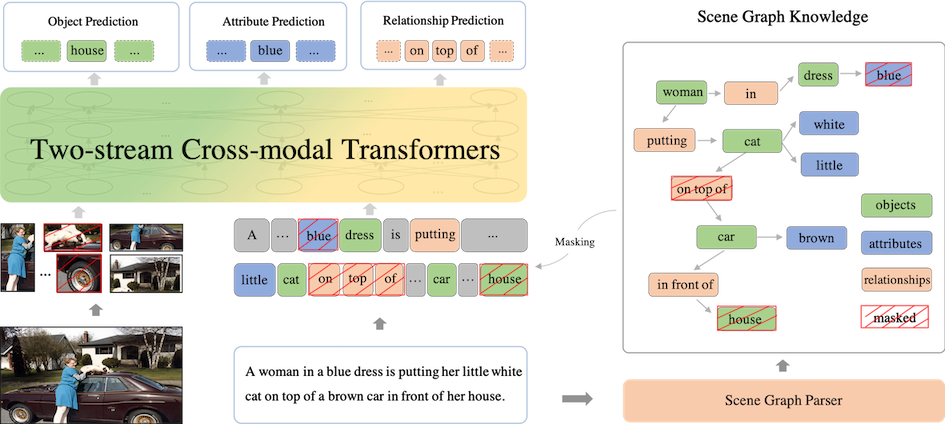
Model Architecture of ERNIE-ViL
## Pre-trained Models
ERNIE-ViL adopts large-scale image-text aligned datasets as the pre-training data. We provide ERNIE-ViL models of two scale settings which are pretrained on two out-of-domain datasets, e.g., [**Conceptual Captions**](https://www.aclweb.org/anthology/P18-1238.pdf) and [**SBU Captions**](http://papers.nips.cc/paper/4470-im2text-describing-images-using-1-million-captio).
- [**ERNIE-ViL _base_**](https://ernie-github.cdn.bcebos.com/model-ernie-vil-base-en.1.tar.gz) (_lowercased | 12-text-stream-layer, 6-visual-stream-layer_)
- [**ERNIE-ViL _large_**](https://ernie-github.cdn.bcebos.com/model-ernie-vil-large-en.1.tar.gz) (_lowercased | 24-text-stream-layer, 6-visual-stream-layer_)
We also provide large scale settings model which are pretrained on both out-of-domain datasets([**Conceptual Captions**](https://www.aclweb.org/anthology/P18-1238.pdf), [**SBU Captions**](http://papers.nips.cc/paper/4470-im2text-describing-images-using-1-million-captio)) and in-domain([**MS-COCO**](https://arxiv.org/abs/1405.0312),[**Visual-Genome**](https://arxiv.org/abs/1602.07332)) datasets.
- [**ERNIE-ViL-Out&in-domain _large_**](https://ernie-github.cdn.bcebos.com/model-ernie-vil-all-domain-large-en.1.tar.gz) (_lowercased | 24-text-stream-layer, 6-visual-stream-layer_)
## Downstream tasks
We finetune ERNIE-ViL on five vision-langage downstream tasks, i.e., Visual Commensense Reasoning([**VCR**](https://openaccess.thecvf.com/content_CVPR_2019/papers/Zellers_From_Recognition_to_Cognition_Visual_Commonsense_Reasoning_CVPR_2019_paper.pdf)),
Visual Question Answering([**VQA**](https://openaccess.thecvf.com/content_iccv_2015/papers/Antol_VQA_Visual_Question_ICCV_2015_paper.pdf)),
Cross-modal Image Retrieval([**IR**](https://www.mitpressjournals.org/doi/abs/10.1162/tacl_a_00166)),
Cross-modal Text Retrieval([**TR**](https://www.mitpressjournals.org/doi/abs/10.1162/tacl_a_00166)) and
Region_to_Phrase_Grounding([**RefCOCO+**](https://www.aclweb.org/anthology/D14-1086.pdf)).
_Code and pre-trained models related to VCR task are made public now, and those of more downstream tasks are planed to be public._
### VCR
* datasets
* The training, validation and testing data of **VCR** task are provided by [**VCR Website**](https://visualcommonsense.com/download/).
* Organization of visual features is modified from [**ViLBERT**](https://github.com/jiasenlu/vilbert_beta), we directly use the data from it. Data can be downloaded [here](https://github.com/jiasenlu/vilbert_beta/tree/master/data).
* Put all downloaded files under diretory "data/vcr".
* Task pre-training: We perform task-pretraining on VCR task, which is also known as task-specific-pretraining. The trained models are as follows:
* [**ERNIE-ViL-VCR-task-pretrain _base_**](https://ernie-github.cdn.bcebos.com/model-ernie-vil-base-VCR-task-pre-en.1.tar.gz)
* [**ERNIE-ViL-VCR-task-pretrain _large_**](https://ernie-github.cdn.bcebos.com/model-ernie-vil-large-VCR-task-pre-en.1.tar.gz)
* Performance: Results of VCR task for different scale settings of ERNIE-ViL model
| Models | Q->A | QA->R | Q->AR |
| :--------------------------------------| :---------------------------: | :----------------------------: | :-----------------------------: |
| ERNIE-ViL (task-pretrain) _base_ | 76.37(77.0) | 79.65(80.3) | 61.24(62.1) |
| ERNIE-ViL (task-pretrain) _large_ | 78.52(79.2) | 83.37(83.5) | 65.81(66.3) |
_Numerical results outside and inside parentheses represent the dev and test performance of VCR task respectively.
Test results are obtained from the [**VCR leadborad**](https://visualcommonsense.com/leaderboard/)._
### VQA
* datasets
* The training, validation and testing data of VCR task are provided by[**VQA Website**](https://visualqa.org/).
* Visual features are extracted by using tools in [bottom-up attention](https://github.com/jiasenlu/bottom-up-attention), The minimum and maximum number of the extracted boxes are 100 and 100.
* A single training & test data is organized as follows:
```script
question_id, question, answer_label, answer_score, image_w, image_h, number_box, image_loc, image_embeddings
```
_The labels and scores of multiple answers are separated by the character ‘|’._
* Performance: Results of **VQA** task for different scale settings of ERNIE-ViL model
| Models | test-dev | test-std |
| :-------------------------------- | :-------------------------------: | :------------------------------: |
| ERNIE-ViL _base_ | 73.18 | 73.36 |
| ERNIE-ViL _large_ | 73.78 | 73.96 |
| ERNIE-ViL-Out&in-domain _large_ | 74.95 | 75.10 |
### IR&TR
* datasets
* The images and captions of Flickr30k datasets can be obtailed from [**here**](https://www.kaggle.com/hsankesara/flickr-image-dataset).
* Visual features are extracted by using tools in [bottom-up attention](https://github.com/jiasenlu/bottom-up-attention). The minimum and maximum number of the extracted boxes are 0 and 36. The organization of visual features is illstruated as follows:
```script
image_w, image_h, number_box, image_loc, image_embeddings
```
* The organization of text data can refer to our given sample, e.g., data/flickr.flickr.dev.data.
* Performance
* Results of **Image Retrieval** task on **Flickr30k dataset** for different scale settings of ERNIE-ViL model
| Models | R@1 | R@5 | R@10 |
| :-------------------------------- | :---------------------: | :----------------------: | :----------------------: |
| ERNIE-ViL _base_ | 74.44 | 92.72 | 95.94 |
| ERNIE-ViL _large_ | 75.10 | 93.42 | 96.26 |
| ERNIE-ViL-Out&in-domain _large_ | 76.66 | 94.16 | 96.76 |
* Results of **Text Retrieval** task on **Flickr30k dataset** for different scale settings of ERNIE-ViL model
| Models | R@1 | R@5 | R@10 |
| :-------------------------------- | :---------------------: | :----------------------: | :----------------------: |
| ERNIE-ViL _base_ | 86.70 | 97.80 | 99.00 |
| ERNIE-ViL _large_ | 88.70 | 97.30 | 99.10 |
| ERNIE-ViL-Out&in-domain _large_ | 89.20 | 98.50 | 99.20 |
### RefCOCO+
* datasets
* Organization of visual features is modified from [MAttNet](https://github.com/lichengunc/MAttNet).
* A single training & test data is organized as follows:
```script
expressions, image_w, image_h, number_box, number_boxes_gt, image_loc, image_embeddings, box_label, label
```
* Performance
* Results of **RefCOCO+** task for different scale settings of ERNIE-ViL model
| Models | val | testA | testB |
| :-------------------------------- | :---------------------: | :----------------------: | :----------------------: |
| ERNIE-ViL _base_ | 74.02 | 80.33 | 64.74 |
| ERNIE-ViL _large_ | 74.24 | 80.97 | 64.70 |
| ERNIE-ViL-Out&in-domain _large_ | 75.89 | 82.39 | 66.91 |
## Usage
### Install PaddlePaddle
This code has been tested with Paddle Fluid 1.8 with Python 2.7. Other dependencies of ERNIE-ViL are listed in `requirements.txt`, you can install them by
```script
pip install -r requirements.txt
```
### Fine-tuning on ERNIE-ViL
Please update LD_LIBRARY_PATH about CUDA, cuDNN, NCCL2 before fine-tuning. You can easily run fine-tuning through
configuration files. You can finetune ERNIE-ViL model on different downstream tasks by the following command:
```script
sh run_finetuning.sh $task_name(vqa/flickr/refcoco_plus/vcr) conf/${task_name}/model_conf_${task_name} $vocab_file $ernie_vil_config $pretrain_models_params
```
Files which are needed by fine-tuning can be found in our given download links, incluing vocabulary dictionary, configuration
file and pre-trained parameters. Training details of different downstream tasks (large scale) are illstruated in the table below.
| Tasks | Batch Size | Learning Rate | # of Epochs | GPUs | Layer Decay rate | Hidden dropout |
| ----- | ----------:| -------------:| -----------:| --------:| ----------------:| --------------:|
| VCR | 16(x4) | 1e-4 | 6 | 4x V100 | 0.9 | 0.1 |
| VQA 2.0 | 64(x4) | 1e-4 | 15 | 4x V100 | 0.9 | 0.1 |
| RefCOCO+ | 64(x2) | 1e-4 | 30 | 2x V100 | 0.9 | 0.2 |
| Flickr | 8(x8) | 2e-5 | 40 | 8x V100 | 0.0 | 0.1 |
Our fine-tuning experiments on downstream tasks are carried on NVIDIA V100 (32GB) GPUs.
If your GPU memory is not enough, you can reduce the batch size in the corresponding configuration file, e.g., "conf/vcr/model_conf_vcr".
### Inference
You can use the following command to infer fine-tuned models.
#### VCR
```script
Task Q->A: sh run_inference.sh vcr qa $split(val/test) conf/vcr/model_conf_vcr $vocab_file $ernie_vil_config $model_params $res_file
```
```script
Task Q->AR: sh run_inference.sh vcr qar $split(val/test) conf/vcr/model_conf_vcr $vocab_file $ernie_vil_config $model_params $res_file
```
#### VQA
```script
sh run_inference.sh vqa eval $split(val/test_dev/test_std) conf/vqa/model_conf_vqa $vocab_file $ernie_vil_config $model_params $res_file
```
_No test labels are given in the released test samples, you can obtailed the final score by submiting the result file to the [VQA website](https://visualqa.org/)_.
#### RefCOCO+
```script
sh run_inference.sh refcoco_plus eval $split(val/test_A/test_B) conf/refcoco_plus/model_conf_refcoco_plus $vocab_file $ernie_vil_config $model_params $res_file
```
#### Flickr
```script
sh run_inference.sh flickr eval $split(dev/test) conf/flickr/model_conf_flickr $vocab_file $ernie_vil_config $model_params $res_file
```
_Get the accuray score by using the given tools of tools/get_recall.py._
## Citation
You can cite the paper as below:
```
@article{yu2020ernie,
title={ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph},
author={Yu, Fei and Tang, Jiji and Yin, Weichong and Sun, Yu and Tian, Hao and Wu, Hua and Wang, Haifeng},
journal={arXiv preprint arXiv:2006.16934},
year={2020}
}
```