English| [简体中文](./README_zh.md)
## _ERNIE-ViL_: Knowledge Enhanced Vision-Language Representations Through Scene Graph
- [Framework](#framework)
- [Pre-trained models](#pre-trained-models)
- [Downstream tasks](#downstream-tasks)
* [VCR](#VCR)
- [Usage](#usage)
* [Install PaddlePaddle](#install-paddlepaddle)
* [Fine-tuning on ERNIE-ViL](#fine-tuning-on-ernie-vil)
* [Inference](#inference)
- [Citation](#citation)
For technical description of the algorithm, please see our paper:
>[_**ERNIE-ViL:Knowledge Enhanced Vision-Language Representations Through Scene Graph**_](https://arxiv.org/abs/2006.16934)
>
>Fei Yu\*, Jiji Tang\*, Weichong Yin, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang (\* : equal contribution)
>
>Preprint June 2020
>


 

**[ERNIE-ViL](https://arxiv.org/abs/2006.16934) is a knowledge-enhanced joint representations for vision-language tasks**, which is the first work that has **introduced structured knowledge to enhance vision-language pre-training**. Utilizing structured knowledge obtained
from scene graphs, ERNIE-ViL constructs three **Scene Graph Prediction tasks**, i.e., **Object Prediction**, **Attribute Prediction** and **Relationship Prediction** tasks.
Thus, ERNIE-ViL can learn the better joint vision-language representations characterizing the alignments of the detailed semantics across vision and language.
## Framework
Based on the scene graph parsed from the text using Scene Graph Parser, we construct Object Prediction, Attribute Prediction and Relationship Prediction tasks:
- **Object Prediction:** We randomly select a set of the objects in the scene graph, then mask and predict the corresponding words in the sentence.
- **Attribute Prediction:** For the object-attribute pairs in the scene graph, we randomly select a part of them to mask and predict the words related to the attribute nodes in the sentence.
- **Realtionship Prediction:** For the object-relationship-object triplets in the scene graph, we randomly select a part of realtionship nodes to mask and predict them.
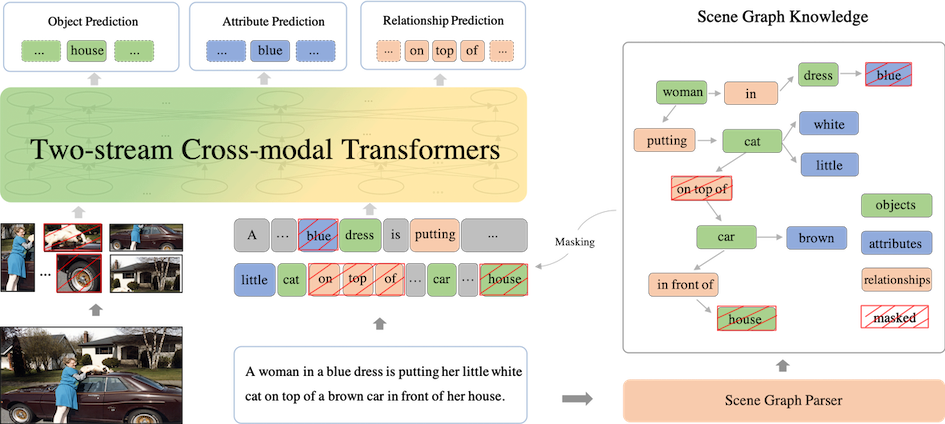
Model Architecture of ERNIE-ViL
## Pre-trained Models
ERNIE-ViL adopts large-scale image-text aligned datasets as the pre-training data. We provide ERNIE-ViL models of two scale settings which are pretrained on [**Conceptual Captions**](https://www.aclweb.org/anthology/P18-1238.pdf) and [**SBU Captions**](http://papers.nips.cc/paper/4470-im2text-describing-images-using-1-million-captio).
- [**ERNIE-ViL _base_**](https://ernie-github.cdn.bcebos.com/model-ernie-vil-base-en.1.tar.gz) (_lowercased | 12-text-stream-layer, 6-visual-stream-layer_)
- [**ERNIE-ViL _large_**](https://ernie-github.cdn.bcebos.com/model-ernie-vil-large-en.1.tar.gz) (_lowercased | 24-text-stream-layer, 6-visual-stream-layer_)
## Downstream tasks
We finetune ERNIE-ViL on five vision-langage downstream tasks, i.e., Visual Commensense Reasoning([**VCR**](https://openaccess.thecvf.com/content_CVPR_2019/papers/Zellers_From_Recognition_to_Cognition_Visual_Commonsense_Reasoning_CVPR_2019_paper.pdf)),
Visual Question Answering([**VQA**](https://openaccess.thecvf.com/content_iccv_2015/papers/Antol_VQA_Visual_Question_ICCV_2015_paper.pdf)),
Cross-modal Image Retrieval([**IR**](https://www.mitpressjournals.org/doi/abs/10.1162/tacl_a_00166)),
Cross-modal Text Retrieval([**TR**](https://www.mitpressjournals.org/doi/abs/10.1162/tacl_a_00166)) and
Region_to_Phrase_Grounding([**RefCOCO+**](https://www.aclweb.org/anthology/D14-1086.pdf)).
_Code and pre-trained models related to VCR task are made public now, and those of more downstream tasks are planed to be public._
### VCR
* datasets
* The training, validation and testing data of VCR task are provided by [**VCR Website**](https://visualcommonsense.com/download/).
* Organization of visual features is modified from [**ViLBERT**](https://github.com/jiasenlu/vilbert_beta), we directly use the data from it. Data can be downloaded [here](https://github.com/jiasenlu/vilbert_beta/tree/master/data).
* Put all downloaded files under diretory "data/vcr".
* Task pre-training: We perform task-pretraining on VCR task, which is also known as task-specific-pretraining. The trained models are as follows:
* [**ERNIE-ViL-VCR-task-pretrain _base_**](https://ernie-github.cdn.bcebos.com/model-ernie-vil-base-VCR-task-pre-en.1.tar.gz)
* [**ERNIE-ViL-VCR-task-pretrain _large_**](https://ernie-github.cdn.bcebos.com/model-ernie-vil-large-VCR-task-pre-en.1.tar.gz)
* Performance: Results of VCR task for ERNIE-ViL model, compared with previous state-of-the-art pre-trained models([**VILLA**](https://arxiv.org/pdf/2006.06195.pdf)).
| Models | Q->A | QA->R | Q->AR |
| :--------------------------------------| :---------------------------: | :----------------------------: | :-----------------------------: |
| VILLA (task-pretrain) _base_ | 75.54(76.4) | 78.78(79.1) | 59.75(60.6) |
| ERNIE-ViL (task-pretrain) _base_ | 76.37(77.0) | 79.65(80.3) | 61.24(62.1) |
| VILLA (task-pretrain) _large_ | 78.45(78.9) | 82.57(82.8) | 65.18(65.7) |
| ERNIE-ViL (task-pretrain) _large_ | 78.52(79.2) | 83.37(83.5) | 65.81(66.3) |
_Numerical results outside and inside parentheses represent the dev and test performance of VCR task respectively.
Test results are obtained from the [**VCR leadborad**](https://visualcommonsense.com/leaderboard/)._
## Usage
### Install PaddlePaddle
This code has been tested with Paddle Fluid 1.8 with Python 2.7. Other dependencies of ERNIE-ViL are listed in `requirements.txt`, you can install them by
```script
pip install -r requirements.txt
```
### Fine-tuning on ERNIE-ViL
Please update LD_LIBRARY_PATH about CUDA, cuDNN, NCCL2 before fine-tuning. You can easily run fine-tuning through
configuration files. For example, you can finetune ERNIE-ViL model on VCR task by
```script
sh run_finetuning.sh vcr conf/vcr/model_conf_vcr $vocab_file $ernie_vil_config $pretrain_models
```
Files which are needed by fine-tuning can be found in our given download links, incluing vocabulary dictionary, configuration
file and pre-trained parameters. Note that our fine-tuning experiments on VCR are carried on 4 NVIDIA V100 (32GB) GPUs.
If your GPU memory is not enough, you can reduce the batch size in the corresponding configuration file, e.g., "conf/vcr/model_conf_vcr".
### Inference
You can use the following command to infer fine-tuned models. For example, you can infer VCR models by the following commands for different sub-tasks:
**Task Q->A**
```script
sh run_inference.sh vcr qa $split(val/test) conf/vcr/model_conf_vcr $vocab_file $ernie_vil_config $model_params $res_file
```
**Task QA->R**
```script
sh run_inference.sh vcr qar $split(val/test) conf/vcr/model_conf_vcr $vocab_file $ernie_vil_config $model_params $res_file
```
## Citation
You can cite the paper as below:
```
@article{yu2020ernie,
title={ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph},
author={Yu, Fei and Tang, Jiji and Yin, Weichong and Sun, Yu and Tian, Hao and Wu, Hua and Wang, Haifeng},
journal={arXiv preprint arXiv:2006.16934},
year={2020}
}
```