Merge pull request #655 from zhanghan1992/develop
merge ernie-gram
Showing
.metas/ernie_gram_framework.png
0 → 100644
{kind=link}
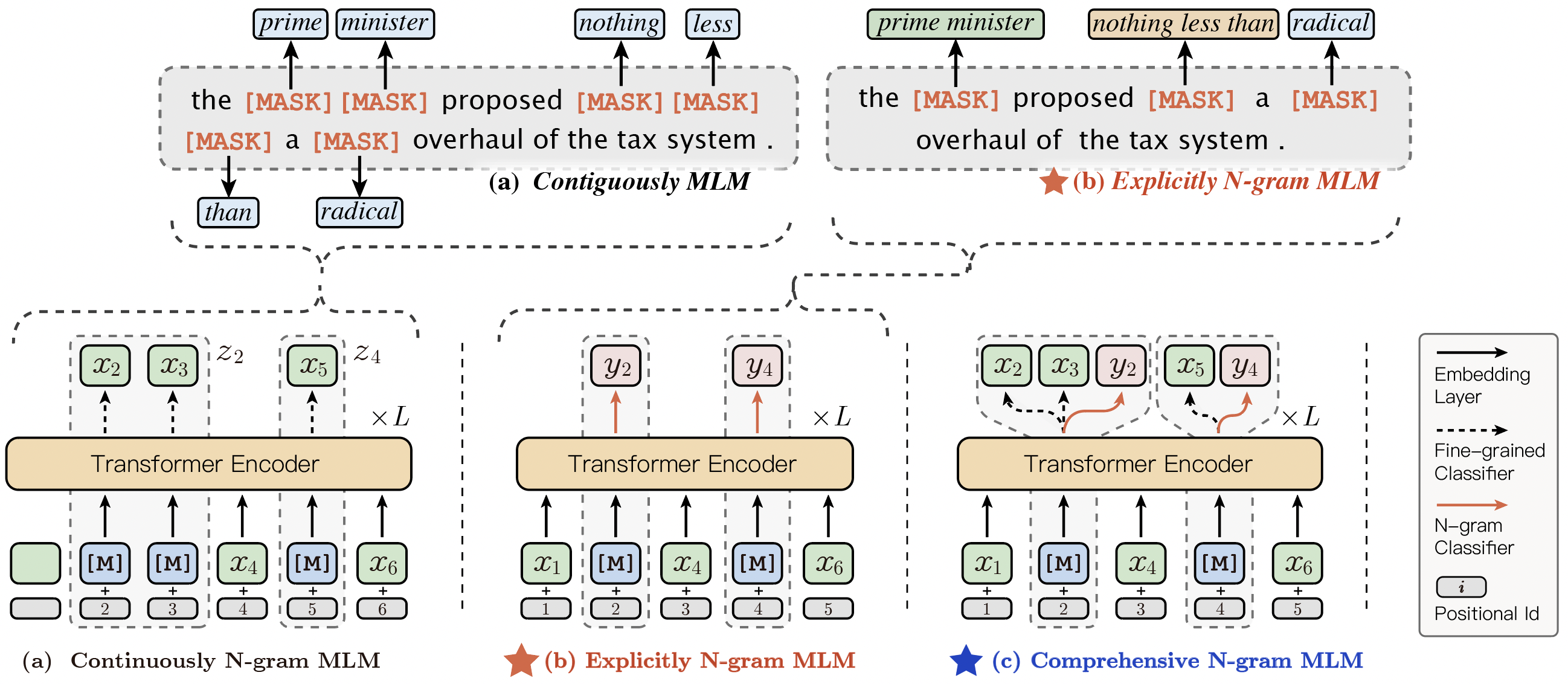
1.0 MB
ernie_gram/.meta/ernie-gram.jpeg
0 → 100644
{kind=link}
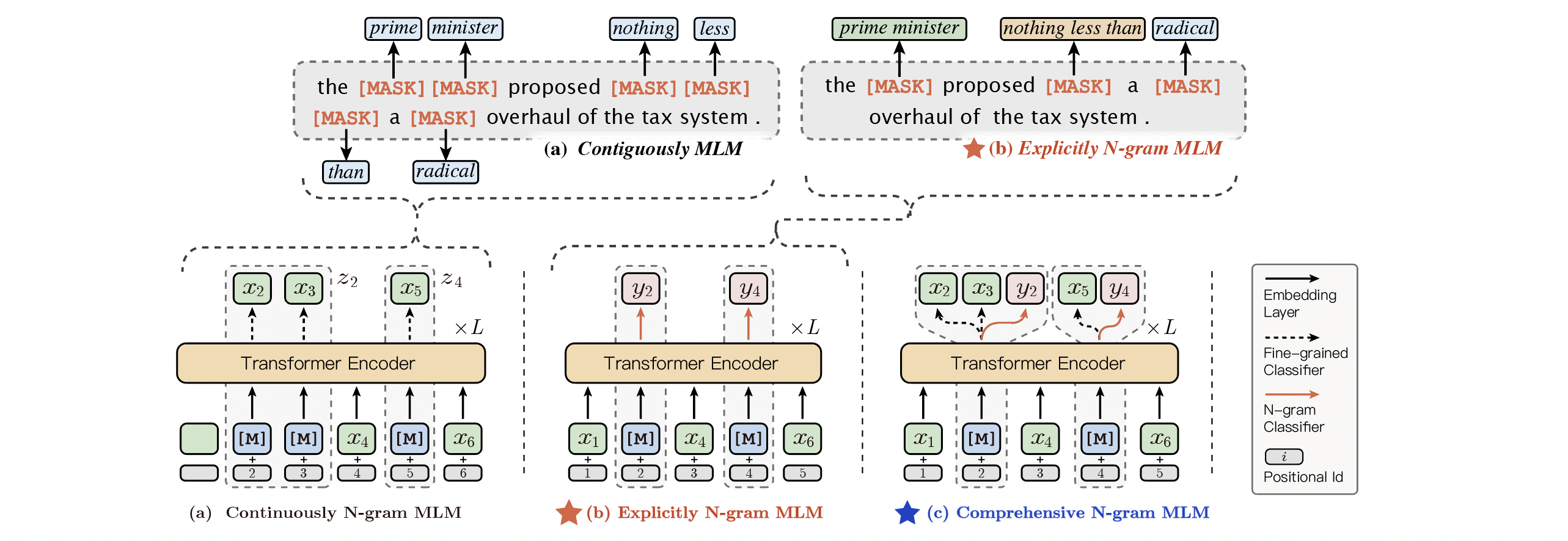
791.3 KB
ernie_gram/README.en.md
0 → 100644
ernie_gram/README.md
0 → 120000
ernie_gram/README.zh.md
0 → 100644
ernie_gram/__init__.py
0 → 100644
ernie_gram/finetune_mrc.py
0 → 100644
ernie_gram/finetune_ner.py
0 → 100644
ernie_gram/mrc/__init__.py
0 → 100644
ernie_gram/mrc/mrc_metrics.py
0 → 100644
ernie_gram/mrc/mrc_reader.py
0 → 100644
ernie_gram/optimization.py
0 → 100644
ernie_gram/run_cls.sh
0 → 100644
ernie_gram/run_mrc.sh
0 → 100644
ernie_gram/run_ner.sh
0 → 100644
ernie_gram/task_configs/cmrc_conf
0 → 100644
ernie_gram/task_configs/xnli_conf
0 → 100644
ernie_gram/utils.py
0 → 100644