League Overview¶
Abstract:
The concept of League training is from AlphaStar. League training is a multi-agent reinforcement learning algorithm that is designed both to address the cycles commonly encountered during self-play training and to integrate a diverse range of strategies. In the league of AlphaStar, there exists different types of agent as league members that differ only in the distribution of opponent they train against. In DI-engine, we call these members player. Each player holds a strategy, i.e. neural networks or rules.
In 1v1 RTS games like StarCraft2, the league is responsible for assigning opponents to players. Different players can fight each other and generate very rich game data to update their own strategies. This is one of the most important components to make AlphaStar successfully.
In the following paragraphs, We’ll first introduce the training pipline of League, then there will be a brief summary of the implementation
of league module in ding.
League Intro¶
In 1v1 competitive games, we always hope to find two players with similar levels. In this way the trajectory generated is more meaningful for strategy optimization. The navie implementation is self-play, which means agents plays with itself to upate its strategy.
In self-play, a problem that is worth taking note of is whether the opponent is exactly the same as the agent itself, with updatable strategies and parameters, or it is the strategies periodically frozen from the best parameters at that time.
In the first case, two identical players play against each other, and the generated trajectory data can be put into the same replay buffer for the learner to sample data and optimize the strategy. In this case, double the training data will be generated. But at the same time, this becomes a 2-agent problem, and once the number of agents in the environment exceeds one, the interaction process is no longer a Markov process, and the stability of the optimization process will be far less than that of a single agent.
In the latter case, the player will freeze a current best strategy every certain number of iterations, and use this frozen player as the opponent in the next stage. It is expected that after each stage, the player will become stronger. At this time, only the non-frozen player generated trajectory can be used for training. In this case, there will be a problem similar to “rock-paper-scissors”: the player is first trained as the best strategy A, then be trained as strategy B after freezing and defeats strategy A, and be trained as strategy C after freezing and defeats strategy B again. Strategy C will lose to strategy A finally.
To alleviate these problems, the training pipline of self-play is usually implemented as follows:
Initialize an empty player pool, then put the first player in it.
At this time, the pool has only one player, only the first approach is possible.
After a certain number of iterations, the current player is frozen to a snapshot, and the snapshot player is added to the player pool.
According to certain rules, league chooses one player from the pool as the opponent, then both the first and the second approach can be used.
When the updatable strategy is good enough, the training process ends.
The DI-engine’s demo of league dizoo/competitive_rl/entry/cpong_dqn_default_config.py is implemented as the above process.
AlphaStar uses a more complicated league training algorithm than self-play, and designs more types of players differ in the distribution of opponent they train against. The “Rock-paper-scissors” problem can be alleviated in this way, also the strategy will be more diverse. More details can be found in the AlphaStar paper’s “Methods - MultiAgent Learning” part.
DI-engine Implementation¶
DI-engine’s implementation of league consists of three parts:
Player:Player is the participant of game, consists of active (i.e. updatable) and historical (i.e. unupdatable) player.
Payoff:Payoff is used to record the results of game play in league. This module is shared by all players, can be the references of to choose opponents.
League:league holds all of the players and payoff records, responsible for maintaining payoff and player status, and assigning opponents to players based on payoff.
Player¶
- Abstract:
Player is the member of the league, also the participant of the competitive games. Each player holds a share of parameters or rules, which means it act in an unique strategy.
Player consists of active player and historical player:
Active means player’s model is updatable. In most cases these are the players in the league which need training.
Historical means player’s model is frozen from the past active player, used as the opponent of active player, to enrich the diversity of data.
- Code Structure:
The main classes are as follows:
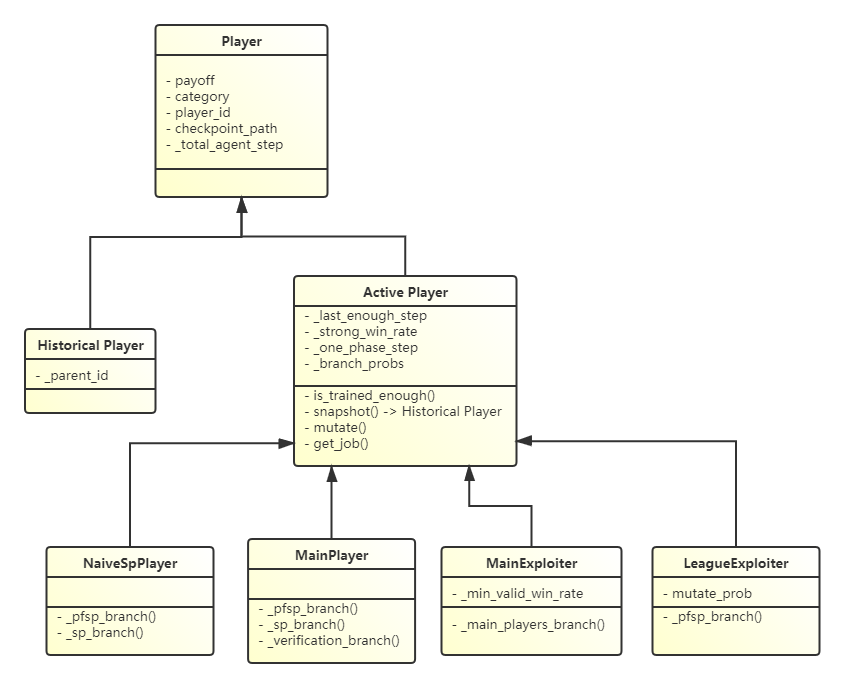
Player: Base class of player, holds most properties.ActivePlayer: Updatable player, can be assigned opponents to play in league. After training for a period of time, historical player can be generated through snapshot of ActivePlayer.HistoricalPlayer: Unupdatable player, can be acquired by loading a pretrained model or snapshot from active player.NaiveSpPlayer: An self play version implementation of active player, can be used to play with historical player or itself.MainPlayer: A special implementation of active player, used in AlphaStar. More details can be found in AlphaStar paper.MainExploiter: A special implementation of active player, used in AlphaStar. More details can be found in AlphaStar paper.LeagueExploiter: A special implementation of active player, used in AlphaStar. More details can be found in AlphaStar paper.
- Base Class Definition:
Player (ding/league/player.py)
Abstract:
Base class player defines properties needed by both active player and historical player, including category, payoff, checkpoint path, id, training iteration, etc. Player is an abstract base class and cannot be instantiated.
HistoricalPlayer (ding/league/player.py)
Abstract:
HistoricalPlayer defines parent id additionally comparing to player class.
ActivePlayer (ding/league/player.py)
Abstract:
League will assign opponents of active player by its
get_jobmethod When it is called by commander to generate new collect job. After collector starting to execute tasks, learner use the generated data train itself. After some iterations, learner will call league by commander, then league use corresponding player’sis_trained_enoughmethod to judge whether the policy of collector is trained enough. If so, callsnapshotormutateto get a snapshot historical player or reset to specific parameters.- API:
__init__: For initialization.is_trained_enough: To judge whether this player is trained enough by training steps.snapshot: Freeze the network parameters, create a historical player and return.mutate: Mutate the model, e.g. resetting to a specific parameters.get_job: Get game play job. To call cooresponding player’s_get_collect_opponentmethod to get opponent.
Methods need to override by users:
ActivePlayerdon’t implement specific methods to select opponent. The example of selecting opponent can be likeNaiveSpPlayer: 50% to naive self play, 50% to select historical players randomly. To archive this, DI-engine needs to modify player class and config:config
# in ding/config/league.py naive_sp_player=dict( # ... branch_probs=dict( pfsp=0.5, sp=0.5, ), )
NaiveSpPlayerclass NaiveSpPlayer(ActivePlayer): def _pfsp_branch(self) -> HistoricalPlayer: return self._get_opponent(historical, p) def _sp_branch(self) -> ActivePlayer: return self
The class hierarchy of player can be shown as follows:
Payoff¶
Abstract:
Payoff is used to record historical game play results, as the reference of assigning opponents. E.g. In competitive games, payoff can be used to calculate the winrate between two players.
Code Structure:
Payoff contains two components:
BattleRecordDict: Succeed from dict, recording game play results between every two players. Initialized to all four keys [‘wins’, ‘draws’, ‘losses’, ‘games’] to 0.
BattleSharedPayoff: UseBattleRecordDictto record specific two player’s game play records, calculate winrate of them.
League¶
Abstract:
league is the class to manage players and their relationship(i.e. payoff), as a property of commander. Commander call league’s
get_job_infomethod to collect task for two players to play a round of game.
- Base Class Definition:
BaseLeague (ding/league/base_league.py)
Abstract:
League follow the commands of commander to provide useful information of game plays for commander.
- API:
__init__: Initialization, call_init_cfgfirst to read config of league, then call_init_leagueto initialize league players.cfg``.get_job_info: When commander assigns job to collector, call this method to get which two players to execute this job.judge_snapshot: After learner use generated data to update its strategy, the corresponding player’s strategy will be updated. After training for some time, commander calls this method to judge whether the model is trained enough.update_active_player: After Learner updated or evaluator evaluated, update cooresponding player’s train stpe or choose opponent for next evaluation.finish_job: When collector task finished, update game play information in shared payoff.
Methods need to override by users:
_get_job_info: called by_launch_job_mutate_player: called by_snapshot_update_player: called byupdate_active_player. All three methods above are abstract method, refer toding/league/one_vs_one_league.pyOneVsOneLeaguefor more implementation details.