diff --git a/docs/uniCloud/clientdb.md b/docs/uniCloud/clientdb.md
index ed3d8fb6c6389a90d2e3d84cb52b9b9d3d46fce8..b9138203f15aec6fbce4e7d868729565dbed9f5a 100644
--- a/docs/uniCloud/clientdb.md
+++ b/docs/uniCloud/clientdb.md
@@ -276,11 +276,6 @@ sql写法,对js工程师而言有学习成本,而且无法处理非关系型
.end()
```
-3. 列表分页写法复杂
-
- 需要使用skip,处理offset
-
-
这些问题竖起一堵墙,让后端开发难度加大,成为一个“专业领域”。但其实这堵墙是完全可以推倒的。
@@ -319,7 +314,7 @@ sql写法,对js工程师而言有学习成本,而且无法处理非关系型
**jql条件语句内变量**
-以下变量同[前端环境变量](uniCloud/database.md?id=variable)
+以下变量同[前端环境变量](uniCloud/clientdb.md?id=variable)
|参数名 |说明 |
|:-: |:-: |
@@ -440,7 +435,7 @@ const order = db.collection('order').where('_id=="1"').getTemp() // 注意结尾
const res = await db.collection(order, 'book').get() // 将获取的order表的临时表和book表进行联表查询
```
-上面两种写法最终结果一致,但是第二种写法性能更好。第一种写法会先将所有数据进行关联,如果数据量很大这一步会消耗浪费很多时间。详细示例见下方说明
+上面两种写法最终结果一致,但是第二种写法性能更好。第一种写法会先将所有数据进行关联,如果数据量很大这一步会消耗很多时间。详细示例见下方说明
**关联查询后的虚拟表数据结构如下:**
diff --git a/docs/uniCloud/jql-cloud.md b/docs/uniCloud/jql-cloud.md
new file mode 100644
index 0000000000000000000000000000000000000000..6fbc49b55be774b11f9a4fe11c556469f607756e
--- /dev/null
+++ b/docs/uniCloud/jql-cloud.md
@@ -0,0 +1,70 @@
+## 云函数内使用JQL
+
+> 新增于HBuilderX 3.3.1版本
+
+HBuilderX 3.3.1之前JQL只能在clientDB及JQL数据库管理里面使用,此次更新为云函数带来了JQL语法,云函数内也可以享受便捷的数据库操作语句编写。
+
+关于JQL语法及其他注意事项请参考此文档:[JQL数据库操作](uniCloud/jql.md)
+
+## 为云函数启用jql扩展能力@use-in-function
+
+需要开发者手动在云函数的package.json内添加云函数的扩展能力。(如果云函数目录下没有package.json,可以通过在云函数目录下执行`npm init -y`来生成)
+
+下面是一个开启了jql扩展能力的云函数的package.json示例,**注意不可有注释,以下文件内容中的注释仅为说明,如果拷贝此文件,切记去除注释**
+
+```js
+{
+ "name": "jql-test",
+ "version": "1.0.0",
+ "description": "",
+ "main": "index.js",
+ "extensions": {
+ "uni-cloud-jql": {} // 配置为此云函数开启jql扩展能力,值为空对象留作后续追加参数,暂无内容
+ },
+ "author": ""
+}
+```
+
+```js
+// 简单的使用示例
+'use strict';
+exports.main = async (event, context) => {
+ const dbJQL = uniCloud.databaseForJQL({ // 获取JQL database引用,此处需要传入云函数的event和context,必传
+ event,
+ context
+ })
+ const bookQueryRes = dbJQL.collection('book').where("name=='三国演义'").get() // 直接执行数据库操作
+ return {
+ bookQueryRes
+ }
+};
+```
+
+上述示例中jql扩展将会使用event内带有的uniIdToken对应的用户作为执行数据库操作的用户,如需指定执行当前数据库操作的用户请使用`setUser`方法
+
+例:
+
+```js
+'use strict';
+exports.main = async (event, context) => {
+ const dbJQL = uniCloud.databaseForJQL({ // 获取JQL database引用,此处需要传入云函数的event和context,必传
+ event,
+ context
+ })
+ dbJQL.setUser({ // 指定后续执行操作的用户信息
+ uid: 'user-id', // 建议此处使用真实uid
+ role: ['admin'], // 指定当前执行用户的角色为admin
+ permission: []
+ })
+ const bookQueryRes = dbJQL.collection('book').where("name=='三国演义'").get() // 直接执行数据库操作
+ return {
+ bookQueryRes
+ }
+};
+```
+
+**注意**
+
+- 启用了JQL扩展的云函数暂不可本地调试,后续会提供支持
+- JQL扩展依赖`uni-id`公共模块
+- 由于此扩展会将`schema`、`action`、`validateFunction`带到模块内,如果你的上述文件较多会大幅增大云函数体积,因此启用此扩展的云函数**冷启动**时间会稍长,建议不要为太多云函数启用此扩展
\ No newline at end of file
diff --git a/docs/uniCloud/jql.md b/docs/uniCloud/jql.md
new file mode 100644
index 0000000000000000000000000000000000000000..7a8152dbfa568f89ba94c68e6a36ea59c506eb27
--- /dev/null
+++ b/docs/uniCloud/jql.md
@@ -0,0 +1,3515 @@
+## JQL数据库操作
+
+`jql`,全称javascript query language,是一种js方式操作数据库的语法规范。
+
+`jql`大幅降低了js工程师操作数据库的难度、大幅缩短开发代码量。并利用json数据库的嵌套特点,极大的简化了联表查询和树查询的复杂度。
+
+#### jql的诞生背景
+
+传统的数据库查询,有sql和nosql两种查询语法。
+
+- sql是一种字符串表达式,写法形如:
+
+```
+select * from table1 where field1="123"
+```
+
+- nosql是js方法+json方式的参数,写法形如:
+
+```js
+const db = uniCloud.database()
+let res = await db.collection('table').where({
+ field1: '123'
+}).get()
+```
+
+sql写法,对js工程师而言有学习成本,而且无法处理非关系型的MongoDB数据库,以及sql的联表查询inner join、left join也并不易于学习。
+
+而nosql的写法,实在过于复杂。比如如下3个例子:
+
+1. 运算符需要转码,`>`需要使用`gt`方法、`==`需要使用`eq`方法
+
+ 比如一个简单的查询,取field1>0,则需要如下复杂写法
+
+ ```js
+ const db = uniCloud.database()
+ const dbCmd = db.command
+ let res = await db.collection('table1').where({
+ field1: dbCmd.gt(0)
+ }).get()
+ ```
+
+ 如果要表达`或`关系,需要用`or`方法,写法更复杂
+
+ ```js
+ field1:dbCmd.gt(4000).or(dbCmd.gt(6000).and(dbCmd.lt(8000)))
+ ```
+
+2. nosql的联表查询写法,比sql还复杂
+
+ sql的inner join、left join已经够乱了,而nosql的代码无论写法还是可读性,都更“令人发指”。比如这个联表查询:
+
+ ```js
+ const db = uniCloud.database()
+ const dbCmd = db.command
+ const $ = dbCmd.aggregate
+ let res = await db.collection('orders').aggregate()
+ .lookup({
+ from: 'books',
+ let: {
+ order_book: '$book',
+ order_quantity: '$quantity'
+ },
+ pipeline: $.pipeline()
+ .match(dbCmd.expr($.and([
+ $.eq(['$title', '$$order_book']),
+ $.gte(['$stock', '$$order_quantity'])
+ ])))
+ .project({
+ _id: 0,
+ title: 1,
+ author: 1,
+ stock: 1
+ })
+ .done(),
+ as: 'bookList',
+ })
+ .end()
+ ```
+
+这些问题竖起一堵墙,让后端开发难度加大,成为一个“专业领域”。但其实这堵墙是完全可以推倒的。
+
+`jql`将解决这些问题,让js工程师没有难操作的数据。
+
+具体看以下示例
+
+ ```js
+ const db = uniCloud.database()
+
+ // 使用`jql`查询list表内`name`字段值为`hello-uni-app`的记录
+ db.collection('list')
+ .where('name == "hello-uni-app"')
+ .get()
+ .then((res)=>{
+ // res 为数据库查询结果
+ }).catch((err)=>{
+ // err.message 错误信息
+ // err.code 错误码
+ })
+ ```
+
+## JQL包含的模块@module
+
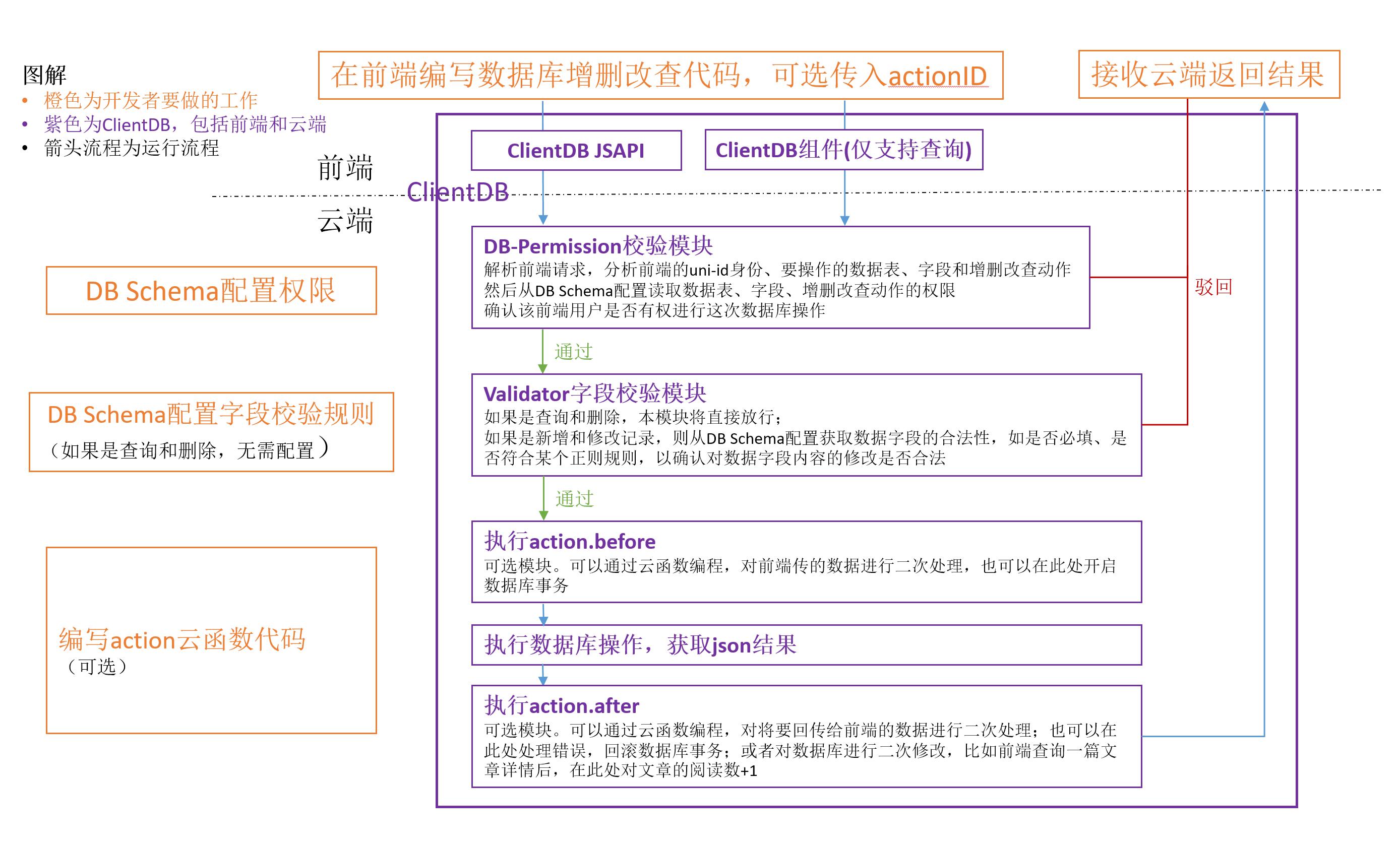
+这里选择以使用了JQL完整功能clientDB为例,JQL操作数据库的流程如下。不同使用场景的区别请参考: [JQL的使用场景](uniCloud/jql.md?id=scene)
+
+
+
+## JQL的使用场景@scene
+
+你可以在以下三种场景使用JQL
+
+- 客户端clientDB,包括js内以及unicloud-db组件内,参考:[clientDB](uniCloud/clientdb.md)
+- HBuilderX JQL数据库管理器,参考:[JQL数据库管理器](uniCloud/jql-runner.md)
+- 启用了jql扩展的云函数,参考:[云函数内使用JQL](uniCloud/jql-cloud.md)
+
+### 不同场景的区别
+
+上述场景在新增、修改数据时都会执行数据校验,但是关于权限校验及action部分稍有不同
+
+**JQL数据库管理器:**
+
+- 不会校验任何权限,相当于以数据库管理员的身份执行
+- 即使是admin不能读写的password类型数据也可以读写
+- 不可以执行action
+
+**客户端clientDB:**
+
+- 完整的权限校验,执行操作的用户不可以操作自己权限之外的数据
+- admin用户不可操作password类型的数据
+
+**云函数JQL:**
+
+- 同clientDB,但是password类型的数据可以配置权限,默认权限是false,可以被admin用户操作。
+- 可以指定当前执行数据库操作的用户身份。
+
+## JQL的限制@limit
+
+- 会对数据库操作进行序列化,除Date类型、RegExp之外的所有不可JSON序列化的参数类型均不支持(例如:undefined)
+- 为了严格控制权限,禁止使用set方法
+- 为了数据校验能严格限制,更新数据库时不可使用更新操作符`db.command.inc`等
+- 更新数据时键值不可使用`{'a.b.c': 1}`的形式,需要写成`{a:{b:{c:1}}}`形式
+
+## jql语句内云端环境变量@variable
+
+|参数名 |说明 |
+|:-: |:-: |
+|$cloudEnv_uid |用户uid,依赖uni-id|
+|$cloudEnv_now |服务器时间戳 |
+|$cloudEnv_clientIP |当前客户端IP |
+
+在字符串内使用
+
+```js
+db.collection('user').where('_id==$cloudEnv_uid').get()
+```
+
+在对象内使用
+
+```js
+db.collection('user').where({
+ _id: db.getCloudEnv('$cloudEnv_uid')
+}).get()
+```
+
+**注意**
+
+- 这些变量使用时并非直接获取对应的值,而是生成一个标记,在执行数据库操作时再将这个标记替换为实际的值
+
+## jql条件语句的运算符@operator
+
+|运算符 |说明 |示例 |示例解释(集合查询) |
+|:-: |:-: |:-: |:-: |
+|== |等于 |name == 'abc' |查询name属性为abc的记录,左侧为数据库字段 |
+|!= |不等于 |name != 'abc' |查询name属性不为abc的记录,左侧为数据库字段 |
+|> |大于 |age>10 |查询条件的 age 属性大于 10,左侧为数据库字段 |
+|>= |大于等于 |age>=10 |查询条件的 age 属性大于等于 10,左侧为数据库字段 |
+|< |小于 |age<10 |查询条件的 age 属性小于 10,左侧为数据库字段 |
+|<= |小于等于 |age<=10 |查询条件的 age 属性小于等于 10,左侧为数据库字段 |
+|in |存在在数组中 |status in ['a','b'] |查询条件的 status 是['a','b']中的一个,左侧为数据库字段 |
+|!(xx in []) |在数组中不存在 |!(status in ['a','b']) |查询条件的 status 不是['a','b']中的任何一个 |
+|&& |与 |uid == auth.uid && age > 10 |查询记录uid属性 为 当前用户uid 并且查询条件的 age 属性大于 10 |
+||| |或 |uid == auth.uid||age>10 |查询记录uid属性 为 当前用户uid 或者查询条件的 age 属性大于 10 |
+|test |正则校验 |/abc/.test(content) |查询 content字段内包含 abc 的记录。可用于替代sql中的like。还可以写更多正则实现更复杂的功能 |
+
+这里的test方法比较强大,格式为:`正则规则.test(fieldname)`。
+
+具体到这个正则 `/abc/.test(content)`,类似于sql中的`content like '%abc%'`,即查询所有字段content包含abc的数据记录。
+
+**注意**
+
+- 不支持非操作
+- 编写查询条件时,除test外,均为运算符左侧为数据库字段,右侧为常量
+
+## 返回值说明@returnvalue
+
+### 正常请求返回结果
+
+不同数据库操作返回的结果结构不一样
+
+**查询数据**
+
+```js
+{
+ code: 0,
+ message: '',
+ data: []
+}
+```
+
+**批量发送数据库查询请求**
+
+只能批量发送查询请求
+
+```js
+{
+ code: 0,
+ message: '',
+ dataList: [] // dataList内每一项都是一个查询数据的响应结果 {code: 0, message: '', data: []}
+}
+```
+
+**新增数据**
+
+新增单条
+
+```js
+{
+ code: 0,
+ message: '',
+ id: '' // 新增数据的id
+}
+```
+
+新增多条
+
+```js
+{
+ code: 0,
+ message: '',
+ ids: [], // 新增数据的id列表
+ inserted: 3 // 新增成功的条数
+}
+```
+
+**删除数据**
+
+```js
+{
+ code: 0,
+ message: '',
+ deleted: 1 // 删除的条数
+}
+```
+
+**更新数据**
+
+```js
+{
+ code: 0,
+ message: '',
+ updated: 1 // 更新的条数,数据更新前后无变化则更新条数为0
+}
+```
+
+### 请求报错返回err格式
+
+```js
+{
+ code: "", // 错误码
+ message: "", // 错误信息
+}
+```
+
+**err.code错误码列表**
+
+|错误码 |描述 |
+|:-: |:-: |
+|TOKEN_INVALID_INVALID_CLIENTID |token校验未通过(设备特征校验未通过) |
+|TOKEN_INVALID |token校验未通过(云端已不包含此token) |
+|TOKEN_INVALID_TOKEN_EXPIRED |token校验未通过(token已过期) |
+|TOKEN_INVALID_WRONG_TOKEN |token校验未通过(token校验未通过) |
+|TOKEN_INVALID_ANONYMOUS_USER |token校验未通过(当前用户为匿名用户) |
+|SYNTAX_ERROR |语法错误 |
+|PERMISSION_ERROR |权限校验未通过 |
+|VALIDATION_ERROR |数据格式未通过 |
+|DUPLICATE_KEY |索引冲突 |
+|SYSTEM_ERROR |系统错误 |
+
+如需自定义返回的err对象,可以在clientDB中挂一个[action云函数](uniCloud/database?id=action),在action云函数的`after`内用js修改返回结果,传入`after`内的result不带code和message。
+
+## 查询数据
+
+### 查询数组字段@querywitharr
+
+如果数据库存在以下记录
+
+```js
+{
+ "_id": "1",
+ "students": ["li","wang"]
+}
+{
+ "_id": "2",
+ "students": ["wang","li"]
+}
+{
+ "_id": "3",
+ "students": ["zhao","qian"]
+}
+```
+
+使用jql查询语法时,可以直接使用`student=='wang'`作为查询条件来查询students内包含wang的记录。
+
+### 使用正则查询@regexp
+
+以搜索用户输入值为例
+
+```js
+const res = await db.collection('goods').where(`${new RegExp(searchVal, 'i')}.test(name)`).get()
+```
+
+如果使用[unicloud-db组件](uniCloud/unicloud-db.md)写法如下
+
+```html
+
+
+
+
+ {{error.message}}
+
+
+
+
+
+
+
+
+
+
+
+```
+
+上面的示例中使用了正则修饰符`i`,用于表示忽略大小写
+
+### 联表查询@lookup
+
+> JQL于2021年4月28日优化了联表查询策略,详情参考:[联表查询策略调整](https://ask.dcloud.net.cn/article/38966)
+
+`JQL`提供了更简单的联表查询方案。不需要学习join、lookup等复杂方法。
+
+只需在db schema中,将两个表的关联字段建立映射关系,就可以把2个表当做一个虚拟表来直接查询。
+
+JQL联表查询有以下两种写法:
+
+```js
+// 直接关联多个表为虚拟表再进行查询
+const res = await db.collection('order,book').where('_id=="1"').get() // 直接关联order和book之后再过滤
+
+// 使用getTemp先过滤处理获取临时表再联表查询
+const order = db.collection('order').where('_id=="1"').getTemp() // 注意结尾的方法是getTemp,对order表过滤得到临时表
+const res = await db.collection(order, 'book').get() // 将获取的order表的临时表和book表进行联表查询
+```
+
+上面两种写法最终结果一致,但是第二种写法性能更好。第一种写法会先将所有数据进行关联,如果数据量很大这一步会消耗很多时间。详细示例见下方说明
+
+**关联查询后的虚拟表数据结构如下:**
+
+> 通过HBuilderX提供的[JQL数据库管理](uniCloud/jql-runner.md)功能方便的查看联表查询时的虚拟表结构
+
+主表某字段foreignKey指向副表时
+
+```js
+{
+ "主表字段名1": "xxx",
+ "主表字段名2": "xxx",
+ "主表内foreignKey指向副表的字段名": [{
+ "副表字段名1": "xxx",
+ "副表字段名2": "xxx",
+ }]
+}
+```
+
+副表某字段foreignKey指向主表时
+
+```js
+{
+ "主表字段名1": "xxx",
+ "主表字段名2": "xxx",
+ "主表内被副表foreignKey指向的字段名": {
+ "副表1表名": [{ // 一个主表字段可能对应多个副表字段的foreignKey
+ "副表1字段名1": "xxx",
+ "副表1字段名2": "xxx",
+ }],
+ "副表2表名": [{ // 一个主表字段可能对应多个副表字段的foreignKey
+ "副表2字段名1": "xxx",
+ "副表2字段名2": "xxx",
+ }],
+ "_value": "主表字段原始值" // 使用副表foreignKey查询时会在关联的主表字段内以_value存储该字段的原始值,新增于HBuilderX 3.1.16-alpha
+ }
+}
+```
+
+比如有以下两个表,book表,存放书籍商品;order表存放书籍销售订单记录。
+
+book表内有以下数据,title为书名、author为作者:
+
+```js
+{
+ "_id": "1",
+ "title": "西游记",
+ "author": "吴承恩"
+}
+{
+ "_id": "2",
+ "title": "水浒传",
+ "author": "施耐庵"
+}
+{
+ "_id": "3",
+ "title": "三国演义",
+ "author": "罗贯中"
+}
+{
+ "_id": "4",
+ "title": "红楼梦",
+ "author": "曹雪芹"
+}
+```
+
+order表内有以下数据,book_id字段为book表的书籍_id,quantity为该订单销售了多少本书:
+
+```js
+{
+ "book_id": "1",
+ "quantity": 111
+}
+{
+ "book_id": "2",
+ "quantity": 222
+}
+{
+ "book_id": "3",
+ "quantity": 333
+}
+{
+ "book_id": "4",
+ "quantity": 444
+}
+{
+ "book_id": "3",
+ "quantity": 555
+}
+```
+
+如果我们要对这2个表联表查询,在订单记录中同时显示书籍名称和作者,那么首先要建立两个表中关联字段`book`的映射关系。
+
+即,在order表的db schema中,配置字段 book_id 的`foreignKey`,指向 book 表的 _id 字段,如下
+
+```json
+// order表schema
+{
+ "bsonType": "object",
+ "required": [],
+ "permission": {
+ "read": true
+ },
+ "properties": {
+ "book_id": {
+ "bsonType": "string",
+ "foreignKey": "book._id" // 使用foreignKey表示,此字段关联book表的_id。
+ },
+ "quantity": {
+ "bsonType": "int"
+ }
+ }
+}
+```
+
+book表的DB Schema也要保持正确
+```json
+// book表schema
+{
+ "bsonType": "object",
+ "required": [],
+ "permission": {
+ "read": true
+ },
+ "properties": {
+ "title": {
+ "bsonType": "string"
+ },
+ "author": {
+ "bsonType": "string"
+ }
+ }
+}
+```
+
+schema保存后,即使用JQL查询。查询表设为order和book这2个表名后,即可自动按照一个合并虚拟表来查询,field、where等设置均按合并虚拟表来设置。
+
+```js
+// 客户端联表查询
+const db = uniCloud.database()
+db.collection('order,book') // 注意collection方法内需要传入所有用到的表名,用逗号分隔,主表需要放在第一位
+ .where('book_id.title == "三国演义"') // 查询order表内书名为“三国演义”的订单
+ .field('book_id{title,author},quantity') // 这里联表查询book表返回book表内的title、book表内的author、order表内的quantity
+ .get()
+ .then(res => {
+ console.log(res);
+ }).catch(err => {
+ console.error(err)
+ })
+```
+
+上面的写法是jql语法,如果不使用jql的话,使用传统MongoDB写法,需要写很长并且不太容易看懂的代码,大致如下
+
+```js
+// 注意JQL内联表查询需要用拼接子查询的方式(let+pipeline)
+const db = uniCloud.database()
+const dbCmd = db.command
+const $ = dbCmd.aggregate
+db.collection('order')
+ .aggregate()
+ .lookup({
+ from: 'book',
+ let: {
+ book_id: '$book_id'
+ },
+ pipeline: $.pipeline()
+ .match(dbCmd.expr(
+ $.eq(['$_id', '$$book_id'])
+ ))
+ .project({
+ title: true,
+ author: true
+ })
+ .done()
+ as: 'book_id'
+ })
+ .match({
+ book_id: {
+ title: '三国演义'
+ }
+ })
+ .project({
+ book_id: true,
+ quantity: true
+ })
+ .end()
+
+// 如果在云函数内还可以使用以下写法
+const db = uniCloud.database()
+const dbCmd = db.command
+const $ = dbCmd.aggregate
+db.collection('order')
+ .aggregate()
+ .lookup({
+ from: 'book',
+ localField: 'book_id',
+ foreignField: '_id',
+ as: 'book_id'
+ })
+ .match({
+ book_id: {
+ title: '三国演义'
+ }
+ })
+ .project({
+ 'book_id.title': true,
+ 'book_id.author': true,
+ quantity: true
+ })
+ .end()
+```
+
+上述查询会返回如下结果,可以看到书籍信息被嵌入到order表的book_id字段下,成为子节点。同时根据where条件设置,只返回书名为三国演义的订单记录。
+
+```js
+{
+ "code": "",
+ "message": "",
+ "data": [{
+ "_id": "b8df3bd65f8f0d06018fdc250a5688bb",
+ "book_id": [{
+ "_id": "3",
+ "author": "罗贯中",
+ "title": "三国演义"
+ }],
+ "quantity": 555
+ }, {
+ "_id": "b8df3bd65f8f0d06018fdc2315af05ec",
+ "book_id": [{
+ "_id": "3",
+ "author": "罗贯中",
+ "title": "三国演义"
+ }],
+ "quantity": 333
+ }]
+}
+
+```
+
+二维关系型数据库做不到这种设计。`jql`充分利用了json文档型数据库的特点,动态嵌套数据,实现了这个简化的联表查询方案。
+
+不止是2个表,3个、4个表也可以通过这种方式查询,多表场景下只能使用副表与主表之间的关联关系(foreignKey),不可使用副表与副表之间的关联关系。
+
+不止js,``组件也支持所有`jql`功能,包括联表查询。
+
+在前端页面调试JQL联表查询且不过滤字段时会受权限影响,导致调试比较困难。可以通过HBuilderX提供的[JQL数据库管理](uniCloud/jql-runner.md)功能方便的查看联表查询时的虚拟表结构。
+
+如上述查询可以直接在`JQL文件`中执行以下代码查看完整的虚拟表字段
+
+```js
+db.collection('order,book').get()
+```
+
+**注意**
+
+- 生成联表查询虚拟表后关联字段会被替换成被关联表的内容,因此不可在生成虚拟表后的where内使用关联字段作为条件。举个例子,在上面的示例中,`where({book_id:"1"})`是无法筛选出正确结果的,但是可以使用`where({'book_id._id':"1"})`
+- 上述示例中如果order表的`book_id`字段是数组形式存放多个book_id,也跟上述写法一致,JQL会自动根据字段类型进行联表查询
+- 各个表的_id字段会默认带上,即使没有指定返回
+
+#### 设置字段别名@lookup-field-alias
+
+联表查询时也可以在field内对字段进行重命名,写法和简单查询时别名写法类似,`原字段名 as 新字段名`即可。[简单查询时的字段别名](uniCloud/jql.md?id=alias)
+
+仍以上述order、book两个表为例,以下查询将联表查询时order表的quantity字段重命名为order_quantity,将book表的title重命名为book_title、author重命名为book_author
+
+```js
+// 客户端联表查询
+const db = uniCloud.database()
+db.collection('order,book')
+ .where('book_id.title == "三国演义"')
+ .field('book_id{title as book_title,author as book_author},quantity as order_quantity')
+ .get()
+ .then(res => {
+ console.log(res);
+ }).catch(err => {
+ console.error(err)
+ })
+```
+
+查询结果如下
+
+```js
+{
+ "code": "",
+ "message": "",
+ "data": [{
+ "_id": "b8df3bd65f8f0d06018fdc250a5688bb",
+ "book_id": [{
+ "book_author": "罗贯中",
+ "book_title": "三国演义"
+ }],
+ "order_quantity": 555
+ }, {
+ "_id": "b8df3bd65f8f0d06018fdc2315af05ec",
+ "book_id": [{
+ "book_author": "罗贯中",
+ "book_title": "三国演义"
+ }],
+ "order_quantity": 333
+ }]
+}
+```
+
+#### 手动指定使用的foreignKey@lookup-foreign-key
+
+如果存在多个foreignKey且只希望部分生效,可以使用foreignKey来指定要使用的foreignKey
+
+> 2021年4月28日10点前此方法仅用于兼容JQL联表查询策略调整前后的写法,在此日期后更新的clientDB(上传schema、uni-id均会触发更新)才会有指定foreignKey的功能,关于此次调整请参考:[联表查询策略调整](https://ask.dcloud.net.cn/article/38966)
+
+```js
+db.collection('comment,user')
+.where('comment_id=="1-1"')
+.field('content,sender,receiver.name')
+.foreignKey('comment.receiver') // 仅使用comment表内receiver字段下的foreignKey进行主表和副表之间的关联
+.get()
+```
+
+#### 副表foreignKey联查@st-foreign-key
+
+`2021年4月28日`之前的JQL只支持主表的foreignKey,把副表内容嵌入主表的foreignKey字段下面。不支持处理副本的foreignKey。
+
+`2021年4月28日`调整后,新版支持副表foreignKey联查。副表的数据以数组的方式嵌入到主表中作为一个虚拟表使用。
+
+**关联查询后的数据结构如下:**
+
+> 通过HBuilderX提供的[JQL数据库管理](uniCloud/jql-runner.md)功能方便的查看联表查询时的虚拟表结构
+
+主表某字段foreignKey指向副表时
+
+```js
+{
+ "主表字段名1": "xxx",
+ "主表字段名2": "xxx",
+ "主表内foreignKey指向副表的字段名": [{
+ "副表字段名1": "xxx",
+ "副表字段名2": "xxx",
+ }]
+}
+```
+
+副表某字段foreignKey指向主表时
+
+```js
+{
+ "主表字段名1": "xxx",
+ "主表字段名2": "xxx",
+ "副表foreignKey指向的主表字段名": {
+ "副表1表名": [{ // 一个主表字段可能对应多个副表字段的foreignKey
+ "副表1字段名1": "xxx",
+ "副表1字段名2": "xxx",
+ }],
+ "副表2表名": [{ // 一个主表字段可能对应多个副表字段的foreignKey
+ "副表2字段名1": "xxx",
+ "副表2字段名2": "xxx",
+ }],
+ "_value": "主表字段原始值" // 使用副表foreignKey查询时会在关联的主表字段内以_value存储该字段的原始值,新增于HBuilderX 3.1.16-alpha
+ }
+}
+```
+
+例:
+
+数据库内schema及数据如下:
+
+```js
+// comment - 评论表
+
+// schema
+{
+ "bsonType": "object",
+ "required": [],
+ "permission": {
+ "read": true,
+ "create": false,
+ "update": false,
+ "delete": false
+ },
+ "properties": {
+ "comment_id": {
+ "bsonType": "string"
+ },
+ "content": {
+ "bsonType": "string"
+ },
+ "article": {
+ "bsonType": "string",
+ "foreignKey": "article.article_id"
+ },
+ "sender": {
+ "bsonType": "string",
+ "foreignKey": "user.uid"
+ },
+ "receiver": {
+ "bsonType": "string",
+ "foreignKey": "user.uid"
+ }
+ }
+}
+
+// data
+{
+ "comment_id": "1-1",
+ "content": "comment1-1",
+ "article": "1",
+ "sender": "1",
+ "receiver": "2"
+}
+{
+ "comment_id": "1-2",
+ "content": "comment1-2",
+ "article": "1",
+ "sender": "2",
+ "receiver": "1"
+}
+{
+ "comment_id": "2-1",
+ "content": "comment2-1",
+ "article": "2",
+ "sender": "1",
+ "receiver": "2"
+}
+{
+ "comment_id": "2-2",
+ "content": "comment2-2",
+ "article": "2",
+ "sender": "2",
+ "receiver": "1"
+}
+```
+
+```js
+// article - 文章表
+
+// schema
+{
+ "bsonType": "object",
+ "required": [],
+ "permission": {
+ "read": true,
+ "create": false,
+ "update": false,
+ "delete": false
+ },
+ "properties": {
+ "article_id": {
+ "bsonType": "string"
+ },
+ "title": {
+ "bsonType": "string"
+ },
+ "content": {
+ "bsonType": "string"
+ },
+ "author": {
+ "bsonType": "string",
+ "foreignKey": "user.uid"
+ }
+ }
+}
+
+// data
+{
+ "article_id": "1",
+ "title": "title1",
+ "content": "content1",
+ "author": "1"
+}
+{
+ "article_id": "2",
+ "title": "title2",
+ "content": "content2",
+ "author": "1"
+}
+{
+ "article_id": "3",
+ "title": "title3",
+ "content": "content3",
+ "author": "2"
+}
+```
+
+以下查询使用comment表的article字段对应的foreignKey进行关联查询
+
+```js
+db.collection('article,comment')
+.where('article_id._value=="1"')
+.field('content,article_id')
+.get()
+```
+
+查询结果如下:
+
+```js
+[{
+ "content": "content1",
+ "article_id": {
+ "comment": [{ // 使用副表foreignKey查询时此处会自动插入一层副表表名
+ "comment_id": "1-1",
+ "content": "comment1-1",
+ "article": "1",
+ "sender": "1",
+ "receiver": "2"
+ },
+ {
+ "comment_id": "1-2",
+ "content": "comment1-2",
+ "article": "1",
+ "sender": "2",
+ "receiver": "1"
+ }],
+ "_value": "1"
+ }
+}]
+```
+
+如需对上述查询的副表字段进行过滤,需要注意多插入的一层副表表名
+
+```js
+// 过滤副表字段
+db.collection('article,comment')
+.where('article_id._value=="1"')
+.field('content,article_id{comment{content}}')
+.get()
+
+// 查询结果如下
+[{
+ "content": "content1",
+ "article_id": {
+ "comment": [{ // 使用副表foreignKey联查时此处会自动插入一层副表表名
+ "content": "comment1-1"
+ },
+ {
+ "content": "comment1-2"
+ }],
+ "_value": "1"
+ }
+}]
+
+```
+
+副表内的字段也可以使用`as`进行重命名,例如上述查询中如果希望将副表的content重命名为value可以使用如下写法
+
+```js
+// 重命名副表字段
+db.collection('article,comment')
+.where('article_id._value=="1"')
+.field('content,article_id{comment{content as value}}')
+.get()
+
+// 查询结果如下
+[{
+ "content": "content1",
+ "article_id": {
+ "comment": [{ // 使用副本foreignKey联查时此处会自动插入一层副表表名
+ "value": "comment1-1"
+ },
+ {
+ "value": "comment1-2"
+ }]
+ }
+}]
+```
+
+#### 临时表联表查询@lookup-with-temp
+
+> 新增于`HBuilderX 3.2.6`
+
+在此之前JQL联表查询只能直接使用虚拟表,而不能先对主表、副表过滤再生成虚拟表。由于生成虚拟表时需要需要整个主表和副表进行联表,在数据量大的情况下性能会很差。
+
+使用临时表进行联表查询,可以先对主表或者副表进行过滤,然后在处理后的临时表的基础上生成虚拟表。
+
+仍以上面article、comment两个表为例
+
+获取article_id为'1'的文章及其评论的数据库操作,在直接联表查询和使用临时表联表查询时写法分别如下
+
+```js
+// 直接使用虚拟表查询
+const res = await db.collection('article,comment')
+.where('article_id._value=="1"')
+.get()
+
+// 先过滤article表,再获取虚拟表联表获取评论
+const article = db.collection('article').where('article_id=="1"').getTemp() // 注意是getTemp不是get
+const res = await db.collection(article, 'comment').get()
+```
+
+直接使用虚拟表联表查询,在第一步生成虚拟表时会以主表所有数据和副表进行联表查询,如果主表数据量很大,这一步会浪费相当多的时间。先过滤主表则没有这个问题,过滤之后仅有一条数据和副表进行联表查询。
+
+**临时表(getTemp)内可以使用如下方法**
+
+> 方法调用必须严格按照顺序,比如field不能放在where之前
+
+```js
+where
+field // 关于field的使用限制见下方说明
+orderBy
+skip
+limit
+```
+
+ ```js
+ const article = db.collection('article').where('article_id=="1"').field('title').getTemp() // 此处过滤article表,仅保留title字段。会导致下一步查询时找不到关联关系而查询失败
+ const res = await db.collection(article, 'comment').get()
+ ```
+
+**组合出来的虚拟表查询时可以使用的方法**
+
+```js
+foreignKey
+where
+field // 关于field的使用限制见下方说明
+orderBy
+skip
+limit
+```
+
+一般情况下不需要再对虚拟表额外处理,因为数据在临时表内已经进行了过滤排序等操作。以下代码仅供演示,并无实际意义
+
+```js
+const article = db.collection('article').getTemp()
+const comment = db.collection('comment').getTemp()
+const res = await db.collection(article, comment).orderBy('title desc').get() // 按照title倒序排列
+```
+
+**field使用限制**
+
+- field内仅可以进行字段过滤,不可对字段重命名、进行运算,`field('name as value')`、`field('add(score1, score2) as totalScore')`都是不支持的用法
+- 进行联表查询时仅能使用临时表内已经过滤的字段间的关联关系,例如上面article、comment的查询,如果换成以下写法就无法联表查询
+
+**权限校验**
+
+要求组成虚拟表的各个临时表都要满足权限限制,即权限校验不会计算组合成虚拟表之后使用的where、field
+
+以下为一个订单表(order)和书籍表(book)的schema示例
+
+```js
+// order schema
+{
+ "bsonType": "object",
+ "required": [],
+ "permission": {
+ "read": "doc.uid==auth.uid",
+ "create": false,
+ "update": false,
+ "delete": false
+ },
+ "properties": {
+ "id": { // 订单id
+ "bsonType": "string"
+ },
+ "book_id": { // 书籍id
+ "bsonType": "string"
+ },
+ "uid": { // 用户id
+ "bsonType": "string"
+ }
+ }
+}
+
+// book schema
+{
+ "bsonType": "object",
+ "required": [],
+ "permission": {
+ "read": true,
+ "create": false,
+ "update": false,
+ "delete": false
+ },
+ "properties": {
+ "id": { // 书籍id
+ "bsonType": "string"
+ },
+ "name": { // 书籍名称
+ "bsonType": "string"
+ }
+ }
+}
+```
+
+如果先对主表进行过滤`where('uid==$cloudEnv_uid')`,则能满足权限限制(`order表的"doc.uid==auth.uid"`)
+
+```js
+const order = db.collection('order')
+.where('uid==$cloudEnv_uid') // 先过滤order表内满足条件的部分
+.getTemp()
+
+const res = await db.collection(order, 'book').get() // 可以通过权限校验
+```
+
+如果不对主表过滤,而是对虚拟表(联表结果)进行过滤,则无法满足权限限制(`order表的"doc.uid==auth.uid"`)
+
+```js
+const order = db.collection('order').getTemp()
+
+const res = await db.collection(order, 'book').where('uid==$cloudEnv_uid').get() // 对虚拟表过滤,无法通过权限校验
+```
+
+### 查询记录过滤where条件@where
+
+> 代码块`dbget`
+
+jql对查询条件进行了简化,开发者可以使用`where('a==1||b==2')`来表示字段`a等于1或字段b等于2`。如果不使用jql语法,上述条件需要写成下面这种形式
+
+```js
+const db = uniCloud.database()
+const dbCmd = db.command
+const res = await db.collection('test')
+ .where(
+ dbCmd.or({
+ a:1
+ },{
+ b:2
+ })
+ )
+ .get()
+```
+
+两种用法性能上并没有太大差距,可以视场景选择合适的写法。
+
+jql支持两种类型的查询条件,以下内容有助于理解两种的区别,实际书写的时候无需过于关心是简单查询条件还是复杂查询条件,**JQL会自动进行选择**
+
+where内还支持使用云端环境变量,详情参考:[云端环境变量](uniCloud/jql.md?id=variable)
+
+#### 简单查询条件@simple-where
+
+简单查询条件包括以下几种,对应着db.command下的各种[操作符](https://uniapp.dcloud.net.cn/uniCloud/cf-database?id=dbcmd)以及不使用操作符的查询如`where({a:1})`。
+
+|运算符 |说明 |
+|--- |--- |
+|> |大于 |
+|< |小于 |
+|== |等于 |
+|>= |大于等于 |
+|<= |小于等于 |
+|!= |不等于 |
+|&& |与 |
+||| |或 |
+|! |非 |
+|test |正则 |
+
+简单查询条件内要求二元运算符两侧不可均为数据库内的字段
+
+上述写法的查询语句可以在权限校验阶段与schema内配置的permission进行一次对比校验,如果校验通过则不会再查库进行权限校验。
+
+#### 复杂查询条件@complex-where
+
+> HBuilderX 3.1.0起支持
+
+复杂查询内可以使用[数据库运算方法](uniCloud/jql.md?id=aggregate-operator)。需要注意的是,与云函数内使用聚合操作符不同jql内对数据库运算方法的用法进行了简化。
+
+例:数据表test内有以下数据
+
+```js
+{
+ "_id": "1",
+ "name": "n1",
+ "chinese": 60, // 语文
+ "math": 60 // 数学
+}
+{
+ "_id": "2",
+ "name": "n2",
+ "chinese": 60,
+ "math": 70
+}
+{
+ "_id": "3",
+ "name": "n3",
+ "chinese": 100,
+ "math": 90
+}
+```
+
+使用如下写法可以筛选语文数学总分大于150的数据
+
+```js
+const db = uniCloud.database()
+const res = await db.collection('test')
+.where('add(chinese,math) > 150')
+.get()
+
+// 返回结果如下
+res = {
+ result: {
+ data: [{
+ "_id": "3",
+ "name": "n3",
+ "chinese": 100,
+ "math": 90
+ }]
+ }
+}
+```
+
+另外与简单查询条件相比,复杂查询条件可以比较数据库内的两个字段,简单查询条件则要求二元运算符两侧不可均为数据库内的字段,**JQL会自动判断要使用简单查询还是复杂查询条件**。
+
+例:仍以上面的数据为例,以下查询语句可以查询数学得分比语文高的记录
+
+```js
+const db = uniCloud.database()
+const res = await db.collection('test')
+.where('math > chinese')
+.get()
+
+// 返回结果如下
+res = {
+ result: {
+ data: [{
+ "_id": "2",
+ "name": "n2",
+ "chinese": 60,
+ "math": 70
+ }]
+ }
+}
+```
+
+在查询条件时也可以使用`new Date()`来获取一个日期对象。
+
+例:数据表test内有以下数据
+
+```js
+{
+ "_id": "1",
+ "title": "t1",
+ "deadline": 1611998723948
+}
+{
+ "_id": "2",
+ "title": "t2",
+ "deadline": 1512312311231
+}
+```
+
+使用下面的写法可以查询deadline小于当前时间(云函数内的时间)的字段
+
+```js
+const db = uniCloud.database()
+const res = await db.collection('test')
+.where('deadline < new Date().getTime()') // 暂不支持使用Date.now(),后续会支持
+.get()
+```
+
+**注意**
+
+- 使用了复杂查询条件时不可以使用正则查询
+
+### 查询列表分页@pagination
+
+可以通过skip+limit来进行分页查询
+
+```js
+const db = uniCloud.database()
+db.collection('book')
+ .where('status == "onsale"')
+ .skip(20) // 跳过前20条
+ .limit(20) // 获取20条
+ .get()
+
+// 上述用法对应的分页条件为:每页20条取第2页
+```
+
+**注意**
+
+- limit不设置的情况下默认返回100条数据;设置limit有最大值,腾讯云限制为最大1000条,阿里云限制为最大500条。
+
+``组件提供了更简单的分页方法,包括两种模式:
+
+1. 滚动到底加载下一页(append模式)
+2. 点击页码按钮切换不同页(replace模式)
+
+详见:[https://uniapp.dcloud.net.cn/uniCloud/unicloud-db?id=page](https://uniapp.dcloud.net.cn/uniCloud/unicloud-db?id=page)
+
+
+### 字段过滤field@field
+
+查询时可以使用field方法指定返回字段。不使用field方法时会返回所有字段
+
+field可以指定字符串,也可以指定一个对象。
+
+- 字符串写法:列出字段名称,多个字段以半角逗号做分隔符。比如`db.collection('book').field("title,author")`,查询结果会返回`_id`、`title`、`author`3个字段的数据。字符串写法,`_id`是一定会返回的
+
+**复杂嵌套json数据过滤**
+
+如果数据库里的数据结构是嵌套json,比如book表有个价格字段,包括普通价格和vip用户价格,数据如下:
+
+```json
+{
+ "_id": "1",
+ "title": "西游记",
+ "author": "吴承恩",
+ "price":{
+ "normal":10,
+ "vip":8
+ }
+}
+```
+
+那么使用`db.collection('book').field("price.vip").get()`,就可以只返回vip价格,而不返回普通价格。查询结果如下:
+
+```json
+{
+ "_id": "1",
+ "price":{
+ "vip":8
+ }
+}
+```
+
+对于联表查询,副表的数据嵌入到了主表的关联字段下面,此时在filed里通过{}来定义副表字段。比如之前联表查询章节举过的例子,book表和order表联表查询:
+```js
+// 联表查询
+db.collection('order,book') // 注意collection方法内需要传入所有用到的表名,用逗号分隔,主表需要放在第一位
+ .field('book_id{title,author},quantity') // 这里联表查询book表返回book表内的title、book表内的author、order表内的quantity
+ .get()
+```
+
+**不使用`{}`过滤副表字段**
+
+> 此写法于2021年4月28日起支持
+
+field方法内可以不使用`{}`进行副表字段过滤,以上面示例为例可以写为
+
+```js
+const db = uniCloud.database()
+db.collection('order,book')
+ .where('book_id.title == "三国演义"')
+ .field('book_id.title,book_id.author,quantity as order_quantity') // book_id.title、book_id.author为副表字段,使用别名时效果和上一个示例不同,请见下方说明
+ .orderBy('order_quantity desc') // 按照order_quantity降序排列
+ .get()
+ .then(res => {
+ console.log(res);
+ }).catch(err => {
+ console.error(err)
+ })
+```
+
+### 字段别名as@alias
+
+自`2020-11-20`起JQL支持字段别名,主要用于在前端需要的字段名和数据库字段名称不一致的情况下对字段进行重命名。
+
+用法形如:`author as book_author`,意思是将数据库的author字段重命名为book_author。
+
+仍以上面的order表和book表为例
+
+```js
+// 客户端联表查询
+const db = uniCloud.database()
+db.collection('book')
+ .where('title == "三国演义"')
+ .field('title as book_title,author as book_author')
+ .get()
+ .then(res => {
+ console.log(res);
+ }).catch(err => {
+ console.error(err)
+ })
+```
+
+上述查询返回结果如下
+
+```js
+{
+ "code": "",
+ "message": "",
+ "data": [{
+ "_id": "3",
+ "book_author": "罗贯中",
+ "book_title": "三国演义"
+ }]
+}
+```
+
+> _id是比较特殊的字段,如果对_id设置别名会同时返回_id和设置的别名字段
+
+例:
+
+```js
+// 客户端联表查询
+const db = uniCloud.database()
+db.collection('book')
+ .where('title == "三国演义"')
+ .field('_id as book_id,title as book_title,author as book_author')
+ .get()
+ .then(res => {
+ console.log(res);
+ }).catch(err => {
+ console.error(err)
+ })
+```
+
+上述查询返回结果如下
+
+```js
+{
+ "code": "",
+ "message": "",
+ "data": [{
+ "_id": "3",
+ "book_id": "3",
+ "book_author": "罗贯中",
+ "book_title": "三国演义"
+ }]
+}
+```
+
+#### 联表查询时字段别名
+
+联表查询时字段别名写法和简单查询类似
+
+```js
+// 客户端联表查询
+const db = uniCloud.database()
+db.collection('order,book')
+ .where('book_id.title == "三国演义"')
+ .field('book_id{title as book_title,author as book_author},quantity as order_quantity') // 这里联表查询book表返回book表内的title、book表内的author、order表内的quantity,并将title重命名为book_title,author重命名为book_author,quantity重命名为order_quantity
+ .orderBy('order_quantity desc') // 按照order_quantity降序排列
+ .get()
+ .then(res => {
+ console.log(res);
+ }).catch(err => {
+ console.error(err)
+ })
+```
+
+上述请求返回的res如下
+
+```js
+{
+ "code": "",
+ "message": "",
+ "data": [{
+ "_id": "b8df3bd65f8f0d06018fdc250a5688bb",
+ "book_id": [{
+ "book_author": "罗贯中",
+ "book_title": "三国演义"
+ }],
+ "order_quantity": 555
+ }, {
+ "_id": "b8df3bd65f8f0d06018fdc2315af05ec",
+ "book_id": [{
+ "book_author": "罗贯中",
+ "book_title": "三国演义"
+ }],
+ "order_quantity": 333
+ }]
+}
+```
+
+副表字段使用别名需要注意,如果写成`.field('book_id.title as book_id.book_title,book_id.author,quantity as order_quantity')` book_title将会是由book_id下每一项的title组成的数组,这点和mongoDB内数组表现一致
+
+```js
+const db = uniCloud.database()
+db.collection('order,book')
+ .where('book_id.title == "三国演义"')
+ .field('book_id.title as book_title,book_id.author as book_author,quantity as order_quantity') // book_id.title、book_id.author为副表字段,使用别名时效果和上一个示例不同,请见下方说明
+ .orderBy('order_quantity desc') // 按照order_quantity降序排列
+ .get()
+ .then(res => {
+ console.log(res);
+ }).catch(err => {
+ console.error(err)
+ })
+```
+
+返回结果如下
+
+```js
+{
+ "code": "",
+ "message": "",
+ "data": [{
+ "_id": "b8df3bd65f8f0d06018fdc250a5688bb",
+ book_title: ["三国演义"],
+ book_author: ["罗贯中"],
+ "order_quantity": 555
+ }, {
+ "_id": "b8df3bd65f8f0d06018fdc2315af05ec",
+ book_title: ["三国演义"],
+ book_author: ["罗贯中"],
+ "order_quantity": 333
+ }]
+}
+```
+
+**注意**
+
+- as后面的别名,不可以和表schema中已经存在的字段重名
+- mongoDB查询指令中,上一阶段处理完毕将结果输出到下一阶段。在上面的例子中表现为where中使用的是原名,orderBy中使用的是别名
+- 目前不支持对联表查询的关联字段使用别名,即上述示例中的book_id不可设置别名
+
+### 各种字段运算方法@db-operator
+
+自`HBuilderX 3.1.0`起,JQL支持在云端数据库对字段进行一定的操作运算之后再返回,详细可用的方法列表请参考:[数据库运算方法](uniCloud/clientdb.md?id=aggregate-operator)
+
+> 需要注意的是,为方便书写,JQL内将数据库运算方法的用法进行了简化(相对于云函数内使用数据库运算方法而言)。用法请参考上述链接
+
+例:数据表class内有以下数据
+
+```js
+{
+ "_id": "1",
+ "grade": 6,
+ "class": "A"
+}
+{
+ "_id": "1",
+ "grade": 2,
+ "class": "A"
+}
+```
+
+如下写法可以由grade计算得到一个isTopGrade来表示是否为最高年级
+
+```js
+const res = await db.collection('class')
+.field('class,eq(grade,6) as isTopGrade')
+.get()
+```
+
+返回结果如下
+
+```js
+{
+ "_id": "1",
+ "class": "A",
+ "isTopGrade": true
+}
+{
+ "_id": "1",
+ "class": "A",
+ "isTopGrade": false
+}
+```
+
+**注意**
+
+- 如果要访问数组的某一项请使用arrayElemAt操作符,形如:`arrayElemAt(arr,1)`
+- 在进行权限校验时,会计算field内访问的所有字段计算权限。上面的例子中会使用表的read权限和grade、class字段的权限,来进行权限校验。
+
+### 排序orderBy@order-by
+
+传统的MongoDB的排序参数是json格式,jql支持类sql的字符串格式,书写更为简单。
+
+sort方法和orderBy方法内可以传入一个字符串来指定排序规则。
+
+orderBy允许进行多个字段排序,以逗号分隔。每个字段可以指定 asc(升序)、desc(降序)。默认是升序。
+
+写在前面的排序字段优先级高于后面。
+
+示例如下:
+
+```js
+orderBy('quantity asc, create_date desc') //按照quantity字段升序排序,quantity相同时按照create_date降序排序
+// asc可以省略,上述代码和以下写法效果一致
+orderBy('quantity, create_date desc')
+
+// 注意不要写错成全角逗号
+```
+
+以上面的order表数据为例:
+
+```js
+const db = uniCloud.database()
+ db.collection('order')
+ .orderBy('quantity asc, create_date desc') // 按照quantity字段升序排序,quantity相同时按照create_date降序排序
+ .get()
+ .then(res => {
+ console.log(res);
+ }).catch(err => {
+ console.error(err)
+ })
+
+// 上述写法等价于
+const db = uniCloud.database()
+ db.collection('order')
+ .orderBy('quantity','asc')
+ .orderBy('create_date','desc')
+ .get()
+ .then(res => {
+ console.log(res);
+ }).catch(err => {
+ console.error(err)
+ })
+```
+
+### 限制查询记录的条数limit@limit
+
+使用limit方法,可以查询有限条数的数据记录。
+
+比如查询销量top10的书籍,或者查价格最高的一本书。
+
+```js
+// 这以上面的book表数据为例,查价格最高的一本书
+ db.collection('book')
+ .orderBy('price desc')
+ .limit(1)
+ .get()
+```
+
+limit默认值是100,即不设置的情况下,默认返回100条数据。
+
+limit有最大值,腾讯云限制为最大1000条,阿里云限制为最大500条。
+
+一般情况下不应该给前端一次性返回过多数据,数据库查询也慢、网络返回也慢。可以通过分页的方式分批返回数据。
+
+在查询的result里,有一个`affectedDocs`。但affectedDocs和limit略有区别。affectedDocs小于等于limit。
+
+比如book表里只有2本书,limit虽然设了10,但查询结果只能返回2条记录,affectedDocs为2。
+
+
+### 只查一条记录getone@getone
+
+使用`JQL`的API方式时,可以在get方法内传入参数`getOne:true`来返回一条数据。
+
+getOne其实等价于上一节的limit(1)。
+
+一般getOne和orderBy搭配。
+
+```js
+// 这以上面的book表数据为例
+const db = uniCloud.database()
+ db.collection('book')
+ .where({
+ title: '西游记'
+ })
+ .get({
+ getOne:true
+ })
+ .then(res => {
+ console.log(res);
+ }).catch(err => {
+ console.error(err)
+ })
+```
+
+返回结果为
+
+```js
+{
+ "code": "",
+ "message": "",
+ "data": {
+ "_id": "1",
+ "title": "西游记",
+ "author": "吴承恩"
+ }
+}
+```
+
+如果使用uniCloud-db组件,则在组件的属性上增加一个 getone。[详见](https://uniapp.dcloud.net.cn/uniCloud/unicloud-db?id=props)
+
+### 统计数量getcount@getcount
+
+统计符合查询条件的记录数,是数据库层面的概念。
+
+在查询的result里,有一个`affectedDocs`。但affectedDocs和count计数不是一回事。
+
+- affectedDocs表示从服务器返回给前端的数据条数。默认100条,可通过limit方法调整。
+- count则是指符合查询条件的记录总数,至于这些记录是否返回给前端,和count无关。
+
+例如book表里有110本书,不写任何where、limit等条件,但写了count方法或getCount参数,那么result会变成如下:
+
+```json
+result:{
+ affectedDocs: 100,
+ code: "",
+ count: 110,
+ data:[...]
+}
+```
+
+也就是数据库查到了110条记录,通过count返回;而网络侧只给前端返回了100条数据,通过affectedDocs表示。
+
+count计数又有2种场景:
+- 单纯统计数量,不查询数据。使用count()方法
+- 查询记录返回详情,同时返回符合查询条件的数量、使用getCount参数
+
+#### 单纯统计数量,不返回数据明细
+
+使用count()方法,如`db.collection('order').count()`
+
+可以继续加where等条件进行数据记录过滤。
+
+#### 查询记录的同时返回计数
+
+使用`JQL`的API方式时,可以在get方法内传入参数`getCount:true`来同时返回总数
+
+```js
+// 这以上面的order表数据为例
+const db = uniCloud.database()
+ db.collection('order')
+ .get({
+ getCount:true
+ })
+ .then(res => {
+ console.log(res);
+ }).catch(err => {
+ console.error(err)
+ })
+```
+
+返回结果为
+
+```js
+{
+ "code": "",
+ "message": "",
+ "data": [{
+ "_id": "b8df3bd65f8f0d06018fdc250a5688bb",
+ "book": "3",
+ "quantity": 555
+ }],
+ "count": 5
+}
+```
+
+如果使用uniCloud-db组件,则在组件的属性上增加一个 getcount。[详见](https://uniapp.dcloud.net.cn/uniCloud/unicloud-db?id=props)
+
+
+### 查询树形数据gettree@gettree
+
+HBuilderX 3.0.3+起,JQL支持在get方法内传入getTree参数查询树状结构数据。(HBuilderX 3.0.5+ unicloud-db组件开始支持,之前版本只能通过js方式使用)
+
+树形数据,在数据库里一般不会按照tree的层次来存储,因为按tree结构通过json对象的方式存储不同层级的数据,不利于对tree上的某个节点单独做增删改查。
+
+一般存储树形数据,tree上的每个节点都是一条单独的数据表记录,然后通过类似parent_id来表达父子关系。
+
+如部门的数据表,里面有2条数据,一条数据记录是“总部”,`parent_id`为空;另一条数据记录“一级部门A”,`parent_id`为总部的`_id`
+```json
+{
+ "_id": "5fe77207974b6900018c6c9c",
+ "name": "总部",
+ "parent_id": "",
+ "status": 0
+}
+```
+```json
+{
+ "_id": "5fe77232974b6900018c6cb1",
+ "name": "一级部门A",
+ "parent_id": "5fe77207974b6900018c6c9c",
+ "status": 0
+}
+```
+
+虽然存储格式是分条记录的,但查询反馈到前端的数据仍然需要是树形的。这种转换在过去比较复杂。
+
+JQL提供了一种简单、优雅的方案,在DB Schema里配置parentKey来表达父子关系,然后查询时声明使用Tree查询,就可以直接查出树形数据。
+
+department部门表的schema中,将字段`parent_id`的"parentKey"设为"_id",即指定了数据之间的父子关系,如下:
+
+```json
+{
+ "bsonType": "object",
+ "required": ["name"],
+ "properties": {
+ "_id": {
+ "description": "ID,系统自动生成"
+ },
+ "name": {
+ "bsonType": "string",
+ "description": "名称"
+ },
+ "parent_id": {
+ "bsonType": "string",
+ "description": "父id",
+ "parentKey": "_id", // 指定父子关系为:如果数据库记录A的_id和数据库记录B的parent_id相等,则A是B的父级。
+ },
+ "status": {
+ "bsonType": "int",
+ "description": "部门状态,0-正常、1-禁用"
+ }
+ }
+}
+```
+
+parentKey字段将数据表不同记录的父子关系描述了出来。查询就可以直接写了。
+
+注意:一个表的一次查询中只能有一个父子关系。如果一个表的schema里多个字段均设为了parentKey,那么需要在JQL中通过parentKey()方法指定某个要使用的parentKey字段。
+
+schema里描述好后,查询就变的特别简单。
+
+查询树形数据,分为 查询所有子节点 和 查询父级路径 这2种需求。
+
+#### 查询所有子节点
+
+指定符合条件的记录,然后查询它的所有子节点,并且可以指定层级,返回的结果是以符合条件的记录为一级节点的所有子节点数据,并以树形方式嵌套呈现。
+
+只需要在JQL的get方法中增加`getTree`参数,如下
+```js
+// get方法示例
+get({
+ getTree: {
+ limitLevel: 10, // 最大查询层级(不包含当前层级),可以省略默认10级,最大15,最小1
+ startWith: "parent_code=='' || parent_code==null" // 第一层级条件,此初始条件可以省略,不传startWith时默认从最顶级开始查询
+ }
+})
+
+// 使用getTree时上述参数可以简写为以下写法
+get({
+ getTree: true
+})
+```
+
+完整的代码如下:
+```js
+db.collection("department").get({
+ getTree: {}
+ })
+ .then((res) => {
+ const resdata = res.result.data
+ console.log("resdata", resdata);
+ }).catch((err) => {
+ uni.showModal({
+ content: err.message || '请求服务失败',
+ showCancel: false
+ })
+ }).finally(() => {
+
+ })
+```
+
+查询的结果如下:
+```json
+"data": [{
+ "_id": "5fe77207974b6900018c6c9c",
+ "name": "总部",
+ "parent_id": "",
+ "status": 0,
+ "children": [{
+ "_id": "5fe77232974b6900018c6cb1",
+ "name": "一级部门A",
+ "parent_id": "5fe77207974b6900018c6c9c",
+ "status": 0,
+ "children": []
+ }]
+}]
+```
+
+可以看出,每个子节点,被嵌套在父节点的"children"下,这个"children"是一个固定的格式。
+
+如果不指定getTree的参数,会把department表的所有数据都查出来,从总部开始到10级部门,以树形结构提供给客户端。
+
+如果有多个总部,即多行记录的`parent_id`为空,则多个总部会分别作为一级节点,把它们下面的所有children一级一级拉出来。如下:
+
+```json
+"data": [
+ {
+ "_id": "5fe77207974b6900018c6c9c",
+ "name": "总部",
+ "parent_id": "",
+ "status": 0,
+ "children": [{
+ "_id": "5fe77232974b6900018c6cb1",
+ "name": "一级部门A",
+ "parent_id": "5fe77207974b6900018c6c9c",
+ "status": 0,
+ "children": []
+ }]
+ },
+ {
+ "_id": "5fe778a10431ca0001c1e2f8",
+ "name": "总部2",
+ "parent_id": "",
+ "children": [{
+ "_id": "5fe778e064635100013efbc2",
+ "name": "总部2的一级部门B",
+ "parent_id": "5fe778a10431ca0001c1e2f8",
+ "children": []
+ }]
+ }
+]
+```
+
+
+如果觉得返回的`parent_id`字段多余,也可以指定`.field("_id,name")`,过滤掉该字段。
+
+**getTree的参数limitLevel的说明**
+
+limitLevel表示查询返回的树的最大层级。超过设定层级的节点不会返回。
+
+- limitLevel的默认值为10。
+- limitLevel的合法值域为1-15之间(包含1、15)。如果数据实际层级超过15层,请分层懒加载查询。
+- limitLevel为1,表示向下查一级子节点。假如数据库中有2级、3级部门,如果设limitLevel为1,且查询的是“总部”,那么返回数据包含“总部”和其下的一级部门。
+
+**getTree的参数startWith的说明**
+
+如果只需要查“总部”的子部门,不需要“总部2”,可以在startWith里指定(`getTree: {"startWith":"name=='总部'"}`)。
+
+使用中请注意startWith和where的区别。where用于描述对所有层级的生效的条件(包括第一层级)。而startWith用于描述从哪个或哪些节点开始查询树。
+
+startWith不填时,默认的条件是 `'parent_id==null||parent_id==""'`,即schema配置parentKey的字段为null(即不存在)或值为空字符串时,这样的节点被默认视为根节点。
+
+假设上述部门表内有以下数据
+
+```js
+{
+ "_id": "1",
+ "name": "总部",
+ "parent_id": "",
+ "status": 0
+}
+{
+ "_id": "11",
+ "name": "一级部门A",
+ "parent_id": "1",
+ "status": 0
+}
+{
+ "_id": "12",
+ "name": "一级部门B",
+ "parent_id": "1",
+ "status": 1
+}
+```
+
+以下查询语句指定startWith为`_id=="1"`、where条件为`status==0`,查询总部下所有status为0的子节点。
+
+```js
+db.collection("department")
+ .where('status==0')
+ .get({
+ getTree: {
+ startWith: '_id=="1"'
+ }
+ })
+ .then((res) => {
+ const resdata = res.result.data
+ console.log("resdata", resdata);
+ }).catch((err) => {
+ uni.showModal({
+ content: err.message || '请求服务失败',
+ showCancel: false
+ })
+ }).finally(() => {
+
+ })
+```
+
+查询的结果如下:
+```json
+{
+ "data": [{
+ "_id": "1",
+ "name": "总部",
+ "parent_id": "",
+ "status": 0,
+ "children": [{
+ "_id": "11",
+ "name": "一级部门A",
+ "parent_id": "1",
+ "status": 0,
+ "children": []
+ }]
+ }]
+}
+```
+
+**需要注意的是where内的条件也会对第一级数据生效**,例如将上面的查询改成如下写法
+
+```js
+db.collection("department")
+ .where('status==1')
+ .get({
+ getTree: {
+ startWith: '_id=="1"'
+ }
+ })
+ .then((res) => {
+ const resdata = res.result.data
+ console.log("resdata", resdata);
+ }).catch((err) => {
+ uni.showModal({
+ content: err.message || '请求服务失败',
+ showCancel: false
+ })
+ }).finally(() => {
+
+ })
+```
+
+此时将无法查询到数据,返回结果如下
+
+```js
+{
+ "data": []
+}
+```
+
+
+**通过parentKey方法指定某个parentKey**
+
+如果表的schema中有多个字段都配置了parentKey,但查询时其实只能有一个字段的parentKey关系可以生效,那么此时就需要通过parentKey()方法来指定这次查询需要的哪个parentKey关系生效。
+
+parentKey()方法的参数是字段名。
+
+```js
+db.collection('department')
+.parentKey('parent_id') // 如果表schema只有一个字段设了parentKey,其实不需要指定。有多个字段被设parentKey才需要用这个方法指定
+.get({
+ getTree: true
+ })
+```
+
+
+**示例**
+
+插件市场有一个 家谱 的示例,可以参阅:[https://ext.dcloud.net.cn/plugin?id=3798](https://ext.dcloud.net.cn/plugin?id=3798)
+
+
+**大数据量的树形数据查询**
+
+如果tree的数据量较大,则不建议一次性把所有的树形数据返回给客户端。建议分层查询,即懒加载。
+
+比如地区选择的场景,全国的省市区数据量很大,一次性查询所有数据返回给客户端非常耗时和耗流量。可以先查省,然后根据选择的省再查市,以此类推。
+
+**注意**
+
+- 暂不支持使用getTree的同时使用联表查询
+- 如果使用了where条件会对所有查询的节点生效
+- 如果使用了limit设置最大返回数量仅对根节点生效
+
+#### 查询树形结构父节点路径@gettreepath
+
+getTree是查询子节点,而getTreePath,则是查询父节点。
+
+get方法内传入getTreePath参数对包含父子关系的表查询返回树状结构数据某节点路径。
+
+```js
+// get方法示例
+get({
+ getTreePath: {
+ limitLevel: 10, // 最大查询层级(不包含当前层级),可以省略默认10级,最大15,最小1
+ startWith: 'name=="一级部门A"' // 末级节点的条件,此初始条件不可以省略
+ }
+})
+```
+
+查询返回的结果为,从“一级部门A”起向上找10级,找到最终节点后,以该节点为根,向下嵌套children,一直到达“一级部门A”。
+
+返回结果只包括“一级部门A”的直系父,其父节点的兄弟节点不会返回。所以每一层数据均只有一个节点。
+
+仍以上面department的表结构和数据为例
+
+```js
+db.collection("department").get({
+ getTreePath: {
+ "startWith": "_id=='5fe77232974b6900018c6cb1'"
+ }
+ })
+ .then((res) => {
+ const treepath = res.result.data
+ console.log("treepath", treepath);
+ }).catch((err) => {
+ uni.showModal({
+ content: err.message || '请求服务失败',
+ showCancel: false
+ })
+ }).finally(() => {
+ uni.hideLoading()
+ // console.log("finally")
+ })
+```
+
+查询返回结果
+
+从根节点“总部”开始,返回到“一级部门A”。“总部2”等节点不会返回。
+
+```json
+{
+ "data": [{
+ "_id": "5fe77207974b6900018c6c9c",
+ "name": "总部",
+ "parent_id": "",
+ "children": [{
+ "_id": "5fe77232974b6900018c6cb1",
+ "name": "一级部门A",
+ "parent_id": "5fe77207974b6900018c6c9c"
+ }]
+ }]
+}
+```
+
+如果startWith指定的节点没有父节点,则返回自身。
+
+如果startWith匹配的节点不止一个,则以数组的方式,返回每个节点的treepath。
+
+例如“总部”和“总部2”下面都有一个部门的名称叫“销售部”,且` "startWith": "name=='销售部'"`,则会返回“总部”和“总部2”两条treepath,如下
+
+```json
+{
+ "data": [{
+ "_id": "5fe77207974b6900018c6c9c",
+ "name": "总部",
+ "parent_id": "",
+ "children": [{
+ "_id": "5fe77232974b6900018c6cb1",
+ "name": "销售部",
+ "parent_id": "5fe77207974b6900018c6c9c"
+ }]
+ }, {
+ "_id": "5fe778a10431ca0001c1e2f8",
+ "name": "总部2",
+ "parent_id": "",
+ "children": [{
+ "_id": "5fe79fea23976b0001508a46",
+ "name": "销售部",
+ "parent_id": "5fe778a10431ca0001c1e2f8"
+ }]
+ }]
+}
+```
+
+
+**注意**
+
+- 暂不支持使用getTreePath的同时使用其他联表查询语法
+- 如果使用了where条件会对所有查询的节点生效
+
+### 分组统计groupby@groupby
+
+> 本地调试支持:`HBuilderX 3.1.0`+;云端支持:2021-1-26日后更新一次云端 DB Schema 生效
+
+数据分组统计,即根据某个字段进行分组(groupBy),然后对其他字段分组后的值进行求和、求数量、求均值。
+
+比如统计每日新增用户数,就是按时间进行分组,对每日的用户记录进行count运算。
+
+分组统计有groupBy和groupField。和传统sql略有不同,传统sql没有单独的groupField。
+
+JQL的groupField里不能直接写field字段,只能使用[分组运算方法](uniCloud/jql.md?id=accumulator)来处理字段,常见的累积器计算符包括:count(*)、sum(字段名称)、avg(字段名称)。更多分组运算方法[详见](uniCloud/clientdb.md?id=accumulator)
+
+其中count(*)是固定写法。
+
+分组统计的写法如下:
+
+```js
+const res = await db.collection('table1').groupBy('field1,field2').groupField('sum(field3) as field4').get()
+```
+
+如果额外还在groupBy之前使用了field方法,那么此field的含义并不是最终返回的字段,而是用于对字段预处理,然后将预处理的字段传给groupBy和groupField使用。
+
+与field不同,使用groupField时返回结果不会默认包含`_id`字段。同时开发者也不应该在groupBy和groupField里使用`_id`字段,`_id`是唯一的,没有统一意义。
+
+举例:
+如果数据库`score`表为某次比赛统计的分数数据,每条记录为一个学生的分数。学生有所在的年级(grade)、班级(class)、姓名(name)、分数(score)等字段属性。
+
+```js
+{
+ _id: "1",
+ grade: "1",
+ class: "A",
+ name: "zhao",
+ score: 5
+}
+{
+ _id: "2",
+ grade: "1",
+ class: "A",
+ name: "qian",
+ score: 15
+}
+{
+ _id: "3",
+ grade: "1",
+ class: "B",
+ name: "li",
+ score: 15
+}
+{
+ _id: "4",
+ grade: "1",
+ class: "B",
+ name: "zhou",
+ score: 25
+}
+{
+ _id: "5",
+ grade: "2",
+ class: "A",
+ name: "wu",
+ score: 25
+}
+{
+ _id: "6",
+ grade: "2",
+ class: "A",
+ name: "zheng",
+ score: 35
+}
+```
+
+接下来我们对这批数据进行分组统计,分别演示如何使用求和、求均值和计数。
+
+#### 求和、求均值示例
+
+groupBy内也可以使用数据库运算方法对数据进行处理,为方便书写,clientDB内将数据库运算方法的用法进行了简化(相对于云函数内使用数据库运算方法而言)。用法请参考:[数据库运算方法](uniCloud/jql.md?id=aggregate-operator)
+
+groupField内可以使用分组运算方法对分组结果进行统计,所有可用的累计方法请参考[分组运算方法](uniCloud/jql.md?id=accumulator),下面以sum(求和)和avg(求均值)为例介绍如何使用
+
+使用sum方法可以对数据进行求和统计。以上述数据为例,如下写法对不同班级进行分数统计
+
+```js
+const res = await db.collection('score')
+.groupBy('grade,class')
+.groupField('sum(score) as totalScore')
+.get()
+```
+
+返回结果如下
+
+```js
+{
+ data: [{
+ grade: "1",
+ class: "A",
+ totalScore: 20
+ },{
+ grade: "1",
+ class: "B",
+ totalScore: 40
+ },{
+ grade: "2",
+ class: "A",
+ totalScore: 60
+ }]
+}
+```
+
+1年级A班、1年级B班、2年级A班,3个班级的总分分别是20、40、60。
+
+求均值方法与求和类似,将上面sum方法换成avg方法即可
+
+```js
+const res = await db.collection('score')
+.groupBy('grade,class')
+.groupField('avg(score) as avgScore')
+.get()
+```
+
+返回结果如下
+
+```js
+{
+ data: [{
+ grade: "1",
+ class: "A",
+ avgScore: 10
+ },{
+ grade: "1",
+ class: "B",
+ avgScore: 20
+ },{
+ grade: "2",
+ class: "A",
+ avgScore: 30
+ }]
+}
+```
+
+
+如果额外还在groupBy之前使用了field方法,此field用于决定将哪些数据传给groupBy和groupField使用
+
+例:如果上述数据中score是一个数组
+
+```js
+{
+ _id: "1",
+ grade: "1",
+ class: "A",
+ name: "zhao",
+ score: [1,1,1,1,1]
+}
+{
+ _id: "2",
+ grade: "1",
+ class: "A",
+ name: "qian",
+ score: [3,3,3,3,3]
+}
+{
+ _id: "3",
+ grade: "1",
+ class: "B",
+ name: "li",
+ score: [3,3,3,3,3]
+}
+{
+ _id: "4",
+ grade: "1",
+ class: "B",
+ name: "zhou",
+ score: [5,5,5,5,5]
+}
+{
+ _id: "5",
+ grade: "2",
+ class: "A",
+ name: "wu",
+ score: [5,5,5,5,5]
+}
+{
+ _id: "6",
+ grade: "2",
+ class: "A",
+ name: "zheng",
+ score: [7,7,7,7,7]
+}
+```
+
+如下field写法将上面的score数组求和之后传递给groupBy和groupField使用。在field内没出现的字段(比如name),在后面的方法里面不能使用
+
+```js
+const res = await db.collection('score')
+.field('grade,class,sum(score) as userTotalScore')
+.groupBy('grade,class')
+.groupField('avg(userTotalScore) as avgScore')
+.get()
+```
+
+返回结果如下
+
+```js
+{
+ data: [{
+ grade: "1",
+ class: "A",
+ avgScore: 10
+ },{
+ grade: "1",
+ class: "B",
+ avgScore: 20
+ },{
+ grade: "2",
+ class: "A",
+ avgScore: 30
+ }]
+}
+```
+
+
+#### 统计数量示例
+
+使用count方法可以对记录数量进行统计。以上述数据为例,如下写法对不同班级统计参赛人数
+
+```js
+const res = await db.collection('score')
+.groupBy('grade,class')
+.groupField('count(*) as totalStudents')
+.get()
+```
+
+返回结果如下
+
+```js
+{
+ data: [{
+ grade: "1",
+ class: "A",
+ totalStudents: 2
+ },{
+ grade: "1",
+ class: "B",
+ totalStudents: 2
+ },{
+ grade: "2",
+ class: "A",
+ totalStudents: 2
+ }]
+}
+```
+
+**注意**
+
+- `count(*)`为固定写法,括号里的*可以省略
+
+#### 按日分组统计示例
+
+按时间段统计是常见的需求,而时间段统计会用到日期运算符。
+
+假设要统计[uni-id-users](https://gitee.com/dcloud/opendb/blob/master/collection/uni-id-users/collection.json)表的每日新增注册用户数量。表内有以下数据:
+
+```json
+{
+ "_id": "1",
+ "username": "name1",
+ "register_date": 1611367810000 // 2021-01-23 10:10:10
+}
+{
+ "_id": "2",
+ "username": "name2",
+ "register_date": 1611367810000 // 2021-01-23 10:10:10
+}
+{
+ "_id": "3",
+ "username": "name3",
+ "register_date": 1611367810000 // 2021-01-23 10:10:10
+}
+{
+ "_id": "4",
+ "username": "name4",
+ "register_date": 1611281410000 // 2021-01-22 10:10:10
+}
+{
+ "_id": "5",
+ "username": "name5",
+ "register_date": 1611281410000 // 2021-01-22 10:10:10
+}
+{
+ "_id": "6",
+ "username": "name6",
+ "register_date": 1611195010000 // 2021-01-21 10:10:10
+}
+```
+
+由于`register_date`字段是时间戳格式,含有时分秒信息。但统计每日新增注册用户时是需要忽略时分秒的。
+
+1. 首先使用add操作符将`register_date`从时间戳转化为日期类型。
+
+add操作符的用法为`add(值1,值2)`。`add(new Date(0),register_date)`表示给字段register_date + 0,这个运算没有改变具体的时间,但把`register_date`的格式从时间戳转为了日期类型。
+
+2. 然后使用dateToString将add得到的日期格式化为形如`2021-01-21`的字符串,去掉时分秒。
+
+dateToString操作符的用法为`dateToString(日期对象,格式化字符串,时区)`。具体如下:`dateToString(add(new Date(0),register_date),"%Y-%m-%d","+0800")`
+
+3. 然后根据此字符串进行分组统计,得到每天注册用户量。代码如下:
+
+```js
+const res = await db.collection('uni-id-users')
+.groupBy('dateToString(add(new Date(0),register_date),"%Y-%m-%d","+0800") as date')
+.groupField('count(*) as newusercount')
+.get()
+```
+
+查询返回结果如下:
+```js
+res = {
+ result: {
+ data: [{
+ date: '2021-01-23',
+ newusercount: 3
+ },{
+ date: '2021-01-22',
+ newusercount: 2
+ },{
+ date: '2021-01-21',
+ newusercount: 1
+ }]
+ }
+}
+```
+
+完整数据库运算方法列表请参考:[JQL内可使用的数据库运算方法](uniCloud/jql.md?id=aggregate-operator)
+
+#### count权限控制
+
+在使用普通的累积器操作符,如sum、avg时,权限控制与常规的权限控制并无不同。
+
+但使用count时,可以单独配置表级的count权限。
+
+请不要轻率的把[uni-id-users](https://gitee.com/dcloud/opendb/blob/master/collection/uni-id-users/collection.json)表的count权限设为true,即任何人都可以count。这意味着游客将可以获取到你的用户总数量。
+
+count权限的控制逻辑如下:
+
+- 在不使用field,仅使用groupBy和groupField的情况下,会以groupBy和groupField内访问的所有字段的权限来校验访问是否合法。
+- 在额外使用field方法的情况下,会计算field内访问的所有字段计算权限。上面的例子中会使用表的read权限和grade、class、score三个字段的权限,来进行权限校验。
+- 在HBuilderX 3.1.0之前,count操作都会使用表级的read权限进行验证。HBuilderX 3.1.0及之后的版本,如果配置了count权限则会使用表级的read+count权限进行校验,两条均满足才可以通过校验
+- 如果schema内没有count权限,则只会使用read权限进行校验
+- 所有会统计数量的操作均会触发count权限校验
+
+### 数据去重distinct@distinct
+
+通过.distinct()方法,对数据查询结果中重复的记录进行去重。
+
+distinct方法将按照field方法指定的字段进行去重(如果field内未指定`_id`,不会按照`_id`去重)
+
+> 本地调试支持:`HBuilderX 3.1.0`+;云端支持:2021-1-26日后更新一次云端 DB Schema生效
+
+```js
+const res = await db.collection('table1')
+.field('field1')
+.distinct() // 注意distinct方法没有参数
+.get()
+```
+
+例:如果数据库`score`表为某次比赛统计的分数数据,每条记录为一个学生的分数
+
+`score`表的数据:
+
+```js
+{
+ _id: "1",
+ grade: "1",
+ class: "A",
+ name: "zhao",
+ score: 5
+}
+{
+ _id: "2",
+ grade: "1",
+ class: "A",
+ name: "qian",
+ score: 15
+}
+{
+ _id: "3",
+ grade: "1",
+ class: "B",
+ name: "li",
+ score: 15
+}
+{
+ _id: "4",
+ grade: "1",
+ class: "B",
+ name: "zhou",
+ score: 25
+}
+{
+ _id: "5",
+ grade: "2",
+ class: "A",
+ name: "wu",
+ score: 25
+}
+{
+ _id: "6",
+ grade: "2",
+ class: "A",
+ name: "zheng",
+ score: 35
+}
+```
+
+以下代码可以按照grade、class两字段去重,获取所有参赛班级
+
+```js
+const res = await db.collection('score')
+.field('grade,class')
+.distinct() // 注意distinct方法没有参数
+.get()
+```
+
+查询返回结果如下
+
+```js
+{
+ data: [{
+ grade:"1",
+ class: "A"
+ },{
+ grade:"1",
+ class: "B"
+ },{
+ grade:"2",
+ class: "A"
+ }]
+}
+```
+
+**注意**
+
+- distinct指对返回结果中完全相同的记录进行去重,重复的记录只保留一条。因为`_id`字段是必然不同的,所以使用distinct时必须同时指定field,且field中不可存在`_id`字段
+
+
+## 新增数据记录@add
+
+> 代码块`dbadd`
+
+获取到db的表对象后,通过`add`方法新增数据记录。
+
+方法:collection.add(data)
+
+**参数说明**
+
+| 参数 | 类型 | 必填 |
+| ---- | ------ | ---- |
+| data | object | array | 是 |
+
+data支持一条记录,也支持多条记录一并新增到集合中。
+
+data中不需要包括`_id`字段,数据库会自动维护该字段。
+
+**返回值**
+
+单条插入时
+
+| 参数 | 类型 | 说明 |
+| ---- | ------| ---------------------------------------- |
+|id | String|插入记录的`_id` |
+
+批量插入时
+
+| 参数 | 类型 | 说明 |
+| ---- | ------| ---------------------------------------- |
+| inserted | Number| 插入成功条数 |
+|ids | Array |批量插入所有记录的`_id` |
+
+**示例:**
+
+比如在user表里新增一个叫王五的记录:
+
+```js
+const db = uniCloud.database();
+db.collection('user').add({name:"王五"})
+```
+
+也可以批量插入数据并获取返回值
+
+```js
+const db = uniCloud.database();
+const collection = db.collection('user');
+let res = await collection.add([{
+ name: '张三'
+},{
+ name: '李四'
+},{
+ name: '王五'
+}])
+```
+
+如果上述代码执行成功,则res的值将包括inserted:3,代表插入3条数据,同时在ids里返回3条记录的`_id`。
+
+如果新增记录失败,会抛出异常,以下代码示例为捕获异常:
+
+```js
+// 插入1条数据,同时判断成功失败状态
+const db = uniCloud.database();
+db.collection("user")
+ .add({name: '张三'})
+ .then((res) => {
+ uni.showToast({
+ title: '新增成功'
+ })
+ })
+ .catch((err) => {
+ uni.showModal({
+ content: err.message || '新增失败',
+ showCancel: false
+ })
+ })
+ .finally(() => {
+
+ })
+```
+
+**Tips**
+
+- 如果是非admin账户新增数据,需要在数据库中待操作表的`db schema`中要配置permission权限,赋予create允许用户操作的权限。
+- 云服务商选择阿里云时,若集合表不存在,调用add方法会自动创建集合表,并且不会报错。
+
+
+## 删除数据记录@remove
+
+> 代码块`dbremove`
+
+获取到db的表对象,然后指定要删除的记录,通过remove方法删除。
+
+注意:如果是非admin账户删除数据,需要在数据库中待操作表的`db schema`中要配置permission权限,赋予delete允许用户操作的权限。
+
+指定要删除的记录有2种方式:
+
+#### 方式1 通过指定文档ID删除
+
+collection.doc(_id).remove()
+
+
+```js
+const db = uniCloud.database();
+await db.collection("table1").doc("5f79fdb337d16d0001899566").remove()
+```
+
+#### 方式2 条件查找文档后删除
+
+collection.where().remove()
+
+```js
+// 删除字段a的值大于2的文档
+try {
+ await db.collection("table1").where("a>2").remove()
+} catch (e) {
+ uni.showModal({
+ title: '提示',
+ content: e.message
+ })
+}
+```
+
+删除该表所有数据
+
+注意:数据量很多的情况下这种方式删除会超时,但是数据仍会全部删除掉
+
+```js
+const dbCmd = db.command
+const db = uniCloud.database();
+await db.collection("table1").where({
+ _id: dbCmd.neq(null)
+}).remove()
+```
+
+#### 回调的res响应参数
+
+| 字段 | 类型 | 必填 | 说明 |
+| --------- | ------- | ---- | ------------------------ |
+| deleted | Number | 否 | 删除的记录数量 |
+
+示例:判断删除成功或失败,打印删除的记录数量
+
+```js
+const db = uniCloud.database();
+db.collection("table1")
+ .where({
+ _id: "5f79fdb337d16d0001899566"
+ })
+ .remove()
+ .then((res) => {
+ uni.showToast({
+ title: '删除成功'
+ })
+ console.log("删除条数: ",res.deleted);
+ }).catch((err) => {
+ uni.showModal({
+ content: err.message || '删除失败',
+ showCancel: false
+ })
+ }).finally(() => {
+
+ })
+```
+
+## 更新数据记录@update
+
+> 代码块`dbupdate`
+
+获取到db的表对象,然后指定要更新的记录,通过update方法更新。
+
+注意:如果是非admin账户修改数据,需要在数据库中待操作表的`db schema`中要配置permission权限,赋予update为true。
+
+collection.doc().update(Object data)
+
+**参数说明**
+
+| 参数 | 类型 | 必填 | 说明 |
+| ---- | ------ | ---- | ---------------------------------------- |
+| data | object | 是 | 更新字段的Object,{'name': 'Ben'} _id 非必填|
+
+**回调的res响应参数**
+
+| 参数 | 类型 | 说明 |
+| ---- | ------| ---------------------------------------- |
+|updated| Number| 更新成功条数,数据更新前后没变化时会返回0。用法与删除数据的响应参数示例相同 |
+
+
+```js
+const db = uniCloud.database();
+let collection = db.collection("table1")
+let res = await collection.where({_id:'doc-id'})
+ .update({
+ name: "Hey",
+ count: {
+ fav: 1
+ }
+ });
+```
+
+```json
+// 更新前的数据
+{
+ "_id": "doc-id",
+ "name": "Hello",
+ "count": {
+ "fav": 0,
+ "follow": 0
+ }
+}
+
+// 更新后的数据
+{
+ "_id": "doc-id",
+ "name": "Hey",
+ "count": {
+ "fav": 1,
+ "follow": 0
+ }
+}
+```
+
+更新数组时,以数组下标作为key即可,比如以下示例将数组arr内下标为1的值修改为 uniCloud
+
+```js
+const db = uniCloud.database();
+let collection = db.collection("table1")
+let res = await collection.where({_id:'doc-id'})
+ .update({
+ arr: {
+ 1: "uniCloud"
+ }
+ })
+```
+
+```json
+// 更新前
+{
+ "_id": "doc-id",
+ "arr": ["hello", "world"]
+}
+// 更新后
+{
+ "_id": "doc-id",
+ "arr": ["hello", "uniCloud"]
+}
+```
+
+#### 批量更新文档
+
+```js
+const db = uniCloud.database();
+let collection = db.collection("table1")
+let res = await collection.where("name=='hey'").update({
+ age: 18,
+})
+```
+
+#### 更新数组内指定下标的元素
+
+JQL暂不支持此用法
+
+#### 更新数组内匹配条件的元素
+
+JQL暂不支持此用法
+
+
+## 同时发送多条数据库请求@multi-send
+
+> HBuilderX 3.1.22及以上版本支持
+
+在实际业务中通常会遇到一个页面需要查询多次的情况,比如应用首页需要查询轮播图列表、公告列表、首页商品列表等。如果分开请求需要发送很多次网络请求,这样会影响性能。使用multiSend可以将多个数据库请求合并成一个发送。
+
+**用法**
+
+```js
+const bannerQuery = db.collection('banner').field('url,image').getTemp() // 这里使用getTemp不直接发送get请求,等到multiSend时再发送
+const noticeQuery = db.collection('notice').field('text,url,level').getTemp()
+const res = await db.multiSend(bannerQuery,noticeQuery)
+```
+
+**返回值**
+
+```js
+// 上述请求返回以下结构
+res = {
+ code: 0, // 请求整体执行错误码,注意如果多条查询执行失败,这里的code依然是0,只有出现网络错误等问题时这里才会出现错误
+ message: '', // 错误信息
+ dataList: [{
+ code: 0, // bannerQuery 对应的错误码
+ message: '', // bannerQuery 对应的错误信息
+ data: [] // bannerQuery 查询到的数据
+ }, {
+ code: 0, // noticeQuery 对应的错误码
+ message: '', // noticeQuery 对应的错误信息
+ data: [] // noticeQuery 查询到的数据
+ }]
+}
+```
+
+unicloud-db组件也支持使用getTemp方法,结合multiSend可以与其他数据库请求一起发送
+
+用法示例:
+
+```html
+
+
+
+
+ {{error.message}}
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+```
+
+## MongoDB聚合操作@aggregate
+
+JQL API支持使用聚合操作读取数据,关于聚合操作请参考[聚合操作](uniCloud/cf-database.md?id=aggregate)
+
+例:取status等于1的随机20条数据
+
+```js
+const db = uniCloud.database()
+const res = await db.collection('test').aggregate()
+.match({
+ status: 1
+})
+.sample({
+ size: 20
+})
+.end()
+```
+
+
+## DBSchema@schema
+
+`DB Schema`是基于 JSON 格式定义的数据结构的规范。
+
+它有很多重要的作用:
+
+- 描述现有的数据格式。可以一目了然的阅读每个表、每个字段的用途。
+- 设定数据操作权限(permission)。什么样的角色可以读/写哪些数据,都在这里配置。
+- 设定字段值域能接受的格式(validator),比如不能为空、需符合指定的正则格式。
+- 设置数据的默认值(defaultValue/forceDefaultValue),比如服务器当前时间、当前用户id等。
+- 设定多个表的字段间映射关系(foreignKey),将多个表按一个虚拟表直接查询,大幅简化联表查询。
+- 根据schema自动生成表单维护界面,比如新建页面和编辑页面,自动处理校验规则。
+
+这些工具大幅减少了开发者的开发工作量和重复劳动。
+
+**`DB Schema`是`JQL`紧密相关的配套,掌握JQL离不开详读[DB Schema文档](uniCloud/schema)。**
+
+**下面示例中使用了注释,实际使用时schema是一个标准的json文件不可使用注释。**完整属性参考[schema字段](https://uniapp.dcloud.net.cn/uniCloud/schema?id=segment)
+
+```js
+{
+ "bsonType": "object", // 表级的类型,固定为object
+ "required": ['book', 'quantity'], // 新增数据时必填字段
+ "permission": { // 表级权限
+ "read": true, // 读
+ "create": false, // 新增
+ "update": false, // 更新
+ "delete": false, // 删除
+ },
+ "properties": { // 字段列表,注意这里是对象
+ "book": { // 字段名book
+ "bsonType": "string", // 字段类型
+ "permission": { // 字段权限
+ "read": true, // 字段读权限
+ "write": false, // 字段写权限
+ },
+ "foreignKey": "book._id" // 其他表的关联字段
+ },
+ "quantity": {
+ "bsonType": "int"
+ }
+ }
+}
+```
+
+### permission@permission
+
+`DB Schema`中的数据权限配置功能非常强大,请详读[DB Schema的数据权限控制](uniCloud/schema?id=permission)
+
+在配置好`DB Schema`的权限后,JQL的查询写法,尤其是非`JQL`的聚合查询写法有些限制,具体如下:
+- 不使用聚合时collection方法之后需紧跟一个where方法,这个where方法内传入的条件必须满足权限控制规则
+- 使用聚合时aggregate方法之后需紧跟一个match方法,这个match方法内的条件需满足权限控制规则
+- 使用lookup时只可以使用拼接子查询的写法(let+pipeline模式),做这个限制主要是因为需要确保访问需要lookup的表时也会传入查询条件,即pipeline参数里面`db.command.pipeline()`之后的match方法也需要像上一条里面的match一样限制
+- 上面用于校验权限的match和where后的project和field是用来确定本次查询需要访问什么字段的(如果没有将会认为是在访问所有字段),访问的字段列表会用来确认使用那些字段权限校验。这个位置的project和field只能使用白名单模式
+- 上面用于校验权限的match和where内如果有使用`db.command.expr`,那么在进行权限校验时expr方法内部的条件会被忽略,整个expr方法转化成一个不与任何条件产生交集的特别表达式,具体表现请看下面示例
+
+**schema内permission配置示例**
+
+```js
+// order表schema
+{
+ "bsonType": "object", // 表级的类型,固定为object
+ "required": ['book', 'quantity'], // 新增数据时必填字段
+ "permission": { // 表级权限
+ "read": "doc.uid == auth.uid", // 每个用户只能读取用户自己的数据。前提是要操作的数据doc,里面有一个字段存放了uid,即uni-id的用户id。(不配置时等同于false)
+ "create": false, // 禁止新增数据记录(不配置时等同于false)
+ "update": false, // 禁止更新数据(不配置时等同于false)
+ "delete": false, // 禁止删除数据(不配置时等同于false)
+ "count": false, // 禁止对本表进行count计数
+ },
+ "properties": { // 字段列表,注意这里是对象
+ "secret_field": { // 字段名
+ "bsonType": "string", // 字段类型
+ "permission": { // 字段权限
+ "read": false, // 禁止读取secret_field字段的数据
+ "write": false // 禁止写入(包括更新和新增)secret_field字段的数据,父级节点存在false时这里可以不配
+ }
+ },
+ "uid":{
+ "bsonType": "string", // 字段类型
+ "foreignKey": "uni-id-users._id"
+ },
+ "book_id": {
+ "bsonType": "string", // 字段类型
+ "foreignKey": "book._id"
+ }
+ }
+}
+```
+
+```js
+// book表schema
+{
+ "bsonType": "object",
+ "required": ['book', 'quantity'], // 新增数据时必填字段
+ "permission": { // 表级权限
+ "read": "doc.status == 'OnSell'" // 允许所有人读取状态是OnSell的数据
+ },
+ "properties": { // 字段列表,注意这里是对象
+ "title": {
+ "bsonType": "string"
+ },
+ "author": {
+ "bsonType": "string"
+ },
+ "secret_field": { // 字段名
+ "bsonType": "string", // 字段类型
+ "permission": { // 字段权限
+ "read": false, // 禁止读取secret_field字段的数据
+ "write": false // 禁止写入(包括更新和新增)secret_field字段的数据
+ }
+ }
+ }
+}
+```
+
+**请求示例**
+
+```js
+const db = uniCloud.database()
+const dbCmd = db.command
+const $ = dbCmd.aggregate
+db.collection('order')
+ .where('uid == $env.uid && book_id.status == "OnSell"')
+ .field('uid,book_id{title,author}')
+ .get()
+```
+
+在进行数据库操作之前,JQL会使用permission内配置的规则对客户端操作进行一次校验,如果本次校验不通过还会通过数据库查询再进行一次校验
+
+例1:
+
+```js
+// 数据库内news表有以下数据
+{
+ _id: "1",
+ user_id: "uid_1",
+ title: "abc"
+}
+```
+
+```js
+// news表对应的schema内做如下配置
+{
+ "bsonType": "object",
+ "permission": { // 表级权限
+ "read": true,
+ "update": "doc.user_id == auth.uid" // 只允许修改自己的数据
+ },
+ "properties": {
+ "user_id": {
+ "bsonType": "string"
+ },
+ "title": {
+ "bsonType": "string"
+ }
+ }
+}
+```
+
+```js
+// 用户ID为uid_1的用户在客户端使用如下操作
+db.collection('news').doc('1').update({
+ title: 'def'
+})
+```
+
+此时客户端条件里面只有`doc._id == 1`,schema内又限制的`doc.user_id == auth.uid`,所以第一次预校验无法通过,会进行一次查库校验判断是否有权限进行操作。发现auth.uid确实和doc.user_id一致,上面的数据库操作允许执行。
+
+例2:
+
+```js
+// 数据库内goods表有以下数据
+{
+ _id: "1",
+ name: "n1",
+ status: 1
+}
+{
+ _id: "2",
+ name: "n2",
+ status: 2
+}
+{
+ _id: "3",
+ name: "n3",
+ status: 3
+}
+```
+
+```js
+// news表对应的schema内做如下配置
+{
+ "bsonType": "object",
+ "permission": { // 表级权限
+ "read": "doc.status > 1",
+ },
+ "properties": {
+ "name": {
+ "bsonType": "string"
+ },
+ "status": {
+ "bsonType": "int"
+ }
+ }
+}
+```
+
+```js
+// 用户在客户端使用如下操作,可以通过第一次校验,不会触发查库校验
+db.collection('goods').where('status > 1').get()
+
+// 用户在客户端使用如下操作,无法通过第一次校验,会触发一次查库校验(原理大致是使用name == "n3" && status <= 1作为条件进行一次查询,如果有结果就认为没有权限访问,了解即可,无需深入)
+db.collection('goods').where('name == "n3"').get()
+
+// 用户在客户端使用如下操作,无法通过第一次校验,会触发一次查库校验,查库校验也会无法通过
+db.collection('goods').where('name == "n1"').get()
+```
+
+
+## action@action
+
+action的作用是在执行前端发起的数据库操作时,额外触发一段云函数逻辑。它是一个可选模块。action是运行于云函数内的,可以使用云函数内的所有接口。
+
+当一个前端操作数据库的方式不能完全满足需求,仍然同时需要在云端再执行一些云函数时,就在前端发起数据库操作时,通过`db.action("someactionname")`方式要求云端同时执行这个叫someactionname的action。还可以在权限规则内指定某些操作必须使用指定的action,比如`"action in ['action-a','action-b']"`,来达到更灵活的权限控制。
+
+**注意action方法是db对象的方法,只能跟在db后面,不能跟在collection()后面**
+- 正确:`db.action("someactionname").collection('table1')`
+- 错误:`db.collection('table1').action("someactionname")`
+
+**尽量不要在action中使用全局变量,如果一定要用请务必确保自己已经阅读并理解了[云函数的启动模式](uniCloud/cf-functions.md?id=launchtype)**
+
+如果使用`组件`,该组件也有action属性,设置action="someactionname"即可。
+```html
+
+```
+
+action支持一次使用多个,比如使用`db.action("action-a,action-b")`,其执行流程为`action-a.before->action-b.before->执行数据库操作->action-b.after->action-a.after`。在任一before环节抛出错误直接进入after流程,在after流程内抛出的错误会被传到下一个after流程。
+
+action是一种特殊的云函数,它不占用服务空间的云函数数量。
+
+**新建action**
+
+
+
+每个action在uni-clientDB-actions目录下存放一个以action名称命名的js文件。
+
+在这个js文件的代码里,包括before和after两部分,分别代表JQL具体操作数据库前和后。
+
+- before在数据库操作执行前触发,before里的代码执行完毕后再开始操作数据库。before的常用用途:
+ * 对前端传入的数据进行二次处理
+ * 在此处开启数据库事务,万一操作数据库失败,可以在after里回滚
+ * 使用throw阻止运行
+ * 如果权限或字段值域校验不想配在schema和validateFunction里,也可以在这里做校验
+
+- after在数据库操作执行后触发,JQL操作数据库后触发after里的代码。after的常用用途:
+ * 对将要返回给前端的数据进行二次处理
+ * 也可以在此处处理错误,回滚数据库事务
+ * 对数据库进行二次操作,比如前端查询一篇文章详情后,在此处对文章的阅读数+1。因为permission里定义,一般是要禁止前端操作文章的阅读数字段的,此时就应该通过action,在云函数里对阅读数+1
+
+示例:
+
+```js
+// 客户端发起请求,给todo表新增一行数据,同时指定action为add-todo
+const db = uniCloud.database()
+db.action('add-todo') //注意action方法是db的方法,只能跟在db后面,不能跟在collection()后面
+ .collection('todo')
+ .add({
+ title: 'todo title'
+ })
+ .then(res => {
+ console.log(res)
+ }).catch(err => {
+ console.error(err)
+ })
+```
+
+```js
+// 一个action文件示例 uni-clientDB-actions/add-todo.js
+module.exports = {
+ // 在数据库操作之前执行
+ before: async(state,event)=>{
+ // state为当前数据库操作状态其格式见下方说明
+ // event为传入云函数的event对象
+
+ // before内可以操作state上的newData对象对数据进行修改,比如:
+ state.newData.create_time = Date.now()
+ // 指定插入或修改的数据内的create_time为Date.now()
+ // 执行了此操作之后实际插入的数据会变成 {title: 'todo title', create_time: xxxx}
+ // 实际上,这个场景,有更简单的实现方案:在db schema内配置defaultValue或者forceDefaultValue,即可自动处理新增记录使用当前服务器时间
+ },
+ // 在数据库操作之后执行
+ after:async (state,event,error,result)=>{
+ // state为当前数据库操作状态其格式见下方说明
+ // event为传入云函数的event对象
+ // error为执行操作的错误对象,如果没有错误error的值为null
+ // result为执行command返回的结果
+
+ if(error) {
+ throw error
+ }
+
+ // after内可以对result进行额外处理并返回
+ result.msg = 'hello'
+ return result
+ }
+}
+```
+
+**state**参数说明
+
+```js
+// state参数格式如下
+{
+ command: {
+ // getMethod('where') 获取所有的where方法,返回结果为[{$method:'where',$param: [{a:1}]}]
+ getMethod,
+ // getParam({name:'where',index: 0}) 获取第1个where方法的参数,结果为数组形式,例:[{a:1}]
+ getParam,
+ // setParam({name:'where',index: 0, param: [{a:1}]}) 设置第1个where方法的参数,调用之后where方法实际形式为:where({a:1})
+ setParam
+ },
+ auth: {
+ uid, // 用户ID,如果未获取或者获取失败uid值为null
+ role, // 通过uni-id获取的用户角色,需要使用1.1.9以上版本的uni-id,如果未获取或者获取失败role值为[]
+ permission // 通过uni-id获取的用户权限,需要使用1.1.9以上版本的uni-id,如果未获取或者获取失败permission值为[],注意登录时传入needPermission才可以获取permission,请参考 https://uniapp.dcloud.net.cn/uniCloud/uni-id?id=rbac
+ },
+ // 事务对象,如果需要用到事务可以在action的before内使用state.transaction = await db.startTransaction()传入
+ transaction,
+ // 更新或新增的数据
+ newData,
+ // 访问的集合
+ collection,
+ // 操作类型,可能的值'read'、'create'、'update'、'delete'
+ type
+}
+```
+
+**如需在before和after内传参,建议直接在state上挂载。但是切勿覆盖上述属性**
+
+### action内可以使用的公共模块@common-for-action
+
+目前JQL依赖了`uni-id`,uni-id 3.0.7及以上版本又依赖了`uni-config-center`,这两个公共模块是可以在action内使用的。
+
+自`HBuilderX 3.2.7-alpha`起,action内可使用任意公共模块。通过在要使用的公共模块的package.json内配置`"includeInClientDB":true`,可以将公共模块和JQL关联。
+
+一个在JQL内使用的公共模块的package.json示例如下。
+
+```js
+{
+ "name": "test-common",
+ "version": "1.0.0",
+ "description": "",
+ "main": "index.js",
+ "keywords": [],
+ "author": "",
+ "license": "ISC",
+ "includeInClientDB": true
+}
+```
+
+**注意**
+
+- 尽量不要依赖体积过大的公共模块,会延长冷启动时间
+
+**参考:**
+
+- [uni-id 文档](https://uniapp.dcloud.net.cn/uniCloud/uni-id)
+- [uni-config-center 文档](https://ext.dcloud.net.cn/plugin?id=4425)
+
+## 数据库运算方法列表@aggregate-operator
+
+uniCloud的云数据库,提供了一批强大的运算方法。这些方法是数据库执行的,而不是云函数执行的。
+
+这些运算方法是与数据查询搭配使用的,它们可以对字段的值或字段的值的一部分进行运算,将运算后的结果返回给查询请求。
+
+数据库运算方法,提供了比传统SQL更大强大和灵活的查询。可以实现更多功能、可以一次性查询出期待的结果。不必多次查库多次运算,那样不仅代码复杂,而且会造成多次查库性能下降;如果使用计费云空间,使用这些方法还可以减少数据库查询次数。
+
+比如sum()方法,可以对多行记录的某个字段值求和、可以对单行记录的若干字段的值求和,如果字段是一个数组,还可以对数组的各项求和。
+
+为方便书写,JQL内将数据库运算方法的用法进行了简化(相对于云函数内使用数据库运算方法而言),主要是参数摊平,以字符串方式表达。以下是可以在JQL中使用的数据库运算方法
+
+|运算方法 |用途 |JQL简化用法 |说明 |
+|--- |--- |--- |--- |
+|abs |返回一个数字的绝对值 |abs(表达式) |- |
+|add |将数字相加或将数字加在日期上。如果参数中的其中一个值是日期,那么其他值将被视为毫秒数加在该日期上 |add(表达式1,表达式2) |- |
+|ceil |向上取整 |ceil(表达式) |- |
+|divide |传入被除数和除数,求商 |divide(表达式1,表达式2) |- |
+|exp |取 e(自然对数的底数,欧拉数) 的 n 次方 |exp(表达式) |- |
+|floor |向下取整 |floor(表达式) |- |
+|ln |计算给定数字在自然对数值 |ln(表达式) |- |
+|log |计算给定数字在给定对数底下的 log 值 |log(表达式1,表达式2) |- |
+|log10 |计算给定数字在对数底为 10 下的 log 值 |log10(表达式) |- |
+|mod |取模运算,第一个数字是被除数,第二个数字是除数 |mod(表达式1,表达式2) |- |
+|multiply |取传入的数字参数相乘的结果 |multiply(表达式1,表达式2) |- |
+|pow |求给定基数的指数次幂 |pow(表达式1,表达式2) |- |
+|sqrt |求平方根 |sqrt(表达式1,表达式2) |- |
+|subtract |将两个数字相减然后返回差值,或将两个日期相减然后返回相差的毫秒数,或将一个日期减去一个数字返回结果的日期。 |subtract(表达式1,表达式2) |- |
+|trunc |将数字截断为整形 |trunc(表达式) |- |
+|arrayElemAt |返回在指定数组下标的元素 |arrayElemAt(表达式1,表达式2) |- |
+|arrayToObject |将一个数组转换为对象 |arrayToObject(表达式) |- |
+|concatArrays |将多个数组拼接成一个数组 |concatArrays(表达式1,表达式2) |- |
+|filter |根据给定条件返回满足条件的数组的子集 |filter(input,as,cond) |- |
+|in |给定一个值和一个数组,如果值在数组中则返回 true,否则返回 false |in(表达式1,表达式2) |- |
+|indexOfArray |在数组中找出等于给定值的第一个元素的下标,如果找不到则返回 -1 |indexOfArray(表达式1,表达式2) |- |
+|isArray |判断给定表达式是否是数组,返回布尔值 |isArray(表达式) |- |
+|map |类似 JavaScript Array 上的 map 方法,将给定数组的每个元素按给定转换方法转换后得出新的数组 |map(input,as,in) |- |
+|objectToArray |将一个对象转换为数组。方法把对象的每个键值对都变成输出数组的一个元素,元素形如 `{ k: , v: }` |objectToArray(表达式) |- |
+|range |返回一组生成的序列数字。给定开始值、结束值、非零的步长,range 会返回从开始值开始逐步增长、步长为给定步长、但不包括结束值的序列。 |range(表达式1,表达式2) |- |
+|reduce |类似 JavaScript 的 reduce 方法,应用一个表达式于数组各个元素然后归一成一个元素 |reduce(input,initialValue,in) |- |
+|reverseArray |返回给定数组的倒序形式 |reverseArray(表达式) |- |
+|size |返回数组长度 |size(表达式) |- |
+|slice |类似 JavaScritp 的 slice 方法。返回给定数组的指定子集 |slice(表达式1,表达式2) |- |
+|zip |把二维数组的第二维数组中的相同序号的元素分别拼装成一个新的数组进而组装成一个新的二维数组。 |zip(inputs,useLongestLength,defaults) |- |
+|and |给定多个表达式,and 仅在所有表达式都返回 true 时返回 true,否则返回 false |and(表达式1,表达式2) |- |
+|not |给定一个表达式,如果表达式返回 true,则 not 返回 false,否则返回 true。注意表达式不能为逻辑表达式(and、or、nor、not) |not(表达式) |- |
+|or |给定多个表达式,如果任意一个表达式返回 true,则 or 返回 true,否则返回 false |or(表达式1,表达式2) |- |
+|cmp |给定两个值,返回其比较值。如果第一个值小于第二个值,返回 -1 如果第一个值大于第二个值,返回 1 如果两个值相等,返回 0 |cmp(表达式1,表达式2) |- |
+|eq |匹配两个值,如果相等则返回 true,否则返回 false |eq(表达式1,表达式2) |- |
+|gt |匹配两个值,如果前者大于后者则返回 true,否则返回 false |gt(表达式1,表达式2) |- |
+|gte |匹配两个值,如果前者大于或等于后者则返回 true,否则返回 false |gte(表达式1,表达式2) |- |
+|lt |匹配两个值,如果前者小于后者则返回 true,否则返回 false |lt(表达式1,表达式2) |- |
+|lte |匹配两个值,如果前者小于或等于后者则返回 true,否则返回 false |lte(表达式1,表达式2) |- |
+|neq |匹配两个值,如果不相等则返回 true,否则返回 false |neq(表达式1,表达式2) |- |
+|cond |计算布尔表达式1,成立返回表达式2,否则返回表达式3 |cond(表达式1,表达式2,表达式3) |- |
+|ifNull |计算给定的表达式,如果表达式结果为 null、undefined 或者不存在,那么返回一个替代值;否则返回原值。 |ifNull(表达式1,表达式2) |- |
+|switch |根据给定的 switch-case-default 计算返回值 |switch(branches,default) |- |
+|dateFromParts |给定日期的相关信息,构建并返回一个日期对象 |dateFromParts(year,month,day,hour,minute,second,millisecond,timezone) |- |
+|isoDateFromParts |给定日期的相关信息,构建并返回一个日期对象 |isoDateFromParts(isoWeekYear,isoWeek,isoDayOfWeek,hour,minute,second,millisecond,timezone) |- |
+|dateFromString |将一个日期/时间字符串转换为日期对象 |dateFromString(dateString,format,timezone,onError,onNull) |- |
+|dateToString |根据指定的表达式将日期对象格式化为符合要求的字符串 |dateToString(date,format,timezone,onNull) |- |
+|dayOfMonth |返回日期字段对应的天数(一个月中的哪一天),是一个介于 1 至 31 之间的数字 |dayOfMonth(date,timezone) |- |
+|dayOfWeek |返回日期字段对应的天数(一周中的第几天),是一个介于 1(周日)到 7(周六)之间的整数 |dayOfWeek(date,timezone) |- |
+|dayOfYear |返回日期字段对应的天数(一年中的第几天),是一个介于 1 到 366 之间的整数 |dayOfYear(date,timezone) |- |
+|hour |返回日期字段对应的小时数,是一个介于 0 到 23 之间的整数。 |hour(date,timezone) |- |
+|isoDayOfWeek |返回日期字段对应的 ISO 8601 标准的天数(一周中的第几天),是一个介于 1(周一)到 7(周日)之间的整数。 |isoDayOfWeek(date,timezone) |- |
+|isoWeek |返回日期字段对应的 ISO 8601 标准的周数(一年中的第几周),是一个介于 1 到 53 之间的整数。 |isoWeek(date,timezone) |- |
+|isoWeekYear |返回日期字段对应的 ISO 8601 标准的天数(一年中的第几天) |isoWeekYear(date,timezone) |- |
+|millisecond |返回日期字段对应的毫秒数,是一个介于 0 到 999 之间的整数 |millisecond(date,timezone) |- |
+|minute |返回日期字段对应的分钟数,是一个介于 0 到 59 之间的整数 |minute(date,timezone) |- |
+|month |返回日期字段对应的月份,是一个介于 1 到 12 之间的整数 |month(date,timezone) |- |
+|second |返回日期字段对应的秒数,是一个介于 0 到 59 之间的整数,在特殊情况下(闰秒)可能等于 60 |second(date,timezone) |- |
+|week |返回日期字段对应的周数(一年中的第几周),是一个介于 0 到 53 之间的整数 |week(date,timezone) |- |
+|year |返回日期字段对应的年份 |year(date,timezone) |- |
+|timestampToDate |传入一个时间戳,返回对应的日期对象 |timestampToDate(timestamp) |仅JQL字符串内支持,HBuilderX 3.1.0起支持 |
+|literal |直接返回一个值的字面量,不经过任何解析和处理 |literal(表达式) |- |
+|mergeObjects |将多个对象合并为单个对象 |mergeObjects(表达式1,表达式2) |- |
+|allElementsTrue |输入一个数组,或者数组字段的表达式。如果数组中所有元素均为真值,那么返回 true,否则返回 false。空数组永远返回 true |allElementsTrue(表达式1,表达式2) |- |
+|anyElementTrue |输入一个数组,或者数组字段的表达式。如果数组中任意一个元素为真值,那么返回 true,否则返回 false。空数组永远返回 false |anyElementTrue(表达式1,表达式2) |- |
+|setDifference |输入两个集合,输出只存在于第一个集合中的元素 |setDifference(表达式1,表达式2) |- |
+|setEquals |输入两个集合,判断两个集合中包含的元素是否相同(不考虑顺序、去重) |setEquals(表达式1,表达式2) |- |
+|setIntersection |输入两个集合,输出两个集合的交集 |setIntersection(表达式1,表达式2) |- |
+|setIsSubset |输入两个集合,判断第一个集合是否是第二个集合的子集 |setIsSubset(表达式1,表达式2) |- |
+|setUnion |输入两个集合,输出两个集合的并集 |setUnion(表达式1,表达式2) |- |
+|concat |连接字符串,返回拼接后的字符串 |concat(表达式1,表达式2) |- |
+|indexOfBytes |在目标字符串中查找子字符串,并返回第一次出现的 UTF-8 的字节索引(从0开始)。如果不存在子字符串,返回 -1 |indexOfBytes(表达式1,表达式2) |- |
+|indexOfCP |在目标字符串中查找子字符串,并返回第一次出现的 UTF-8 的 code point 索引(从0开始)。如果不存在子字符串,返回 -1 |indexOfCP(表达式1,表达式2) |- |
+|split |按照分隔符分隔数组,并且删除分隔符,返回子字符串组成的数组。如果字符串无法找到分隔符进行分隔,返回原字符串作为数组的唯一元素 |split(表达式1,表达式2) |- |
+|strLenBytes |计算并返回指定字符串中 utf-8 编码的字节数量 |strLenBytes(表达式) |- |
+|strLenCP |计算并返回指定字符串的UTF-8 code points 数量 |strLenCP(表达式) |- |
+|strcasecmp |对两个字符串在不区分大小写的情况下进行大小比较,并返回比较的结果 |strcasecmp(表达式1,表达式2) |- |
+|substr |返回字符串从指定位置开始的指定长度的子字符串 |substr(表达式1,表达式2) |- |
+|substrBytes |返回字符串从指定位置开始的指定长度的子字符串。子字符串是由字符串中指定的 UTF-8 字节索引的字符开始,长度为指定的字节数 |substrBytes(表达式1,表达式2) |- |
+|substrCP |返回字符串从指定位置开始的指定长度的子字符串。子字符串是由字符串中指定的 UTF-8 字节索引的字符开始,长度为指定的字节数 |substrCP(表达式1,表达式2) |- |
+|toLower |将字符串转化为小写并返回 |toLower(表达式) |- |
+|toUpper |将字符串转化为大写并返回 |toUpper(表达式) |- |
+|addToSet |聚合运算符。向数组中添加值,如果数组中已存在该值,不执行任何操作。它只能在 group stage 中使用 |addToSet(表达式) |- |
+|avg |返回指定表达式对应数据的平均值 |avg(表达式) |- |
+|first |返回指定字段在一组集合的第一条记录对应的值。仅当这组集合是按照某种定义排序( sort )后,此操作才有意义 |first(表达式) |- |
+|last |返回指定字段在一组集合的最后一条记录对应的值。仅当这组集合是按照某种定义排序( sort )后,此操作才有意义。 |last(表达式) |- |
+|max |返回一组数值的最大值 |max(表达式) |- |
+|min |返回一组数值的最小值 |min(表达式) |- |
+|push |返回一组中表达式指定列与对应的值,一起组成的数组 |push(表达式) |- |
+|stdDevPop |返回一组字段对应值的标准差 |stdDevPop(表达式) |- |
+|stdDevSamp |计算输入值的样本标准偏差 |stdDevSamp(表达式) |- |
+|sum |在groupField内返回一组字段所有数值的总和,非groupField内返回一个数组所有元素的和 |sum(表达式) |- |
+|let |自定义变量,并且在指定表达式中使用,返回的结果是表达式的结果 |let(vars,in) |- |
+
+以上操作符还可以组合使用
+
+例:数据表article内有以下数据
+
+```js
+{
+ "_id": "1",
+ "publish_date": 1611141512751,
+ "content": "hello uniCloud content 01",
+ "content": "hello uniCloud title 01",
+}
+
+{
+ "_id": "2",
+ "publish_date": 1611141512752,
+ "content": "hello uniCloud content 02",
+ "content": "hello uniCloud title 02",
+}
+
+{
+ "_id": "3",
+ "publish_date": 1611141512753,
+ "content": "hello uniCloud content 03",
+ "content": "hello uniCloud title 03",
+}
+```
+
+可以通过以下查询将publish_date字段从时间戳转为`2021-01-20`形式,然后进行按天进行统计
+
+```js
+const res = await db.collection('article')
+.groupBy('dateToString(add(new Date(0),publish_date),"%Y-%m-%d","+0800") as publish_date_str')
+.groupField('count(*) as total')
+.get()
+```
+
+上述代码使用add方法将publish_date时间戳转为日期类型,再用dateToString将上一步的日期按照时区'+0800'(北京时间),格式化为`4位年-2位月-2位日`格式,完整格式化参数请参考[dateToString](uniCloud/cf-database.md?id=datetostring)。
+
+上述代码执行结果为
+
+```js
+res = {
+ result: {
+ data: [{
+ publish_date_str: '2021-01-20',
+ total: 3
+ }]
+ }
+}
+```
+
+**注意**
+
+运算方法中仅数据库字段可以直接去除引号作为变量书写,其他字符串仍要写成字符串形式
+
+例:
+
+数据库内有以下数据:
+
+```js
+{
+ "_id": 1,
+ "sales": [ 1.32, 6.93, 2.48, 2.82, 5.74 ]
+}
+{
+ "_id": 2,
+ "sales": [ 2.97, 7.13, 1.58, 6.37, 3.69 ]
+}
+```
+
+云函数内对以下数据中的sales字段取整
+
+```js
+const db = uniCloud.database()
+const $ = db.command.aggregate
+let res = await db.collection('stats').aggregate()
+ .project({
+ truncated: $.map({
+ input: '$sales',
+ as: 'num',
+ in: $.trunc('$$num'),
+ })
+ })
+ .end()
+```
+
+JQL语法内同样功能的实现
+
+```js
+const db = uniCloud.database()
+const res = await db.collection('stats')
+.field('map(sales,"num",trunc("$$num")) as truncated')
+.get()
+```
+
+### 分组运算方法@accumulator
+
+分组运算方法是专用于统计汇总的数据库运算方法。它也是数据库的方法,而不是js的方法。
+
+**等同于mongoDB累计器操作符概念**
+
+groupField内可使用且仅能使用如下运算方法。
+
+|操作符 |用途 |用法 |说明 |
+|--- |--- |--- |--- |
+|addToSet |向数组中添加值,如果数组中已存在该值,不执行任何操作 |addToSet(表达式) |- |
+|avg |返回指定表达式对应数据的平均值 |avg(表达式) |- |
+|first |返回指定字段在一组集合的第一条记录对应的值。仅当这组集合是按照某种定义排序( sort )后,此操作才有意义 |first(表达式) |- |
+|last |返回指定字段在一组集合的最后一条记录对应的值。仅当这组集合是按照某种定义排序( sort )后,此操作才有意义。 |last(表达式) |- |
+|max |返回一组数值的最大值 |max(表达式) |- |
+|min |返回一组数值的最小值 |min(表达式) |- |
+|push |返回一组中表达式指定列与对应的值,一起组成的数组 |push(表达式) |- |
+|stdDevPop |返回一组字段对应值的标准差 |stdDevPop(表达式) |- |
+|stdDevSamp |计算输入值的样本标准偏差 |stdDevSamp(表达式) |- |
+|sum |返回一组字段所有数值的总和 |sum(表达式) |- |
+|mergeObjects |将一组对象合并为一个对象 |mergeObjects(表达式) |在groupField内使用时仅接收一个参数 |