Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
醒狮指南
JavaGuide
提交
99e7e29b
J
JavaGuide
项目概览
醒狮指南
/
JavaGuide
与 Fork 源项目一致
从无法访问的项目Fork
通知
5
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
J
JavaGuide
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
99e7e29b
编写于
10月 17, 2019
作者:
K
Kou Shuang
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
分库分表之后,id 主键如何处理?
上级
9e6bbcb5
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
216 addition
and
2 deletion
+216
-2
docs/database/MySQL.md
docs/database/MySQL.md
+13
-2
media/pictures/kafaka/前言.md
media/pictures/kafaka/前言.md
+203
-0
未找到文件。
docs/database/MySQL.md
浏览文件 @
99e7e29b
点击关注
[
公众号
](
#公众号
)
及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
<!-- TOC -->
-
[
书籍推荐
](
#书籍推荐
)
-
[
文字教程推荐
](
#文字教程推荐
)
-
[
视频教程推荐
](
#视频教程推荐
)
...
...
@@ -288,6 +286,19 @@ InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到 **SERIALI
详细内容可以参考: MySQL大表优化方案:
[
https://segmentfault.com/a/1190000006158186
](
https://segmentfault.com/a/1190000006158186
)
### 分库分表之后,id 主键如何处理?
因为要是分成多个表之后,每个表都是从 1 开始累加,这样是不对的,我们需要一个全局唯一的 id 来支持。
生成全局 id 有下面这几种方式:
-
**UUID**
:不适合作为主键,因为太长了,并且无序不可读,查询效率低。比较适合用于生成唯一的名字的标示比如文件的名字。
-
**数据库自增 id**
: 两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。这种方式生成的 id 有序,但是需要独立部署数据库实例,成本高,还会有性能瓶颈。
-
**利用 redis 生成 id :**
性能比较好,灵活方便,不依赖于数据库。但是,引入了新的组件造成系统更加复杂,可用性降低,编码更加复杂,增加了系统成本。
-
**Twitter的snowflake算法**
:Github 地址:https://github.com/twitter-archive/snowflake。
-
**美团的[Leaf](https://tech.meituan.com/2017/04/21/mt-leaf.html)分布式ID生成系统**
:Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。感觉还不错。美团技术团队的一篇文章:https://tech.meituan.com/2017/04/21/mt-leaf.html 。
-
......
### 一条SQL语句在MySQL中如何执行的
[
一条SQL语句在MySQL中如何执行的
](
<
https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485097&idx=1&sn=84c89da477b1338bdf3e9fcd65514ac1&chksm=cea24962f9d5c074d8d3ff1ab04ee8f0d6486e3d015cfd783503685986485c11738ccb542ba7&token=79317275&lang=zh_CN#rd
>
)
...
...
media/pictures/kafaka/前言.md
0 → 100644
浏览文件 @
99e7e29b
# 前言
谈到java的线程池最熟悉的莫过于ExecutorService接口了,jdk1.5新增的java.util.concurrent包下的这个api,大大的简化了多线程代码的开发。而不论你用FixedThreadPool还是CachedThreadPool其背后实现都是ThreadPoolExecutor。ThreadPoolExecutor是一个典型的缓存池化设计的产物,因为池子有大小,当池子体积不够承载时,就涉及到拒绝策略。JDK中已经预设了4种线程池拒绝策略,下面结合场景详细聊聊这些策略的使用场景,以及我们还能扩展哪些拒绝策略。
# 池化设计思想
池话设计应该不是一个新名词。我们常见的如java线程池、jdbc连接池、redis连接池等就是这类设计的代表实现。这种设计会初始预设资源,解决的问题就是抵消每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。就好比你去食堂打饭,打饭的大妈会先把饭盛好几份放那里,你来了就直接拿着饭盒加菜即可,不用再临时又盛饭又打菜,效率就高了。除了初始化资源,池化设计还包括如下这些特征:池子的初始值、池子的活跃值、池子的最大值等,这些特征可以直接映射到java线程池和数据库连接池的成员属性中。
# 线程池触发拒绝策略的时机
和数据源连接池不一样,线程池除了初始大小和池子最大值,还多了一个阻塞队列来缓冲。数据源连接池一般请求的连接数超过连接池的最大值的时候就会触发拒绝策略,策略一般是阻塞等待设置的时间或者直接抛异常。而线程池的触发时机如下图:
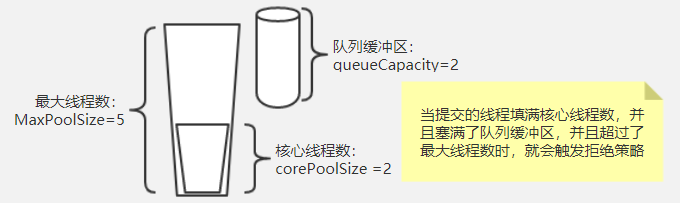
如图,想要了解线程池什么时候触发拒绝粗略,需要明确上面三个参数的具体含义,是这三个参数总体协调的结果,而不是简单的超过最大线程数就会触发线程拒绝粗略,当提交的任务数大于corePoolSize时,会优先放到队列缓冲区,只有填满了缓冲区后,才会判断当前运行的任务是否大于maxPoolSize,小于时会新建线程处理。大于时就触发了拒绝策略,总结就是:当前提交任务数大于(maxPoolSize + queueCapacity)时就会触发线程池的拒绝策略了。
# JDK内置4种线程池拒绝策略
# 拒绝策略接口定义
在分析JDK自带的线程池拒绝策略前,先看下JDK定义的 拒绝策略接口,如下:
```
java
public
interface
RejectedExecutionHandler
{
void
rejectedExecution
(
Runnable
r
,
ThreadPoolExecutor
executor
);
}
```
接口定义很明确,当触发拒绝策略时,线程池会调用你设置的具体的策略,将当前提交的任务以及线程池实例本身传递给你处理,具体作何处理,不同场景会有不同的考虑,下面看JDK为我们内置了哪些实现:
# CallerRunsPolicy(调用者运行策略)
```
java
public
static
class
CallerRunsPolicy
implements
RejectedExecutionHandler
{
public
CallerRunsPolicy
()
{
}
public
void
rejectedExecution
(
Runnable
r
,
ThreadPoolExecutor
e
)
{
if
(!
e
.
isShutdown
())
{
r
.
run
();
}
}
}
```
功能:当触发拒绝策略时,只要线程池没有关闭,就由提交任务的当前线程处理。
使用场景:一般在不允许失败的、对性能要求不高、并发量较小的场景下使用,因为线程池一般情况下不会关闭,也就是提交的任务一定会被运行,但是由于是调用者线程自己执行的,当多次提交任务时,就会阻塞后续任务执行,性能和效率自然就慢了。
# AbortPolicy(中止策略)
```
java
public
static
class
AbortPolicy
implements
RejectedExecutionHandler
{
public
AbortPolicy
()
{
}
public
void
rejectedExecution
(
Runnable
r
,
ThreadPoolExecutor
e
)
{
throw
new
RejectedExecutionException
(
"Task "
+
r
.
toString
()
+
" rejected from "
+
e
.
toString
());
}
}
```
功能:当触发拒绝策略时,直接抛出拒绝执行的异常,中止策略的意思也就是打断当前执行流程
使用场景:这个就没有特殊的场景了,但是一点要正确处理抛出的异常。ThreadPoolExecutor中默认的策略就是AbortPolicy,ExecutorService接口的系列ThreadPoolExecutor因为都没有显示的设置拒绝策略,所以默认的都是这个。但是请注意,ExecutorService中的线程池实例队列都是无界的,也就是说把内存撑爆了都不会触发拒绝策略。当自己自定义线程池实例时,使用这个策略一定要处理好触发策略时抛的异常,因为他会打断当前的执行流程。
# DiscardPolicy(丢弃策略)
```
java
public
static
class
DiscardPolicy
implements
RejectedExecutionHandler
{
public
DiscardPolicy
()
{
}
public
void
rejectedExecution
(
Runnable
r
,
ThreadPoolExecutor
e
)
{
}
}
```
功能:如果线程池未关闭,就弹出队列头部的元素,然后尝试执行
使用场景:这个策略还是会丢弃任务,丢弃时也是毫无声息,但是特点是丢弃的是老的未执行的任务,而且是待执行优先级较高的任务。基于这个特性,我能想到的场景就是,发布消息,和修改消息,当消息发布出去后,还未执行,此时更新的消息又来了,这个时候未执行的消息的版本比现在提交的消息版本要低就可以被丢弃了。因为队列中还有可能存在消息版本更低的消息会排队执行,所以在真正处理消息的时候一定要做好消息的版本比较
# 第三方实现的拒绝策略
# dubbo中的线程拒绝策略
```
java
public
class
AbortPolicyWithReport
extends
ThreadPoolExecutor
.
AbortPolicy
{
protected
static
final
Logger
logger
=
LoggerFactory
.
getLogger
(
AbortPolicyWithReport
.
class
);
private
final
String
threadName
;
private
final
URL
url
;
private
static
volatile
long
lastPrintTime
=
0
;
private
static
Semaphore
guard
=
new
Semaphore
(
1
);
public
AbortPolicyWithReport
(
String
threadName
,
URL
url
)
{
this
.
threadName
=
threadName
;
this
.
url
=
url
;
}
@Override
public
void
rejectedExecution
(
Runnable
r
,
ThreadPoolExecutor
e
)
{
String
msg
=
String
.
format
(
"Thread pool is EXHAUSTED!"
+
" Thread Name: %s, Pool Size: %d (active: %d, core: %d, max: %d, largest: %d), Task: %d (completed: %d),"
+
" Executor status:(isShutdown:%s, isTerminated:%s, isTerminating:%s), in %s://%s:%d!"
,
threadName
,
e
.
getPoolSize
(),
e
.
getActiveCount
(),
e
.
getCorePoolSize
(),
e
.
getMaximumPoolSize
(),
e
.
getLargestPoolSize
(),
e
.
getTaskCount
(),
e
.
getCompletedTaskCount
(),
e
.
isShutdown
(),
e
.
isTerminated
(),
e
.
isTerminating
(),
url
.
getProtocol
(),
url
.
getIp
(),
url
.
getPort
());
logger
.
warn
(
msg
);
dumpJStack
();
throw
new
RejectedExecutionException
(
msg
);
}
private
void
dumpJStack
()
{
//省略实现
}
}
```
可以看到,当dubbo的工作线程触发了线程拒绝后,主要做了三个事情,原则就是尽量让使用者清楚触发线程拒绝策略的真实原因
-
输出了一条警告级别的日志,日志内容为线程池的详细设置参数,以及线程池当前的状态,还有当前拒绝任务的一些详细信息。可以说,这条日志,使用dubbo的有过生产运维经验的或多或少是见过的,这个日志简直就是日志打印的典范,其他的日志打印的典范还有spring。得益于这么详细的日志,可以很容易定位到问题所在
-
输出当前线程堆栈详情,这个太有用了,当你通过上面的日志信息还不能定位问题时,案发现场的dump线程上下文信息就是你发现问题的救命稻草。
-
继续抛出拒绝执行异常,使本次任务失败,这个继承了JDK默认拒绝策略的特性
# Netty中的线程池拒绝策略
```
java
private
static
final
class
NewThreadRunsPolicy
implements
RejectedExecutionHandler
{
NewThreadRunsPolicy
()
{
super
();
}
public
void
rejectedExecution
(
Runnable
r
,
ThreadPoolExecutor
executor
)
{
try
{
final
Thread
t
=
new
Thread
(
r
,
"Temporary task executor"
);
t
.
start
();
}
catch
(
Throwable
e
)
{
throw
new
RejectedExecutionException
(
"Failed to start a new thread"
,
e
);
}
}
}
```
Netty中的实现很像JDK中的CallerRunsPolicy,舍不得丢弃任务。不同的是,CallerRunsPolicy是直接在调用者线程执行的任务。而 Netty是新建了一个线程来处理的。所以,Netty的实现相较于调用者执行策略的使用面就可以扩展到支持高效率高性能的场景了。但是也要注意一点,Netty的实现里,在创建线程时未做任何的判断约束,也就是说只要系统还有资源就会创建新的线程来处理,直到new不出新的线程了,才会抛创建线程失败的异常
# ActiveMq中的线程池拒绝策略
```
java
new
RejectedExecutionHandler
()
{
@Override
public
void
rejectedExecution
(
final
Runnable
r
,
final
ThreadPoolExecutor
executor
)
{
try
{
executor
.
getQueue
().
offer
(
r
,
60
,
TimeUnit
.
SECONDS
);
}
catch
(
InterruptedException
e
)
{
throw
new
RejectedExecutionException
(
"Interrupted waiting for BrokerService.worker"
);
}
throw
new
RejectedExecutionException
(
"Timed Out while attempting to enqueue Task."
);
}
});
```
ActiveMq中的策略属于最大努力执行任务型,当触发拒绝策略时,在尝试一分钟的时间重新将任务塞进任务队列,当一分钟超时还没成功时,就抛出异常
# pinpoint中的线程池拒绝策略
```
java
public
class
RejectedExecutionHandlerChain
implements
RejectedExecutionHandler
{
private
final
RejectedExecutionHandler
[]
handlerChain
;
public
static
RejectedExecutionHandler
build
(
List
<
RejectedExecutionHandler
>
chain
)
{
Objects
.
requireNonNull
(
chain
,
"handlerChain must not be null"
);
RejectedExecutionHandler
[]
handlerChain
=
chain
.
toArray
(
new
RejectedExecutionHandler
[
0
]);
return
new
RejectedExecutionHandlerChain
(
handlerChain
);
}
private
RejectedExecutionHandlerChain
(
RejectedExecutionHandler
[]
handlerChain
)
{
this
.
handlerChain
=
Objects
.
requireNonNull
(
handlerChain
,
"handlerChain must not be null"
);
}
@Override
public
void
rejectedExecution
(
Runnable
r
,
ThreadPoolExecutor
executor
)
{
for
(
RejectedExecutionHandler
rejectedExecutionHandler
:
handlerChain
)
{
rejectedExecutionHandler
.
rejectedExecution
(
r
,
executor
);
}
}
}
```
pinpoint的拒绝策略实现很有特点,和其他的实现都不同。他定义了一个拒绝策略链,包装了一个拒绝策略列表,当触发拒绝策略时,会将策略链中的rejectedExecution依次执行一遍
# 结语
前文从线程池设计思想,以及线程池触发拒绝策略的时机引出java线程池拒绝策略接口的定义。并辅以JDK内置4种以及四个第三方开源软件的拒绝策略定义描述了线程池拒绝策略实现的各种思路和使用场景。希望阅读此文后能让你对java线程池拒绝策略有更加深刻的认识,能够根据不同的使用场景更加灵活的应用。
\ No newline at end of file
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录