[](https://cnocr.readthedocs.io/zh/latest/)
[](./LICENSE)
[](https://cnocr.readthedocs.io/zh/latest/?badge=latest)
[](https://badge.fury.io/py/cnocr)
[](https://github.com/breezedeus/cnocr)
[](https://github.com/breezedeus/cnocr)


[](https://twitter.com/breezedeus)
[📖 Doc](https://cnocr.readthedocs.io/zh/latest/) |
[🛠️ Install](https://cnocr.readthedocs.io/zh/latest/install/) |
[🧳 Models](https://cnocr.readthedocs.io/zh/latest/models/) |
[🕹 Training](https://cnocr.readthedocs.io/zh/latest/train/) |
[🛀🏻 Online Demo](https://share.streamlit.io/breezedeus/cnstd/st-deploy/cnstd/app.py) |
[💬 Contact](https://cnocr.readthedocs.io/zh/latest/contact/)
[中文](./README.md) | English
# CnOCR
Tech should serve the people, not enslave them!
Please do NOT use this project for text censorship!
---
[**CnOCR**](https://github.com/breezedeus/cnocr) is an **Optical Character Recognition (OCR)** toolkit for **Python 3**. It supports recognition of common characters in **English and numbers**, **Simplified Chinese**, **Traditional Chinese** (some models), and **vertical text** recognition. It comes with [**20+ well-trained models**](https://cnocr.readthedocs.io/zh/latest/models/) for different application scenarios and can be used directly after installation. Also, CnOCR provides simple training [commands](https://cnocr.readthedocs.io/zh/latest/train/) for users to train their own models. Welcome to join the WeChat contact group.
The author also maintains **Planet of Knowledge** [**CnOCR/CnSTD Private Group**](https://t.zsxq.com/FEYZRJQ), welcome to join. The **Planet of Knowledge Private Group** will release some CnOCR/CnSTD related private materials one after another, including [**more detailed training tutorials**](https://articles.zsxq.com/id_u6b4u0wrf46e.html), **non-public models**, answers to problems encountered during usage, etc. This group also releases the latest research materials related to OCR/STD. In addition, **the author in the private group provides free training services for unique data twice a month**.
## Documentation
See [CnOCR online documentation](https://cnocr.readthedocs.io/) , in Chinese.
## Usage
Starting from **V2.2**, **CnOCR** internally uses the text detection engine **[CnSTD](https://github.com/breezedeus/cnstd)** for text detection and positioning. So **CnOCR** V2.2 can recognize not only typographically simple printed text images, such as screenshot images, scanned copies, etc., but also **scene text in general images**.
Here are some examples of usages for different scenarios.
## Start On Cloud IDE
[https://idegithub.com/breezedeus/CnOCR](https://idegithub.com/breezedeus/CnOCR)
## Usages for Different Scenarios
### Common image recognition
Just use default values for all parameters. If you find that the result is not good enough, try different parameters more to see the effect, and usually you will end up with a more desirable accuracy.
```python
from cnocr import CnOcr
img_fp = './docs/examples/huochepiao.jpeg'
ocr = CnOcr() # Use default values for all parameters
out = ocr.ocr(img_fp)
print(out)
```
Recognition results:
### English Recognition
Although Chinese detection and recognition models can also recognize English, **detectors and recognizers trained specifically for English texts tend to be more accurate**. For English-only application scenarios, it is recommended to use the English detection model `det_model_name='en_PP-OCRv3_det'` and the English recognition model `rec_model_name='en_PP-OCRv3'` from [**PaddleOCR**](https://github.com/PaddlePaddle/PaddleOCR) (also called **ppocr**).
```python
from cnocr import CnOcr
img_fp = './docs/examples/en_book1.jpeg'
ocr = CnOcr(det_model_name='en_PP-OCRv3_det', rec_model_name='en_PP-OCRv3')
out = ocr.ocr(img_fp)
print(out)
```
Recognition results:
### Recognition of typographically screenshot images
For **typographically simple typographic text images**, such as screenshot images, scanned images, etc., you can use `det_model_name='naive_det'`, which is equivalent to not using a text detection model, but using simple rules for branching.
> **Note**
>
> `det_model_name='naive_det'` is equivalent to CnOCR versions before `V2.2` (`V2.0.*`, `V2.1.*`).
The biggest advantage of using `det_model_name='naive_det'` is that the speech is **fast** and the disadvantage is that it is picky about images. How do you determine if you should use the detection model `'naive_det'`? The easiest way is to take your application image and try the effect, if it works well, use it, if not, don't.
```python
from cnocr import CnOcr
img_fp = './docs/examples/multi-line_cn1.png'
ocr = CnOcr(det_model_name='naive_det')
out = ocr.ocr(img_fp)
print(out)
```
Recognition results:
| 图片 | OCR结果 |
| ----------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------- |
|  | 网络支付并无本质的区别,因为
每一个手机号码和邮件地址背后
都会对应着一个账户--这个账
户可以是信用卡账户、借记卡账
户,也包括邮局汇款、手机代
收、电话代收、预付费卡和点卡
等多种形式。 |
### Vertical text recognition
Chinese recognition model `rec_model_name='ch_PP-OCRv3'` from **ppocr** is used for recognition.
```python
from cnocr import CnOcr
img_fp = './docs/examples/shupai.png'
ocr = CnOcr(rec_model_name='ch_PP-OCRv3')
out = ocr.ocr(img_fp)
print(out)
```
Recognition results:
### Traditional Chinese Recognition
Use the traditional Chinese recognition model from ppocr `rec_model_name='english_cht_PP-OCRv3'` for recognition.
```python
from cnocr import CnOcr
img_fp = './docs/examples/fanti.jpg'
ocr = CnOcr(rec_model_name='chinese_cht_PP-OCRv3') # use the traditional Chinese recognition model
out = ocr.ocr(img_fp)
print(out)
```
When using this model, please note the following issues:
* The recognition accuracy is average and not very good.
* The recognition of punctuation, English and numbers is not good except for traditional Chinese characters.
* This model does not support the recognition of vertical text.
### Single line text image recognition
If it is clear that the image to be recognized is a single line text image (as shown below), you can use the class function `CnOcr.ocr_for_single_line()` for recognition. This saves the time of text detection and will be more than twice as fast.
The code is as follows:
```python
from cnocr import CnOcr
img_fp = './docs/examples/helloworld.jpg'
ocr = CnOcr()
out = ocr.ocr_for_single_line(img_fp)
print(out)
```
### More Applications
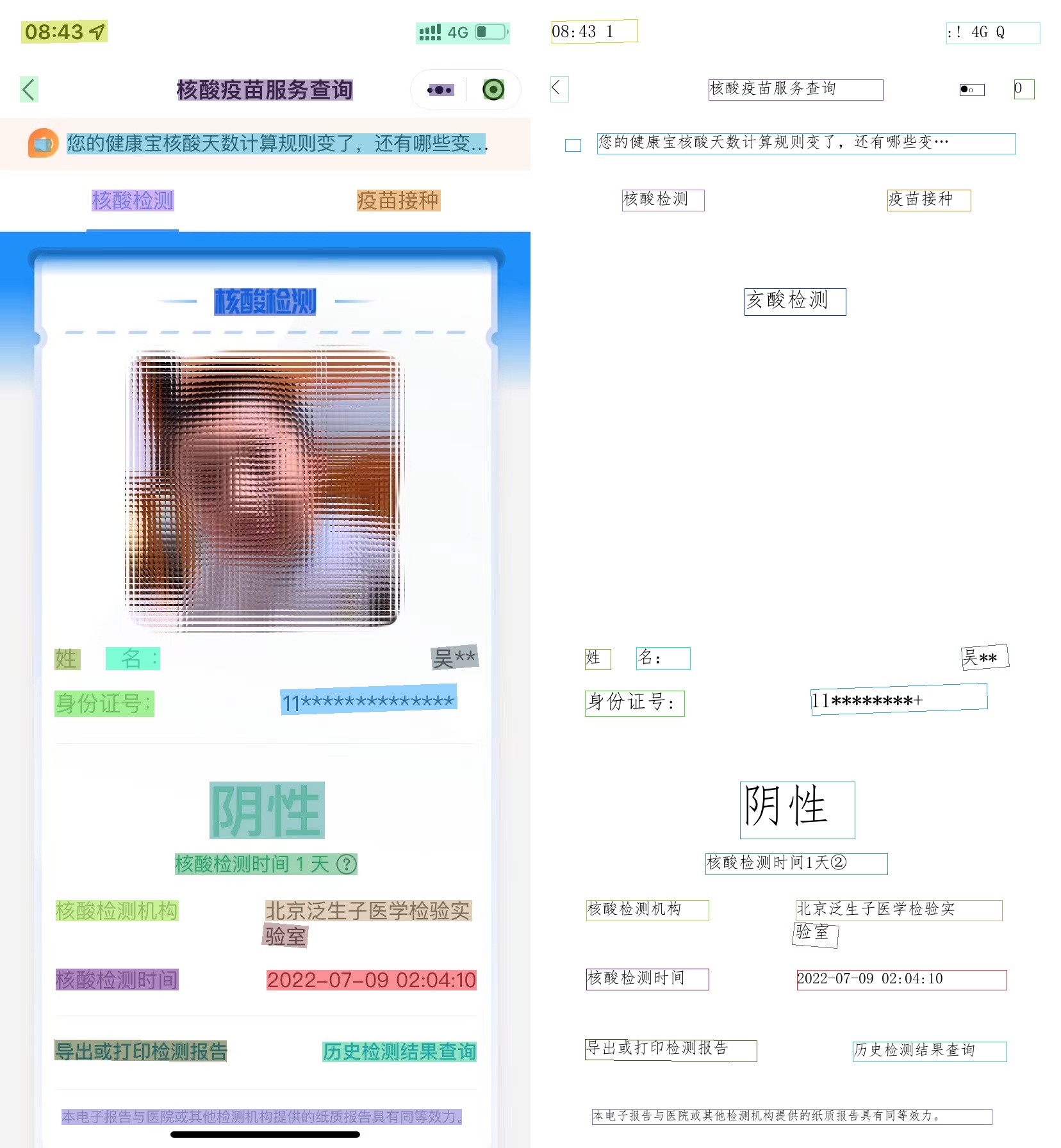
* **Recognition of Vaccine App Screenshot**
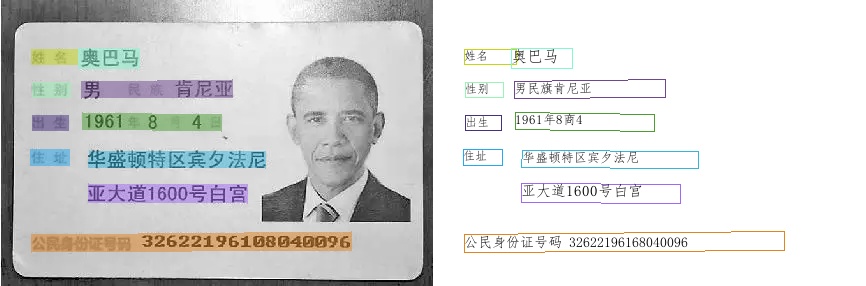
* **Recognition of ID Card**
* **Recognition of Restaurant Ticket**
## Install
Well, one line of command is enough if it goes well.
```bash
pip install cnocr
```
If the installation is slow, you can specify a domestic installation source, such as using the Douban source:
```bash
pip install cnocr -i https://pypi.doubanio.com/simple
```
> **Note**
>
> Please use **Python3** (3.6 and later should work), I haven't tested if it's okay under Python2.
More instructions can be found in the [installation documentation](https://cnocr.readthedocs.io/zh/latest/install/) (in Chinese).
> **Warning**
>
> If you have never installed `PyTorch`, `OpenCV` python packages on your computer, you may encounter problems with the first installation, but they are usually common problems that can be solved by Baidu/Google.
## Pre-trained Models
### Pre-trained Detection Models
| `det_model_name` | PyTorch Version | ONNX Version | Model original source | Model File Size | Supported Language | Whether to support vertical text detection |
| ------------------------------------------------------------ | ------------ | --------- | ------------ | ------------ | ------------------------------ | -------------------- |
| **en_PP-OCRv3_det** | X | √ | ppocr | 2.3 M | **English**、Numbers | √ |
| db_shufflenet_v2 | √ | X | cnocr | 18 M | Simplified Chinese, Traditional Chinese, English, Numbers | √ |
| **db_shufflenet_v2_small** | √ | X | cnocr | 12 M | Simplified Chinese, Traditional Chinese, English, Numbers | √ |
| [db_shufflenet_v2_tiny](https://mp.weixin.qq.com/s/fHPNoGyo72EFApVhEgR6Nw) | √ | X | cnocr | 7.5 M | Simplified Chinese, Traditional Chinese, English, Numbers | √ |
| db_mobilenet_v3 | √ | X | cnocr | 16 M | Simplified Chinese, Traditional Chinese, English, Numbers | √ |
| db_mobilenet_v3_small | √ | X | cnocr | 7.9 M | Simplified Chinese, Traditional Chinese, English, Numbers | √ |
| db_resnet34 | √ | X | cnocr | 86 M | Simplified Chinese, Traditional Chinese, English, Numbers | √ |
| db_resnet18 | √ | X | cnocr | 47 M | Simplified Chinese, Traditional Chinese, English, Numbers | √ |
| ch_PP-OCRv3_det | X | √ | ppocr | 2.3 M | Simplified Chinese, Traditional Chinese, English, Numbers | √ |
| ch_PP-OCRv2_det | X | √ | ppocr | 2.2 M | Simplified Chinese, Traditional Chinese, English, Numbers | √ |
### Pre-trained Recognition Models
| `rec_model_name` | PyTorch Version | ONNX Version | Model original source | Model File Size | Supported Language | Whether to support vertical text recognition |
| ------------------------- | ------------ | --------- | ------------ | ------------ | ------------------------ | -------------------- |
| **en_PP-OCRv3** | X | √ | ppocr | 8.5 M | **English**、Numbers | √ |
| **en_number_mobile_v2.0** | X | √ | ppocr | 1.8 M | **English**、Numbers | √ |
| **chinese_cht_PP-OCRv3** | X | √ | ppocr | 11 M | **Traditional Chinese**, English, Numbers | X |
| densenet_lite_114-fc | √ | √ | cnocr | 4.9 M | Simplified Chinese, English, Numbers | X |
| densenet_lite_124-fc | √ | √ | cnocr | 5.1 M | Simplified Chinese, English, Numbers | X |
| densenet_lite_134-fc | √ | √ | cnocr | 5.4 M | Simplified Chinese, English, Numbers | X |
| **densenet_lite_136-fc** | √ | √ | cnocr | 5.9 M | Simplified Chinese, English, Numbers | X |
| densenet_lite_134-gru | √ | X | cnocr | 11 M | Simplified Chinese, English, Numbers | X |
| densenet_lite_136-gru | √ | X | cnocr | 12 M | Simplified Chinese, English, Numbers | X |
| ch_PP-OCRv3 | X | √ | ppocr | 10 M | Simplified Chinese, English, Numbers | √ |
| ch_ppocr_mobile_v2.0 | X | √ | ppocr | 4.2 M | Simplified Chinese, English, Numbers | √ |
## Future work
* [x] Support for images containing multiple lines of text (`Done`)
* [x] crnn model support for variable length prediction, improving flexibility (since `V1.0.0`)
* [x] Refine test cases (`Doing`)
* [x] Fix bugs (The code is still messy.) (`Doing`)
* [x] Support `space` recognition (since `V1.1.0`)
* [x] Try new models like DenseNet to further improve recognition accuracy (since `V1.1.0`)
* [x] Optimize the training set to remove unreasonable samples; based on this, retrain each model
* [x] Change from MXNet to PyTorch architecture (since `V2.0.0`)
* [x] Train more efficient models based on PyTorch
* [x] Support text recognition in column format (since `V2.1.2`)
* [x] Integration with [CnSTD](https://github.com/breezedeus/cnstd) (since `V2.2`)
* [ ] Support more application scenarios, such as formula recognition, table recognition, layout analysis, etc.
## A cup of coffee for the author
It is not easy to maintain and evolve the project, so if it is helpful to you, please consider [offering the author a cup of coffee 🥤](https://cnocr.readthedocs.io/zh/latest/buymeacoffee/).
---
Official code base: [https://github.com/breezedeus/cnocr](https://github.com/breezedeus/cnocr). Please cite it properly.