# candock
| English | [中文版](./README_CN.md) |
A time series signal analysis and classification framework.
It contain multiple network and provide data preprocessing, data augmentation, training, evaluation, testing and other functions.
Some output examples: [heatmap](./image/heatmap_eg.png) [running_loss](./image/running_loss_eg.png) [log.txt](./docs/log_eg.txt)
## Feature
### Data preprocessing
* Normliaze : 5_95 | maxmin | None
* Filter : fft | fir | iir | wavelet | None
### Data augmentation
Various data augmentation method.
[[Time Series Data Augmentation for Deep Learning: A Survey]](https://arxiv.org/pdf/2002.12478.pdf)
* Base : scale, warp, app, aaft, iaaft, filp, crop
* Noise : spike, step, slope, white, pink, blue, brown, violet
* Gan : dcgan
### Network
Various networks for evaluation.
>1d
>
>>lstm, cnn_1d, resnet18_1d, resnet34_1d, multi_scale_resnet_1d, micro_multi_scale_resnet_1d,autoencoder,mlp
>2d(stft spectrum)
>
>>mobilenet, resnet18, resnet50, resnet101, densenet121, densenet201, squeezenet, dfcnn, multi_scale_resnet,
### K-fold
Use k-fold to make the results more reliable.
```--k_fold```&```--fold_index```
* --k_fold
```python
# fold_num of k-fold. If 0 or 1, no k-fold and cut 80% to train and other to eval.
```
* --fold_index
```python
"""--fold_index
When --k_fold != 0 or 1:
Cut dataset into sub-set using index , and then run k-fold with sub-set
If input 'auto', it will shuffle dataset and then cut dataset equally
If input: [2,4,6,7]
when len(dataset) == 10
sub-set: dataset[0:2],dataset[2:4],dataset[4:6],dataset[6:7],dataset[7:]
-------
When --k_fold == 0 or 1:
If input 'auto', it will shuffle dataset and then cut 80% dataset to train and other to eval
If input: [5]
when len(dataset) == 10
train-set : dataset[0:5] eval-set : dataset[5:]
"""
```
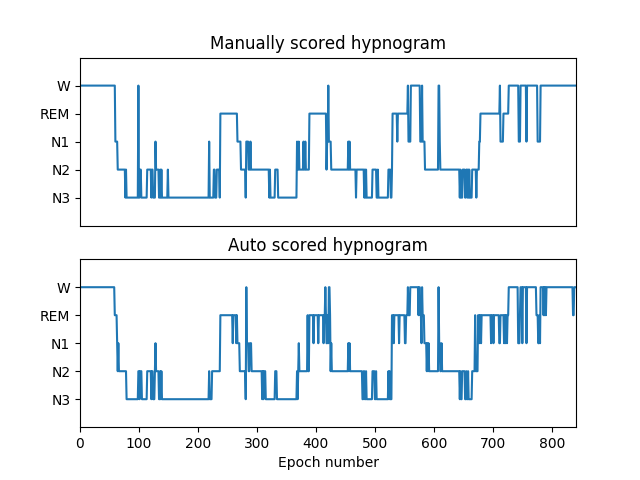
## A example: Use EEG to classify sleep stage
[sleep-edfx](https://github.com/HypoX64/candock/tree/f24cc44933f494d2235b3bf965a04cde5e6a1ae9)
Thank [@swalltail99](https://github.com/swalltail99)for the bug. In other to load sleep-edfx dataset,please install mne==0.18.0
```bash
pip install mne==0.18.0
```
## Getting Started
### Prerequisites
- Linux, Windows,mac
- CPU or NVIDIA GPU + CUDA CuDNN
- Python 3
- Pytroch 1.0+
### Dependencies
This code depends on torchvision, numpy, scipy, pywt, matplotlib, available via pip install.
For example:
```bash
pip install matplotlib
```
### Clone this repo:
```bash
git clone https://github.com/HypoX64/candock
cd candock
```
### Download dataset and pretrained-model
[[Google Drive]](https://drive.google.com/open?id=1NTtLmT02jqlc81lhtzQ7GlPK8epuHfU5) [[百度云,y4ks]](https://pan.baidu.com/s/1WKWZL91SekrSlhOoEC1bQA)
* This datasets consists of signals.npy(shape:18207, 1, 2000) and labels.npy(shape:18207) which can be loaded by "np.load()".
* samples:18207, channel:1, length of each sample:2000, class:50
* Top1 err: 2.09%
### Train
```bash
python3 train.py --label 50 --input_nc 1 --dataset_dir ./datasets/simple_test --save_dir ./checkpoints/simple_test --model_name micro_multi_scale_resnet_1d --gpu_id 0 --batchsize 64 --k_fold 5
# if you want to use cpu to train, please input --gpu_id -1
```
* More [options](./util/options.py).
### Test
```bash
python3 simple_test.py --label 50 --input_nc 1 --model_name micro_multi_scale_resnet_1d --gpu_id 0
# if you want to use cpu to test, please input --gpu_id -1
```
## Training with your own dataset
* step1: Generate signals.npy and labels.npy in the following format.
```python
#1.type:numpydata signals:np.float32 labels:np.int64
#2.shape signals:[num,ch,length] labels:[num]
#num:samples_num, ch :channel_num, length:length of each sample
#for example:
signals = np.zeros((10,1,10),dtype='np.float64')
labels = np.array([0,0,0,0,0,1,1,1,1,1]) #0->class0 1->class1
```
* step2: input ```--dataset_dir "your_dataset_dir"``` when running code.
### [ More training options](./util/options.py).