backup
Showing
Notes/Sublime-settings.md
已删除
100644 → 0
Notes/dl/CNN.md
0 → 100644
Notes/dl/DML.md
0 → 100644
Notes/dl/MMML.md
0 → 100644
Notes/dl/md_imgs/CNN/CNN.gif
0 → 100644
{kind=link}

984.3 KB
Notes/dl/md_imgs/CNN/DenseNet.jpg
0 → 100644
{kind=link}
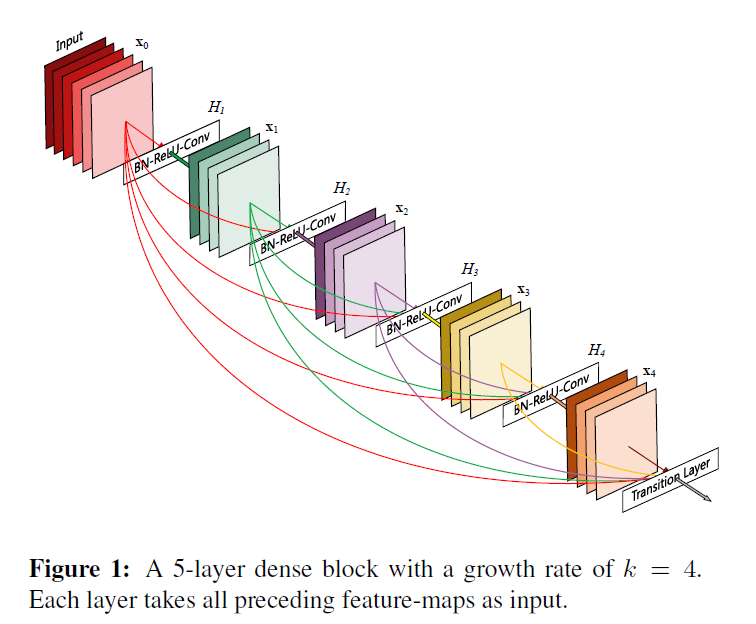
65.2 KB
{kind=link}

64.5 KB
{kind=link}
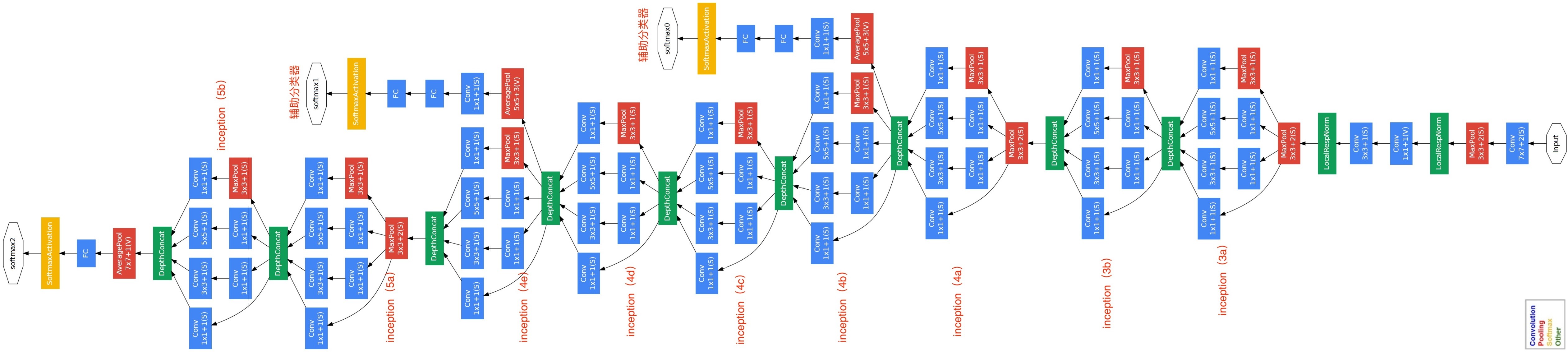
576.9 KB
Notes/dl/md_imgs/CNN/RF.jpg
0 → 100644
{kind=link}

24.7 KB
Notes/dl/md_imgs/CNN/geili.jpg
0 → 100644
{kind=link}

7.0 KB
Notes/dl/md_imgs/CNN/niubi.jpg
0 → 100644
{kind=link}

8.0 KB
Notes/dl/md_imgs/CNN/nobug.jpg
0 → 100644
{kind=link}

65.3 KB
Notes/dl/md_imgs/CNN/resnet.jpg
0 → 100644
{kind=link}
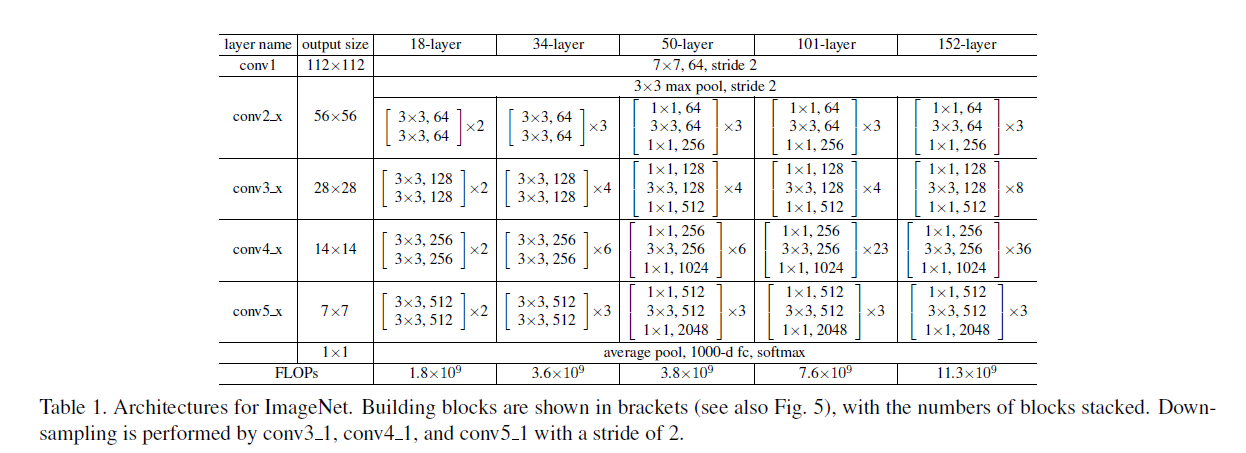
85.6 KB
Notes/dl/md_imgs/CNN/resnet_1.jpg
0 → 100644
{kind=link}

123.0 KB
{kind=link}
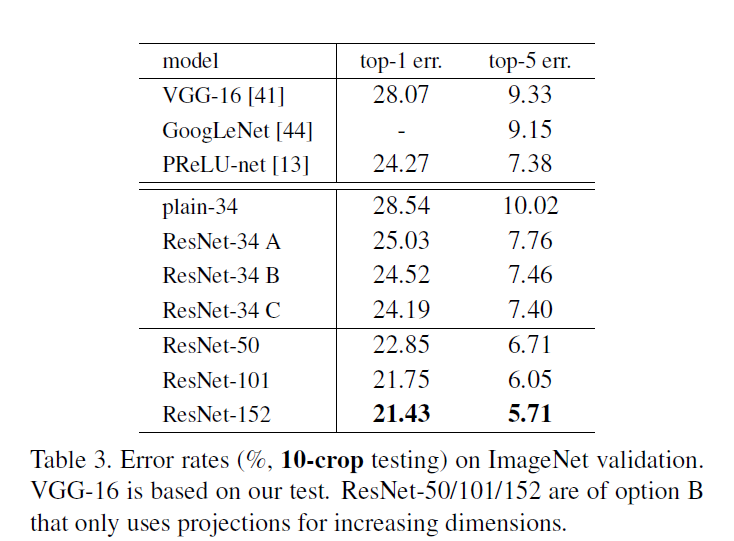
66.8 KB
Notes/dl/md_imgs/CNN/shortcut.jpg
0 → 100644
{kind=link}
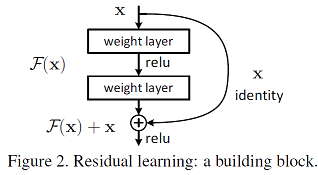
18.5 KB
Notes/dl/md_imgs/CNN/whatfack.jpg
0 → 100644
{kind=link}

5.4 KB
Notes/dl/md_imgs/CNN/退化.jpg
0 → 100644
{kind=link}

103.1 KB
{kind=link}

33.7 KB
{kind=link}
27.3 KB
Notes/dl/md_imgs/DML/ImageNet.jpg
0 → 100644
{kind=link}
264.7 KB
{kind=link}

21.8 KB
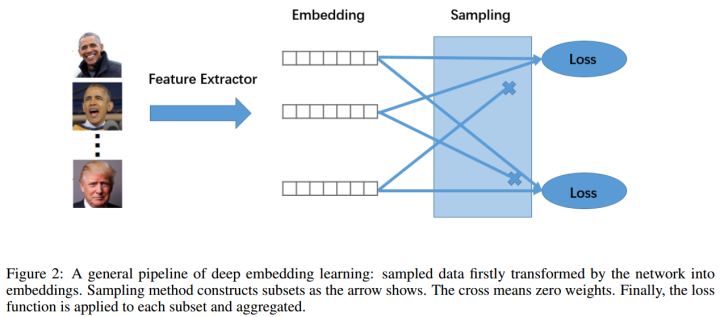
Notes/dl/md_imgs/DML/dml_eg.jpg
0 → 100644
{kind=link}
28.4 KB
Notes/dl/md_imgs/DML/dml_eg_1.jpg
0 → 100644
{kind=link}
41.4 KB
Notes/dl/md_imgs/DML/fecere.jpg
0 → 100644
{kind=link}
40.9 KB
Notes/dl/md_imgs/DML/knn.png
0 → 100644
{kind=link}
105.3 KB
Notes/dl/md_imgs/DML/mnist.png
0 → 100644
{kind=link}

6.6 KB
{kind=link}
78.3 KB
{kind=link}

167.5 KB
{kind=link}
20.5 KB
{kind=link}

107.4 KB
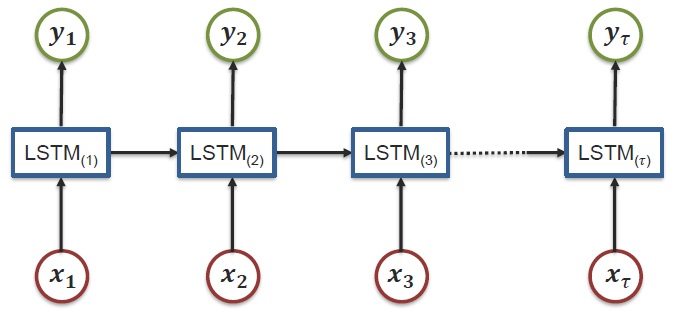
Notes/dl/md_imgs/MMML/LSTM_1.jpg
0 → 100644
{kind=link}
30.3 KB
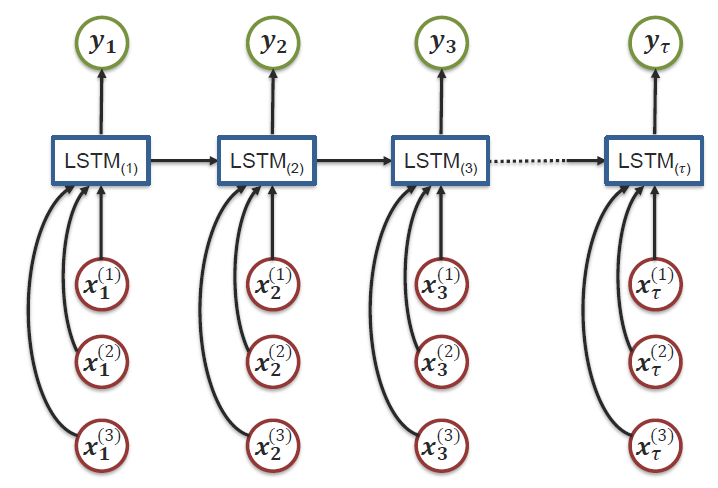
Notes/dl/md_imgs/MMML/LSTM_2.jpg
0 → 100644
{kind=link}
74.7 KB
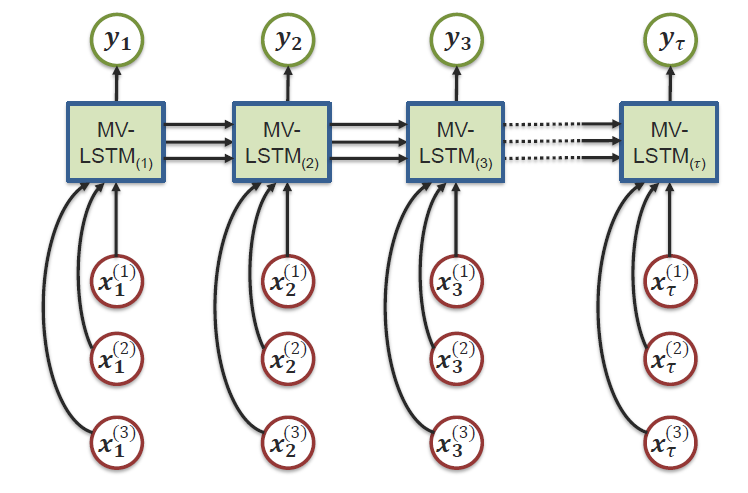
Notes/dl/md_imgs/MMML/LSTM_3.jpg
0 → 100644
{kind=link}
80.9 KB
Notes/dl/md_imgs/MMML/LSTM_4.jpg
0 → 100644
{kind=link}
52.8 KB
{kind=link}
23.2 KB
{kind=link}
26.6 KB
{kind=link}
33.1 KB
{kind=link}
48.7 KB
System/monitor_linux.py
已删除
100644 → 0