New version V0.2.0 #4 #6
Showing
docs/exe_help.md
0 → 100644
docs/exe_help_CN.md
0 → 100644
docs/options_introduction.md
0 → 100644
docs/options_introduction_CN.md
0 → 100644
{kind=link}
{kind=link}
| W: | H:

| W: | H:
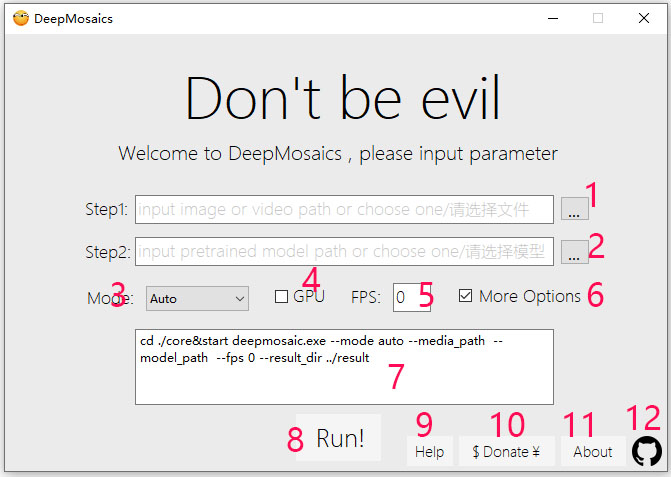
imgs/GUI_Instructions.jpg
0 → 100644
{kind=link}
83.6 KB
imgs/example/SZU.jpg
0 → 100644
{kind=link}

73.6 KB
{kind=link}

64.3 KB
imgs/example/SZU_vangogh.jpg
0 → 100644
{kind=link}

80.5 KB
imgs/example/a_dcp.png
0 → 100644
{kind=link}

117.6 KB
imgs/example/b_dcp.png
0 → 100644
{kind=link}

135.2 KB
imgs/example/face_a_clean.jpg
0 → 100644
{kind=link}

26.1 KB
imgs/example/face_a_mosaic.jpg
0 → 100644
{kind=link}

26.6 KB
imgs/example/face_b_clean.jpg
0 → 100644
{kind=link}

32.5 KB
imgs/example/face_b_mosaic.jpg
0 → 100644
{kind=link}

34.6 KB
imgs/example/lena.jpg
0 → 100644
{kind=link}

28.8 KB
imgs/example/lena_add.jpg
0 → 100644
{kind=link}

27.0 KB
imgs/example/lena_clean.jpg
0 → 100644
{kind=link}

25.4 KB
imgs/example/youknow.png
0 → 100644
{kind=link}

86.5 KB
imgs/example/youknow_add.png
0 → 100644
{kind=link}
76.9 KB
imgs/example/youknow_clean.png
0 → 100644
{kind=link}

89.1 KB
models/videoHD_model.py
0 → 100644