Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
梦想橡皮擦
爬虫100例(复盘中)
提交
09c56f3a
爬
爬虫100例(复盘中)
项目概览
梦想橡皮擦
/
爬虫100例(复盘中)
通知
309
Star
13
Fork
9
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
爬
爬虫100例(复盘中)
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
09c56f3a
编写于
9月 15, 2021
作者:
梦想橡皮擦
💬
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
斗鱼爬虫
上级
18efcb3b
变更
1
显示空白变更内容
内联
并排
Showing
1 changed file
with
174 addition
and
0 deletion
+174
-0
无法过审的文章备份/Python爬虫入门教程 96-100 帮粉丝写Python爬虫之【寻找最美女主播】.md
无法过审的文章备份/Python爬虫入门教程 96-100 帮粉丝写Python爬虫之【寻找最美女主播】.md
+174
-0
未找到文件。
无法过审的文章备份/Python爬虫入门教程 96-100 帮粉丝写Python爬虫之【寻找最美女主播】.md
0 → 100644
浏览文件 @
09c56f3a
> 给美女打分,好需求,这个需求听到就想把它快速的实现,对于这样的需求,梦想橡皮擦一直是来者不拒的。
> 该案例也因为版权问题,无法完整展示,博客内容迁移到 code 上
## 写在前面
为了测试需要,我们拿斗鱼的颜值频道做测试,这里面的主播比较漂亮。具体页面如下
[
斗鱼颜值频道
](
https://www.douyu.com/g_yz
)
当然对于颜值频道里面混入的帅哥们,肉眼忽略即可。
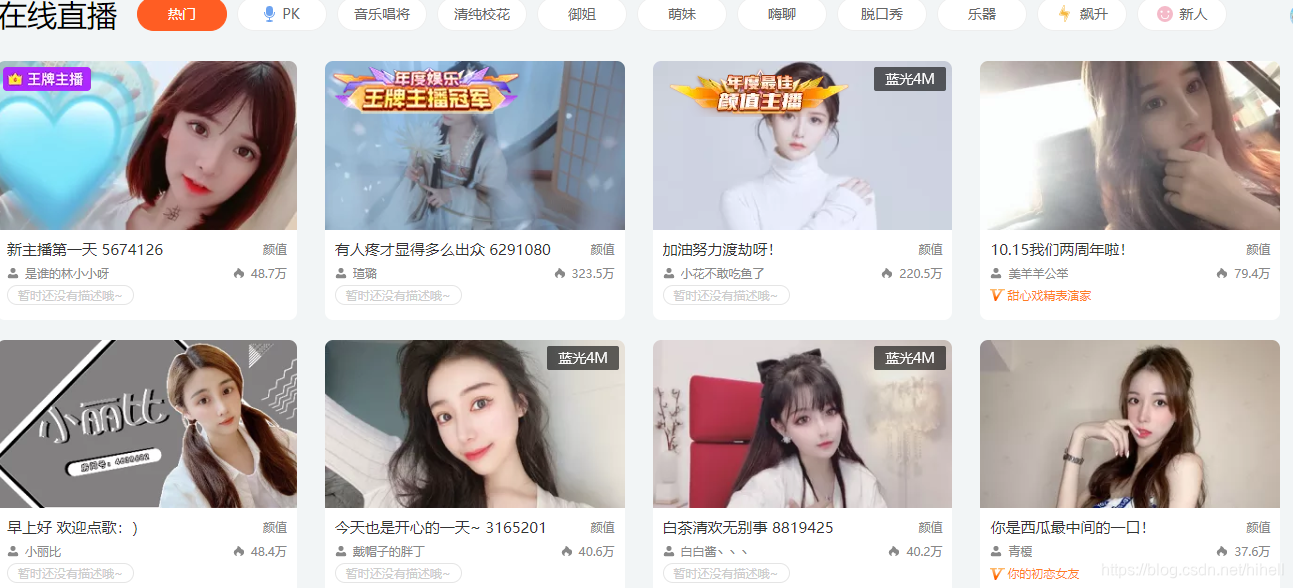
本案例实现基本思路:
1.
获取页面上所有主播的缩略图
2.
调用人脸打分API,为图片打分
3.
将得分最高的图片打开,欣赏,并且把直播间地址输出
## 编码时间
斗鱼的该页面是动态的,当主播在线的时候就会出现在列表中,所以该程序即用即走。
爬虫的重点是找到带爬取的页面接口,如果数据返回的接口中有我们想要的全部数据,并且格式为JSON格式,那剩下的工作就变得非常简单了,本案例恰好满足了该要求。
Python待爬取链接 :
[
斗鱼数据链接
](
https://www.douyu.com/gapi/rknc/directory/yzRec/1
)
由于页面总页码数是动态的,所以先从接口中获取到该页码,方便后续进行迭代爬取。下述代码我未做整理,核心思路是当爬取第一页的时候,获取一下总页码,然后循环所有的页面获取数据。
```
python
def
get_mm
(
page
):
# 页码大于1 不获取总页码直接爬取
if
page
>
1
:
res
=
requests
.
get
(
f
"https://www.douyu.com/gapi/rknc/directory/yzRec/
{
page
}
"
,
headers
=
headers
)
res_json
=
res
.
json
()
code
=
res_json
[
"code"
]
if
code
==
0
:
# 获取总数据量
rl
=
res_json
[
"data"
][
"rl"
]
save_imgs
(
rl
)
# 调用保存图片接口
else
:
print
(
"数据获取失败!"
)
else
:
res
=
requests
.
get
(
f
"https://www.douyu.com/gapi/rknc/directory/yzRec/
{
page
}
"
,
headers
=
headers
)
res_json
=
res
.
json
()
code
=
res_json
[
"code"
]
if
code
==
0
:
# 获取总数据量
pgcnt
=
int
(
res_json
[
"data"
][
"pgcnt"
])
rl
=
int
(
res_json
[
"data"
][
"rl"
])
save_imgs
(
rl
)
# 第一页数据获取
# 编码全部编写完毕,注意把该处打开
# for i in range(2, pgcnt+1):
# get_mm(i)
else
:
print
(
"数据获取失败!"
)
```
关于人脸打分检测,调用的是百度的API,具体网址如下:
[
https://console.bce.baidu.com/ai/?_=1602467530258&fromai=1#/ai/face/overview/index
](
https://console.bce.baidu.com/ai/?_=1602467530258&fromai=1#/ai/face/overview/index
)
使用百度账号登录之后,创建应用即可获取所需参数。
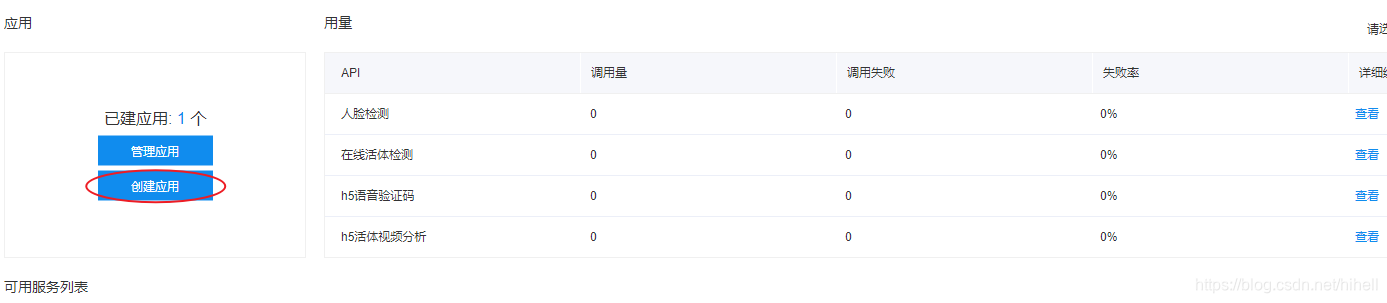
API的使用方法和下载。
下载地址:
[
http://ai.baidu.com/docs#/Face-Python-SDK/top
](
http://ai.baidu.com/docs#/Face-Python-SDK/top
)
使用说明:
[
http://ai.baidu.com/ai-doc/FACE/ek37c1qiz
](
http://ai.baidu.com/ai-doc/FACE/ek37c1qiz
)
保存图片代码如下,在保存的过程中需要对图片进行打分,当然你直接下载全部图片,在对本地图片打分也可
```
python
import
time
import
requests
from
fake_useragent
import
UserAgent
from
aip
import
AipFace
import
base64
import
json
user_agent
=
UserAgent
()
headers
=
{
"user-agent"
:
user_agent
.
random
,
"referer"
:
"https://www.douyu.com"
,
"x-requested-with"
:
"XMLHttpRequest"
,
"content-type"
:
"application/x-www-form-urlencoded; charset=UTF-8"
}
def
beauty
(
base64_data
):
""" 你的 APPID AK SK """
APP_ID
=
'你的 App ID'
API_KEY
=
'你的 Api Key'
SECRET_KEY
=
'你的 Secret Key'
client
=
AipFace
(
APP_ID
,
API_KEY
,
SECRET_KEY
)
client
=
AipFace
(
APP_ID
,
API_KEY
,
SECRET_KEY
)
# image = "https://rpic.douyucdn.cn/live-cover/appCovers/2020/08/27/6796447_20200827022844_big.jpg/dy2"
image
=
base64_data
imageType
=
"BASE64"
""" 调用人脸检测 """
client
.
detect
(
image
,
imageType
)
""" 如果有可选参数 """
options
=
{}
options
[
"face_field"
]
=
"age,beauty,gender"
options
[
"max_face_num"
]
=
2
options
[
"face_type"
]
=
"LIVE"
options
[
"liveness_control"
]
=
"LOW"
""" 带参数调用人脸检测 """
a
=
client
.
detect
(
image
,
imageType
,
options
)
return
a
def
save_imgs
(
rl
):
for
user
in
rl
:
# https://www.douyu.com/9190725
rid
=
user
[
"rid"
]
face
=
user
[
"rs1"
]
try
:
print
(
"访问接口等待中"
)
time
.
sleep
(
2
)
res
=
requests
.
get
(
face
,
headers
=
headers
)
img
=
res
.
content
base64_data
=
str
(
base64
.
b64encode
(
img
),
encoding
=
'utf-8'
)
bea
=
beauty
(
base64_data
)
if
bea
[
"error_code"
]
==
222202
:
print
(
"非人类!"
)
with
open
(
f
"./faces/非人:
{
rid
}
.jpg"
,
"wb"
)
as
file
:
file
.
write
(
img
)
else
:
# 获取得分
print
(
bea
)
beauty_count
=
bea
[
"result"
][
"face_list"
][
0
][
"beauty"
]
with
open
(
f
"./faces/
{
beauty_count
}
:
{
rid
}
.jpg"
,
"wb"
)
as
file
:
file
.
write
(
img
)
except
Exception
as
e
:
print
(
e
)
```
上述代码中有个接口访问限制时间,该时间是百度API调用的限制时间,建议设置为1~2秒。
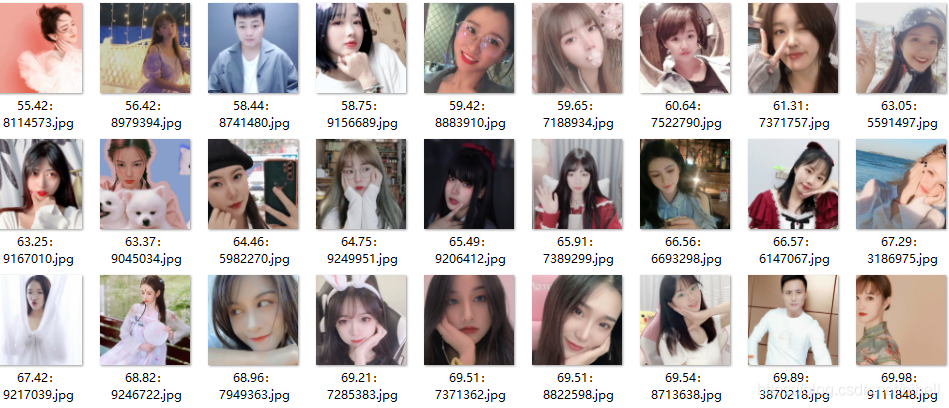
代码编写完毕 ,运行效果如图,在代码中加入了一些判断,打分之后会写入到文件名中,这样我们就能发现最高分了。
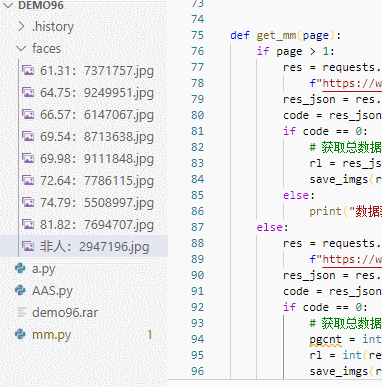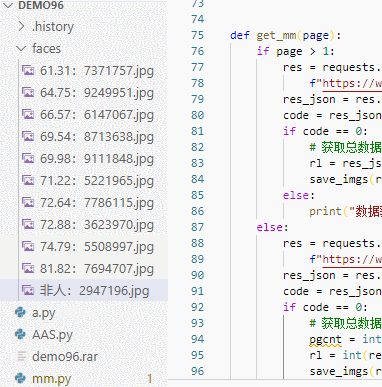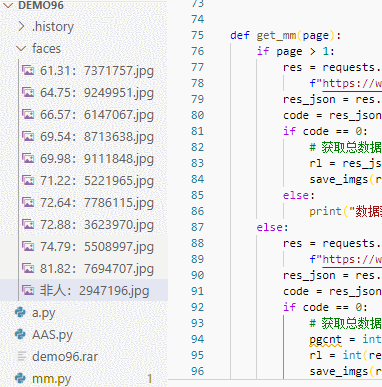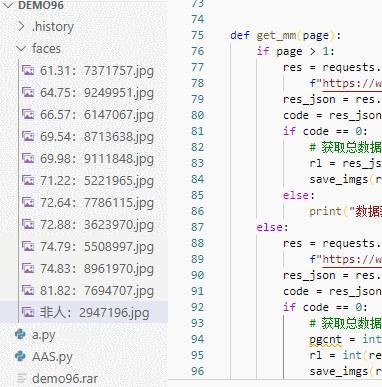
最终爬取完毕,会出现一大堆主播头像,以后头像使用有着落了。这里面混入了一些
**男人**
最神奇的是接口判断下面是非人类....这就比较神奇了。代码难度不大,有需要的加我V:
**moshanba**
即可。

## 广宣时间
> 如果你想跟博主建立亲密关系,可以关注同名公众号 “`梦想橡皮擦`”,近距离接触一个逗趣的互联网高级网虫。
> 博主 ID:`梦想橡皮擦`,希望大家点赞、评论、收藏。

爬虫百例教程导航链接 :
[
https://blog.csdn.net/hihell/article/details/86106916
](
https://blog.csdn.net/hihell/article/details/86106916
)
<font
size=
1
color=
white
>
以下内容无用,为本篇博客被搜索引擎抓取使用
(
* ̄︶ ̄)(*
 ̄︶ ̄)(
* ̄︶ ̄)(*
 ̄︶ ̄)(
* ̄︶ ̄)(*
 ̄︶ ̄)(
* ̄︶ ̄)(*
 ̄︶ ̄)
python是干什么的 零基础学python要多久 python为什么叫爬虫
python爬虫菜鸟教程 python爬虫万能代码 python爬虫怎么挣钱
python基础教程 网络爬虫python python爬虫经典例子
(
* ̄︶ ̄)(*
 ̄︶ ̄)(
* ̄︶ ̄)(*
 ̄︶ ̄)(
* ̄︶ ̄)(*
 ̄︶ ̄)(
* ̄︶ ̄)(*
 ̄︶ ̄)
以下内容无用,为本篇博客被搜索引擎抓取使用
</font>
\ No newline at end of file
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
