Update documents
Showing
docs/developer/logging.md
已删除
100644 → 0
docs/development/contributing.md
0 → 100644
docs/docker/usage.md
已删除
100644 → 0
docs/faq.md
0 → 100644
docs/getting_started/docker.rst
0 → 100644
docs/getting_started/op_lists.rst
0 → 100644
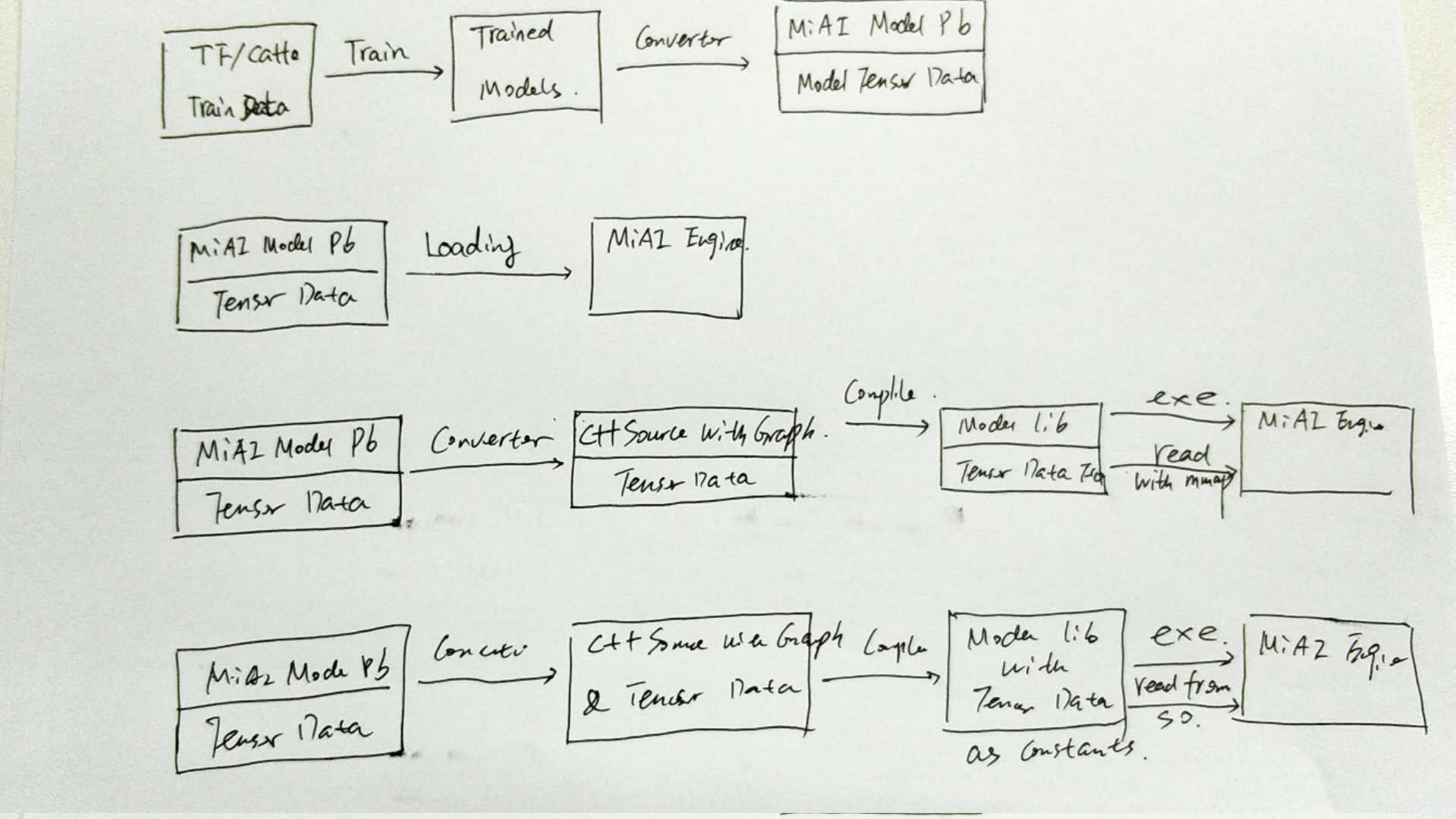
docs/getting_started/workflow.jpg
0 → 100644
{kind=link}
116.3 KB
docs/user/introduction.md
已删除
100644 → 0