Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
晶之木
advanced-java
提交
ffeb3460
A
advanced-java
项目概览
晶之木
/
advanced-java
与 Fork 源项目一致
从无法访问的项目Fork
通知
3
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
A
advanced-java
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
ffeb3460
编写于
6月 27, 2020
作者:
A
AmyliaY
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
补充 分布式事务解决方案Saga
上级
8f5ace25
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
47 addition
and
16 deletion
+47
-16
docs/distributed-system/distributed-transaction.md
docs/distributed-system/distributed-transaction.md
+47
-16
docs/distributed-system/images/distributed-transaction-saga.png
...istributed-system/images/distributed-transaction-saga.png
+0
-0
未找到文件。
docs/distributed-system/distributed-transaction.md
浏览文件 @
ffeb3460
...
...
@@ -2,20 +2,24 @@
分布式事务了解吗?你们是如何解决分布式事务问题的?
## 面试官心理分析
只要聊到你做了分布式系统,必问分布式事务,你对分布式事务一无所知的话,确实会很坑,你起码得知道有哪些方案,一般怎么来做,每个方案的优缺点是什么。
现在面试,分布式系统成了标配,而分布式系统带来的
**分布式事务**
也成了标配了。因为你做系统肯定要用事务吧,如果是分布式系统,肯定要用分布式事务吧。先不说你搞过没有,起码你得明白有哪几种方案,每种方案可能有啥坑?比如 TCC 方案的网络问题、XA 方案的一致性问题。
## 面试题剖析
分布式事务的实现主要有以下 5 种方案:
-
XA 方案
-
TCC 方案
-
本地消息表
-
可靠消息最终一致性方案
-
最大努力通知方案
分布式事务的实现主要有以下 6 种方案:
*
XA 方案
*
TCC 方案
*
SAGA 方案
*
本地消息表
*
可靠消息最终一致性方案
*
最大努力通知方案
### 两阶段提交方案/XA方案
所谓的 XA 方案,即:两阶段提交,有一个
**事务管理器**
的概念,负责协调多个数据库(资源管理器)的事务,事务管理器先问问各个数据库你准备好了吗?如果每个数据库都回复 ok,那么就正式提交事务,在各个数据库上执行操作;如果任何其中一个数据库回答不 ok,那么就回滚事务。
这种分布式事务方案,比较适合单块应用里,跨多个库的分布式事务,而且因为严重依赖于数据库层面来搞定复杂的事务,效率很低,绝对不适合高并发的场景。如果要玩儿,那么基于
`Spring + JTA`
就可以搞定,自己随便搜个 demo 看看就知道了。
...
...
@@ -26,14 +30,15 @@
如果你要操作别人的服务的库,你必须是通过
**调用别的服务的接口**
来实现,绝对不允许交叉访问别人的数据库。


### TCC 方案
TCC 的全称是:
`Try`
、
`Confirm`
、
`Cancel`
。
-
Try 阶段:这个阶段说的是对各个服务的资源做检测以及对资源进行
**锁定或者预留**
。
-
Confirm 阶段:这个阶段说的是在各个服务中
**执行实际的操作**
。
-
Cancel 阶段:如果任何一个服务的业务方法执行出错,那么这里就需要
**进行补偿**
,就是执行已经执行成功的业务逻辑的回滚操作。(把那些执行成功的回滚)
TCC 的全称是:
`Try`
、
`Confirm`
、
`Cancel`
。
*
Try 阶段:这个阶段说的是对各个服务的资源做检测以及对资源进行
**锁定或者预留**
。
*
Confirm 阶段:这个阶段说的是在各个服务中
**执行实际的操作**
。
*
Cancel 阶段:如果任何一个服务的业务方法执行出错,那么这里就需要
**进行补偿**
,就是执行已经执行成功的业务逻辑的回滚操作。(把那些执行成功的回滚)
这种方案说实话几乎很少人使用,我们用的也比较少,但是也有使用的场景。因为这个
**事务回滚**
实际上是
**严重依赖于你自己写代码来回滚和补偿**
了,会造成补偿代码巨大,非常之恶心。
...
...
@@ -43,9 +48,32 @@ TCC 的全称是:`Try`、`Confirm`、`Cancel`。
但是说实话,一般尽量别这么搞,自己手写回滚逻辑,或者是补偿逻辑,实在太恶心了,那个业务代码是很难维护的。


### Saga方案
金融核心等业务 可能会选择TCC方案,以追求强一致性和更高的并发量,而对于更多的金融核心以上的业务系统 往往会选择补偿事务,补偿事务处理在30多年前就提出了 Saga 理论,随着微服务的发展,近些年才逐步受到大家的关注。目前业界比较公认的是采用 Saga 作为长事务的解决方案。
#### 基本原理
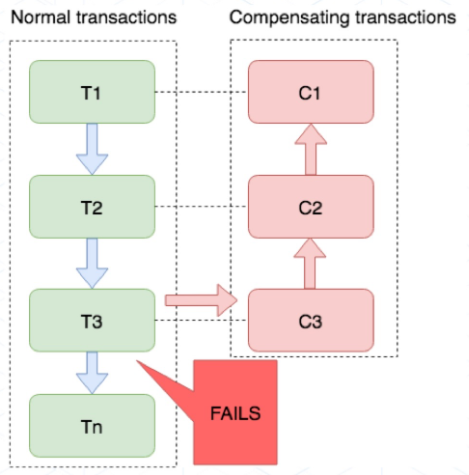
业务流程中每个参与者都提交本地事务,若某一个参与者失败,则补偿前面已经成功的参与者。下图左侧是正常的事务流程,当执行到 T3 时发生了错误,则开始执行右边的事务补偿流程,反向执行T3、T2、T1 的补偿服务C3、C2、C1,将T3、T2、T1 已经修改的数据补偿掉。

#### 使用场景
对于一致性要求高、短流程、并发高 的场景,如:金融核心系统,会优先考虑 TCC方案。而在另外一些场景下,我们并不需要这么强的一致性,只需要保证最终一致性即可。
比如 很多金融核心以上的业务(渠道层、产品层、系统集成层),这些系统的特点是最终一致即可、流程多、流程长、还可能要调用其它公司的服务。这种情况如果选择TCC方案开发的话,一来成本高,二来无法要求其它公司的服务也遵循 TCC 模式。同时流程长,事务边界太长,加锁时间长,也会影响并发性能。
所以 Saga 模式的适用场景是:
-
业务流程长、业务流程多;
-
参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口。
#### 优势
-
一阶段提交本地事务,无锁,高性能;
-
参与者可异步执行,高吞吐;
-
补偿服务易于实现,因为一个更新操作的反向操作是比较容易理解的。
#### 缺点
-
不保证事务的隔离性。
### 本地消息表
本地消息表其实是国外的 ebay 搞出来的这么一套思想。
这个大概意思是这样的:
...
...
@@ -59,9 +87,10 @@ TCC 的全称是:`Try`、`Confirm`、`Cancel`。
这个方案说实话最大的问题就在于
**严重依赖于数据库的消息表来管理事务**
啥的,如果是高并发场景咋办呢?咋扩展呢?所以一般确实很少用。


### 可靠消息最终一致性方案
这个的意思,就是干脆不要用本地的消息表了,直接基于 MQ 来实现事务。比如阿里的 RocketMQ 就支持消息事务。
大概的意思就是:
...
...
@@ -71,11 +100,12 @@ TCC 的全称是:`Try`、`Confirm`、`Cancel`。
3.
如果发送了确认消息,那么此时 B 系统会接收到确认消息,然后执行本地的事务;
4.
mq 会自动
**定时轮询**
所有 prepared 消息回调你的接口,问你,这个消息是不是本地事务处理失败了,所有没发送确认的消息,是继续重试还是回滚?一般来说这里你就可以查下数据库看之前本地事务是否执行,如果回滚了,那么这里也回滚吧。这个就是避免可能本地事务执行成功了,而确认消息却发送失败了。
5.
这个方案里,要是系统 B 的事务失败了咋办?重试咯,自动不断重试直到成功,如果实在是不行,要么就是针对重要的资金类业务进行回滚,比如 B 系统本地回滚后,想办法通知系统 A 也回滚;或者是发送报警由人工来手工回滚和补偿。
6.
这个还是比较合适的,目前国内互联网公司大都是这么玩儿的,要不你
举
用 RocketMQ 支持的,要不你就自己基于类似 ActiveMQ?RabbitMQ?自己封装一套类似的逻辑出来,总之思路就是这样子的。
6.
这个还是比较合适的,目前国内互联网公司大都是这么玩儿的,要不你
就
用 RocketMQ 支持的,要不你就自己基于类似 ActiveMQ?RabbitMQ?自己封装一套类似的逻辑出来,总之思路就是这样子的。


### 最大努力通知方案
这个方案的大致意思就是:
1.
系统 A 本地事务执行完之后,发送个消息到 MQ;
...
...
@@ -83,10 +113,11 @@ TCC 的全称是:`Try`、`Confirm`、`Cancel`。
3.
要是系统 B 执行成功就 ok 了;要是系统 B 执行失败了,那么最大努力通知服务就定时尝试重新调用系统 B,反复 N 次,最后还是不行就放弃。
### 你们公司是如何处理分布式事务的?
如果你真的被问到,可以这么说,我们某某特别严格的场景,用的是 TCC 来保证强一致性;然后其他的一些场景基于阿里的 RocketMQ 来实现分布式事务。
你找一个严格资金要求绝对不能错的场景,你可以说你是用的 TCC 方案;如果是一般的分布式事务场景,订单插入之后要调用库存服务更新库存,库存数据没有资金那么的敏感,可以用可靠消息最终一致性方案。
友情提示一下,RocketMQ 3.2.6 之前的版本,是可以按照上面的思路来的,但是之后接口做了一些改变,我这里不再赘述了。
当然如果你愿意,你可以参考可靠消息最终一致性方案来自己实现一套分布式事务,比如基于 RocketMQ 来玩儿。
\ No newline at end of file
当然如果你愿意,你可以参考可靠消息最终一致性方案来自己实现一套分布式事务,比如基于 RocketMQ 来玩儿。
docs/distributed-system/images/distributed-transaction-saga.png
0 → 100644
浏览文件 @
ffeb3460
81.3 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}