# uni-ai
ai大潮来袭,如何把ai能力引入自己的应用中?几乎是每个开发者都在关心的问题。
`uni-ai`,定位就是开发者使用ai能力的最佳开发库,更丰富、更易用、更高效。
## 特点
1. 聚合
`uni-ai`,聚合了国内外各种流行的ai能力。包括
- 大语言模型LLM:chatGPT、GPT-4、百度文心一言、minimax等
- 图形能力:stable diffusion、文心一格、midjourney等(暂未发布)
`uni-ai`支持配置自己在AI厂商处申请的API Key和代理,也支持免配直接使用。
2. prompt辅助
自然语言谁都会说,但想提出一个好prompt来指挥ai满足自己的需求并不简单。所以出现了prompt工程师的说法。
`uni-ai`整合了大量prompt模板,并将提供 `format prompt`和`prompt插件市场`。
举个例子,如果你需要写一个产品营销文案,你可以使用自然语言,如`请帮我编写一份产品营销文案,产品名称叫uni-app,它的特点是开发一次全端覆盖。`
但实际上,自然语言这么写是繁琐且容易纰漏的。format prompt是弹出一个表单,你在表单里填写:
```
产品名称:uni-app
目标用户:程序员
产品归类:前端应用开发框架
产品用途:使用该框架开发应用,一次编码可覆盖到Android app、iOS app、web、以及各家小程序,如微信、百度、支付宝、抖音、qq、京东等小程序和快应用。
卖点:高效、易学、生态完善
文风:技术风格
字数:500字
```
`uni-ai`,为你提供更好的prompt。
3. 私有数据训练
目前的大模型,没有最新的、以及企业私有的数据。各家也未开放fine-turning微调模型。
如何把私有数据灌入ai中,几乎是每个企业都关心的事情。
`uni-ai`将提供一整套方案解决这个问题,只需把私有数据按指定格式提交到你的uniCloud服务空间,就可以自动把这些最新的、私有的知识加入到ai的回答中。
4. 现成开源项目
ai能力非常常见的应用场景,有智能客服和自动生成文稿。
`uni-ai`把这些常见场景对应的应用均已做好,并且开源。开发者可以直接拿走使用。
- uni-cms,内置了智能内容生成。[详见](https://uniapp.dcloud.net.cn/uniCloud/uni-cms.html)
- uni-ai-chat,独立的ai聊天模板。[详见](https://uniapp.dcloud.net.cn/uniCloud/uni-ai-chat.html)
- uni-im,内置了智能客服。[详见](https://uniapp.dcloud.net.cn/uniCloud/uni-im.html)
这些完善的项目,包括了前端页面(全端可用)、云对象、云数据库等全套代码,开箱即用。
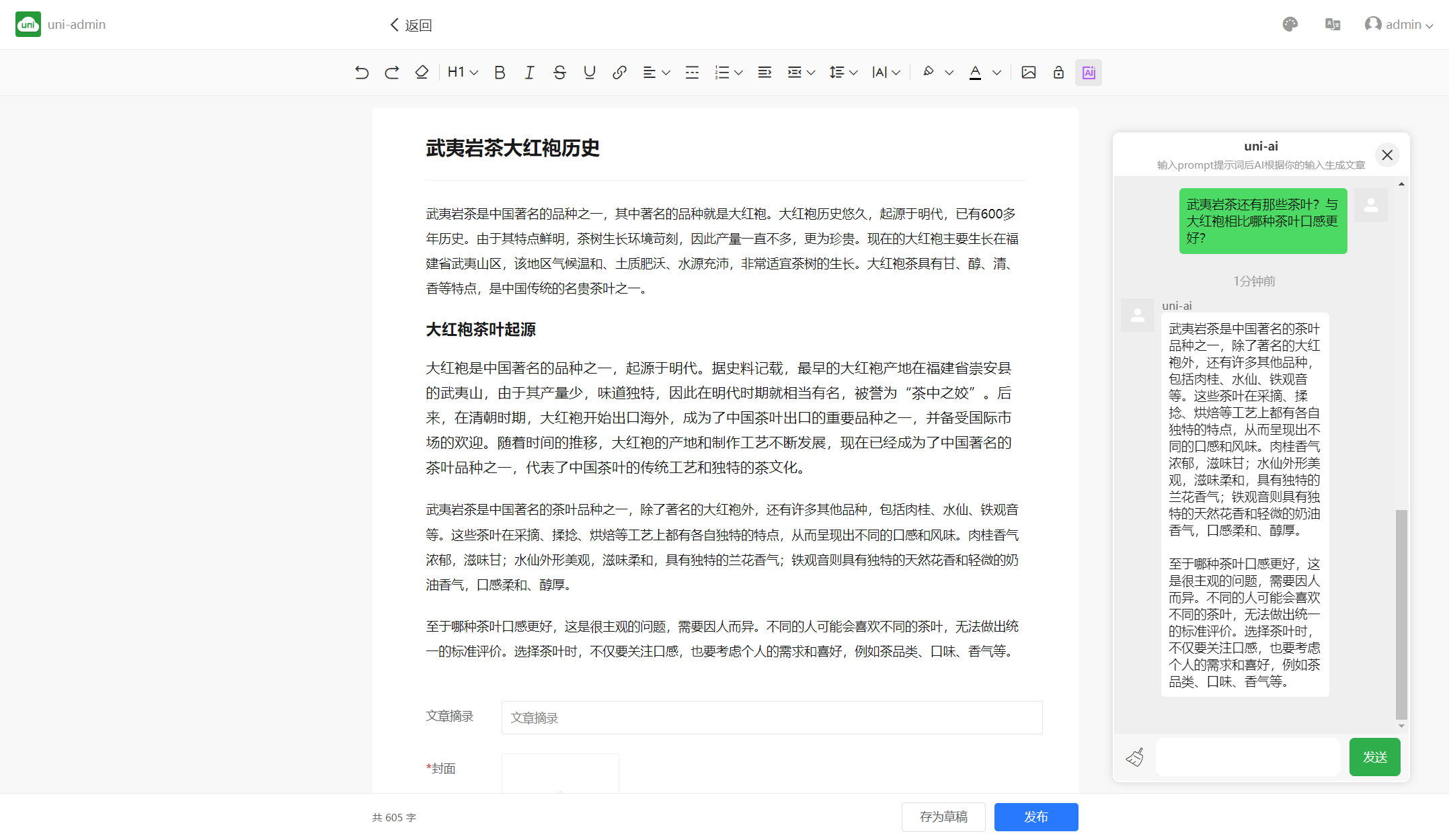
在线体验:[https://hellouniadmin.dcloud.net.cn/](https://hellouniadmin.dcloud.net.cn/)。
这是一个集成了uni-cms的[uni-admin](admin.md)系统。登录后,左侧内容管理中新建一篇文章,toolbar右上角有ai按钮。注意测试系统的数据会定时清除。
注意这个系统不等于uni-ai,uni-ai是底层的api。uni-cms是集成了uni-ai的开源应用。
5. 费用优化
ai能力调用,是需要按token数量付费的。token太少会回答不准,太多则费用太高。在反复对话的场景下尤其涉及之前对话记忆多久的问题。`uni-im`等集成了uni-ai的对话应用,已经内置了平衡策略。开发者无需再编写复杂的代码。
6. 后置命令处理
ai都是回答文字内容,但实际场景中经常需要自动化执行一些命令。
`uni-ai`将提供action机制,让ai变的更加强大。
例如,请ai帮忙写一段代码,其中涉及了未引用的三方插件,那么action可以通知HBuilder弹出下载这个插件的界面,不但代码生成了,其中的插件也自动下载了。
使用简单的js api,快速开始你的ai之旅吧!
```js
// 因涉及费用,ai能力调用均需在服务器端进行,也就是uniCloud云函数或云对象中
let llm = uniCloud.ai.getLLMManager()
llm.chatCompletion({
messages: [{
role: 'user',
content: '你好,ai'
}]
})
```
## API@api
> 新增于HBuilderX正式版 3.7.10+, alpha版 3.7.13+
:::warning 注意
使用低版本HBuilder,只能上传到uniCloud云端联调。因为低版本的uniCloud本地运行插件不支持`uni-ai`。云端和本地扩展库差异参考:[云端和本地扩展库差异](rundebug.md#diff-extension)
:::
ai作为一种云能力,相关调用被整合到uniCloud中。
如您的服务器业务不在uniCloud上,可以把[云函数URL化](http.md),把`uni-ai`当做http接口调用。
在实际应用中,大多数场景是直接使用`uni-im`和`uni-cms`的ai功能,这些开源项目已经把完整逻辑都实现,无需自己研究API。
ai能力由`uni-cloud-ai`扩展库提供,在云函数或云对象中,对右键配置`uni-cloud-ai`扩展库。如何使用扩展库请参考:[使用扩展库](cf-functions.md#extension)
如果HBuilderX版本过低,在云函数的扩展库界面里找不到`uni-ai`。
注意`uni-ai`是云函数扩展库,其api是`uniCloud.ai`,不是需要下载的三方插件。而`uni-cms`、`uni-im`等开源项目,是需要在插件市场下载的。
### 获取LLM实例@get-llm-manager
LLM,全称为Large Language Models,指大语言模型。
LLM的主要特点为输入一段前文,可以推导预测下文。
LLM不等于ai的全部,除了LLM,还有ai生成图片等其他模型。
用法:`uniCloud.ai.getLLMManager(Object GetLLMManagerOptions);`
注意需在相关云函数或云对象中加载`uni-cloud-ai`[使用扩展库](cf-functions.md#extension),否则会报找不到ai对象。
**参数说明GetLLMManagerOptions**
|参数 |类型 |必填 |默认值 |说明 |
|--- |--- |--- |--- |--- |
|provider |string |否 |- |llm服务商,目前支持`openai`、`baidu`、`minimax`。不指定时由uni-ai自动分配 |
|apiKey |string |否 |- |llm服务商的apiKey,如不填则使用uni-ai的key。如指定openai和baidu则必填 |
|accessToken|string |否 |- |llm服务商的accessToken。目前百度文心一言是必填,如何获取请参考:[百度AI鉴权认证机制](https://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjhhu) |
|proxy |string |否 |- |可有效连接openai服务器的、可被uniCloud云函数连接的代理服务器地址。格式为IP或域名,域名不包含http前缀,协议层面仅支持https。配置为`openai`时必填 |
**关于proxy参数的说明**
如果使用的代理需要用户名和密码,请在代理地址中加入用户名和密码,例如:`username:password@ip:port`。uni-ai在请求openai时会自动将openai的域名替换为配置的代理域名或ip,一般的反向代理服务器均可满足此需求。
**示例**
在云函数或云对象中编写如下代码:
```js
// 不指定provider
const llm = uniCloud.ai.getLLMManager()
// 指定openai,需自行配置相关key,以及中转代理服务器
const openai = uniCloud.ai.getLLMManager({
provider: 'openai',
apiKey:'your key',
proxy:'www.yourdomain.com' //也可以是ip
})
```
现阶段,不指定provider时,uni-ai分配的ai引擎无需开发者支付费用。同时也不会自动分配到gpt-4等比较昂贵但精准的模型上。如有变化会提前公告。
开发者使用openai等已经商用的ai时,需自行向相关服务商支付费用。
### 对话@chat-completion
:::warning 注意
对话接口响应一般比较慢,建议将云函数超时时间配置的长一些,比如30秒(客户端访问云函数最大超时时间:腾讯云为30秒,阿里云为40秒)。如何配置云函数超时时间请参考:[云函数超时时间](cf-functions.md#timeout)
:::
用法:`llm.chatCompletion(Object ChatCompletionOptions)`
**参数说明ChatCompletionOptions**
|参数 |类型 |必填 |默认值 |说明 |兼容性说明 |
|--- |--- |--- |--- |--- |--- |
|messages |array |是 | - |提问信息 | |
|model |string |否 |默认值见下方说明 |模型名称。每个AI Provider有多个model,见下方说明 |百度文心一言不支持此参数 |
|~~maxTokens~~ |number |否 |- |【已废弃,请使用tokensToGenerate替代】生成的token数量限制,需要注意此值和传入的messages对应的token数量相加不可大于4096 |百度文心一言不支持此参数 |
|tokensToGenerate |number |否 |默认值见下方说明 |生成的token数量限制,需要注意此值和传入的messages对应的token数量相加不可大于4096 |百度文心一言不支持此参数 |
|temperature |number |否 |1 |较高的值将使输出更加随机,而较低的值将使输出更加集中和确定。建议temperature和top_p同时只调整其中一个 |百度文心一言不支持此参数 |
|topP |number |否 |1 |采样方法,数值越小结果确定性越强;数值越大,结果越随机 |百度文心一言不支持此参数 |
|stream |boolean|否 |false |是否使用流式响应,见下方[流式响应](#chat-completion-stream)章节 |百度文心一言不支持此参数 |
**messages参数说明**
需注意messages末尾有个`s`,它是数组,而不是简单的字符串。其中每项由消息内容content和角色role组成。
一个最简单的示例:
```js
await llm.chatCompletion({
messages: [{
role: 'user',
content: '你好'
}]
})
```
role,即角色,有三个值:
- system 系统,对应的content一般用于对话背景设定等功能。system角色及信息如存在时只能放在messages数组第一项。baidu不支持此角色
- user 用户,对应的content为用户输入的信息
- assistant ai助手,对应的content为ai返回的信息
当开发者需要为用户的场景设置背景时,则需在云端代码写死system,而用户输入的问题则被放入user中,然后一起提交给LLM。
例如,提供一个法律咨询的ai咨询助手。
开发者可以在system里限制对话背景,防止ai乱答问题。然后给用户提供输入框,假使用户咨询了:“谣言传播多少人可以定罪?”,那么拼接的message就是:
```js
const messages = [{
role: 'system',
content: '你是一名律师,回答内容仅限法律范围。'
},{
role: 'user',
content: '谣言传播多少人可以定罪?'
}]
```
对于不支持system的情况,如baidu,只能把system对应的内容写到第一条user信息内,也可以达到一定范围内的控制效果。
> 注意:对于法律、医学等专业领域需要准确回答的,建议使用gpt-4模型。其他模型更适合闲聊、文章内容生成。
assistant这个角色的内容,是ai返回的。当需要持续聊天、记忆前文时,需使用此角色。
因为LLM没有记忆能力,messages参数内需要包含前文,LLM才能记得之前聊天的内容。
以下的messages示例,是第二轮ai对话时发送的messages的示例。在这个示例中,第一个user和assistant的内容,是第一轮ai对话的聊天记录。
最后一个user是第二轮对话时用户提的问题。
因为用户提问的内容“从上述方法名中筛选首字母为元音字母的方法名”,其中有代词“上述”,为了让ai知道“上述”是什么,需要把第一轮的对话内容也提交。
```js
const messages = [{
role: 'system',
content: '以下对话只需给出结果,不要对结果进行解释。'
},{
role: 'user',
content: '以数组形式返回nodejs os模块的方法列表,数组的每一项是一个方法名。'
}, {
role: 'assistant',
content: '以下是 Node.js 的 os 模块的方法列表,以数组形式返回,每一项是一个方法名:["arch","cpus","endianness","freemem","getPriority","homedir","hostname","loadavg","networkInterfaces","platform","release","setPriority","tmpdir","totalmem","type","uptime","userInfo"]'
}, {
role: 'user',
content: '从上述方法名中筛选首字母为元音字母的方法名,以数组形式返回'
}]
```
在持续对话中需注意,messages内容越多则消耗的token越多,而LLM都是以token计费的。
token是LLM的术语,ai认知的语言是经过转换的,对于英语,1个token平均是4个字符,大约0.75个单词;对于中文,1个汉字大约是2个token。
如何在节省token和保持持续对话的记忆之间平衡,是一个挺复杂的事情。开发者需在适合时机要求ai对上文进行总结压缩,下次对话传递总结及总结之后的对话内容以实现更长的对话。
DCloud在[uni-im](https://uniapp.dcloud.net.cn/uniCloud/uni-im.html)和[uni-cms](https://uniapp.dcloud.net.cn/uniCloud/uni-cms.html)中,
已经写好了这些复杂逻辑。开发者直接使用DCloud封装好的开源项目模板即可。
在上述例子中,还可以看到一种有趣的用法,即要求ai以数组方式回答问题。这将有利于开发者格式化数据,并进行后置增强处理。
**model参数说明**
每个AI Provider可以有多个model,比如对于openai,ChatGPT的模型是`gpt-3.5-turbo`,而gpt-4的模型就是`gpt-4`。不同模型的功能、性能、价格都不一样。
也有一些AI Provider只有一个模型,此时model参数可不填。
如果您需要非常精准的问答,且不在乎成本,推荐使用`gpt-4`。如果是普通的文章内容生成、续写,大多数模型均可胜任。
|服务商 |接口 |模型 |
|--- |--- |--- |
|openai |chatCompletion |gpt-4、gpt-4-0314、gpt-4-32k、gpt-4-32k-0314、gpt-3.5-turbo(默认值)、gpt-3.5-turbo-0301 |
|minimax|chatCompletion |abab4-chat、abab5-chat(默认值) |
**tokensToGenerate参数说明**
tokensToGenerate指生成的token数量限制,即返回的文本对应的token数量不能超过此值。注意这个值不是总token。此参数名称后续可能改名。
注意此值和传入messages对应的token数量,两者相加不可大于4096。如果messages对应的token数为1024,当传递的tokensToGenerate参数大于(4096-1024)时接口会抛出错误。
未指定provider时默认最多生成512个token的结果,也就是返回结果不会很长。如有需求请自行调整此值。此默认值为512(在HBuilderX alpha 3.7.13版本默认为128)
**chatCompletion方法的返回值**
|参数 |类型 |必备 |默认值 |说明 |兼容性说明 |
|--- |--- |--- |--- |--- |--- |
|id |string |openai必备 | - |本次回复的id |仅openai返回此项 |
|reply |string |是 | - |ai对本次消息的回复 | |
|choices |array<object>|否 |- |所有生成结果 |百度文心一言不返回此项 |
||--finishReason |string |否 |- |截断原因,stop(正常结束)、length(超出maxTokens被截断) | |
||--message |object |否 |- |返回消息 | |
| |--role |string |否 |- |角色 | |
| |--content|string |否 |- |消息内容 | |
|usage |object |是 |- |本次对话token消耗详情 | |
||--promptTokens |number |否 |- |输入的token数量 |minimax不返回此项 |
||--completionTokens |number |否 |- |生成的token数量 |minimax不返回此项 |
||--totalTokens |number |是 |- |总token数量 | |
#### 简单示例
在你的云函数中加载`uni-cloud-ai`扩展库,写下如下代码,ctrl+r运行,即可调用ai返回结果。
```js
const llmManager = uniCloud.ai.getLLMManager()
const res = await llmManager.chatCompletion({
messages: [{
role: 'user',
content: 'uni-app是什么,20个字以内进行说明'
}]
})
console.log(res);
```
如果你之前未使用过uniCloud,后续有专门的[新手指南](#first)章节。
#### 流式响应@chat-completion-stream
> 新增于HBuilderX正式版 3.7.10+, alpha版 HBuilderX 3.8.0
访问AI聊天接口时,如生成内容过大,响应时间会很久,前端用户需要等待很长时间才会收到结果。
实际上AI是逐渐生成下一个token的,所以可使用流式响应,类似不停打字的打字机那样,让前端用户陆续看到AI生成的内容。
以往云函数只有return的时候,才能给客户端返回消息。在流式响应中,需要云函数支持sse,在return前给客户端一直发送通知。
uniCloud的云函数,基于uni-push2,于 HBuilderX 新版提供了sse通道,即[云函数请求中的中间状态通知通道](sse-channel.md)。
在调用`chatCompletion`接口时传递参数`stream: true`即可开启流式响应。
**注意:**
1. 需提前为应用开通[uni-push2](/unipush-v2.md)
2. 不同provide的流式支持度不同,有的是按字输出、有的是按句输出。考虑到push的频繁调用压力,目前uni-ai自动分配provide时是按句输出。如果您指定provide为openai并配置自己的apikey,可以按字输出。
3. 开启流式响应后`chatCompletion`接口将返回流对象,而不会返回具体结果。开发者需要使用流获取AI响应的内容。
4. 如使用nginx代理,需要将代理配置为`proxy_buffering off;`,否则可能会遇到`Unexpected end of JSON input`错误
stream对象有四个事件:
- message: 收到AI响应的事件,回调函数内可以获取AI返回的信息。需要注意的是在使用不同服务商时message事件的响应可能有些不同,有些服务商是一个字一个字的返回,有些则是一段一段的返回。
- line: AI响应一行文字时触发,回调函数内可以获取这行文字的内容。uni-ai对服务商返回内容做了处理,AI每响应一个段落会触发一次此事件
- end: AI响应完毕事件
- error: AI响应错误事件,回调函数内可以获取具体错误信息
**stream云函数代码示例**
```js
'use strict';
exports.main = async (event, context) => {
const llmManager = uniCloud.ai.getLLMManager({})
let streamRes
try {
streamRes = await llmManager.chatCompletion({
messages: [{
role: 'user',
content: '介绍一下uni-app,400字以内,分为两段'
}],
tokensToGenerate: 400,
stream: true // 开启流式返回
})
} catch (e) {
console.error(e)
throw e
}
return new Promise((resolve, reject) => { //流式给客户端返回数据
streamRes.on('line', (line) => {
console.log('---line----', line) // 返回一行时触发,即\n
})
streamRes.on('message', (message) => {
console.log('---message----', message) // 实时触发
})
streamRes.on('end', () => {
console.log('---end----') // 响应结束
resolve({
errCode: 0
})
})
streamRes.on('error', (err) => {
console.log('---error----', err)
reject(err)
})
})
};
```
客户端也需要接收云函数的流式响应。
DCloud提供了开源的`uni-ai-chat`,对流式响应进行了前后端一体的封装,使用更简单,参考:[uni-ai-chat](uni-ai-chat.md)
### 错误码@err-code
在调用`uni-cloud-ai`提供的api时,如果出现错误,接口会将错误对象抛出。如需处理此类错误需对错误进行捕获
**捕获错误的代码示例**
```js
try {
await llm.chatCompletion({
messages: [{
role: 'user',
content: '你好'
}]
})
} catch (e) {
console.log(e.errCode, e.errMsg)
// TODO 处理错误
}
```
完整错误码列表如下
|错误码 |错误描述 |
|-- |-- |
|50001 |缺少参数 |
|50002 |参数错误 |
|60000 |请求服务商接口时遇到网络错误 |
|60001 |服务商接口抛出的错误 |
|60002 |接口调用凭证、key等信息有误 |
|60003 |触发了服务商限流策略 |
**常见错误信息**
- 错误码:60000,错误信息:"A network error occurred while requesting xxx"
请求服务商接口时遇到网络错误,如果是请求openai接口请注意需要使用代理,如果使用了代理仍遇到此错误,请检查代理连通性是否有问题
- 错误信息:"certificate has expired"
请参考文档:[云函数通过https访问其他服务器时出现“certificate has expired”](faq.md#lets-encrypt-cert)
## 费用
- 如果您自己去ai厂商申请和缴费,比如openai,则缴费后在uni-ai中配置相关key即可使用。
- 如果您使用uni-ai自动分配的ai服务,目前也是免费的。未来若计费会提前公告。未来计费原则也必然是市场标准价格,不会出现歧视性、收割性定价。
## 后续版本计划
uni-ai会持续快速迭代,未来会陆续提供:
- 聚合更多ai引擎
- 提供私有数据训练方案
- 提供prompt辅助和插件市场
- 后置命令处理
## 常见用途场景
现阶段的ai,被称之为AIGC,即生成式ai。我们需要了解它擅长和不擅长的地方,并管理预期。
ai是模糊的、概率的,不是精确的,不要问生成式ai数学题。
从本质来讲,生成式ai不是在回答问题,而是在通过前文预测下文。你的前文可以恰好是一个问题,也可以不是问题。
ai会推理出很多下文并打分,选择最高分的下文返回给你。但“不知道”这个下文的打分往往不如其他胡诌的下文得分高,所以你很少会遇到ai的下文是“不知道”。
ai会使用互联网上的数据进行学习训练,但训练语料不会包含最新的知识和互联网上未公开的知识。比如openai的训练数据是2021年9月以前的数据。
虽然ai学习了互联网的知识,但它不是复读机,它把知识压缩形成自己的理解。你的前文和它的理解碰撞出它的下文(所以合适的前文,也就是prompt很重要)。
越好的ai,其知识储备、理解和推理能力越优秀,预测的下文可以更逼近真实,甚至超过普通人的水平。
目前生成式ai的主要用途有:
- 文章生成、润色、续写:常见于生成文案、文书、标语、名字、营销邮件、笑话、诗词等。[uni-cms](https://uniapp.dcloud.net.cn/uniCloud/uni-cms.html)中,已经内置了这个功能
- 闲聊:情感咨询、常识问答。由于聊天本身有不少代码工作量,推荐使用现成开源项目。比如单纯的ai聊天模板[uni-ai-chat](https://uniapp.dcloud.net.cn/uniCloud/uni-ai-chat.html),或专业的im工具、支持私聊群聊的[uni-im](https://ext.dcloud.net.cn/plugin?id=11771)
- 翻译:各国各民族语言翻译
- 代码注释补充和简单代码生成:需使用openai,其他provider在代码领域的能力暂时还不行
**如对生成内容有较高的准确性要求,一方面使用gpt-4等高级的模型;另一方面需要追加专业甚至私有的语料训练。**
目前gpt-4未开放微调,但uni-ai正在开发其他私有数据训练方案,后续会升级提供。
gpt-4是目前准确性最高的ai,也是最贵的ai。开发者需根据需求场景选择,一般的文章生成和闲聊,可以不用gpt-4。
另外想得到良好的推理结果,优化prompt前文也非常重要。
## 合规注意
国内使用ai,需注意合规性。监管部门并不拒绝使用ai提升生产效率,但对于可能造成社会动员能力、价值观影响等政治问题、以及黄赌毒等违法问题非常敏感。
- ai生成的文章,如发布到互联网上,应当调用内容安全审查后再发布。比如[uni内容安全](https://ext.dcloud.net.cn/plugin?id=5460)。[uni-cms](https://uniapp.dcloud.net.cn/uniCloud/uni-cms.html)已经内置了uni内容安全,只需在配置里开启即可。
- 如开放给用户聊天使用,也应该通过内容安全来管控,避免出现违法违规内容,导致被下架。
- 在微信小程序等平台,名字或内容涉及ChatGPT,都会被平台封禁。所以上微信小程序时不能提及ChatGPT,也不要使用uni-ai的openai配置功能。可以使用国内ai或让uni-ai自动分配。同时输入和返回的内容都需要做安全审查,具体见上。
- 如果在企业内部通过openai提升生产力,这不涉及合规问题,可以放心使用。
## 初次使用uniCloud用户指南@first
如之前未使用过uni-app,那请重头学起。[uni-app官网](https://uniapp.dcloud.net.cn)
如了解uni-app,但未使用过uniCloud。请参考本章节继续。
1. 首先注册开通uniCloud,登录[https://unicloud.dcloud.net.cn/](https://unicloud.dcloud.net.cn/),创建一个服务空间。
2. 在uni-app项目点右键创建uniCloud环境,关联之前创建的服务空间。
3. 创建uniCloud云函数
在项目下uniCloud目录右键,新建云函数
 - 填写云函数名称,比如`ai-demo`。此云函数需要调用`uni-cloud-ai`扩展库,所以需点击`添加公共模块或扩展库依赖`按钮。
- 填写云函数名称,比如`ai-demo`。此云函数需要调用`uni-cloud-ai`扩展库,所以需点击`添加公共模块或扩展库依赖`按钮。
 - 找到`uni-cloud-ai`勾选,点击确认,创建云函数
- 找到`uni-cloud-ai`勾选,点击确认,创建云函数
 4. 云函数中添加如下代码:
```js
// 云函数的代码运行在uniCloud服务器上
console.log('event',event) // event为客户端上传的参数
const {messages} = event
// 校验客户端提交的参数
try{
if(messages === undefined){
throw "messages为必传参数"
}else if(!Array.isArray(messages)){
throw "参数messages的值类型必须是[object,object...]"
}else{
messages.forEach(item=>{
if(typeof item != 'object'){
throw "参数messages的值类型必须是[object,object...]"
}
let itemRoleArr = ["assistant","user","system"]
if(!itemRoleArr.includes(item.role)){
throw "参数messages[{role}]的值只能是:"+itemRoleArr.join('或')
}
if(typeof item.content != 'string'){
throw "参数messages[{content}]的值类型必须是字符串"
}
})
}
}catch(errMsg){
return {
errSubject: 'ai-demo',
errCode: 'param-error',
errMsg
}
}
const LLMManager = uniCloud.ai.getLLMManager() //创建llm对象
return await LLMManager.chatCompletion({
messages // 初次调试时,可注掉本行代码,不从客户端获取数据,直接使用下面写死在云函数里的数据
// messages: [{
// role: 'user',
// content: 'uni-app是什么,20个字以内进行说明'
// }]
})
```
如果不从客户端获取参数,直接在云函数里写messages,可以在云函数中直接按Ctrl+R(或工具栏的运行按钮),在本地运行云函数。
还可以断点调试云函数,详见[uniCloud运行调试教程](rundebug.md)
5. 在客户端通过callFunction调用`ai-demo`云函数
注意uni-app客户端连接uniCloud不是通过`uni.request`。如果调用云函数是`uniCloud.callFunction`。(如调用云对象是`uniCloud.importObject`)
```js
const content = "你能给我提供什么服务"
uni.showLoading();
uniCloud.callFunction({
name: "ai-demo", // 这里是你的云函数的名称。如果你的云函数不叫ai-demo请自行更换
data: {
messages: [{
role: 'user',
content
}]
}
})
.then(res=>{
console.log(res);
uni.showModal({
content: JSON.stringify(res),
showCancel: false
});
})
.catch(e=> {
uni.showModal({
content: JSON.stringify(e),
showCancel: false
});
})
.finally(()=>{
uni.hideLoading()
})
```
运行客户端项目,比如运行到web浏览器,即可联调客户端和云端。
上述代码只是最简示例,真正的多轮聊天需要的代码较多较复杂,推荐使用现成的[uni-ai-chat](uni-ai-chat.md)、[uni-im](uni-im.md)或[uni-cms](uni-cms.md)。
官方的`uni-ai-chat`、`uni-im`、`uni-cms`等项目一般不使用云函数,而是使用云对象。想看懂这些项目源码,需要了解[云对象](cloud-obj.md)
## 非uniCloud服务器调用
如需在非uniCloud的传统服务器调用`uni-ai`,需要先在uniCloud上创建一个云函数或云对象,加载uni-cloud-ai扩展库,编写上述uni-ai的调用代码。
然后将云函数或云对象进行URL化,转成http接口,[详见](http.md)
注意如果使用URL化后,将无法使用stream流式输出。
如果在您的传统服务器和uniCloud云函数之间需要建立安全通信机制,可使用s2s公共模块,[详见](uni-cloud-s2s.md)
## 交流群
更多问题欢迎加入uni-ai官方交流群 qq群号:[699680439](https://qm.qq.com/cgi-bin/qm/qr?k=P_JoYXY56vNfb78uNHwwzqpODwl9e89B&jump_from=webapi&authKey=GDp321q9ZYW4V0ZQcejXikwMnNRs4KVBcQXMADs8lvC0hifSH9ORHsyERy6vO4bA)
4. 云函数中添加如下代码:
```js
// 云函数的代码运行在uniCloud服务器上
console.log('event',event) // event为客户端上传的参数
const {messages} = event
// 校验客户端提交的参数
try{
if(messages === undefined){
throw "messages为必传参数"
}else if(!Array.isArray(messages)){
throw "参数messages的值类型必须是[object,object...]"
}else{
messages.forEach(item=>{
if(typeof item != 'object'){
throw "参数messages的值类型必须是[object,object...]"
}
let itemRoleArr = ["assistant","user","system"]
if(!itemRoleArr.includes(item.role)){
throw "参数messages[{role}]的值只能是:"+itemRoleArr.join('或')
}
if(typeof item.content != 'string'){
throw "参数messages[{content}]的值类型必须是字符串"
}
})
}
}catch(errMsg){
return {
errSubject: 'ai-demo',
errCode: 'param-error',
errMsg
}
}
const LLMManager = uniCloud.ai.getLLMManager() //创建llm对象
return await LLMManager.chatCompletion({
messages // 初次调试时,可注掉本行代码,不从客户端获取数据,直接使用下面写死在云函数里的数据
// messages: [{
// role: 'user',
// content: 'uni-app是什么,20个字以内进行说明'
// }]
})
```
如果不从客户端获取参数,直接在云函数里写messages,可以在云函数中直接按Ctrl+R(或工具栏的运行按钮),在本地运行云函数。
还可以断点调试云函数,详见[uniCloud运行调试教程](rundebug.md)
5. 在客户端通过callFunction调用`ai-demo`云函数
注意uni-app客户端连接uniCloud不是通过`uni.request`。如果调用云函数是`uniCloud.callFunction`。(如调用云对象是`uniCloud.importObject`)
```js
const content = "你能给我提供什么服务"
uni.showLoading();
uniCloud.callFunction({
name: "ai-demo", // 这里是你的云函数的名称。如果你的云函数不叫ai-demo请自行更换
data: {
messages: [{
role: 'user',
content
}]
}
})
.then(res=>{
console.log(res);
uni.showModal({
content: JSON.stringify(res),
showCancel: false
});
})
.catch(e=> {
uni.showModal({
content: JSON.stringify(e),
showCancel: false
});
})
.finally(()=>{
uni.hideLoading()
})
```
运行客户端项目,比如运行到web浏览器,即可联调客户端和云端。
上述代码只是最简示例,真正的多轮聊天需要的代码较多较复杂,推荐使用现成的[uni-ai-chat](uni-ai-chat.md)、[uni-im](uni-im.md)或[uni-cms](uni-cms.md)。
官方的`uni-ai-chat`、`uni-im`、`uni-cms`等项目一般不使用云函数,而是使用云对象。想看懂这些项目源码,需要了解[云对象](cloud-obj.md)
## 非uniCloud服务器调用
如需在非uniCloud的传统服务器调用`uni-ai`,需要先在uniCloud上创建一个云函数或云对象,加载uni-cloud-ai扩展库,编写上述uni-ai的调用代码。
然后将云函数或云对象进行URL化,转成http接口,[详见](http.md)
注意如果使用URL化后,将无法使用stream流式输出。
如果在您的传统服务器和uniCloud云函数之间需要建立安全通信机制,可使用s2s公共模块,[详见](uni-cloud-s2s.md)
## 交流群
更多问题欢迎加入uni-ai官方交流群 qq群号:[699680439](https://qm.qq.com/cgi-bin/qm/qr?k=P_JoYXY56vNfb78uNHwwzqpODwl9e89B&jump_from=webapi&authKey=GDp321q9ZYW4V0ZQcejXikwMnNRs4KVBcQXMADs8lvC0hifSH9ORHsyERy6vO4bA)