Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
CSDN 技术社区
skill_tree_opencv
提交
436fad32
S
skill_tree_opencv
项目概览
CSDN 技术社区
/
skill_tree_opencv
通知
174
Star
9
Fork
1
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
2
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
S
skill_tree_opencv
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
2
Issue
2
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
提交
436fad32
编写于
12月 17, 2021
作者:
X
xiaozhi_5638
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
上传图像分类题目
上级
699801ef
变更
9
展开全部
显示空白变更内容
内联
并排
Showing
9 changed file
with
139 addition
and
0 deletion
+139
-0
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/MY_TEST/eagle.png
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/MY_TEST/eagle.png
+0
-0
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/MY_TEST/ocean-liner.jpg
.../1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/MY_TEST/ocean-liner.jpg
+0
-0
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/bvlc_googlenet.caffemodel
....OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/bvlc_googlenet.caffemodel
+0
-0
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/bvlc_googlenet.prototxt
.../1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/bvlc_googlenet.prototxt
+0
-0
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/classification.md
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/classification.md
+99
-0
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/classification.png
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/classification.png
+0
-0
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/classification.py
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/classification.py
+40
-0
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/labels.py
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/labels.py
+0
-0
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/result.png
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/result.png
+0
-0
未找到文件。
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/MY_TEST/eagle.png
0 → 100755
浏览文件 @
436fad32
335.5 KB
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/MY_TEST/ocean-liner.jpg
0 → 100755
浏览文件 @
436fad32
80.9 KB
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/bvlc_googlenet.caffemodel
0 → 100755
浏览文件 @
436fad32
文件已添加
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/bvlc_googlenet.prototxt
0 → 100755
浏览文件 @
436fad32
此差异已折叠。
点击以展开。
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/classification.md
0 → 100755
浏览文件 @
436fad32
# opencv.dnn做图像分类
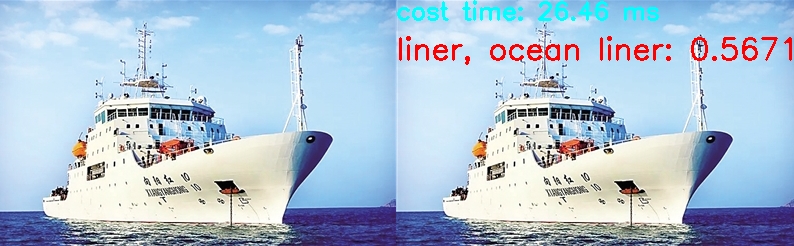
图像分类是基于深度学习的计算机视觉任务中最简单、也是最基础的一类,它其中用到的CNN特征提取技术也是目标检测、目标分割等视觉任务的基础。

具体到图像分类任务而言,其具体流程如下:
1.
输入指定大小RGB图像,1/3通道,宽高一般相等
2.
通过卷积神经网络进行多尺度特征提取,生成高维特征值
3.
利用全连接网络、或其他结构对高维特征进行分类,输出各目标分类的概率值(概率和为1)
4.
选择概率值最高的作为图像分类结果

`opencv.dnn`
模块可以直接加载深度学习模型,并进行推理输出运行结果。下面是opencv.dnn模块加载googlenet caffe模型进行图片分类的代码,请你完善其中TO-DO部分的代码。
> 代码中LABEL_MAP是图像分类名称字典,给定索引得到具体分类名称(string)。
```
python
import
cv2
import
numpy
as
np
from
labels
import
LABEL_MAP
# 1000 labels in imagenet dataset
# caffe model, googlenet aglo
weights
=
"bvlc_googlenet.caffemodel"
protxt
=
"bvlc_googlenet.prototxt"
# read caffe model from disk
net
=
cv2
.
dnn
.
readNetFromCaffe
(
protxt
,
weights
)
# create input
image
=
cv2
.
imread
(
"ocean-liner.jpg"
)
blob
=
cv2
.
dnn
.
blobFromImage
(
image
,
1.0
,
(
224
,
224
),
(
104
,
117
,
123
),
False
,
crop
=
False
)
result
=
np
.
copy
(
image
)
# run!
net
.
setInput
(
blob
)
out
=
net
.
forward
()
# TO-DO your code...
# time cost
t
,
_
=
net
.
getPerfProfile
()
label
=
'cost time: %.2f ms'
%
(
t
*
1000.0
/
cv2
.
getTickFrequency
())
cv2
.
putText
(
result
,
label
,
(
0
,
20
),
cv2
.
FONT_HERSHEY_SIMPLEX
,
0.8
,
(
255
,
255
,
0
),
2
)
# render on image
label
=
'%s: %.4f'
%
(
LABEL_MAP
[
classId
]
if
LABEL_MAP
else
'Class #%d'
%
classId
,
confidence
)
cv2
.
putText
(
result
,
label
,
(
0
,
60
),
cv2
.
FONT_HERSHEY_SIMPLEX
,
1
,
(
0
,
0
,
255
),
2
)
show_img
=
np
.
hstack
((
image
,
result
))
# normal codes in opencv
cv2
.
imshow
(
"Image"
,
show_img
)
cv2
.
waitKey
(
0
)
```
## 答案
```
python
# output probability, find the right index
out
=
out
.
flatten
()
classId
=
np
.
argmax
(
out
)
confidence
=
out
[
classId
]
```
## 输出理解错误
```
python
# output probability, find the right index
classId
=
out
[
0
]
confidence
=
out
[
1
]
```
## 输出维度理解错误
```
python
# output probability, find the right index
classId
=
np
.
argmax
(
out
)
confidence
=
out
[
classId
]
```
## 输出理解错误
```
python
# output probability, find the right index
out
=
out
.
flatten
()
classId
=
np
.
argmax
(
out
[
1
:])
confidence
=
out
[
classId
+
1
]
```
\ No newline at end of file
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/classification.png
0 → 100755
浏览文件 @
436fad32
47.9 KB
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/classification.py
0 → 100755
浏览文件 @
436fad32
import
cv2
import
numpy
as
np
from
labels
import
LABEL_MAP
# 1000 labels in imagenet dataset
# caffe model, googlenet aglo
weights
=
"bvlc_googlenet.caffemodel"
protxt
=
"bvlc_googlenet.prototxt"
# read caffe model from disk
net
=
cv2
.
dnn
.
readNetFromCaffe
(
protxt
,
weights
)
# create input
image
=
cv2
.
imread
(
"MY_TEST/ocean-liner.jpg"
)
blob
=
cv2
.
dnn
.
blobFromImage
(
image
,
1.0
,
(
224
,
224
),
(
104
,
117
,
123
),
False
,
crop
=
False
)
result
=
np
.
copy
(
image
)
# run!
net
.
setInput
(
blob
)
out
=
net
.
forward
()
# output probability, find the right index
out
=
out
.
flatten
()
classId
=
np
.
argmax
(
out
)
confidence
=
out
[
classId
]
# time cost
t
,
_
=
net
.
getPerfProfile
()
label
=
'cost time: %.2f ms'
%
(
t
*
1000.0
/
cv2
.
getTickFrequency
())
cv2
.
putText
(
result
,
label
,
(
0
,
20
),
cv2
.
FONT_HERSHEY_SIMPLEX
,
0.8
,
(
255
,
255
,
0
),
2
)
# render on image
label
=
'%s: %.4f'
%
(
LABEL_MAP
[
classId
]
if
LABEL_MAP
else
'Class #%d'
%
classId
,
confidence
)
cv2
.
putText
(
result
,
label
,
(
0
,
60
),
cv2
.
FONT_HERSHEY_SIMPLEX
,
1
,
(
0
,
0
,
255
),
2
)
show_img
=
np
.
hstack
((
image
,
result
))
# normal codes in opencv
cv2
.
imshow
(
"Image"
,
show_img
)
cv2
.
waitKey
(
0
)
\ No newline at end of file
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/labels.py
0 → 100755
浏览文件 @
436fad32
此差异已折叠。
点击以展开。
data/1.OpenCV初阶/7.OpenCV中的深度学习/1.图像分类/result.png
0 → 100755
浏览文件 @
436fad32
205.5 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}

{kind=link}

{kind=link}
{kind=link}