 +
+给定一个二叉树,检查它是否是镜像对称的。
+ ++ +
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1 + / \ + 2 2 + / \ / \ +3 4 4 3 ++ +
+ +
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1 + / \ + 2 2 + \ \ + 3 3 ++ +
+ +
进阶:
+ +你可以运用递归和迭代两种方法解决这个问题吗?
+ + +## template + +```java + +public class TreeNode { + int val; + TreeNode left; + TreeNode right; + + TreeNode(int x) { + val = x; + } +} + +class Solution { + public boolean isSymmetric(TreeNode root) { + if (root == null) { + return true; + } + + return isSymmetric(root.left, root.right); + } + + public boolean isSymmetric(TreeNode n1, TreeNode n2) { + if (n1 == null || n2 == null) { + return n1 == n2; + } + + if (n1.val != n2.val) { + return false; + } + + return isSymmetric(n1.left, n2.right) && isSymmetric(n1.right, n2.left); + } +} + +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/161.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/2.java/104.exercises/config.json" similarity index 67% rename from "data_source/exercises/\344\270\255\347\255\211/java/161.exercises/config.json" rename to "data/1.dailycode\345\210\235\351\230\266/2.java/104.exercises/config.json" index ab669edf23a4422e5a2051e29d2948b8b9eef0b1..aaa93dd7fda1d470fbb2bab118c3ce01d39fff95 100644 --- "a/data_source/exercises/\344\270\255\347\255\211/java/161.exercises/config.json" +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/104.exercises/config.json" @@ -1,5 +1,5 @@ { - "node_id": "dailycode-a49b8a8141784360b8a3e9f68e694db6", + "node_id": "dailycode-ca242207dcca46e98a855afe39ba7bc6", "keywords": [], "children": [], "keywords_must": [], diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/104.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/2.java/104.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..2284a92adb8b8c980928a213dcd4475d530aad08 --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/104.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "14ab4d85d03c4c1e9bae31166d22c95b", + "author": "csdn.net", + "keywords": "树,深度优先搜索,广度优先搜索,二叉树" +} \ No newline at end of file diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/104.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/2.java/104.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..1d5766383fdda74d979389ba8a69b332ef2a7a20 --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/104.exercises/solution.md" @@ -0,0 +1,88 @@ +# 二叉树的最大深度 + +给定一个二叉树,找出其最大深度。
+ +二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
+ +说明: 叶子节点是指没有子节点的节点。
+ +示例:
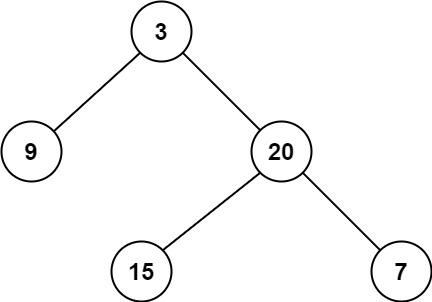
+给定二叉树 [3,9,20,null,null,15,7],
3 + / \ + 9 20 + / \ + 15 7+ +
返回它的最大深度 3 。
+ + +## template + +```java + +public class TreeNode { + int val; + TreeNode left; + TreeNode right; + + TreeNode(int x) { + val = x; + } +} + +class Solution { + public int maxDepth(TreeNode root) { + + if (root == null) { + return 0; + } + + int deep = 1; + if (root.left == null && root.right == null) { + return 1; + } + + int leftDeep = 0; + if (root.left != null) { + + leftDeep = 1 + maxDepth(root.left); + } + + int rightDeep = 0; + if (root.right != null) { + rightDeep = 1 + maxDepth(root.right); + } + + return deep + leftDeep > rightDeep ? leftDeep : rightDeep; + } +} + +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/177.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/2.java/108.exercises/config.json" similarity index 67% rename from "data_source/exercises/\344\270\255\347\255\211/java/177.exercises/config.json" rename to "data/1.dailycode\345\210\235\351\230\266/2.java/108.exercises/config.json" index c11e108442fd128eabc06add068ab52cc5d50651..7fff488f1c159db46829a513eaa9fadd2c8ca3fe 100644 --- "a/data_source/exercises/\344\270\255\347\255\211/java/177.exercises/config.json" +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/108.exercises/config.json" @@ -1,5 +1,5 @@ { - "node_id": "dailycode-371bbacdc9d94528911b28efdc64e849", + "node_id": "dailycode-c3fc112caa8346719353b5b53dd23b67", "keywords": [], "children": [], "keywords_must": [], diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/108.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/2.java/108.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..a13fae224fcb516087f85660ecaa36e25a5d0893 --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/108.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "42d0f88da8434410bbeb20c494e40359", + "author": "csdn.net", + "keywords": "树,二叉搜索树,数组,分治,二叉树" +} \ No newline at end of file diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/108.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/2.java/108.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..9656e855510746a2e2ef7a20c1ba61d15bcc2421 --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/108.exercises/solution.md" @@ -0,0 +1,101 @@ +# 将有序数组转换为二叉搜索树 + +给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
+ ++ +
示例 1:
+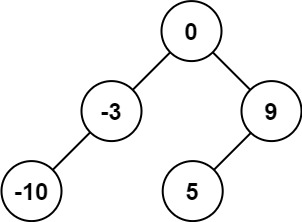 +
++输入:nums = [-10,-3,0,5,9] +输出:[0,-3,9,-10,null,5] +解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案: ++ +
示例 2:
+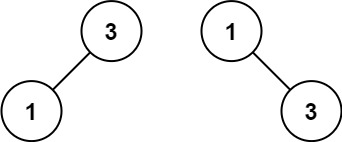 +
++输入:nums = [1,3] +输出:[3,1] +解释:[1,3] 和 [3,1] 都是高度平衡二叉搜索树。 ++ +
+ +
提示:
+ +1 <= nums.length <= 104-104 <= nums[i] <= 104nums 按 严格递增 顺序排列给定一个二叉树,判断它是否是高度平衡的二叉树。
+ +本题中,一棵高度平衡二叉树定义为:
+ +++ +一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
+
+ +
示例 1:
+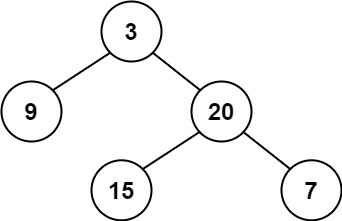 +
++输入:root = [3,9,20,null,null,15,7] +输出:true ++ +
示例 2:
+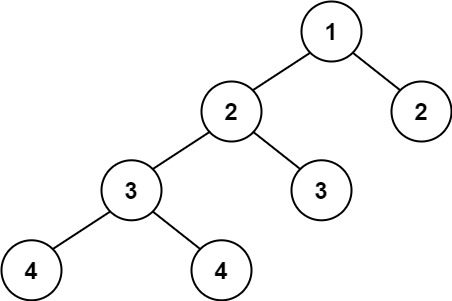 +
++输入:root = [1,2,2,3,3,null,null,4,4] +输出:false ++ +
示例 3:
+ ++输入:root = [] +输出:true ++ +
+ +
提示:
+ +[0, 5000] 内-104 <= Node.val <= 104给定一个二叉树,找出其最小深度。
+ +最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
+ +说明:叶子节点是指没有子节点的节点。
+ ++ +
示例 1:
+ +
++输入:root = [3,9,20,null,null,15,7] +输出:2 ++ +
示例 2:
+ ++输入:root = [2,null,3,null,4,null,5,null,6] +输出:5 ++ +
+ +
提示:
+ +[0, 105] 内-1000 <= Node.val <= 1000给你二叉树的根节点 root 和一个表示目标和的整数 targetSum ,判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。
叶子节点 是指没有子节点的节点。
+ ++ +
示例 1:
+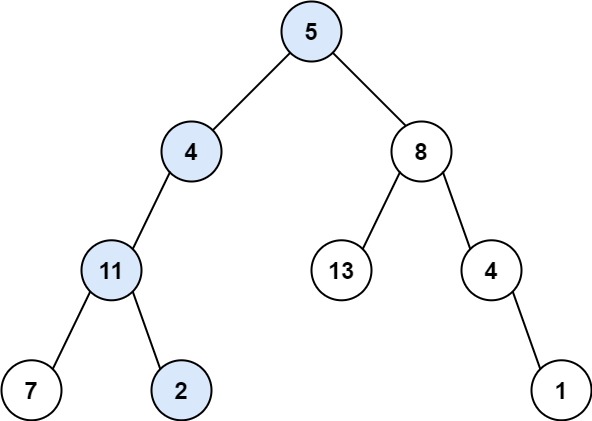 +
++输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22 +输出:true ++ +
示例 2:
+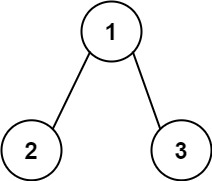 +
++输入:root = [1,2,3], targetSum = 5 +输出:false ++ +
示例 3:
+ ++输入:root = [1,2], targetSum = 0 +输出:false ++ +
+ +
提示:
+ +[0, 5000] 内-1000 <= Node.val <= 1000-1000 <= targetSum <= 1000给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。
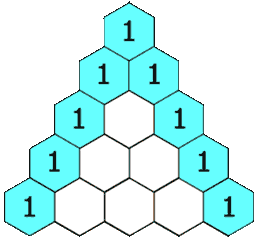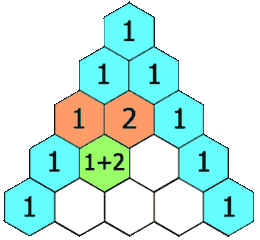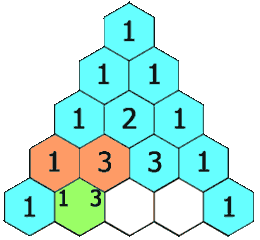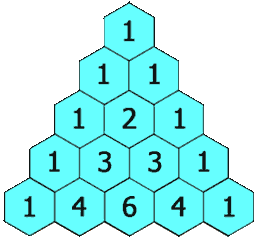
在「杨辉三角」中,每个数是它左上方和右上方的数的和。
+ +
+ +
示例 1:
+ ++输入: numRows = 5 +输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]] ++ +
示例 2:
+ ++输入: numRows = 1 +输出: [[1]] ++ +
+ +
提示:
+ +1 <= numRows <= 30给定一个非负索引 rowIndex,返回「杨辉三角」的第 rowIndex 行。
在「杨辉三角」中,每个数是它左上方和右上方的数的和。
+ +
+ +
示例 1:
+ ++输入: rowIndex = 3 +输出: [1,3,3,1] ++ +
示例 2:
+ ++输入: rowIndex = 0 +输出: [1] ++ +
示例 3:
+ ++输入: rowIndex = 1 +输出: [1,1] ++ +
+ +
提示:
+ +0 <= rowIndex <= 33+ +
进阶:
+ +你可以优化你的算法到 O(rowIndex) 空间复杂度吗?
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
+ +返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
+ +
示例 1:
+ ++输入:[7,1,5,3,6,4] +输出:5 +解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。 + 注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。 ++ +
示例 2:
+ ++输入:prices = [7,6,4,3,1] +输出:0 +解释:在这种情况下, 没有交易完成, 所以最大利润为 0。 ++ +
+ +
提示:
+ +1 <= prices.length <= 1050 <= prices[i] <= 104给定一个数组 prices ,其中 prices[i] 是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
+ +注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
+ ++ +
示例 1:
+ ++输入: prices = [7,1,5,3,6,4] +输出: 7 +解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 + 随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。 ++ +
示例 2:
+ ++输入: prices = [1,2,3,4,5] +输出: 4 +解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 + 注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。 ++ +
示例 3:
+ ++输入: prices = [7,6,4,3,1] +输出: 0 +解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。+ +
+ +
提示:
+ +1 <= prices.length <= 3 * 1040 <= prices[i] <= 104给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
+ +说明:本题中,我们将空字符串定义为有效的回文串。
+ ++ +
示例 1:
+ ++输入: "A man, a plan, a canal: Panama" +输出: true +解释:"amanaplanacanalpanama" 是回文串 ++ +
示例 2:
+ ++输入: "race a car" +输出: false +解释:"raceacar" 不是回文串 ++ +
+ +
提示:
+ +1 <= s.length <= 2 * 105s 由 ASCII 字符组成给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
+ +说明:
+ +你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
+ +示例 1:
+ +输入: [2,2,1] +输出: 1 ++ +
示例 2:
+ +输入: [4,1,2,1,2] +输出: 4+ + +## template + +```java +class Solution { + public int singleNumber(int[] nums) { + int res = 0; + for (int num : nums) { + res ^= num; + } + return res; + } +} + +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/141.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/2.java/141.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..b21be7d33965eb495ac29ec7c572b2e4dd1fda3b --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/141.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-370c10ca633548ccb9204d042c41b60a", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data_source/exercises/\347\256\200\345\215\225/java/160.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/2.java/141.exercises/solution.json" similarity index 69% rename from "data_source/exercises/\347\256\200\345\215\225/java/160.exercises/solution.json" rename to "data/1.dailycode\345\210\235\351\230\266/2.java/141.exercises/solution.json" index 311c98cd2581ee447bdac4382056ffc28c8625c0..35d5cc8d44bb126054fca7090ceed419737860ac 100644 --- "a/data_source/exercises/\347\256\200\345\215\225/java/160.exercises/solution.json" +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/141.exercises/solution.json" @@ -1,7 +1,7 @@ { "type": "code_options", "source": "solution.md", - "exercise_id": "c67f79a9c54d421d9a06e510234d7ae5", + "exercise_id": "a0cd256a454c4708ade034055b3c2d27", "author": "csdn.net", "keywords": "哈希表,链表,双指针" } \ No newline at end of file diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/141.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/2.java/141.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..04feeba296420193fb2bf2e47cae370bff9f3386 --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/141.exercises/solution.md" @@ -0,0 +1,110 @@ +# 环形链表 + +
给定一个链表,判断链表中是否有环。
+ +如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
如果链表中存在环,则返回 true 。 否则,返回 false 。
+ +
进阶:
+ +你能用 O(1)(即,常量)内存解决此问题吗?
+ ++ +
示例 1:
+ +
输入:head = [3,2,0,-4], pos = 1 +输出:true +解释:链表中有一个环,其尾部连接到第二个节点。 ++ +
示例 2:
+ +
输入:head = [1,2], pos = 0 +输出:true +解释:链表中有一个环,其尾部连接到第一个节点。 ++ +
示例 3:
+ +
输入:head = [1], pos = -1 +输出:false +解释:链表中没有环。 ++ +
+ +
提示:
+ +[0, 104]-105 <= Node.val <= 105pos 为 -1 或者链表中的一个 有效索引 。给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
+ +
示例 1:
+ +
++输入:root = [1,null,2,3] +输出:[1,2,3] ++ +
示例 2:
+ ++输入:root = [] +输出:[] ++ +
示例 3:
+ ++输入:root = [1] +输出:[1] ++ +
示例 4:
+ +
++输入:root = [1,2] +输出:[1,2] ++ +
示例 5:
+ +
++输入:root = [1,null,2] +输出:[1,2] ++ +
+ +
提示:
+ +[0, 100] 内-100 <= Node.val <= 100+ +
进阶:递归算法很简单,你可以通过迭代算法完成吗?
+ + +## template + +```java + +public class TreeNode { + int val; + TreeNode left; + TreeNode right; + + TreeNode(int x) { + val = x; + } +} + +class Solution { + public List给定一个二叉树,返回它的 后序 遍历。
+ +示例:
+ +输入: [1,null,2,3] + 1 + \ + 2 + / + 3 + +输出: [3,2,1]+ +
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
+ + +## template + +```java + +public class TreeNode { + int val; + TreeNode left; + TreeNode right; + + TreeNode(int x) { + val = x; + } +} + +class Solution { + public List设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
push(x) —— 将元素 x 推入栈中。pop() —— 删除栈顶的元素。top() —— 获取栈顶元素。getMin() —— 检索栈中的最小元素。+ +
示例:
+ +输入: +["MinStack","push","push","push","getMin","pop","top","getMin"] +[[],[-2],[0],[-3],[],[],[],[]] + +输出: +[null,null,null,null,-3,null,0,-2] + +解释: +MinStack minStack = new MinStack(); +minStack.push(-2); +minStack.push(0); +minStack.push(-3); +minStack.getMin(); --> 返回 -3. +minStack.pop(); +minStack.top(); --> 返回 0. +minStack.getMin(); --> 返回 -2. ++ +
+ +
提示:
+ +pop、top 和 getMin 操作总是在 非空栈 上调用。给定一个已按照 非递减顺序排列 的整数数组 numbers ,请你从数组中找出两个数满足相加之和等于目标数 target 。
函数应该以长度为 2 的整数数组的形式返回这两个数的下标值。numbers 的下标 从 1 开始计数 ,所以答案数组应当满足 1 <= answer[0] < answer[1] <= numbers.length 。
你可以假设每个输入 只对应唯一的答案 ,而且你 不可以 重复使用相同的元素。
+ + +示例 1:
+ ++输入:numbers = [2,7,11,15], target = 9 +输出:[1,2] +解释:2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。 ++ +
示例 2:
+ ++输入:numbers = [2,3,4], target = 6 +输出:[1,3] ++ +
示例 3:
+ ++输入:numbers = [-1,0], target = -1 +输出:[1,2] ++ +
+ +
提示:
+ +2 <= numbers.length <= 3 * 104-1000 <= numbers[i] <= 1000numbers 按 非递减顺序 排列-1000 <= target <= 1000给你一个整数 columnNumber ,返回它在 Excel 表中相对应的列名称。
例如:
+ ++A -> 1 +B -> 2 +C -> 3 +... +Z -> 26 +AA -> 27 +AB -> 28 +... ++ +
+ +
示例 1:
+ ++输入:columnNumber = 1 +输出:"A" ++ +
示例 2:
+ ++输入:columnNumber = 28 +输出:"AB" ++ +
示例 3:
+ ++输入:columnNumber = 701 +输出:"ZY" ++ +
示例 4:
+ ++输入:columnNumber = 2147483647 +输出:"FXSHRXW" ++ +
+ +
提示:
+ +1 <= columnNumber <= 231 - 1给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
+ ++ +
示例 1:
+ ++输入:[3,2,3] +输出:3+ +
示例 2:
+ ++输入:[2,2,1,1,1,2,2] +输出:2 ++ +
+ +
进阶:
+ +给你一个字符串 columnTitle ,表示 Excel 表格中的列名称。返回该列名称对应的列序号。
+ +
例如,
+ ++ A -> 1 + B -> 2 + C -> 3 + ... + Z -> 26 + AA -> 27 + AB -> 28 + ... ++ +
+ +
示例 1:
+ ++输入: columnTitle = "A" +输出: 1 ++ +
示例 2:
+ ++输入: columnTitle = "AB" +输出: 28 ++ +
示例 3:
+ ++输入: columnTitle = "ZY" +输出: 701+ +
示例 4:
+ ++输入: columnTitle = "FXSHRXW" +输出: 2147483647 ++ +
+ +
提示:
+ +1 <= columnTitle.length <= 7columnTitle 仅由大写英文组成columnTitle 在范围 ["A", "FXSHRXW"] 内给定一个整数 n ,返回 n! 结果中尾随零的数量。
提示 n! = n * (n - 1) * (n - 2) * ... * 3 * 2 * 1
+ +
示例 1:
+ ++输入:n = 3 +输出:0 +解释:3! = 6 ,不含尾随 0 ++ +
示例 2:
+ ++输入:n = 5 +输出:1 +解释:5! = 120 ,有一个尾随 0 ++ +
示例 3:
+ ++输入:n = 0 +输出:0 ++ +
+ +
提示:
+ +0 <= n <= 104+ +
进阶:你可以设计并实现对数时间复杂度的算法来解决此问题吗?
+ + +## template + +```java +class Solution { + public int trailingZeroes(int n) { + int count = 0; + while (n >= 5) { + + count += n / 5; + n /= 5; + } + return count; + } +} + +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/190.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/2.java/190.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..cbcdaa3dbb856771434f4a65620591c07e7e18f1 --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/190.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-e8bccfcdf74e4031916b9771f8935ac4", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/190.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/2.java/190.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..442be3e05f9d43c7495434696afdd03705f6e688 --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/190.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "192a41fa78f94fb4a61b2e637cc02185", + "author": "csdn.net", + "keywords": "位运算,分治" +} \ No newline at end of file diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/190.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/2.java/190.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..0a4f4361f1b3eed389d7f735742b64e1139a5b54 --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/190.exercises/solution.md" @@ -0,0 +1,86 @@ +# 颠倒二进制位 + +颠倒给定的 32 位无符号整数的二进制位。
+ +提示:
+ +-3,输出表示有符号整数 -1073741825。+ +
示例 1:
+ ++输入:n = 00000010100101000001111010011100 +输出:964176192 (00111001011110000010100101000000) +解释:输入的二进制串 00000010100101000001111010011100 表示无符号整数 43261596, + 因此返回 964176192,其二进制表示形式为 00111001011110000010100101000000。+ +
示例 2:
+ ++输入:n = 11111111111111111111111111111101 +输出:3221225471 (10111111111111111111111111111111) +解释:输入的二进制串 11111111111111111111111111111101 表示无符号整数 4294967293, + 因此返回 3221225471 其二进制表示形式为 10111111111111111111111111111111 。+ +
+ +
提示:
+ +32 的二进制字符串+ +
进阶: 如果多次调用这个函数,你将如何优化你的算法?
+ + +## template + +```java +public class Solution { + + public int reverseBits(int n) { + int m = 0; + for (int i = 0; i < 32; i++) { + m <<= 1; + m = m | (n & 1); + n >>= 1; + } + return m; + + } +} + +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/191.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/2.java/191.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..51dcfbad2582983039dddfe0469636ebe2130807 --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/191.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-18e0740c78224c0d83c1948419e53eeb", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/192.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/2.java/191.exercises/solution.json" similarity index 66% rename from "data_source/exercises/\344\270\255\347\255\211/java/192.exercises/solution.json" rename to "data/1.dailycode\345\210\235\351\230\266/2.java/191.exercises/solution.json" index eefd584978238c0d6cc6839061595a593e0821e7..b38de7e6cbf17a20796f4fcfd471b6f57c840f73 100644 --- "a/data_source/exercises/\344\270\255\347\255\211/java/192.exercises/solution.json" +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/191.exercises/solution.json" @@ -1,7 +1,7 @@ { "type": "code_options", "source": "solution.md", - "exercise_id": "b3b497521b344e26bb6259fb5dc21337", + "exercise_id": "fa66dcd535544b94bad5b9e43593bea7", "author": "csdn.net", "keywords": "位运算" } \ No newline at end of file diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/191.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/2.java/191.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..138c8617f764598da8d35ffe60561f8edb578fef --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/191.exercises/solution.md" @@ -0,0 +1,101 @@ +# 位1的个数 + +编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 '1' 的个数(也被称为汉明重量)。
+ ++ +
提示:
+ +-3。+ +
示例 1:
+ +
+输入:00000000000000000000000000001011
+输出:3
+解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。
+
+
+示例 2:
+ ++输入:00000000000000000000000010000000 +输出:1 +解释:输入的二进制串 00000000000000000000000010000000 中,共有一位为 '1'。 ++ +
示例 3:
+ ++输入:11111111111111111111111111111101 +输出:31 +解释:输入的二进制串 11111111111111111111111111111101 中,共有 31 位为 '1'。+ +
+ +
提示:
+ +32 的 二进制串 。+ +
进阶:
+ +编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」定义为:
+ +如果 n 是快乐数就返回 true ;不是,则返回 false 。
+ +
示例 1:
+ ++输入:19 +输出:true +解释: +12 + 92 = 82 +82 + 22 = 68 +62 + 82 = 100 +12 + 02 + 02 = 1 ++ +
示例 2:
+ ++输入:n = 2 +输出:false ++ +
+ +
提示:
+ +1 <= n <= 231 - 1head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
++ +
示例 1:
+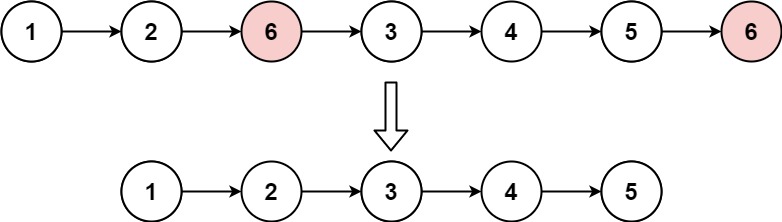 +
++输入:head = [1,2,6,3,4,5,6], val = 6 +输出:[1,2,3,4,5] ++ +
示例 2:
+ ++输入:head = [], val = 1 +输出:[] ++ +
示例 3:
+ ++输入:head = [7,7,7,7], val = 7 +输出:[] ++ +
+ +
提示:
+ +[0, 104] 内1 <= Node.val <= 500 <= val <= 50统计所有小于非负整数 n 的质数的数量。
+ +
示例 1:
+ +输入:n = 10 +输出:4 +解释:小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 。 ++ +
示例 2:
+ +输入:n = 0 +输出:0 ++ +
示例 3:
+ +输入:n = 1 +输出:0 ++ +
+ +
提示:
+ +0 <= n <= 5 * 106给定两个字符串 s 和 t,判断它们是否是同构的。
+ +如果 s 中的字符可以按某种映射关系替换得到 t ,那么这两个字符串是同构的。
+ +每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相同字符只能映射到同一个字符上,字符可以映射到自己本身。
+ ++ +
示例 1:
+ ++输入:s =+ +"egg",t ="add"+输出:true +
示例 2:
+ ++输入:s =+ +"foo",t ="bar"+输出:false
示例 3:
+ ++输入:s =+ +"paper",t ="title"+输出:true
+ +
提示:
+ +head ,请你反转链表,并返回反转后的链表。
++ +
示例 1:
+ +
++输入:head = [1,2,3,4,5] +输出:[5,4,3,2,1] ++ +
示例 2:
+ +
++输入:head = [1,2] +输出:[2,1] ++ +
示例 3:
+ ++输入:head = [] +输出:[] ++ +
+ +
提示:
+ +[0, 5000]-5000 <= Node.val <= 5000+ +
进阶:链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
+给定一个整数数组,判断是否存在重复元素。
+ +如果存在一值在数组中出现至少两次,函数返回 true 。如果数组中每个元素都不相同,则返回 false 。
+ +
示例 1:
+ ++输入: [1,2,3,1] +输出: true+ +
示例 2:
+ ++输入: [1,2,3,4] +输出: false+ +
示例 3:
+ ++输入: [1,1,1,3,3,4,3,2,4,2] +输出: true+ + +## template + +```java +class Solution { + public boolean containsDuplicate(int[] nums) { + Map
给定一个整数数组和一个整数 k,判断数组中是否存在两个不同的索引 i 和 j,使得 nums [i] = nums [j],并且 i 和 j 的差的 绝对值 至多为 k。
+ ++ +
示例 1:
+ +输入: nums = [1,2,3,1], k = 3 +输出: true+ +
示例 2:
+ +输入: nums = [1,0,1,1], k = 1 +输出: true+ +
示例 3:
+ +输入: nums = [1,2,3,1,2,3], k = 2 +输出: false+ + +## template + +```java +public class Solution { + public boolean containsNearbyDuplicate(int[] nums, int k) { + int left = 0; + int right = -1; + HashMap
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。
实现 MyStack 类:
void push(int x) 将元素 x 压入栈顶。int pop() 移除并返回栈顶元素。int top() 返回栈顶元素。boolean empty() 如果栈是空的,返回 true ;否则,返回 false 。+ +
注意:
+ +push to back、peek/pop from front、size 和 is empty 这些操作。+ +
示例:
+ ++输入: +["MyStack", "push", "push", "top", "pop", "empty"] +[[], [1], [2], [], [], []] +输出: +[null, null, null, 2, 2, false] + +解释: +MyStack myStack = new MyStack(); +myStack.push(1); +myStack.push(2); +myStack.top(); // 返回 2 +myStack.pop(); // 返回 2 +myStack.empty(); // 返回 False ++ +
+ +
提示:
+ +1 <= x <= 9100 次 push、pop、top 和 emptypop 和 top 都保证栈不为空+ +
进阶:你能否实现每种操作的均摊时间复杂度为 O(1) 的栈?换句话说,执行 n 个操作的总时间复杂度 O(n) ,尽管其中某个操作可能需要比其他操作更长的时间。你可以使用两个以上的队列。
翻转一棵二叉树。
+ +示例:
+ +输入:
+ +4 + / \ + 2 7 + / \ / \ +1 3 6 9+ +
输出:
+ +4 + / \ + 7 2 + / \ / \ +9 6 3 1+ +
备注:
+这个问题是受到 Max Howell 的 原问题 启发的 :
谷歌:我们90%的工程师使用您编写的软件(Homebrew),但是您却无法在面试时在白板上写出翻转二叉树这道题,这太糟糕了。+ + +## template + +```java +public class TreeNode { + int val; + TreeNode left; + TreeNode right; + + TreeNode(int x) { + val = x; + } +} + + +class Solution { + + public TreeNode invertTree(TreeNode root) { + + if (root == null) + return null; + Queue
给定一个无重复元素的有序整数数组 nums 。
返回 恰好覆盖数组中所有数字 的 最小有序 区间范围列表。也就是说,nums 的每个元素都恰好被某个区间范围所覆盖,并且不存在属于某个范围但不属于 nums 的数字 x 。
列表中的每个区间范围 [a,b] 应该按如下格式输出:
"a->b" ,如果 a != b"a" ,如果 a == b+ +
示例 1:
+ ++输入:nums = [0,1,2,4,5,7] +输出:["0->2","4->5","7"] +解释:区间范围是: +[0,2] --> "0->2" +[4,5] --> "4->5" +[7,7] --> "7" ++ +
示例 2:
+ ++输入:nums = [0,2,3,4,6,8,9] +输出:["0","2->4","6","8->9"] +解释:区间范围是: +[0,0] --> "0" +[2,4] --> "2->4" +[6,6] --> "6" +[8,9] --> "8->9" ++ +
示例 3:
+ ++输入:nums = [] +输出:[] ++ +
示例 4:
+ ++输入:nums = [-1] +输出:["-1"] ++ +
示例 5:
+ ++输入:nums = [0] +输出:["0"] ++ +
+ +
提示:
+ +0 <= nums.length <= 20-231 <= nums[i] <= 231 - 1nums 中的所有值都 互不相同nums 按升序排列给你一个整数 n,请你判断该整数是否是 2 的幂次方。如果是,返回 true ;否则,返回 false 。
如果存在一个整数 x 使得 n == 2x ,则认为 n 是 2 的幂次方。
+ +
示例 1:
+ ++输入:n = 1 +输出:true +解释:20 = 1 ++ +
示例 2:
+ ++输入:n = 16 +输出:true +解释:24 = 16 ++ +
示例 3:
+ ++输入:n = 3 +输出:false ++ +
示例 4:
+ ++输入:n = 4 +输出:true ++ +
示例 5:
+ ++输入:n = 5 +输出:false ++ +
+ +
提示:
+ +-231 <= n <= 231 - 1+ +
进阶:你能够不使用循环/递归解决此问题吗?
+ + +## template + +```java +class Solution { + public boolean isPowerOfTwo(int n) { + if (n <= 0) + return false; + return countBit(n) == 1; + } + + public int countBit(int num) { + int count = 0; + while (num != 0) { + count += (num & 1); + num >>= 1; + } + return count; + + } +} +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/232.exercises/config.json" "b/data/1.dailycode\345\210\235\351\230\266/2.java/232.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..67ad65529dd5b443cc4fb59e7be300b92170836d --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/232.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-cba24ee1b0204e13b21c169db5661dfc", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/232.exercises/solution.json" "b/data/1.dailycode\345\210\235\351\230\266/2.java/232.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..2a702ee81dfd90679b2e0ce7b30cb6bda19c9219 --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/232.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "d0c31ea817924ac0b91f30e846b3e1ad", + "author": "csdn.net", + "keywords": "栈,设计,队列" +} \ No newline at end of file diff --git "a/data/1.dailycode\345\210\235\351\230\266/2.java/232.exercises/solution.md" "b/data/1.dailycode\345\210\235\351\230\266/2.java/232.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..1acfb954062e6cd604200da8ef393f478158bef8 --- /dev/null +++ "b/data/1.dailycode\345\210\235\351\230\266/2.java/232.exercises/solution.md" @@ -0,0 +1,140 @@ +# 用栈实现队列 + +请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
实现 MyQueue 类:
void push(int x) 将元素 x 推到队列的末尾int pop() 从队列的开头移除并返回元素int peek() 返回队列开头的元素boolean empty() 如果队列为空,返回 true ;否则,返回 false+ +
说明:
+ +push to top, peek/pop from top, size, 和 is empty 操作是合法的。+ +
进阶:
+ +O(1) 的队列?换句话说,执行 n 个操作的总时间复杂度为 O(n) ,即使其中一个操作可能花费较长时间。+ +
示例:
+ ++输入: +["MyQueue", "push", "push", "peek", "pop", "empty"] +[[], [1], [2], [], [], []] +输出: +[null, null, null, 1, 1, false] + +解释: +MyQueue myQueue = new MyQueue(); +myQueue.push(1); // queue is: [1] +myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue) +myQueue.peek(); // return 1 +myQueue.pop(); // return 1, queue is [2] +myQueue.empty(); // return false ++ +
+ +
提示:
+ +1 <= x <= 9100 次 push、pop、peek 和 emptypop 或者 peek 操作)给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
+ +
示例 1:
+ +
++输入:head = [1,2,2,1] +输出:true ++ +
示例 2:
+ +
++输入:head = [1,2] +输出:false ++ +
+ +
提示:
+ +[1, 105] 内0 <= Node.val <= 9+ +
进阶:你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
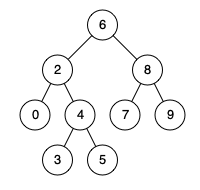
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
+ +百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
+ +例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
+ +
+ +
示例 1:
+ +输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 +输出: 6 +解释: 节点+ +2和节点8的最近公共祖先是6。+
示例 2:
+ +输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4 +输出: 2 +解释: 节点+ +2和节点4的最近公共祖先是2, 因为根据定义最近公共祖先节点可以为节点本身。
+ +
说明:
+ +给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
+ ++ +
示例:
+二叉树:[3,9,20,null,null,15,7],
+ 3 + / \ + 9 20 + / \ + 15 7 ++ +
返回其层序遍历结果:
+ ++[ + [3], + [9,20], + [15,7] +] ++ + +## template + +```java +public class TreeNode { + int val; + TreeNode left; + TreeNode right; + + TreeNode(int x) { + val = x; + } +} + +class Solution { + public List
给定一个二叉树,返回其节点值的锯齿形层序遍历。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
+ +例如:
+给定二叉树 [3,9,20,null,null,15,7],
+ 3 + / \ + 9 20 + / \ + 15 7 ++ +
返回锯齿形层序遍历如下:
+ ++[ + [3], + [20,9], + [15,7] +] ++ + +## template + +```java + +public class TreeNode { + int val; + TreeNode left; + TreeNode right; + + TreeNode(int x) { + val = x; + } +} + +class Solution { + public List
给定一棵树的前序遍历 preorder 与中序遍历 inorder。请构造二叉树并返回其根节点。
+ +
示例 1:
+ +
++Input: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7] +Output: [3,9,20,null,null,15,7] ++ +
示例 2:
+ ++Input: preorder = [-1], inorder = [-1] +Output: [-1] ++ +
+ +
提示:
+ +1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder 和 inorder 均无重复元素inorder 均出现在 preorderpreorder 保证为二叉树的前序遍历序列inorder 保证为二叉树的中序遍历序列根据一棵树的中序遍历与后序遍历构造二叉树。
+ +注意:
+你可以假设树中没有重复的元素。
例如,给出
+ +中序遍历 inorder = [9,3,15,20,7] +后序遍历 postorder = [9,15,7,20,3]+ +
返回如下的二叉树:
+ +3 + / \ + 9 20 + / \ + 15 7 ++ + +## template + +```java +public class TreeNode { + int val; + TreeNode left; + TreeNode right; + + TreeNode(int x) { + val = x; + } +} + +class Solution { + public TreeNode buildTree(int[] inorder, int[] postorder) { + return helper(inorder, postorder, postorder.length - 1, 0, inorder.length - 1); + } + + public TreeNode helper(int[] inorder, int[] postorder, int postEnd, int inStart, int inEnd) { + if (inStart > inEnd) { + return null; + } + + int currentVal = postorder[postEnd]; + TreeNode current = new TreeNode(currentVal); + + int inIndex = 0; + for (int i = inStart; i <= inEnd; i++) { + if (inorder[i] == currentVal) { + inIndex = i; + } + } + TreeNode left = helper(inorder, postorder, postEnd - (inEnd - inIndex) - 1, inStart, inIndex - 1); + TreeNode right = helper(inorder, postorder, postEnd - 1, inIndex + 1, inEnd); + current.left = left; + current.right = right; + return current; + } +} + +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/107.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/2.java/107.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..ad5090a0ced51d0dcb65a5fc31d739edc024018c --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/107.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-7bc90c68c2e040abaf544ce5034b98be", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/107.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/2.java/107.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..0fd5e27564e3f6aae1e7cd395ca8d6acfba2dd27 --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/107.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "c243d27f11ae40178101f3a631183c6e", + "author": "csdn.net", + "keywords": "树,广度优先搜索,二叉树" +} \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/107.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/2.java/107.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..9177280110d7d9bde39ab26e3482e60f61c6f417 --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/107.exercises/solution.md" @@ -0,0 +1,92 @@ +# 二叉树的层序遍历 II + +
给定一个二叉树,返回其节点值自底向上的层序遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
+ +例如:
+给定二叉树 [3,9,20,null,null,15,7],
+ 3 + / \ + 9 20 + / \ + 15 7 ++ +
返回其自底向上的层序遍历为:
+ ++[ + [15,7], + [9,20], + [3] +] ++ + +## template + +```java +public class TreeNode { + int val; + TreeNode left; + TreeNode right; + + TreeNode(int x) { + val = x; + } +} + +class Solution { + public List
给定一个单链表,其中的元素按升序排序,将其转换为高度平衡的二叉搜索树。
+ +本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
+ +示例:
+ +给定的有序链表: [-10, -3, 0, 5, 9], + +一个可能的答案是:[0, -3, 9, -10, null, 5], 它可以表示下面这个高度平衡二叉搜索树: + + 0 + / \ + -3 9 + / / + -10 5 ++ + +## template + +```java + +public class ListNode { + int val; + ListNode next; + + ListNode() { + } + + ListNode(int val) { + this.val = val; + } + + ListNode(int val, ListNode next) { + this.val = val; + this.next = next; + } +} + +public class TreeNode { + int val; + TreeNode left; + TreeNode right; + + TreeNode() { + } + + TreeNode(int val) { + this.val = val; + } + + TreeNode(int val, TreeNode left, TreeNode right) { + this.val = val; + this.left = left; + this.right = right; + } +} + +class Solution { + public TreeNode sortedListToBST(ListNode head) { + if (head == null) + return null; + return helper(head, null); + } + + private TreeNode helper(ListNode start, ListNode end) { + if (start == end) + return null; + + ListNode slow = start; + ListNode fast = start; + + while (fast != end && fast.next != end) { + + slow = slow.next; + + fast = fast.next.next; + } + + TreeNode root = new TreeNode(slow.val); + + root.left = helper(start, slow); + + root.right = helper(slow.next, end); + return root; + } +} + +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/113.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/2.java/113.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..a4d23201ae4435d2e07a319f69faec6491a699b5 --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/113.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-7d17892d955e4c4199329919b6f5f2fa", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/113.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/2.java/113.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..a42d367c507390d65063ad0e9e06927369b4f623 --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/113.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "b7b39f6a4e2c422e9ea675fdb15c7443", + "author": "csdn.net", + "keywords": "树,深度优先搜索,回溯,二叉树" +} \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/113.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/2.java/113.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..f6ae8e888a02f8cec21b94d75b34274913d8f54b --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/113.exercises/solution.md" @@ -0,0 +1,101 @@ +# 路径总和 II + +
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
+ ++ +
示例 1:
+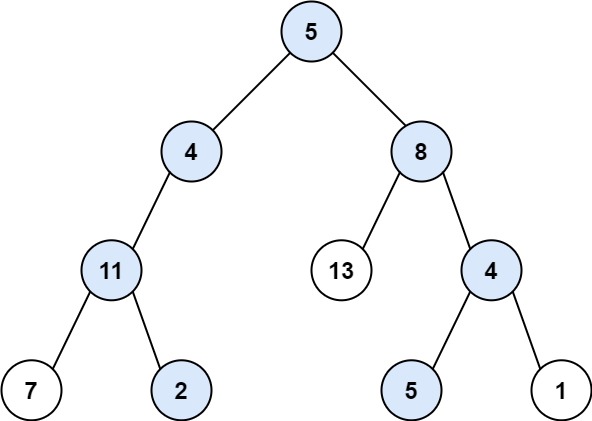 +
++输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22 +输出:[[5,4,11,2],[5,8,4,5]] ++ +
示例 2:
+
++输入:root = [1,2,3], targetSum = 5 +输出:[] ++ +
示例 3:
+ ++输入:root = [1,2], targetSum = 0 +输出:[] ++ +
+ +
提示:
+ +[0, 5000] 内-1000 <= Node.val <= 1000-1000 <= targetSum <= 1000给你二叉树的根结点 root ,请你将它展开为一个单链表:
TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。+ +
示例 1:
+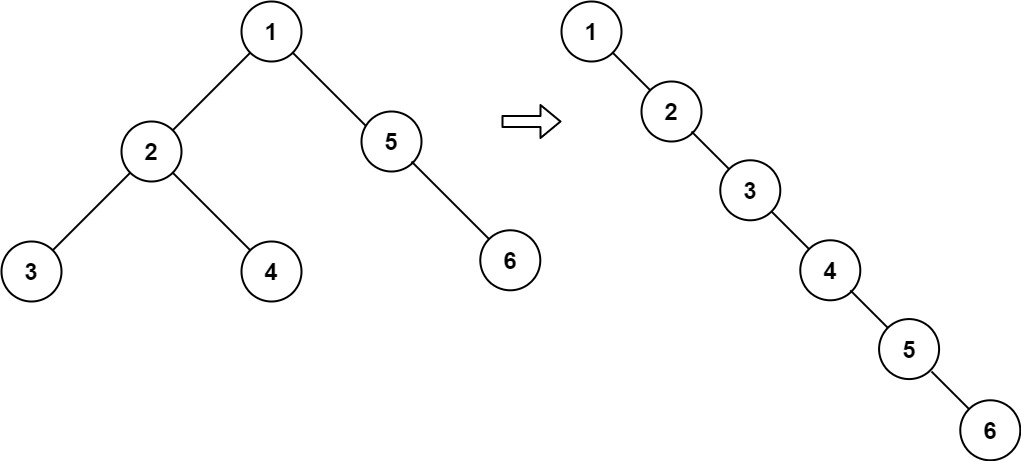 +
++输入:root = [1,2,5,3,4,null,6] +输出:[1,null,2,null,3,null,4,null,5,null,6] ++ +
示例 2:
+ ++输入:root = [] +输出:[] ++ +
示例 3:
+ ++输入:root = [0] +输出:[0] ++ +
+ +
提示:
+ +[0, 2000] 内-100 <= Node.val <= 100+ +
进阶:你可以使用原地算法(O(1) 额外空间)展开这棵树吗?
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
+ +
+struct Node {
+ int val;
+ Node *left;
+ Node *right;
+ Node *next;
+}
+
+填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
+ +
进阶:
+ ++ +
示例:
+ +
+输入:root = [1,2,3,4,5,6,7] +输出:[1,#,2,3,#,4,5,6,7,#] +解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,'#' 标志着每一层的结束。 ++ +
+ +
提示:
+ +4096-1000 <= node.val <= 1000给定一个二叉树
+ +
+struct Node {
+ int val;
+ Node *left;
+ Node *right;
+ Node *next;
+}
+
+填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
+ +
进阶:
+ ++ +
示例:
+ +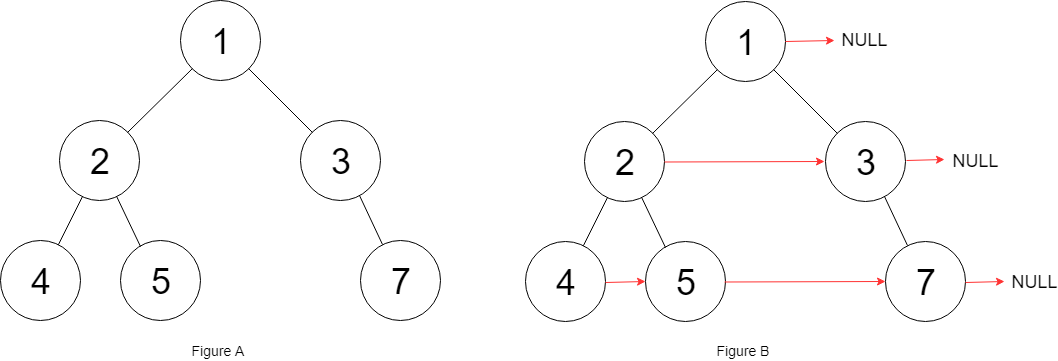
+输入:root = [1,2,3,4,5,null,7] +输出:[1,#,2,3,#,4,5,7,#] +解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化输出按层序遍历顺序(由 next 指针连接),'#' 表示每层的末尾。+ +
+ +
提示:
+ +6000-100 <= node.val <= 100+ +
给定一个三角形 triangle ,找出自顶向下的最小路径和。
每一步只能移动到下一行中相邻的结点上。相邻的结点 在这里指的是 下标 与 上一层结点下标 相同或者等于 上一层结点下标 + 1 的两个结点。也就是说,如果正位于当前行的下标 i ,那么下一步可以移动到下一行的下标 i 或 i + 1 。
+ +
示例 1:
+ ++输入:triangle = [[2],[3,4],[6,5,7],[4,1,8,3]] +输出:11 +解释:如下面简图所示: + 2 + 3 4 + 6 5 7 +4 1 8 3 +自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。 ++ +
示例 2:
+ ++输入:triangle = [[-10]] +输出:-10 ++ +
+ +
提示:
+ +1 <= triangle.length <= 200triangle[0].length == 1triangle[i].length == triangle[i - 1].length + 1-104 <= triangle[i][j] <= 104+ +
进阶:
+ +O(n) 的额外空间(n 为三角形的总行数)来解决这个问题吗?给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
+ +
示例 1:
+ +
+输入:nums = [100,4,200,1,3,2]
+输出:4
+解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
+
+示例 2:
+ ++输入:nums = [0,3,7,2,5,8,4,6,0,1] +输出:9 ++ +
+ +
提示:
+ +0 <= nums.length <= 105-109 <= nums[i] <= 109root ,树中每个节点都存放有一个 0 到 9 之间的数字。
+每条从根节点到叶节点的路径都代表一个数字:
+ +1 -> 2 -> 3 表示数字 123 。计算从根节点到叶节点生成的 所有数字之和 。
+ +叶节点 是指没有子节点的节点。
+ ++ +
示例 1:
+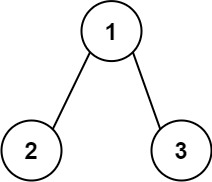 +
++输入:root = [1,2,3] +输出:25 +解释: +从根到叶子节点路径+ +1->2代表数字12+从根到叶子节点路径1->3代表数字13+因此,数字总和 = 12 + 13 =25
示例 2:
+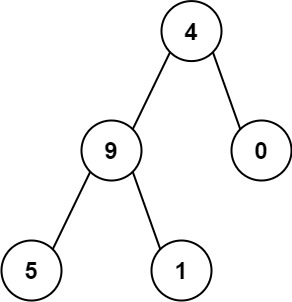 +
++输入:root = [4,9,0,5,1] +输出:1026 +解释: +从根到叶子节点路径+ +4->9->5代表数字 495 +从根到叶子节点路径4->9->1代表数字 491 +从根到叶子节点路径4->0代表数字 40 +因此,数字总和 = 495 + 491 + 40 =1026+
+ +
提示:
+ +[1, 1000] 内0 <= Node.val <= 910m x n 的矩阵 board ,由若干字符 'X' 和 'O' ,找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
++ +
示例 1:
+ +
++输入:board = [["X","X","X","X"],["X","O","O","X"],["X","X","O","X"],["X","O","X","X"]] +输出:[["X","X","X","X"],["X","X","X","X"],["X","X","X","X"],["X","O","X","X"]] +解释:被围绕的区间不会存在于边界上,换句话说,任何边界上的+ +'O'都不会被填充为'X'。 任何不在边界上,或不与边界上的'O'相连的'O'最终都会被填充为'X'。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。 +
示例 2:
+ ++输入:board = [["X"]] +输出:[["X"]] ++ +
+ +
提示:
+ +m == board.lengthn == board[i].length1 <= m, n <= 200board[i][j] 为 'X' 或 'O'给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
回文串 是正着读和反着读都一样的字符串。
+ ++ +
示例 1:
+ ++输入:s = "aab" +输出:[["a","a","b"],["aa","b"]] ++ +
示例 2:
+ ++输入:s = "a" +输出:[["a"]] ++ +
+ +
提示:
+ +1 <= s.length <= 16s 仅由小写英文字母组成给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
+ +图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
class Node {
+ public int val;
+ public List<Node> neighbors;
+}
+
++ +
测试用例格式:
+ +简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1(val = 1),第二个节点值为 2(val = 2),以此类推。该图在测试用例中使用邻接列表表示。
邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
+ +给定节点将始终是图中的第一个节点(值为 1)。你必须将 给定节点的拷贝 作为对克隆图的引用返回。
+ ++ +
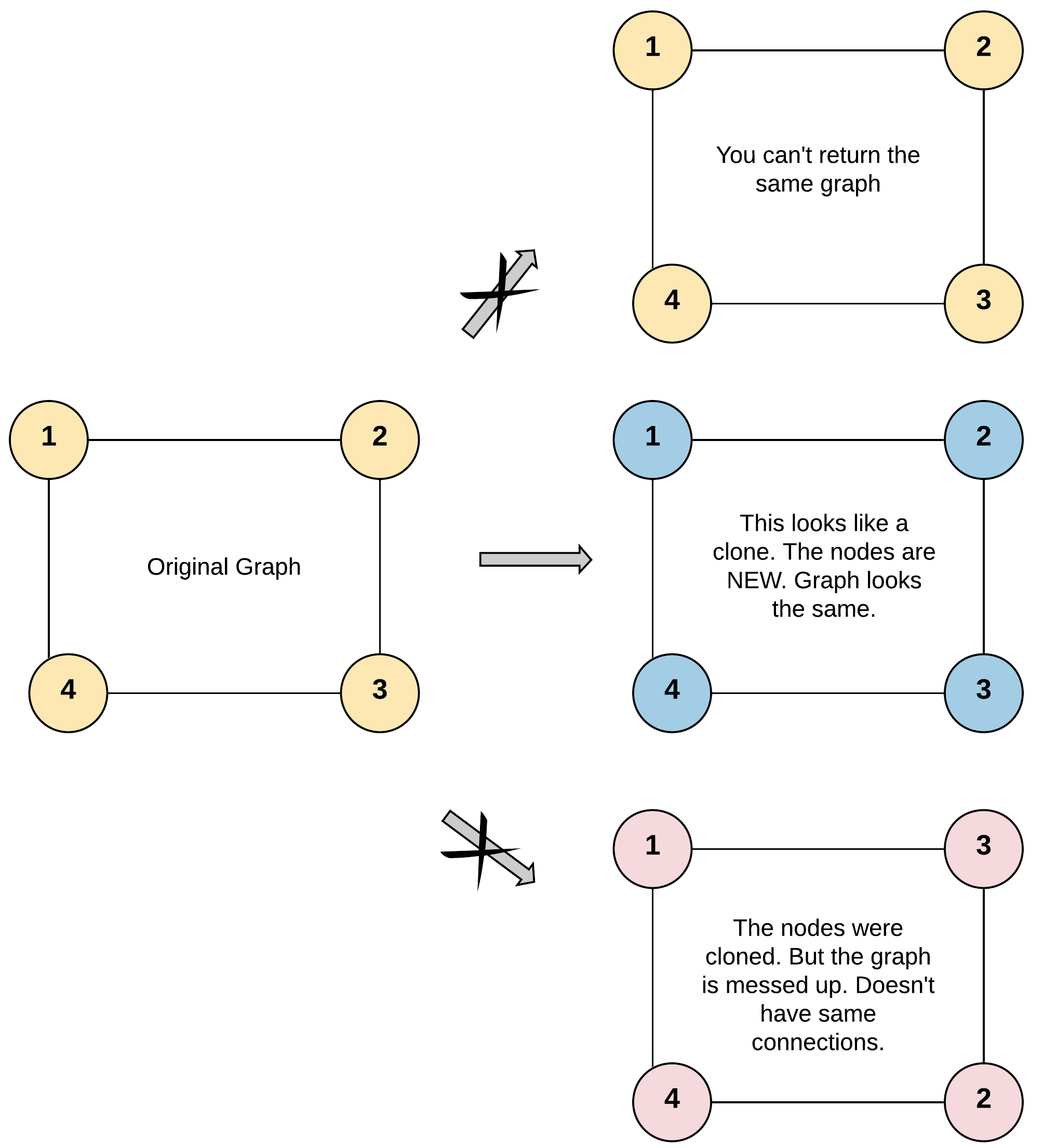
示例 1:
+ +
输入:adjList = [[2,4],[1,3],[2,4],[1,3]] +输出:[[2,4],[1,3],[2,4],[1,3]] +解释: +图中有 4 个节点。 +节点 1 的值是 1,它有两个邻居:节点 2 和 4 。 +节点 2 的值是 2,它有两个邻居:节点 1 和 3 。 +节点 3 的值是 3,它有两个邻居:节点 2 和 4 。 +节点 4 的值是 4,它有两个邻居:节点 1 和 3 。 ++ +
示例 2:
+ +
输入:adjList = [[]] +输出:[[]] +解释:输入包含一个空列表。该图仅仅只有一个值为 1 的节点,它没有任何邻居。 ++ +
示例 3:
+ +输入:adjList = [] +输出:[] +解释:这个图是空的,它不含任何节点。 ++ +
示例 4:
+ +
输入:adjList = [[2],[1]] +输出:[[2],[1]]+ +
+ +
提示:
+ +Node.val 都是唯一的,1 <= Node.val <= 100。在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1。
+ +说明:
+ +示例 1:
+ +输入: +gas = [1,2,3,4,5] +cost = [3,4,5,1,2] + +输出: 3 + +解释: +从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油 +开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油 +开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油 +开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油 +开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油 +开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。 +因此,3 可为起始索引。+ +
示例 2:
+ +输入: +gas = [2,3,4] +cost = [3,4,3] + +输出: -1 + +解释: +你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。 +我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油 +开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油 +开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油 +你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。 +因此,无论怎样,你都不可能绕环路行驶一周。+ + +## template + +```java +class Solution { + public int canCompleteCircuit(int[] gas, int[] cost) { + int n = gas.length; + int sum = 0, cur = 0, start = 0; + for (int i = 0; i < n; i++) { + sum = sum + gas[i] - cost[i]; + if (cur < 0) { + start = i; + cur = gas[i] - cost[i]; + } else + cur = cur + gas[i] - cost[i]; + } + if (sum < 0) + return -1; + return start; + } +} + + +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/137.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/2.java/137.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..dd5c7a6c171460bc28239899853cec5d14a910c0 --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/137.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-e63bc430999940118df0d565da770675", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/137.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/2.java/137.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..3c77f7412c7c25e8ff838d999d42add15aeec283 --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/137.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "45585dd9d6054a9cb9b039029175d81b", + "author": "csdn.net", + "keywords": "位运算,数组" +} \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/137.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/2.java/137.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..5f5a4a67f4b82074c8b9ca3be06ee8fa7878ab62 --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/137.exercises/solution.md" @@ -0,0 +1,87 @@ +# 只出现一次的数字 II + +
给你一个整数数组 nums ,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次 。请你找出并返回那个只出现了一次的元素。
+ +
示例 1:
+ ++输入:nums = [2,2,3,2] +输出:3 ++ +
示例 2:
+ ++输入:nums = [0,1,0,1,0,1,99] +输出:99 ++ +
+ +
提示:
+ +1 <= nums.length <= 3 * 104-231 <= nums[i] <= 231 - 1nums 中,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次+ +
进阶:你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
+ + +## template + +```java +class Solution { + public int singleNumber(int[] nums) { + + int ret = 0; + for (int i = 0; i < 32; ++i) { + int bitnums = 0; + + int bit = 1 << i; + for (int num : nums) { + + if ((num & bit) != 0) + bitnums++; + } + + if (bitnums % 3 != 0) + ret |= bit; + } + return ret; + } +} + + +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/138.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/2.java/138.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..62ac7f1ce97980614dde0fc5c25e9948cbab11dd --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/138.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-55e51a28f29444599868b299e1d57cbe", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/138.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/2.java/138.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..d8917b22c977172fbd0ac9bd3ca40ab52df22a9f --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/138.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "5392710266504c69ac6bb4002bfd7407", + "author": "csdn.net", + "keywords": "哈希表,链表" +} \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/138.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/2.java/138.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..eda011dcc6a96b6aca7c72be21ada4850de7149f --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/138.exercises/solution.md" @@ -0,0 +1,138 @@ +# 复制带随机指针的链表 + +给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
+ +用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。你的代码 只 接受原链表的头节点 head 作为传入参数。
+ +
示例 1:
+ +
+输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] +输出:[[7,null],[13,0],[11,4],[10,2],[1,0]] ++ +
示例 2:
+ +
+输入:head = [[1,1],[2,1]] +输出:[[1,1],[2,1]] ++ +
示例 3:
+ +
+输入:head = [[3,null],[3,0],[3,null]] +输出:[[3,null],[3,0],[3,null]] ++ +
示例 4:
+ ++输入:head = [] +输出:[] +解释:给定的链表为空(空指针),因此返回 null。 ++ +
+ +
提示:
+ +0 <= n <= 1000-10000 <= Node.val <= 10000Node.random 为空(null)或指向链表中的节点。给定一个非空字符串 s 和一个包含非空单词的列表 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
+ +说明:
+ +示例 1:
+ +输入: s = "leetcode", wordDict = ["leet", "code"] +输出: true +解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。 ++ +
示例 2:
+ +输入: s = "applepenapple", wordDict = ["apple", "pen"] +输出: true +解释: 返回 true 因为+ +"applepenapple"可以被拆分成"apple pen apple"。 + 注意你可以重复使用字典中的单词。 +
示例 3:
+ +输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] +输出: false ++ + +## template + +```java + +public class Solution { + public boolean wordBreak(String s, List
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。注意,pos 仅仅是用于标识环的情况,并不会作为参数传递到函数中。
说明:不允许修改给定的链表。
+ +进阶:
+ +O(1) 空间解决此题?+ +
示例 1:
+ +
+输入:head = [3,2,0,-4], pos = 1 +输出:返回索引为 1 的链表节点 +解释:链表中有一个环,其尾部连接到第二个节点。 ++ +
示例 2:
+ +
+输入:head = [1,2], pos = 0 +输出:返回索引为 0 的链表节点 +解释:链表中有一个环,其尾部连接到第一个节点。 ++ +
示例 3:
+ +
+输入:head = [1], pos = -1 +输出:返回 null +解释:链表中没有环。 ++ +
+ +
提示:
+ +[0, 104] 内-105 <= Node.val <= 105pos 的值为 -1 或者链表中的一个有效索引给定一个单链表 L 的头节点 head ,单链表 L 表示为:
L0 → L1 → … → Ln-1 → Ln
+请将其重新排列后变为:
L0 → Ln → L1 → Ln-1 → L2 → Ln-2 → …
不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
+ ++ +
示例 1:
+ +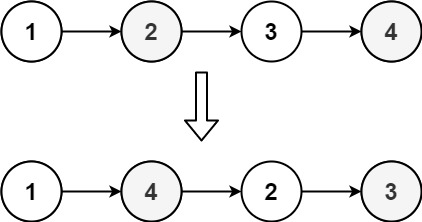
+输入: head = [1,2,3,4] +输出: [1,4,2,3]+ +
示例 2:
+ +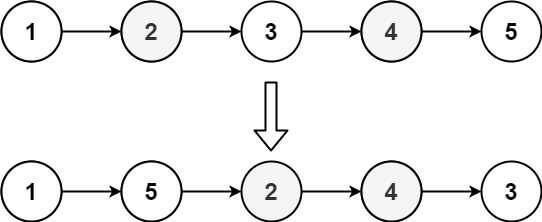
+输入: head = [1,2,3,4,5] +输出: [1,5,2,4,3]+ +
+ +
提示:
+ +[1, 5 * 104]1 <= node.val <= 1000实现 LRUCache 类:
LRUCache(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。void put(int key, int value) 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。+
进阶:你是否可以在 O(1) 时间复杂度内完成这两种操作?
+ +
示例:
+ +
+输入
+["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
+[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
+输出
+[null, null, null, 1, null, -1, null, -1, 3, 4]
+
+解释
+LRUCache lRUCache = new LRUCache(2);
+lRUCache.put(1, 1); // 缓存是 {1=1}
+lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
+lRUCache.get(1); // 返回 1
+lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
+lRUCache.get(2); // 返回 -1 (未找到)
+lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
+lRUCache.get(1); // 返回 -1 (未找到)
+lRUCache.get(3); // 返回 3
+lRUCache.get(4); // 返回 4
+
+
++ +
提示:
+ +1 <= capacity <= 30000 <= key <= 100000 <= value <= 1052 * 105 次 get 和 put对链表进行插入排序。
+ +
+插入排序的动画演示如上。从第一个元素开始,该链表可以被认为已经部分排序(用黑色表示)。
+每次迭代时,从输入数据中移除一个元素(用红色表示),并原地将其插入到已排好序的链表中。
+ +
插入排序算法:
+ ++ +
示例 1:
+ +输入: 4->2->1->3 +输出: 1->2->3->4 ++ +
示例 2:
+ +输入: -1->5->3->4->0 +输出: -1->0->3->4->5 ++ + +## template + +```java +public class ListNode { + int val; + ListNode next; + + ListNode(int x) { + val = x; + } +} + + +class Solution { + public ListNode insertionSortList(ListNode head) { + if (head == null) + return head; + ListNode res = new ListNode(head.val); + ListNode left = head.next; + while ((left != null)) { + ListNode cur = left; + left = left.next; + + if (cur.val <= res.val) { + cur.next = res; + res = cur; + continue; + } + + ListNode p = res; + ListNode last = p; + while (p != null && p.val < cur.val) { + last = p; + p = p.next; + } + last.next = cur; + last.next.next = p; + } + return res; + } +} +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/148.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/2.java/148.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..9a06fba03f32980581a8b4b723a7a91dbe6d3fc9 --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/148.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-60835a48fea84f49a675dd21417d061b", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/148.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/2.java/148.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..223d7fba75119f7ebc35a44c157c01f8eb71b263 --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/148.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "71419e1d7bc74b23958e1b78923ad9a1", + "author": "csdn.net", + "keywords": "链表,双指针,分治,排序,归并排序" +} \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/148.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/2.java/148.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..bb862a6a5095775fd7248d243c91d9a3050b1ed6 --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/148.exercises/solution.md" @@ -0,0 +1,142 @@ +# 排序链表 + +
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
进阶:
+ +O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?+ +
示例 1:
+ +
++输入:head = [4,2,1,3] +输出:[1,2,3,4] ++ +
示例 2:
+ +
++输入:head = [-1,5,3,4,0] +输出:[-1,0,3,4,5] ++ +
示例 3:
+ ++输入:head = [] +输出:[] ++ +
+ +
提示:
+ +[0, 5 * 104] 内-105 <= Node.val <= 105根据 逆波兰表示法,求表达式的值。
+ +有效的算符包括 +、-、*、/ 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
+ +
说明:
+ ++ +
示例 1:
+ ++输入:tokens = ["2","1","+","3","*"] +输出:9 +解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9 ++ +
示例 2:
+ ++输入:tokens = ["4","13","5","/","+"] +输出:6 +解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6 ++ +
示例 3:
+ ++输入:tokens = ["10","6","9","3","+","-11","*","/","*","17","+","5","+"] +输出:22 +解释: +该算式转化为常见的中缀算术表达式为: + ((10 * (6 / ((9 + 3) * -11))) + 17) + 5 += ((10 * (6 / (12 * -11))) + 17) + 5 += ((10 * (6 / -132)) + 17) + 5 += ((10 * 0) + 17) + 5 += (0 + 17) + 5 += 17 + 5 += 22+ +
+ +
提示:
+ +1 <= tokens.length <= 104tokens[i] 要么是一个算符("+"、"-"、"*" 或 "/"),要么是一个在范围 [-200, 200] 内的整数+ +
逆波兰表达式:
+ +逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
+ +( 1 + 2 ) * ( 3 + 4 ) 。( ( 1 2 + ) ( 3 4 + ) * ) 。逆波兰表达式主要有以下两个优点:
+ +1 2 + 3 4 + * 也可以依据次序计算出正确结果。给你一个字符串 s ,逐个翻转字符串中的所有 单词 。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
请你返回一个翻转 s 中单词顺序并用单个空格相连的字符串。
说明:
+ +s 可以在前面、后面或者单词间包含多余的空格。+ +
示例 1:
+ ++输入:s = "+ +the sky is blue" +输出:"blue is sky the" +
示例 2:
+ ++输入:s = " hello world " +输出:"world hello" +解释:输入字符串可以在前面或者后面包含多余的空格,但是翻转后的字符不能包括。 ++ +
示例 3:
+ ++输入:s = "a good example" +输出:"example good a" +解释:如果两个单词间有多余的空格,将翻转后单词间的空格减少到只含一个。 ++ +
示例 4:
+ ++输入:s = " Bob Loves Alice " +输出:"Alice Loves Bob" ++ +
示例 5:
+ ++输入:s = "Alice does not even like bob" +输出:"bob like even not does Alice" ++ +
+ +
提示:
+ +1 <= s.length <= 104s 包含英文大小写字母、数字和空格 ' 's 中 至少存在一个 单词+ +
进阶:
+ +O(1) 额外空间复杂度的原地解法。给你一个整数数组 nums ,请你找出数组中乘积最大的连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
+ +
示例 1:
+ +输入: [2,3,-2,4]
+输出: 6
+解释: 子数组 [2,3] 有最大乘积 6。
+
+
+示例 2:
+ +输入: [-2,0,-1] +输出: 0 +解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。+ + +## template + +```java + +class Solution { + public int maxProduct(int[] nums) { + int max = Integer.MIN_VALUE, imax = 1, imin = 1; + for (int i = 0; i < nums.length; i++) { + if (nums[i] < 0) { + int tmp = imax; + imax = imin; + imin = tmp; + } + imax = Math.max(imax * nums[i], nums[i]); + imin = Math.min(imin * nums[i], nums[i]); + + max = Math.max(max, imax); + } + return max; + } +} +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/153.exercises/config.json" "b/data/2.dailycode\344\270\255\351\230\266/2.java/153.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..d5dc518bf41823443d264c15d1858a091d446a4d --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/153.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-c4642447f1a1419ea730cc38c0d1a1e5", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/153.exercises/solution.json" "b/data/2.dailycode\344\270\255\351\230\266/2.java/153.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..ca494072f6b430f5ad666a51d017ae0902188848 --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/153.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "27c7eb432aa541659f91e42739ce47c5", + "author": "csdn.net", + "keywords": "数组,二分查找" +} \ No newline at end of file diff --git "a/data/2.dailycode\344\270\255\351\230\266/2.java/153.exercises/solution.md" "b/data/2.dailycode\344\270\255\351\230\266/2.java/153.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..cbe9dce6a6c8676d0db413439ae0117e0107d15a --- /dev/null +++ "b/data/2.dailycode\344\270\255\351\230\266/2.java/153.exercises/solution.md" @@ -0,0 +1,97 @@ +# 寻找旋转排序数组中的最小值 + +已知一个长度为
n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums = [0,1,2,4,5,6,7] 在变化后可能得到:
+4 次,则可以得到 [4,5,6,7,0,1,2]7 次,则可以得到 [0,1,2,4,5,6,7]注意,数组 [a[0], a[1], a[2], ..., a[n-1]] 旋转一次 的结果为数组 [a[n-1], a[0], a[1], a[2], ..., a[n-2]] 。
给你一个元素值 互不相同 的数组 nums ,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。
+ +
示例 1:
+ ++输入:nums = [3,4,5,1,2] +输出:1 +解释:原数组为 [1,2,3,4,5] ,旋转 3 次得到输入数组。 ++ +
示例 2:
+ ++输入:nums = [4,5,6,7,0,1,2] +输出:0 +解释:原数组为 [0,1,2,4,5,6,7] ,旋转 4 次得到输入数组。 ++ +
示例 3:
+ ++输入:nums = [11,13,15,17] +输出:11 +解释:原数组为 [11,13,15,17] ,旋转 4 次得到输入数组。 ++ +
+ +
提示:
+ +n == nums.length1 <= n <= 5000-5000 <= nums[i] <= 5000nums 中的所有整数 互不相同nums 原来是一个升序排序的数组,并进行了 1 至 n 次旋转峰值元素是指其值严格大于左右相邻值的元素。
+ +给你一个整数数组 nums,找到峰值元素并返回其索引。数组可能包含多个峰值,在这种情况下,返回 任何一个峰值 所在位置即可。
你可以假设 nums[-1] = nums[n] = -∞ 。
你必须实现时间复杂度为 O(log n) 的算法来解决此问题。
+ +
示例 1:
+ +
+输入:nums = [1,2,3,1]
+输出:2
+解释:3 是峰值元素,你的函数应该返回其索引 2。
+
+示例 2:
+ +
+输入:nums = [1,2,1,3,5,6,4]
+输出:1 或 5
+解释:你的函数可以返回索引 1,其峰值元素为 2;
+ 或者返回索引 5, 其峰值元素为 6。
+
+
++ +
提示:
+ +1 <= nums.length <= 1000-231 <= nums[i] <= 231 - 1i 都有 nums[i] != nums[i + 1]给你两个版本号 version1 和 version2 ,请你比较它们。
版本号由一个或多个修订号组成,各修订号由一个 '.' 连接。每个修订号由 多位数字 组成,可能包含 前导零 。每个版本号至少包含一个字符。修订号从左到右编号,下标从 0 开始,最左边的修订号下标为 0 ,下一个修订号下标为 1 ,以此类推。例如,2.5.33 和 0.1 都是有效的版本号。
比较版本号时,请按从左到右的顺序依次比较它们的修订号。比较修订号时,只需比较 忽略任何前导零后的整数值 。也就是说,修订号 1 和修订号 001 相等 。如果版本号没有指定某个下标处的修订号,则该修订号视为 0 。例如,版本 1.0 小于版本 1.1 ,因为它们下标为 0 的修订号相同,而下标为 1 的修订号分别为 0 和 1 ,0 < 1 。
返回规则如下:
+ +version1 > version2 返回 1,version1 < version2 返回 -1,0。+ +
示例 1:
+ ++输入:version1 = "1.01", version2 = "1.001" +输出:0 +解释:忽略前导零,"01" 和 "001" 都表示相同的整数 "1" ++ +
示例 2:
+ ++输入:version1 = "1.0", version2 = "1.0.0" +输出:0 +解释:version1 没有指定下标为 2 的修订号,即视为 "0" ++ +
示例 3:
+ ++输入:version1 = "0.1", version2 = "1.1" +输出:-1 +解释:version1 中下标为 0 的修订号是 "0",version2 中下标为 0 的修订号是 "1" 。0 < 1,所以 version1 < version2 ++ +
示例 4:
+ ++输入:version1 = "1.0.1", version2 = "1" +输出:1 ++ +
示例 5:
+ ++输入:version1 = "7.5.2.4", version2 = "7.5.3" +输出:-1 ++ +
+ +
提示:
+ +1 <= version1.length, version2.length <= 500version1 和 version2 仅包含数字和 '.'version1 和 version2 都是 有效版本号version1 和 version2 的所有修订号都可以存储在 32 位整数 中给定两个整数,分别表示分数的分子 numerator 和分母 denominator,以 字符串形式返回小数 。
如果小数部分为循环小数,则将循环的部分括在括号内。
+ +如果存在多个答案,只需返回 任意一个 。
+ +对于所有给定的输入,保证 答案字符串的长度小于 104 。
+ +
示例 1:
+ ++输入:numerator = 1, denominator = 2 +输出:"0.5" ++ +
示例 2:
+ ++输入:numerator = 2, denominator = 1 +输出:"2" ++ +
示例 3:
+ ++输入:numerator = 2, denominator = 3 +输出:"0.(6)" ++ +
示例 4:
+ ++输入:numerator = 4, denominator = 333 +输出:"0.(012)" ++ +
示例 5:
+ ++输入:numerator = 1, denominator = 5 +输出:"0.2" ++ +
+ +
提示:
+ +-231 <= numerator, denominator <= 231 - 1denominator != 0BSTIterator ,表示一个按中序遍历二叉搜索树(BST)的迭代器:
+BSTIterator(TreeNode root) 初始化 BSTIterator 类的一个对象。BST 的根节点 root 会作为构造函数的一部分给出。指针应初始化为一个不存在于 BST 中的数字,且该数字小于 BST 中的任何元素。boolean hasNext() 如果向指针右侧遍历存在数字,则返回 true ;否则返回 false 。int next()将指针向右移动,然后返回指针处的数字。注意,指针初始化为一个不存在于 BST 中的数字,所以对 next() 的首次调用将返回 BST 中的最小元素。
你可以假设 next() 调用总是有效的,也就是说,当调用 next() 时,BST 的中序遍历中至少存在一个下一个数字。
+ +
示例:
+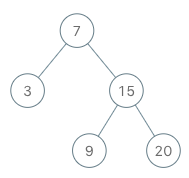 +
++输入 +["BSTIterator", "next", "next", "hasNext", "next", "hasNext", "next", "hasNext", "next", "hasNext"] +[[[7, 3, 15, null, null, 9, 20]], [], [], [], [], [], [], [], [], []] +输出 +[null, 3, 7, true, 9, true, 15, true, 20, false] + +解释 +BSTIterator bSTIterator = new BSTIterator([7, 3, 15, null, null, 9, 20]); +bSTIterator.next(); // 返回 3 +bSTIterator.next(); // 返回 7 +bSTIterator.hasNext(); // 返回 True +bSTIterator.next(); // 返回 9 +bSTIterator.hasNext(); // 返回 True +bSTIterator.next(); // 返回 15 +bSTIterator.hasNext(); // 返回 True +bSTIterator.next(); // 返回 20 +bSTIterator.hasNext(); // 返回 False ++ +
+ +
提示:
+ +[1, 105] 内0 <= Node.val <= 106105 次 hasNext 和 next 操作+ +
进阶:
+ +next() 和 hasNext() 操作均摊时间复杂度为 O(1) ,并使用 O(h) 内存。其中 h 是树的高度。给定一组非负整数 nums,重新排列每个数的顺序(每个数不可拆分)使之组成一个最大的整数。
注意:输出结果可能非常大,所以你需要返回一个字符串而不是整数。
+ ++ +
示例 1:
+ ++输入+ +:nums = [10,2]+输出:"210"
示例 2:
+ ++输入+ +:nums = [3,30,34,5,9]+输出:"9534330"+
示例 3:
+ +
+输入:nums = [1]
+输出:"1"
+
+
+示例 4:
+ +
+输入:nums = [10]
+输出:"10"
+
+
++ +
提示:
+ +1 <= nums.length <= 1000 <= nums[i] <= 109所有 DNA 都由一系列缩写为 'A','C','G' 和 'T' 的核苷酸组成,例如:"ACGAATTCCG"。在研究 DNA 时,识别 DNA 中的重复序列有时会对研究非常有帮助。
编写一个函数来找出所有目标子串,目标子串的长度为 10,且在 DNA 字符串 s 中出现次数超过一次。
+ +
示例 1:
+ ++输入:s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT" +输出:["AAAAACCCCC","CCCCCAAAAA"] ++ +
示例 2:
+ ++输入:s = "AAAAAAAAAAAAA" +输出:["AAAAAAAAAA"] ++ +
+ +
提示:
+ +0 <= s.length <= 105s[i] 为 'A'、'C'、'G' 或 'T'给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
+ +
进阶:
+ ++ +
示例 1:
+ ++输入: nums = [1,2,3,4,5,6,7], k = 3 +输出:+ +[5,6,7,1,2,3,4]+解释: +向右旋转 1 步:[7,1,2,3,4,5,6]+向右旋转 2 步:[6,7,1,2,3,4,5] +向右旋转 3 步:[5,6,7,1,2,3,4]+
示例 2:
+ ++输入:nums = [-1,-100,3,99], k = 2 +输出:[3,99,-1,-100] +解释: +向右旋转 1 步: [99,-1,-100,3] +向右旋转 2 步: [3,99,-1,-100]+ +
+ +
提示:
+ +1 <= nums.length <= 2 * 104-231 <= nums[i] <= 231 - 10 <= k <= 105你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
+ +给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
+ ++ +
示例 1:
+ ++输入:[1,2,3,1] +输出:4 +解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。 + 偷窃到的最高金额 = 1 + 3 = 4 。+ +
示例 2:
+ ++输入:[2,7,9,3,1] +输出:12 +解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。 + 偷窃到的最高金额 = 2 + 9 + 1 = 12 。 ++ +
+ +
提示:
+ +1 <= nums.length <= 1000 <= nums[i] <= 400给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
+ +
示例 1:
+ +
+输入: [1,2,3,null,5,null,4] +输出: [1,3,4] ++ +
示例 2:
+ ++输入: [1,null,3] +输出: [1,3] ++ +
示例 3:
+ ++输入: [] +输出: [] ++ +
+ +
提示:
+ +[0,100]-100 <= Node.val <= 100 给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
+ +此外,你可以假设该网格的四条边均被水包围。
+ ++ +
示例 1:
+ ++输入:grid = [ + ["1","1","1","1","0"], + ["1","1","0","1","0"], + ["1","1","0","0","0"], + ["0","0","0","0","0"] +] +输出:1 ++ +
示例 2:
+ ++输入:grid = [ + ["1","1","0","0","0"], + ["1","1","0","0","0"], + ["0","0","1","0","0"], + ["0","0","0","1","1"] +] +输出:3 ++ +
+ +
提示:
+ +m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j] 的值为 '0' 或 '1'给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)
题目数据保证答案符合 32 位带符号整数范围。
+ ++ +
示例 1:
+ ++输入:s = "rabbbit", t = "rabbit"+ ++输出:3 +解释: +如下图所示, 有 3 种可以从 s 中得到"rabbit" 的方案。 +rabbbit+rabbbit+rabbbit
示例 2:
+ ++输入:s = "babgbag", t = "bag" ++ +输出:5 +解释: +如下图所示, 有 5 种可以从 s 中得到"bag" 的方案。 +babgbag+babgbag+babgbag+babgbag+babgbag+
+ +
提示:
+ +0 <= s.length, t.length <= 1000s 和 t 由英文字母组成给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
+ +注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
+ ++ +
示例 1:
+ ++输入:prices = [3,3,5,0,0,3,1,4] +输出:6 +解释:在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。 + 随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3 。+ +
示例 2:
+ ++输入:prices = [1,2,3,4,5] +输出:4 +解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 + 注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。 + 因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。 ++ +
示例 3:
+ ++输入:prices = [7,6,4,3,1] +输出:0 +解释:在这个情况下, 没有交易完成, 所以最大利润为 0。+ +
示例 4:
+ ++输入:prices = [1] +输出:0 ++ +
+ +
提示:
+ +1 <= prices.length <= 1050 <= prices[i] <= 105路径 被定义为一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
+ +路径和 是路径中各节点值的总和。
+ +给你一个二叉树的根节点 root ,返回其 最大路径和 。
+ +
示例 1:
+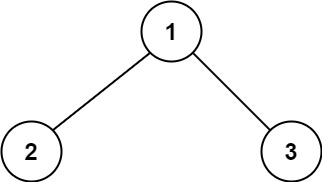 +
++输入:root = [1,2,3] +输出:6 +解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6+ +
示例 2:
+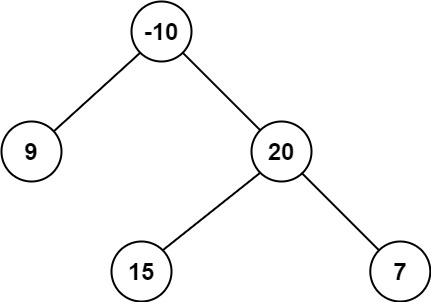 +
++输入:root = [-10,9,20,null,null,15,7] +输出:42 +解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42 ++ +
+ +
提示:
+ +[1, 3 * 104]-1000 <= Node.val <= 1000按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一个表示此过程的 转换序列 是形式上像 beginWord -> s1 -> s2 -> ... -> sk 这样的单词序列,并满足:
si(1 <= i <= k)必须是字典 wordList 中的单词。注意,beginWord 不必是字典 wordList 中的单词。sk == endWord给你两个单词 beginWord 和 endWord ,以及一个字典 wordList 。请你找出并返回所有从 beginWord 到 endWord 的 最短转换序列 ,如果不存在这样的转换序列,返回一个空列表。每个序列都应该以单词列表 [beginWord, s1, s2, ..., sk] 的形式返回。
+ +
示例 1:
+ ++输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] +输出:[["hit","hot","dot","dog","cog"],["hit","hot","lot","log","cog"]] +解释:存在 2 种最短的转换序列: +"hit" -> "hot" -> "dot" -> "dog" -> "cog" +"hit" -> "hot" -> "lot" -> "log" -> "cog" ++ +
示例 2:
+ ++输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"] +输出:[] +解释:endWord "cog" 不在字典 wordList 中,所以不存在符合要求的转换序列。 ++ +
+ +
提示:
+ +1 <= beginWord.length <= 7endWord.length == beginWord.length1 <= wordList.length <= 5000wordList[i].length == beginWord.lengthbeginWord、endWord 和 wordList[i] 由小写英文字母组成beginWord != endWordwordList 中的所有单词 互不相同字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列:
beginWord 。endWord 。wordList 中的单词。给你两个单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0。
示例 1:
+ ++输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] +输出:5 +解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。 ++ +
示例 2:
+ ++输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"] +输出:0 +解释:endWord "cog" 不在字典中,所以无法进行转换。+ +
+ +
提示:
+ +1 <= beginWord.length <= 10endWord.length == beginWord.length1 <= wordList.length <= 5000wordList[i].length == beginWord.lengthbeginWord、endWord 和 wordList[i] 由小写英文字母组成beginWord != endWordwordList 中的所有字符串 互不相同给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是回文。
返回符合要求的 最少分割次数 。
+ ++ +
示例 1:
+ ++输入:s = "aab" +输出:1 +解释:只需一次分割就可将 s 分割成 ["aa","b"] 这样两个回文子串。 ++ +
示例 2:
+ ++输入:s = "a" +输出:0 ++ +
示例 3:
+ ++输入:s = "ab" +输出:1 ++ +
+ +
提示:
+ +1 <= s.length <= 2000s 仅由小写英文字母组成老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
+ +你需要按照以下要求,帮助老师给这些孩子分发糖果:
+ +那么这样下来,老师至少需要准备多少颗糖果呢?
+ ++ +
示例 1:
+ ++输入:[1,0,2] +输出:5 +解释:你可以分别给这三个孩子分发 2、1、2 颗糖果。 ++ +
示例 2:
+ ++输入:[1,2,2] +输出:4 +解释:你可以分别给这三个孩子分发 1、2、1 颗糖果。 + 第三个孩子只得到 1 颗糖果,这已满足上述两个条件。+ + +## template + +```java +class Solution { + public int candy(int[] ratings) { + int len = ratings.length; + int[] left = new int[len]; + int[] right = new int[len]; + + left[0] = 1; + right[len - 1] = 1; + + for (int i = 1; i < len; i++) { + if (ratings[i] > ratings[i - 1]) { + left[i] = left[i - 1] + 1; + } else { + left[i] = 1; + } + } + + for (int i = len - 2; i >= 0; i--) { + if (ratings[i] > ratings[i + 1]) { + right[i] = right[i + 1] + 1; + } else { + right[i] = 1; + } + } + + int res = 0; + for (int i = 0; i < len; i++) { + res += Math.max(left[i], right[i]); + } + + return res; + } +} + +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/3.dailycode\351\253\230\351\230\266/2.java/140.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/2.java/140.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..31d92b348b1fbadcdf04b62c2be5a3d5486f5a84 --- /dev/null +++ "b/data/3.dailycode\351\253\230\351\230\266/2.java/140.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-20dd73b360dd44a3996b60964b566e60", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data/3.dailycode\351\253\230\351\230\266/2.java/140.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/2.java/140.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..e7987869ee047738b291b48d4bad5853eb1fd9b7 --- /dev/null +++ "b/data/3.dailycode\351\253\230\351\230\266/2.java/140.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "58347641730142b0b6d4a50156cdf7fc", + "author": "csdn.net", + "keywords": "字典树,记忆化搜索,哈希表,字符串,动态规划,回溯" +} \ No newline at end of file diff --git "a/data/3.dailycode\351\253\230\351\230\266/2.java/140.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/2.java/140.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..a82f1a19c361f3bc8c1480d4bf81a7cf5cb3848b --- /dev/null +++ "b/data/3.dailycode\351\253\230\351\230\266/2.java/140.exercises/solution.md" @@ -0,0 +1,125 @@ +# 单词拆分 II + +
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,在字符串中增加空格来构建一个句子,使得句子中所有的单词都在词典中。返回所有这些可能的句子。
+ +说明:
+ +示例 1:
+ +输入: +s = "+ +catsanddog" +wordDict =["cat", "cats", "and", "sand", "dog"]+输出: +[ + "cats and dog", + "cat sand dog" +]+
示例 2:
+ +输入: +s = "pineapplepenapple" +wordDict = ["apple", "pen", "applepen", "pine", "pineapple"] +输出: +[ + "pine apple pen apple", + "pineapple pen apple", + "pine applepen apple" +] +解释: 注意你可以重复使用字典中的单词。 ++ +
示例 3:
+ +输入: +s = "catsandog" +wordDict = ["cats", "dog", "sand", "and", "cat"] +输出: +[] ++ + +## template + +```java +class Solution { + public List
给你一个数组 points ,其中 points[i] = [xi, yi] 表示 X-Y 平面上的一个点。求最多有多少个点在同一条直线上。
+ +
示例 1:
+ +
++输入:points = [[1,1],[2,2],[3,3]] +输出:3 ++ +
示例 2:
+ +
++输入:points = [[1,1],[3,2],[5,3],[4,1],[2,3],[1,4]] +输出:4 ++ +
+ +
提示:
+ +1 <= points.length <= 300points[i].length == 2-104 <= xi, yi <= 104points 中的所有点 互不相同n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums = [0,1,4,4,5,6,7] 在变化后可能得到:
+4 次,则可以得到 [4,5,6,7,0,1,4]7 次,则可以得到 [0,1,4,4,5,6,7]注意,数组 [a[0], a[1], a[2], ..., a[n-1]] 旋转一次 的结果为数组 [a[n-1], a[0], a[1], a[2], ..., a[n-2]] 。
给你一个可能存在 重复 元素值的数组 nums ,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。
+ +
示例 1:
+ ++输入:nums = [1,3,5] +输出:1 ++ +
示例 2:
+ ++输入:nums = [2,2,2,0,1] +输出:0 ++ +
+ +
提示:
+ +n == nums.length1 <= n <= 5000-5000 <= nums[i] <= 5000nums 原来是一个升序排序的数组,并进行了 1 至 n 次旋转+ +
进阶:
+ +给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的差值。
+ +如果数组元素个数小于 2,则返回 0。
+ +示例 1:
+ +输入: [3,6,9,1] +输出: 3 +解释: 排序后的数组是 [1,3,6,9], 其中相邻元素 (3,6) 和 (6,9) 之间都存在最大差值 3。+ +
示例 2:
+ +输入: [10] +输出: 0 +解释: 数组元素个数小于 2,因此返回 0。+ +
说明:
+ +一些恶魔抓住了公主(P)并将她关在了地下城的右下角。地下城是由 M x N 个房间组成的二维网格。我们英勇的骑士(K)最初被安置在左上角的房间里,他必须穿过地下城并通过对抗恶魔来拯救公主。
+ +骑士的初始健康点数为一个正整数。如果他的健康点数在某一时刻降至 0 或以下,他会立即死亡。
+ +有些房间由恶魔守卫,因此骑士在进入这些房间时会失去健康点数(若房间里的值为负整数,则表示骑士将损失健康点数);其他房间要么是空的(房间里的值为 0),要么包含增加骑士健康点数的魔法球(若房间里的值为正整数,则表示骑士将增加健康点数)。
+ +为了尽快到达公主,骑士决定每次只向右或向下移动一步。
+ ++ +
编写一个函数来计算确保骑士能够拯救到公主所需的最低初始健康点数。
+ +例如,考虑到如下布局的地下城,如果骑士遵循最佳路径 右 -> 右 -> 下 -> 下,则骑士的初始健康点数至少为 7。
| -2 (K) | +-3 | +3 | +
| -5 | +-10 | +1 | +
| 10 | +30 | +-5 (P) | +
+ +
说明:
+ +骑士的健康点数没有上限。
+给定一个整数数组 prices ,它的第 i 个元素 prices[i] 是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。
+ +注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
+ ++ +
示例 1:
+ ++输入:k = 2, prices = [2,4,1] +输出:2 +解释:在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4-2 = 2 。+ +
示例 2:
+ ++输入:k = 2, prices = [3,2,6,5,0,3] +输出:7 +解释:在第 2 天 (股票价格 = 2) 的时候买入,在第 3 天 (股票价格 = 6) 的时候卖出, 这笔交易所能获得利润 = 6-2 = 4 。 + 随后,在第 5 天 (股票价格 = 0) 的时候买入,在第 6 天 (股票价格 = 3) 的时候卖出, 这笔交易所能获得利润 = 3-0 = 3 。+ +
+ +
提示:
+ +0 <= k <= 1000 <= prices.length <= 10000 <= prices[i] <= 1000给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词。
单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
+ ++ +
示例 1:
+ +
++输入:board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"] +输出:["eat","oath"] ++ +
示例 2:
+ +
++输入:board = [["a","b"],["c","d"]], words = ["abcb"] +输出:[] ++ +
+ +
提示:
+ +m == board.lengthn == board[i].length1 <= m, n <= 12board[i][j] 是一个小写英文字母1 <= words.length <= 3 * 1041 <= words[i].length <= 10words[i] 由小写英文字母组成words 中的所有字符串互不相同给定一个字符串 s,你可以通过在字符串前面添加字符将其转换为回文串。找到并返回可以用这种方式转换的最短回文串。
+ ++ +
示例 1:
+ ++输入:s = "aacecaaa" +输出:"aaacecaaa" ++ +
示例 2:
+ ++输入:s = "abcd" +输出:"dcbabcd" ++ +
+ +
提示:
+ +0 <= s.length <= 5 * 104s 仅由小写英文字母组成城市的天际线是从远处观看该城市中所有建筑物形成的轮廓的外部轮廓。给你所有建筑物的位置和高度,请返回由这些建筑物形成的 天际线 。
+ +每个建筑物的几何信息由数组 buildings 表示,其中三元组 buildings[i] = [lefti, righti, heighti] 表示:
lefti 是第 i 座建筑物左边缘的 x 坐标。righti 是第 i 座建筑物右边缘的 x 坐标。heighti 是第 i 座建筑物的高度。天际线 应该表示为由 “关键点” 组成的列表,格式 [[x1,y1],[x2,y2],...] ,并按 x 坐标 进行 排序 。关键点是水平线段的左端点。列表中最后一个点是最右侧建筑物的终点,y 坐标始终为 0 ,仅用于标记天际线的终点。此外,任何两个相邻建筑物之间的地面都应被视为天际线轮廓的一部分。
注意:输出天际线中不得有连续的相同高度的水平线。例如 [...[2 3], [4 5], [7 5], [11 5], [12 7]...] 是不正确的答案;三条高度为 5 的线应该在最终输出中合并为一个:[...[2 3], [4 5], [12 7], ...]
+ +
示例 1:
+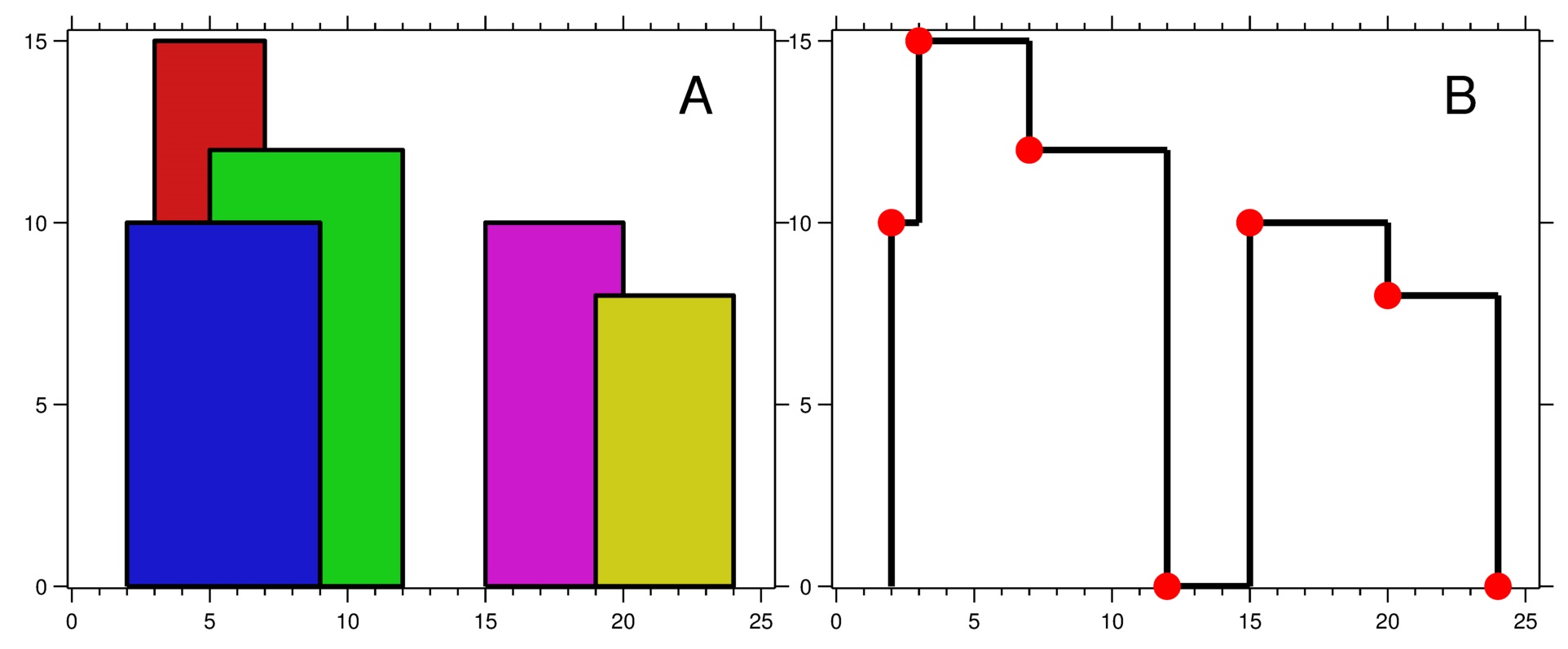 +
++输入:buildings = [[2,9,10],[3,7,15],[5,12,12],[15,20,10],[19,24,8]] +输出:[[2,10],[3,15],[7,12],[12,0],[15,10],[20,8],[24,0]] +解释: +图 A 显示输入的所有建筑物的位置和高度, +图 B 显示由这些建筑物形成的天际线。图 B 中的红点表示输出列表中的关键点。+ +
示例 2:
+ ++输入:buildings = [[0,2,3],[2,5,3]] +输出:[[0,3],[5,0]] ++ +
+ +
提示:
+ +1 <= buildings.length <= 1040 <= lefti < righti <= 231 - 11 <= heighti <= 231 - 1buildings 按 lefti 非递减排序给你一个字符串表达式 s ,请你实现一个基本计算器来计算并返回它的值。
+ +
示例 1:
+ ++输入:s = "1 + 1" +输出:2 ++ +
示例 2:
+ ++输入:s = " 2-1 + 2 " +输出:3 ++ +
示例 3:
+ ++输入:s = "(1+(4+5+2)-3)+(6+8)" +输出:23 ++ +
+ +
提示:
+ +1 <= s.length <= 3 * 105s 由数字、'+'、'-'、'('、')'、和 ' ' 组成s 表示一个有效的表达式给定一个整数 n,计算所有小于等于 n 的非负整数中数字 1 出现的个数。
+ +
示例 1:
+ ++输入:n = 13 +输出:6 ++ +
示例 2:
+ ++输入:n = 0 +输出:0 ++ +
+ +
提示:
+ +0 <= n <= 109给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回滑动窗口中的最大值。
+ ++ +
示例 1:
+ ++输入:nums = [1,3,-1,-3,5,3,6,7], k = 3 +输出:[3,3,5,5,6,7] +解释: +滑动窗口的位置 最大值 +--------------- ----- +[1 3 -1] -3 5 3 6 7 3 + 1 [3 -1 -3] 5 3 6 7 3 + 1 3 [-1 -3 5] 3 6 7 5 + 1 3 -1 [-3 5 3] 6 7 5 + 1 3 -1 -3 [5 3 6] 7 6 + 1 3 -1 -3 5 [3 6 7] 7 ++ +
示例 2:
+ ++输入:nums = [1], k = 1 +输出:[1] ++ +
示例 3:
+ ++输入:nums = [1,-1], k = 1 +输出:[1,-1] ++ +
示例 4:
+ ++输入:nums = [9,11], k = 2 +输出:[11] ++ +
示例 5:
+ ++输入:nums = [4,-2], k = 2 +输出:[4]+ +
+ +
提示:
+ +1 <= nums.length <= 105-104 <= nums[i] <= 1041 <= k <= nums.length将非负整数 num 转换为其对应的英文表示。
+ +
示例 1:
+ ++输入:num = 123 +输出:"One Hundred Twenty Three" ++ +
示例 2:
+ ++输入:num = 12345 +输出:"Twelve Thousand Three Hundred Forty Five" ++ +
示例 3:
+ ++输入:num = 1234567 +输出:"One Million Two Hundred Thirty Four Thousand Five Hundred Sixty Seven" ++ +
示例 4:
+ ++输入:num = 1234567891 +输出:"One Billion Two Hundred Thirty Four Million Five Hundred Sixty Seven Thousand Eight Hundred Ninety One" ++ +
+ +
提示:
+ +0 <= num <= 231 - 1给定一个仅包含数字 0-9 的字符串 num 和一个目标值整数 target ,在 num 的数字之间添加 二元 运算符(不是一元)+、- 或 * ,返回所有能够得到目标值的表达式。
+ +
示例 1:
+ +
+输入: num = "123", target = 6
+输出: ["1+2+3", "1*2*3"]
+
+
+示例 2:
+ +
+输入: num = "232", target = 8
+输出: ["2*3+2", "2+3*2"]
+
+示例 3:
+ +
+输入: num = "105", target = 5
+输出: ["1*0+5","10-5"]
+
+示例 4:
+ +
+输入: num = "00", target = 0
+输出: ["0+0", "0-0", "0*0"]
+
+
+示例 5:
+ +
+输入: num = "3456237490", target = 9191
+输出: []
+
++ +
提示:
+ +1 <= num.length <= 10num 仅含数字-231 <= target <= 231 - 1中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。
+ +例如,
+ +[2,3,4] 的中位数是 3
+ +[2,3] 的中位数是 (2 + 3) / 2 = 2.5
+ +设计一个支持以下两种操作的数据结构:
+ +示例:
+ +addNum(1) +addNum(2) +findMedian() -> 1.5 +addNum(3) +findMedian() -> 2+ +
进阶:
+ +序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
+ +请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
+ +提示: 输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
+ ++ +
示例 1:
+ +
++输入:root = [1,2,3,null,null,4,5] +输出:[1,2,3,null,null,4,5] ++ +
示例 2:
+ ++输入:root = [] +输出:[] ++ +
示例 3:
+ ++输入:root = [1] +输出:[1] ++ +
示例 4:
+ ++输入:root = [1,2] +输出:[1,2] ++ +
+ +
提示:
+ +[0, 104] 内-1000 <= Node.val <= 1000给你一个由若干括号和字母组成的字符串 s ,删除最小数量的无效括号,使得输入的字符串有效。
返回所有可能的结果。答案可以按 任意顺序 返回。
+ ++ +
示例 1:
+ ++输入:s = "()())()" +输出:["(())()","()()()"] ++ +
示例 2:
+ ++输入:s = "(a)())()" +输出:["(a())()","(a)()()"] ++ +
示例 3:
+ +
+输入:s = ")("
+输出:[""]
+
+
++ +
提示:
+ +1 <= s.length <= 25s 由小写英文字母以及括号 '(' 和 ')' 组成s 中至多含 20 个括号有 n 个气球,编号为0 到 n - 1,每个气球上都标有一个数字,这些数字存在数组 nums 中。
现在要求你戳破所有的气球。戳破第 i 个气球,你可以获得 nums[i - 1] * nums[i] * nums[i + 1] 枚硬币。 这里的 i - 1 和 i + 1 代表和 i 相邻的两个气球的序号。如果 i - 1或 i + 1 超出了数组的边界,那么就当它是一个数字为 1 的气球。
求所能获得硬币的最大数量。
+ ++示例 1: + +
+输入:nums = [3,1,5,8] +输出:167 +解释: +nums = [3,1,5,8] --> [3,5,8] --> [3,8] --> [8] --> [] +coins = 3*1*5 + 3*5*8 + 1*3*8 + 1*8*1 = 167+ +
示例 2:
+ ++输入:nums = [1,5] +输出:10 ++ +
+ +
提示:
+ +n == nums.length1 <= n <= 5000 <= nums[i] <= 100给你`一个整数数组 nums ,按要求返回一个新数组 counts 。数组 counts 有该性质: counts[i] 的值是 nums[i] 右侧小于 nums[i] 的元素的数量。
+ +
示例 1:
+ +
+输入:nums = [5,2,6,1]
+输出:[2,1,1,0]
+解释:
+5 的右侧有 2 个更小的元素 (2 和 1)
+2 的右侧仅有 1 个更小的元素 (1)
+6 的右侧有 1 个更小的元素 (1)
+1 的右侧有 0 个更小的元素
+
+
+示例 2:
+ ++输入:nums = [-1] +输出:[0] ++ +
示例 3:
+ ++输入:nums = [-1,-1] +输出:[0,0] ++ +
+ +
提示:
+ +1 <= nums.length <= 105-104 <= nums[i] <= 104给定长度分别为 m 和 n 的两个数组,其元素由 0-9 构成,表示两个自然数各位上的数字。现在从这两个数组中选出 k (k <= m + n) 个数字拼接成一个新的数,要求从同一个数组中取出的数字保持其在原数组中的相对顺序。
求满足该条件的最大数。结果返回一个表示该最大数的长度为 k 的数组。
说明: 请尽可能地优化你算法的时间和空间复杂度。
+ +示例 1:
+ +输入: +nums1 =+ +[3, 4, 6, 5]+nums2 =[9, 1, 2, 5, 8, 3]+k =5+输出: +[9, 8, 6, 5, 3]
示例 2:
+ +输入: +nums1 =+ +[6, 7]+nums2 =[6, 0, 4]+k =5+输出: +[6, 7, 6, 0, 4]
示例 3:
+ +输入: +nums1 =+ + +## template + +```java + +class Solution { + + private int[] maxInNums(int[] nums, int k) { + int[] max = new int[k]; + int len = nums.length; + + for (int i = 0, j = 0; i < len; ++i) { + + while (j > 0 && k - j < len - i && max[j - 1] < nums[i]) + --j; + if (j < k) + max[j++] = nums[i]; + } + return max; + } + + private boolean greater(int[] nums1Max, int i, int[] nums2Max, int j) { + int lenNums1Max = nums1Max.length; + int lenNums2Max = nums2Max.length; + + while (i < lenNums1Max && j < lenNums2Max && nums1Max[i] == nums2Max[j]) { + ++i; + ++j; + } + + return j == lenNums2Max || (i < lenNums1Max && nums1Max[i] > nums2Max[j]); + } + + private int[] merge(int[] nums1Max, int[] nums2Max) { + int lenCurRes = nums1Max.length + nums2Max.length; + int[] curRes = new int[lenCurRes]; + for (int i = 0, j = 0, m = 0; m < lenCurRes; ++m) { + curRes[m] = greater(nums1Max, i, nums2Max, j) ? nums1Max[i++] : nums2Max[j++]; + } + return curRes; + } + + public int[] maxNumber(int[] nums1, int[] nums2, int k) { + int[] res = null; + for (int i = Math.max(k - nums2.length, 0); i <= Math.min(nums1.length, k); ++i) { + int[] merge = merge(maxInNums(nums1, i), maxInNums(nums2, k - i)); + res = (res == null || greater(merge, 0, res, 0)) ? merge : res; + } + return res; + } +} +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/3.dailycode\351\253\230\351\230\266/2.java/327.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/2.java/327.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..a6a35af838dc8e66b485b135cb0b45a277d83793 --- /dev/null +++ "b/data/3.dailycode\351\253\230\351\230\266/2.java/327.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-6b0808a529524be2afa75c84d9c72795", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data/3.dailycode\351\253\230\351\230\266/2.java/327.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/2.java/327.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..4f627537331d6850a2f319b03f75b4ee7079a051 --- /dev/null +++ "b/data/3.dailycode\351\253\230\351\230\266/2.java/327.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "88d40224a81542f4819bfca909d91ef9", + "author": "csdn.net", + "keywords": "树状数组,线段树,数组,二分查找,分治,有序集合,归并排序" +} \ No newline at end of file diff --git "a/data/3.dailycode\351\253\230\351\230\266/2.java/327.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/2.java/327.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..989b99bcbeaf30ea9500ddf4da49f6b122b9cb3f --- /dev/null +++ "b/data/3.dailycode\351\253\230\351\230\266/2.java/327.exercises/solution.md" @@ -0,0 +1,116 @@ +# 区间和的个数 + +[3, 9]+nums2 =[8, 9]+k =3+输出: +[9, 8, 9]
给你一个整数数组 nums 以及两个整数 lower 和 upper 。求数组中,值位于范围 [lower, upper] (包含 lower 和 upper)之内的 区间和的个数 。
区间和 S(i, j) 表示在 nums 中,位置从 i 到 j 的元素之和,包含 i 和 j (i ≤ j)。
+示例 1: + +
+输入:nums = [-2,5,-1], lower = -2, upper = 2 +输出:3 +解释:存在三个区间:[0,0]、[2,2] 和 [0,2] ,对应的区间和分别是:-2 、-1 、2 。 ++ +
示例 2:
+ ++输入:nums = [0], lower = 0, upper = 0 +输出:1 ++ +
+ +
提示:
+ +1 <= nums.length <= 105-231 <= nums[i] <= 231 - 1-105 <= lower <= upper <= 105给定一个 m x n 整数矩阵 matrix ,找出其中 最长递增路径 的长度。
对于每个单元格,你可以往上,下,左,右四个方向移动。 你 不能 在 对角线 方向上移动或移动到 边界外(即不允许环绕)。
+ ++ +
示例 1:
+ +
+
+输入:matrix = [[9,9,4],[6,6,8],[2,1,1]]
+输出:4
+解释:最长递增路径为 [1, 2, 6, 9]。
+
+示例 2:
+ +
+
+输入:matrix = [[3,4,5],[3,2,6],[2,2,1]]
+输出:4
+解释:最长递增路径是 [3, 4, 5, 6]。注意不允许在对角线方向上移动。
+
+
+示例 3:
+ ++输入:matrix = [[1]] +输出:1 ++ +
+ +
提示:
+ +m == matrix.lengthn == matrix[i].length1 <= m, n <= 2000 <= matrix[i][j] <= 231 - 1给定一个已排序的正整数数组 nums,和一个正整数 n 。从 [1, n] 区间内选取任意个数字补充到 nums 中,使得 [1, n] 区间内的任何数字都可以用 nums 中某几个数字的和来表示。请输出满足上述要求的最少需要补充的数字个数。
示例 1:
+ +输入: nums =+ +[1,3], n =6+输出: 1 +解释: +根据 nums 里现有的组合[1], [3], [1,3],可以得出1, 3, 4。 +现在如果我们将2添加到 nums 中, 组合变为:[1], [2], [3], [1,3], [2,3], [1,2,3]。 +其和可以表示数字1, 2, 3, 4, 5, 6,能够覆盖[1, 6]区间里所有的数。 +所以我们最少需要添加一个数字。
示例 2:
+ +输入: nums =+ +[1,5,10], n =20+输出: 2 +解释: 我们需要添加[2, 4]。 +
示例 3:
+ +输入: nums =+ + +## template + +```java +class Solution { + public int minPatches(int[] nums, int n) { + int patches = 0, i = 0; + long miss = 1; + while (miss <= n) { + if (i < nums.length && nums[i] <= miss) + miss += nums[i++]; + else { + miss += miss; + patches++; + } + } + return patches; + } +} + +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/3.dailycode\351\253\230\351\230\266/2.java/335.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/2.java/335.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..f361f3112963e9e520583403a489d3c7e701005a --- /dev/null +++ "b/data/3.dailycode\351\253\230\351\230\266/2.java/335.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-99e37371b73f4c7eae96ca1ad461fed9", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data/3.dailycode\351\253\230\351\230\266/2.java/335.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/2.java/335.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..a047ff3361094c971abaf33dffe6d1a1acd97143 --- /dev/null +++ "b/data/3.dailycode\351\253\230\351\230\266/2.java/335.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "4caea52122df439b895b005ba78c3be9", + "author": "csdn.net", + "keywords": "几何,数组,数学" +} \ No newline at end of file diff --git "a/data/3.dailycode\351\253\230\351\230\266/2.java/335.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/2.java/335.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..af2ed686fc17587e13488a2f208ecefb51a4d15a --- /dev/null +++ "b/data/3.dailycode\351\253\230\351\230\266/2.java/335.exercises/solution.md" @@ -0,0 +1,92 @@ +# 路径交叉 + +[1,2,2], n =5+输出: 0 +
给你一个整数数组 distance 。
从 X-Y 平面上的点 (0,0) 开始,先向北移动 distance[0] 米,然后向西移动 distance[1] 米,向南移动 distance[2] 米,向东移动 distance[3] 米,持续移动。也就是说,每次移动后你的方位会发生逆时针变化。
判断你所经过的路径是否相交。如果相交,返回 true ;否则,返回 false 。
+ +
示例 1:
+ +
++输入:distance = [2,1,1,2] +输出:true ++ +
示例 2:
+ +
++输入:distance = [1,2,3,4] +输出:false ++ +
示例 3:
+ +
++输入:distance = [1,1,1,1] +输出:true+ +
+ +
提示:
+ +1 <= distance.length <= 1051 <= distance[i] <= 105给定一组 互不相同 的单词, 找出所有 不同 的索引对 (i, j),使得列表中的两个单词, words[i] + words[j] ,可拼接成回文串。
+ +
示例 1:
+ +
+输入:words = ["abcd","dcba","lls","s","sssll"]
+输出:[[0,1],[1,0],[3,2],[2,4]]
+解释:可拼接成的回文串为 ["dcbaabcd","abcddcba","slls","llssssll"]
+
+
+示例 2:
+ +
+输入:words = ["bat","tab","cat"]
+输出:[[0,1],[1,0]]
+解释:可拼接成的回文串为 ["battab","tabbat"]
+
+示例 3:
+ ++输入:words = ["a",""] +输出:[[0,1],[1,0]] ++ + +
提示:
+ +1 <= words.length <= 50000 <= words[i].length <= 300words[i] 由小写英文字母组成 给你一个由非负整数 a1, a2, ..., an 组成的数据流输入,请你将到目前为止看到的数字总结为不相交的区间列表。
实现 SummaryRanges 类:
SummaryRanges() 使用一个空数据流初始化对象。void addNum(int val) 向数据流中加入整数 val 。int[][] getIntervals() 以不相交区间 [starti, endi] 的列表形式返回对数据流中整数的总结。+ +
示例:
+ ++输入: +["SummaryRanges", "addNum", "getIntervals", "addNum", "getIntervals", "addNum", "getIntervals", "addNum", "getIntervals", "addNum", "getIntervals"] +[[], [1], [], [3], [], [7], [], [2], [], [6], []] +输出: +[null, null, [[1, 1]], null, [[1, 1], [3, 3]], null, [[1, 1], [3, 3], [7, 7]], null, [[1, 3], [7, 7]], null, [[1, 3], [6, 7]]] + +解释: +SummaryRanges summaryRanges = new SummaryRanges(); +summaryRanges.addNum(1); // arr = [1] +summaryRanges.getIntervals(); // 返回 [[1, 1]] +summaryRanges.addNum(3); // arr = [1, 3] +summaryRanges.getIntervals(); // 返回 [[1, 1], [3, 3]] +summaryRanges.addNum(7); // arr = [1, 3, 7] +summaryRanges.getIntervals(); // 返回 [[1, 1], [3, 3], [7, 7]] +summaryRanges.addNum(2); // arr = [1, 2, 3, 7] +summaryRanges.getIntervals(); // 返回 [[1, 3], [7, 7]] +summaryRanges.addNum(6); // arr = [1, 2, 3, 6, 7] +summaryRanges.getIntervals(); // 返回 [[1, 3], [6, 7]] ++ +
+ +
提示:
+ +0 <= val <= 104addNum 和 getIntervals 方法 3 * 104 次+ +
进阶:如果存在大量合并,并且与数据流的大小相比,不相交区间的数量很小,该怎么办?
+ + +## template + +```java +class SummaryRanges { + private final TreeSet给你一个二维整数数组 envelopes ,其中 envelopes[i] = [wi, hi] ,表示第 i 个信封的宽度和高度。
当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。
+ +请计算 最多能有多少个 信封能组成一组“俄罗斯套娃”信封(即可以把一个信封放到另一个信封里面)。
+ +注意:不允许旋转信封。
+ + +示例 1:
+ +
+输入:envelopes = [[5,4],[6,4],[6,7],[2,3]]
+输出:3
+解释:最多信封的个数为 3, 组合为: [2,3] => [5,4] => [6,7]。
+
+示例 2:
+ ++输入:envelopes = [[1,1],[1,1],[1,1]] +输出:1 ++ +
+ +
提示:
+ +1 <= envelopes.length <= 5000envelopes[i].length == 21 <= wi, hi <= 104给你一个 m x n 的矩阵 matrix 和一个整数 k ,找出并返回矩阵内部矩形区域的不超过 k 的最大数值和。
题目数据保证总会存在一个数值和不超过 k 的矩形区域。
+ +
示例 1:
+ +
+
+输入:matrix = [[1,0,1],[0,-2,3]], k = 2
+输出:2
+解释:蓝色边框圈出来的矩形区域 [[0, 1], [-2, 3]] 的数值和是 2,且 2 是不超过 k 的最大数字(k = 2)。
+
+
+示例 2:
+ ++输入:matrix = [[2,2,-1]], k = 3 +输出:3 ++ +
+ +
提示:
+ +m == matrix.lengthn == matrix[i].length1 <= m, n <= 100-100 <= matrix[i][j] <= 100-105 <= k <= 105+ +
进阶:如果行数远大于列数,该如何设计解决方案?
+ + +## template + +```java +class Solution { + public int maxSumSubmatrix(int[][] matrix, int k) { + + int row = matrix.length; + if (row <= 0) + return 0; + int line = matrix[0].length; + int max = Integer.MIN_VALUE; + + for (int left = 0; left < line; left++) { + + int[] rowSum = new int[row]; + + for (int right = left; right < line; right++) { + + for (int i = 0; i < row; i++) { + rowSum[i] += matrix[i][right]; + } + + max = Math.max(max, dpmax(rowSum, k)); + + } + + } + + return max; + + } + + private int dpmax(int[] arr, int k) { + int max = Integer.MIN_VALUE; + int n = arr.length; + for (int top = 0; top < n; top++) { + int sum = 0; + for (int bottom = top; bottom < n; bottom++) { + sum += arr[bottom]; + if (sum > max && sum <= k) + max = sum; + } + } + return max; + } + +} + + +``` + +## 答案 + +```java + +``` + +## 选项 + +### A + +```java + +``` + +### B + +```java + +``` + +### C + +```java + +``` \ No newline at end of file diff --git "a/data/3.dailycode\351\253\230\351\230\266/2.java/381.exercises/config.json" "b/data/3.dailycode\351\253\230\351\230\266/2.java/381.exercises/config.json" new file mode 100644 index 0000000000000000000000000000000000000000..40e61ffbc1835756b7f01847bd755250c7640768 --- /dev/null +++ "b/data/3.dailycode\351\253\230\351\230\266/2.java/381.exercises/config.json" @@ -0,0 +1,10 @@ +{ + "node_id": "dailycode-100343f408f44221b30732cc26603dc1", + "keywords": [], + "children": [], + "keywords_must": [], + "keywords_forbid": [], + "export": [ + "solution.json" + ] +} \ No newline at end of file diff --git "a/data/3.dailycode\351\253\230\351\230\266/2.java/381.exercises/solution.json" "b/data/3.dailycode\351\253\230\351\230\266/2.java/381.exercises/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..6f6be79b09f65a45695764e13537b2e90044b1eb --- /dev/null +++ "b/data/3.dailycode\351\253\230\351\230\266/2.java/381.exercises/solution.json" @@ -0,0 +1,7 @@ +{ + "type": "code_options", + "source": "solution.md", + "exercise_id": "db1158dcd7384feb9692778d45fbab07", + "author": "csdn.net", + "keywords": "设计,数组,哈希表,数学,随机化" +} \ No newline at end of file diff --git "a/data/3.dailycode\351\253\230\351\230\266/2.java/381.exercises/solution.md" "b/data/3.dailycode\351\253\230\351\230\266/2.java/381.exercises/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..09c4b8b80ee3c06ac655046fe7230e86a8ddd8eb --- /dev/null +++ "b/data/3.dailycode\351\253\230\351\230\266/2.java/381.exercises/solution.md" @@ -0,0 +1,142 @@ +# O(1) 时间插入、删除和获取随机元素 + +设计一个支持在平均 时间复杂度 O(1) 下, 执行以下操作的数据结构。
+ +注意: 允许出现重复元素。
+ +insert(val):向集合中插入元素 val。remove(val):当 val 存在时,从集合中移除一个 val。getRandom:从现有集合中随机获取一个元素。每个元素被返回的概率应该与其在集合中的数量呈线性相关。示例:
+ +// 初始化一个空的集合。 +RandomizedCollection collection = new RandomizedCollection(); + +// 向集合中插入 1 。返回 true 表示集合不包含 1 。 +collection.insert(1); + +// 向集合中插入另一个 1 。返回 false 表示集合包含 1 。集合现在包含 [1,1] 。 +collection.insert(1); + +// 向集合中插入 2 ,返回 true 。集合现在包含 [1,1,2] 。 +collection.insert(2); + +// getRandom 应当有 2/3 的概率返回 1 ,1/3 的概率返回 2 。 +collection.getRandom(); + +// 从集合中删除 1 ,返回 true 。集合现在包含 [1,2] 。 +collection.remove(1); + +// getRandom 应有相同概率返回 1 和 2 。 +collection.getRandom(); ++ + +## template + +```java +class RandomizedCollection { + + private Map
我们有 N 个与坐标轴对齐的矩形, 其中 N > 0, 判断它们是否能精确地覆盖一个矩形区域。
+ +每个矩形用左下角的点和右上角的点的坐标来表示。例如, 一个单位正方形可以表示为 [1,1,2,2]。 ( 左下角的点的坐标为 (1, 1) 以及右上角的点的坐标为 (2, 2) )。
+ +
示例 1:
+ +rectangles = [ + [1,1,3,3], + [3,1,4,2], + [3,2,4,4], + [1,3,2,4], + [2,3,3,4] +] + +返回 true。5个矩形一起可以精确地覆盖一个矩形区域。 ++ +
+ +
示例 2:
+ +rectangles = [ + [1,1,2,3], + [1,3,2,4], + [3,1,4,2], + [3,2,4,4] +] + +返回 false。两个矩形之间有间隔,无法覆盖成一个矩形。 ++ +
+ +
示例 3:
+ +rectangles = [ + [1,1,3,3], + [3,1,4,2], + [1,3,2,4], + [3,2,4,4] +] + +返回 false。图形顶端留有间隔,无法覆盖成一个矩形。 ++ +
+ +
示例 4:
+ +rectangles = [ + [1,1,3,3], + [3,1,4,2], + [1,3,2,4], + [2,2,4,4] +] + +返回 false。因为中间有相交区域,虽然形成了矩形,但不是精确覆盖。 ++ + +## template + +```java + +class Solution { + + public boolean isRectangleCover(int[][] rectangles) { + int left = Integer.MAX_VALUE; + int right = Integer.MIN_VALUE; + int top = Integer.MIN_VALUE; + int bottom = Integer.MAX_VALUE; + int n = rectangles.length; + + Set
一只青蛙想要过河。 假定河流被等分为若干个单元格,并且在每一个单元格内都有可能放有一块石子(也有可能没有)。 青蛙可以跳上石子,但是不可以跳入水中。
+ +给你石子的位置列表 stones(用单元格序号 升序 表示), 请判定青蛙能否成功过河(即能否在最后一步跳至最后一块石子上)。
开始时, 青蛙默认已站在第一块石子上,并可以假定它第一步只能跳跃一个单位(即只能从单元格 1 跳至单元格 2 )。
+ +如果青蛙上一步跳跃了 k 个单位,那么它接下来的跳跃距离只能选择为 k - 1、k 或 k + 1 个单位。 另请注意,青蛙只能向前方(终点的方向)跳跃。
+ +
示例 1:
+ ++输入:stones = [0,1,3,5,6,8,12,17] +输出:true +解释:青蛙可以成功过河,按照如下方案跳跃:跳 1 个单位到第 2 块石子, 然后跳 2 个单位到第 3 块石子, 接着 跳 2 个单位到第 4 块石子, 然后跳 3 个单位到第 6 块石子, 跳 4 个单位到第 7 块石子, 最后,跳 5 个单位到第 8 个石子(即最后一块石子)。+ +
示例 2:
+ ++输入:stones = [0,1,2,3,4,8,9,11] +输出:false +解释:这是因为第 5 和第 6 个石子之间的间距太大,没有可选的方案供青蛙跳跃过去。+ +
+ +
提示:
+ +2 <= stones.length <= 20000 <= stones[i] <= 231 - 1stones[0] == 0编写一个 SQL 查询,获取 Employee 表中第 n 高的薪水(Salary)。
+----+--------+ -| Id | Salary | -+----+--------+ -| 1 | 100 | -| 2 | 200 | -| 3 | 300 | -+----+--------+ -- -
例如上述 Employee 表,n = 2 时,应返回第二高的薪水 200。如果不存在第 n 高的薪水,那么查询应返回 null。
+------------------------+ -| getNthHighestSalary(2) | -+------------------------+ -| 200 | -+------------------------+ -- - -## template - -```java - - -``` - -## 答案 - -```java - -``` - -## 选项 - -### A - -```java - -``` - -### B - -```java - -``` - -### C - -```java - -``` \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/178.exercises/config.json" "b/data_source/exercises/\344\270\255\347\255\211/java/178.exercises/config.json" deleted file mode 100644 index 5cb1b35d9f824b794fe65f9e60ce7265b78ce4ce..0000000000000000000000000000000000000000 --- "a/data_source/exercises/\344\270\255\347\255\211/java/178.exercises/config.json" +++ /dev/null @@ -1,10 +0,0 @@ -{ - "node_id": "dailycode-82e2c01379fa42e9a9914367270ff513", - "keywords": [], - "children": [], - "keywords_must": [], - "keywords_forbid": [], - "export": [ - "solution.json" - ] -} \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/178.exercises/solution.json" "b/data_source/exercises/\344\270\255\347\255\211/java/178.exercises/solution.json" deleted file mode 100644 index 0827f10492e8aa143d444192e1589f48050efcab..0000000000000000000000000000000000000000 --- "a/data_source/exercises/\344\270\255\347\255\211/java/178.exercises/solution.json" +++ /dev/null @@ -1,7 +0,0 @@ -{ - "type": "code_options", - "source": "solution.md", - "exercise_id": "5c4c5b520d1045db809a310366487eec", - "author": "csdn.net", - "keywords": "数据库" -} \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/178.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/java/178.exercises/solution.md" deleted file mode 100644 index a40402e396ccd61574b33730f2acfb67e3883276..0000000000000000000000000000000000000000 --- "a/data_source/exercises/\344\270\255\347\255\211/java/178.exercises/solution.md" +++ /dev/null @@ -1,67 +0,0 @@ -# 分数排名 - -
编写一个 SQL 查询来实现分数排名。
- -如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
- -+----+-------+ -| Id | Score | -+----+-------+ -| 1 | 3.50 | -| 2 | 3.65 | -| 3 | 4.00 | -| 4 | 3.85 | -| 5 | 4.00 | -| 6 | 3.65 | -+----+-------+ -- -
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
+-------+------+ -| Score | Rank | -+-------+------+ -| 4.00 | 1 | -| 4.00 | 1 | -| 3.85 | 2 | -| 3.65 | 3 | -| 3.65 | 3 | -| 3.50 | 4 | -+-------+------+ -- -
重要提示:对于 MySQL 解决方案,如果要转义用作列名的保留字,可以在关键字之前和之后使用撇号。例如 `Rank`
- - -## template - -```java - - -``` - -## 答案 - -```java - -``` - -## 选项 - -### A - -```java - -``` - -### B - -```java - -``` - -### C - -```java - -``` \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/179.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/java/179.exercises/solution.md" index 174aa61d143d95aea16ce513b4e22352769a0652..f562d2d23b4befacdd84ecfa9d5c9d63d0eab245 100644 --- "a/data_source/exercises/\344\270\255\347\255\211/java/179.exercises/solution.md" +++ "b/data_source/exercises/\344\270\255\347\255\211/java/179.exercises/solution.md" @@ -46,7 +46,38 @@ ## template ```java - +class Solution { + public String largestNumber(int[] nums) { + + String[] str = new String[nums.length]; + + for (int i = 0; i < nums.length; i++) + str[i] = String.valueOf(nums[i]); + + Arrays.parallelSort(str); + + for (int i = 1; i < str.length; i++) + for (int j = 0; j < i; j++) { + if (str[i].length() > str[j].length() && str[i].substring(0, str[j].length()).equals(str[j])) { + StringBuilder str1 = new StringBuilder(); + StringBuilder str2 = new StringBuilder(); + str1.append(str[i] + str[j]); + str2.append(str[j] + str[i]); + if (str2.toString().compareTo(str1.toString()) > 0) { + String tmp = str[i]; + str[i] = str[j]; + str[j] = tmp; + } + } + } + StringBuilder ans = new StringBuilder(); + + for (int i = str.length - 1; i >= 0; i--) + ans.append(str[i]); + + return ans.charAt(0) == '0' ? "0" : ans.toString(); + } +} ``` diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/180.exercises/config.json" "b/data_source/exercises/\344\270\255\347\255\211/java/180.exercises/config.json" deleted file mode 100644 index fba3c2994e62ec5828f017888b991067cff44c94..0000000000000000000000000000000000000000 --- "a/data_source/exercises/\344\270\255\347\255\211/java/180.exercises/config.json" +++ /dev/null @@ -1,10 +0,0 @@ -{ - "node_id": "dailycode-5f05b742e35445149011055afed9fa9e", - "keywords": [], - "children": [], - "keywords_must": [], - "keywords_forbid": [], - "export": [ - "solution.json" - ] -} \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/180.exercises/solution.json" "b/data_source/exercises/\344\270\255\347\255\211/java/180.exercises/solution.json" deleted file mode 100644 index 8a1052979f437b09e784cd1594bd01a9f422e18e..0000000000000000000000000000000000000000 --- "a/data_source/exercises/\344\270\255\347\255\211/java/180.exercises/solution.json" +++ /dev/null @@ -1,7 +0,0 @@ -{ - "type": "code_options", - "source": "solution.md", - "exercise_id": "bdda9c0e7f924dd2b600b11de361e606", - "author": "csdn.net", - "keywords": "数据库" -} \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/180.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/java/180.exercises/solution.md" deleted file mode 100644 index fd8c3be80c93fdb141d7d1c9cb9594fcdaae41b8..0000000000000000000000000000000000000000 --- "a/data_source/exercises/\344\270\255\347\255\211/java/180.exercises/solution.md" +++ /dev/null @@ -1,81 +0,0 @@ -# 连续出现的数字 - -表:Logs
-+-------------+---------+ -| Column Name | Type | -+-------------+---------+ -| id | int | -| num | varchar | -+-------------+---------+ -id 是这个表的主键。- -
- -
编写一个 SQL 查询,查找所有至少连续出现三次的数字。
- -返回的结果表中的数据可以按 任意顺序 排列。
- -- -
查询结果格式如下面的例子所示:
- -- -
-Logs 表: -+----+-----+ -| Id | Num | -+----+-----+ -| 1 | 1 | -| 2 | 1 | -| 3 | 1 | -| 4 | 2 | -| 5 | 1 | -| 6 | 2 | -| 7 | 2 | -+----+-----+ - -Result 表: -+-----------------+ -| ConsecutiveNums | -+-----------------+ -| 1 | -+-----------------+ -1 是唯一连续出现至少三次的数字。 -- - -## template - -```java - - -``` - -## 答案 - -```java - -``` - -## 选项 - -### A - -```java - -``` - -### B - -```java - -``` - -### C - -```java - -``` \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/184.exercises/config.json" "b/data_source/exercises/\344\270\255\347\255\211/java/184.exercises/config.json" deleted file mode 100644 index 44292f68871444fadb38798f6223bdecf149ee23..0000000000000000000000000000000000000000 --- "a/data_source/exercises/\344\270\255\347\255\211/java/184.exercises/config.json" +++ /dev/null @@ -1,10 +0,0 @@ -{ - "node_id": "dailycode-868aee1532de49d78dc95a814bd83b28", - "keywords": [], - "children": [], - "keywords_must": [], - "keywords_forbid": [], - "export": [ - "solution.json" - ] -} \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/184.exercises/solution.json" "b/data_source/exercises/\344\270\255\347\255\211/java/184.exercises/solution.json" deleted file mode 100644 index c03374c69e4257f78824dcbbf0fe38fc1884a191..0000000000000000000000000000000000000000 --- "a/data_source/exercises/\344\270\255\347\255\211/java/184.exercises/solution.json" +++ /dev/null @@ -1,7 +0,0 @@ -{ - "type": "code_options", - "source": "solution.md", - "exercise_id": "9d681ac067df42ebad48106a3a426611", - "author": "csdn.net", - "keywords": "数据库" -} \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/184.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/java/184.exercises/solution.md" deleted file mode 100644 index 3c0319bfb8dcc8e4a8869bf69bbfe19976523626..0000000000000000000000000000000000000000 --- "a/data_source/exercises/\344\270\255\347\255\211/java/184.exercises/solution.md" +++ /dev/null @@ -1,70 +0,0 @@ -# 部门工资最高的员工 - -
Employee 表包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
+----+-------+--------+--------------+ -| Id | Name | Salary | DepartmentId | -+----+-------+--------+--------------+ -| 1 | Joe | 70000 | 1 | -| 2 | Jim | 90000 | 1 | -| 3 | Henry | 80000 | 2 | -| 4 | Sam | 60000 | 2 | -| 5 | Max | 90000 | 1 | -+----+-------+--------+--------------+- -
Department 表包含公司所有部门的信息。
+----+----------+ -| Id | Name | -+----+----------+ -| 1 | IT | -| 2 | Sales | -+----+----------+- -
编写一个 SQL 查询,找出每个部门工资最高的员工。对于上述表,您的 SQL 查询应返回以下行(行的顺序无关紧要)。
- -+------------+----------+--------+ -| Department | Employee | Salary | -+------------+----------+--------+ -| IT | Max | 90000 | -| IT | Jim | 90000 | -| Sales | Henry | 80000 | -+------------+----------+--------+- -
解释:
- -Max 和 Jim 在 IT 部门的工资都是最高的,Henry 在销售部的工资最高。
- - -## template - -```java - - -``` - -## 答案 - -```java - -``` - -## 选项 - -### A - -```java - -``` - -### B - -```java - -``` - -### C - -```java - -``` \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/186.exercises/config.json" "b/data_source/exercises/\344\270\255\347\255\211/java/186.exercises/config.json" deleted file mode 100644 index 4df94a5422e93b4aaa40aca078a638c88cc8ca66..0000000000000000000000000000000000000000 --- "a/data_source/exercises/\344\270\255\347\255\211/java/186.exercises/config.json" +++ /dev/null @@ -1,10 +0,0 @@ -{ - "node_id": "dailycode-13e12e894dc14a74acbdd071409e92a6", - "keywords": [], - "children": [], - "keywords_must": [], - "keywords_forbid": [], - "export": [ - "solution.json" - ] -} \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/186.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/java/186.exercises/solution.md" deleted file mode 100644 index 43980f895488e2e77deb4cd732b46f52da2e2f18..0000000000000000000000000000000000000000 --- "a/data_source/exercises/\344\270\255\347\255\211/java/186.exercises/solution.md" +++ /dev/null @@ -1,36 +0,0 @@ -# 翻转字符串里的单词 II - - - -## template - -```java - - -``` - -## 答案 - -```java - -``` - -## 选项 - -### A - -```java - -``` - -### B - -```java - -``` - -### C - -```java - -``` \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/187.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/java/187.exercises/solution.md" index 3e02b37e22a9bbd1c543bc054a0c3af579b1c7b2..aebf1f37ff7d3ab440e2277b494967251ee3e1ac 100644 --- "a/data_source/exercises/\344\270\255\347\255\211/java/187.exercises/solution.md" +++ "b/data_source/exercises/\344\270\255\347\255\211/java/187.exercises/solution.md" @@ -33,6 +33,18 @@ ## template ```java +class Solution { + public List写一个 bash 脚本以统计一个文本文件 words.txt 中每个单词出现的频率。
为了简单起见,你可以假设:
- -words.txt只包括小写字母和 ' ' 。示例:
- -假设 words.txt 内容如下:
the day is sunny the the -the sunny is is -- -
你的脚本应当输出(以词频降序排列):
- -the 4 -is 3 -sunny 2 -day 1 -- -
说明:
- -给定一个文件 file.txt,转置它的内容。
你可以假设每行列数相同,并且每个字段由 ' ' 分隔。
- -
示例:
- -假设 file.txt 文件内容如下:
-name age -alice 21 -ryan 30 -- -
应当输出:
- --name alice ryan -age 21 30 -- - -## template - -```java - - -``` - -## 答案 - -```java - -``` - -## 选项 - -### A - -```java - -``` - -### B - -```java - -``` - -### C - -```java - -``` \ No newline at end of file diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/198.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/java/198.exercises/solution.md" index 6b4f0c91b411be0864aff084ca7790963a333bdb..b9eee115a00e74b68db40f510ad4172922dcd099 100644 --- "a/data_source/exercises/\344\270\255\347\255\211/java/198.exercises/solution.md" +++ "b/data_source/exercises/\344\270\255\347\255\211/java/198.exercises/solution.md" @@ -36,6 +36,22 @@ ## template ```java +class Solution { + public int rob(int[] nums) { + if (nums.length == 0) + return 0; + if (nums.length == 1) + return nums[0]; + int result[] = new int[nums.length]; + result[0] = nums[0]; + result[1] = Math.max(nums[0], nums[1]); + for (int i = 2; i < result.length; i++) { + result[i] = Math.max(result[i - 1], result[i - 2] + nums[i]); + } + + return result[result.length - 1]; + } +} ``` diff --git "a/data_source/exercises/\344\270\255\347\255\211/java/199.exercises/solution.md" "b/data_source/exercises/\344\270\255\347\255\211/java/199.exercises/solution.md" index 4d28a0790f6fe768f5f3fe979b5a85ecb9d73af2..0f1f99f0005c3f00123078903285b2c78b1962ae 100644 --- "a/data_source/exercises/\344\270\255\347\255\211/java/199.exercises/solution.md" +++ "b/data_source/exercises/\344\270\255\347\255\211/java/199.exercises/solution.md" @@ -40,7 +40,37 @@ ## template ```java - +public class TreeNode { + int val; + TreeNode left; + TreeNode right; + + TreeNode(int x) { + val = x; + } +} + +class Solution { + public List
Employee 表包含所有员工信息,每个员工有其对应的工号 Id,姓名 Name,工资 Salary 和部门编号 DepartmentId 。
+----+-------+--------+--------------+ -| Id | Name | Salary | DepartmentId | -+----+-------+--------+--------------+ -| 1 | Joe | 85000 | 1 | -| 2 | Henry | 80000 | 2 | -| 3 | Sam | 60000 | 2 | -| 4 | Max | 90000 | 1 | -| 5 | Janet | 69000 | 1 | -| 6 | Randy | 85000 | 1 | -| 7 | Will | 70000 | 1 | -+----+-------+--------+--------------+- -
Department 表包含公司所有部门的信息。
+----+----------+ -| Id | Name | -+----+----------+ -| 1 | IT | -| 2 | Sales | -+----+----------+- -
编写一个 SQL 查询,找出每个部门获得前三高工资的所有员工。例如,根据上述给定的表,查询结果应返回:
- -+------------+----------+--------+ -| Department | Employee | Salary | -+------------+----------+--------+ -| IT | Max | 90000 | -| IT | Randy | 85000 | -| IT | Joe | 85000 | -| IT | Will | 70000 | -| Sales | Henry | 80000 | -| Sales | Sam | 60000 | -+------------+----------+--------+- -
解释:
- -IT 部门中,Max 获得了最高的工资,Randy 和 Joe 都拿到了第二高的工资,Will 的工资排第三。销售部门(Sales)只有两名员工,Henry 的工资最高,Sam 的工资排第二。
- - -## template - -```java - - -``` - -## 答案 - -```java - -``` - -## 选项 - -### A - -```java - -``` - -### B - -```java - -``` - -### C - -```java - -``` \ No newline at end of file diff --git "a/data_source/exercises/\345\233\260\351\232\276/java/188.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/java/188.exercises/solution.md" index 805439cbbc4912b067e1fb8dafb1b7193499d09d..a87799eb8ac453fad218e90b90e145b1badac720 100644 --- "a/data_source/exercises/\345\233\260\351\232\276/java/188.exercises/solution.md" +++ "b/data_source/exercises/\345\233\260\351\232\276/java/188.exercises/solution.md" @@ -37,6 +37,36 @@ ## template ```java +class Solution { + public int maxProfit(int k, int[] prices) { + if (k < 1) + return 0; + if (k >= prices.length / 2) + return greedy(prices); + int[][] t = new int[k][2]; + for (int i = 0; i < k; ++i) + t[i][0] = Integer.MIN_VALUE; + for (int p : prices) { + t[0][0] = Math.max(t[0][0], -p); + t[0][1] = Math.max(t[0][1], t[0][0] + p); + for (int i = 1; i < k; ++i) { + + t[i][0] = Math.max(t[i][0], t[i - 1][1] - p); + t[i][1] = Math.max(t[i][1], t[i][0] + p); + } + } + return t[k - 1][1]; + } + + private int greedy(int[] prices) { + int max = 0; + for (int i = 1; i < prices.length; ++i) { + if (prices[i] > prices[i - 1]) + max += prices[i] - prices[i - 1]; + } + return max; + } +} ``` diff --git "a/data_source/exercises/\345\233\260\351\232\276/java/212.exercises/solution.md" "b/data_source/exercises/\345\233\260\351\232\276/java/212.exercises/solution.md" index 4558e3fdd4eaed174a879a7cb0f359e5db57cd9f..8062a438d5695a18718e8d68636842ff300d40c0 100644 --- "a/data_source/exercises/\345\233\260\351\232\276/java/212.exercises/solution.md" +++ "b/data_source/exercises/\345\233\260\351\232\276/java/212.exercises/solution.md" @@ -40,7 +40,82 @@ ```java - +class Solution { + static int[][] d = new int[][] { { -1, 0 }, { 1, 0 }, { 0, -1 }, { 0, 1 } }; + static Map