给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
进阶:
- 一个直观的解决方案是使用
O(mn)的额外空间,但这并不是一个好的解决方案。 - 一个简单的改进方案是使用
O(m + n)的额外空间,但这仍然不是最好的解决方案。 - 你能想出一个仅使用常量空间的解决方案吗?
示例 1:
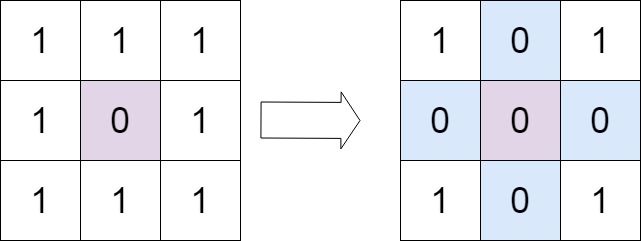
输入:matrix = [[1,1,1],[1,0,1],[1,1,1]]
输出:[[1,0,1],[0,0,0],[1,0,1]]
示例 2:
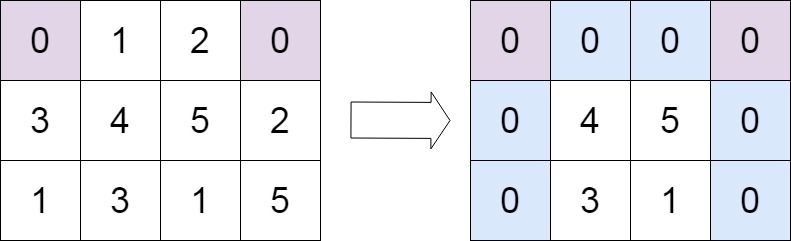
输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]]
输出:[[0,0,0,0],[0,4,5,0],[0,3,1,0]]
提示:
m == matrix.lengthn == matrix[0].length1 <= m, n <= 200-231 <= matrix[i][j] <= 231 - 1
以下错误的选项是?
+## aop +### before +```cpp +#include编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
- 每行中的整数从左到右按升序排列。
- 每行的第一个整数大于前一行的最后一个整数。
示例 1:
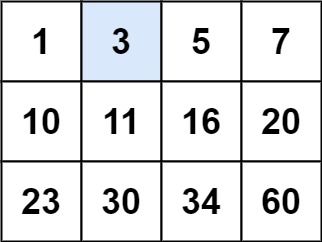
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3
输出:true
示例 2:
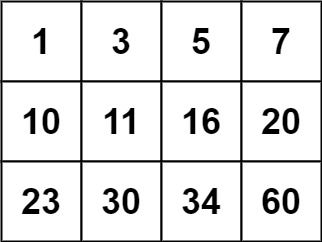
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 13
输出:false
提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 100-104 <= matrix[i][j], target <= 104
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
- 每行中的整数从左到右按升序排列。
- 每行的第一个整数大于前一行的最后一个整数。
示例 1:
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3
输出:true
示例 2:
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 13
输出:false
提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 100-104 <= matrix[i][j], target <= 104
以下错误的选项是?
+## aop +### before +```cpp +#include给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
提示:
1 <= nums.length <= 10-10 <= nums[i] <= 10nums中的所有元素 互不相同
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
提示:
1 <= nums.length <= 10-10 <= nums[i] <= 10nums中的所有元素 互不相同
以下错误的选项是?
+## aop +### before +```cpp +#include给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使每个元素 最多出现两次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
++
说明:
+为什么返回数值是整数,但输出的答案是数组呢?
+请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
+你可以想象内部操作如下:
+
+ // nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
+ int len = removeDuplicates(nums);// 在函数里修改输入数组对于调用者是可见的。
+ // 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
+ for (int i = 0; i < len; i++) {
+ print(nums[i]);
+ }
++
示例 1:
+输入:nums = [1,1,1,2,2,3]+
输出:5, nums = [1,1,2,2,3]
解释:函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3 。 不需要考虑数组中超出新长度后面的元素。
示例 2:
+输入:nums = [0,0,1,1,1,1,2,3,3]+
输出:7, nums = [0,0,1,1,2,3,3]
解释:函数应返回新长度 length = 7, 并且原数组的前五个元素被修改为 0, 0, 1, 1, 2, 3, 3 。 不需要考虑数组中超出新长度后面的元素。
+
提示:
+-
+
1 <= nums.length <= 3 * 104
+ -104 <= nums[i] <= 104
+ nums已按升序排列
+
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使每个元素 最多出现两次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
++
说明:
+为什么返回数值是整数,但输出的答案是数组呢?
+请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
+你可以想象内部操作如下:
+
+ // nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
+ int len = removeDuplicates(nums);// 在函数里修改输入数组对于调用者是可见的。
+ // 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
+ for (int i = 0; i < len; i++) {
+ print(nums[i]);
+ }
++
示例 1:
+输入:nums = [1,1,1,2,2,3]+
输出:5, nums = [1,1,2,2,3]
解释:函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3 。 不需要考虑数组中超出新长度后面的元素。
示例 2:
+输入:nums = [0,0,1,1,1,1,2,3,3]+
输出:7, nums = [0,0,1,1,2,3,3]
解释:函数应返回新长度 length = 7, 并且原数组的前五个元素被修改为 0, 0, 1, 1, 2, 3, 3 。 不需要考虑数组中超出新长度后面的元素。
+
提示:
+-
+
1 <= nums.length <= 3 * 104
+ -104 <= nums[i] <= 104
+ nums已按升序排列
+
以下错误的选项是?
+## aop +### before +```cpp +#include已知存在一个按非降序排列的整数数组 nums ,数组中的值不必互不相同。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转
+ ,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0
+ 开始 计数)。例如, [0,1,2,4,4,4,5,6,6,7] 在下标 5 处经旋转后可能变为
+ [4,5,6,6,7,0,1,2,4,4] 。
+
给你 旋转后 的数组 nums 和一个整数 target ,请你编写一个函数来判断给定的目标值是否存在于数组中。如果
+ nums 中存在这个目标值 target ,则返回 true ,否则返回 false 。
+
+
示例 1:
+输入:nums = [2,5,6,0,0,1,2], target = 0+
输出:true
示例 2:
+输入:nums = [2,5,6,0,0,1,2], target = 3+
输出:false
+
提示:
+-
+
1 <= nums.length <= 5000
+ -104 <= nums[i] <= 104
+ - 题目数据保证
nums在预先未知的某个下标上进行了旋转
+ -104 <= target <= 104
+
+
进阶:
+-
+
- 这是 搜索旋转排序数组 的延伸题目,本题中的
nums+ 可能包含重复元素。
+ - 这会影响到程序的时间复杂度吗?会有怎样的影响,为什么? +
已知存在一个按非降序排列的整数数组 nums ,数组中的值不必互不相同。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转
+ ,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0
+ 开始 计数)。例如, [0,1,2,4,4,4,5,6,6,7] 在下标 5 处经旋转后可能变为
+ [4,5,6,6,7,0,1,2,4,4] 。
+
给你 旋转后 的数组 nums 和一个整数 target ,请你编写一个函数来判断给定的目标值是否存在于数组中。如果
+ nums 中存在这个目标值 target ,则返回 true ,否则返回 false 。
+
+
示例 1:
+输入:nums = [2,5,6,0,0,1,2], target = 0+
输出:true
示例 2:
+输入:nums = [2,5,6,0,0,1,2], target = 3+
输出:false
+
提示:
+-
+
1 <= nums.length <= 5000
+ -104 <= nums[i] <= 104
+ - 题目数据保证
nums在预先未知的某个下标上进行了旋转
+ -104 <= target <= 104
+
+
进阶:
+-
+
- 这是 搜索旋转排序数组 的延伸题目,本题中的
nums+ 可能包含重复元素。
+ - 这会影响到程序的时间复杂度吗?会有怎样的影响,为什么? +
以下错误的选项是?
+## aop +### before +```cpp +#include给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
此题中,我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
示例 1:
输入:nums = [2,0,2,1,1,0]
输出:[0,0,1,1,2,2]
示例 2:
输入:nums = [2,0,1]
输出:[0,1,2]
示例 3:
输入:nums = [0]
输出:[0]
示例 4:
输入:nums = [1]
输出:[1]
提示:
n == nums.length1 <= n <= 300nums[i]为0、1或2
进阶:
- 你可以不使用代码库中的排序函数来解决这道题吗?
- 你能想出一个仅使用常数空间的一趟扫描算法吗?
给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
此题中,我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
示例 1:
输入:nums = [2,0,2,1,1,0]
输出:[0,0,1,1,2,2]
示例 2:
输入:nums = [2,0,1]
输出:[0,1,2]
示例 3:
输入:nums = [0]
输出:[0]
示例 4:
输入:nums = [1]
输出:[1]
提示:
n == nums.length1 <= n <= 300nums[i]为0、1或2
进阶:
- 你可以不使用代码库中的排序函数来解决这道题吗?
- 你能想出一个仅使用常数空间的一趟扫描算法吗?
以下错误的选项是?
+## aop +### before +```cpp +#include存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除链表中所有存在数字重复情况的节点,只保留原始链表中 没有重复出现 的数字。
返回同样按升序排列的结果链表。
示例 1:
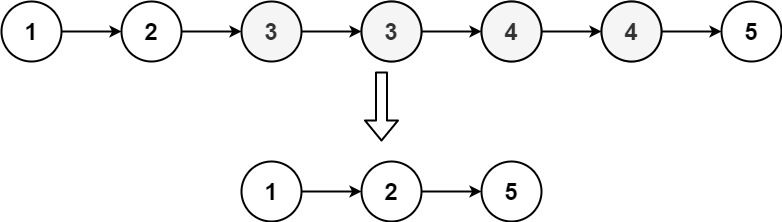
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:
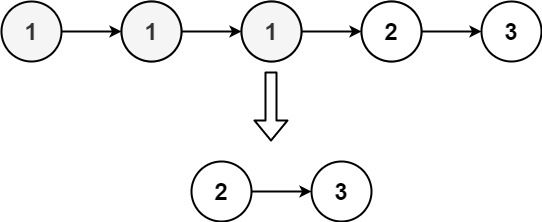
输入:head = [1,1,1,2,3]
输出:[2,3]
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序排列
存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除链表中所有存在数字重复情况的节点,只保留原始链表中 没有重复出现 的数字。
返回同样按升序排列的结果链表。
示例 1:
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:
输入:head = [1,1,1,2,3]
输出:[2,3]
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序排列
以下错误的选项是?
+## aop +### before +```cpp +#include存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除所有重复的元素,使每个元素 只出现一次 。
返回同样按升序排列的结果链表。
示例 1:
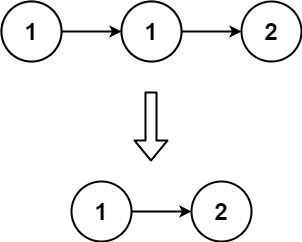
输入:head = [1,1,2]
输出:[1,2]
示例 2:
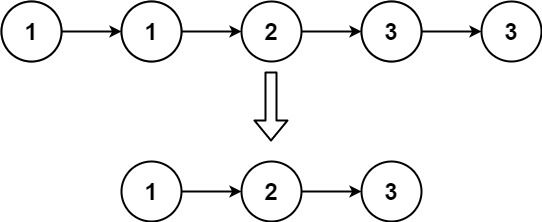
输入:head = [1,1,2,3,3]
输出:[1,2,3]
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序排列
存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除所有重复的元素,使每个元素 只出现一次 。
返回同样按升序排列的结果链表。
示例 1:
输入:head = [1,1,2]
输出:[1,2]
示例 2:
输入:head = [1,1,2,3,3]
输出:[1,2,3]
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序排列
以下错误的选项是?
+## aop +### before +```cpp +#include给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
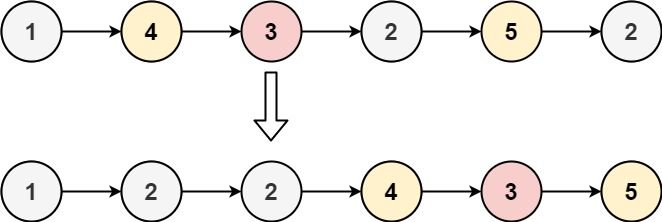
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2
输出:[1,2]
提示:
- 链表中节点的数目在范围
[0, 200]内 -100 <= Node.val <= 100-200 <= x <= 200
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2
输出:[1,2]
提示:
- 链表中节点的数目在范围
[0, 200]内 -100 <= Node.val <= 100-200 <= x <= 200
以下错误的选项是?
+## aop +### before +```cpp +#include有效数字(按顺序)可以分成以下几个部分:
- 一个 小数 或者 整数
- (可选)一个
'e'或'E',后面跟着一个 整数
小数(按顺序)可以分成以下几个部分:
- (可选)一个符号字符(
'+'或'-') - 下述格式之一:
- 至少一位数字,后面跟着一个点
'.' - 至少一位数字,后面跟着一个点
'.',后面再跟着至少一位数字 - 一个点
'.',后面跟着至少一位数字
- 至少一位数字,后面跟着一个点
整数(按顺序)可以分成以下几个部分:
- (可选)一个符号字符(
'+'或'-') - 至少一位数字
部分有效数字列举如下:
["2", "0089", "-0.1", "+3.14", "4.", "-.9", "2e10", "-90E3", "3e+7", "+6e-1", "53.5e93", "-123.456e789"]
部分无效数字列举如下:
["abc", "1a", "1e", "e3", "99e2.5", "--6", "-+3", "95a54e53"]
给你一个字符串 s ,如果 s 是一个 有效数字 ,请返回 true 。
示例 1:
输入:s = "0"
输出:true
示例 2:
输入:s = "e"
输出:false
示例 3:
输入:s = "."
输出:false
示例 4:
输入:s = ".1"
输出:true
提示:
1 <= s.length <= 20s仅含英文字母(大写和小写),数字(0-9),加号'+',减号'-',或者点'.'。
有效数字(按顺序)可以分成以下几个部分:
- 一个 小数 或者 整数
- (可选)一个
'e'或'E',后面跟着一个 整数
小数(按顺序)可以分成以下几个部分:
- (可选)一个符号字符(
'+'或'-') - 下述格式之一:
- 至少一位数字,后面跟着一个点
'.' - 至少一位数字,后面跟着一个点
'.',后面再跟着至少一位数字 - 一个点
'.',后面跟着至少一位数字
- 至少一位数字,后面跟着一个点
整数(按顺序)可以分成以下几个部分:
- (可选)一个符号字符(
'+'或'-') - 至少一位数字
部分有效数字列举如下:
["2", "0089", "-0.1", "+3.14", "4.", "-.9", "2e10", "-90E3", "3e+7", "+6e-1", "53.5e93", "-123.456e789"]
部分无效数字列举如下:
["abc", "1a", "1e", "e3", "99e2.5", "--6", "-+3", "95a54e53"]
给你一个字符串 s ,如果 s 是一个 有效数字 ,请返回 true 。
示例 1:
输入:s = "0"
输出:true
示例 2:
输入:s = "e"
输出:false
示例 3:
输入:s = "."
输出:false
示例 4:
输入:s = ".1"
输出:true
提示:
1 <= s.length <= 20s仅含英文字母(大写和小写),数字(0-9),加号'+',减号'-',或者点'.'。
以下错误的选项是?
+## aop +### before +```cpp +#include给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'//')都被视为单个斜杠 '/' 。 对于此问题,任何其他格式的点(例如,'...')均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
- 始终以斜杠
'/'开头。 - 两个目录名之间必须只有一个斜杠
'/'。 - 最后一个目录名(如果存在)不能 以
'/'结尾。 - 此外,路径仅包含从根目录到目标文件或目录的路径上的目录(即,不含
'.'或'..')。
返回简化后得到的 规范路径 。
示例 1:
输入:path = "/home/"
输出:"/home"
解释:注意,最后一个目录名后面没有斜杠。
示例 2:
输入:path = "/../"
输出:"/"
解释:从根目录向上一级是不可行的,因为根目录是你可以到达的最高级。
示例 3:
输入:path = "/home//foo/"
输出:"/home/foo"
解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。
示例 4:
输入:path = "/a/./b/../../c/"
输出:"/c"
提示:
1 <= path.length <= 3000path由英文字母,数字,'.','/'或'_'组成。path是一个有效的 Unix 风格绝对路径。
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'//')都被视为单个斜杠 '/' 。 对于此问题,任何其他格式的点(例如,'...')均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
- 始终以斜杠
'/'开头。 - 两个目录名之间必须只有一个斜杠
'/'。 - 最后一个目录名(如果存在)不能 以
'/'结尾。 - 此外,路径仅包含从根目录到目标文件或目录的路径上的目录(即,不含
'.'或'..')。
返回简化后得到的 规范路径 。
示例 1:
输入:path = "/home/"
输出:"/home"
解释:注意,最后一个目录名后面没有斜杠。
示例 2:
输入:path = "/../"
输出:"/"
解释:从根目录向上一级是不可行的,因为根目录是你可以到达的最高级。
示例 3:
输入:path = "/home//foo/"
输出:"/home/foo"
解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。
示例 4:
输入:path = "/a/./b/../../c/"
输出:"/c"
提示:
1 <= path.length <= 3000path由英文字母,数字,'.','/'或'_'组成。path是一个有效的 Unix 风格绝对路径。
以下错误的选项是?
+## aop +### before +```cpp +#include给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
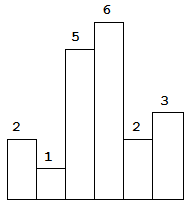
以上是柱状图的示例,其中每个柱子的宽度为 1,给定的高度为 [2,1,5,6,2,3]。
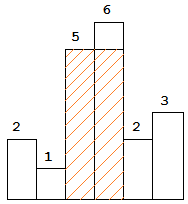
图中阴影部分为所能勾勒出的最大矩形面积,其面积为 10 个单位。
示例:
输入: [2,1,5,6,2,3]\ No newline at end of file diff --git "a/data/2.\347\256\227\346\263\225\344\270\255\351\230\266/4.leetcode\346\240\210\344\270\216\351\230\237\345\210\227/83_\346\237\261\347\212\266\345\233\276\344\270\255\346\234\200\345\244\247\347\232\204\347\237\251\345\275\242/solution.cpp" "b/data/2.\347\256\227\346\263\225\344\270\255\351\230\266/4.leetcode\346\240\210\344\270\216\351\230\237\345\210\227/83_\346\237\261\347\212\266\345\233\276\344\270\255\346\234\200\345\244\247\347\232\204\347\237\251\345\275\242/solution.cpp" new file mode 100644 index 0000000000000000000000000000000000000000..0e775884346d1a3ed58492e3bb9d41de6786c2de --- /dev/null +++ "b/data/2.\347\256\227\346\263\225\344\270\255\351\230\266/4.leetcode\346\240\210\344\270\216\351\230\237\345\210\227/83_\346\237\261\347\212\266\345\233\276\344\270\255\346\234\200\345\244\247\347\232\204\347\237\251\345\275\242/solution.cpp" @@ -0,0 +1,42 @@ +#include
输出: 10
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
以上是柱状图的示例,其中每个柱子的宽度为 1,给定的高度为 [2,1,5,6,2,3]。
图中阴影部分为所能勾勒出的最大矩形面积,其面积为 10 个单位。
示例:
输入: [2,1,5,6,2,3]+
输出: 10
以下错误的选项是?
+## aop +### before +```cpp +#include给定一个包含非负整数的 m x n 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
说明:每次只能向下或者向右移动一步。
示例 1:
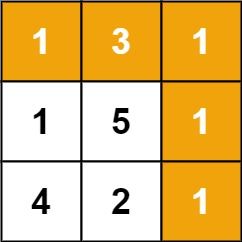
输入:grid = [[1,3,1],[1,5,1],[4,2,1]]
输出:7
解释:因为路径 1→3→1→1→1 的总和最小。
示例 2:
输入:grid = [[1,2,3],[4,5,6]]
输出:12
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 2000 <= grid[i][j] <= 100
给定一个包含非负整数的 m x n 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
说明:每次只能向下或者向右移动一步。
示例 1:
输入:grid = [[1,3,1],[1,5,1],[4,2,1]]
输出:7
解释:因为路径 1→3→1→1→1 的总和最小。
示例 2:
输入:grid = [[1,2,3],[4,5,6]]
输出:12
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 2000 <= grid[i][j] <= 100
以下错误的选项是?
+## aop +### before +```cpp +#include假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
注意:给定 n 是一个正整数。
示例 1:
输入: 2
输出: 2
解释: 有两种方法可以爬到楼顶。1. 1 阶 + 1 阶2. 2 阶
示例 2:
输入: 3\ No newline at end of file diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/11.leetcode\345\212\250\346\200\201\350\247\204\345\210\222/69_\347\210\254\346\245\274\346\242\257/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/11.leetcode\345\212\250\346\200\201\350\247\204\345\210\222/69_\347\210\254\346\245\274\346\242\257/solution.cpp" new file mode 100644 index 0000000000000000000000000000000000000000..b6bf8ef906263ad914a67ac4e6b9a942d103daa4 --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/11.leetcode\345\212\250\346\200\201\350\247\204\345\210\222/69_\347\210\254\346\245\274\346\242\257/solution.cpp" @@ -0,0 +1,19 @@ +#include
输出: 3
解释: 有三种方法可以爬到楼顶。1. 1 阶 + 1 阶 + 1 阶2. 1 阶 + 2 阶3. 2 阶 + 1 阶
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
注意:给定 n 是一个正整数。
示例 1:
输入: 2
输出: 2
解释: 有两种方法可以爬到楼顶。1. 1 阶 + 1 阶2. 2 阶
示例 2:
输入: 3+
输出: 3
解释: 有三种方法可以爬到楼顶。1. 1 阶 + 1 阶 + 1 阶2. 1 阶 + 2 阶3. 2 阶 + 1 阶
以下错误的选项是?
+## aop +### before +```cpp +#include给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
示例 1:
输入:word1 = "horse", word2 = "ros"
输出:3
解释:horse -> rorse (将 'h' 替换为 'r')rorse -> rose (删除 'r')rose -> ros (删除 'e')
示例 2:
输入:word1 = "intention", word2 = "execution"
输出:5
解释:intention -> inention (删除 't')inention -> enention (将 'i' 替换为 'e')enention -> exention (将 'n' 替换为 'x')exention -> exection (将 'n' 替换为 'c')exection -> execution (插入 'u')
提示:
0 <= word1.length, word2.length <= 500word1和word2由小写英文字母组成
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
示例 1:
输入:word1 = "horse", word2 = "ros"
输出:3
解释:horse -> rorse (将 'h' 替换为 'r')rorse -> rose (删除 'r')rose -> ros (删除 'e')
示例 2:
输入:word1 = "intention", word2 = "execution"
输出:5
解释:intention -> inention (删除 't')inention -> enention (将 'i' 替换为 'e')enention -> exention (将 'n' 替换为 'x')exention -> exection (将 'n' 替换为 'c')exection -> execution (插入 'u')
提示:
0 <= word1.length, word2.length <= 500word1和word2由小写英文字母组成
以下错误的选项是?
+## aop +### before +```cpp +#include给定一个仅包含 0 和 1 、大小为 rows x cols 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
示例 1:

输入:matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]]
输出:6
解释:最大矩形如上图所示。
示例 2:
输入:matrix = []
输出:0
示例 3:
输入:matrix = [["0"]]
输出:0
示例 4:
输入:matrix = [["1"]]
输出:1
示例 5:
输入:matrix = [["0","0"]]
输出:0
提示:
rows == matrix.lengthcols == matrix[0].length0 <= row, cols <= 200matrix[i][j]为'0'或'1'
给定一个仅包含 0 和 1 、大小为 rows x cols 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
示例 1:
输入:matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]]
输出:6
解释:最大矩形如上图所示。
示例 2:
输入:matrix = []
输出:0
示例 3:
输入:matrix = [["0"]]
输出:0
示例 4:
输入:matrix = [["1"]]
输出:1
示例 5:
输入:matrix = [["0","0"]]
输出:0
提示:
rows == matrix.lengthcols == matrix[0].length0 <= row, cols <= 200matrix[i][j]为'0'或'1'
以下错误的选项是?
+## aop +### before +```cpp +#includes 得到字符串 t :
+ -
+
- 如果字符串的长度为 1 ,算法停止 +
- 如果字符串的长度 > 1 ,执行下述步骤:
+
-
+
- 在一个随机下标处将字符串分割成两个非空的子字符串。即,如果已知字符串
s,则可以将其分成两个子字符串x和y+ ,且满足s = x + y。
+ - 随机 决定是要「交换两个子字符串」还是要「保持这两个子字符串的顺序不变」。即,在执行这一步骤之后,
s可能是 +s = x + y或者s = y + x。 +
+ - 在
x和y这两个子字符串上继续从步骤 1 开始递归执行此算法。
+
+ - 在一个随机下标处将字符串分割成两个非空的子字符串。即,如果已知字符串
给你两个 长度相等 的字符串 s1
+ 和 s2,判断 s2 是否是 s1 的扰乱字符串。如果是,返回
+ true ;否则,返回 false 。
+
+ +
示例 1:
+ +输入:s1 = "great", s2 = "rgeat" ++ +
输出:true +
解释:s1 上可能发生的一种情形是: +"great" --> "gr/eat" // 在一个随机下标处分割得到两个子字符串 +"gr/eat" --> "gr/eat" // 随机决定:「保持这两个子字符串的顺序不变」 +"gr/eat" --> "g/r / e/at" // 在子字符串上递归执行此算法。两个子字符串分别在随机下标处进行一轮分割 +"g/r / e/at" --> "r/g / e/at" // 随机决定:第一组「交换两个子字符串」,第二组「保持这两个子字符串的顺序不变」 +"r/g / e/at" --> "r/g / e/ a/t" // 继续递归执行此算法,将 "at" 分割得到 "a/t" +"r/g / e/ a/t" --> "r/g / e/ a/t" // 随机决定:「保持这两个子字符串的顺序不变」 +算法终止,结果字符串和 s2 相同,都是 "rgeat" +这是一种能够扰乱 s1 得到 s2 的情形,可以认为 s2 是 s1 的扰乱字符串,返回 true +
示例 2:
+ +输入:s1 = "abcde", s2 = "caebd" ++ +
输出:false +
示例 3:
+ +输入:s1 = "a", s2 = "a" ++ +
输出:true +
+ +
提示:
+ +-
+
s1.length == s2.length
+ 1 <= s1.length <= 30
+ s1和s2由小写英文字母组成
+
s 得到字符串 t :
+ -
+
- 如果字符串的长度为 1 ,算法停止 +
- 如果字符串的长度 > 1 ,执行下述步骤:
+
-
+
- 在一个随机下标处将字符串分割成两个非空的子字符串。即,如果已知字符串
s,则可以将其分成两个子字符串x和y+ ,且满足s = x + y。
+ - 随机 决定是要「交换两个子字符串」还是要「保持这两个子字符串的顺序不变」。即,在执行这一步骤之后,
s可能是 +s = x + y或者s = y + x。 +
+ - 在
x和y这两个子字符串上继续从步骤 1 开始递归执行此算法。
+
+ - 在一个随机下标处将字符串分割成两个非空的子字符串。即,如果已知字符串
给你两个 长度相等 的字符串 s1
+ 和 s2,判断 s2 是否是 s1 的扰乱字符串。如果是,返回
+ true ;否则,返回 false 。
+
+ +
示例 1:
+ +输入:s1 = "great", s2 = "rgeat" ++ +
输出:true +
解释:s1 上可能发生的一种情形是: +"great" --> "gr/eat" // 在一个随机下标处分割得到两个子字符串 +"gr/eat" --> "gr/eat" // 随机决定:「保持这两个子字符串的顺序不变」 +"gr/eat" --> "g/r / e/at" // 在子字符串上递归执行此算法。两个子字符串分别在随机下标处进行一轮分割 +"g/r / e/at" --> "r/g / e/at" // 随机决定:第一组「交换两个子字符串」,第二组「保持这两个子字符串的顺序不变」 +"r/g / e/at" --> "r/g / e/ a/t" // 继续递归执行此算法,将 "at" 分割得到 "a/t" +"r/g / e/ a/t" --> "r/g / e/ a/t" // 随机决定:「保持这两个子字符串的顺序不变」 +算法终止,结果字符串和 s2 相同,都是 "rgeat" +这是一种能够扰乱 s1 得到 s2 的情形,可以认为 s2 是 s1 的扰乱字符串,返回 true +
示例 2:
+ +输入:s1 = "abcde", s2 = "caebd" ++ +
输出:false +
示例 3:
+ +输入:s1 = "a", s2 = "a" ++ +
输出:true +
+ +
提示:
+ +-
+
s1.length == s2.length
+ 1 <= s1.length <= 30
+ s1和s2由小写英文字母组成
+
以下错误的选项是?
+## aop +### before +```cpp +#include给定一个单词数组和一个长度 maxWidth,重新排版单词,使其成为每行恰好有 maxWidth 个字符,且左右两端对齐的文本。
+ +你应该使用“贪心算法”来放置给定的单词;也就是说,尽可能多地往每行中放置单词。必要时可用空格 ' ' 填充,使得每行恰好有 maxWidth 个字符。
+
要求尽可能均匀分配单词间的空格数量。如果某一行单词间的空格不能均匀分配,则左侧放置的空格数要多于右侧的空格数。
+ +文本的最后一行应为左对齐,且单词之间不插入额外的空格。
+ +说明:
+ +-
+
- 单词是指由非空格字符组成的字符序列。 +
- 每个单词的长度大于 0,小于等于 maxWidth。 +
- 输入单词数组
words至少包含一个单词。
+
示例:
+ +输入: + words = ["This", "is", "an", "example", "of", "text", "justification."] + maxWidth = 16 ++ +
输出: + [ + "This is an", + "example of text", + "justification. " + ] +
示例 2:
+ +输入: + words = ["What","must","be","acknowledgment","shall","be"] + maxWidth = 16 ++ +
输出: + [ + "What must be", + "acknowledgment ", + "shall be " + ] +
解释: 注意最后一行的格式应为 "shall be " 而不是 "shall be" + 因为最后一行应为左对齐,而不是左右两端对齐,第二行同样为左对齐,这是因为这行只包含一个单词。 +
示例 3:
+ +输入: + words = ["Science","is","what","we","understand","well","enough","to","explain", + "to","a","computer.","Art","is","everything","else","we","do"] + maxWidth = 20 ++
输出: + [ + "Science is what we", + "understand well", + "enough to explain to", + "a computer. Art is", + "everything else we", + "do " + ] +
给定一个单词数组和一个长度 maxWidth,重新排版单词,使其成为每行恰好有 maxWidth 个字符,且左右两端对齐的文本。
+ +你应该使用“贪心算法”来放置给定的单词;也就是说,尽可能多地往每行中放置单词。必要时可用空格 ' ' 填充,使得每行恰好有 maxWidth 个字符。
+
要求尽可能均匀分配单词间的空格数量。如果某一行单词间的空格不能均匀分配,则左侧放置的空格数要多于右侧的空格数。
+ +文本的最后一行应为左对齐,且单词之间不插入额外的空格。
+ +说明:
+ +-
+
- 单词是指由非空格字符组成的字符序列。 +
- 每个单词的长度大于 0,小于等于 maxWidth。 +
- 输入单词数组
words至少包含一个单词。
+
示例:
+ +输入: + words = ["This", "is", "an", "example", "of", "text", "justification."] + maxWidth = 16 ++ +
输出: + [ + "This is an", + "example of text", + "justification. " + ] +
示例 2:
+ +输入: + words = ["What","must","be","acknowledgment","shall","be"] + maxWidth = 16 ++ +
输出: + [ + "What must be", + "acknowledgment ", + "shall be " + ] +
解释: 注意最后一行的格式应为 "shall be " 而不是 "shall be" + 因为最后一行应为左对齐,而不是左右两端对齐,第二行同样为左对齐,这是因为这行只包含一个单词。 +
示例 3:
+ +输入: + words = ["Science","is","what","we","understand","well","enough","to","explain", + "to","a","computer.","Art","is","everything","else","we","do"] + maxWidth = 20 ++
输出: + [ + "Science is what we", + "understand well", + "enough to explain to", + "a computer. Art is", + "everything else we", + "do " + ] +
以下错误的选项是?
+## aop +### before +```cpp +#include给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
注意:如果 s 中存在这样的子串,我们保证它是唯一的答案。
示例 1:
输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
示例 2:
输入:s = "a", t = "a"
输出:"a"
提示:
1 <= s.length, t.length <= 105s和t由英文字母组成
进阶:你能设计一个在
o(n) 时间内解决此问题的算法吗?
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/6.leetcode\345\223\210\345\270\214\350\241\250/75_\346\234\200\345\260\217\350\246\206\347\233\226\345\255\220\344\270\262/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/6.leetcode\345\223\210\345\270\214\350\241\250/75_\346\234\200\345\260\217\350\246\206\347\233\226\345\255\220\344\270\262/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..074e28830596c8dd37437ff0f1a20469148d20e5
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/6.leetcode\345\223\210\345\270\214\350\241\250/75_\346\234\200\345\260\217\350\246\206\347\233\226\345\255\220\344\270\262/solution.cpp"
@@ -0,0 +1,37 @@
+#include 给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
注意:如果 s 中存在这样的子串,我们保证它是唯一的答案。
示例 1:
输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
示例 2:
输入:s = "a", t = "a"
输出:"a"
提示:
1 <= s.length, t.length <= 105s和t由英文字母组成
进阶:你能设计一个在
o(n) 时间内解决此问题的算法吗?
+以下错误的选项是?
+## aop +### before +```cpp +#include给定两个整数 n 和 k,返回 1 ... n 中所有可能的 k 个数的组合。
+示例:
+输入: n = 4, k = 2\ No newline at end of file diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/7.leetcode\345\233\276\344\270\216\346\220\234\347\264\242/76_\347\273\204\345\220\210/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/7.leetcode\345\233\276\344\270\216\346\220\234\347\264\242/76_\347\273\204\345\220\210/solution.cpp" new file mode 100644 index 0000000000000000000000000000000000000000..006e5510cff4c6deae2e246f0f54648df5d5aa37 --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/7.leetcode\345\233\276\344\270\216\346\220\234\347\264\242/76_\347\273\204\345\220\210/solution.cpp" @@ -0,0 +1,30 @@ +#include
输出:[[2,4],[3,4],[2,3],[1,2],[1,3],[1,4],]
给定两个整数 n 和 k,返回 1 ... n 中所有可能的 k 个数的组合。
+示例:
+输入: n = 4, k = 2+
输出:[[2,4],[3,4],[2,3],[1,2],[1,3],[1,4],]
以下错误的选项是?
+## aop +### before +```cpp +#include给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例 1:
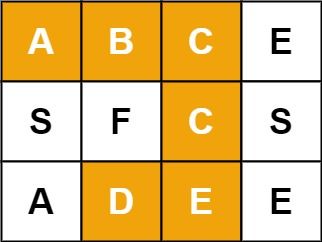
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
输出:true
示例 2:
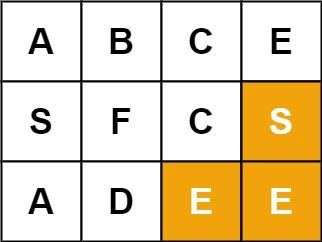
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE"
输出:true
示例 3:

输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB"
输出:false
提示:
m == board.lengthn = board[i].length1 <= m, n <= 61 <= word.length <= 15board和word仅由大小写英文字母组成
进阶:你可以使用搜索剪枝的技术来优化解决方案,使其在 board 更大的情况下可以更快解决问题?
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例 1:
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
输出:true
示例 2:
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE"
输出:true
示例 3:
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB"
输出:false
提示:
m == board.lengthn = board[i].length1 <= m, n <= 61 <= word.length <= 15board和word仅由大小写英文字母组成
进阶:你可以使用搜索剪枝的技术来优化解决方案,使其在 board 更大的情况下可以更快解决问题?
以下错误的选项是?
+## aop +### before +```cpp +#include给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
输入:digits = [1,2,3]
输出:[1,2,4]
解释:输入数组表示数字 123。
示例 2:
输入:digits = [4,3,2,1]
输出:[4,3,2,2]
解释:输入数组表示数字 4321。
示例 3:
输入:digits = [0]
输出:[1]
提示:
1 <= digits.length <= 1000 <= digits[i] <= 9
给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
输入:digits = [1,2,3]
输出:[1,2,4]
解释:输入数组表示数字 123。
示例 2:
输入:digits = [4,3,2,1]
输出:[4,3,2,2]
解释:输入数组表示数字 4321。
示例 3:
输入:digits = [0]
输出:[1]
提示:
1 <= digits.length <= 1000 <= digits[i] <= 9
以下错误的选项是?
+## aop +### before +```cpp +#include给你两个二进制字符串,返回它们的和(用二进制表示)。
输入为 非空 字符串且只包含数字 1 和 0。
示例 1:
输入: a = "11", b = "1"
输出: "100"
示例 2:
输入: a = "1010", b = "1011"
输出: "10101"
提示:
- 每个字符串仅由字符
'0'或'1'组成。 1 <= a.length, b.length <= 10^4- 字符串如果不是
"0",就都不含前导零。
给你两个二进制字符串,返回它们的和(用二进制表示)。
输入为 非空 字符串且只包含数字 1 和 0。
示例 1:
输入: a = "11", b = "1"
输出: "100"
示例 2:
输入: a = "1010", b = "1011"
输出: "10101"
提示:
- 每个字符串仅由字符
'0'或'1'组成。 1 <= a.length, b.length <= 10^4- 字符串如果不是
"0",就都不含前导零。
以下错误的选项是?
+## aop +### before +```cpp +#include实现 int sqrt(int x) 函数。
计算并返回 x 的平方根,其中 x 是非负整数。
+由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
+示例 1:
+输入: 4+
输出: 2
示例 2:
+输入: 8\ No newline at end of file diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode\346\225\260\345\255\246/68_x \347\232\204\345\271\263\346\226\271\346\240\271/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode\346\225\260\345\255\246/68_x \347\232\204\345\271\263\346\226\271\346\240\271/solution.cpp" new file mode 100644 index 0000000000000000000000000000000000000000..4f139bfa532c78c34e759e3a2491cdfc5752f029 --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode\346\225\260\345\255\246/68_x \347\232\204\345\271\263\346\226\271\346\240\271/solution.cpp" @@ -0,0 +1,35 @@ +#include
输出: 2
说明: 8 的平方根是 2.82842..., 由于返回类型是整数,小数部分将被舍去。
实现 int sqrt(int x) 函数。
计算并返回 x 的平方根,其中 x 是非负整数。
+由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
+示例 1:
+输入: 4