&nums, int target)
+ {
+ int lo = -1;
+ int hi = nums.size();
+ while (lo + 1 < hi)
+ {
+ int mid = lo + (hi - lo) / 2;
+ if (target > nums[mid])
+ {
+ lo = mid;
+ }
+ else
+ {
+ hi = mid;
+ }
+ }
+ return hi;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/35_\346\234\211\346\225\210\347\232\204\346\225\260\347\213\254/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/35_\346\234\211\346\225\210\347\232\204\346\225\260\347\213\254/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..7091d6a26c83fa8f35c6a62e3fe0d8bc42d2d1e8
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/35_\346\234\211\346\225\210\347\232\204\346\225\260\347\213\254/desc.html"
@@ -0,0 +1,48 @@
+请你判断一个 9x9 的数独是否有效。只需要 根据以下规则 ,验证已经填入的数字是否有效即可。
+
+ - 数字
1-9 在每一行只能出现一次。
+ - 数字
1-9 在每一列只能出现一次。
+ - 数字
1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图)
+
+数独部分空格内已填入了数字,空白格用 '.' 表示。
+注意:
+
+ - 一个有效的数独(部分已被填充)不一定是可解的。
+ - 只需要根据以上规则,验证已经填入的数字是否有效即可。
+
+
+示例 1:
 +
+输入:board =
+ [["5","3",".",".","7",".",".",".","."]
+ ,["6",".",".","1","9","5",".",".","."]
+ ,[".","9","8",".",".",".",".","6","."]
+ ,["8",".",".",".","6",".",".",".","3"]
+ ,["4",".",".","8",".","3",".",".","1"]
+ ,["7",".",".",".","2",".",".",".","6"]
+ ,[".","6",".",".",".",".","2","8","."]
+ ,[".",".",".","4","1","9",".",".","5"]
+ ,[".",".",".",".","8",".",".","7","9"]]
+
输出:true
+
+示例 2:
+输入:board =
+ [["8","3",".",".","7",".",".",".","."]
+ ,["6",".",".","1","9","5",".",".","."]
+ ,[".","9","8",".",".",".",".","6","."]
+ ,["8",".",".",".","6",".",".",".","3"]
+ ,["4",".",".","8",".","3",".",".","1"]
+ ,["7",".",".",".","2",".",".",".","6"]
+ ,[".","6",".",".",".",".","2","8","."]
+ ,[".",".",".","4","1","9",".",".","5"]
+ ,[".",".",".",".","8",".",".","7","9"]]
+
输出:false
+
解释:除了第一行的第一个数字从 5 改为 8 以外,空格内其他数字均与 示例1 相同。 但由于位于左上角的 3x3 宫内有两个 8 存在, 因此这个数独是无效的。
+
+提示:
+
+ board.length == 9board[i].length == 9board[i][j] 是一位数字或者 '.'
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/35_\346\234\211\346\225\210\347\232\204\346\225\260\347\213\254/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/35_\346\234\211\346\225\210\347\232\204\346\225\260\347\213\254/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..987dfacbc0d74a36e288e689f412899a653616fb
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/35_\346\234\211\346\225\210\347\232\204\346\225\260\347\213\254/solution.cpp"
@@ -0,0 +1,65 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ bool isValidSudoku(vector> &board)
+ {
+ for (int i = 0; i < board.size(); i++)
+ {
+ vector mark(10);
+ for (int j = 0; j < board.size(); j++)
+ {
+ if (!valid(board, mark, i, j))
+ {
+ return false;
+ }
+ }
+ }
+ for (int j = 0; j < board.size(); j++)
+ {
+ vector mark(10);
+ for (int i = 0; i < board.size(); i++)
+ {
+ if (!valid(board, mark, i, j))
+ {
+ return false;
+ }
+ }
+ }
+ for (int k = 0; k < board.size(); k++)
+ {
+ int sr = k / 3 * 3;
+ int sc = (k % 3) * 3;
+ vector mark(10);
+ for (int i = sr; i < sr + 3; i++)
+ {
+ for (int j = sc; j < sc + 3; j++)
+ {
+ if (!valid(board, mark, i, j))
+ {
+ return false;
+ }
+ }
+ }
+ }
+ return true;
+ }
+private:
+ bool valid(vector> &board, vector &mark, int i, int j)
+ {
+ if (board[i][j] != '.')
+ {
+ int index = board[i][j] - '0';
+ if (mark[index])
+ {
+ return false;
+ }
+ else
+ {
+ mark[index] = 1;
+ }
+ }
+ return true;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/36_\350\247\243\346\225\260\347\213\254/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/36_\350\247\243\346\225\260\347\213\254/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..a63fa6228013bb869fcb6913c08936b877e5e229
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/36_\350\247\243\346\225\260\347\213\254/desc.html"
@@ -0,0 +1,51 @@
+编写一个程序,通过填充空格来解决数独问题。
+数独的解法需 遵循如下规则:
+
+ - 数字
1-9 在每一行只能出现一次。
+ - 数字
1-9 在每一列只能出现一次。
+ - 数字
1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图)
+
+数独部分空格内已填入了数字,空白格用 '.' 表示。
+
+
+
+
+
示例:

+
输入:board =
+ [["5","3",".",".","7",".",".",".","."],
+ ["6",".",".","1","9","5",".",".","."],
+ [".","9","8",".",".",".",".","6","."],
+ ["8",".",".",".","6",".",".",".","3"],
+ ["4",".",".","8",".","3",".",".","1"],
+ ["7",".",".",".","2",".",".",".","6"],
+ [".","6",".",".",".",".","2","8","."],
+ [".",".",".","4","1","9",".",".","5"],
+ [".",".",".",".","8",".",".","7","9"]]
+
输出:
+ [["5","3","4","6","7","8","9","1","2"],
+ ["6","7","2","1","9","5","3","4","8"],
+ ["1","9","8","3","4","2","5","6","7"],
+ ["8","5","9","7","6","1","4","2","3"],
+ ["4","2","6","8","5","3","7","9","1"],
+ ["7","1","3","9","2","4","8","5","6"],
+ ["9","6","1","5","3","7","2","8","4"],
+ ["2","8","7","4","1","9","6","3","5"],
+ ["3","4","5","2","8","6","1","7","9"]]
+
解释:输入的数独如上图所示,唯一有效的解决方案如下所示:
+
+
+

+
+
+
提示:
+
+ board.length == 9board[i].length == 9board[i][j] 是一位数字或者 '.'- 题目数据 保证 输入数独仅有一个解
+
+
+
+
+
给定一个正整数 n ,输出外观数列的第 n 项。
+
+
「外观数列」是一个整数序列,从数字 1 开始,序列中的每一项都是对前一项的描述。
+
+
你可以将其视作是由递归公式定义的数字字符串序列:
+
+
+ countAndSay(1) = "1"countAndSay(n) 是对 countAndSay(n-1) 的描述,然后转换成另一个数字字符串。
+
+
前五项如下:
+
+
+ 1. 1
+ 2. 11
+ 3. 21
+ 4. 1211
+ 5. 111221
+ 第一项是数字 1
+ 描述前一项,这个数是 1 即 “ 一 个 1 ”,记作 "11"
+ 描述前一项,这个数是 11 即 “ 二 个 1 ” ,记作 "21"
+ 描述前一项,这个数是 21 即 “ 一 个 2 + 一 个 1 ” ,记作 "1211"
+ 描述前一项,这个数是 1211 即 “ 一 个 1 + 一 个 2 + 二 个 1 ” ,记作 "111221"
+
+
+
要 描述 一个数字字符串,首先要将字符串分割为 最小 数量的组,每个组都由连续的最多 相同字符
+ 组成。然后对于每个组,先描述字符的数量,然后描述字符,形成一个描述组。要将描述转换为数字字符串,先将每组中的字符数量用数字替换,再将所有描述组连接起来。
+
+
例如,数字字符串 "3322251" 的描述如下图:
+

+
+
+
+
+
示例 1:
+
+
输入:n = 1
+
输出:"1"
+
解释:这是一个基本样例。
+
+
+
示例 2:
+
+
输入:n = 4
+
输出:"1211"
+
解释:
+countAndSay(1) = "1"
+countAndSay(2) = 读 "1" = 一 个 1 = "11"
+countAndSay(3) = 读 "11" = 二 个 1 = "21"
+countAndSay(4) = 读 "21" = 一 个 2 + 一 个 1 = "12" + "11" = "1211"
+
+
+
+
+
提示:
+
+
+
给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
+
+candidates 中的数字可以无限制重复被选取。
+说明:
+
+ - 所有数字(包括
target)都是正整数。
+ - 解集不能包含重复的组合。
+
+示例 1:
+输入:candidates = [2,3,6,7], target = 7,
输出:[[7],[2,2,3]]
+示例 2:
+输入:candidates = [2,3,5], target = 8,
输出:[[2,2,2,2],[2,3,3],[3,5]]
+
+提示:
+
+ 1 <= candidates.length <= 301 <= candidates[i] <= 200candidate 中的每个元素都是独一无二的。1 <= target <= 500
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/38_\347\273\204\345\220\210\346\200\273\345\222\214/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/38_\347\273\204\345\220\210\346\200\273\345\222\214/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..7f066d4210f4e63cb5de5b495aaeafb5b8546722
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/38_\347\273\204\345\220\210\346\200\273\345\222\214/solution.cpp"
@@ -0,0 +1,34 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ vector> combinationSum(vector &candidates, int target)
+ {
+ vector> res;
+ dfs(candidates, 0, target, res);
+ return res;
+ }
+private:
+ vector stack;
+ void dfs(vector &candidates, int start, int target, vector> &res)
+ {
+ if (target < 0)
+ {
+ return;
+ }
+ else if (target == 0)
+ {
+ res.push_back(stack);
+ }
+ else
+ {
+ for (int i = start; i < candidates.size(); i++)
+ {
+ stack.push_back(candidates[i]);
+ dfs(candidates, i, target - candidates[i], res);
+ stack.pop_back();
+ }
+ }
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/39_\347\273\204\345\220\210\346\200\273\345\222\214 II/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/39_\347\273\204\345\220\210\346\200\273\345\222\214 II/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..868079e12742fd3ea08b075057e7091848869286
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/39_\347\273\204\345\220\210\346\200\273\345\222\214 II/desc.html"
@@ -0,0 +1,12 @@
+给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
+
+candidates 中的每个数字在每个组合中只能使用一次。
+说明:
+
+ - 所有数字(包括目标数)都是正整数。
+ - 解集不能包含重复的组合。
+
+示例 1:
+输入: candidates = [10,1,2,7,6,1,5], target = 8,
所求解集为:[[1, 7],[1, 2, 5],[2, 6],[1, 1, 6]]
+示例 2:
+输入: candidates = [2,5,2,1,2], target = 5,
所求解集为:[[1,2,2],[5]]
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/39_\347\273\204\345\220\210\346\200\273\345\222\214 II/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/39_\347\273\204\345\220\210\346\200\273\345\222\214 II/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..5e4586464842b0945e1a816b70b274308d58365c
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/39_\347\273\204\345\220\210\346\200\273\345\222\214 II/solution.cpp"
@@ -0,0 +1,40 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ vector> combinationSum2(vector &candidates, int target)
+ {
+ vector> res;
+ sort(candidates.begin(), candidates.end());
+ dfs(candidates, 0, target, res);
+ return res;
+ }
+private:
+ vector stack;
+ void dfs(vector &candidates, int start, int target, vector> &res)
+ {
+ if (target < 0)
+ {
+ return;
+ }
+ else if (target == 0)
+ {
+ res.push_back(stack);
+ }
+ else
+ {
+ int last = INT_MIN;
+ for (int i = start; i < candidates.size(); i++)
+ {
+ if (last != candidates[i])
+ {
+ stack.push_back(candidates[i]);
+ dfs(candidates, i + 1, target - candidates[i], res);
+ stack.pop_back();
+ }
+ last = candidates[i];
+ }
+ }
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/3_\345\257\273\346\211\276\344\270\244\344\270\252\346\255\243\345\272\217\346\225\260\347\273\204\347\232\204\344\270\255\344\275\215\346\225\260/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/3_\345\257\273\346\211\276\344\270\244\344\270\252\346\255\243\345\272\217\346\225\260\347\273\204\347\232\204\344\270\255\344\275\215\346\225\260/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..583e3f649fbbd9efe8408e73543822f651d90099
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/3_\345\257\273\346\211\276\344\270\244\344\270\252\346\255\243\345\272\217\346\225\260\347\273\204\347\232\204\344\270\255\344\275\215\346\225\260/desc.html"
@@ -0,0 +1 @@
+给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
示例 1:
输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2
示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
示例 3:
输入:nums1 = [0,0], nums2 = [0,0]
输出:0.00000
示例 4:
输入:nums1 = [], nums2 = [1]
输出:1.00000
示例 5:
输入:nums1 = [2], nums2 = []
输出:2.00000
提示:
nums1.length == mnums2.length == n0 <= m <= 10000 <= n <= 10001 <= m + n <= 2000-106 <= nums1[i], nums2[i] <= 106
进阶:你能设计一个时间复杂度为 O(log (m+n)) 的算法解决此问题吗?
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/3_\345\257\273\346\211\276\344\270\244\344\270\252\346\255\243\345\272\217\346\225\260\347\273\204\347\232\204\344\270\255\344\275\215\346\225\260/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/3_\345\257\273\346\211\276\344\270\244\344\270\252\346\255\243\345\272\217\346\225\260\347\273\204\347\232\204\344\270\255\344\275\215\346\225\260/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..a1dc00653eb6ff53f77563b10c0662612ddabb37
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/3_\345\257\273\346\211\276\344\270\244\344\270\252\346\255\243\345\272\217\346\225\260\347\273\204\347\232\204\344\270\255\344\275\215\346\225\260/solution.cpp"
@@ -0,0 +1,35 @@
+class Solution
+{
+public:
+ double findMedianSortedArrays(vector &nums1, vector &nums2)
+ {
+ int nums1Size = nums1.size();
+ int nums2Size = nums2.size();
+ int na = nums1Size + nums2Size;
+ int *ns = (int *)malloc(4 * na);
+ int i = 0, j = 0, d = 0;
+ int m = na / 2 + 1;
+ while (d < m)
+ {
+ int n;
+ if (i < nums1Size && j < nums2Size)
+ {
+ n = (nums1[i] < nums2[j]) ? nums1[i++] : nums2[j++];
+ }
+ else if (i < nums1Size)
+ {
+ n = nums1[i++];
+ }
+ else if (j < nums2Size)
+ {
+ n = nums2[j++];
+ }
+ ns[d++] = n;
+ }
+ if (na % 2)
+ {
+ return ns[d - 1];
+ }
+ return (ns[d - 1] + ns[d - 2]) / 2.0;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/40_\347\274\272\345\244\261\347\232\204\347\254\254\344\270\200\344\270\252\346\255\243\346\225\260/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/40_\347\274\272\345\244\261\347\232\204\347\254\254\344\270\200\344\270\252\346\255\243\346\225\260/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..7dafadcd64817b9c748bdfb9be04ed154d62f44a
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/40_\347\274\272\345\244\261\347\232\204\347\254\254\344\270\200\344\270\252\346\255\243\346\225\260/desc.html"
@@ -0,0 +1 @@
+给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。
进阶:你可以实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案吗?
示例 1:
输入:nums = [1,2,0]
输出:3
示例 2:
输入:nums = [3,4,-1,1]
输出:2
示例 3:
输入:nums = [7,8,9,11,12]
输出:1
提示:
0 <= nums.length <= 300-231 <= nums[i] <= 231 - 1
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/40_\347\274\272\345\244\261\347\232\204\347\254\254\344\270\200\344\270\252\346\255\243\346\225\260/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/40_\347\274\272\345\244\261\347\232\204\347\254\254\344\270\200\344\270\252\346\255\243\346\225\260/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..5cdad38162662e53cfcaf0fec240e995a179e479
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/40_\347\274\272\345\244\261\347\232\204\347\254\254\344\270\200\344\270\252\346\255\243\346\225\260/solution.cpp"
@@ -0,0 +1,33 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ int firstMissingPositive(vector &nums)
+ {
+ if (nums.size() == 0)
+ {
+ return 1;
+ }
+ int i = 0;
+ while (i < nums.size())
+ {
+ if (nums[i] > 0 && nums[i] != i + 1 && nums[i] - 1 < nums.size() && nums[nums[i] - 1] != nums[i])
+ {
+ swap(nums[i], nums[nums[i] - 1]);
+ }
+ else
+ {
+ i++;
+ }
+ }
+ for (i = 0; i < nums.size(); i++)
+ {
+ if (nums[i] != i + 1)
+ {
+ break;
+ }
+ }
+ return i + 1;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/41_\346\216\245\351\233\250\346\260\264/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/41_\346\216\245\351\233\250\346\260\264/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..3e62577c4e1e3fc579046d1f439c54491b97273d
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/41_\346\216\245\351\233\250\346\260\264/desc.html"
@@ -0,0 +1 @@
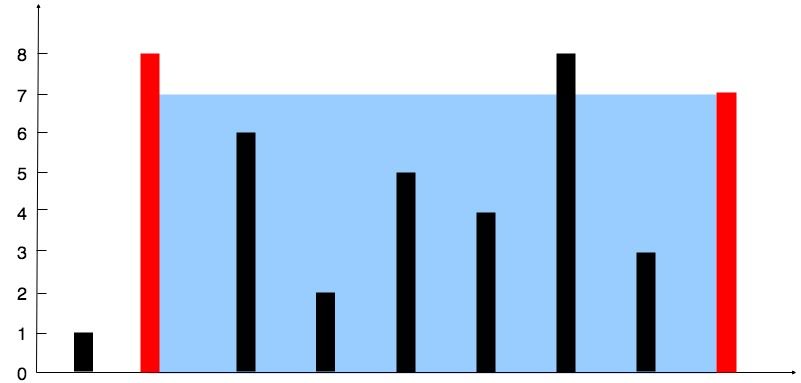
+给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:

输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2:
输入:height = [4,2,0,3,2,5]
输出:9
提示:
n == height.length0 <= n <= 3 * 1040 <= height[i] <= 105
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/41_\346\216\245\351\233\250\346\260\264/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/41_\346\216\245\351\233\250\346\260\264/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..922511f498ff29ec8e6137e6aeedb3734c76ab28
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/41_\346\216\245\351\233\250\346\260\264/solution.cpp"
@@ -0,0 +1,40 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ int trap(vector &height)
+ {
+ int res = 0;
+ int left = 0, left_max = 0;
+ int right = height.size() - 1, right_max = 0;
+ while (left < right)
+ {
+ if (height[left] < height[right])
+ {
+ if (height[left] > left_max)
+ {
+ left_max = height[left];
+ }
+ else
+ {
+ res += left_max - height[left];
+ }
+ left++;
+ }
+ else
+ {
+ if (height[right] > right_max)
+ {
+ right_max = height[right];
+ }
+ else
+ {
+ res += right_max - height[right];
+ }
+ right--;
+ }
+ }
+ return res;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/42_\345\255\227\347\254\246\344\270\262\347\233\270\344\271\230/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/42_\345\255\227\347\254\246\344\270\262\347\233\270\344\271\230/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..8131716551fae75fdbfd4c1d431017a683fc2dcb
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/42_\345\255\227\347\254\246\344\270\262\347\233\270\344\271\230/desc.html"
@@ -0,0 +1 @@
+给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。
示例 1:
输入: num1 = "2", num2 = "3"
输出: "6"
示例 2:
输入: num1 = "123", num2 = "456"
输出: "56088"
说明:
num1 和 num2 的长度小于110。num1 和 num2 只包含数字 0-9。num1 和 num2 均不以零开头,除非是数字 0 本身。- 不能使用任何标准库的大数类型(比如 BigInteger)或直接将输入转换为整数来处理。
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/42_\345\255\227\347\254\246\344\270\262\347\233\270\344\271\230/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/42_\345\255\227\347\254\246\344\270\262\347\233\270\344\271\230/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..3d92a26be08308044e70c30f81790b6b76a762de
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/42_\345\255\227\347\254\246\344\270\262\347\233\270\344\271\230/solution.cpp"
@@ -0,0 +1,30 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ string multiply(string num1, string num2)
+ {
+ string res(num1.length() + num2.length(), '0');
+ for (int i = num2.length() - 1; i >= 0; i--)
+ {
+ int j, carry = 0;
+ for (j = num1.length() - 1; j >= 0; j--)
+ {
+ carry += (num1[j] - '0') * (num2[i] - '0') + (res[i + j + 1] - '0');
+ res[i + j + 1] = carry % 10 + '0';
+ carry /= 10;
+ }
+ res[i + j + 1] = carry + '0';
+ }
+ int i;
+ for (i = 0; i < res.length() - 1; i++)
+ {
+ if (res[i] != '0')
+ {
+ break;
+ }
+ }
+ return res.substr(i);
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/43_\351\200\232\351\205\215\347\254\246\345\214\271\351\205\215/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/43_\351\200\232\351\205\215\347\254\246\345\214\271\351\205\215/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..c0f44e72e28acdaf82a1129274d3b35d68c247c3
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/43_\351\200\232\351\205\215\347\254\246\345\214\271\351\205\215/desc.html"
@@ -0,0 +1 @@
+给定一个字符串 (s) 和一个字符模式 (p) ,实现一个支持 '?' 和 '*' 的通配符匹配。
'?' 可以匹配任何单个字符。'*' 可以匹配任意字符串(包括空字符串)。
两个字符串完全匹配才算匹配成功。
说明:
s 可能为空,且只包含从 a-z 的小写字母。p 可能为空,且只包含从 a-z 的小写字母,以及字符 ? 和 *。
示例 1:
输入:s = "aa"p = "a"
输出: false
解释: "a" 无法匹配 "aa" 整个字符串。
示例 2:
输入:s = "aa"p = "*"
输出: true
解释: '*' 可以匹配任意字符串。
示例 3:
输入:s = "cb"p = "?a"
输出: false
解释: '?' 可以匹配 'c', 但第二个 'a' 无法匹配 'b'。
示例 4:
输入:s = "adceb"p = "*a*b"
输出: true
解释: 第一个 '*' 可以匹配空字符串, 第二个 '*' 可以匹配字符串 "dce".
示例 5:
输入:s = "acdcb"p = "a*c?b"
输出: false
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/43_\351\200\232\351\205\215\347\254\246\345\214\271\351\205\215/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/43_\351\200\232\351\205\215\347\254\246\345\214\271\351\205\215/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..c02c2b975739ecfd15b3dd05fa6ca4d3e92242f3
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/43_\351\200\232\351\205\215\347\254\246\345\214\271\351\205\215/solution.cpp"
@@ -0,0 +1,50 @@
+#include
+#include
+#include
+#include
+static bool isMatch(char *s, char *p)
+{
+ char *last_s = NULL;
+ char *last_p = NULL;
+ while (*s != '\0')
+ {
+ if (*p == '*')
+ {
+ if (*++p == '\0')
+ {
+ return true;
+ }
+ last_s = s;
+ last_p = p;
+ }
+ else if (*p == '?' || *s == *p)
+ {
+ s++;
+ p++;
+ }
+ else if (last_s != NULL)
+ {
+ p = last_p;
+ s = ++last_s;
+ }
+ else
+ {
+ return false;
+ }
+ }
+ while (*p == '*')
+ {
+ p++;
+ }
+ return *p == '\0';
+}
+int main(int argc, char **argv)
+{
+ if (argc != 3)
+ {
+ fprintf(stderr, "Usage: ./test string pattern\n");
+ exit(-1);
+ }
+ printf("%s\n", isMatch(argv[1], argv[2]) ? "true" : "false");
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/44_\350\267\263\350\267\203\346\270\270\346\210\217 II/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/44_\350\267\263\350\267\203\346\270\270\346\210\217 II/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..033059c845f2ce89539106c5859ae4b2c57c5a34
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/44_\350\267\263\350\267\203\346\270\270\346\210\217 II/desc.html"
@@ -0,0 +1,7 @@
+给定一个非负整数数组,你最初位于数组的第一个位置。
+数组中的每个元素代表你在该位置可以跳跃的最大长度。
+你的目标是使用最少的跳跃次数到达数组的最后一个位置。
+示例:
+输入: [2,3,1,1,4]
输出: 2
解释: 跳到最后一个位置的最小跳跃数是 2。从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。
+说明:
+假设你总是可以到达数组的最后一个位置。
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/44_\350\267\263\350\267\203\346\270\270\346\210\217 II/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/44_\350\267\263\350\267\203\346\270\270\346\210\217 II/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..1248a538229b531162c91c264ba05f341c65da78
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/44_\350\267\263\350\267\203\346\270\270\346\210\217 II/solution.cpp"
@@ -0,0 +1,23 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ int jump(vector &nums)
+ {
+ int steps = 0;
+ int lo = 0, hi = 0;
+ while (hi < nums.size() - 1)
+ {
+ int right = 0;
+ for (int i = lo; i <= hi; i++)
+ {
+ right = max(i + nums[i], right);
+ }
+ lo = hi + 1;
+ hi = right;
+ steps++;
+ }
+ return steps;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/45_\345\205\250\346\216\222\345\210\227/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/45_\345\205\250\346\216\222\345\210\227/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..125d29fe191d97ef2d29843935001ed158056ac0
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/45_\345\205\250\346\216\222\345\210\227/desc.html"
@@ -0,0 +1 @@
+给定一个 没有重复 数字的序列,返回其所有可能的全排列。
示例:
输入: [1,2,3]
输出:[ [1,2,3], [1,3,2], [2,1,3], [2,3,1], [3,1,2], [3,2,1]]
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/45_\345\205\250\346\216\222\345\210\227/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/45_\345\205\250\346\216\222\345\210\227/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..bdc46606c53ff4e56c66e3f88b96b7cd6459ebf1
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/45_\345\205\250\346\216\222\345\210\227/solution.cpp"
@@ -0,0 +1,36 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ vector> permute(vector &nums)
+ {
+ vector> res;
+ vector used(nums.size());
+ dfs(nums, used, res);
+ return res;
+ }
+private:
+ vector stack;
+ void dfs(vector &nums, vector &used, vector> &res)
+ {
+ if (stack.size() == nums.size())
+ {
+ res.push_back(stack);
+ }
+ else
+ {
+ for (int i = 0; i < nums.size(); i++)
+ {
+ if (!used[i])
+ {
+ used[i] = true;
+ stack.push_back(nums[i]);
+ dfs(nums, used, res);
+ stack.pop_back();
+ used[i] = false;
+ }
+ }
+ }
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/46_\345\205\250\346\216\222\345\210\227 II/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/46_\345\205\250\346\216\222\345\210\227 II/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..eaf0afc9cb0bd3ac65ba5c4cff112ec185c85540
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/46_\345\205\250\346\216\222\345\210\227 II/desc.html"
@@ -0,0 +1 @@
+给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2]
输出:[[1,1,2], [1,2,1], [2,1,1]]
示例 2:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
提示:
1 <= nums.length <= 8-10 <= nums[i] <= 10
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/46_\345\205\250\346\216\222\345\210\227 II/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/46_\345\205\250\346\216\222\345\210\227 II/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..5e96086b78d4b679071444f8f256312a63f87f83
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/46_\345\205\250\346\216\222\345\210\227 II/solution.cpp"
@@ -0,0 +1,41 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ vector> permuteUnique(vector &nums)
+ {
+ vector> res;
+ vector used(nums.size());
+ sort(nums.begin(), nums.end());
+ dfs(nums, used, res);
+ return res;
+ }
+private:
+ vector stack;
+ void dfs(vector &nums, vector &used, vector> &res)
+ {
+ if (stack.size() == nums.size())
+ {
+ res.push_back(stack);
+ }
+ else
+ {
+ for (int i = 0; i < nums.size(); i++)
+ {
+ if (!used[i])
+ {
+ if (i > 0 && !used[i - 1] && nums[i - 1] == nums[i])
+ {
+ continue;
+ }
+ stack.push_back(nums[i]);
+ used[i] = true;
+ dfs(nums, used, res);
+ stack.pop_back();
+ used[i] = false;
+ }
+ }
+ }
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/47_\346\227\213\350\275\254\345\233\276\345\203\217/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/47_\346\227\213\350\275\254\345\233\276\345\203\217/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..5792b68f180d63ef5e157aaa182aed3fc2d002ca
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/47_\346\227\213\350\275\254\345\233\276\345\203\217/desc.html"
@@ -0,0 +1 @@
+给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。
示例 1:
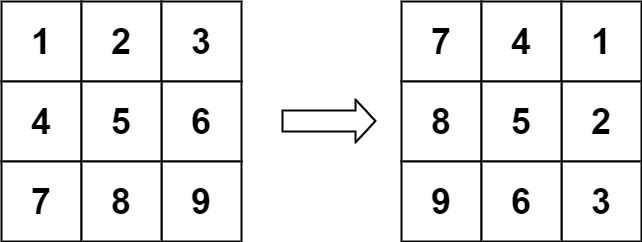
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]]
示例 2:
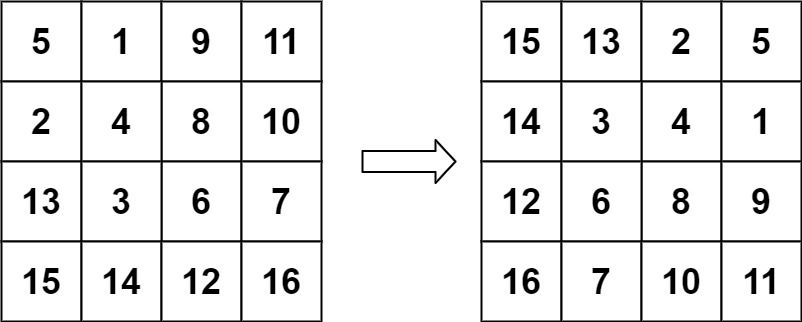
输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]]
示例 3:
输入:matrix = [[1]]
输出:[[1]]
示例 4:
输入:matrix = [[1,2],[3,4]]
输出:[[3,1],[4,2]]
提示:
matrix.length == nmatrix[i].length == n1 <= n <= 20-1000 <= matrix[i][j] <= 1000
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/47_\346\227\213\350\275\254\345\233\276\345\203\217/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/47_\346\227\213\350\275\254\345\233\276\345\203\217/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..567612da00bee2c32aa01434cba2b959e03a365c
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/47_\346\227\213\350\275\254\345\233\276\345\203\217/solution.cpp"
@@ -0,0 +1,22 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ void rotate(vector> &matrix)
+ {
+ int size = matrix.size();
+ for (int i = 0; i < size / 2; i++)
+ {
+ int low = i, high = size - i - 1;
+ for (int j = low; j < high; j++)
+ {
+ int tmp = matrix[i][j];
+ matrix[i][j] = matrix[size - 1 - j][i];
+ matrix[size - 1 - j][i] = matrix[size - 1 - i][size - 1 - j];
+ matrix[size - 1 - i][size - 1 - j] = matrix[j][size - 1 - i];
+ matrix[j][size - 1 - i] = tmp;
+ }
+ }
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/48_\345\255\227\346\257\215\345\274\202\344\275\215\350\257\215\345\210\206\347\273\204/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/48_\345\255\227\346\257\215\345\274\202\344\275\215\350\257\215\345\210\206\347\273\204/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..64bcde129c584db632a25aaadc61580475970269
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/48_\345\255\227\346\257\215\345\274\202\344\275\215\350\257\215\345\210\206\347\273\204/desc.html"
@@ -0,0 +1,8 @@
+给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
+示例:
+输入:[eat", "tea", "tan", "ate", "nat", "bat"]
输出:[[ate","eat","tea"],["nat","tan"],["bat"]]
+说明:
+
+ - 所有输入均为小写字母。
+ - 不考虑答案输出的顺序。
+
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/48_\345\255\227\346\257\215\345\274\202\344\275\215\350\257\215\345\210\206\347\273\204/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/48_\345\255\227\346\257\215\345\274\202\344\275\215\350\257\215\345\210\206\347\273\204/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..055df48aa7cca1c208ec1180565756221c1167dc
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/48_\345\255\227\346\257\215\345\274\202\344\275\215\350\257\215\345\210\206\347\273\204/solution.cpp"
@@ -0,0 +1,31 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ vector> groupAnagrams(vector &strs)
+ {
+ vector> res;
+ unordered_map> ht;
+ for (const auto &str : strs)
+ {
+ int counts[26] = {0};
+ for (char c : str)
+ {
+ counts[c - 'a']++;
+ }
+ string key;
+ for (int i : counts)
+ {
+ key.push_back('#');
+ key.push_back(i + '0');
+ }
+ ht[key].push_back(str);
+ }
+ for (const auto &t : ht)
+ {
+ res.push_back(t.second);
+ }
+ return res;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/49_Pow(x, n)/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/49_Pow(x, n)/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..0d9e7a2ce0328556e676d24952d66a21e96d9f25
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/49_Pow(x, n)/desc.html"
@@ -0,0 +1 @@
+实现 pow(x, n) ,即计算 x 的 n 次幂函数(即,xn)。
示例 1:
输入:x = 2.00000, n = 10
输出:1024.00000
示例 2:
输入:x = 2.10000, n = 3
输出:9.26100
示例 3:
输入:x = 2.00000, n = -2
输出:0.25000
解释:2-2 = 1/22 = 1/4 = 0.25
提示:
-100.0 < x < 100.0-231 <= n <= 231-1-104 <= xn <= 104
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/49_Pow(x, n)/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/49_Pow(x, n)/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..0f9724280d60ac3e66b18258a7d006dfeb11cd91
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/49_Pow(x, n)/solution.cpp"
@@ -0,0 +1,35 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ double myPow(double x, int n)
+ {
+ if (n == INT_MIN)
+ {
+ double t = dfs(x, -(n / 2));
+ return 1 / t * 1 / t;
+ }
+ else
+ {
+ return n < 0 ? 1 / dfs(x, -n) : dfs(x, n);
+ }
+ }
+private:
+ double dfs(double x, int n)
+ {
+ if (n == 0)
+ {
+ return 1;
+ }
+ else if (n == 1)
+ {
+ return x;
+ }
+ else
+ {
+ double t = dfs(x, n / 2);
+ return (n % 2) ? (x * t * t) : (t * t);
+ }
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/4_\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\344\270\262/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/4_\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\344\270\262/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..2b999715b185264d9d76cfd0786ba75e8654440f
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/4_\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\344\270\262/desc.html"
@@ -0,0 +1 @@
+给你一个字符串 s,找到 s 中最长的回文子串。
示例 1:
输入:s = "babad"
输出:"bab"
解释:"aba" 同样是符合题意的答案。
示例 2:
输入:s = "cbbd"
输出:"bb"
示例 3:
输入:s = "a"
输出:"a"
示例 4:
输入:s = "ac"
输出:"a"
提示:
1 <= s.length <= 1000s 仅由数字和英文字母(大写和/或小写)组成
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/4_\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\344\270\262/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/4_\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\344\270\262/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..6d931dbdc42324d063e5f2f8e04592012467a46b
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/4_\346\234\200\351\225\277\345\233\236\346\226\207\345\255\220\344\270\262/solution.cpp"
@@ -0,0 +1,44 @@
+class Solution
+{
+public:
+ string longestPalindrome(string s)
+ {
+ int ti = 0, maxlen = 0, i, t;
+ for (i = 0; s[i]; i++)
+ {
+ t = 1;
+ while (t <= i && s[i + t])
+ {
+ if (s[i + t] == s[i - t])
+ t++;
+ else
+ break;
+ }
+ t--;
+ if (2 * t + 1 > maxlen)
+ {
+ ti = i - t;
+ maxlen = 2 * t + 1;
+ }
+ }
+ for (i = 0; s[i]; i++)
+ {
+ t = 1;
+ while (t <= i + 1 && s[i + t])
+ {
+ if (s[i - t + 1] == s[i + t])
+ t++;
+ else
+ break;
+ }
+ t--;
+ if (2 * t > maxlen)
+ {
+ ti = i - t + 1;
+ maxlen = 2 * t;
+ }
+ }
+ s[ti + maxlen] = 0;
+ return s.c_str() + ti;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/50_N \347\232\207\345\220\216/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/50_N \347\232\207\345\220\216/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..b632b83636069a7837924c1c7281c4ee24b7d26e
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/50_N \347\232\207\345\220\216/desc.html"
@@ -0,0 +1 @@
+n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
示例 1:
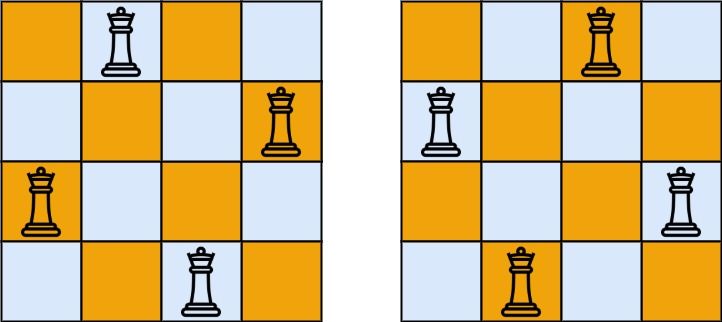
输入:n = 4
输出:[[".Q..","...Q","Q...","..Q."],["..Q.","Q...","...Q",".Q.."]]
解释:如上图所示,4 皇后问题存在两个不同的解法。
示例 2:
输入:n = 1
输出:[["Q"]]
提示:
1 <= n <= 9- 皇后彼此不能相互攻击,也就是说:任何两个皇后都不能处于同一条横行、纵行或斜线上。
+
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
+
+
给你一个整数 n ,返回 n 皇后问题 不同的解决方案的数量。
+
+
+
+
+
+
示例 1:
+

+
输入:n = 4
+
输出:2
+
解释:如上图所示,4 皇后问题存在两个不同的解法。
+
+
+
示例 2:
+
+
输入:n = 1
+
输出:1
+
+
+
+
+
提示:
+
+
+ 1 <= n <= 9- 皇后彼此不能相互攻击,也就是说:任何两个皇后都不能处于同一条横行、纵行或斜线上。
+
+
+
+
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例 1:
输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
输出:6
解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
示例 2:
输入:nums = [1]
输出:1
示例 3:
输入:nums = [0]
输出:0
示例 4:
输入:nums = [-1]
输出:-1
示例 5:
输入:nums = [-100000]
输出:-100000
提示:
1 <= nums.length <= 3 * 104-105 <= nums[i] <= 105
进阶:如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的 分治法 求解。
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/52_\346\234\200\345\244\247\345\255\220\345\272\217\345\222\214/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/52_\346\234\200\345\244\247\345\255\220\345\272\217\345\222\214/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..1b3933c918c7ff42ab801fba9df11d590e0247db
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/52_\346\234\200\345\244\247\345\255\220\345\272\217\345\222\214/solution.cpp"
@@ -0,0 +1,23 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ int maxSubArray(vector &nums)
+ {
+ int sum = 0, max_sum = INT_MIN;
+ for (int i = 0; i < nums.size(); i++)
+ {
+ if (sum < 0)
+ {
+ sum = nums[i];
+ }
+ else
+ {
+ sum += nums[i];
+ }
+ max_sum = max(sum, max_sum);
+ }
+ return max_sum;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/53_\350\236\272\346\227\213\347\237\251\351\230\265/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/53_\350\236\272\346\227\213\347\237\251\351\230\265/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..4c1fee1593951572971fdaab7ba2217a62d3f2c8
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/53_\350\236\272\346\227\213\347\237\251\351\230\265/desc.html"
@@ -0,0 +1 @@
+给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
示例 1:
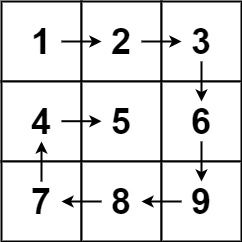
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]
示例 2:
输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
输出:[1,2,3,4,8,12,11,10,9,5,6,7]
提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 10-100 <= matrix[i][j] <= 100
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/53_\350\236\272\346\227\213\347\237\251\351\230\265/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/53_\350\236\272\346\227\213\347\237\251\351\230\265/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..624f59aba6c5c77ef07ae6bef354288c47c7ced9
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/53_\350\236\272\346\227\213\347\237\251\351\230\265/solution.cpp"
@@ -0,0 +1,54 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ vector spiralOrder(vector> &matrix)
+ {
+ vector res;
+ int hor_top = 0;
+ int hor_bottom = matrix.size() - 1;
+ int ver_left = 0;
+ int ver_right = matrix[0].size() - 1;
+ int direction = 0;
+ while (hor_top <= hor_bottom && ver_left <= ver_right)
+ {
+ switch (direction)
+ {
+ case 0:
+ for (int i = ver_left; i <= ver_right; i++)
+ {
+ res.push_back(matrix[hor_top][i]);
+ }
+ hor_top++;
+ break;
+ case 1:
+ for (int i = hor_top; i <= hor_bottom; i++)
+ {
+ res.push_back(matrix[i][ver_right]);
+ }
+ ver_right--;
+ break;
+ case 2:
+ for (int i = ver_right; i >= ver_left; i--)
+ {
+ res.push_back(matrix[hor_bottom][i]);
+ }
+ hor_bottom--;
+ break;
+ case 3:
+ for (int i = hor_bottom; i >= hor_top; i--)
+ {
+ res.push_back(matrix[i][ver_left]);
+ }
+ ver_left++;
+ break;
+ default:
+ break;
+ }
+ direction++;
+ direction %= 4;
+ }
+ return res;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/54_\350\267\263\350\267\203\346\270\270\346\210\217/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/54_\350\267\263\350\267\203\346\270\270\346\210\217/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..8568db0aa76c0dcfdb318d3b6f0212d54ad6aa3e
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/54_\350\267\263\350\267\203\346\270\270\346\210\217/desc.html"
@@ -0,0 +1 @@
+给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标。
示例 1:
输入:nums = [2,3,1,1,4]
输出:true
解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。
示例 2:
输入:nums = [3,2,1,0,4]
输出:false
解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。
提示:
1 <= nums.length <= 3 * 1040 <= nums[i] <= 105
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/54_\350\267\263\350\267\203\346\270\270\346\210\217/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/54_\350\267\263\350\267\203\346\270\270\346\210\217/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..7f05c2e64de38fa0fb99dab2d6ab5b8251db0021
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/54_\350\267\263\350\267\203\346\270\270\346\210\217/solution.cpp"
@@ -0,0 +1,31 @@
+#include
+#include
+#include
+static inline int max(int a, int b)
+{
+ return a > b ? a : b;
+}
+static bool canJump(int *nums, int numsSize)
+{
+ int i, pos = 0;
+ for (i = 0; i < numsSize - 1; i++)
+ {
+ if (pos < i || pos >= numsSize - 1)
+ {
+ break;
+ }
+ pos = max(i + nums[i], pos);
+ }
+ return pos >= numsSize - 1;
+}
+int main(int argc, char **argv)
+{
+ int i, count = argc - 1;
+ int *nums = malloc(count * sizeof(int));
+ for (i = 0; i < count; i++)
+ {
+ nums[i] = atoi(argv[i + 1]);
+ }
+ printf("%s\n", canJump(nums, count) ? "true" : "false");
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/55_\345\220\210\345\271\266\345\214\272\351\227\264/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/55_\345\220\210\345\271\266\345\214\272\351\227\264/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..b280dc8398176aa3973ef5e6fafaa312ef623a5a
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/55_\345\220\210\345\271\266\345\214\272\351\227\264/desc.html"
@@ -0,0 +1 @@
+以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入:intervals = [[1,4],[4,5]]
输出:[[1,5]]
解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
提示:
1 <= intervals.length <= 104intervals[i].length == 20 <= starti <= endi <= 104
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/55_\345\220\210\345\271\266\345\214\272\351\227\264/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/55_\345\220\210\345\271\266\345\214\272\351\227\264/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..cd2443d65314595c91e04c937054adfae7b19939
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/55_\345\220\210\345\271\266\345\214\272\351\227\264/solution.cpp"
@@ -0,0 +1,71 @@
+#include
+#include
+#include
+static int compare(const void *a, const void *b)
+{
+ return ((int *)a)[0] - ((int *)b)[0];
+}
+int **merge(int **intervals, int intervalsSize, int *intervalsColSize, int *returnSize, int **returnColumnSizes)
+{
+ if (intervalsSize == 0)
+ {
+ *returnSize = 0;
+ return intervals;
+ }
+ int i, len = 0;
+ int *tmp = malloc(intervalsSize * 2 * sizeof(int));
+ for (i = 0; i < intervalsSize; i++)
+ {
+ tmp[i * 2] = intervals[i][0];
+ tmp[i * 2 + 1] = intervals[i][1];
+ }
+ qsort(tmp, intervalsSize, 2 * sizeof(int), compare);
+ intervals[0][0] = tmp[0];
+ intervals[0][1] = tmp[1];
+ for (i = 1; i < intervalsSize; i++)
+ {
+ if (tmp[i * 2] > intervals[len][1])
+ {
+ len++;
+ intervals[len][0] = tmp[i * 2];
+ intervals[len][1] = tmp[i * 2 + 1];
+ }
+ else if (tmp[i * 2 + 1] > intervals[len][1])
+ {
+ intervals[len][1] = tmp[i * 2 + 1];
+ }
+ }
+ len += 1;
+ *returnSize = len;
+ *returnColumnSizes = malloc(len * sizeof(int));
+ for (i = 0; i < len; i++)
+ {
+ (*returnColumnSizes)[i] = 2;
+ }
+ return intervals;
+}
+int main(int argc, char **argv)
+{
+ if (argc < 1 || argc % 2 == 0)
+ {
+ fprintf(stderr, "Usage: ./test s0 e0 s1 e1...");
+ exit(-1);
+ }
+ int i, count = 0;
+ int *sizes = malloc((argc - 1) / 2 * sizeof(int));
+ int **intervals = malloc((argc - 1) / 2 * sizeof(int *));
+ for (i = 0; i < (argc - 1) / 2; i++)
+ {
+ sizes[i] = 2;
+ intervals[i] = malloc(2 * sizeof(int));
+ intervals[i][0] = atoi(argv[i * 2 + 1]);
+ intervals[i][1] = atoi(argv[i * 2 + 2]);
+ }
+ int *col_sizes;
+ int **results = merge(intervals, (argc - 1) / 2, sizes, &count, &col_sizes);
+ for (i = 0; i < count; i++)
+ {
+ printf("[%d,%d]\n", results[i][0], results[i][1]);
+ }
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/56_\346\217\222\345\205\245\345\214\272\351\227\264/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/56_\346\217\222\345\205\245\345\214\272\351\227\264/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..1f4137a476e913a2814cc3790e088e83b6eb60a4
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/56_\346\217\222\345\205\245\345\214\272\351\227\264/desc.html"
@@ -0,0 +1,23 @@
+给你一个 无重叠的 ,按照区间起始端点排序的区间列表。
+在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。
+
+示例 1:
+输入:intervals = [[1,3],[6,9]], newInterval = [2,5]
输出:[[1,5],[6,9]]
+示例 2:
+输入:intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8]
输出:[[1,2],[3,10],[12,16]]
解释:这是因为新的区间 [4,8] 与 [3,5],[6,7],[8,10] 重叠。
+示例 3:
+输入:intervals = [], newInterval = [5,7]
输出:[[5,7]]
+示例 4:
+输入:intervals = [[1,5]], newInterval = [2,3]
输出:[[1,5]]
+示例 5:
+输入:intervals = [[1,5]], newInterval = [2,7]
输出:[[1,7]]
+
+提示:
+
+ 0 <= intervals.length <= 104intervals[i].length == 20 <= intervals[i][0] <= intervals[i][1] <= 105intervals 根据 intervals[i][0] 按 升序 排列newInterval.length == 20 <= newInterval[0] <= newInterval[1] <= 105
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/56_\346\217\222\345\205\245\345\214\272\351\227\264/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/56_\346\217\222\345\205\245\345\214\272\351\227\264/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..e20ed7e6e2049725fdfffe72061fd78263aedd33
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/56_\346\217\222\345\205\245\345\214\272\351\227\264/solution.cpp"
@@ -0,0 +1,73 @@
+#include
+#include
+static int compare(const void *a, const void *b)
+{
+ return ((int *)a)[0] - ((int *)b)[0];
+}
+int **insert(int **intervals, int intervalsSize, int *intervalsColSize, int *newInterval,
+ int newIntervalSize, int *returnSize, int **returnColumnSizes)
+{
+ int i, len = 0;
+ int *tmp = malloc((intervalsSize + 1) * 2 * sizeof(int));
+ for (i = 0; i < intervalsSize; i++)
+ {
+ tmp[i * 2] = intervals[i][0];
+ tmp[i * 2 + 1] = intervals[i][1];
+ }
+ tmp[i * 2] = newInterval[0];
+ tmp[i * 2 + 1] = newInterval[1];
+ qsort(tmp, intervalsSize + 1, 2 * sizeof(int), compare);
+ int **results = malloc((intervalsSize + 1) * sizeof(int *));
+ results[0] = malloc(2 * sizeof(int));
+ results[0][0] = tmp[0];
+ results[0][1] = tmp[1];
+ for (i = 1; i < intervalsSize + 1; i++)
+ {
+ results[i] = malloc(2 * sizeof(int));
+ if (tmp[i * 2] > results[len][1])
+ {
+ len++;
+ results[len][0] = tmp[i * 2];
+ results[len][1] = tmp[i * 2 + 1];
+ }
+ else if (tmp[i * 2 + 1] > results[len][1])
+ {
+ results[len][1] = tmp[i * 2 + 1];
+ }
+ }
+ len += 1;
+ *returnSize = len;
+ *returnColumnSizes = malloc(len * sizeof(int));
+ for (i = 0; i < len; i++)
+ {
+ (*returnColumnSizes)[i] = 2;
+ }
+ return results;
+}
+int main(int argc, char **argv)
+{
+ if (argc < 3 || argc % 2 == 0)
+ {
+ fprintf(stderr, "Usage: ./test new_s new_e s0 e0 s1 e1...");
+ exit(-1);
+ }
+ int new_interv[2];
+ new_interv[0] = atoi(argv[1]);
+ new_interv[1] = atoi(argv[2]);
+ int i, count = 0;
+ int *size = malloc((argc - 3) / 2 * sizeof(int));
+ int **intervals = malloc((argc - 3) / 2 * sizeof(int *));
+ for (i = 0; i < (argc - 3) / 2; i++)
+ {
+ intervals[i] = malloc(2 * sizeof(int));
+ intervals[i][0] = atoi(argv[i * 2 + 3]);
+ intervals[i][1] = atoi(argv[i * 2 + 4]);
+ }
+ int *col_sizes;
+ int **results = insert(intervals, (argc - 3) / 2, size, new_interv, 2, &count, &col_sizes);
+ for (i = 0; i < count; i++)
+ {
+ printf("[%d,%d]\n", results[i][0], results[i][1]);
+ }
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/57_\346\234\200\345\220\216\344\270\200\344\270\252\345\215\225\350\257\215\347\232\204\351\225\277\345\272\246/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/57_\346\234\200\345\220\216\344\270\200\344\270\252\345\215\225\350\257\215\347\232\204\351\225\277\345\272\246/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..efee0d7964386f94cdc4fba70b4fcfdd197edf05
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/57_\346\234\200\345\220\216\344\270\200\344\270\252\345\215\225\350\257\215\347\232\204\351\225\277\345\272\246/desc.html"
@@ -0,0 +1 @@
+给你一个字符串 s,由若干单词组成,单词之间用空格隔开。返回字符串中最后一个单词的长度。如果不存在最后一个单词,请返回 0 。
单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。
示例 1:
输入:s = "Hello World"
输出:5
示例 2:
输入:s = " "
输出:0
提示:
1 <= s.length <= 104s 仅有英文字母和空格 ' ' 组成
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/57_\346\234\200\345\220\216\344\270\200\344\270\252\345\215\225\350\257\215\347\232\204\351\225\277\345\272\246/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/57_\346\234\200\345\220\216\344\270\200\344\270\252\345\215\225\350\257\215\347\232\204\351\225\277\345\272\246/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..6c642f87c078ba37d78eeab3931c2063491a3811
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/57_\346\234\200\345\220\216\344\270\200\344\270\252\345\215\225\350\257\215\347\232\204\351\225\277\345\272\246/solution.cpp"
@@ -0,0 +1,29 @@
+#include
+#include
+int lengthOfLastWord(char *s)
+{
+ int len = 0;
+ while (*s != '\0')
+ {
+ if (s[-1] == ' ' && s[0] != ' ')
+ {
+ len = 1;
+ }
+ else if (*s != ' ')
+ {
+ len++;
+ }
+ s++;
+ }
+ return len;
+}
+int main(int argc, char **argv)
+{
+ if (argc != 2)
+ {
+ fprintf(stderr, "Usage: ./test word\n");
+ exit(-1);
+ }
+ printf("%d\n", lengthOfLastWord(argv[1]));
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/58_\350\236\272\346\227\213\347\237\251\351\230\265 II/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/58_\350\236\272\346\227\213\347\237\251\351\230\265 II/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..1c1f3eb87cb8d5c59df71c3f17f047fae774db57
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/58_\350\236\272\346\227\213\347\237\251\351\230\265 II/desc.html"
@@ -0,0 +1 @@
+给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
示例 1:
输入:n = 3
输出:[[1,2,3],[8,9,4],[7,6,5]]
示例 2:
输入:n = 1
输出:[[1]]
提示:
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/58_\350\236\272\346\227\213\347\237\251\351\230\265 II/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/58_\350\236\272\346\227\213\347\237\251\351\230\265 II/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..effdd08849afeb6e42e6b0fc41a60da53bce4d7e
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/58_\350\236\272\346\227\213\347\237\251\351\230\265 II/solution.cpp"
@@ -0,0 +1,53 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ vector> generateMatrix(int n)
+ {
+ vector> matrix(n, vector(n));
+ int direction = 0;
+ int hor_top = 0;
+ int hor_bottom = n - 1;
+ int ver_left = 0;
+ int ver_right = n - 1;
+ int num = 0;
+ while (num < n * n)
+ {
+ switch (direction)
+ {
+ case 0:
+ for (int i = ver_left; i <= ver_right; i++)
+ {
+ matrix[hor_top][i] = ++num;
+ }
+ hor_top++;
+ break;
+ case 1:
+ for (int i = hor_top; i <= hor_bottom; i++)
+ {
+ matrix[i][ver_right] = ++num;
+ }
+ ver_right--;
+ break;
+ case 2:
+ for (int i = ver_right; i >= ver_left; i--)
+ {
+ matrix[hor_bottom][i] = ++num;
+ }
+ hor_bottom--;
+ break;
+ case 3:
+ for (int i = hor_bottom; i >= hor_top; i--)
+ {
+ matrix[i][ver_left] = ++num;
+ }
+ ver_left++;
+ break;
+ }
+ direction++;
+ direction %= 4;
+ }
+ return matrix;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/59_\346\216\222\345\210\227\345\272\217\345\210\227/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/59_\346\216\222\345\210\227\345\272\217\345\210\227/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..9a3181df51c3afda8692f444627d080ada499b6d
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/59_\346\216\222\345\210\227\345\272\217\345\210\227/desc.html"
@@ -0,0 +1 @@
+给出集合 [1,2,3,...,n],其所有元素共有 n! 种排列。
按大小顺序列出所有排列情况,并一一标记,当 n = 3 时, 所有排列如下:
"123""132""213""231""312""321"
给定 n 和 k,返回第 k 个排列。
示例 1:
输入:n = 3, k = 3
输出:"213"
示例 2:
输入:n = 4, k = 9
输出:"2314"
示例 3:
输入:n = 3, k = 1
输出:"123"
提示:
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/59_\346\216\222\345\210\227\345\272\217\345\210\227/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/59_\346\216\222\345\210\227\345\272\217\345\210\227/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..5f441bc809d34769b352206b50922703dec71b3d
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/59_\346\216\222\345\210\227\345\272\217\345\210\227/solution.cpp"
@@ -0,0 +1,47 @@
+#include
+#include
+#include
+#include
+static char *getPermutation(int n, int k)
+{
+ int i;
+ char *result = malloc(n + 1);
+ bool *used = malloc(n * sizeof(bool));
+ memset(used, false, n * sizeof(bool));
+ int total = 1;
+ for (i = 1; i <= n; i++)
+ {
+ total *= i;
+ }
+ k = k - 1;
+ for (i = 0; i < n; i++)
+ {
+ total /= (n - i);
+ int gid = k / total;
+ k %= total;
+ int x = -1;
+ int count = 0;
+ while (count <= gid)
+ {
+ x = (x + 1) % n;
+ if (!used[x])
+ {
+ count++;
+ }
+ }
+ used[x] = true;
+ result[i] = x + 1 + '0';
+ }
+ result[n] = '\0';
+ return result;
+}
+int main(int argc, char **argv)
+{
+ if (argc != 3)
+ {
+ fprintf(stderr, "Usage: ./test n, k\n");
+ exit(-1);
+ }
+ printf("%s\n", getPermutation(atoi(argv[1]), atoi(argv[2])));
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/5_Z \345\255\227\345\275\242\345\217\230\346\215\242/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/5_Z \345\255\227\345\275\242\345\217\230\346\215\242/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..550e2f59d436254fa06040ec2a3d563c6904e7f7
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/5_Z \345\255\227\345\275\242\345\217\230\346\215\242/desc.html"
@@ -0,0 +1,50 @@
+
+
将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。
+
+
比如输入字符串为 "PAYPALISHIRING" 行数为 3 时,排列如下:
+
+
+ P A H N
+ A P L S I I G
+ Y I R
+
+
之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:"PAHNAPLSIIGYIR"。
+
+
请你实现这个将字符串进行指定行数变换的函数:
+
+
string convert(string s, int numRows);
+
+
+
+
示例 1:
+
+
输入:s = "PAYPALISHIRING", numRows = 3
+
输出:"PAHNAPLSIIGYIR"
+
+
示例 2:
+
+
输入:s = "PAYPALISHIRING", numRows = 4
+
输出:"PINALSIGYAHRPI"
+
解释:
+P I N
+A L S I G
+Y A H R
+P I
+
+
+
示例 3:
+
+
输入:s = "A", numRows = 1
+
输出:"A"
+
+
+
+
+
提示:
+
+
+ 1 <= s.length <= 1000s 由英文字母(小写和大写)、',' 和 '.' 组成1 <= numRows <= 1000
+
给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。
示例 1:
输入:head = [1,2,3,4,5], k = 2
输出:[4,5,1,2,3]
示例 2:
输入:head = [0,1,2], k = 4
输出:[2,0,1]
提示:
- 链表中节点的数目在范围
[0, 500] 内 -100 <= Node.val <= 1000 <= k <= 2 * 109
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/60_\346\227\213\350\275\254\351\223\276\350\241\250/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/60_\346\227\213\350\275\254\351\223\276\350\241\250/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..6dccf8c0acad4a1bbc94d1a20f5347455165de87
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/60_\346\227\213\350\275\254\351\223\276\350\241\250/solution.cpp"
@@ -0,0 +1,45 @@
+#include
+using namespace std;
+struct ListNode
+{
+ int val;
+ ListNode *next;
+ ListNode() : val(0), next(nullptr) {}
+ ListNode(int x) : val(x), next(nullptr) {}
+ ListNode(int x, ListNode *next) : val(x), next(next) {}
+};
+class Solution
+{
+public:
+ ListNode *rotateRight(ListNode *head, int k)
+ {
+ if (head == nullptr)
+ {
+ return head;
+ }
+ int len = 0;
+ ListNode dummy;
+ dummy.next = head;
+ ListNode *tail = &dummy;
+ while (tail->next != nullptr)
+ {
+ len++;
+ tail = tail->next;
+ }
+ ListNode *prev = &dummy;
+ ListNode *p = head;
+ k = k % len;
+ for (int i = 0; i < len - k; i++)
+ {
+ prev = p;
+ p = p->next;
+ }
+ if (p != nullptr)
+ {
+ prev->next = tail->next;
+ tail->next = head;
+ head = p;
+ }
+ return head;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/61_\344\270\215\345\220\214\350\267\257\345\276\204/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/61_\344\270\215\345\220\214\350\267\257\345\276\204/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..e5f4cd08a38248192bc9515fe5be8f422eb3d5a0
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/61_\344\270\215\345\220\214\350\267\257\345\276\204/desc.html"
@@ -0,0 +1,19 @@
+一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
+机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
+问总共有多少条不同的路径?
+
+示例 1:
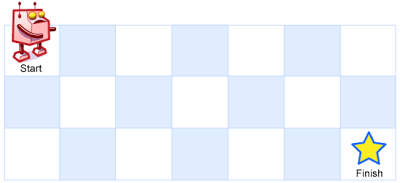 +
+输入:m = 3, n = 7
输出:28
+示例 2:
+输入:m = 3, n = 2
输出:3
解释:从左上角开始,总共有 3 条路径可以到达右下角。
1. 向右 -> 向下 -> 向下
2. 向下 -> 向下 -> 向右
3. 向下 -> 向右 -> 向下
+示例 3:
+输入:m = 7, n = 3
输出:28
+示例 4:
+输入:m = 3, n = 3
输出:6
+
+提示:
+
+ 1 <= m, n <= 100- 题目数据保证答案小于等于
2 * 109
+
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/61_\344\270\215\345\220\214\350\267\257\345\276\204/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/61_\344\270\215\345\220\214\350\267\257\345\276\204/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..77c10aa690b0c7416a867441c0e4dc518e90229f
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/61_\344\270\215\345\220\214\350\267\257\345\276\204/solution.cpp"
@@ -0,0 +1,33 @@
+#include
+#include
+static int uniquePaths(int m, int n)
+{
+ int row, col;
+ int *grids = malloc(m * n * sizeof(int));
+ for (col = 0; col < m; col++)
+ {
+ grids[col] = 1;
+ }
+ for (row = 0; row < n; row++)
+ {
+ grids[row * m] = 1;
+ }
+ for (row = 1; row < n; row++)
+ {
+ for (col = 1; col < m; col++)
+ {
+ grids[row * m + col] = grids[row * m + col - 1] + grids[(row - 1) * m + col];
+ }
+ }
+ return grids[m * n - 1];
+}
+int main(int argc, char **argv)
+{
+ if (argc != 3)
+ {
+ fprintf(stderr, "Usage: ./test m n\n");
+ exit(-1);
+ }
+ printf("%d\n", uniquePaths(atoi(argv[1]), atoi(argv[2])));
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/62_\344\270\215\345\220\214\350\267\257\345\276\204 II/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/62_\344\270\215\345\220\214\350\267\257\345\276\204 II/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..58ea060cc65369cab0405d0ae4c6c1379dd5faf5
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/62_\344\270\215\345\220\214\350\267\257\345\276\204 II/desc.html"
@@ -0,0 +1,23 @@
+一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
+机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
+现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
+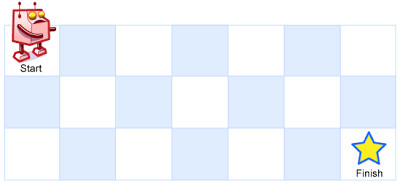
+网格中的障碍物和空位置分别用 1 和 0 来表示。
+
+示例 1:
 +
+输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]
输出:2
解释:3x3 网格的正中间有一个障碍物。从左上角到右下角一共有 2 条不同的路径:
1. 向右 -> 向右 -> 向下 -> 向下
2. 向下 -> 向下 -> 向右 -> 向右
+示例 2:
 +
+输入:obstacleGrid = [[0,1],[0,0]]
输出:1
+
+提示:
+
+ m == obstacleGrid.lengthn == obstacleGrid[i].length1 <= m, n <= 100obstacleGrid[i][j] 为 0 或 1
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/62_\344\270\215\345\220\214\350\267\257\345\276\204 II/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/62_\344\270\215\345\220\214\350\267\257\345\276\204 II/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..24844393a5a8f9658967a6ac24a14e874e3aa4c7
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/62_\344\270\215\345\220\214\350\267\257\345\276\204 II/solution.cpp"
@@ -0,0 +1,82 @@
+#include
+#include
+static int uniquePathsWithObstacles(int **obstacleGrid, int obstacleGridRowSize, int obstacleGridColSize)
+{
+ int row, col;
+ int reset = 0;
+ for (row = 0; row < obstacleGridRowSize; row++)
+ {
+ if (reset)
+ {
+ obstacleGrid[row][0] = 1;
+ }
+ else
+ {
+ if (obstacleGrid[row][0] == 1)
+ {
+ reset = 1;
+ }
+ }
+ }
+ reset = 0;
+ for (col = 0; col < obstacleGridColSize; col++)
+ {
+ if (reset)
+ {
+ obstacleGrid[0][col] = 1;
+ }
+ else
+ {
+ if (obstacleGrid[0][col] == 1)
+ {
+ reset = 1;
+ }
+ }
+ }
+ for (row = 0; row < obstacleGridRowSize; row++)
+ {
+ int *line = obstacleGrid[row];
+ for (col = 0; col < obstacleGridColSize; col++)
+ {
+ line[col] ^= 1;
+ }
+ }
+ for (row = 1; row < obstacleGridRowSize; row++)
+ {
+ int *last_line = obstacleGrid[row - 1];
+ int *line = obstacleGrid[row];
+ for (col = 1; col < obstacleGridColSize; col++)
+ {
+ if (line[col] != 0)
+ {
+ line[col] = line[col - 1] + last_line[col];
+ }
+ }
+ }
+ return obstacleGrid[obstacleGridRowSize - 1][obstacleGridColSize - 1];
+}
+int main(int argc, char **argv)
+{
+ if (argc < 3)
+ {
+ fprintf(stderr, "Usage: ./test m n\n");
+ exit(-1);
+ }
+ int i, j, k = 3;
+ int row_size = atoi(argv[1]);
+ int col_size = atoi(argv[2]);
+ int **grids = malloc(row_size * sizeof(int *));
+ for (i = 0; i < row_size; i++)
+ {
+ grids[i] = malloc(col_size * sizeof(int));
+ int *line = grids[i];
+ for (j = 0; j < col_size; j++)
+ {
+ line[j] = atoi(argv[k++]);
+ printf("%d ", line[j]);
+ }
+ printf("\n");
+ }
+ printf("%d\n", uniquePathsWithObstacles(grids, row_size, col_size));
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/63_\346\234\200\345\260\217\350\267\257\345\276\204\345\222\214/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/63_\346\234\200\345\260\217\350\267\257\345\276\204\345\222\214/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..94ffa23c203407987aa5471be10d3977512000bd
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/63_\346\234\200\345\260\217\350\267\257\345\276\204\345\222\214/desc.html"
@@ -0,0 +1 @@
+给定一个包含非负整数的 m x n 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
说明:每次只能向下或者向右移动一步。
示例 1:
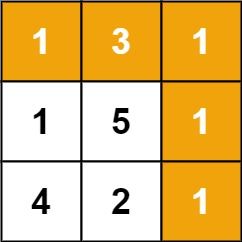
输入:grid = [[1,3,1],[1,5,1],[4,2,1]]
输出:7
解释:因为路径 1→3→1→1→1 的总和最小。
示例 2:
输入:grid = [[1,2,3],[4,5,6]]
输出:12
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 2000 <= grid[i][j] <= 100
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/63_\346\234\200\345\260\217\350\267\257\345\276\204\345\222\214/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/63_\346\234\200\345\260\217\350\267\257\345\276\204\345\222\214/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..816e8b61059ebd57329b73fc3191516bd0d63e6c
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/63_\346\234\200\345\260\217\350\267\257\345\276\204\345\222\214/solution.cpp"
@@ -0,0 +1,56 @@
+#include
+#include
+#include
+static inline int min(int a, int b)
+{
+ return a < b ? a : b;
+}
+int minPathSum(int **grid, int gridRowSize, int gridColSize)
+{
+ int i, j;
+ int **dp = malloc(gridRowSize * sizeof(int *));
+ for (i = 0; i < gridRowSize; i++)
+ {
+ dp[i] = malloc(gridColSize * sizeof(int));
+ }
+ dp[0][0] = grid[0][0];
+ int sum = dp[0][0];
+ for (i = 1; i < gridRowSize; i++)
+ {
+ sum += grid[i][0];
+ dp[i][0] = sum;
+ }
+ sum = dp[0][0];
+ for (i = 1; i < gridColSize; i++)
+ {
+ sum += grid[0][i];
+ dp[0][i] = sum;
+ }
+ for (i = 1; i < gridRowSize; i++)
+ {
+ for (j = 1; j < gridColSize; j++)
+ {
+ dp[i][j] = grid[i][j] + min(dp[i - 1][j], dp[i][j - 1]);
+ }
+ }
+ return dp[gridRowSize - 1][gridColSize - 1];
+}
+int main(int argc, char **argv)
+{
+ int i, j;
+ int row = argc - 1;
+ int col = strlen(argv[1]);
+ int **grid = malloc(row * sizeof(int *));
+ for (i = 0; i < row; i++)
+ {
+ grid[i] = malloc(col * sizeof(int));
+ for (j = 0; j < col; j++)
+ {
+ grid[i][j] = argv[i + 1][j] - '0';
+ printf("%d ", grid[i][j]);
+ }
+ printf("\n");
+ }
+ printf("%d\n", minPathSum(grid, row, col));
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/64_\346\234\211\346\225\210\346\225\260\345\255\227/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/64_\346\234\211\346\225\210\346\225\260\345\255\227/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..ca39ca6c6749bea6e31f15ab2795aa176547486a
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/64_\346\234\211\346\225\210\346\225\260\345\255\227/desc.html"
@@ -0,0 +1 @@
+有效数字(按顺序)可以分成以下几个部分:
- 一个 小数 或者 整数
- (可选)一个
'e' 或 'E' ,后面跟着一个 整数
小数(按顺序)可以分成以下几个部分:
- (可选)一个符号字符(
'+' 或 '-') - 下述格式之一:
- 至少一位数字,后面跟着一个点
'.' - 至少一位数字,后面跟着一个点
'.' ,后面再跟着至少一位数字 - 一个点
'.' ,后面跟着至少一位数字
整数(按顺序)可以分成以下几个部分:
- (可选)一个符号字符(
'+' 或 '-') - 至少一位数字
部分有效数字列举如下:
["2", "0089", "-0.1", "+3.14", "4.", "-.9", "2e10", "-90E3", "3e+7", "+6e-1", "53.5e93", "-123.456e789"]
部分无效数字列举如下:
["abc", "1a", "1e", "e3", "99e2.5", "--6", "-+3", "95a54e53"]
给你一个字符串 s ,如果 s 是一个 有效数字 ,请返回 true 。
示例 1:
输入:s = "0"
输出:true
示例 2:
输入:s = "e"
输出:false
示例 3:
输入:s = "."
输出:false
示例 4:
输入:s = ".1"
输出:true
提示:
1 <= s.length <= 20s 仅含英文字母(大写和小写),数字(0-9),加号 '+' ,减号 '-' ,或者点 '.' 。
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/64_\346\234\211\346\225\210\346\225\260\345\255\227/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/64_\346\234\211\346\225\210\346\225\260\345\255\227/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..9ca289758d67bb6661f3b84f7d868af257b9daec
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/64_\346\234\211\346\225\210\346\225\260\345\255\227/solution.cpp"
@@ -0,0 +1,49 @@
+#include
+#include
+#include
+#include
+static bool isNumber(const char *s)
+{
+ while (*s == ' ')
+ ++s;
+ bool if_find_num = false;
+ if (*s == '-' || *s == '+')
+ ++s;
+ while (isdigit(*s))
+ {
+ if_find_num = true;
+ ++s;
+ }
+ if (*s == '.')
+ ++s;
+ while (isdigit(*s))
+ {
+ if_find_num = true;
+ ++s;
+ }
+ if (if_find_num == true && *s == 'e')
+ {
+ ++s;
+ if (*s == '+' || *s == '-')
+ ++s;
+ if_find_num = false;
+ while (isdigit(*s))
+ {
+ if_find_num = true;
+ ++s;
+ }
+ }
+ while (*s == ' ')
+ ++s;
+ return *s == '\0' && if_find_num == true;
+}
+int main(int argc, char **argv)
+{
+ if (argc != 2)
+ {
+ fprintf(stderr, "Usage: ./test number\n");
+ exit(-1);
+ }
+ printf("%s\n", isNumber(argv[1]) ? "true" : "false");
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/65_\345\212\240\344\270\200/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/65_\345\212\240\344\270\200/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..10063d7442c27058826b5128794601fbb18bc520
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/65_\345\212\240\344\270\200/desc.html"
@@ -0,0 +1 @@
+给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
输入:digits = [1,2,3]
输出:[1,2,4]
解释:输入数组表示数字 123。
示例 2:
输入:digits = [4,3,2,1]
输出:[4,3,2,2]
解释:输入数组表示数字 4321。
示例 3:
输入:digits = [0]
输出:[1]
提示:
1 <= digits.length <= 1000 <= digits[i] <= 9
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/65_\345\212\240\344\270\200/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/65_\345\212\240\344\270\200/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..36f8e0ee895501f12b936de042e2c0144f555fa9
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/65_\345\212\240\344\270\200/solution.cpp"
@@ -0,0 +1,23 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ vector plusOne(vector &digits)
+ {
+ int carry = 1;
+ vector res;
+ for (int i = digits.size() - 1; i >= 0; i--)
+ {
+ int d = digits[i] + carry;
+ res.push_back(d % 10);
+ carry = d / 10;
+ }
+ if (carry > 0)
+ {
+ res.push_back(carry);
+ }
+ reverse(res.begin(), res.end());
+ return res;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/66_\344\272\214\350\277\233\345\210\266\346\261\202\345\222\214/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/66_\344\272\214\350\277\233\345\210\266\346\261\202\345\222\214/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..3b2f1b0ac5f50fa97ffe3a33c9578c372068b52f
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/66_\344\272\214\350\277\233\345\210\266\346\261\202\345\222\214/desc.html"
@@ -0,0 +1 @@
+给你两个二进制字符串,返回它们的和(用二进制表示)。
输入为 非空 字符串且只包含数字 1 和 0。
示例 1:
输入: a = "11", b = "1"
输出: "100"
示例 2:
输入: a = "1010", b = "1011"
输出: "10101"
提示:
- 每个字符串仅由字符
'0' 或 '1' 组成。 1 <= a.length, b.length <= 10^4- 字符串如果不是
"0" ,就都不含前导零。
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/66_\344\272\214\350\277\233\345\210\266\346\261\202\345\222\214/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/66_\344\272\214\350\277\233\345\210\266\346\261\202\345\222\214/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..0df722720e113d793b890a0374643861d9e84189
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/66_\344\272\214\350\277\233\345\210\266\346\261\202\345\222\214/solution.cpp"
@@ -0,0 +1,101 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ string addBinary(string a, string b)
+ {
+ string res;
+ int carry = 0;
+ int i = a.length() - 1;
+ int j = b.length() - 1;
+ for (; i >= 0 && j >= 0; i--, j--)
+ {
+ if (a[i] == '1' && b[j] == '1')
+ {
+ if (carry > 0)
+ {
+ res.push_back('1');
+ }
+ else
+ {
+ res.push_back('0');
+ }
+ carry = 1;
+ }
+ else if (a[i] == '0' && b[j] == '0')
+ {
+ if (carry > 0)
+ {
+ res.push_back('1');
+ }
+ else
+ {
+ res.push_back('0');
+ }
+ carry = 0;
+ }
+ else
+ {
+ if (carry > 0)
+ {
+ res.push_back('0');
+ carry = 1;
+ }
+ else
+ {
+ res.push_back('1');
+ carry = 0;
+ }
+ }
+ }
+ while (i >= 0)
+ {
+ if (a[i--] == '1')
+ {
+ if (carry > 0)
+ {
+ res.push_back('0');
+ carry = 1;
+ }
+ else
+ {
+ res.push_back('1');
+ carry = 0;
+ }
+ }
+ else
+ {
+ res.push_back(carry + '0');
+ carry = 0;
+ }
+ }
+ while (j >= 0)
+ {
+ if (b[j--] == '1')
+ {
+ if (carry > 0)
+ {
+ res.push_back('0');
+ carry = 1;
+ }
+ else
+ {
+ res.push_back('1');
+ carry = 0;
+ }
+ }
+ else
+ {
+ res.push_back(carry + '0');
+ carry = 0;
+ }
+ }
+ if (carry > 0)
+ {
+ res.push_back('1');
+ }
+ reverse(res.begin(), res.end());
+ return res;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/67_\346\226\207\346\234\254\345\267\246\345\217\263\345\257\271\351\275\220/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/67_\346\226\207\346\234\254\345\267\246\345\217\263\345\257\271\351\275\220/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..7c583861df28ba89a41548447bd7a310b1b8ffd0
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/67_\346\226\207\346\234\254\345\267\246\345\217\263\345\257\271\351\275\220/desc.html"
@@ -0,0 +1,63 @@
+
+
给定一个单词数组和一个长度 maxWidth,重新排版单词,使其成为每行恰好有 maxWidth 个字符,且左右两端对齐的文本。
+
+
你应该使用“贪心算法”来放置给定的单词;也就是说,尽可能多地往每行中放置单词。必要时可用空格 ' ' 填充,使得每行恰好有 maxWidth 个字符。
+
+
+
要求尽可能均匀分配单词间的空格数量。如果某一行单词间的空格不能均匀分配,则左侧放置的空格数要多于右侧的空格数。
+
+
文本的最后一行应为左对齐,且单词之间不插入额外的空格。
+
+
说明:
+
+
+ - 单词是指由非空格字符组成的字符序列。
+ - 每个单词的长度大于 0,小于等于 maxWidth。
+ - 输入单词数组
words 至少包含一个单词。
+
+
+
示例:
+
+
输入:
+ words = ["This", "is", "an", "example", "of", "text", "justification."]
+ maxWidth = 16
+
输出:
+ [
+ "This is an",
+ "example of text",
+ "justification. "
+ ]
+
+
+
示例 2:
+
+
输入:
+ words = ["What","must","be","acknowledgment","shall","be"]
+ maxWidth = 16
+
输出:
+ [
+ "What must be",
+ "acknowledgment ",
+ "shall be "
+ ]
+
解释: 注意最后一行的格式应为 "shall be " 而不是 "shall be"
+ 因为最后一行应为左对齐,而不是左右两端对齐,第二行同样为左对齐,这是因为这行只包含一个单词。
+
+
+
示例 3:
+
+
输入:
+ words = ["Science","is","what","we","understand","well","enough","to","explain",
+ "to","a","computer.","Art","is","everything","else","we","do"]
+ maxWidth = 20
+
输出:
+ [
+ "Science is what we",
+ "understand well",
+ "enough to explain to",
+ "a computer. Art is",
+ "everything else we",
+ "do "
+ ]
+
+
实现 int sqrt(int x) 函数。
+计算并返回 x 的平方根,其中 x 是非负整数。
+由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
+示例 1:
+输入: 4
输出: 2
+示例 2:
+输入: 8
输出: 2
说明: 8 的平方根是 2.82842..., 由于返回类型是整数,小数部分将被舍去。
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/68_x \347\232\204\345\271\263\346\226\271\346\240\271/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/68_x \347\232\204\345\271\263\346\226\271\346\240\271/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..4f139bfa532c78c34e759e3a2491cdfc5752f029
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/68_x \347\232\204\345\271\263\346\226\271\346\240\271/solution.cpp"
@@ -0,0 +1,35 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ int mySqrt(int x)
+ {
+ if (x == 0)
+ {
+ return 0;
+ }
+ unsigned int lo = 1, hi = x;
+ unsigned int mid = (lo + hi) / 2;
+ for (;;)
+ {
+ if (mid > x / mid)
+ {
+ hi = mid;
+ }
+ else
+ {
+ if (mid + 1 > x / (mid + 1))
+ {
+ break;
+ }
+ else
+ {
+ lo = mid;
+ }
+ }
+ mid = (lo + hi) / 2;
+ }
+ return mid;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/69_\347\210\254\346\245\274\346\242\257/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/69_\347\210\254\346\245\274\346\242\257/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..5a5fba907bd4c6ecbc4ca72b559a9b4bb23d9f1e
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/69_\347\210\254\346\245\274\346\242\257/desc.html"
@@ -0,0 +1 @@
+假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
注意:给定 n 是一个正整数。
示例 1:
输入: 2
输出: 2
解释: 有两种方法可以爬到楼顶。1. 1 阶 + 1 阶2. 2 阶
示例 2:
输入: 3
输出: 3
解释: 有三种方法可以爬到楼顶。1. 1 阶 + 1 阶 + 1 阶2. 1 阶 + 2 阶3. 2 阶 + 1 阶
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/69_\347\210\254\346\245\274\346\242\257/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/69_\347\210\254\346\245\274\346\242\257/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..b6bf8ef906263ad914a67ac4e6b9a942d103daa4
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/69_\347\210\254\346\245\274\346\242\257/solution.cpp"
@@ -0,0 +1,19 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ int climbStairs(int n)
+ {
+ int a = 1;
+ int b = 2;
+ int c = 0;
+ for (int i = 3; i <= n; i++)
+ {
+ c = a + b;
+ a = b;
+ b = c;
+ }
+ return n == 1 ? a : (n == 2 ? b : c);
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/6_\346\225\264\346\225\260\345\217\215\350\275\254/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/6_\346\225\264\346\225\260\345\217\215\350\275\254/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..9143d6bb2d989afbf42da2dfd445c8de65dde9b6
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/6_\346\225\264\346\225\260\345\217\215\350\275\254/desc.html"
@@ -0,0 +1 @@
+给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果。
如果反转后整数超过 32 位的有符号整数的范围 [−231, 231 − 1] ,就返回 0。
假设环境不允许存储 64 位整数(有符号或无符号)。
示例 1:
输入:x = 123
输出:321
示例 2:
输入:x = -123
输出:-321
示例 3:
输入:x = 120
输出:21
示例 4:
输入:x = 0
输出:0
提示:
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/6_\346\225\264\346\225\260\345\217\215\350\275\254/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/6_\346\225\264\346\225\260\345\217\215\350\275\254/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..6668f76b702bfc815d5cbb2d97884bc61f3079b0
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/6_\346\225\264\346\225\260\345\217\215\350\275\254/solution.cpp"
@@ -0,0 +1,14 @@
+int reverse(int x)
+{
+ long long int r = 0;
+ while (x)
+ {
+ r = r * 10 + (x % 10);
+ x /= 10;
+ }
+ if (r > 2147483647)
+ return 0;
+ if (r < -2147483648)
+ return 0;
+ return (int)r;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/70_\347\256\200\345\214\226\350\267\257\345\276\204/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/70_\347\256\200\345\214\226\350\267\257\345\276\204/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..f730116eeb0fd294fc4f88d188df0f62381cb294
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/70_\347\256\200\345\214\226\350\267\257\345\276\204/desc.html"
@@ -0,0 +1 @@
+给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'//')都被视为单个斜杠 '/' 。 对于此问题,任何其他格式的点(例如,'...')均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
- 始终以斜杠
'/' 开头。 - 两个目录名之间必须只有一个斜杠
'/' 。 - 最后一个目录名(如果存在)不能 以
'/' 结尾。 - 此外,路径仅包含从根目录到目标文件或目录的路径上的目录(即,不含
'.' 或 '..')。
返回简化后得到的 规范路径 。
示例 1:
输入:path = "/home/"
输出:"/home"
解释:注意,最后一个目录名后面没有斜杠。
示例 2:
输入:path = "/../"
输出:"/"
解释:从根目录向上一级是不可行的,因为根目录是你可以到达的最高级。
示例 3:
输入:path = "/home//foo/"
输出:"/home/foo"
解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。
示例 4:
输入:path = "/a/./b/../../c/"
输出:"/c"
提示:
1 <= path.length <= 3000path 由英文字母,数字,'.','/' 或 '_' 组成。path 是一个有效的 Unix 风格绝对路径。
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/70_\347\256\200\345\214\226\350\267\257\345\276\204/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/70_\347\256\200\345\214\226\350\267\257\345\276\204/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..eeb87488be19424f81c05ca3a9fefb2147b98795
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/70_\347\256\200\345\214\226\350\267\257\345\276\204/solution.cpp"
@@ -0,0 +1,93 @@
+#include
+#include
+#include
+static char *simplifyPath(char *path)
+{
+ int len = strlen(path);
+ if (len == 0)
+ {
+ return path;
+ }
+ char *p = path;
+ int *indexes = malloc(len * sizeof(int));
+ int depth = 0;
+ int name_start = 1;
+ while (*p != '\0')
+ {
+ if (*p == '/')
+ {
+ if (p > path && *(p - 1) != '/' && *(p - 1) != '.')
+ {
+ name_start = 1;
+ }
+ }
+ else if (*p == '.')
+ {
+ if (*(p + 1) == '\0' || *(p + 1) == '/')
+ {
+ p += 1;
+ }
+ else if (*(p + 1) == '.' && (*(p + 2) == '\0' || *(p + 2) == '/'))
+ {
+ if (depth > 0)
+ {
+ depth--;
+ name_start = 1;
+ }
+ p += 2;
+ }
+ else
+ {
+ indexes[depth++] = p - path;
+ while (*p != '/' && *p != '\0')
+ {
+ p++;
+ }
+ }
+ if (*p == '\0')
+ {
+ break;
+ }
+ }
+ else
+ {
+ if (name_start && depth >= 0)
+ {
+ indexes[depth++] = p - path;
+ name_start = 0;
+ }
+ }
+ p++;
+ }
+ int i;
+ char *result = malloc(len + 1);
+ char *q = result;
+ if (depth <= 0)
+ {
+ *q++ = '/';
+ }
+ else
+ {
+ for (i = 0; i < depth; i++)
+ {
+ p = path + indexes[i];
+ *q++ = '/';
+ while (*p != '/')
+ {
+ *q++ = *p++;
+ }
+ }
+ }
+ *q = '\0';
+ return result;
+}
+int main(int argc, char **argv)
+{
+ if (argc != 2)
+ {
+ fprintf(stderr, "Usage: ./test path\n");
+ exit(-1);
+ }
+ printf("%s\n", simplifyPath(argv[1]));
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/71_\347\274\226\350\276\221\350\267\235\347\246\273/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/71_\347\274\226\350\276\221\350\267\235\347\246\273/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..d4f47ed6adb59876010f2be07a0b1259632743b7
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/71_\347\274\226\350\276\221\350\267\235\347\246\273/desc.html"
@@ -0,0 +1 @@
+给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
示例 1:
输入:word1 = "horse", word2 = "ros"
输出:3
解释:horse -> rorse (将 'h' 替换为 'r')rorse -> rose (删除 'r')rose -> ros (删除 'e')
示例 2:
输入:word1 = "intention", word2 = "execution"
输出:5
解释:intention -> inention (删除 't')inention -> enention (将 'i' 替换为 'e')enention -> exention (将 'n' 替换为 'x')exention -> exection (将 'n' 替换为 'c')exection -> execution (插入 'u')
提示:
0 <= word1.length, word2.length <= 500word1 和 word2 由小写英文字母组成
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/71_\347\274\226\350\276\221\350\267\235\347\246\273/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/71_\347\274\226\350\276\221\350\267\235\347\246\273/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..e9e0e674c3574f8a7090148b0f1cced6c9aef14d
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/71_\347\274\226\350\276\221\350\267\235\347\246\273/solution.cpp"
@@ -0,0 +1,36 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ int minDistance(string word1, string word2)
+ {
+ int l1 = word1.length();
+ int l2 = word2.length();
+ vector dp(l2 + 1);
+ for (int i = 0; i <= l2; i++)
+ {
+ dp[i] = i;
+ }
+ int up = 0;
+ for (int i = 1; i <= l1; i++)
+ {
+ int left_up = dp[0];
+ dp[0] = i;
+ for (int j = 1; j <= l2; j++)
+ {
+ up = dp[j];
+ if (word1[i - 1] == word2[j - 1])
+ {
+ dp[j] = left_up;
+ }
+ else
+ {
+ dp[j] = 1 + min(left_up, min(up, dp[j - 1]));
+ }
+ left_up = up;
+ }
+ }
+ return dp[l2];
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/72_\347\237\251\351\230\265\347\275\256\351\233\266/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/72_\347\237\251\351\230\265\347\275\256\351\233\266/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..92e1e2d4354605b9f4e618dc27b98f3331bf24f2
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/72_\347\237\251\351\230\265\347\275\256\351\233\266/desc.html"
@@ -0,0 +1 @@
+给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
进阶:
- 一个直观的解决方案是使用
O(mn) 的额外空间,但这并不是一个好的解决方案。 - 一个简单的改进方案是使用
O(m + n) 的额外空间,但这仍然不是最好的解决方案。 - 你能想出一个仅使用常量空间的解决方案吗?
示例 1:
输入:matrix = [[1,1,1],[1,0,1],[1,1,1]]
输出:[[1,0,1],[0,0,0],[1,0,1]]
示例 2:
输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]]
输出:[[0,0,0,0],[0,4,5,0],[0,3,1,0]]
提示:
m == matrix.lengthn == matrix[0].length1 <= m, n <= 200-231 <= matrix[i][j] <= 231 - 1
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/72_\347\237\251\351\230\265\347\275\256\351\233\266/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/72_\347\237\251\351\230\265\347\275\256\351\233\266/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..546f95b40b321aafdd290db7076572ab4d9b1f8d
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/72_\347\237\251\351\230\265\347\275\256\351\233\266/solution.cpp"
@@ -0,0 +1,51 @@
+#include
+using namespace std;
+public:
+void setZeroes(vector> &matrix)
+{
+ bool bRow = false, bCol = false;
+ for (int row = 0; row < matrix.size(); row++)
+ {
+ for (int col = 0; col < matrix[row].size(); col++)
+ {
+ if (matrix[row][col] == 0)
+ {
+ if (row == 0)
+ {
+ bRow = true;
+ }
+ if (col == 0)
+ {
+ bCol = true;
+ }
+ matrix[0][col] = matrix[row][0] = 0;
+ }
+ }
+ }
+ for (int row = 1; row < matrix.size(); row++)
+ {
+ for (int col = 1; col < matrix[row].size(); col++)
+ {
+ if (matrix[0][col] == 0 || matrix[row][0] == 0)
+ {
+ matrix[row][col] = 0;
+ }
+ }
+ }
+ if (bRow)
+ {
+ for (auto &m : matrix[0])
+ {
+ m = 0;
+ }
+ }
+ if (bCol)
+ {
+ for (int row = 0; row < matrix.size(); row++)
+ {
+ matrix[row][0] = 0;
+ }
+ }
+}
+}
+;
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/73_\346\220\234\347\264\242\344\272\214\347\273\264\347\237\251\351\230\265/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/73_\346\220\234\347\264\242\344\272\214\347\273\264\347\237\251\351\230\265/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..78246975ab5b3310135c98e910e759a89188e149
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/73_\346\220\234\347\264\242\344\272\214\347\273\264\347\237\251\351\230\265/desc.html"
@@ -0,0 +1 @@
+编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
- 每行中的整数从左到右按升序排列。
- 每行的第一个整数大于前一行的最后一个整数。
示例 1:
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3
输出:true
示例 2:
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 13
输出:false
提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 100-104 <= matrix[i][j], target <= 104
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/73_\346\220\234\347\264\242\344\272\214\347\273\264\347\237\251\351\230\265/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/73_\346\220\234\347\264\242\344\272\214\347\273\264\347\237\251\351\230\265/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..171fe55689bb63925516f4790c09d34a142dca0e
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/73_\346\220\234\347\264\242\344\272\214\347\273\264\347\237\251\351\230\265/solution.cpp"
@@ -0,0 +1,91 @@
+#include
+#include
+#include
+static int binary_search(int *nums, int len, int target)
+{
+ int low = -1;
+ int high = len;
+ while (low + 1 < high)
+ {
+ int mid = low + (high - low) / 2;
+ if (target > nums[mid])
+ {
+ low = mid;
+ }
+ else
+ {
+ high = mid;
+ }
+ }
+ if (high == len || nums[high] != target)
+ {
+ return -high - 1;
+ }
+ else
+ {
+ return high;
+ }
+}
+static bool searchMatrix(int **matrix, int matrixRowSize, int matrixColSize, int target)
+{
+ if (matrixRowSize == 0 || matrixColSize == 0)
+ {
+ return false;
+ }
+ if (target < matrix[0][0] || target > matrix[matrixRowSize - 1][matrixColSize - 1])
+ {
+ return false;
+ }
+ int row = 0;
+ int *nums = NULL;
+ if (matrixRowSize > 0)
+ {
+ nums = malloc(matrixRowSize * sizeof(int));
+ for (row = 0; row < matrixRowSize; row++)
+ {
+ nums[row] = matrix[row][0];
+ }
+ row = binary_search(nums, matrixRowSize, target);
+ if (row >= 0)
+ {
+ return true;
+ }
+ else
+ {
+ row = -row - 1;
+ if (row == 0)
+ {
+ return false;
+ }
+ else
+ {
+ row--;
+ }
+ }
+ }
+ int col = binary_search(matrix[row], matrixColSize, target);
+ return col >= 0;
+}
+int main(int argc, char **argv)
+{
+ int row = 3;
+ int col = 4;
+ int **mat = malloc(row * sizeof(int *));
+ mat[0] = malloc(col * sizeof(int));
+ mat[0][0] = 1;
+ mat[0][1] = 3;
+ mat[0][2] = 5;
+ mat[0][3] = 7;
+ mat[1] = malloc(col * sizeof(int));
+ mat[1][0] = 10;
+ mat[1][1] = 11;
+ mat[1][2] = 16;
+ mat[1][3] = 20;
+ mat[2] = malloc(col * sizeof(int));
+ mat[2][0] = 23;
+ mat[2][1] = 30;
+ mat[2][2] = 34;
+ mat[2][3] = 50;
+ printf("%s\n", searchMatrix(mat, row, col, atoi(argv[1])) ? "true" : "false");
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/74_\351\242\234\350\211\262\345\210\206\347\261\273/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/74_\351\242\234\350\211\262\345\210\206\347\261\273/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..a79029d7419b6797c9074afab084221974160412
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/74_\351\242\234\350\211\262\345\210\206\347\261\273/desc.html"
@@ -0,0 +1 @@
+给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
此题中,我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
示例 1:
输入:nums = [2,0,2,1,1,0]
输出:[0,0,1,1,2,2]
示例 2:
输入:nums = [2,0,1]
输出:[0,1,2]
示例 3:
输入:nums = [0]
输出:[0]
示例 4:
输入:nums = [1]
输出:[1]
提示:
n == nums.length1 <= n <= 300nums[i] 为 0、1 或 2
进阶:
- 你可以不使用代码库中的排序函数来解决这道题吗?
- 你能想出一个仅使用常数空间的一趟扫描算法吗?
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/74_\351\242\234\350\211\262\345\210\206\347\261\273/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/74_\351\242\234\350\211\262\345\210\206\347\261\273/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..fc1d9739dfaec209635737d4d3cc70b08585f103
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/74_\351\242\234\350\211\262\345\210\206\347\261\273/solution.cpp"
@@ -0,0 +1,39 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ void sortColors(vector &nums)
+ {
+ int i = 0, j = nums.size() - 1;
+ while (i < j)
+ {
+ if (nums[i] == 0)
+ {
+ i++;
+ continue;
+ }
+ if (nums[j] != 0)
+ {
+ j--;
+ continue;
+ }
+ swap(nums[i], nums[j]);
+ }
+ j = nums.size() - 1;
+ while (i < j)
+ {
+ if (nums[i] == 1)
+ {
+ i++;
+ continue;
+ }
+ if (nums[j] != 1)
+ {
+ j--;
+ continue;
+ }
+ swap(nums[i], nums[j]);
+ }
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/75_\346\234\200\345\260\217\350\246\206\347\233\226\345\255\220\344\270\262/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/75_\346\234\200\345\260\217\350\246\206\347\233\226\345\255\220\344\270\262/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..bfa0f67a92d13e69b146e71e8dd9b11733e1ecd6
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/75_\346\234\200\345\260\217\350\246\206\347\233\226\345\255\220\344\270\262/desc.html"
@@ -0,0 +1 @@
+给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
注意:如果 s 中存在这样的子串,我们保证它是唯一的答案。
示例 1:
输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
示例 2:
输入:s = "a", t = "a"
输出:"a"
提示:
1 <= s.length, t.length <= 105s 和 t 由英文字母组成
进阶:你能设计一个在 o(n) 时间内解决此问题的算法吗?
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/75_\346\234\200\345\260\217\350\246\206\347\233\226\345\255\220\344\270\262/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/75_\346\234\200\345\260\217\350\246\206\347\233\226\345\255\220\344\270\262/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..074e28830596c8dd37437ff0f1a20469148d20e5
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/75_\346\234\200\345\260\217\350\246\206\347\233\226\345\255\220\344\270\262/solution.cpp"
@@ -0,0 +1,37 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ string minWindow(string s, string t)
+ {
+ vector count(128);
+ for (char c : t)
+ {
+ count[c]++;
+ }
+ int l = 0, r = 0;
+ int need_to_meet = t.length();
+ int start, min_len = INT_MAX;
+ while (r < s.length())
+ {
+ if (--count[s[r++]] >= 0)
+ {
+ need_to_meet--;
+ }
+ while (need_to_meet == 0)
+ {
+ if (r - l < min_len)
+ {
+ start = l;
+ min_len = r - l;
+ }
+ if (++count[s[l++]] > 0)
+ {
+ need_to_meet++;
+ }
+ }
+ }
+ return min_len == INT_MAX ? "" : s.substr(start, min_len);
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/76_\347\273\204\345\220\210/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/76_\347\273\204\345\220\210/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..8ded3769c89fc68a7c806aeda5eecc1fc3285a6b
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/76_\347\273\204\345\220\210/desc.html"
@@ -0,0 +1,3 @@
+给定两个整数 n 和 k,返回 1 ... n 中所有可能的 k 个数的组合。
+示例:
+输入: n = 4, k = 2
输出:[[2,4],[3,4],[2,3],[1,2],[1,3],[1,4],]
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/76_\347\273\204\345\220\210/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/76_\347\273\204\345\220\210/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..006e5510cff4c6deae2e246f0f54648df5d5aa37
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/76_\347\273\204\345\220\210/solution.cpp"
@@ -0,0 +1,30 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ vector> combine(int n, int k)
+ {
+ vector> res;
+ dfs(n, k, 1, res);
+ return res;
+ }
+private:
+ vector stack;
+ void dfs(int n, int k, int start, vector> &res)
+ {
+ if (stack.size() == k)
+ {
+ res.push_back(stack);
+ }
+ else
+ {
+ for (int i = start; i <= n; i++)
+ {
+ stack.push_back(i);
+ dfs(n, k, i + 1, res);
+ stack.pop_back();
+ }
+ }
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/77_\345\255\220\351\233\206/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/77_\345\255\220\351\233\206/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..b599426d6b1f96c2802b08750dd00f8d68bf7560
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/77_\345\255\220\351\233\206/desc.html"
@@ -0,0 +1 @@
+给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
提示:
1 <= nums.length <= 10-10 <= nums[i] <= 10nums 中的所有元素 互不相同
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/77_\345\255\220\351\233\206/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/77_\345\255\220\351\233\206/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..7cf9fd19096bde4a5620450af094593c2ec947eb
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/77_\345\255\220\351\233\206/solution.cpp"
@@ -0,0 +1,24 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ vector> subsets(vector &nums)
+ {
+ vector> res;
+ dfs(nums, 0, res);
+ return res;
+ }
+private:
+ vector stack;
+ void dfs(vector &nums, int start, vector> &res)
+ {
+ res.push_back(stack);
+ for (int i = start; i < nums.size(); i++)
+ {
+ stack.push_back(nums[i]);
+ dfs(nums, i + 1, res);
+ stack.pop_back();
+ }
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/78_\345\215\225\350\257\215\346\220\234\347\264\242/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/78_\345\215\225\350\257\215\346\220\234\347\264\242/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..d0da23d85612108f5b53a153a19bdf4eea24807c
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/78_\345\215\225\350\257\215\346\220\234\347\264\242/desc.html"
@@ -0,0 +1 @@
+给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例 1:
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
输出:true
示例 2:
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE"
输出:true
示例 3:

输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB"
输出:false
提示:
m == board.lengthn = board[i].length1 <= m, n <= 61 <= word.length <= 15board 和 word 仅由大小写英文字母组成
进阶:你可以使用搜索剪枝的技术来优化解决方案,使其在 board 更大的情况下可以更快解决问题?
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/78_\345\215\225\350\257\215\346\220\234\347\264\242/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/78_\345\215\225\350\257\215\346\220\234\347\264\242/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..19ab6b777c3c7f500c8eb25dd96589a2c5e18556
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/78_\345\215\225\350\257\215\346\220\234\347\264\242/solution.cpp"
@@ -0,0 +1,68 @@
+#include
+#include
+#include
+#include
+static bool dfs(char *word, char **board, bool *used,
+ int row, int col, int row_size, int col_size)
+{
+ if (board[row][col] != *word)
+ {
+ return false;
+ }
+ used[row * col_size + col] = true;
+ if (*(word + 1) == '\0')
+ {
+ return true;
+ }
+ bool result = false;
+ if (row > 0 && !used[(row - 1) * col_size + col])
+ {
+ result = dfs(word + 1, board, used, row - 1, col, row_size, col_size);
+ }
+ if (!result && row < row_size - 1 && !used[(row + 1) * col_size + col])
+ {
+ result = dfs(word + 1, board, used, row + 1, col, row_size, col_size);
+ }
+ if (!result && col > 0 && !used[row * col_size + col - 1])
+ {
+ result = dfs(word + 1, board, used, row, col - 1, row_size, col_size);
+ }
+ if (!result && col < col_size - 1 && !used[row * col_size + col + 1])
+ {
+ result = dfs(word + 1, board, used, row, col + 1, row_size, col_size);
+ }
+ used[row * col_size + col] = false;
+ return result;
+}
+static bool exist(char **board, int boardRowSize, int boardColSize, char *word)
+{
+ int i, j;
+ int len = strlen(word);
+ if (len > boardRowSize * boardColSize)
+ {
+ return false;
+ }
+ bool *used = malloc(boardRowSize * boardColSize);
+ for (i = 0; i < boardRowSize; i++)
+ {
+ for (j = 0; j < boardColSize; j++)
+ {
+ memset(used, false, boardRowSize * boardColSize);
+ if (dfs(word, board, used, i, j, boardRowSize, boardColSize))
+ {
+ return true;
+ }
+ }
+ }
+ return false;
+}
+int main(int argc, char **argv)
+{
+ if (argc < 3)
+ {
+ fprintf(stderr, "Usage: ./test word row1 row2...\n");
+ exit(-1);
+ }
+ printf("%s\n", exist(argv + 2, argc - 2, strlen(argv[2]), argv[1]) ? "true" : "false");
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/79_\345\210\240\351\231\244\346\234\211\345\272\217\346\225\260\347\273\204\344\270\255\347\232\204\351\207\215\345\244\215\351\241\271 II/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/79_\345\210\240\351\231\244\346\234\211\345\272\217\346\225\260\347\273\204\344\270\255\347\232\204\351\207\215\345\244\215\351\241\271 II/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..af2e6a569017c01d985ec4092606fae089d71c18
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/79_\345\210\240\351\231\244\346\234\211\345\272\217\346\225\260\347\273\204\344\270\255\347\232\204\351\207\215\345\244\215\351\241\271 II/desc.html"
@@ -0,0 +1,28 @@
+给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使每个元素 最多出现两次 ,返回删除后数组的新长度。
+不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
+
+说明:
+为什么返回数值是整数,但输出的答案是数组呢?
+请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
+你可以想象内部操作如下:
+
+ // nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
+ int len = removeDuplicates(nums);// 在函数里修改输入数组对于调用者是可见的。
+ // 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
+ for (int i = 0; i < len; i++) {
+ print(nums[i]);
+ }
+
+示例 1:
+输入:nums = [1,1,1,2,2,3]
输出:5, nums = [1,1,2,2,3]
解释:函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3 。 不需要考虑数组中超出新长度后面的元素。
+示例 2:
+输入:nums = [0,0,1,1,1,1,2,3,3]
输出:7, nums = [0,0,1,1,2,3,3]
解释:函数应返回新长度 length = 7, 并且原数组的前五个元素被修改为 0, 0, 1, 1, 2, 3, 3 。 不需要考虑数组中超出新长度后面的元素。
+
+提示:
+
+ 1 <= nums.length <= 3 * 104-104 <= nums[i] <= 104nums 已按升序排列
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/79_\345\210\240\351\231\244\346\234\211\345\272\217\346\225\260\347\273\204\344\270\255\347\232\204\351\207\215\345\244\215\351\241\271 II/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/79_\345\210\240\351\231\244\346\234\211\345\272\217\346\225\260\347\273\204\344\270\255\347\232\204\351\207\215\345\244\215\351\241\271 II/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..033af79f96297f6410c8f97cf37e5032aceb128b
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/79_\345\210\240\351\231\244\346\234\211\345\272\217\346\225\260\347\273\204\344\270\255\347\232\204\351\207\215\345\244\215\351\241\271 II/solution.cpp"
@@ -0,0 +1,44 @@
+#include
+#include
+static int removeDuplicates(int *nums, int numsSize)
+{
+ if (numsSize == 0)
+ {
+ return 0;
+ }
+ int i;
+ int len = 0;
+ int count = 1;
+ for (i = 1; i < numsSize; i++)
+ {
+ if (nums[len] == nums[i])
+ {
+ if (count < 2)
+ {
+ count++;
+ nums[++len] = nums[i];
+ }
+ }
+ else
+ {
+ count = 1;
+ nums[++len] = nums[i];
+ }
+ }
+ return len + 1;
+}
+int main(int argc, char **argv)
+{
+ int i, count = argc - 1;
+ int *nums = malloc(count * sizeof(int));
+ for (i = 0; i < count; i++)
+ {
+ nums[i] = atoi(argv[i + 1]);
+ }
+ count = removeDuplicates(nums, count);
+ for (i = 0; i < count; i++)
+ {
+ printf("%d ", nums[i]);
+ }
+ printf("\n");
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/7_\345\255\227\347\254\246\344\270\262\350\275\254\346\215\242\346\225\264\346\225\260 (atoi)/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/7_\345\255\227\347\254\246\344\270\262\350\275\254\346\215\242\346\225\264\346\225\260 (atoi)/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..3065185176da4940ffde14d074f1055e07f27253
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/7_\345\255\227\347\254\246\344\270\262\350\275\254\346\215\242\346\225\264\346\225\260 (atoi)/desc.html"
@@ -0,0 +1,109 @@
+
+
请你来实现一个 myAtoi(string s) 函数,使其能将字符串转换成一个 32 位有符号整数(类似 C/C++ 中的 atoi 函数)。
+
+
函数 myAtoi(string s) 的算法如下:
+
+
+ - 读入字符串并丢弃无用的前导空格
+ - 检查下一个字符(假设还未到字符末尾)为正还是负号,读取该字符(如果有)。 确定最终结果是负数还是正数。 如果两者都不存在,则假定结果为正。
+ - 读入下一个字符,直到到达下一个非数字字符或到达输入的结尾。字符串的其余部分将被忽略。
+ - 将前面步骤读入的这些数字转换为整数(即,"123" -> 123, "0032" -> 32)。如果没有读入数字,则整数为
0 。必要时更改符号(从步骤 2 开始)。
+ - 如果整数数超过 32 位有符号整数范围
[−231, 231 − 1]
+ ,需要截断这个整数,使其保持在这个范围内。具体来说,小于 −231 的整数应该被固定为 −231 ,大于
+ 231 − 1 的整数应该被固定为 231 − 1 。
+
+ - 返回整数作为最终结果。
+
+
+
注意:
+
+
+ - 本题中的空白字符只包括空格字符
' ' 。
+ - 除前导空格或数字后的其余字符串外,请勿忽略 任何其他字符。
+
+
+
+
+
示例 1:
+
+
输入:s = "42"
+
输出:42
+
解释:加粗的字符串为已经读入的字符,插入符号是当前读取的字符。
+第 1 步:"42"(当前没有读入字符,因为没有前导空格)
+ ^
+第 2 步:"42"(当前没有读入字符,因为这里不存在 '-' 或者 '+')
+ ^
+第 3 步:"42"(读入 "42")
+ ^
+解析得到整数 42 。
+由于 "42" 在范围 [-231, 231 - 1] 内,最终结果为 42 。
+
+
示例 2:
+
+
输入:s = " -42"
+
输出:-42
+
解释:
+第 1 步:" -42"(读入前导空格,但忽视掉)
+ ^
+第 2 步:" -42"(读入 '-' 字符,所以结果应该是负数)
+ ^
+第 3 步:" -42"(读入 "42")
+ ^
+解析得到整数 -42 。
+由于 "-42" 在范围 [-231, 231 - 1] 内,最终结果为 -42 。
+
+
+
示例 3:
+
+
输入:s = "4193 with words"
+
输出:4193
+
解释:
+第 1 步:"4193 with words"(当前没有读入字符,因为没有前导空格)
+ ^
+第 2 步:"4193 with words"(当前没有读入字符,因为这里不存在 '-' 或者 '+')
+ ^
+第 3 步:"4193 with words"(读入 "4193";由于下一个字符不是一个数字,所以读入停止)
+ ^
+解析得到整数 4193 。
+由于 "4193" 在范围 [-231, 231 - 1] 内,最终结果为 4193 。
+
+
+
示例 4:
+
+
输入:s = "words and 987"
+
输出:0
+
解释:
+第 1 步:"words and 987"(当前没有读入字符,因为没有前导空格)
+ ^
+第 2 步:"words and 987"(当前没有读入字符,因为这里不存在 '-' 或者 '+')
+ ^
+第 3 步:"words and 987"(由于当前字符 'w' 不是一个数字,所以读入停止)
+ ^
+解析得到整数 0 ,因为没有读入任何数字。
+由于 0 在范围 [-231, 231 - 1] 内,最终结果为 0 。
+
+
示例 5:
+
+
输入:s = "-91283472332"
+
输出:-2147483648
+
解释:
+第 1 步:"-91283472332"(当前没有读入字符,因为没有前导空格)
+ ^
+第 2 步:"-91283472332"(读入 '-' 字符,所以结果应该是负数)
+ ^
+第 3 步:"-91283472332"(读入 "91283472332")
+ ^
+解析得到整数 -91283472332 。
+由于 -91283472332 小于范围 [-231, 231 - 1] 的下界,最终结果被截断为 -231 = -2147483648 。
+
+
+
+
提示:
+
+
+ 0 <= s.length <= 200s 由英文字母(大写和小写)、数字(0-9)、' '、'+'、'-' 和
+ '.' 组成
+
+
已知存在一个按非降序排列的整数数组 nums ,数组中的值不必互不相同。
+在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转
+ ,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0
+ 开始 计数)。例如, [0,1,2,4,4,4,5,6,6,7] 在下标 5 处经旋转后可能变为
+ [4,5,6,6,7,0,1,2,4,4] 。
+
+给你 旋转后 的数组 nums 和一个整数 target ,请你编写一个函数来判断给定的目标值是否存在于数组中。如果
+ nums 中存在这个目标值 target ,则返回 true ,否则返回 false 。
+
+
+示例 1:
+输入:nums = [2,5,6,0,0,1,2], target = 0
输出:true
+示例 2:
+输入:nums = [2,5,6,0,0,1,2], target = 3
输出:false
+
+提示:
+
+ 1 <= nums.length <= 5000-104 <= nums[i] <= 104- 题目数据保证
nums 在预先未知的某个下标上进行了旋转
+ -104 <= target <= 104
+
+进阶:
+
+ - 这是 搜索旋转排序数组 的延伸题目,本题中的
nums
+ 可能包含重复元素。
+ - 这会影响到程序的时间复杂度吗?会有怎样的影响,为什么?
+
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/80_\346\220\234\347\264\242\346\227\213\350\275\254\346\216\222\345\272\217\346\225\260\347\273\204 II/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/80_\346\220\234\347\264\242\346\227\213\350\275\254\346\216\222\345\272\217\346\225\260\347\273\204 II/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..989beac50f4137916e01a5c5bc326f799cb395f0
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/80_\346\220\234\347\264\242\346\227\213\350\275\254\346\216\222\345\272\217\346\225\260\347\273\204 II/solution.cpp"
@@ -0,0 +1,57 @@
+#include
+#include
+#include
+static bool search(int *nums, int numsSize, int target)
+{
+ int lo = 0;
+ int hi = numsSize - 1;
+ while (lo <= hi)
+ {
+ int mid = lo + (hi - lo) / 2;
+ if (nums[mid] == target)
+ {
+ return true;
+ }
+ if (nums[lo] == nums[mid] && nums[mid] == nums[hi])
+ {
+ lo++;
+ hi--;
+ }
+ else if (nums[lo] <= nums[mid])
+ {
+ if (nums[lo] <= target && target < nums[mid])
+ {
+ hi = mid - 1;
+ }
+ else
+ {
+ lo = mid + 1;
+ }
+ }
+ else
+ {
+ if (nums[mid] < target && target <= nums[hi])
+ {
+ lo = mid + 1;
+ }
+ else
+ {
+ hi = mid - 1;
+ }
+ }
+ }
+ return false;
+}
+int main(int argc, char **argv)
+{
+ int i;
+ int target = atoi(argv[1]);
+ int size = argc - 2;
+ int *nums = malloc(size * sizeof(int));
+ for (i = 0; i < argc - 2; i++)
+ {
+ nums[i] = atoi(argv[i + 2]);
+ }
+ printf("%d\n", search(nums, size, target));
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/81_\345\210\240\351\231\244\346\216\222\345\272\217\351\223\276\350\241\250\344\270\255\347\232\204\351\207\215\345\244\215\345\205\203\347\264\240 II/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/81_\345\210\240\351\231\244\346\216\222\345\272\217\351\223\276\350\241\250\344\270\255\347\232\204\351\207\215\345\244\215\345\205\203\347\264\240 II/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..96eb961693a9336bb79a74cce1d29513513f5d65
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/81_\345\210\240\351\231\244\346\216\222\345\272\217\351\223\276\350\241\250\344\270\255\347\232\204\351\207\215\345\244\215\345\205\203\347\264\240 II/desc.html"
@@ -0,0 +1 @@
+存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除链表中所有存在数字重复情况的节点,只保留原始链表中 没有重复出现 的数字。
返回同样按升序排列的结果链表。
示例 1:
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:
输入:head = [1,1,1,2,3]
输出:[2,3]
提示:
- 链表中节点数目在范围
[0, 300] 内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序排列
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/81_\345\210\240\351\231\244\346\216\222\345\272\217\351\223\276\350\241\250\344\270\255\347\232\204\351\207\215\345\244\215\345\205\203\347\264\240 II/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/81_\345\210\240\351\231\244\346\216\222\345\272\217\351\223\276\350\241\250\344\270\255\347\232\204\351\207\215\345\244\215\345\205\203\347\264\240 II/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..c2fef49775ccd7a5d03e840323e2f5972cf70a03
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/81_\345\210\240\351\231\244\346\216\222\345\272\217\351\223\276\350\241\250\344\270\255\347\232\204\351\207\215\345\244\215\345\205\203\347\264\240 II/solution.cpp"
@@ -0,0 +1,63 @@
+#include
+#include
+struct ListNode
+{
+ int val;
+ struct ListNode *next;
+};
+struct ListNode *deleteDuplicates(struct ListNode *head)
+{
+ struct ListNode dummy;
+ struct ListNode *p, *q, *prev;
+ prev = &dummy;
+ dummy.next = head;
+ p = q = head;
+ while (p != NULL)
+ {
+ while (q != NULL && q->val == p->val)
+ {
+ q = q->next;
+ }
+ if (p->next == q)
+ {
+ prev = p;
+ }
+ else
+ {
+ prev->next = q;
+ }
+ p = q;
+ }
+ return dummy.next;
+}
+int main(int argc, char **argv)
+{
+ int i;
+ struct ListNode *head = NULL;
+ struct ListNode *prev = NULL;
+ struct ListNode *p;
+ for (i = 0; i < argc - 1; i++)
+ {
+ p = malloc(sizeof(*p));
+ p->val = atoi(argv[i + 1]);
+ p->next = NULL;
+ if (head == NULL)
+ {
+ head = p;
+ prev = head;
+ }
+ else
+ {
+ prev->next = p;
+ prev = p;
+ }
+ }
+ p = deleteDuplicates(head);
+ while (p != NULL)
+ {
+ printf("%d ", p->val);
+ p = p->next;
+ }
+ printf("\n");
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/82_\345\210\240\351\231\244\346\216\222\345\272\217\351\223\276\350\241\250\344\270\255\347\232\204\351\207\215\345\244\215\345\205\203\347\264\240/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/82_\345\210\240\351\231\244\346\216\222\345\272\217\351\223\276\350\241\250\344\270\255\347\232\204\351\207\215\345\244\215\345\205\203\347\264\240/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..380d1bf4815ff5725d96d951b0201de3244686a8
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/82_\345\210\240\351\231\244\346\216\222\345\272\217\351\223\276\350\241\250\344\270\255\347\232\204\351\207\215\345\244\215\345\205\203\347\264\240/desc.html"
@@ -0,0 +1 @@
+存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除所有重复的元素,使每个元素 只出现一次 。
返回同样按升序排列的结果链表。
示例 1:
输入:head = [1,1,2]
输出:[1,2]
示例 2:
输入:head = [1,1,2,3,3]
输出:[1,2,3]
提示:
- 链表中节点数目在范围
[0, 300] 内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序排列
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/82_\345\210\240\351\231\244\346\216\222\345\272\217\351\223\276\350\241\250\344\270\255\347\232\204\351\207\215\345\244\215\345\205\203\347\264\240/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/82_\345\210\240\351\231\244\346\216\222\345\272\217\351\223\276\350\241\250\344\270\255\347\232\204\351\207\215\345\244\215\345\205\203\347\264\240/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..fcd68c74c6da9fc1d69ec4ffeb0d9e14fb6e91d1
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/82_\345\210\240\351\231\244\346\216\222\345\272\217\351\223\276\350\241\250\344\270\255\347\232\204\351\207\215\345\244\215\345\205\203\347\264\240/solution.cpp"
@@ -0,0 +1,34 @@
+#include
+using namespace std;
+struct ListNode
+{
+ int val;
+ ListNode *next;
+ ListNode() : val(0), next(nullptr) {}
+ ListNode(int x) : val(x), next(nullptr) {}
+ ListNode(int x, ListNode *next) : val(x), next(next) {}
+};
+class Solution
+{
+public:
+ ListNode *deleteDuplicates(ListNode *head)
+ {
+ if (head == nullptr)
+ {
+ return nullptr;
+ }
+ ListNode *prev = head;
+ ListNode *p = prev->next;
+ while (p != nullptr)
+ {
+ if (p->val != prev->val)
+ {
+ prev->next = p;
+ prev = p;
+ }
+ p = p->next;
+ }
+ prev->next = p;
+ return head;
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/83_\346\237\261\347\212\266\345\233\276\344\270\255\346\234\200\345\244\247\347\232\204\347\237\251\345\275\242/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/83_\346\237\261\347\212\266\345\233\276\344\270\255\346\234\200\345\244\247\347\232\204\347\237\251\345\275\242/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..2bcf9513b8f640658b0ccb6790009ed037969e1d
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/83_\346\237\261\347\212\266\345\233\276\344\270\255\346\234\200\345\244\247\347\232\204\347\237\251\345\275\242/desc.html"
@@ -0,0 +1 @@
+给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
以上是柱状图的示例,其中每个柱子的宽度为 1,给定的高度为 [2,1,5,6,2,3]。
图中阴影部分为所能勾勒出的最大矩形面积,其面积为 10 个单位。
示例:
输入: [2,1,5,6,2,3]
输出: 10
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/83_\346\237\261\347\212\266\345\233\276\344\270\255\346\234\200\345\244\247\347\232\204\347\237\251\345\275\242/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/83_\346\237\261\347\212\266\345\233\276\344\270\255\346\234\200\345\244\247\347\232\204\347\237\251\345\275\242/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..0e775884346d1a3ed58492e3bb9d41de6786c2de
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/83_\346\237\261\347\212\266\345\233\276\344\270\255\346\234\200\345\244\247\347\232\204\347\237\251\345\275\242/solution.cpp"
@@ -0,0 +1,42 @@
+#include
+#include
+static int largestRectangleArea(int *heights, int heightsSize)
+{
+ int *indexes = malloc(heightsSize * sizeof(int));
+ int *left = malloc(heightsSize * sizeof(int));
+ int *right = malloc(heightsSize * sizeof(int));
+ int i, pos = 0;
+ for (i = 0; i < heightsSize; i++)
+ {
+ while (pos > 0 && heights[indexes[pos - 1]] >= heights[i])
+ {
+ pos--;
+ }
+ left[i] = pos == 0 ? -1 : indexes[pos - 1];
+ indexes[pos++] = i;
+ }
+ pos = 0;
+ for (i = heightsSize - 1; i >= 0; i--)
+ {
+ while (pos > 0 && heights[indexes[pos - 1]] >= heights[i])
+ {
+ pos--;
+ }
+ right[i] = pos == 0 ? heightsSize : indexes[pos - 1];
+ indexes[pos++] = i;
+ }
+ int max_area = 0;
+ for (i = 0; i < heightsSize; i++)
+ {
+ int area = heights[i] * (right[i] - left[i] - 1);
+ max_area = area > max_area ? area : max_area;
+ }
+ return max_area;
+}
+int main(void)
+{
+ int nums[] = {2, 1, 5, 6, 2, 3};
+ int count = sizeof(nums) / sizeof(*nums);
+ printf("%d\n", largestRectangleArea(nums, count));
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/84_\346\234\200\345\244\247\347\237\251\345\275\242/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/84_\346\234\200\345\244\247\347\237\251\345\275\242/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..6d9bdc4aabd460b0832d14bee37868aeba7e9dbf
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/84_\346\234\200\345\244\247\347\237\251\345\275\242/desc.html"
@@ -0,0 +1 @@
+给定一个仅包含 0 和 1 、大小为 rows x cols 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
示例 1:

输入:matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]]
输出:6
解释:最大矩形如上图所示。
示例 2:
输入:matrix = []
输出:0
示例 3:
输入:matrix = [["0"]]
输出:0
示例 4:
输入:matrix = [["1"]]
输出:1
示例 5:
输入:matrix = [["0","0"]]
输出:0
提示:
rows == matrix.lengthcols == matrix[0].length0 <= row, cols <= 200matrix[i][j] 为 '0' 或 '1'
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/84_\346\234\200\345\244\247\347\237\251\345\275\242/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/84_\346\234\200\345\244\247\347\237\251\345\275\242/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..51b4724397f100a6345b2cdd27df8be887ced34d
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/84_\346\234\200\345\244\247\347\237\251\345\275\242/solution.cpp"
@@ -0,0 +1,73 @@
+#include
+#include
+#include
+#include
+static inline int max(int a, int b)
+{
+ return a > b ? a : b;
+}
+static int area_calc(int *heights, int size)
+{
+ int *indexes = malloc(size * sizeof(int));
+ int *lhist = malloc(size * sizeof(int));
+ int *rhist = malloc(size * sizeof(int));
+ int i, pos = 0;
+ for (i = 0; i < size; i++)
+ {
+ while (pos > 0 && heights[indexes[pos - 1]] >= heights[i])
+ {
+ pos--;
+ }
+ lhist[i] = pos == 0 ? -1 : indexes[pos - 1];
+ indexes[pos++] = i;
+ }
+ pos = 0;
+ for (i = size - 1; i >= 0; i--)
+ {
+ while (pos > 0 && heights[indexes[pos - 1]] >= heights[i])
+ {
+ pos--;
+ }
+ rhist[i] = pos == 0 ? size : indexes[pos - 1];
+ indexes[pos++] = i;
+ }
+ int max_area = 0;
+ for (i = 0; i < size; i++)
+ {
+ int area = heights[i] * (rhist[i] - lhist[i] - 1);
+ max_area = max(area, max_area);
+ }
+ return max_area;
+}
+static int maximalRectangle(char **matrix, int matrixRowSize, int matrixColSize)
+{
+ int i, j, max_area = 0;
+ int *heights = malloc(matrixColSize * sizeof(int));
+ memset(heights, 0, matrixColSize * sizeof(int));
+ for (i = 0; i < matrixRowSize; i++)
+ {
+ for (j = 0; j < matrixColSize; j++)
+ {
+ heights[j] = matrix[i][j] == '1' ? heights[j] + 1 : 0;
+ }
+ max_area = max(max_area, area_calc(heights, matrixColSize));
+ }
+ return max_area;
+}
+int main(int argc, char **argv)
+{
+ if (argc < 2)
+ {
+ fprintf(stderr, "Usage: ./test row1 row2...\n");
+ exit(-1);
+ }
+ int i, j;
+ int row_size = argc - 1;
+ int col_size = strlen(argv[1]);
+ for (i = 0; i < row_size; i++)
+ {
+ printf("%s\n", argv[i + 1]);
+ }
+ printf("%d\n", maximalRectangle(argv + 1, argc - 1, strlen(argv[1])));
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/85_\345\210\206\351\232\224\351\223\276\350\241\250/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/85_\345\210\206\351\232\224\351\223\276\350\241\250/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..2962177ef1376c5176fb4fe57f83ac0a71899de3
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/85_\345\210\206\351\232\224\351\223\276\350\241\250/desc.html"
@@ -0,0 +1 @@
+给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2
输出:[1,2]
提示:
- 链表中节点的数目在范围
[0, 200] 内 -100 <= Node.val <= 100-200 <= x <= 200
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/85_\345\210\206\351\232\224\351\223\276\350\241\250/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/85_\345\210\206\351\232\224\351\223\276\350\241\250/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..3cabea1af03af264315c4b43429625843625dc25
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/85_\345\210\206\351\232\224\351\223\276\350\241\250/solution.cpp"
@@ -0,0 +1,76 @@
+#include
+#include
+struct ListNode
+{
+ int val;
+ struct ListNode *next;
+};
+struct ListNode *partition(struct ListNode *head, int x)
+{
+ struct ListNode dummy;
+ struct ListNode *prev1 = &dummy, *pivot;
+ dummy.next = head;
+ for (pivot = head; pivot != NULL; pivot = pivot->next)
+ {
+ if (pivot->val >= x)
+ {
+ break;
+ }
+ prev1 = pivot;
+ }
+ struct ListNode *p = pivot->next;
+ struct ListNode *prev2 = pivot;
+ while (p != NULL)
+ {
+ if (p->val < x)
+ {
+ prev2->next = p->next;
+ p->next = prev1->next;
+ prev1->next = p;
+ prev1 = p;
+ p = prev2->next;
+ }
+ else
+ {
+ prev2 = p;
+ p = p->next;
+ }
+ }
+ return dummy.next;
+}
+int main(int argc, char **argv)
+{
+ if (argc < 2)
+ {
+ fprintf(stderr, "Usage: ./test target n1 n2 n3...\n");
+ exit(-1);
+ }
+ int i, target = atoi(argv[1]);
+ struct ListNode *head = NULL;
+ struct ListNode *prev = NULL;
+ struct ListNode *p;
+ for (i = 0; i < argc - 2; i++)
+ {
+ p = malloc(sizeof(*p));
+ p->val = atoi(argv[i + 2]);
+ p->next = NULL;
+ if (head == NULL)
+ {
+ head = p;
+ prev = head;
+ }
+ else
+ {
+ prev->next = p;
+ prev = p;
+ }
+ }
+ p = partition(head, target);
+ while (p != NULL)
+ {
+ printf("%d ", p->val);
+ p = p->next;
+ }
+ printf("\n");
+ return 0;
+}
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/86_\346\211\260\344\271\261\345\255\227\347\254\246\344\270\262/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/86_\346\211\260\344\271\261\345\255\227\347\254\246\344\270\262/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..dcca706ce80d43a55c602188265912215f566fb0
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/86_\346\211\260\344\271\261\345\255\227\347\254\246\344\270\262/desc.html"
@@ -0,0 +1,59 @@
+使用下面描述的算法可以扰乱字符串
s 得到字符串
t :
+
+ - 如果字符串的长度为 1 ,算法停止
+ - 如果字符串的长度 > 1 ,执行下述步骤:
+
+ - 在一个随机下标处将字符串分割成两个非空的子字符串。即,如果已知字符串
s ,则可以将其分成两个子字符串 x 和 y
+ ,且满足 s = x + y 。
+ - 随机 决定是要「交换两个子字符串」还是要「保持这两个子字符串的顺序不变」。即,在执行这一步骤之后,
s 可能是
+ s = x + y 或者 s = y + x 。
+
+ - 在
x 和 y 这两个子字符串上继续从步骤 1 开始递归执行此算法。
+
+
+
+
+
给你两个 长度相等 的字符串 s1
+ 和 s2,判断 s2 是否是 s1 的扰乱字符串。如果是,返回
+ true ;否则,返回 false 。
+
+
+
+
+
示例 1:
+
+
输入:s1 = "great", s2 = "rgeat"
+
输出:true
+
解释:s1 上可能发生的一种情形是:
+"great" --> "gr/eat" // 在一个随机下标处分割得到两个子字符串
+"gr/eat" --> "gr/eat" // 随机决定:「保持这两个子字符串的顺序不变」
+"gr/eat" --> "g/r / e/at" // 在子字符串上递归执行此算法。两个子字符串分别在随机下标处进行一轮分割
+"g/r / e/at" --> "r/g / e/at" // 随机决定:第一组「交换两个子字符串」,第二组「保持这两个子字符串的顺序不变」
+"r/g / e/at" --> "r/g / e/ a/t" // 继续递归执行此算法,将 "at" 分割得到 "a/t"
+"r/g / e/ a/t" --> "r/g / e/ a/t" // 随机决定:「保持这两个子字符串的顺序不变」
+算法终止,结果字符串和 s2 相同,都是 "rgeat"
+这是一种能够扰乱 s1 得到 s2 的情形,可以认为 s2 是 s1 的扰乱字符串,返回 true
+
+
+
示例 2:
+
+
输入:s1 = "abcde", s2 = "caebd"
+
输出:false
+
+
+
示例 3:
+
+
输入:s1 = "a", s2 = "a"
+
输出:true
+
+
+
+
+
提示:
+
+
+ s1.length == s2.length1 <= s1.length <= 30s1 和 s2 由小写英文字母组成
+
给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 nums1 成为一个有序数组。
初始化 nums1 和 nums2 的元素数量分别为 m 和 n 。你可以假设 nums1 的空间大小等于 m + n,这样它就有足够的空间保存来自 nums2 的元素。
示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
输出:[1,2,2,3,5,6]
示例 2:
输入:nums1 = [1], m = 1, nums2 = [], n = 0
输出:[1]
提示:
nums1.length == m + nnums2.length == n0 <= m, n <= 2001 <= m + n <= 200-109 <= nums1[i], nums2[i] <= 109
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/87_\345\220\210\345\271\266\344\270\244\344\270\252\346\234\211\345\272\217\346\225\260\347\273\204/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/87_\345\220\210\345\271\266\344\270\244\344\270\252\346\234\211\345\272\217\346\225\260\347\273\204/solution.cpp"
new file mode 100644
index 0000000000000000000000000000000000000000..e5d43b3dd5cc47780ed944d57dd1fcecc966efe1
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/87_\345\220\210\345\271\266\344\270\244\344\270\252\346\234\211\345\272\217\346\225\260\347\273\204/solution.cpp"
@@ -0,0 +1,27 @@
+#include
+using namespace std;
+class Solution
+{
+public:
+ void merge(vector &nums1, int m, vector &nums2, int n)
+ {
+ int i = m - 1;
+ int j = n - 1;
+ int k = nums1.size() - 1;
+ while (i >= 0 && j >= 0)
+ {
+ if (nums1[i] < nums2[j])
+ {
+ nums1[k--] = nums2[j--];
+ }
+ else
+ {
+ nums1[k--] = nums1[i--];
+ }
+ }
+ while (j >= 0)
+ {
+ nums1[k--] = nums2[j--];
+ }
+ }
+};
\ No newline at end of file
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/88_\346\240\274\351\233\267\347\274\226\347\240\201/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/88_\346\240\274\351\233\267\347\274\226\347\240\201/desc.html"
new file mode 100644
index 0000000000000000000000000000000000000000..aeca3b47c907522eb8d45df66c2a157af1dd3d16
--- /dev/null
+++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/88_\346\240\274\351\233\267\347\274\226\347\240\201/desc.html"
@@ -0,0 +1,8 @@
+格雷编码是一个二进制数字系统,在该系统中,两个连续的数值仅有一个位数的差异。
+给定一个代表编码总位数的非负整数