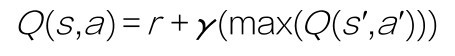
Deep Q Network算法,简称DQN算法,是Deep Mind公司于2013年1月在NIPS发表的论文《Playing Atari with Deep Reinforcement Learning》中提出的。该算法是Q-Learning算法的加强版。
论文摘要中指出:“这是第一个使用强化学习直接从高维特征视觉输入信号中成功学习控制策略的深度学习模型。该模型通过卷积神经网络来训练Q-Learning算法,其输入是原始像素,输出是未来期望奖励的值函数。在不调整架构和学习算法的前提下,将此算法应用于Arcade学习环境中的7个Atari 2600游戏。经测试,算法在6个游戏中优于以前的所有算法,并且在3个游戏中的性能超过了人类专家。”Atari游戏是类似街机的游戏,在美国的流行程度大概与20世纪90年代的任天堂游戏类似。刚才也说了,在Open AI的Gym库中,提供了很多基于Atari 2600的API,帮助我们生成游戏环境,训练智能体。
刚才我们是应用Q-Table来记录冰湖挑战中的各种状态下的最优动作,但是,那个环境是很简单的情况。不难想象,在十分复杂的环境中,状态和动作都将变得复杂,维度也非常大,那么如何记录、更新和训练Q-Table呢?深度神经网络成为不二之选。
而DQN算法使用神经网络替换Q-Table,如下图所示。此时的Q函数多了一个参数θ,表示为Q(s,a;θ)。其中的θ,就是神经网络的可训练权重,也就是我们以前常提到的参数w。现在把Q函数看作神经网络的损失函数,先复习一下这个函数:
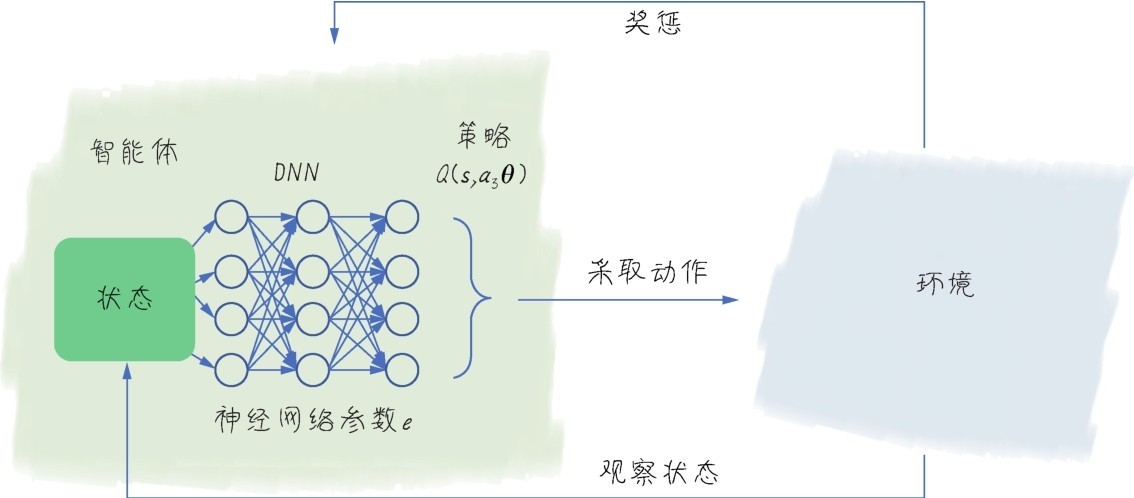
DQN算法使用神经网络替换Q-Table
那么需要最小化的是什么呢?
其实,在强化学习问题中,我们希望最小化的是Q函数的左右差异。也就是说,当Q值达到其收敛状态时,环境奖励和期望奖励与当前的Q-Table中的Q值应该是几乎完全相同的。而这正是我们的目标。
因此DQN算法的损失函数可以表示为:
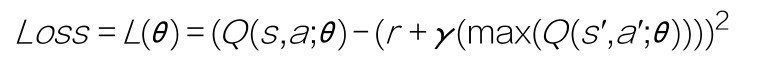
是不是似曾相识?这难道不正是第一个机器学习算法线性回归中所介绍的均方误差函数的翻版吗?
有了损失函数,神经网络的训练及优化自然就有了实现的基础。这就是DQN算法的基本思路。
通过DQN算法完成冰湖挑战就作为家庭作业,留给同学们自己去完成。