 咖哥发言
咖哥发言我们早已经知道了内容参数和超参数的区别。内容参数是算法内部的权重和偏置,而超参数是算法的参数,例如逻辑回归中的C值、神经网络的层数和优化器、KNN中的K值,都是超参数。
算法的内部参数,是算法通过梯度下降自行优化,而超参数通常依据经验手工调整。
在第4课的学习中,我们手工调整过逻辑回归算法中的C值,那时小冰就提出过一个问题:为什么要手工调整,而不能由机器自动地选择最优的超参数?
而本次课程中,我们看到了同一个KNN算法,不同K值所带来的不同结果。因此,机器是可以通过某种方法自动找到最佳的K值的。
现在揭晓这个“秘密武器”:利用Sklearn的网格搜索(Grid Search)功能,可以为特定机器学习算法找到每一个超参数指定范围内的最佳值。
什么是指定范围内的最佳值呢?思路很简单,就是列举出一组组可选超参数值。网格搜索会遍历其中所有的可能组合,并根据指定的评估指标比较每一个超参数组合的性能。这个思路正如刚才在KNN算法中,选择1~15来逐个检查哪一个K值效果最好。当然,通常来说,超参数并不是一个,因此组合起来,可能的情况也多。
下面用网格搜索功能进一步优化随机森林算法的超参数,看看预测准确率还有没有能进一步提升的空间:
from sklearn.model_selection import Stratified KFold # 导入K折验证工具
from sklearn.model_selection import Grid Search CV # 导入网格搜索工具
kfold = Stratified KFold(n_splits=10) # 10折验证
rf = Random Forest Classifier() # 随机森林模型
# 对随机森林算法进行参数优化
rf_param_grid = {"max_depth": [None],
"max_features": [3, 5, 12],
"min_samples_split": [2, 5, 10],
"min_samples_leaf": [3, 5, 10],
"bootstrap": [False],
"n_estimators" :[100,300],
"criterion": ["gini"]}
rf_gs = Grid Search CV(rf,param_grid = rf_param_grid, cv=kfold,
scoring="accuracy", n_jobs= 10, verbose = 1)
rf_gs.fit(X_train, y_train) # 用优化后的参数拟合训练数据集
此处选择了准确率作为各个参数组合的评估指标,并且应用10折验证以提高准确率。程序开始运行之后,10个“后台工作者”开始分批同步对54种参数组合中的每一组参数,用10折验证的方式对训练集进行训练(因为是10折验证,所以共需训练540次)并比较,试图找到最佳参数。
咖哥发言
对于随机森林算法中每一个超参数的具体功能,请同学们自行查阅Sklearn文档。
输出结果如下:
Fitting 10 folds for each of 54 candidates, totalling 540 fits
[Parallel(n_jobs=10)]: Using backend Loky Backend with 10 concurrent workers.
[Parallel(n_jobs=10)]: Done 30 tasks | elapsed: 3.1s
[Parallel(n_jobs=10)]: Done 180 tasks | elapsed: 24.3s
[Parallel(n_jobs=10)]: Done 430 tasks | elapsed: 1.0min
[Parallel(n_jobs=10)]: Done 540 out of 540 | elapsed: 1.3min finished
在GPU的加持之下,整个540次拟合只用了1.3分钟(不是每一个训练集的训练速度都这么快,当参数组合数目很多、训练数据集很大时,网格搜索还是挺耗费资源的)。
下面使用找到的最佳参数进行预测:
from sklearn.metrics import (accuracy_score, confusion_matrix)
y_hat_rfgs = rf_gs.predict(X_test) # 用随机森林算法的最佳参数进行预测
print("参数优化后随机森林预测准确率:", accuracy_score(y_test.T, y_hat_rfgs))
在测试集上,对心脏病的预测准确率达到了90%以上,这是之前多种算法都没有达到过的最好成绩:
参数优化后随机森林测试准确率: 0.9016393442622951
显示一下混淆矩阵,发现 “假正”进一步下降为3人,也就是说测试集中仅有3个健康的人被误判为心脏病患者,同时仅有3个真正的心脏病患者成了漏网之鱼,被误判为健康的人:
cm_rfgs = confusion_matrix(y_test, y_had_rfgs) # 显示混淆矩阵
plt.figure(figsize=(4, 4))
plt.title("Random Forest (Best Score) Confusion Matrix")#随机森林(最优参数)混淆矩阵
sns.heatmap(cm_rfgs, annot=True, cmap="Blues", fmt="d", cbar=False)
参数优化后随机森林算法的混淆矩阵如下图所示。
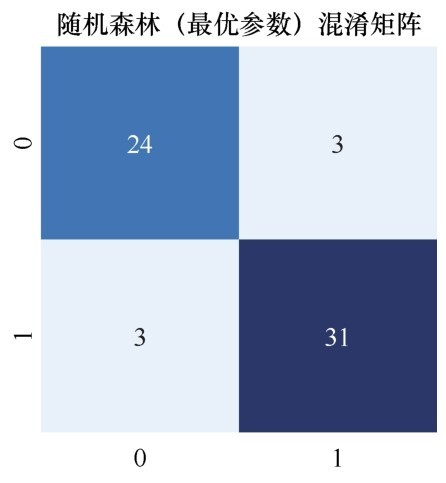
参数优化后随机森林算法的混淆矩阵
那么,如果得到了好的结果,能把参数输出来,留着以后重用吗?
输出最优模型的best_params_属性就行!
示例代码如下:
print("最佳参数组合:", rf_gs.best_params_)
输出结果如下:
最佳参数:
{'bootstrap': False,
'criterion': 'gini',
'max_depth': None,
'max_features': 3,
'min_samples_leaf': 3,
'min_samples_split': 2,
'n_estimators': 100}
这就是网格搜索帮我们找到的随机森林算法的最佳参数组合。