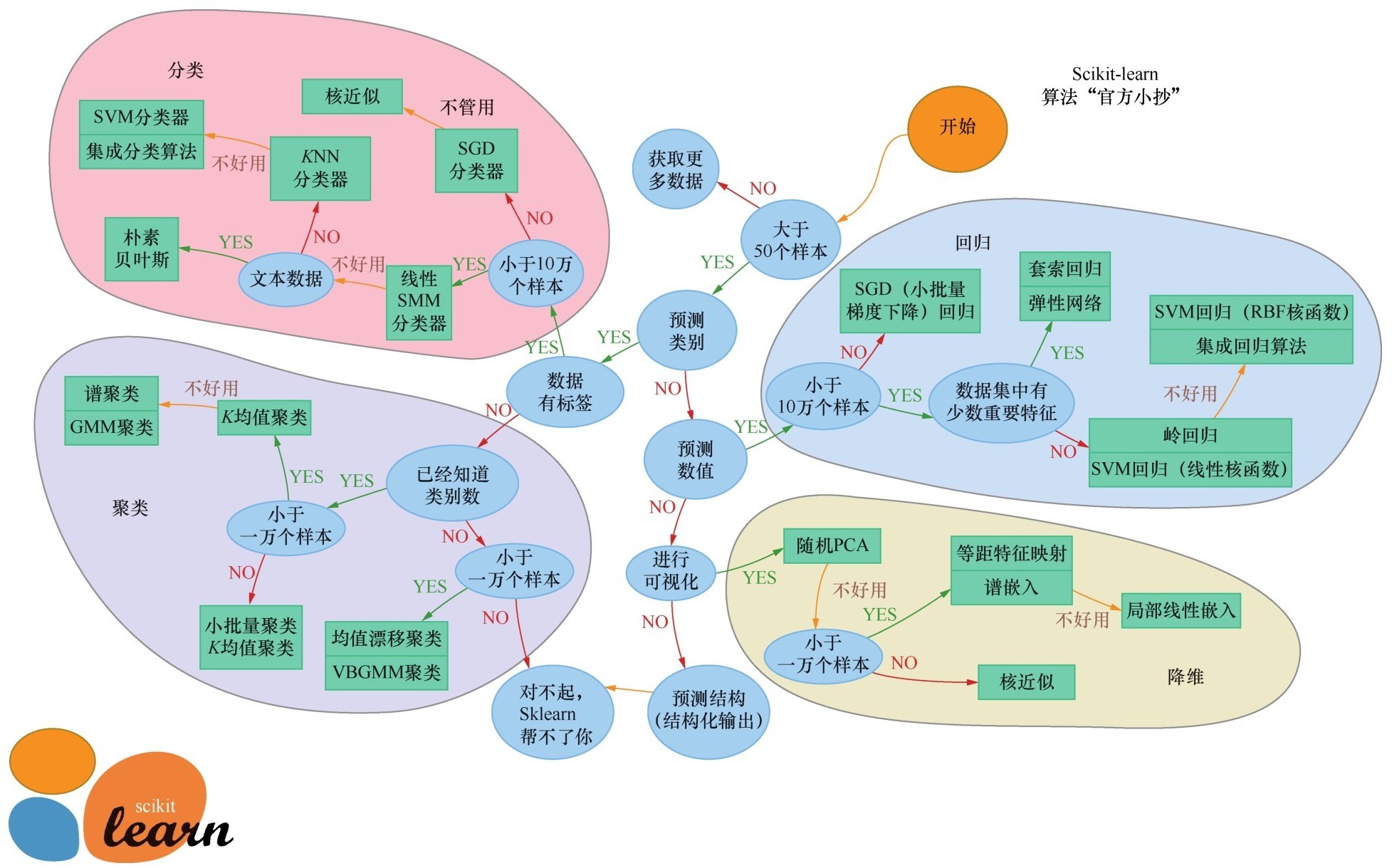
Sklearn的算法“官方小抄”
讲完随机森林算法之后,小冰开口问道:“咖哥,上面的这几种经典算法,你讲得简明扼要,感觉都挺好。不过,现在的问题来了,算法一多,我反而不知道如何选择了。你能不能给我们说说,什么样的算法适合解决什么样的问题?”
咖哥回答:“这很值得说一说。没有任何一种机器学习算法,能够做到针对任何数据集都是最佳的。通常,拿到一个具体的数据集后,会根据一系列的考量因素进行评估。这些因素包括:要解决的问题的性质、数据集大小、数据集特征、有无标签等。有了这些信息后,再来寻找适宜的算法。”
让我们从下页这张Sklearn的算法“官方小抄”图入手来简单说说机器学习算法的选择。顺着这张图过一遍各种机器学习算法,也是一个令我们将所学知识融会贯通的过程。
在开始选择Sklearn算法之前,先额外加一个IF语句:
Sklearn的算法“官方小抄”
IF机器学习问题 = 感知类问题(也就是图像、语言、文本等非结构化问题)
THEN深度学习算法(例如使用Keras深度学习库)
因为适合深度学习的问题通常不用Sklearn库来解决,而对于浅层的机器学习问题,Sklearn就可以大显身手了。
Sklearn库中的算法选择流程如下:
IF数据量小于50个
数据样本太少了, 先获取更多数据
ELSE数据量大于50个
IF是分类问题
IF数据有标签
IF数据量小于10万个
选择SGD分类器
ELSE数据量大于10万个
先尝试线性SVM分类器, 如果不好用, 再继续尝试其他算法
IF特征为文本数据
选择朴素贝叶斯
ELSE
先尝试KNN分类器, 如果不好用, 再尝试SVM分类器加集成分类算法(参见第9课内容)
ELSE数据没有标签
选择各种聚类算法(参见第10课内容)
ELSE不是分类问题
IF需要预测数值, 就是回归问题
IF数据量大于10万个
选择SGD回归
ELSE数据量小于10万个
根据数据集特征的特点, 有套索回归和岭回归、集成回归算法、SVM回归等几种选择
ELSE进行可视化,
则考虑几种降维算法(参见第10课内容)
ELSE预测结构
对不起, Sklearn帮不了你
选择机器学习算法的思路大致如此。此外,经验和直觉在机器学习领域的重要性当然是不言而喻。其实,不光机器学习,经验和直觉无论在什么领域也都是关键。
当然,选取多种算法去解决同一个问题,然后将各种算法的效率进行比较,也不失为一个好的方案。
刚才,我们已经应用了好几个机器学习算法处理同一个数据集。再加上以前讲过的逻辑回归,现在就可以对各种算法的性能进行一个横向比较。
下面是用逻辑回归算法解决心脏病的预测问题的示例代码。
from sklearn.linear_model import Logistic Regression # 导入逻辑回归模型
lr = Logistic Regression()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test) # 预测心脏病结果
lr_acc = lr.score(X_test, y_test)*100
lr_f1 = f1_score(y_test, y_pred)*100
print("逻辑回归预测准确率:{:.2f}%".format(lr_acc))
print("逻辑回归预测F1分数: {:.2f}%".format(lr_f1))
print('逻辑回归混淆矩阵:\n', confusion_matrix(y_test, y_pred))
下面就输出所有这些算法针对心脏病预测的准确率直方图:
methods = ["Logistic Regression", "KNN", "SVM",
"Naive Bayes", "Decision Tree", "Random Forest"]
accuracy = [lr_acc, KNN_acc, svm_acc, nb_acc, dtc_acc, rf_acc]
colors = ["orange", "red", "purple", "magenta", "green", "blue"]
sns.set_style("whitegrid")
plt.figure(figsize=(16, 5))
plt.yticks(np.arange(0, 100, 10))
plt.ylabel("Accuracy %")
plt.xlabel("Algorithms")
sns.barplot(x=methods, y=accuracy, palette=colors)
plt.grid(b=None)
plt.show()
各种算法的准确率比较如下图所示。

各种算法的准确率比较
从结果上看,KNN和随机森林等算法对于这个问题来说是较好的算法。
 咖哥发言
咖哥发言
不要对算法的优劣妄下结论,目前的比较结果仅针对这个数据集而言。
再绘制出各种算法的混淆矩阵:
# 绘制出各种算法的混淆矩阵
from sklearn.metrics import confusion_matrix
y_pred_lr = lr.predict(X_test)
KNN3 = KNeighbors Classifier(n_neighbors = 3)
KNN3.fit(X_train, y_train)
y_pred_KNN = KNN3.predict(X_test)
y_pred_svm = svm.predict(X_test)
y_pred_nb = nb.predict(X_test)
y_pred_dtc = dtc.predict(X_test)
y_pred_rf = rf.predict(X_test)
cm_lr = confusion_matrix(y_test, y_pred_lr)
cm_KNN = confusion_matrix(y_test, y_pred_KNN)
cm_svm = confusion_matrix(y_test, y_pred_svm)
cm_nb = confusion_matrix(y_test, y_pred_nb)
cm_dtc = confusion_matrix(y_test, y_pred_dtc)
cm_rf = confusion_matrix(y_test, y_pred_rf)
plt.figure(figsize=(24, 12))
plt.suptitle("Confusion Matrixes", fontsize=24) #混淆矩阵
plt.subplots_adjust(wspace = 0.4, hspace= 0.4)
plt.subplot(2, 3, 1)
plt.title("Logistic Regression Confusion Matrix") #逻辑回归混淆矩阵
sns.heatmap(cm_lr, annot=True, cmap="Blues", fmt="d", cbar=False)
plt.subplot(2, 3, 2)
plt.title("K Nearest Neighbors Confusion Matrix") #KNN混淆矩阵
sns.heatmap(cm_KNN, annot=True, cmap="Blues", fmt="d", cbar=False)
plt.subplot(2, 3, 3)
plt.title("Support Vector Machine Confusion Matrix") #SVM混淆矩阵
sns.heatmap(cm_svm, annot=True, cmap="Blues", fmt="d", cbar=False)
plt.subplot(2, 3, 4)
plt.title("Naive Bayes Confusion Matrix") #朴素贝叶斯混淆矩阵
sns.heatmap(cm_nb, annot=True, cmap="Blues", fmt="d", cbar=False)
plt.subplot(2, 3, 5)
plt.title("Decision Tree Classifier Confusion Matrix") #决策树混淆矩阵
sns.heatmap(cm_dtc, annot=True, cmap="Blues", fmt="d", cbar=False)
plt.subplot(2, 3, 6)
plt.title("Random Forest Confusion Matrix") #随机森林混淆矩阵
sns.heatmap(cm_rf, annot=True, cmap="Blues", fmt="d", cbar=False)
plt.show()
各种算法的混淆矩阵如下图所示。

各种算法的混淆矩阵
从图中可以看出,KNN和随机森林这两种算法中“假负”的数目为3,也就是说本来没有心脏病,却判定为有心脏病的客户有3人;而“假正”的数目为4,也就是说本来有心脏病,判定为没有心脏病的客户有4人。