
广袤的宇宙,浩瀚的星空
咖哥说:“除了语音、文本这些语言相关的序列数据之外,另外一大类序列数据是时间序列。时间序列数据集中的所有数据都伴随着一个时戳,比如股票、天气数据。没有时戳,分析这些数据就没有任何意义。本课不会介绍机器学习在股市、天气变化中的应用,因为那些东西太老生常谈了。咱们冲出地球的限制,把机器学习用于无垠的宇宙。”
原本昏昏欲睡的同学们瞬间被咖哥这夸张的话激活了。
“说一个仍然在进行的项目。”咖哥望着窗外的天际线,缓缓说道,“让我们从头讲起……从蒙昧时期开始,人类对宇宙的探索就从未曾止歇。人类幻想着,一望无垠的宇宙中有些什么?自从发明了开普勒天文望远镜……”
小冰说:“我感觉这个开头讲得比较远,你还是不要介绍过多背景了吧。直接说数据集里面的东西,我们都听得懂。”
咖哥说:“也行。这个数据集吧,是科学家们多年间用开普勒天文望远镜观察并记录下来的银河系中的一些恒星的亮度。”
广袤的宇宙,浩瀚的星空
在过去很长一段时间里,人类是没有办法证明系外行星的存在的,因为行星是不发光的。但是随着科学的发展,我们已经知道了一些方法,可以用于判定恒星是否拥有行星。方法之一就是记录恒星的亮度变化,科学家们推断行星的环绕会周期性地影响这些恒星的亮度。如果收集了足够多的时序数据,就可以用机器学习的方法推知哪些恒星像太阳一样,拥有行星系统。
这个目前仍然在不断被世界各地的科学家更新的数据集如下图所示。
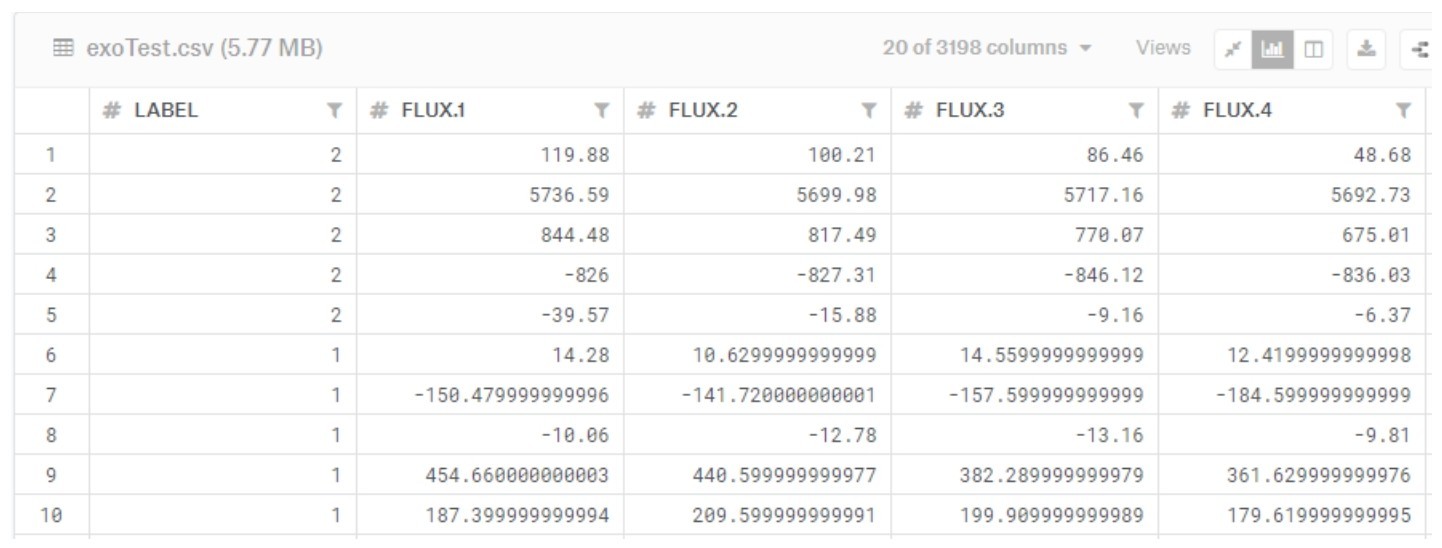
恒星亮度时序数据集
其中,每一行代表一颗恒星,而每一列的含义如下。
■第1列,LABLE,恒星是否拥有行星的标签,2代表有行星,1代表无行星。
■第2列~第3 198列,即FLUX.n字段,是科学家们通过开普勒天文望远镜记录的每一颗恒星在不同时间点的亮度,其中n代表不同时间点。
这样的时序数据集因为时戳的关系,形成的张量是比普通数据集多一阶、比图像数据集少一阶的3D张量,其中第2阶就专门用于存储时戳。
 咖哥发言
咖哥发言
这是深度学习部分的最后一个示例,我们将利用它多介绍一些比较高级的深度学习技巧,请大家集中注意力。
具体要介绍的内容如下。
(1)时序数据的导入与处理。
(2)不同类型的神经网络层的组合使用,如CNN和RNN的组合。
(3)面对分类极度不平衡数据集时的阈值调整。
(4)使用函数式API。
小冰和同学们听说有这么多新东西学,眼睛一亮,纷纷认真听课。