训练集中的前五条数据
理论介绍完了,下面回到鉴定评论文本的情感属性这个案例。先把这些文本向量化,然后用Keras中最简单的循环网络神经结构—Simple RNN层,构建循环神经网络,鉴定一下哪些客户的留言是好评,哪些是差评。
同学们可以在Kaggle网站通过关键字Product Comments搜索该数据集,然后基于该数据集新建Notebook。
读入这个评论文本数据集:
import pandas as pd # 导入Pandas
import numpy as np # 导入Num Py
dir = '../input/product-comments/'
dir_train = dir+'Clothing Reviews.csv'
df_train = pd.read_csv(dir_train) # 读入训练集
df_train.head() # 输出部分数据
训练集中的前五条数据
然后对数据集进行分词工作。词典的大小设定为2万。
from keras.preprocessing.text import Tokenizer # 导入分词工具
X_train_lst = df_train["Review Text"].values # 将评论读入张量(训练集)
y_train = df_train["Rating"].values # 构建标签集
dictionary_size = 20000 # 设定词典的大小
tokenizer = Tokenizer(num_words=dictionary_size) # 初始化词典
tokenizer.fit_on_texts( X_train_lst ) # 使用训练集创建词典索引
# 为所有的单词分配索引值,完成分词工作
X_train_tokenized_lst = tokenizer.texts_to_sequences(X_train_lst)
分词之后,如果随机显示X_train_tokenized_lst的几个数据,会看到完成了以下两个目标。
■评论句子已经被分解为单词。
■每个单词已经被分配一个唯一的词典索引。
X_train_tokenized_lst目前是列表类型的数据。
[[665, 75, 1, 135, 118, 178, 28, 560, 4639, 12576, 1226, 82, 324, 52, 2339, 18256,
51, 7266, 15, 63, 4997, 146, 6, 3858, 34, 121, 1262, 9902, 2843, 4, 49, 61, 267, 1,
403, 33, 1, 39, 27, 142, 71, 4093, 89, 3185, 3859, 2208, 1068],
[18257, 50, 2209, 13, 771, 6469, 71, 3485, 2562, 20, 93, 39, 952, 3186, 1194, 607,
5886, 184],
… … … …
[5, 1607, 19, 28, 2844, 53, 1030, 5, 637, 40, 27, 201, 15]]
还可以随机显示目前标签集的一个数据,目前y_train是形状为(22 641,)的张量:
[4]
下面将通过直方图显示各条评论中单词个数的分布情况,这个步骤是为词嵌入做准备:
import matplotlib.pyplot as plt # 导入matplotlib
word_per_comment = [len(comment) for comment in X_train_tokenized_lst]
plt.hist(word_per_comment, bins = np.arange(0,500,10)) # 显示评论长度分布
plt.show()
评论长度分布直方图如下图所示。
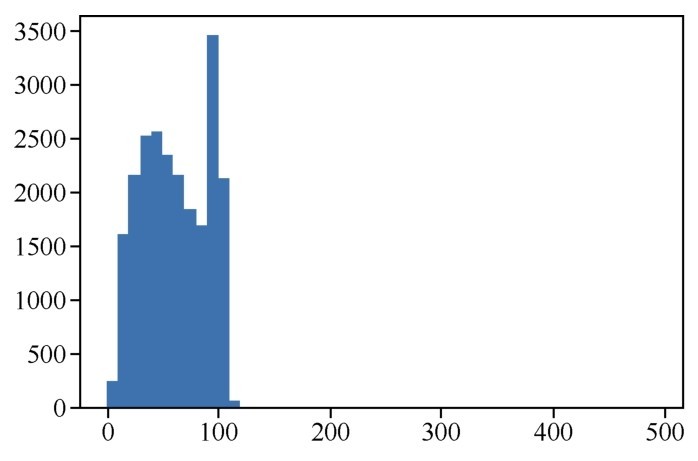
评论长度分布
上图中的评论长度分布情况表明多数评论的词数在120以内,所以我们只需要处理前120个词,就能够判定绝大多数评论的类型。如果这个数目太大,那么将来构造出的词嵌入张量就达不到密集矩阵的效果。而且,词数太长的序列,Simple RNN处理起来效果也不好。
下面的pad_sequences方法会把数据截取成相同的长度。如果长度大于120,将被截断;如果长度小于120,将填充无意义的0值。
from keras.preprocessing.sequence import pad_sequences
max_comment_length = 120 # 设定评论输入长度为120,并填充默认值(如字数少于120)
X_train = pad_sequences(X_train_tokenized_lst, maxlen=max_comment_length)
至此,分词工作就完成了。此时尚未做词嵌入的工作,因为词嵌入是要和神经网络的训练过程中一并进行的。
现在通过Keras来构建一个含有词嵌入的Simple RNN:
from keras.models import Sequential # 导入序贯模型
from keras.layers.embeddings import Embedding #导入词嵌入层
from keras.layers import Dense #导入全连接层
from keras.layers import Simple RNN #导入Simple RNN层
embedding_vecor_length = 60 # 设定词嵌入向量长度为60
rnn = Sequential() #序贯模型
rnn.add(Embedding(dictionary_size, embedding_vecor_length,
input_length=max_comment_length)) # 加入词嵌入层
rnn.add(Simple RNN(100)) # 加入Simple RNN层
rnn.add(Dense(10, activation='relu')) # 加入全连接层
rnn.add(Dense(6, activation='softmax')) # 加入分类输出层
rnn.compile(loss='sparse_categorical_crossentropy', #损失函数
optimizer='adam', # 优化器
metrics=['acc']) # 评估指标
print(rnn.summary()) #输出网络模型
神经网络的构建我们已经相当熟悉了,并不需要太多的解释,这里的流程如下。
■先通过Embedding层进行词嵌入的工作,词嵌入之后学到的向量长度为60(密集矩阵),其维度远远小于词典的大小20 000(稀疏矩阵)。
■加一个含有100个神经元的Simple RNN层。
■再加一个含有10个神经元的全连接层。
■最后一个全连接层负责输出分类结果。使用Softmax函数激活的原因是我们试图实现的是一个从0到5的多元分类。
■编译网络时,损失函数选择的是sparse_categorical_crossentropy,我们是第一次使用这个损失函数,因为这个训练集的标签,是1,2,3,4,5这样的整数,而不是one-hot编码。优化器的选择是adam,评估指标还是选择acc。
网络结构如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 300, 60) 1200000
_________________________________________________________________
simple_rnn_1 (Simple RNN) (None, 100) 16100
_________________________________________________________________
dense_1 (Dense) (None, 10) 1010
_________________________________________________________________
dense_2 (Dense) (None, 6) 66
=================================================================
Total params: 1,217,176
Trainable params: 1,217,176
Non-trainable params: 0
_________________________________________________________________
网络构建完成后,开始训练网络:
history = rnn.fit(X_train, y_train,
validation_split = 0.3,
epochs=10,
batch_size=64)
这里在训练网络的同时把原始训练集临时拆分成训练集和验证集,不使用测试集。而且理论上Kaggle竞赛根本不提供验证集的标签,因此也无法用验证集进行验证。
训练结果显示,10轮之后的验证准确率为0.5606:
Train on 7000 samples, validate on 3000 samples
Epoch 1/10
15848/15848 [============================] - 24s 1ms/step - loss: 1.2480 - acc:
0.5503 - val_loss: 1.2242 - val_acc: 0.5429
Epoch 2/10
15848/15848 [============================] - 35s 2ms/step - loss: 1.1596 - acc:
0.5622 - val_loss: 1.1692 - val_acc: 0.5520
… …
Epoch 10/10
15848/15848 [==============================] - 24s 2ms/step - loss: 0.8630 - acc:
0.6456 - val_loss: 1.1032 - val_acc: 0.5606
如果采用其他类型的前馈神经网络,其效率和RNN的成绩会相距甚远。如何进一步提高验证集准确率呢?我们下面会继续寻找方法。