 咖哥发言
咖哥发言先把要解决的问题放在一边,下面讲一讲循环神经网络的原理。刚才提到,人类处理序列性数据,比如阅读文章时,是逐词、逐句地阅读,读了后面的内容,同时也会记住之前的一些内容。这让我们能动态理解文章的意义。人类的智能可以循序渐进地接收并处理信息,同时保存近期所处理内容的信息,用以将上下文连贯起来,完成理解过程。
咖哥发言
记忆可分为瞬时记忆、短时记忆和长时记忆。瞬时记忆能够处理的信息少,而且持续时间短,但是对当前的即时判断很重要。短时记忆是保持时间在1分钟以内的记忆。长时记忆可以存储较多信息,信息也能持续很久,但是读取访问的速度稍微慢一点。
那么神经网络能否模拟人脑记忆功能去构建模型呢?这个模型需要记忆已经读入的信息,并不断地随着新信息的到来而更新。
复习一下什么是序列数据,什么不是序列数据。比如,上一课的一组狗狗图像,在文件夹里面无论怎么放置,甚至翻转图像、移位特征,输入CNN之后还是可以被轻松识别,所以图像的特征具有平移不变性。再比如,加州房价的特征集,先告诉机器地区的经度、维度,还是先告诉机器地区周边的犯罪率情况,都是无关紧要的。这些数据,都不是序列数据。
序列数据,是其特征的先后顺序对于数据的解释和处理十分重要的数据。
语音数据、文本数据,都是序列数据。一个字,如果不结合前面几个字来一起解释,其意思可就大相径庭了。一句话,放在前面或者放在后面,会使文意有很大的不同。
文本数据集的形状为3D张量:(样本,序号,字编码)。
时间序列数据也有这种特点。这类数据是按时间顺序收集的,用于描述现象随时间变化的情况。如果不记录时戳,这些数字本身就没有意义。
时序数据集的形状为3D张量:(样本,时戳,标签)。
这些序列数据具体包括以下应用场景。
■文档分类,比如识别新闻的主题或书的类型、作者。
■文档或时间序列对比,比如估测两个文档或两支股票的相关程度。
■文字情感分析,比如将评论、留言的情感划分为正面或负面。
■时间序列预测,比如根据某地天气的历史数据来预测未来天气。
■序列到序列的学习,比如两种语言之间的翻译。
之前介绍的两种网络(普通人工神经网络和卷积神经网络)可以称为前馈神经网络(feedforward neural network),各神经元分层排列。每个神经元只与前一层的神经元相连,接收前一层的输出,并输出给下一层,各层间没有反馈。每一层内部的神经元之间,也没有任何反馈机制。
前馈神经网络也可以处理序列数据,但它是对数据整体读取、整体处理。比如一段文本,需要整体输入神经网络,然后一次性地进行解释。这样的网络,每个单词处理过程中的权重是无差别的。网络并没有对相临近的两个单词进行特别的对待。
请看下图中的示例,输入是一句简单的话“我离开南京,明天去北京”。这句话中每一个词都是特征,标签是目的地。机器学习的目标是判断这个人要去的地方。这一句话输入机器之后,每一个词都是等价的,都会一视同仁去对待。大家想一想,在这种不考虑特征之间的顺序的模型中,如果“去”字为投“北京”票的网络节点加了分,同样,这个“去”字也会给投“南京”票的网络节点加完全一样的分。最后,输入的分类概率,南京和北京竟然各占50%!
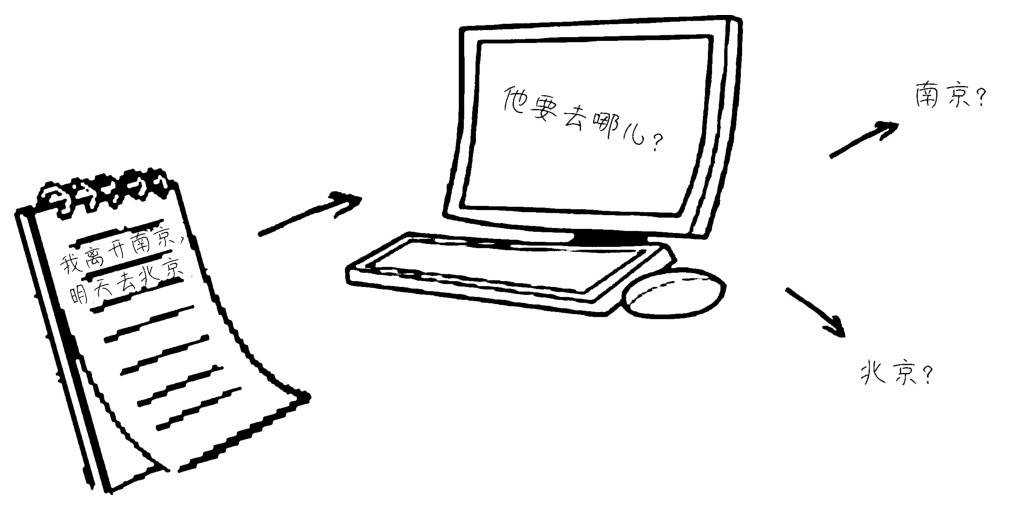
他要去哪儿?
这个简单的问题竟然让“聪明”的前馈神经网络如此“失败”。
此时,“救星”来了。循环神经网络专门为处理这种序列数据而生。它是一种具有“记忆”功能的神经网络,其特点是能够把刚刚处理过的信息放进神经网络的内存中。这样,离目标近的特征(单词)的影响会比较大,从而和“去”字更近的“北京”的支持者(神经元)会得到更高的权重。
再举一个例子,如果我们正在进行明天的天气的预测,输入的是过去一年的天气数据,那么是今天和昨天的天气数据比较重要,还是一个月前的天气数据比较重要呢?答案不言自明。
循环神经网络的结构,与普通的前馈神经网络差异也不是特别大,其实最关键的地方,有以下两处。
(1)以一段文字的处理为例,如果是普通的神经网络,一段文字是整体读入网络处理—只处理一次;而循环神经网络则是每一个神经节点,随着序列的发展处理N次,第一次处理一个字、第二次处理两个字,直到处理完为止。
(2)循环神经网络的每个神经节点增加了一个对当前状态的记忆功能,也就是除了权重w和偏置b之外,循环神经网络的神经元中还多出一个当前状态的权重w。这个记录当前状态的w,在网络学习的过程中就全权负责了对刚才所读的文字记忆的功能。
介绍循环神经网络的结构之前,先回忆一个普通神经网络的神经元,如右图所示。
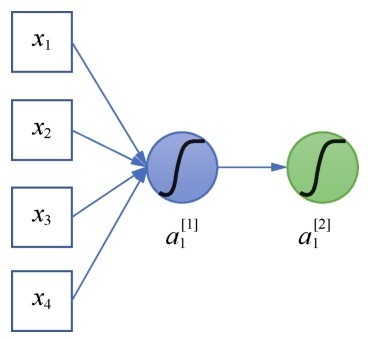
普通网络的神经元
普通的神经网络中的神经元一次性读入全部特征,作为其输入。
而循环神经网络的神经元需要沿着时间轴线(也就是向量X的“时戳”或“序号”特征维)循环很多遍,因此也称RNN是带环的网络。这个“带环”,指的是神经元,也就是网络节点自身带环,如下图所示。
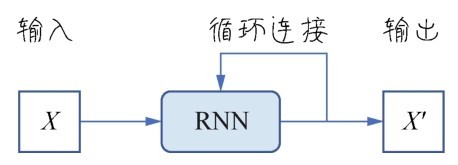
循环神经网络中的神经元
多个循环神经网络的神经元在循环神经网络中组合的示意如下图所示。
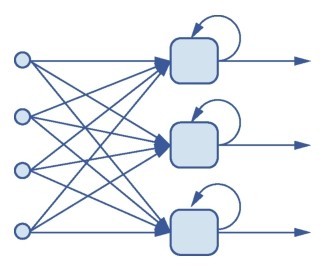
多个循环神经网络的神经元
如果把这个循环过程按序列进行展开,假设时间轴上有4个点,也就是4个序列特征,那么对于一个网络节点,就要循环4次。这里引入隐状态h,并且需要多一个参数向量U,用于实现网络的记忆功能。第一次读入特征时间点1时的状态如下图所示。

时间点1:读入一个特征
下一个时间点,继续读入特征x2,此时的状态已经变为ht1,这个状态记忆着刚才读入x1时的一些信息,如下图所示。把这个状态与U进行点积运算。
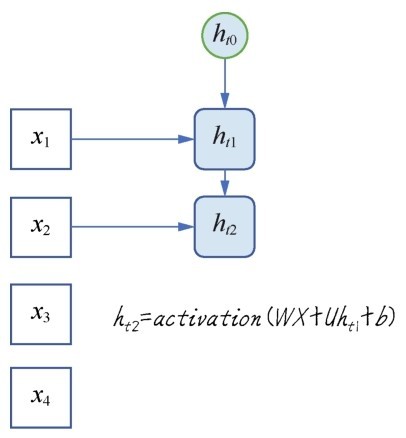
时间点2:读入两个特征
持续进行时间轴上其他序列数据的处理,反复更新状态,更新输出值。这里要强调的是,目前进行的只是一个神经元的操作,此处的W和U,分别是一个向量。

对于每一个循环神经元,需要遍历所有的特征之后再输出
时间轴上的节点遍历完成之后,循环就结束了,循环神经元向下一层网络输出x'。不难发现,x'受最近的状态和最新的特征(x4)的影响最大。