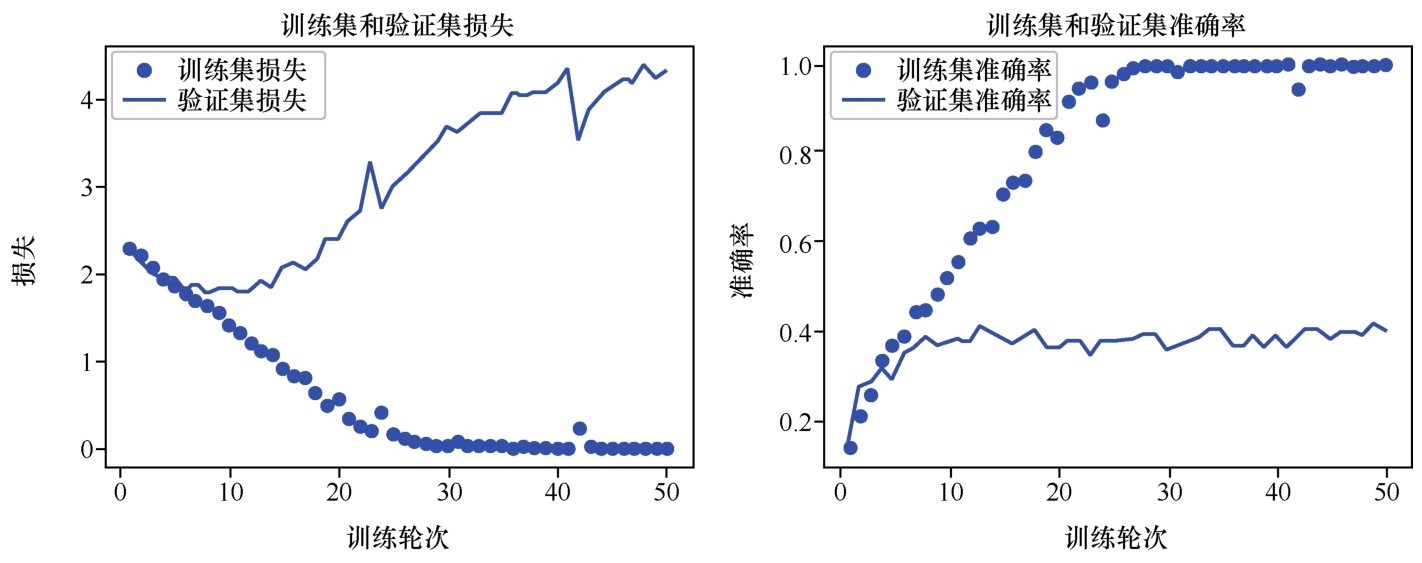
训练集和验证集上的损失曲线和准确率曲线(第一次调优)
大家休息了一会儿,回到课堂上继续讨论如何优化这个卷积网络的性能。
一个同学率先发言:“是不是像上一课讲的归一化一样,即特征缩放方面的问题?”
“非常好!”咖哥回答,“你倒是记住了上一课的要点。放入神经网络中的数据的确需要归一化,然而这件事我们已经做了—图像数据张量的值已经压缩至[0,1]区间。”
“是激活函数的关系?”另一个同学发言。咖哥说:“使用ReLU函数进行卷积网络的激活,基本上是没有大问题的。当然,你们也可以试一试其他的激活函数,如eLU等。而后面的Softmax函数对于多分类问题的激活是标配。因此,也没有问题。”
小冰突然喊道:“那个Drop……解决过拟合的……”
“嗯,Dropout,”咖哥终于点头,“这倒是值得一试。实践是检验真理的唯一标准,我们来动手试几招。”
从最简单的修改开始,暂时不改变网络结构,先考虑一下优化器的调整,并尝试使用不同的学习速率进行梯度下降。因为很多时候神经网络完全没有训练起来,是学习速率设定得 不好。
示例代码如下:
from keras import optimizers # 导入优化器
cnn = models.Sequential() # 贯序模型
cnn.add(layers.Conv2D(32, (3, 3), activation='relu', # 卷积层
input_shape=(150, 150, 3)))
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(64, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(128, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(256, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化层
cnn.add(layers.Flatten()) # 展平层
cnn.add(layers.Dense(512, activation='relu')) # 全连接层
cnn.add(layers.Dense(10, activation='sigmoid')) # 分类输出
cnn.compile(loss='categorical_crossentropy', # 损失函数
optimizer=optimizers.Adam(lr=1e-4), # 更新优化器并设定学习速率
metrics=['acc']) # 评估指标
history = cnn.fit(X_train, y_train, # 指定训练集
epochs=50, # 指定轮次
batch_size=256, # 指定批量大小
validation_data=(X_test, y_test)) # 指定验证集
输出结果如下:
Train on 1537 samples, validate on 385 samples
Epoch 1/50
1537/1537 [==============================] - 2s 1ms/step - loss: 2.2900 - acc: 0.1386
- val_loss: 2.2611 - val_acc: 0.1714
Epoch 2/50 1537/1537 [==============================] - 1s 876us/step - loss: 2.2068 - acc:
0.2088 - val_loss: 2.1376 - val_acc: 0.2753
… …
Epoch 50/50
1537/1537 [==============================] - 2s 1ms/step - loss: 0.0190 - acc: 0.9967
- val_loss: 4.4028 - val_acc: 0.3896
更换了优化器,并设定了学习速率之后,再次训练网络,发现准确率有了很大的提升,最后达到了40%左右,提高了近一倍。不过,从损失曲线上看(如下图所示),20轮之后,验证集的损失突然飙升了。这是比较典型的过拟合现象。
训练集和验证集上的损失曲线和准确率曲线(第一次调优)
“那么下一步怎么办呢?”咖哥说,“这时可以考虑一下小冰刚才说的Dropout层,降低过拟合风险。”
示例代码如下:
cnn = models.Sequential() # 序贯模型
cnn.add(layers.Conv2D(32, (3, 3), activation='relu', # 卷积层
input_shape=(150, 150, 3)))
cnn.add(layers.Max Pooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(64, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.Dropout(0.5)) # Dropout层
cnn.add(layers.Max Pooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(128, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.Dropout(0.5)) # Dropout层
cnn.add(layers.Max Pooling2D((2, 2))) # 最大池化层
cnn.add(layers.Conv2D(256, (3, 3), activation='relu')) # 卷积层
cnn.add(layers.Max Pooling2D((2, 2))) # 最大池化层
cnn.add(layers.Flatten()) # 展平层
cnn.add(layers.Dropout(0.5)) # Dropout
cnn.add(layers.Dense(512, activation='relu')) # 全连接层
cnn.add(layers.Dense(10, activation='sigmoid')) # 分类输出
cnn.compile(loss='categorical_crossentropy', # 损失函数
optimizer=optimizers.Adam(lr=1e-4), # 更新优化器并设定学习速率
metrics=['acc']) # 评估指标
history = cnn.fit(X_train, y_train, # 指定训练集
epochs=50, # 指定轮次
batch_size=256, # 指定批量大小
validation_data=(X_test, y_test)) # 指定验证集
输出结果如下:
Train on 1537 samples, validate on 385 samples
Epoch 1/50
1537/1537 [==============================] - 2s 1ms/step - loss: 2.2998 - acc: 0.1496
- val_loss: 2.2810 - val_acc: 0.2416
Epoch 2/50
1537/1537 [==============================] - 2s 987us/step - loss: 2.1917 - acc:
0.2219 - val_loss: 2.2217 - val_acc: 0.2416
… …
Epoch 50/50
1537/1537 [==============================] - 2s 1ms/step - loss: 0.0190 - acc: 0.9967
- val_loss: 4.4028 - val_acc: 0.3896
添加了Dropout层防止过拟合之后,损失曲线显得更平滑了(如下图所示),不再出现在验证集上飙升的现象。但是准确率的提升不大,还是40%左右。而且训练集和验证集之间的准确率,仍然是天壤之别。

训练集和验证集上的损失曲线和准确率曲线(第二次调优)
大家看到各种调试还是取得了一些效果,于是继续献计。有的同学提议像搭积木一样再多加几层,看看增加网络的深度是否会进一步提高性能。
咖哥说:“先别试了,等会儿你们可以自己慢慢调试。现在我要给大家介绍一个提高卷积网络图像处理问题的性能的‘大杀器’,名字叫作数据增强(data augmentation)。这种方法肯定能够进一步提高计算机视觉问题的准确率,同时降低过拟合。”
同学们听到还有这么神奇的方法后,纷纷集中注意力。咖哥说:“机器学习,数据量是多多益善的。数据增强,能把一张图像当成7张、8张甚至10张、100张来用,也就是从现有的样本中生成更多的训练数据。”
怎么做到的?是通过对图像的平移、颠倒、倾斜、虚化、增加噪声等多种手段。这是利用能够生成可信图像的随机变换来增加样本数,如下图所示。这样,训练集就被大幅地增强了,无论是图像的数目,还是多样性。因此,模型在训练后能够观察到数据的更多内容,从而具有更好的准确率和泛化能力。

针对同一张狗狗图像的数据增强:一张变多张
在Keras中,可以用Image Data- Generator工具来定义一个数据增强器:
# 定义一个数据增强器, 并设定各种增强选项
from keras.preprocessing.image import ImageDataGenerator
augs_gen = ImageDataGenerator(
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
rotation_range=10,
zoom_range = 0.1,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
vertical_flip=False)
augs_gen.fit(X_train) # 针对训练集拟合数据增强器
网络还是用回相同的网络,唯一的区别是在训练时,需要通过fit_generator方法动态生成被增强后的训练集:
history = cnn.fit_generator( # 使用fit_generator
augs_gen.flow(X_train, y_train, batch_size=16), # 增强后的训练集
validation_data = (X_test, y_test), # 指定验证集
validation_steps = 100, # 指定验证步长
steps_per_epoch = 100, # 指定每轮步长
epochs = 50, # 指定轮次
verbose = 1) # 指定是否显示训练过程中的信息
输出结果如下:
Epoch 1/50
100/100 [==============================] - 8s 76ms/step - loss: 2.3003 - acc: 0.1293
- val_loss: 2.2951 - val_acc: 0.1532
Epoch 2/50
100/100 [==============================] - 7s 71ms/step - loss: 2.2571 - acc: 0.1735
- val_loss: 2.2648 - val_acc: 0.1662
… …
Epoch 50/50
100/100 [==============================] - 7s 73ms/step - loss: 1.3982 - acc: 0.5091
- val_loss: 1.7499 - val_acc: 0.5065
训练集和验证集上的损失曲线和准确率曲线如下图所示。
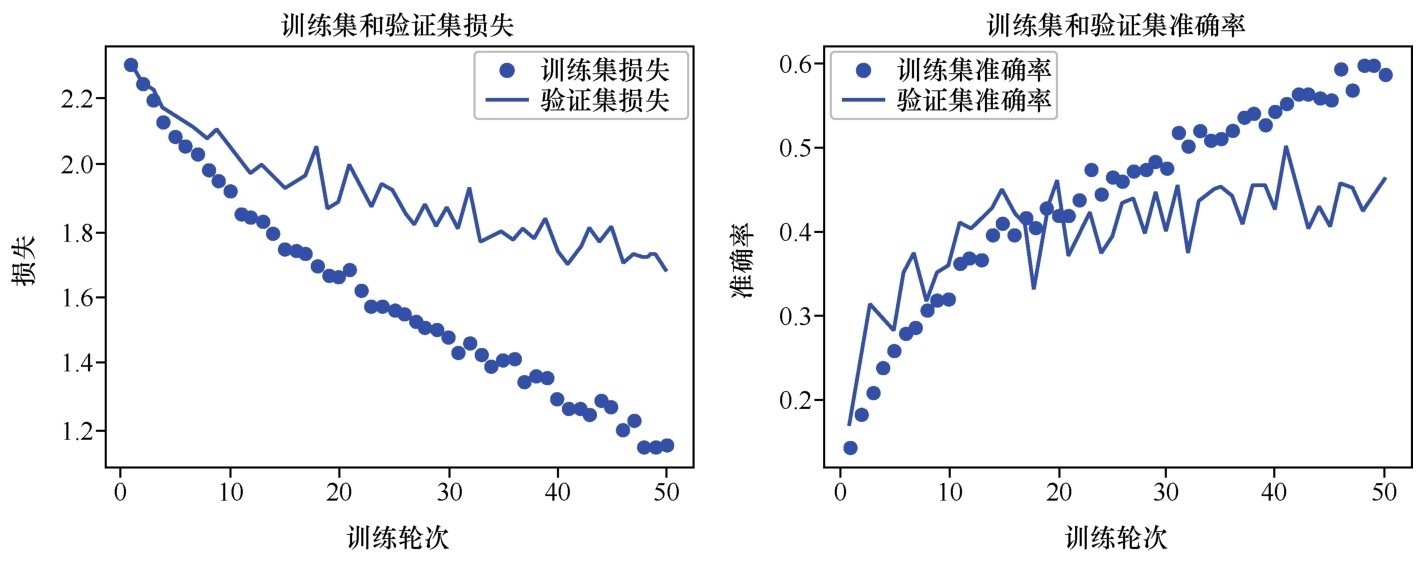
训练集和验证集上的损失曲线和准确率曲线(数据增强后)
这次训练的速度似乎变慢了很多(因为数据增强需要时间),但是训练结果更令人满意。而且,训练集和验证集的准确率最终呈现出在相同区间内同步上升的状态,这是很好的现象。从损失曲线上看,过拟合的问题基本解决了。而验证集准确率也上升至50%左右。对于这个多种狗狗的分类问题来说,这已经是一个相当不错的成绩了。
下面的代码可以将神经网络模型(包括训练好的权重等所有参数)保存到一个文件中,并随时可以读取。
from keras.models import load_model # 导入模型保存工具
cnn.save('../my_dog_cnn.h5') # 创建一个HDF5格式的文件'my_dog_cnn.h5'
del cnn # 删除当前模型
cnn = load_model('../my_dog_cnn.h5') # 重新载入已经保存的模型
总结一下,深度神经网络的性能优化是一个很大的课题。希望上一课和本课两次的尝试能带给大家一个基本的思路。此外,其他可以考虑的方向还包括以下几种。
■增加或减少网络层数。
■尝试不同的优化器和正则化方法。
■尝试不同的激活函数和损失函数。