表5-2 数据集真值和机器学习模型预测的合格品/劣质品个数

曲线显示2、3次迭代之后,训练集的损失就迅速下降而且不再有大的变化,而验证集的损失则反复地振荡。这种不甚平滑的曲线形状让同学们都觉得有点奇怪,但是又不知道是否正常。小冰问道:“这个曲线显示出来的情况有问题吗?”
咖哥笑而不答,突然问了一个貌似不相关的问题:“79.75%的预测准确率,小冰,你觉得满意吗?”
小冰说:“大概还行吧。”
咖哥笑了:“我闭着眼睛,不用任何机器学习算法,也可以达到这个预测准确率。”
小冰说:“你在开玩笑吧。”
咖哥说:“我的方法就是预测全部客户都不会离开,也就是标签y值永远为0。由于这个数据集中的客户流失率其实就是20%左右,因此我预测全部标签y值为0,就达到了80%的准确率。”
小冰回头看看当初数据分析时绘制的分布图表中右下角的“Exited”小图,也就是y值的分布图,说道:“真的耶,10 000个客户里面,大概是有8 000个客户,也就是80%左右的客户没有离开,只有20%的客户流失—这就是你刚才所说的这个数据集的显著的特点吧。”
咖哥说:“对,这类问题你们要注意,标签的类别分布是不均衡的。就这个80%∶20%的比例来说,80%以下的准确率等于机器什么也没做。这是无法令人满意的。”
小冰思考了一下,觉得咖哥说得很有道理。但她又想不出如何去评估这种标签类别不平衡数据集的预测结果。
咖哥似乎已经读出了小冰的心思,他说:“对于这种问题,我们需要从每一个类别的预测精确率和召回率上面入手。”
假设有一个手机生产厂商,每天生产手机1 000部。某一天生产的手机中,出现了2个劣质品。目前要通过机器学习来分析数据特征(如手机的重量、形状规格等),鉴定劣质品样本。其中数据集真值和机器学习模型的合格品和劣质品个数如表5-2所示。
表5-2 数据集真值和机器学习模型预测的合格品/劣质品个数
表中机器学习模型的预测结果显示合格品999个,劣质品1个,则其准确率为99.9%。因为准确率就是预测命中的数据个数/数据总数,即999/1 000。1 000个样本只猜错一个,可以说是相当准的模型了。
然而从我们的目标来说,这个模型实际上是失败了。这个模型本就是为了检测劣质品而生(劣质品即标签值为1的阳性正样本),但一共有2个劣质品,只发现了1个,有50%的正样本没有测准。因此,模型的好与不好,是基于用什么标准衡量。对于这种正样本和负样本比例极度不平衡的样本集,我们需要引进新的评估指标。
为了评估这种数据集,需要引入一个预测值与真值组成的矩阵,4个象限从上到下、从左到右分别为真负(真值为负,预测为负,即True Negative,TN)、假正(真值为负,预测为正,即False Positive,FP)、假负(真值为正,预测为负,即False Negative,FN)、真正(真值为正,预测为正,即True Positive,TP)。
大家是否被这真真假假、正正负负的绕得头晕?请看下面的表5-3。
表5-3 预测值和真值对照表
表格中显示了我们所关心的劣质品检验的每一种情况,而不仅是结果的准确率。首先注意绝大多数样本都是负样本,也就是合格品。那么这个预测值与真值的对比矩阵中,998个合格品均被测准,也没有劣质品被误判为合格品,因此有998个真负,0个假正。2个劣质品中,有一个误判,这个被标为假负,因为此样本真值不是合格品,不应为负。而另一个被测准,所以是真正。
上面这种矩阵,在机器学习中也是一种对模型的可视化评估工具,在监督学习中叫作混淆矩阵(confusion matrix),如右图所示。

混淆矩阵
从这个混淆矩阵出发,又形成了一些新的评估指标,这里介绍其中的几个。
一个标准是精确率,也叫查准率,其公式是用“被模型预测为正的正样本”除以“被模型预测为正的正样本”与“被模型预测为负的正样本”的和。公式如下:

对于上面的例子,就劣质品而言有以下几种情况。
■真正:被模型判断为劣质品的劣质品样本数是1。
■假正:被模型判断为劣质品的合格品样本数是0。
■假负:被模型判断为合格品的劣质品样本数是1。
■真负:被模型判断为合格品的合格品样本数是998。
因此,精确率是对“假正”的测量。本例的精确率为1/(1+0) = 100%。
这样看来,这个模型相对于劣质品的精确率也不差。因为判定的一个劣质品果然是劣质品,而且没有任何合格品被判为劣质品。
另一个标准是召回率,也叫查全率。你们听说过“召回”这个名词吧,就是劣质品蒙混过了质检这关,“跑”出厂了,得召回来,销毁掉。这和精确率是成对出现的概念。公式如下:

召回率针对的是对于“假负”的衡量。意思是什么呢?就是需要考虑被误判为合格品的劣质品,而这种情况正是需要被“召回”的产品。本例的召回率为1/(1+1) = 50%。
所以这个模型对于劣质品来说,召回率不高。
把精确率和召回率结合起来,就得到F1分数。这是一个可以同时体现上面两个评估效果的标准,数学上定义为精确率和召回率的调和均值。它也是在评估这类样本分类数据不平衡的问题时,所着重看重的标准。

 咖哥发言
咖哥发言
这些名词听着的确有点晕。你们只要记住,对于这种大量标签是普通值,一小部分标签是特殊值的数据集来说,这3个标准的重要性在此时要远远高于准确率。
了解了这类数据集的评估指标之后,现在就继续用神经网络模型的predict方法预测测试集的分类标签,然后把真值和预测值做比较,并利用Sklearn中的分类报告(classification report)功能来计算上面这几种标准。
代码如下:
from sklearn.metrics import classification_report # 导入分类报告
y_pred = ann.predict(X_test, batch_size=10) # 预测测试集的标签
y_pred = np.round(y_pred) # 四舍五入, 将分类概率值转换成0/1整数值
y_test = y_test.values # 把Pandas series转换成Num Py array
y_test = y_test.reshape((len(y_test), 1)) # 转换成与y_pred相同的形状
print(classification_report(y_test, y_pred, labels=[0, 1])) #调用分类报告
这段代码不是很复杂,只需要注意以下几点。
■神经网络模型的predict方法给出的预测结果也是一个概率,需要基于0.5的阈值进行转换,舍入成0、1整数值。
■y_test一直都是一个Pandas的Series格式数据,并没有被转换为NumPy数组。神经网络模型是可以接收Series和Dataframe格式的数据的,但是此时为了和y_pred进行比较,需要用values方法进行格式转换。
■y_test转换成NumPy数组后,需要再转换为与y_pred形状一致的张量,才输入classification_ report函数进行评估。
这段程序需要在模型的fit拟合之后执行,运行之后将给出目前机器的预测结果:
precision recall f1-score support
0 0.79 1.00 0.88 1583
1 0.00 0.00 0.00 417
accuracy 0.79 2000
macro avg 0.40 0.50 0.44 2000
weighted avg 0.63 0.79 0.70 2000
结果实在是让人大跌眼镜,果然不出咖哥所料。神经网络只是简单地把所有的客户判定为该银行忠实的“铁杆”支持者,没有给出任何一例可能离开的客户样本。因此,尽管准确率达到79%,但对于标签为1的类别而言,精确率、召回率和F1分数居然都为0。
如果此时输出y_pred值,你们会看到清一色的0值。
下面画出此时的混淆矩阵:
from sklearn.metrics import confusion_matrix # 导入混淆矩阵
cm = confusion_matrix(y_test, y_pred) # 调用混淆矩阵
plt.title("ANN Confusion Matrix") # 标题:人工神经网络混淆矩阵
sns.heatmap(cm, annot=True, cmap="Blues", fmt="d", cbar=False) # 热力图设定
plt.show() # 显示混淆矩阵
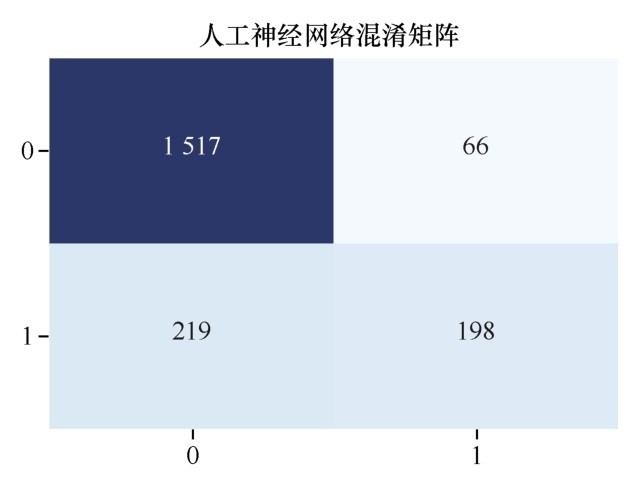
混淆矩阵如下图所示。

单隐层神经网络的混淆矩阵
混淆矩阵显示417个客户流失正样本竟然一例都没测中。这样的神经网络尽管准确率为79%,但实际上是训练完全失败了。
小冰和同学们都陷入了深深的忧虑。传说中神乎其神的神经网络,自己用起来竟然这么“不顺”。
“我倒觉得得到这个结果值得庆祝,”咖哥说,“因为现在咱们明白问题出在哪里了,也拥有了更为适合的评估指标,就是混淆矩阵、精确率、召回率,以及F1分数。既然方向已经有了,想办法解决问题就可以了。”
其实解决问题的奥秘在面前的课程中已经多次提及了。
我们刚才忽略了一个步骤,就是特征缩放。初学者必须牢记,对于神经网络而言,特征缩放(feature scaling)极为重要。神经网络不喜欢大的取值范围,因此需要将输入神经网络的数据标准化,把数据约束在较小的区间,这样可消除离群样本对函数形状的影响。
数值过大的数据以及离群样本的存在(如下图所示)会使函数曲线变得奇形怪状,从而影响梯度下降过程中的收敛。而特征缩放,将极大地提高梯度下降(尤其是神经网络中常用的随机梯度下降)的效率。
一个离群数据样本
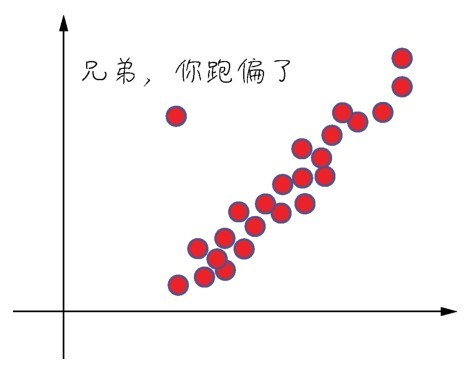
前面讲过,特征缩放有多种形式。这里对数据进行标准化。其步骤是:对于输入数据的每个特征(也就是输入数据矩阵中的一整列),减去特征平均值,再除以标准差,之后得到的特征平均值为0,标准差为1。
公式如下:
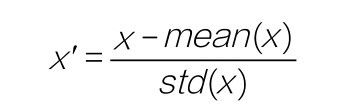
代码如下:
mean = X_train.mean(axis=0) # 计算训练集均值
X_train -= mean # 训练集减去训练集均值
std = X_train.std(axis=0) # 计算训练集标准差
X_train /= std # 训练集除以训练集标准差
X_test -= mean # 测试集减去训练集均值
X_test /= std # 测试集除以训练集标准差
也可以直接使用Standard Scaler工具:
from sklearn.preprocessing import Standard Scaler # 导入特征缩放器
sc = Standard Scaler() # 特征缩放器
X_train = sc.fit_transform(X_train) # 拟合并应用于训练集
X_test = sc.transform (X_test) # 训练集结果应用于测试集
无论采用哪种方法,特征缩放的代码必须要放在数据集拆分之后。
缩放后的数据集特征的值区间显著减小,如下图所示。

特征缩放之后的数据
 咖哥发言
咖哥发言
注意,均值和标准差都是在训练数据上计算而得的,然后将同样的均值和标准差应用于训练集和测试集。在机器学习中,原则上不能使用在测试数据上计算得到的任何结果训练机器或优化模型,造成的结果就是测试数据信息泄露,尽管提高了测试集准确率,但影响了模型泛化效果。
测试集除了进行测试不能做其他用处,即使是计算均值和标准差。
下面就来看看进行了特征缩放之后,重新运行相同的逻辑回归和单隐层神经网络模型,效果有何不同。
首先,逻辑回归模型的准确率升至80.50% — 仍然不能令我们满意。看来逻辑回归模型对于本案例不大好使。
from sklearn.linear_model import Logistic Regression
lr = Logistic Regression() # 逻辑回归模型
history = lr.fit(X_train, y_train) # 训练机器
print("逻辑回归预测准确率 {:.2f}%".format(lr.score(X_test, y_test)*100))
逻辑回归预测准确率:80.50%
而重新训练刚才的单隐层神经网络后,预测准确率就升至86.15%,这比逻辑回归模型的高出不少,此时神经网络的效率才开始得以体现:
history = ann.fit(X_train, y_train, # 指定训练集
epochs=30, # 指定轮次
batch_size=64, # 指定批量大小
validation_data=(X_test, y_test)) #指定验证集
单隐层神经网络预测准确率: 86.15%
如果显示损失曲线和准确率曲线,会发现特征缩放之后,曲线也变得比较平滑(如下图所示),这是神经网络比较“训”得起来的表现。

训练集和验证集上的损失曲线和准确率曲线(特征缩放之后)
更为重要的精确率、召回率和F1分数也大幅提高,尤其是我们关注的阳性正样本类别(标签为1)所对应的F1分数达到了0.58,如下输出结果所示。虽然仍不完美,但是比起原来的0值是一个飞跃。等一会儿再看看更深层的神经网络是否能够继续提高这个分数。
precision recall f1-score support
0 0.87 0.96 0.91 1583
1 0.75 0.47 0.58 417
混淆矩阵显示(如下图所示),目前有大概180个即将流失的客户被贴上“阳性”的标签,那么银行的工作人员就可以采取一些相应的措施,去挽留他们。然而,400多个人中,还有200多个注定要离开的客户没有被预测出来,因此模型还有进步的空间。
单隐层神经网络的混淆矩阵(特征缩放之后)
讲到这里,单隐层神经网络模型就完成了。不过在继续讲深度神经网络之前,我认为有必要针对这种分类数据不平衡的问题,再多说两句。
之所以分类数据不平衡会影响机器学习模型的预测结果,是因为许多模型的输出类别是基于阈值的,如逻辑回归中小于0.5的为反例,大于等于0.5的则为正例。因此,在数据不平衡时,默认的阈值会导致模型输出倾向于数据多的类别。
在面对数据极度不平衡的时候(本例还称不上极度),实际上还有以下一些方法。
■首先就是选择合适的评估指标。除了我们刚才选用的F1分数,还有ROC/AUC,以及G-mean等标准,大家有兴趣的话课后可以自学。
■然后还可以考虑调整分类阈值(例如把阈值从0.5下调到更接近0的值)。这样,更多的客户会被标注为1分类。这样的做法使分类更倾向于类别较少的数据,更敏感地监控这些有可能离开的客户(也就是“宁可错杀一千,不可放过一个”的意思)。
■还有一种方法是采样(sampling)法,分为欠采样(undersampling)和过采样(oversampling)。
□ 过采样:人为地重复类别较少的数据,使数据集中各种类别的数据大致数目相同。
□ 欠采样:人为地丢弃大量类别较多的数据,使数据集中各种类别的数据大致数目相同。
这种方法看起来简单有效,但是实际上容易产生模型过拟合的问题。因为少数类样本的特定信息实际上是被放大了,过分强调它们,模型容易因此特别化而不够泛化,所以应搭配正则化模型使用。
对过采样法的一种改进方案是数据合成。常见的数据合成方法是SMOTE(Synthetic Minority Oversampling Technique),其基本思路是基于少数类样本进行数据的构造,在临近的特征空间内生成与之类似的少数类新样本并添加到数据集,构成均衡数据集。