
银行客户数据集的前5行数据
前面说了不少理论,目的只是从直观上去理解一个关键字:神经网络的“ 分层”。
层,是神经网络的基本元素。之所以这么说,是因为在实际应用中,神经网络是通过不同类型的“层”来建构的,而这个建构过程并不需要具体到每层内部的神经元。
下面就开始实战吧,直接看看如何通过单隐层神经网络解决具体问题。之后你们可能会发现,神经网络听起来吓人,但其实还挺容易上手的。
在电子资源打开Bank Customer.csv这个文件,打开观察一下这个数据集的话,我们会发现里面主要是客户的个人资料以及在该银行的历史交易信息,如信用评级等。具体包括以下信息。
■Name:客户姓名。
■Gender:性别。
■Age:年龄。
■City:城市。
■Tenure:已经成为客户的年头。
■Products No:拥有的产品数量。
■Has Card:是否有信用卡。
■Active Member:是否为活跃用户。
■Credit:信用评级。
■Account Bal:银行存款余额。
■Salary:薪水。
■Exited:客户是否已经流失。
这些信息对于客户是否会流失是具有指向性的。
首先读取文件:
import numpy as np #导入Num Py库
import pandas as pd #导入Pandas库
df_bank = pd.read_csv("../input/bank-customer/Bank Customer.csv") # 读取文件
df_bank.head() # 显示文件前5行数据
输出的前5行数据如下图所示。
银行客户数据集的前5行数据
显示一下数据的分布情况:
import matplotlib.pyplot as plt #导入Matplotlib库
import seaborn as sns #导入Seaborn库
# 显示不同特征的分布情况
features=[ 'City', 'Gender', 'Age', 'Tenure',
'Products No', 'Has Card', 'Active Member', 'Exited']
fig=plt.subplots(figsize=(15, 15))
for i, j in enumerate(features):
plt.subplot(4, 2, i+1)
plt.subplots_adjust(hspace = 1.0)
sns.countplot(x=j, data = df_bank)
plt.title("No.of costumers")
输出的数据的分布情况如下图所示。
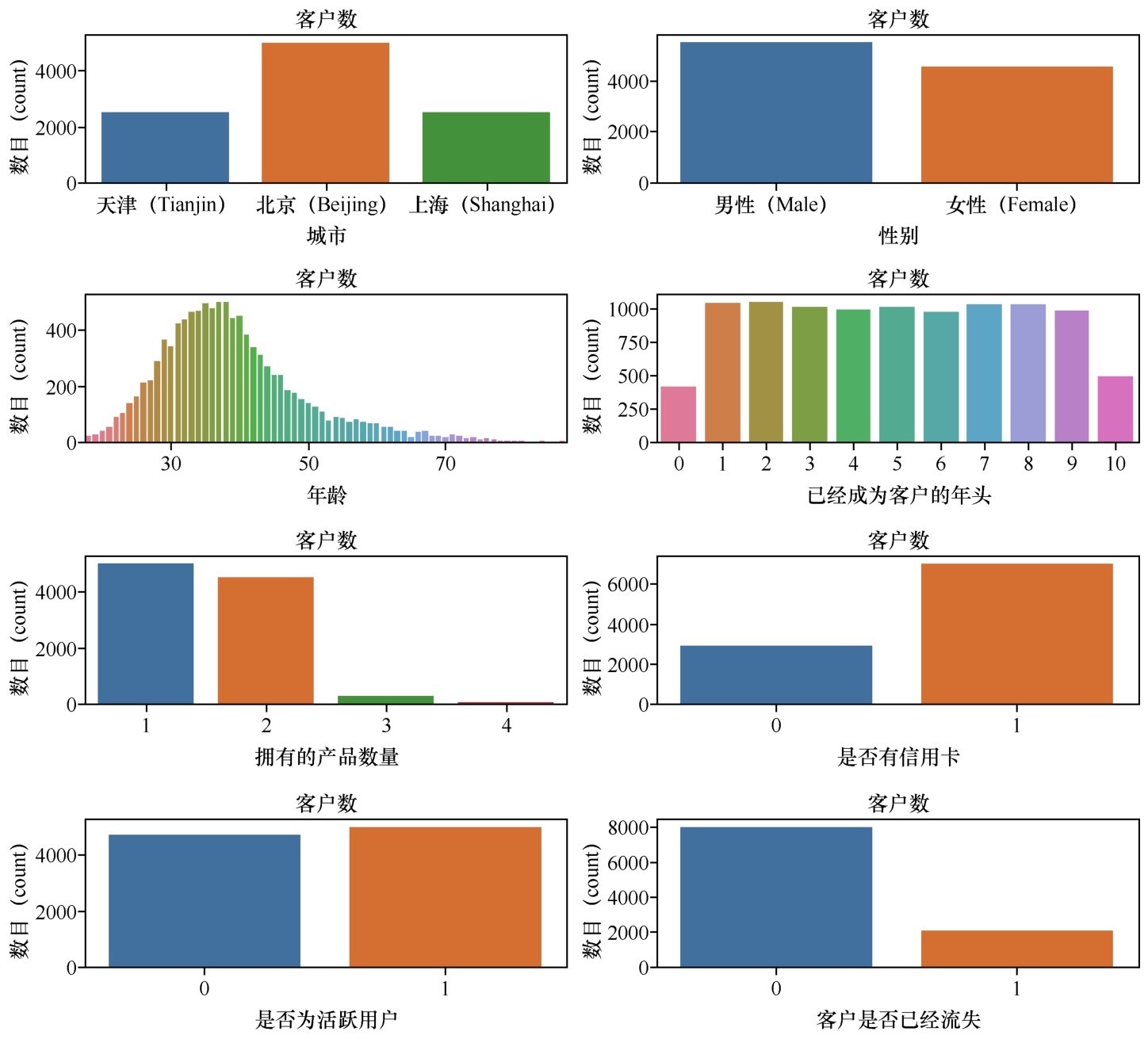
银行客户数据的分布情况
从图中大概看得出,北京的客户最多,男女客户比例大概一致,年龄和客户数量呈现正态分布(钟形曲线,中间高两边低)。这个数据集还有一个显著的特点,等会儿指出来。
对这个数据集,我们主要做以下3方面的清理工作。
(1)性别。这是一个二元类别特征,需要转换为0/1代码格式进行读取处理(机器学习中的文本格式数据都要转换为数字代码)。
(2)城市。这是一个多元类别特征,应把它转换为多个二元类别哑变量(这个技术在上一课已使用过)。
(3)姓名这个字段对于客户流失与否的预测应该是完全不相关的,可以在进一步处理之前忽略。
当然,原始数据集中的标签也应被移除,放置于标签集y:
# 把二元类别文本数字化
df_bank['Gender'].replace("Female", 0, inplace = True)
df_bank['Gender'].replace("Male", 1, inplace=True)
# 显示数字类别
print("Gender unique values", df_bank['Gender'].unique())
# 把多元类别转换成多个二元类别哑变量, 然后放回原始数据集
d_city = pd.get_dummies(df_bank['City'], prefix = "City")
df_bank = [df_bank, d_city]
df_bank = pd.concat(df_bank, axis = 1)
# 构建特征和标签集合
y = df_bank ['Exited']
X = df_bank.drop(['Name', 'Exited', 'City'], axis=1)
X.head() #显示新的特征集
输出的清理之后的数据集如下图所示。此时新数据集的特征数目是12个,即特征维度是12。
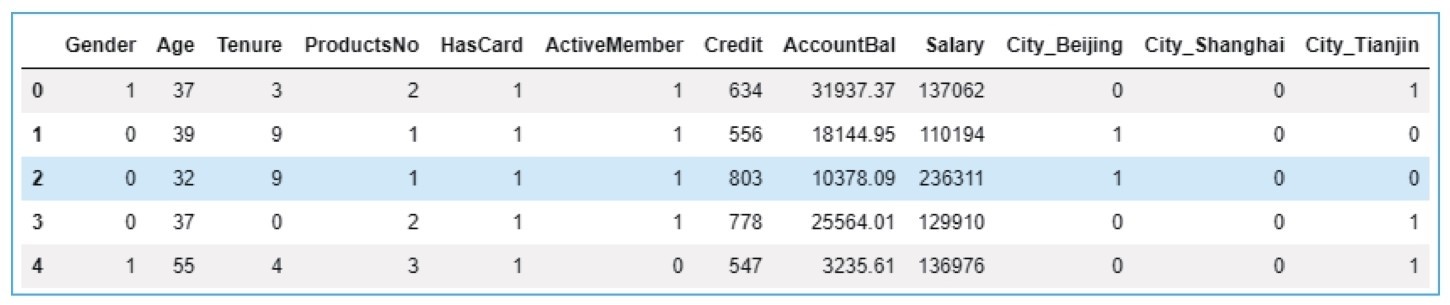
清理之后的银行客户数据集
然后用标准方法拆分数据集为测试集和训练集:
from sklearn.model_selection import train_test_split #拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=0)
上一课介绍的逻辑回归算法完全能够解决这个“是”与“否”的分类问题。下面我们就在没有进行任何特征工程的情况下,先使用逻辑回归直接进行机器学习,看看训练之后的模型会带来什么样的结果:
from sklearn.linear_model import Logistic Regression # 导入Sklearn模型
lr = Logistic Regression() # 逻辑回归模型
history = lr.fit(X_train, y_train) # 训练机器
print("逻辑回归预测准确率 {:.2f}%".format(lr.score(X_test, y_test)*100))
输出结果如下:
逻辑回归预测准确率:78.30%
结果显示预测准确率为78.30%。作为分类问题,这个准确率表面上看还算可以,比盲目猜测强很多。我们可以把它看作一个评估基准,看看采用神经网络的算法进行机器学习之后,准确率会不会有所提高。
如何构建出神经网络机器学习模型呢?通过Keras的深度学习API应该是最简单的方法。
Keras的特点是用户友好,注重用户体验。它提供一致且简单的API,并力求减少常见案例所需的用户操作步骤,同时提供清晰和可操作的反馈。

Keras的图标
Keras建构出来的神经网络模型通过模块(也就是API)组装在一起。各个深度学习元件都是Keras模块,比如神经网络层、损失函数、优化器、参数初始化、激活函数、模型正则化,都是可以组合起来构建新模型的模块。
 咖哥发言
咖哥发言
为什么取名为Keras?
Keras,最初是作为ONEIROS(开放式神经电子智能机器人操作系统)项目研究工作的一部分而开发的。Keras在希腊语中意为牛角、号角 ,源自古希腊史诗《奥德赛》中关于梦神(Oneiros)的故事。冥界的出口有两扇门,一个是象牙之门,一个是牛角之门。梦神用虚幻的景象欺骗通过象牙之门抵达的人,而让通过牛角之门的人将看到真相,到达真理的彼岸。
1.用序贯模型构建网络
单隐层神经网络的实现代码如下。
首先导入Keras库:
import keras # 导入Keras库
from keras.models import Sequential # 导入Keras序贯模型
from keras.layers import Dense # 导入Keras全连接层
■序贯(sequential)模型,也可以叫作顺序模型,是最常用的深度网络层和层间的架构,也就是一个层接着一个层,顺序地堆叠。
■密集(dense)层,是最常用的深度网络层的类型,也称为全连接层,即当前层和其下一层的所有神经元之间全有连接。
然后搭建网络模型:
ann = Sequential() # 创建一个序贯ANN模型
ann.add(Dense(units=12, input_dim=11, activation = 'relu')) # 添加输入层
ann.add(Dense(units=24, activation = 'relu')) # 添加隐层
ann.add(Dense(units=1, activation = 'sigmoid')) # 添加输出层
ann.summary() # 显示网络模型(这个语句不是必需的)
运行上面的代码后,将输出神经网络的结构信息:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_01 (Dense) (None, 12) 156
_________________________________________________________________
dense_02 (Dense) (None, 24) 312
_________________________________________________________________
dense_03 (Dense) (None, 1) 25
=================================================================
Total params: 493
Trainable params: 493
Non-trainable params: 0
_________________________________________________________________
summary方法显示了神经网络的结构,包括每个层的类型、输出张量的形状、参数数量以及整个网络的参数数量。这个网络只有3层,493个参数(就是每个神经元的权重等),这对于神经网络来说,参数数量已经算是很少了。
通过下面的代码,还可以展示出神经网络的形状结构:
from IPython.display import SVG # 实现神经网络结构的图形化显示
from keras.utils.vis_utils import model_to_dot
SVG(model_to_dot(ann, show_shapes=True).create(prog='dot', format='svg'))
表5-1左边就是所输出的网络结构,表中也列出了对应层的生成语句和简单说明。
表5-1 神经网络结构及对应层生成的语句

解释一下上面的代码。
■模型的创建:ann = Sequential()创建了一个序贯神经网络模型(其实就是一个Python的类)。在Keras中,绝大多数的神经网络都是通过序贯模型所创建的。与之对应的还有另外一种模型,称为函数式API,可以创建更为复杂的网络结构,后续课程中会略做介绍。
■输入层:通过add方法,可开始神经网络层的堆叠,序贯模型,也就是一层一层的顺序堆叠。
□Dense是层的类型,代表密集层网络,是神经网络层中最基本的层,也叫全连接层。
在后面的课程中,我们还将会看到CNN中的Conv2D层,RNN中的LSTM层,等等。解决回归、分类等普通机器学习问题,用全连接层就可以了。
□ i nput_dim是输入维度,输入维度必须与特征维度相同。这里指定的网络能接收的输入维度是11。如果和实际输入网络的特征维度不匹配,Python就会报错。
□unit是输出维度,设置为12。该参数也可写为output_dim=12,甚至忽略参数名,写为Dense(12,input_dim=11,activation='relu'),这些都是正确格式。12这个值目前是随意选择的,这代表了经过线性变化和激活之后的假设空间维度,其实也就是神经元的个数。维度越大,则模型的覆盖面也越大,但是模型也就越复杂,需要的计算量也多。对于简单问题,12维也许是一个合适的数字:太多的话容易过拟合,太少的话(不要少于特征维度)则拟合能力不够。
□activation是激活函数,这是每一层都需要设置的参数。这里的激活函数选择的是“relu”,而不是Sigmoid。relu是神经网络中常用的激活函数。(为什么不用Sigmoid,原因过一会儿再讲。)
■隐层:仍然通过add方法。在输入层之后的所有层都不需要重新指定输入维度,因为网络能够通过上一层的输出自动地调整。这一层的类型同样是全连接层。在输入维度方面,我进一步扩充了神经网络的假设空间,神经元的个数从12增加到24。随着网络层级的加深,逐步地增大特征空间,这是密集连接型网络的常见做法(但不是必需的做法)。
■输出层:仍然是一个全连接层,指定的输出维度是1。因为对于二分类问题,输出维度必须是1。而对于多分类问题,有多少个类别,维度就是多少。激活函数方面,最后一层中使用的是熟悉的Sigmiod激活函数。对于二分类问题的输出层,Sigmoid是固定的选择。如果是用神经网络解决回归问题的话,那么输出层不用指定任何激活函数。
下面编译刚才建好的这个网络:
# 编译神经网络, 指定优化器、损失函数, 以及评估指标
ann.compile(optimizer = 'adam', #优化器
loss = 'binary_crossentropy', #损失函数
metrics = ['acc']) #评估指标
用Sequential模型的compile方法对整个网络进行编译时,需要指定以下几个关键参数。
■优化器(optimizer):一般情况下,“adam”或者“rmsprop”都是很好的优化器选项,但也有其他可选的优化器。等一会我们再稍微深入地说说优化器的选择。
■损失函数(loss):对于二分类问题来说,基本上二元交叉熵函数(binary_crossentropy)是固定选项;如果是用神经网络解决线性的回归问题,那么均方误差函数是合适的选择。
■评估指标(metrics):这里采用预测准确率acc(也就是accuracy的缩写,两者在代码中是等价的)作为评估网络性能的标准;而对于回归问题,平均误差函数是合适的选择。准确率,也就是正确地预测占全部数据的比重,是最为常用的分类评估指标。但它是不是唯一正确的分类评估指标呢?等一会还会深入分析这个问题。
2.全连接层
关于神经网络的全连接层(Dense层),再多说两句。它是最常见的神经网络层,用于处理最普通的机器学习向量数据集,即形状为(样本,标签)的2D张量数据集。它实现的就是一个逻辑回归功能:
Output=Activation(dot(input,kernel)+bias)
这公式中的kernel,其实就是我们常说的权重。因为网络是多节点的,所以它从向量升级为矩阵,把输入和权重矩阵做点积,然后加上一个属于该层的偏置(bias),激活之后,就得到了全连接层往下一层的输出了。另外,偏置在神经网络层中是可有可无的,不是必需项。
其实,每层最基本的、必须设置的参数只有以下两个。
■units:输出维度。
■activation:激活函数。
对于输入层,当然还要多指定一个输入维度。对于后面的隐层和输出层,则连输入维度也可以省略了。
那么在每一个全连接层中,还有一些参数,用于初始化权重和偏置,以及正则化设定:
# Dense层中可设置的参数
keras.layers.Dense(units=12,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None)
层内参数通常都是由机器学习通过梯度下降自动优化的,因此除了上面提到的输入输出维度、激活函数的选择之外,初学者不必特别关注其他的初始化和正则化参数。
3.神经网络中其他类型的层
有一位同学发问:“那么其他类型的层是什么样的呢?”
咖哥回答:“全连接层,适用于2D张量数据集,其他类型的层则负责处理其他不同维度的数据集,解决不同类型的问题。”
下面介绍两个其他类型的层。
■循环层(如Keras的LSTM层),用于处理保存在形状为(样本,时戳,标签)的3D张量中的序列数据。
■二维卷积层(如Keras的Conv2D层),用于处理保存在形状为(样本,帧数,图像高度,图像宽度,颜色深度)的4D张量中的图像数据。
其实,层就像是深度学习的乐高积木块,将相互兼容的、相同或者不同类型的多个层拼接在一起,建立起各种神经网络模型,这也是深度学习的有趣之处。
下面开始训练刚才编译好的神经网络。
和其他传统机器学习算法一样,神经网络的拟合过程也是通过fit方法实现的。在此,通过history变量把训练过程中的信息保存下来,留待以后分析:
history = ann.fit(X_train, y_train, # 指定训练集
epochs=30, # 指定轮次
batch_size=64, # 指定批量大小
validation_data=(X_test, y_test)) #指定验证集
这里,必须要指定的参数只是训练集,以及训练的轮次(epochs)。其他参数包括以下几个。
■batch_size:用于指定数据批量,也就是每一次梯度下降更新参数时所同时训练的样本数量。这是利用了CPU/GPU的并行计算功能,系统默认值是32。如果硬件给力,批量数目越大,每一轮训练得越快。
■validation_data:用于指定验证集。这样就可以一边用训练集训练网络,一边验证某评估网络的效果。这里为了简化模型,就直接使用测试集来做验证了,因此本例中的x_test, y_test也就成了验证集。但更规范的方法应该是把验证集和测试集区分开。
下面运行一下代码。
然而运行之后,Python竟然报错:
---------------------------------------------------------------------------
Value Error Traceback (most recent call last)
----> 1 history = acc.fit(X_train, y_train, epochs=30, batch_size=10, validation_
data=(X_test, y_test))
……
Value Error: Error when checking input: expected dense_48_input to have shape 11,
but got array with shape (12, )
 咖哥发言
咖哥发言
看到出错,小冰吓了一跳,但咖哥似乎很冷静,面不改色,对同学们严肃地说道:“大家可别以为出这个错是我水平不行,此乃鄙人故意为之,目的就是提醒大家注意输入维度。”
回头审视一下刚才的代码,在通过add方法构建网络时,我们将第一层的输入维度设置为了11:
ann.add(Dense(units=12, input_dim=11, activation = 'relu')) # 添加输入层
但是,同学们数一数,这个数据集的实际特征维度是多少维?是12维!因此,Error信息中说得已经很明确了,神经网络所定义的输入数组形状和数据集实际的输入数组形状不匹配。修改输入维度如下:
ann.add(Dense(units=12, input_dim=12, activation = 'relu')) # 添加输入层
调整了输入维度之后, 重新运行fit方法,神经网络的训练就开始了!接着开始逐步输出每个轮次的训练集准确率和验证集准确率,问题解决了。
 咖哥发言
咖哥发言
大家松了一口气。咖哥说:“还是那句话,遇到报错,不必紧张,冷静排查即可解决问题。”
Train on 8000 samples, validate on 2000 samples
Epoch 1/30 8000/8000 [==============================]
- 4s 525us/step - loss: 3.5385 - acc: 0.7776 - val_loss: 3.2142 - val_acc: 0.7975
Epoch 2/30 8000/8000 [==============================]
- 2s 246us/step - loss: 3.2902 - acc: 0.7941 - val_loss: 3.2463 - val_acc: 0.7975
… …
Epoch 29/29 8000/8000 [==============================]
- 2s 209us/step - loss: 0.5058 - acc: 0.7960 - val_loss: 0.5047 - val_acc: 0.7975
Epoch 30/30 8000/8000 [==============================]
- 2s 205us/step - loss: 0.5058 - acc: 0.7960 - val_loss: 0.5049 - val_acc: 0.7975
单隐层神经网络预测准确率: 79.75%
这样我们的第一个神经网络的训练就算是完成了。从表面上看,从78.30%到79.75%,单隐层神经网络的预测准确率比逻辑回归似乎有所提高。
训练过程中输出的信息包括每轮训练的损失值、准确率等。但是这个输出信息有30轮的数据,很冗长、看起来特别费力。有没有更直观的方法来显示这些信息呢?
有。可以用下面的代码定义一个函数,显示基于训练集和验证集的损失曲线,以及准确率随迭代次数变化的曲线。
# 这段代码参考了《Python深度学习》一书中的学习曲线的实现
def show_history(history): # 显示训练过程中的学习曲线
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
acc = history.history['acc']
val_acc = history.history['val_acc']
plt.subplot(1, 2, 2)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
show_history(history) # 调用这个函数, 并将神经网络训练历史数据作为参数输入
这种图形化的显示看起来就清晰多了,如下图所示(图中准确率均以小数形式表示,正文中以百分数形式表示)。
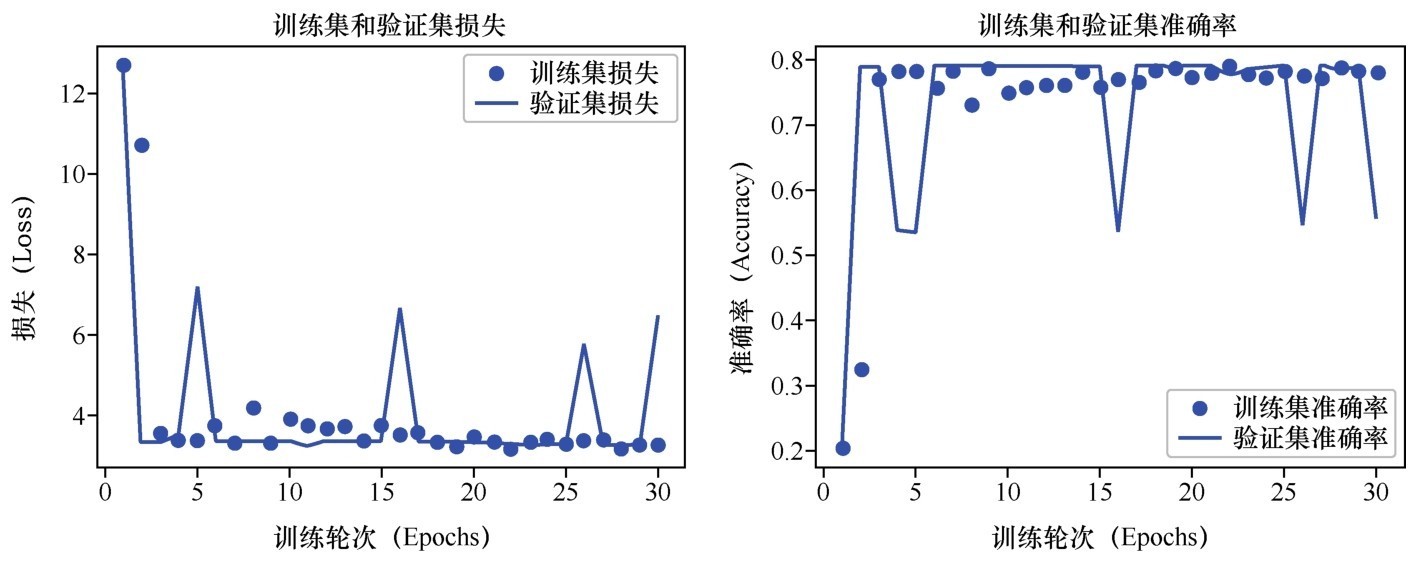
训练集和验证集上的损失曲线和准确率曲线