
在大数据领域,神经网络的效能显著地领先于其他算法
神经网络其实有一段“悠久”的历史。早在1958年,计算机科学家罗森布拉特(Rosenblatt)就提出了一种具有单层网络特性的神经网络结构,称为“感知器”(perceptron)。感知器出现之后很受瞩目,大家对它的期望很高。然而好景不长—一段时间后,人们发现感知器的实用性很弱。1969年,AI的创始人之一马文·明斯基(Marvin Minsky)指出简单神经网络只能运用于线性问题的求解。这之后神经网络就逐渐被遗忘了。
直到1985年,杰弗里·辛顿(Geoffrey Hinton,深度学习“三巨头”之一)和特伦斯·谢诺夫斯基(Terrence Sejnowski)提出了一种随机神经网络模型—受限玻尔兹曼机。紧接着, Rumelhart、Hinton、Williams提出了BP算法,即多层感知器的梯度反向传播算法。这也是神经网络的核心算法,人们以此为基础搭建起几乎现代所有的深度网络模型。因此,可以说神经网络的理论基础在20世纪60年代出现,并在80年代几乎完全形成。
在工程界,当时神经网络也已经有了应用。杨立昆(Yann Le Cun,深度学习“三巨头”之一)于20世纪80年代末在贝尔实验室研发出了卷积神经网络,他将其应用到手写识别和OCR,并在美国广泛应用于手写邮编、支票的读取。然而后来,另一种理论相当完善的机器学习技术支持向量机(Support Vector Machine,SVM)被发明出来,成为了业界“新宠”,神经网络再一次被遗忘了。
大约2009年,计算机最终有了足够的算力进行深度计算,神经网络开始在语音和图像识别方面战胜传统算法。杰弗里·辛顿、杨立昆和约书亚·本吉奥(Yoshua Bengio)3人联合提出深度学习的概念。这是新瓶装旧酒,名称变了,技术还是一样的技术。然而时代也已经改变,此时深度神经网络开始实证性地在工程界展示出绝对的优势。2012年年底,基于卷积神经网络模型的Inception结构在ImageNet图片分类竞赛中获胜。此后深度学习火山爆发式发展,科技“巨头”们开始在这个领域投资:计算机视觉、语音识别、自然语言处理、棋类竞赛和机器人技术,这些应用领域的突破一个接着一个出现……
其实,从一开始就不是神经网络不行,而是原来的数据量和计算速度两方面都跟不上。在这个数据泛滥的时代,海量数据的获取不再是什么难事。可以预见,在5G时代,深度学习必然还会有更大发展的空间……
在大数据领域,神经网络的效能显著地领先于其他算法
讲完历史,咖哥抛出了一个问题让大家去思索—机器学习应用领域,也就是回归和分类这两大块,既然有了线性回归和逻辑回归两大机器学习基础算法,这两类问题都可解了。那么,为什么还需要神经网络?它有什么特别的优势?
先说一说传统机器学习算法的局限性。首先,越简单的关系越容易拟合。比如,第3课中的广告投放金额和商品销售额的例子,一个线性函数就能轻松地搞定。然而对于一个非线性的问题(如下图所示),就需要通过更复杂的函数模型(如高阶多项式)去拟合。此时,单纯线性回归明显不给力,因而我们把特征重新组合,变化出新的特征。比如,一次函数不够用时,可以把x1做平方变成x12,做立方变成x13,甚至可以和x2做组合,变成x1x2、x12x2等,不断创造出新的特征,构造新的函数,直到把训练集的数据拟合好为止。

复杂的关系需要复杂的函数去拟合
这种对特征的变换、升阶,以及多个特征相互组合形成新特征的过程,就是机器学习过程中既耗时又耗力的特征工程的一个例子。
当特征的维度越来越大时,特征之间相互组合的可能性将以几何级数递增,特征空间急剧膨胀,对应的假设空间也随之膨胀。此时,你们会惊奇地发现,单纯用线性回归和逻辑回归模型进行的机器学习会显得越来越力不从心,因为特征工程本身就已经把机器“累死”了。
 咖哥发言
咖哥发言
特征空间是数据特征所形成的空间,特征维度越高,特征空间越复杂。而假设空间则是假设函数形成的空间,特征越多,特征和标签之间的对应的关系越难拟合,假设空间也就越复杂。
此时,要进一步扩展机器学习的应用领域,我们就需要更强的系统去减少对特征工程的需求,去解决巨大特征量的问题,这就是……
“等一下。”小冰发问,“有这样多特征的实际问题吗?前面介绍的房价预测、销售额预测、客户分类等,感觉特征的数量两只手都能比划出来,房屋面积、广告投放金额、胸痛类型、休息时血压等,也就这些东西,怎么就难了?”
“啊,原来你是这么想的。”咖哥说,“那我再多解释一下。”
前几课中咱们处理的问题,都是结构化数据。这种结构化数据有一个特点,就是人弄起来很费劲儿,但是计算机会很快搞定。比如一堆堆的血压、脉搏计数,让很有经验的医生去分析,如果数据量很大的话,他也得看一阵子。因为人脑在处理数字、运算时是有局限性的,和计算机比的话既不够快也不够准。
那么什么是非结构化数据呢?就是没有什么预定义的数据结构,不方便用数据库存储,也不方便用Excel表格来表现的数据。比如,办公文档、文本、图片、网页、各种图像/音频/视频信息等,都是非结构化数据。你们可能看出来了,这些数据大都和人类的感觉、知觉相关。笼统地说,也可称为感知类数据。人脑理解和处理感知类数据在深度学习出现之前比计算机好使。比如一只猫的图片,我们不会根据一个个像素点去分析特征,哪个像素点是耳朵的一部分,哪个像素点是鼻子的一部分,哪个像素点应该是红色,哪个像素点应该是黑色。小孩子看了,也能轻而易举地知道图片里面的内容是猫。因为可能很多“深度”的经验已经集成在人脑的潜意识里面了。
对于这种类型的问题,传统的机器学习模型比如线性回归或者逻辑回归,就不大好使。因为要训练一个分类器来判断图片是否为一只猫时,计算机实际上看到的是一个巨大的数字矩阵(如下图所示),矩阵中的每一个数字代表一个像素的强度(亮度、颜色)值,比如猫眼睛处像素值对应为黑色、猫的嘴处为红色等。我们会输入大量的猫图片样本集,希望经过学习之后,模型知道大概什么地方会出现什么样的像素,比如猫眼睛是什么样,或者是猫耳朵是什么样的,等等。
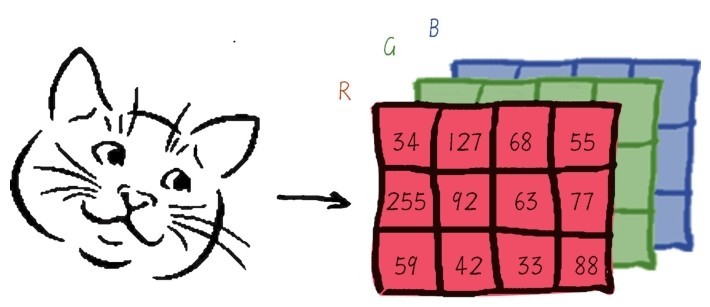
人眼看猫,计算机看数字矩阵
即使图片很小,长宽也各有50像素,也就是有2 500个特征 。如果是RGB彩色图像,那么特征的数目就是7 500了。如果特征之间还可以组合,特征空间可以达到上百万的级别。不仅是图片,其他感知类数据如文本、网页,都出现类似特征维度超大的现象。对于传统机器学习算法来说,计算成本太高了。而且,这些像素特征和分类结果之间的拟合过于复杂,如果通过手工特征工程来辅助机器学习的建模,这个特征工程本身的难度也将是巨大的。
 咖哥发言
咖哥发言
机器学习中有个术语叫“维度灾难”,即高维度带来了超高的复杂度和超巨大的特征空间。比如,对于围棋来说,特征维度是19×19,但是它的有效状态数量超过了10170。
而神经网络就是专门为了解决这类超高特征维度的感知类问题而生的。数学上已经证明,浅层神经网络可以模拟任何连续函数。而深层神经网络更是可以用更少的参数来学到更好的拟合。特征数量越大,神经网络优势越明显。机器学习,学的就是对客观世界事物之间关系的拟合,谁的拟合能力更强,实现起来更简便,谁就是“王者”。因而,神经网络,尤其是深度神经网络,在大数据时代肩负着处理超高维特征问题以及减少特征工程两大重任,是处理感知类问题的一把利刃。
还是借着刚才这个猫的例子,说说神经网络是怎么做到这种不惧巨大特征量的“深度学习”的。
假设我们是在传统AI模型上弄一个猫识别器,首先需要花大量的时间来帮机器定义什么是“猫”—2个眼睛,4条腿,尖尖的耳朵,软软的毛…… 这些信息输入机器,组合起来构成了一只猫。然后对图片里面的特征进行分解,拆分成一小块一小块的元素,眼睛、毛发颜色、胡须、爪子,等等。最后将这些元素和机器记忆中的信息进行比对,如果大多数都吻合了,那么这就是一只猫。
而现在用神经网络去识别猫可就省力多了。不必手工去编写猫的定义,它的定义只存在于网络中大量的“分道器”之中。这些分道器负责控制在网络的每一个分岔路口把图片往目的地输送。而神经网络就像一张无比庞大、带有大量分岔路的铁轨网,如右图所示。
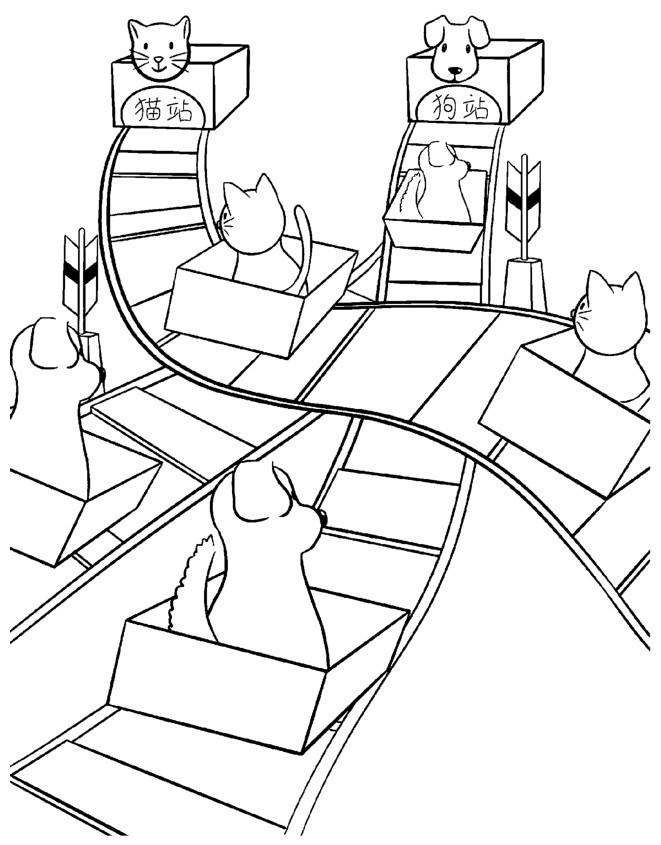
网络把猫全都输送到猫站,狗全都输送到狗站
在这密密麻麻的铁轨的一边是输入的图片,另一边则是对应的输出结果,也就是道路的终点。网络会通过调整其中的每一个分道器来确保输入映射到正确的输出。训练数据越多,这个网络中的轨道越多,分岔路口越多,网络也就越复杂。一旦训练好了,我们就拥有了大量的预定轨道,对新图片也能做出可靠的预测,这就是神经网络的自我学习原理(本小节内容部分参考了《谷歌大脑养成记》,由公众号机器之心编译)。
小冰插嘴:“咦?好像这个神经网络的原理和线性回归或者逻辑回归完全相同,不就是通过不断地训练寻找最佳的参数嘛!”
咖哥答:“你说得简直太正确了!它们本来就是一回事,唯一的不同是,神经网络的参数多、层级深,需要的数据量也多。”
那么为什么这个网络需要如此多的神经元和数据呢?
因为这是训练机器的必需项。到底是猫是狗,由网络中成千上万个“分道器” 神经元决定。拿出一张猫图片问:这是什么?铁轨大网经过重重分叉,在第一次判断中把它输送到了狗站。
机器告诉铁轨大网:不对,这是猫。你再弄一次。
然后,网络中负责统计的人员回头检查各个神经元的分道情况。因为错误的回答,神经元的参数,也就是权重w,得到了惩罚。而下一次呢?正确的结果将使参数得到强化和肯定。这样不断地调整,直到这个网络能够对大多数的训练数据得到正确的答案。所以重要的不是单个分道器,而是整个轨道网络中集体意见的组合结果。因此数据越多,投票者越多,就能获得越多的模式。如果有数百万个投票者,就能获得数十亿种模式。每一种模式都可以对应一种结果,都代表着一种极为具体的从输入到输出的函数。这些不同的模式使网络拥有归类的能力。训练的数据越多,网络就越了解一种模式属于哪一个类别,就能在未来遇到没有标签的图片时做出更准确的分类。

当得出错误结果时,神经元的权重会受惩罚
因此,深度学习并不是去尝试定义到底什么是一只猫,而是通过大量的数据和大量的投票器,把网络里面的开关训练成“猫通路”“狗通路”。对数据量的需求远远胜过对具体“猫特征”定义的需求。所以,程序员所做的是源源不断地把数据输入神经网络,让它自己优化自己,而不是坚持不懈地告诉神经网络,猫这里有胡须,一般是8根,有时候是6根。这些机械化的定义在神经网络面前变得不再有任何用处。
这里你们也看得出样本的重要性,数据样本才是网络中每个投票器参数值的决定者(而不是作为网络设计者的人类!)。如果这一批样本中,所有的猫都有8根胡须,那么这个特征—结果的线路,很可能被训练得很强。突然之间,样本中出现了一只有6根胡须的猫。由于神经网络里面什么先验知识也没有。神经网络本来就是一张白纸,没有人告诉它,有几根胡须的是猫。因此被这样的训练样本训练出来的网络也许会告诉我们有6根胡须的猫不是猫。
所以,用精炼语言来总结一下神经网络,即深度学习的机理:它是用一串一串的函数,也就是层,堆叠起来,作用于输入数据,进行从原始数据到分类结果的过滤与提纯。这些层通过权重来参数化,通过损失函数来判断当前网络的效能,然后通过优化器来调整权重,寻找从输入到输出的最佳函数。注意以下两点。
■学习:就是为神经网络的每个层中的每个神经元寻找最佳的权重。
■知识:就是学到的权重。