从二元分类到多元分类
复习一下刚才解决二元分类问题的基本思路:通过逻辑回归算法确定一个种类或者一种情况出现的概率。除了我们刚才举的例子客户是否患病之外,类似的应用还可以用来判断一种商品是否值得进货,结果大于等于0.5就进货(类别1),小于0.5就不进货(类别0),诸如此类,等等。
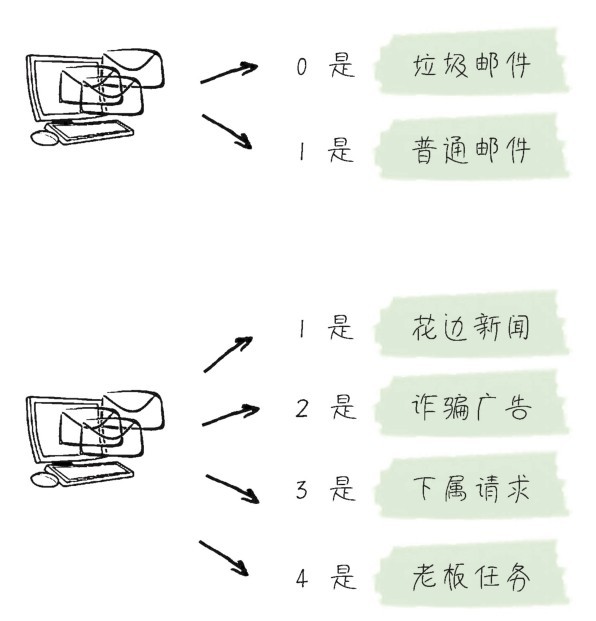
然而,在实际生活中,分类并不总是二元的。多元分类就是多个类别,而且每一个类别和其他类别都是互斥的情况。也就是说,最终所预测的标签只能属于多个类别中的某一个。下图所示,同样是邮件分类问题,可以存在二元或多元的应用场景。
从二元分类到多元分类
咖哥说:“用逻辑回归解决多元分类问题的思路是‘以一对多’,英文是one vs all或one vs rest。”
小冰打断咖哥:“别说英文,说英文我更糊涂,还是用中文解释吧。”
“唔……”咖哥说,“意思就是,有多个类别的情况下,如果确定一个数据样本属于某一个类(1),那么就把其他所有类看成另一类(0)。”
小冰说:“还是不懂!”
咖哥接着解释:“也就是说,有多少类别,就要训练多少二元分类器。每次选择一个类别作为正例,标签为1,其他所有类别都视为负例,标签为0,以此类推至所有的类别。训练好多个二元分类器之后,做预测时,将所有的二元分类器都运行一遍,然后对每一个输入样本,选择最高可能性的输出概率,即为该样本多元分类的类别。”
即

下图就是多元分类示意。

多元分类示意
举例来说,如果对3个二元分类器分别做一次逻辑回归,机器的分类结果告诉我们,数据A是孔雀的可能性为0.5,是熊猫的可能性为0.1,是独角兽的可能性为0.4。那就会判断数据A是孔雀。尽管是独角兽的概率和是孔雀的概率相差不多,但它已经是孔雀了,就不可能同时是独角兽。
这就是多分类问题的解决思路。
 咖哥发言
咖哥发言
还有另外一种分类叫作“多标签分类”,指的是如果每种样本可以分配多个标签,就称为多标签分类。比如,一个图片标注任务,猫和狗同时出现在图片中,就需要同时标注“猫”“狗”。这是更为复杂的分类任务,但基本原理也是一样的。
多元分类的损失函数的选择与输出编码,与标签的格式有关。
多元分类的标签共有以下两种格式。
■一种是one-hot格式的分类编码,比如,数字0~9分类中的数字8,格式为[0,0,0, 0,0,0,0,1,0]。
■一种是直接转换为类别数字,如1、2、3、4。
因此损失函数也有以下两种情况。
■如果通过one-hot分类编码输出标签,则应使用分类交叉熵(categorical crossentropy)作为损失函数。
■如果输出的标签编码为类别数字,则应使用稀疏分类交叉熵(sparse categorical crossentropy)作为损失函数。