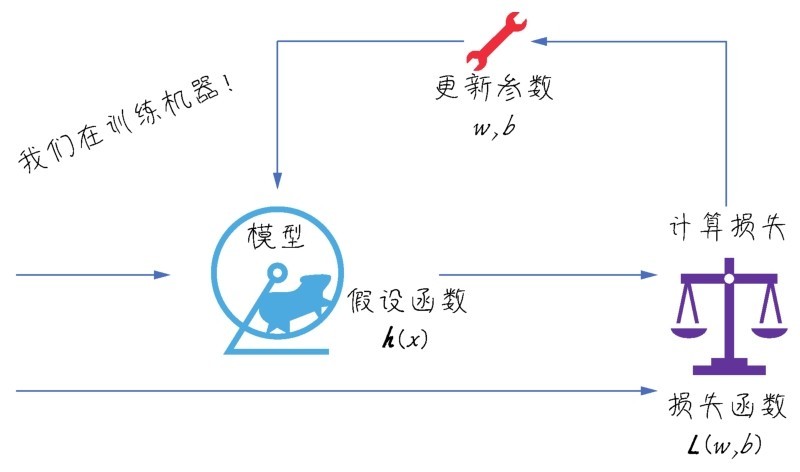
计算参数更新的过程是一个迭代过程,也就是训练机器的过程
现在,数据集已读入张量,我们也选定了以线性回归作为机器学习模型,并且准备好了损失函数MSE,下面要正式开始训练机器。
所谓训练机器,也称拟合的过程,也就是确定模型内部参数的过程。具体到线性模型,也就是确定y'=wx+b函数中的w和b。那么怎样才能知道它们的最佳值呢?刚才我们随便设定了两组参数,(3,5)和(100,1),通过损失函数来比较两组参数带来的误差,发现(3,5)这一组参数好一些。对于这种简单的线性关系,数学功底强的人,通过观察数据和直觉也许就能够给出比较好的参数值。
但机器没有直觉,只能通过算法减小损失。一个最简单无脑的算法是让计算机随机生成一万个w和b的不同组合,然后挨个计算损失函数,最后确定其中损失最小的参数,并宣布:这是一万个组合里面的最优模型。这也是一种算法,也许结果还真不错。
如下图所示,每生成一组参数就通过假设函数求y',然后计算损失,记录下来并更新参数,形成新的假设函数—这是一个不断循环的迭代过程。
计算参数更新的过程是一个迭代过程,也就是训练机器的过程
小冰开始皱眉头:“难道这就是机器学习寻找参数的方式?这也太没有含金量了。”
咖哥继续解释:“漫无目的去猜测一万次,然后给出一个损失最小的模型,告诉别人说这个是我随机猜测一万次里面最好的结果,这实在是谈不上任何‘智能’。如果机器是利用它们天文级的‘算力’做这样的事情,那简直太让人失望了。因此,比较理想的情况是,每一次猜测都应该比上一次更好,更接近真相,也就是每次的损失都应该减小,而不是好一次,坏一次地乱猜。好消息是,对于线性回归来说,有一种方法可以使猜测沿着正确的方向前进,因此总能找到比起上一次猜测时误差更小的w和b组合。这种方法就是针对损失函数的梯度下降(gradient descent)。”
 咖哥发言
咖哥发言
梯度下降可以说是整个机器学习的精髓,堪称机器学习之魂。在我们身边发生的种种机器学习和深度学习的奇迹,归根结底都是拜梯度下降所赐。
这就是方向的重要性。
咖哥喟叹:“不仅人生需要方向,连机器也需要正确的方向……”
咖哥接着说:“只是前进的方向对了,这还不够,还有另外一个关键点,就是你要知道什么时候停下来最合适。”
小冰说:“这是跑马拉松吗?还要知道什么时候停。”
咖哥说:“这就是原来说过的凸函数和全局最低点的重要性所在了。”
让我们回忆一下均方误差函数:
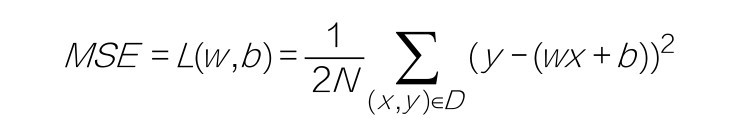
前面已经强调过,函数方程式中的x,y都可以视为常量,则L就只随着w和b而变,而函数是连续的平滑曲线,每一个微小的w和b的改变都会带来微小的L的改变,而且这个函数很显然是个二次函数(w和b被平方)。为了简化描述,方便绘图,先忽略参数b。对于给定的数据集来说,平均损失L和w的对应关系如下图所示。

均方误差函数的损失曲线是一个凸函数
我们将这个函数图像称为损失曲线,这是一个凸函数。凸函数的图像会流畅、连续地形成相对于y轴的全局最低点,也就是说存在着全局最小损失点。这也是此处选择MSE作为线性回归的损失函数的原因。
 咖哥发言
咖哥发言
如果同学们回忆一下第2课中提到过的线性函数和多次函数图像,就会发现它们不满足凸函数的要求。
如果画出w和b共同作用时的三维图像,就可以把它想象成一个有底儿(最低点)的碗,如下图所示。
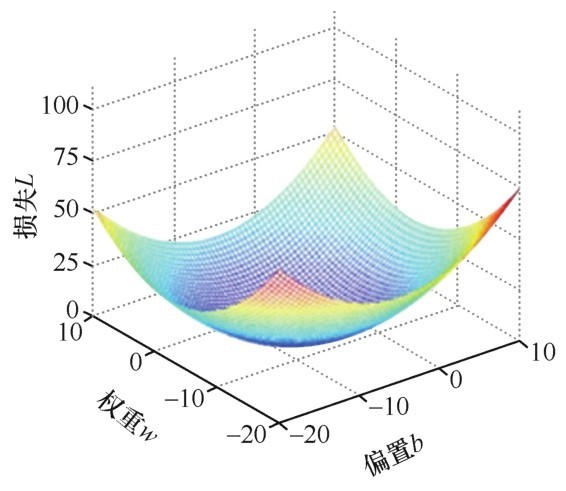
均方误差函数—w和b共同作用时的三维图像
这种“存在着底部最低点”的函数为梯度下降奠定了基础。不管再增加多少个维度(特征,也就是相应地增加参数w的个数),二次函数都是有最低点的。如果没有这个最低点,那么梯度下降到了一定程度,停是停了,但是根本没法判断此时的损失是不是最小的。
 咖哥发言
咖哥发言
一只在二维平面上爬来爬去的蚂蚁,永远也无法想象如果它站起来以后的空间是什么样子。前面说过,我们现在身处于三维空间,因此不能够描述四维以上的空间。所以,如果再多一个参数,其图像就无法展示了。但还是可以推知,对于多维特征的多变量线性回归的均方误差函数,仍然会存在着底部最低点。
梯度下降的过程就是在程序中一点点变化参数w和b,使L,也就是损失值,逐渐趋近最低点(也称为机器学习中的最优解)。这个过程经常用“下山”来比喻:想象你站在一座山的山腰上,正在寻找一条下山的路,这时你环望四周,找到一个最低点并向那个方向迈出一步;接着再环望四周,朝最低点方向再迈出一步……一步接一步,走到最低点。
这里用图来详细解释比较清楚,为了简化说明,还是暂时只考虑权重w和损失L之间的关系。给w随机分配一个初始值(如5)的时候,损失曲线上对应的点就是下图中有小猴子的地方。

梯度下降的实现
此时w等于5,下一步要进行新的猜测了,w应该往哪个方向移动,才能得到更小的损失L?也就是说,w应该是增大(5.01)还是减小(4.99),L才能更快地趋近最小损失点(五角星)?
咖哥问同学们:“如果图中的小猴子代表损失值的大小,那么它应该是往左走,还是往右走呢?机器能不能告诉它正确的方向?”
小冰大叫一声:“求导!”
咖哥吓了一跳:“对!上一课学的东西看来是记住了。”
秘密武器正是导数。导数描述了函数在某点附近的变化率(L正在随着w增大而增大还是减小),而这正是进一步猜测更好的权重时所需要的全部内容。
程序中用梯度下降法通过求导来计算损失曲线在起点处的梯度。此时,梯度就是损失曲线导数的矢量,它可以让我们了解哪个方向距离目标“更近”或“更远”。
■如果求导后梯度为正值,则说明L正在随着w增大而增大,应该减小w,以得到更小的损失。
■如果求导后梯度为负值,则说明L正在随着w增大而减小,应该增大w,以得到更小的损失。
 咖哥发言
咖哥发言
此处在单个权重参数的情况下,损失相对于权重的梯度就称为导数;若考虑偏置,或存在多个权重参数时,损失相对于单个权重的梯度就称为偏导数。
因此,通过对损失曲线进行求导之后,就得到了梯度。梯度具有以下两个特征。
■方向(也就是梯度的正负)。
■大小(也就是切线倾斜的幅度)。
这两个重要的特征,尤其是方向特征确保了梯度始终指向损失函数中增长最为迅猛的方向。梯度下降法会沿着负梯度的方向走一步,以降低损失,如右图所示。
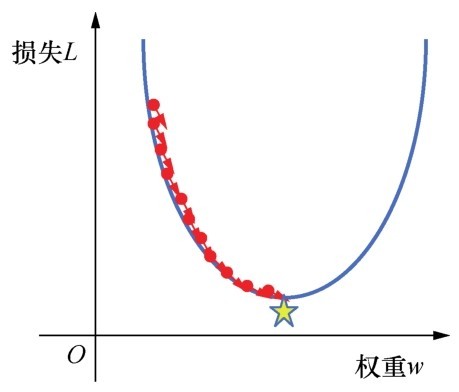
梯度下降:找到损失最小时的权重
通过梯度下降法,如果初始估计的w值落在最优值左边,那么梯度下降会将w增大,以趋近最低值;如果初始估计的w值落在最优值右边,那么梯度下降会将w减小,以趋近最低值。这个逐渐趋近于最优值的过程也叫作损失函数的收敛。
用数学语言描述梯度计算过程如下:
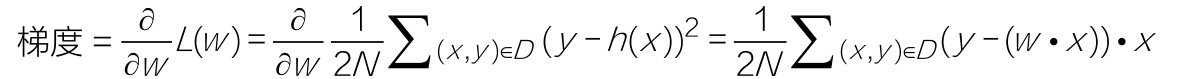
也可以写成
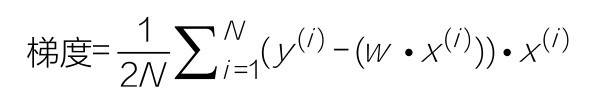
此处的N是数据集的数目。符号 代表对所有训练数据集中的特征和标签进行处理并求和,这是已经推导出来的求梯度的具体步骤。如果不熟悉导数(也就是对损失函数的微分)的演算也没有什么影响。因为梯度的计算过程都已经封装在各种机器学习框架中,并不用我们自己写代码实现。
代表对所有训练数据集中的特征和标签进行处理并求和,这是已经推导出来的求梯度的具体步骤。如果不熟悉导数(也就是对损失函数的微分)的演算也没有什么影响。因为梯度的计算过程都已经封装在各种机器学习框架中,并不用我们自己写代码实现。
而且即使要通过Python来实现梯度下降公式,代码同样是非常的简洁:
y_hat = weight*X + bias # 这是向量化运算实现的假设函数
loss = y_hat-y # 这是中间过程, 求得的是假设函数预测的y'和真正的y值之间的差值
derivative_wight = X.T.dot(loss)/len(X) # 对权重求导, len(X)就是样本总数
derivative_bias = sum(loss)*1/len(X) # 对偏置求导, len(X)就是样本总数
简单地解释一下这段代码。
■weight*X是求出X数据集中的全部数据的y'值,就是w·x(i)的实现,是对数组的整体操作,不用通过循环去分别操作每一个数据。
■对weight求导的过程中,使用了上一课中介绍过的多项式点积规则—两个相同维度的向量对应元素先相乘,后相加。这其中的两个向量是X和loss,也就是y(i)−(w·x(i)))·x(i)的实现。
■对偏置b求导并不需要与特征X相乘,因为偏置与权重不同,它与特征并不相关。另外还有一种思路,是把偏置看作w0,那么就需要给X特征矩阵添加一行数字1,形成x0,与偏置相乘,同时确保偏置值不变—我们会在多变量线性回归的代码中试一下这个技巧。
最关键的问题已经通过求导的方法解决了,我们知道权重w应该往哪个方向走。下一个问题是小猴子应该以多快的速度下山。这在机器学习中被称为学习速率(learning rate)的确定。学习速率也记作α,读作alpha。
学习速率乘以损失曲线求导之后的微分值,就是一次梯度变化的步长(step size)。它控制着当前梯度下降的节奏,或快或慢,w将在每一次迭代过程中被更新、优化。
引入学习速率之后,用数学语言描述参数w随梯度更新的公式如下:
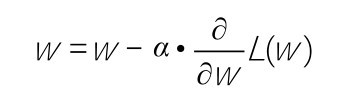
即

Python代码实现如下:
weight = weight - alpha*derivative_wight # 结合学习速率alpha更新权重
bias = bias - alpha*derivative_bias # 结合学习速率alpha更新偏置
 咖哥发言
咖哥发言
本课中,为了学习过程中的理解,给出了求导、梯度下降的实现、损失函数的计算的细节。然而在实战中,这些内容基本不需要编程人员自己写代码实现。而大多数机器学习从业者真正花费相当多的时间来调试的,是像学习速率、迭代次数这样的参数,我们称这类位于模型外部的人工可调节的参数为超参数。而权重w、偏置b,当然都是模型内部参数,由梯度下降负责优化,不需要人工调整。
如果所选择的学习速率过小,机器就会花费很长的学习时间,需要迭代很多次才能到达损失函数的最底点,如下面左图所示。相反,如果学习速率过大,导致L的变化过大,越过了损失曲线的最低点,则下一个点将永远在U形曲线的底部随意弹跳,损失可能越来越大,如下面右图所示。在机器学习实战中,这种损失不仅不会随着迭代次数减小,反而会越来越大的情况时有发生。

学习速率过大和过小都不好
最佳学习速率(如右图所示)与具体问题相关。因为在不同问题中,损失函数的平坦程度不同。如果我们知道损失函数的梯度较小,则可以放心地试着采用更大的学习速率,以补偿较小的梯度并获得更大的步长。
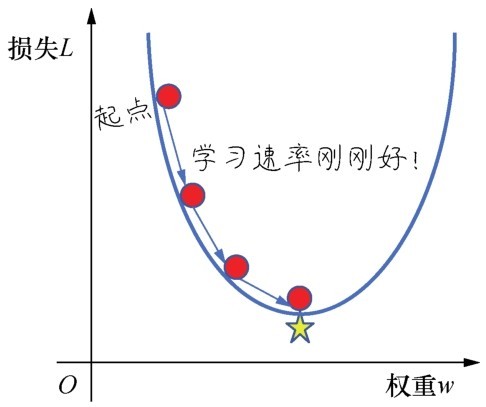
要选择一个最佳学习速率
寻找最佳学习速率很考验经验和感觉。一个常见的策略是,在机器学习刚刚开始的时候,学习速率可以设置得大一些,快速几步达到靠近最佳权重的位置,当逐渐地接近最佳权重时,可以减小学习速率,防止一下子越过最优值。
下面给出梯度下降的完整代码(已经封装在一个自定义的函数gradient_descent中):
def gradient_descent(X, y, w, b, lr, iter): # 定义一个实现梯度下降的函数
l_history = np.zeros(iter) # 初始化记录梯度下降过程中损失的数组
w_history = np.zeros(iter) # 初始化记录梯度下降过程中权重的数组
b_history = np.zeros(iter) # 初始化记录梯度下降过程中偏置的数组
for i in range(iter): # 进行梯度下降的迭代, 就是下多少级台阶
y_hat = w*X + b # 这是向量化运算实现的假设函数
loss = y_hat-y # 这是中间过程, 求得的是假设函数预测的y'和真正的y值间的差值
derivative_w = X.T.dot(loss)/len(X) # 对权重求导, len(X)是样本总数
derivative_b = sum(loss)*1/len(X) # 对偏置求导
w = w - lr*derivative_w # 结合学习速率alpha更新权重
b = b - lr*derivative_b # 结合学习速率alpha更新偏置
l_history[i] = loss_function(X, y, w, b) # 梯度下降过程中损失的历史记录
w_history[i] = w # 梯度下降过程中权重的历史记录
b_history[i] = b # 梯度下降过程中偏置的历史记录
return l_history, w_history, b_history # 返回梯度下降过程中的数据
注意梯度下降的代码在程序中实现时,会被置入一个循环中,比如下降50次、100次甚至10 000次,调试程序时,需要观察损失曲线是否已经开始收敛。具体迭代多少次合适,和学习速率一样,需要具体问题具体分析,还需要根据程序运行情况及时调整,这是在下一小节中即将详细介绍的内容。