
二维向量—平面上的点
Python的语法介绍暂告一段落。接下来同学们思索一个较为抽象的问题:如何用几何(形状、大小、图形的相对位置等空间区域)的方式去表述机器学习的本质呢?这个题目很大,我在这里做一点点肤浅的尝试。
张量,可以被解释为某种几何空间内点的坐标。这样,机器学习中特征向量就形成了特征空间,这个空间的维度和特征向量的维度相同。
二维向量—平面上的点
现在考虑这样一个二维向量:A = (0.5,1)。
这个向量可以看作二维空间中的一个点,一般将它描绘成原点到这个点的箭头,如右图所示。那么更高维的向量呢?应该也可以想象为更高维空间的点。像这样把平面数字转换为空间坐标的思考方式其实是很有难度的。
张量运算都有几何意义。举个例子,我们来看二维向量的加法,如下图所示。向量的加法在几何上体现为一个封闭的图形。两个向量的和形成一个平行四边形,结果向量就是起点到终点的对角线。

二维向量的加法
 咖哥发言
咖哥发言
不知道你们是否还记得初中物理中曾讲过的向量相加的效果:对于力、位移、速度、加速度等向量,其相加后的效果等于几个分向量的效果之和。
而二维向量的点积的几何意义则是两个向量之间的夹角,以及在b向量和a向量方向上的投影(如右图所示):
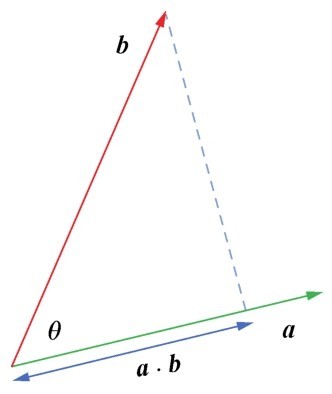
向量的点积
a·b=|a||b|cosθ
其中θ是a向量与b向量的夹角,点积结果则是a(或b)向量在b(或a)向量上的投影长度,是一个标量。
这些例子展示了平面中一些二维向量操作的几何意义,推而广之:机器学习模型是在更高维度的几何空间中对特征向量进行操作、变形,计算其间的距离,并寻找从特征向量到标签之间的函数拟合-这就是从几何角度所阐述的机器学习本质。
几种常见的机器学习模型都可以通过特征空间进行几何描述,如下图所示。

几种常见的机器学习模型
下面继续介绍深度学习的几何意义。前面我们也提过,深度学习的过程,实际上也就是一个数据提纯的过程。数据从比较粗放的格式,到逐渐变得“计算机友好”。
数据为什么需要提纯呢?主要还是因为特征维度过高,导致特征空间十分复杂,进而导致机器学习建模过程难度过大。有一种思路是通过流形(manifold)学习将高维特征空间中的样本分布群“平铺”至一个低维空间,同时能保存原高维空间中样本点之间的局部位置相关信息。
原始数据特征空间中的样本分布可能极其扭曲,平铺之后将更有利于样本之间的距离度量,其距离将能更好地反映两个样本之间的相似性。原始空间中相邻较近的点可能不是同一类点,而相邻较远的点有可能是同一类,“平铺”至低维空间后就能解决这一问题。
 咖哥发言
咖哥发言
流形,其概念相当的抽象,属于比较高端的数学。我查阅过资料,坦白说,不能完全理解。“流形”这个漂亮的翻译源自北大数学系老教授江泽涵,江教授的灵感则源自文天祥的名作《正气歌》中“天地有正气,杂然赋流形”。
在传统的机器学习中,流形学习主要用于特征提取和数据降维,特征提取使特征变得更加友好,降维是因为高维数据通常有冗余。
而在深度学习出现之后,有一种说法认为神经网络能够自动自发地将复杂的特征数据流形展开,从而减少了特征提取的需要。从直观上,这个展开过程可以用一团揉皱了的纸来解释,如下图所示。

通过神经网络展开数据流形
如果有好几张揉皱了的纸上写满了数字,要读取上面的信息是不可能的事。但把这样的纸展开,而又不损害纸,也挺麻烦。因此,现代的深度神经网络(Deep Neural Networks,DNN)通过参数学习,展开了高维数据的流形—这可以说是深度学习的几何意义[2]。