
机器学习建模三部曲:选择函数模型,评估函数的优劣,确定最优的函数
今天课程的最后,我们来重点讲解如何进行机器学习项目的实战:如何开始、关键的步骤有哪些,以及每个步骤中要注意些什么。
李宏毅老师曾用将大象装进冰箱来比喻机器学习。大象怎么被装进冰箱?这分为3个步骤:打开冰箱门,将大象放进去,关闭冰箱门。机器学习也就是个“三部曲”:选择函数模型,评估函数的优劣,确定最优的函数,如下图所示。
机器学习建模三部曲:选择函数模型,评估函数的优劣,确定最优的函数
这个比喻非常精彩,但它主要聚焦于“建模”过程,未强调机器学习项目其他环节。机器学习项目的实际过程要更复杂一些,大致分为以下5个环节。
(1)问题定义。
(2)数据的收集和预处理。
(3)模型(算法)的选择。
(4)选择机器学习模型。
(5)超参数调试和性能优化。
这5个环节,每一步的处理是否得当,都直接影响机器学习项目的成败。而且,如下图所示,这些步骤还需要在项目实战中以迭代的方式反复进行,以实现最优的效果。

机器学习项目实战的5个环节
现在就详细说说机器学习项目实战中的每个具体环节都在做些什么。
机器学习项目是相当直观的。换句话说,机器学习项目都是为了解决实际的问题而存在。
第一个环节是对问题的构建和概念化。同学们想象一下一个医生接到一个病人后,如果不仔细研究病情,分析问题出在何处,就直接开药、动手术,后果会如何呢?在心理咨询领域,有一个名词叫作 “个案概念化”。它的意思是心理咨询师通过观察分析,先评估界定来访者的问题,以指导后续的咨询进程;否则,可能很多次的咨询、治疗,都是在原地绕圈。
我们做机器学习项目,道理也很类似。如果每个团队成员都知道项目要解决的是什么问题,那么项目也许已经成功了一半,然而有很多人其实是不知道大方向所在的。
因此,不是一开始就建立模型,而是首先构建你的问题。反复问一问自己、问一问客户和其他项目干系人,目前的痛点是什么、要解决的问题是什么、目标是什么。对这些关键问题的回答可以说是相当重要的,但是很奇怪的是在现实中最关键的内容反而最有可能被忽略。
举例来说,看一下下面这个问题的定义。
■痛点:某商家准备推出一系列促销活动,目的是增加顾客黏性,降低流失率。但是如果促销活动的参与度不高,就不会有好的效果,力气也就白费。因此,只有设计出来的活动是顾客所感兴趣的,才会起到作用。
■现状:已经收集了过去几年顾客的信息及其行为模式数据,如顾客所购买商品的价格、数量、频率等。
■目标:根据已有的顾客行为模式数据,推断(学习)出最佳的商品和折扣项目,以确保设计出来的活动有较高的参与度。
这就是一个定义比较清楚,有可能起到作用的机器学习项目。再看一下下面这个问题的定义。
■痛点:股票市场的波动性大,难以预测。
■现状:已经收集了股票市场过去10年的详细信息,例如每一只股票每天的收盘价、月报、季报等。
■目标:通过学习历史数据,预测股市。
这个“预测股市”,看起来也许是机器学习问题,实际上可能是一个伪机器学习问题。因为对目标的定义太不具体了。预测股市的什么内容?是某只股票的第二天的价格,还是未来一个月整体的走势?而且机器学习是否能在股市预测中发挥作用?似乎不大可能。我们可以运用这样一个简单的方法去评判机器学习是否会生效:如果机器学习无法预测历史,它就无法预测未来。这是因为机器学习只能识别出它曾经见过的东西。要想在过去的数据的基础上预测未来,其实存在一个假设,就是未来的规律与过去相同。但对于股价而言,事实往往并非如此[6]。也就是说,即使用1998—2007年的全部数据去训练机器,机器也不能预测出2008年的金融危机,因此它也不大可能成功预测未来。
小冰点头称是。
咖哥接着说:“下面我们一边讲,一边同步进行另一个机器学习项目的实战。”
这里要向大家介绍MNIST数据集。这个数据集相当于是机器学习领域的Hello World,非常的经典,里面包含60 000张训练图像和10 000张测试图像,都是28px×28px的手写数字灰度图像,如下图所示。”
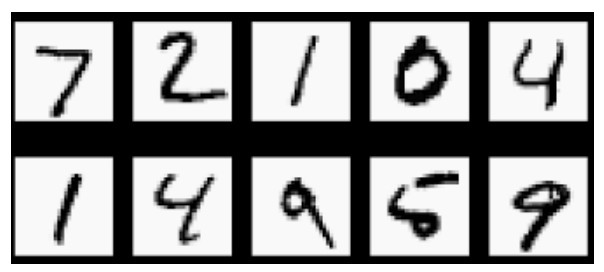
MNIST数据集中的手写数字灰度图像
此处要解决的问题是:将手写数字灰度图像分类为0,1,2,3,4,5,6,7,8,9,共10个类别。
 咖哥发言
咖哥发言
灰度图像与黑白图像不同哦,黑白图像只有黑、白两种颜色,对应的像素的值是0和1;而灰度图像在黑色与白色之间还有许多灰度级别,取值为0~255。
数据是机器学习的燃料。机器学习项目的成败,数据很可能是关键。
下面主要介绍以下内容。
■原始数据的准备。
■数据的预处理。
■特征工程和特征提取。
■载入MNIST数据集。
1.原始数据的准备
原始数据如何获得呢?有时候是自有的数据(如互联网公司拥有的大量的客户资料、购物行为历史信息),或者需要上网爬取数据;有时候是去各种开源数据网站下载(Image Net、Kaggle、Google Public Data Explorer,甚至Youtube和维基百科,都是机器学习的重要数据源),或者可以购买别人的数据。
2.数据的预处理
从本机或者网络中载入原始数据之后,预处理工作包括以下几个部分。
■可视化(visualization):要用Excel表和各种数据分析工具(如前面说的Matplotlib或者Seaborn)从各种角度(如列表、直方图、散点图等)看一看数据。对数据有了基本的了解,才方便进一步分析判断。
■数据向量化(data vectorization):把原始数据格式化,使其变得机器可以读取。例如,将原始图片转换为机器可以读取的数字矩阵,将文字转换为one-hot编码,将文本类别(如男、女)转换成0、1这样的数值。
■处理坏数据和缺失值:一笔数据可不是全部都能用,要利用数据处理工具来把“捣乱”的“坏数据”(冗余数据、离群数据、错误数据)处理掉,把缺失值补充上。
■特征缩放(feature scaling):特征缩放方法有很多,包括数据标准化(standardization)和规范化(normalization)等。
□标准化,是对数据特征分布的转换,目标是使其符合正态分布(均值为0,标准差为1)。因为如果数据特征不符合正态分布的话,就会影响机器学习效率。在实践中,会去除特征的均值来转换数据,使其居中,然后除以特征的标准差来对其进行缩放。
□标准化的一种变体是将特征压缩到给定的最小值和最大值之间,通常为0~1。因此这种特征缩放方法也叫归一化。归一化不会改变数据的分布状态。
□规范化,则是将样本缩放为具有单位范数的过程,然后放入机器学习模型,这个过程消除了数据中的离群值。
□在Sklearn的preprocessing工具中可以找到很多特征缩放的方法。在实战中,要根据数据集和项目特点选择适宜的特征缩放方法。
数据预处理的原则如下。
■全部数据应转换成数字格式(即向量、矩阵、3D、4D、5D)的数组(张量)。
■大范围数据值要压缩成较小值,分布不均的数据特征要进行标准化。
■异质数据要同质化(homogenous),即同一个特征的数据类型要尽量相同。
3.特征工程和特征提取
特征工程和特征提取仍然是在机器对数据集学习之前进行的操作,广义上也算数据预处理。
■特征工程是使用数据的领域知识来创建使机器学习算法起作用的特征的过程。特征工程是机器学习的重要环节,然而这个环节实施困难又开销昂贵,相当费时费力。
■特征提取(feature extraction)则是通过子特征的选择来减少冗余特征,使初始测量数据更简洁,同时保留最有用的信息。
为什么要对数据的特征进行处理?因为机器学习之所以能够学到好的算法,关键看特征的质量。那就需要思考下面的问题。
(1)如何选择最有用的特征给机器进行学习?(进行特征提取。)
(2)如何把现有的特征进行转换、强化、组合,创建出来新的、更好的特征?(进行特征 工程。)
比如,对于图像数据,可以通过计算直方图来统计图像中像素强度的分布,得到描述图像颜色的特征。又比如,通过调整原始输入数据的坐标轴的方向(坐标变换),就有可能使问题得到更好的描述。总而言之,就是通过各种手段让数据更好地为机器所用。
在深度学习时代,对于一部分机器学习问题,自动化的特征学习可以减少对手动特征工程的需求。但特征工程在另一些机器学习问题中,仍然是不可或缺的环节。
4.载入MNIST数据集
下面用1.2.4节中介绍过的方法新建一个Kaggle Notebook,并在其中直接载入Keras自带的MNIST数据集,如下段代码所示(注意,需要打开屏幕右侧Settings的Internet选项才能载入该数据集,如下图所示)。
import numpy as np # 导入Num Py库
import pandas as pd # 导入Pandas库
from keras.datasets import mnist #从Keras中导入MNIST数据集
#读入训练集和测试集
(X_train_image, y_train_lable), (X_test_image, y_test_lable) = mnist.load_data()
Kaggle Notebook的Internet选项
单击Kaggle Notebook中的 图标运行上面的代码后,这个数据集里面的数据就被读入以下Num Py张量。
图标运行上面的代码后,这个数据集里面的数据就被读入以下Num Py张量。
■X_train_image:训练集特征—图片。
■y_train_lable:训练集标签—数字。
■X_test_image:测试集特征—图片。
■y_test_lable:测试集标签—数字。
数据向量化的工作MNIST数据集已经为我们做好了,可以直接显示这些张量里面的内容:
print ("数据集张量形状:", X_train_image.shape) #用shape方法显示张量的形状
print ("第一个数据样本:\n", X_train_image[0]) #注意Python的索引是从0开始的
代码运行后的输出结果如下:
数据集张量形状:(60000,28,28)
第一个数据样本:
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
… …
… …
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253
225 172 253 242 195 64 0 0 0 0]
[ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251
93 82 82 56 39 0 0 0 0 0]
… …
… …
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]]
shape方法显示的是X_train_image张量的形状。灰度图像数据集是3D张量,第一个维度是样本维(也就是一张一张的图片,共60 000张),后面两个是特征维(也就是图片的28px×28px的矩阵)。因为28px×28px的矩阵太大,这里省略了部分输入内容,你们可以发现灰度信息主要集中在矩阵的中部,边缘部分都是0填充,是图片的背景。数字矩阵的内容差不多如下图所示。
再看一下标签的格式:
print ("第一个数据样本的标签:", y_train_lable[0])

数字矩阵存储图片信息的方式—这个矩阵就是机器需要学习的内容
输出显示数字8—上面这么大的一个数字矩阵,到头来只变成一个简单的信息8:
第一个数据样本的标签:8
上面的数据集在输入机器学习模型之前还要做一些数据格式转换的工作:
from keras.utils import to_categorical # 导入keras.utils工具库的类别转换工具
X_train = X_train_image.reshape(60000, 28, 28, 1) # 给标签增加一个维度
X_test = X_test_image.reshape(10000, 28, 28, 1) # 给标签增加一个维度
y_train = to_categorical(y_train_lable, 10) # 特征转换为one-hot编码
y_test = to_categorical(y_test_lable, 10) # 特征转换为one-hot编码
print ("训练集张量形状:", X_train.shape) # 训练集张量的形状
print ("第一个数据标签:", y_train[0]) # 显示标签集的第一个数据
输出新的数据格式:
训练集张量形状:(60000, 28, 28, 1)
第一个数据标签:[0.0.0.0.0.0.0.0.1.0.]
解释一下为何需要新的格式。
(1)Keras要求图像数据集导入卷积网络模型时为4阶张量,最后一阶代表颜色深度,灰度图像只有一个颜色通道,可以设置其值为1。
(2)在机器学习的分类问题中,标签[0.0.0.0.0.0.0.0.1.0.]就代表着类别值8。这是等会儿还要提到的one-hot编码。
第3个环节先是选择机器学习模型的算法类型,然后才开始训练机器确定参数。
各种Python机器学习框架中有很多类型的算法,主要包括以下几种。
■线性模型(线性回归、逻辑回归)。
■非线性模型(支持向量机、k最邻近分类)。
■基于树和集成的模型(决策树、随机森林、梯度提升树等)。
■神经网络(人工神经网络、卷积神经网络、长短期记忆网络等)。
那么究竟用哪个呢?
答案是—这与要解决的问题有关。没有最好的算法,也没有最差的算法。随机森林也许处理回归类型问题很给力,而神经网络则适合处理特征量巨大的数据,有些算法还能够通过集成学习的方法组织在一起使用。只有通过实践和经验的积累,深入地了解各个算法,才能慢慢地形成“机器学习直觉”。遇见的多了,一看到问题,就知道大概何种算法比较适合。
那么我们为MNIST数据集手写数字识别的问题选择什么算法作为机器学习模型呢?这里挑一个图片处理最强的工具,就是大名鼎鼎的卷积神经网络。
咖哥此处忽然笑了两声。小冰说:“你笑什么呢?”咖哥说:“卷积神经网络处理这个MNIST小问题,我都觉得‘杀鸡用牛刀’了。下面看看代码吧。”
from keras import models # 导入Keras模型, 以及各种神经网络的层
from keras.layers import Dense, Dropout, Flatten, Conv2D, Max Pooling2D
model = models.Sequential() # 用序贯方式建立模型
model.add(Conv2D(32, (3, 3), activation='relu', # 添加Conv2D层
input_shape=(28, 28, 1))) # 指定输入数据样本张量的类型
model.add(Max Pooling2D(pool_size=(2, 2))) # 添加Max Pooling2D层
model.add(Conv2D(64, (3, 3), activation='relu')) # 添加Conv2D层
model.add(Max Pooling2D(pool_size=(2, 2))) # 添加Max Pooling2D层
model.add(Dropout(0.25)) # 添加Dropout层
model.add(Flatten()) # 展平
model.add(Dense(128, activation='relu')) # 添加全连接层
model.add(Dropout(0.5)) # 添加Dropout层
model.add(Dense(10, activation='softmax')) # Softmax分类激活, 输出10维分类码
# 编译模型
model.compile(optimizer='rmsprop', # 指定优化器
loss='categorical_crossentropy', # 指定损失函数
metrics=['accuracy']) # 指定验证过程中的评估指标
这里先简单地解释一下代码中都做了些什么(当然更多的细节要以后再说)。这段代码把数据集放入卷积神经网络进行处理。这个网络中包括两个Conv2D(二维卷积)层,两个MaxPooling2D(最大池化)层,两个Dropout层用于防止过拟合,还有Dense(全连接)层,最后通过Softmax分类器输出预测标签y'值,也就是所预测的分类值。这个y'值,是一个one-hot(即“一位有效编码”)格式的10维向量。我们可以将y'与标签真值y进行比较,以计算预测的准确率。整个过程如下图所示。
 咖哥发言
咖哥发言
我当然知道上面这段话里面出现了很多生词,比如Softmax、卷积、最大池化、过拟合、one-hot、10维向量等,我们后面将一点一点把这些词语全部搞明白。现在的目的主要是解释项目实战的流程,所以大家先不要害怕新概念,耐心一点跟着我往下走。
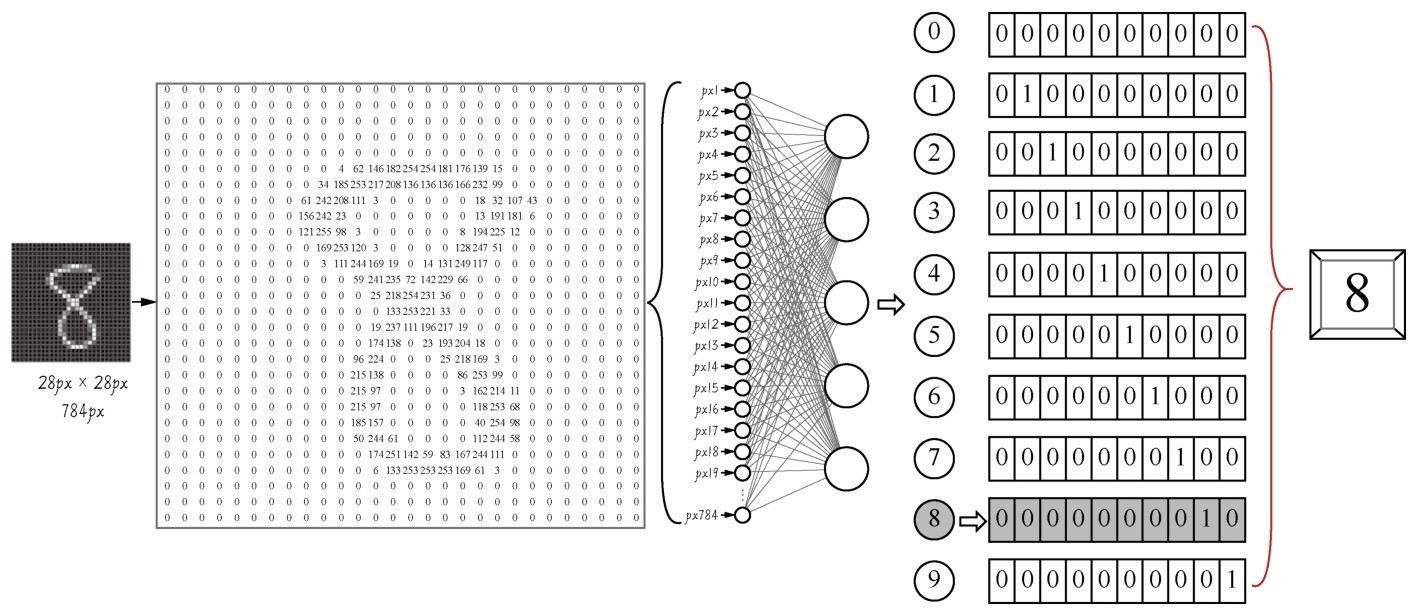
卷积神经网络实现手写数字识别
确定机器学习模型的算法类型之后,就进行机器的学习,训练机器以确定最佳的模型内部参数,并使用模型对新数据集进行预测。之所以说在这一环节中确定的是模型内部参数,是因为机器学习中还有超参数的概念。
■内部参数:机器学习模型的具体参数值,例如线性函数y=2x+1,其中的2和1就是模型内参数。在机器学习里面这叫作权重(weight)和偏置(bias)。神经网络也类似,每一个节点都有自己的权重(或称kernel),网络的每一层也有偏置。模型内参数在机器的训练过程中被确定,机器学习的过程就是把这些参数的最佳值找出来。
■超参数(hyperparameter):位于机器学习模型的外部,属于训练和调试过程中的参数。机器学习应该迭代(被训练)多少次?迭代时模型参数改变的速率(即学习率)是多大?正则化参数如何选择?这些都是超参数的例子,它们需要在反复调试的过程中被最终确定。这是机器学习第5个环节中所着重要做的工作。
下面用fit(拟合)方法,开始对机器进行5轮的训练:
model.fit(X_train, y_train, # 指定训练特征集和训练标签集
validation_split = 0.3, # 部分训练集数据拆分成验证集
epochs=5, # 训练轮次为5轮
batch_size=128) # 以128为批量进行训练
在上面的训练过程中,fit方法还自动地把训练集预留出30%的数据作为验证集(马上就会讲到什么是验证集),来验证模型准确率。
输出结果如下:
Train on 42000 samples, validate on 18000 samples
Epoch 1/5
42000/42000 [==============================] - 62s 1ms/step - loss: 0.9428 -
accuracy: 0.8827 - val_loss: 0.1172 - val_accuracy: 0.9677
Epoch 2/5
42000/42000 [==============================] - 61s 1ms/step - loss: 0.1422 -
accuracy: 0.9605 - val_loss: 0.0917 - val_accuracy: 0.9726
Epoch 3/5
42000/42000 ============================== - 62s 1ms/step - loss: 0.1065 -
accuracy: 0.9700 - val_loss: 0.0735 - val_accuracy: 0.9807
Epoch 4/5
42000/42000 [==============================] - 61s 1ms/step - loss: 0.0885 -
accuracy: 0.9756 - val_loss: 0.0602 - val_accuracy: 0.9840
Epoch 5/5
42000/42000 [==============================] - 61s 1ms/step - loss: 0.0813 -
accuracy: 0.9779 - val_loss: 0.0692 - val_accuracy: 0.9842
以上显示的5轮训练中,准确率逐步提高。
■accuracy:代表训练集上的预测准确率,最后一轮达到0.977 9。
■val_accuracy:代表验证集上的预测准确率,最后一轮达到0.984 2。
小冰发问:“刚才预测加州房价也是用的fit方法,怎么没看见程序输出这个一轮一轮的训练过程信息呢?”咖哥说:“我们现在训练的是神经网络,训练一次称为一轮。刚才用的是Sklearn里面的Linear Regression模型,训练的过程也是经过了多次迭代,只是该过程已经完全封装在方法内部了,并没有显示出来。”
小冰又问:“那么训练5轮之后,咱们这个卷积神经网络模型的模型内参数都是什么呢?怎么看呢?”咖哥说:“那是看不到的,因为卷积神经网络中的参数太多了,以万为计。但是我们可以把训练好的模型保存下来,以供将来调用。”
机器学习重在评估,只有通过评估,才能知道当前模型的效率,才能在不同模型或同一模型的不同超参数之间进行比较。举例来说,刚才的训练轮次—5轮,是一个超参数。我们想知道对于当前的卷积神经网络模型来说,训练多少轮对于MNIST数据集最为合适。这就是一个调试超参数的例子,而这个过程中需要各种评估指标作为调试过程的“风向标”。正确的评估指标相当重要,因为如果标准都不对,最终模型的效果会南辕北辙,性能优化更是无从谈起。
下面介绍两个重要的评估点。
■在机器训练过程中,对于模型内部参数的评估是通过损失函数进行的。以后还要详细介绍各种损失函数,例如回归问题的均方误差函数、分类问题的交叉熵(就是本例中的categorical_crossentropy)函数,都是内部参数的评估方法。这些损失函数指出了当前模型针对训练集的预测误差。这个过程在第4个环节中,调用fit方法后就已经完成了。
■在机器训练结束后,还要进行验证,验证过程采用的评估方式包括前面出现过的R2分数以及均方误差函数、平均绝对误差函数、交叉熵函数等各种标准。目前的这个卷积神经网络模型中的参数设定项metrics=['accuracy'],指明了以accuracy,即分类的准确率作为验证指标。验证过程中的评估,既评估了模型的内部参数,也评估了模型的超参数。
1.训练集、验证集和测试集
为了进行模型的评估,一般会把数据划分成3个集合:训练数据集、验证数据集和测试数据集,简称训练集(trainsing set)、验证集(validation set)和测试集(test set)。在训练集上训练模型,在验证集上评估模型。感觉已经找到最佳的模型内部参数和超参数之后,就在测试集上进行最终测试,以确定模型。
小冰问:“一个训练集和一个测试集还不够吗?”
咖哥答道:“也许简单的机器学习项目,2个集合也就够了。但是大型机器学习项目,至少需要3个集合”。
机器学习模型训练时,会自动调节模型内部参数。这个过程中经常出现过拟合(overfit)的现象。过拟合现在是个新名词,不过后面我们几乎随时都要和过拟合现象作战。目前来说,大家可以把过拟合理解为模型对当前数据集的针对性过强了,虽然对训练集拟合效果很好,但是换一批新数据就不灵了。这叫作模型的泛化能力弱。
解决了在训练集上的过拟合问题之后,在继续优化模型的过程中,又需要反复地调整模型外部的超参数,这个过程是在训练集和验证集中共同完成的。这个调试、验证过程会导致模型在验证集上也可能过拟合,因为调试超参数本身也是一种训练。这个现象叫作信息泄露(information leak)。也就是说,即使我们选择了对验证集效果最好的超参数,这个好结果也不一定真的能泛化到最终的测试集。
即使得到的模型在验证集上的性能已经非常好,我们关心的还是模型在全新数据上的性能。因此,我们需要使用一个完全不同的、前所未见的数据集来对模型进行最终的评估和校正,它就是测试集。在最终验证之前,我们的模型一定不能读取任何与测试集有关的任何信息,一次也不行。
下面就在MNIST测试集上进行模型效率的验证,如下段代码所示。这个测试集的任何数据信息都没有在模型训练的过程中暴露过。
score = model.evaluate(X_test, y_test) # 在验证集上进行模型评估
print('测试集预测准确率:', score[1]) # 输出测试集上的预测准确率
结果显示测试准确率达到0.983 8,成绩相当不错:
测试集预测准确率: 0.9838
2.K折验证
上面的测试集测试结果相当不错,但问题是,如果最终验证结果仍不尽如人意的话,那么继续调试和优化就会导致这个最终的测试集又变成了一个新的验证集。因此需要大量新数据的供给,以创造出新的测试数据集。
数据,很多时候都是十分珍贵的。因此,如果有足够的数据可用,一般来说按照60%、20%、20%的比例划分为训练集、验证集和测试集。但是如果数据本身已经不大够用,还要拆分出3个甚至更多个集合,就更令人头疼。而且样本数量过少,学习出来的规律会失去代表性。因此,机器学习中有重用同一个数据集进行多次验证的方法,即K折验证,如下图所示。
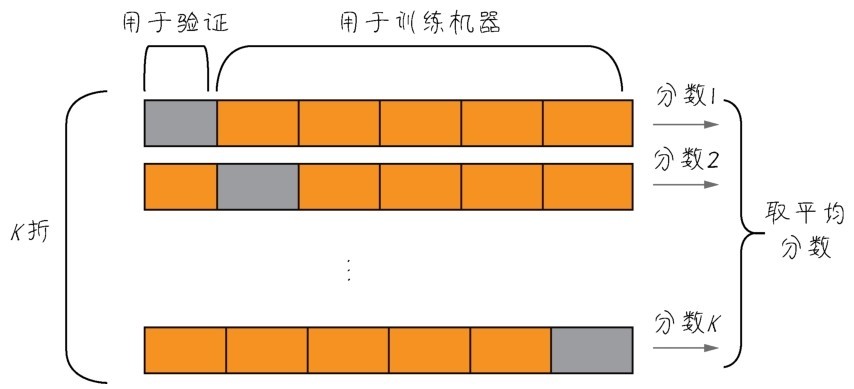
K折验证将数据划分为大小相同的K个分区
K折验证(K-fold validation)的思路是将数据划分为大小相同的K个分区,对于每个分区,都在剩余的K-1个分区上训练模型,然后在留下的分区上评估模型。最终分数等于K个分数的平均值。对于数据集的规模比较小或者模型性能很不稳定的情况,这是一种很有用的方法。注意K折验证仍需要预留独立的测试集再次进行模型的校正[7]。
3.模型的优化和泛化
优化(optimization)和泛化(generalization),这是机器学习的两个目标。它们之间的关系很微妙,是一种此消彼长的状态。
■如何成功地拟合已有的数据,这是性能的优化。
■但是更为重要的是如何把当前的模型泛化到其他数据集。
模型能否泛化,也许比模型在当前数据集上的性能优化更重要。经过训练之后100张猫图片都能被认出来了,但是也没什么了不起,因为这也许是通过死记硬背实现的,再给几张新的猫图片,就不认识了。这就有可能是出现了“过拟合”的问题—机器学习到的模型太过于关注训练数据本身。
关于优化、泛化和过拟合,这里就先蜻蜓点水式地简单说说它们的概念。在后面的课程中还会很详细地讲如何避免过拟合的问题。而对于目前的MNIST数据集,卷积神经网络模型是没有出现过拟合的问题的,因为在训练集、验证集和测试集中,评估后的结果都差不多,预测准确率均为98%以上,所以模型泛化功能良好。
这时小冰又开口了:“我憋了半天,一直想问一个问题呢。这里预测准确率是给出来了,但是具体的预测结果在什么地方呢?你说的百分之九十八点多少,我也没看见啊?怎么证明呢?”
小冰一说,其他同学频频点头。
4.怎么看预测结果
其实在测试集上进行评估之后,机器学习项目就大功告成了。想知道具体的预测结果,可以使用predict方法得到模型的预测值。下面看看代码吧。
pred = model.predict(X_test[0].reshape(1, 28, 28, 1)) # 预测测试集第一个数据
print(pred[0], "转换一下格式得到:", pred.argmax()) # 把one-hot编码转换为数字
import matplotlib.pyplot as plt # 导入绘图工具包
plt.imshow(X_test[0].reshape(28, 28), cmap='Greys') # 输出这个图片
前两行代码,是对测试集第一个数据(Python索引是从0开始的)进行预测,并输出预测结果。argmax方法就是输出数组里面最大元素的索引,也就是把one-hot编码转换为实际数值。
输出结果如下:
[[0.0.0.0.0.0.0.1.0.0.]]转换一下格式得到:7
后面的plt.imshow函数则输出原始图片,如下图所示。
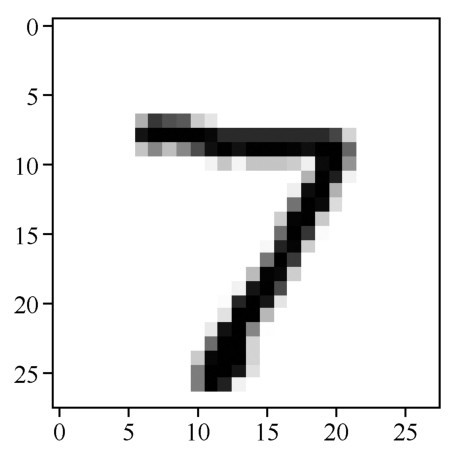
原始图片:手写数字7
果然是正确答案7,与预测结果的one-hot编码相匹配,证明预测对了!
5.调试过程出错怎么办
前面的实战过程都比较顺利,那是因为代码都是现成的。然而,在同学们自己进行Python程序调试、运行的时候,难免遇到系统报错。这些信息有时只是Warning(警告),说明一些参数或设置可能要过时了,但是目前还能用。这些警告信息暂时可以忽略,也可以跟着Python的提示进行修正。
然而,如果出现类似于下图所示的Error信息,说明程序代码出错了。这时不要着急, Python会用箭头指出出错的语句,接着给出出错的具体原因。跟着这些信息,需要进行相应的代码修改。
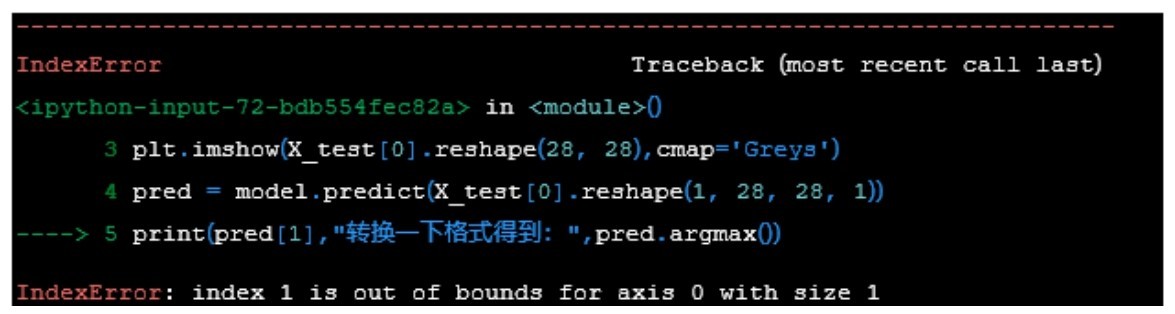
Error信息
很难预测到具体实战时会出现什么样的错误。此时,不要恐慌,冷静分析是第一步。如果多次尝试也无法解决问题,去Google搜索一下报错的内容,可能就会得到答案,或者,鼓起勇气请教身边的Python“专家”吧。
在本节的最后,再强调一下,在机器学习实战开始之前,以及过程当中,应反复问问自己以下几个问题。
■要解决的问题是什么,即机器学习项目的最终目标是什么?
■我们目前拥有或者要搜集的数据集是哪种类型?数值型、类别型还是图像?
■有现成的数据吗?数据集搜集整理过程中可能会遇到哪些困难?
■以目前的知识来看,哪些算法可能是比较好的选择?
■如何评判算法的优劣,即如何定义和衡量机器学习的“准确率”?
那么如果机器学习模型的调试过程中出现了问题,原因会出在哪里呢?可能出在任何一个环节:问题定义得不好,数据集质量不好,模型选得不好,机器训练得不好,评估调试得不好,都有可能使机器学习项目停止,无法进一步优化。