---
title: '带权重的随机选择算法'
tags: ['数组', '随机算法', '二分查找', '前缀和数组']
---




**通知:[数据结构精品课](https://aep.h5.xeknow.com/s/1XJHEO) 已更新到 V2.1,[手把手刷二叉树系列课程](https://aep.xet.tech/s/3YGcq3) 上线。[第 18 期每日打卡](https://aep.xet.tech/s/2PLO1n) 开始报名。反馈或修正 chatGPT 翻译的多语言代码 [点击这里](https://github.com/labuladong/fucking-algorithm/issues/1113)。另外,建议你在我的 [网站](https://labuladong.github.io/algo/) 学习文章,体验更好。**
读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
| LeetCode | 力扣 | 难度 |
| :----: | :----: | :----: |
| [528. Random Pick with Weight](https://leetcode.com/problems/random-pick-with-weight/) | [528. 按权重随机选择](https://leetcode.cn/problems/random-pick-with-weight/) | 🟠
| - | [剑指 Offer II 071. 按权重生成随机数](https://leetcode.cn/problems/cuyjEf/) | 🟠
**-----------**
写这篇的文章的原因是玩 LOL 手游。
我有个朋友抱怨说打排位匹配的队友太菜了,我就说我打排位觉得队友都挺行的啊,好像不怎么坑?
朋友意味深长地说了句:一般隐藏分比较高的玩家,排位如果排不到实力相当的队友,就会排到一些菜狗。
嗯?我想了几秒钟感觉这小伙子不对劲,他意思是说我隐藏分低,还是说我就是那条菜狗?
我立马要求和他开黑打一把,证明我不是菜狗,他才是菜狗。开黑结果这里不便透露,大家猜猜吧。
打完之后我就来发文了,因为我对游戏的匹配机制有了一点思考。

**所谓「隐藏分」我不知道是不是真的,毕竟匹配机制是所有竞技类游戏的核心环节,想必非常复杂,不是简单几个指标就能搞定的**。
但是如果把这个「隐藏分」机制简化,倒是一个值得思考的算法问题:系统如何以不同的随机概率进行匹配?
或者简单点说,如何带权重地做随机选择?
不要觉得这个很容易,如果给你一个长度为 `n` 的数组,让你从中等概率随机抽取一个元素,你肯定会做,random 一个 `[0, n-1]` 的数字出来作为索引就行了,每个元素被随机选到的概率都是 `1/n`。
但假设每个元素都有不同的权重,权重地大小代表随机选到这个元素的概率大小,你如何写算法去随机获取元素呢?
力扣第 528 题「按权重随机选择」就是这样一个问题:

我们就来思考一下这个问题,解决按照权重随机选择元素的问题。
### 解法思路
首先回顾一下我们和随机算法有关的历史文章:
前文 [设计随机删除元素的数据结构](https://labuladong.github.io/article/fname.html?fname=随机集合) 主要考察的是数据结构的使用,每次把元素移到数组尾部再删除,可以避免数据搬移。
前文 [谈谈游戏中的随机算法](https://labuladong.github.io/article/fname.html?fname=随机算法) 讲的是经典的「水塘抽样算法」,运用简单的数学运算,在无限序列中等概率选取元素。
前文 [算法笔试技巧](https://labuladong.github.io/article/fname.html?fname=刷题技巧) 中我还分享过一个巧用概率最大化测试用例通过率的骗分技巧。
**不过上述旧文并不能解决本文提出的问题,反而是前文 [前缀和技巧](https://labuladong.github.io/article/fname.html?fname=前缀和技巧) 加上 [二分搜索详解](https://labuladong.github.io/article/fname.html?fname=二分查找详解) 能够解决带权重的随机选择算法**。
这个随机算法和前缀和技巧和二分搜索技巧能扯上啥关系?且听我慢慢道来。
假设给你输入的权重数组是 `w = [1,3,2,1]`,我们想让概率符合权重,那么可以抽象一下,根据权重画出这么一条彩色的线段:

如果我在线段上面随机丢一个石子,石子落在哪个颜色上,我就选择该颜色对应的权重索引,那么每个索引被选中的概率是不是就是和权重相关联了?
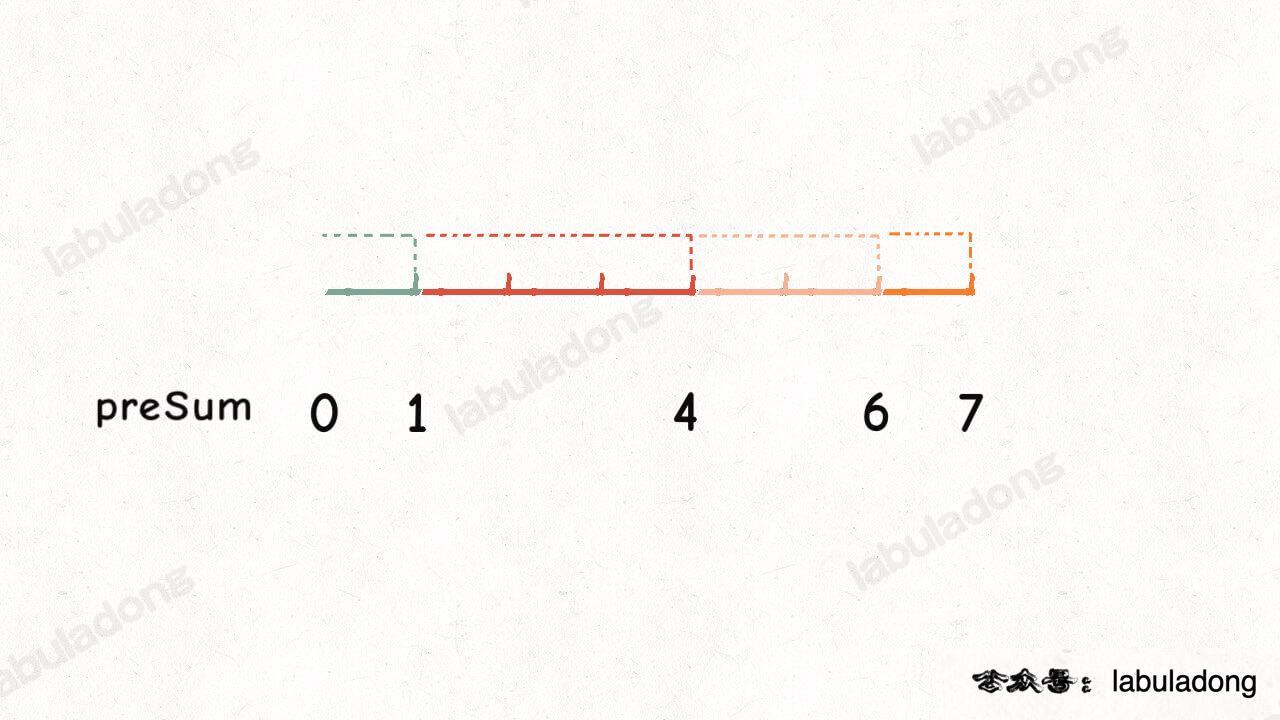
**所以,你再仔细看看这条彩色的线段像什么?这不就是 [前缀和数组](https://labuladong.github.io/article/fname.html?fname=前缀和技巧) 嘛**:
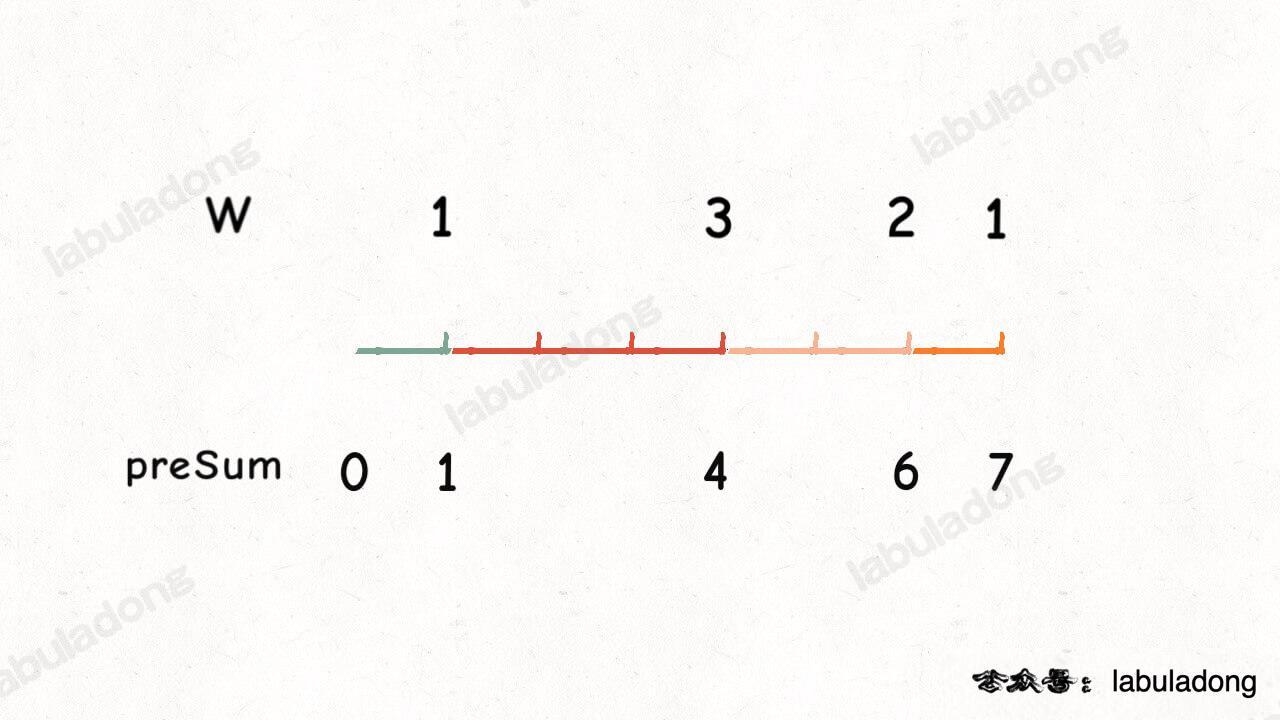
那么接下来,如何模拟在线段上扔石子?
当然是随机数,比如上述前缀和数组 `preSum`,取值范围是 `[1, 7]`,那么我生成一个在这个区间的随机数 `target = 5`,就好像在这条线段中随机扔了一颗石子:
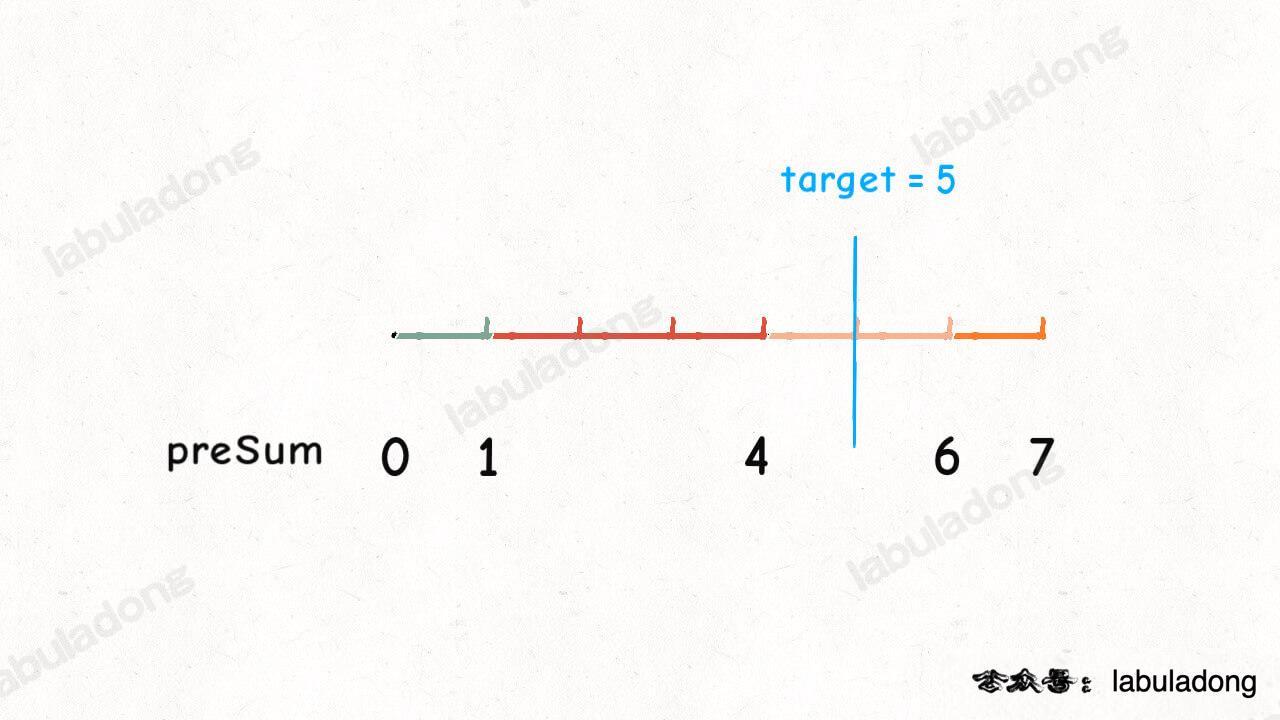
还有个问题,`preSum` 中并没有 5 这个元素,我们应该选择比 5 大的最小元素,也就是 6,即 `preSum` 数组的索引 3:
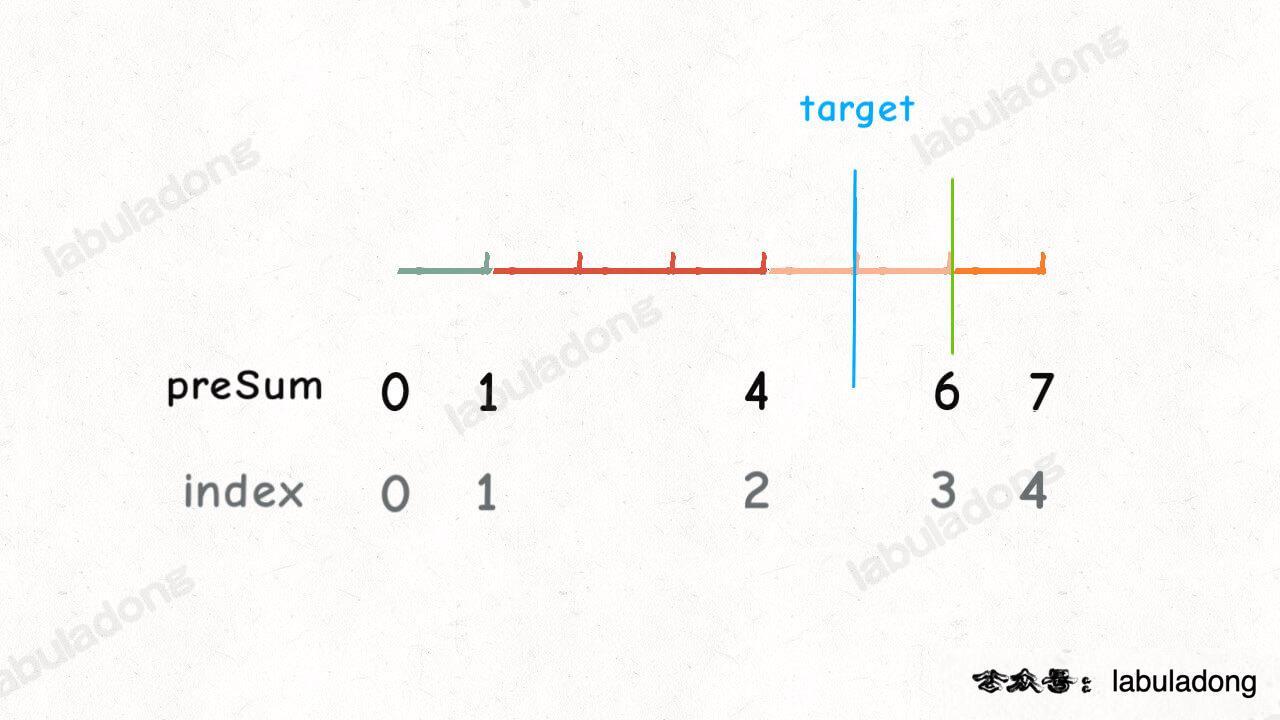
**如何快速寻找数组中大于等于目标值的最小元素?[二分搜索算法](https://labuladong.github.io/article/fname.html?fname=二分查找详解) 就是我们想要的**。
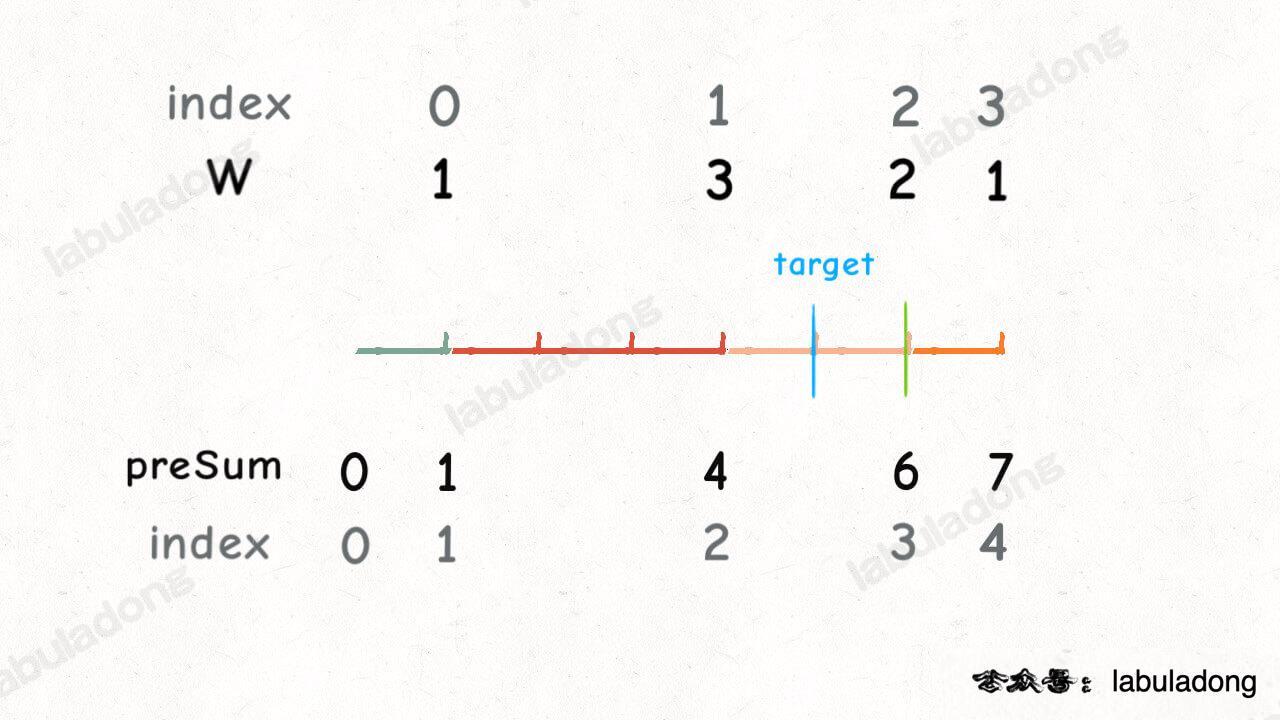
到这里,这道题的核心思路就说完了,主要分几步:
1、根据权重数组 `w` 生成前缀和数组 `preSum`。
2、生成一个取值在 `preSum` 之内的随机数,用二分搜索算法寻找大于等于这个随机数的最小元素索引。
3、最后对这个索引减一(因为前缀和数组有一位索引偏移),就可以作为权重数组的索引,即最终答案:
### 解法代码
上述思路应该不难理解,但是写代码的时候坑可就多了。
要知道涉及开闭区间、索引偏移和二分搜索的题目,需要你对算法的细节把控非常精确,否则会出各种难以排查的 bug。
下面来抠细节,继续前面的例子:

就比如这个 `preSum` 数组,你觉得随机数 `target` 应该在什么范围取值?闭区间 `[0, 7]` 还是左闭右开 `[0, 7)`?
都不是,应该在闭区间 `[1, 7]` 中选择,**因为前缀和数组中 0 本质上是个占位符**,仔细体会一下:
所以要这样写代码:
```java
int n = preSum.length;
// target 取值范围是闭区间 [1, preSum[n - 1]]
int target = rand.nextInt(preSum[n - 1]) + 1;
```
接下来,在 `preSum` 中寻找大于等于 `target` 的最小元素索引,应该用什么品种的二分搜索?搜索左侧边界的还是搜索右侧边界的?
实际上应该使用搜索左侧边界的二分搜索:
```java
// 搜索左侧边界的二分搜索
int left_bound(int[] nums, int target) {
if (nums.length == 0) return -1;
int left = 0, right = nums.length;
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
right = mid;
} else if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid;
}
}
return left;
}
```
前文 [二分搜索详解](https://labuladong.github.io/article/fname.html?fname=二分查找详解) 着重讲了数组中存在目标元素重复的情况,没仔细讲目标元素不存在的情况,这里补充一下。
**当目标元素 `target` 不存在数组 `nums` 中时,搜索左侧边界的二分搜索的返回值可以做以下几种解读**:
1、返回的这个值是 `nums` 中大于等于 `target` 的最小元素索引。
2、返回的这个值是 `target` 应该插入在 `nums` 中的索引位置。
3、返回的这个值是 `nums` 中小于 `target` 的元素个数。
比如在有序数组 `nums = [2,3,5,7]` 中搜索 `target = 4`,搜索左边界的二分算法会返回 2,你带入上面的说法,都是对的。
所以以上三种解读都是等价的,可以根据具体题目场景灵活运用,显然这里我们需要的是第一种。
综上,我们可以写出最终解法代码:
```java
class Solution {
// 前缀和数组
private int[] preSum;
private Random rand = new Random();
public Solution(int[] w) {
int n = w.length;
// 构建前缀和数组,偏移一位留给 preSum[0]
preSum = new int[n + 1];
preSum[0] = 0;
// preSum[i] = sum(w[0..i-1])
for (int i = 1; i <= n; i++) {
preSum[i] = preSum[i - 1] + w[i - 1];
}
}
public int pickIndex() {
int n = preSum.length;
// Java 的 nextInt(n) 方法在 [0, n) 中生成一个随机整数
// 再加一就是在闭区间 [1, preSum[n - 1]] 中随机选择一个数字
int target = rand.nextInt(preSum[n - 1]) + 1;
// 获取 target 在前缀和数组 preSum 中的索引
// 别忘了前缀和数组 preSum 和原始数组 w 有一位索引偏移
return left_bound(preSum, target) - 1;
}
// 搜索左侧边界的二分搜索
private int left_bound(int[] nums, int target) {
// 见上文
}
}
```
有了之前的铺垫,相信你能够完全理解上述代码,这道随机权重的题目就解决了。
经常有读者留言调侃,每次都是看我的文章「云刷题」,看完就会了,也不用亲自动手刷了。
但我想说的是,很多题目思路一说就懂,但是深入一些的话很多细节都可能有坑,本文讲的这道题就是一个例子,所以还是建议多实践,多总结。
> 最后打个广告,我亲自制作了一门 [数据结构精品课](https://aep.h5.xeknow.com/s/1XJHEO),以视频课为主,手把手带你实现常用的数据结构及相关算法,旨在帮助算法基础较为薄弱的读者深入理解常用数据结构的底层原理,在算法学习中少走弯路。
引用本文的文章
- [谈谈游戏中的随机算法](https://labuladong.github.io/article/fname.html?fname=随机算法)
**_____________**
**《labuladong 的算法小抄》已经出版,关注公众号查看详情;后台回复关键词「**进群**」可加入算法群;回复「**全家桶**」可下载配套 PDF 和刷题全家桶**:

