While using Paddle V2 API for Training, data feeding completely depends on the Python code. To get rid of the Python environment and achieve the goal of "wrapping the whole training by a while loop op" in Paddle Fluid, a C++ data feeding mechanism is required.
While using Paddle V2 API for training, data feeding completely depends on the Python code. To get rid of the Python environment and achieve the goal of "wrapping the whole training by a while loop op" in Paddle Fluid, a C++ data feeding mechanism is required.
In this document we show the fundamental design of a C++ data feeding process, which includes data reading, shuffling and batching.
In this document, we show the fundamental design of a C++ data feeding process, which includes data reading, shuffling and batching.
## Overview

## Reader
## Reader
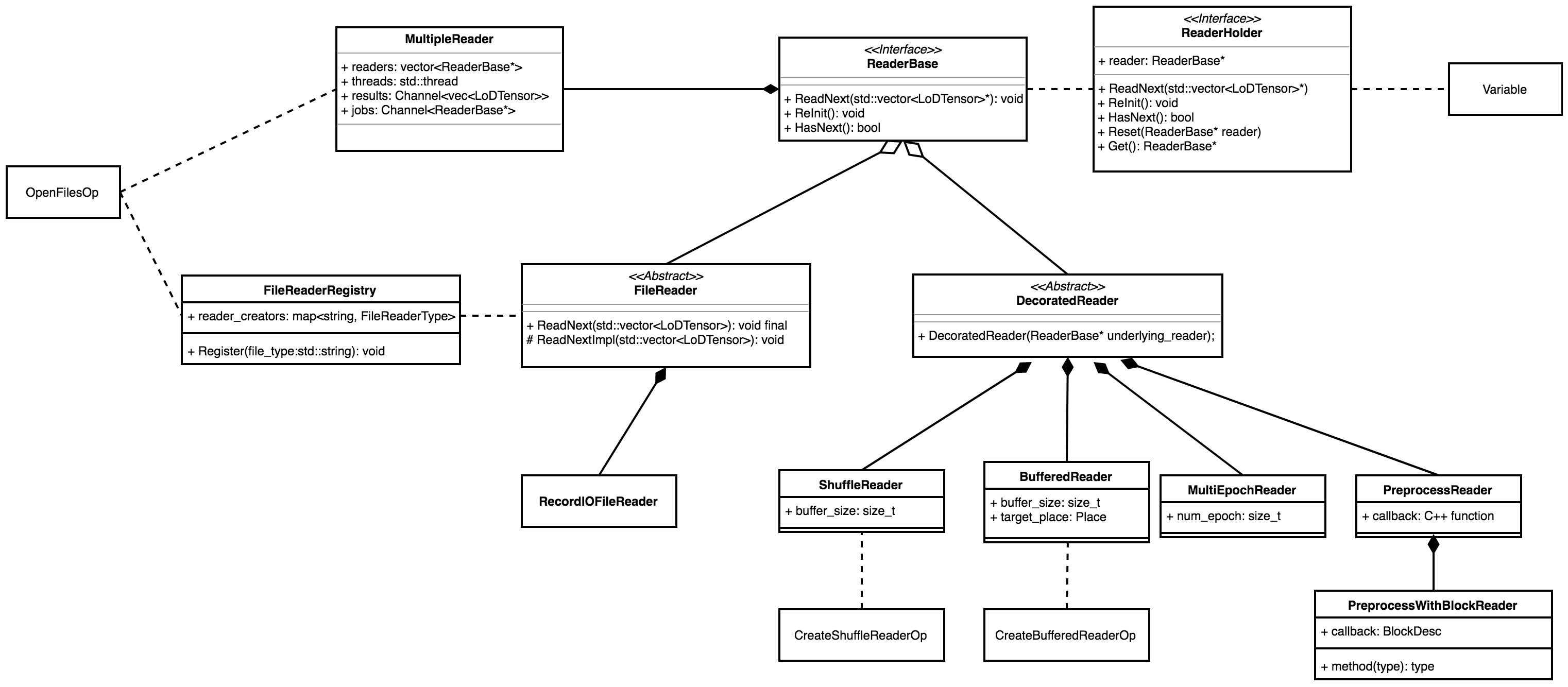
In order to handle the abovementioned problem, a new concept called 'Reader' is introduced. `Reader` is a series of inherited classes which can be held by our `Variable` and they are used to read or process file data.
In order to handle the above-mentioned problem, a new concept called 'Reader' is introduced. `Reader` is a series of inherited classes which can be held by our `Variable` and they are used to read or process file data.
### `ReaderBase`
### ReaderBase
`ReaderBase` is the abstract base class for all readers. It defines the interface for all readers.
`ReaderBase` is the abstract base class for all readers. It defines the interface for all readers.
A file reader binds with a single file and reads one data instance at a time. Each type of file reader shall implement its own `ReadNextImpl()`, `HasNext()` and `ReInit()`.
The `ReadNextImpl()` is invoked by `ReadNext()`. Besides invoking `ReadNextImpl()`, `ReadNext()` is also responsible for checking the output, making sure that each shape of `LoDTensor` in `*out` is consistent with the one in `dims_`.
### DecoratedReader
A decorated reader takes another reader(both file reader and decorated reader are OK) as its 'underlying reader'. It gets data from its underlying reader, does some processing on them(shuffling, batching or something else), then yields processed data. The output data of a decorated reader can be a single instance or a batch. `ShuffleReader` and `BatchReader` are both decorated readers.
Both the `FileReader` and `DecoratedReader` share exactly the same interface as defined in `ReaderBase`. So they can be decorated for multiple times: We can **shuffle** a reader's outputs and then **batch** the shuffled outputs. The interface consistency also allows related ops use readers without knowing their underlying type.
These two classes are derived from the `ReaderBase` and will further be derived by more specific readers. Thus, in our design, there are two kinds of readers: file readers and decorated readers. A file reader reads from a file of some specific format, and yield only one instance of data at a time. For example, RecordIO reader, jpg reader, .... A decorated reader takes another reader(both file reader and decorated reader are OK) as its 'underlying reader'. It gets data from its underlying reader, does some processing on them(shuffling, or batching), then yields processed data. The output data of a decorated reader can be a single instance or a batch. `ShuffleReader` and `BatchReader` are both decorated readers.
### MultipleReader
All the readers share exactly the same interface as defined in `ReaderBase`. So they can be decorated for more than one time: We can **shuffle** a reader's outputs and then **batch** the shuffle outputs. The interface consistency also allows related ops use readers without knowing what they are exactly.
All `FileReader` binds with a single file and are single-threaded. However, sometimes we need to read data from more than one file. In this case, it's not enough to only have `FileReader` and `DecoratedReader`.
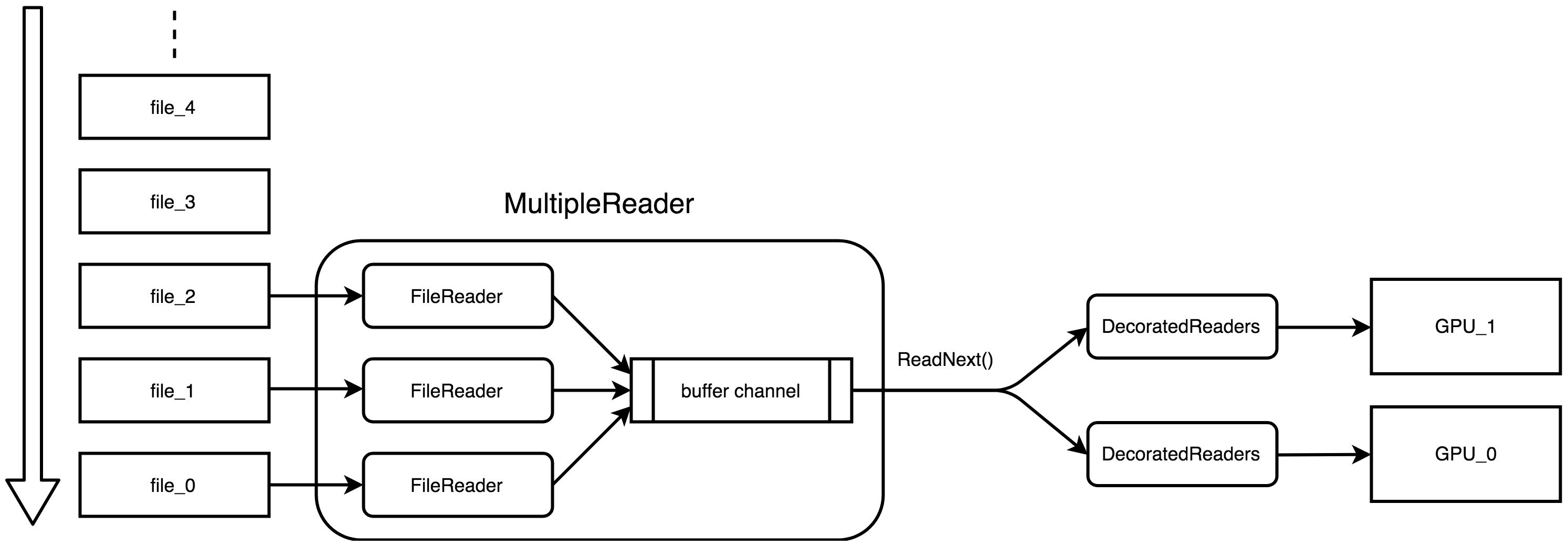
So `MultipleReader` is introduced. It is also derived from `ReaderBase`. A `MultipleReader` holds several prefetching `FileReaders` and these readers run concurrently. Another pivotal part of a `MultipleReader` is a buffer channel. The channel collects data yield by all prefetching readers and makes subsequent OPs or decorated readers be able to fetch data without concerning about multiple readers scheduling.
### `ReaderHolder`

This graph shows how a `MultipleReader` works with three prefetching file readers and two GPUs. There is a queue of files which are going to be read. Each time when a prefetching file reader is free(complete reading from one file), it fetches a new file from the queue. Each prefetching file reader runs in a separated prefetch thread and dumps their outputs to the same channel.
To the subsequent two decorated readers, the `MultipleReader` is **a single reader**. They don't need to concern about how prefetch readers are scheduled. They only need to invoke `MultipleReader::ReadNext()` to get the next data from the buffer channel.
### ReaderHolder
Different readers belong to different class types. This leads to a problem: How can we drop them into `Variable`s and fetch them out by a unified method? For example, if a Variable holds a `BatchReader`, we can not get it by the following code:
Different readers belong to different class types. This leads to a problem: How can we drop them into `Variable`s and fetch them out by a unified method? For example, if a Variable holds a `BatchReader`, we can not get it by the following code:
...
@@ -69,10 +113,59 @@ To solve this problem, we introduce `ReaderHolder` as a wrapper. It acts as an e
...
@@ -69,10 +113,59 @@ To solve this problem, we introduce `ReaderHolder` as a wrapper. It acts as an e
To create and invoke readers, some new ops are introduced:
To create and invoke readers, some new ops are introduced:
### `CreateReaderOp`
### CreateReaderOp
Each reader has its creation op. File readers' creation ops have no input and yield the created file reader as its output. Decorated readers' creation ops take the underlying readers as inputs and then yield new decorated readers.
Each reader has its creation op. File readers' creation ops have no input and yield the created file reader as its output. Decorated readers' creation ops take the underlying readers as inputs and then yield new decorated readers.
### `ReadOp`
However, direct usage of file readers' creation ops is not recommended because a file reader can only read one file via a single thread. Using `OpenFilesOp` is a better choice.
### OpenFilesOp
The `OpenFilesOp` is the creation op of `MultipleReader`. It takes no input but requires a list of file names as one of its attributes. The newly created `MultipleReader` then creates its own prefetching readers according to given file names.
To make sure that created prefetching readers match file formats, we need a name prefix rule to append file format tags to file names, as well as a file reader registry mechanism to map file format tags to their corresponding file readers' constructors.
### HasNextOp
`HasNextOp` is used to check whether the next data batch exists via the reader's `HasNext()` interface.
### ResetOp
`ResetOp` is used to reset a reader via its `ReInit()` interface.
### ReadOp
A reader is only a Variable. It cannot trigger the reading process by itself. So we add the `ReadOp` to execute it. A `ReadOp` takes a reader Variable as its input. Each time it runs, it invokes the reader‘s `ReadNext()` function and gets a new batch of data(or only one instance of data, if we use file reader directly). The output data of a reader are in the form of `std::vector<LoDTenosr>`, so the `ReadOp` also needs to split the vector and move LoDTensors to their respective output Variables.
A reader is only a Variable. It cannot trigger the reading process by itself. So we add the `ReadOp` to execute it. A `ReadOp` takes a reader Variable as its input. Each time it runs, it invokes the reader‘s `ReadNext()` function and gets a new batch of data(or only one instance of data, if we use file reader directly). The output data of a reader are in the form of `std::vector<LoDTenosr>`, so the `ReadOp` also needs to split the vector and move LoDTensors to their respective output Variables.
## Program with Readers
A `Program` holds readers as its persistable variables. These variables are created by `CreateReaderOp` or `OpenFilesOp`. These ops shall run only once. So they shall be settled in the `startup_program`. `HasNextOp`, `ResetOp` and `ReadOp` are required by training loop, so they shall be in the `main_program`.
The ops of a `startup_program` with readers would be like this:
The forwarding ops of the corresponding `main_program` would be like this:
```
while_op {
has_next = has_next_op(double_buffer_reader)
if_else_op(has_next) {
batch_data = read_op(double_buffer_reader)
... (subsequent training ops)
} else {
reset_op(double_buffer_reader)
}
}
```
Two important considerations for these programs are as follows:
1. The multiple\_reader is the batch\_reader's underlying reader, and the batch\_reader is the double\_buffer\_reader's underlying reader. `read_op`, `has_next_op` and other reader related ops will only invoke the top-most reader. In this case, it's the double\_buffer\_reader.
2. All readers exist in both `startup_program` and `main_program`. And they are persistable.
{kind=link}
{kind=link}