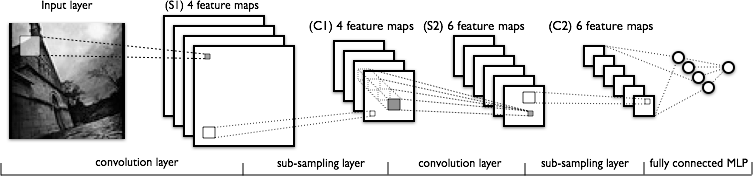
图像分类教程¶
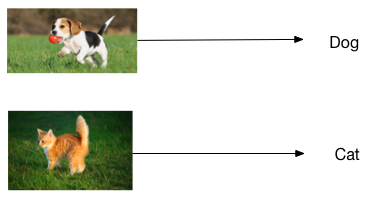
在本教程中,我们将使用CIFAR-10数据集训练一个卷积神经网络,并使用这个神经网络来对图片进行分类。如下图所示,卷积神经网络可以辨识图片中的主体,并给出分类结果。
数据准备¶
首先下载CIFAR-10数据集。下面是CIFAR-10数据集的官方网址:
https://www.cs.toronto.edu/~kriz/cifar.html
我们准备了一个脚本,可以用于从官方网站上下载CIFAR-10数据集,转为jpeg文件并存入特定的目录。使用这个脚本前请确认已经安装了pillow及相关依赖模块。可以参照下面的命令进行安装:
- 安装pillow
sudo apt-get install libjpeg-dev
pip install pillow
- 下载数据集
cd demo/image_classification/data/
sh download_cifar.sh
CIFAR-10数据集包含60000张32x32的彩色图片。图片分为10类,每个类包含6000张。其中50000张图片作为训练集,10000张作为测试集。
下图展示了所有的图片类别,每个类别中随机抽取了10张图片。

脚本运行完成后,我们应当会得到一个名为cifar-out的文件夹,其下子文件夹的结构如下
train
---airplane
---automobile
---bird
---cat
---deer
---dog
---frog
---horse
---ship
---truck
test
---airplane
---automobile
---bird
---cat
---deer
---dog
---frog
---horse
---ship
---truck
cifar-out下包含train和test两个文件夹,其中分别包含了CIFAR-10中的训练集和测试集。这两个文件夹下各自有10个子文件夹,每个子文件夹下存储相应分类的图片。将图片按照上述结构存储好之后,我们就可以着手对分类模型进行训练了。
预处理¶
数据下载之后,还需要进行预处理,将数据转换为Paddle的格式。我们可以通过如下命令进行预处理工作:
cd demo/image_classification/
sh preprocess.sh
其中preprocess.sh 调用 ./demo/image_classification/preprocess.py 对图片进行预处理
export PYTHONPATH=$PYTHONPATH:../../
data_dir=./data/cifar-out
python preprocess.py -i $data_dir -s 32 -c 1
./demo/image_classification/preprocess.py 使用如下参数:
-i或--input给出输入数据所在路径;-s或--size给出图片尺寸;-c或--color标示图片是彩色图或灰度图
模型训练¶
在开始训练之前,我们需要先创建一个模型配置文件。下面我们给出了一个配置示例。注意,这里的列出的和vgg_16_cifar.py文件稍有差别,因为该文件可适用于预测。
from paddle.trainer_config_helpers import *
data_dir='data/cifar-out/batches/'
meta_path=data_dir+'batches.meta'
args = {'meta':meta_path, 'mean_img_size': 32,
'img_size': 32, 'num_classes': 10,
'use_jpeg': 1, 'color': "color"}
define_py_data_sources2(train_list=data_dir+"train.list",
test_list=data_dir+'test.list',
module='image_provider',
obj='processData',
args=args)
settings(
batch_size = 128,
learning_rate = 0.1 / 128.0,
learning_method = MomentumOptimizer(0.9),
regularization = L2Regularization(0.0005 * 128))
img = data_layer(name='image', size=3*32*32)
lbl = data_layer(name="label", size=10)
# small_vgg is predined in trainer_config_helpers.network
predict = small_vgg(input_image=img, num_channels=3)
outputs(classification_cost(input=predict, label=lbl))
在第一行中我们载入用于定义网络的函数。
from paddle.trainer_config_helpers import *
之后定义的define_py_data_sources2使用Python数据提供器,其中 args将在image_provider.py进行使用,该文件负责产生图片数据并传递给Paddle系统
meta: 训练集平均值。mean_img_size: 平均特征图的高度及宽度。img_size:输入图片的高度及宽度。num_classes:类别个数。use_jpeg:处理过程中数据存储格式。color:标示是否为彩色图片。
settings用于设置训练算法。在下面的例子中,learning rate被设置为0.1除以batch size,而weight decay则为0.0005乘以batch size。
settings(
batch_size = 128,
learning_rate = 0.1 / 128.0,
learning_method = MomentumOptimizer(0.9),
regularization = L2Regularization(0.0005 * 128)
)
small_vgg定义了网络结构。这里我们使用的是一个小的VGG网络。关于VGG卷积神经网络的描述可以参考:http://www.robots.ox.ac.uk/~vgg/research/very_deep/。
# small_vgg is predined in trainer_config_helpers.network
predict = small_vgg(input_image=img, num_channels=3)
配置创建完毕后,可以运行脚本train.sh来训练模型。
config=vgg_16_cifar.py
output=./cifar_vgg_model
log=train.log
paddle train \
--config=$config \
--dot_period=10 \
--log_period=100 \
--test_all_data_in_one_period=1 \
--use_gpu=1 \
--save_dir=$output \
2>&1 | tee $log
python -m paddle.utils.plotcurve -i $log > plot.png
- 这里我们使用的是GPU模式进行训练。如果你没有GPU环境,可以设置
use_gpu=0。 ./demo/image_classification/vgg_16_cifar.py是网络和数据配置文件。各项参数的详细说明可以在命令行参数相关文档中找到。- 脚本
plotcurve.py依赖于python的matplotlib模块。因此如果这个脚本运行失败,也许是因为需要安装matplotlib。 在训练完成后,训练及测试误差曲线图会被plotcurve.py脚本保存在plot.png中。下面是一个误差曲线图的示例:

预测¶
在训练完成后,模型及参数会被保存在路径./cifar_vgg_model/pass-%05d下。例如第300个pass的模型会被保存在./cifar_vgg_model/pass-00299。
要对一个图片的进行分类预测,我们可以使用predict.sh,该脚本将输出预测分类的标签:
sh predict.sh
predict.sh:
model=cifar_vgg_model/pass-00299/
image=data/cifar-out/test/airplane/seaplane_s_000978.png
use_gpu=1
python prediction.py $model $image $use_gpu
练习¶
在CUB-200数据集上使用VGG模型训练一个鸟类图片分类模型。相关的鸟类数据集可以从如下地址下载,其中包含了200种鸟类的照片(主要来自北美洲)。