
MovieLens数据集评分回归模型¶
这里我们在MovieLens数据集描述一种 余弦相似度回归 任务。 该示例将展示paddle如何进行词向量嵌入,处理相似度回归,针对文本 的单词级别的卷积神经网络,以及paddle如何处理多种类型的输入。 需要注意的是,该模型网络只是用于进行demo展示paddle如何工作,而 没有进行结构的微调。
我们非常欢迎您用PADDLEPADDLE构建更好的示例,如果您有好的建议来 让这个示例变得更好,希望能让我们知晓。
数据准备¶
下载并解压数据集¶
这里我们使用 MovieLens数据集 。 要下载和解压数据集,只需要简单的运行下面的命令即可。
cd demo/recommendation/data
./ml_data.sh
demo/recommendation/data/ml-1m 的目录结构为:
+--ml-1m
+--- movies.dat # 电影特征
+--- ratings.dat # 评分
+--- users.dat # 用户特征
+--- README # 数据集描述
字段配置文件¶
字段配置文件 用来具体说明数据集的字段和文件格式, 例如,说明每个特征文件具体字段是 什么 类型。
ml-1m的字段配置文件在目录 demo/recommendation/data/config.json 中。
其具体说明了字段类型和文件名称:
- 用户文件中有四种类型的字段: 编号,性别,年龄和职业;
- 文件名称为”users.dat”,文件的分隔符为”::”。
{
"user": {
"file": {
"name": "users.dat",
"delimiter": "::"
},
"fields": ["id", "gender", "age", "occupation"]
},
"movie": {
"file": {
"name": "movies.dat",
"delimiter": "::"
},
"fields": ["id", "title", "genres"]
}
}
准备数据¶
你需要安装python的第三方库。 强烈推荐使用VIRTUALENV来创造一个干净的python环境。
pip install -r requirements.txt
预处理数据一般的命令为:
cd demo/recommendation
./preprocess.sh
下面介绍预处理过程具体的步骤。
提取电影或用户的特征并生成python对象¶
在movielens 1m数据集中,电影和用户有许多的特征。 评分文件的每一行仅仅提供电影或用户的编号来代表相应的电影或用户。 我们首先处理电影或用户的特征文件,然后用pickle命令将特征( Meta )对象存储为文件。
Meta配置文件¶
Meta配置文件 用来具体描述 如何 解析数据集中的每一个字段。 该文件可以从字段配置文件生成,或是手动编辑生成。文件的格式可以 为json或yaml格式。解析器能通过文件的扩展名自动识别文件的格式。
要将字段配置文件转化为meta配置文件,只需要运行:
cd demo/recommendation/data
python config_generator.py config.json > meta_config.json
生成的meta配置文件如下所示:
{
"meta": {
"movie": {
"fields": [
{
"type": "id",
"pos": 0
},
{
"regex": {
"pattern": "^(.*)\\((\\d+)\\)$",
"group_id": 1,
"strip": true
},
"type": {
"seq_type": "sequence",
"name": "embedding"
},
"dict": {
"type": "char_based"
},
"name": "title",
"pos": 1
},
{
"type": "one_hot_dense",
"dict": {
"delimiter": "|",
"type": "split"
},
"name": "genres",
"pos": 2
}
],
"file": {
"delimiter": "::",
"type": "split",
"name": "movies.dat"
}
},
"user": {
"fields": [
{
"type": "id",
"pos": 0
},
{
"type": "embedding",
"dict": {
"type": "char_based"
},
"name": "gender",
"pos": 1
},
{
"type": "embedding",
"dict": {
"sort": true,
"type": "whole_content"
},
"name": "age",
"pos": 2
},
{
"type": "embedding",
"dict": {
"sort": "true",
"type": "whole_content"
},
"name": "occupation",
"pos": 3
}
],
"file": {
"delimiter": "::",
"type": "split",
"name": "users.dat"
}
}
}
}
在meta文件中有两种特征: 电影和用户。
- 在电影文件movies.dat中
- 我们仅用”::”来分隔每一行
- pos 0 代表编号
- pos 1 特征:
- name是电影名
- 利用正则表达式来解析该特征
- 基于字母的词嵌入特征
- 是序列
- pos 2 特征:
- name是体裁
- type是one hot稠密向量
- dictionary由解析自动生成,每一个key由’|’分隔
- 在用户文件users.dat中
- 我们仅用”::”来分隔每一行
- pos 0 代表编号
- pos 1 特征:
- name是性别
- 简单的基于字母的词嵌入
- pos 2 特征:
- name是年龄
- 是整个的词嵌入
- 嵌入编号会根据单词排序
- pos 3 特征:
- name是职业
- 简单的整个词嵌入
Meta文件¶
有了meta配置文件之后,我们可以生成 Meta文件 ,该文件是python的pickle对象, 存储着电影或用户信息。可以运行下面的命令来生成。
python meta_generator.py ml-1m meta.bin --config=meta_config.json
meta文件 meta.bin 的结构如下:
+--+ movie
| +--+ __meta__
| | +--+ raw_meta # 每个特征的meta配置。列表
| | | +
| | | | # 编号字段,我们用编号作为key
| | | +--+ {'count': 3883, 'max': 3952, 'is_key': True, 'type': 'id', 'min': 1}
| | | |
| | | | # 电影名字段,嵌入特征字典
| | | +--+ {'dict': [ ... ], 'type': 'embedding', 'name': 'title', 'seq': 'sequence'}
| | | |
| | | | # 体裁字段,体裁字典
| | | +--+ {'dict': [ ... ], 'type': 'one_hot_dense', 'name': 'genres'}
| | |
| | +--+ feature_map [1, 2] # a list for raw_meta index for feature field.
| | # it means there are 2 features for each key.
| | # * 0 offset of feature is raw_meta[1], Title.
| | # * 1 offset of feature is raw_meta[2], Genres.
| |
| +--+ 1 # 电影1的特征
| | +
| | +---+ [[...], [...]] # title ids, genres dense vector
| |
| +--+ 2
| |
| +--+ ...
|
+--- user
+--+ __meta__
| +
| +--+ raw_meta
| | +
| | +--+ id field as user
| | |
| | +--+ {'dict': ['F', 'M'], 'type': 'embedding', 'name': 'gender', 'seq': 'no_sequence'}
| | |
| | +--+ {'dict': ['1', '18', '25', '35', '45', '50', '56'], 'type': 'embedding', 'name': 'age', 'seq': 'no_sequence'}
| | |
| | +--+ {'dict': [...], 'type': 'embedding', 'name': 'occupation', 'seq': 'no_sequence'}
| |
| +--+ feature_map [1, 2, 3]
|
+--+ 1 # 用户1的特征
|
+--+ 2
+--+ ...
分割训练/测试文件¶
我们将 ml-1m/ratings.dat 文件分割为训练和测试文件。分割文件的方法是:对于每位用户,我们将评分分成两部分。
这样的话每位用户在测试文件中将与训练文件含有同样的信息。
用 separate.py 来分离训练和测试文件。
python split.py ml-1m/ratings.dat --delimiter="::" --test_ratio=0.1
这样就会生成两个文件:ml-1m/ratings.dat.train 和 ml-1m/ratings.data.test 。
将他们移动到目录 data ,然后进行随机打乱,再为paddle的训练过程提供文件列表。
shuf ml-1m/ratings.dat.train > ratings.dat.train
cp ml-1m/ratings.dat.test .
echo "./data/ratings.dat.train" > train.list
echo "./data/ratings.dat.test" > test.list
神经网络结构配置¶
训练器配置文件¶
网络结构如下图所示:
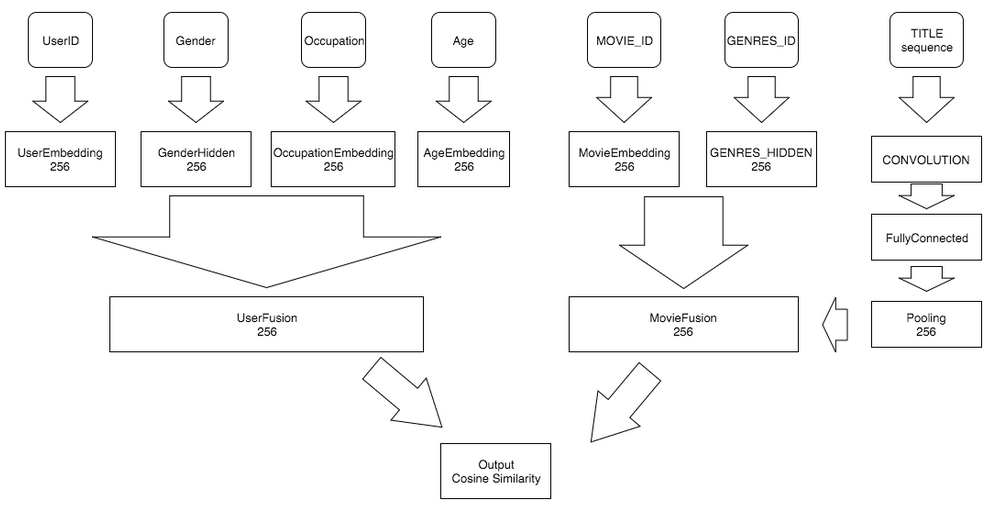
该示例的神经网络配置文件 trainer_config.py 如下所示:
from paddle.trainer_config_helpers import *
try:
import cPickle as pickle
except ImportError:
import pickle
is_predict = get_config_arg('is_predict', bool, False)
META_FILE = 'data/meta.bin'
with open(META_FILE, 'rb') as f:
# load meta file
meta = pickle.load(f)
settings(
batch_size=1600, learning_rate=1e-3, learning_method=RMSPropOptimizer())
def construct_feature(name):
"""
Construct movie/user features.
This method read from meta data. Then convert feature to neural network due
to feature type. The map relation as follow.
* id: embedding => fc
* embedding:
is_sequence: embedding => context_projection => fc => pool
not sequence: embedding => fc
* one_hot_dense: fc => fc
Then gather all features vector, and use a fc layer to combined them as
return.
:param name: 'movie' or 'user'
:type name: basestring
:return: combined feature output
:rtype: LayerOutput
"""
__meta__ = meta[name]['__meta__']['raw_meta']
fusion = []
for each_meta in __meta__:
type_name = each_meta['type']
slot_name = each_meta.get('name', '%s_id' % name)
if type_name == 'id':
slot_dim = each_meta['max']
embedding = embedding_layer(
input=data_layer(
slot_name, size=slot_dim), size=256)
fusion.append(fc_layer(input=embedding, size=256))
elif type_name == 'embedding':
is_seq = each_meta['seq'] == 'sequence'
slot_dim = len(each_meta['dict'])
din = data_layer(slot_name, slot_dim)
embedding = embedding_layer(input=din, size=256)
if is_seq:
fusion.append(
text_conv_pool(
input=embedding, context_len=5, hidden_size=256))
else:
fusion.append(fc_layer(input=embedding, size=256))
elif type_name == 'one_hot_dense':
slot_dim = len(each_meta['dict'])
hidden = fc_layer(input=data_layer(slot_name, slot_dim), size=256)
fusion.append(fc_layer(input=hidden, size=256))
return fc_layer(name="%s_fusion" % name, input=fusion, size=256)
movie_feature = construct_feature("movie")
user_feature = construct_feature("user")
similarity = cos_sim(a=movie_feature, b=user_feature)
if not is_predict:
outputs(mse_cost(input=similarity, label=data_layer('rating', size=1)))
define_py_data_sources2(
'data/train.list',
'data/test.list',
module='dataprovider',
obj='process',
args={'meta': meta})
else:
outputs(similarity)
在文件 trainer_config.py 中,我们仅仅是将每个特征种类映射到一个特征向量中,以下
展示了如何将每个特征映射到一个向量。
id: 仅仅是简单的嵌入,然后添加一个全连接层。embedding:- 如果是序列,则先做嵌入,然后再做一次文本卷积网络操作, 然后得到平均采样的结果。
- 如果不是序列,则先做嵌入,然后添加一个全连接层。
one_host_dense:- 仅仅是两个全连接层。
然后我们利用多输入的:code:fc_layer 全连接层将电影的每个特征结合成一个电影特征, 并且对用户的特征做同样的操作,也得到一个用户特征。然后我们求这两个特征的余弦相似度。
在这些网络中,我们用以下的一些:ref:api_trainer_config 中的接口。
- 数据层, api_trainer_config_helpers_layers_data_layer
- 全连接层, api_trainer_config_helpers_layers_fc_layer
- 嵌入层, api_trainer_config_helpers_layers_embedding_layer
- 文本投影层, api_trainer_config_helpers_layers_context_projection
- 采样层, api_trainer_config_helpers_layers_pooling_layer
- 余弦相似度层, api_trainer_config_helpers_layers_cos_sim
- 文本卷积采样层, text_conv_pool
- 声明Python数据源, api_trainer_config_helpers_data_sources
数据提供脚本¶
from paddle.trainer.PyDataProvider2 import *
import common_utils # parse
def __list_to_map__(lst):
ret_val = dict()
for each in lst:
k, v = each
ret_val[k] = v
return ret_val
def hook(settings, meta, **kwargs):
"""
Init hook is invoked before process data. It will set obj.slots and store
data meta.
:param obj: global object. It will passed to process routine.
:type obj: object
:param meta: the meta file object, which passed from trainer_config. Meta
file record movie/user features.
:param kwargs: unused other arguments.
"""
del kwargs # unused kwargs
# Header define slots that used for paddle.
# first part is movie features.
# second part is user features.
# final part is rating score.
# header is a list of [USE_SEQ_OR_NOT?, SlotType]
movie_headers = list(common_utils.meta_to_header(meta, 'movie'))
settings.movie_names = [h[0] for h in movie_headers]
headers = movie_headers
user_headers = list(common_utils.meta_to_header(meta, 'user'))
settings.user_names = [h[0] for h in user_headers]
headers.extend(user_headers)
headers.append(("rating", dense_vector(1))) # Score
# slot types.
settings.input_types = __list_to_map__(headers)
settings.meta = meta
@provider(init_hook=hook, cache=CacheType.CACHE_PASS_IN_MEM)
def process(settings, filename):
with open(filename, 'r') as f:
for line in f:
# Get a rating from file.
user_id, movie_id, score = map(int, line.split('::')[:-1])
# Scale score to [-5, +5]
score = float(score) * 2 - 5.0
# Get movie/user features by movie_id, user_id
movie_meta = settings.meta['movie'][movie_id]
user_meta = settings.meta['user'][user_id]
outputs = [('movie_id', movie_id - 1)]
# Then add movie features
for i, each_meta in enumerate(movie_meta):
outputs.append((settings.movie_names[i + 1], each_meta))
# Then add user id.
outputs.append(('user_id', user_id - 1))
# Then add user features.
for i, each_meta in enumerate(user_meta):
outputs.append((settings.user_names[i + 1], each_meta))
# Finally, add score
outputs.append(('rating', [score]))
# Return data to paddle
yield __list_to_map__(outputs)
数据提供脚本仅仅是读取meta.bin和评分文件,生成训练需要的样本。
在脚本 dataprovider.py 中,我们需要设置:
- obj.slots: 特征的类型和维度。
- use_seq:
dataprovider.py中的数据是否为序列模式。 - process: 返回数据的每一条样本给
paddle。
数据提供脚本的细节文档可以参考 PyDataProvider2的使用 。
训练¶
准备好数据,配置了网络,编写好数据提供脚本后,现在我们可以开始paddle训练了。
代码 run.sh 如下:
paddle train \
--config=trainer_config.py \
--save_dir=./output \
--use_gpu=false \
--trainer_count=4\
--test_all_data_in_one_period=true \
--log_period=100 \
--dot_period=1 \
--num_passes=50 2>&1 | tee 'log.txt'
paddle usage -l log.txt -e $? -n "recommendation" >/dev/null 2>&1
该脚本仅仅是开始一个paddle训练过程,将日志写入文件 log.txt ,然后
打印在屏幕上。
脚本 run.sh 中的每一行命令,请参考页面 设置命令行参数 。
这些参数的简短介绍如下:
- config: 告诉paddle哪个文件是神经网络的配置文件。
- save_dir: 告诉paddle将模型保存在: code:./output 中。
- use_gpu: 是否使用GPU,默认为不使用。
- trainer_count: 一台机器上面的线程数量。
- test_all_data_in_one_period: 每一个测试周期测试一次所有数据。否则, 每个测试周期测试: code:batch_size 批次的数据。
- log_period: 在训练了: code:log_period 批次后打印日志。
- dot_period: 在每训练: code:dot_period 个批次后打印一个
.。 - num_passes: 训练至多: code:num_passes 轮。
如果训练过程启动成功的话,输出应该类似如下:
I0601 08:07:22.832059 10549 TrainerInternal.cpp:157] Batch=100 samples=160000 AvgCost=4.13494 CurrentCost=4.13494 Eval: CurrentEval:
I0601 08:07:50.672627 10549 TrainerInternal.cpp:157] Batch=200 samples=320000 AvgCost=3.80957 CurrentCost=3.48421 Eval: CurrentEval:
I0601 08:08:18.877369 10549 TrainerInternal.cpp:157] Batch=300 samples=480000 AvgCost=3.68145 CurrentCost=3.42519 Eval: CurrentEval:
I0601 08:08:46.863963 10549 TrainerInternal.cpp:157] Batch=400 samples=640000 AvgCost=3.6007 CurrentCost=3.35847 Eval: CurrentEval:
I0601 08:09:15.413025 10549 TrainerInternal.cpp:157] Batch=500 samples=800000 AvgCost=3.54811 CurrentCost=3.33773 Eval: CurrentEval:
I0601 08:09:36.058670 10549 TrainerInternal.cpp:181] Pass=0 Batch=565 samples=902826 AvgCost=3.52368 Eval:
I0601 08:09:46.215489 10549 Tester.cpp:101] Test samples=97383 cost=3.32155 Eval:
I0601 08:09:46.215966 10549 GradientMachine.cpp:132] Saving parameters to ./output/model/pass-00000
I0601 08:09:46.233397 10549 ParamUtil.cpp:99] save dir ./output/model/pass-00000
I0601 08:09:46.233438 10549 Util.cpp:209] copy trainer_config.py to ./output/model/pass-00000
I0601 08:09:46.233541 10549 ParamUtil.cpp:147] fileName trainer_config.py
模型被保存在 output/ 目录中。你可以在任何时候用 Ctrl-C 来停止训练。
模型评估和预测¶
在训练了几个轮次以后,你可以对模型进行评估,得到最好轮次下的模型。运行下面命令即可:
./evaluate.sh
你将看到如下的信息:
Best pass is 00009, error is 3.06949, which means predict get error as 0.875998002281
evaluating from pass output/pass-00009
然后,你可以预测任何用户对于任何一部电影的评价,运行下面命令即可:
python prediction.py 'output/pass-00009/'
预测程序将读取用户的输入,然后输出预测分数。用户预测的命令行界面如下:
Input movie_id: 9
Input user_id: 4
Prediction Score is 2.56
Input movie_id: 8
Input user_id: 2
Prediction Score is 3.13