Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into Add_conv3d_Python_API
Showing
cmake/external/anakin.cmake
0 → 100644
doc/fluid/api/detection.rst
0 → 100644
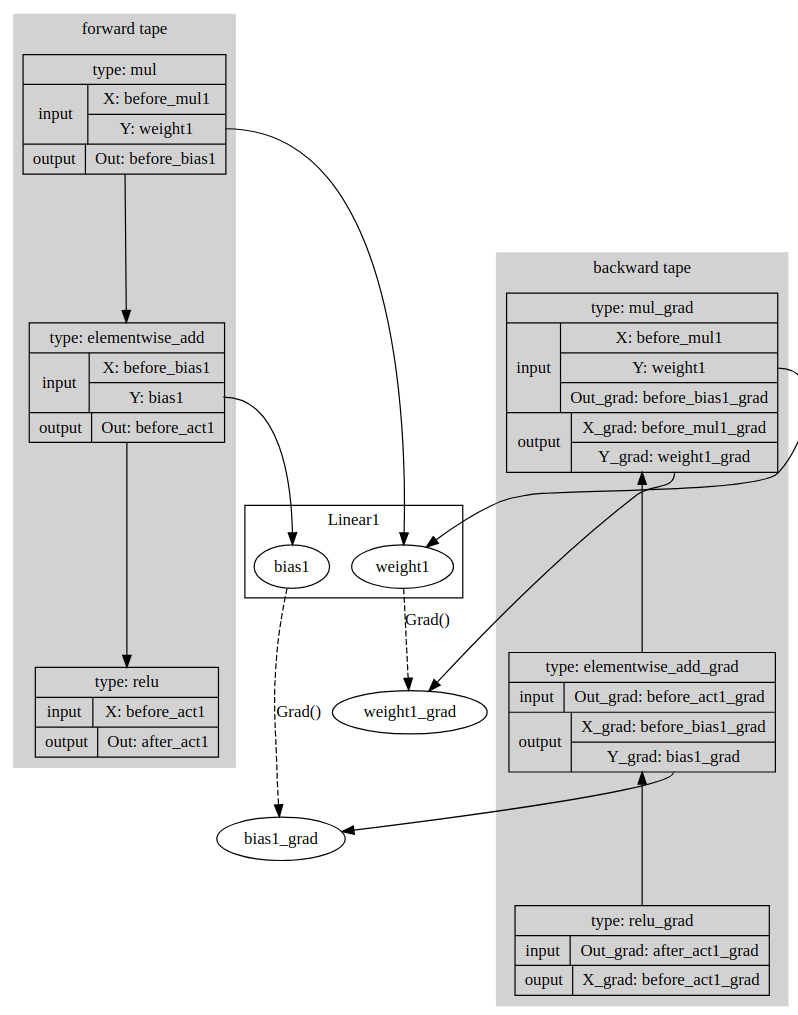
paddle/contrib/tape/README.md
0 → 100644
{kind=link}
94.4 KB
paddle/contrib/tape/function.h
0 → 100644
paddle/contrib/tape/tape.cc
0 → 100644
paddle/contrib/tape/tape.h
0 → 100644
paddle/contrib/tape/test_tape.cc
0 → 100644
paddle/contrib/tape/variable.cc
0 → 100644
paddle/contrib/tape/variable.h
0 → 100644