Merge pull request #10961 from weixing02/fluid_guide
add fluid_guide
Showing
doc/fluid/images/1.png
0 → 100644
{kind=link}
147.5 KB
doc/fluid/images/2.png
0 → 100644
{kind=link}
420.3 KB
doc/fluid/images/3.png
0 → 100644
{kind=link}
416.8 KB
doc/fluid/images/4.png
0 → 100644
{kind=link}
359.9 KB
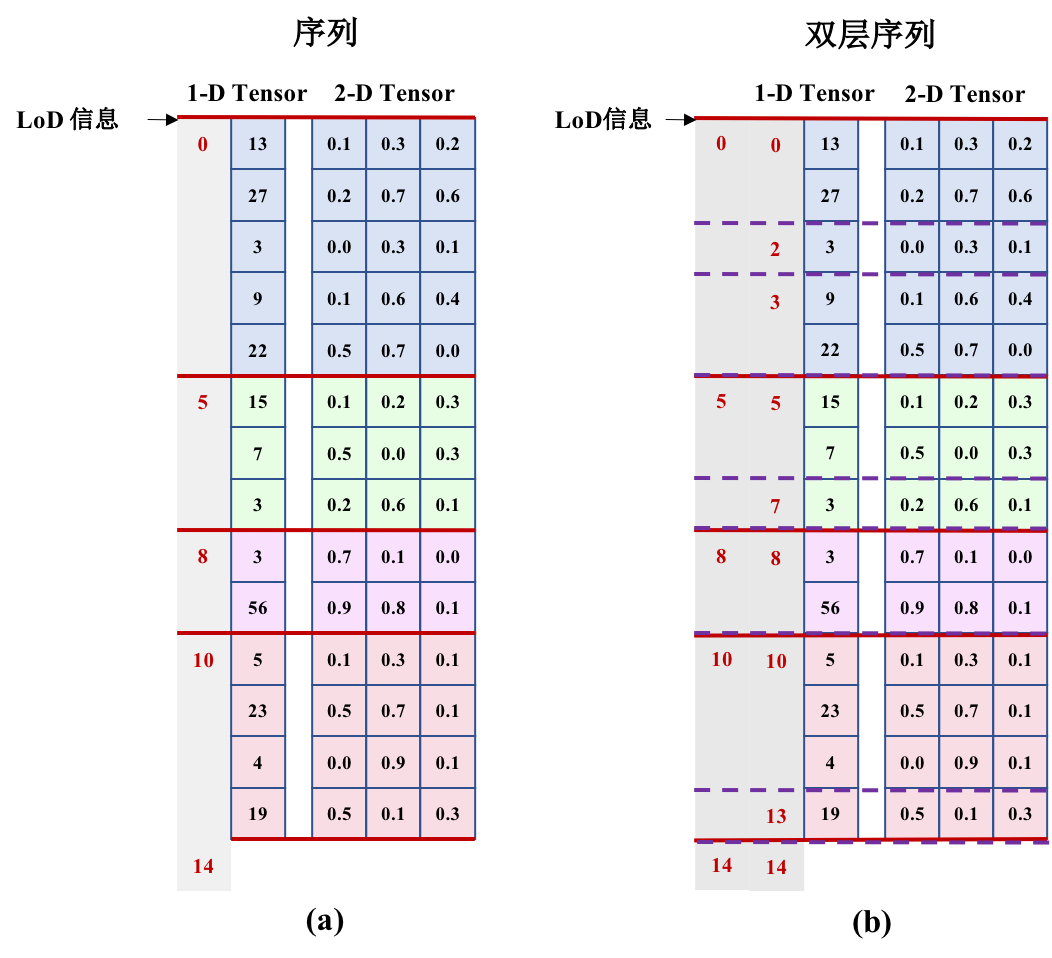
doc/fluid/images/LoDTensor.png
0 → 100644
{kind=link}
109.1 KB
{kind=link}
121.8 KB
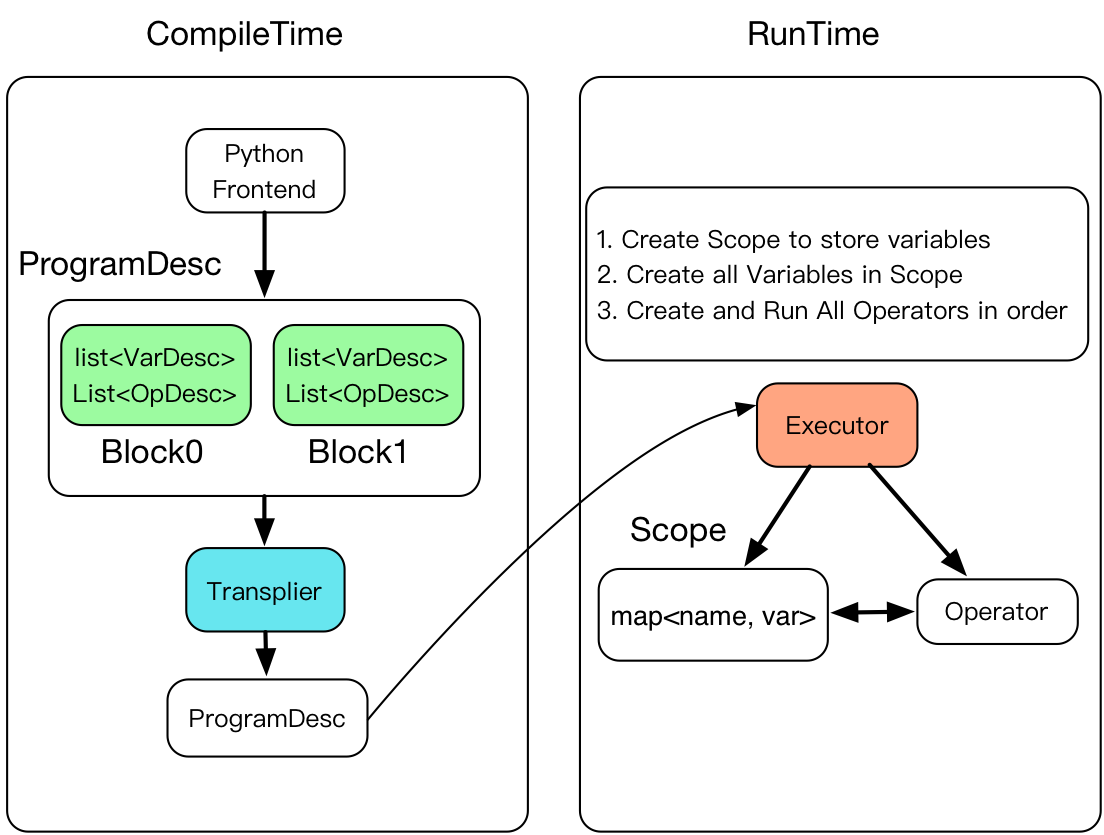
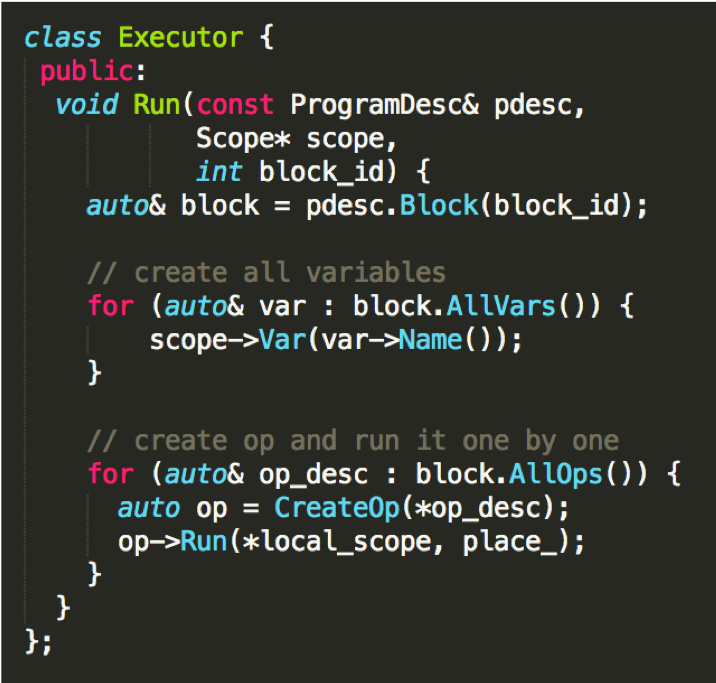
doc/fluid/images/executor.png
0 → 100644
{kind=link}
188.7 KB
{kind=link}
188.3 KB
{kind=link}
122.5 KB
{kind=link}
28.2 KB
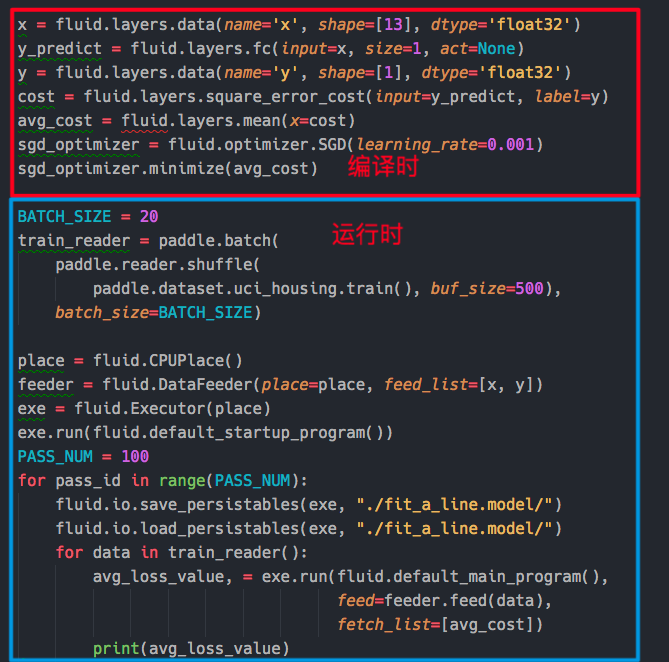
doc/fluid/images/layer.png
0 → 100644
{kind=link}

122.3 KB
doc/fluid/images/operator1.png
0 → 100644
{kind=link}
108.9 KB
doc/fluid/images/operator2.png
0 → 100644
{kind=link}
137.7 KB
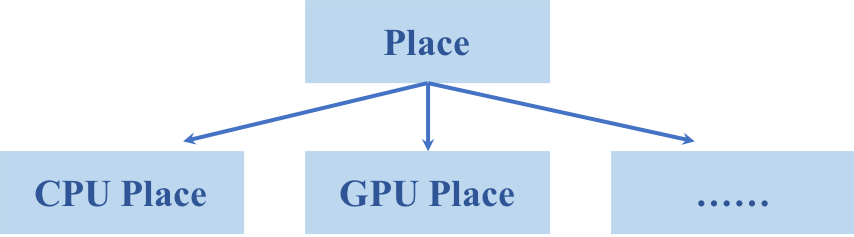
doc/fluid/images/place.png
0 → 100644
{kind=link}
18.8 KB
{kind=link}
91.3 KB
{kind=link}
43.7 KB
{kind=link}
41.6 KB
doc/fluid/images/raw_input.png
0 → 100644
{kind=link}
341.5 KB
{kind=link}
121.0 KB
doc/fluid/images/sorted_input.png
0 → 100644
{kind=link}
268.6 KB
doc/fluid/images/transpiler.png
0 → 100644
{kind=link}
53.4 KB
{kind=link}
95.7 KB