diff --git "a/20171012 \347\254\25410\346\234\237/A Gentle Introduction to the Bag-of-Words Model.md" "b/20171012 \347\254\25410\346\234\237/A Gentle Introduction to the Bag-of-Words Model.md"
deleted file mode 100644
index e3f2fb093401bad5bd10cb7ebf07c630f2d599ec..0000000000000000000000000000000000000000
--- "a/20171012 \347\254\25410\346\234\237/A Gentle Introduction to the Bag-of-Words Model.md"
+++ /dev/null
@@ -1,304 +0,0 @@
-# A Gentle Introduction to the Bag-of-Words Model
-
-原文链接:[A Gentle Introduction to the Bag-of-Words Model](A Gentle Introduction to the Bag-of-Words Model)
-
-The bag-of-words model is a way of representing text data when modeling text with machine learning algorithms.
-
-The bag-of-words model is simple to understand and implement and has seen great success in problems such as language modeling and document classification.
-
-In this tutorial, you will discover the bag-of-words model for feature extraction in natural language processing.
-
-After completing this tutorial, you will know:
-
-- What the bag-of-words model is and why it is needed to represent text.
-- How to develop a bag-of-words model for a collection of documents.
-- How to use different techniques to prepare a vocabulary and score words.
-
-Let’s get started.
-
-
-
-A Gentle Introduction to the Bag-of-Words Model
-Photo by [Do8y](https://www.flickr.com/photos/beorn_ours/5675267679/), some rights reserved.
-
-## Tutorial Overview
-
-This tutorial is divided into 6 parts; they are:
-
-1. The Problem with Text
-2. What is a Bag-of-Words?
-3. Example of the Bag-of-Words Model
-4. Managing Vocabulary
-5. Scoring Words
-6. Limitations of Bag-of-Words
-
-
-
-
-
-
-
-### Need help with Deep Learning for Text Data?
-
-Take my free 7-day email crash course now (with code).
-
-Click to sign-up and also get a free PDF Ebook version of the course.
-
-[Start Your FREE Crash-Course Now](https://machinelearningmastery.lpages.co/leadbox/144855173f72a2%3A164f8be4f346dc/5655638436741120/)
-
-
-
-
-
-
-
-## The Problem with Text
-
-A problem with modeling text is that it is messy, and techniques like machine learning algorithms prefer well defined fixed-length inputs and outputs.
-
-Machine learning algorithms cannot work with raw text directly; the text must be converted into numbers. Specifically, vectors of numbers.
-
-> In language processing, the vectors x are derived from textual data, in order to reflect various linguistic properties of the text.
-
-— Page 65, [Neural Network Methods in Natural Language Processing](http://amzn.to/2wycQKA), 2017.
-
-This is called feature extraction or feature encoding.
-
-A popular and simple method of feature extraction with text data is called the bag-of-words model of text.
-
-## What is a Bag-of-Words?
-
-A bag-of-words model, or BoW for short, is a way of extracting features from text for use in modeling, such as with machine learning algorithms.
-
-The approach is very simple and flexible, and can be used in a myriad of ways for extracting features from documents.
-
-A bag-of-words is a representation of text that describes the occurrence of words within a document. It involves two things:
-
-1. A vocabulary of known words.
-2. A measure of the presence of known words.
-
-It is called a “*bag*” of words, because any information about the order or structure of words in the document is discarded. The model is only concerned with whether known words occur in the document, not where in the document.
-
-> A very common feature extraction procedures for sentences and documents is the bag-of-words approach (BOW). In this approach, we look at the histogram of the words within the text, i.e. considering each word count as a feature.
-
-— Page 69, [Neural Network Methods in Natural Language Processing](http://amzn.to/2wycQKA), 2017.
-
-The intuition is that documents are similar if they have similar content. Further, that from the content alone we can learn something about the meaning of the document.
-
-The bag-of-words can be as simple or complex as you like. The complexity comes both in deciding how to design the vocabulary of known words (or tokens) and how to score the presence of known words.
-
-We will take a closer look at both of these concerns.
-
-## Example of the Bag-of-Words Model
-
-Let’s make the bag-of-words model concrete with a worked example.
-
-### Step 1: Collect Data
-
-Below is a snippet of the first few lines of text from the book “[A Tale of Two Cities](https://www.gutenberg.org/ebooks/98)” by Charles Dickens, taken from Project Gutenberg.
-
-> It was the best of times,
-> it was the worst of times,
-> it was the age of wisdom,
-> it was the age of foolishness,
-
-For this small example, let’s treat each line as a separate “document” and the 4 lines as our entire corpus of documents.
-
-### Step 2: Design the Vocabulary
-
-Now we can make a list of all of the words in our model vocabulary.
-
-The unique words here (ignoring case and punctuation) are:
-
-- “it”
-- “was”
-- “the”
-- “best”
-- “of”
-- “times”
-- “worst”
-- “age”
-- “wisdom”
-- “foolishness”
-
-That is a vocabulary of 10 words from a corpus containing 24 words.
-
-### Step 3: Create Document Vectors
-
-The next step is to score the words in each document.
-
-The objective is to turn each document of free text into a vector that we can use as input or output for a machine learning model.
-
-Because we know the vocabulary has 10 words, we can use a fixed-length document representation of 10, with one position in the vector to score each word.
-
-The simplest scoring method is to mark the presence of words as a boolean value, 0 for absent, 1 for present.
-
-Using the arbitrary ordering of words listed above in our vocabulary, we can step through the first document (“*It was the best of times*“) and convert it into a binary vector.
-
-The scoring of the document would look as follows:
-
-- “it” = 1
-- “was” = 1
-- “the” = 1
-- “best” = 1
-- “of” = 1
-- “times” = 1
-- “worst” = 0
-- “age” = 0
-- “wisdom” = 0
-- “foolishness” = 0
-
-As a binary vector, this would look as follows:
-
-
-
-| 1 | [1, 1, 1, 1, 1, 1, 0, 0, 0, 0] |
-| ---- | ------------------------------ |
-| | |
-
-The other three documents would look as follows:
-
-
-
-| 123 | "it was the worst of times" = [1, 1, 1, 0, 1, 1, 1, 0, 0, 0]"it was the age of wisdom" = [1, 1, 1, 0, 1, 0, 0, 1, 1, 0]"it was the age of foolishness" = [1, 1, 1, 0, 1, 0, 0, 1, 0, 1] |
-| ---- | ------------------------------------------------------------ |
-| | |
-
-All ordering of the words is nominally discarded and we have a consistent way of extracting features from any document in our corpus, ready for use in modeling.
-
-New documents that overlap with the vocabulary of known words, but may contain words outside of the vocabulary, can still be encoded, where only the occurrence of known words are scored and unknown words are ignored.
-
-You can see how this might naturally scale to large vocabularies and larger documents.
-
-## Managing Vocabulary
-
-As the vocabulary size increases, so does the vector representation of documents.
-
-In the previous example, the length of the document vector is equal to the number of known words.
-
-You can imagine that for a very large corpus, such as thousands of books, that the length of the vector might be thousands or millions of positions. Further, each document may contain very few of the known words in the vocabulary.
-
-This results in a vector with lots of zero scores, called a sparse vector or sparse representation.
-
-Sparse vectors require more memory and computational resources when modeling and the vast number of positions or dimensions can make the modeling process very challenging for traditional algorithms.
-
-As such, there is pressure to decrease the size of the vocabulary when using a bag-of-words model.
-
-There are simple text cleaning techniques that can be used as a first step, such as:
-
-- Ignoring case
-- Ignoring punctuation
-- Ignoring frequent words that don’t contain much information, called stop words, like “a,” “of,” etc.
-- Fixing misspelled words.
-- Reducing words to their stem (e.g. “play” from “playing”) using stemming algorithms.
-
-A more sophisticated approach is to create a vocabulary of grouped words. This both changes the scope of the vocabulary and allows the bag-of-words to capture a little bit more meaning from the document.
-
-In this approach, each word or token is called a “gram”. Creating a vocabulary of two-word pairs is, in turn, called a bigram model. Again, only the bigrams that appear in the corpus are modeled, not all possible bigrams.
-
-> An N-gram is an N-token sequence of words: a 2-gram (more commonly called a bigram) is a two-word sequence of words like “please turn”, “turn your”, or “your homework”, and a 3-gram (more commonly called a trigram) is a three-word sequence of words like “please turn your”, or “turn your homework”.
-
-— Page 85, [Speech and Language Processing](http://amzn.to/2vaEb7T), 2009.
-
-For example, the bigrams in the first line of text in the previous section: “It was the best of times” are as follows:
-
-- “it was”
-- “was the”
-- “the best”
-- “best of”
-- “of times”
-
-A vocabulary then tracks triplets of words is called a trigram model and the general approach is called the n-gram model, where n refers to the number of grouped words.
-
-Often a simple bigram approach is better than a 1-gram bag-of-words model for tasks like documentation classification.
-
-> a bag-of-bigrams representation is much more powerful than bag-of-words, and in many cases proves very hard to beat.
-
-— Page 75, [Neural Network Methods in Natural Language Processing](http://amzn.to/2wycQKA), 2017.
-
-## Scoring Words
-
-Once a vocabulary has been chosen, the occurrence of words in example documents needs to be scored.
-
-In the worked example, we have already seen one very simple approach to scoring: a binary scoring of the presence or absence of words.
-
-Some additional simple scoring methods include:
-
-- **Counts**. Count the number of times each word appears in a document.
-- **Frequencies**. Calculate the frequency that each word appears in a document out of all the words in the document.
-
-### Word Hashing
-
-You may remember from computer science that a [hash function](https://en.wikipedia.org/wiki/Hash_function) is a bit of math that maps data to a fixed size set of numbers.
-
-For example, we use them in hash tables when programming where perhaps names are converted to numbers for fast lookup.
-
-We can use a hash representation of known words in our vocabulary. This addresses the problem of having a very large vocabulary for a large text corpus because we can choose the size of the hash space, which is in turn the size of the vector representation of the document.
-
-Words are hashed deterministically to the same integer index in the target hash space. A binary score or count can then be used to score the word.
-
-This is called the “*hash trick*” or “*feature hashing*“.
-
-The challenge is to choose a hash space to accommodate the chosen vocabulary size to minimize the probability of collisions and trade-off sparsity.
-
-### TF-IDF
-
-A problem with scoring word frequency is that highly frequent words start to dominate in the document (e.g. larger score), but may not contain as much “informational content” to the model as rarer but perhaps domain specific words.
-
-One approach is to rescale the frequency of words by how often they appear in all documents, so that the scores for frequent words like “the” that are also frequent across all documents are penalized.
-
-This approach to scoring is called Term Frequency – Inverse Document Frequency, or TF-IDF for short, where:
-
-- **Term Frequency**: is a scoring of the frequency of the word in the current document.
-- **Inverse Document Frequency**: is a scoring of how rare the word is across documents.
-
-The scores are a weighting where not all words are equally as important or interesting.
-
-The scores have the effect of highlighting words that are distinct (contain useful information) in a given document.
-
-> Thus the idf of a rare term is high, whereas the idf of a frequent term is likely to be low.
-
-— Page 118, [An Introduction to Information Retrieval](http://amzn.to/2hAR7PH), 2008.
-
-## Limitations of Bag-of-Words
-
-The bag-of-words model is very simple to understand and implement and offers a lot of flexibility for customization on your specific text data.
-
-It has been used with great success on prediction problems like language modeling and documentation classification.
-
-Nevertheless, it suffers from some shortcomings, such as:
-
-- **Vocabulary**: The vocabulary requires careful design, most specifically in order to manage the size, which impacts the sparsity of the document representations.
-- **Sparsity**: Sparse representations are harder to model both for computational reasons (space and time complexity) and also for information reasons, where the challenge is for the models to harness so little information in such a large representational space.
-- **Meaning**: Discarding word order ignores the context, and in turn meaning of words in the document (semantics). Context and meaning can offer a lot to the model, that if modeled could tell the difference between the same words differently arranged (“this is interesting” vs “is this interesting”), synonyms (“old bike” vs “used bike”), and much more.
-
-## Further Reading
-
-This section provides more resources on the topic if you are looking go deeper.
-
-### Articles
-
-- [Bag-of-words model on Wikipedia](https://en.wikipedia.org/wiki/N-gram)
-- [N-gram on Wikipedia](https://en.wikipedia.org/wiki/N-gram)
-- [Feature hashing on Wikipedia](https://en.wikipedia.org/wiki/Feature_hashing)
-- [tf–idf on Wikipedia](https://en.wikipedia.org/wiki/Tf%E2%80%93idf)
-
-### Books
-
-- Chapter 6, [Neural Network Methods in Natural Language Processing](http://amzn.to/2wycQKA), 2017.
-- Chapter 4, [Speech and Language Processing](http://amzn.to/2vaEb7T), 2009.
-- Chapter 6, [An Introduction to Information Retrieval](http://amzn.to/2vvnPHP), 2008.
-- Chapter 6, [Foundations of Statistical Natural Language Processing](http://amzn.to/2vvnPHP), 1999.
-
-## Summary
-
-In this tutorial, you discovered the bag-of-words model for feature extraction with text data.
-
-Specifically, you learned:
-
-- What the bag-of-words model is and why we need it.
-- How to work through the application of a bag-of-words model to a collection of documents.
-- What techniques can be used for preparing a vocabulary and scoring words.
-
-Do you have any questions?
-Ask your questions in the comments below and I will do my best to answer.
\ No newline at end of file
diff --git "a/20171012 \347\254\25410\346\234\237/A Research to Engineering Workflow.md" "b/20171012 \347\254\25410\346\234\237/A Research to Engineering Workflow.md"
deleted file mode 100644
index 1b9cf47505d00b5fe0c962c080d3f137da00e3a8..0000000000000000000000000000000000000000
--- "a/20171012 \347\254\25410\346\234\237/A Research to Engineering Workflow.md"
+++ /dev/null
@@ -1,178 +0,0 @@
-# A Research to Engineering Workflow
-
-原文链接:[A Research to Engineering Workflow](http://dustintran.com/blog/a-research-to-engineering-workflow?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com)
-
-Going from a research idea to experiments is fundamental. But this step is typically glossed over with little explicit advice. In academia, the graduate student is often left toiling away—fragmented code, various notes and LaTeX write-ups scattered around. New projects often result in entirely new code bases, and if they do rely on past code, are difficult to properly extend to these new projects.
-
-Motivated by this, I thought it’d be useful to outline the steps I personally take in going from research idea to experimentation, and how that then improves my research understanding so I can revise the idea. This process is crucial: given an initial idea, all my time is spent on this process; and for me at least, the experiments are key to learning about and solving problems that I couldn’t predict otherwise.[1](http://dustintran.com/blog/a-research-to-engineering-workflow?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com#references)
-
-## Finding the Right Problem
-
-Before working on a project, it’s necessary to decide how ideas might jumpstart into something more official. Sometimes it’s as simple as having a mentor suggest a project to work on; or tackling a specific data set or applied problem; or having a conversation with a frequent collaborator and then striking up a useful problem to work on together. More often, I find that research is a result of a long chain of ideas which were continually iterated upon—through frequent conversations, recent work, longer term readings of subjects I’m unfamiliar with (e.g., [Pearl (2000)](http://dustintran.com/blog/a-research-to-engineering-workflow?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com#pearl2000causality)), and favorite papers I like to revisit (e.g.,[Wainwright & Jordan (2008)](http://dustintran.com/blog/a-research-to-engineering-workflow?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com#wainwright2008graphical), [Neal (1994)](http://dustintran.com/blog/a-research-to-engineering-workflow?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com#neal1994bayesian)).
-
-
-
-*A master document of all my unexplored research ideas.*
-
-
-
-One technique I’ve found immensely helpful is to maintain a single master document.[2](http://dustintran.com/blog/a-research-to-engineering-workflow?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com#references) It does a few things.
-
-First, it has a bulleted list of all ideas, problems, and topics that I’d like to think more carefully about (Section 1.3 in the figure). Sometimes they’re as high-level as “Bayesian/generative approaches to reinforcement learning” or “addressing fairness in machine learning”; or they’re as specific as “Inference networks to handle memory complexity in EP” or “analysis of size-biased vs symmetric Dirichlet priors.”. I try to keep the list succinct: subsequent sections go in depth on a particular entry (Section 2+ in the figure).
-
-Second, the list of ideas is sorted according to what I’d like to work on next. This guides me to understand the general direction of my research beyond present work. I can continually revise my priorities according to whether I think the direction aligns with my broader research vision, and if I think the direction is necessarily impactful for the community at large. Importantly, the list isn’t just about the next publishable idea to work on, but generally what things I’d like to learn about next. This contributes long-term in finding important problems and arriving at simple or novel solutions.
-
-Every so often, I revisit the list, resorting things, adding things, deleting things. Eventually I might elaborate upon an idea enough that it becomes a formal paper. In general, I’ve found that this process of iterating upon ideas within one location (and one format) makes the transition to formal paper-writing and experiments to be a fluid experience.
-
-## Managing Papers
-
-
-
-Good research requires reading *a lot* of papers. Without a good way of organizing your readings, you can easily get overwhelmed by the field’s hurried pace. (These past weeks have been especially notorious in trying to catch up on the slew of NIPS submissions posted to arXiv.)
-
-I’ve experimented with a lot of approaches to this, and ultimately I’ve arrived at the [Papers app](http://papersapp.com/) which I highly recommend.3
-
-The most fundamental utility in a good management system is a centralized repository which can be referenced back to. The advantage of having one location for this cannot be underestimated, whether it be 8 page conference papers, journal papers, surveys, or even textbooks. Moreover, Papers is a nice tool for actually reading PDFs, and it conveniently syncs across devices as I read and star things on my tablet or laptop. As I cite papers when I write, I can go back to Papers and get the corresponding BibTeX file and citekey.
-
-I personally enjoy taking painstaking effort in organizing papers. In the screenshot above, I have a sprawling list of topics as paper tags. These range from `applications`, `models`, `inference` (each with subtags), and there are also miscellaneous topics such as `information-theory` and `experimental-design`. An important collection not seen in the screenshot is a tag called `research`, which I bin all papers relevant to a particular research topic into. For example, [the PixelGAN paper](https://arxiv.org/abs/1706.00531) presently highlighted is tagged into two topics I’ve currently been thinking a lot about—these are sorted into `research→alignment-semi`and `research→generative-images`.
-
-## Managing a Project
-
-
-
-*The repository we used for a recent arXiv preprint.*
-
-
-
-I like to maintain one research project in one Github repository. They’re useful not only for tracking code but also in tracking general research progress, paper writing, and tying others in for collaboration. How Github repositories are organized is a frequent pain point. I like the following structure, based originally from [Dave Blei’s preferred one](http://www.cs.columbia.edu/~blei/seminar/2016_discrete_data/notes/week_01.pdf):
-
-```
--- doc/
- -- 2017-nips/
- -- preamble/
- -- img/
- -- main.pdf
- -- main.tex
- -- introduction.tex
--- etc/
- -- 2017-03-25-whiteboard.jpg
- -- 2017-04-03-whiteboard.jpg
- -- 2017-04-06-dustin-comments.md
- -- 2017-04-08-dave-comments.pdf
--- src/
- -- checkpoints/
- -- codebase/
- -- log/
- -- out/
- -- script1.py
- -- script2.py
--- README.md
-```
-
-`README.md` maintains a list of todo’s, both for myself and collaborators. This makes it transparent how to keep moving forward and what’s blocking the work.
-
-`doc/` contains all write-ups. Each subdirectory corresponds to a particular conference or journal submission, with `main.tex`being the primary document and individual sections written in separate files such as `introduction.tex`. Keeping one section per file makes it easy for multiple people to work on separate sections simultaneously and avoid merge conflicts. Some people prefer to write the full paper after major experiments are complete. I personally like to write a paper more as a summary of the current ideas and, as with the idea itself, it is continually revised as experiments proceed.
-
-`etc/` is a dump of everything not relevant to other directories. I typically use it to store pictures of whiteboards during conversations about the project. Or sometimes as I’m just going about my day-to-day, I’m struck with a bunch of ideas and so I dump them into a Markdown document. It’s also a convenient location to handle various commentaries about the work, such as general feedback or paper markups from collaborators.
-
-`src/` is where all code is written. Runnable scripts are written directly in `src/`, and classes and utilities are written in`codebase/`. I’ll elaborate on these next. (The other three are directories outputted from scripts, which I’ll also elaborate upon.)
-
-## Writing Code
-
-
-
-Any code I write now uses [Edward](http://edwardlib.org/). I find it to be the best framework for quickly experimenting with modern probabilistic models and algorithms.
-
-On a conceptual level, Edward’s appealing because the language explicitly follows the math: the model’s generative process translates to specific lines of Edward code; then the proposed algorithm translates to the next lines; etc. This clean translationavoids future abstraction headaches when trying to extend the code with natural research questions: for example, what if I used a different prior, or tweaked the gradient estimator, or tried a different neural net architecture, or applied the method on larger scale data sets?
-
-On a practical level, I most benefit from Edward by building off pre-existing model examples (in [`edward/examples/`](https://github.com/blei-lab/edward/tree/master/examples) or [`edward/notebooks/`](https://github.com/blei-lab/edward/tree/master/notebooks)), and then adapting it to my problem. If I am also implementing a new algorithm, I take a pre-existing algorithm’s source code (in [`edward/inferences/`](https://github.com/blei-lab/edward/tree/master/edward/inferences)), paste it as a new file in my research project’s `codebase/` directory, and then I tweak it. This process makes it really easy to start afresh—beginning from templates and avoiding low-level details.
-
-When writing code, I always follow PEP8 (I particularly like the [`pep8`](https://pypi.python.org/pypi/pep8) package), and I try to separate individual scripts from the class and function definitions shared across scripts; the latter is placed inside `codebase/` and then imported. Maintaining code quality from the beginning is always a good investment, and I find this process scales well as the code gets increasingly more complicated and worked on with others.
-
-**On Jupyter notebooks.** Many people use [Jupyter notebooks](http://jupyter.org/) as a method for interactive code development, and as an easy way to embed visualizations and LaTeX. I personally haven’t found success in integrating it into my workflow. I like to just write all my code down in a Python script and then run the script. But I can see why others like the interactivity.
-
-## Managing Experiments
-
-
-
-Investing in a good workstation or cloud service is a must. Features such as GPUs should basically be a given with [their wide availability](http://timdettmers.com/2017/04/09/which-gpu-for-deep-learning/), and one should have access to running many jobs in parallel.
-
-After I finish writing a script on my local computer, my typical workflow is:
-
-1. Run `rsync` to synchronize my local computer’s Github repository (which includes uncommitted files) with a directory in the server;
-2. `ssh` into the server.
-3. Start `tmux` and run the script. Among many things, `tmux` lets you detach the session so you don’t have to wait for the job to finish before interacting with the server again.
-
-When the script is sensible, I start diving into experiments with multiple hyperparameter configurations. A useful tool for this is [`argparse`](https://docs.python.org/3/library/argparse.html). It augments a Python script with commandline arguments, where you add something like the following to your script:
-
-```
-parser = argparse.ArgumentParser()
-parser.add_argument('--batch_size', type=int, default=128,
- help='Minibatch during training')
-parser.add_argument('--lr', type=float, default=1e-5,
- help='Learning rate step-size')
-args = parser.parse_args()
-
-batch_size = args.batch_size
-lr = args.lr
-```
-
-Then you can run terminal commands such as
-
-```
-python script1.py --batch_size=256 --lr=1e-4
-```
-
-This makes it easy to submit server jobs which vary these hyperparameters.
-
-Finally, let’s talk about managing the output of experiments. Recall the `src/` directory structure above:
-
-```
--- src/
- -- checkpoints/
- -- codebase/
- -- log/
- -- out/
- -- script1.py
- -- script2.py
-```
-
-We described the individual scripts and `codebase/`. The other three directories are for organizing experiment output:
-
-- `checkpoints/` records saved model parameters during training. Use `tf.train.Saver` to save parameters as the algorithm runs every fixed number of iterations. This helps with running long experiments, where you might want to cut the experiment short and later restore the parameters. Each experiment outputs a subdirectory in `checkpoints/` with the convention,`20170524_192314_batch_size_25_lr_1e-4/`. The first number is the date (`YYYYMMDD`); the second is the timestamp (`%H%M%S`); and the rest is hyperparameters.
-- `log/` records logs for visualizing learning. Each experiment belongs in a subdirectory with the same convention as `checkpoints/`. One benefit of Edward is that for logging, you can simply pass an argument as `inference.initialize(logdir='log/' + subdir)`. Default TensorFlow summaries are tracked which can then be visualized using TensorBoard (more on this next).
-- `out/` records exploratory output after training finishes; for example, generated images or matplotlib plots. Each experiment belongs in a subdirectory with the same convention as `checkpoints/`.
-
-**On data sets.** Data sets are used across many research projects. I prefer storing them in the home directory `~/data`.
-
-**On software containers.** [virtualenv](http://python-guide-pt-br.readthedocs.io/en/latest/dev/virtualenvs/) is a must for managing Python dependencies and avoiding difficulties with system-wide Python installs. It’s particularly nice if you like to write Python 2/3-agnostic code. [Docker containers](https://www.docker.com/) are an even more powerful tool if you require more from your setup.
-
-## Exploration, Debugging, & Diagnostics
-
-
-
-[Tensorboard](https://www.tensorflow.org/get_started/summaries_and_tensorboard) is an excellent tool for visualizing and exploring your model training. With TensorBoard’s interactivity, I find it particularly convenient in that I don’t have to configure a bunch of matplotlib functions to understand training. One only needs to percolate a bunch of `tf.summary`s on tensors in the code.
-
-Edward logs a bunch of summaries by default in order to visualize how loss function values, gradients, and parameter change across training iteration. TensorBoard also includes wall time comparisons, and a sufficiently decorated TensorFlow code base provides a nice computational graph you can stare at. For nuanced issues I can’t diagnose with TensorBoard specifically, I just output things in the `out/` directory and inspect those results.
-
-**Debugging error messages.** My debugging workflow is terrible. I percolate print statements across my code and find errors by process of elimination. This is primitive. Although I haven’t tried it, I hear good things about [TensorFlow’s debugger](https://www.tensorflow.org/programmers_guide/debugger).
-
-## Improving Research Understanding
-
-Interrogating your model, algorithm, and generally the learning process lets you better understand your work’s success and failure modes. This lets you go back to the drawing board, thinking deeply about the method and how it might be further improved. As the method indicates success, one can go from tackling simple toy configurations to increasingly large scale and high-dimensional problems.
-
-From a higher level, this workflow is really about implementing the scientific method in the real world. No major ideas are necessarily discarded at each iteration of the experimental process, but rather, as in the ideal of science, you start with fundamentals and iteratively expand upon them as you have a stronger grasp of reality.
-
-Experiments aren’t alone in this process either. Collaboration, communicating with experts from other fields, reading papers, working on both short and longer term ideas, and attending talks and conferences help broaden your perspective in finding the right problems and solving them.
-
-## Footnotes & References
-
-1 This workflow is specifically for empirical research. Theory is a whole other can of worms, but some of these ideas still generalize.
-
-2 The template for the master document is available [`here`](https://github.com/dustinvtran/latex-templates).
-
-3 There’s one caveat to Papers. I use it for everything: there are at least 2,000 papers stored in my account, and with quite a few dense textbooks. The application sifts through at least half a dozen gigabytes, and so it suffers from a few hiccups when reading/referencing back across many papers. I’m not sure if this is a bug or just inherent to me exploiting Papers almost *too*much.
-
-1. Neal, R. M. (1994). *Bayesian Learning for Neural Networks* (PhD thesis). University of Toronto.
-2. Pearl, J. (2000). *Causality*. Cambridge University Press.
-3. Wainwright, M. J., & Jordan, M. I. (2008). Graphical Models, Exponential Families, and Variational Inference. *Foundations and Trends in Machine Learning*, *1*(1–2), 1–305.
\ No newline at end of file
diff --git "a/20171012 \347\254\25410\346\234\237/Introduction to Information Theory and Why You Should Care.md" "b/20171012 \347\254\25410\346\234\237/Introduction to Information Theory and Why You Should Care.md"
deleted file mode 100644
index d85b207c7540cde44f08364325b28a4b49c7f746..0000000000000000000000000000000000000000
--- "a/20171012 \347\254\25410\346\234\237/Introduction to Information Theory and Why You Should Care.md"
+++ /dev/null
@@ -1,185 +0,0 @@
-# Introduction to Information Theory and Why You Should Care
-
-原文链接:[Introduction to Information Theory and Why You Should Care](https://recast.ai/blog/introduction-information-theory-care/?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com)
-
-Let’s talk about information – what is it? Can we compress it and how much? What are the limits on the communication of information? We’ll try to answer these questions by looking at the revolutionary work of one man – Claude E. Shannon, and the men and women who followed in his footsteps. Most importantly, we’ll try to answer the question ‘is this important for machine learning and why?’. I hope that by the time you finish reading this post you too will be convinced that information theory can be very beneficial to anybody who’s interested in developing machine learning systems. Let’s start by discussing the general way the word “information” was understood before Shannon’s work in 1948. Then we will be ready to understand the revolutionary nature of this work.
-
-# **A Brief History of Information Theory**
-
-In the first half of the 20th century, the world was quickly becoming more and more connected through different types of **analogue communication**. This included public radio broadcasts as well as 2-way radio communication (such as for ships or aircraft). A general understanding of the term “information” was lacking at the time, and the communication of each type of data (such as voice, pictures, film etc.) was based on its own theory and practices. However, the main understanding was: for any given communication channel, communication has two characteristics – rate (the amount of data that can be transmitted in a given period of time) and reliability. Increasing each of these would invariably come at the expense of the other. When computer science started to emerge as a field, the general understanding was that this trade-off would stay true in this case as well. (Note: in this post I chose to simplify matters by treating information theory as the science of digital communication, ignoring analogue aspects.)
-
-Consider the following channel, called the BEC (binary erasure channel): each bit, when transmitted over the channel, can either be received on the other side error-free (with probability 1-p) or be erased (with probability p):
-
-
-
-[](https://recast.ai/blog/wp-content/uploads/2017/09/BEC.png)
-
-*Binary Erasure Channel (BEC). Each bit is erased with probability p*
-
-Assume that we want to transmit the bit “0”. If we send it once, there is a significant chance (p) that it won’t survive. We can try sending it twice, and reduce that probability to , but we will pay a heavy price in rate – we will have to use the channel twice in order to transmit one bit of information. Of course, we can continue to reduce the probability of erasure by sending the same bit again and again, but the price in rate would continue to increase. Shannon showed that this trade-off can be broken, and we will come back to the BEC later and see how.
-
-Let’s start exploring Shannon’s results and information theory as a whole now. To understand the math in this post, you need some basic concepts of probability theory, but don’t worry about that too much, I will explain everything intuitively.
-
-# **Basic Concepts**
-
-## **Important quantities and their meaning**
-
-Most practitioners of machine learning already use some concepts from information theory, sometimes without even knowing it. Here are a few basic quantities you may already be familiar with.
-
-### **Entropy**
-
-The entropy of a random variable X, usually referred to as 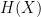 ,can be calculated through . The entropy can be thought of as a measure of the “mess” inherent in the variable X – given the size of the alphabet (the number of different values X can take), a uniform distribution over the alphabet maximizes the entropy, while a known value () gives . For example, consider the Bernoulli distribution, defined over an alphabet of size 2: . The entropy is maximized for  (“uniform” distribution) and minimized for  or  (certainty). Notice also that for discrete random variables, the entropy cannot be negative:
-
-
-
-[](https://recast.ai/blog/wp-content/uploads/2017/09/Binary_entropy_plot.png)
-
-*Entropy of a Bernoulli random variable X, as a function of X’s probability of being 1*
-
-
-
-Sometimes we want to measure the “mess” that is left after some information is already known. In order to do that, we can use the conditioned version of the entropy, defined as follows: . Here, Y represents the information we already know. Note though, that in the calculation we don’t assume the actual value of Y, instead we average over it: ![H(X|Y) = \mathbb{E}[H(X|Y=y)]](https://s0.wp.com/latex.php?latex=H%28X%7CY%29+%3D+%5Cmathbb%7BE%7D%5BH%28X%7CY%3Dy%29%5D&bg=ffffff&fg=000000&s=0).
-
-### **Mutual information**
-
-The mutual information is a measure defined over two random variables. It helps us gain insight about the information that one piece of data (or one random variable) carries about the other. Looking at the mathematical definition of the mutual information: , it can be seen that in fact it gives us insight about the answer to the question “how far are X and Y from being independent from each other?”. Through some simple algebra it can be shown that . In other words, the mutual information is the difference between the “mess” inherent in X, and the “mess” left in X after knowing Y (and the same is also true when the variables change roles). Note that while both the mutual information of two variables and their correlation give hints about their relationship, they look at the question from two very different angles. Here’s a picture of different two-dimensional scatters and the corresponding values of mutual information:
-
-[](https://recast.ai/blog/wp-content/uploads/2017/09/Mutual_Information_Examples.svg_.png)
-
-*Values of Mutual Information for different 2-variable probability distributions. In each sub-figure, the scatter represents a distribution over the variables, represented by the X and Y axis (source).*
-
-You can think about the correlation of the X and Y axis for each of these pictures and see for yourselves that sometimes correlation and mutual information behave very differently (for example: what would be the correlation between the axis for a narrow straight line? And for a circle? You can go [here](https://commons.wikimedia.org/wiki/File:Correlation_examples.png) to find out.)
-
-### **KL Divergence**
-
-When we want to compare two probability distributions,  and , one way of doing so is through the Kullback-Leibler (KL) divergence (sometimes referred to as the KL distance, although it is not a mathematical distance): . This quantity turns out to be very useful in many cases. For example, it constitutes the penalty to pay in code length when trying to encode a source  as if it was distributed according to . One of the reasons the KL divergence is so useful is the property , with equality if and only if . Note however, that , which is why the KL divergence is not a mathematical distance. Also, the mutual information is in fact just a private case of the KL divergence, where we compare the joint distribution of X and Y with their product distribution: .
-
-If you are interested in digging deeper into the KL divergence, as well as other quantities mentioned above and more, take a look at [this blog post](http://colah.github.io/posts/2015-09-Visual-Information/). It contains neat visualisations and explains the relation of all of this to coding theory.
-
-## **Let’s play**
-
-Now that we know the three most basic quantities in information theory, let’s have some fun with them! Here are some important concepts to remember:
-
-### **Conditioning reduces entropy**
-
-. This concept is very intuitive – the “mess” in X when Y is known cannot be bigger than the “mess” in X without knowing Y. If that were the case, we could always just “ignore” our knowledge of Y! As for the proof,we already have all the tools to do it. The mutual information between X and Y is just the KL divergence between  and . As such,  and thus .
-
-### **Chain rule**
-
-The chain rule is quite easy to prove through basic logarithmic properties – try it! It tells us that the joint “mess” in X and Y is exactly equal to the “mess” in X in addition to the mess in Y,when X is already known: .
-
-### **Data Processing Theorem**
-
-If you only remember one thing from this blog post, I hope this is it. Let’s start with the mathematical formulation and leave the explanation for later:
-
-Let  form a Markov chain, in that order. Then ![I(X;Z) \leq \min [I(X;Y), I(Y;Z)]](https://s0.wp.com/latex.php?latex=I%28X%3BZ%29+%5Cleq+%5Cmin+%5BI%28X%3BY%29%2C+I%28Y%3BZ%29%5D&bg=ffffff&fg=000000&s=0).
-
-But what does that mean? We say that  form a Markov chain, if Y is the only “connection” between X and Z. In other words, given Y, knowing also Z doesn’t give any additional information about X. In that case, the mutual information between X and Z is smaller than both  and . An interesting private case of this theorem is to consider . In this case, do form a Markov chain, and the significance of this is that by processing data, we can never gain information about a hidden quality. For example, assume that Y represents possible pictures in a dataset and Z represents the main object in the picture (the alphabet of Z is thus “cat”, “dog”, “ball”, “car” etc.). By processing Y (for example through a convolutional neural network) it is **impossible** to create new information about Z, all we can hope for is to lose as little as possible. How come convolutional neural networks work so well then, you may ask? It is because they can **extract** the important information from the picture in order to make the classification, but they can never **create** it.
-
-### **Asymptotic Equipartition Property**
-
-One could argue that this property is single handedly responsible for making the magic happen in information theory. It tells us that given a large series of independent and identically distributed (i.i.d.) experiments, , their empirical entropy will be very close to the theoretical entropy of :  (in probability). This means that, given a large series of such experiments, all of the probability will be divided only between a relatively small set of sequences, which we call **typical**. Let’s take an example: Imagine a **non-fair** coin, that lands on heads with probability 0.7. Throwing this coin 100 times, clearly the probability of any specific sequence is very small. Nevertheless, almost all of the probability will be inside the set of results that have about (but not necessarily exactly) 70 heads and 30 tails. If we continue and throw the coin 1000 times, the probability of the set that contains only results with about 700 heads would be even closer to 1. Implementing a small python code of 1000 such experiments, each with 1000 coin tosses, only one experiment resulted in a number of heads not between 650 and 750:
-
-```
-import random
-
-experiments = 1000 # number of complete experiments
-toss_per_experiment = 1000 #number of tosses per experiment
-delta = 50 # the tolerance
-prob_heads = 0.7 # the probability the coin lands on heads
-count = 0
-
-for exper in range(experiments):
- heads = 0
- for toss in range(toss_per_experiment):
- if random.random() <= prob_heads:
- heads += 1
- if (heads <= toss_per_experiment * prob_heads - delta) or (heads >= toss_per_experiment * prob_heads + delta):
- count += 1
-
-print(count)
-```
-
-I invite you to play with the parameters yourselves – try to separately change the number of experiments, the tosses per experiment and the tolerance ‘delta’ and see what happens.
-
-# **Capacity**
-
-The original paper by Shannon from 1948 is packed full of important and interesting results (go take a look yourself, it is very pleasantly written. See a full citation and a link at the final section of this post). Arguably the two most important results in this paper can be referred to as the **Source Coding Theorem** and the **Channel Coding Theorem**.
-
-## **Source Coding Theorem**
-
-n random variables , all independently distributed by , can be compressed into any number of bits that is strictly larger than  with negligible risk of information loss as 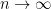.
-
-But how can this be achieved, from a theoretical point of view? Well, the asymptotic equipartition property tells us that all of the probability is in the typical set. Thus, it makes no sense to distribute codewords in our code to sequences that are **not** in this set. And what is the size of the typical set? It contains about  sequences, so it makes sense that we would not need more than about  bits in order to represent these sequences, and them only!
-
-This result takes us back to the intuitive explanation about the nature of the entropy: For each of the random variables , the “mess” inherent in it is 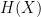. Doesn’t it make sense then, that in order to compress the result of each of these “experiments”, all we need to do is to dissipate the inherent “mess”? Note however that this is only true in the limit where n is very large – if we only want to compress the result of a few experiments we may need more resources.
-
-## **Channel Coding Theorem**
-
-The noisy channel coding theorem states that any communication channel has a capacity – a maximum rate of communication (in bits per channel use, for example) that can be transmitted on the channel reliably (with the probability of error being as low as we want it to be!). This is true for **any channel**, no matter how noisy it may be. Of course, if the channel does not let the signal pass at all, the capacity is zero. Let’s take a simple example: Consider the **binary erasure channel** (BEC) that we have already seen:
-
-[](https://recast.ai/blog/wp-content/uploads/2017/09/BEC.png)
-
-*Binary Erasure Channel. Despite erasures, reliable communication is possible under the channel capacity*
-
-Clearly, sending n bits (and assuming n is large), we can assume that about  of these bits would arrive safely. Unfortunately, if we choose this “blind” strategy, we cannot know in advance which of the bits would be dropped. Amazingly enough, the capacity of this channel is in fact ! This means that if, for n channel uses, we are willing to contend with only transmitting  bits of information instead of the n bits we can physically “push” into the channel, we can guarantee that these  bits will arrive safely to the other side! It is important, however, to remember the big difference between the amount of information (measured in bits) and the number of bits on the channel, which is equal to the number of channel uses – We would still send n bits on the channel during the communication, but the information embedded in them would only be equivalent to  bits. These  bits of information, however, would arrive safely to the other side.
-
-# **Information Theory in Machine Learning (or: Why Should I Care?)**
-
-Congratulations on making it all the way down here! I hope I succeeded in my mission to convey these principles in an intuitive way, and that the math that I did have to include was understandable enough. Your prize for getting here is to find out – why does all of this matter for machine learning?
-
-Before anything else, in my opinion the intuition and basic understanding of concepts that comes with knowing a little about information theory is the most valuable lesson to take into the world of machine learning. Looking at any ML problem as the problem of creating a **channel** from the original data-point at the input to an answer at the output, for which the **information** it conveys about the desired property of the data is maximized, would allow you to look at many different problems from a different angle than usual. The quantities presented above also turn out to be helpful in many different situations. Consider for example a situation where we would like to compare two unsupervised clustering algorithms over the same data, in order to check if they give similar results or not. Why not use the mutual information between the results of each of the algorithms, where X is the random variable that represents the cluster chosen for any data point by the first algorithm and Y represents the second? Another option is to use the conditioned entropy ( or ) in order to see how much “mess” is left when guessing the result of clustering by one algorithm, while the result of clustering by the other is already known (these two methods of comparison are very similar but there is a difference, can you spot it?).
-
-In the remainder of this section, let’s try to take a closer look at some interesting results in ML, that were the direct result of a connection with information theory:
-
-## **Training a Decision Tree**
-
-One of the most popular algorithms for training decision trees is based on the principle of maximizing the **information gain**. Although given a different name, the information gain that corresponds to each feature is exactly the mutual information between that feature and the labels of the data points (You can go see for yourself [here](https://en.wikipedia.org/wiki/Decision_tree_learning)). This actually makes a lot of sense – when trying to decide which is the best feature to split the tree on, why not choose the one that gives the most information about the result? In other words, why not choose the one that, after splitting, would dissipate as much of the “mess” as possible? What happens after the split? How do we continue building the tree? Each node after the split can be represented by a new random variable, and we can start the whole process again for each of the resulting nodes.
-
-Considering this process, we may also be able to gain some understanding about another very important issue – regularization. Decision trees are one of the models that requires the most regularization, as experience tells us that completely “free” trees would overfit almost every time. Let’s consider this issue through the data processing theorem: What we wish to do is to increase the mutual information between the actual label of a data point (let’s call the label Z to stay consistent with the data processing theorem above) and the predicted label X. Unfortunately, in order to predict the label, we can only use the attributes Y. We do our best by increasing the mutual information between X and Y, but according to the theorem this does not guarantee an increase also in . , you may remember, only constitutes an **upper bound** over . Thus, in the first steps, the information gain is significant and there’s a good chance that it contributes, at least in part, to a gain also in , which is what we really want. As the information gain becomes less and less significant as the tree grows, the hope of increasing  diminishes and instead all we get is overfitting to the data. Hence, it is better to truncate the tree when the information gain becomes insignificant.
-
-## **Clustering by Compression**
-
-Another interesting example is that of clustering by compression. The main idea here is to use popular compression algorithms, like the ones responsible for ZIP, RAR, Gif and more, that present good performance especially for files that have repetitive features, in order to determine which category a data point belongs to. We do so by appending the new data point to each of the files representing the classes, and choosing the one that is most performant in compressing the data point.
-
-This approach takes advantage of the Lempel Ziv (LZ) family of compression algorithms, (see for example [here](https://en.wikipedia.org/wiki/LZ77_and_LZ78)). While these algorithms come in many different variations, the main idea stays the same: Going over the document to be compressed from beginning to end, at each point known passages are encoded through a reference to a previous appearance, while completely new information is added to the “dictionary”, in order to be available for use when a similar segment is encountered again. The way this dictionary is created and managed may differ between members of the LZ family of algorithms, but the main idea stays the same.
-
-Using this type of algorithm to compress a file, it is clear that the type of documents that would benefit the most out of this type of compression are **long, repetitive documents.** That is because the Source Coding Theorem tells us that lossless compression is bounded from below by  and the entropy, which represents mess, is much bigger for random files than it is for repetitive ones. For these repetitive documents, the algorithm would have enough “time” to learn the patterns in them, and then use them again and again in order to save the information in an efficient manner.
-
-It turns out that the fact that similarities in a file make for good compression can be used for classification. For supervised classification (where the classes exist and contain a significant amount of data as “examples”), a new data-point can be appended to any of the existing files (where each file represents a “class”), and the declared class for the data-point is the one that was successful in compressing the data-point the most, relative to its original size (in bits). Note that since we append the data-point to the end of each of the documents, all the information in the existing documents should already exist in the respective “dictionaries” when the compression algorithm reaches the new data-point. Thus, if there are similarities between any of the existing documents and the new data-point, they will be automatically used in order to create good compression.
-
-Considering unsupervised classification (or **clustering**), a similar approach can still be helpful. Using the level of “successfulness” of joint compression of different combinations of data-points, clusters can be created such as the data-points within each class compress well together. Of course, in this case there are some more questions to answer, mainly having to do with the vast amount of combinations to test and the complexity of the final clustering algorithm, but these problems can be addressed, as was done for example in [this very complete work](https://arxiv.org/abs/cs/0312044). The advantage of this clustering approach is that there is no need to predefine the characteristics to be used. Taking for example the problem of the clustering of music files, other approaches would require us to first define and extract different characteristics of the files, such as beat, pitch, name of artist and so on. Here, all we need to do is to check which files compress well together. It is important to remember, however, the **No Free Lunch Lemma**: The whole magic here is contained in the compression process, thus understanding the specific compression algorithm chosen is imperative. How is the dictionary built? How is it used? What is a “long enough” document to be compressed by it? etc. These specificities can determine the type of similarities the compression is susceptible to use, and thus the characteristics that control the clusterization.
-
-## [ Happy bot building ](https://recast.ai/blog/build-your-first-bot-with-recast-ai/?utm_source=blog&utm_medium=article)
-
-# **Where Can I Learn More?**
-
-The world of Information Theory is vast and there’s a lot to learn. If this post gave you the desire to do so (and I hope it did), here are some good places to start:
-
-If you are interested in the biography and achievements of Claude E. Shannon, I invite you to take a look at this blog post, which I found to be very interesting:
-
-In addition, you can find a newly published biography of Shannon here:
-
-If it is Information Theory itself that interests you, I invite you to start from Shannon’s original paper, which is quite comprehensive and also easy to read:
-
-- C. E. Shannon, “A mathematical theory of communication,” in *The Bell System Technical Journal*, vol. 27, no. 3, pp. 379-423, July 1948.
-
-
-In addition, there are a few books that are also a good place to start. Most students start with one of these, as far as I know:
-
-- Cover, T. M., & Thomas, J. A. (2012). *Elements of information theory*. John Wiley & Sons.
-- Gallager, R. G. (1968). *Information theory and reliable communication* (Vol. 2). New York: Wiley.
-
-A book that is a bit harder to start with but may be worth the work for its mathematical completeness is the following one:
-
-- Csiszar, I., & Körner, J. (2011). *Information theory: coding theorems for discrete memoryless systems*. Cambridge University Press.
-
-If you are specifically interested in Lempel-Ziv compression, there are a lot of papers you could start with. Try this one:
-
-- Ziv, J., & Lempel, A. (1977). A universal algorithm for sequential data compression. *IEEE Transactions on information theory*, *23*(3), 337-343.
-
-Other resources are included in the body of this post, and of course the world of information theory is rich in interesting results and you can probably find what your heart desires quite easily. Have fun and thank you for reading.
-
-#### Want to build your own conversational bot? Get started with Recast.AI !
-
-
\ No newline at end of file
diff --git "a/20171012 \347\254\25410\346\234\237/README.md" "b/20171012 \347\254\25410\346\234\237/README.md"
index 04b9d4fc5c946197c236aa698841b2bf5e7d1fe4..1a6f13cea170510efdf5967977c898f0b93f3b20 100644
--- "a/20171012 \347\254\25410\346\234\237/README.md"
+++ "b/20171012 \347\254\25410\346\234\237/README.md"
@@ -3,3 +3,4 @@
| [A Research to Engineering Workflow](http://dustintran.com/blog/a-research-to-engineering-workflow?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com) | |
| [Introduction to Information Theory and Why You Should Care](https://recast.ai/blog/introduction-information-theory-care/?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com) | |
| [A Gentle Introduction to the Bag-of-Words Model](https://machinelearningmastery.com/gentle-introduction-bag-words-model/) | |
+
diff --git "a/20171012 \347\254\25410\346\234\237/\344\277\241\346\201\257\347\220\206\350\256\272\346\246\202\350\256\272\345\222\214\344\275\240\345\272\224\350\257\245\345\205\263\345\277\203\347\232\204\345\216\237\345\233\240.md" "b/20171012 \347\254\25410\346\234\237/\344\277\241\346\201\257\347\220\206\350\256\272\346\246\202\350\256\272\345\222\214\344\275\240\345\272\224\350\257\245\345\205\263\345\277\203\347\232\204\345\216\237\345\233\240.md"
new file mode 100644
index 0000000000000000000000000000000000000000..a94791466e8641d7f4cfd107d0f6004eccd14e9c
--- /dev/null
+++ "b/20171012 \347\254\25410\346\234\237/\344\277\241\346\201\257\347\220\206\350\256\272\346\246\202\350\256\272\345\222\214\344\275\240\345\272\224\350\257\245\345\205\263\345\277\203\347\232\204\345\216\237\345\233\240.md"
@@ -0,0 +1,182 @@
+# 信息理论概论和你应该关心的原因
+
+原文链接:[信息理论概论和你应该关注的原因](https://recast.ai/blog/introduction-information-theory-care/?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com)
+
+我们来谈谈信息 - 它是什么?我们可以多大程度的压缩它?信息沟通有哪些限制?我们将通过观察一群人 - 克劳德·香农(Claude E. Shannon)以及跟随他的脚步的男人和女人的革命性工作来回答这些问题。最重要的是,我们将尝试回答“这对机器学习至关重要吗?为什么?”。我希望当你读完这篇文章时,你也会相信信息理论对任何对开发机器学习系统感兴趣的人都非常有益。让我们首先讨论香农1948年工作之前理解“信息”这个词的一般方式。然后我们将准备好理解这项工作的革命性质。
+
+# **信息论简史**
+
+在20世纪上半叶,世界迅速通过不同类型的**模拟通信**变得越来越紧密。这包括公共无线电广播以及双向无线电通信(例如船舶或飞机)。当时缺乏对“信息”一词的理解,每种类型的数据(如语音,图片,电影等)的传播都是基于其自身的理论和实践。然而,一般的理解是:对于任何给定的通信信道,通信具有两个特征 - 速率(在给定时间段内可以传输的数据量)和可靠性。增加其中的每一个都会以牺牲另一个为代价。当计算机科学开始成为一个领域时,一般的理解是这种权衡在这种情况下也将保持正确。(注意:在这篇文章中,我选择通过将信息理论视为数字通信科学来简化问题,
+
+考虑以下通道,称为BEC(二进制擦除通道):每个位在通过通道传输时,可以在另一侧无错接收(概率为1-p)或被擦除(概率为p):
+
+
+
+[](https://recast.ai/blog/wp-content/uploads/2017/09/BEC.png)
+
+*二进制擦除通道(BEC)。每个比特以概率p擦除*
+
+假设我们想要传输比特“0”。如果我们发送一次,那么很有可能(p)它将无法生存。我们可以尝试发送两次,并降低概率,但我们将付出沉重的代价 - 我们必须使用两次通道才能传输一位信息。当然,我们可以通过一次又一次地发送相同的比特来继续降低擦除的可能性,但是费率的价格会继续增加。Shannon表明这种权衡可以被打破,我们稍后会回到BEC,看看如何。
+
+让我们现在开始探索香农的结果和信息理论。要理解这篇文章中的数学,你需要概率论的一些基本概念,但不要太担心,我会直观地解释一切。
+
+# **基本概念**
+
+## **重要物理量及其含义**
+
+大多数机器学习从业者已经使用了信息理论中的一些概念,有时甚至不知道它。以下是您可能已经熟悉的一些基本数量。
+
+### **熵**
+
+通常称为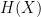随机变量X的熵 可以通过计算得到。 熵可以被认为是变量X中 固有的“混乱”的度量- 给定字母表的大小(X 可以采用的不同值的数量),字母表上的均匀分布使熵最大化,而已知value() 给出。例如,考虑伯纳利分布,在大小为2的字母表中定义:。 熵最大化 (“均匀”分布)并且最小化或 (确定性)。另请注意,对于离散随机变量,熵不能为负数:
+
+
+
+[](https://recast.ai/blog/wp-content/uploads/2017/09/Binary_entropy_plot.png)
+
+*伯努利随机变量X的熵,作为X的概率为1的函数*
+
+
+
+有时我们想要测量一些信息已经知道后留下的“混乱”。为了做到这一点,我们可以使用熵的条件版本,定义如下:。在这里,Y 代表我们已经知道的信息。但请注意,在计算中我们不假设Y 的实际值,而是用它的平均值:![H(X | Y)= \ mathbb {E} [H(X | Y = y)]](https://s0.wp.com/latex.php?latex=H%28X%7CY%29+%3D+%5Cmathbb%7BE%7D%5BH%28X%7CY%3Dy%29%5D&bg=ffffff&fg=000000&s=0)。
+
+### **相互信息**
+
+互信息是在两个随机变量上定义的度量。它有助于我们深入了解一个数据(或一个随机变量)携带的信息。看一下互信息的数学定义:可以看出,实际上它让我们对“ X 和Y 彼此独立多远?” 这一问题的答案有所了解。通过一些简单的代数可以证明。换句话说,互信息是X中固有的“混乱”与知道Y 后X中剩下的“混乱” 之间的差异。(当变量改变角色时也是如此)。请注意,虽然两个变量的相互信息及其相关性都给出了关于它们之间关系的提示,但它们从两个非常不同的角度来看问题。这是不同二维散点图和相互信息的相应值:
+
+[](https://recast.ai/blog/wp-content/uploads/2017/09/Mutual_Information_Examples.svg_.png)
+
+*不同2变量概率分布的互信息值。在每个子图中,散点表示变量上的分布,由X轴和Y轴(源)表示。*
+
+您可以考虑每个图片的X 轴和Y 轴的相关性,并亲眼看看相关和互信息的行为有很大不同(例如:窄直线的轴之间的相关性是什么?一个圆圈?你可以到[这里](https://commons.wikimedia.org/wiki/File:Correlation_examples.png)找出来。)
+
+### **KL分歧**
+
+当我们要比较两个概率分布,并且,这样做的一个方式是通过库尔贝克-莱布勒(KL)散度(有时被称为KL距离,虽然它不是一个数学距离)。在许多情况下,这个数量非常有用。例如,它构成了在尝试对源进行编码时支付代码长度的代价, 就好像它是根据分发一样。吉隆坡分歧如此有用的原因之一是财产,当且仅当相等时才具有平等性。注^ h H但是,那,这就是为什么KL信息量不是数学距离。此外,互信息实际上只是KL分歧的一个私人案例,我们在那里比较联合分布X 和Y 及其产品分布:。
+
+如果您有兴趣深入了解KL分歧,以及上面提到的其他数量等,请查看[此博客文章](http://colah.github.io/posts/2015-09-Visual-Information/)。它包含整洁的可视化,并解释了所有这些与编码理论的关系。
+
+## **让我们玩**
+
+现在我们已经了解了信息理论中最基本的三个数量,让我们对它们有一些乐趣!以下是一些需要记住的重要概念:
+
+### **调节减少熵**
+
+。这个概念是非常直观-在“大锅饭” X 时Ÿ 知道不能比的“烂摊子”做大X 不知道ÿ 。如果是这样的话,我们总是可以“忽略”我们对Y 的了解!至于证明,我们已经拥有了所有这些工具。之间的相互信息X 和Ÿ 只是之间的KL散度和。因此, 因此。
+
+### **连锁规则**
+
+通过基本的对数属性很容易证明链式规则 - 试试吧!它告诉我们X 和Y 中的联合“混乱” 正好等于X 中的“混乱” ,除了Y中的混乱,当X 已经知道时:。
+
+### **数据处理定理**
+
+如果你只记得这篇博文中的一件事,我希望就是这样。让我们从数学公式开始,稍后留下解释:
+
+让我们 按顺序形成马尔可夫链。然后![I(X; Z)\ leq \ min [I(X; Y),I(Y; Z)]](https://s0.wp.com/latex.php?latex=I%28X%3BZ%29+%5Cleq+%5Cmin+%5BI%28X%3BY%29%2C+I%28Y%3BZ%29%5D&bg=ffffff&fg=000000&s=0)。
+
+但是,这是什么意思? 如果Y 是X 和Z 之间唯一的“连接” ,我们说形成马尔可夫链。换句话说,给定Y ,知道Z 也不提供关于X的任何附加信息。在这种情况下,X 和Z 之间的互信息小于和。这个定理的一个有趣的私人案例是要考虑。在这种情况下, 确实形成马尔可夫链,其重要性在于通过处理数据,我们永远无法获得有关隐藏质量的信息。例如,假设Y. 表示数据集中的可能图片,Z 表示图片中的主要对象(Z 的字母表因此是“猫”,“狗”,“球”,“汽车”等)。通过处理Y (例如通过卷积神经网络),**不可能**创建关于Z的新信息,我们所希望的是尽可能少地丢失。你可能会问,卷积神经网络如何运作得如此之好?这是因为他们可以从图片中**提取**重要信息以进行分类,但他们永远无法**创建**它。
+
+### **渐近均分属性**
+
+有人可能会争辩说,这个属性是单独负责使信息理论发生魔力。它告诉我们,给定一系列独立且相同分布(iid)的实验,他们的经验熵将非常接近理论熵:(  概率)。这意味着,鉴于大量此类实验,所有概率将仅在相对较小的序列集之间划分,我们称之为**典型**序列。让我们举一个例子:想象一个**非公平的**硬币,以0.7的概率落在头上。投掷这个硬币100次,显然任何特定序列的概率非常小。尽管如此,几乎所有的概率都在一组结果中,这些结果具有大约(但不一定完全)70个头和30个尾部。如果我们继续投掷硬币1000次,那么仅包含大约700个头的结果的概率将更接近1.实现1000个这样的实验的小蟒蛇代码,每个实验有1000个硬币投掷,只有一个实验结果在650到750之间的许多头中:
+
+```
+import random
+
+experiments = 1000 # number of complete experiments
+toss_per_experiment = 1000 #number of tosses per experiment
+delta = 50 # the tolerance
+prob_heads = 0.7 # the probability the coin lands on heads
+count = 0
+
+for exper in range(experiments):
+ heads = 0
+ for toss in range(toss_per_experiment):
+ if random.random() <= prob_heads:
+ heads += 1
+ if (heads <= toss_per_experiment * prob_heads - delta) or (heads >= toss_per_experiment * prob_heads + delta):
+ count += 1
+
+print(count)
+```
+
+我邀请你自己玩参数 - 尝试分别改变实验次数,每次实验的投掷和容差'delta',看看会发生什么。
+
+# **容量**
+
+Shannon从1948年开始的原始论文中充满了重要而有趣的结果(请自己看看,写得非常愉快。请参阅本文末尾的完整引文和链接)。可以说,本文中两个最重要的结果可以称为**源编码定理**和**信道编码定理**。
+
+## **源编码定理**
+
+Ñ 随机变量,所有独立地被分布,可以压缩成任何数目的比特是严格大于 与信息损失的风险可忽略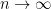。
+
+但是,从理论的角度来看,如何实现这一目标呢?嗯,渐近均分属性告诉我们所有的概率都在典型的集合中。因此,将代码中的代码字分发给**不在**此集合中的 序列是没有意义的。典型套装的尺寸是多少?它包含有关序列的内容,因此有意义的是 ,为了表示这些序列,我们不需要超过一些位,而且它们只是!
+
+这个结果让我们回到关于熵性质的直观解释:对于每个随机变量, 其中固有的“混乱”是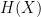。那么,有意义的是,为了压缩每个“实验”的结果,我们需要做的就是消除固有的“混乱”吗?但请注意,这仅适用于n 非常大的限制- 如果我们只想压缩一些实验的结果,我们可能需要更多资源。
+
+## **信道编码定理**
+
+有噪声的信道编码定理表明任何通信信道都具有容量 - 可以在信道上可靠地传输的最大通信速率(例如,每个信道使用的比特数)(错误概率低至我们想要的低)成为!)。**任何频道**都是如此,无论它有多嘈杂。当然,如果信道根本不让信号通过,则容量为零。让我们举一个简单的例子:考虑我们已经看到的**二进制擦除通道**(BEC):
+
+[](https://recast.ai/blog/wp-content/uploads/2017/09/BEC.png)
+
+*二进制擦除通道。尽管有擦除,但在信道容量下可以进行可靠的通信*
+
+显然,发送n比特(假设n很大),我们可以假设 这些比特中的大约会安全到达。不幸的是,如果我们选择这种“盲目”策略,我们无法预先知道哪些比特会被丢弃。令人惊讶的是,这个频道的容量实际上是! 这意味着,如果对于n通道使用,我们愿意仅仅传输 信息比特而不是n比特,我们可以物理地“推”到通道中,我们可以保证这些 位将安全到达另一侧!然而,重要的是要记住信息量(以比特为单位)和信道上的比特数之间的巨大差异,这等于信道使用的数量 - 我们仍将在信道上发送n比特。通信,但嵌入其中的信息只相当于 比特。 然而,这些信息将安全地到达另一方。
+
+# **机器学习中的信息理论(或:我为什么要关心?)**
+
+恭喜你一直在这里!我希望我能够以直观的方式成功地传达这些原则,而且我所做的数学运算必须包含在内。你来到这里的奖励是找出 - 为什么所有这些对于机器学习都很重要?
+
+在其他任何事情之前,在我看来,对于了解一点信息理论所带来的概念的直觉和基本理解是进入机器学习世界的最有价值的教训。将任何ML问题视为从输入处的原始数据点到输出处的答案创建**通道**的问题,对于该问题,**信息**它传达了数据所需的属性最大化,可以让你从不同的角度看待许多不同的问题。上面提到的数量在许多不同的情况下也是有用的。例如,考虑我们想要在相同数据上比较两个无监督聚类算法的情况,以便检查它们是否给出相似结果。为什么不使用每个算法的结果之间的互信息,其中X是随机变量,表示第一个算法为任何数据点选择的簇,Y代表第二个算法?另一种选择是使用条件熵(或)当用一种算法猜测聚类结果时,看到剩下多少“乱七八糟”,而另一种算法聚类的结果已经知道(这两种比较方法非常相似,但有区别,你能不能发现它?)。
+
+在本节的其余部分,让我们试着仔细研究ML中的一些有趣结果,这是与信息理论联系的直接结果:
+
+## **培训决策树**
+
+用于训练决策树的最流行的算法之一基于最大化**信息增益**的原理。虽然给出了不同的名称,但与每个特征相对应的信息增益恰好是该特征与数据点标签之间的相互信息(您可以[在此处查看](https://en.wikipedia.org/wiki/Decision_tree_learning))。这实际上很有意义 - 当试图确定哪个是分割树的最佳功能时,为什么不选择提供结果最多信息的那个?换句话说,为什么不选择在分裂之后尽可能多地消散“混乱”的那个呢?拆分后会发生什么?我们如何继续建造树木?拆分后的每个节点都可以用新的随机变量表示,我们可以为每个结果节点再次启动整个过程。
+
+考虑到这个过程,我们也可以对另一个非常重要的问题 - 正规化 - 有所了解。决策树是需要最多正规化的模型之一,因为经验告诉我们几乎每次都会完全“自由”树木。让我们通过数据处理定理来考虑这个问题:我们希望做的是增加数据点的实际标签之间的互信息(让我们称之为标签Z以保持与上面的数据处理定理一致)和预测标签X不幸的是,为了预测标签,我们只能使用属性Y.我们通过增加X和Y之间的互信息来尽力而为,但根据定理,这并不能保证增加。你可能还记得,只构成**上界**了。因此,在第一步中,信息增益是显着的,并且很有可能它至少部分地促进了增益,这是我们真正想要的。随着树的增长,信息增益变得越来越不重要,增加的希望 减少了,而我们得到的只是过度拟合数据。因此,当信息增益变得无关紧要时,最好截断树。
+
+## **通过压缩进行聚类**
+
+另一个有趣的例子是通过压缩进行聚类。这里的主要思想是使用流行的压缩算法,例如负责ZIP,RAR,Gif等的压缩算法,这些算法对于具有重复特征的文件具有良好的性能,以便确定数据点属于哪个类别。我们通过将新数据点附加到表示类的每个文件,并选择在压缩数据点时性能最高的文件来实现。
+
+这种方法利用了Lempel Ziv(LZ)系列压缩算法(例如参见[此处](https://en.wikipedia.org/wiki/LZ77_and_LZ78))。虽然这些算法有许多不同的变化,但主要思想保持不变:从头到尾压缩文档,在每个点上,已知段落通过对先前外观的引用进行编码,同时添加全新信息“词典”,以便在再次遇到类似的段时可用。LZ系列算法的成员之间创建和管理此字典的方式可能不同,但主要思想保持不变。
+
+使用这种类型的算法来压缩文件,很明显,从这种类型的压缩中受益最多的文档类型是**长而重复的文档。**这是因为源编码定理告诉我们无损压缩是从下面开始的 ,并且表示混乱的熵对于随机文件比对重复文件要大得多。对于这些重复文档,算法将有足够的“时间”来学习它们中的模式,然后一次又一次地使用它们以便以有效的方式保存信息。
+
+事实证明,文件中的相似性可以用于良好压缩的事实可以用于分类。对于监督分类(类存在且包含大量数据作为“示例”),可以将新数据点附加到任何现有文件(其中每个文件代表“类”),以及声明的类数据点是相对于其原始大小(以位为单位)成功压缩数据点的数据点。请注意,由于我们将数据点附加到每个文档的末尾,因此当压缩算法到达新数据点时,现有文档中的所有信息应该已经存在于相应的“词典”中。因此,如果任何现有文档与新数据点之间存在相似性,
+
+考虑到无监督分类(或**聚类**),类似的方法仍然有用。使用不同数据点组合的联合压缩的“成功”水平,可以创建聚类,例如每个类中的数据点一起压缩得很好。当然,在这种情况下,有一些问题需要解决,主要有与大量组合的测试和最终的聚类算法的复杂性做的,但这些问题是可以解决的,如在例如做[这个非常完成工作](https://arxiv.org/abs/cs/0312044)。这种聚类方法的优点是不需要预先定义要使用的特征。以音乐文件聚类的问题为例,其他方法要求我们首先定义和提取文件的不同特征,例如节拍,音高,艺术家姓名等。在这里,我们需要做的就是检查哪些文件压缩得很好。然而,重要的是要记住**无免费午餐引理**:这里的整个魔法都包含在压缩过程中,因此了解所选择的具体压缩算法势在必行。字典是如何构建的?怎么用?什么是“足够长”的文件要被它压缩?这些特性可以确定压缩易于使用的相似性类型,从而确定控制聚类的特征。
+
+## [ 快乐机器人大楼 ](https://recast.ai/blog/build-your-first-bot-with-recast-ai/?utm_source=blog&utm_medium=article)
+
+# **我在哪里可以了解更多?**
+
+信息理论世界是巨大的,需要学习很多东西。如果这篇文章给你这样做的愿望(我希望它这样做),这里有一些好的开始:
+
+如果你对Claude E. Shannon的传记和成就感兴趣,我邀请你看看这篇博文,我觉得这篇文章非常有趣:[https](https://www.technologyreview.com/s/401112/claude-shannon-reluctant-father-of-the-digital-age/):[//www.technologyreview.com/s/401112/claude -shannon-不愿意,父亲的最数字时代/](https://www.technologyreview.com/s/401112/claude-shannon-reluctant-father-of-the-digital-age/)
+
+此外,您可以在这里找到新出版的香农传记:[https](https://www.amazon.com/Mind-Play-Shannon-Invented-Information/dp/1476766681/ref=sr_1_1?ie=UTF8&qid=1503066163&sr=8-1&keywords=a+mind+at+play):[//www.amazon.com/Mind-Play-Shannon-Invented-Information/dp/1476766681/ref=sr_1_1?ie = UTF8&qid = 1503066163&sr = 8- 1个关键字+游戏= A +心态+](https://www.amazon.com/Mind-Play-Shannon-Invented-Information/dp/1476766681/ref=sr_1_1?ie=UTF8&qid=1503066163&sr=8-1&keywords=a+mind+at+play)
+
+如果您感兴趣的是信息理论本身,我邀请您从Shannon的原始论文开始,该论文非常全面且易于阅读:
+
+- CE Shannon,“通信的数学理论”,载于*“贝尔系统技术期刊”*,第一卷。27,不。3,第379-423,1948年七月
+
+此外,还有一些书籍也是一个很好的起点。据我所知,大多数学生从其中一个开始:
+
+- Cover,TM和Thomas,JA(2012)。*信息论的要素*。John Wiley&Sons。
+- 加拉格,RG(1968)。*信息理论和可靠的沟通*(第2卷)。纽约:威利。
+
+一本有点难以开始的书但可能值得为它的数学完整性而工作的是以下一本:
+
+- Csiszar,I。,&Körner,J。(2011)。*信息论:离散无记忆系统的编码定理*。剑桥大学出版社。
+
+如果您对Lempel-Ziv压缩特别感兴趣,可以从很多论文开始。试试这个:
+
+- Ziv,J。和Lempel,A。(1977)。用于顺序数据压缩的通用算法。*IEEE信息理论学报*,*23*(3),337-343。
+
+其他资源包含在这篇文章的正文中,当然,信息理论世界也有丰富的有趣结果,你可以很容易地找到你的心愿。玩得开心,谢谢你的阅读。
+
+#### 想建立自己的会话机器人?开始使用Recast.AI!
\ No newline at end of file
diff --git "a/20171012 \347\254\25410\346\234\237/\345\267\245\347\250\213\345\267\245\344\275\234\346\265\201\347\250\213\347\240\224\347\251\266.md" "b/20171012 \347\254\25410\346\234\237/\345\267\245\347\250\213\345\267\245\344\275\234\346\265\201\347\250\213\347\240\224\347\251\266.md"
new file mode 100644
index 0000000000000000000000000000000000000000..d73aa7b999b6edd3845abeb201a2daf101dd9203
--- /dev/null
+++ "b/20171012 \347\254\25410\346\234\237/\345\267\245\347\250\213\345\267\245\344\275\234\346\265\201\347\250\213\347\240\224\347\251\266.md"
@@ -0,0 +1,174 @@
+# 工程工作流程研究
+
+原文链接:[工程工作流程研究](http://dustintran.com/blog/a-research-to-engineering-workflow?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com)
+
+从研究理念到实验是至关重要的。但是这个步骤通常只有很少的明确建议。在学术界,研究生常常会分散各种各样的代码,各种各样的笔记和散落的LaTeX文章。新项目通常会产生全新的代码库,如果它们依赖于过去的代码,则难以适当地扩展到这些新项目。
+
+受此启发,我认为概述我个人从研究思路到实验所采取的步骤,以及如何改善我的研究理解,以便我可以修改这个想法。这个过程至关重要:给出一个初步的想法,我所有的时间都用在这个过程上; 至少对我来说,实验是学习和解决我无法预测的问题的关键。[1](http://dustintran.com/blog/a-research-to-engineering-workflow?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com#references)
+
+## 找到正确的问题
+
+在开展项目之前,有必要决定如何将想法推向更正式的事物。有时它就像导师建议一个项目一样简单; 或处理特定数据集或应用问题; 或者与频繁的合作者进行对话,然后找出有用的问题一起工作。更常见的是,我发现研究是一系列思想的结果,这些思想不断被迭代 - 通过频繁的对话,最近的工作,对我不熟悉的科目的长期阅读(例如,[Pearl(2000)](http://dustintran.com/blog/a-research-to-engineering-workflow?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com#pearl2000causality)),以及最喜欢的我想重温的论文(例如,[Wainwright&Jordan(2008)](http://dustintran.com/blog/a-research-to-engineering-workflow?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com#wainwright2008graphical),[Neal(1994)](http://dustintran.com/blog/a-research-to-engineering-workflow?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com#neal1994bayesian))。
+
+[](https://camo.githubusercontent.com/f4f85e4b2e1b8fa4c5a0fa8ca7b3716fdd13010d/687474703a2f2f64757374696e7472616e2e636f6d2f626c6f672f6173736574732f323031372d30362d30332d666967302e706e67)
+
+*我所有未开发的研究思路的主文件。*
+
+我发现一种非常有用的技术是维护一个主文档。[2](http://dustintran.com/blog/a-research-to-engineering-workflow?from=hackcv&hmsr=hackcv.com&utm_medium=hackcv.com&utm_source=hackcv.com#references)它做了一些事情。
+
+首先,它有一个包含所有想法,问题和主题的项目符号列表,我想更仔细地考虑一下(图中的1.3节)。有时它们与“强化学习的贝叶斯/生成方法”或“解决机器学习的公平性”一样高; 或者它们与“用于处理EP中的存储器复杂性的推理网络”或“尺寸偏差与对称Dirichlet先验的分析”一样具体。我试着保持清单简洁:后续部分深入讨论特定条目(图中的第2节)。
+
+其次,根据我接下来要做的工作对想法列表进行排序。这引导我理解我的研究超越当前工作的总体方向。我可以根据我是否认为方向与我更广泛的研究愿景一致,以及我是否认为这个方向对整个社会有一定影响而不断修改我的优先事项。重要的是,该列表不仅仅是关于下一个可以发表的可发表的想法,而且通常是我接下来要学习的内容。这有助于长期发现重要问题并找到简单或新颖的解决方案。
+
+每隔一段时间,我就会重新审视清单,诉诸事物,添加内容,删除内容。最终,我可能会详细阐述一个想法,使其成为一份正式的论文。总的来说,我发现这个在一个位置(和一种格式)内迭代思想的过程使得向正式的论文写作和实验过渡成为一种流畅的体验。
+
+## 管理论文
+
+[](https://camo.githubusercontent.com/0c2534e468fd58112614fffc66d0cdd4bc1c5737/687474703a2f2f64757374696e7472616e2e636f6d2f626c6f672f6173736574732f323031372d30362d30332d666967352e706e67)
+
+好的研究需要阅读*大量*论文。如果没有一个好的方式来组织你的阅读,你很容易被这个领域的匆忙节奏所淹没。(过去几周在试图赶上向arXiv发布的大量NIPS提交文件时尤其臭名昭着。)
+
+我已经尝试了很多方法,最终我得到了我强烈推荐的[Papers应用程序](http://papersapp.com/)
+
+良好管理系统中最基本的实用程序是集中式存储库,可以回来参考。无论是8页会议论文,期刊论文,调查甚至教科书,都有一个位置的优势不容小觑。此外,Papers是一个实际阅读PDF的好工具,它可以在我阅读和平板电脑或笔记本电脑上的东西时方便地同步设备。当我写作时,我会引用论文,我可以回到Papers并获得相应的BibTeX文件(配置文件)和citekey。
+
+我个人喜欢在组织论文时付出艰辛的努力。在上面的截图中,我有一个庞大的主题列表纸质标签。这些范围从`applications(应用程序)`,`models(模型)`,`inference(推理)`(每个子标签),并且也有杂主题,如`information-theory(信息论)`和`experimental-design(实验设计)`。截图中未显示的一个重要集合是一个名为的标签`research`,我将所有与特定研究主题相关的论文都包含在内。例如,目前突出显示[的PixelGAN论文](https://arxiv.org/abs/1706.00531)被标记为我目前一直在思考的两个主题 - 这些主题分为`research→alignment-semi`和`research→generative-images`。
+
+## 管理项目
+
+[](https://camo.githubusercontent.com/b36c06c4a5c8578dff3414cb9d7f009582aef0df/687474703a2f2f64757374696e7472616e2e636f6d2f626c6f672f6173736574732f323031372d30362d30332d666967312e706e67)
+
+*我们用于最近的arXiv预印本的存储库。*
+
+我想在一个Github存储库中维护一个研究项目。它们不仅可用于跟踪代码,还可用于跟踪一般研究进展,论文写作以及与其他人的协作联系起来。如何组织Github存储库是一个常见的痛点。我喜欢以下结构,最初来自[Dave Blei的首选](http://www.cs.columbia.edu/~blei/seminar/2016_discrete_data/notes/week_01.pdf)结构:
+
+```
+-- doc/
+ -- 2017-nips/
+ -- preamble/
+ -- img/
+ -- main.pdf
+ -- main.tex
+ -- introduction.tex
+-- etc/
+ -- 2017-03-25-whiteboard.jpg
+ -- 2017-04-03-whiteboard.jpg
+ -- 2017-04-06-dustin-comments.md
+ -- 2017-04-08-dave-comments.pdf
+-- src/
+ -- checkpoints/
+ -- codebase/
+ -- log/
+ -- out/
+ -- script1.py
+ -- script2.py
+-- README.md
+```
+
+`README.md`为我自己和合作者维护一份待办事项列表。这使得如何继续前进以及阻碍工作的方式变得透明。
+
+`doc/`包含所有的报道。每个子目录对应于特定的会议或日记提交,其中`main.tex`主要文档和各个部分用不同的文件编写,例如`introduction.tex`。保留每个文件一个部分使多个人可以轻松地同时处理不同的部分并避免合并冲突。有些人喜欢在主要实验完成后写完整篇论文。我个人更喜欢写一篇论文作为当前想法的总结,并且与想法本身一样,它随着实验的进行而不断修订。
+
+`etc/`是与其他目录无关的内容的转储。我通常用它来存储关于项目的对话的白板图片。或者有时因为我正在处理我的日常工作,我对一堆想法很震惊,因此我将它们转储到Markdown文档中。它也是处理有关工作的各种评论的便利位置,例如来自协作者的一般反馈或纸质标记。
+
+`src/`是所有代码存放的地方。Runnable脚本直接编写`src/`,并编写类和实用程序`codebase/`。我接下来会详细说明。(其他三个是从脚本输出的目录,我也将详细说明。)
+
+## 编写代码
+
+[](https://camo.githubusercontent.com/8044da6bcb1fce3603e59588316d3caffa1f6f1d/687474703a2f2f64757374696e7472616e2e636f6d2f626c6f672f6173736574732f323031372d30362d30332d666967322e706e67)
+
+我现在写的任何代码都使用[Edward](http://edwardlib.org/)。我发现它是快速试验现代概率模型和算法的最佳框架。
+
+在概念层面上,爱德华的吸引力是因为语言明确地遵循了数学:模型的生成过程转化为爱德华代码的特定线; 然后,所提出的算法转换为下一行; 当试图用自然研究问题扩展代码时,这种干净的翻译避免了未来的抽象难题:例如,如果我使用不同的先验,或调整梯度估计,或尝试不同的神经网络架构,或在大规模数据集上应用该方法该怎么办?
+
+在实践层面上,我通过建立预先存在的模型示例(in [`edward/examples/`](https://github.com/blei-lab/edward/tree/master/examples)或[`edward/notebooks/`](https://github.com/blei-lab/edward/tree/master/notebooks)),然后使其适应我的问题,从而最大程度上受益于Edward 。如果我也在实现一个新算法,我会使用预先存在的算法的源代码(in [`edward/inferences/`](https://github.com/blei-lab/edward/tree/master/edward/inferences)),将其粘贴为我的研究项目`codebase/`目录中的新文件,然后我调整它。这个过程使得从模板重新开始并避免低级细节变得非常容易。
+
+在编写代码时,我总是遵循PEP8(我特别喜欢这个[`pep8`](https://pypi.python.org/pypi/pep8)包),并尝试将各个脚本与脚本之间共享的类和函数定义分开; 后者放在里面`codebase/`然后导入。从一开始就保持代码质量始终是一项很好的投资,我发现这个过程可以很好地扩展,因为代码变得越来越复杂并且与其他人一起工作。
+
+**在Jupyter笔记本上。**许多人使用[Jupyter笔记本](http://jupyter.org/)作为交互式代码开发的方法,并且作为嵌入可视化和LaTeX的简单方法。我个人没有成功将其集成到我的工作流程中。我喜欢在Python脚本中编写所有代码,然后运行脚本。但我可以看到为什么其他人喜欢互动。
+
+## 管理实验
+
+[](https://camo.githubusercontent.com/ae3e351706f9e0ff04a8ee0e067021555e9c98a1/687474703a2f2f64757374696e7472616e2e636f6d2f626c6f672f6173736574732f323031372d30362d30332d666967332e706e67)
+
+投资一个好的工作站或云服务是必须的。GPU等功能基本上应该具有[广泛的可用性](http://timdettmers.com/2017/04/09/which-gpu-for-deep-learning/),并且应该能够并行运行多个作业。
+
+在我的本地计算机上完成脚本编写后,我的典型工作流程是:
+
+1. 运行`rsync`以将本地计算机的Github存储库(包括未提交的文件)与服务器中的目录同步;
+2. `ssh` 进入服务器。
+3. 启动`tmux`并运行脚本。在许多方面,`tmux`让您分离会话,这样您就不必在再次与服务器交互之前等待作业完成。
+
+当脚本合情合理时,我开始深入研究多个超参数配置的实验。一个有用的工具是[`argparse`](https://docs.python.org/3/library/argparse.html)。它使用命令行参数扩充Python脚本,您可以在脚本中添加以下内容:
+
+```
+parser = argparse.ArgumentParser()
+parser.add_argument('--batch_size', type=int, default=128,
+ help='Minibatch during training')
+parser.add_argument('--lr', type=float, default=1e-5,
+ help='Learning rate step-size')
+args = parser.parse_args()
+
+batch_size = args.batch_size
+lr = args.lr
+```
+
+然后你可以运行终端命令,如
+
+```
+python script1.py --batch_size=256 --lr=1e-4
+```
+
+这使得提交改变这些超参数的服务器作业变得容易。
+
+最后,我们来谈谈管理实验的输出。回想一下`src/`上面的目录结构:
+
+```
+-- src/
+ -- checkpoints/
+ -- codebase/
+ -- log/
+ -- out/
+ -- script1.py
+ -- script2.py
+```
+
+我们描述了各个脚本和`codebase/`。其他三个目录用于组织实验输出:
+
+- `checkpoints/`记录训练期间保存的模型参数。使用`tf.train.Saver`的算法运行的迭代的每一个固定号码,储存的参数。这有助于运行长时间的实验,您可能希望缩短实验并稍后恢复参数。每个实验都输出一个`checkpoints/`带有约定的子目录`20170524_192314_batch_size_25_lr_1e-4/`。第一个数字是date(`YYYYMMDD`); 第二个是时间戳(`%H%M%S`); 其余的是超参数。
+- `log/`记录可视化学习的日志。每个实验都属于一个子目录,其约定与`checkpoints/`。爱德华的一个好处是,对于日志记录,您可以简单地将参数传递为`inference.initialize(logdir='log/' + subdir)`。跟踪默认的TensorFlow摘要,然后可以使用TensorBoard对其进行可视化(接下来将详细介绍)。
+- `out/`记录训练结束后的探索性输出; 例如,生成的图像或matplotlib图。每个实验都属于一个子目录,其约定与`checkpoints/`。
+
+**在数据集上。**数据集用于许多研究项目。我更喜欢将它们存储在主目录中`~/data`。
+
+**在软件容器上。** [virtualenv](http://python-guide-pt-br.readthedocs.io/en/latest/dev/virtualenvs/)是管理Python依赖项和避免系统范围Python安装困难的必备工具。如果你喜欢编写Python 2/3不可知代码,那就特别好了。如果您需要更多设置,[Docker容器](https://www.docker.com/)是一个更强大的工具。
+
+## 探索,调试和诊断
+
+[](https://camo.githubusercontent.com/de52d78ff8d22cdb62af0ed9fd2c2d9c33595337/687474703a2f2f64757374696e7472616e2e636f6d2f626c6f672f6173736574732f323031372d30362d30332d666967342e706e67)
+
+[Tensorboard](https://www.tensorflow.org/get_started/summaries_and_tensorboard)是用于可视化和探索模型训练的出色工具。通过TensorBoard的交互性,我发现它特别方便,因为我不需要配置一堆matplotlib函数来理解训练。人们只需要`tf.summary`在代码中渗透一堆张量。
+
+Edward默认记录了一堆摘要,以便可视化损失函数值,渐变和参数在训练迭代中的变化。TensorBoard还包括壁时间比较,并且充分装饰的TensorFlow代码库提供了一个可以盯着的漂亮计算图。对于细微问题,我无法专门用TensorBoard诊断,我只是在`out/`目录中输出内容并检查这些结果。
+
+**调试错误消息。**我的调试工作流程非常糟糕。我在我的代码中渗透打印语句,并通过消除过程发现错误。这是原始的。虽然我没有尝试过,但我听说[TensorFlow的调试器](https://www.tensorflow.org/programmers_guide/debugger)很好。
+
+## 提高研究理解
+
+通过询问您的模型,算法以及学习过程,您可以更好地了解工作的成功和失败模式。这使您可以回到绘图板,深入思考方法以及如何进一步改进。由于该方法表明成功,人们可以从解决简单的玩具配置到越来越大规模和高维度的问题。
+
+从更高的层面来看,这个工作流程实际上是关于在现实世界中实施科学方法。在实验过程的每次迭代中都不一定要丢弃重要的想法,而是在科学的理想中,你从基础知识开始,并在你对现实有更强的把握时反复扩展它们。
+
+在这个过程中,实验并不孤单。协作,与其他领域的专家交流,阅读论文,研究短期和长期的想法,参加会谈和会议,有助于拓宽您找到正确问题和解决问题的视角。
+
+## 注解和参考
+
+1此工作流程专门用于实证研究。理论是另一种蠕虫,但其中一些思想仍然概括。
+
+2可以使用主文档的模板[`here`](https://github.com/dustinvtran/latex-templates)。
+
+3 Papers有一点需要注意。我将它用于所有事情:我的帐户中至少存储了2,000篇论文,并且有相当多的密集教科书。该应用程序至少可以筛选出6个千兆字节,因此在阅读/引用许多文件时会遇到一些小问题。我不知道这是否是一个错误或只是固有的对我论文利用几乎*过*了。
+
+1. Neal,RM(1994)。*神经网络的贝叶斯学习*(博士论文)。多伦多大学。
+2. Pearl,J。(2000)。*因果关系*。剑桥大学出版社。
+3. Wainwright,MJ,&Jordan,MI(2008)。图形模型,指数族和变分推理。*机器学习的基础和趋势*,*1*(1-2),1-305。
\ No newline at end of file
diff --git "a/20171012 \347\254\25410\346\234\237/\346\265\205\350\260\210\350\257\215\350\242\213\346\250\241\345\236\213.md" "b/20171012 \347\254\25410\346\234\237/\346\265\205\350\260\210\350\257\215\350\242\213\346\250\241\345\236\213.md"
index 1b4c55d7cf6bc64fc61945e81fbd671c46205470..e813c03778992c1f730229715be57f38656d3b80 100644
--- "a/20171012 \347\254\25410\346\234\237/\346\265\205\350\260\210\350\257\215\350\242\213\346\250\241\345\236\213.md"
+++ "b/20171012 \347\254\25410\346\234\237/\346\265\205\350\260\210\350\257\215\350\242\213\346\250\241\345\236\213.md"
@@ -1,6 +1,6 @@
# 浅谈词袋模型
-原文链接:[对词袋模型的温和介绍](对词袋模型的温和介绍)
+原文链接:[A Gentle Introduction to the Bag-of-Words Model](A Gentle Introduction to the Bag-of-Words Model)
词袋模型是一种在使用机器学习算法建模文本时表示文本数据的方式。
diff --git a/README.md b/README.md
index a32a0b932102392728cb2905ac8ad8d9de4e3cb2..adf7ed4fa6f0b936f97f5d141031af331e9f0a4c 100644
--- a/README.md
+++ b/README.md
@@ -15,26 +15,26 @@
## 翻译贡献者
-| 日期 | 翻译 | 校对 |
-| --------------------------------------------------- | ---------------------------------------------- | ---- |
-| [2017/09/25 第1期](https://hackcv.com/daily/p/1/) | [@wnma](https://github.com/wnma3mz) | |
-| [2017/10/04 第2期](https://hackcv.com/daily/p/2/) | [@doordiey](https://github.com/doordiey) | |
-| [2017/10/05 第3期](https://hackcv.com/daily/p/3/) | [@Arron206](https://github.com/Arron206) | |
-| [2017/10/06 第4期](https://hackcv.com/daily/p/4/) | [@mllove](https://github.com/mllove) | |
-| [2017/10/07 第5期](https://hackcv.com/daily/p/5/) | [@wnma](https://github.com/wnma3mz) | |
-| [2017/10/08 第6期](https://hackcv.com/daily/p/6/) | [@doordiey](https://github.com/doordiey) | |
-| [2017/10/09 第7期](https://hackcv.com/daily/p/7/) | [@mllove](https://github.com/mllove) | |
-| [2017/10/10 第8期](https://hackcv.com/daily/p/8/) | [@AlexdanerZe](https://github.com/AlexdanerZe) | |
-| [2017/10/11 第9期](https://hackcv.com/daily/p/9/) | | |
-| [2017/10/11 第10期](https://hackcv.com/daily/p/10/) | | |
-| [2017/10/13 第11期](https://hackcv.com/daily/p/11/) | [@wnma](https://github.com/wnma3mz) | |
-| [2017/10/14 第12期](https://hackcv.com/daily/p/12/) | [@wnma](https://github.com/wnma3mz) | |
-| [2017/10/15 第13期](https://hackcv.com/daily/p/13/) | | |
-| [2017/10/16 第14期](https://hackcv.com/daily/p/14/) | | |
-| [2017/10/17 第15期](https://hackcv.com/daily/p/15/) | | |
-| [2017/10/18 第16期](https://hackcv.com/daily/p/16/) | | |
-| [2017/10/19 第17期](https://hackcv.com/daily/p/17/) | | |
-| [2017/10/20 第18期](https://hackcv.com/daily/p/18/) | | |
+| 日期 | 翻译 | 校对 |
+| --------------------------------------------------- | -------------------------------------------------- | ---- |
+| [2017/09/25 第1期](https://hackcv.com/daily/p/1/) | [@wnma](https://github.com/wnma3mz) | |
+| [2017/10/04 第2期](https://hackcv.com/daily/p/2/) | [@doordiey](https://github.com/doordiey) | |
+| [2017/10/05 第3期](https://hackcv.com/daily/p/3/) | [@Arron206](https://github.com/Arron206) | |
+| [2017/10/06 第4期](https://hackcv.com/daily/p/4/) | [@mllove](https://github.com/mllove) | |
+| [2017/10/07 第5期](https://hackcv.com/daily/p/5/) | [@wnma](https://github.com/wnma3mz) | |
+| [2017/10/08 第6期](https://hackcv.com/daily/p/6/) | [@doordiey](https://github.com/doordiey) | |
+| [2017/10/09 第7期](https://hackcv.com/daily/p/7/) | [@mllove](https://github.com/mllove) | |
+| [2017/10/10 第8期](https://hackcv.com/daily/p/8/) | [@AlexdanerZe](https://github.com/AlexdanerZe) | |
+| [2017/10/11 第9期](https://hackcv.com/daily/p/9/) | [@exqlnet](https://github.com/exqlnet) | |
+| [2017/10/11 第10期](https://hackcv.com/daily/p/10/) | [@aboutmydreams](https://github.com/aboutmydreams) | |
+| [2017/10/13 第11期](https://hackcv.com/daily/p/11/) | [@wnma](https://github.com/wnma3mz) | |
+| [2017/10/14 第12期](https://hackcv.com/daily/p/12/) | [@wnma](https://github.com/wnma3mz) | |
+| [2017/10/15 第13期](https://hackcv.com/daily/p/13/) | | |
+| [2017/10/16 第14期](https://hackcv.com/daily/p/14/) | | |
+| [2017/10/17 第15期](https://hackcv.com/daily/p/15/) | | |
+| [2017/10/18 第16期](https://hackcv.com/daily/p/16/) | | |
+| [2017/10/19 第17期](https://hackcv.com/daily/p/17/) | | |
+| [2017/10/20 第18期](https://hackcv.com/daily/p/18/) | | |
## 贡献指南